
Программа для распознавания текста со сканера: 3 лучших варианта
Очень часто в ходе работы с документами может потребоваться получить какой-либо из них в электронном виде, хотя на руках у пользователя имеется только бумажный распечатанный вариант.
В этом случае и используется сканер, так как изображение, полученное с него легко, например, отправить на электронную почту, тогда как факс есть уже далеко не у всех пользователей.
Ну а в случаях, когда документ требуется именно в текстовом виде, для того, чтобы не перепечатывать его вручную, пользователю нужна будет программа для распознавания текста со сканера.
Содержание:
Принцип действия
Что представляет из себя такая программа, как она работает и каков принцип ее действия?
Такие программы устанавливаются на персональный компьютер, к которому подключен сканер.
У таких программ имеется база возможных визуальных отображений тех или иных печатных символов на множестве мировых языков.
Важно! Обычно, абсолютно все программы поддерживают только русский и английский языки, список же других распознаваемых символьных групп может отличаться. По этой причине, если документ, который вам надо обработать, напечатан на каком либо достаточно редком языке, то перед тем как скачивать программу, убедитесь, что она поддерживает именно этот язык и у нее есть база его символьных групп.
После сканирования какого либо документа, пользователь отправляет это изображение программе, и она просит пользователя указать язык текста, а затем, основываясь на содержании своих баз, ищет соответствия между изображенными на картинке со сканера участками и печатными символами указанного языка.
Причем, если совпадений не найдено, то программа может начать искать их в базах других распространенных языков (например, когда в тексте содержатся ссылки или иные иностранные слова при преобладании другого языка).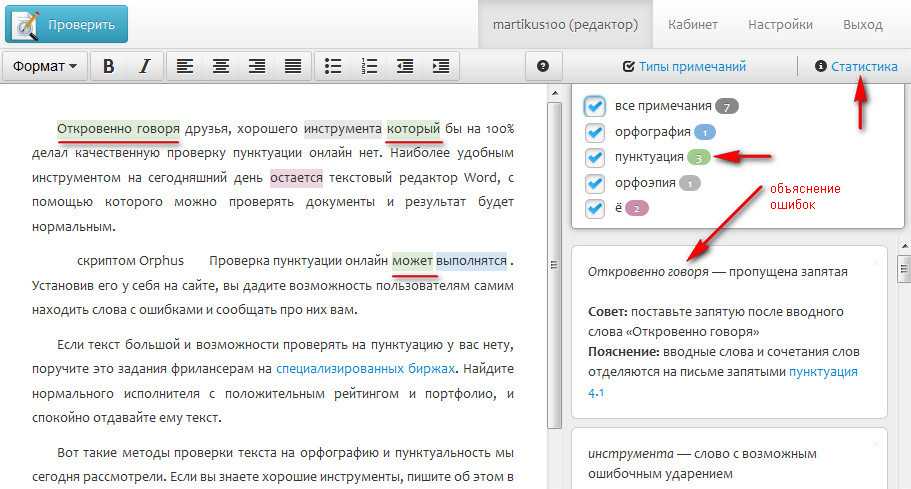
<Рис. 1 Принцип работы>
к содержанию ↑Виды
Есть такие программы, которые синхронизируют свои действия со сканером напрямую, то есть они работают совместно и изображение со сканера сразу попадает в программу.
Другие виды софта работают отдельно, то есть, в них можно загрузить любое текстовое изображение.
Кстати, именно они, обычно, могут работать не только с изображениями со сканера, но с любыми другими – с фотоаппарата, скриншота и т. п.
Кроме того, все эти программы можно разделить на те, что необходимо скачивать на свой компьютер, и те, что работают в режиме онлайн и представлены на сайтах в виде специальных сервисов (качество обработки и распознавания у них, обычно, ниже).
При этом софт, устанавливаемый на ПК, может быть как полностью офлайновым, то есть работать вообще без доступа в интернет, так и при необходимости подключаться к символьным базам на серверах своих разработчиков.
<Рис. 2 Методы распознавания>
к содержанию ↑Сфера применения
Для чего же может потребоваться такое программное обеспечение и в чем его преимущество?
Во-первых, оно позволяет значительно экономить время на перепечатывание текста – это основная цель такого софта и его главное преимущество.
В каких случаях такая возможность бывает необходима?
- При написании научных работ, когда есть необходимость в длительном цитировании;
- При необходимости составить документ, используя текст, имеющийся в образце;
- Пре необходимости перевода большого объема текста, имеющегося в бумажном виде для упрощения процесса его обработки;
- Когда нужно провести редактирование большого объема текста, имеющегося у редактора только в напечатанной форме и т. д.
