Как перевести PDF документ в WORD
В сегодняшнем видеоуроке я расскажу как распознать текст и конвертировать в Word с помощью бесплатной программы CuneiForm. В конце поста вы сможете скачать CuneiForm бесплатно…
После публикации поста PDF-Viewer vs Adobe Reader и Foxit Reader в комментариях появились вопросы о том, как редактировать сам текст документа, так как PDF-Viewer позволяет что-то вписывать в pdf документы, ставить штампы, заметки, но сам текст документа не изменяет…
Поэтому я пообещал, что сделаю видеоурок о программе распознавания текста, что и делаю сегодня!
Итак, вперед!
Если вы зададите поисковику найти «pdf в текст», “как распознать текст“, “конвертировать в word“, “перевести в ворд“, “распознавание текста со скана“ или “скан в текст“, то найдете, в основном, только платные программы!
А в самом верху списка, конечно же будет ABBYY FineReader!
Действительно ABBYY FineReader — лидер среди программ распознавателей текста! Но его единственный недостаток — платность! Например, ABBYY FineReader 11 Professional Edition стоит 3590 р! ABBYY FineReader 10 Home Edition — 1340 р.
Вроде и недорого, но если мне раз в месяц нужно распознать документ, то нет смысла тратиться!
Хотя у меня есть бесплатная 6-я версия ABBYY FineReader! Она шла в программном обеспечении моего принтера EPSON. Но в лицензии написано, что я не имею права передавать ее кому-либо, более одного раза!
Можно, конечно, найти и пиратскую версию! Точнее взломанный FineReader с кряком или кейгеном или патчем, но это уже уголовное преступление!
Лучше все-таки распознать текст с CuneiForm
Поэтому, хорошо поискав, я нашел совершенно бесплатную программу для распознавания текста и конвертирования в Word – CuneiForm!
CuneiForm, по качеству распознавания текста, ничем не уступает ABBYY FineReader! Единственный недостаток – CuneiForm не конвертирует pdf в текст! Она делает распознавание текста со скана или фото!
Я в видеоуроке это не упомянул, но даже не обязательно сканировать документ! Можно воспользоваться программой для снятия скринов FSCapture! О том, как с ней работать, посмотрите видеоурок здесь. ..
..
Делаете скрин документа, сохраняете в JPG и распознаете в CuneiForm! Все очень просто! Кстати, FSCapture — очень полезная программа не только для снятия скринов! Очень рекомендую освоить!
Но, вернемся к CuneiForm!
