
Как распознать текст из картинки. 4 бесплатных решения.
Если вам необходимо извлечь текст из изображения, то, вероятно, наилучшим решением будет покупка приложения ABBY Finereader. Однако у него есть и бесплатные аналоги, которых может оказаться вполне достаточно.
Используйте OneNote
Электронный блокнот от Microsoft умеет распознавать текст из картинок уже много лет, хотя эта его возможность до сих пор мало известна. Распознавание происходит быстро и качественно.
Для работы необходимо вставить в программу соответствующее изображение. Как вариант, для этого можно создать новую пустую страницу. Для добавления изображения используйте пункт меню «Вставка» и команду «Рисунки», либо же «Вырезку экрана», если надо сделать скриншот из интернета.
Далее кликните на самой картинке правой клавишей мыши и из контекстного меню выберите пункт «Поиск текста в рисунках» и укажите на каком языке приведен текст в изображении. После этого еще раз вызовите контекстное меню и выберите пункт «Копировать текст из рисунка». После этого просто вставьте его в любое свободное место страницы – Ctrl+V.
После этого просто вставьте его в любое свободное место страницы – Ctrl+V.
Скрытая возможность Диска Google
Если в OneNote опция извлечения текста из картинки редко используемая, а потому и малоизвестная, то в облачном хранилище от Google данная возможность столь неочевидна, что догадаться о ее существовании не так-то просто. Вместе с тем, Диск Google также позволяет быстро переконвертировать изображение в текст.
Для этого загрузите картинку в онлайн-хранилище. Затем, используя веб-интерфейс, кликните правой клавишей мыши на файле с картинкой и выберите команду «Открыть с помощью» – «Google Документы». У вас автоматически создастся текстовый файл и в нем откроется само изображение и извлеченный текст под ним. Традиционно для офисных файлов Google полученный результат распознанного текста с картинки можно скачать в одном из удобных форматов, в том числе Microsoft Word.
Через интернет-сайт
Ресурс onlineocr.net позволяет бесплатно в режиме онлайн распознать текст из картинки.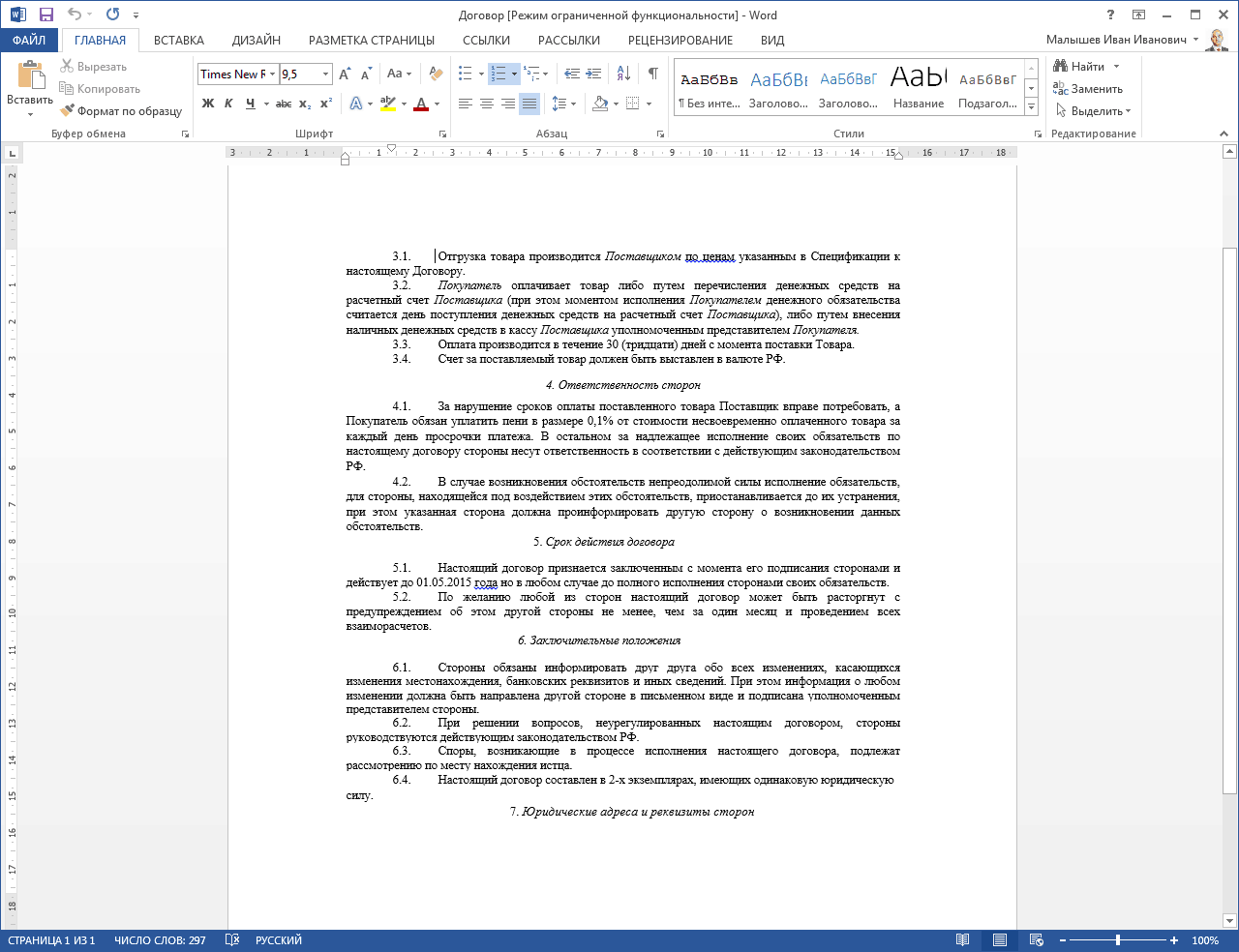 Загрузите изображение с текстом, выберите язык текста (помимо русского и английского предлагается еще около 20-ти вариантов языков) и один из трех вариантов формата для скачиваемого файла. Впрочем, скачивать файл вам не обязательно, транскрипция текста с изображения будет доступна и в браузере для копирования.
Загрузите изображение с текстом, выберите язык текста (помимо русского и английского предлагается еще около 20-ти вариантов языков) и один из трех вариантов формата для скачиваемого файла. Впрочем, скачивать файл вам не обязательно, транскрипция текста с изображения будет доступна и в браузере для копирования.
Всё это доступно без регистрации на сайте. При этом для зарегистрированных пользователей предлагаются более широкие возможности, вроде использования дополнительных форматов для вывода текста и больший размер изображений для загрузки (ограничение для незарегистрированных пользователей – 5Мб для картинки).
Попробуйте Photron Image Translator
Бесплатное приложение доступно в Windows Store для обладателей 10-й версии операционной системы от Microsoft и подойдет как для обладателей ПК, так и планшетов. Помимо распознавания текста из картинок Photron Image Translator умеет переводить этот текст на другие языки и даже озвучивать полученное сообщение. А чтение текста с картинки с каждым годом становится всё актуальнее.
После установки приложения, выберите изображение (Image) как метод ввода и пункт галереи (Gallery) для загрузки файла с жесткого диска. После выбора картинки перейдите во вкладку «Извлеченный текст» (Extracted text). Результат даже лучше, чему у OneNote. Возможно, это лучшая среди бесплатных программа для распознавания текста с картинки.
Распознавание текста с картинки. Python Tesseract ORC + OpenCV
Сегодня мы с вами поговорим на тему языка Python и рассмотрим пример создания крутого приложения. Наша программа будет способна считывать текст из любой фотографии.
Что сделаем за урок?
Мы с вами рассмотрим пример работы с библиотекой Tesseract ORC и на её основе построим приложение для распознавания текста с фото.
Что забавно, так это возраст библиотеки. Tesseract — является программой, разрабатывавшейся компанией Hewlett-Packard с середины 1980-х по середину 1990-х годов. Затем программа около 10 лет «пролежала на полке» и в августе 2006 года её купила Google. Google открыл исходный код под лицензией Apache 2.0 для продолжения разработки.
Google открыл исходный код под лицензией Apache 2.0 для продолжения разработки.
На сегодняшний день библиотека является наиболее крутым решением, если вам требуется считать данные из какого-либо фото.
Установка библиотеки
Первое, что необходимо сделать, то это выполнить установку Tesseract ORC. Установка Tesseract удобна на Маке и Линукс. Если вы на Windows, то придется выполнить на одно движение больше.
Если вы на Маке, то скачайте HomeBrew и далее в терминале пропишите brew install tesseract. Если вы на Линукс, тогда в зависимости от операционной системы вам нужно прописать соответствующую команду в терминале.
