
Как легко и быстро установить нейронную сеть на домашний ПК / Информационная безопасность, Законы, Программы, ПО, сайты / iXBT Live
Для работы проектов iXBT.com нужны файлы cookie и сервисы аналитики. Продолжая посещать сайты проектов вы соглашаетесь с нашей Политикой в отношении файлов cookie
Продолжаем знакомиться с технологиями ближайшего будущего. Ранее мне уже доводилось рассказывать о способе установки нейронной сети на личный ПК для генерации картинок по любому текстовому запросу. Однако, даже несмотря на весьма подробную инструкцию, у многих пользователей она вызывала затруднения. Всем хотелось простого решения, где всего за два клика можно было бы выполнить установку всего и вся и сразу приступить к генерации желаемых изображений. Ну что же, фанфары, гром и молния! Ваше желание исполнено.
Содержание
- Установка нейронной сети
- Установка модели
- Генерация
- Результат
- Выводы
Stable Diffusion UI – это простая и удобная оболочка с открытым исходным кодом для нейронной сети Stable Diffusion.
Минимальный системные требования:
ОС: Windows 10/11/Linux 64 Бит.
RAM: 8+ Гб.
CPU: 2/4+ ядра 3.0+ ГГц.
GPU: Nvidia с поддержкой CUDA (Возможна работа силами CPU).
В установке нет ничего сложного, благо всё довольно просто.
1. Скачиваем установщик с нейронной сетью.
2. Выполняем распаковку файлов в корень любого диска (Это важно!).
3. После распаковки запускаем в папке
Если входе загрузки появится подобная ошибка, то выполните перезапуск программы.
4. Ближе к завершению установки вас автоматически перенесёт в браузере по адресу localhost:9000. И можно гордо заявить, что дело сделано. Однако не спешите вводить запрос и нажимать Make Image, так как перед нами пока всего лишь тело без мозгов.
И можно гордо заявить, что дело сделано. Однако не спешите вводить запрос и нажимать Make Image, так как перед нами пока всего лишь тело без мозгов.
Чтобы нейронная сеть понимала, что и как рисовать, ей необходимы обученные мозги. Вручную обучать их слишком долго, и ради экономии времени люди создали веб-ресурсы, где делятся заранее обученными моделями.
Популярные ресурсы:
- https://civitai.com/?types=Checkpoint – множество моделей с удобным поиском и демонстрацией результата.
- https://huggingface.co/models – множество различных моделей.
Скачиваем желаемую модель. Я остановил свой выбор на NeverEnding Dream.
Переносим файл обученной модели в:
C:\stable-diffusion-ui\models\stable-diffusion
Перезапускаем нейронную сеть через Start Stable Diffusion UI.cmd и в панели управления выбираем скаченную модель.
На этом установка модели официально завершена и можно переходить к генерации желаемой картинки.
У меня видеокарта AMD и я вынужден всё считать ресурсами CPU. У вас качество и скорость генерации может отличаться.
Мои параметры:
- Запрос: A necromancer girl with green eyes, realistic, ultra HD (Девушка-некромант с зелеными глазами).
- Модель: NeverEnding Dream.
- Количество проходов: 180 (CPU).
- Сэмплер: PLMS.
- Фильтры и стили: подробный, красивое освещение, зло.
- Исправление лица
- Апскейлинг: активирован.
Нажимаем на Make Image.
Если прикупить Nvidia и добавить пару сотен проходов, то станет ещё лучше!
Со всей ответственностью заявляю, что художникам средний руки – кранты! Новое время наступило, и никто не в силах этому помешать. Познавайте, делитесь своими прекрасными творениями и самое главное – никогда не предавайте себя!
ПС. Инструкция для видеокарт AMD.
