
Распознавание текста на картинке с помощью tesseract на Kotlin / Хабр
Ни для кого не секрет, что Python прочно занял первенство в ML и Data Science. А что если посмотреть на другие языки и платформы? Насколько в них удобно делать аналогичные решения?
К примеру, распознавание текста на картинке.
Среди текущих решений одним из наиболее распространённым инструментом является tesseract. В Python для него существует удобная библиотека, а для первоначальной обработки изображений, как правило, используется OpenCV. Для обоих этих инструментов есть исходные C++ библиотеки, поэтому их также возможно вызывать и из других экосистем. Попробуем это сделать в jvm и, в частности, на Kotlin.
Несколько слов о Kotlin. У него есть много удобных вещей для Data Science. В совокупности с экосистемой jvm получается «статически типизированный Python на jvm». А не так давно ещё появилась возможность использовать Kotlin вместе с Apache Spark.
Первым делом установим tesseract.
tesseract input_file.jpg stdout -l eng --tessdata-dir /usr/local/share/tessdata/Где –tessdata-dir — путь до файлов tesseract (/usr/local/share/tessdata/ в macos). В случае успешной установки в stdout будет выведен распознанные текст.
После этого можно подключить tesseract в jvm и сравнить результат работы с нативным вызовом. Для этого подключим библиотеку:
implementation("net.sourceforge.tess4j:tess4j:4.5.3")Для тех, кто не очень хорошо знаком с экосистемой jvm, есть лёгкий способ быстро себе всё настроить. Понадобится только установленная Java 13+. Её проще всего поставить через sdkman. Далее для удобства можно скачать Intellij IDEA, подойдёт и Community version. Основу проекта можно создать из IDE (new project -> Kotlin, gradle Kotlin) или можно клонировать репозиторий github, в котором перейти на ветку start.

После подключения библиотеки доступ к tesseract становится простым. Вызов той же команды из примера выше будет выглядеть следующим образом:
val api = Tesseract() api.setDatapath("/usr/local/share/tessdata/") api.setLanguage("eng") val image = ImageIO.read(File("input_file.jpg")) val result: String = api.doOCR(image)
Как видно, практически все команды совпадают с используемыми в вызове из командной строки. Но, как минимум, на macos нужно ещё дополнительно настроить системную переменную jna.library.path, в которую нужно добавить путь до dylib-библиотеки tesseract.
val libPath = "/usr/local/lib" val libTess = File(libPath, "libtesseract.dylib") if (libTess.exists()) { val jnaLibPath = System.getProperty("jna.library.path") if (jnaLibPath == null) { System.setProperty("jna.library.path", libPath) } else { System.setProperty("jna.library.path", libPath + File.pathSeparator + jnaLibPath) } }
После всех настроек можно попробовать запустить распознавание для того же файла и результат должен полностью соответствовать вызову из командной строки.
Перейдём теперь к обработке изображений с OpenCV. В Python для работы с ней не требуется ставить каких-либо дополнительных инструментов, кроме пакета в pip. В описании OpenCV под java указан порядок установки, когда всё ставится отдельно. Для самой jvm-экосистемы подход, когда требуются установки каких-либо нативных библиотек, не совсем привычен. Чаще всего если зависимости требуется какие-либо дополнительные библиотеки, то либо она сама их скачивает (как, например, djl-pytorch), либо при подключении через систему сборки внутри себя уже содержит библиотеки под различные операционные системы. К счастью, для OpenCV есть такая сборка, которой и воспользуемся:
implementation("org.openpnp:opencv:4.3.0-2")Перед началом работы с OpenCV потребуется подгрузить нативные библиотеки через:
nu.pattern.OpenCV.loadLocally()После чего можно использовать все доступные инструменты. Как, например, конвертация изображения в чёрно-белый цвет:
Imgproc.
cvtColor(mat, mat, Imgproc.COLOR_BGR2GRAY)Как вы уже обратили внимание, аргументом для OpenCV выступает Mat, который представляет из себя основной класс-обёртку вокруг изображения в OpenCV в jvm, похожий на привычный BufferedImage.
Сам экземпляр Mat можно получить привычным для Python кода вызовом imread:
val mat = Imgcodecs.imread("input.jpg")В таком виде экземпляр можно дальше передавать в OpenCV и проделывать с ним различные манипуляции. Но для Java общепринятым является BufferedImage, вокруг которого, как правило, уже может быть выстроен pipeline загрузки и обработки изображения. В связи с чем возникает необходимость конвертации BufferedImage в Mat:
val image: BufferedImage = ...
val pixels = (image.raster.dataBuffer as DataBufferByte).data
val mat = Mat(image.height, image.width, CvType.CV_8UC3)
.apply { put(0, 0, pixels) }И обратной конвертации Mat в BufferedImage:
val mat = ... var type = BufferedImage.TYPE_BYTE_GRAY if (mat.channels() > 1) { type = BufferedImage.TYPE_3BYTE_BGR } val bufferSize = mat.channels() * mat.cols() * mat.rows() val b = ByteArray(bufferSize) mat[0, 0, b] // get all the pixels val image = BufferedImage(mat.cols(), mat.rows(), type) val targetPixels = (image.raster.dataBuffer as DataBufferByte).data System.arraycopy(b, 0, targetPixels, 0, b.size)
В частности, тот же tesseract в методе doOCR поддерживает как файл, так и BufferedImage. Используя вышеописанные преобразования, можно вначале обработать изображения с помощью OpenCV, преобразовать Mat в Bufferedimage и передать подготовленное изображение на вход tesseract.
Попробуем теперь на практике собрать рабочий вариант приложения, который сможет найти текст на следующей картинке:
Для начала проверим результат нахождения текста на изображении без обработки. И вместо метода doOCR будем использовать getWords
val image = ImageIO. read(URL("http://img.ifcdn.com/images/b313c1f095336b6d681f75888f8932fc8a531eacd4bc436e4d4aeff7b599b600_1.jpg"))
val result = api.getWords(preparedImage, ITessAPI.TessPageIteratorLevel.RIL_WORD)
read(URL("http://img.ifcdn.com/images/b313c1f095336b6d681f75888f8932fc8a531eacd4bc436e4d4aeff7b599b600_1.jpg"))
val result = api.getWords(preparedImage, ITessAPI.TessPageIteratorLevel.RIL_WORD)В результате будет найден только разный «мусор»:
[ie, [Confidence: 2.014679 Bounding box: 100 0 13 14], bad [Confidence: 61.585358 Bounding box: 202 0 11 14], oy [Confidence: 24.619446 Bounding box: 21 68 18 22], ' [Confidence: 4.998787 Bounding box: 185 40 11 18], | [Confidence: 60.889648 Bounding box: 315 62 4 14], ae. [Confidence: 27.592728 Bounding box: 0 129 320 126], c [Confidence: 0.000000 Bounding box: 74 301 3 2], ai [Confidence: 24.988930 Bounding box: 133 283 41 11], ee [Confidence: 27.483231 Bounding box: 186 283 126 41]]
Если внимательней посмотреть на изображение, то можно увидеть, что шрифт для текста белый, а значит, можно попробовать использовать threshold вместе с последующей инверсией, чтобы оставить текст только на картинке:
Пробуем следующие преобразования:
// convert to gray Imgproc.cvtColor(mat, mat, Imgproc.COLOR_BGR2GRAY) // text -> white, other -> black Imgproc.threshold(mat, mat, 244.0, 255.0, Imgproc.THRESH_BINARY) // inverse Core.bitwise_not(mat, mat)
После них посмотрим на картинку в результате (которую можно сохранить в файл через Imgcodecs.imwrite("output.jpg", mat) )
Теперь если посмотреть на результаты вызова getWords, то получим следующее:
[WHEN [Confidence: 94.933418 Bounding box: 48 251 52 14], SHE [Confidence: 95.249252 Bounding box: 109 251 34 15], CATCHES [Confidence: 95.973259 Bounding box: 151 251 80 15], YOU [Confidence: 96.446579 Bounding box: 238 251 33 15], CHEATING [Confidence: 96.458656 Bounding box: 117 278 86 15]]Как видно, весь текст успешно распознался.
Итоговый код по обработке изображения будет выглядеть следующим образом:
import net.sourceforge.tess4j.ITessAPI
import net.sourceforge.tess4j.Tesseract
import nu.pattern.OpenCV
import org. opencv.core.Core
import org.opencv.core.CvType
import org.opencv.core.Mat
import org.opencv.imgproc.Imgproc
import java.awt.image.BufferedImage
import java.awt.image.DataBufferByte
import java.io.File
import java.net.URL
import javax.imageio.ImageIO
fun main() {
setupOpenCV()
setupTesseract()
val image = ImageIO.read(URL("http://img.ifcdn.com/images/b313c1f095336b6d681f75888f8932fc8a531eacd4bc436e4d4aeff7b599b600_1.jpg"))
val mat = image.toMat()
Imgproc.cvtColor(mat, mat, Imgproc.COLOR_BGR2GRAY)
Imgproc.threshold(mat, mat, 244.0, 255.0, Imgproc.THRESH_BINARY)
Core.bitwise_not(mat, mat)
val preparedImage = mat.toBufferedImage()
val api = Tesseract()
api.setDatapath("/usr/local/share/tessdata/")
api.setLanguage("eng")
val result = api.getWords(preparedImage, ITessAPI.TessPageIteratorLevel.RIL_WORD)
println(result)
}
private fun setupTesseract() {
val libPath = "/usr/local/lib"
val libTess = File(libPath, "libtesseract.dylib")
if (libTess.
opencv.core.Core
import org.opencv.core.CvType
import org.opencv.core.Mat
import org.opencv.imgproc.Imgproc
import java.awt.image.BufferedImage
import java.awt.image.DataBufferByte
import java.io.File
import java.net.URL
import javax.imageio.ImageIO
fun main() {
setupOpenCV()
setupTesseract()
val image = ImageIO.read(URL("http://img.ifcdn.com/images/b313c1f095336b6d681f75888f8932fc8a531eacd4bc436e4d4aeff7b599b600_1.jpg"))
val mat = image.toMat()
Imgproc.cvtColor(mat, mat, Imgproc.COLOR_BGR2GRAY)
Imgproc.threshold(mat, mat, 244.0, 255.0, Imgproc.THRESH_BINARY)
Core.bitwise_not(mat, mat)
val preparedImage = mat.toBufferedImage()
val api = Tesseract()
api.setDatapath("/usr/local/share/tessdata/")
api.setLanguage("eng")
val result = api.getWords(preparedImage, ITessAPI.TessPageIteratorLevel.RIL_WORD)
println(result)
}
private fun setupTesseract() {
val libPath = "/usr/local/lib"
val libTess = File(libPath, "libtesseract.dylib")
if (libTess.
exists()) {
val jnaLibPath = System.getProperty("jna.library.path")
if (jnaLibPath == null) {
System.setProperty("jna.library.path", libPath)
} else {
System.setProperty("jna.library.path", libPath + File.pathSeparator + jnaLibPath)
}
}
}
private fun setupOpenCV() {
OpenCV.loadLocally()
}
private fun BufferedImage.toMat(): Mat {
val pixels = (raster.dataBuffer as DataBufferByte).data
return Mat(height, width, CvType.CV_8UC3)
.apply { put(0, 0, pixels) }
}
private fun Mat.toBufferedImage(): BufferedImage {
var type = BufferedImage.TYPE_BYTE_GRAY
if (channels() > 1) {
type = BufferedImage.TYPE_3BYTE_BGR
}
val bufferSize = channels() * cols() * rows()
val b = ByteArray(bufferSize)
this[0, 0, b] // get all the pixels
val image = BufferedImage(cols(), rows(), type)
val targetPixels = (image.raster.dataBuffer as DataBufferByte).data
System.arraycopy(b, 0, targetPixels, 0, b. size)
return image
}
size)
return image
}Если сравнить полученный код с Python-версией, то разница будет минимальная. Производительность тоже должна быть практически сравнимой (за исключением, быть может, чуть больших преобразований изображения между Mat и BufferedImage).