Пользоваться программой очень легко! Перевести в Word текст можно всего одной кнопкой! Все делается пости на автопилоте! Уверен, что вы разберетесь даже без видеоурока! 🙂
Но все же можете посмотреть! И, если нужно скачать урок себе на компьютер, то здесь можете посмотреть, как это сделать!
Скачать CuneiForm, программу распознавания текста, можно здесь…
Теперь, собственно видеоурок —
Как конвертировать текст в Word из другого формата
Как распознать текст? Программа для распознавания текста
Главная › Уроки по компьютеру › Как распознать текст? Программа для распознавания текста – ABBYY FineReader
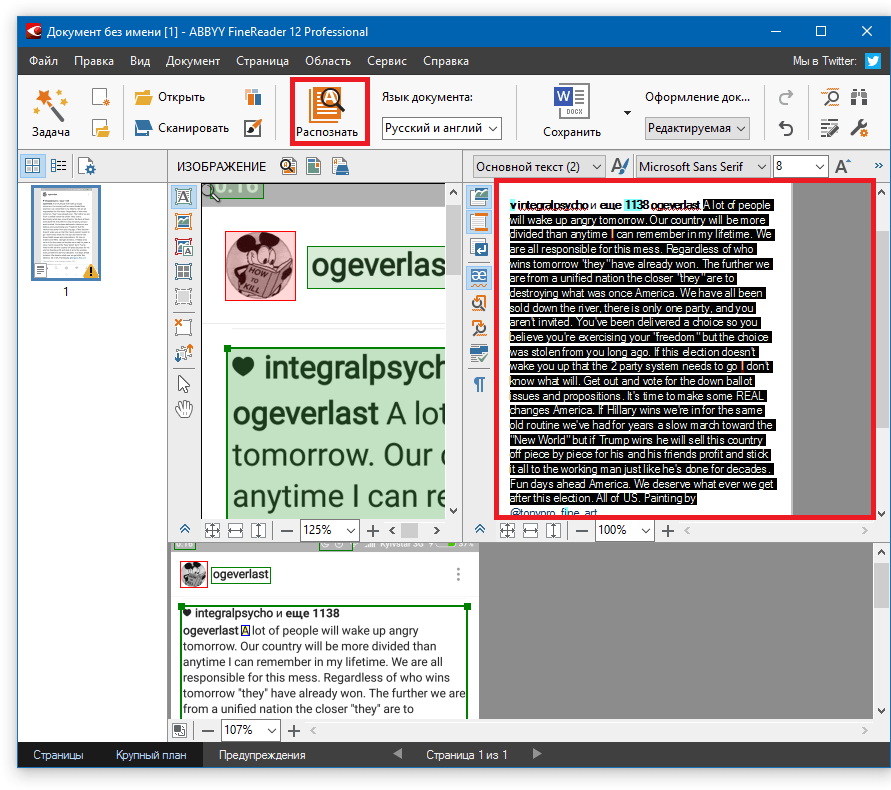
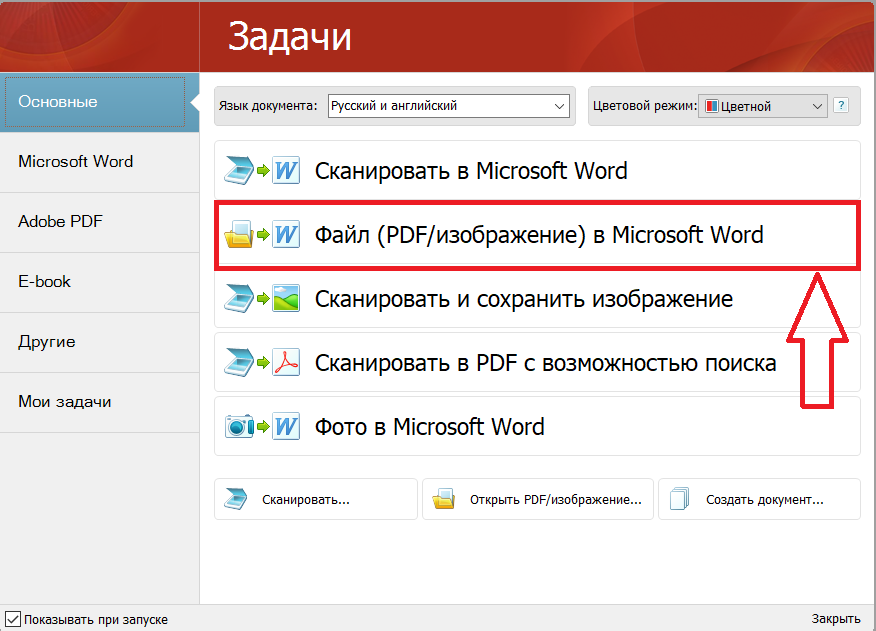
Функция распознавания текста может понадобиться в тех случаях, когда нужно перевести текст из книжного формата, в физическом варианте, в электронный. Здесь есть два варианта, либо сделать все как нужно, перепечатав текст из книги руками самому, и потратив на это уйму времени, либо второй вариант – это воспользоваться специальной программой для распознавания текста. Одна из таких называется ABBYY FineReader. О ней то мы сегодня и будем говорить. Программа ABBYY FineReader была разработана специально для осуществления возможности распознавания текста, который отсканирован из книги, журнала, газеты и прочих печатных изданий. Давайте я на реальном примере покажу Вам, как распознать текст после сканирования или после скачивания уже отсканированной книги, в программе ABBYY FineReader. Подготовьте программу: найдите её, скачайте, установите, запустите. Подготовьте текст, который вам нужно распознать. А теперь давайте запустим программу ABBYY FineReader. Процесс распознавания текста я буду показывать на примере последней, 11-ой, на данный момент версии. Например, нам нужно книгу в PDF формате конвертировать в обычный текст в страницы Word. Для этого в открывшемся окне программы выбираем задачу «Файл (PDF/изображение) в Microsoft Word». Нам сразу же предлагают указать на компьютере PDF файл для распознавания текста, который в нём имеется. В течение нескольких минут выбранный файл будет открываться. Мы можем наблюдать за процессом. Затем произойдет распознавание текста и по окончанию весь текст программа FineReader переместит в Word файл и откроет его. Нам остается только исправить некоторые ошибки, если они будут, и сохранить файл в любое