
27 – Устройства ввода
1. Отметьте все устройства ввода. | |
| сканер | |
| клавиатура | |
| веб-камера | |
| флэш-диск | |
| мышь | |
2. Какой способ обмена данными используется при вводе с клавиатуры? | |
| программно-управляемый обмен данными | |
| обмен по прерываниям | |
| прямой доступ к памяти | |
3. Как называется номер нажатой клавиши на клавиатуре? |
| Ответ: |
4. Какие утверждения верны для беспроводных мышей? | |
| передают данные с помощью радиоволн | |
| передают звуковые сигналы | |
| передают данные с помощью телепатии | |
| им требуется источник питания | |
| компьютер должен иметь приемник излучения (адаптер) | |
5. |
| Ответ: |
 Как называется устройство, позволяющее принимать и декодировать сигналы от беспроводных устройств ввода?
Как называется устройство, позволяющее принимать и декодировать сигналы от беспроводных устройств ввода?6. Как называется мышь, которая использует луч света или портативного лазера для определения своего перемещения? |
| Ответ: |
7. В каких единицах обычно измеряется разрешение оптического сенсора мыши? | |
| точки на дюйм (dpi) | |
| пиксели на дюйм (ppi) | |
| точки на сантиметр | |
| пиксели на сантиметр | |
8. Как называется режим сенсорных панелей, в котором они могут воспринимать касание одновременно в нескольких точках? |
| Ответ: |
9. Как называется устройство для ввода в компьютер графической информации с бумаги или плёнки? |
| Ответ: |
10. | |
| в точках на дюйм (dpi) | |
| в пикселях на дюйм (ppi) | |
| в точках на сантиметр | |
| в пикселях на сантиметр | |
| в точках на миллиметр | |
 В каких единицах измеряется разрешающая способность сканера?
В каких единицах измеряется разрешающая способность сканера?11. Как с помощью сканера вводится текст? | |
| сканер сам распознает символы | |
| сканер вводит текст в виде рисунка | |
| специальная программа распознает символы | |
| сканер не умеет вводить текст | |
| можно ввести текст только на одном заданном языке | |
12. Выберите минимальное разрешение сканера, достаточное для распознавания отсканированного текста. | |
| 150 ppi | |
| 300 ppi | |
| 600 ppi | |
| 2000 ppi | |
13. | |
| принтер | |
| сканер | |
| графический планшет | |
| микрофон | |
| фотоаппарат | |
 Какие устройства используются для ввода графической информации?
Какие устройства используются для ввода графической информации?14. Почему многие современные устройства подключаются через порты USB? | |
| это дешевле | |
| можно подключать устройства, не выключая питание | |
| это увеличивает скорость передачи данных | |
| на материнской плате не делают других портов | |
| к одному порту можно подключать несколько устройств | |
15. Что необходимо для ввода звука в компьютер? | |
| звуковая карта | |
| микрофон | |
| быстродействующий процессор | |
| соответствующее программное обеспечение | |
| много оперативной памяти | |
Компьютер читает
Компьютер читаетКомпьютер читает
Текст в компьютер мы вводим с помощью клавиатуры. А если нужно ввести журнальную статью, реферат, книгу, наконец? Сомнительное удовольствие перепечатывать сотни страниц. Тем более, что во многих случаях ввести большой текст можно с помощью сканера. Правда, сканер, считывая страницу, создает файл в графическом формате, то есть в виде картинки – набора черных и белых точек. Сканер ничего не знает о буквах, словах, алфавитах и языках – буквы для него неотличимы от рисунков. Он одинаково отсканирует и фотографию из семейного альбома, и текст из журнала. Если вы захотите поменять в таком тексте (в картинке) букву “а” на букву “о”, то вам придется это делать в специальном графическом редакторе, стирая и рисуя отдельные точки, составляющие буквы. А вам-то нужен файл в формате текстового редактора. Иными словами, текст, который вы можете быстро и легко исправлять, редактировать, цитировать. “Учат” компьютер читать картинку с текстом (переводить его из одного формата в другой) специальные программы – системы оптического распознавания символов.
