
Конвертер изображения в текст – извлечение текста из изображения
Изображение В Текст
Превратите изображение в текст с помощью нашего бесплатного конвертера изображений в текст. Просто загрузите свои фотографии в OCR онлайн и извлеките текст из изображения одним щелчком мыши.
ADVERTISEMENT
Загрузить или перетащить несколько изображений для извлечения текста.
Конвертер изображения в текст:
Это онлайн-инструмент, конвертирующий текст изображения в редактируемый текстовый формат. Разработан с помощью OCR (оптического распознавания символов), технологии, которая получает информацию из изображений и преобразует ее в электронную копию .
Как работает инструмент преобразования изображения в текст?
Основанный на технологии оптического распознавания символов, инструмент преобразования изображения в текст разрабатывается с помощью машинного обучения, при котором устройство обучается в первую очередь.
Различные шаблоны символов подразделяются на разные прототипы. Обычно устройство OCR выполняет следующие функции:
Обычно устройство OCR выполняет следующие функции:
- Вход
- Сканирование
- Сегментация местоположения
- Извлечение функций
- Обучение и признание
- Вывод
Как использовать это изображение в текстовый инструмент?
Этот инструмент получает все типы изображений в текстовые файлы. Следуй этим шагам.
- Перетащите или загрузите изображение в указанную область.
- Результат будет отображаться в текстовом поле.
- Впоследствии вы можете сохранить его или скопировать текст..
Основные особенности:
Средство извлечения изображений с низким разрешением:
Наш инструмент извлекает даже размытые изображения с низким разрешением. Изображения книг, самописные книги и скриншоты тусклые, и их трудно понять. Тем не менее, этот инструмент может получать данные из таких изображений .
Определить математический синтаксис:
Этот инструмент для преобразования фото в текст содержит широкий спектр данных, введенных в него посредством машинного обучения. Вы можете использовать его для обнаружения математических проблем. Арифметические уравнения и полиномиальные выражения часто бывают сложными, но наш инструмент идентифицирует их как человека .
Вы можете использовать его для обнаружения математических проблем. Арифметические уравнения и полиномиальные выражения часто бывают сложными, но наш инструмент идентифицирует их как человека .
Бесплатное использование:
Этот инструмент доступен всем. Вы можете извлечь текст из изображения без регистрации .
Обрабатывает несколько языков:
Отличной особенностью этого инструмента является его универсальность в понимании множества языков. С помощью этого инструмента вы можете преобразовать изображения на нескольких языках в текст. Эти языки включают английский, французский, испанский, румынский, индонезийский и т. Д.
Извлекает изображения во всех форматах:
Используя этот инструмент, вы можете извлекать изображения во всех форматах. Например:
- JPG
- PNG
- JPEG
- BMP
- GIF
- TIFF
Зачем использовать наш инструмент для преобразования изображения в текст?
Автоматизация бизнеса:
Обычная бумажная работа стала антикварной вещью в ведении бизнеса. Автоматизированные предприятия сейчас занимают лидирующие позиции в деловом мире .
Автоматизированные предприятия сейчас занимают лидирующие позиции в деловом мире .
В частности, ручная работа с документами для создания баз данных очень трудоемка и дорога.
С помощью онлайн-распознавания текста вы можете упростить всю свою административную работу. Более того, он может оптимизировать ваше оборудование, индексируя необходимую информацию и извлекая ее, когда захотите .
Банковский сектор:
В эту эпоху мы говорим, что данные – это новая нефть. Это означает, что, понимая данные и манипулируя ими для нашего использования, мы можем открыть новые горизонты. Наш конвертер изображений в текст поможет вам хранить, связывать, понимать и манипулировать данными. Кроме того, данные, введенные вручную, подвержены ошибкам. Банки могут использовать OCR для сохранения своих баз данных с полезной, но органичной информацией о своих клиентах, просто сканируя документы. Более того, это избавляет их от непредвиденных обстоятельств, связанных с хранением данных в твердой форме, таких как пожар, подделка и кража .
Сектор здоровья:
Сектор здравоохранения может обновить свои настройки, полагаясь на OCR. Они могут использовать электронные медицинские записи, такие как страховка, история болезни пациента, удостоверения личности и т. Д.
Оцифровка документов
С помощью этого конвертера изображений в текст мы можем преобразовать печатные документы в оцифрованные версии.
Заметки учащихся
С помощью нашего онлайн-конвертера изображений в текст мы можем преобразовать рукописные изображения заметок в текст
Газетные СМИ
Возможно, новостями из газет нужно поделиться в социальных сетях или в группах WhatsApp. Этот инструмент может позволить вам конвертировать печатные материалы в цифровой формат. С помощью этой бесплатной технологии OCR вы можете быстро преобразовывать изображения в текст.
Доступно на нескольких языках
Языки:: 中国人 OCR, Bahasa Indonesia OCR, dansk OCR, Deutsch OCR, English OCR, español OCR, français OCR, italiano OCR, 中国人 OCR, português OCR, română OCR, svenska OCR, čeština OCR, русский OCR, ไทย OCR, 한국어 OCR,
Recommended Article
Как из картинки вытащить текст в word
Распознавание текста на изображении онлайн
Главное нужно указать изображение с текстом на вашем компьютере или телефоне, обязательно выбрать основной язык текста и нажать кнопку OK внизу страницы.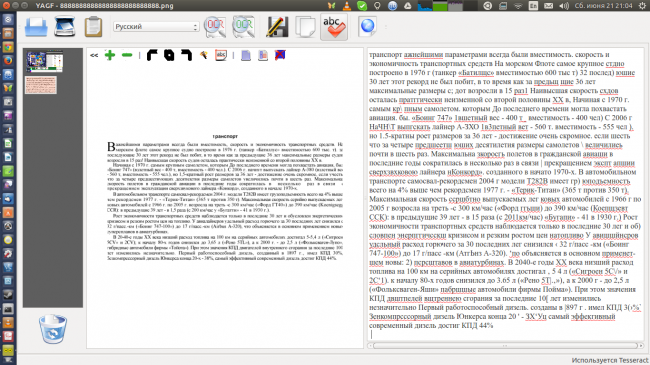 Остальные настройки уже выставлены по умолчанию.