И если вы на Windows, то вам нужно скачать приложение на ПК. Вам нужно скачать файл Windows Installer. После скачивания выполните установку данной программы.
С самой программой вам никак не придется взаимодействовать, а лишь скопировать её расположение. Обычно оно устанавливается на диск С в Program files. Найдите вашу программу и скопируйте путь к этой папке.
Разработка проекта
Полная разработка проекта показывается в видео. Вы можете просмотреть его ниже:
Полезные ссылки:
Код для реализации проекта из видео:
import cv2
import pytesseract
# Путь для подключения tesseract
# pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
# Подключение фото
img = cv2.imread('yourPhoto.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Будет выведен весь текст с картинки
config = r'--oem 3 --psm 6'
# print(pytesseract.image_to_string(img, config=config))
# Делаем нечто более крутое!!!
data = pytesseract.image_to_data(img, config=config)
# Перебираем данные про текстовые надписи
for i, el in enumerate(data.splitlines()):
if i == 0:
continue
el = el.split()
try:
# Создаем подписи на картинке
x, y, w, h = int(el[6]), int(el[7]), int(el[8]), int(el[9])
cv2.
rectangle(img, (x, y), (w + x, h + y), (0, 0, 255), 1)
cv2.putText(img, el[11], (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 1)
except IndexError:
print("Операция была пропущена")
# Отображаем фото
cv2.imshow('Result', img)
cv2.waitKey(0)Как распознать текст с картинки онлайн
Распознать текст бесплатно с картинки онлайн можно с помощью Документов Google. Для этого нужно завести аккаунт или почту в Гугл. Делать все это мы будет через сервис Google Диск. После создания аккаунта вам будет доступно пространство в размере 15 ГБ — его мы и будем использовать.
- Заходим в Google Диск по ссылке
https://www.google.com/intl/ru_ru/drive/
- Загружаем фото/картинку или PDF документ нажав на кнопку «Создать» и выбрав «Загрузить файлы». Выбираем файл и загружаем.
- Жмем правой кнопкой мышки по загруженному файлу и выбираем «Открыть с помощью > Документы Google».
- Ждем пока наша картинка откроется в документе Гугл.
 Под картинкой будет распознанный текст. Его можно скопировать и вставить в WORD или в любой другой документ.
Под картинкой будет распознанный текст. Его можно скопировать и вставить в WORD или в любой другой документ.
Ограничения
- Максимальный размер файла — 2 МБ.
- Поддерживаемые форматы — JPG, GIF, PNG и PDF.
- В файлах PDF распознаются только первые 10 страниц. (Как разделить файл PDF на части или страницы).
- Текст на картинке должен быть расположен ровно. Если он под углом, необходимо в любом графическом редакторе повернуть изображение на требуемый угол.
Если вы хотите качественного распознавания нужно сделать четкую фотографию или картинку с равномерным освещением и без размытостей.
Официально заявлена поддержка китайского языка.
Подробно про оптическое распознавание символов на Google Диске можно прочитать здесь.
Еще интересное:
Распознавайте текст с картинок бесплатно с удовольствием еще и онлайн).
Как распознать текст с фотографии на смартфонах Huawei и Honor
Чтобы получить копию документа необходимо потратить время и силы на поиски ксерокопии? А что если появилась необходимость перевести текст из бумажного в электронный вариант? Неужели сложной процедуры сканирования с применением громоздкой техники не избежать? Только не для владельцев смартфонов Huawei и Honor.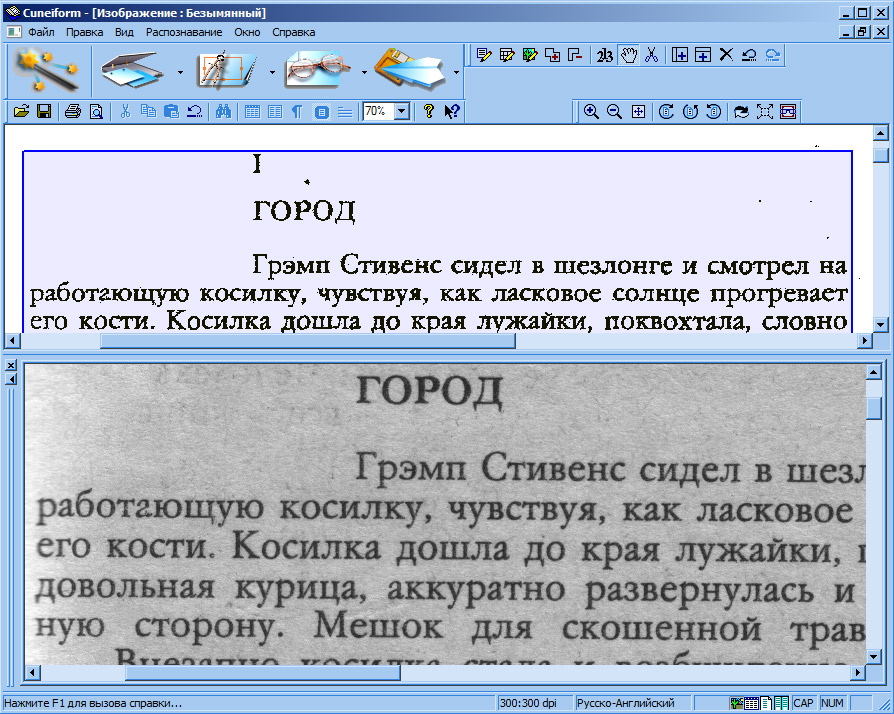
Как сфотографировать текст для распознавания на смартфоне
Чтобы сделать бумажный документ доступным для работы на смартфоне достаточно правильно сфотографировать его и распознать его. Безошибочное распознавание текста зависит от следующих факторов:
- Фотография должна быть пропорциональная размерам оригинального документа;
- Текст на фото располагается строго горизонтально;
- Документ должен быть равномерно освещен без резких перепадов и пятен;
- Фотография в высоком разрешении с большей долей вероятности позволит точно распознать текст.
Для фотографирования документа не нужно устанавливать каких-либо специальных приложений, просто активируем стандартную камеру на своем смартфоне Honor или Huawei. Перед началом съемки открываем вкладку «Еще» и выбираем значок «Документы».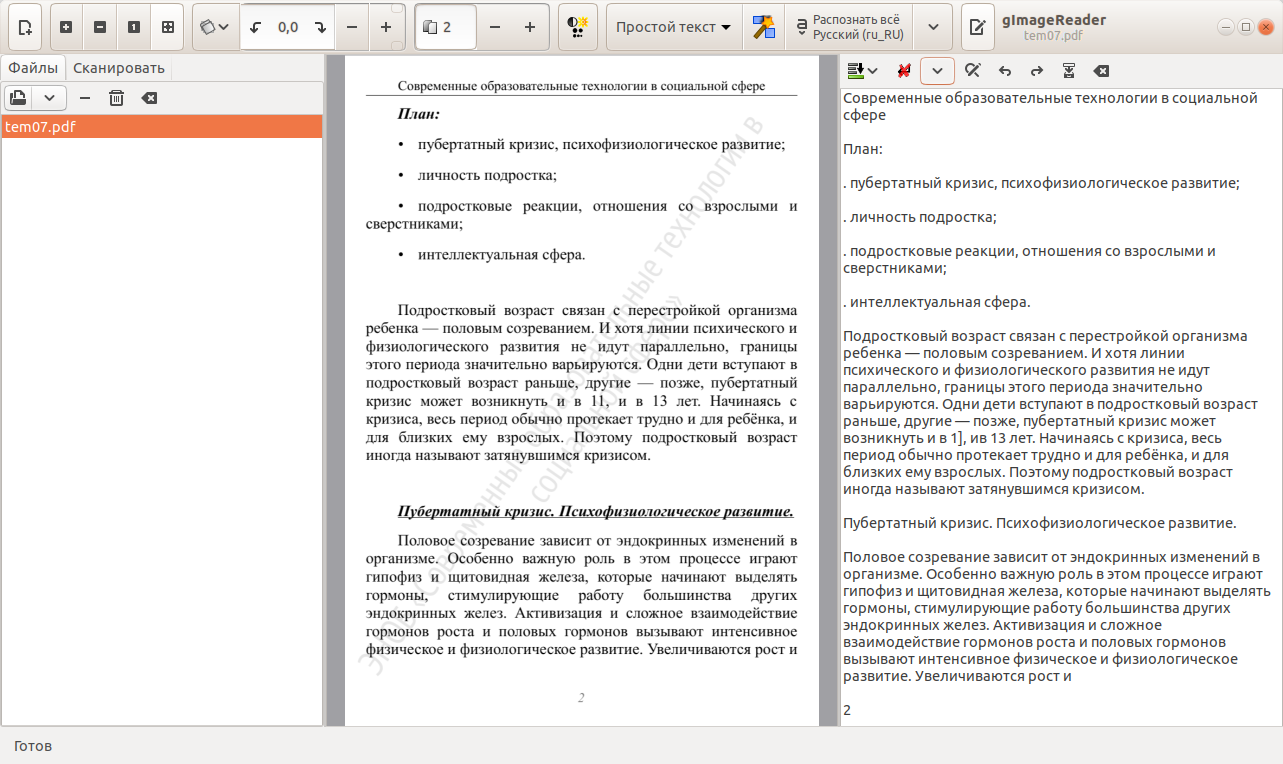 Этот режим позволит сфотографировать текст в подходящем для распознавания и дальнейшей работы формате.