Преимущество Python в рамках текущего примера будет только в бесшовной передаче изображений между OpenCV и tesseract. Экосистема Python сама по себе удобна тем, что все библиотеки общаются одними и теми же типами.
В jvm-экосистеме тоже есть свои преимущества. Это и статическая типизация, и многопоточность, и общая скорость работы вместе с наличием огромного количества инструментов под любые требования. Может, текущий пример не сильно раскрывает все преимущества, но, как минимум, он демонстрирует, что для данной задачи решение на jvm и Kotlin получается ничуть не сложнее.
Python на текущий момент, беcспорно, лидер в ML. И в первую очередь все инструменты и библиотеки появляются на нём. Тем не менее, в других экосистемах можно использовать те же инструменты. Особенно учитывая, что если что-то есть под Python, то должна быть и нативная библиотека, которую можно легко подключить.
Особенно учитывая, что если что-то есть под Python, то должна быть и нативная библиотека, которую можно легко подключить.
Надеюсь, что в этой статье вы нашли для себя что-нибудь полезное и новое. Спасибо за внимание, и напоследок несколько полезных ссылок:
djl.ai — Deep Learning на jvm, где можно подключать модели из pytorch и tensorflow
deeplearning4j.org — аналогичное решение с возможностью обучать модели и импортировать существующие на tensorflow и keras
kotlinlang.org/docs/reference/data-science-overview — разные полезные вещи по Data Science на Kotlin (и Java)
Весь код доступен в репозитории.
Краткое описание функций и технологий, реализованных в ридерах
Экраны E Ink (электронная бумага, электронные чернила) изначально создавались в качестве современной замены обычной бумаге. Поэтому ключевая задача дисплеев E Ink — отображение текста таким образом, чтобы он выглядел один в один как напечатанный на бумаге. Впрочем, не только текста: с 2020 года существуют серийные ридеры с цветными экранами E Ink. Они подходят не только для чтения текста, но и для изучения иллюстраций, будь то картинки в сказках, диаграммы в документах, картинки на интернет-сайтах или комиксы. Вместе с тем абсолютно все экраны E Ink изначально разрабатывались так, чтобы избежать появления недостатков, свойственных экранам иных типов.
Впрочем, не только текста: с 2020 года существуют серийные ридеры с цветными экранами E Ink. Они подходят не только для чтения текста, но и для изучения иллюстраций, будь то картинки в сказках, диаграммы в документах, картинки на интернет-сайтах или комиксы. Вместе с тем абсолютно все экраны E Ink изначально разрабатывались так, чтобы избежать появления недостатков, свойственных экранам иных типов.
В отличие от цветных экранов смартфонов и планшетов, дисплеи E Ink визуально не отличаются от обычной бумаги. Читать с ридера можно часами напролет — глаза не устанут, а зрение не «сядет» со временем.
Экраны E Ink — как монохромные, так и цветные — совершенно не выцветают на солнце, не мерцают и не бликуют: можно читать в погожий летний денек, на ярком солнце, не вглядываясь в текст и не напрягая зрение. Для сравнения: цветные экраны планшетов, смартфонов и ноутбуков на солнце превращаются в бликующие темные прямоугольники; текст на них практически не виден — даже если выкрутить подсветку на максимум.
Для сравнения: цветные экраны планшетов, смартфонов и ноутбуков на солнце превращаются в бликующие темные прямоугольники; текст на них практически не виден — даже если выкрутить подсветку на максимум.
Экраны E Ink крайне экономичны. Ридер потребляет ничтожно мало энергии: она расходуется только в момент смены изображения на экране, в частности, при перелистывании страниц электронной книги. Благодаря этому свойству покетбук необходимо заряжать примерно раз в месяц-полтора при условии регулярного чтения по два-три часа в день. Для сравнения: смартфон обычно просится к розетке раз в один-два дня, планшетный компьютер — и того чаще. Ноутбуки в большинстве своем «живут» без подзарядки и вовсе несколько часов.
E Ink Pearl E Ink Carta
E Ink Carta
Все актуальные монохромные ридеры PocketBook оснащены дисплеями Carta, способными отображать до 16 градаций серого цвета. Это последнее поколение черно-белых экранов E Ink. На картинке ниже можно оценить разницу между экранами Carta и Pearl — предыдущим поколением монохромных дисплеев E Ink. Экраны Carta светлее и контрастнее, они еще приятнее глазу и еще сильнее визуально напоминают бумагу.
Это последнее поколение черно-белых экранов E Ink. На картинке ниже можно оценить разницу между экранами Carta и Pearl — предыдущим поколением монохромных дисплеев E Ink. Экраны Carta светлее и контрастнее, они еще приятнее глазу и еще сильнее визуально напоминают бумагу.
E Ink Kaleido
Летом 2020 года в линейке PocketBook появился первый ридер с цветным дисплеем нового поколения E Ink Kaleido — модель PocketBook 633 Color, а зимой 2021 – PocketBook 740 Color. Технология E Ink Kaleido предполагает использование классической черно-белой панели E Ink в связке со специальным RGB-фильтром, который позволяет экрану отображать уже не 16 градаций серого цвета, а 4096 оттенков. Что это дает? Теперь на ридере можно с максимальным комфортом изучать детские книги с цветными картинками, бизнес-литературу с графиками и диаграммами, комиксы, электронные учебники с картами и схемами, интернет-сайты с обилием графики… Словом, любой контент с цветными иллюстрациями!
Как читают тексты на сайте 📖 [Новый обзор исследований]
Правда ли, что сейчас никто не читает тексты на сайтах? Обновили обзор исследований и вывели несколько советов: что делать, чтобы статьи на сайте не просто читали, а дочитывали до конца.
Если пользователь прочитает контент, тогда автор сможет воздействовать на пользователя. Можно будет подвести его к покупке, помочь с выбором товара, расположить к себе, убедить в экспертности компании или выполнить другие цели, поставленные перед блогом.
Авторы могут анализировать дочитываемость на сайтах с помощью метрик: доскроллов, вовлеченности, тепловых карт, конверсии посетителей сайта в читателей рассылки, и исходя из этого понимать, что можно доработать. Но, возможно, культура чтения в принципе изменилась?
Как люди читают онлайн: мнения
Мы встречали разные мнения о том, как люди относятся к чтению в цифровую эпоху, их можно разделить на три направления:
Большинство охотно читает до сих пор
Сейчас модно развиваться, получать новые знания. Стало проще добывать интересный контент, находить статьи на любые темы, поэтому многие охотно читают.Длинный текст не воспринимают
Мышление стало клиповым, читатель стал как ребенок — распыляется между несколькими задачами, отвлекается на уведомления, хочет что-то полегче и повеселее.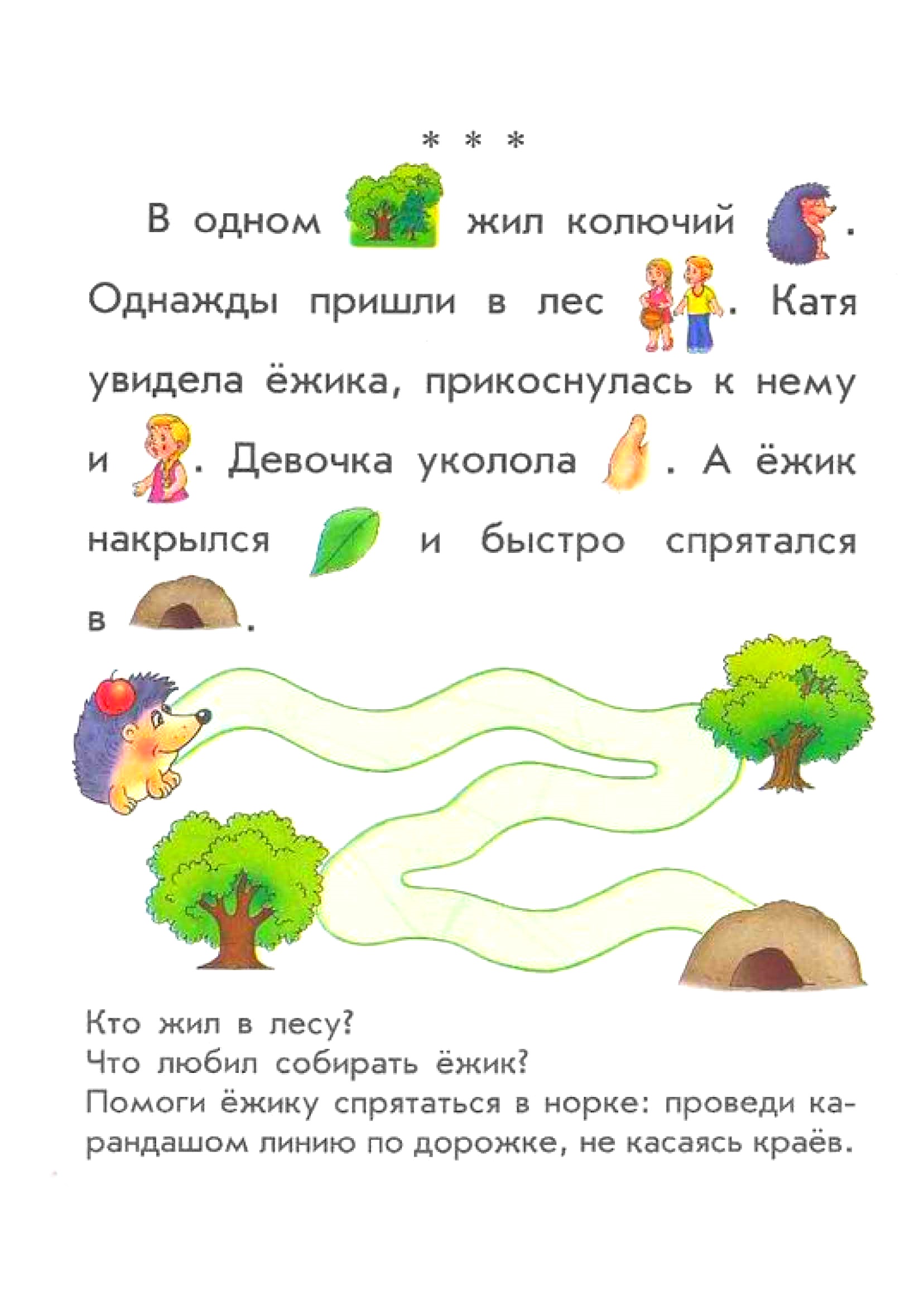 Он не может долго фокусировать внимание на чем-то одном и читать длинные статьи. Нужно укорачивать и дозировать контент, вставлять больше развлекательных элементов.