Остальные настройки уже выставлены по умолчанию.
Пример сфотографированного текста из книги и скриншот распознанного текста на этой фотографии:
В зависимости от размера исходного изображения и количества текста обработка может продлиться около 1 минуты.
Для достижения лучшего результата распознания текста желательно обратить внимание на подсказки возле настроек. Перед обработкой изображение нужно повернуть на нормальный угол, чтобы текст шёл в правильном направлении и небыл перевёрнут вверх ногами, а также желательно обрезать лишние однотонные края без текста, если они есть.
Обе OCR-программы для распознования текста отличаются друг от друга и могут давать разные результаты, что позволяет выбрать наиболее приемлемый вариант из двух.
Исходное изображение никак не изменяется, вам будет предоставлен распознанный текст в обычном текстовом документе в формате .txt с кодировкой utf-8 и после обработки его можно будет открыть прямо в окне браузера или же после скачивания – в любом текстовом редакторе.
Как из картинки сделать текст в ворде
Перед каждым пользователем ПК хоть раз возникала необходимость получения текстовой информации из картинок. Работая в программах для набора, иногда приходится перепечатывать текст, находящийся в растровом или векторном изображении. Этот долгий процесс можно сократить, если знать, как из картинки вытащить текст в Word.
Для преобразования текста на картинке в документ Ворд — следуйте инструкциям ниже
Выход из ситуации
Обычно процесс распознавания с изображения достаточно трудоёмкий. В нём основную работу придётся делать вручную, но конечный результат сэкономит общее затраченное время. Это бывает необходимо, когда в распоряжении присутствует только электронное изображение документа или страницы книги, с которой нужно вытащить текст.
Вместо собственноручного перепечатывания информации, можно воспользоваться специализированными программами и сервисами, которые автоматизируют эту работу. Они позволяют распознать текст, используя картинки большинства популярных форматов, среди которых jpg, gif и png.
Порядок работ
Если данные находятся на печатном документе, с него придётся предварительно сделать изображение. Для этого потребуется сканер. Также это бывает необходимо, если текст на картинке имеет плохое разрешение или он размытый. К сканеру должны прилагаться «родные» драйвера и программы, которые позволят перевести всё в высоком качестве. На результат влияет не только чёткость букв, но и их «ровное» положение, а также отсутствие помех.
Если вам необходимо получить текст с бумажного носителя — потребуется сканер
При неимении сканера можно обойтись фотоаппаратом. В этом случае потребуется правильно выставить свет. На следующем этапе требуется использование специальных программ, которые позволят непосредственно распознать текст с jpg. Среди таких программ особое место занимает ABBYY FineReader, которая считается лидером на рынке. Она платная, но её качество соответствует стоимости.
Особенности процесса
В функционале программного обеспечения присутствует много функций, позволяющих работать с большинством шрифтов. Среди передовых возможностей присутствует способность распознать рукописный текст Word из jpg. Она имеет много преимуществ:
Среди передовых возможностей присутствует способность распознать рукописный текст Word из jpg. Она имеет много преимуществ:
- выбор качества. Пользователь может сам остановить предпочтительное качество для сканирования. Лучше выбирать не ниже 300 DPI, чтобы программа затрагивала для обработки даже мелкие детали, и смогла работать с мелкими шрифтами.
- цветность. Необходимо, когда на изображении присутствуют таблицы или другая символика. В других же вариантах предпочтительно выбирать чёрно-белый режим, который уберёт смещения цветового диапазона с букв, сделав их чище. Цветной режим подойдёт для ярких картинок, где важно передать цвет текста.
- фотография. Если картинка выполнена снимком, программа повысит приоритет сканирования. Также можно непосредственно с ABBYY FineReader сфотографировать текст, чтобы распознать его в jpg. Правда, это сильно ухудшит качество, отчего финальный результат будет иметь много ошибок.
Среди аналогичных программ присутствуют также бесплатные сервисы. Среди них выделяется также Google Drive, которая доступная непосредственно в браузере. Работа с OCR Convert имеет среднее качество, поэтому подходит для тех, у кого изображение имеет высокое расширение и чёткие шрифты. Сервис i2OCR предлагает аналогичные услуги, только картинки можно ещё загрузить с URL-ссылки. Они имеют больше любительский формат, поэтому не рассматриваются для профессионального использования.
Среди них выделяется также Google Drive, которая доступная непосредственно в браузере. Работа с OCR Convert имеет среднее качество, поэтому подходит для тех, у кого изображение имеет высокое расширение и чёткие шрифты. Сервис i2OCR предлагает аналогичные услуги, только картинки можно ещё загрузить с URL-ссылки. Они имеют больше любительский формат, поэтому не рассматриваются для профессионального использования.
Открыв картинку через Google Документы, вы получите документ с уже распознанным текстом
Получить результат
После начала сканирования обычно проходит пару минут, чтобы получить результат. Этот показатель зависит от сложности и количества располагаемого текста. После старта работы, программы в автоматическом режиме будут выделять участки для проверки, и преобразовать их. После окончания процесса, можно повторно распознать jpg данные, или сосредоточиться на определённых участках документа.
Готовый результат экспортируется в файл Word. Полученный текст можно редактировать при наблюдении ошибок, или продолжить с ним дальнейшую работу. Распознать текст с jpg картинок не представляет труда, если правильно подготовить изображение. Этот процесс может существенно сэкономить время, в отличие от ручного перепечатывания информации.
Распознать текст с jpg картинок не представляет труда, если правильно подготовить изображение. Этот процесс может существенно сэкономить время, в отличие от ручного перепечатывания информации.
Поскольку работа с распознаванием текста с картинки требует качественного исходника, нужно изначально найти изображение с высоким разрешением. Это ускорит сам процесс обработки данных, а также уменьшит общий объем ошибок.