Новости
Публикации
Мы каждый
день пользуемся смартфонами, и иногда даже не подозреваем, что некоторые
привычные действия могут негативно сказаться на работе гаджета.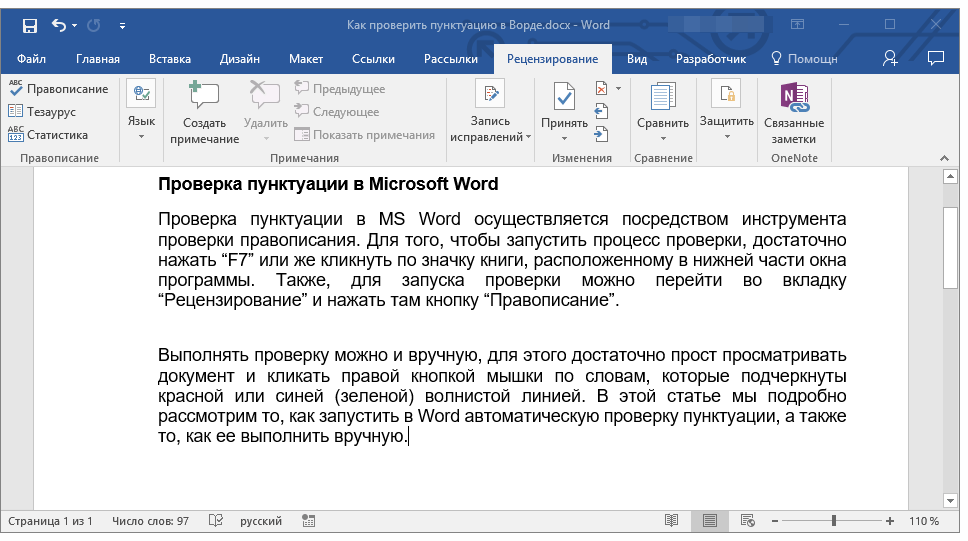
Обнаружилось, что при нахождении в международном роуминге, МТС регулярно списывает деньги за звонки, которых фактически не было. За время моего нахождения в Египте МТС четыре раза списывал…
Защишенные смартфоны Unihertz предлагают своим пользователям высокую степень надежности и защиты, что делает их особенно привлекательными для тех, кто предпочитает активный образ жизни. Эти…
Фрезерный стол на базе фрезера DEKO DKR1600E. Модель представляет собой компактный фрезер для обработки дерева с мощностью 1600 Вт, двумя цангами в комплекте и подарочным набором фрез (RBS12, 12…
Вы, наверняка, слышали о концепции гиперзвуковых самолетов, которые могут сократить время перелетов в несколько раз. Но что, если я скажу Вам, что в скором времени мы можем увидеть сверхзвуковые…
Металлы – это не просто элементы, которые мы используем в повседневной жизни. Они могут быть очень дорогими и иметь огромную ценность для науки и технологий. Всех дороже считается Калифорний-252,…
Всех дороже считается Калифорний-252,…
Как проверять орфографию и грамматику в Excel
Работа в Excel может доставить массу разочарований, когда дело доходит до грамматики. В отличие от Microsoft Word, Excel не вносит автоматических грамматических изменений в вашу работу. Это может быть довольно неловко, когда вы отправляете некачественную работу.
К счастью, существует множество способов исправить ошибки в листах и книгах Excel. В этой статье мы дадим несколько советов о том, как проверять орфографию и грамматику в Microsoft Excel.
Активация проверки грамматики вручную
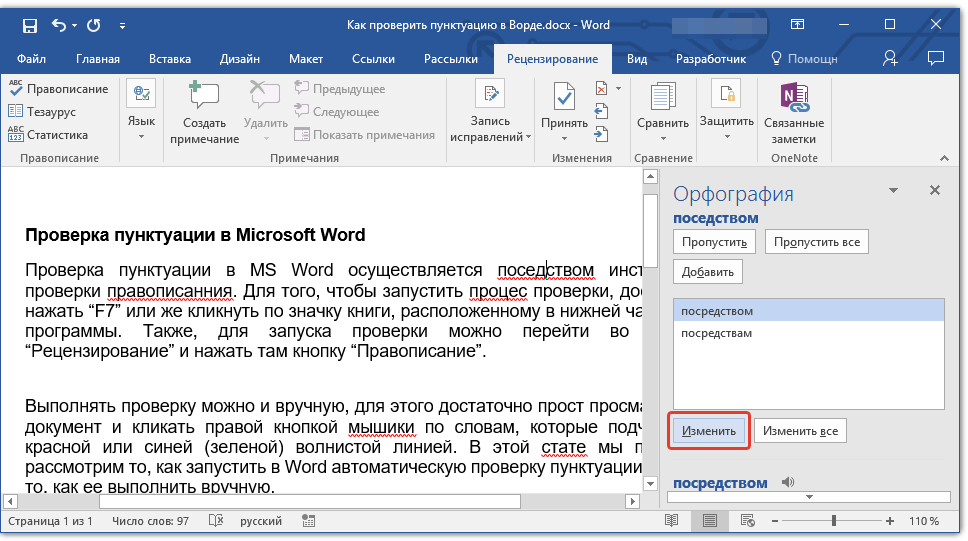
Вы можете активировать проверку орфографии и грамматики, нажав F7 , не выходя из листа Excel. Если это не работает на вашем компьютере, выполните следующие действия, чтобы активировать средство проверки грамматики:
1. Оставаясь в файле Excel, выберите вкладку Review .