Он не может долго фокусировать внимание на чем-то одном и читать длинные статьи. Нужно укорачивать и дозировать контент, вставлять больше развлекательных элементов.Текст вообще не воспринимают
Сейчас люди совсем отвыкли читать, гораздо удобнее воспринимать информацию в формате, который можно совмещать с другой деятельностью. Например, вместо текста записывать видео, подкасты, проводить прямые эфиры и вебинары. Могут привлечь картинки и комиксы.
Поделитесь своим мнением в комментариях: какое из трех вам ближе или у вас есть другая точка зрения?
Мы собрали несколько актуальных исследований того, как сейчас люди читают с экрана, и вывели несколько закономерностей по объему, наполнению и оформлению текстов.
Обзор исследований: как читают контент на сайте
Как люди читают в интернете: новые и старые выводы
Лидеры в области изучения UX «Nielsen Norman Group» провели шесть айтрекинговых исследований с 2006 до 2019 года. Айтрекинг или окулография — это технология отслеживания перемещения взгляда пользователя на экран.
Айтрекинг или окулография — это технология отслеживания перемещения взгляда пользователя на экран.
Выводы исследования актуальны и для русскоязычных сайтов. Модели чтения похожи в разных языках и культурах, потому что они основаны на поведении человека. Различия исследователи находили, если сравнивали американскую или европейскую культуры с азиатскими, вероятно это связано с особенностями письменности.
Пользователи не читают, а сканируют взглядом
«Мы говорим об этом с 1997 года: люди редко читают в интернете — они гораздо чаще сканируют, чем читают слова по порядку. Это одна из основополагающих истин поведения при поиске информации в интернете, которая не изменилась за 23 года», — Nielsen Norman Group.
Читатели прыгают взглядом по странице, пропускают некоторый контент, возвращаются к пропущенным местам и повторно просматривают то, что уже прочитали. Так они хотят найти на странице информацию, которая больше всего соответствует их текущим потребностям, но не тратить время на чтение всего материала.
Слева просмотр сайта по F-модели в начале 2000-х годов на сайте 1900storm.com, а справа свежее отслеживание взгляда по F-модели на Investopedia.com. Стало меньше зон сосредоточения и фокусировки взгляда.
Сравнение F-моделей чтенияКоличество времени, которое пользователь готов потратить на чтение, зависит от четырех факторов:
Уровень мотивации: насколько ему важна эта информация?
Тип задачи: пользователь ищет конкретный факт, просматривает новую или интересную информацию или исследует тему в общем?
Уровень внимания: насколько сосредоточен пользователь на поставленной задаче?
Личные характеристики: тот конкретный человек проявляет склонность к сканированию информации или он в принципе очень внимателен к деталям?
Читатели не хотят тратить время или силы в сети, поэтому единственный путь владельца сайта — не пытаться заставить пользователя прочитать контент, а направлять его к той информации, которую он хочет найти.

В этом поможет правильное оформление текста:
Четкая понятная структура с заметными заголовками и подзаголовками, отражающими суть материала, чтобы пользователи ориентировались по ним в содержании.
Содержание с якорными ссылками на блоки статьи, чтобы люди могли сразу оценить, что им даст материал.
Методы форматирования, позволяющие зацепиться взглядом: маркированные списки, полужирный текст, цитаты с ключевой информацией.
Простой язык для краткости и понятности, наглядные форматы представления контента — например, сравнительные таблицы.
Картинки для иллюстрации — что можно показать, лучше показать наглядно, а не описывать словами.
Больше в статье о типографике на сайте
Мы привыкли читать текст слева направо, но картинки привлекают нас в первую очередь. Многие сайты располагают текст и картинки зигзагообразно, поэтому взгляд двигается по строчкам, как газонокосилка по траве. Схематично это выглядит так:
Многие сайты располагают текст и картинки зигзагообразно, поэтому взгляд двигается по строчкам, как газонокосилка по траве. Схематично это выглядит так:
К примеру, так выглядит карта перемещения взгляда пользователя по лендингу. Картинки и текст на странице скомпонованы зигзагообразно, пользователь движется по последовательно от картинки к тексту, потом к следующей картинке вниз и опять к тексту.
Перемещение взгляда пользователя по экрануКаким бы структурированным ни был текст, его не будут читать, если он не полезен читателю или устарел. Оформление вторично, в первую очередь изучайте потребности своей аудитории и пишите о том, что ее волнует, а также следите за свежестью материалов.
Исследователи отмечают:
Несмотря на то, что за последние два десятилетия дизайн изменился, поведение при чтении в интернете осталось по сути одинаковым. Технологии быстро меняются, а люди — нет.
Поэтому следующие в статье исследования 2016-2018 годов тоже можно считать актуальными. Они касаются поведения пользователей на скроллах экрана, удержания внимания и разницы чтения с мобильных и дестопов.
Они касаются поведения пользователей на скроллах экрана, удержания внимания и разницы чтения с мобильных и дестопов.
Как внимание распределяется по скроллам экрана
Исследование, опубликованное в 2018 году, о том, как пользователи воспринимают информацию, когда скроллят сайт. Проводила та же компания Nielsen Norman Group. В общей сложности проанализировали 130 000 фиксаций глаз на экране, участвовали 120 человек.
Больше половины времени чтения проводят на первом скроллеВ 2010 году аналогичное исследование показало, что 80% времени пользователи проводили на первом экране скролла. В 2018 году исследование показывает 57% времени. Возможно, пользователи привыкли к тому, что иногда информация разделена тематически по скроллам на лонгридах. А может быть, причина в дизайне, он не дает ощущения законченности страницы на первом скролле.
Мало кто доходит ниже третьего скроллаВ 2010 году 80% времени пользователи тратили на первый экран, в 2018 году 81% распределяется между первыми тремя. Первому отдается около 57% времени, на второй примерно 17%, а 26% на все остальные экраны.
Первому отдается около 57% времени, на второй примерно 17%, а 26% на все остальные экраны.
Около 65% времени от того, когда пользователи читают первый экран, они смотрят на его верхнюю часть. Важную информацию мало просто поместить на первый скролл, нужно еще и поднять ее выше к началу.
Верхняя часть выдачи ПС самая важная75% времени пользователь смотрит на самый верх. Еще одно подтверждение, что нужно быть как можно ближе к первой позиции.
Итак, самую важную информацию нужно поместить на первый экран скролла, причем чем выше к началу страницы, тем лучше. Планируйте дизайн страниц так, чтобы на каждом скролле не было ощущения конца страницы, тогда пользователь будет листать дальше.
Как люди читают медиаресурсы
Исследование компании «Медиатор» за 2018 год. Мы не будем рассматривать сайты с новостными федеральными и региональными порталами, но если вам интересно, это есть в полном исследовании. О новостных проектах у нас есть отдельный материал.
О новостных проектах у нас есть отдельный материал.
Участвовали 10 респондентов, исследователи анализировали то, как аудитория подбирает ресурсы для чтения, как смотрит ленту и статьи.
До конца материалы дочитывают только 45% пользователей, остальные проскролливают текст. Некоторые передумывают и уходят со страницы, не начав чтение, с десктопа так делает 2,7% пользователей, с мобильного 5,6%.
За время наблюдения ни один не добавил себе новый ресурс для чтения. Пользователь формирует себе полюбившиеся источники и обращается к ним за новым контентом. Новым ресурсам будет тяжело попасть в круг чтения пользователя.
Среднее время вовлечения в чтение для новостных и информационных ресурсов: 1,17 минут для десктопа и 1,12 для мобильных. В тематических и развлекательных проектах реальное время вовлечения: 2,15 для десктопа и 2,08 для мобильных.
В тематических и развлекательных проектах реальное время вовлечения: 2,15 для десктопа и 2,08 для мобильных.
В соответствии с этим изменилась подача контента на сайтах, авторы стали больше внимания уделять типографике и иллюстрированию, вставлять видео. При этом важно сохранить быструю скорость загрузки.
Распределения по каналам трафикаМедиа занимают несколько площадокМедиа становятся мультиканальными, дублируют контент в соцсетях, изменяя его вид под формат соцсети или мессенджера.
Нарратив удобен для восприятияСерия карточек текстом, видео и изображениями, которые пользователь свайпит или скроллит, идеальны под мобильный просмотр и удобны аудитории, которая привыкла свайпить.
Материалы в формате нарративовИтак, большинство читателей переходит к статьям из соцсетей, поэтому не думайте, что эта площадка не для вас. Главная страница медиаресурсов почти не интересна, важны сами статьи. У каждого читателя есть привычный набор ресурсов, к которым он обращается за новым контентом, и привычные способы перейти к статьям. Многие пользователи переходят по контекстным ссылкам, значит нужно подбирать их по теме и вовремя предлагать для продолжения чтения.
Главная страница медиаресурсов почти не интересна, важны сами статьи. У каждого читателя есть привычный набор ресурсов, к которым он обращается за новым контентом, и привычные способы перейти к статьям. Многие пользователи переходят по контекстным ссылкам, значит нужно подбирать их по теме и вовремя предлагать для продолжения чтения.
Как читают с мобильных
Исследование провела компания Nielsen Norman Group в 2016 году. Целью было понять поведение пользователей при чтении с мобильных. Участники читают половину статей на компьютере и половину статей на телефоне, рандомайзер выбирает, какую статью в каком виде будут читать. После чтения респонденты отвечают на вопросы по прочитанному, чтобы определить, как они поняли текст и запомнили информацию.
Различий между пониманием прочитанного с телефона и с десктопа не обнаружилось. Наоборот, в среднем понимание было несколько лучше при чтении с мобильного, но показатель не был статистически значимым. Возможно, дело в том, что мобильные устройства стали удобнее для чтения, чем были раньше, и сайты с контентом стали лучше оптимизированы под смартфоны.
