
Как распознать текст с картинки в Word: лучшие способы и ресурсы
Бывало ли у вас такое, что, например, партнеры по бизнесу прислали какую-то документацию или проект договора о сотрудничестве в виде файла графического формата (обычной картинки или документа PDF)? По всей видимости, с этим сталкивались, если не все, то очень многие. А ведь документ вам бывает нужно срочно изменить, а чаще всего это касается редактирования текстовой части, которая может содержаться в исходном файле. Как распознать текст с картинки, чтобы затратить на это минимум времени и избежать возможного появления всевозможных ошибок и опечаток? Об этом и многом другом далее и пойдет речь. Способов «вытаскивания» текста из файлов графических типов или универсального формата PDF на сегодняшний день существует много, однако при рассмотрении некоторых из них будем отталкиваться от наиболее интересных, простых и понятных любому пользователю методов.
Как распознать текст с картинки в Word?
Начать стоит с одного из самых простых методов, который подойдет всем без исключения пользователям. Если речь идет о том, чтобы «вытащить» текст из PDF-документа, а затем отредактировать его и сохранить в «родном» формате текстового редактора Word, далеко ходить не нужно, поскольку все последние версии этого приложения, начиная с «Офиса» 2010 года выпуска, поддерживают работу с файлами PDF и позволяют их редактировать точно так же просто, как если бы это был самый обычный документ Word.
Если речь идет о том, чтобы «вытащить» текст из PDF-документа, а затем отредактировать его и сохранить в «родном» формате текстового редактора Word, далеко ходить не нужно, поскольку все последние версии этого приложения, начиная с «Офиса» 2010 года выпуска, поддерживают работу с файлами PDF и позволяют их редактировать точно так же просто, как если бы это был самый обычный документ Word.
Чтобы в «Ворде» распознать текст с картинки формата PDF, который, если кто не знает, относится именно к графическим типам файлов, достаточно задать открытие документа, а в типе файла выбрать именно формат PDF. После этого текст можно будет и отредактировать, и сохранить повторно в виде «родного» формата редактора, выбрав в том же поле нужный тип (например, DOC или DOCX).
I2ocr.com – бесплатная идентификация текста онлайн
I2OCR – это бесплатный OCR-сервис, позволяющий выполнить идентификацию текста с изображения online. Его возможности позволяют извлечь текст с изображения онлайн для его последующего редактирования, форматирования, индексирования, поиска или перевода. Сервис распознаёт более 60 языков, поддерживает распознавание нескольких языков на одном изображении, многоколонный анализ документов, бесплатную загрузку неограниченного количества изображений.
Сервис распознаёт более 60 языков, поддерживает распознавание нескольких языков на одном изображении, многоколонный анализ документов, бесплатную загрузку неограниченного количества изображений.
Для работы с сервисом выполните следующее:
- Выполните вход на i2ocr.com;
- В графе «Select language» выберите язык распознавания;
- Нажмите на кнопку «Select image» в центре, и загрузите изображение на ресурс;
- Поставьте галочку рядом с надписью «Я не робот»;
- Нажмите на «Extract Text» для получения результата (будет отображён внизу).
Дополнительные инструменты для Office 2003
Если же проблема состоит в том, как распознать текст с картинки в редакторе, входящем в состав офисного пакета, скажем, 2003 года, в котором формат PDF не поддерживается, то и в этом случае ничего сложного нет.
В довесок к самому текстовому редактору дополнительно можно установить инструмент в виде интегрируемого в Word расширения под названием File Format Converters, который добавит возможностей редактору в том плане, что он сможет работать и с файлами PDF, и с документами обновленных форматов вроде DOCX.
Как распознать текст с картинки в PDF?
Еще один способ извлечения текста непосредственно из графического объекта в PDF-формате состоит в том, чтобы воспользоваться любым из известных редакторов, рассчитанных на работу с такими документами. Одним из наиболее универсальных и практичных приложений можно назвать небезызвестную программу Reader от Adobe. Обратите внимание, что в данном случае речь идет именно о приложении «Ридер», а не об аналогичном просмотрщике «Акробат», который поддерживает только чтение документов (просмотр без возможности редактирования).
В самой программе вам нужно будет просто выделить нужный фрагмент текста, скопировать его в буфер обмена, а затем вставить в документ Word и сохранить в нужном конечном формате.
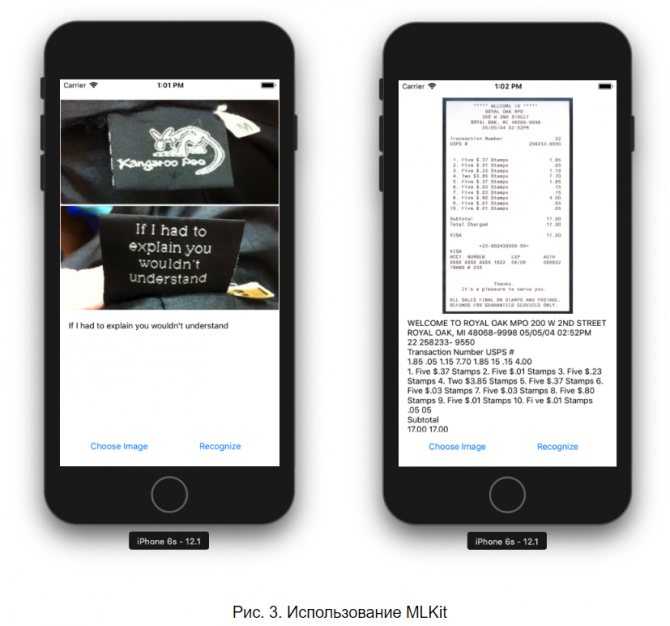
Как убрать надпись с фото на телефоне
Популярное приложение ПиксАрт поможет вам избавиться от метки на снимке с телефона. Редактор уникален тем, что по своему функционалу приближен к знаменитому Фотошопу, но кроме снимков может обрабатывать еще и видеоролики, плюс является своеобразной социальной сетью. Вы сможете оценивать фотографии других участников, выкладывать свои работы, принимать участие в конкурсах. Скачайте программу в Play Маркете, если у вас смартфон на платформе Android, или в App Store, если у вас iPhone. Программа платная, но имеет бесплатную семидневную версию с ограниченным функционалом.
Вы сможете оценивать фотографии других участников, выкладывать свои работы, принимать участие в конкурсах. Скачайте программу в Play Маркете, если у вас смартфон на платформе Android, или в App Store, если у вас iPhone. Программа платная, но имеет бесплатную семидневную версию с ограниченным функционалом.
Выберите фото, которое хотите отредактировать. Увеличьте нужный участок, просто приблизив фотографию пальцами. Далее тапните по иконке «Инструменты». Откроется окно с набором различных опций. Нам нужен инструмент с незамысловатым названием «Удалить». Активируйте его и настройте размер кисти. Теперь просто проведите по дате/надписи. Если случайно отметили тот или иной участок, возьмите ластик и сотрите лишнее.
Запустите PicsArt и последовательно выполните приведенные шаги
Выделение готово? Нажмите кнопку «Удалить». Сохраните результат, тапнув по стрелочке в верхней части экрана. Стоит отметить, что в пробной версии эта стрелочка не появляется и вам предлагают перейти на версию «Gold». Кроме того, удалив метку, PicsArt ставит свою собственную. Так что если вы не счастливый обладатель полноценного редактора, вам лучше обратить свое внимание на менее популярное приложение. Например, Snapseed.
Кроме того, удалив метку, PicsArt ставит свою собственную. Так что если вы не счастливый обладатель полноценного редактора, вам лучше обратить свое внимание на менее популярное приложение. Например, Snapseed.
Принцип удаления надписи примерно аналогичен PicsArt. Вы загружаете картинку, идете в раздел «Инструменты» и выбираете «Точечно». Затем просто начинайте замазывать надпись, которая будет удалена автоматически. Если действие было произведено некорректно, сбросьте результат, нажав на дугообразную стрелочку слева внизу.
В Snapseed удалить лишнее можно за 2 шага
Сохраните работу, тапнув по галочке. Далее нам нужна опция «Экспорт» – «Сохранить». К минусам этого приложения можно отнести отсутствие ластика и настроек кисти.
Использование приложения OneNote
Если разбираться в тонкостях того, как распознать текст с картинки без использования вышеописанных приложений, можно посоветовать воспользоваться еще одним уникальным апплетом, входящим в состав последних модификаций и сборок самих офисных пакетов, под названием OneNote, о возможностях которого многие пользователи в большинстве своем или забывают, или не знают вовсе. В программе потребуется для удобства работы всего лишь создать пустой документ, используя меню вставки поместить в него изображение с текстом из графического файла (любого формата), а затем настроить язык распознавания.
В программе потребуется для удобства работы всего лишь создать пустой документ, используя меню вставки поместить в него изображение с текстом из графического файла (любого формата), а затем настроить язык распознавания.
После этого останется только скопировать текст в буфер обмена, для чего используется специальный пункт «Копировать текст с картинки», после чего его можно будет вставить из буфера в любую другую программу.
Примечание: если вопросы касаются того, как с картинки распознать китайский текст или содержимое, представленное на любом другом неподдерживаемом для отображения языке, вам потребуется установить дополнительный языковой пакет, загрузив его, например, из официального источника Microsoft и интернете.
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы. До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование | Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат |
Хотя рынок заполнен программным обеспечением OCR, которое может извлекать текст из изображений, хорошая программа OCR должна делать больше, чем просто распознавание текста. Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Система распознавания ABBYY Finereader
Естественно, если речь идет исключительно о том, как распознать текст с картинки в графических форматах, лучше всего применять для этого специализированные OCR-системы. Одной из самых мощных и популярных является программа ABBYY Finereader, а также ее онлайн-аналог в виде официального интернет-портала.
Это приложение работает по типу виртуального сканера, в котором нужно всего лишь задать направление распознавания, а иногда может потребоваться указать язык исходного документа (это относится к устаревшим версиям пакета). Когда сканирование текста на том же печатном листе или в графическом файле будет закончено, он будет автоматически перенаправлен, например, в Word или в любой другой офисный редактор.
Конвертеры форматов
Пока это были самые простые приложения, позволяющие распознать текст с картинки. Программы для выполнения таких действий включают в себя и еще одну категорию ПО, называемого конвертерами. Они интересны тем, что выполнять именно распознавание текстового содержимого графического файла в них не нужно. Суть состоит в том, чтобы переконвертировать исходный графический формат в выбранный текстовый, после чего преобразованный файл и можно будет открыть в нужном редакторе. Кроме того, очень часто именно такие приложения оказываются максимально эффективными, когда вам требуется обработать несколько десятков однотипных документов. Это называется пакетным режимом. Что же до самих программ, их в том же интернете можно найти огромное количество.