А если нужно ввести журнальную статью, реферат, книгу, наконец? Сомнительное удовольствие перепечатывать сотни страниц. Тем более, что во многих случаях ввести большой текст можно с помощью сканера. Правда, сканер, считывая страницу, создает файл в графическом формате, то есть в виде картинки – набора черных и белых точек. Сканер ничего не знает о буквах, словах, алфавитах и языках – буквы для него неотличимы от рисунков. Он одинаково отсканирует и фотографию из семейного альбома, и текст из журнала. Если вы захотите поменять в таком тексте (в картинке) букву “а” на букву “о”, то вам придется это делать в специальном графическом редакторе, стирая и рисуя отдельные точки, составляющие буквы. А вам-то нужен файл в формате текстового редактора. Иными словами, текст, который вы можете быстро и легко исправлять, редактировать, цитировать. “Учат” компьютер читать картинку с текстом (переводить его из одного формата в другой) специальные программы – системы оптического распознавания символов.
Четкое изображение – меньше ошибок
Представьте себе, как трудно учителю научить ребенка читать, если текст в книжке напечатан нечетко, расплывчато, на каждой букве приходится спотыкаться, выяснять ее. То же самое и с компьютером. Системы оптического распознавания символов – OCR (optical character recognition) – не любят “грязные” тексты. Чем качественнее мы отсканируем для них документ, тем меньше ошибок допустит “ученик”. Сделать это на хорошем аппарате несложно.
В сканере есть три ручки, с помощью которых можно управлять процессом сканирования. Первая из них – яркость. Если “фотография” получится очень светлой (высокая яркость), то символы на ней в тонких перешейках будут иметь разрывы, и буква “о” превратится в букву “с”. А на темной “фотографии” (низкая яркость) соседние буквы склеятся друг с другом, и будет сложно понять, где начинается одна буква и заканчивается другая. В большинстве систем OCR есть модуль автоматического подбора яркости, но, если вы не удовлетворены результатом его работы, установите яркость вручную.
Первая из них – яркость. Если “фотография” получится очень светлой (высокая яркость), то символы на ней в тонких перешейках будут иметь разрывы, и буква “о” превратится в букву “с”. А на темной “фотографии” (низкая яркость) соседние буквы склеятся друг с другом, и будет сложно понять, где начинается одна буква и заканчивается другая. В большинстве систем OCR есть модуль автоматического подбора яркости, но, если вы не удовлетворены результатом его работы, установите яркость вручную.
Вторая ручка – разрешение сканера. Не будем подробно расшифровывать этот термин, скажем только, что, чем выше разрешение сканера, тем отчетливее будут прорисованы мелкие детали изображения. Для систем распознавания в большинстве случаев оптимальным значением разрешения считается диапазон от 300 до 600 dpi.
И третья ручка управления сканером – контрастность, с помощью которой регулируется отделение фона от текста. Предположим, вы сканируете текст, напечатанный через синюю копирку на пожелтевшей бумаге. Увеличивая контрастность, вы можете добиться хорошего изображения букв без лишних точек, “грязи”.
Увеличивая контрастность, вы можете добиться хорошего изображения букв без лишних точек, “грязи”.
Читаем по слогам
После того как сканер передал изображение в систему OCR, установленную в компьютере, начинается процедура сегментирования. Если документ положен в сканер с наклоном или вообще перевернут вверх ногами, программа его выправляет. Анализируя изображение, система OCR делит его на участки. Одни будут преобразовываться в текст; другие (в которых, например, располагаются картинки) будут оставлены без изменений; третьи участки содержат таблицы, поэтому при их обработке включатся специальные модули. В большинстве систем распознавания возможна как автоматическая сегментация, так и ручная. Допустим, программа ошиблась в анализе структуры документа, выделила таблицу как картинку – вы можете откорректировать результат. Далее разбитый на участки документ поступает на распознавание.
