
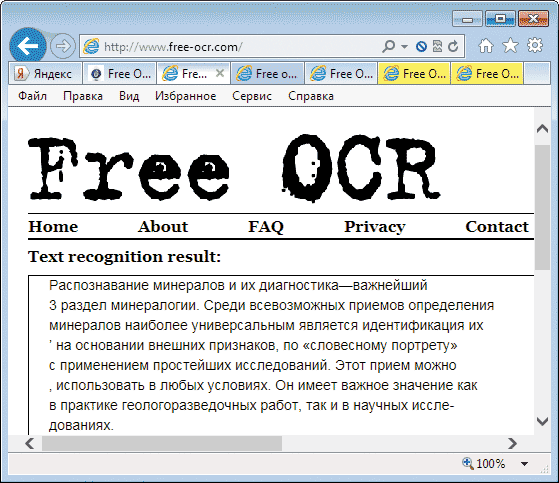
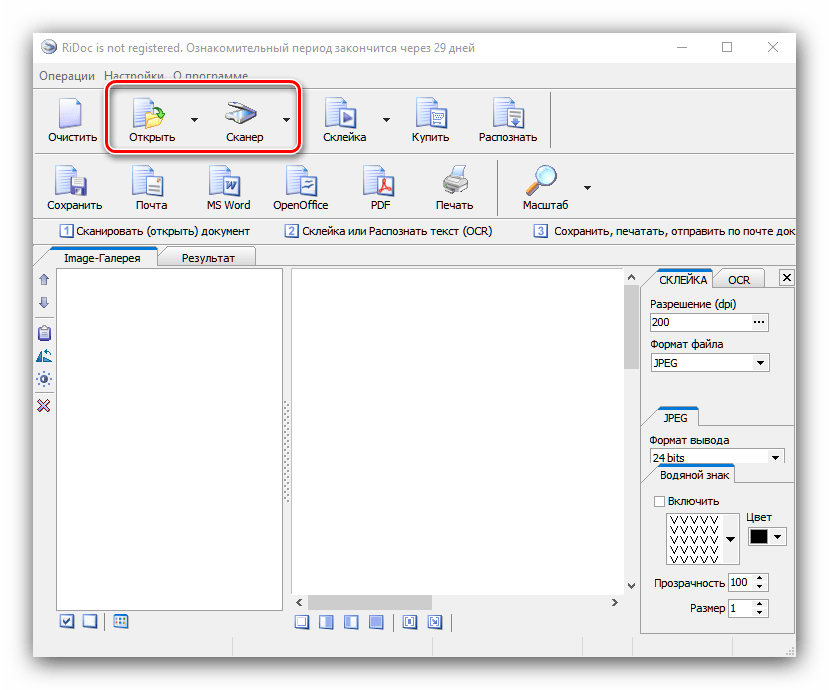
Распознать отсканированный текст в Word – Какие программы для распознавания текста использовать в офисе
Меня часто спрашивают: «Отсканировали (сфотографировали) страничку, файл открывается, читается. Как теперь внести в этот документ исправления?» Ответ: просто так — никак! То, что вы отсканировали — изображение, картинка, набор разноцветных точек. Редактировать можно только документ, состоящий из знаков (символов). Самое большее, что вы можете сделать с картинкой — в графическом редакторе (Paint, GIMP и т. п.) закрасить или вырезать на ней отдельные участки и нарисовать буквы и цифры. Редактируемым документом от этого изображение не станет!
Однако решение есть: оптическое распознавание символов (optical character recognition, OCR). Программа анализирует изображение, выделяет из него характерные очертания букв и цифр, а потом создает настоящий редактируемый документ. Примерно то же самое делаете вы, когда читаете написанное и набираете прочитанное на клавиатуре. Правда, в распознавании символов компьютеру еще очень далеко до человека.
Весьма эффективное средство распознавания входит в состав пакета Microsoft Office. В предыдущих версиях пакета этим занималось отдельное приложение Microsoft Office Document Imaging (MODI). В Microsoft Office 2010 задача распознавания возложена на компонент OneNote. Примечательно, что теперь эта функция скромно именуется поиском и копированием текста в рисунках и вызывается «как бы между прочим». Как ею пользоваться?
- Изображение, текст с которого нужно распознать, любым образом вставьте в заметку OneNote.
Например, перетащите мышью файл рисунка в окно OneNote или на ленте воспользуйтесь кнопками Вставка → Рисунок — как вам удобнее.
- В окне OneNote щелкните на рисунке правой кнопкой мыши и в контекстном меню выберите команду Копировать текст из рисунка
- Вставьте скопированный текст в любой документ. Пункт Поиск текста в рисунках в контекстном меню служит для выбора языка распознавания. Эта настройка позволяет точнее определить набор символов, ведь многие буквы разных алфавитов похожи по начертанию.
Одно из лучших приложений для распознавания документов и таблиц — ABBYY FineReader. Программа легко обрабатывает изображения документов со сложной структурой и очень точно воспроизводит ее в распознанном документе. Хотя в FineReader предусмотрено множество гибких настроек, с большинством типичных задач программа прекрасно справляется «на полном автомате».
Например, если вы выберете сценарий Сканировать в Microsoft Word, сначала откроется диалоговое окно сканирования. После сканирования первой страницы программа запрашивает, нужно ли сканировать следующую, либо можно переходить к следующему шагу. Когда получены изображения всех страниц, начинается их обработка и распознавание. Ход и результаты распознавания отображаются в главном окне программы. В левой части окна показаны эскизы страниц, а в рабочей области вы видите исходное изображение и рядом с ним — уже распознанный документ.
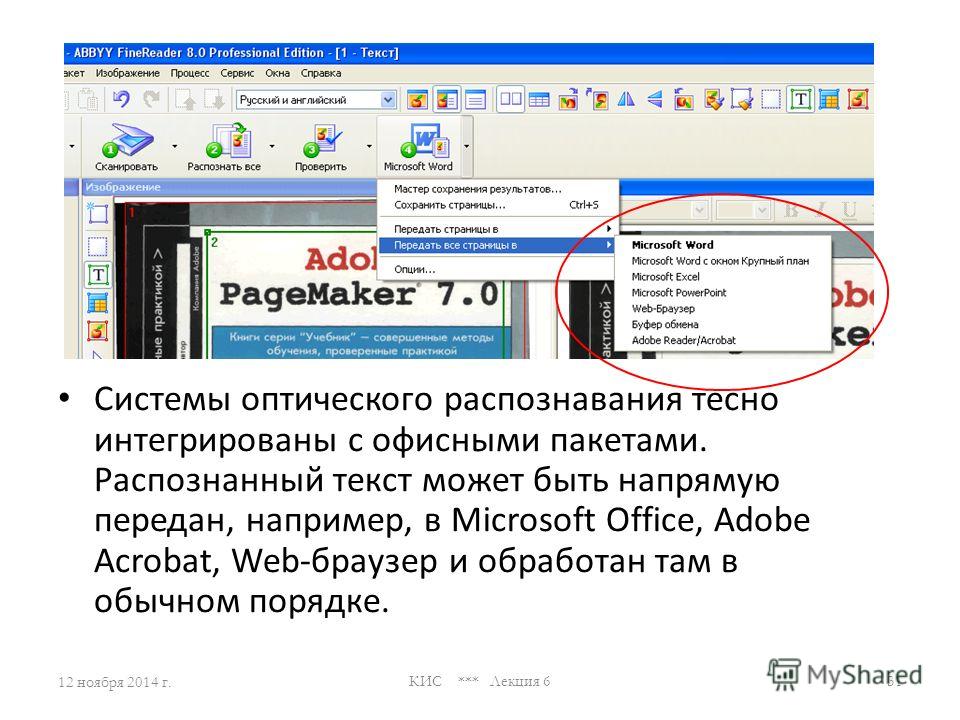
Результат распознавания FineReader в соответствии со сценарием передает в другую программу или сохраняет. Например, в данном случае автоматически откроется окно Microsoft Word с новым документом. Как правило, в созданном документе заголовки, абзацы и другие составляющие оформления выглядят почти так же, как на исходном изображении.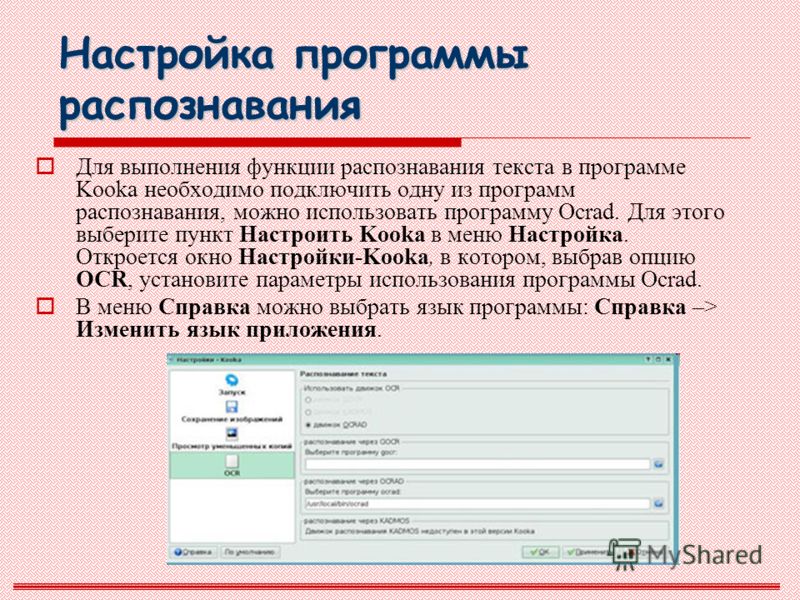 Подбирается даже наиболее похожий шрифт! Другие сценарии позволяют отправить результат распознавания в Microsoft Excel — это удобно, если на оригинале изображена таблица, сохранить его в виде документа Adobe Reader (PDF), вместо сканирования открыть сделанное раньше фото оригинала и т. д.
Подбирается даже наиболее похожий шрифт! Другие сценарии позволяют отправить результат распознавания в Microsoft Excel — это удобно, если на оригинале изображена таблица, сохранить его в виде документа Adobe Reader (PDF), вместо сканирования открыть сделанное раньше фото оригинала и т. д.
Кроме того, программу можно запустить в пошаговом режиме. Для этого на панели инструментов нажмите кнопку Новое задание. Окно выбора сценариев закроется. Нажимая кнопки на панели инструментов, вы сможете последовательно и под полным контролем отсканировать документ или открыть готовое изображение, при необходимости исправить его дефекты и искажения, проанализировать и выделить то, что нужно распознавать, проверить и сохранить результат.
К сожалению, программа FineReader передает документы лишь в приложения Microsoft Office (если они установлены), а с пакетом OpenOffice.org она не знакома. В таком случае очевидный выход — сохранять результаты распознавания в универсальном формате RTF, который прекрасно «понимают» любые редакторы документов.
Существуют ли бесплатные альтернативы?
Давний конкурент ABBYY — компания Cognitive Technologies в 2007 г. выпустила бесплатную версию программы CuneiForm и открыла ее исходные тексты. С тех пор поддержкой проекта (www.cuneiform.ru) занялось сообщество программистов, а сама программа сегодня работает на платформах Windows, Linux, FreeBSD и Mac OS X. Другой полностью свободный проект — Tesseract. Бесплатная программа COCR2 примечательна тем, что распознает китайские иероглифы. В связке с электронным переводом, например Переводчиком Google, это приложение дает удивительную возможность прочитать и понять документацию на китайском прямо «с листа»! Коммерческими программами Readiris и CrystalOCR комплектуются многие МФУ. Для конечного пользователя OEM-лицензия является бесплатной — фактически она была оплачена при покупке аппарата.
Сервисы распознавания символов появились и в Интернете: FineReaderOnline.
Как отсканировать документ и распознать его в MS Word
Если Вы выбрали быстрый путь написания теоретической главы, о котором мы говорили в параграфе 2.1., вероятней всего Вам не обойтись без сканирования документов. В ином случае, этот пункт можете пропустить и начинать конспектировать материалы найденные в библиотеке.
Перед началом сканирования нужно определиться, что именно Вы хотите использовать при написании работы. А для этого нужно сначала просмотреть имеющуюся литературу и выделить карандашом нужные моменты.