Возможно, дело в том, что мобильные устройства стали удобнее для чтения, чем были раньше, и сайты с контентом стали лучше оптимизированы под смартфоны.
Есть небольшие различия в зависимости от сложности контента. Очень сложный контент читать на телефоне труднее, чем на компьютере.
Средние оценки понимания прочитанных простых и сложных статей в зависимости от устройстваИнтересное по теме:
Переупаковка контента: как выжать максимум из каждой статьи, поста и видео
Выводы: как сделать, чтобы статьи читали до конца
Пользователи все еще читают тексты, причем не только короткие заметки, но и лонгриды. Но поскольку конкуренция контента очень высока, многие переключаются на что-то другое и не дочитывают. Задача автора — сделать текст настолько удобным для восприятия, полезным и интересным, чтобы его не хотелось закрыть или быстро проскроллить.
По результатам исследований можно выделить такие рекомендации:
- Охотнее читают статьи среднего объема, поэтому особенно длинные тексты лучше делить по смысловым частям или делать серию статей.

- Большая часть пользователей переходят на страницы статей из ленты в социальных сетях, потому нужно дублировать туда контент, редактируя его под формат.
- Иллюстрации, медиаконтент, списки и все, что сделает статью нагляднее и удобнее, повысит ее дочитываемость.
- Важную информацию стоит помещать на верхний скролл, желательно в самое начало страницы, именно это место читает большинство пользователей.
Но самое важное — попадание в потребности пользователя. Он не будет читать даже самый структурированный контент, если содержание материала ему никак не пригодится, не попадает в сферу интересов и не обещает его развлечь. Изучайте интересы ваших клиентов и подбирайте контент под них.
Могу ли я сфотографировать текст и прочитать его мне? | by Alejandro Brega
Мир платформ TTS может многое сделать для людей со всего мира, и есть так много фантастического программного обеспечения, которое может помочь нам во многих отношениях.
Преобразование текста в речь — очень популярная вспомогательная технология, при которой компьютер или планшет читает человеку вслух слова на экране (иногда ее называют технологией «чтения вслух»). Это устройство используется людьми всех возрастов, а также открывает двери для всех, кто ищет более простые способы доступа к цифровому контенту.
Преобразование текста в речь и использование этой технологии для изображений, безусловно, является преимуществом для повышения производительности. На самом деле преобразование текста в речь день ото дня расширяется благодаря человеческим голосам.
Существует множество онлайн-сервисов для перевода текста в речь, но этот процесс настолько скучен, что за некоторые из этих услуг приходится платить. Однако, используя некоторые бесплатные инструменты, вы можете гораздо проще выполнять перевод текста в речь.
Многие люди считают, что программное обеспечение Woord для преобразования текста в речь дает огромную поддержку людям всех возрастов, чтобы следить за речью текста на компьютере. Прослушивание текста на картинках, который читается вслух естественным голосом, — это новая технология, которая постоянно развивается. Для многих гораздо проще и непринужденнее услышать ошибки через Woord, чем распознать их при чтении.
Прослушивание текста на картинках, который читается вслух естественным голосом, — это новая технология, которая постоянно развивается. Для многих гораздо проще и непринужденнее услышать ошибки через Woord, чем распознать их при чтении.
С помощью этого программного обеспечения вы можете легко преобразовать свой текст в профессиональную речь бесплатно, используя женские или мужские премиальные голоса, делая его более естественным. Он идеально подходит не только для преобразования изображений в речь, но и для людей с дислексией, детей, которые начинают читать, электронного обучения, презентаций, видео на YouTube и повышения доступности веб-сайта.
Онлайн-ридер Woord — это уникальный инструмент, предназначенный для создания широкого спектра услуг и продуктов с поддержкой искусственного интеллекта, таких как преобразование текста в речь.
Эта услуга преобразования текста в речь отличается высоким качеством, реалистично звучащими мужскими или женскими голосами премиум-класса. Как вы используете бесплатную онлайн-читалку Woord?
Как вы используете бесплатную онлайн-читалку Woord?
- Просто введите слово или фразу или импортируйте любой документ.
- Выберите скорость речи, которая вам подходит.
- Начать с любой позиции в тексте.
- Повторите текст столько раз, сколько пожелаете.
Зарегистрируйтесь здесь: www.getwoord.com
Если вы хотите послушать некоторые аудиофайлы перед регистрацией, вы можете изучить его публичную аудиотеку.
Вы также можете воспользоваться этой услугой, чтобы потренировать у детей навыки аудирования и разговорной речи, оттачивая произношение. Кроме того, вы можете слушать любые письменные материалы аутентичными голосами, занимаясь чем-то другим.
Помогите людям с нарушениями зрения, развлеките или обучите своих детей, создав аудиоверсию из письменного контента.Запомните положение паузы, начните говорить с того места, где остановились в последний раз.
Если вам нужна бесплатная служба преобразования текста в речь для различных акцентов, таких как: австралийский английский, французский, американский английский, франко-канадский или бразильский португальский, можно также воспользоваться Woord. Акценты доступны как в женских, так и в мужских голосах.
Акценты доступны как в женских, так и в мужских голосах.
В дополнение к английскому языку онлайн-ридер Woord также поддерживает голоса на итальянском, французском, китайском, голландском, немецком, хинди, индонезийском, японском, корейском, польском, португальском, русском и испанском языках.
Если вы хотите взглянуть на расширение Woord для Chrome, нажмите здесь.
Какой формат контента является эффективным?
Копирайтер и графический дизайнер заходят в бар.
Копирайтер уверенно заявляет, что «текст важнее визуала», но графический дизайнер протестующе кричит: «Ни за что, визуальные эффекты правят миром!»
Так за кого мы должны болеть?
Здесь нет двух вариантов: продуманный контент и красивые визуальные эффекты помогут превратить вашу историю, сообщение или контент в увлекательную часть, которая привлечет внимание вашей аудитории.
Несмотря на то, что вдумчивый текстовый контент имеет свои преимущества в том, что касается воздействия, в последние годы произошел значительный сдвиг в пользу сочетания текста и визуальных элементов — привлекающей внимание инфографики, красивой анимации, умных GIF-файлов и потрясающих презентаций Powerpoint.
Но задумывались ли вы когда-нибудь, почему вы предпочитаете нажимать на сообщение в социальной сети с картинкой или видео, а не на ссылку без изображений?
Почему легче прочитать статью, в которой между текстами вставлены изображения?
В этом тематическом исследовании мы приводим аргументы в пользу использования визуальных средств вместо текста в эффективном деловом общении, обучении и запоминании.
Конечно, мы можем быть немного предвзятыми, потому что помогаем людям создавать привлекательную, эффективную инфографику и анимацию, но мы старались придерживаться фактов, последних результатов и достоверных сведений, которые мы можем найти.
Почему ваш мозг любит смотреть на картинки
Зрение превосходит все чувства. Картинки также побеждают текст, отчасти потому, что чтение настолько неэффективно для нас. Наш мозг воспринимает слова как множество крошечных картинок, и мы должны различать определенные особенности букв, чтобы читать их.
Это требует времени.
– Правила мозга, Джон Медина
Текст и изображения в повседневном общении
Вот несколько идей и результатов исследований о том, почему визуальные эффекты превосходят текст в повседневном общении:
Человеческий мозг может обрабатывать целые изображения, которые видит глаз, всего за 13 миллисекунд. – Источник
Когда изображение просматривается всего за 13 миллисекунд до появления следующего изображения, часть мозга продолжает обрабатывать изображения дольше, чем время, в течение которого оно было просмотрено.– Источник
Люди, следующие указаниям с текстом и иллюстрациями, справляются на 323% лучше, чем те, кто следует указаниям без иллюстраций. – Источник
Когда люди слышат информацию, они, скорее всего, вспомнят только 10 процентов этой информации через три дня. С другой стороны, если релевантное изображение сочетается с той же информацией, люди сохраняют 65% информации через три дня.
 Источник
ИсточникЛюди лучше запоминают диаграммы с яркими визуальными образами, чем их простые аналоги.– Источник
Эксперимент, проведенный Департаментом компьютерных наук Университета Саскачевана, показал, что с точки зрения эстетики участники предпочитали украшенные диаграммы простым (минималистичным) диаграммам. Кроме того, не было никакой разницы в точности интерпретации участниками приукрашенных графиков и простых графиков во время эксперимента.
Между тем, участники смогли вспомнить значительно больше об украшенных диаграммах после перерыва более чем в 12 дней, предполагая, что добавление ярких визуальных образов в украшенные диаграммы помогло участникам запомнить как тему, так и детали диаграммы.
Текст против визуальных средств в образовании
Быть визуально грамотным, понимать изображения и то, как они на нас влияют, так же важно, как и словесно грамотными. Многие из нас используют визуальный язык, часто не осознавая этого.
Свободное владение языком образов дает нам преимущество в школе, на работе и дома».
– Визуальная грамотность: зачем она нам нужна, Брайан Кеннеди
Использование наглядных пособий в классе помогает улучшить процесс обучения до 400 процентов.В частности, это помогает учащимся совершенствоваться в следующих областях:
- Разъяснение содержания
- Мотивация учащихся к обучению
- Экономия времени при подготовке к уроку
- Расширение словарного запаса
- Избегайте скуки во время занятий
- Дайте непосредственный опыт в качестве сенсорных объектов, которые инициируют или стимулируют обучение
Текст и визуальные эффекты в маркетинге и деловых коммуникациях
Визуальные эффекты не просто роскошны; они могут помочь определить и усложнить идентичность бренда, дав маркетологам возможность говорить на другом языке.
И дело не только в дизайне логотипа — фирменный визуальный контент рассказывает свою собственную историю с помощью цвета, ритма, юмора и тона. Если вы можете показать своей аудитории, кто вы есть, вам не нужно тратить время на то, чтобы рассказывать им снова и снова. – Эмили Годетт, Привлечение вашей аудитории с помощью визуального контента: отчет за 2019 год
Анимированная инфографика, как правило, генерирует наибольшее количество репостов в социальных сетях, чем диаграммы, графики и другие визуальные элементы.- Источник
Анализ блогов в различных отраслях, проведенный Quicksprout, показал, что статьи с визуальными элементами, основанными на данных, такими как диаграммы и графики, получают больше обратных ссылок — на 258 процентов больше, чем сообщения в блогах с другими типами изображений.
Они также обнаружили, что анимированная инфографика генерирует наибольшее количество репостов в социальных сетях по сравнению с графиками, диаграммами и другими визуальными элементами.