Распознавание – ядро любой системы OCR. От его качественной работы, то есть малого количества допущенных ошибок, зависит время, которое придется потратить на их исправление.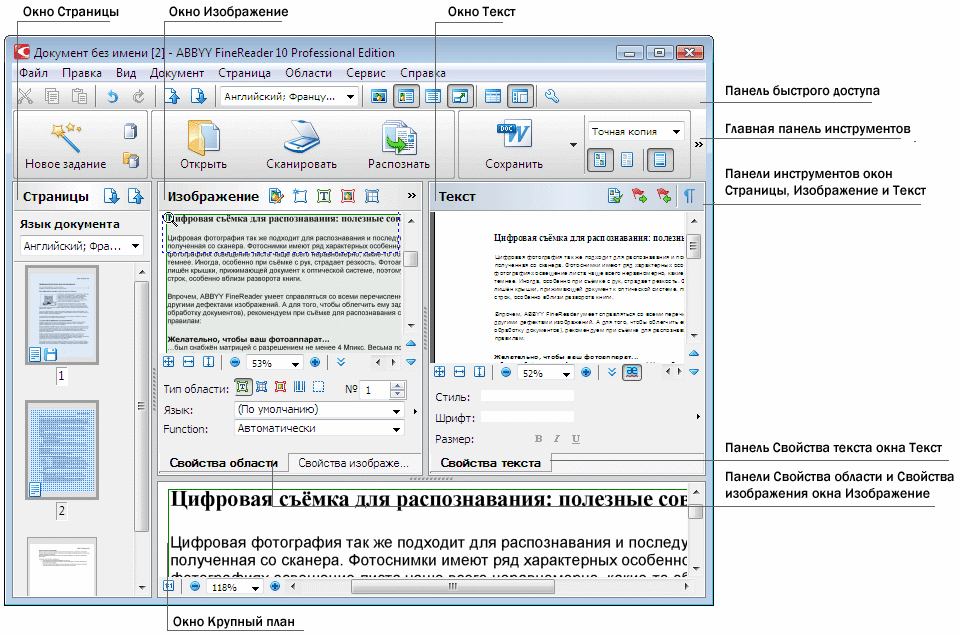
Распознавание осложняют дефекты печати, о которых мы говорили ранее, – склеенные и разорванные символы. Для улучшения распознавания некачественно напечатанных текстов часто используют специальные контекстные модули. В систему OCR закладываются словари языков, модели словоизменения. Например, в слове “дом” буква “о”, написанная с дефектом, превратилась в букву “с”. Но программа знает, что слова “дсм” в русском языке нет, а слово “дом” есть, значит, решает программа, “скорее всего, это буква “о”.
После того как текст распознан, вам предлагается исправить в нем ошибки.
Обычно система распознавания сохраняет связь между распознанным текстом и исходным изображением. Как только вы становитесь курсором на слове, в другом окне вы видите часть картинки, с которой выделенное слово было распознано. Это очень удобно, так как можно проверять ошибки, не доставая листа из сканера.
Результатом работы системы распознавания становится документ в текстовом формате. Вы можете оставить или изменить оформление документа: шрифты, картинки, разбивку на столбцы, таблицы.
Так выглядят этапы работы системы распознавания. Время, которое вы сейчас потратили на чтение их описания, больше, чем потребуется для их распознавания в ОСR. Сканирование одной страницы длится 15-40 секунд, распознавание – 30 секунд, то есть страница текста вводится в компьютер за одну минуту. Система OCR может работать в пакетном режиме: сначала сканируются все листы, а затем запускается распознавание, которое может работать круглосуточно, без перерывов.
Ищем кошку в темной комнате
Как мы отличаем одну букву от другой, стол от стула, собаку от кошки? Без ответа на этот вопрос невозможно и искусственную систему научить различать объекты. Наблюдая за человеком и животными, ученые выдвинули гипотезу об используемых “живыми системами” принципах распознавания предметов. А затем применили эти принципы при проектировании компьютерных программ.