2. Нажмите на Правописание .
3. Вы увидите диалоговое окно, содержащее первое слово с ошибкой, с вариантами изменения, игнорирования или добавления его в пользовательский словарь.
Вы увидите диалоговое окно, содержащее первое слово с ошибкой, с вариантами изменения, игнорирования или добавления его в пользовательский словарь.
4. Исправьте орфографическую ошибку, и диалоговое окно автоматически отобразит следующую ошибку.
Различные варианты проверки грамматики
В зависимости от характера вашего файла и объема данных в нем вы можете выбрать один из трех способов проверки грамматики в своей работе. В зависимости от вашей срочности и потребности вы можете проверить отдельные ячейки и диапазоны, выбранные рабочие листы или всю книгу. Вот пошаговое руководство для каждой категории:
1. Проверка отдельных ячеек
- Выберите нужную ячейку и нажмите сочетание клавиш F7 на клавиатуре, чтобы проверить правописание.
- В диалоговом окне отобразятся варианты написания. Выберите способ устранения ошибки: исправление, игнорирование или добавление слова в словарь.
2. Проверка диапазона ячеек
Чтобы проверить орфографию в нескольких ячейках на одном листе:
1. Выберите ячейки, которые вы хотите проверить, например, D3:D10 .
Выберите ячейки, которые вы хотите проверить, например, D3:D10 .
2. Активируйте проверку орфографии, нажав F7 или выбрав Проверить > Правописание .
3. Устраните орфографические ошибки, изменив их, добавив в свой пользовательский словарь или проигнорировав.
3. Проверка правописания на выбранных листах
Вы можете проверить правописание на определенных листах, выбрав их на нижней вкладке.
1. Нажмите клавишу Ctrl на клавиатуре, одновременно щелкая листы, которые вы хотите проверить.
2. Активируйте проверку орфографии, нажав клавишу F7 на клавиатуре.
3. Появится диалоговое окно. Устраните отображаемую орфографическую ошибку. Затем в поле будет последовательно отображаться следующая ошибка, пока весь диапазон рабочих листов не будет безошибочным.
4. Проверка правописания всей рабочей книги
При работе со всей рабочей книгой вы можете облегчить себе работу, проверив ее коллективно.
1. Выберите любой рабочий лист в рабочей книге и щелкните его правой кнопкой мыши, чтобы открыть всплывающее меню.
2. Нажмите «Выбрать все листы».
3. Нажмите клавишу F7 на клавиатуре, появится диалоговое окно проверки правописания.
4. Исправьте орфографические ошибки по мере их появления, пока не дойдете до последнего исправления.
Связано: Чрезвычайно полезные сумасшедшие формулы Microsoft Excel
Проверка грамматики с использованием макросов VBA
Если вы предпочитаете более автоматизированный метод, вам следует использовать макросы проверки орфографии VBA. Эти макросы представляют собой строки кода в Microsoft Excel, которые позволяют вам идентифицировать и заменять слова с ошибками.
Макросы VBA особенно полезны, поскольку они используют визуальные цвета для выделения слов с ошибками, делая их более заметными и легко находимыми. Чтобы использовать макрос VBA, вам необходимо создать макрос VBA в редакторе Excel:
1. Откройте нужный файл Excel.
Откройте нужный файл Excel.
2. Нажмите клавиш Alt+F11 . Откроется окно Excel VBA Editor .
3. Нажмите Вставить > Модуль .
4. Вставьте этот код в Редактор модулей :
Sub ColorMispelledCells()
Для каждого cl In ActiveSheet.UsedRange
If Not Application.CheckSpelling(Word:=cl.Text) Then _
cl.Interior.ColorIndex = 12
Next cl
End Sub
5. Нажмите клавишу F5 на клавиатуре, чтобы запустить макрос.
