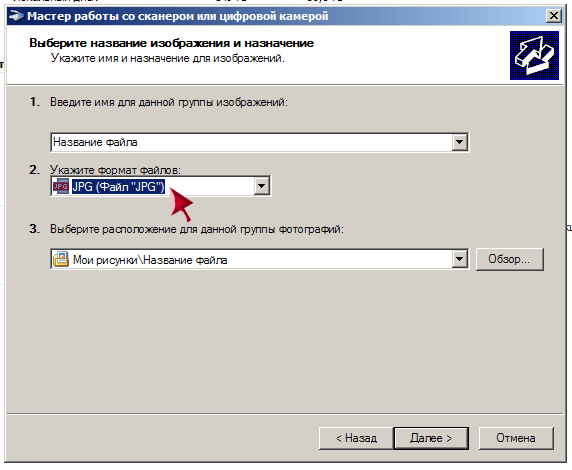
Как отформатировать отсканированный документ в ворд. Как изменить отсканированный документ в word. Как сканированный документ PDF перевести в Ворд для редактирования: программа
С помощью программы FineReader можно легко преобразовать текст с бумажного носителя в файл формата Ворд и отредактировать его при необходимости.
Узнать все этапы проведения данной процедуры можно в представленной статье.
Большое количество пользователей, работающих с документами, нередко сталкиваются с необходимостью копирования текста с бумажного носителя в Word. В этом случае самым оптимальным выбором будет сканирование текста и его дальнейшее редактирование.
Сделать это возможно с помощью современной программы FineReader, она успешно преобразует обычную фотографию, полученную со скана, в осмысленный набор слов.
Что нам понадобится для сканирования и распознавания текста по фото?
Для сканирования и распознавания текста нам не обойтись без кое-каких вещей:
- Сканер
. Собственно, роль сканера может выполнять не только этот вид техники, но и фотоаппарат (в смартфоне, например). Если вы пользуетесь сканером, убедитесь, что на компьютере установлены системные драйвера и программы, необходимые для его полноценной работы. Если сканера нет, но вы собираетесь его купить, обратите внимание на скорость обработки одного листа. Некоторые приборы обрабатывают лист за 10 секунд, другим для этого понадобится 30 и более. И если работать вам придется с объемными материалами по 300-400 листов, то этот фактор имеет значение.
Собственно, роль сканера может выполнять не только этот вид техники, но и фотоаппарат (в смартфоне, например). Если вы пользуетесь сканером, убедитесь, что на компьютере установлены системные драйвера и программы, необходимые для его полноценной работы. Если сканера нет, но вы собираетесь его купить, обратите внимание на скорость обработки одного листа. Некоторые приборы обрабатывают лист за 10 секунд, другим для этого понадобится 30 и более. И если работать вам придется с объемными материалами по 300-400 листов, то этот фактор имеет значение. - Программы для распознавания текста или онлайн-сервисы
. Мы уже писали статью по сервисам, которые помогают распознать текст после сканирования документа через сканер. Но сейчас хотели бы посоветовать вам программу ABBYY FineReader. Несмотря на то, что она платная, ее функционал поистине впечатляет. И если вы будете работать с огромными объемами документов, она станет вашим незаменимым помощником. Впрочем, есть и бесплатный ее аналог Cunei Form, которая отлично справляется со сканированием и распознаванием текста онлайн. Правда, ее функционал сильно ограничен по сравнению с предыдущим собратом.
Правда, ее функционал сильно ограничен по сравнению с предыдущим собратом. - Документы для сканирования
. Студентам часто приходиться сталкиваться со сканированием документа в виде журналов, статей, книг, конспектов, распечаток, откуда потом зачастую нужно скопировать текст. И просто так, в виде совета – перед началом сканирования постарайтесь поискать эти документы в сети. Если до вас этими материалами уже пользовались, существует огромная вероятность, что добрый человек уже проделал всю работу за вас. Атк что вам останется только скопировать текст готового сканированного документа и заняться редактированием текста после сканирования.