Этот режим позволит сфотографировать текст в подходящем для распознавания и дальнейшей работы формате.
Наводим камеру на страницу с текстом. Ждем, пока программа подстроится под формат и обрежет все лишнее, на это может уйти до 30 секунд. В зависимости от модели смартфона. Граница документа будет очерчена голубой линией, значит можно нажимать «Съемка». В течение 1-2 секунд фото документа будет продемонстрировано и сохранено.
Чтобы просмотреть фото еще раз необходимо нажать на «Просмотр документа», если есть желание что-то исправить, кликаем по кнопке «Сканер». В открывшемся режиме редактирования можно переместить границы, подровнять или повернуть документ. Как только желаемый результат достигнут, нажимаем на галочку для сохранения последнего варианта.
Распознаем сфотографированный на камеру смартфона текст
Как только документ сфотографирован и сохранен, его можно распознать для дальнейшей работы в электронном виде. Для распознавания и работы с текстом смартфон использует инновационные программы Optical character recognition (OCR).
За распознавание текста отвечает встроенная по умолчанию программа Google Lens, которая также используется для считывания QR-кодов и других штрих-кодов. Чтобы распознать текст из картинки папку Google и находим там стандартное приложение Google Фото.
Открываем фотографию, которую необходимо распознать, и кликаем по пункту меню «Google Lens». В течение пары секунд после запуска программа будет анализировать изображение, после чего выделит текст на экране.
Чтобы быстро выделить весь текст на документе, нажимаем в нижней части экрана «Текст документа» и кликаем по строке «Выбрать все».
Распознанный программой текст будет выделен синим цветом. Все, что нужно сделать для продолжения работы с ним и редактирования, скопировать его и перенести в текстовый редактор. Если исходный документ был на иностранном языке, перевести его можно, кликнув по активному значку в этой же программе.
Всего за несколько минут фотографирования, распознавания и копирования текста можно получить качественный документ в электронном виде и продолжить работу с ним по своему усмотрению.
Поделиться ссылкой:
Новости партнёров и реклама
Как распознать текст с картинки
В предыдущем уроке мы рассматривали процесс сканирования информации с бумажных носителей, но при написании дипломного проекта в качестве источника информации широко используется также Интернет. Казалось бы, при работе с электронными документами не должно возникать никаких проблем, но и тут есть свои особенности. Дело в том, что нередко публикуемые в сети статьи в формате .pdf защищены от копирования. Содержимое защищенного документа нельзя просто выделить и скопировать в нужное место. Если Вам попался подобный файл, информацию из него можно “изъять” без особого труда с помощью специальной программы – 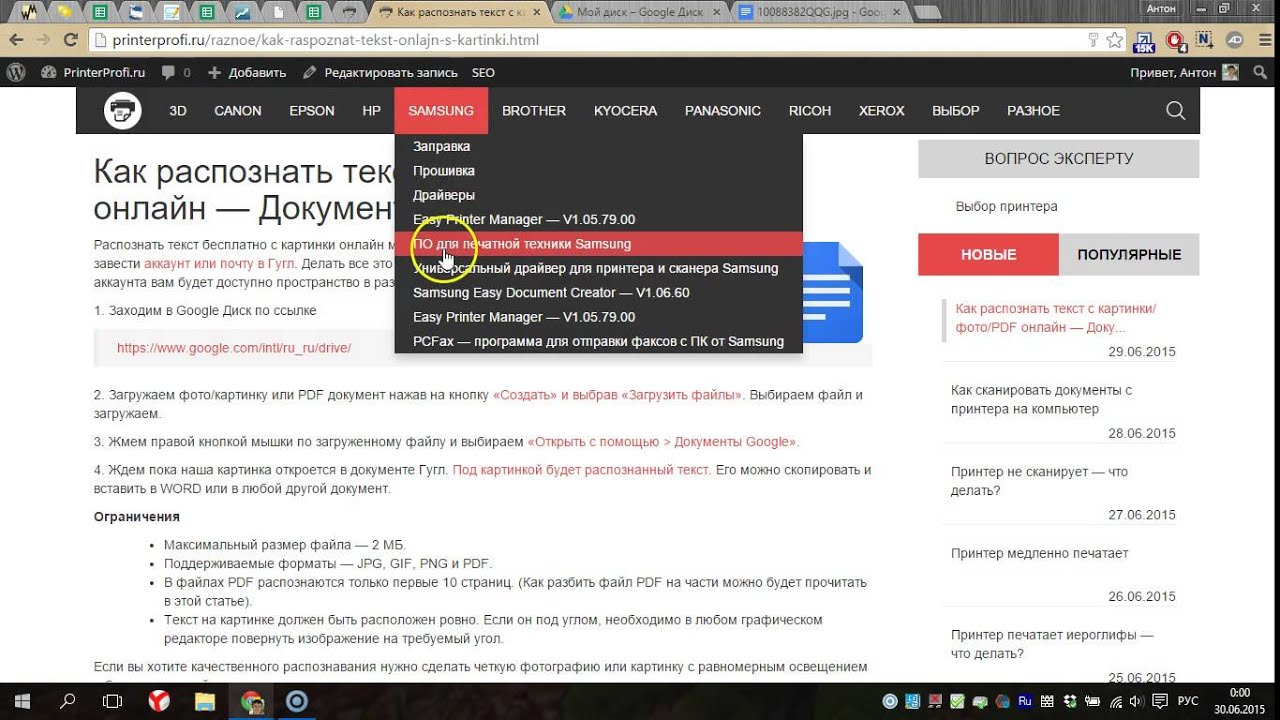
Например, у нас есть защищенный pdf-документ автореферата диссертации. Скачайте (258 Kb) его на свой компьютер и откройте с помощью программы Adobe Reader:
Текст из подобных авторефератов я часто использую при написании введения, аннотации дипломной работы.
Если Вы попытаетесь просто выделить и скопировать текст из этого документа, у Вас ничего не выйдет, потому что автор автореферата запретил копирование в настройках. Чтобы скопировать нужный нам текст, запускаем программу Adobe Screenshot Reader. Эта программка поставляется вместе с
Чтобы настроить ScreenshotReader для распознавания текст с экрана монитора кликните на кнопку и выберите язык для распознавания:
После этого в главном окне программы выберите, что именно и как Вы хотите распознать (Текст в буфер обмена):
Далее, нажмите на кнопку , выделите нужный блок текста в pdf-документе и дождитесь пока программа обработает задание.
Я часто использую ScreenshotReader и для других целей. Например, в случаях, когда нужно быстро сделать скриншот из компьютерной программы и вставить его в текст в качестве иллюстрации. Настройки ScreenshotReader при этом должны быть соответствующие.
4.3 / 5 ( 3 голоса )
новые возможности фреймворка Vision / Блог компании Dodo Engineering / Хабр
Теперь фреймворк Vision умеет распознавать текст по-настоящему, а не как раньше. С нетерпением ждём, когда сможем применить это в Dodo IS. А пока перевод статьи о распознавании карточек из настольной игры Magic The Gathering и извлечении из них текстовой информации.Впервые фреймворк Vision был представлен широкой общественности на WWDC в 2017 году, вместе с iOS 11.
Vision был создан, чтобы помочь разработчикам классифицировать и идентифицировать объекты, горизонтальные плоскости, штрих-коды, выражения лица и текст.
Однако с распознаванием текста была проблема: Vision мог найти место, где находится текст, но фактического распознавания текста не происходило. Конечно, было приятно видеть ограничивающую рамку вокруг отдельных фрагментов текста, но затем их нужно было вытаскивать и распознавать самостоятельно.
Эту проблему решили в обновлении Vision, которое вошло в iOS 13. Теперь Vision framework предоставляет истинное распознавание текста.