Когда я впервые сканировал статью из журнала для своей первой курсовой, для меня это занятие было невообразимо сложным. В результате нескольких часов работы со сканером и FineReader’ом у меня на выходе вышла бредятина, не поддающаяся редактированию. В итоге пришлось все набирать руками. Чтобы у Вас не случилось подобного, рассмотрим подробнее все технические моменты сканирования.
Для сканирования вам понадобится:
- Книга или журнал, который нужно отсканировать
- Компьютер с установленным FineReader’ом
- Качественный сканер
Сканер не обязательно покупать. Можно, например, взять на время у товарища. Я пользуюсь сканером CanoScan Lide 60. Это хоть и не самая новая модель, но мне очень нравится этот компактный, быстрый и удобный в работе “девайс”. Если Вы взяли на время сканер, для того чтобы он работал нужно сначала установить программу-драйвер. Драйвера и руководство по установке всегда можно найти на установочном диске, который прилагается к устройству или скачать на сайте у производителя.
Но сначала немного теории. Вы должны знать, что процесс сканирования состоит из двух этапов:
1. Непосредственно сканирование документа. На этом этапе сканнер как бы фотографирует поверхность сканируемого документа и сохраняет полученное изображение на компьютер в виде обычного файла .jpg .gif или в другом формате;
2. Распознавание документа. Это процесс преобразования текста из изображения сделанного сканером в обычный тест, который потом можно сохранить в Word и редактировать. Распознавание осуществляется без участия сканера, с помощью специальной программы (самая популярная Adobe FineReader). Таким образом, Вы можете сначала отсканировать несколько листов текста и сохранить их в виде изображения и только потом преобразовывать в текст.
Итак, начнем этап первый – сканирование:
Запускаем драйвер сканера:
Пуск – Все программы – Canon – ScanGear (название драйвера я указываю для своего сканера). Появится окно драйвера:
Появится окно драйвера:
Открываем крышку сканера и кладем книгу. Книгу, журнал или что у вас там есть нужно класть текстом вниз, как можно ровнее по отношению к краям рабочей поверхности сканера:
Очень важно сделать так, чтобы крышка сканера как можно плотнее прижимала сканируемый документ, не допуская попадания внешнего освещения не рабочую поверхность сканера, которая соприкасается с документом.
Выполним необходимые установки в драйвере сканера.
Первым делом нужно установить разрешение, в котором будет отсканирован документ. Разрешение – это показатель, который определяет уровень детализации объекта при сканировании и определяется в точках на дюйм (dpi, или т/д). Чем больше разрешение, тем качественнее получается изображение. Но, при сканировании текстовых документов нет смысла устанавливать максимальное разрешение, поскольку толку от этого будет ноль. Кроме того, сканирование с большим разрешением занимает больше времени. Я рекомендую устанавливать разрешение в пределах 400-500 т/д (dpi). При такой настройке изображения получаются достаточно качественными для хорошего их распознания, а сам процесс сканирования не занимает много времени. Посмотрите скриншот установок моего сканера:
При такой настройке изображения получаются достаточно качественными для хорошего их распознания, а сам процесс сканирования не занимает много времени. Посмотрите скриншот установок моего сканера:
Для начала нужно перейти в “Расширенный режим”. Источником всегда будет “Планшет” (планшетный сканер). Цветной режим лучше установить “Черно-белый”, ведь для сканирования текста нам цвета не нужны, а это уменьшит размер изображений на выходе. Разрешение, как я уже сказал, следует установить 400 т/д. Выходной размер изображения – обязательно “А4”. Теперь можно смело жать на кнопку “Сканировать”. Мой сканер устроен таким образом, что сначала запоминает отсканированные изображения во внутренней памяти, и только при закрытии окна драйвера предлагает сохранить их на компьютер. Мне остается только указать место, куда будут сохранены результаты работы.
У вас должны получаться файлы такого типа:
При увеличении такого изображения должен быть отчетливо виден текст.
Распознавание
Второй этап – распознание полученных изображений и их преобразование в текст. Как я уже говорил, для этого понадобится специальная программа – FineReader. Скачайте программу по этой ссылке (72Мб). Чтобы скачать нажмите на стрелочку в правом верхнем углу окна. Распакуйте архив и в папке afr_lrp найдите файл – ABBYY FineReader 12.0.101.exe. Двойной клик на этом файле запустит установку программы на вашем компьютере. Эта версия программы достаточно новая. Все скриншоты ниже я делал используя более старую версию, поэтому интерфейс программы будет немного отличаться от скриншотов. Учтите это при изучении данной инструкции.
Окно FineReader имеет следующий вид:
После установки языка, на котором напечатаны отсканированные Вами ранее документы, можно начинать распознание. Если в тексте присутствует сразу два языка (например, русский и английский) установку сделайте соответственно.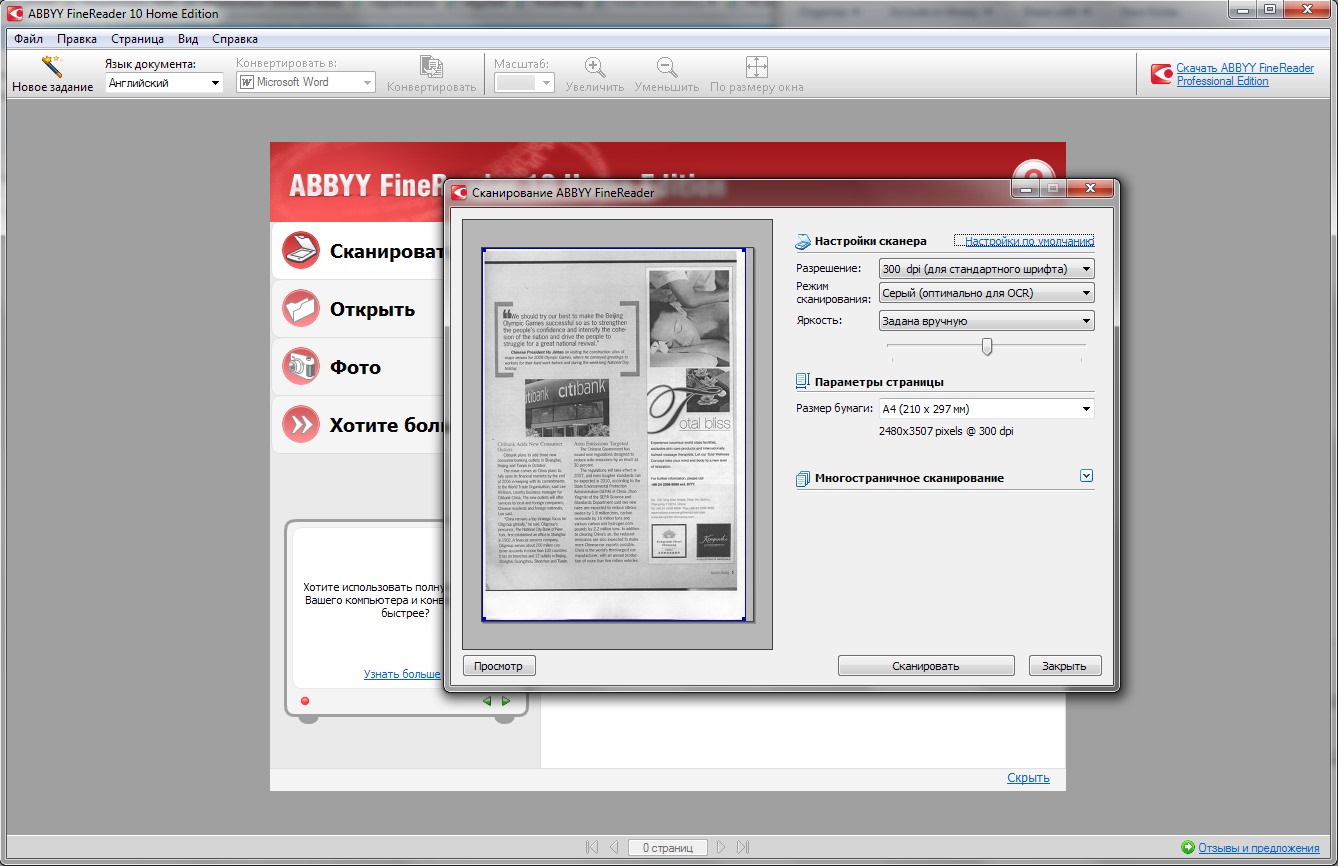
Чтобы начать распознание нажмите на стрелку справа от первой кнопки Сканировать – а затем – Открыть изображение:
Откроется окно выбора изображений. Откройте папку в которую Вы сохранили отсканированные изображения, нажмите CTRL + A (английское) на клавиатуре и нажмите на кнопку Открыть.