 Собственно, роль сканера может выполнять не только этот вид техники, но и фотоаппарат (в смартфоне, например). Если вы пользуетесь сканером, убедитесь, что на компьютере установлены системные драйвера и программы, необходимые для его полноценной работы. Если сканера нет, но вы собираетесь его купить, обратите внимание на скорость обработки одного листа. Некоторые приборы обрабатывают лист за 10 секунд, другим для этого понадобится 30 и более. И если работать вам придется с объемными материалами по 300-400 листов, то этот фактор имеет значение.
Собственно, роль сканера может выполнять не только этот вид техники, но и фотоаппарат (в смартфоне, например). Если вы пользуетесь сканером, убедитесь, что на компьютере установлены системные драйвера и программы, необходимые для его полноценной работы. Если сканера нет, но вы собираетесь его купить, обратите внимание на скорость обработки одного листа. Некоторые приборы обрабатывают лист за 10 секунд, другим для этого понадобится 30 и более. И если работать вам придется с объемными материалами по 300-400 листов, то этот фактор имеет значение.Как сканировать через смартфон, используя Office Lens
- Загрузить приложение «Office Lens» можно с Play Market или Apps Store (зависит от типа ОС на смартфоне).
 Установка ничем не отличается от инсталляции других программ.
Установка ничем не отличается от инсталляции других программ. - После первого запуска на новом телефоне «Office Lens» делает запрос на разрешение доступа к файлам. Предоставьте его.
- Теперь можно приступать к работе. Нажмите кнопку «Document» внизу окна.
- Положите лист с текстом на стол и направьте на него камеру, чтобы тот полностью оказался в экране смартфона.
- Сделайте фото кнопкой (круглая с красным ободком и белая внутри).
- Утвердите согласие на сохранение кликом по галочке. Если нужно отсканировать еще страницы, то слева есть значок с «+».
- Теперь переходим в меню приложения «Сохранить» на закладке «Экспорт в». В нем ищет и нажимаем значок «Ворд».
- Далее будет предложено авторизоваться в сервисе OneDrive с логином и паролем учетной записи Microsoft.
- Переходим на свой ПК или ноутбук. Открываем Ворд, а в нем нажимаем на пиктограмму «Открыть» в меню «Файл» или на главной панели инструментов.
- Слева в списке ищем диск «OneDrive», а в нем наш файл.
 Выбираем его.
Выбираем его. - По необходимости можно внести правки.
Параметры сканирования текста
Итак, сканер купили, документы подготовили, программы установили. Что дальше? Дальше нам нужно будет сделать нужные настройки, которые тоже порой помогают существенно облегчить задачу, например, распознать сканированный текст в определенном формате, редактировать текст после сканирования в определенном режиме и так далее.
В общем, от настроек будет зависеть качество и скорость вашей работы. Итак, разбираемся вместе.
DPI-качество
Это разрешение изображения, которое будет важно при редактировании текста в сканированном документе. Ставьте в настройках качество не меньше 300 DPI, а если возможно — то больше. Чем выше эта величина, тем более четким получится изображение после сканирования.
А от четкости будет зависеть скорость обработки. То есть исправить или изменить сканированный текст, текст сканированного листа будет быстрее, а еще программа сделает меньше ошибок (да-да, программы тоже ошибаются, но обо всем по порядку).
Цветность
Благодаря этому параметру можно влиять на скорость сканирования текста. Как правило, в сканерах есть 3 режима: черно-белый (подходит для листов с обычным печатным текстом), серый (подходит для работы с документами с таблицами и простыми картинками), цветной (для журналов, книг и остальных документов, где цвет играет значение). Чем меньше цвета, тем выше скорость обработки документа.
Фото
Как мы уже говорили, для сканирования можно использовать не только сканер, но и фотографирование. Но здесь будьте осторожны – любое смазывание, нечеткость и прочие искажения изображения могут повлиять на дальнейшее распознавание и редактирование текста в сканированном документе.