Чтобы проверить это, я создал очень простое приложение, которое может распознать карточку из настольной игры Magic The Gathering и извлекать из нее текстовую информацию:
- имя карты;
- код выпуска;
- коллекционный номер (он же индекс).
Вот пример карты и выделенного текста, который я хотел бы получить.
Глядя на карточку вы можете подумать: «Этот текст довольно мелкий, плюс на карточке есть много другого текста, который может помешать». Но для Vision это не проблема.
Но для Vision это не проблема.
Для начала нам нужно создать VNRecognizeTextRequest. По сути, это описание того, что мы надеемся распознать, плюс настройка языка распознавания и уровень точности:
let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText)
request.recognitionLevel = .accurate
request.recognitionLanguages = ["en_GB"]Блок завершения имеет вид
handleDetectedText(request: VNRequest?, error: Error?). Мы передаём его в конструктор VNRecognizeTextRequest и затем устанавливаем оставшиеся свойства.Доступно два уровня точности распознавания: .fast и .accurate. Поскольку на нашей карточке довольно маленький текст в нижней части, я выбрал более высокую точность. Быстрый же вариант скорее лучше подойдет для больших объемов текста.
Я ограничил распознавание британским английским, так как все мои карты именно на нём.Вы можете указать несколько языков, но при этом нужно понимать, что сканирование и распознавание может занять немного больше времени для каждого дополнительного языка.
Есть еще два свойства, которые стоит упомянуть:
customWords: вы можете добавить массив строк, которые будут использоваться поверх встроенного лексикона. Это полезно, если в вашем тексте есть какие-нибудь необычные слова. Я не применял опцию для этого проекта. Но если бы я делал коммерческое приложение-распознавалку для карточек Magic The Gathering, то добавил бы некоторые из наиболее сложных карт (например, Fblthp, the Lost), чтобы избежать проблем.minimumTextHeight: это float-значение. Оно обозначает размер относительно высоты изображения, при котором текст больше не должен быть распознан. Если бы я создавал этот сканер, чтобы просто получить имя карты, это было бы полезно для удаления всего другого текста, который не нужен. Но мне нужны самые маленькие кусочки текста, поэтому пока я проигнорировал это свойство. Очевидно, при игнорировании мелких текстов скорость распознавания будет выше.
Теперь, когда у нас есть наш запрос, его вместе с картинкой надо передать обработчику запросов:
let requests = [textDetectionRequest]
let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: . right, options: [:])
DispatchQueue.global(qos: .userInitiated).async {
do {
try imageRequestHandler.perform(requests)
} catch let error {
print("Error: \(error)")
}
}
right, options: [:])
DispatchQueue.global(qos: .userInitiated).async {
do {
try imageRequestHandler.perform(requests)
} catch let error {
print("Error: \(error)")
}
}Я использую изображение прямо с камеры, преобразовав его из
UIImage в CGImage. Это используется в VNImageRequestHandler вместе с флагом ориентации, чтобы помочь обработчику понять, какой текст он должен распознавать.В рамках этого демо я использую телефон только в портретной ориентации. Поэтому, естественно, я добавляю ориентацию .right. Так, падажжи!
Оказывается, ориентация камеры на вашем устройстве полностью отделена от вращения устройства и всегда считается слева (как по умолчанию было принято в 2009 году, что для съемки фотографий нужно держать телефон в альбомной ориентации). Конечно, времена изменились, и мы в основном снимаем фотографии и видео в формате портретной ориентации, но камера по-прежнему выровнена слева.
Как только наш обработчик настроен, мы переходим в поток с приоритетом .userInitiated и пытаемся выполнить наши запросы. Вы можете заметить, что это массив запросов. Так происходит, потому что вы можете попытаться вытащить несколько фрагментов данных за один проход (т. е. идентифицировать лица и текст из одного и того же изображения). Если ошибок нет, обратный вызов, созданный с помощью нашего запроса, будет вызван после обнаружения текста:
func handleDetectedText(request: VNRequest?, error: Error?) {
if let error = error {
print("ERROR: \(error)")
return
}
guard let results = request?.results, results.count > 0 else {
print("No text found")
return
}
for result in results {
if let observation = result as? VNRecognizedTextObservation {
for text in observation.topCandidates(1) {
print(text.string)
print(text.confidence)
print(observation. boundingBox)
print("\n")
}
}
}
}
boundingBox)
print("\n")
}
}
}
}Наш обработчик возвращает наш запрос, который теперь имеет свойство results. Каждый результат является
VNRecognizedTextObservation, у которого для нас есть сразу несколько вариантов результата (далее — кандидаты).Вы можете получить до 10 кандидатов на каждую единицу распознанного текста, и они сортируются в порядке убывания уверенности. Это может быть полезным, если у вас есть определенная терминология, которую синтаксический анализатор неправильно распознает с первой попытки. Но определяет правильно позже, даже если он менее уверен в правильности результата.
В этом примере нам нужен только первый результат, поэтому мы проходимся циклом по observation.topCandidates(1) и извлекаем как текст, так и уверенность. В то время как сам кандидат имеет различный текст и уверенность, .boundingBox остается той же. .boundingBox использует нормализованную систему координат с началом координат в левом нижнем углу, поэтому, если она в дальшнейем будет использоваться в UIKit, для вашего же удобства её надо преобразовать.
Это почти всё, что нужно. Если я прогоню фотографию карты через это, я получу следующий результат чуть менее чем за 0,5 секунд на iPhone XS Max:
Carnage Tyrant
1.0
(0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786)
Creature
1.0
(0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635)
Dinosaur
1.0
(0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364)
Carnage Tyrant can't be countered.
1.0
(0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906)
Trample, hexproof
0.5
(0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653)
Sun Empire commanders are well versed
1.0
(0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302)
in advanced martial strategy. Still, the
1.0
(0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136)
correct maneuver is usually to deploy the
1. 0
(0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009)
giant, implacable death lizard.
1.0
(0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258)
7/6
0.5
(0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593)
179/279 M
1.0
(0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193)
XLN: EN N YEONG-HAO HAN
0.5
(0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319)
TN & 0 2017 Wizards of the Coast
1.0
(0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)
0
(0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009)
giant, implacable death lizard.
1.0
(0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258)
7/6
0.5
(0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593)
179/279 M
1.0
(0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193)
XLN: EN N YEONG-HAO HAN
0.5
(0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319)
TN & 0 2017 Wizards of the Coast
1.0
(0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)Это невероятно! Каждый фрагмент текста был распознан, помещен в его собственную ограничивающую рамку и возвращен в результате с рейтингом доверия 1.0.
Даже очень маленький копирайт в основном корректен. Все это было сделано на изображении 3024×4032 весом в 3,1 МБ. Процесс был бы еще быстрее, если бы я сначала уменьшил изображение.
 Также стоит отметить, что этот процесс намного быстрее на новых бионических чипах A12, которые имеют специальный нейронный движок.
Также стоит отметить, что этот процесс намного быстрее на новых бионических чипах A12, которые имеют специальный нейронный движок.Когда текст распознан, последнее, что нужно сделать, это вытащить нужную мне информацию. Я не буду помещать весь код здесь, но ключевая логика состоит в том, чтобы перебирая каждую .boundingBox определять местоположение, чтобы я мог выбрать текст в нижнем левом углу и в верхнем левом углу, игнорируя что-либо дальше справа.
Конечным результатом получилось приложение сканирующее карточку и возвращающее мне результат менее, чем за одну секунду.
P.S. На самом деле мне нужен только код выпуска и коллекционный номер (он же индекс). Затем их можно использованы в API сервиса Scryfall для получения всей возможной информации об этой карте, включая правила игры и стоимость.
Пример приложения доступен на GitHub.
Как скопировать текст с фотографии, используя Google Фото
Возможно, лучшее приложение для хранения фотографий в облаке — это небезызвестная программа Google Фото. Она удобна для Android-пользователей еще и тем, что позволяет не захламлять память устройства ненужными снимками и при этом связана с вашим Google-аккаунтом. А значит вам не придется регистрироваться в «левых» сервисах и проходить нудную процедуру авторизации. Однако есть у Google Фото и еще одна полезная опция — возможность распознавания текста с изображений и фотографий. И сейчас мы расскажем вам, как ей воспользоваться.
Она удобна для Android-пользователей еще и тем, что позволяет не захламлять память устройства ненужными снимками и при этом связана с вашим Google-аккаунтом. А значит вам не придется регистрироваться в «левых» сервисах и проходить нудную процедуру авторизации. Однако есть у Google Фото и еще одна полезная опция — возможность распознавания текста с изображений и фотографий. И сейчас мы расскажем вам, как ей воспользоваться.