Они интересны тем, что выполнять именно распознавание текстового содержимого графического файла в них не нужно. Суть состоит в том, чтобы переконвертировать исходный графический формат в выбранный текстовый, после чего преобразованный файл и можно будет открыть в нужном редакторе. Кроме того, очень часто именно такие приложения оказываются максимально эффективными, когда вам требуется обработать несколько десятков однотипных документов. Это называется пакетным режимом. Что же до самих программ, их в том же интернете можно найти огромное количество.
Среди наиболее востребованных приложений можно отметить утилиты для преобразования PDF-файлов в любые другие форматы, конвертеры PDF или JPG в Word, универсальные преобразователи любого типа графики в текстовые файлы и т. д.
Как в ворд вставить фото
Рассмотрим пример вставки изображения из файла на вашем компьютере:
- Кликните левой кнопкой мыши в текстовом документе для указания места вставки вашего изображения.
 Текстовый курсор будет находиться в месте клика.
Текстовый курсор будет находиться в месте клика. - На вкладке Вставка в разделе Иллюстрации нажмите кнопку Рисунки.
- В открывшемся окне выберите папку с фотографией или рисунком. Выделите нужный файл и нажмите кнопку Вставить.
Окно вставки рисунка с компьютера
Изображение появиться в вашем документе.
Вставить изображение в документ можно просто перетащив его мышкой из папки в нужное место. Также можно использовать горячие клавиши Ctrl +C и Ctrl+V
Вставленное изображение может занять всю ширину страницы. Если необходимо сделать его меньше, то кликните по нему. Картинка станет выделена рамкой (смотрите рисунок ниже). Теперь захватив мышкой любой угол (кружок 7) изображения потяните его к центру фото.
Размещение рисунка в тексте документа
Изображение будет уменьшаться. Отпустите кнопку мыши, чтобы зафиксировать размер.
Для уменьшенного рисунка необходимо задать его положение относительно текста и страницы. Нажмите кнопку 8 и в появившемся списке параметров разметки укажите нужное положение. Также установите привязку к абзацу или к странице (переключатели 9).
Изображения из Интернета
Этот инструмент поможет вам сэкономить время на поиск подходящего изображения, с соблюдением авторских прав на использование в своем документе. Кликнув на кнопку инструмента, вы попадете в поисковое окно Bing. Вводите ключевое слова для поиска и нажимайте Enter или значок лупы.
Вставка изображения из Интернет
Изображения в поиске можно отфильтровать по четырём параметрам: размер, тип, цвет и лицензия. Выберите одно или несколько найденных картинок и нажмите кнопку Вставка.
Фильтрация по размеру происходит исходя из параметров ширины или длины картинки в пикселах:
- Маленький — изображения до 200 пикселов в любом измерении.
- Средний — от 200 до 500 пиксел.
- Большой — от 500 до 1000 пиксел.
- Очень большой — все изображения с длиной стороны более 1000 пиксел.
Фильтрация по типу:
- Фотография — любые фотографические изображения.
- Картинки — рисованные изображения или отредактированные фото.
- Рисунок линиями — не раскрашенные рисунки.
- Прозрачный — рисунки без фона.
Фильтр по цвету: здесь просто выбираете цветовую гамму для рисунков и получаете картинки с преобладанием выбранного цвета.
Геометрические фигуры и элементы схем
Раздел Фигуры в Word содержит большую библиотеку готовых графических элементов для построения новых изображений и схем.
Библиотека графических элементов
Чтобы нарисовать фигуру, выберите её из библиотеки и удерживая левую кнопку мыши растяните её на листе до нужных размеров.
Удерживайте кнопку Shift для получения правильной фигуры с соблюдением пропорциональных размеров (круг, квадрат и др.
).
После создания фигуры её можно изменить. Кликните по фигуре. Она будет выделена рамкой. Круговая стрелка сверху позволяет повернуть фигуру на произвольный угол. Белые кружки (квадратики) регулируют размеры автофигуры. Некоторые фигуры могут иметь несколько вспомогательных элементов желтый кружок (ромбик в предыдущих версиях). Желтый манипулятор изменяет внешний вид графического элемента. Но и это еще не всё.
Изменение автофигуры
Кликните правой кнопкой на графическом объекте и выберите из контекстного меню команду Начать изменение узлов. В этом режиме передвигая узлы и изменяя кривизну линий в этих узлах с помощью узловых манипуляторов можно добиться большего преобразования фигуры.
Изменение формы фигуры с помощью узлов
Онлайн-сервисы: нюансы использования и возможные ограничения
Наконец, если ни одно из предложенных решений вам не подходит, заниматься преобразованиями вручную просто лень или нет времени, пожалуйста, в интернете представлено огромное количество ресурсов, на которых все эти операции будут выполнены без вашего прямого участия. От вас потребуется только загрузить исходный графический файл, дождаться окончания извлечения текста и скачать готовый текстовый файл на собственный компьютер (или даже просто скопировать текст из окна с результатом). Правда, неудобство некоторых таких сервисов состоит только в том, что зачастую могут устанавливаться ограничения по количеству одновременно загружаемых для обработки файлов и лимиты, касающиеся их размера, не говоря уже и о том, что некоторые сервисы являются отнюдь не бесплатными. Зато многие из таких ресурсов определяют используемый в тексте язык автоматически, что избавляет вас от дополнительных ненужных действий по переводу.
От вас потребуется только загрузить исходный графический файл, дождаться окончания извлечения текста и скачать готовый текстовый файл на собственный компьютер (или даже просто скопировать текст из окна с результатом). Правда, неудобство некоторых таких сервисов состоит только в том, что зачастую могут устанавливаться ограничения по количеству одновременно загружаемых для обработки файлов и лимиты, касающиеся их размера, не говоря уже и о том, что некоторые сервисы являются отнюдь не бесплатными. Зато многие из таких ресурсов определяют используемый в тексте язык автоматически, что избавляет вас от дополнительных ненужных действий по переводу.
Панель инструментов для вставки изображений
Раздел Иллюстрации на панели Вставка
- Рисунки. Вставка изображений с вашего компьютера или с сетевого хранилища.
- Изображения из Интернета. Поиск и вставка фото и изображений из различных источников всемирной сети «Интернет». Используется поисковая система Bing.
- Фигуры.
 Вставка готовых геометрических фигур (круги, стрелки многоугольники, линии и т.п.)
Вставка готовых геометрических фигур (круги, стрелки многоугольники, линии и т.п.) - Вставка графического элемента из коллекции SmartArt для улучшенного визуального представления различной информации.
- Добавление диаграмм и графиков самых разных типов, включая гистограммы и круговые диаграммы.
- Быстрая вставка снимков любой прямоугольной области открытого окна.
В приложениях Microsoft Office, начиная с версии 2013, больше нет коллекций картинок, которые были в предыдущих версиях. Также больше не поддерживается добавление изображений со сканера.
Как распознать текст на изображении. Самый простой способ
Бывают случаи, когда вам нужно распознать текст на изображении, чтобы в итоге у вас была не картинка, а то, что можно распечатать или отредактировать. Можно, конечно, перепечатать текст самостоятельно, но зачем это делать, если в век цифровых технологий есть куда более доступные, а главное — быстрые способы. И о них мы сейчас вам и расскажем.
Распознать текст можно в два счета. Главное — иметь доступ к сети
Немного теории. Как программа распознает изображение
Извлечение текста из изображения осуществляется с помощью программного обеспечения, которое называется OCR (сокращенно от optical character recognition). Программа считывает файл изображения (формат тут не важен, будь то jpg, png, pdf и так далее). Выявляет там то, что потенциально может быть текстом и затем «сравнивает» с базой шрифтов. В итоге на выходе мы получаем текстовый файл. При этом чем лучше качество исходного файла и чем более распространенный там используется шрифт — тем лучше произойдет распознавание текста.
В то время, как нет недостатка в OCR-приложениях для смартфонов на Android и даже расширений браузера Сhrome не наблюдается, они не всегда могут оказаться у вас под рукой. О самых лучших программах в самых разных категориях мы регулярно, так что подписывайтесь на нас в Телеграм, чтобы ничего не пропустить. Однако если под рукой нет нужны программ, можно использовать более простой, а главное — всегда доступный метод.
Как распознать текст на картинке
Распознаем текст онлайн без СМС и регистрации
Для начала рассмотрим ситуацию, когда вы работаете на ПК. Откройте веб-версию Google Keep по этой ссылке и загрузите свое изображение в виде заметки в этот сервис, нажмите на три вертикальные точки под вашим изображением и выберите опцию «Распознать текст изображения». Сервис в максимально короткий срок сделает все необходимое, после чего вы сможете работать с получившимся текстом.
Да, популярное приложение для создания заметок Google Кeep обладает, как вы догадались, возможностью по распознаванию текста. Конечно, вы можете держать его на своем смартфоне для подобных ситуаций и мы рекомендуем вам скачать его из магазина Google Play. Но мы рассматриваем простой способ без лишних загрузок, верно? В этом случае вам опять же поможет веб-интерфейс Google Кeep, который отлично работает и при загрузке со смартфона.
Читайте также: Лучшие приложения для преобразования голоса в текст
Однако стоит заметить, что если у вас установлено приложение Google Кeep, то вы получите некоторые дополнительные опции. Например, вы можете создать новую заметку в приложении и после этого нажать на кнопку камеры в углу интерфейса программы. Теперь у вас есть два варианта: вы можете либо сделать снимок документа или какой-то надписи, либо же выбрать изображение из памяти устройства.
Например, вы можете создать новую заметку в приложении и после этого нажать на кнопку камеры в углу интерфейса программы. Теперь у вас есть два варианта: вы можете либо сделать снимок документа или какой-то надписи, либо же выбрать изображение из памяти устройства.
Google Keep способен на многое
При любом исходе приложение загрузит фото в память и после нажатия на меню опции вы увидите заветную надпись «Распознать текст изображения». После этого вы можете сохранить результат в эту же заметку, либо же сформировать из него отдельный текстовый документ. Ах да, если у вас включена синхронизация с аккаунтом Google, то вы можете тут же «расшарить» заметку на Google Диск и иметь к ней доступ с любого устройства, подключенного к сети.
- Теги
- Новичкам в Android
- Операционная система Android
Лонгриды для вас
Как сделать свой emoji в Telegram
Все знают, что эмодзи – это гораздо лучше визуализированный аналог смайликов, который, впрочем, к улыбающимся мордашкам из точек и скобок имеет довольно посредственное отношение. Несмотря на это, люди по-прежнему продолжают отождествлять их, а потому искренне удивляются, что им не дозволено придумывать свои собственные эмодзи, как было со смайликами. Да, Apple и Google планомерно расширяют количество доступных улыбочек, давно выйдя за рамки здравого смысла. Однако возможности делать самостоятельные эмодзи пользователям никто не давал. Но теперь это в прошлом.
Несмотря на это, люди по-прежнему продолжают отождествлять их, а потому искренне удивляются, что им не дозволено придумывать свои собственные эмодзи, как было со смайликами. Да, Apple и Google планомерно расширяют количество доступных улыбочек, давно выйдя за рамки здравого смысла. Однако возможности делать самостоятельные эмодзи пользователям никто не давал. Но теперь это в прошлом.