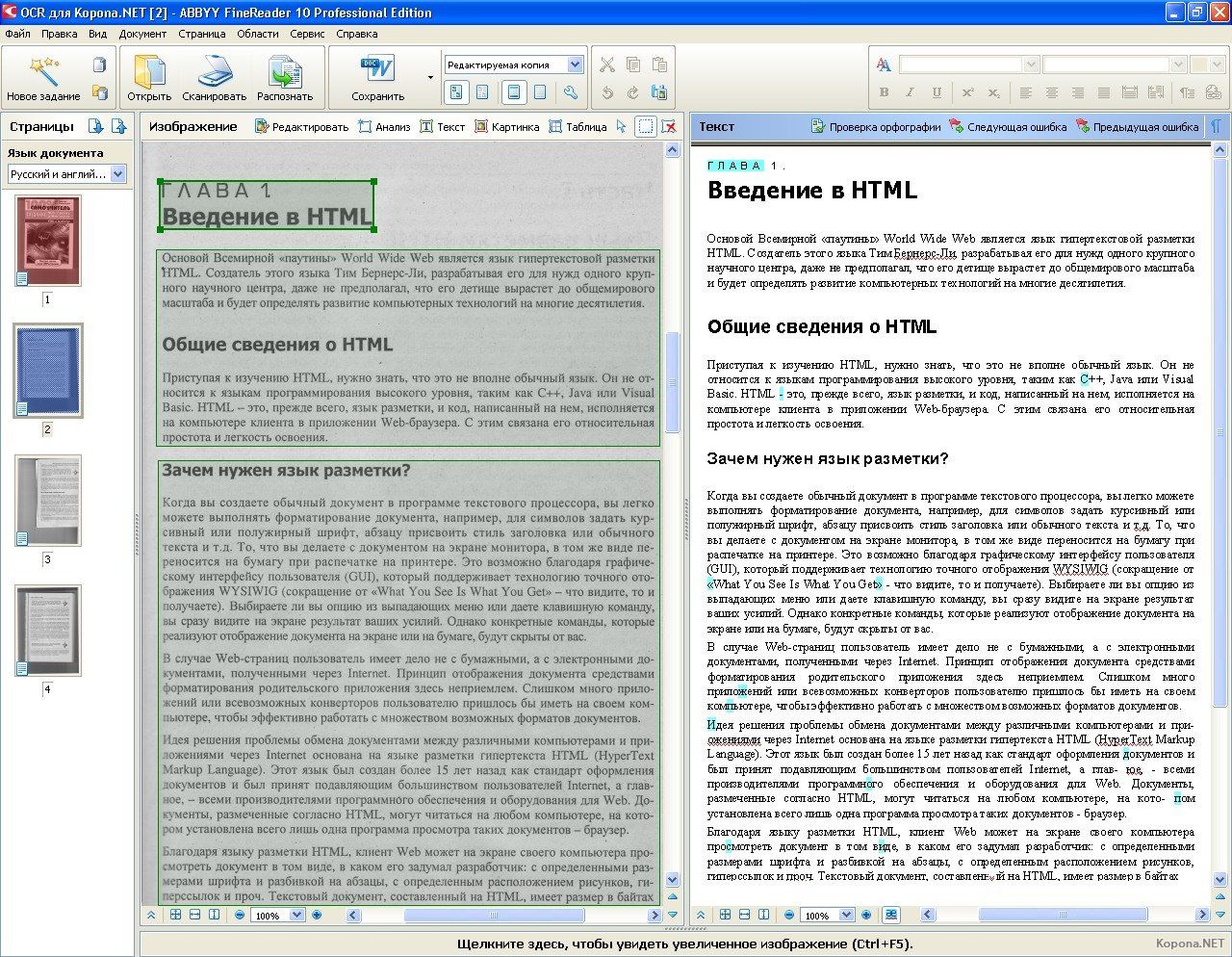
После этого слева в окне FineReader’а появятся эскизы добавленных файлов, по центру – на данный момент выделенный эскиз в увеличенном виде, снизу – еще большее увеличение, а справа результат распознания:
Для примера я взял всего два изображения. На скриншоте выше выделено первое из них, его сейчас и распознаем. Как видите, изображение отсканировано вертикально, чтобы распознать текст снимок нужно сначала развернуть на 90 градусов. Для этого воспользуемся кнопками и . Следующим шагом нужно указать программе, какую именно часть изображения нужно распознать, а также задать тип данных, которые должны получиться на выходе текст, таблица или изображение. Для этого существуют кнопки, соответственно: . Например, если нужно отметить текстовый блок, нажимаем левой кнопкой на , после этого нажимаем левой кнопкой мышки в левом верхнем углу текстового блока и, удерживая левую кнопку, перетягиваем в правый нижний угол. Для примера я полностью подготовил к распознанию одно изображение:
Для этого существуют кнопки, соответственно: . Например, если нужно отметить текстовый блок, нажимаем левой кнопкой на , после этого нажимаем левой кнопкой мышки в левом верхнем углу текстового блока и, удерживая левую кнопку, перетягиваем в правый нижний угол. Для примера я полностью подготовил к распознанию одно изображение:
Как видите, все текстовые блоки в примере выше выделены зеленым, а рисунки – красным. Таблицы подготавливаются к распознанию аналогично. Для этого предназначена кнопка . Для того, чтобы перейти к следующему снимку, кликните левой кнопкой мыши на его эскизе слева. Таким образом подготавливаются к распознанию все полученные в результате сканирования изображения. После того, как подготовка изображений завершена, следует выделить их все. Для этого кликните левой кнопкой в пустом месте на панели эскизов (она называется Пакет) и нажмите Ctrl+A (английское) на клавиатуре. Далее кликните на кнопку и подождите пока FineReader преобразует изображения в текст.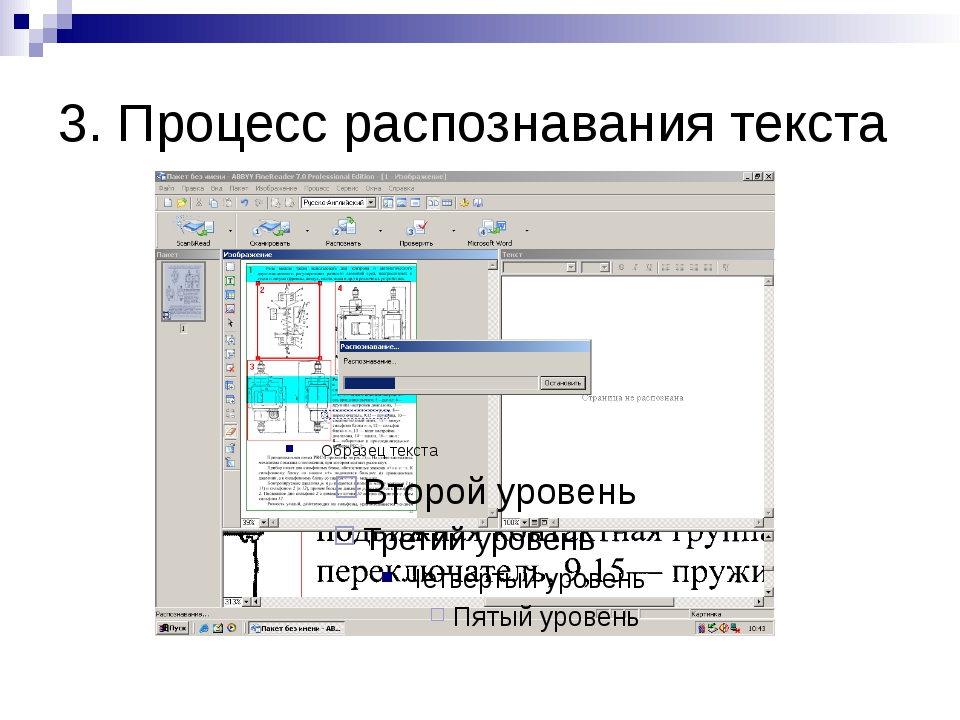 После этого можно сохранять полученный текст в Word с помощью кнопки , после нажатия на которую откроется окно Мастер сохранения результатов. В нем необходимо выбрать формат для сохранения – Microsoft Word, а также поставить отметку чтобы сохранились все страницы:
После этого можно сохранять полученный текст в Word с помощью кнопки , после нажатия на которую откроется окно Мастер сохранения результатов. В нем необходимо выбрать формат для сохранения – Microsoft Word, а также поставить отметку чтобы сохранились все страницы:
После нажатия кнопки ОК программа создаст документ Word и вставит в него текст из распознанных страниц в том порядке, в котором они находятся на панели эскизов (Пакет). Полученный документ сразу же сохраните в папку в файловой структуре дипломной работы и можете приступать к редактированию. Как это делается, описано в моем бесплатном курсе.
И последний момент. Эсли Вы сканировали газету или журнал, текст там часто дается в виде колонок (как в рассматриваемом примере выше). Эти колонки в Ворде нужно преобразовать в одну. Выделите текст в виде колонок и выполните команду: Формат – Колонки – Одна – ОК. Только после этого можно ставить Книжную ориентацию в Параметрах страницы, отступы полей, шрифт и т. д.
д.
4.3 / 5 ( 18 голосов )
Как распознать текст с помощью ABBYY FineReader: пошаговая инструкция
[contents]
В этот раз расскажу как превращать бумажные документы в электронный вид формата PDF, а также, как бумажный документ перекинуть в компьютер с целью изменить текст. Итак начнем.
У меня на руках бумажный документ.
СКАНИРОВАНИЕ в PDF
Задача: перекинуть в компьютер (перевести в электронный вид) этот документ. Притом нужно сделать именно в таком виде чтобы нельзя было его в будущем изменить (грубо говоря надо сделать фото документа). Потом этот электронный документ нужно переслать по почте на электронный адрес. Притом клиент просит именно в формате pdf.
По этапам:
1) пропускаю документ через сканер
2) сохраняю полученный отпечаток в формате pdf на свой компьютер
3) пересылаю полученный файл по почте
В своей работе я использую для решения такой задачи 2 программы:
Foxit Phantom или ABBYY FineReader. Для понятности прикладываю скриншоты:
Для понятности прикладываю скриншоты:
В Foxit Phantom при включенном сканере необходимо в главном меню выбрать ФАЙЛ-СОЗДАТЬ PDF-СО СКАНЕРА…
Произойдет сканирование и появится предложение сохранить файл. Выбираем место, пишем название файла и сохраняем.
В ABBYY FineReader в панели инструментов есть огромные кнопки. Одна из них называется СКАНИРОВАТЬ в PDF. Её и используем.
Если же надо отсканировать многостраничный документ то, по этапам:
1) Нажимаем кнопку под номером 1 СКАНИРОВАНИЕ
Получаем отсканированный документ
Также сканируем ещё одну страницу (нажимаем ещё раз кнопку под номером 1 СКАНИРОВАНИЕ).
2) Сохраняем в PDF
В итоге получаем готовый многостраничный документ в виде файла в формате PDF.
Теперь данный файл можно отправлять по электронной почте.
РАСПОЗНАВАНИЕ ТЕКСТА
Задача: перевести бумажный документ в электронный вид (в компьютер)
По этапам:
1) Сканирование (кнопка 1 СКАНИРОВАНИЕ)
2) Распознавание (кнопка 2 РАСПОЗНАТЬ ВСЕ)
Распознавание нужно понимать как процесс перевода фотографии (картинки) в текст (буквы, цифры, знаки).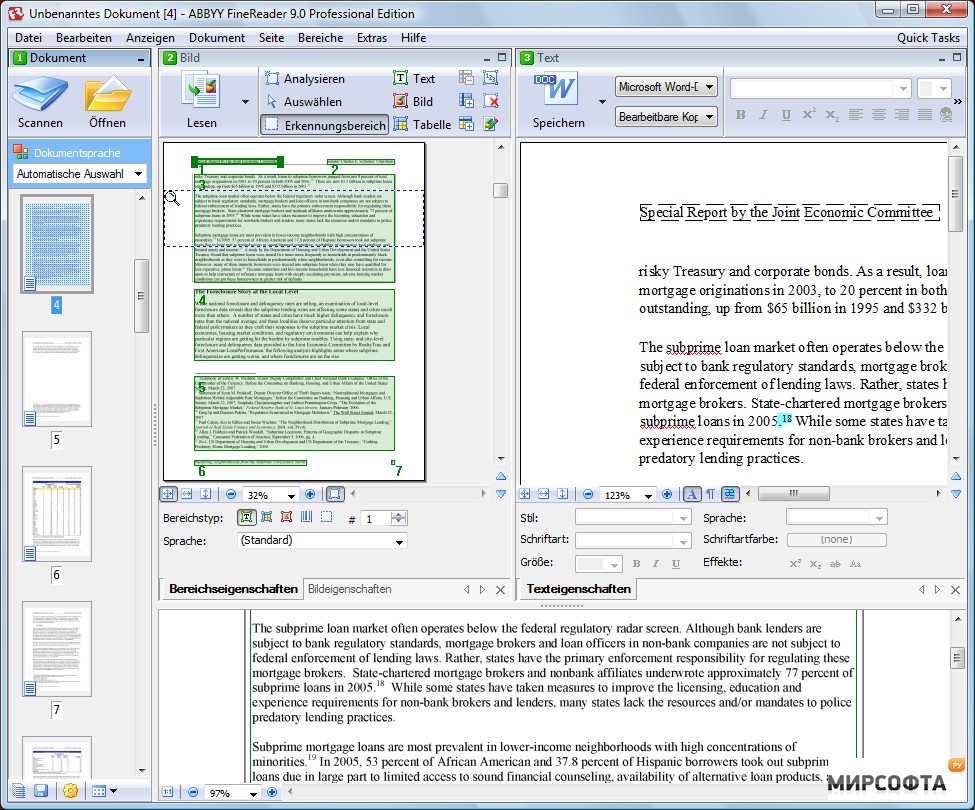 Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
3) Сохранение в текстовый редактор (кнопка 4 Сохранить)
Советую выбирать ПЕРЕДАТЬ ВСЕ СТРАНИЦЫ В—MICROSOFT WORD
Получаем
Хотелось бы указать на важные моменты при процедуре РАСПОЗНАВАНИЯ. Есть нюансы при работе.
Сразу после распознавания советую поглядеть на результат. Особенно на блоки, которые создает программа FineReader.
Это области выделенные в прямоугольные рамки. Рамки эти разного цвета. Если красного цвета-то этот блок распознался как КАРТИНКА. Если черного цвета — то ТЕКСТ. Блоки бывают разного типа. Тип блока можно узнать щелкнув на блоке ПРАВОЙ клавишей мыши и выбрав ИЗМЕНИТЬ ТИП БЛОКА.
Маленькая хитрость: можно выделить произвольную область и пометить любым типом блок. Например выделим ту часть текста, которая плохо распознается, при помощи левой клавиши мыши (нажимает, удерживаем и тянем, рамка меняет размер).
В итоге документ в Word-е будет иметь блок текста и блок картинка. Блок картинка будет иметь абсолютно неизменный вид. Данный способ я использую при сохранении печатей, нестандартных шрифтов, картинок, фотографий.
ЗЫ: Знания и умения работать с PDF, сканировать и распознавать документы очень часто выручают в офисной работе. Знание — экономит Ваше время!
Не пропусти самое интересное!
Подписывайтесь на нас в Facebook и Вконтакте!
Преобразование сканированных документов в текст (технология OCR)
Вы можете сканировать документы и преобразовывать их в текст с помощью программы обработки текста. Технология, позволяющая компьютерам «читать» текст с физических объектов, назывется OCR. Для сканирования и последующего распознавания текста необходимо установить соответствующую программу, например, ABBYY FineReader, которая включена в комплект поставки устройства.