Как распознать текст на картинке
На самом деле, встроенная функция распознавания текста с картинок и фотографий — это то, чего не хватало очень давно. И удивительно, что этого никто не сделал раньше. Конечно, были отдельные приложения для этих нужд, но это именно что сторонние программы. Объединение функции галереи с возможностью распознавания текста — это как раз то, что отличает Google Фото от других подобных облачных сервисов.
Но вернемся к тому, как же воспользоваться этой опцией. Для начала, естественно, вам нужно скачать приложение Google Фото на свой смартфон, если его по какой-либо причине у вас еще нет. Теперь открывайте программу и нажимайте на строку поиска в верхней части, если вам нужно найти определенное фото. Если же нет, то просто выбирайте фотографию из галереи приложения. Как только вы найдете изображение, которое искали, нажмите на него, чтобы открыть его в приложении «Фотографии». Теперь найдите кнопку помощника в нижней части экрана (на фото ниже она обозначена стрелочкой). Нажмите на него, чтобы начать работу с ИИ-алгоритмом Google.
Теперь открывайте программу и нажимайте на строку поиска в верхней части, если вам нужно найти определенное фото. Если же нет, то просто выбирайте фотографию из галереи приложения. Как только вы найдете изображение, которое искали, нажмите на него, чтобы открыть его в приложении «Фотографии». Теперь найдите кнопку помощника в нижней части экрана (на фото ниже она обозначена стрелочкой). Нажмите на него, чтобы начать работу с ИИ-алгоритмом Google.
Далее найдите опцию поиска в левой части экрана и на следующем шаге вам нужно будет выбрать опцию распознавания текста (вторая клавиша слева, на фото ниже на нее также указывает стрелочка).
Теперь алгоритму может потребоваться какое-то время для того, чтобы обработать информацию. В итоге на выходе вы получите возможность скопировать распознанный текст для того, чтобы сохранить его или отредактировать. Также прямо в окне приложения вы можете перевести текст на другой язык, используя сервис Google Translate, если вам это требуется.
Программа без труда работает и с русским текстом
Также у вас есть возможность тут же произвести поиск теста или его части в поисковике Google. После выбора этой опции вас перебросит в браузер на страницу с найденными результатами.
Теперь распознавание текста стало простым как никогда
Для чего может понадобиться эта опция? На самом деле вариантов применения технологии масса: от распознавания длинных текстов, напечатанных на листе бумаги до сканирования визиток и «вытаскивания» оттуда данных. А какие еще применения можно найти подобной технологии? Напишите об этом в нашем чате в Телеграм.
Также стоит иметь в виду, что сервис работает лишь с напечатанным «машинным» текстом. И если «скормить» ему что-то, что написано от руки, требуемого результата вы, к сожалению, не получите. Хотя над возможностью распознавания рукописного ввода сейчас работает множество компаний и нельзя исключать появления такой опции в будущем.
Онлайн-конвертер файлов | PNG, JPG, PSD, AI, PDF и многое другое
Нужно ли мне платить за использование Workbench?
Нет! Workbench на 100% бесплатен. Не требуется лицензии, подписки или даже адреса электронной почты.
Не требуется лицензии, подписки или даже адреса электронной почты.
Будете ли вы добавлять новые инструменты в Workbench в будущем?
Да!
Наша команда будет продолжать наращивать полезные ресурсы и со временем выпускать их.
Как работает автоматическая пометка AI?
Автоматическая пометкаAI – это функция, используемая платформами управления цифровыми активами (DAM), чтобы помочь пользователям сэкономить время за счет исключения ручной работы, поощрения организации и упрощения поиска файлов.
Технология работает путем анализа объектов в изображении и создания набора тегов, возвращаемых системой машинного обучения. На основе оценки достоверности к изображению будут применены теги с наибольшей вероятностью точности. При использовании в DAM теги предоставляют удобный метод поиска.
Как работает генератор цветовой палитры?
Генератор цветовой палитры Workbench извлекает серию цветов HEX из изображения при загрузке.Он считает каждый пиксель и его цвет и генерирует палитру, содержащую до 6 HEX-кодов наиболее повторяющихся цветов.
Что такое метаданные?
Метаданные предоставляют информацию о содержимом актива.
Например, изображение может включать в себя метаданные, описывающие размер изображения, глубину цвета, разрешение изображения, дату создания и другие данные. Метаданные текстового документа могут включать информацию о длине документа, авторе, дате публикации и краткое изложение документа.
Что такое управление цифровыми активами?
Управление цифровыми активами (DAM) в последние годы стало критически важной системой для компаний всех отраслей и размеров. DAM – это программная платформа, которую бренды используют для хранения, редактирования, распространения и отслеживания активов своего бренда. DAM предназначены для поощрения организации цифровой архитектуры компании, исключая использование скрытых файлов и папок, обычно хранящихся на Google Диске или Dropbox.
СистемыDAM масштабируются для хранения огромных объемов цифровых активов, включая, помимо прочего: фотографии, аудиофайлы, графику, логотипы, цвета, анимацию, 3D-видео, файлы PDF, шрифты и т. Д.Помимо тщательной организации в центральной файловой системе DAM, эти файлы можно обнаружить с помощью уникальных идентификаторов, таких как их метаданные и теги (автоматически и вручную).
При использовании для распространения DAM поощряют разрешение и истечение срока действия ресурсов, гарантируя, что только правильный контент будет доступен правильному получателю в течение определенного периода времени. После публикации или распространения DAM могут анализировать, как, где и кем используются активы.
Платформы управления цифровыми активами используются маркетинговыми, коммерческими и творческими командами некоторых крупнейших мировых брендов.Хотите узнать больше о том, как DAM может принести пользу вашей команде? Подпишитесь на бесплатную пробную версию Brandfolder или запланируйте демонстрацию с одним из наших экспертов DAM здесь.
Workbench Suite | Инструменты изображения
Нужно ли мне платить за использование Workbench?
Нет! Workbench на 100% бесплатен. Не требуется лицензии, подписки или даже адреса электронной почты.
Будете ли вы добавлять новые инструменты в Workbench в будущем?
Да!
Наша команда будет продолжать наращивать полезные ресурсы и со временем выпускать их.
Как работает автоматическая пометка AI?
Автоматическая пометкаAI – это функция, используемая платформами управления цифровыми активами (DAM), чтобы помочь пользователям сэкономить время за счет исключения ручной работы, поощрения организации и упрощения поиска файлов.
Технология работает путем анализа объектов в изображении и создания набора тегов, возвращаемых системой машинного обучения. На основе оценки достоверности к изображению будут применены теги с наибольшей вероятностью точности.При использовании в DAM теги предоставляют удобный метод поиска.
Как работает генератор цветовой палитры?
Генератор цветовой палитры Workbench извлекает серию цветов HEX из изображения при загрузке. Он считает каждый пиксель и его цвет и генерирует палитру, содержащую до 6 HEX-кодов наиболее повторяющихся цветов.
Что такое метаданные?
Метаданные предоставляют информацию о содержимом актива.
Например, изображение может включать в себя метаданные, описывающие размер изображения, глубину цвета, разрешение изображения, дату создания и другие данные. Метаданные текстового документа могут включать информацию о длине документа, авторе, дате публикации и краткое изложение документа.
Что такое управление цифровыми активами?
Управление цифровыми активами (DAM) в последние годы стало критически важной системой для компаний всех отраслей и размеров.DAM – это программная платформа, которую бренды используют для хранения, редактирования, распространения и отслеживания активов своего бренда. DAM предназначены для поощрения организации цифровой архитектуры компании, исключая использование скрытых файлов и папок, обычно хранящихся на Google Диске или Dropbox.
СистемыDAM масштабируются для хранения огромных объемов цифровых активов, включая, помимо прочего: фотографии, аудиофайлы, графику, логотипы, цвета, анимацию, 3D-видео, файлы PDF, шрифты и т. Д. В дополнение к тщательной организации в центральной части DAM файловой системе эти файлы можно обнаружить с помощью уникальных идентификаторов, таких как их метаданные и теги (автоматически и вручную).
При использовании для распространения DAM поощряют разрешение и истечение срока действия ресурсов, гарантируя, что только правильный контент будет доступен правильному получателю в течение определенного периода времени. После публикации или распространения DAM могут анализировать, как, где и кем используются активы.
Платформы управления цифровыми активами используются маркетинговыми, коммерческими и творческими командами некоторых крупнейших мировых брендов. Хотите узнать больше о том, как DAM может принести пользу вашей команде? Подпишитесь на бесплатную пробную версию Brandfolder или запланируйте демонстрацию с одним из наших экспертов DAM здесь.
Изменить размер изображений | Приложение для быстрого и простого изменения размера изображений
Нужно ли мне платить за использование Workbench?