Согласно принципу целостности, каждый объект (например, человек) состоит из значимых частей (голова, руки, ноги, туловище), находящихся в определенных отношениях друг с другом (голова находится наверху туловища, руки – на противоположных сторонах туловища, ноги не могут быть выше рук). Если нам нужно распознать объект, мы должны найти все составляющие его части и проверить, выполняются ли заданные для них отношения.
Второй принцип – целенаправленность. Распознавание строится как процесс выдвижения и доказательства или опровержения гипотез. Например, услышав шорох в углу темной комнаты, мы делаем предположение, что это кошка. И пытаемся опровергнуть нашу догадку или подтвердить ее. Мы говорим себе: “Если это кошка, то у нее должны быть голова кошки, лапы кошки, кошачий хвост и она должна мяукать”. Когда мы разглядим в темноте все перечисленные части и удостоверимся, что они соответствуют нашим представлениям о кошке, мы “распознаем” кошку. Таким образом, мы не просто наблюдали объект, а вначале выдвинули гипотезу о том, что он собой представляет, и начали целенаправленно искать черты, присущие этому объекту.
И пытаемся опровергнуть нашу догадку или подтвердить ее. Мы говорим себе: “Если это кошка, то у нее должны быть голова кошки, лапы кошки, кошачий хвост и она должна мяукать”. Когда мы разглядим в темноте все перечисленные части и удостоверимся, что они соответствуют нашим представлениям о кошке, мы “распознаем” кошку. Таким образом, мы не просто наблюдали объект, а вначале выдвинули гипотезу о том, что он собой представляет, и начали целенаправленно искать черты, присущие этому объекту.
Такова природа процесса распознавания, которое, по сути, не что иное, как классификация. В систему заложены описания эталонов (или классов), и исследуемый объект соотносится с одним из них. Система не может распознать объект вообще, она только может сказать, относится ли он к одному из известных ей классов. И если да, то к какому именно.
И третий принцип – адаптивность, способность системы самообучаться. Когда человек разбирает непонятное слово, написанное незнакомым почерком, он находит похожие закорючки в других, уже прочитанных словах и запоминает, как автор письма пишет, например, букву “д”. Затем возвращается к вызвавшему затруднение слову и читает его, обладая уже новыми знаниями о написании конкретных букв данным почерком.
Эти три принципа делают живые организмы идеальными системами распознавания, способными идентифицировать сотни объектов за считанные доли секунды. И если использовать те же принципы при построении искусственных систем, можно рассчитывать на высокие результаты. Разница в том, что человеческий мозг совершает эту работу с помощью сложных биохимических реакций, а компьютер – путем вычислений.
Затем возвращается к вызвавшему затруднение слову и читает его, обладая уже новыми знаниями о написании конкретных букв данным почерком.
Эти три принципа делают живые организмы идеальными системами распознавания, способными идентифицировать сотни объектов за считанные доли секунды. И если использовать те же принципы при построении искусственных систем, можно рассчитывать на высокие результаты. Разница в том, что человеческий мозг совершает эту работу с помощью сложных биохимических реакций, а компьютер – путем вычислений.
Прочтите рукопись мою
Распознавание печатных текстов компьютером – область, сегодня достаточно хорошо исследованная. Существующие системы обладают высокой точностью распознавания: более 99,9% на текстах хорошего и среднего качества печати, и спор между компьютерными программами идет за сотые доли процентов. Что же касается распознавания рукописного текста, то качественный рывок еще впереди. Хотя уже есть несколько отработанных направлений. Во-первых, это системы распознавания форм, заполненных печатными буквами от руки (анкеты, бюллетени, накладные, чеки и т. д.), которые применяются во многих областях. Например, всем уже хорошо известны машиночитаемые формы налоговых деклараций и анкеты Пенсионного фонда.
Во-первых, это системы распознавания форм, заполненных печатными буквами от руки (анкеты, бюллетени, накладные, чеки и т. д.), которые применяются во многих областях. Например, всем уже хорошо известны машиночитаемые формы налоговых деклараций и анкеты Пенсионного фонда.