Таким образом, можно сказать, что данная программа необходима во всех тех случаях, когда пользователю нужно так или иначе обработать или поместить в документ некоторое количество текста, которое есть у него в распечатанном виде.
При этом ручная печать может занимать много времени и сил, хотя стоит отметить, что и распознанный таким программным обеспечением текст также нуждается в последующей редакции вручную.
<Рис. 3 Ход использования>
к содержанию ↑Какие же отрицательные стороны имеют данные программы?
Стоит сказать, что идеальной программы, поддерживающей одинаково качественно большинство относительно распространенных языков, не существует.
Программы могут работать лучше или хуже с какими-то конкретными языками или при некоторых особенностях (например, качественная обработка только первой страницы текста, а затем – существенное снижение качества и т. п.).
И так, в большинстве самых широко распространенных программ пользователи отмечают следующие недостатки:
- Сложно найти программу, которая бы поддерживала тот или иной редкий язык;
- Низкое качество работы с языками азиатских групп, что связано с высокой сложностью символов, которые, именно из-за их высокой сложности, нормально программа распознать не может;
- Неодинаковое качество работы с разными языками, форматированиями, шрифтами – иногда то, что является объектом форматирования, распознается как шрифт и наоборот, может вовсе не обрабатываться какой либо конкретный шрифт;
- Снижение качества работы при большом объеме текста – тогда как первая страница расшифровывается и преобразовывается максимально качественно, то качество предобразования последующих падает от страницы к странице;
- Невозможность нормально работать с грязными или потрепанными бумагами, старыми пожелтевшими книгами с нечеткой печатью – софт может просто не распознавать такие буквы;
- Ошибки такого типа, когда буквы имеют внешнее сходство (в том числе, в разных языках) и распознаются ошибочно.
 В этом случае в некотором софте не помогает даже указание языка исходного документа;
В этом случае в некотором софте не помогает даже указание языка исходного документа; - Ошибки, когда один символ принимается за два или наоборот, обычно, при этом, путаются таким образом именно буквы в разных языках (например, Jl может распознаваться, как русская буква Л и наоборот), причем, при использовании некоторых определенных шрифтов такие неполадки и неточности возникают чаще;
- В документе на выходе часто отсутствует полностью или имеется, но очень некачественное, форматирование.
 В этом случае в некотором софте не помогает даже указание языка исходного документа;
В этом случае в некотором софте не помогает даже указание языка исходного документа;Нужно понимать, что многое в этом смысле зависит и от сканера. От качества изображения, полученного с него – настройки качества изображения должны быть максимальными для наиболее качественного распознавания.
Но если сканер старый, то изображение он может давать нечеткое, в результате чего качество распознавания будет очень низким.
Интересно, что перечисленные недостатки в большей или меньшей степени характерны почти для всех программ, работающих в режиме онлайн или оффлайн.
<Рис. 4 Низкое качество работы>
к содержанию ↑Где взять такую программу?
Как уже говорилось выше, могут иметься онлайновые сервисы обработки фото с текстом таким образом.
Они обладают более низким качеством работы, чаще всего, но зато не занимают память компьютера.
Это, например, такие сервисы, как https://img2txt.com/, https://www.imgonline.com.ua/ocr.php и т. д.
Программы, устанавливаемые на ПК, обычно нужно скачивать.
Ссылки на скачивание такого программного обеспечения будут размещены ниже, отдельно для каждой конкретной программы.
Иногда такие программы поставляются прямо при покупке сканера в пакете его программного обеспечения.
к содержанию ↑Abby Fine Reader
Программа хороша тем, что имеет многоязыковой интерфейс, в том числе можно выбрать и русский язык для удобства использования меню.
Такое программное обеспечение рассчитано для работы в системах Windows, оно имеет хорошие рейтинги и отзывы среди пользователей и также не занимает много памяти.
1Не оказывает значительной нагрузки на аппаратную часть компьютера;
2Работает с разными типами изображений, как с PDF (что актуально для старых операционных систем. Базовые программы для просмотра PDF у которых не давали возможности копирования текстового содержимого), так и с изображениями со сканера и цифрового фотоаппарата;
3Документ на выходе имеет формат, который открывается во всех версиях и видах текстового редактора;
4С большей или меньшей степенью точности он способен сохранять форматирование исходного документа в документе на выходе;
5Работает синхронизировано со сканером или многофункциональным устройством. А также, отдельно от него, при этом поддерживает большинство современных моделей таких устройств;
6Софт может работать со сканером, оснащенным автоподатчиком бумаги, то есть при автоматическом сканировании – нужно лишь правильно выставить настройки.