Нет! Workbench на 100% бесплатен. Не требуется лицензии, подписки или даже адреса электронной почты.
Будете ли вы добавлять новые инструменты в Workbench в будущем?
Да!
Наша команда будет продолжать наращивать полезные ресурсы и со временем выпускать их.
Как работает автоматическая пометка AI?
Автоматическая пометкаAI – это функция, используемая платформами управления цифровыми активами (DAM), чтобы помочь пользователям сэкономить время за счет исключения ручной работы, поощрения организации и упрощения поиска файлов.
Технология работает путем анализа объектов в изображении и создания набора тегов, возвращаемых системой машинного обучения. На основе оценки достоверности к изображению будут применены теги с наибольшей вероятностью точности. При использовании в DAM теги предоставляют удобный метод поиска.
Как работает генератор цветовой палитры?
Генератор цветовой палитры Workbench извлекает серию цветов HEX из изображения при загрузке.Он считает каждый пиксель и его цвет и генерирует палитру, содержащую до 6 HEX-кодов наиболее повторяющихся цветов.
Что такое метаданные?
Метаданные предоставляют информацию о содержимом актива.
Например, изображение может включать в себя метаданные, описывающие размер изображения, глубину цвета, разрешение изображения, дату создания и другие данные. Метаданные текстового документа могут включать информацию о длине документа, авторе, дате публикации и краткое изложение документа.
Что такое управление цифровыми активами?
Управление цифровыми активами (DAM) в последние годы стало критически важной системой для компаний всех отраслей и размеров. DAM – это программная платформа, которую бренды используют для хранения, редактирования, распространения и отслеживания активов своего бренда. DAM предназначены для поощрения организации цифровой архитектуры компании, исключая использование скрытых файлов и папок, обычно хранящихся на Google Диске или Dropbox.
СистемыDAM масштабируются для хранения огромных объемов цифровых активов, включая, помимо прочего: фотографии, аудиофайлы, графику, логотипы, цвета, анимацию, 3D-видео, файлы PDF, шрифты и т. Д.Помимо тщательной организации в центральной файловой системе DAM, эти файлы можно обнаружить с помощью уникальных идентификаторов, таких как их метаданные и теги (автоматически и вручную).
При использовании для распространения DAM поощряют разрешение и истечение срока действия ресурсов, гарантируя, что только правильный контент будет доступен правильному получателю в течение определенного периода времени. После публикации или распространения DAM могут анализировать, как, где и кем используются активы.
Платформы управления цифровыми активами используются маркетинговыми, коммерческими и творческими командами некоторых крупнейших мировых брендов.Хотите узнать больше о том, как DAM может принести пользу вашей команде? Подпишитесь на бесплатную пробную версию Brandfolder или запланируйте демонстрацию с одним из наших экспертов DAM здесь.
Как извлечь текст из изображения
Приходит время, когда вы сталкиваетесь с изображениями и PDF-файлами, содержащими важный текстовый контент, который вы хотите извлечь для дальнейшего использования. Что вы будете делать? Большинство из вас может ввести слова или фразу в отдельный документ Word или блокнот. Но этот процесс может занять довольно много времени.К счастью, была разработана новая технология для извлечения текста из изображения , которую они называют OCR или оптическим распознаванием символов. Если вы впервые слышите об оптическом распознавании текста, вот несколько программ, оснащенных такой функцией, которые просты в использовании и эффективно извлекают слова из изображений.
3 Отличные инструменты оптического распознавания текста для извлечения слов из изображения
LightPDFi2OCR
OCR.Space
LightPDF
LightPDF – это выдающаяся веб-программа для работы с PDF, которая предлагает различные инструменты для управления PDF.Он имеет встроенную функцию распознавания текста, которой очень легко пользоваться. Он поддерживает широкий спектр языков, например английский, французский, итальянский, японский и т. Д. Кроме того, этот инструмент OCR может обрабатывать такие форматы, как JPG, PNG и PDF. Вот пошаговое руководство по извлечению текста.
- Откройте страницу OCR.
- Загрузите изображение, которое необходимо обработать, перетащив мышью или нажав «Выбрать файл».
- Затем вы можете выбрать один или несколько языков, содержащихся в вашем файле.
- Выберите выходной формат, который вы хотите получить. После завершения всех процессов нажмите «Преобразовать», чтобы начать преобразование.
- Чтобы сохранить файл на локальном диске, просто нажмите кнопку загрузки.
Почему мы рекомендуем:
- Программа может преобразовывать изображение в различные редактируемые форматы, такие как PDF, Word, PPT, Excel и т. Д. И сохраняет высокую точность.
- Инструмент имеет удобный интерфейс – на странице нет рекламы.И вам просто нужно открыть файл изображения, сделать несколько щелчков мышью, и ваш файл готов к работе.
- Что касается конфиденциальности ваших загруженных файлов, страница автоматически удаляет изображения или другие файлы после завершения использования инструмента.
i2OCR
Второй инструмент для извлечения текста из изображения онлайн – i2OCR. Как следует из названия, он предназначен для работы со службами, связанными с OCR. Несмотря на то, что это онлайн-приложение, этот инструмент работает так же хорошо, как и другие настольные инструменты распознавания текста.Эта программа поддерживает такие форматы, как JPG, PNG, PGM, TIF, PPM и PBM. Что касается языков, инструмент может распознавать до 60 языков. Он также имеет чистый и простой в использовании интерфейс, а также обеспечивает конфиденциальность для пользователей, поскольку их сервер удаляет файлы мгновенно через час.
- Перейти на главную страницу этого инструмента.
- На странице выберите язык текста, который нужно извлечь.
- После этого выберите, откуда вы хотите загрузить изображения. У вас будет 2 варианта: загрузить его с компьютера или получить по URL-ссылке.
- Чтобы начать процесс, установите флажок для проверки и нажмите «Извлечь текст».
- После этого вы можете скачать файл.
Почему мы рекомендуем:
- Программа также бесплатна для использования.
- Он предлагает два способа загрузки изображения. Таким образом, если вы хотите извлечь текст из изображения, размещенного в Интернете, вам не нужно загружать его заранее.
- Имеет несколько методов вывода.
- Позволяет предварительно просмотреть изображение и извлеченные слова перед загрузкой.
- Он поддерживает переход к страницам перевода и позволяет редактировать в Документах Google.
OCR.Space
Последней подходящей программой, которую мы рекомендуем для преобразования изображений в текст, является OCR.Space. Это также веб-инструмент, специализирующийся на услугах, связанных с оптическим распознаванием текста. В настоящее время программа поддерживает около 20 языков, а среди поддерживаемых форматов файлов – PNG, JPG и PDF. Давайте извлечем слова из картинки, выполнив следующие действия.
- Посетите официальный сайт OCR.Space.
- Нажмите «Выбрать файл» или вставьте URL-адрес изображения. Затем выберите язык файла, с которым вы работаете.
- Выберите нужный режим извлечения и нажмите «Начать распознавание текста!»
- Когда процесс будет завершен, нажмите «Загрузить», чтобы сохранить извлеченный текст на жесткий диск вашего компьютера.
Почему мы рекомендуем:
- Этот онлайн-инструмент бесплатный.
- Он прост в использовании и имеет чистый интерфейс для работы.
- Он может предварительно просмотреть изображение или файл после загрузки.
Совет: Если ваше изображение содержит какие-либо числа, то перед началом процесса извлечения рекомендуется выбрать корейский или китайский язык.
Заключение
Это возможные и простые методы, которые вы можете использовать для извлечения текста из изображения в Интернете. Но выходные результаты OCR не всегда так точны, как мы ожидаем, поэтому мы настоятельно рекомендуем вам проверять результат после обработки, особенно когда шрифт особенный или контент включает более одного языка.
Более того, после тестирования мы обнаружили, что LightPDF работает лучше всего из трех инструментов, когда дело доходит до распознавания контента.
Рейтинг: 4.3 / 5 (на основе 25 оценок) Спасибо за вашу оценку!
как извлечь текст из изображения
Иногда нужно просто скопировать текст с изображения. Возможно, вы хотите взять фразу из снимка экрана, раскрывающегося меню, сообщения об ошибке или всплывающего окна, в котором нельзя выбирать текст.Это также может быть имя файла, размер файла или дата изменения, хранящиеся в каталоге файлов.
В таких случаях, если вы попытаетесь просто скопировать текст, вы заметите, что это не сработает. Даже если весь текст может показаться вам одинаковым, существует большая разница между реальным текстом и текстом, встроенным в графику для вашего компьютера.