Во-вторых, распознавание раздельных рукописных букв, написанных особым пером на специальном экране (touch-screen), широко применяется в карманных компьютерах и электронных записных книжках. Эти распознающие системы показывают достаточно высокую точность, приближающуюся к точности клавиатуры.
Чтение компьютером слитных букв, то есть обычного письма, сегодня мало разработано. Прежде всего, потому, что мала в этом потребность. Нам известны две области возможного практического применения подобных систем: распознавание почтовых адресов на конвертах и распознавание квитанций при оплате кредитной карточкой (слипов). Но исследовательские проблемы, которые надо решить на этом пути, чрезвычайно интересны.Почему непросто распознать слитный текст? Дело в том, что в этой задаче на распознавание приходится лишь 30%, а остальные 70% лежат в области понимания компьютером смысла документа.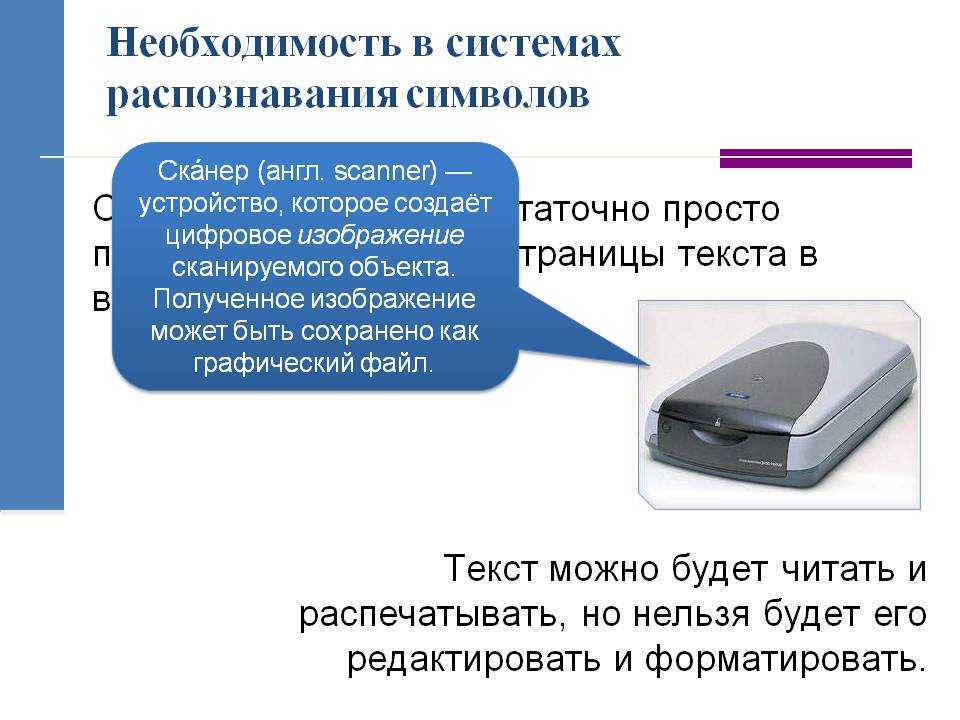 Приведем простой пример. Допустим, вы изучили буквы бразильского языка, знаете правила составления слов и их произношения. Теперь включите радио и попробуйте за бразильским диктором записать текст. В лучшем случае вам удастся “распознать” не более 30%. Это происходит потому, что вы не понимаете смысла того, что говорит диктор.
Решить задачу распознавания слитного текста с высоким результатом можно будет, только когда компьютер, сможет понимать смысл предлагаемого текста. Нужно создать модель представления о мире и заложить ее в компьютер. И тогда можно будет выпускать качественно новые системы распознавания рукописных слитных текстов, а также решать близкие задачи: распознавание звучащей речи, машинный перевод.