место на своем компьютере. Кроме этого мы можем сами в программе распознанный текст передать или даже сразу сохранить в Ворд файл. Также в программе ABBYY FineReader можно распознать текст сразу со сканера, то есть кладем печатный вариант в сканер и в программе выбираем чтобы она сразу распознавала текст. Есть и другие варианты. Надеюсь эти примеры по распознаванию текста в программе ABBYY FineReader вам понятны и с другими способами вы уже разберетесь сами. Ранее я уже писал урок про то, как распознать текст, но там мы использовали не программу FineReader, а онлайн сервис. Впрочем, если вам эта тема интересна, то рекомендую почитать этот урок: Как распознать текст онлайн. Удачи! Интересные статьи по теме: Как удалить страницу в Одноклассниках? Как удалиться из Одноклассников навсегда? Как смотреть телевизор на компьютере? Просмотр телеканалов через Интернет онлайн! Как записать Windows на диск? Как создать аккаунт в Google (Гугл) ? Как удалить программу VKsaver с компьютера? |
 Ну, представим такую ситуацию: у нас есть книга на руках, которую нужно перенести на компьютер в файл Ворд, как будто мы её перепечатали сами с клавиатуры.
Ну, представим такую ситуацию: у нас есть книга на руках, которую нужно перенести на компьютер в файл Ворд, как будто мы её перепечатали сами с клавиатуры. Отсканируйте его, если нужно.
Отсканируйте его, если нужно. 
Преобразование файлов PDF, содержащих только изображения, с помощью распознавания текста в Adobe Acrobat Pro | Справка
Adobe Acrobat Pro DC имеет встроенную функцию оптического распознавания символов (OCR), которая распознает большую часть текста и позволяет преобразовывать PDF-файлы, содержащие только изображения, в удобочитаемые.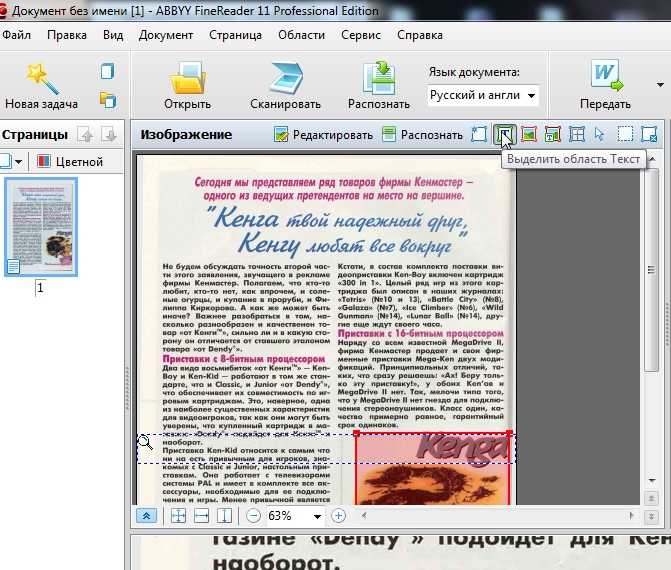 Вы можете распознавать текст несколькими способами. Не забудьте использовать максимально возможное качество сканирования.
Вы можете распознавать текст несколькими способами. Не забудьте использовать максимально возможное качество сканирования.
Способ 1. Средство сканирования и оптического распознавания символов
Средство улучшения сканирования попытается преобразовать отсканированные документы или фотографии бумажных документов в файлы PDF с выбираемым текстом. Этот инструмент также очистит контраст страницы и сгладит страницы, где текст может искривляться из-за переплетов книг.