Читать далее
Как заставить Xiaomi работать нормально. 5 советов владельцам
Рано или поздно каждый владельцы смартфонов Xiaomi, Redmi или Poco понимают, что им необходимы доработки. Проблема с глючащим датчиком приближения при разговорах тянется в этих устройствах уже не один год. С выходом MIUI 12 появились уведомления от высплывающих чатов, которые работают, откровенно говоря, ужасно. Или когда при записи разговора приложение «Телефон» оглушает собеседника фразой, что идет запись разговора. Все это можно исправить, надо лишь немного свободного времени и терпения. Давайте разберемся, как можно сделать жизнь владельцев Xiaomi значительно удобнее. Все инструкции, представленные в настоящей статье, были опробованы автором, включая установку предложенных приложений.
Давайте разберемся, как можно сделать жизнь владельцев Xiaomi значительно удобнее. Все инструкции, представленные в настоящей статье, были опробованы автором, включая установку предложенных приложений.
Читать далее
Почему обновления Android и iOS такие скучные
Уже больше месяца назад Google представила Android 13 на конференции I/O. Мы уже довольно много знали об операционной системе, так как в феврале вышла первая предварительная версия для разработчиков. Но именно на конференции мы начали получать некоторые новые функции, которые были подготовлены для Android 13. Многие из них не впечатлили по-настоящему, но это наша реальность, которая становится все более грустной. Отсутствие чего-то принципиально нового – это не только особенность Android. Это же относится и к iOS. Здесь есть много причин, но одна из них является основной, и если убрать ее, ситуация уже станет намного лучше.
Читать далее
Новый комментарий
Новости партнеров
Apple выпустила iOS 16.
 1 beta 4 для разработчиков. Что нового и как обновиться
1 beta 4 для разработчиков. Что нового и как обновиться10 отличных товаров с AliExpress, за которыми вы встанете в очередь
Apple выпустила iOS 16.1 beta 4 для разработчиков. Что нового и как обновиться
Личный опыт. Чего не стоит делать с iPhone 13
Как распознать рукописный текст на русском языке?
- Главная
- Рынок
- Технологии
20.07.2022
Российские исследователи искусственного интеллекта разработали новую свёрточную нейросеть (CNN), способную распознавать изображения рукописных букв русского алфавита с точностью 99%.
ПО способно распознать рукопись, написанную кириллическими знаками. Причем распознавание текста практически не зависит от почерка, что само по себе трудно даже для человека. Приложение, созданное под эту нейросеть, защищено от утечки информации и не требует подключения к Интернету. Следовательно, в перспективе сможет использоваться для обработки конфиденциальных сведений
«С развитием IT-технологий растет важность быстрого и качественного преобразования рукописного текста в цифровую печатную версию, чтобы было удобнее копировать, редактировать или извлекать из него данные. Целью нашего исследования было распознавание рукописного текста на русском языке нейросетью с использованием моделей глубокого обучения. Насколько нам известно, это первая в мире работа такого рода», — отметил соавтор исследования, студент Института информационных и космических технологий СФУ Андрей Левков.
Обучение нейросети проводилось с помощью данных хранилища CoMNIST — это известная база данных, содержащая образцы рукописного написания букв на латинице и кириллице.
После этого представили полное описание сверточной нейросети и исходного кода, чтобы другие исследователи могли проверить результаты на своих примерах. Для написания ПО был выбран язык Python и интерактивная среда разработки Jupyter.
«Набор данных для анализа содержит 13299 фотографий, на которых зафиксированы прописные, печатные и написанные курсивом буквы. Приблизительно на 85% этих снимков нейронная сеть (CNN) училась распознавать буквы русского алфавита, а ещё на 15% шла проверка усвоенных «знаний». Мы сравнили разработанную нашим коллективом модель с наиболее мощными моделями CNN, например, с VGG-16, VGG-19 и другими. Оказалось, что точность нашей модели во время обучения составляла до 99%, всё обучение заняло 3 часа.
В итоге удалось зарегистрировать уникальную программу ЭВМ, правообладателем которой выступает СФУ. В дальнейшем эксперты планируют обучить модель «читать» целые слова и предложения, а также освоить различные стили письма. Разработка выполнена специалистами Сибирского федерального университета (СФУ) и Санкт-Петербургского государственного электротехнического университета «ЛЭТИ».
Скачать код, чтобы обучить модель на своем собственном наборе данных, можно здесь.
Разработка ПООтечественные разработки
Предыдущая
В Шотландии будут разрабатывать лазерные средства борьбы против беспилотников
Следующая
Новости зеленых технологий США
Хотите узнавать о новых материалах первыми?
Подписывайтесь на рассылку
Еженедельник
Лента материалов
Нажимая на кнопку, я принимаю условия соглашения.
Совместное решение для голосовых AI-проектов
Облачная платформа Yandex Cloud и вендор технологий разговорного искусственного интеллекта Just AI запустили партнерскую интеграцию своих продуктов.
Яндекс, Just AIБизнес, 20.09.22
Как российские ИТ-разработчики воспринимают новые вызовы отрасли
Куда ни пойдешь — везде нужно российское ПО. Причем нельзя выделить что-то одно как более перспективную и востребованную разработку: нужно все, равном…
Михаил ГрибовТренды, 14.09.22
Российские банкоматы должны появиться на рынке осенью
Но создать сейчас полностью отечественный банкомат, локализованный в России на 100%, технически невозможно, полагают эксперты.
Бизнес, 12.09.22
Ракеты-носители «Ангара» и отечественный инструментарий
АО «Протон-ПМ» сообщает, что полностью отказалось от иностранного абразивного инструмента. (борфрезы, шарошки, шлифовальные круги) и планирует…
Технологии, 23.08.22
Загрузить ещё1 2 3 4 5 »» Следующая →
Оптическое распознавание символов | Службы управления записями
Оптическое распознавание символов или OCR — это технология, которая распознает текст в цифровом изображении. Процесс преобразования отсканированного изображения в распознаваемые символы может сделать отсканированные документы доступными для поиска, чтобы найти уникальные ключевые термины или фразы в файле. У вас может быть отсканированный документ длиной 200 страниц, но вам нужно найти только те страницы, на которых упоминается название вашего отдела. Или, может быть, у вас есть целый общий диск с отсканированными документами, и вам нужно найти каждый документ, содержащий определенный номер бюджета. Этот ресурс объяснит, как преобразовать PDF-файлы, чтобы сделать текст распознаваемым, а затем объяснит, как лучше всего искать эти файлы.
Процесс преобразования отсканированного изображения в распознаваемые символы может сделать отсканированные документы доступными для поиска, чтобы найти уникальные ключевые термины или фразы в файле. У вас может быть отсканированный документ длиной 200 страниц, но вам нужно найти только те страницы, на которых упоминается название вашего отдела. Или, может быть, у вас есть целый общий диск с отсканированными документами, и вам нужно найти каждый документ, содержащий определенный номер бюджета. Этот ресурс объяснит, как преобразовать PDF-файлы, чтобы сделать текст распознаваемым, а затем объяснит, как лучше всего искать эти файлы.
По мере того, как мы движемся к цифровому будущему, пришло время отказаться от бумаги и улучшить ваши электронные данные. Сканирование бумажных документов — отличный способ сделать информацию более доступной и надежной. К сожалению, по умолчанию отсканированный документ представляет собой не более чем фотографию высокой четкости. В результате пользователи не могут легко редактировать содержимое этих отсканированных изображений и не могут легко выполнять поиск по содержимому файла.
Представьте, что вы отсканировали документ с гербом Вашингтонского университета. В то время как наши глаза могут читать и интерпретировать, что на отсканированном изображении написано «Вашингтонский университет» и «1861», ваша компьютерная программа может не распознать или интерпретировать автоматически, что отсканированный документ имеет читаемые символы. В результате после сканирования записи единственный способ для пользователей легко узнать, что содержит файл, — это стратегически использовать структуры папок, соглашения об именах файлов и фактически читать документ.
Однако у вас под рукой есть удивительные инструменты, которые могут превратить отсканированные документы в ценные информационные активы путем преобразования отсканированных изображений в доступные для поиска символы. Этот процесс преобразования отсканированных изображений в доступные для поиска символы известен как оптическое распознавание символов или OCR. Применяя процесс OCR к приведенному выше примеру, программа может затем понять, что в отсканированном документе выше есть слова «Вашингтонский университет» и «1861». После преобразования отсканированного документа пользователи могут легко выполнять поиск в отдельном документе или среди документов в папках по определенным словам или фразам.
После преобразования отсканированного документа пользователи могут легко выполнять поиск в отдельном документе или среди документов в папках по определенным словам или фразам.
Одна из самых простых программ для проведения этого процесса преобразования OCR находится в Adobe Acrobat Pro. Рекомендуется сканировать бумажные документы в файлы PDF, поэтому Adobe Acrobat Pro является очевидным выбором при работе с файлами PDF. Однако для использования этих возможностей требуется подписка Adobe Acrobat Pro. Вы не сможете использовать процесс преобразования OCR с помощью Adobe Reader.
Преобразование большинства форматов файлов Microsoft Word, Excel или PowerPoint не требуется. Это связано с тем, что текст уже распознается в этих программах, и пользователи уже имеют возможность редактировать или вносить изменения в содержимое файлов этих типов. Вместо этого этот ресурс сможет направлять пользователей в том, как распознавать PDF-файлы и как после этого использовать функции расширенного поиска.
OCR также помогает сделать документ более доступным. Обратитесь к веб-сайту UWIT для получения дополнительной информации о правилах доступности.
Узнайте, как:
OCR Преобразование файлов PDF с помощью Adobe Acrobat Pro:
- Распознавание текста в одном документе PDF
- Распознавание текста в нескольких документах PDF
Поиск текста
- Поиск текста в одном документе PDF
- Поиск по документам PDF с помощью расширенного поиска Adobe
- Поиск в папках с использованием функций поиска Windows
Распознавание текста в одном документе PDF
Процесс распознавания текста в Adobe Acrobat называется распознаванием текста. Первый шаг — открыть PDF-документ, который вы хотите включить для расширенных возможностей поиска. Затем на панели инструментов в верхней части документа:
- Нажмите Инструменты
- Click Улучшение сканирования
- На верхней панели инструментов появится ряд новых опций, в том числе Вставить ; Улучшение ; Распознать текст
- Нажмите на A A Распознать текст и появится раскрывающееся меню
- Нажмите кнопку В этом файле
- Появится новая панель инструментов
- Убедитесь, что выбрано:
- Все страницы
- Язык: английский (США)
- Настройки должны выглядеть так:
- Все страницы
- Язык документа: английский (США)
- Вывод: изображение с возможностью поиска
- Понизить разрешение до: 600 dpi
- Нажмите ОК
- Нажмите кнопку Распознать текст
- В нижней части страницы появится строка состояния, пока Adobe распознает текст в документе PDF
- Обязательно сохраните документ, который вы открыли после завершения преобразования.