Приведем простой пример. Допустим, вы изучили буквы бразильского языка, знаете правила составления слов и их произношения. Теперь включите радио и попробуйте за бразильским диктором записать текст. В лучшем случае вам удастся “распознать” не более 30%. Это происходит потому, что вы не понимаете смысла того, что говорит диктор.
Решить задачу распознавания слитного текста с высоким результатом можно будет, только когда компьютер, сможет понимать смысл предлагаемого текста. Нужно создать модель представления о мире и заложить ее в компьютер. И тогда можно будет выпускать качественно новые системы распознавания рукописных слитных текстов, а также решать близкие задачи: распознавание звучащей речи, машинный перевод.
А. АБРАМЕНКО.
Как компьютер, вернее, программа отличает одну букву от другой? Традиционно существует три метода распознавания (или типа классификаторов): шаблонные, признаковые и структурные. Шаблонные классификаторы преобразуют исходное изображение символа в набор точек и затем накладывают его на шаблоны, имеющиеся в базе системы. Шаблон, имеющий меньше всего отличий, и будет искомым. У этих систем достаточно высокая точность распознавания дефектных символов (склеенных или разорванных). Недостаток – невозможность распознать шрифт, хоть немного отличающийся от заложенного в систему (размером, наклоном или начертанием). Признаковые классификаторы по каждому символу вычисляют набор чисел (признаков). И сравнивают эти наборы. Но так как набор признаков никогда полностью не соответствует объекту, то заведомо часть информации о символе будет теряться. Структурные классификаторы хранят информацию о топологии символа. Например, буква “о” описывается как непрерывная кривая, не имеющая пересечений. Этот способ тоже имеет свои недостатки: как только вы представите “разорванную” из-за дефектов печати букву “о”, она уже не подойдет под свое описание и может быть распознана как “с” или “п”.
Программисты российской компании ABBYY разработали оригинальные технологии, улучшающие качество распознавания. Идея нового способа хранения знаний о букве – структурно-пятенный эталон – впервые появилась на свет в студенческих работах Д.
Шаблон, имеющий меньше всего отличий, и будет искомым. У этих систем достаточно высокая точность распознавания дефектных символов (склеенных или разорванных). Недостаток – невозможность распознать шрифт, хоть немного отличающийся от заложенного в систему (размером, наклоном или начертанием). Признаковые классификаторы по каждому символу вычисляют набор чисел (признаков). И сравнивают эти наборы. Но так как набор признаков никогда полностью не соответствует объекту, то заведомо часть информации о символе будет теряться. Структурные классификаторы хранят информацию о топологии символа. Например, буква “о” описывается как непрерывная кривая, не имеющая пересечений. Этот способ тоже имеет свои недостатки: как только вы представите “разорванную” из-за дефектов печати букву “о”, она уже не подойдет под свое описание и может быть распознана как “с” или “п”.
Программисты российской компании ABBYY разработали оригинальные технологии, улучшающие качество распознавания. Идея нового способа хранения знаний о букве – структурно-пятенный эталон – впервые появилась на свет в студенческих работах Д. Яна, К. Анисимовича и П. Сенаторова.
Яна, К. Анисимовича и П. Сенаторова.
Он лишен недостатков, присущих шаблонным и структурным системам (высокая чувствительность к начертаниям и дефектам символов), и объединяет их достоинства. В структурно-пятенном эталоне изображение представляется в виде пятен, связанных парными отношениями. Наглядно это можно представить себе в виде теннисных шаров, нанизанных на резиновый жгут. Шары могут сдвигаться относительно друг друга. Такую связку подвижных шаров можно “натянуть” на различные изображения одного символа, и система становится менее зависимой от шрифтов и дефектов. Технология распознавания с помощью структурно-пятенных эталонов получила название “фонтанное преобразование” (от английского font – шрифт).