Шаг 1. Выберите инструмент «Сканирование и распознавание»
Выберите инструмент «Сканирование и распознавание» на панели инструментов в правой части экрана. Это откроет панель инструментов в верхней части экрана.
Шаг 2. Выберите параметр «Улучшить»
Чтобы улучшить качество документа, выберите параметр «Улучшение» на панели инструментов «Улучшение сканирования», затем выберите «Отсканированный документ».
Шаг 3. Распознать и улучшить
Установите флажок «Распознать текст», затем нажмите кнопку «Улучшить». После завершения распознавания текста сохраните документ.
Шаг 4. Исправьте распознанный текст
В инструменте «Улучшение сканирования» откройте раскрывающийся список «Распознать текст» и выберите «Исправить распознанный текст». Установите флажок «Просмотреть распознанный текст» и просмотрите подозрительный текст, найденный инструментом, при необходимости исправьте его и нажмите «Принять». Сохраните документ.
Шаг 5. Документ с автоматическим добавлением тегов
После того, как весь текст будет распознан, перейдите на панель тегов, щелкните правой кнопкой мыши пункт Нет доступных тегов. Выберите опцию «Добавить теги в документ». Функция Auto-Tag попытается интерпретировать ваш документ на основе размера и стиля шрифтов, которые вы использовали. Более крупный и жирный текст обычно распознается как Заголовок 1 и Заголовок 2, даже если они не должны быть заголовками.
Шаг 6. Проверка и обновление тегов документа
Параметр автоматической пометки не будет на 100% правильным. Проверьте и при необходимости обновите теги документа. Сохраните документ.
Способ 2: инструмент «Редактировать PDF»
Параметр «Инструмент редактирования PDF» не пытается исправить качество сканирования перед распознаванием текста и не дает возможности исправить распознанный текст.
Шаг 1. Выберите инструмент «Редактировать PDF»
Выберите инструмент «Редактировать PDF» на панели инструментов в правой части экрана.
Acrobat Pro автоматически запустит OCR для вашего документа. После завершения сканирования вы сможете редактировать и выделять большую часть текста в документе. Не забудьте сохранить документ.
Если вы не можете выделить весь текст, определите, является ли текст изображением или нет. Некоторые изображения текста или рукописного текста могут не распознаваться OCR.
Мы не рекомендуем использовать изображения текста, поскольку текст, встроенный в изображения, не может быть воспроизведен вспомогательными технологиями, такими как программы чтения с экрана.В то же время изображения текста создают проблему для мобильных устройств, поскольку изображения текста могут искажаться и становиться неразборчивыми при открытии на мобильном устройстве или планшете. Вы можете попробовать Enhance Scan в качестве еще одного варианта OCR. Короткий раздел рукописного ввода, как и подписи, может быть помечен как рисунок и снабжен альтернативным текстом с соответствующим текстом. Для более длинных рукописных документов рассмотрите возможность повторного ввода текста в новый документ.
Шаг 2. Документ с автоматическим добавлением тегов
После того, как весь текст будет распознан, перейдите на панель тегов, щелкните правой кнопкой мыши пункт Нет доступных тегов. Выберите опцию «Добавить теги в документ». Функция Auto-Tag попытается интерпретировать ваш документ на основе размера и стиля шрифтов, которые вы использовали. Более крупный и жирный текст обычно распознается как Заголовок 1 и Заголовок 2, даже если они не должны быть заголовками.
Шаг 3. Проверка и обновление тегов документа
Параметр автоматической пометки не будет на 100% правильным. Проверьте и при необходимости обновите теги документа. Сохраните документ.
Преобразование документов в файлы PDF с возможностью поиска по тексту с помощью проприетарного программного обеспечения
Преобразование документов в файлы PDF с возможностью поиска по тексту с помощью проприетарного программного обеспеченияПоследнее обновление: 16 марта 2021 г.
Независимо от того, преобразовывают ли пользователи документ в PDF из другого файла или создают его как PDF, содержимое может быть недоступно для автоматического поиска по тексту.