Работает с форматами PDF, BMP, PCX, DCX, JPEG, JPEG2000, TIFF, PNG, DjVu. Может самостоятельно обрабатывать фото, повышая их качество для улучшения распознавания.
Может самостоятельно обрабатывать фото, повышая их качество для улучшения распознавания.
<Рис. 5 Распознавание>
к содержанию ↑OCR CuneiForm
В отличие от программы, описанной выше, у которой бесплатно работает только демо-версия на 15 дней, эта предоставляется полностью бесплатно и в этом ее значительный плюс.
Однако имеется и минус – качество распознавания текста у нее гораздо ниже, чем у предыдущей программы.
Но все же функционал достаточно значительный, особенно, для бесплатной программы.
Программа способна распознавать не только текст, но и изображения, и даже таблица (как разлинованные, так и не разлинованные), списки.
Такие возможности вообще недоступны некоторым платным программам.
Приложение даже может сохранить краткие данные об оформлении исходного текста на фото – его шрифт, размер, интервалы и т. п. (интересно, что эта функция доступна даже при распознавании текста, напечатанного на пишущей машинке).
К недостаткам программы, помимо неточности в работе, можно отнести малое количество поддерживаемых языков, по сравнению с аналогичным софтом.
К преимуществам относится способность работать с копиями плохого качества, достаточно грязными ксерокопиями. Использование словарей для контроля орфографии и, конечно, бесплатное распространение.
Скачать ее можно по ссылке http://programdownloadfree.com/load/text/scanning_recognition/ocr_cuneiform/74-1-0-131.
<Рис. 6 Abby Fine Reader>
к содержанию ↑WinScan2PDF
Winscan2pdf — это скорее не программное обеспечение, а утилита, которая не требует установки. Рабочий файл очень легкий, так что она почти не занимает память компьютера и не оказывает нагрузки на его аппаратную часть.
Распознавание и обработка происходят очень быстро даже по сравнению с двумя программами, описанными выше. Однако готовый результат сохраняется только в формате PDF.
Управление предельно простое – нужно только запустить программу. Указать файл и указать, куда сохранить результат, а затем нажать на кнопку запуска процесса.
Указать файл и указать, куда сохранить результат, а затем нажать на кнопку запуска процесса.
Языковой пакет достаточно значительный, утилита, несмотря на свою простоту, рассчитана на работу с большими объемами текста.
<Рис. 7 OCR CuneiForm>
К плюсам утилиты относятся высокая скорость работы, простота в применении и высокая портативность, мобильность, малый вес.
Существенный недостаток – только один формат файла с обработанным текстом.
8.5 Рейтинг
Как напечатать текст на фото, рисунке
Напечатать текст на фотографии или рисунке можно в бесплатной программе, которая встроена в систему Windows. Называется она Paint.
Для ее запуска щелкните по Пуск, в списке найдите «Стандартные-Windows» и выберите Paint.
Примерно так выглядит программа:
Сначала откройте в ней то фото или картинку, на которую нужно нанести надпись. Для этого нажмите на в левом верхнем углу и щелкните по «Открыть».
Появится окно для выбора картинки. Обычно компьютер предлагает найти ее в папке «Изображения», но можно указать и другое место. Для этого воспользуйтесь левой частью окошка.
Когда откроете нужное место и найдете рисунок (фото), кликните по нему два раза левой кнопкой мышки.
Чтобы найти изображение быстрее, щелкните правой кнопкой внутри окошка (по белой части), из списка выберите «Вид» и укажите «Крупные значки», «Огромные значки» или «Эскизы страниц».
Изображение добавится в программу. Часто оно довольно большого размера и целиком не помещается (как будто обрезается). Для уменьшения масштаба используйте ползунок в правом нижнем углу.
Теперь, когда картинка открыта, на ней можно напечатать текст. Для этого щелкните по кнопке с буквой «А» в верхней панели.
Для этого щелкните по кнопке с буквой «А» в верхней панели.
Далее наведите на ту часть фото, где хотите сделать надпись, и кликните один раз левой кнопкой мыши. Высветится область для ввода текста.
При этом в верхней панели программы появятся инструменты оформления: шрифт, размер букв, начертание (полужирный, курсив и другие).