Система оптического распознавания текста “FineReader Рукопись”, разработанная российской компанией ABBYY, применяется для обработки Анкеты Пенсионного фонда и налоговых деклараций. Точность распознавания (прочтения) – до 99,9%.
http://ocrai.narod.ru E-Mail: ocrai@narod. ru последнее обновление: 26;11;2000
ru последнее обновление: 26;11;2000
Как добавить текст в отсканированные документы в Word | Small Business
By Filonia LeChat
Сканирование файлов для импорта в документ Word — идеальный способ дополнить ваши годовые отчеты, сводки заинтересованных сторон или исполнительные письма, но в большинстве случаев отсканированные файлы заблокированы. Word не может вмешаться в них, чтобы добавить текст, но это не значит, что вы должны довольствоваться тем, как они отображаются на странице Word. Используйте текстовые поля Word для наложения документов, добавляя текст к отсканированным файлам. После печати конечные пользователи никогда не поймут, что вы смешали исходный контент с ранее созданными документами.
Откройте документ Word, содержащий отсканированный документ, чтобы добавить текстовые поля.
Прокрутите до раздела, где должен быть первый текст. Если отсканированный документ очень сложный или текстовый раздел небольшой, используйте ползунок масштабирования в рабочей области, чтобы увеличить рабочую область.

Перейдите на вкладку «Вставка», затем нажмите кнопку «Текстовое поле». Выберите первый вариант «Простое текстовое поле», который добавляет текстовое поле Word по умолчанию в отсканированный документ.
Щелкните внутри текстового поля с текстом-заполнителем и введите текст, который нужно поместить поверх скана. Если ваш текст меньше или больше, чем по умолчанию в Word, щелкните угол поля и перетащите его внутрь или наружу, чтобы настроить.
Щелкните границу текстового поля, чтобы открыть оранжевую вкладку «Инструменты для текстового поля». Эта вкладка доступна только тогда, когда включено само текстовое поле.
Щелкните меню «Заливка фигуры» на ленте новой вкладки и выберите «Без заливки». Это делает ваше текстовое поле прозрачным, а не заполненным белым фоном, поэтому оно не будет заслонять отсканированный документ. Если вы хотите, чтобы фон текстового поля оставался белым и скрывал то, что находится за ним на скане, вы можете пропустить этот шаг.

Щелкните меню «Контур фигуры» на ленте новой вкладки и выберите «Без контура». Это удаляет черную рамку Word по умолчанию вокруг текстового поля. Теперь текст просто плавает на скане, как если бы он был на оригинале.
Повторите процесс, чтобы добавить дополнительные текстовые поля во время сканирования. Вы также можете щелкнуть правой кнопкой мыши, скопировать и вставить текстовое поле, которое вы только что создали, затем выделить и ввести текст поверх текста, чтобы изменить его, сохранив настройки «Без заливки» и «Без контура».
Перейдите на вкладку «Файл» и выберите «Сохранить как». Переименуйте документ, чтобы сохранить оригинал без добавленного текста, а затем нажмите кнопку «Сохранить».
Список литературы
- Dickinson College: Microsoft Word 2010 – Добавление цитат и боковой панели
Ресурсы
- Goodwin College: Microsoft Word 2010 Tutorial
Советы
- отсканированный документ в Word, вы можете сделать это, щелкнув небольшое меню «Объект» на вкладке «Вставка».
 Выберите «Объект» из двух раскрывающихся вариантов, затем нажмите вкладку «Создать из файла». Найдите отсканированный документ и дважды щелкните его, затем нажмите кнопку «ОК», чтобы вставить его.
Выберите «Объект» из двух раскрывающихся вариантов, затем нажмите вкладку «Создать из файла». Найдите отсканированный документ и дважды щелкните его, затем нажмите кнопку «ОК», чтобы вставить его. - Отформатируйте текст в текстовом поле так же, как при вводе текста в документе Word, используя раздел «Шрифт» на ленте. Вы можете попытаться сопоставить текст в текстовом поле с любым текстом, уже имеющимся на отсканированном документе.
Писатель Биография
Фиония ЛеЧат — технический писатель, чьи основные навыки включают набор MS Office (Word, PowerPoint, Excel, Publisher), Photoshop, Paint, настольные издательские системы, дизайн и графику. ЛеШат имеет степень магистра технических наук, степень магистра гуманитарных наук в области связей с общественностью и коммуникаций и степень бакалавра гуманитарных наук в области письма/английского языка.