Примечание|
В некоторых странах приложение ABBYY FineReader Sprint Plus может быть не включено в комплект поставки. |

Перечисленные далее типы документов не могут быть распознаны или затрудняют распознавание:
рукописные тексты;
копии с других копий;
факсы;
текст с плотно расположенными символами или строками;
текст в таблицах или подчеркнутый текст;
текст с наклоном или с размером символов меньше 8 пунктов.
Обратитесь к одному из следующих разделов, чтобы выполнить сканирование и распознать текст с помощью программы ABBYY FineReader.
Автоматический режим: Преобразование сканированных документов в текст в автоматическом режиме Офисный режим: Преобразование сканированных документов в текст в офисном режиме Простой режим: Преобразование сканированных документов в текст в простом режиме Профессиональный режим: Преобразование сканированных документов в текст в профессиональном режимеПреобразование сканированных документов в текст в автоматическом режиме
|
Запустите ABBYY FineReader одним из следующих способов. |

В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6.0 Sprint > ABBYY FineReader 6.0 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
Откроется окно ABBYY FineReader.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. |
 Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan.
Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan.|
Щелкните Scan (Сканировать). Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader. |
|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Преобразование сканированных документов в текст в офисном режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6 Sprint > ABBYY FineReader 6 Sprint.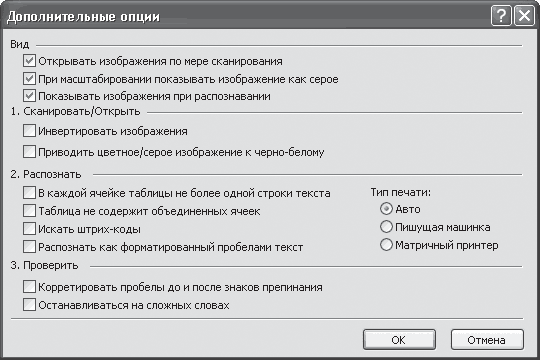
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Для параметра Image Type (Тип изображения) выберите значение Color (Цвет), Grayscale (Оттенки серого) или Black&White (Черно-белый). |

|
Выберите значение Document Table (Планшет для документов) для параметра Document Source (Источник документа). |
|
Выберите значение параметра Size (Размер), соответствующее размеру загруженных документов. |
|
Выберите 300 для параметра Resolution (Разрешение). |
|
Щелкните Scan (Сканировать). Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader. |
|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Преобразование сканированных документов в текст в простом режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6 Sprint > ABBYY FineReader 6 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Для параметра Document Type (Тип документа) выберите Magazine (Журнал), Newspaper (Газета) или Text/Line Art (Текст/штриховой рисунок). |

|
Для параметра Image Type (Тип изображения) выберите значение Color (Цвет) или Black&White (Черно-белый). |
|
Для параметра Destination (Назначение) выберите значение Printer (Принтер) или Other (Другое). |
|
Если вы выбрали Other (Другое), для параметра Resolution (Разрешение) выберите значение 300. |
|
Щелкните Scan (Сканировать). |
 Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader.
Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader.|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Преобразование сканированных документов в текст в профессиональном режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6 Sprint > ABBYY FineReader 6 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Выберите Reflective (Непрозрачный) для параметра Document Type (Тип документа). |
|
Выберите значение Document Table (Планшет для документов) для параметра Document Source (Источник документа). |

|
Выберите значение Document (Документ) для параметра Auto Exposure Type (Тип автоэкспозиции). |
|
Выберите Black & White (Черно-белый), 24-bit Color (Цветной 24 бита) или 48-bit Color (Цветной 48 бит) для параметра Image Type (Тип изображения). |
|
Выберите 300 для параметра Resolution (Разрешение). |
|
Щелкните Scan (Сканировать). Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader. |

|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Как преобразовать сканированный документ в word. Распознать Сканированный текст в Word
Если имеющаяся печатного документа или рисунок, который нужно вставить в документ Word, существует несколько способов, вы можете сделать это.
Примечание: Если вы ищете инструкции о том, как подключить сканер или копирование Microsoft Windows, посетите веб-сайт поддержки производителя для своего устройства.
Сканирование изображения в Word
Чтобы отсканировать изображение в документ Word, воспользуйтесь сканера, многофункциональный принтер, цифровой камеры или копирование с возможностью поиска.
Вставка отсканированного текста в Word
Лучший способ сканирование документа в Microsoft Word будет использовать наши бесплатное приложение Office Lens на смартфоне или планшете. Используется камеру вашего устройства на получение сведений о документе, можно сохранять непосредственно в формате Word как редактируемый документ. Доступно для бесплатной на iPad , iPhone , Windows Phone и Android.
Используется камеру вашего устройства на получение сведений о документе, можно сохранять непосредственно в формате Word как редактируемый документ. Доступно для бесплатной на iPad , iPhone , Windows Phone и Android.
Если вы не хотите использовать Office Lens, следующий лучшим вариантом будет сканировать документ в формате PDF с помощью собственного сканер и повторно откройте PDF-файл в Word.
Дополнительные сведения см. в статье Редактирование содержимого PDF-документа в Word .
Примечание: Точность распознавания текста зависит от качества сканирования и четкости отсканированного текста. Рукописный текст редко распознается, поэтому для лучших результатов сканируйте печатные материалы. Всегда проверяйте текст после его открытия в Word, чтобы убедиться, что он правильно распознан.
Кроме того, со сканером может поставляться приложение для распознавания текста (OCR). Обратитесь к документации своего устройства или к его производителю.
Остались вопросы о Word?
Помогите нам улучшить Word
У вас есть предложения, как улучшить Word? Поделитесь ими на странице
Здравствуйте. Сегодня я расскажу, как сканировать текст в документ Word . Зачем это нужно делать? Ответ очевиден, для дальнейшего редактирования текста. Ведь изображение не так просто будет отредактировать. Что лучше использовать, программы или онлайн сервис для перевода сканированного текста в документ Word? Об этом я расскажу ниже в статье.
Сегодня я расскажу, как сканировать текст в документ Word . Зачем это нужно делать? Ответ очевиден, для дальнейшего редактирования текста. Ведь изображение не так просто будет отредактировать. Что лучше использовать, программы или онлайн сервис для перевода сканированного текста в документ Word? Об этом я расскажу ниже в статье.
Для того что бы максимально ускорить и упростить задачу , я искал сайты, на которых онлайн можно конвертировать сканированный документ в формат Word. Для этого мне пришлось сначала сканировать, а затем уже конвертировать. Сразу скажу, что многие сайты ограничивают количество переводов в Word, а что бы не ограничено конвертировать нужно заплатить. Мне удалось найти пару сайтов, которые не ограничено решают эту задачу, но делится не буду, так как конвертировать сканированный текст в Word онлайн оказалось пустой тратой времени. Процент распознания текста очень низкий , проще было бы перепечатать документ с нуля.
В таком случае, если онлайн инструменты на данный момент плохо переводят сканированный документ в Word , то как же сделать это максимально качественно? Читайте об этом дальше в статье, я приведу понятную инструкцию.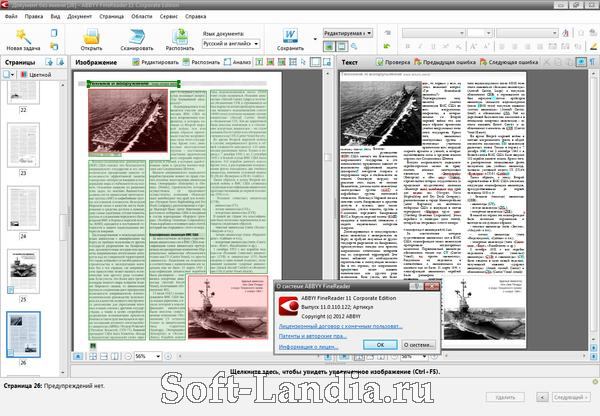
Погулив ещё несколько минут, нашел программу, называется ABBYY FineReader Professional. Наверняка Вы уже слышали про неё. Скачал её тут http://nnm-club.me/forum/viewtopic.php?t=851116 , легко устанавливается и отлично работает.
ABBYY FineReader может перевести сканированные документы не только в Word, но и в PDF и многие другие текстовые и журнальные форматы.
Пользоваться ею очень просто. Устанавливаете и запускаете. На мониторе должны увидеть вот такое окно, как ниже не скриншоте.
Тут ничего сложного, интуитивно понятно, что нужно нажать в нашем случае на «Сканировать в Microsoft Word» . Затем увидим окно настроек сканирования, в котором можно ничего не менять.
Поставим программе не простую задачу — сканировать и распознать страницу книги . Кладем книгу или любой другой документ на сканер и нажимаем сканировать. Программа начинает сканирование, а затем должна автоматически распознать документ. Если автоматического распознания не произошло , то нажмите правой кнопкой на сканированный документ и нажмите «Распознать». Ниже на скриншоте видно какой результат получился у меня.
Ниже на скриншоте видно какой результат получился у меня.
Далее нажимаете на значок Word вверху и документ сохранится в текстовый формат документа Microsoft Word. Разумеется нужно учитывать, что распознанный текст нужно обязательно перечитывать, ведь в любом случае возможны ошибки.
Задавайте вопросы, пишите комментарии. Спасибо за внимание.
При работе с текстовыми документами очень часто возникает необходимость набирать текст с уже распечатанного документа. Подобная работа не очень приятная и отнимает много времени.
К счастью, сейчас существуют программы, которые позволяют значительно упростить и ускорить решения подобных задач. С помощью этих программ можно быстро перевести отсканированный документ в формат текстового редактора Word и избежать рутинной работы по набору текста.
В данной статье мы продемонстрируем, как это делается на примере программы ABBY Finereader 12 Professional. Если у вас нет именно такой программы, то вы можете заменить ее другой версией ABBY Finereader либо совершенно другой программой от другого разработчика.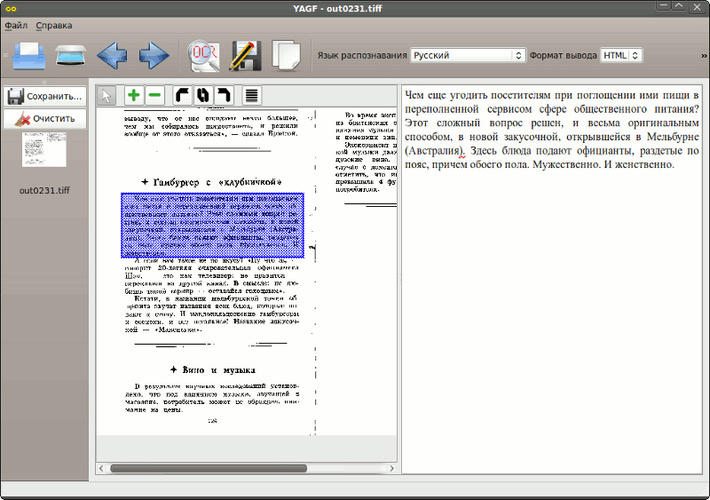 Например, вы можете использовать программы CuneiForm, Free OCR, Readiris Pro или SimpleOCR.
Например, вы можете использовать программы CuneiForm, Free OCR, Readiris Pro или SimpleOCR.
Шаг № 1. Запускаем ABBY Finereader и открываем отсканированный документ.
Первым делом нужно запустить программу ABBY Finereader. После запуска программы нужно нажать на кнопку «Открыть» на панели инструментов.
После этого появится окно для открытия отсканированного документа. Выберите изображение или несколько изображений и нажмите на кнопку «Открыть».
Кроме этого, вместо использования кнопки «Открыть» вы можете просто перетащить отсканированные изображения в программу ABBY Finereader.
Шаг № 2. Ждем пока ABBY Finereader проанализирует выбранные изображение.
Дальше нужно подождать, пока программа ABBY Finereader проанализирует выбранные вами изображение и распознает на них текст. Время необходимое на анализ зависит от количества выбранных изображений и производительности вашего компьютера.
Когда анализ изображений будет завершен, появится сообщение с кнопкой «Закрыть».