6. Все слова с ошибками на листе теперь должны быть выделены, как показано на рисунке ниже.
Исправление по мере ввода
Лучший способ сэкономить время в Excel — исправлять ошибки по мере ввода. Таким образом, вы не будете тратить дополнительное время на исправление опечаток, накопившихся за всю рабочую нагрузку. Чтобы исправить ошибки при вводе, вы можете использовать Автозамена и Функции автозаполнения в Excel.
Функция автозаполнения часто используется по умолчанию в большинстве программ Excel. Это поддерживает вашу точность при вводе совпадающих записей в разных ячейках на ваших листах.
Автозамена, с другой стороны, будет исправлять ошибки по мере их возникновения. Однако вам нужно будет активировать его заранее. Вот как вы можете активировать его.
1. Щелкните Файл > Опции .
2. Появится окно параметров Excel. Нажмите на Проверка правописания категория > Параметры автозамены > проверьте распространенные ошибки.
3. Нажмите Ok .
Добавление слов в пользовательский словарь
При вводе иностранных слов, которых нет в словаре, т. е. названия компании или родного имени человека, Excel помечает их как неправильные. Чтобы избежать этого в будущем, вы должны добавить слово в свой пользовательский словарь.
1. Щелкните Файл > Опции > Проверка .
2. Щелкните Пользовательские словари.
3. Выберите пользовательский словарь или создайте новый пользовательский словарь.
Когда ваш пользовательский словарь будет готов, вы можете добавлять в него слова, нажимая кнопку Добавить в словарь каждый раз, когда Excel помечает правильное слово как неправильное. Обратите внимание, что Excel будет игнорировать ошибку, пока слово все еще находится в вашем пользовательском словаре.
Проверка грамматики на разных языках
Вы также можете проверять грамматику текста и записей на разных языках, отличных от языка системы по умолчанию. Для этого:
1. Нажмите Файл > Опции .
2. В диалоговом окне «Параметры Excel» нажмите Языки > Добавить дополнительные языки редактирования .
3. В раскрывающемся меню выберите язык, выберите Добавить .
4. Нажмите Ok .
Дополнительные ресурсы по грамматике в Excel
Тезаурус
Тезаурус Excel — бесценный инструмент для поиска синонимов в программе Excel. Вы можете использовать его, чтобы оживить скучные цепочки повторяющихся данных. Чтобы использовать тезаурус:
1. Щелкните слово, синоним которого вы хотите найти.
2. Нажмите Обзор > Тезаурус .
3. Выберите наиболее подходящее слово и выберите Вставить .
Функция тезауруса полезна для улучшения грамматики в вашем рабочем листе.
Перевод
Функция перевода необходима при работе с записями данных на разных языках. Иногда Excel может пометить слово как написанное с ошибкой, хотя в действительности оно написано на иностранном языке. Чтобы перевести иностранное слово:
1. Нажмите на слово, которое хотите перевести.
2. Выберите Просмотреть > Перевести .
3. В появившемся меню выберите исходный язык и язык целевого .
4. Затем выберите Вставить .
Исследование
Вероятно, вы столкнулись с одним или двумя новыми словами при работе в Excel. Кнопка «Исследовать» позволяет использовать доступные онлайн-ресурсы для получения дополнительной информации по любому вопросу.
Этот инструмент может быть очень полезен, если вы не уверены в значении слова. Чтобы найти слово:
1. Щелкните Review > Research .
2. В появившейся области Search For введите слово, которое вы хотите исследовать.
3. Выберите предпочтительные ссылки в Интернете.
4. Выберите Начать поиск .
Что делать, если проверка орфографии в Excel не работает
Возможно, вам не удалось активировать средство проверки орфографии, так как файл Excel защищен паролем. В этом случае вам нужно будет либо снять эту защиту, либо проверить правописание с помощью макроса.