404: Страница не найдена
Страница, которую вы пытались открыть по этому адресу, похоже, не существует. Обычно это результат плохой или устаревшей ссылки. Мы приносим свои извинения за доставленные неудобства.
Обычно это результат плохой или устаревшей ссылки. Мы приносим свои извинения за доставленные неудобства.
Что я могу сделать сейчас?
Если вы впервые посещаете TechTarget, добро пожаловать! Извините за обстоятельства, при которых мы встречаемся. Вот куда вы можете пойти отсюда:
Поиск- Узнайте последние новости.
- Наша домашняя страница содержит самую свежую информацию о Java-разработке.
- Наша страница «О нас» содержит дополнительную информацию о сайте, на котором вы находитесь, TheServerSide.com.
- Если вам нужно, пожалуйста, свяжитесь с нами, мы будем рады услышать от вас.
Поиск по категории
SearchAppArchitecture
- Растущая роль разработчиков, ориентированных на данные
Больше, чем когда-либо, растущая зависимость разработчиков от данных, источников данных и пользователей подталкивает разработчиков к пониманию ИТ-покупок …
- 12 рекомендаций по безопасности API для защиты вашего бизнеса
Как и в любом цикле разработки программного обеспечения, безопасность API должна быть встроена с самого начала.
 Следуйте этим рекомендациям по проектированию, развертыванию…
Следуйте этим рекомендациям по проектированию, развертыванию… - Основы, преимущества и риски сотовой архитектуры
Разработчикам, работающим с микросервисами, эта концепция может показаться знакомой, но архитектура на основе ячеек имеет свои особенности …
ПоискSoftwareQuality
- Разработчики хотят повышения производительности и эффективности в Java 20
Java 20, вероятно, будет включать полезные функции, такие как улучшения параллелизма и профилирования, но добавочные обновления …
- Обзор тестирования API на основе данных
Тестирование API, включая тестирование API на основе данных, отличается от других тестов программного обеспечения своим общим процессом и соответствующими показателями…
- Разработчики предупредили: код GitHub Copilot может быть лицензионным
Вопросы связаны с использованием GitHub Copilot открытого исходного кода, но это решение Верховного суда по искусству Уорхола, которое разработчики.
 ..
..
SearchCloudComputing
- С помощью этого руководства настройте базовый рабочий процесс AWS Batch
AWS Batch позволяет разработчикам запускать тысячи пакетов в AWS. Следуйте этому руководству, чтобы настроить этот сервис, создать свой собственный…
- Партнеры Oracle теперь могут продавать Oracle Cloud как свои собственные
Alloy, новая инфраструктурная платформа, позволяет партнерам и аффилированным с Oracle предприятиям перепродавать OCI клиентам в регулируемых …
- Dell добавляет Project Frontier для периферии, расширяет гиперконвергентную инфраструктуру с помощью Azure
На этой неделе Dell представила новости на отдельных мероприятиях — одно из которых демонстрировало программное обеспечение для управления периферийными устройствами, другое — углубление гиперконвергентной инфраструктуры …
ПоискБезопасность
- CISA предупреждает об атаках программ-вымогателей на поставщиков медицинских услуг
Новый бюллетень CISA предупредил администраторов больниц и поставщиков медицинских услуг о недавно обнаруженном варианте программы-вымогателя, получившем название.
 ..
.. - 6 способов предотвратить атаки с повышением привилегий
Привилегии определяют доступ, который пользователь или устройство получает в сети. Хакеры, получившие доступ к этим привилегиям, могут создать огромные …
- 5 лучших этических хакерских инструментов для изучения
Этичные хакеры имеют в своем распоряжении множество инструментов для поиска уязвимостей в системах. Узнайте о пяти таких инструментах…
ПоискAWS
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Услуга автоматизирует…
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных. Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу.