Нажмите на кнопку «Закрыть» и переходите к следующему шагу.
Шаг № 3. Переведите отсканированный документ в формат Word.
После завершения анализа, отсканированный документ можно перевести в формат Word. Для этого в программе ABBY Finereader есть кнопка «Сохранить».
После нажатия на кнопку «Сохранить» появится окно для сохранения отсканированного документа в текстовом формате. При этом вы можете выбрать один из множества текстовых форматов (DOC, DOCX, RTF, ODT, PDF, HTM, TXT, XLS, XLSX, PPTX, CSV, FB2, EPUB, DJVU). Для того чтобы без проблем отредактировать документ в редакторе Word выберите формат «Документ Microsoft Word 97-2003 (*.doc)» либо формат «Документ Microsoft Word (*.docx)».
После сохранения документа в формате Word откроется текстовый редактор, и вы сможете начать редактировать отсканированный документ.
Что делать если нет возможности установить программу?
Если у вас нет возможности установить описанные выше программы, то вы можете воспользоваться онлайн аналогами. Наиболее продвинутым онлайн сервисом такого рода является . Данный сервис позволяет перевести отсканированный документ в формат Word, а также в другие популярные текстовые форматы.
Наиболее продвинутым онлайн сервисом такого рода является . Данный сервис позволяет перевести отсканированный документ в формат Word, а также в другие популярные текстовые форматы.
К недостаткам ABBY Finereader Online можно отнести то, что данный онлайн сервис требует регистрации и бесплатно обрабатывает только 10 страниц отсканированного текста. Для обработки большего количества страниц нужно покупать подписку, которая стоит от 5 долларов в месяц.
Вы когда-нибудь сталкивались с ситуацией, когда хотели изменить содержимое отсканированного файла и не могли сделать это? Теперь вы можете сделать это мгновенно, просто поменяв формат файла. В статье приведены шаги, как конвертировать отсканированный документ в Microsoft Word.
При сканировании документа или сканер предлагает вам список форматов,
в которых вы можете сохранить файл. Однако, как правило, дальнейшее
редактирование файла невозможно. Если же вам нужно изменить содержимое
файла, то придется пройти через утомительный процесс перезаписывания
или повторного сканирования документа. Сберечь время и усилия можно,
просто изменив несколько настроек в компьютере. Так вы получите отсканированный
документ в формате.doc, который затем сможете отредактировать.
Сберечь время и усилия можно,
просто изменив несколько настроек в компьютере. Так вы получите отсканированный
документ в формате.doc, который затем сможете отредактировать.
Примечание: Для редактирования сначала нужно установить программу Microsoft Office Document Imaging .
Как это сделать?
Для пользователей ОС Windows 7 или Vista:
Пуск-Панель управления-Программы-Программы и компоненты
Для пользователей ОС Windows XP:
Пуск-Панель управления-Установка и удаление программ-Изменение или
удаление программ
В появившемся списке программ найдите Microsoft Office и кликните по
нему правой кнопкой мыши. Из открывшегося выпадающего меню выберите
пункт Изменить
Вы будете перенаправлены на окно “Измените установку”. Выберите пункт “Добавить или удалить компоненты ” и нажмите кнопку Продолжить .
Выберите там опцию Средства Office и найдите в открывшемся списке
Microsoft Office Document Imaging. Кликните правой кнопкой мыши, и в
открывшемся списке выберите Запускать все с моего компьютера ,
и нажмите Продолжить (Обновить)
Кликните правой кнопкой мыши, и в
открывшемся списке выберите Запускать все с моего компьютера ,
и нажмите Продолжить (Обновить)
Теперь Microsoft Office Document Imaging установлена и готова к использованию.
Создание документа Word
Если у вас уже есть отсканированный документ, просто откройте его в Paint. Если же нет – в той же программе выберите в меню Файл-Со сканера или камеры и запустите процесс сканирования. Так как вы сканируете документ для текстового файла, в окне настроек сканера выберите опцию Черно-белый рисунок или текст . После того, как документ отсканирован, откройте его в Paint.
Выберите Пуск – Все программы – Microsoft Office – Средства Microsoft Office – Microsoft Office Document Imaging
В окне программы выберите в меню пункт Файл-Открыть , найдите в открывшемся диалоговом окне созданный нами ранее tiff-файл, и откройте его
Теперь нужно выделить текст, содержащийся в нем. Для этого нажмите
комбинацию клавиш CTRL+A, а затем CTRL+C, чтобы скопировать текст в
буфер обмена.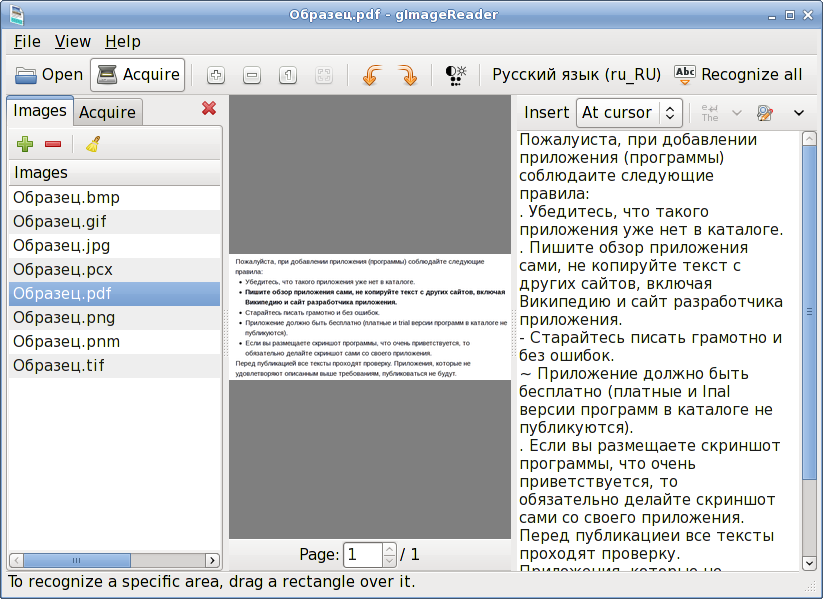
Создайте новый документ в Microsoft Word, и нажмите CTRL+V, чтобы вставить скопированный ранее текст. Затем через пункт Файл-Сохранить как сохраните файл с расширением.doc.
Таким образом, документ Word создан. Теперь только осталось внести в него изменения, если это необходимо.
С помощью программы FineReader можно легко преобразовать текст с бумажного носителя в файл формата Ворд и отредактировать его при необходимости.
Узнать все этапы проведения данной процедуры можно в представленной статье.
Большое количество пользователей, работающих с документами, нередко сталкиваются с необходимостью копирования текста с бумажного носителя в Word. В этом случае самым оптимальным выбором будет сканирование текста и его дальнейшее редактирование.
Сделать это возможно с помощью современной программы FineReader, она успешно преобразует обычную фотографию, полученную со скана, в осмысленный набор слов.
Работа с документом в FineReader
FineReader – наиболее актуальная программа автоматического распознавания отсканированного документа, она была создана российскими программистами. Ее главными достоинствами можно считать возможность поддерживания большого количества языков, среди которых имеются даже самые древние.
Ее главными достоинствами можно считать возможность поддерживания большого количества языков, среди которых имеются даже самые древние.
Помимо этого в этой программе допускается пакетная обработка многостраничного текста.
Ее преимуществами также можно назвать:
Пробную версию данной программы можно загрузить на официальном сайте, ее единственный недостаток заключается в том, что там установлено ограничение. Бесплатно можно обработать не более пятидесяти отсканированных страниц текста.
Полная версия программы стоит около пятидесяти долларов, на ней подобное ограничение отсутствует.
Загрузка и сканирование
Самым первым этапом работы в FineReader является загрузка и сканирование файла.
Для запуска процесса:
Данная программа автоматом выделит фрагменты документа, рисунки и таблицы, при необходимости повернет сканированный текст по нужному направлению.
После завершения сканирования, в данной программе требуется выбрать язык для расшифровки написанного.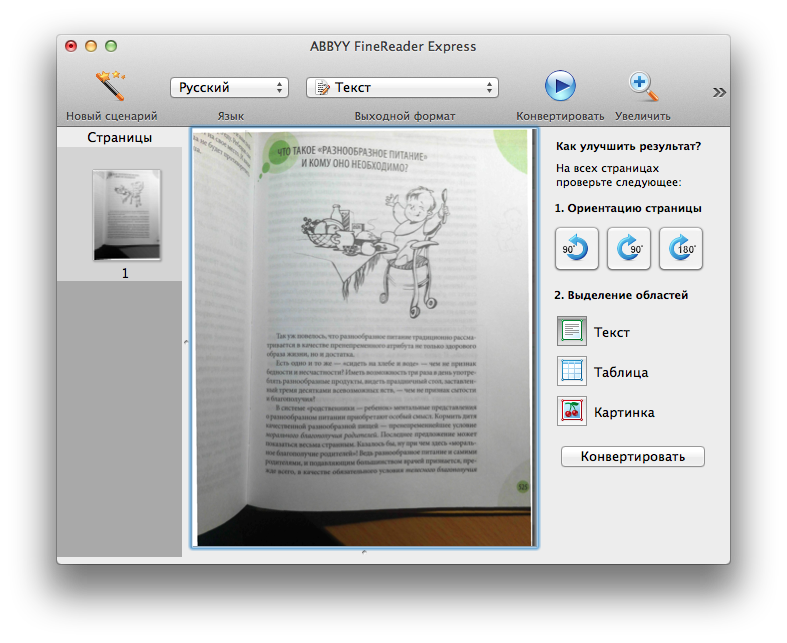
Выбрать его можно в выпадающем окне «Язык документа», если загруженный скан будет написан на нескольких иностранных языках – следует выбрать автоматический режим.
Удаление форматирования из документа
Сейчас мы более подробно разберем, как можно отредактировать отсканированный документ в программе FineReader. На представленном изображении таблицы, картинки и тексты будут отличаться разными цветами.
Данные области расшифровываются автоматически в зависимости от своего типа. В дальнейшем работать с ними в данной программе позволяет раздел под названием «Проверьте области», он располагается в правом окне FineReader.
Для удаления какой-либо области из документа необходимо выбрать в выпадающем меню кнопку «Удалить область», а затем можно будет щелкать мышкой по тем фрагментам, которые следует удалить.
Допускается уничтожение всех картинок и таблиц, можно оставить только лишь нужный для распознавания и дальнейшего сохранения текст.
Видео: Как изображение перевести в Microsoft Word
Редактирование
Чтобы выделить какую-либо область требуется выполнить следующие действия:
- кликнуть мышью по кнопке «Выделить область Текст»;
- нажатой левой кнопкой обвести границы текстового блока в рамку.

А чтобы выделить картинку или таблицу потребуется:
- выбрать кнопку «Выделить область Картинка» или же «Выделить область Таблица»;
- точно также обвести границы блока также левой кнопкой мыши.
Многих пользователей интересует, можно ли в программе FineReader поменять размеры выделенного фрагмента. Это вполне реально, необходимо лишь щелкнуть мышью по нужному фрагменту, навести курсор на его границу до возникновения специального курсива.
Именно на нее требуется нажать левой кнопкой мыши и, удерживая, менять размер, перемещая мышь в большую или меньшую сторону.
Конвертирование в формат Word
После того, как все области будут выделены и отредактированы так, как нужно, можно будет приступить к распознаванию написанного документа и его сохранению в формате Word. Для проведения подобной процедуры следует нажать кнопку «Конвертировать» в меню программы.
Пользователю нужно будет подождать некоторое количество времени, после чего он сможет просмотреть результаты проделанной работы. Для сохранения текста необходимо ввести имя файла, выбрать для него место и формат сохранения.
Для сохранения текста необходимо ввести имя файла, выбрать для него место и формат сохранения.
Для создания файла в формате Microsoft Word нужно выбрать в окне «Rich Text Format (*.rtf)».
Завершающее редактирование отсканированного документа в Ворде
После проведенных манипуляций документ будет создан в формате Ворд, пользователь может открыть его и сравнить с оригиналом. Если будут выявлены какие-либо ошибки, их можно будет без труда отредактировать в обычном режиме программы.