+–Преобразование PDF в PDF с возможностью поиска по тексту (Adobe Acrobat DC New Versions)
- Открыть документ в Adobe Acrobat DC
Выберите File > Open , а затем перейдите к папке на вашем компьютере где находится PDF-файл, который вы хотите преобразовать. - Выберите Tools > Scan & OCR или выберите Scan & OCR на правой панели, если она у вас открыта.
- На дополнительной панели инструментов, которая появляется под подменю, выберите
- Нажмите синюю кнопку «Распознать текст» в правом нижнем углу.
- После того, как программа преобразует отсканированное изображение в доступное для поиска изображение, проверьте преобразованный документ на предмет ошибок и точности.
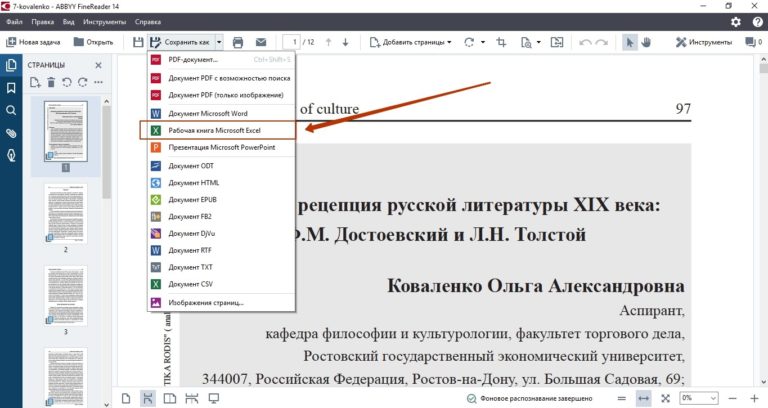 У вас есть возможность выбрать Исправить распознанный текст из раскрывающегося списка Распознать текст , который открывает мастер возможных ошибок.
У вас есть возможность выбрать Исправить распознанный текст из раскрывающегося списка Распознать текст , который открывает мастер возможных ошибок. - Когда вы исправите все ошибки, выберите Файл
+–Преобразование PDF в PDF с возможностью поиска по тексту (предыдущие версии Adobe Acrobat DC)
- Открыть документ в Adobe Acrobat DC
Выберите File > Open , а затем перейдите к папке на вашем компьютере где находится PDF-файл, который вы хотите преобразовать. - Распознать текст
Выберите Инструменты > Распознать текст > При необходимости щелкните раскрывающийся список «Язык» и выберите нужный язык из списка параметров. Щелкните Распознать текст , чтобы преобразовать изображение в текст, который можно выбрать и отредактировать.
При необходимости щелкните раскрывающийся список «Язык» и выберите нужный язык из списка параметров. Щелкните Распознать текст , чтобы преобразовать изображение в текст, который можно выбрать и отредактировать. - Поиск/редактирование текста (дополнительно)
После того, как вы воспользуетесь инструментом «Распознать текст» для преобразования отсканированного изображения в пригодный для использования файл PDF, вы сможете выбирать и выполнять поиск по тексту в этом файле, что упрощает поиск, изменение и повторно используйте информацию из ваших старых бумажных документов. Выберите инструмент «Найти текст» и введите текст для поиска в поле «Найти». Теперь, когда текст доступен для редактирования, вы можете заменить его, если это необходимо. Щелкните Нет, чтобы больше не вносить изменения в файл.
Щелкните Нет, чтобы больше не вносить изменения в файл.
Примечание: Вы можете сохранить PDF-файл под новым именем, чтобы сохранить содержимое исходного документа.
+–Преобразование отсканированного документа в PDF с возможностью поиска по тексту
- Откройте изображение вашего документа
Откройте файл одного из ваших собственных отсканированных документов или изображение вашего документа в Acrobat DC. На правой панели выберите инструмент Enhance Scans . Примечание: Исходный отсканированный документ или фотографию документа необходимо сохранить в формате PDF. - Настройка перекоса
Выберите Enhance > Camera Image , чтобы вызвать подменю Enhance. Выберите правильный вариант в раскрывающемся списке «Содержимое». Автоопределение используется по умолчанию и работает с большинством отсканированных документов. Перетащите синие точки, чтобы обрамить ту часть страницы, которую вы хотите сохранить. Выровняйте точки по краям документа, чтобы исправить перекос, и нажмите «Улучшить страницу».