Рядом можно выбрать цвет букв.
По умолчанию текст будет печататься на прозрачном фоне. Но иногда нужно, чтобы он находился на плашке какого-то цвета. В этом случае кликните по пункту «Непрозрачный» вверху, затем по «Цвет 2» и выберите заливку.
Укажите нужные параметры (шрифт, размер и другие) и напечатайте текст.
Если в процессе нужно изменить настройки, выделите буквы. Для этого нажмите левую кнопку мышки в конце набранного текста и, не отпуская ее, тяните в начало.
Когда надпись выделится (закрасится), можно изменить ее через верхнюю панель — увеличить или уменьшить размер, поменять шрифт, сделать полужирной, курсивной или подчеркнуть.
Кстати, размер букв можно указать и больше максимального значения (72). Для этого удалить цифры в поле выбора, напечатать другие (например, 150) и нажать клавишу Enter на клавиатуре.
Для закрепления надписи (окончательного её нанесения) щелкните по пустому месту левой кнопкой мыши.
На заметку. После печати у вас, скорее всего, не получится отредактировать надпись. Можно будет только отменить ее, нажав на иконку вверху.
Чтобы внести изменения в рисунок, то есть записать его в компьютер в новом виде, нужно сделать сохранение. Самый простой способ: нажать на пункт «Файл» в левом верхнем углу программы и выбрать «Сохранить». Или нажать на иконку с изображением дискеты (). В этом случае изначальное фото перезапишется — заменится новым вариантом.
Но я рекомендую поступать иначе: сохранять копию картинки. Тогда на компьютере будет два варианта: и изначальный, и с надписью. Для этого щелкните по пункту «Файл» в левом верхнем углу и выберите «Сохранить как…».
Появится окошко, в котором перейдите в ту папку компьютера, куда нужно записать новое фото. Например, на Рабочий стол.
Например, на Рабочий стол.
В поле «Имя файла» введите для него название. То есть сотрите то, которое указано по умолчанию, и наберите другое (например, цифру). И щелкните по «Сохранить».
Картинка будет записана в то место и под тем названием, которое вы выбрали.
Автор: Илья Кривошеев
Извлечение текста из изображения с помощью Python | Misha SV
Фотография Яна Шнайдера на UNSPLASHСОДЕРЖАНИЕ
- ВВЕДЕНИЕ
- Образец изображения
- Текст извлечения из одного изображения с использованием Python
- Извлечение текста из множественных изображений с использованием Python
- Заключение
. текст из изображений — очень популярная задача в операционных подразделениях бизнеса (извлечение информации из счетов и квитанций), а также в других областях.
OCR (оптическое распознавание символов) — это электронный компьютерный подход к преобразованию изображений текста в машинно-кодированный текст, который затем можно извлечь и использовать в текстовом формате.
Чтобы продолжить следовать этому руководству, нам понадобится:
- Tesseract
- pytesseract
- подушка
Tesseract — это механизм OCR (оптическое распознавание символов) с открытым исходным кодом, который позволяет извлекать текст из изображений.
Чтобы использовать его в Python, нам также понадобится библиотека pytesseract , которая является оболочкой для движка Tesseract.
Поскольку мы работаем с изображениями, нам также понадобится библиотека Pillow , которая добавляет возможности обработки изображений в Python.
Сначала найдите программу установки Tesseract для вашей операционной системы. Для Windows вы можете найти последнюю версию установщика Tesseract здесь. Просто скачайте файл .exe и установите его на свой компьютер.