Тем не менее, возможность копировать текст с изображений сэкономит вам время, необходимое для ручной расшифровки слов в текстовом процессоре. К счастью, преобразование изображения в текст занимает всего несколько шагов.Существуют приложения, которые анализируют буквы на изображении и преобразуют их, чтобы вы могли легко переносить и редактировать текст на вашем Mac. Вот как идет процесс.
Способы преобразования изображения в текст
Есть несколько способов скопировать текст, который вам нужен. Очевидно, что в первую очередь следует попробовать известные сочетания клавиш, такие как Command + C и Command + V, просто из-за скорости и простоты. Но если не сработали – читайте дальше.
✕Скопируйте текст с изображений с помощью OCR
Вы хотите извлечь текст из изображений, фотографий или макетов дизайна и сделать его редактируемым? Это не трудно.Но сначала вам понадобится приложение, которое может распознавать текст с помощью OCR (оптического распознавания символов). Prizmo – идеальный инструмент для этого и действует как мощный сканер для преобразования текста изображения в пригодный для использования текст за секунды. Для копирования необходимого текста с изображений:
- Щелкните значок «плюс» и выберите источник изображения в раскрывающемся меню.
- Выделите изображения, которые вы хотите перенести в Prizmo, и они появятся в левой части окна.
- Нажмите «Обрезать» и устраните любые искажения изображения с помощью значки рамки и сетки
- С помощью кнопки «Настроить» измените резкость или контраст текста для повышения читабельности
- Чтобы начать процесс распознавания текста, нажмите «Распознать»
- Просмотрите извлеченный текст в правой части окна приложения, чтобы исправить любые ошибки форматирования
Хотя Prizmo отлично работает с распознаванием текста на изображениях, он в значительной степени ограничен этим единственным вариантом использования.Если вам нужен более надежный инструмент, который может извлекать текст из любого места – от онлайн-презентации до снимка экрана или видео на YouTube, вам понадобится TextSniper.
TextSniper – это универсальный инструмент распознавания текста, который может захватывать любую часть экрана и автоматически распознавать текст на снимке экрана. Вот как это работает:
- Щелкните значок TextSniper в строке меню> Захват текста или нажмите Shift + Command + 2
- Выберите часть экрана с текстом
- Текст внутри снимка экрана будет автоматически скопирован в буфер обмена
- Нажмите Command + V, чтобы вставьте текст куда угодно – текстовый документ, приложение для заметок, мессенджер и т. д.
Чтобы избежать беспорядка, TextSniper позволяет вам выбрать, хотите ли вы сохранить скопированный текст как отдельный абзац или сохранить разрывы строк. Более того, в приложении есть функция преобразования текста в речь, поэтому вы можете слушать то, что скопировали, и сохранять только важную информацию.
Людям нравится TextSniper, потому что это, вероятно, самый быстрый способ быстро захватить текст из видео – скажем, когда вы смотрите онлайн-конференцию или презентацию на YouTube. Но вы также можете использовать его в любом сценарии OCR.
Преобразовать jpg / png в текст
Такой же поток можно использовать для изображений jpg / png и снимков экрана.
Если у вас нет Prizmo для чтения изображения, вы можете вместо этого использовать программу для чтения PDF-файлов с поддержкой OCR. Таким образом, преобразовать изображение в текст означало бы преобразовать его в PDF, а затем скопировать текст из PDF. Вот как можно быстро преобразовать jpg / png в PDF:
- Откройте изображение в режиме предварительного просмотра.
- Перейдите в раздел «Файл» и выберите «Экспортировать как».
- Выберите PDF в качестве формата вывода.
Чтобы быстро скопировать текст из PDF, вы можете использовать такие инструменты, как PDFpen, расширенный редактор PDF для Mac. Приложение позволяет копировать, а также редактировать и вставлять богатый текст вместе с форматированием. Таким образом, гибкость здесь принадлежит вам.
Чтение квитанций и счетов
Если вам нужен инструмент OCR для упрощения бухгалтерского учета на Mac, вы можете использовать приложение Receipts для работы:
- Перетащите изображение PDF прямо в окно «Квитанции».
- Настройте приложение для извлечения данных, таких как дата документа, банковское соединение и налоги.
- Гибкая организация и фильтрация квитанций по тегам и категориям.
Как сделать отсканированный документ PDF доступным для поиска
Хотя PDF-файлы являются обычным явлением на наших компьютерах, их все еще сложно редактировать. Вашему компьютеру может быть даже сложно распознать текст в отсканированном PDF-файле для его копирования. Для этого вам, скорее всего, понадобится программное обеспечение OCR.
Если вы хотите сделать отсканированный PDF-файл доступным для поиска, вы можете начать с попытки использовать то, что у вас уже есть в macOS, а затем перейти на профессиональное программное обеспечение для оптического распознавания текста, такое как Prizmo и PDF Search, для большей гибкости.
Чтение PDF-файлов с помощью встроенных инструментов macOS
Preview – самый распространенный инструмент для чтения и управления PDF-файлами на Mac. И хорошая новость в том, что многие PDF-файлы можно сканировать по умолчанию, поэтому вы можете просто открыть их в режиме предварительного просмотра и скопировать и вставить все, что вам нужно:
Небольшой совет по повышению продуктивности копирования и вставки – использование диспетчера буфера обмена, такого как Paste, который запоминает все, что вы копировали раньше, и освобождает вас от одного из самых ужасных ограничений macOS – функции единственного копирования и вставки.
В отличие от стандартного буфера обмена, приложение «Вставить» позволяет копировать и вставлять несколько элементов:
- Скопируйте все, от изображений до фрагментов текста точно так же, как вы это делали раньше.
- Получите все, что вы скопировали, нажав Показать Вставить в строке меню или используя сочетание клавиш Command + Shift + V
Если, однако, ваш PDF-файл представляет собой отсканированный документ или документ на основе изображений, вы не сможете вносить в него изменения, поскольку в предварительном просмотре нет функции распознавания текста (для этого используйте Prizmo).В этом случае вы можете использовать собственное приложение TextEdit для извлечения нужного текста.
- Откройте файл PDF. Хотя приложение Preview является программой просмотра PDF-файлов по умолчанию на Mac, вы также можете использовать другие приложения для просмотра PDF-файлов, такие как Adobe Acrobat.
- Выберите весь PDF-файл, нажав «Изменить» и «Выбрать все», или используйте Command + A.
- . Скопируйте содержимое PDF-файла, нажав «Редактировать и копировать» в меню, или используя сочетание клавиш Command + C
- . Откройте приложение TextEdit, расположенное в приложениях или используйте панель поиска macOS, чтобы найти его.
- В левом углу нового окна откройте новый документ
- Измените TextEdit на режим обычного текста, нажав «Форматировать» и «Сделать обычный текст» или нажав сочетание клавиш Shift + Command + T
- Вставьте содержимое PDF-файла, нажав Edit и Paste в меню или нажав Command + V.Поскольку TextEdit находится в режиме обычного текста, вы увидите только вставленный текст, а не изображения или форматирование из исходного PDF-файла.
- Возможно, вам потребуется исправить некоторые ошибки с интервалом после вставки текста
Извлечь текст из отсканированного PDF-файла
В качестве альтернативы вам может потребоваться просто найти фрагмент текста в большом PDF-документе. В некоторых случаях простой поиск Command + F может творить чудеса, но если PDF-файл был получен из изображений, единственный выход – использовать какое-нибудь профессиональное программное обеспечение, такое как PDF Search.
PDF Search – это приложение, которое позволит вам сканировать сотни страниц PDF, чтобы найти именно то, что вы ищете, с молниеносными результатами. PDF Search делает больше, чем просто находит совпадения с вашими поисковыми запросами: он также ищет несколько комбинаций и проверяет связанные термины.
Если вам нужен мощный инструмент, который позволит вам увидеть, появляется ли слово в заголовке, подзаголовке или основном абзаце, PDF Search позволит вам найти наиболее релевантные результаты.Вы также сможете конвертировать офисные документы в PDF.
✕ Возможность быстро извлекать текст из изображения или PDF-файла и редактировать, сохранять или вносить в него какие-либо другие изменения может иметь большое значение для производительности вашего текстового редактора. Приложения OCR позволяют распознавать текст, встроенный в графику, и превращать его в текстовый файл, который вы можете редактировать, чтобы вы могли легко преобразовать изображение в текст или сделать доступным для поиска отсканированный PDF-файл.
Скопировать текст из изображения онлайн
Если вы хотите извлечь текст из изображения без использования каких-либо инструментов распознавания текста, вы можете сделать это онлайн.Google Диск предоставляет вам бесплатную помощь по оптическому распознаванию текста за считанные минуты. Хотя он может некорректно отображать форматирование, вы получаете редактируемый текст из любого изображения, включая снимки экрана.