Перетащите синие точки, чтобы обрамить ту часть страницы, которую вы хотите сохранить. Выровняйте точки по краям документа, чтобы исправить перекос, и нажмите «Улучшить страницу». - Настройка контрастности
В полученном предварительном просмотре улучшенного изображения перетащите ползунок Настройка уровня улучшения влево или вправо, чтобы уменьшить или увеличить контрастность. Когда вы закончите, нажмите «Закрыть», чтобы вернуться в главное меню «Улучшение сканирования». На данный момент у вас есть улучшенное изображение вашего документа, но вы по-прежнему не можете редактировать, выбирать или искать текст. - Распознать текст
Выберите Распознать текст > В этом файле , чтобы вызвать подменю распознавания текста. При необходимости щелкните раскрывающийся список «Язык» и выберите нужный язык из списка параметров. Щелкните Распознать текст , чтобы преобразовать изображение в текст, который можно выбрать и отредактировать.
При необходимости щелкните раскрывающийся список «Язык» и выберите нужный язык из списка параметров. Щелкните Распознать текст , чтобы преобразовать изображение в текст, который можно выбрать и отредактировать. - Поиск/редактирование текста (дополнительно)
После того, как вы воспользуетесь инструментом «Распознать текст» для преобразования отсканированного изображения в пригодный для использования файл PDF, вы сможете выбирать и выполнять поиск по тексту в этом файле, что упрощает поиск, изменение и повторно используйте информацию из своих старых бумажных документов. Выберите инструмент «Найти текст» и введите текст для поиска в поле «Найти». Теперь, когда текст доступен для редактирования, вы можете заменить его, если это необходимо. Примечание: Вы можете получить предупреждение о сканировании с низким разрешением, указывающее, что редактирование документа может не дать наилучших результатов. Нажмите Да, чтобы продолжить и отредактировать отсканированный документ. Щелкните Нет, чтобы больше не вносить изменения в файл.
Щелкните Нет, чтобы больше не вносить изменения в файл. - Сохраните файл для завершения преобразования!
- Откройте изображение вашего документа
Примечание: Вы можете сохранить PDF-файл под новым именем, чтобы сохранить содержимое исходного документа.
+–Преобразование документа Word в PDF с возможностью поиска по тексту
- Откройте документ в Word, чтобы начать экспорт
Выберите Файл > Экспорт > Создать PDF/XPS - Если свойства вашего документа Word содержат информацию, которую вы не хотите включать в PDF, в окне Опубликовать как PDF или XPS выберите Параметры . Затем выберите Документ и снимите флажок Свойства документа . Установите любые другие параметры, которые вы хотите, и выберите OK .
- В Опубликовать как PDF или XPS перейдите туда, где вы хотите сохранить файл.
 Кроме того, измените имя файла, если вы хотите другое имя.
Кроме того, измените имя файла, если вы хотите другое имя. - Нажмите Опубликовать , чтобы завершить преобразование!
+–Преобразование документа Pages в PDF с возможностью поиска по тексту
- Откройте документ в Pages, чтобы начать экспорт
Выберите Файл > Экспортировать в , затем выберите PDF. - В окне «Экспорт документа» вы можете выбрать другой формат или настроить любые дополнительные параметры.
- Нажмите Далее .
- Введите имя файла и выберите папку для его сохранения.
- Нажмите Экспорт , чтобы завершить преобразование! Примечание: Обязательно сохраните файл перед закрытием. Если вы вносите какие-либо изменения после экспорта файла в другой формат, они отображаются только в файле Pages, с которым вы работаете.
+–Преобразование документа Open Office в формат PDF с возможностью поиска по тексту
- Откройте документ в Open Office, чтобы начать экспорт
Выберите Файл > Экспорт в формате PDF.