Согласно опросу HubSpot, 54 процента потребителей хотели бы видеть больше видеоконтента от бренда или компании, которую они поддерживают.- Источник
Исследование слежения за движением глаз показывает, что пользователи уделяют пристальное внимание фотографиям и другим изображениям, которые содержат важную информацию, но игнорируют пушистые изображения, используемые для «оживления» веб-страниц. – Источник
Визуальные типы контента, такие как инфографика, фотографии и видео, составляют значительную часть контента, который используют маркетологи B2B. – Источник
Твиты с изображениями получают на 150% больше ретвитов, чем твиты без изображений. – Источник
Когда контент-маркетологов спросили, какой визуальный контент они, скорее всего, будут использовать в 2019 году, их топ-5 ответов были следующими: короткое видео, оригинальные фотографии, инфографика, анимированные GIF-изображения и истории из Instagram.
 – Источник
– ИсточникВаш план действий
Таким образом, использование визуальных элементов с текстом имеет больше смысла, если вы хотите произвести эффектное общение и сделать свой контент более запоминающимся.
Используйте следующие руководства, чтобы помочь вам начать общение с помощью изображений и визуальных материалов, будь то в школе или на работе:
Хотите поделиться этой статьей в видеоформате? Посмотрите видео ниже!
Нужна помощь в создании инфографики? Мы поможем вам с помощью нашего инструмента для создания инфографики или с помощью нашей службы дизайна инфографики.
Лаборатория Axess | Альтернативные тексты: Полное руководство
Мой опыт работы с изображениями в Интернете
При просмотре веб-страниц я использую комбинацию увеличения и чтения с экрана. Как правило, я использую увеличение на больших экранах и программу чтения с экрана на небольших устройствах.
Как правило, я использую увеличение на больших экранах и программу чтения с экрана на небольших устройствах.
Я, как и все остальные, натыкаюсь на множество изображений при серфинге в Интернете. Если я использую программу чтения с экрана, мне нужно, чтобы описание изображения — альтернативный текст — читалось мне.
Во многих случаях альтернативный текст бесполезен, часто это даже пустая трата моего времени, потому что он не передает никакого смысла.
Позвольте мне проиллюстрировать это на стартовой странице The Verge. Вот как это выглядит для зрячих:
Ниже то, что я вижу. Я заменил изображения тем, что прочитал мой скринридер:
Не очень полезно, да?
Вот некоторые распространенные ошибки alt-text, с которыми я сталкивался:
- «cropped_img32_900px.png» или «1521591232.jpg» — имена файлов, вероятно, потому, что у изображения нет атрибута alt.
- «<Название статьи>» — на каждом изображении в статье, вероятно, для улучшения поискового рейтинга (SEO).

- «Фотограф: Эмма Ли» — вероятно, потому, что редактор не знает, для чего нужен альтернативный текст.
Альтернативные тексты не всегда так уж плохи, но обычно есть над чем поработать. Итак, являетесь ли вы полным новичком или хотите вывести свою «игру» на новый уровень, вот наше исчерпывающее руководство по альтернативным текстам!
Что такое альтернативный текст
Альтернативный текст — это описание изображения, которое показывается людям, которые по какой-то причине не могут видеть это изображение. Среди прочего, альтернативные тексты помогают:
- людям со слабым зрением или без него
- людям, которые отключили изображения для сохранения данных
- поисковых систем
Первая группа — люди со слабым зрением или без него — возможно, самая который больше всего выигрывает от альтернативных текстов.Они используют что-то, называемое программой чтения с экрана, для навигации по сети. Программа чтения с экрана преобразует визуальную информацию в речь или шрифт Брайля. Чтобы сделать это точно, изображения вашего сайта должны иметь альтернативный текст.
Чтобы сделать это точно, изображения вашего сайта должны иметь альтернативный текст.
Альтернативные тексты очень важны! Настолько важно, что в Руководстве по обеспечению доступности веб-контента (WCAG) альтернативные тексты указаны в качестве самого первого руководства:
Весь нетекстовый контент, представляемый пользователю, имеет текстовую альтернативу, которая служит той же цели.
– Руководство WCAG 1.1.1
Как добавить альтернативный текст?
В html альтернативный текст является атрибутом элемента изображения:

Большинство систем управления контентом (CMS), таких как WordPress, позволяют создавать альтернативный текст при загрузке изображения:
Поле обычно называется «Альтернативный текст», «Альтернативный текст» или «Альтернативный текст» , но в некоторых интерфейсах это называется «Описание изображения» или что-то подобное.
Давайте создадим идеальный альтернативный текст!
Вот шаги по созданию потрясающих альтернативных текстов!
Опишите изображение
Это может показаться очевидным, но альтернативный текст должен описывать изображение.Например:
«Группа людей на вокзале».
«Счастливый малыш играет в песочнице».
«Пять человек в очереди в супермаркете».
Вещи, которые не относятся к альтернативному тексту:
- Имя фотографа. Это очень распространено, но не имеет абсолютно никакого смысла.
- Ключевые слова для поисковой оптимизации. Не переполняйте альтернативный текст нерелевантными словами, с помощью которых вы надеетесь занять высокие позиции в Google. Это не то, для чего нужны альтернативные тексты, и это запутает ваших пользователей.
Содержание альтернативного текста зависит от контекста
То, как вы описываете изображение, зависит от его контекста. Позвольте мне привести вам пример:
Если бы это изображение использовалось в статье о фотографии, альтернативный текст мог бы быть примерно таким:
«Крупный план, фотография человека снаружи в оттенках серого, лицо в фокусе, фон не сфокусирован». ».
».
Если изображение размещено на веб-сайте о телесериале, соответствующий альтернативный текст может быть совершенно другим:
«Звезда шоу, Адам Ли, выглядит напряженным на улице под дождем.
Итак, напишите альтернативный текст, максимально значимый для пользователя в том контексте, в котором он находится. зрячий пользователь может увидеть много деталей на изображении, например, кто это, как он сфотографирован, тип куртки, примерный возраст парня и многое другое. Почему бы не написать подробный, длинный альтернативный текст, чтобы пользователь с нарушением зрения получил столько же информации, сколько и я?»
Рад, что вы спросили!
Честно говоря, вы также можете получить необходимую информацию из изображения с первого взгляда , и это то, чего мы пытаемся добиться и для пользователей программ чтения с экрана.Дайте необходимую информацию в альтернативном тексте, но сделайте ее максимально короткой и лаконичной.
Один из немногих случаев, когда вы должны писать длинные альтернативные тексты, — это когда вы описываете изображение, содержащее важный текст. В идеале у вас не должно быть изображений текста, но иногда это необходимо. Как на некоторых скриншотах или фото знаков.
В идеале у вас не должно быть изображений текста, но иногда это необходимо. Как на некоторых скриншотах или фото знаков.
Но общее эмпирическое правило — сохранять краткость и избегать многословия.
Не говорите, что это изображение
Не начинайте альтернативный текст словами «Изображение», «Фото» и т.п.Программа чтения с экрана добавит это по умолчанию. Поэтому, если вы напишете «Изображение» в альтернативном тексте, программа чтения с экрана скажет «Изображение Изображение…», когда пользователь сосредоточится на изображении. Не очень приятно.
Одна вещь, которую вы можете сделать, это закончить альтернативный текст, указав, является ли это особым типом изображения, например иллюстрацией.
«Собака прыгает через обруч. Иллюстрация».
Окончание точкой.
Заканчивайте альтернативный текст точкой. Это заставит программы чтения с экрана немного приостановиться после последнего слова в альтернативном тексте, что сделает чтение более приятным для пользователя.
Не используйте атрибут title
Во многих интерфейсах рядом с полем для добавления замещающего текста есть поле для добавления заголовков к изображениям. Пропустите текст заголовка! Их никто не использует — они не работают на сенсорных экранах, а на десктопе требуют, чтобы пользователь некоторое время наводил курсор на изображение, чего никто не делает. Кроме того, добавление текста заголовка заставляет некоторые программы чтения с экрана читать и текст заголовка, и альтернативный текст, что становится излишним. Так что просто не добавляйте заголовок-текст.
Когда не следует использовать замещающий текст
В большинстве случаев следует использовать замещающий текст для изображений, но есть некоторые исключения, когда замещающий текст следует оставить пустым.Важное примечание: никогда не удаляйте атрибут alt, это будет означать нарушение html-стандарта. Но вы можете установить его в пустую строку, то есть: alt=””. Делайте это в следующих случаях.
Повторяющиеся изображения в лентах
Представьте, что вы просматриваете ленту Twitter. Каждый раз, когда вы хотите прочитать новый твит, вам сначала нужно прослушать «Изображение профиля пользователя <имя пользователя, опубликовавшего сообщение>». На мой взгляд, это было бы очень раздражающе!
Другие примеры каналов:
- Список ссылок на статьи.Как и на нашей странице Статьи.
- Ленты чатов или сообщений
- Ленты комментариев
Поэтому для идеального взаимодействия с пользователем оставьте альтернативный текст пустым для изображений, которые неоднократно используются в лентах.
Значки с текстовыми метками
Рядом со значками всегда должны быть текстовые метки. Предполагая, что вы это сделаете, значок не должен иметь альтернативный текст. Позвольте мне объяснить, почему!
Возьмем в качестве примера кнопку социальной сети:
Если вы напишете замещающий текст к значку Facebook, программа чтения с экрана скажет что-то вроде: «Facebook Facebook. «Очень избыточно!
«Очень избыточно!
ОК, технически это не касается альтернативных текстов, но все же важно: убедитесь, что и значок, и текст ссылки имеют один и тот же атрибут ссылки, чтобы получить плавный опыт. Вот так:
 Фейсбук
Фейсбук
Другая распространенная ошибка со значками связана с кнопками меню:
Если кнопка меню не имеет визуальной текстовой метки — что, кстати, очень плохо для пользователя — тогда ей нужен альтернативный текст. (или другой способ описания его функции в коде, например, aria-label).Объясните функцию значка, например «Меню». Не пишите «Три горизонтальные линии» или «Основной гамбургер», которые, к сожалению, являются реальными примерами, на которые я наткнулся.
Если у значка меню есть метка, вы должны оставить альтернативный текст пустым. Я часто нахожу кнопки меню, которые читаются как «меню меню». Однажды я даже наткнулся на «меню меню гамбургеров». Несколько запутанно, не так ли?
Изображения в ссылках
Обычно изображение в ссылке сопровождается текстом ссылки. Как в примере ниже:
Как в примере ниже:
В этом случае изображение и ссылка должны находиться в одном теге ссылки в html.В этом случае вы можете просто оставить альтернативный текст пустым. Для пользователя важно услышать текст ссылки. Альтернативный текст изображения будет только отвлекать, добавляя информацию, которую пользователь не сочтет нужной. Изображение, вероятно, находится на странице, на которую есть ссылка, и тогда вы можете дать ему хорошее объяснение в альтернативном тексте.
Если вам действительно нужно изображение в ссылке без сопроводительного текста, то альтернативный текст должен описывать место назначения ссылки, а не изображение.
Декоративные изображения
Желательно, чтобы декоративные изображения, не несущие никакой смысловой нагрузки для пользователя, размещались в качестве фоновых изображений в css. Вероятно, это само собой разумеется, но это означает, что вам вообще не нужны альтернативные тексты.