Другая причина, по которой средство проверки орфографии может не работать, заключается в том, что вы выбрали одну ячейку в режиме редактирования.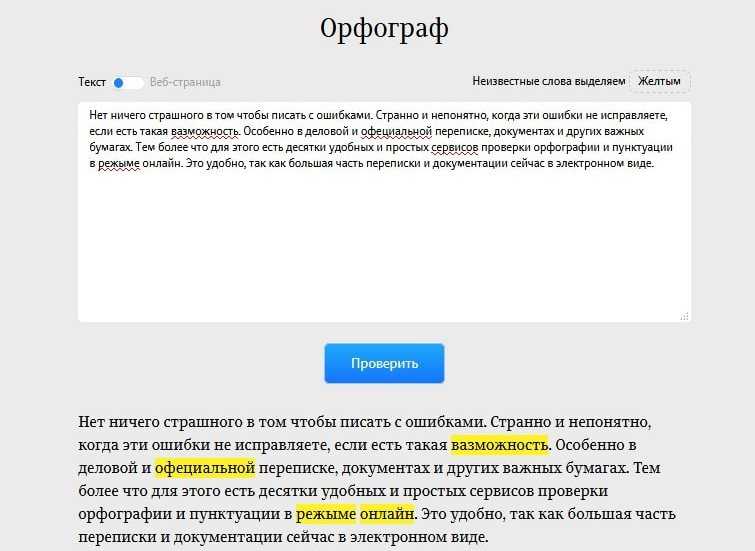 В этом случае средство проверки орфографии будет проверять только выбранную ячейку, а не весь лист. Чтобы решить эту проблему, щелкните вкладку рабочего листа перед запуском проверки орфографии.
В этом случае средство проверки орфографии будет проверять только выбранную ячейку, а не весь лист. Чтобы решить эту проблему, щелкните вкладку рабочего листа перед запуском проверки орфографии.
Обратите внимание, что средства проверки орфографии и грамматики Excel не будут работать с ячейками, содержащими формулы. Для ячеек с формулами вам нужно будет щелкнуть конкретную ячейку, а затем исправить ее в строке формул.
Наконец, ваша проверка орфографии может не работать, если вы не активировали пользовательский словарь Microsoft. Существует множество способов настроить словарь и обеспечить его наилучшую работу во всех ваших программах Microsoft.
Вычитка стала проще
Вычитка файлов Excel вручную никогда не была такой простой. К счастью, вы можете создавать собственные ярлыки, которые помогут вам автоматизировать целые процессы, сделав их намного проще и управляемее.
Сочетание всех методов, описанных в этой статье, гарантирует, что ваша работа будет идеальной без каких-либо следов грубых грамматических ошибок. Так что теперь вы можете попрощаться с некачественными рабочими листами!
Так что теперь вы можете попрощаться с некачественными рабочими листами!
Исправление орфографических ошибок с помощью программно-маскированного BERT
Шаохуа Чжан, Хаоран Хуан, Джиконг Лю, Hang Li
Abstract
Исправление орфографических ошибок является важной, но сложной задачей, поскольку для ее удовлетворительного решения требуется способность понимать язык на уровне человека. Без ограничения общности в данной статье мы рассматриваем исправление китайских орфографических ошибок (CSC). Современный метод решения задачи выбирает символ из списка кандидатов на исправление (в том числе без исправления) в каждой позиции предложения на основе модели языкового представления BERT. Однако точность метода может быть субоптимальной, поскольку BERT не имеет достаточных возможностей для обнаружения ошибки в каждой позиции, по-видимому, из-за способа предварительного обучения с использованием моделирования на языке масок. В этой работе мы предлагаем новую нейронную архитектуру для решения вышеупомянутой проблемы, которая состоит из сети для обнаружения ошибок и сети для исправления ошибок на основе BERT, причем первая связана со второй с помощью того, что мы называем методом мягкого маскирования.
- Anthology ID:
- 2020.acl-main.82
- Volume:
- Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
- Month:
- July
- Year:
- 2020
- Address :
- Online
- Venue:
- ACL
- SIG:
- Publisher:
- Association for Computational Linguistics
- Note:
- Pages:
- 882–890
- Язык:
- URL:
- https://aclanthology.org/2020.

- DOI:
- 10.18653/v1/2020.AC-MAIN.MAIN.8.