Как вставить отсканированный текст или изображения в Word
Если вы хотите вставить в документ Word печатный документ или рисунок, это можно сделать несколькими способами.
Примечание: Если вам нужно получить инструкции по подключению сканера или копироватора к Microsoft Windows, посетите веб-сайт службы поддержки изготовителя вашего устройства.
Сканирование изображения в Word
Для сканирования изображения в документ Word можно использовать сканер, многофункциональный принтер, копировальный аппарат с возможностью сканирования или цифровую камеру.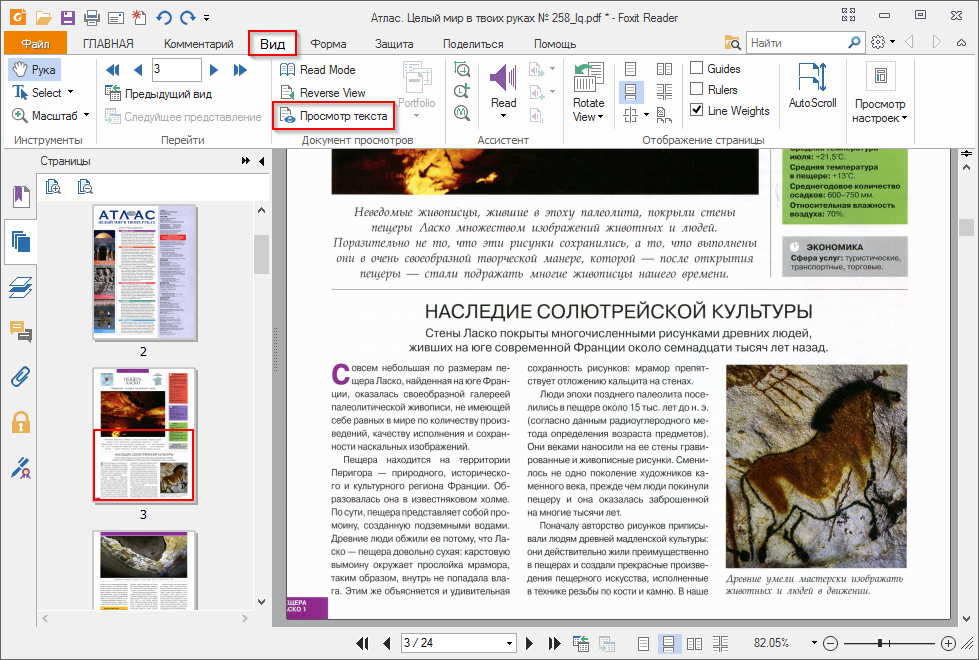
Отсканируйте изображение или сделайте его снимок с помощью цифровой камеры или смартфона.
Сохраните изображение в стандартном формате, таком как JPG, PNG или GIF. Поместите его в папку на своем компьютере.
В Word, поместите курсор туда, куда вы хотите вставить отсканированное изображение, а затем на вкладке Вставка нажмите кнопку Рисунки.
Выберите отсканированный рисунок в диалоговом окне и нажмите кнопку Вставить.
Вставка отсканированного текста в Word
Для сканирования документа в Microsoft Word проще всего использовать наше бесплатное приложение Office Lens на смартфоне или планшете. Оно получает снимок документа с помощью камеры устройства и сохраняет его в виде редактируемого документа непосредственно в Word. Она доступна бесплатно на iPad,iPhone,Windows Phone и Android.
Если вы не хотите использовать Office Lens, лучше всего отсканировать документ в формате PDF с помощью программного обеспечения сканера, а затем открыть его в Word.
В Word выберите Файл > Открыть.
Перейдите к папке, в которой хранится PDF-файл, и откройте его.
Word откроет диалоговое окно, в котором нужно подтвердить импорт текста PDF-файла. Нажмите кнопку ОК, Word импортировать текст. Word постарается сохранить форматирование текста.
Примечание: Точность распознавания текста зависит от качества сканирования и четкости отсканированного текста. Рукописный текст редко распознается, поэтому для лучших результатов сканируйте печатные материалы. Всегда проверяйте текст после его открытия в Word, чтобы убедиться, что он правильно распознан.
Кроме того, со сканером может поставляться приложение для распознавания текста (OCR). Обратитесь к документации своего устройства или к его производителю.
Остались вопросы о Word?
Помогите нам улучшить Word
У вас есть предложения, как улучшить Word? Поделитесь ими на странице Word User Voice.
Преобразовать изображение в текст
Онлайн-конвертер распознавания текста
Преобразуйте изображение в текст. Извлекайте текст из изображений, фотографий и других рисунков. Этот бесплатный конвертер OCR позволяет извлекать текст из изображений и преобразовывать его в обычный текстовый файл TXT.
Извлекайте текст из изображений, фотографий и других рисунков. Этот бесплатный конвертер OCR позволяет извлекать текст из изображений и преобразовывать его в обычный текстовый файл TXT.
Ошибка: количество входящих данных превысило лимит в 3.
Чтобы продолжить, вам необходимо обновить свою учетную запись:
Ошибка: общий размер файла превысил лимит в 100 MB.
Чтобы продолжить, вам необходимо обновить свою учетную запись:
Ошибка: общий размер файла превысил абсолютный лимит в 8GB.
Для платных аккаунтов мы предлагаем:
- Вплоть до 8GB общего размера файла за один сеанс конвертирования 200 файлов на одно конвертирование Высокий приоритет и скорость конвертирования Полное отсутствие рекламы на странице Гарантированный возврат денег
- До 100 Мб общего размера файла за один сеанс конвертирования 5 файлов на одно конвертирование Обычный приоритет и скорость конвертирования Наличие объявлений
Мы не может загружать видео с Youtube.
В настоящее время мы поддерживаем следующие типы конвертирования изображений в текст: JPG в текст, PNG в текст, TIFF в текст, SVG в текст, BMP в текст, WEBP в текст — и многое другое!