Вот как преобразовать картинку в текст с помощью Google Диска:
- Откройте диск и нажмите «Создать»> «Загрузить файл».
- После загрузки изображения щелкните его правой кнопкой мыши и выберите Открыть с помощью> Документы Google.
Новая вкладка с документом Google Docs откроется автоматически.Чтобы преобразовать сканированную копию в текст:
- Внизу вы увидите изображение и извлеченный из него редактируемый текст.
- Внесите необходимые изменения и удалите изображение.
- Документ с текстом будет доступен с Google Диска
Обратите внимание, что этот поток удобен с короткими фрагментами текста. Чем больше текста вы извлечете, тем больше в нем будет ошибок.
Как работать с цифровыми заметками на Mac
Преобразование рукописных заметок в цифровые – легкая задача, если это происходит на iPad.Apple Pencil работает с многочисленными приложениями для создания заметок, позволяя рисовать или писать и преобразовывать свои записи в цифровые заметки. Хорошая новость в том, что вы можете использовать iPad и Apple Pencil вместе с Mac в качестве расширенного рабочего пространства на macOS Catalina и macOS Big Sur.
Самый простой способ – использовать Apple Notes. Помимо поддержки рукописного ввода, приложение имеет возможности аннотации и встроенного сканирования. Благодаря поддержке iCloud вы можете легко получить доступ к своим цифровым заметкам на Mac.
Если вам нужно преобразовать математический почерк в цифровой LaTeX, MathML или изображение, MathKey всегда рядом.Приложение работает на основе технологии MyScript Interactive Ink и легко преобразует простой текст в математические формулы.
Ваша macOS мощная. Фактически, он предлагает несколько бесплатных решений для чтения изображений и PDF-файлов. Для расширенных функций, таких как чтение квитанций или автоматическое преобразование изображения в текст, вам все равно нужно немного больше. Но не беспокойтесь, есть и ярлыки – все приложения для распознавания текста и сканирования PDF, упомянутые в этой статье, доступны для бесплатной 7-дневной пробной версии с Setapp. Теперь вы можете перестать печатать и преобразовать этот текст за секунды, сэкономив часы.
Google Фото теперь позволяет искать текст на фотографиях, которые вы сделали
Google сделал сегодня тонкое объявление в Twitter: он находится в процессе развертывания новых функций искусственного интеллекта для своей платформы Lens, которые позволят вам искать в своей библиотеке Google Фото текст, который появляется на фотографиях и снимках экрана. Затем вы сможете легко скопировать и вставить этот текст в заметку, документ или форму.
Обе новые функции используют технику, известную как оптическое распознавание символов (OCR), с возможностью копирования / вставки, основанной на существующей способности Lens понимать и извлекать текст, найденный на фотографиях, будь то снимок экрана или фотография. физического знака или документа.Согласно 9to5Google , эта функция сейчас доступна на некоторых устройствах Android, хотя, похоже, она еще не активна на iOS. Возможно, вы уже сможете искать на своих фотографиях текст с помощью Google Фото в Интернете.
Google позиционирует функцию Lens как способ легко найти сбивающий с толку пароль Wi-Fi, но ее также можно использовать для захвата любой части текста с любой фотографии или снимка экрана в вашей библиотеке Google Фото в каждом конкретном случае. . Однако более впечатляющим достижением является возможность поиска любого фрагмента текста без предварительного выбора фотографии.Это говорит о том, что Google автоматически выполняет распознавание текста для всей вашей коллекции фотографий.
Вау, в @googlephotos есть функция распознавания текста, позволяющая преобразовывать снимки экрана в текст для копирования и вставки!
A. Откройте Google Фото и выберите снимок экрана
B. Выберите функцию «Объектив» [изображение 1]
C. Выделите текст [изображение 2]
D. Выберите копировать / вставить [изображение 2,3]Отлично выполненная команда Google ! pic.twitter.com/Um49ika2yT
– ☕️ (@hunterwalk) 21 августа 2019 г.
«Начиная с этого месяца мы внедряем возможность поиска ваших фотографий по тексту в них», – написал Google в ответ известному венчурному капиталисту Хантеру Уолку, который ранее на этой неделе заметил, что для его учетная запись.«Найдя нужную фотографию, нажмите кнопку« Объектив », чтобы легко скопировать и вставить текст. Возьми этот невозможный пароль Wi-Fi. ”
Вы это заметили! С этого месяца мы внедряем возможность поиска ваших фотографий по тексту на них.
Найдя нужную фотографию, нажмите кнопку «Объектив», чтобы легко скопировать и вставить текст. Взять хотя бы невозможные пароли Wi-Fi
– Google Фото (@googlephotos) 22 августа 2019 г.
Похоже, что эти функции связаны с функцией, о которой было объявлено еще на конференции разработчиков Google I / O в 2017 году.В то время генеральный директор Сундар Пичаи отметил новую, находящуюся в разработке, функцию, которая позволит камере объектива с искусственным интеллектом понимать контекст фотографии. Таким образом, вы можете направить камеру своего смартфона на наклейку с паролем маршрутизатора и автоматически подключиться к Wi-Fi с помощью программного обеспечения, считывающего пароль и понимающего, что вы хотите подключиться к сети, используя его.
С тех пор Google Lens добавил возможность поиска в Интернете фотографий пунктов меню, добавления контактной информации с визитной карточки в адресную книгу и всевозможных других уловок, связанных с оптическим распознаванием текста.Но эти новые функции фотографий кажутся более масштабным развертыванием техники искусственного интеллекта, сделанной так во всей библиотеке пользователя, чтобы сделать ее доступной для поиска и дать вам возможность извлекать этот текст из фотографий.
Как Evernote делает текст внутри изображений доступным для поиска – справочный центр Evernote
Как Evernote делает текст внутри изображений доступным для поиска
Знаете ли вы, что когда вы делаете снимок или прикрепляете изображение к заметке, Evernote может найти и идентифицировать текст, включая рукописный текст, внутри этого изображения?
Как это работает
Машинописный текст и рукописные заметки в формате JPG, PNG или GIF оцениваются нашей системой индексирования.Текст, найденный в изображении, будет оцениваться, если он соответствует одной из следующих ориентаций в пределах нескольких градусов:
- 0 ° – нормальная горизонтальная ориентация
- 90 ° – вертикальная ориентация
- 270 ° – вертикальная ориентация
Текст, не соответствующий одной из этих ориентаций, будет проигнорирован (включая диагональный и перевернутый текст). Когда изображения индексируются, они могут показывать несколько результатов. Например, система индексации может взглянуть на слово и решить, что это «кошка», «летучая мышь» или «3at».
Лучший способ убедиться, что почерк, в частности, найден и проиндексирован, – это следовать этим рекомендациям:
- Изображения, содержащие рукописный текст, следует добавлять в Evernote как изображения JPG, а не в формате PDF. Файлы PDF являются предпочтительным форматом для машинописных документов или отсканированных страниц, содержащих машинописный текст. Рукописный ввод не индексируется в файлах PDF.
- Чем четче почерк, тем больше вероятность, что он будет точно проиндексирован для поиска. Если почерк трудно читается, то Evernote будет труднее различать написанные слова.
- Имейте в виду, что вместо того, чтобы генерировать одно совпадение для данного рукописного слова, Evernote будет генерировать несколько возможных совпадений для этого слова. Например, слово «плоский» в формате JPG может быть проиндексировано как «плоский», «плавающий» или «фиатный».
В настоящее время Evernote может индексировать 28 машинописных языков и 11 рукописных языков. Вы можете выбрать, какой язык будет использоваться при индексировании, изменив параметр «Язык распознавания» в настройках своей учетной записи.
Подробнее о том, как работает распознавание изображений Evernote
Примеры
- Делайте снимки меню ресторана (включая меню на вынос) и сохраняйте их в своей учетной записи Evernote для использования в будущем.
- Делайте снимки этикеток вина и пива, чтобы отслеживать свои любимые товары и любые дегустационные заметки.
- Делайте снимки подарочных карт и подарочных сертификатов, чтобы всегда знать, где можно потратить лишние деньги.
- Делайте фотографии рукописных поздравительных открыток и просматривайте их, когда душе угодно.
- Сделайте фотографии гарантийных обязательств, инструкций по уходу за продуктами и любую другую полезную информацию, которую вы встретите в бумажной форме.
LANGUAGES_SUPPORT LANGUAGES_INCLUDE = ms
Ключевые слова:
- текстовый поиск
- поисковый текст
- текст в изображениях
- индекс
- индексирование изображений
- ocr
- распознавание изображений
- распознавание текста
- индексных изображений
- почерк
- рукописное