- Благоразумно нажать кнопку “Сохранить” и перезаписать существующий файл. Перезаписывая существующий файл, вы исключаете создание дубликатов. Процесс OCR фактически не изменяет содержимое отсканированной записи, поэтому нет необходимости поддерживать две копии одного и того же файла.
Распознавание текста в нескольких документах PDF
У вас может быть целая папка, заполненная ранее отсканированными документами, которые вы хотите улучшить. Эти инструкции позволят вам конвертировать с помощью оптического распознавания символов сразу несколько PDF-документов.
Предупреждение. Вы не сможете открывать другие файлы Adobe PDF во время процесса распознавания, поэтому обязательно планируйте заранее. Если у вас есть более десяти файлов или , файлы имеют длину в сотни страниц, подождите до конца дня, чтобы сделать это, чтобы он мог обработать все, пока вы находитесь вдали от компьютера.
- Откройте PDF-документ
- Щелкните Инструменты
- Click Улучшение сканирования
- На верхней панели инструментов в верхней части окна появится ряд новых параметров, включая Вставить ; Улучшение ; Распознать текст
- Щелкните AA Recognize Text , и появится раскрывающееся меню.

- Нажмите В нескольких файлах…
- Появится всплывающее окно с документом, над которым вы только что работали, уже в списке
- Добавьте другие файлы для распознавания текста:
Это можно сделать двумя способами. Один из способов — найти файлы в программе и выбрать их для добавления в очередь (вариант А). Кроме того, вы можете вручную перетащить файлы в очередь (вариант B).- Вариант A:
- В левом верхнем углу есть кнопка Добавить файлы…
- Нажмите на эту кнопку
- В раскрывающемся меню выберите Добавить файлы…
- Выберите дополнительные файлы, в которых вы хотите распознавать текст.
- Вы можете выбрать несколько документов, удерживая кнопку Ctrl
- Вы можете выбрать все документы в папке, нажав Ctrl + A
- Нажмите Открыть
- PDF-документ или несколько PDF-файлов теперь будут добавлены в список.

- Если вы хотите отменить выбор файлов, которые были помещены во всплывающее окно для распознавания текста, щелкните имя файла, чтобы оно было выделено. Нажмите Удалить кнопку в левом нижнем углу.
- Когда вы будете готовы, нажмите кнопку OK
- В левом верхнем углу есть кнопка Добавить файлы…
- Вариант B:
- Кроме того, вы можете перетаскивать файлы из файловых структур Windows в пустое пространство списка Adobe. Вам нужно будет открыть исходную папку и Adobe Acrobat, чтобы вы могли просматривать оба приложения на одном экране.
- Вы можете выбрать несколько документов, удерживая кнопку Ctrl. После выбора просто перетащите его в пустое место на экране Adobe Acrobat.
- Вы можете выбрать все документы в папке, нажав Ctrl + A. После выбора просто перетащите в пустое пространство на экране Adobe Acrobat.
- Файлы PDF будут добавлены в список, как только вы отпустите курсор
- Вы можете повторять этот процесс перетаскивания, пока не будут добавлены все файлы.

- Если вы хотите отменить выбор файлов, которые были помещены во всплывающее окно для распознавания текста, щелкните имя файла, чтобы оно было выделено. Нажмите Удалить кнопку в левом нижнем углу.
- Когда будете готовы, нажмите кнопку OK
- После нажатия OK появится новое всплывающее окно
- Сохраните все настройки и варианты выбора.
- Целевая папка: та же папка, которая была выбрана при запуске
- Именование файлов: сохранить исходные имена файлов
- Флажок перезаписывать существующие файлы
- Нажмите ОК
Перезапись существующих файлов предусмотрительна. Перезаписывая существующие файлы, вы исключаете создание дубликатов одной и той же записи. Фактическое содержание записи останется неизменным. Все, что делает этот процесс, — делает существующий контент более доступным и доступным для поиска.
- Появится всплывающее окно
- Сохранить страницы как выбранные «Все страницы»
- Сохранить настройки как есть
- Язык документа: английский (США)
- Вывод: изображение с возможностью поиска
- Понизить разрешение до: 600 dpi
- Сохраните все настройки и варианты выбора.
- Появится строка состояния, пока Adobe распознает текст во всех документах PDF
- Кроме того, вы можете перетаскивать файлы из файловых структур Windows в пустое пространство списка Adobe. Вам нужно будет открыть исходную папку и Adobe Acrobat, чтобы вы могли просматривать оба приложения на одном экране.
- Вариант A:
Вернуться к началу страницы
Поиск текста в одном документе PDF
Приведенные ниже инструкции позволяют найти определенное слово или фразу в документе PDF, который вы преобразовали с помощью процесса OCR.
- Открытие документа PDF с помощью Adobe Acrobat Pro
- Перейдите на вкладку Редактировать , расположенную в левом верхнем углу.
- Нажмите на Найдите (или нажмите Ctrl+F)
- Появится всплывающее окно под названием Find
- Введите слово или фразу, которую вы хотите найти
- Нажмите Далее
- Начиная со страницы, на которой вы находитесь, Adobe будет искать каждый экземпляр в документе, соответствующий параметрам поиска, и выделять их
- Нажатие Next приведет вас к следующему результату в документе.
- Когда у вас больше не будет новых результатов поиска, появится всплывающее окно с сообщением о том, что совпадений больше не найдено
- Если вы хотите выполнить более расширенный поиск в документе, обратитесь к приведенным ниже инструкциям по использованию функций расширенного поиска
К началу страницы
Поиск в документах PDF с помощью расширенного поиска Adobe
Приведенные ниже инструкции позволяют найти конкретное слово или фразу в любых и всех записях PDF, текст которых был распознан. Возможно, вы ищете номер бюджета в нескольких файлах и папках. Возможно, вы ищете имя студента или факультета. Этот метод найдет все случаи появления ключевого слова или фразы.
Возможно, вы ищете номер бюджета в нескольких файлах и папках. Возможно, вы ищете имя студента или факультета. Этот метод найдет все случаи появления ключевого слова или фразы.
ПРЕДУПРЕЖДЕНИЕ. Прежде чем начать, всегда держите открытым один PDF-документ при использовании расширенного поиска. Если вы закроете последний PDF-документ, он закроет все приложение Adobe Acrobat вместе с результатами расширенного поиска.
- Открытие документа PDF с помощью Adobe Acrobat Pro
- Перейдите на вкладку Редактировать , расположенную в левом верхнем углу.
- Щелкните Расширенный поиск (или нажмите Shift+Ctrl+F)
- Появится всплывающее окно с названием «Поиск
- » Щелкните кружок рядом с: Все PDF-документы в
- Щелкните раскрывающееся меню папки и выберите папку, в которой вы хотите выполнить поиск.
- Если вы не найдете нужную папку в предлагаемом списке. Выберите Поиск местоположения.
 ..
.. - В новом всплывающем окне просмотрите и найдите папку, в которой вы хотите выполнить поиск, и нажмите OK
- Если вы не найдете нужную папку в предлагаемом списке. Выберите Поиск местоположения.
- Введите слово или фразу для поиска
- Выберите любой из четырех флажков, если применимо
- Нажмите Поиск
- Затем вы можете развернуть результаты, щелкнув значок стрелки рядом с именем документа.
- При этом будет показано, сколько раз и краткое место в документе встречается слово/фраза.
- Если вы наведете указатель мыши на маленький значок Adobe или на заголовок PDF-файла, вы сможете найти местоположение документа.
- Если щелкнуть результат поиска, он автоматически откроет PDF-документ и перейдет к месту в документе слова/фразы.
К началу страницы
Поиск в папках с использованием функций поиска Windows
Знакомая всем нам функция поиска Windows ищет только названия файлов.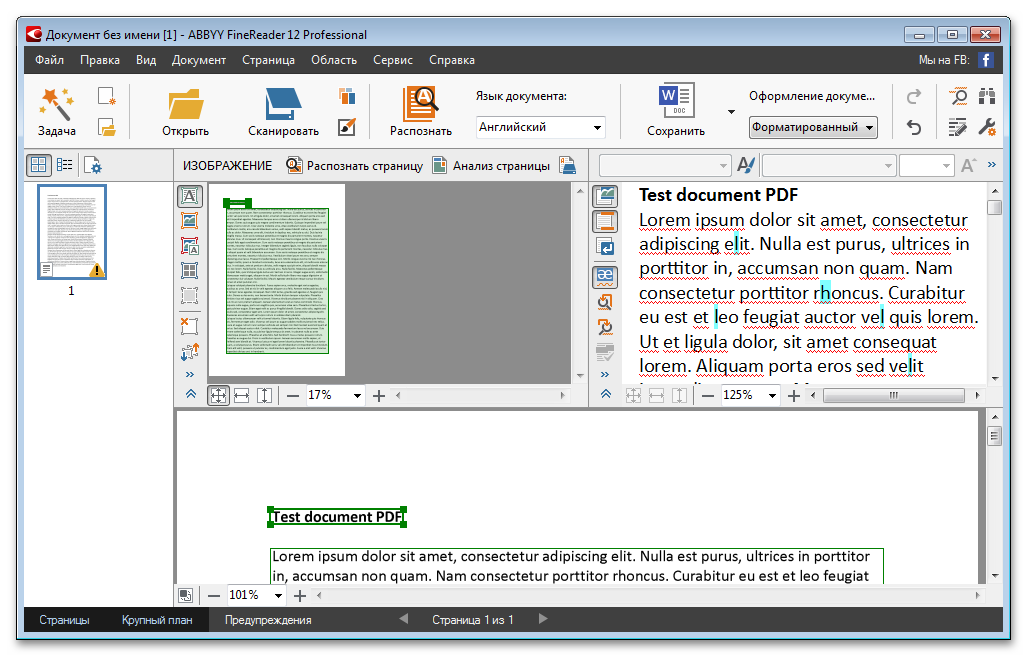 Следуя приведенным ниже инструкциям, вы сможете искать и находить определенное слово или фразу в отдельных документах в проводнике Windows. После преобразования PDF-файла с помощью описанных выше процессов OCR эти инструкции помогут сделать этот PDF-файл доступным для обнаружения при использовании функций поиска Windows File Explorer.
Следуя приведенным ниже инструкциям, вы сможете искать и находить определенное слово или фразу в отдельных документах в проводнике Windows. После преобразования PDF-файла с помощью описанных выше процессов OCR эти инструкции помогут сделать этот PDF-файл доступным для обнаружения при использовании функций поиска Windows File Explorer.
- Откройте проводник Windows для верхней папки, в которой вы хотите выполнить поиск
- В этом примере при выполнении поиска на этом уровне папки будут выполняться поиск отдельных документов, а также каждой из подпапок.
- Щелкните в окне поиска в правом верхнем углу и введите параметры поиска.
- Нажмите Enter на клавиатуре, чтобы начать поиск
- В этом примере первоначальный поиск не дал результатов
- На панели инструментов в верхней части страницы в разделе Инструменты поиска щелкните Поиск
- В этом раскрывающемся меню можно сузить параметры поиска, включая формат файла, размер файла, теги и измененные данные.