TXT (Raw text file)
Textfile (TXT) заменил своего предшественника — flafile. Этот формат файлов структурирует набор строк текста. Окончание таких файлов очень часто указывается с помощью маркеров окончания файла.
Что такое TXT?
OCR РАСПОЗНАВАНИЕ ТЕКСТА ИЗ PDF И ИЗОБРАЖЕНИЙ
Вы когда-нибудь хотели иметь возможность найти в печатном цифровом материале или отсканированном документе конкретный текст? Или возникла ли у вас необходимость отредактировать содержимое журнала или отсканированного PDF-документа, не перепечатывая весь документ? Классическим решением во всех этих случаях было бы перенабрать весь контент и его отредактировать. Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
Что такое OCR
Оптическое распознавание символов или OCR — это технология, позволяющая преобразовывать печатные или рукописные документы в редактируемые текстовый материал. Просто отсканировав напечатанные документы с помощью программного обеспечения для распознавания текста OCR, вы можете легко конвертировать файлы в печатные копии, которые можно редактировать, копировать или распространять согласно вашим требованиям. Сканеры текста OCR очень универсальны и могут сканировать текст из изображений, печатных документов и файлов PDF. Программное обеспечение OCR можно загрузить или использовать в качестве онлайн-сервисов.
Как работает OCR
Хотя понятие “машинного распознавания текста” не ново и появилось еще в 1960-х годах, в то время компьютер мог считать единственный вариант шрифта, называемый OCR-A. С развитием технологии сканеры текста OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два различных метода для преобразования печатного текста в редактируемый.
С развитием технологии сканеры текста OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два различных метода для преобразования печатного текста в редактируемый.
Метод сопоставления матриц
Первый метод — это метод сопоставления матриц. Этот метод работает по принципу сопоставления печатного текста с базой данных шаблонов символов и шрифтов. Сканер текста OCR сканирует напечатанный текст, сравнивает его с существующей библиотекой шаблонов и, когда совпадение найдено, преобразует данные в соответствующий код ASCII. Затем вы можете манипулировать этими данными в соответствии с вашими требованиями. Этот метод быстро возвращает результаты, но из-за ограниченной базы данных символов метод сопоставления матриц имеет свои ограничения. Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
Метод извлечения особенностей
Другой метод, используемый программным обеспечением OCR, — это метод извлечения признаков текста. Этот метод основан на искусственном интеллекте, где онлайн программное обеспечение OCR предназначено для определения общих точек в форме букв, таких как искривления, наклоны и пробелы в алфавите. Сканеры текста OCR ищут эти общие точки в тексте и возвращают результаты в коде символов ASCII после того, как найден определенный процент «совпадения». Следовательно, этот метод ищет повторяющиеся шаблоны или правила, которые представляют букву, и программное обеспечение может предсказать букву, просто просматривая общие точки, найденные в шаблоне. Метод является более гибким и может работать с большим количеством печатных или рукописных документов.
Кроме того, искусственный интеллект постоянно обновляет свои знания о различных почерках и шрифтах, что делает его более универсальным в использовании и оставляет возможности дальнейших улучшений и модернизаций алгоритма.
OCR онлайн сервисы
Самый простой способ сконвертировать распечатанные файлы в редактируемую версию — использование онлайн-сервисов OCR, в том числе нашим сервисом. Использовать онлайн-сервисы OCR чрезвычайно просто, поскольку вам нужно только отсканировать документ, загрузить его, и файл будет преобразован в редактируемую версию. Бесплатный сервис OCR — это отличная возможность для бизнеса сэкономить своё драгоценное время и деньги.
Есть несколько преимуществ использования бесплатных услуг OCR онлайн сервисов. Эти преимущества включают в себя:
- Время, затрачиваемое на весь процесс, значительно сокращается, и большие документы можно подготовить всего за несколько минут. Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
- Упрощение процесса извлечения данных из сложных документов.
- Снижение вероятности человеческой ошибки, связанной с методом чтения и перепечатывания.
- Устранение трудозатрат в часах, необходимых для затратного процесса ввода данных.

- Сканеры текста OCR являются сложными и могут также распознавать сложные почерки, которые могут занять время, чтобы человеческий глаз мог их прочитать и обработать.
Благодаря более быстрому циклу обработки и современным сканерам распознавания текста, эта технология может сэкономить достаточно значительное количество времени и средств для пользователей, которые смогут распорядиться своим временем более эффективно.
Обнаружение и извлечение текста из изображения с помощью Python | by Roman | NOP::Nuances of Programming
Из этой статьи вы узнаете о способах извлечения текста из цифровых изображений с использованием python и библиотеки pytesseract. Изображение должно иметь текст внутри, чтобы получить выходной текст.
Для извлечения текста с помощью pytesseract необходимо установить библиотеки в среду системы. Приведенные ниже команды помогут установить необходимые библиотеки в системе.