Если у вас не установлены библиотеки Python, откройте «Командную строку» (в Windows) и установите их, используя следующий код:
pip install pytesseract
pip install Pillow
Чтобы продолжить этот урок, нам понадобятся некоторые изображения для работы.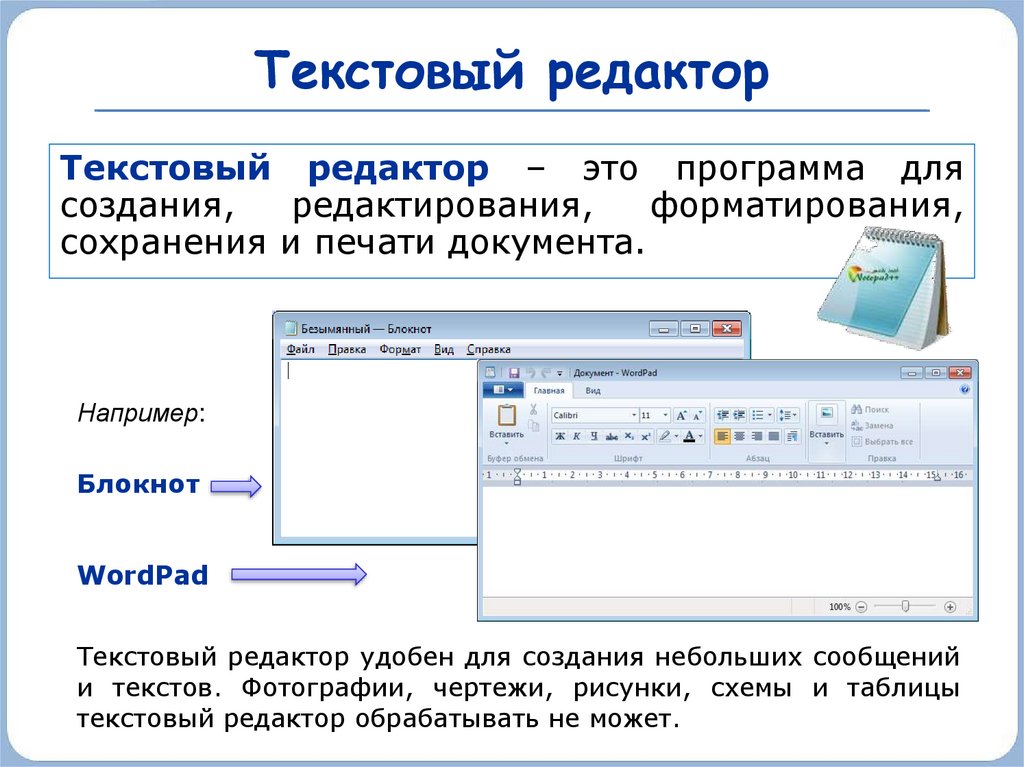
Вот три изображения, которые мы будем использовать в этом уроке:
Изображение от AuthorImage от AuthorImage от AuthorВ этом уроке мы будем использовать простые изображения с текстом, выровненным по горизонтали, которые не требуют дополнительной обработки изображения.
Начнем с извлечения текста из одного изображения с помощью Python.
В этом примере мы будем работать с первым изображением, представленным в предыдущем разделе: sampletext1-ocr.png
Вот как выглядит структура моих файлов:
Изображение автораВсе изображения размещены в папке images и код находится в main.py
Путь к нам нужно изображение: images/sampletext1-ocr.png
Еще один путь, который нам нужен, это путь к tessaract.exe , который был создан после установки. В Windows он должен находиться в: C:\Program Files\Tesseract-OCR\tesseract.exe
Теперь у нас есть все необходимое, и мы можем легко извлечь текст из изображения с помощью Python:
И вы должны получить:
Образец текста 1
В этом разделе мы рассмотрим, как извлечь текст из нескольких изображений с помощью Python.
Мы знаем, что все изображения размещены в папке images , а код находится в main.py
Одним из способов извлечения текста из каждого изображения было бы использование имен файлов каждого изображения и извлечение текста из этих изображения одно за другим.
Но что, если у нас в папке 100 изображений? Используя библиотеку os , мы можем получить доступ ко всем именам файлов в данном каталоге.
Как только мы получим доступ ко всем именам файлов в папке images , мы пройдемся по ним и извлечем текст из каждого изображения с помощью Python:
И вы должны получить:
Sample Text 1
Sample Text 2
Образец текста 3
, который является именно тем текстом, который у нас есть на изображениях.
В этой статье мы рассмотрели, как извлечь текст из одного изображения и нескольких изображений с помощью Python и Tesseract.
Не стесняйтесь оставлять комментарии ниже, если у вас есть какие-либо вопросы или предложения по некоторым изменениям, и ознакомьтесь с другими моими руководствами по программированию на Python.
Первоначально опубликовано по адресу https://pyshark.com 12 мая 2022 г.
А.И. программа под названием DALL-E превращает ваши слова в картинки
Программа DALL-E Mini от группы разработчиков с открытым исходным кодом не идеальна, но иногда она действительно позволяет создавать изображения, соответствующие текстовым описаниям людей.
Скриншот
В последнее время, просматривая ленты новостей в социальных сетях, вы наверняка заметили иллюстрации, сопровождаемые подписями. Они сейчас популярны.