- Процитируйте (ACL):
- Шаохуа Чжан, Хаоран Хуан, Джиконг Лю и Ханг Ли. 2020. Исправление орфографических ошибок с помощью BERT с мягкой маской. В материалах 58-го ежегодного собрания Ассоциации компьютерной лингвистики , страницы 882–890, онлайн. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициально):
- Исправление орфографических ошибок с помощью BERT с мягкой маской (Zhang et al., ACL 2020)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2020.acl-main.82.pdf
- Видео:
- http://slideslive.com/38928853
- Код
- 4 Код сообщества дополнение
- 160_subset

- BibTeX
- MODS XML
- Примечание
- Предварительно отформатировано
@inproceedings{zhang-etal-2020-правописание,
title = "Исправление орфографических ошибок с помощью мягкого маскирования {BERT}",
автор = "Чжан, Шаохуа и
Хуан, Хаоран и
Лю, Цзицонг и
Ли, Ханг",
booktitle = "Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики",
месяц = июль,
год = "2020",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology. org/2020.acl-main.82",
doi = "10.18653/v1/2020.acl-main.82",
страницы = "882--890",
abstract = "Исправление орфографических ошибок является важной, но сложной задачей, потому что для ее удовлетворительного решения по существу требуется способность понимать язык на человеческом уровне. Без ограничения общности в этой статье мы рассматриваем исправление китайских орфографических ошибок (CSC). -арт-метод для задания выбирает символ из списка кандидатов на исправление (в том числе неисправленное) в каждой позиции предложения на основе BERT, модели языкового представления Точность метода может быть субоптимальной, однако, поскольку BERT не имеет достаточных возможностей для обнаружения ошибки в каждой позиции, по-видимому, из-за способа предварительного обучения с использованием моделирования языка масок, В этой работе мы предлагаем новую нейронную архитектуру для решения вышеупомянутой проблемы. , который состоит из сети для обнаружения ошибок и сети для исправления ошибок на основе BERT, причем первая связана со второй с помощью того, что мы называем методом мягкого маскирования. Наш метод использования {`}мягкого маскирования BERT{'} является общим, и его можно использовать в других задачах обнаружения-исправления языка. Экспериментальные результаты на двух наборах данных, включая один большой набор данных, который мы создаем и планируем выпустить, демонстрируют, что производительность предложенного нами метода значительно выше, чем у базовых показателей, включая тот, который основан исключительно на BERT».
}

 Наш метод использования {`}мягкого маскирования BERT{'} является общим, и его можно использовать в других задачах обнаружения-исправления языка. Экспериментальные результаты на двух наборах данных, включая один большой набор данных, который мы создаем и планируем выпустить, демонстрируют, что производительность предложенного нами метода значительно выше, чем у базовых показателей, включая тот, который основан исключительно на BERT».
}
Наш метод использования {`}мягкого маскирования BERT{'} является общим, и его можно использовать в других задачах обнаружения-исправления языка. Экспериментальные результаты на двух наборах данных, включая один большой набор данных, который мы создаем и планируем выпустить, демонстрируют, что производительность предложенного нами метода значительно выше, чем у базовых показателей, включая тот, который основан исключительно на BERT».
}
<моды> <информация о заголовке> Исправление орфографических ошибок с помощью BERT с программной маской <название типа="личное">Шаохуа Чжан <роль>автор <название типа="личное">Хаоран Хуан <роль>автор <название типа="личное">Джиконг Лю <роль>автор <название типа="личное">Повесить Ли <роль>автор <информация о происхождении>2020-07 текст <информация о заголовке> Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции Исправление орфографических ошибок является важной, но сложной задачей, поскольку для ее удовлетворительного решения требуется способность понимать язык на уровне человека. zhang-etal-2020-правописание 10.18653/v1/2020.acl-main.82 <местоположение> https://aclanthology.org/2020.acl-main.82 <часть> <дата>2020-07 <единица экстента="страница">882 <конец>890
 Без ограничения общности в данной статье мы рассматриваем исправление китайских орфографических ошибок (CSC). Современный метод решения задачи выбирает символ из списка кандидатов на исправление (в том числе без исправления) в каждой позиции предложения на основе модели языкового представления BERT. Однако точность метода может быть субоптимальной, поскольку BERT не имеет достаточных возможностей для обнаружения ошибки в каждой позиции, по-видимому, из-за способа предварительного обучения с использованием моделирования на языке масок. В этой работе мы предлагаем новую нейронную архитектуру для решения вышеупомянутой проблемы, которая состоит из сети для обнаружения ошибок и сети для исправления ошибок на основе BERT, причем первая связана со второй с помощью того, что мы называем методом мягкого маскирования. . Наш метод использования «мягко-маскированного BERT» является общим, и его можно использовать в других задачах обнаружения-исправления языка. Экспериментальные результаты на двух наборах данных, в том числе на одном большом наборе данных, который мы создали и планируем выпустить, демонстрируют, что производительность предложенного нами метода значительно выше, чем у базовых показателей, включая метод, основанный исключительно на BERT.