Команда для установки библиотеки OpenCV:
pip install opencv-python
Команда для установки библиотеки pytesseract-ocr:
pip install pytesseract
Необходимо также установить конфигурационный файл tesseract, чтобы получить файл tesseract.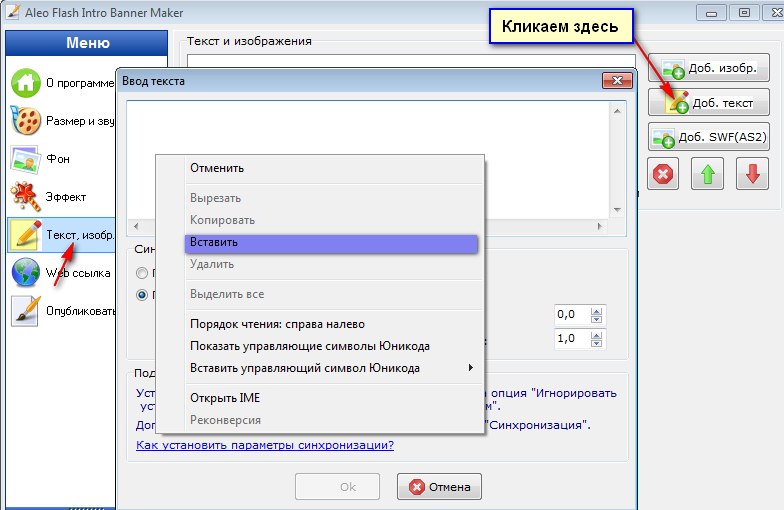 exe по следующей ссылке:
exe по следующей ссылке:
https://github.com/UB-Mannheim/tesseract/wiki
Скачайте вышеуказанный файл в соответствии с конфигурацией системы, затем установите его. Файл tesseract.exe будет располагаться по следующему пути:
C:\Program Files\Tesseract-OCR\tesseract.exe"
Посмотрим на входное изображение, из которого нужно извлечь текст:
Входное изображение. Картинка автораНа этом примере рассмотрим способ извлечения текста из полутонового изображения, а на следующем примере — из цветного изображения с ограничительной рамкой.
Извлечение текста из полутонового изображения
Для начала импортируем необходимые библиотеки:
from PIL import Image
from pytesseract import pytesseract
Теперь будем использовать библиотеку pillow для открытия/чтения изображения:
image = Image.open('ocr.png')
image = image.resize((400,200))
image.save('sample.png')Примечания:
- Метод
openиспользуется для чтения изображения из рабочего каталога.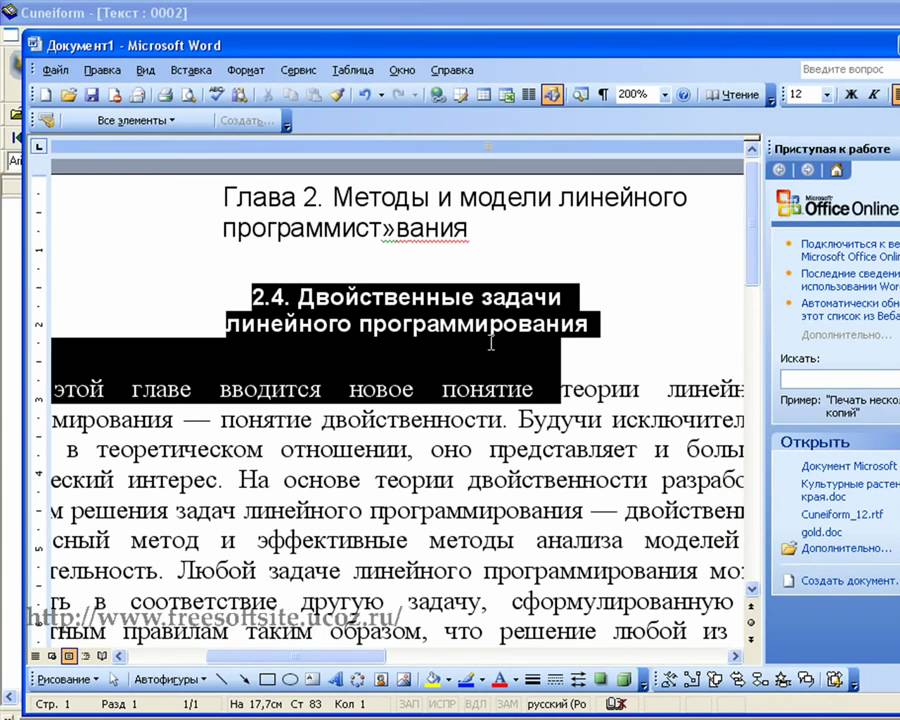
- Метод
resizeиспользуется для изменения размера изображения. - Метод
saveиспользуется для сохранения изображения после изменения размера.
Определим путь к бинарному файлу tesseract, как показано ниже:
path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
pytesseract.tesseract_cmd = path_to_tesseract
Пришло время использовать метод image_to_string класса tesseract для извлечения текста из изображения:
text = pytesseract.image_to_string(image)#печать текста построчно
print(text[:-1])
Обнаружение и извлечение текста из цветного изображения
На этот раз будем извлекать текст из цветного изображения. Образец цветного изображения показан ниже.
Входное изображение. Картинка автораВ этом примере будем использовать ограничительную рамку и другие методы OpenCV.
Установите необходимые библиотеки:
import cv2
from pytesseract import pytesseract
Теперь определим путь к бинарному файлу tesseract, как показано ниже:
path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
pytesseract.tesseract_cmd = path_to_tesseract
Чтение изображения с помощью метода OpenCV:
img = cv2.imread("color_ocr.png")Преобразование цветного изображения в полутоновое для лучшей обработки текста:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
Теперь преобразуем полутоновое изображение в бинарное, чтобы повысить вероятность извлечения текста:
ret, thresh2 = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU |
cv2.THRESH_BINARY_INV)
cv2.imwrite('threshold_image.jpg',thresh2)
Здесь метод imwrite используется для сохранения изображения в рабочем каталоге.
Чтобы задать размер предложений или даже слов изображения, понадобится метод структурных элементов в OpenCV с размером ядра в зависимости от площади текста:
rect_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (12, 12))
Следующий шаг — применение метода расширения двоичного изображения для получения границ текста:
dilation = cv2.Операция расширения изображения. Картинка автораdilate(thresh2, rect_kernel, iterations = 3)
cv2.imwrite('dilation_image.jpg',dilation)
Можно увеличить число итераций в зависимости от пикселей переднего плана, т.е. белых пикселей, чтобы получить правильную форму ограничительной рамки.
Теперь воспользуемся методом find contour для получения площади белых пикселей.