Картинки, которые вы видите, вероятно, созданы программой преобразования текста в изображение под названием DALL-E. Перед публикацией иллюстраций люди вставляют слова, которые затем преобразуются в изображения с помощью моделей искусственного интеллекта.
Например, пользователь Твиттера опубликовал твит с текстом «Быть или не быть, раввин держит авокадо, мраморная скульптура». На прилагаемом изображении, довольно изящном, изображена мраморная статуя бородатого мужчины в мантии и котелке, сжимающего авокадо.
Модели ИИ взяты из программного обеспечения Google Imagen, а также из OpenAI, стартапа, поддерживаемого Microsoft, который разработал DALL-E 2. На своем веб-сайте OpenAI называет DALL-E 2 «новой системой ИИ, которая может создавать реалистичные изображения и искусство из описания на естественном языке».
Но большая часть того, что происходит в этой области, исходит от относительно небольшой группы людей, которые делятся своими фотографиями и, в некоторых случаях, вызывают активное участие. Это связано с тем, что Google и OpenAI не сделали эту технологию широко доступной для общественности.
Многие из первых пользователей OpenAI являются друзьями и родственниками сотрудников. Если вы ищете доступ, вы должны присоединиться к списку ожидания и указать, являетесь ли вы профессиональным художником, разработчиком, академическим исследователем, журналистом или онлайн-создателем.
«Мы прилагаем все усилия, чтобы ускорить доступ, но, вероятно, потребуется некоторое время, прежде чем мы доберемся до всех; по состоянию на 15 июня мы пригласили 10 217 человек попробовать DALL-E», — написала Джоан Джанг из OpenAI на странице справки на сайт компании.
Одной из общедоступных систем является DALL-E Mini. он основан на открытом исходном коде слабо организованной команды разработчиков и часто перегружен спросом. Попытки использовать его могут быть встречены диалоговым окном с надписью «Слишком много трафика, попробуйте еще раз».
Это немного напоминает службу Gmail от Google, которая в 2004 году привлекала людей неограниченным пространством для хранения электронной почты. Ранние пользователи могли войти в систему только по приглашению, оставив миллионы ждать. Сейчас Gmail — один из самых популярных почтовых сервисов в мире.
Создание изображений из текста никогда не будет таким распространенным явлением, как электронная почта. Но у технологии, безусловно, есть момент, и часть ее привлекательности заключается в эксклюзивности.
Частная исследовательская лаборатория Midjourney требует, чтобы люди заполнили форму, если они хотят поэкспериментировать с ее ботом для создания изображений из канала в приложении чата Discord. Только избранная группа людей использует Imagen и публикует изображения с него.
Только избранная группа людей использует Imagen и публикует изображения с него.
Службы преобразования текста в картинку сложны, они определяют наиболее важные части подсказок пользователя, а затем угадывают лучший способ проиллюстрировать эти термины. Google обучил свою модель Imagen с сотнями собственных чипов искусственного интеллекта на 460 миллионах внутренних пар изображение-текст в дополнение к внешним данным.
Интерфейсы просты. Обычно есть текстовое поле, кнопка для запуска процесса генерации и область ниже для отображения изображений. Чтобы указать источник, Google и OpenAI добавляют водяные знаки в правый нижний угол изображений с DALL-E 2 и Imagen.
Компании и группы, разрабатывающие программное обеспечение, справедливо обеспокоены тем, что все сразу штурмуют ворота. Обработка веб-запросов для выполнения запросов с помощью этих моделей ИИ может стать дорогостоящей. Что еще более важно, модели не идеальны и не всегда дают результаты, которые точно представляют мир.
Инженеры обучали модели на обширных коллекциях слов и изображений из Интернета, включая фотографии, размещенные людьми на Flickr.
OpenAI, базирующаяся в Сан-Франциско, признает потенциальный вред, который может исходить от модели, которая научилась создавать изображения, по сути, просматривая Интернет. Чтобы попытаться снизить риск, сотрудники удалили из данных обучения материалы, содержащие насилие, и существуют фильтры, которые не позволяют DALL-E 2 генерировать изображения, если пользователи отправляют запросы, которые могут нарушать политику компании в отношении наготы, насилия, заговоров или политического контента.
«Процесс повышения безопасности этих систем продолжается», — сказал Прафулла Дхаривал, научный сотрудник OpenAI.
Предвзятость в результатах также важна для понимания и представляет более широкую проблему для ИИ. Борис Дайма, разработчик из Техаса, и другие, работавшие над DALL-E Mini, изложили проблему в описании своего программного обеспечения.