- В этом раскрывающемся меню можно сузить параметры поиска, включая формат файла, размер файла, теги и измененные данные.
- Нажмите кнопку Дополнительные параметры
- В раскрывающемся меню под В неиндексированных местах щелкните Содержимое файла.
- Если галочка уже видна, этот шаг можно пропустить.
- После нажатия этой кнопки поиск будет повторен. Но на этот раз Windows будет искать не только по названию файлов, но и по содержимому ваших документов.
- Если вы распознали текст в документах PDF, документы PDF появятся в результатах, если они соответствуют параметрам поиска
- В этом примере 3 элемента были найдены путем изменения этой настройки. Одним из них был PDF-документ с распознанным текстом.
- Вы можете вернуться к инструментам поиска и дополнительным параметрам и заметить, что рядом с содержимым файла теперь стоит галочка.
- Готово! Если вы хотите изменить настройки обратно на поиск только по заголовкам файлов, а не по содержимому документов, обязательно снимите флажок Содержимое файла .

4 фантастических способа распознавания текста в PDF (офлайн, бесплатно онлайн)
4 фантастических способа распознавания текста в PDF (офлайн, бесплатно онлайн)Конни Уисли
04 августа 2022 г. 329
Электронные файлы или изображения, созданные путем сканирования бумажных документов, на самом деле безопасны для окружающей среды и их легко хранить. Тем не менее, эти отсканированные файлы недоступны для поиска и не позволяют пользователям выделять и редактировать. Для решения этой проблемы на рынке программного обеспечения появилась технология OCR (оптическое распознавание символов).
Необходимо распознавать текст в PDF и сделать отсканированный PDF доступным для поиска с помощью оптического распознавания символов? Цель этой статьи — порекомендовать инструменты распознавания текста с наивысшим уровнем точности. Вот 4 фантастических способа распознавания текста в PDF офлайн и бесплатно онлайн, читайте дальше!
- Самое надежное: распознавание текста в PDF с помощью автономного программного обеспечения
- Проще всего: распознавать текст в PDF онлайн бесплатно
Самое надежное: распознавание текста в PDF с помощью автономного программного обеспечения
Вы ищете комплексное программное обеспечение для работы с PDF, которое может не только распознавать текст в PDF так же просто, как пирог, но и преобразовывать PDF в различные форматы? На рынке программного обеспечения появляется все больше профессиональных конвертеров PDF, поэтому для нас это простая задача.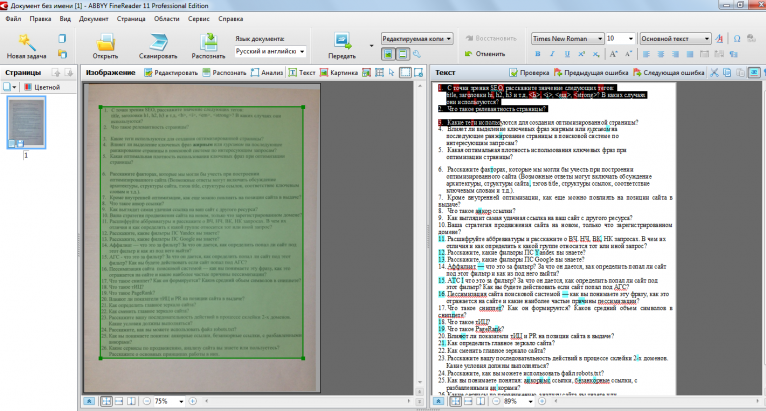 Основная причина, по которой подавляющее большинство пользователей предпочитают использовать автономное программное обеспечение онлайн-сайтам, заключается в том, что первое является более надежным, безопасным и практичным. Вот 3 варианта для вас, продолжайте.
Основная причина, по которой подавляющее большинство пользователей предпочитают использовать автономное программное обеспечение онлайн-сайтам, заключается в том, что первое является более надежным, безопасным и практичным. Вот 3 варианта для вас, продолжайте.
Ваше идеальное распознавание символов: распознавание текста в отсканированных PDF-файлах с помощью Cisdem PDFMaster
Преобразование фотографий бумажных документов или отсканированных изображений в доступные для поиска файлы с доступным для поиска текстом, неотделимым от передовой технологии оптического распознавания символов. Из всего автономного программного обеспечения, предоставляющего услугу распознавания текста, Cisdem PDFMaster является самым надежным, безопасным и мощным.
Cisdem PDFMaster — это высокоэффективное программное обеспечение для работы с файлами PDF, которое представляет собой мощное средство для создания и преобразования PDF с более чем 15 форматами. Пакетное преобразование, высокое качество преобразования, впечатляющая скорость преобразования и удобные настройки — это услуги, которые PDFMaster может предоставить пользователям Mac и пользователям Windows.
Мы получили отзыв от пользователей в обзоре с пятью звездами, в котором говорилось: «Очень ценно, что Cisdem представила многоцелевые функции в одном приложении». Итак, давайте посмотрим, какие привлекательные и удобные функции доступны.
- Создать PDF из: DOC, DOCX, XLSX, ODT, PPTX, JPEG, BMP, PNG, JPG, JPEG, GIF, TIFF, EPUB, HTML, HTM, CHM, RTF, RTFD, TXT, ICO
- Преобразование PDF в: DOCX, DOX, XLSX, PPTX, Pages, Key, JPEG, BMP, PNG, GIF, TIFF, EPUB, HTML, RTF, TXT
- Используйте мощный редактор для редактирования текста, изменения текста, замены текста в PDF. С легкостью добавляйте аннотации, такие как подчеркивание, фигуры, штампы, подпись, дату, текстовое поле
- Легко вносите изменения в страницы, включая разделение страниц, поворот одной или нескольких страниц, удаление страниц из PDF, вставку пустой страницы, перемещение страницы, обрезку страниц
- Добавление полей формы для создания заполняемой формы PDF, а также позволяет создавать другие поля формы, такие как поля цифровой подписи, радиополя, поля флажков и поля списков
- Добавьте пароль для защиты ваших данных или удалите пароль, если вы его забыли.

Как распознать текст в отсканированном PDF с лучшим OCR?
- Скачать бесплатно лучшее программное обеспечение для распознавания текста на Mac или Windows.
Скачать бесплатно - Откройте инструмент OCR и импортируйте отсканированный файл PDF с локального устройства или из Интернета.
- Нажмите Применить OCR , чтобы начать распознавание текста в Cisdem.
- Тогда весь текст в вашем PDF-файле доступен для поиска, вы можете переместить курсор, чтобы скопировать текст по желанию.
- Нажмите «Загрузить», чтобы сохранить PDF-файл с возможностью поиска.
Простое распознавание текста в PDF с помощью Adobe Acrobat Pro DC
Adobe Acrobat Pro, соответствующий мировому стандарту, безусловно, незаменим для функции распознавания текста. Функция Scan & OCR позволяет пользователям распознавать не только отсканированный документ, но и изображение с камеры. Качество и скорость распознавания текста в отсканированном документе или изображении с камеры являются лучшими в своем классе. Кроме того, эта программа доступна для компьютеров Mac, Windows и даже для веб-браузера.
Качество и скорость распознавания текста в отсканированном документе или изображении с камеры являются лучшими в своем классе. Кроме того, эта программа доступна для компьютеров Mac, Windows и даже для веб-браузера.
Как распознать текст в PDF с помощью Adobe Acrobat Pro?
- Щелкните Файл > Откройте , чтобы загрузить отсканированный документ со своего компьютера или из облака.
- Перейдите к Инструменты > Сканирование и оптическое распознавание символов .
- Выберите параметр Enhance , чтобы улучшить качество документа. В раскрывающемся меню выберите Отсканированный документ .
- Затем перейдите к Распознать текст . После настройки диапазона страниц, языка и других параметров OCR нажмите кнопку Распознать текст Кнопка, чтобы начать распознавание текста в Adobe Acrobat Pro.
- Тогда весь ваш текст в формате PDF можно будет легко найти и скопировать.

Распознавание текста в PDF с помощью Bluebeam Revu для Windows
Bluebeam Revu пользуется популярностью у многих архитекторов, инженеров и профессионалов по всему миру благодаря своим профессиональным инструментам проектирования для создания, редактирования, измерения и маркировки. Когда вы откроете программное обеспечение, вы увидите, что оно черного цвета, а интерфейс окружен инструментами рисования.
Думаю, людей больше волнует цена. Он стоит от 349 до 599 долларов за место, что действительно является значительным расходом для обычных пользователей и малого бизнеса. Так что это программное обеспечение больше подходит для людей с профессиональными потребностями.
Как использовать инструмент распознавания текста в Revu?
- Перейдите к Файл > Откройте , чтобы импортировать файл, который необходимо распознать.
- Щелкните Документ > OCR , чтобы запустить инструмент OCR.

- В диалоговом окне OCR есть несколько разделов и опций.
- Вам разрешено выбирать диапазон страниц, 14 языков и типы документов. Существует также раздел файлов, позволяющий добавлять дополнительные файлы.
Затем нажмите OK , чтобы запустить средство распознавания текста. - Перейдите к Редактировать > Содержимое PDF > Выбрать текст , чтобы выбрать и скопировать любой текст в доступном для поиска PDF-файле.
- Теперь вы сможете выделить большую часть текста в документе.
Сравнение программного обеспечения для распознавания текста
Самое простое: распознавание текста в PDF онлайн бесплатно
PDF24 — это совершенно бесплатный онлайн-сайт PDF, на котором представлены такие инструменты PDF, как объединение файлов, уменьшение размера файла, защита PDF, разблокировка пароля, сравнение PDF-файлов, редактирование PDF, OCR, добавление водяных знаков и более 20 инструментов. Премиум-версии нет, поэтому каждый пользователь может использовать все инструменты PDF24 бесплатно без каких-либо ограничений.
Премиум-версии нет, поэтому каждый пользователь может использовать все инструменты PDF24 бесплатно без каких-либо ограничений.
PDF24 также поставляется с рядом опций для настройки выходного файла при использовании функции OCR для распознавания текста. Самое удивительное, что он поддерживает распознавание более 120+ языков. Более того, функция предварительного просмотра перед загрузкой также удобна для пользователей.
Как распознать текст в PDF онлайн бесплатно?
- Выберите файлы, загрузив их или перетащив.
- Программа показывает параметры для выбора языков, типа вывода, поворота страниц и объединения файлов. Для получения дополнительной информации введите заголовок, автора, тему и даже ключевые слова.
Когда выбрано, нажмите Start OCR . - После завершения распознавания текста не забудьте сохранить файл, нажав Загрузить.
Окончательный вердикт
Возможно, вам нужно распознавать текст в PDF бесплатно онлайн или вы не хотите загружать офлайн-приложения, инструменты PDF24 — отличный онлайн-выбор для вас. Но если вы предпочитаете работать в автономном режиме, у Cisdem PDFMaster есть абсолютное преимущество в цене, функциях, дизайне и обслуживании по сравнению с двумя другими настольными программами в списке.