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_NONE)
Чтобы выполнить некоторые операции с изображением, скопируйте его в другую переменную:
im2 = img.copy()
Теперь пришло время магического преобразования изображения. Для этого получим координаты области белых пикселей и нарисуем вокруг нее ограничительную рамку, а также сохраним текст с изображением в текстовый файл:
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)# Рисуем ограничительную рамку на текстовой области
rect=cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)# Обрезаем область ограничительной рамки
cropped = im2[y:y + h, x:x + w]cv2.
imwrite('rectanglebox.jpg',rect)
# открываем текстовый файл
file = open("text_output2.txt", "a")# Использование tesseract на обрезанной области изображения для
получения текста
text = pytesseract.image_to_string(cropped)# Добавляем текст в файл
file.write(text)
file.write("\n")# Закрываем файл
file.close
Вывод изображения с ограничительной рамкой.
Ограничительная рамка на тексте. Картинка автораРезультат работы с текстовым файлом.
Извлеченный текст в файле. Картинка автораУчтите следующую закономерность: если число итераций равно 1, то текст не сохраняется в текстовом файле; результат получается после увеличения числа итераций до 3.
Если код работает правильно, но результат не выводится, проверьте или измените размер ядра и число итераций.
Чтобы извлечь изображение каждой ограничительной рамки, выполните следующие действия:
crop_number=0Извлечение многократного кадрирования изображения. Картинка автора
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)# Рисуем ограничительную рамку на текстовой области
rect = cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Обрезаем область ограничительной рамки
cropped = im2[y:y + h, x:x + w]cv2.imwrite("crop"+str(crop_number)+".jpeg",cropped)
crop_number+=1cv2.imwrite('rectanglebox.jpg',rect)
# открываем текстовый файл
file = open("text_output2.txt", "a")# Использование tesseract на обрезанной области изображения для
получения текста
text = pytesseract.image_to_string(cropped)# Добавляем текст в файл
file.write(text)
file.write("\n")# Закрываем файл
file.close
Читайте также:
- Разворачиваем декораторы
- Как быстро найти проблемы с Python-типами через Pytype
- Знакомство с Anaconda: что это такое и как установить
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Amit Chauhan, Text Detection and Extraction From Image with Python
Изображение в текст в App Store
Описание
Text Capture позволяет захватывать текст с камеры вашего устройства. Просто наведите камеру, смотрите текст в режиме реального времени и снимайте его, нажав кнопку «Захват»!
Просто наведите камеру, смотрите текст в режиме реального времени и снимайте его, нажав кнопку «Захват»!
Text Capture работает на 100 % в автономном режиме, защищая вашу конфиденциальность и содержимое ваших отсканированных изображений, поскольку отсканированные данные никогда не покидают ваше устройство.
После захвата текста вы можете:
– Редактировать
– Копировать в буфер обмена
– Поделиться в других приложениях
– Слушайте вслух
– Перевод текста
* Захват текста работает с любым текстом на латинице
* Преобразование текста в речь и перевод работает для текста, написанного на следующих языках:
Арабский, китайский, чешский, датский, голландский, Английский, финский, французский, немецкий, греческий, иврит, хинди, венгерский, индонезийский, итальянский, японский, корейский, норвежский, польский, португальский, румынский, русский, словацкий, испанский, шведский, тайский, турецкий.
Версия 2.5.5
Улучшения пользовательского интерфейса;
Повышение качества активов
Рейтинги и обзоры
1,8 тыс. оценок
Вероятно, лучший выбор для OCR
Кажется, все переходят на модель подписки, которую я ненавижу. Я просмотрел множество приложений OCR, и что бы ни говорилось в описании, они всегда заканчивались какой-то моделью подписки. Много обманчивого маркетинга.
Это приложение все еще обманывает вас. Вы загружаете его, и OCR работает, ЕСЛИ вы не хотите редактировать или копировать этот текст.
Вот покупка в приложении.
Это 1,99 доллара США, но за разблокировку этой функции взимается разовая плата. Не думаю, что им нужно было это скрывать.
Приложение бесполезно, если вы не заплатите за него. Почему бы просто не сказать, что приложение платное, оно стоит 1,99 доллара? Это того стоит, и я думаю, что, учитывая другие варианты, это лучший выбор. Может быть, не самый красивый, но чрезвычайно интуитивно понятный. Точность в порядке, но я открою вам маленький секрет: все используют одну и ту же библиотеку OCR с открытым исходным кодом. Таким образом, наибольшее влияние на точность оказывают качество и контрастность сканирования.
Итак, я купил это приложение. Если вы хотите купить еще одно, более красивое, и платить 2,00 доллара в месяц за какое-то другое приложение (до конца своей жизни, поскольку вы, вероятно, забудете, что платите), больше возможностей для вас.

Спасибо за прекрасный обзор, FlashInPan! Мы рады, что вам понравился Text Capture!
Фантастика!! претензий нет!
это распознавание превзошло мои ожидания во всех отношениях.
скорость, точность, простота использования.
У меня очень хорошо зарекомендовавший себя настольный сканер, и этот iphone ocr превосходит его по скорости безоговорочно — никакого сравнения — и точность кажется примерно одинаковой — оба достаточно высоки для моего использования. возможно, одна или две ошибки каждые 100 символов.Я учусь на юридическом факультете, много читаю и пишу, и это действительно изменило мою работу. сканируйте текст, отправляйте редактируемый файл по электронной почте на ноутбук, вырезайте и вставляйте, делайте все, что хотите, и все это без проблем. больше не нужно печатать вручную, чтобы создать редактируемый файл. Могу ли я переусердствовать, если скажу, что этот продукт показал самое большое положительное соотношение ожиданий и фактических результатов среди всего, что у меня когда-либо было? я так не думаю. на чашку кофе. когда вы выйдете с возможностью изучения азиатского языка? это то, чего я жду. Вы установили для себя очень высокую планку.
Пейзаж?
Text Capture превосходит все другие приложения для захвата, которые я использовал.
Это будет 5+ с двумя модификациями:
1. Ландшафтный режим, поэтому мне не нужно будет крутить свой iPad.
2. «Ластик» для удаления фонового текста на снимках экрана с бродячими «символами».