Без ограничения общности в данной статье мы рассматриваем исправление китайских орфографических ошибок (CSC). Современный метод решения задачи выбирает символ из списка кандидатов на исправление (в том числе без исправления) в каждой позиции предложения на основе модели языкового представления BERT. Однако точность метода может быть субоптимальной, поскольку BERT не имеет достаточных возможностей для обнаружения ошибки в каждой позиции, по-видимому, из-за способа предварительного обучения с использованием моделирования на языке масок. В этой работе мы предлагаем новую нейронную архитектуру для решения вышеупомянутой проблемы, которая состоит из сети для обнаружения ошибок и сети для исправления ошибок на основе BERT, причем первая связана со второй с помощью того, что мы называем методом мягкого маскирования. . Наш метод использования «мягко-маскированного BERT» является общим, и его можно использовать в других задачах обнаружения-исправления языка. Экспериментальные результаты на двух наборах данных, в том числе на одном большом наборе данных, который мы создали и планируем выпустить, демонстрируют, что производительность предложенного нами метода значительно выше, чем у базовых показателей, включая метод, основанный исключительно на BERT.
%0 Материалы конференции Исправление орфографических ошибок %T с помощью BERT с мягкой маской %А Чжан, Шаохуа %А Хуанг, Хаоран %А Лю, Джиконг %А Ли, Ханг %S Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики %D 2020 %8 июля %I Ассоциация компьютерной лингвистики %С онлайн %F zhang-etal-2020-правописание %X Исправление орфографических ошибок является важной, но сложной задачей, потому что удовлетворительное ее решение требует способности понимать язык на уровне человека. Без ограничения общности в данной статье мы рассматриваем исправление китайских орфографических ошибок (CSC).
 Современный метод решения задачи выбирает символ из списка кандидатов на исправление (в том числе без исправления) в каждой позиции предложения на основе модели языкового представления BERT. Однако точность метода может быть субоптимальной, поскольку BERT не имеет достаточных возможностей для обнаружения ошибки в каждой позиции, по-видимому, из-за способа предварительного обучения с использованием моделирования на языке масок. В этой работе мы предлагаем новую нейронную архитектуру для решения вышеупомянутой проблемы, которая состоит из сети для обнаружения ошибок и сети для исправления ошибок на основе BERT, причем первая связана со второй с помощью того, что мы называем методом мягкого маскирования. . Наш метод использования «мягко-маскированного BERT» является общим, и его можно использовать в других задачах обнаружения-исправления языка. Экспериментальные результаты на двух наборах данных, включая один большой набор данных, который мы создаем и планируем выпустить, демонстрируют, что производительность предложенного нами метода значительно выше, чем у базовых показателей, включая метод, основанный исключительно на BERT.
Современный метод решения задачи выбирает символ из списка кандидатов на исправление (в том числе без исправления) в каждой позиции предложения на основе модели языкового представления BERT. Однако точность метода может быть субоптимальной, поскольку BERT не имеет достаточных возможностей для обнаружения ошибки в каждой позиции, по-видимому, из-за способа предварительного обучения с использованием моделирования на языке масок. В этой работе мы предлагаем новую нейронную архитектуру для решения вышеупомянутой проблемы, которая состоит из сети для обнаружения ошибок и сети для исправления ошибок на основе BERT, причем первая связана со второй с помощью того, что мы называем методом мягкого маскирования. . Наш метод использования «мягко-маскированного BERT» является общим, и его можно использовать в других задачах обнаружения-исправления языка. Экспериментальные результаты на двух наборах данных, включая один большой набор данных, который мы создаем и планируем выпустить, демонстрируют, что производительность предложенного нами метода значительно выше, чем у базовых показателей, включая метод, основанный исключительно на BERT.