Большинство изображений, на которых вы размещаете текст, я бы отнес к декоративным. Вам не нужен альтернативный текст на них. Одним из примеров является фоновое изображение на стартовой странице Netflix:
Вам не нужен альтернативный текст на них. Одним из примеров является фоновое изображение на стартовой странице Netflix:
Особые случаи
Логотипы в баннере
Логотипы в баннере почти всегда ведут на стартовую страницу веб-сайта.Мнения немного расходятся по теме альтернативных текстов для логотипов.
Некоторые говорят, что это должно включать название компании, тот факт, что это логотип и пункт назначения ссылки. Например:
«Axess Lab, логотип, перейти на стартовую страницу».
На мой взгляд, это немного многословно. Слишком много шума! Поскольку мой скринридер уже сказал мне, что это изображение и ссылка, я чувствую, что мне нужно услышать только название компании. Из того факта, что это изображение, я предполагаю, что это логотип, а из того факта, что это ссылка, я предполагаю, что она соответствует правилам и ссылкам на стартовую страницу.
Svg
Масштабируемая векторная графика (svg) — это формат изображения, который становится все более и более популярным в Интернете. И я люблю их! Они сохраняют четкость при масштабировании и занимают меньше места, поэтому веб-сайты загружаются быстрее.
И я люблю их! Они сохраняют четкость при масштабировании и занимают меньше места, поэтому веб-сайты загружаются быстрее.
Существует два основных способа добавления svg на html-страницу.
- Внутри элемента img. В этом случае просто добавьте альтернативный текст, как обычно:

- Использование тега svg.Если вы используете этот метод, вы не можете добавить атрибут alt, потому что он не поддерживается. Однако вы можете обойти это, добавив два атрибута wai-aria: role=”img” и aria-label=”
.
На самом деле, во втором случае вы должны иметь возможность добавлять свой альтернативный текст в качестве элемента заголовка в svg, но на данный момент браузеры и вспомогательные технологии недостаточно поддерживают это.
Разве машина не может сделать это за меня?
Хотя машинное обучение и искусственный интеллект быстро совершенствуются и могут довольно точно описывать некоторые изображения, на данный момент они недостаточно хорошо понимают соответствующий контекст. Вдобавок ко всему, машины недостаточно хорошо определяют, что является «кратким», и часто описывают слишком много или слишком мало изображения.
Вдобавок ко всему, машины недостаточно хорошо определяют, что является «кратким», и часто описывают слишком много или слишком мало изображения.
Facebook фактически встроил функцию, которая автоматически описывает изображения. Но мне кажется, что описания обычно слишком общие. Одно изображение в моей ленте прямо сейчас описано как: «Кошка в помещении». На настоящей фотографии кошка охотится на игрушечную мышь.
Так что, извините, вам все равно придется писать альтернативные тексты самостоятельно!
Спасибо, что делаете Интернет лучше!
Я рад, что вы дочитали до этого места! Это означает, что вы заботитесь о том, чтобы сделать Интернет лучше для всех пользователей.Распространяйте знания и продолжайте быть крутыми!
Получайте уведомления, когда мы пишем что-то новое
Примерно раз в месяц мы пишем статью о доступности или удобстве использования, она такая же классная, как эта (#HumbleBrag)!
Получайте уведомления, подписываясь на нас в Twitter @AxessLab или Facebook.
Или просто оставьте свой адрес электронной почты ниже!
Gale Apps – Технические трудности
Технические трудности
Приложение, к которому вы пытаетесь получить доступ, в настоящее время недоступно.Приносим свои извинения за доставленные неудобства. Повторите попытку через несколько секунд.
Если проблемы с доступом сохраняются, обратитесь за помощью в наш отдел технической поддержки по телефону 1-800-877-4253. Еще раз спасибо, что выбрали Gale, обучающую компанию Cengage.
org.springframework.remoting.RemoteAccessException: невозможно получить доступ к удаленной службе [authorizationService@theBLISAuthorizationService]; вложенным исключением является Ice.Неизвестное исключение
unknown = “java.lang.IndexOutOfBoundsException: индекс 0 выходит за границы для длины 0
в java. base/jdk.internal.util.Preconditions.outOfBounds(Preconditions.java:64)
в java.base/jdk.internal.util.Preconditions.outOfBoundsCheckIndex(Preconditions.java:70)
в java.base/jdk.internal.util.Preconditions.checkIndex(Preconditions.java:248)
в java.base/java.util.Objects.checkIndex(Objects.java:372)
на Яве.база/java.util.ArrayList.get(ArrayList.java:458)
в com.gale.blis.data.subscription.dao.LazyUserSessionDataLoaderStoredProcedure.populateSessionProperties(LazyUserSessionDataLoaderStoredProcedure.java:60)
в com.gale.blis.data.subscription.dao.LazyUserSessionDataLoaderStoredProcedure.reQuery(LazyUserSessionDataLoaderStoredProcedure.java:53)
в com.gale.blis.data.model.session.UserGroupEntitlementsManager.reinitializeUserGroupEntitlements(UserGroupEntitlementsManager.ява:30)
в com.gale.blis.data.model.session.UserGroupSessionManager.getUserGroupEntitlements(UserGroupSessionManager.
base/jdk.internal.util.Preconditions.outOfBounds(Preconditions.java:64)
в java.base/jdk.internal.util.Preconditions.outOfBoundsCheckIndex(Preconditions.java:70)
в java.base/jdk.internal.util.Preconditions.checkIndex(Preconditions.java:248)
в java.base/java.util.Objects.checkIndex(Objects.java:372)
на Яве.база/java.util.ArrayList.get(ArrayList.java:458)
в com.gale.blis.data.subscription.dao.LazyUserSessionDataLoaderStoredProcedure.populateSessionProperties(LazyUserSessionDataLoaderStoredProcedure.java:60)
в com.gale.blis.data.subscription.dao.LazyUserSessionDataLoaderStoredProcedure.reQuery(LazyUserSessionDataLoaderStoredProcedure.java:53)
в com.gale.blis.data.model.session.UserGroupEntitlementsManager.reinitializeUserGroupEntitlements(UserGroupEntitlementsManager.ява:30)
в com.gale.blis.data.model.session.UserGroupSessionManager.getUserGroupEntitlements(UserGroupSessionManager. java:17)
в com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getProductSubscriptionCriteria(CrossSearchProductContentModuleFetcher.java:244)
на com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getSubscribedCrossSearchProductsForUser(CrossSearchProductContentModuleFetcher.ява:71)
на com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getAvailableContentModulesForProduct(CrossSearchProductContentModuleFetcher.java:52)
на com.gale.blis.api.authorize.strategy.productentry.strategy.AbstractProductEntryAuthorizer.getContentModules(AbstractProductEntryAuthorizer.java:130)
на com.gale.blis.api.authorize.strategy.productentry.strategy.CrossSearchProductEntryAuthorizer.isAuthorized(CrossSearchProductEntryAuthorizer.ява:82)
на com.gale.blis.api.authorize.strategy.productentry.strategy.CrossSearchProductEntryAuthorizer.
java:17)
в com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getProductSubscriptionCriteria(CrossSearchProductContentModuleFetcher.java:244)
на com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getSubscribedCrossSearchProductsForUser(CrossSearchProductContentModuleFetcher.ява:71)
на com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getAvailableContentModulesForProduct(CrossSearchProductContentModuleFetcher.java:52)
на com.gale.blis.api.authorize.strategy.productentry.strategy.AbstractProductEntryAuthorizer.getContentModules(AbstractProductEntryAuthorizer.java:130)
на com.gale.blis.api.authorize.strategy.productentry.strategy.CrossSearchProductEntryAuthorizer.isAuthorized(CrossSearchProductEntryAuthorizer.ява:82)
на com.gale.blis.api.authorize.strategy.productentry.strategy.CrossSearchProductEntryAuthorizer. authorizeProductEntry(CrossSearchProductEntryAuthorizer.java:44)
на com.gale.blis.api.authorize.strategy.ProductEntryAuthorizer.authorize(ProductEntryAuthorizer.java:31)
в com.gale.blis.api.BLISAuthorizationServiceImpl.authorize_aroundBody0(BLISAuthorizationServiceImpl.java:57)
на com.gale.blis.api.BLISAuthorizationServiceImpl.authorize_aroundBody1$advice(BLISAuthorizationServiceImpl.ява: 61)
на com.gale.blis.api.BLISAuthorizationServiceImpl.authorize(BLISAuthorizationServiceImpl.java:1)
на com.gale.blis.auth._AuthorizationServiceDisp._iceD_authorize(_AuthorizationServiceDisp.java:141)
в com.gale.blis.auth._AuthorizationServiceDisp._iceDispatch(_AuthorizationServiceDisp.java:359)
в IceInternal.Incoming.invoke(Incoming.java:209)
в Ice.ConnectionI.invokeAll(ConnectionI.java:2800)
на льду.ConnectionI.dispatch(ConnectionI.java:1385)
в Ice.ConnectionI.
authorizeProductEntry(CrossSearchProductEntryAuthorizer.java:44)
на com.gale.blis.api.authorize.strategy.ProductEntryAuthorizer.authorize(ProductEntryAuthorizer.java:31)
в com.gale.blis.api.BLISAuthorizationServiceImpl.authorize_aroundBody0(BLISAuthorizationServiceImpl.java:57)
на com.gale.blis.api.BLISAuthorizationServiceImpl.authorize_aroundBody1$advice(BLISAuthorizationServiceImpl.ява: 61)
на com.gale.blis.api.BLISAuthorizationServiceImpl.authorize(BLISAuthorizationServiceImpl.java:1)
на com.gale.blis.auth._AuthorizationServiceDisp._iceD_authorize(_AuthorizationServiceDisp.java:141)
в com.gale.blis.auth._AuthorizationServiceDisp._iceDispatch(_AuthorizationServiceDisp.java:359)
в IceInternal.Incoming.invoke(Incoming.java:209)
в Ice.ConnectionI.invokeAll(ConnectionI.java:2800)
на льду.ConnectionI.dispatch(ConnectionI.java:1385)
в Ice.ConnectionI. message(ConnectionI.java:1296)
в IceInternal.ThreadPool.run(ThreadPool.java:396)
в IceInternal.ThreadPool.access$500(ThreadPool.java:7)
в IceInternal.ThreadPool$EventHandlerThread.run(ThreadPool.java:765)
в java.base/java.lang.Thread.run(Thread.java:834)
”
org.springframework.remoting.ice.IceClientInterceptor.convertIceAccessException(IceClientInterceptor.java:365) org.springframework.remoting.ice.IceClientInterceptor.invoke(IceClientInterceptor.java:327) org.springframework.remoting.ice.MonitoringIceProxyFactoryBean.invoke(MonitoringIceProxyFactoryBean.java:71) org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186) org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:212) com.sun.proxy.$Proxy130.authorize(Неизвестный источник) com.gale.auth.service.BlisService.getAuthorizationResponse(BlisService.