Высокий приоритет для №1, не так важен №2.
Спасибо за разработку такого превосходного ядра для захвата текста!
Разработчик, Артур Эдуардо Скаэтта Альварес Десенволвименто де Софтвер LTDA., указал, что политика конфиденциальности приложения может включать обработку данных, как описано ниже. Для получения дополнительной информации см. политику конфиденциальности разработчика.
Данные, не связанные с вами
Могут быть собраны следующие данные, но они не связаны с вашей личностью:
- Данные об использовании
Методы обеспечения конфиденциальности могут различаться, например, в зависимости от используемых вами функций или вашего возраста. Узнать больше
Узнать больше
Информация
- Продавец
- Артур Эдуардо Скэтта Альварес Desenvolvimento de Software LTDA.
- Размер
- 71,7 МБ
- Категория
- Производительность
- Возрастной рейтинг
- 4+
- Авторское право
- © Артур Альварес
- Цена
- Бесплатно
- Тех. поддержка
- Политика конфиденциальности
Еще от этого разработчика
Вам также может понравиться
Извлечение текста из изображения с помощью Python – Программирование на Python
В этом руководстве мы рассмотрим, как извлечь текст из изображения с помощью Python.
Table of Contents
- Introduction
- Sample images
- Extract text from a single image using Python
- Extract text from multiple images using Python
- Conclusion
Introduction
Extracting text from изображения — очень популярная задача в операционных подразделениях бизнеса (извлечение информации из счетов и квитанций), а также в других областях.
OCR (оптическое распознавание символов) — это электронный компьютерный подход к преобразованию изображений текста в машинно-кодированный текст, который затем можно извлечь и использовать в текстовом формате.
Чтобы продолжить следовать этому руководству, нам понадобится:
- Tesseract
- Две библиотеки Python:
- pytesseract
- подушка
Tesseract — это механизм распознавания символов с открытым исходным кодом из OCR картинки.
Чтобы использовать его в Python, нам также понадобится библиотека pytesseract , которая является оболочкой для движка Tesseract.
Поскольку мы работаем с изображениями, нам также понадобится библиотека Pillow , которая добавляет возможности обработки изображений в Python.
Сначала найдите программу установки Tesseract для вашей операционной системы. Для Windows вы можете найти последнюю версию установщика Tesseract здесь. Просто скачайте файл .exe и установите его на свой компьютер.
Если у вас не установлены библиотеки Python, откройте «Командную строку» (в Windows) и установите их, используя следующий код:
pip установить pytesseract пип установить подушку
Примеры изображений
Чтобы продолжить работу с этим уроком, нам понадобятся некоторые изображения.
Вот три изображения, которые мы будем использовать в этом уроке:
В этом уроке мы будем использовать простые изображения с текстом, выровненным по горизонтали, которые не требуют дополнительной обработки изображения.
Начнем с извлечения текста из одного изображения с помощью Python.
В этом примере мы будем работать с первым изображением, предоставленным в предыдущем разделе: sampletext1-ocr.png
Вот как выглядит структура моих файлов:
Все изображения размещены в папке изображений и код находится в main.py
Путь к нужному нам изображению: images/sampletext1-ocr.png
Еще один путь, который нам нужен, это путь к tessaract.exe который был создан после установки. В Windows он должен находиться в: C:\Program Files\Tesseract-OCR\tesseract.exe
Теперь у нас есть все, что нам нужно, и мы можем легко извлечь текст из изображения с помощью Python:
из изображения импорта PIL из pytesseract импортировать pytesseract #Определяем путь к tessaract.exe path_to_tesseract = r'C:\Program Files\Tesseract-OCR\tesseract.exe' #Определяем путь к изображению path_to_image = 'изображения/sampletext1-ocr.png' #Укажите tessaract_cmd на tessaract.exe pytesseract.tesseract_cmd = путь_к_тессеракту #Открыть изображение с помощью PIL img = Image.open(путь_к_изображению) #Извлечь текст из изображения текст = pytesseract.image_to_string(img) печать (текст)
И вы должны получить:
Образец текста 1
В этом разделе мы рассмотрим, как извлечь текст из нескольких изображений с помощью Python.
Мы знаем, что все изображения размещены в папке images , а код находится в main.py
Одним из способов извлечения текста из каждого изображения было бы использование имен файлов каждого изображения и извлечение текста из этих изображения одно за другим.
А что, если у нас в папке 100 изображений? Использование os мы можем получить доступ ко всем именам файлов в данном каталоге.
Как только мы получим доступ ко всем именам файлов в папке images , мы будем перебирать их и извлекать текст из каждого изображения с помощью Python:
из изображения импорта PIL из pytesseract импортировать pytesseract импорт ОС #Определяем путь к tessaract.exe path_to_tesseract = r'C:\Program Files\Tesseract-OCR\tesseract.exe' #Определяем путь к папке с изображениями path_to_images = r'изображения/' #Укажите tessaract_cmd на tessaract.exe pytesseract.tesseract_cmd = путь_к_тессеракту #Получить имена файлов в каталоге для корня, каталогов, имен файлов в os.walk(path_to_images): # Перебираем каждое имя файла в папке для имя_файла в именах_файлов: #Открыть изображение с помощью PIL img = Image.open(путь_к_изображениям + имя_файла) #Извлечь текст из изображения текст = pytesseract.image_to_string(img) печать (текст)
И вы должны получить:
Образец текста 1 Образец текста 2 Образец текста 3
, который является именно тем текстом, который у нас есть на изображениях.
Заключение
В этой статье мы рассмотрели, как извлечь текст из одного и нескольких изображений с помощью Python и Tesseract.
Не стесняйтесь оставлять комментарии ниже, если у вас есть какие-либо вопросы или предложения по некоторым изменениям, и ознакомьтесь с другими моими руководствами по программированию на Python.
Как извлечь текст из PDF или изображения на Google Диске
Как извлечь текст из PDF или изображения на Google Диске
Если вы хотите преобразовать изображение в текст, в Документах Google есть встроенная мощная функция оптического распознавания символов. Вот как заставить ее работать.