Как правило, программа FineReader отлично распознает написанное на любом языке, но при плохом качестве исходника некоторые слова могут быть распознаны неверно.
Программа FineReader позволяет пользователям существенно экономить свое время при обработке текста, таблиц или картинок с бумажного носителя. Для того чтобы действительно оценить все преимущества работы с ней, можно скачать бесплатную пробную версию программы на пятнадцать дней на официальном сайте.
Как изменить отсканированный текст?
Получение высшего образования предусматривает постоянную работу с текстом. Вам придется посещать лекции, писать конспекты, разрабатывать презентации, оформлять многочисленные рефераты.
Для подготовки к экзамену приходится составлять конспекты. Свои записи рекомендуется дополнять сведениями из учебников. Следовательно, студенту приходится много времени тратить на подготовку к занятиям.
Иногда нужно отредактировать свой или чужой конспект. При переписывании текста вручную тратится очень много времени. Что делать? Студенты знают, что можно отсканировать любой документ, график или таблицу.
Если вы пропустили какую-либо лекцию, то можно сфотографировать чужой конспект. Вам потребуется смартфон, позволяющий переснять текст. В итоге у вас будет изображение чужих записей.
Однако, что делать, если полученную картинку нужно изменить? Вы хотите что-то вписать или дополнить текст? Современные программы позволяют изменять сканированные изображения.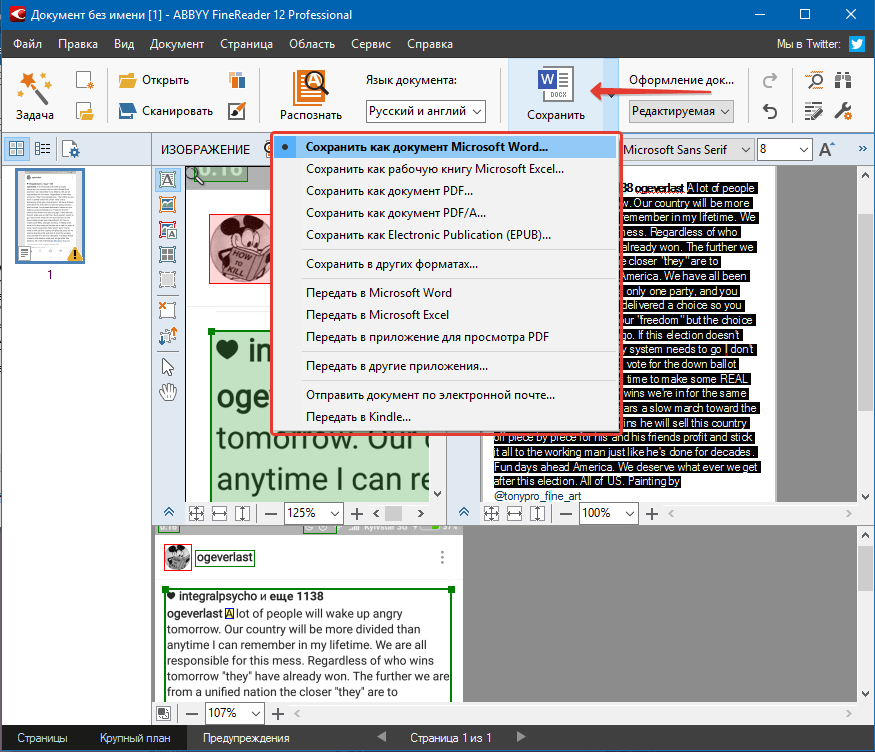
Возможности работы с текстом для студентов
Вам известно, что любой текст можно сканировать. Данная функция удобна для того, чтобы не тратить время на переписывание конспектов. Вы сможете даже сделать шпаргалки при помощи сканера.
Однако, имеется также возможность распознавания текста. Такая функция позволяет превращать любое изображение в обычный документ, который вы сможете редактировать.
Сканирование текста
Вам просто нужно отсканировать текст или картинку, а затем приступить к редактированию. Специальная программа распознает информацию, превращая ее в обычный текст. Вы сможете работать с любым изображением, как с документом, созданным в Word.
Для того, чтобы программа смогла преобразовать сканированный текст в документ Word вам нужно правильно сохранить полученное изображение. Вам предлагаются форматы BMP, JPG, PNG, GIF.
Сохранив текст в одном из вышеуказанных форматов, вы получите привычный документ. Далее вы сможете работать в Wordе, удаляя или вставляя информацию. Вам доступны все инструменты привычной программы.
Вам доступны все инструменты привычной программы.
Сканирование и распознавание текста
Студенту приходится постоянно работать с текстом, поэтому нужно разобраться, какие технологии смогут облегчить процесс обучения в ВУЗе. Вам потребуются следующие вещи:
- Сканер. Данный аппарат должен быть совместим с вашим стационарным компьютером или ноутбуком. Однако, без специального аппарата можно обойтись, используя фотоаппарат смартфона. Собираетесь приобрести сканер? Обратите внимание на скорость сканирования одного листа. Если скорость небольшая, то придется тратить много времени на сканирование конспектов иди изображений.
- Вам нужна специальная программа, которая способна распознавать любой текст. Отлично зарекомендовала себя платная программа ABBYY FineReader, которая успешно справляется с текстами большого объема. Бесплатная версия Cunei Form работает в режиме онлайн, но она имеет ограниченные возможности.
- Поиск необходимой информации в Интернете. Если вам нужно отсканировать и отредактировать текст из какого-либо учебника, то перед началом работы следует поискать информацию в сети.
 Возможно, кто-то из студентов уже занимался подобной работой, поэтому в сети имеются сохраненные документы. В таком случае вы сможете сразу приступить к редактированию.
Возможно, кто-то из студентов уже занимался подобной работой, поэтому в сети имеются сохраненные документы. В таком случае вы сможете сразу приступить к редактированию.
Распознавание текста
Вы подготовили сканер, установили специальную программу? Что делать дальше? Для облегчения работы рекомендуется установить на своем компьютере настройки, позволяющие сразу сканировать текст в нужном формате.
Так вы сэкономите время, необходимое для редактирования текста. Вы будете сохранять текст в том режиме, который является самым удобным для вас.
Как студенту сэкономить на распознавании текста
Если вам иногда нужно отсканировать чужие записи, то не стоит тратиться на приобретение специальной техники. Достаточно просто сфотографировать конспект при помощи собственного смартфона.
Далее вы сможете скопировать полученные изображения в компьютер. Размеры картинок несложно уменьшить или увеличить. Вам не потребуются специальные программы и устройства.
Вам нужно преобразовать свой конспект в шпаргалки? Вы сможете сфотографировать свои записи при помощи телефона, а далее необходимо уменьшить размеры полученных картинок.
При наличии сканера вы сможете просто переснять все записи. У вас получится прекрасный комплект шпаргалок, которые помогут успешно сдать экзамен.
Однако, если вы хотите работать со сканированными документами в режиме редактирования, то придется установить специальную программу. Так вы сможете создавать новые документы, полученные из стандартных изображений.
Хотите быстро редактировать сканированный текст? Имеет смысл приобрести специальную программу ABBYY FineReader, которая позволит вам полностью работать с любой картинкой.
Вы сможете изменять текст, исправлять ошибки, добавлять информацию. Не получается купить специализированную программу? Вы можете сложиться с однокурсниками, чтобы работать совместно.
Стоимость программы вы разделите на всех, получится небольшая сумма. Зато на протяжении всего периода обучения в ВУЗе у вас будет прекрасный помощник, позволяющий работать со сканированными документами.
При наличии Интернета вы сможете использовать программу Cunei Form, позволяющую бесплатно распознавать текст. Перед вами откроются достаточно ограниченные возможности, но вы также сможете работать с картинками, таблицами и сканированным текстом.
Перед вами откроются достаточно ограниченные возможности, но вы также сможете работать с картинками, таблицами и сканированным текстом.
Современные возможности облегчают процесс обучения для студентов ВУЗов. Вам нужно установить специальные программы, позволяющие создавать документы различной сложности.
Проживая в общежитии, вы сможете использовать смартфон и ноутбук. Например, в библиотеке имеет смысл сфотографировать необходимые страницы журнала, книги или учебника.
В общежитии вы сможете скинуть полученные изображения на ноутбук, а затем распознать текст. Далее вам предстоит процесс редактирования текста, получение желаемого документа.
Как сканировать и распознать текст
В данной статье мы рассмотрим, как переделать «бумажный» текст в цифровой, то есть разберем процесс сканирования документа. Сканировать документ просто так нельзя, для этого, естественно, необходимо такое оборудование, как сканер. Сканер должен быть подключен к компьютеру и на него должны быть установлены драйвера.
Для того чтобы иметь возможность сканировать документ, должна быть установлена программа Fine Reader. Программа, к сожалению, платная. Если вы приобретали данную программу, то с установкой проблем не будет.
Для того чтобы начать сканировать документ, кладем его под крышку сканера, естественно, текстом вниз. Запускаем Fine Reader. Я запускаю 7-ю версию, вы какую есть, принцип работы везде одинаковый. Нажимаем «Файл – Сканировать изображение».
Внимание!!! Если у вас уже есть готовая картинка с текстом, которую вы где-то взяли либо файл PDF, то в таком случае никакой сканер вообще не нужен и вы должны выбрать пункт «Открыть изображение» и далее просто распознать его.
Далее запускаются настройки сканера, и я выбираю пункт «Черно-белый рисунок или текст», потому что для меня важен именно текст.
Через некоторое время страница отсканируется, и изображение появляется на экране. Я выделяю необходимую мне область текста и кликаю по выделенному участку правой кнопкой мыши. Выбираю «Тип блока — Текст». Если вам нужна картинка, то, значит, ее и выбирайте.
Блок выделяется зеленой границей. Я опять кликаю по нему правой кнопкой мыши и выбираю пункт «Распознать блок».
Справа в окошке появляется уже необходимый нам текст, который можно копировать и вставлять в любой документ. Для того чтобы передать отсканированный текст в Word, необходимо нажать «Файл – Передать все страницы в – Microsoft Word»
На самом деле программа Fine Reader очень мощная и в этой статье я показал лишь небольшую долю ее возможностей.
Оценить статью: Загрузка… Поделиться новостью в соцсетях
Об авторе: Олег Каминский
Вебмастер. Высшее образование по специальности “Защита информации”. Создатель портала comp-profi.com. Автор большинства статей и уроков компьютерной грамотности
Высшее образование по специальности “Защита информации”. Создатель портала comp-profi.com. Автор большинства статей и уроков компьютерной грамотности
Как преобразовать отсканированное изображение в текст
Теперь гораздо проще редактировать текст, поступающий со сканера, мобильного телефона, камеры или от руки. Преобразование текста из отсканированного изображения или из файла JPEG можно выполнить с помощью инструмента «Microsoft Office». Однако, если у вас нет Microsoft Office или вам нужны более сложные инструменты преобразования, вам понадобится одна из доступных программ оптического распознавания символов (OCR). Некоторые программы бесплатны или содержат бесплатные услуги.
Microsoft Office
Шаг 1
Отсканируйте изображение и выберите его сохранение как документ TIFF. Если у вас нет этой опции, сохраните его как документ JPEG. Откройте файл в MS Paint, если вам нужно было сохранить в формате JPEG. Нажмите «Сохранить как» и конвертируйте JPEG в документ TIFF.
Шаг 2
Откройте Microsoft Office и выберите Инструменты Microsoft Office, затем щелкните Microsoft Office Document Imaging. Выберите «Файл», «Открыть». Щелкните «Значок глаза». Там написано: «Распознать текст с помощью OCR.Выберите «Отправить текст в Word», и документ Word откроется с преобразованным текстом.
Шаг 3
Прочтите текст и исправьте ошибки. Добавьте в документ текст, изображения или что-нибудь еще, что вам нужно.
Программное обеспечение OCR
Step 1
Загрузите программу OCR (оптического распознавания символов), такую как «Read Soft», «Simple OCR» или «Top OCR» (см. Ресурсы). Следуйте инструкциям на экране для установки. Эти программы имеют различные функции, такие как распознавание рукописного ввода, распознавание изображений или изображений и текста с мобильных телефонов.