message(ConnectionI.java:1296)
в IceInternal.ThreadPool.run(ThreadPool.java:396)
в IceInternal.ThreadPool.access$500(ThreadPool.java:7)
в IceInternal.ThreadPool$EventHandlerThread.run(ThreadPool.java:765)
в java.base/java.lang.Thread.run(Thread.java:834)
”
org.springframework.remoting.ice.IceClientInterceptor.convertIceAccessException(IceClientInterceptor.java:365) org.springframework.remoting.ice.IceClientInterceptor.invoke(IceClientInterceptor.java:327) org.springframework.remoting.ice.MonitoringIceProxyFactoryBean.invoke(MonitoringIceProxyFactoryBean.java:71) org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186) org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:212) com.sun.proxy.$Proxy130.authorize(Неизвестный источник) com.gale.auth.service.BlisService.getAuthorizationResponse(BlisService. java:61) com.gale.apps.service.impl.MetadataResolverService.resolveMetadata(MetadataResolverService.java:65) com.gale.apps.controllers.DiscoveryController.resolveDocument(DiscoveryController.java:57) ком.gale.apps.controllers.DocumentController.redirectToDocument(DocumentController.java:22) jdk.internal.reflect.GeneratedMethodAccessor305.invoke (неизвестный источник) java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) java.base/java.lang.reflect.Method.invoke(Method.java:566) org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.ява: 215) org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:142) org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:102) org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod (RequestMappingHandlerAdapter.
java:61) com.gale.apps.service.impl.MetadataResolverService.resolveMetadata(MetadataResolverService.java:65) com.gale.apps.controllers.DiscoveryController.resolveDocument(DiscoveryController.java:57) ком.gale.apps.controllers.DocumentController.redirectToDocument(DocumentController.java:22) jdk.internal.reflect.GeneratedMethodAccessor305.invoke (неизвестный источник) java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) java.base/java.lang.reflect.Method.invoke(Method.java:566) org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.ява: 215) org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:142) org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:102) org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod (RequestMappingHandlerAdapter. java:895) org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal (RequestMappingHandlerAdapter.java:800) org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87) org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1038) org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:942) орг.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:998) org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:890) javax.servlet.http.HttpServlet.service(HttpServlet.java:626) org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:875) javax.servlet.http.HttpServlet.service(HttpServlet.java:733) орг.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:227) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.
java:895) org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal (RequestMappingHandlerAdapter.java:800) org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87) org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1038) org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:942) орг.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:998) org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:890) javax.servlet.http.HttpServlet.service(HttpServlet.java:626) org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:875) javax.servlet.http.HttpServlet.service(HttpServlet.java:733) орг.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:227) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain. java:162) org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.ява: 162) org.apache.catalina.filters.HttpHeaderSecurityFilter.doFilter(HttpHeaderSecurityFilter.java:126) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.servlet.resource.ResourceUrlEncodingFilter.doFilter(ResourceUrlEncodingFilter.java:63) орг.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:101) org.apache.catalina.core.ApplicationFilterChain.
java:162) org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.ява: 162) org.apache.catalina.filters.HttpHeaderSecurityFilter.doFilter(HttpHeaderSecurityFilter.java:126) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.servlet.resource.ResourceUrlEncodingFilter.doFilter(ResourceUrlEncodingFilter.java:63) орг.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:101) org.apache.catalina.core.ApplicationFilterChain. internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:101) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:101) орг.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.boot.web.servlet.support.ErrorPageFilter.doFilter(ErrorPageFilter.java:130) org.springframework.boot.web.servlet.support.ErrorPageFilter.access$000(ErrorPageFilter.java:66) org.springframework.boot.web.servlet.support.ErrorPageFilter$1.doFilterInternal(ErrorPageFilter.java:105) org.
internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:101) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:101) орг.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.boot.web.servlet.support.ErrorPageFilter.doFilter(ErrorPageFilter.java:130) org.springframework.boot.web.servlet.support.ErrorPageFilter.access$000(ErrorPageFilter.java:66) org.springframework.boot.web.servlet.support.ErrorPageFilter$1.doFilterInternal(ErrorPageFilter.java:105) org. springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.springframework.boot.web.servlet.support.ErrorPageFilter.doFilter(ErrorPageFilter.java:123) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.ява: 162) org.springframework.boot.actuate.web.trace.servlet.HttpTraceFilter.doFilterInternal(HttpTraceFilter.java:90) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) орг.springframework.web.filter.RequestContextFilter.doFilterInternal (RequestContextFilter.java: 99) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.
springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.springframework.boot.web.servlet.support.ErrorPageFilter.doFilter(ErrorPageFilter.java:123) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.ява: 162) org.springframework.boot.actuate.web.trace.servlet.HttpTraceFilter.doFilterInternal(HttpTraceFilter.java:90) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) орг.springframework.web.filter.RequestContextFilter.doFilterInternal (RequestContextFilter.java: 99) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain. internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.FormContentFilter.doFilterInternal (FormContentFilter.java: 92) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.HiddenHttpMethodFilter.doFilterInternal (HiddenHttpMethodFilter.ява:93) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.filterAndRecordMetrics(WebMvcMetricsFilter.
internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.FormContentFilter.doFilterInternal (FormContentFilter.java: 92) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.HiddenHttpMethodFilter.doFilterInternal (HiddenHttpMethodFilter.ява:93) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.filterAndRecordMetrics(WebMvcMetricsFilter. java:154) орг.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.filterAndRecordMetrics(WebMvcMetricsFilter.java:122) org.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.doFilterInternal(WebMvcMetricsFilter.java:107) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) орг.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal (CharacterEncodingFilter.java:200) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.
java:154) орг.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.filterAndRecordMetrics(WebMvcMetricsFilter.java:122) org.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.doFilterInternal(WebMvcMetricsFilter.java:107) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) орг.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal (CharacterEncodingFilter.java:200) org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve. java:202) org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97) org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:542) org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:143) org.apache.каталина.клапаны.ErrorReportValve.invoke(ErrorReportValve.java:92) org.apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:687) org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78) org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:357) org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:374) орг.apache.койот.AbstractProcessorLight.process(AbstractProcessorLight.java:65) org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:893) org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1707) org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) java.
java:202) org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97) org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:542) org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:143) org.apache.каталина.клапаны.ErrorReportValve.invoke(ErrorReportValve.java:92) org.apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:687) org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78) org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:357) org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:374) орг.apache.койот.AbstractProcessorLight.process(AbstractProcessorLight.java:65) org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:893) org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1707) org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) java. base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) Ява.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) java.base/java.lang.Thread.run(Thread.java:834)
base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) Ява.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) java.base/java.lang.Thread.run(Thread.java:834)
Могу ли я сфотографировать текст и прочитать его мне?
Платформы World of TTS могут многое сделать для людей со всего мира, и есть так много фантастического программного обеспечения, которое может помочь нам во многих отношениях.
Преобразование текста в речь — очень популярная вспомогательная технология, при которой компьютер или планшет читает человеку вслух слова на экране (иногда ее называют технологией «чтения вслух»). Это устройство используется людьми всех возрастов, а также открывает двери для всех, кто ищет более простые способы доступа к цифровому контенту.
Преобразование текста в речь и использование этой технологии для изображений, безусловно, является преимуществом для повышения производительности. На самом деле преобразование текста в речь день ото дня расширяется благодаря человеческим голосам.
На самом деле преобразование текста в речь день ото дня расширяется благодаря человеческим голосам.
Существует множество онлайн-сервисов для перевода текста в речь, но этот процесс настолько скучен, что за некоторые из этих услуг приходится платить. Однако, используя некоторые бесплатные инструменты, вы можете гораздо проще выполнять перевод текста в речь.
Многие люди считают, что программное обеспечение Woord для преобразования текста в речь дает огромную поддержку людям всех возрастов, чтобы следить за речью текста на компьютере. Прослушивание текста на картинках, который читается вслух естественным голосом, — это новая технология, которая постоянно развивается.Для многих гораздо проще и непринужденнее услышать ошибки через Woord, чем распознать их при чтении.
С помощью этого программного обеспечения вы можете легко преобразовать свой текст в профессиональную речь бесплатно, используя женские или мужские премиальные голоса, делая его более естественным. Он идеально подходит не только для преобразования изображений в речь, но и для людей с дислексией, детей, которые начинают читать, электронного обучения, презентаций, видео на YouTube и повышения доступности веб-сайта.
Woord’s Online Reader — это уникальный инструмент, предназначенный для создания широкого спектра услуг и продуктов с поддержкой искусственного интеллекта, таких как преобразование текста в речь.
Этот сервис преобразования текста в речь говорит в высоком качестве с реалистично звучащими мужскими или женскими голосами премиум-класса. Как вы используете бесплатную онлайн-читалку Woord?
- Просто введите слово или фразу или импортируйте любой документ.
- Выберите скорость речи, которая вам подходит.
- Начать с любой позиции в тексте.
- Повторите текст столько раз, сколько пожелаете.
Зарегистрируйтесь здесь: www.getwoord.com
Если вы хотите послушать несколько аудиозаписей перед регистрацией, вы можете изучить его публичную аудиотеку.
Вы также можете использовать эту услугу, чтобы тренировать навыки аудирования и разговорной речи ваших детей, улучшая их произношение. Кроме того, вы можете слушать любые письменные материалы аутентичными голосами, занимаясь чем-то другим.
Помогите людям с нарушениями зрения, развлеките или обучите своих детей, создав аудиоверсию из письменного контента. Запомните положение паузы, начните говорить с того места, где остановились в последний раз.
Если вам нужна бесплатная служба преобразования текста в речь для различных акцентов, таких как австралийский английский, французский, американский английский, франко-канадский или бразильский португальский, можно использовать Woord.Акценты доступны как в женских, так и в мужских голосах.
В дополнение к английскому языку онлайн-читатель Woord также поддерживает голоса на итальянском, французском, китайском, голландском, немецком, хинди, индонезийском, японском, корейском, польском, португальском, русском и испанском языках.
Если вы хотите взглянуть на расширение Woord для Chrome, нажмите здесь.
Также опубликовано на Medium.
Нравится:
Нравится Загрузка…
РодственныеКак оказалось, картинка не стоит тысячи слов
Интернет — или, точнее, Всемирная паутина — произвел революцию в том, как мы публикуем и потребляем информацию. Одним из наиболее заметных нововведений, появившихся в Интернете, была возможность смешивать текст с другими медиа, такими как изображения и видео, что привело к рождению и успеху таких компаний, как Flickr, imgur, Instagram, YouTube и DailyMotion. Возможность публиковать мультимедийный контент была движущей силой других сдвигов парадигмы в нашем поведении, таких как онлайн-покупки; Что было бы с Amazon без изображений товаров?