Но если вы предпочитаете работать в автономном режиме, у Cisdem PDFMaster есть абсолютное преимущество в цене, функциях, дизайне и обслуживании по сравнению с двумя другими настольными программами в списке.
Конни Уисли
Конни пишет для Mac продуктивные и служебные приложения с 2009 года. Каждый обзор и решение основаны на ее практических тестах, она всегда энергична и заслуживает доверия в этой области.
Комментарии (0) Оставить комментарий
Горячие статьи
Как конвертировать PDF в Word на Mac без потери форматирования (обновление 2022 г.) Обновление 2022 г.: как распознавать PDF-файлы на Mac (поддержка Ventura и Monterey) Как уменьшить размер файла PDF на Mac с предварительным просмотром или без него?Главная > 4 фантастических способа распознавания текста в PDF (офлайн, бесплатно онлайн)
4 способа распознать текст в PDF
Если вы когда-либо пытались внести изменения в PDF, вы знаете, насколько это сложно.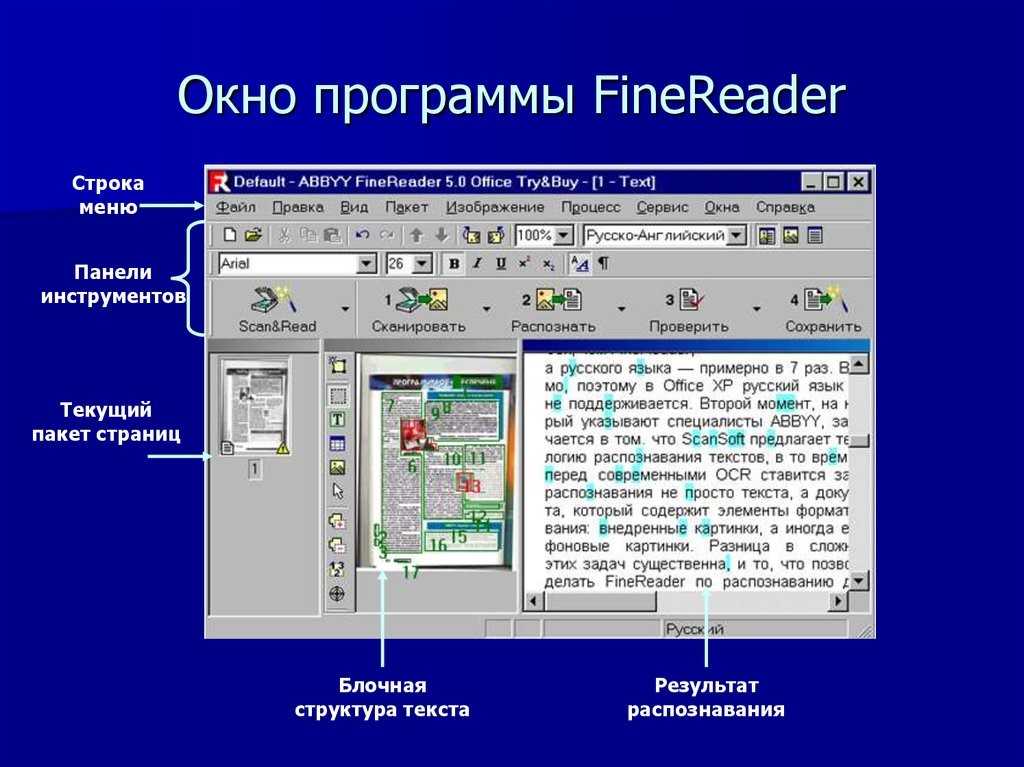 Однако распознавание текста PDF — самый простой и успешный метод. При таком подходе редактирование текстов является простой задачей. Этот пост научит вас наиболее эффективному методу распознавать текст в PDF .
Однако распознавание текста PDF — самый простой и успешный метод. При таком подходе редактирование текстов является простой задачей. Этот пост научит вас наиболее эффективному методу распознавать текст в PDF .
- Часть 1. Как распознать текст в PDF путем преобразования с помощью OCR?
- Часть 2. Как распознать текст в PDF с помощью Adobe Acrobat?
- Часть 3: Как распознать текст в PDF Online?
- Часть 4. Как использовать распознавание текста Bluebeam?
- Часть 5. Часто задаваемые вопросы о рукописном вводе в текст
Часть 1. Как распознать текст в PDF путем преобразования с помощью OCR?
Если вам нужно решение для работы с PDF, выберите UPDF — комплексный вариант корпоративного уровня. Существует множество вариантов, и создатели постоянно учитывают отзывы для улучшения продукта.
Он прост в использовании и содержит множество полезных функций. UPDF — это не только редактор PDF, но и программа для чтения PDF, инструмент для создания аннотаций PDF и органайзер PDF. Самое лучшее в UPDF — это то, что вам легче распознавать слова в PDF. Кроме того, есть и много других особенностей. Вы можете скачать его для пробной версии.
Самое лучшее в UPDF — это то, что вам легче распознавать слова в PDF. Кроме того, есть и много других особенностей. Вы можете скачать его для пробной версии.
Вот наиболее важные и популярные функции UPDF:
- Ваш PDF-файл можно редактировать так же, как документ Word, что позволяет легко вносить изменения в текущее содержимое.
- Вы можете выделить свои PDF-документы, выделив текст, абзацы и области.
- Пустые страницы и другие страницы PDF можно вставлять с помощью UPDF. Используя UPDF, вы можете заменить одну страницу или весь PDF-файл.
- Вы можете выбрать один из нескольких различных форматов чтения. Можно открыть много PDF-файлов на разных вкладках.
- Вы также можете с легкостью подписывать свои PDF-документы цифровой подписью.
Вот как выполнить распознавание текста OCR с помощью UPDF:
Шаг 1. Загрузите и установите UPDF
Сначала перейдите на официальный сайт UPDF и загрузите последнюю версию UPDF. Теперь запустите UPDF на вашем устройстве.
Теперь запустите UPDF на вашем устройстве.
Шаг 2. Откройте файл PDF и щелкните значок «Экспорт PDF».
Теперь откройте документ PDF, который вы хотите использовать для распознавания текста. Вы можете вручную открыть PDF-файл, используя опцию «Открыть файл», или просто перетащить PDF-файл в интерфейс UPDF.
Теперь перейдите в верхнюю правую панель интерфейса и щелкните значок «Экспорт PDF».
Шаг 3. Выберите формат вывода
Вы увидите список форматов вывода, доступных в UPDF. Чтобы распознать текст, вам необходимо преобразовать документ PDF в текстовый формат. Выберите формат текста.
Шаг 4. Включите функцию OCR
Теперь появится всплывающее окно. Включите функцию OCR и установите предпочитаемый язык. Вы также можете выбрать страницы, которые хотите использовать для распознавания текста.
Шаг 5. Преобразование PDF в текст
После настройки всех параметров нажмите кнопку «Экспорт», и ваш PDF-файл будет преобразован в текстовый файл. Теперь вы можете легко редактировать или изменять текст.
Теперь вы можете легко редактировать или изменять текст.
Выше приведены шаги по преобразованию PDF в текст. Это просто? Вы можете нажать кнопку загрузки, чтобы получить пробную версию.
Часть 2. Как распознавать текст в PDF с помощью Adobe Acrobat
Когда дело доходит до создания, редактирования и чтения PDF-файлов, Adobe Acrobat является золотым стандартом. Если вам нужно быстро распознавать документы на Mac или ПК, распознавание текста Adobe — это фантастическое приложение для использования.
- Запустите Adobe Acrobat Pro DC и откройте файл.
- На правой боковой панели выберите Сканировать и OCR.
- Параметр «Распознать текст» отобразится на плавающей панели инструментов.
- Чтобы получить к нему доступ, выберите его в раскрывающемся меню и нажмите «В этом файле».
- Чтобы получить доступ к панели инструментов, выберите «Настройки».
- Чтобы уменьшить размер конечного изображения, выберите «Изображение с возможностью поиска» в качестве «Вывод» и «600 dpi» в качестве «Уменьшить до».
 После обработки OCR размер файла будет уменьшен.
После обработки OCR размер файла будет уменьшен. - Используйте «Изображение с возможностью поиска (точное)», если вам не важен размер файла. После обработки OCR вывод будет максимально приближен к исходному документу.
- OCR можно запустить, щелкнув синий значок «Распознать текст».
- По завершении нажмите «Распознать текст» еще раз.
- Щелкните раскрывающееся меню и выберите «Исправить распознанный текст».
- Если Acrobat обнаруживает текст, который, по его мнению, может быть неправильно прочитан, он выделяет этот текст красным цветом.
- Неточности в распознавании могут существовать за пределами красных прямоугольников. Вместо того, чтобы показывать изображение страницы, Acrobat покажет текстовый слой, который может быть найден, если вы выберете соответствующий параметр в левом верхнем углу.
- Если вы хотите снова увидеть изображение страницы, снимите флажок «Просмотреть» или нажмите «Отмена».
- Продолжайте, пока текст не будет правильно идентифицирован.
 Любой текст, который был точно идентифицирован, не будет выделен красным цветом.
Любой текст, который был точно идентифицирован, не будет выделен красным цветом.
Часть 3. Как распознать текст в PDF Online
С помощью инструмента оптического распознавания символов (OCR) Google Диска преобразование PDF-файлов и изображений в текст становится удовольствием. Давайте проверим некоторые варианты распознавания текста PDF онлайн.
- Войдите в свою учетную запись Google Диска и загрузите файлы, которые вы хотите OCR. Чтобы получить доступ к своему собственному Google Диску, выберите его из списка дисков в левой части экрана после нажатия кнопки «Создать». Выберите, чтобы добавить файлы.
- Чтобы добавить файл на Google Диск, выберите параметр «Загрузить файлы». Найдите документ, который вы хотите преобразовать в текстовый формат (будь то PDF, изображение или что-то еще). Выберите опцию «Открыть».
- Ваша копия документа загружена на Google Диск. Щелкнув правой кнопкой мыши по файлу, появится контекстное меню.
- Если Google Docs отображается как вариант, выберите его.
 Когда файл будет загружен, появится значок листа. Преобразование текста OCR в PDF вашего файла PDF или изображения в настоящее время выполняется в Google.
Когда файл будет загружен, появится значок листа. Преобразование текста OCR в PDF вашего файла PDF или изображения в настоящее время выполняется в Google. - PDF-файл будет преобразован в текст, и файл откроется в Документах Google, но с небольшим форматированием. Вновь созданный текстовый файл можно редактировать и форматировать любым удобным для вас способом.
Часть 4. Как использовать Bluebeam Text Recognition
Профессиональные инструменты проектирования Bluebeam Revu для создания, редактирования, измерения и маркировки сделали его фаворитом среди архитекторов, инженеров и других специалистов во всем мире. Интерфейс программы темный и при открытии окружен несколькими инструментами рисования.