Шаг 2
Отсканируйте документ или скопируйте файл на свой компьютер. Скопируйте документы со своего мобильного телефона или сделайте снимок цифровой камерой и перенесите их на свой компьютер, как обычный документ или изображение.
Step 3
Откройте выбранное программное обеспечение OCR. Откройте изображение или отсканированное изображение в программе OCR. Выберите желаемую опцию вывода из выпадающего окна опций программы. Выберите RTF, текст, PDF, Word, PowerPoint или Excel.Нажмите кнопку «Преобразовать», «ОК» или «Готово». Эта кнопка называется по-разному в зависимости от используемой программы. Подождите, пока программа OCR завершит преобразование, и выберите сохранение файла на свой компьютер.
Шаг 4
Откройте документ. Например, если вы преобразовали в PowerPoint, откройте PowerPoint. Если вы преобразовали в RTF, откройте Word или Word Pad.
Шаг 5
Прочтите документ и найдите орфографические или грамматические ошибки. Выполните проверку орфографии в документе.Программы оптического распознавания текста могут запутаться при преобразовании определенных букв, поэтому вам необходимо внимательно просмотреть документ на предмет ошибок.
Вы можете сканировать документ и преобразовывать текст в формат, который можно редактировать с помощью текстового редактора. не может распознать или испытывает трудности с распознаванием следующих типов документов или текста. Рукописные символы Элементы, скопированные с других копий Факсы Текст с короткими интервалами или межстрочным интервалом Табличный или подчеркнутый текст Курсивный или курсивный шрифт и размер шрифта менее 8 пунктов См. Один из этих разделов, чтобы сканировать и преобразовывать текст с помощью ABBYY FineReader. Офисный режим : Преобразование в редактируемый текст в офисном режиме Стандартный режим : Преобразование в редактируемый текст в простом режиме Профессиональный режим : Преобразование в редактируемый текст в профессиональном режимеПреобразование в редактируемый текст в офисном режиме
Mac OS X : Выберите Applications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint .
Преобразование в редактируемый текст в простом режиме
Mac OS X : Выберите Applications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint .
Преобразование в редактируемый текст в профессиональном режиме
Mac OS X : Выберите Applications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint .
|
 Этот процесс называется OCR (оптическое распознавание символов). Чтобы сканировать и использовать OCR, вам необходимо использовать программу OCR, такую как программа ABBYY FineReader, поставляемая вместе со сканером.
Этот процесс называется OCR (оптическое распознавание символов). Чтобы сканировать и использовать OCR, вам необходимо использовать программу OCR, такую как программа ABBYY FineReader, поставляемая вместе со сканером.
 Затем выберите Scan & Read в меню Scan & Read, чтобы запустить Epson Scan.
Затем выберите Scan & Read в меню Scan & Read, чтобы запустить Epson Scan.
 Этот параметр доступен, только если для параметра Тип изображения установлено значение Черно-белое.
Этот параметр доступен, только если для параметра Тип изображения установлено значение Черно-белое.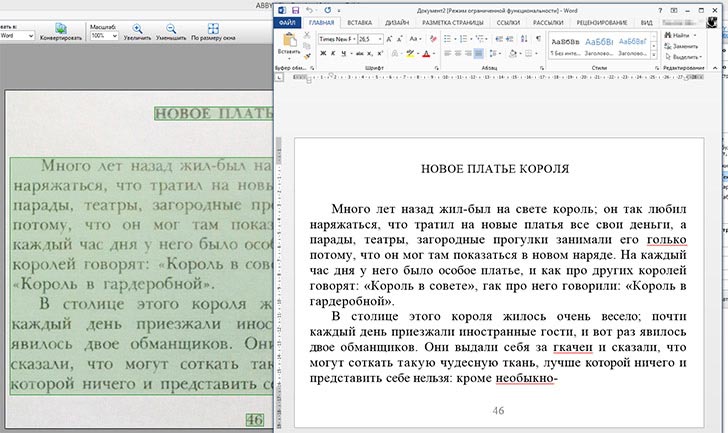

 Затем выберите Scan & Read в меню Scan & Read, чтобы запустить Epson Scan.
Затем выберите Scan & Read в меню Scan & Read, чтобы запустить Epson Scan.
 Затем выберите Scan & Read в меню Scan & Read, чтобы запустить Epson Scan.
Затем выберите Scan & Read в меню Scan & Read, чтобы запустить Epson Scan. Чтобы получить доступ к настройке, нажмите кнопку + (Windows) или (Mac OS X) рядом с параметром «Тип изображения».
Чтобы получить доступ к настройке, нажмите кнопку + (Windows) или (Mac OS X) рядом с параметром «Тип изображения».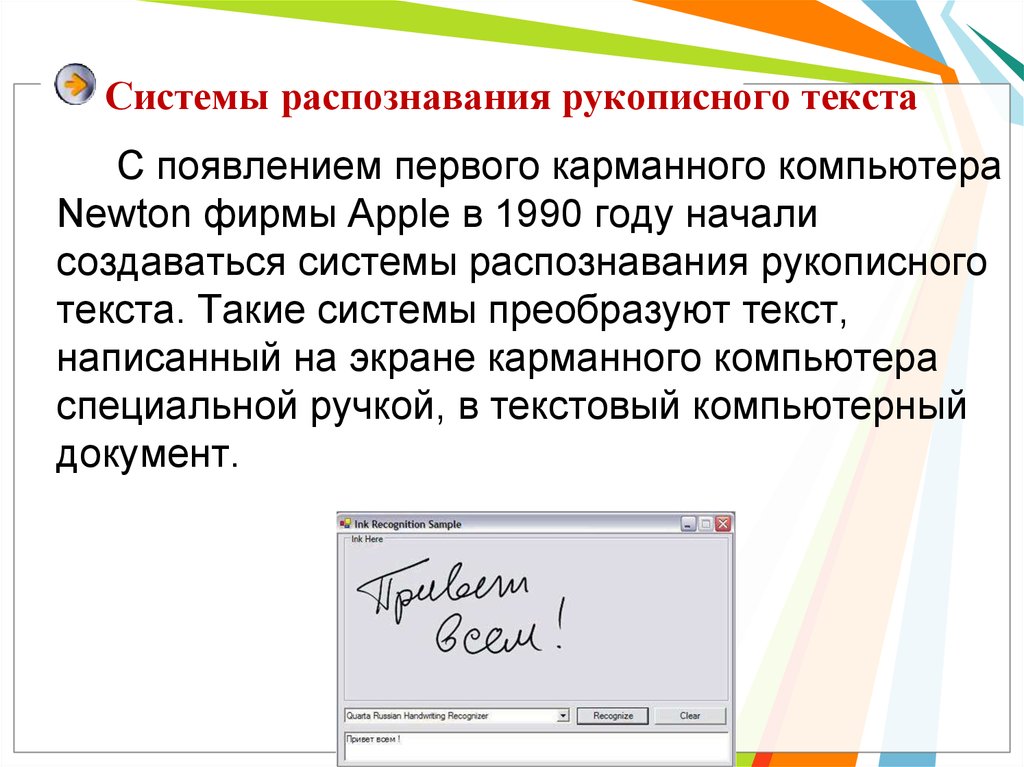
 Этот параметр доступен, только если для параметра Тип изображения установлено значение Черно-белое.
Этот параметр доступен, только если для параметра Тип изображения установлено значение Черно-белое.
Вы можете сканировать документ и преобразовывать текст в данные, которые можно редактировать с помощью текстового редактора. Этот процесс называется OCR (оптическое распознавание символов).Для сканирования и использования OCR вам необходимо использовать программу OCR, например, ABBYY FineReader. Программное обеспечениеOCR не может распознавать рукописные символы, а некоторые типы документов или текста трудно распознать программному обеспечению OCR, например: Элементы, скопированные с других копий Факсы Текст с короткими интервалами или межстрочным интервалом Табличный или подчеркнутый текст Курсивный или курсивный шрифт и размер шрифта менее 8 пунктов Чтобы отсканировать и преобразовать текст с помощью ABBYY FineReader, выполните следующие действия.
Windows : выберите Пуск> Программы или Все программы> ABBYY FineReader 6.0 Sprint> ABBYY FineReader 6.0 Sprint . Mac OS X : откройте папки Applications> ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint . Перед вами откроется окно ABBYY FineReader.
В полностью автоматическом режиме Epson Scan предварительно просматривает, сканирует и преобразует текст в редактируемый формат, а затем отображает его в окне FineReader.  Затем нажмите Сканировать . Ваш документ будет отсканирован, преобразован в редактируемый текст и открыт в окне FineReader. Примечание: Затем нажмите Сканировать . Ваш документ будет отсканирован, преобразован в редактируемый текст и открыт в окне FineReader. Примечание:
|


Выполнение оптического распознавания символов в отсканированном документе PDF для отображения фактического текста
Пример 1: Создание фактического текста, а не изображений текста с использованием Adobe Acrobat 9 Pro
Этот пример показан с Adobe Acrobat Pro. Есть и другие программные инструменты, которые
выполняют аналогичные функции. См. Список других программных инструментов в.
Есть и другие программные инструменты, которые
выполняют аналогичные функции. См. Список других программных инструментов в.
В этом примере используется простое отсканированное изображение текста на одной странице. Для обеспечения что фактический текст хранится в документе, выполните следующие действия:
- Отсканируйте документ с максимально возможным разрешением для улучшения производительность OCR.
- Загрузите отсканированный документ в Acrobat Pro. Выберите Документ> OCR. Распознавание текста> Распознать текст с помощью OCR …
- В следующем диалоговом окне выберите переключатель «Все страницы» в разделе «Страницы».
(или Текущая страница, если вы конвертируете только одну страницу), а затем выберите
OK.

- В списке «Параметры» выберите «Изменить».В следующем диалоговом окне выберите Форматированный текст и графика в раскрывающемся списке «Стиль вывода PDF». Это важно для обеспечения доступности.
- В зависимости от разрешения и четкости текста OCR преобразует изображения слов и символов в фактический текст. Напишите что Acrobat Pro не распознает, указан как “подозреваемый в распознавании текста” или текстовый элемент, который, как подозревает Acrobat, был распознан неправильно.
- Чтобы исправить подозреваемых, выберите «Документ»> «Распознавание текста»> «Найти». Первый подозреваемый OCR. Acrobat Pro представляет каждого подозреваемого по одному, которые можно исправить с помощью инструментов коррекции Acrobat Pro.
- Выполните «Дополнительно»> «Специальные возможности»> «Добавить теги к документу ».
- Тест на доступность: Advanced> Accessibility> Full Проверять…
Примечание
Вы также можете использовать Document> OCR. Распознавание текста> Найти всех подозреваемых OCR для отображения всех подозреваемых OCR в то же время для более быстрого редактирования.
На следующем изображении показан отсканированный одностраничный документ в Adobe Acrobat. Pro.
Рис. 1 Отсканированная страница в Acrobat Pro с рецептами супов.На следующем изображении показано преобразованное содержимое после добавления тегов в документ. Вероятно, потребуется использовать TouchUp Reading Инструмент заказа и панель тегов, чтобы правильно пометить контент для предполагаемого итоговый документ. В этом примере изображение спирального переплета книги был отмечен при преобразовании.Использовался инструмент TouchUp Reading Order. скрыть изображение как фоновое (декоративное) изображение (см.). Рецепт заголовки были помечены как заголовки первого уровня.
Рис. 2 Преобразованная страница с тегами в Acrobat Pro, на которой показаны рецепты супов. Название каждого супа заголовок первого уровня. Изображение спирального переплета книги было скрыто как декоративное. изображение.Примечание. Acrobat Pro может автоматически добавлять теги при запуске файла. через OCR.
Этот пример показан в действии на рабочем примере генерации фактического текста и результата выполнения OCR.
PDF7: выполнение оптического распознавания символов в отсканированном документе PDF для отображения фактического текста
Цель этого метода – гарантировать, что визуально отображаемый текст представлен таким образом, что его можно воспринимать без его визуальное представление, мешающее его читабельности.