Одним из наиболее заметных нововведений, появившихся в Интернете, была возможность смешивать текст с другими медиа, такими как изображения и видео, что привело к рождению и успеху таких компаний, как Flickr, imgur, Instagram, YouTube и DailyMotion. Возможность публиковать мультимедийный контент была движущей силой других сдвигов парадигмы в нашем поведении, таких как онлайн-покупки; Что было бы с Amazon без изображений товаров?
Однако легко упустить из виду тот факт, что текст по-прежнему доминирует в онлайновом обмене информацией.Подавляющее большинство действий, которые мы совершаем в Интернете, по-прежнему основаны на чтении текста: социальные сети, новости, поиск, электронная почта, обзоры продуктов и многие другие. Было подсчитано, что более 80% действий, которые мы совершаем в Интернете, основаны на тексте. Хотя многие из этих онлайн-действий дополняются мультимедийным контентом, основная часть информации по-прежнему исходит из текста, и вряд ли это когда-либо изменится.
Мы, люди, не очень хорошо справляемся с большими объемами текста. Чтение отнимает много времени и может легко перегрузить нас.Неудивительно, что 92% пользователей Google нажимают на ссылку на первой странице результатов: прокрутка длинных списков текста трудна и занимает много времени.
Есть поговорка, что «картинка стоит тысячи слов», но на самом деле между взглядом на картинку и чтением есть принципиальная разница. Наша зрительная система эволюционировала, чтобы обрабатывать изображения в основном параллельно, тогда как текст, появившийся всего несколько тысяч лет назад, требует от нашей зрительной системы сканирования отдельных символов, одного за другим, распознавания их и объединения их в слова, а затем в предложения. и т. д. (аналогичный процесс происходит с идеографическими языками).Можно сказать, что история стоит тысячи слов, а видео стоит тысячи изображений. Но с точки зрения того, как мы обрабатываем информацию, между текстом и изображениями существует фундаментальная пропасть.
Наша биологическая склонность к изображениям отчасти объясняет, почему использование мультимедиа стало таким повсеместным в Интернете. Однако точно так же, как слова не могут реально превратиться в картинки, картинки не могут заменить слова с точки зрения их способности передавать четкую, (в основном) недвусмысленную информацию.И, таким образом, мы застряли в онлайн-опыте, в котором нам приходится страдать от большого количества текста, чтобы узнать, что произошло вчера в мире, что люди думают о ресторане за углом или что наши коллеги обсуждают по электронной почте.
Эта проблема никуда не исчезает, но, к счастью, есть кое-что, что может помочь. Одним из них, конечно же, является использование интерактивных облаков слов, таких как те, которые мы разработали в Infomous, которые упрощают «увидеть» то, что в тренде в большом объеме текста, и исследовать только те вещи, которые мы считаем релевантными. .В качестве забавного примера взгляните на облачное хранилище Review за 2013 год, которое Infomous разработало для USA TODAY. Оно показывает еженедельную визуальную сводку примерно 5 000 статей, опубликованных в USA TODAY.
Оно показывает еженедельную визуальную сводку примерно 5 000 статей, опубликованных в USA TODAY.
Недавно я узнал о Spritz, еще одной очень интересной компании, которая также стремится сделать чтение менее трудоемким. Ребята из Spritz поняли, что когда мы читаем, только около 20 % времени уходит на обработку контента, а остальные 80 % тратятся на перемещение глаз для просмотра текста. Они разработали технологию, которая обеспечивает 90 458 текстовых потоков из 90 459 слов, которые появляются последовательно в фиксированном месте.Благодаря тщательному тестированию и усовершенствованиям они нашли конкретную конфигурацию, которая требует наименьших усилий для чтения текстового потока со все возрастающей скоростью. На сайте Spritz утверждается, что пользователи могут легко удвоить свою обычную скорость чтения, а некоторые испытуемые могут научиться читать до 900 слов в минуту — примерно в 4 раза больше обычной скорости чтения — при этом понимая прочитанное.
Поиграв со Spritz, я обнаружил, что могу без особых проблем дойти до лимита в 600 слов в минуту в их демоверсии. Теперь я не уверен, что смог бы прочитать целую книгу, но, безусловно, для многих онлайн-действий, которые мы делаем каждый день, «брызги» могут быть фантастическим способом сэкономить время и уменьшить усталость глаз.
Теперь я не уверен, что смог бы прочитать целую книгу, но, безусловно, для многих онлайн-действий, которые мы делаем каждый день, «брызги» могут быть фантастическим способом сэкономить время и уменьшить усталость глаз.
Я аплодирую Spritz за решение фундаментальной проблемы того, как мы работаем с онлайн-контентом. На самом деле, я бы сказал, что преобладание текста является одной из самых больших проблем, с которыми мы сталкиваемся при публикации и потреблении информации в Интернете. И все же, именно потому, что это так распространено, большинство людей даже не осознают, что это проблема.
Паоло Гаудиано — ученый, ставший серийным предпринимателем.
Автор сообщения:
Паоло Гаудиано Вернуться к началу. Перейти к: Начало статьи.Что такое эффект превосходства изображения?
9. авг. 2017 г.
Благодаря эффекту превосходства изображения изображения запоминаются гораздо лучше, чем устное слово или письменный текст. Это знал даже великий римский оратор Цицерон. Две тысячи лет назад он рекомендовал использовать образы как часть тренировки памяти.Он также использовал визуальные эффекты в виде реквизита в своих выступлениях. Возможно, это одна из причин, по которой мы до сих пор восхищаемся речами Цицерона 😉
Две тысячи лет назад он рекомендовал использовать образы как часть тренировки памяти.Он также использовал визуальные эффекты в виде реквизита в своих выступлениях. Возможно, это одна из причин, по которой мы до сих пор восхищаемся речами Цицерона 😉
Мы хорошо знаем поговорку о том, что «картинка говорит тысячу слов». Но оказывается, это не просто старое клише! Психологи подтверждают, что изображения узнаются быстрее и быстрее вспоминаются, чем произнесенное или написанное слово.
Этот эффект известен как эффект превосходства изображения. Когда мы читаем текст или слушаем его аудиоверсию, через 3 дня мы, скорее всего, вспомним только 10 процентов информации.Однако мы с большей вероятностью запомним информацию на более длительный период времени, если текст (или его аудиоверсия) будет представлен с подходящими изображениями. На самом деле, если информация представлена нам в виде текста в сочетании с соответствующими изображениями, мы, вероятно, вспомним 65 процентов информации через 3 дня!
Как работает эффект превосходства изображения?Никто не может с абсолютной уверенностью объяснить, как работает эффект превосходства изображения. Похоже, что мозг способен обрабатывать изображения быстрее, чем словесную или письменную информацию.(Ученые считают, что мозг способен обрабатывать изображения примерно в 60 000 раз быстрее, чем он обрабатывает такой же объем письменной информации!)
Некоторые эксперты предполагают, что изображения запоминаются с большей вероятностью, чем слова, потому что наш мозг кодирует изображения двояко: но кодировать слова только один раз. Что это значит? Это означает, что когда вы видите изображение, оно сохраняется в вашей памяти «в виде картинки», но также и «в виде слова». Однако когда вы слышите (или видите) слово, оно сохраняется в вашей памяти только «в виде слова».
Вы, вероятно, прямо сейчас участвуете в эффекте превосходства изображения Эффект превосходства изображения особенно очевиден, если мы посмотрим на корпоративный мир и образование. Только подумайте об этом, гигантские рекламные щиты привлекают внимание; длинных статей на досках объявлений нет. Газетная реклама с картинками приносит больше прибыли, чем многословная реклама. Посты в социальных сетях с фотографиями получают больше лайков!
Только подумайте об этом, гигантские рекламные щиты привлекают внимание; длинных статей на досках объявлений нет. Газетная реклама с картинками приносит больше прибыли, чем многословная реклама. Посты в социальных сетях с фотографиями получают больше лайков!
Как работает эффект превосходства изображения в бизнесе и образовании
Когда учитель объясняет сложную концепцию, ученик, скорее всего, будет гораздо менее уверен в себе, когда ему придется выполнять домашнее задание по предмету через день или два.Однако, когда учитель объясняет, набрасывая несколько диаграмм на доске, у ученика больше шансов успешно выполнить домашнее задание, даже если оно будет выполнено через пару дней. Вот почему учителя держат под рукой доски, чтобы облегчить объяснение, иллюстрируя ключевые понятия!
В любой презентации, независимо от того, проводится ли она в академическом учреждении, политике или в деловом мире, наглядные пособия имеют жизненно важное значение , чтобы сообщение дошло до аудитории. Например, содержание многословных слайдов PowerPoint вряд ли запомнится.(На самом деле, весьма вероятно, что аудитория уже потерялась во время презентации!) Однако слайды с короткими фразами, подкрепленными соответствующими изображениями, гораздо мощнее, чем слайды с полными абзацами.
Например, содержание многословных слайдов PowerPoint вряд ли запомнится.(На самом деле, весьма вероятно, что аудитория уже потерялась во время презентации!) Однако слайды с короткими фразами, подкрепленными соответствующими изображениями, гораздо мощнее, чем слайды с полными абзацами.
Если вы хотите, чтобы ваша аудитория запоминала информацию, вот как максимально эффективно использовать визуальные эффекты:
Визуализируйте, прежде чем выбирать визуальные эффекты!
Попробуйте визуализировать то, что вы хотите передать, особенно если это сложная концепция! Затем постарайтесь дать вашей аудитории взглянуть на визуальные эффекты в вашей голове, чтобы им тоже было легко понять концепцию.
Делайте изображения простыми.
Чем проще изображение, тем легче оно узнается, тем легче запоминается. Таким образом, изображения должны быть простыми и четкими, чтобы добиться оптимального запоминания представленной информации аудиторией.
Сохраняйте актуальность изображения.
Эффект превосходства изображения применяется не только к изображениям, но и к другим изображениям, таким как диаграммы, графики и диаграммы. Что бы вы ни выбрали, важно, чтобы визуальные эффекты соответствовали содержанию, чтобы усилить ваше сообщение.
Рассмотрим самостоятельно созданные образы.
Для оптимального эффекта не нужны высокотехнологичные визуальные эффекты. Относительно простые изображения, созданные самостоятельно, могут быть наиболее запоминающимися, в отличие от более сложной сложной графики.
Используйте метафоры.
Вы можете обеспечить понимание, используя простую метафору в форме изображения. Если это относится к чему-то, что аудитория уже знает или понимает, вы можете легко объяснить сложную концепцию.Аудитория затем будет использовать этот образ в будущем, чтобы запомнить то, что вы передали.
Изображения оказывают существенное положительное влияние на различных уровнях: они привлекают внимание, улучшают понимание и улучшают память.