- Выберите «Файл» > «Открыть», чтобы загрузить распознаваемый файл.
- Диалоговое окно OCR содержит ряд различных вкладок и настроек.
- На ваш выбор доступно 14 языков и типов документов. Кроме того, вы можете загружать файлы с помощью вкладки «Файл».

- Затем вы можете перейти к использованию инструмента распознавания текста, нажав кнопку OK.
- Выберите «Правка» > «Содержимое PDF» > «Выбрать текст», чтобы найти текст в PDF-файле с возможностью поиска и скопировать его.
- Теперь большая часть текста на вашей странице должна быть доступна.
Часть 5. Часто задаваемые вопросы о написании текста от руки
Как заставить PDF распознавать текст?
Вы можете использовать редактор UPDF для распознавания текста из файлов PDF.
Как включить распознавание текста в Adobe?
Adobe Acrobat может читать текст из PDF-файлов и изображений на многих языках.
Чтобы выполнить оптическое распознавание символов (OCR), просто откройте отсканированный документ или изображение, которое необходимо обработать, а затем выберите «Инструменты» на верхней правой панели инструментов. Если вы хотите распознать текст в текущем файле, вы можете сделать это, нажав кнопку «В этом файле» в разделе «Распознать текст» этой боковой панели.
Почему мой PDF не распознает текст?
Документ недоступен для поиска, если он не позволяет выделить текст. При использовании функции «Распознать текст» в PDF исходное разрешение сканирования должно быть 72 dpi или выше.
Заключение
Имея все эти методы распознавания текста в PDF, мы рекомендуем вам использовать UPDF. Это быстро, безопасно и надежно.
OCR для перевода изображений PDF в машиночитаемый текст
pdf editor scan ocrВ этой статье рассказывается, как распознавать файлы PDF и портфолио PDF с помощью Foxit PDF Editor.
Как это работает? Оптическое распознавание символов, или OCR, представляет собой программный процесс, который позволяет преобразовывать изображения или печатный текст в машиночитаемый текст. OCR чаще всего используется при сканировании бумажных документов для создания электронных копий, но также может применяться к существующим электронным документам (например, PDF или PDF-портфолио).
Когда для изображения выполняется распознавание символов, программное обеспечение анализирует изображение и ищет шаблоны, представляющие символы (например, буквы, цифры, знаки препинания). Затем он сравнивает эти шаблоны с библиотекой известных форм символов и пытается сопоставить их. Как только символы будут идентифицированы, программа OCR преобразует их в машиночитаемый текст.
Действия по распознаванию текстаFoxit PDF Editor может определить, является ли PDF-файл отсканированным или основанным на изображении, и сделать соответствующие предложения для запуска OCR при открытии отсканированного или основанного на изображении PDF-файла. Вы также можете запустить OCR в любое время, чтобы распознать текст на основе изображения в PDF.
Чтобы распознать текст на основе изображения или отсканированный текст в файле PDF, выполните следующие действия:
1. Нажмите Преобразовать > Распознать текст > Текущий файл , в диалоговом окне Распознать текст укажите нужный вам диапазон страниц.
2. Выберите язык, используемый в вашем документе. Вы также можете выбрать несколько языков.
3. В типе вывода установите флажок Текст с возможностью поиска Изображение , чтобы сделать текст изображения доступным для выбора и поиска (или установите флажок Редактируемый текст , чтобы разрешить редактирование текста изображения с помощью Foxit PDF Editor). Затем нажмите OK , чтобы распознать текст.
Текстовое изображение с возможностью поиска :Во время процесса оптического распознавания текста Foxit PDF Editor анализирует текст изображения и заменяет слова/символы, максимально приближенные к тексту изображения. Замещающие слова/символы будут помещены на невидимый слой текста в PDF-файле, что сделает текст изображения доступным для выбора и поиска. Если замена неопределенна, текст будет помечен как подозрительный на OCR, который необходимо исправить вручную.
Текст изображения можно извлечь из PDF и сохранить в виде файла . txt.
txt.
- 1. Откройте Foxit PDF Editor и выберите «Файл» > «Открыть». Найдите PDF-файл, который вы хотите распознать, выберите его и нажмите «Открыть».
- 2. Выберите «Инструменты» > «Распознавание изображений». Появится диалоговое окно распознавания изображений OCR.
- 3. В раскрывающемся списке «Язык» выберите язык текста в PDF-файле.
- 4. В разделе «Параметры вывода» можно выбрать вывод распознанного текста в новый файл или его наложение на текст исходного изображения в PDF-файле.
- 5. Нажмите Пуск. Foxit PDF Editor начнет процесс OCR. Появится индикатор выполнения, показывающий состояние процесса OCR.
После завершения процесса оптического распознавания символов диалоговое окно распознавания изображений можно закрыть. Теперь текст в вашем PDF-файле должен быть доступным для выбора и поиска. Если в процессе OCR есть какие-либо ошибки, они будут помечены как подозрительные OCR. Вы можете исправить эти ошибки, выбрав «Инструменты» > «Исправить подозреваемые».
Вы можете исправить эти ошибки, выбрав «Инструменты» > «Исправить подозреваемые».
Во время процесса OCR Foxit PDF Editor сравнивает форму текста изображения с приблизительными шрифтами, установленными в вашей системе, и превращает текст изображения в редактируемый текст.
Примечание : Если вам будет предложено загрузить компонент OCR после нажатия OK , нажмите Да , чтобы загрузить и установить его, или загрузите его позже по предоставленной ссылке и установите, нажав Установить Подключаемый модуль в диалоговом окне «О подключаемых модулях Foxit», которое появляется при нажатии кнопки 9.0470 Подключаемые модули Foxit на вкладке Справка . Чтобы получить полную версию Foxit PDF Editor, свяжитесь с нами.
Выполните следующие простые шаги:- 1. (Необязательно) Если вы отметите Найти все подозрительные (показать все результаты OCR, которые, возможно, необходимо изменить.
 ) , появится диалоговое окно Подозрительные вам проверить и исправить подозрительные OCR сразу после завершения распознавания. Чтобы узнать, как исправить подозрительные ошибки OCR, см. инструкции в разделе «Найти и исправить подозрительные ошибки OCR».
) , появится диалоговое окно Подозрительные вам проверить и исправить подозрительные OCR сразу после завершения распознавания. Чтобы узнать, как исправить подозрительные ошибки OCR, см. инструкции в разделе «Найти и исправить подозрительные ошибки OCR». - Если выбрать Редактируемый текст в типе вывода с выбранным параметром Найти все подозрительные (Показать все результаты OCR, которые, возможно, необходимо изменить.) , текст с распознанным распознаванием, в отношении которого Foxit PDF Editor не уверен, будет помечен как подозревает OCR, и исходный текст изображения будет сохранен до тех пор, пока вы вручную не обработаете все подозрительные OCR. Вы также можете отменить выбор этого параметра, чтобы превратить текст изображения в редактируемый текст без подозреваемых OCR после распознавания. И вы можете изменить текст напрямую, используя команды в Правка вкладка.
- 2. (Необязательно) Если вы выберете Редактируемый текст на шаге 3, будет доступен параметр Распознавать сегменты линий как объекты пути в PDF .
 Если текст изображения в вашем документе содержит таблицы, выбор этого параметра помогает лучше распознавать сегменты линий, но полное распознавание может занять больше времени.
Если текст изображения в вашем документе содержит таблицы, выбор этого параметра помогает лучше распознавать сегменты линий, но полное распознавание может занять больше времени. - 3. Появится всплывающая панель процесса распознавания, показывающая ход выполнения.
- 4. Используйте функцию поиска, текст на изображении или отсканированном документе будет доступен для поиска.
Совет: Foxit PDF Editor предоставляет команду Quick Recognition на вкладке Home / Convert для распознавания всех страниц отсканированного PDF-файла или PDF-файла на основе изображения с настройками по умолчанию или предыдущими настройками одним щелчком мыши. .
Редактор PDF преобразовать Чтобы распознать текст в нескольких файлах:- 1. Нажмите Преобразовать > Распознать текст > Несколько файлов .

- 2. В диалоговом окне Распознать текст нажмите Добавить файлы , чтобы добавить файлы, папки или открытые в данный момент файлы. Используйте Переместить вверх , Переместить вниз и Удалить для настройки порядка файлов.
- 3. Нажмите Параметры вывода… . В диалоговом окне Параметры вывода выберите папку назначения, укажите, как назвать новый файл и следует ли перезаписывать существующий, а затем нажмите OK .
- 4. Нажмите OK . После распознавания появится всплывающее окно с сообщением о том, что распознавание завершено.
- 1. При первом использовании модуля CJK OCR система напомнит вам загрузить и установить модуль с сервера Foxit.
- 2. Если добавлен какой-либо неподдерживаемый файл, в окне Распознать текст появится кнопка «Удалить неподдерживаемый файл(ы)».
 диалоговое окно 0471. Нажмите кнопку, чтобы удалить неподдерживаемые файлы, а затем продолжите. При распознавании портфолио PDF Foxit PDF Editor будет извлекать и распознавать только PDF-файлы в портфолио.
диалоговое окно 0471. Нажмите кнопку, чтобы удалить неподдерживаемые файлы, а затем продолжите. При распознавании портфолио PDF Foxit PDF Editor будет извлекать и распознавать только PDF-файлы в портфолио.
Портфолио PDF предлагает множество преимуществ по сравнению с традиционными PDF-файлами, а файлы OCR PDF являются важной частью обеспечения машиночитаемости портфолио PDF. Портфолио в формате PDF можно легко передавать, отправлять по электронной почте и загружать, что делает их идеальными для обмена большими файлами или несколькими файлами одновременно.
Кроме того, портфолио PDF может быть защищено паролем, что гарантирует доступ к файлам только авторизованным пользователям. PDF-файлы OCR также меньше по размеру, чем традиционные PDF-файлы, что упрощает их хранение и управление.
Таким образом, портфолио PDF предлагает удобный и безопасный способ обмена информацией.
БЕСПЛАТНАЯ пробная версия на 14 дней — нажмите здесь
Сканер текста (OCR) в App Store
Описание
OCR-Text Scanner — приложение для распознавания любого текста на изображении с помощью 9Точность от 8% до 100%. Дали поддержку 92 языка.
Дали поддержку 92 языка.
Здесь технология OCR (оптическое распознавание символов) используется для распознавания текста на изображении.
Свяжитесь со мной, если ваш язык отсутствует для поддержки.
Особенности текстового сканера:
* Извлечение любого текста/слов на изображении.
* Сканирование нескольких изображений – извлечение текста в фоновом режиме.
* Распознавание текста с изображения поддерживает 92 языка.
* Копировать – текст на экране, используя снимок экрана
* Обрезать изображение перед распознаванием символов.
* Изменить и поделиться результатом распознавания.
* Получите переводы более чем на 100 языков.
* Недавняя история сканирования.
* Организуйте сканы внутри папки.
* Сортировать сканы по дате в порядке убывания или возрастания.