Документ, состоящий из отсканированных изображений текста, изначально недоступен потому что содержание документа – изображения, а не текст, доступный для поиска.Вспомогательные технологии не могут читать или извлекать слова; пользователи не могут выделять, редактировать, изменять размер или перекомпоновку текста, а также они не могут изменять текст и фон цвета; и авторы не могут управлять PDF-файлом для обеспечения доступности.
По этим причинам авторам следует использовать фактический текст, а не изображения. текста, используя инструмент разработки, такой как Microsoft Word или Oracle Open Office для создания и преобразования содержимого в PDF.
Если авторы не имеют доступа к исходному файлу и инструменту разработки, отсканированные изображения текста можно преобразовать в PDF с помощью оптических символов распознавание (OCR).Затем Adobe Acrobat Pro можно использовать для создания доступных текст.
Этот пример показан с Adobe Acrobat Pro. Существуют и другие программные инструменты, выполняющие аналогичные функции. См. Список других программных инструментов в PDF Authoring Tools, которые обеспечивают поддержку специальных возможностей.
В этом примере используется простое сканированное изображение текста на одной странице. Для обеспечения что фактический текст хранится в документе, выполните следующие действия:
Отсканируйте документ с максимально высоким разрешением для улучшения производительность OCR.
Загрузите отсканированный документ в Acrobat Acrobat Pro. Выберите Документ> OCR. Распознавание текста> Распознать текст с помощью OCR …
В следующем диалоговом окне выберите переключатель Все страницы в разделе Страницы (или Текущая страница, если вы конвертируете только одну страницу), а затем выберите OK.
В списке «Параметры» выберите «Изменить». В следующем диалоговом окне выберите Форматированный текст и графика в раскрывающемся списке «Стиль вывода PDF».Это важно для обеспечения доступности.
В зависимости от разрешения и четкости текста OCR преобразует изображения слов и символов в фактический текст. Напишите что Acrobat Pro не распознает, указан как “подозреваемый в распознавании текста” или текстовый элемент, который, как подозревает Acrobat, был распознан неправильно.
Чтобы исправить подозреваемых, выберите «Документ»> «Распознавание текста с оптическим распознаванием текста»> «Найти». Первый подозреваемый OCR.Acrobat Pro представляет каждого подозреваемого по одному, которые можно исправить с помощью инструментов коррекции Acrobat Pro.
Запустите Advanced> Accessibility> Add Tags to Document
Test for accessibility: Advanced> Accessibility> Full Проверить …
Примечание: В качестве альтернативы вы можете использовать Document> OCR Распознавание текста> Найти всех подозреваемых OCR для отображения всех подозреваемых OCR в то же время для более быстрого редактирования.
На следующем изображении показан отсканированный одностраничный документ в Adobe Acrobat. Pro.
На следующем изображении показано преобразованное содержимое после добавления тегов в документ. Вероятно, потребуется использовать TouchUp Reading Инструмент заказа и панель тегов, чтобы правильно пометить контент для предполагаемого итоговый документ. В этом примере изображение спирального переплета книги был отмечен при преобразовании. Использовался инструмент TouchUp Reading Order. , чтобы скрыть изображение как фоновое (декоративное) (см. PDF4: Скрытие декоративных изображений с помощью тега Artifact в документах PDF ).Рецепт заголовки были помечены как заголовки первого уровня.
Примечание. Acrobat Pro может автоматически добавлять теги при запуске файла. через OCR.
Этот пример показан в действии на рабочем примере генерации фактического текста и результата выполнения OCR.
Ресурсы предназначены только для информационных целей, без какой-либо поддержки.
Процедура
Для каждой страницы, преобразованной в текст с помощью OCR, убедитесь, что результат PDF-файл был преобразован правильно одним из следующих способов:
Прочтите PDF-документ с помощью программы чтения с экрана или инструмента, который читает вслух, прислушиваясь к тому, что весь текст читается правильно и в правильном порядке чтения.
Сохраните документ как текст и убедитесь, что преобразованный текст является полным и в правильном порядке чтения.
Используйте инструмент, способный отображать преобразованный контент чтобы открыть PDF-документ и убедиться, что весь текст был преобразован и находится в правильном порядке чтения.
Используйте инструмент, открывающий доступ к документу API и убедитесь, что весь текст был преобразован и находится в правильном порядок чтения.
Ожидаемые результаты
Если это достаточный метод для критерия успеха, неудача этой процедуры тестирования не обязательно означает, что критерий успеха не был удовлетворен каким-либо другим способом, только то, что этот метод не был успешным реализованы и не могут использоваться для подтверждения соответствия.
Используйте Adobe Acrobat Pro – оцифровывайте свои источники (DIY)
Используйте Adobe Acrobat Pro – оцифровывайте свои источники (DIY) – Библиотечные руководства в Университете Тулейна Перейти к основному содержаниюПохоже, вы используете Internet Explorer 11 или старше.Этот веб-сайт лучше всего работает с современными браузерами, такими как последние версии Chrome, Firefox, Safari и Edge. Если вы продолжите работу в этом браузере, вы можете увидеть неожиданные результаты.
OCR и Adobe Acrobat Pro DC
Adobe Acrobat Pro DC использует программное обеспечение оптического распознавания текста для преобразования отсканированных документов в редактируемые / доступные для поиска документы.На всех компьютерах в Мемориальной библиотеке Говарда-Тилтона установлен Adobe Acrobat Pro DC.
Ниже приведены инструкции для:
- Превратите отсканированные PDF-файлы в документы с возможностью поиска, сохранив при этом исходное качество изображения.
- Создание PDF-файлов из файлов других форматов, таких как документы Word или файлы изображений JPEG и TIFF.
- Преобразование ваших PDF-файлов в редактируемый текст. Вы можете использовать эту функцию автоматического распознавания текста, если хотите работать с текстом и изображениями в документе.Эта функция действительно уменьшает количество пикселей в вашем изображении, поэтому лучше иметь резервную копию вашего оригинального высококачественного сканирования.
Как сделать ваши PDF-файлы доступными для поиска
Как создать PDF из текстовых файлов и файлов изображений:
- Щелкните «Инструменты», а затем щелкните инструмент «Создать PDF», чтобы легко преобразовать файл в формат PDF.
- Выберите файл и нажмите «Открыть». Acrobat отобразит предварительный просмотр вашего файла.
- Щелкните “Создать”. Acrobat создает и открывает файл PDF, сохраняя его в том же месте и с тем же именем, что и исходный файл, но с расширением .pdf.
Как преобразовать отсканированные PDF-файлы в редактируемый текст с помощью программного обеспечения для автоматического распознавания текста в Acrobat:
- Откройте файл PDF, содержащий отсканированное изображение, в Acrobat.
- Щелкните инструмент «Редактировать PDF» на правой панели. Acrobat автоматически применяет оптическое распознавание символов (OCR) к вашему документу и преобразует его в полностью редактируемую копию вашего PDF-файла. Примечание : этот процесс может занять от нескольких секунд до нескольких минут, в зависимости от размера вашего документа.
- Щелкните текстовый элемент, который хотите отредактировать, и начните вводить текст. Новый текст соответствует внешнему виду оригинальных шрифтов на отсканированном изображении.
- Выберите «Файл»> «Сохранить как» и введите новое имя для редактируемого документа.
Эта работа находится под международной лицензией Creative Commons Attribution-NonCommercial 4.0.
10 лучших бесплатных программ для оптического распознавания текста для работы с отсканированными файлами PDF
OCR – это технология, используемая для преобразования файлов изображений в редактируемый текст. Файлы на основе изображений относятся к документам, которые были отсканированы из учебников, журналов или любых текстовых источников и обычно сохраняются в формате PDF.OCR может извлекать текст из этих изображений и делать его редактируемым. В этой статье мы представим 10 лучших бесплатных программ для распознавания текста , которые помогут вам легко редактировать отсканированные файлы PDF.
10 лучших бесплатных программ для распознавания текста
1. PDFelement
PDFelement может легко помочь вам в работе со отсканированными документами PDF благодаря передовой технологии распознавания текста. Эта функция может распознавать текст в отсканированных PDF-файлах, чтобы сделать ваш файл и текст доступными для редактирования. Кроме того, он также может конвертировать ваши отсканированные PDF-файлы в другие редактируемые форматы документов, такие как Excel, Word, PPT, Text и другие.Качество вашего исходного документа также будет полностью сохранено.
PDFelement оснащен мощными инструментами редактирования, которые позволяют вставлять, удалять или изменять текст, изображения и страницы. Вы также можете заполнять как интерактивные, так и неинтерактивные формы и создавать новые формы с различными вариантами заполнения форм и создания форм.
2. FreeOCR
Этот онлайн-инструмент OCR совершенно бесплатный и не требует регистрации или предоставления адреса электронной почты.Он поддерживает такие типы файлов изображений, как GIF, JPG, BMP, TIFF или PDF с текстом в несколько столбцов. И он распознает более 30 разных языков. Размер загрузки ограничен 2 МБ или 5000 пикселей, и вы можете загружать только 10 изображений в час.
3. i2OCR
i2OCR имеет возможность загружать типы файлов изображений, такие как JPEG, TIF, BMP, PNG, PBM, GIF, PPM, PGM или URL-адрес изображения. Эта программа позволяет конвертировать изображения с вашего локального диска или из Интернета. Регистрация не требуется.Он поддерживает документы PDF с текстом в несколько столбцов и распознает 33 языка. В отличие от FreeOCR, он позволяет пользователям загружать изображения без каких-либо ограничений по количеству.
4. OCR в Интернете
Online OCR может преобразовывать фотографии и цифровые изображения в текст. Он распознает 32 языка и конвертирует отсканированные PDF-файлы в форматы Text, Word и RTF. Он также извлекает текст из изображений JPG, JPEG, BMP, TIFF и GIF и преобразует его в редактируемые документы Word, Text, PDF, Excel или HTML.Вы можете конвертировать 15 изображений в час.
5. Бесплатное распознавание текста в Интернете
Free Online OCR может преобразовывать снимки экрана, отсканированные документы, факсы и фотографии в доступный для поиска и редактируемый текст, такой как TXT, DOC, RTF и PDF. Он поддерживает форматы BMP, PDF, PNG, TIFF, JPG (JPEG) и GIF.
6. Cvisiontech
Cvisiontech также поддерживает одновременную загрузку нескольких файлов TIFF, PDF, BMP и JPG. Вам необходимо убедиться, что размер любого загруженного файла не превышает 100 МБ.Эта программа позволит вам сжать целевой файл и оптимизировать его для веб-сайта.
7. SuperGeek Free Document OCR
SuperGeek Free Document OCR – это удобный и мощный конвертер изображений OCR, предназначенный как для профессиональных, так и для домашних пользователей. Он может читать текст из JPG, JPEG, TIF, TIFF, PNG, BMP, PSD, GIF, EMF, WMF, J2K, DCX, PCX, JP2 и т. Д. И конвертировать файлы в редактируемые документы MSWord и TXT всего за несколько кликов.
8. onOCR
Независимо от размера отсканированного PDF-файла или файла изображения onOCR справится с этим.Бесплатное распознавание текста может преобразовать нередактируемый документ в текст, который можно копировать и редактировать любым удобным для вас способом. Он также позволяет обрабатывать как большие, так и маленькие изображения и превращать их в редактируемый текст.
9. Инвестинтех
Able2Extract от Investintech – это мощный инструмент для управления PDF-файлами, который можно использовать для преобразования отсканированных PDF-файлов в более 10 различных редактируемых типов файлов. Вы также можете создавать защищенные PDF-файлы практически из любого типа файлов, просматривать и редактировать PDF-файлы, извлекать текст из отсканированного документа, а также изменять и предварительно просматривать преобразованный файл.
10. OCRGeek
OCRGeek.com позволяет выполнять онлайн-оптическое распознавание текста партиями. Это позволяет без проблем загружать несколько файлов одновременно. Весь процесс быстрый и легкий. Все ваши документы будут сразу упорядочены и преобразованы в формат TXT. OCRgeek может поддерживать следующие форматы ввода: JPG, PNG, TIFF, PDF, DJVU, GIF и BMP.
Видео: 5 лучших программ для распознавания текста
Если вы хотите узнать больше полезных видеороликов о PDFelement и других продуктах Wondershare, вы можете найти больше в сообществе Wondershare Video Community.