Сколько раз вы находили старый корпоративный PDF-файл или изображение, и вам нужно было получить быстрый доступ к тексту внутри, только чтобы обнаружить, что вы не можете найти редактируемую версию файла, или копирование и вставка терпят неудачу? Или, может быть, вам нужно только преобразовать PDF-файл или изображение в документ Word или LibreOffice, чтобы его можно было использовать для другой цели.
Конечно, вы можете приобрести программное обеспечение, которое позволит вам это сделать, но если вы являетесь пользователем Google Диска, у вас уже есть эта возможность. Правильно, Google Docs делает довольно впечатляющую работу по преобразованию PDF-документов в обычные Google Docs. Это не идеально — это скорее оптическое распознавание символов (OCR) для PDF-файлов и изображений — но если вы ищете способ добраться до этого драгоценного текста, это удобный способ сделать именно это.
Это не идеально — это скорее оптическое распознавание символов (OCR) для PDF-файлов и изображений — но если вы ищете способ добраться до этого драгоценного текста, это удобный способ сделать именно это.
Как ты это делаешь? Из коробки это не сработает. К счастью, способ заставить его работать невероятно прост. Позвольте мне показать вам, как это сделать.
Включение функции
Откройте Google Диск и щелкните значок шестеренки. В раскрывающемся списке нажмите Настройки. В появившемся окне ( Рисунок A ) убедитесь, что установлен флажок «Преобразовать загрузки».
Рисунок А
Использование функции Загрузите PDF-файл или изображение на Google Диск. Загруженное изображение не конвертируется автоматически. На самом деле он останется именно таким, каким был загружен. Как только файл окажется в вашей учетной записи Google Диска, щелкните его правой кнопкой мыши и выберите Открыть с помощью | Документы Google ( Рисунок B ).
Рисунок В
После этого файл будет преобразован в текст и открыт в новом документе Google Docs. Я создал образец изображения ( Рисунок C ), используя текст из этой статьи, и загрузил его для конвертации.
Рисунок С
Результат преобразования будет включать как изображение, так и извлеченный текст ( Рисунок D ).
Рисунок D
Вы сами можете судить, насколько хорошо Google Диск справился с преобразованием. В этом случае он попал в самую точку. Слово в слово, Google Диск извлек точный текст из изображения. Теперь я могу копировать и вставлять этот текст без необходимости вводить его вручную. Это экономия времени, которую мы все могли бы использовать.
Одно предостережение
Если вы ожидаете, что Google Диск успешно откроет PDF-документ, например налоговую форму W9, в качестве редактируемого документа, вы будете разочарованы. Конечно, вы можете загрузить документ, и Диск извлечет текст, но это будет именно текст. Преобразование Google Диска из PDF или изображения на самом деле является очень мощной и точной формой OCR.
Преобразование Google Диска из PDF или изображения на самом деле является очень мощной и точной формой OCR.
Даже с учетом этой оговорки эта функция значительно повысит эффективность вашего повседневного рабочего процесса, особенно если вы тратите много времени на ввод текста из PDF-файлов или изображений.
Джек Уоллен
Опубликовано: Изменено: Увидеть больше ОблакоСм. также
- Как снова включить быстрый доступ к Google Фото на Google Диске (ТехРеспублика)
- Как интегрировать Google Keep с Google Docs (ТехРеспублика)
- Как установить менеджер паролей Enpass и синхронизировать его с вашей учетной записью Google Диска (ТехРеспублика)
- Как получить доступ к файлам вашего Google Диска из Linux (Видео TechRepublic)
- Как сделать так, чтобы резервная копия Google Диска не занимала драгоценное место на вашем локальном диске (ТехРеспублика)
- Как создать изображение Word Cloud в Google Docs (ТехРеспублика)
- Документы Google только что съели вашу домашнюю работу (СЕТ)
- Облако
Выбор редактора
- Изображение: Rawpixel/Adobe Stock
ТехРеспублика Премиум
Редакционный календарь TechRepublic Premium: ИТ-политики, контрольные списки, наборы инструментов и исследования для загрузки
Контент TechRepublic Premium поможет вам решить самые сложные проблемы с ИТ и дать толчок вашей карьере или новому проекту.
Персонал TechRepublic
Опубликовано: Изменено: Читать далее Узнать больше - Изображение: diy13/Adobe Stock
Программного обеспечения
Виндовс 11 22х3 уже здесь
Windows 11 получает ежегодное обновление 20 сентября, а также ежемесячные дополнительные функции. На предприятиях ИТ-отдел может выбирать, когда их развертывать.
Мэри Бранскомб
Опубликовано: Изменено: Читать далее Увидеть больше Программное обеспечение - Изображение: Кто такой Дэнни/Adobe Stock
Край
ИИ на переднем крае: 5 трендов, за которыми стоит следить
Edge AI предлагает возможности для нескольких приложений. Посмотрите, что организации делают для его внедрения сегодня и в будущем.
Меган Краус
Опубликовано: Изменено: Читать далее Увидеть больше - Изображение: яблоко
Программного обеспечения
Шпаргалка по iPadOS: все, что вы должны знать
Это полное руководство по iPadOS от Apple.
 Узнайте больше об iPadOS 16, поддерживаемых устройствах, датах выпуска и основных функциях с помощью нашей памятки.
Узнайте больше об iPadOS 16, поддерживаемых устройствах, датах выпуска и основных функциях с помощью нашей памятки.Персонал TechRepublic
Опубликовано: Изменено: Читать далее Увидеть больше Программное обеспечение - Изображение: Worawut/Adobe Stock
- Изображение: Bumblee_Dee, iStock/Getty Images
Программного обеспечения
108 советов по Excel, которые должен усвоить каждый пользователь
Независимо от того, являетесь ли вы новичком в Microsoft Excel или опытным пользователем, эти пошаговые руководства принесут вам пользу.