* Расширение Share для обмена изображением для извлечения текста.
* Выбор нескольких столбцов в тексте изображения.
Пожалуйста, отправьте письмо, если вы обнаружите какие-либо ошибки, проблемы или вам нужна какая-либо функция.
Планы подписки
Неограниченное количество сканирований в месяц
————————-
Неограниченное количество сканирований
Без рекламы до 50 сканирований в день.
сроком на один месяц.
в месяц 7,99 $
Неограниченное количество сканирований Ежегодно
———————-
Неограниченное количество сканирований
Без рекламы до 50 сканирований в день.
сроком на один год.
годовых 60,99 $.
——————
Оплата будет снята с учетной записи iTunes при подтверждении покупки.
Подписка продлевается автоматически, если автоматическое продление не будет отключено по крайней мере за 24 часа до окончания текущего периода.
С аккаунта будет взиматься плата за продление в соответствии с тарифом существующего плана в течение 24 часов до окончания текущего периода.
Пользователь может управлять подписками, а автоматическое продление может быть отключено в настройках учетной записи пользователя после покупки.
Любая неиспользованная часть бесплатного пробного периода, если она предлагается, будет аннулирована, когда пользователь приобретет подписку на эту публикацию, где это применимо.
——————
Политика конфиденциальности: https://sites.google.com/view/appsiites/ios/textscanner/privacypolicy
Условия использования: https: //sites.google.com/view/appsiites/ios/textscanner/termsofuse
Версия 1.5.5
1. Следующее и предыдущее сканирование можно перемещать с помощью левой и правой кнопок.
2. Изменения пользовательского интерфейса и исправления ошибок.
3. Повышение производительности.
Рейтинги и обзоры
12 оценок
Удивительно, но.
 ..
..На сегодняшний день лучшее приложение для распознавания текста, которое я использовал (а я использовал несколько приложений за эти годы).
Больше всего меня беспокоит попытка нормализовать подписки на мобильные приложения. Экосистема для iOS слишком разнообразна и многочисленна, чтобы гарантировать такую модель ценообразования. Я также не планирую использование приложений по периодам времени.
Если бы вы предложили возможность разовой покупки, это было бы более привлекательно для меня. Поскольку такого рода приложения я не использую регулярно, я использую их всего месяц, а потом отменяю подписку.
Прерывание рекламы обесценивает опыт OK
Это первое распознавание текста на моем мобильном телефоне, которое я использовал, поэтому не могу сравнивать с другими, но то, что я видел, не впечатляет.
Кажется, большинство слов передано правильно, хотя было странное переключение фразы с исходного места на другое и одна опечатка (нет в оригинале). Он также не распознает дроби, что немного раздражает при чтении рецепта.
Больше всего раздражают промежуточные объявления, которые появляются при переходе с одного экрана на другой. По этой причине я удаляю его с телефона. Более тонкое расположение в нижней части главного экрана — это нормально — меня это не сильно беспокоит.
Работает отлично, но есть 1 проблема.
Это палочка-выручалочка, но когда я работаю в Walmart, дневной лимит будет увеличиваться, я возьму свой телефон на случай, если увижу текст для отправки кому-то, тогда я использую это для текстовых сообщений в 50 раз быстрее. Это спасает жизнь, я даже могу отправлять описания навыков в Clicker Heroes намного быстрее, вместо того, чтобы смотреть и печатать.
Это чрезвычайно полезно, полезно, но бесполезно на 5-м, и сразу же важно.
Разработчик, Говартани Раджеш, указал, что политика конфиденциальности приложения может включать обработку данных, как описано ниже. Для получения дополнительной информации см. политику конфиденциальности разработчика.
Данные, используемые для отслеживания вас
Следующие данные могут использоваться для отслеживания вас в приложениях и на веб-сайтах, принадлежащих другим компаниям:
- Расположение
- Идентификаторы
- Данные об использовании
- Диагностика
Данные, связанные с вами
Следующие данные могут быть собраны и связаны с вашей личностью:
- Расположение
- Идентификаторы
- Данные об использовании
- Диагностика
Данные, не связанные с вами
Могут быть собраны следующие данные, но они не связаны с вашей личностью:
Методы обеспечения конфиденциальности могут различаться, например, в зависимости от используемых вами функций или вашего возраста. Узнать больше
Узнать больше
Информация
- Продавец
- Говартани Раджеш
- Размер
- 31,1 МБ
- Категория
- Производительность
- Возрастной рейтинг
- 4+
- Авторское право
- © 2017 Говартани Раджеш
- Цена
- Бесплатно
- Тех. поддержка
- Политика конфиденциальности
Еще от этого разработчика
Вам также может понравиться
Что такое оптическое распознавание символов? – Когнитивные службы Azure
Обратная связь Редактировать
Твиттер LinkedIn Фейсбук Эл.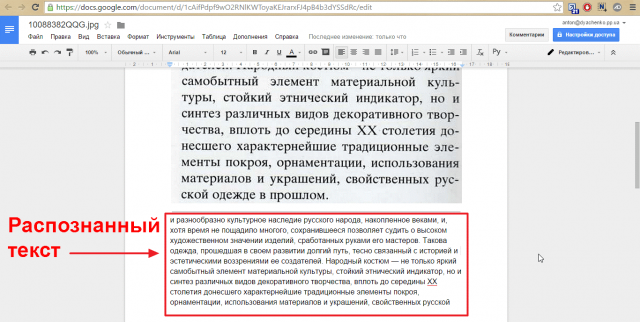 адрес
адрес
- Статья
- 3 минуты на чтение
Оптическое распознавание символов (OCR) позволяет извлекать печатный или рукописный текст из изображений, таких как фотографии уличных знаков и продуктов, а также из документов — счетов-фактур, счетов, финансовых отчетов, статей и т. д. Технологии OCR от Microsoft поддерживают извлечение печатного текста на нескольких языках.
Следуйте краткому руководству, чтобы начать работу с REST API или клиентским SDK. Или быстро и легко опробуйте возможности OCR в своем браузере с помощью Vision Studio.
Попробуйте Vision Studio
Эта документация содержит следующие типы статей:
- Краткие руководства представляют собой пошаговые инструкции, которые позволяют совершать звонки в службу и получать результаты за короткий период времени.
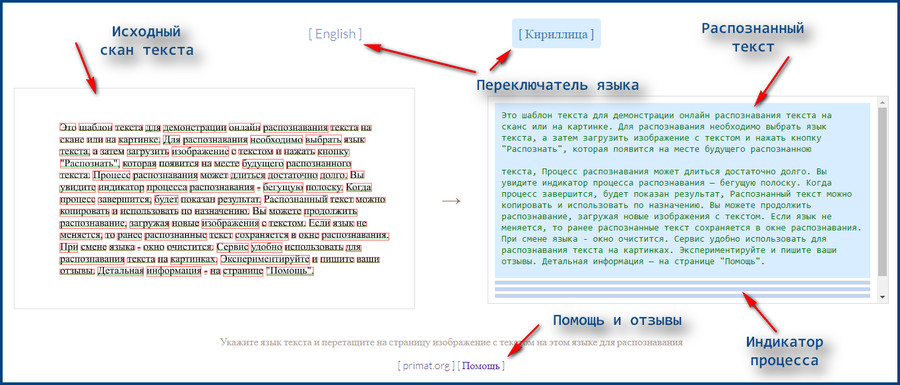
- Практические руководства содержат инструкции по использованию службы более конкретными или индивидуальными способами.
API чтения
API чтения Computer Vision — это новейшая технология OCR Azure (узнайте, что нового), которая извлекает печатный текст (на нескольких языках), рукописный текст (на нескольких языках), цифры и символы валюты из изображений и многостраничных PDF-документы. Он оптимизирован для извлечения текста из изображений с большим количеством текста и многостраничных документов PDF со смешанными языками. Он поддерживает извлечение как печатного, так и рукописного текста в одном изображении или документе.
Требования к вводу
Вызов Read использует в качестве входных данных изображения и документы. К ним предъявляются следующие требования:
- Поддерживаемые форматы файлов: JPEG, PNG, BMP, PDF и TIFF
- Для файлов PDF и TIFF обрабатывается до 2000 страниц (только первые две страницы для бесплатного уровня).

- Размер файлов изображений должен быть менее 500 МБ (4 МБ для бесплатного уровня) и иметь размеры не менее 50 x 50 пикселей и не более 10000 x 10000 пикселей. Файлы PDF не имеют ограничений по размеру.
- Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768. Это соответствует тексту размером около 8 пунктов при разрешении 150 точек на дюйм.
Поддерживаемые языки
Последняя общедоступная (GA) модель Read API поддерживает 164 языка для печатного текста и 9 языков для рукописного текста.
OCR для печатного текста включает поддержку английского, французского, немецкого, итальянского, португальского, испанского, китайского, японского, корейского, русского, арабского, хинди и других международных языков, использующих латиницу, кириллицу, арабский и деванагари.
Распознавание рукописного текста включает поддержку английского, упрощенного китайского, французского, немецкого, итальянского, японского, корейского, португальского и испанского языков.
См. Как указать версию модели для использования языков и функций предварительного просмотра. См. полный список языков, поддерживаемых OCR.
Основные функции
Read API включает следующие функции.
- Извлечение текста для печати на 164 языках
- Извлечение рукописного текста на девяти языках
- Текстовые строки и слова с оценкой местоположения и достоверности
- Идентификация языка не требуется
- Поддержка смешанных языков, смешанный режим (печатный и рукописный)
- Выбор страниц и диапазонов страниц из больших многостраничных документов
- Опция естественного порядка чтения для вывода текстовой строки (только латиница)
- Классификация почерка для текстовых строк (только латиница)
- Доступен как контейнер Distroless Docker для локального развертывания
Узнайте, как использовать функции OCR.
Использование облачного API или локальное развертывание
Облачные API Read 3. x являются предпочтительным вариантом для большинства клиентов из-за простоты интеграции и высокой производительности. Azure и служба Computer Vision обеспечивают масштабирование, производительность, безопасность данных и соответствие требованиям, а вы сосредоточены на удовлетворении потребностей своих клиентов.
x являются предпочтительным вариантом для большинства клиентов из-за простоты интеграции и высокой производительности. Azure и служба Computer Vision обеспечивают масштабирование, производительность, безопасность данных и соответствие требованиям, а вы сосредоточены на удовлетворении потребностей своих клиентов.
При локальном развертывании контейнер Read Docker (предварительная версия) позволяет развернуть новые возможности OCR в собственной локальной среде. Контейнеры отлично подходят для конкретных требований безопасности и управления данными.
Предупреждение
Операции Computer Vision RecognizeText и OCR больше не поддерживаются и устаревают в пользу нового API чтения, описанного в этой статье. Существующие клиенты должны перейти на использование операций чтения.
Конфиденциальность и безопасность данных
Как и в случае со всеми Cognitive Services, разработчики, использующие службу Computer Vision, должны знать политики Microsoft в отношении данных клиентов.