Распознавание
Итак, отсканировали и получили странички в электронном виде. Затем открываем программу для распознавания (например, FineReader) и начинаем распознавать текст. Некоторые программы (в том числе и наша) делают этот процесс с ошибками. Тогда область с ошибкой нужно будет выделять вручную.
Работа с текстом
В области Текст можно будет выделить текст. Любые таблицы и изображения можно будет удалить. А вот для работы с необычными и редкими символами придется поработать ручками. Вот как это выглядит в программе:
Картинки
Эта область в программе используется для работы с изображениями и с теми областями текста, которые плохо поддались распознаванию.
Таблицы
Кнопка выделения таблиц помогает работать с таблицами. Однако эта функция не очень хорошо развита. Иногда проще использовать редактор Картинка для работы с таблицами. Это сэкономит кучу времени и нервов, а доработать все потом можно в обычном ворде.
Лишние элементы
Если на странице остались элементы, которые вам совершенно не нужны или бесполезны, выделите ненужную область и удалите ее с помощью ластика. Достаточно перейти в режим редактирования и провести работу. Причем чем больше ненужных элементов вы уберете, тем быстрее будет происходить процесс распознавания текста.
Проверка ошибок и сохранение результатов работы
Как мы уже говорили, ошибки могут возникать тогда, когда вы используете некачественные, смазанные, нечеткие изображения или документы с редкими символами. Поэтому всегда проверяйте документ после процесса распознавания.
Нашли? Замечательно – просто введите нужный символ. Кстати, в программе есть режим проверки, который поможет быстро и без вашего участия проверить документ на наличие ошибок программы. И сразу же после окончания проверки можете прямо из программы импортировать документ (сохранить его в формате) в ворд или любую другую программу.
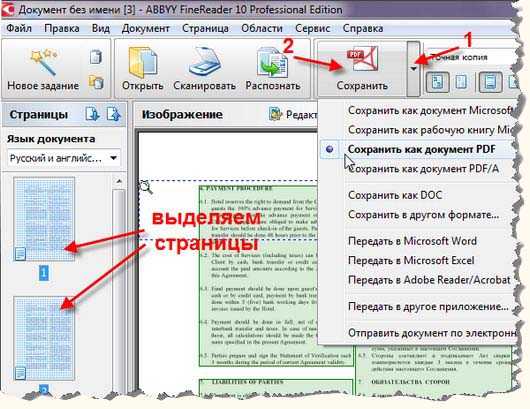
Тип копии
При сохранении документа (в режиме редактирования) вам предложат сохранить его в трех видах копии. Точная копия
– это полная копия сканированного документа со всем произведенным форматированием. Если вы потом планируете редактировать текст после сканирования в ворде, то лучше всего выбрать именно этот вариант.
Редактируемая копия
помогает сохранить уже отредактированный текст. Хорошо подходит, если вам предстоит обильное последующее редактирование. Простой текст – идеально подходит для тех, кто хочет получить в итоге обычный текст без всех остальных элементов страницы.
Хорошо подходит, если вам предстоит обильное последующее редактирование. Простой текст – идеально подходит для тех, кто хочет получить в итоге обычный текст без всех остальных элементов страницы.
Вот, собственно и все. Сложно, долго и нудно, но гораздо быстрее сканировать и распознать текст (даже рукописный) программой, чем переписывать 100500 документов вручную. Ну а если вам и этим некогда заниматься – обращайтесь за помощьюв студенческий сервис . Тут вам быстро, дешево и качественно выполнят все, что нужно.
Хранить отсканированные документы на жестком диске компьютера или внешнем носителе удобно и безопасно. Однако как внести изменения в страницы, обычно представленные в виде изображения? Нам понадобятся специальные программы, об установке и управлении которыми мы расскажем ниже.
Решение задачи с помощью OCR
Если вам нужно редактирование отсканированных документов, то воспользуйтесь любой программой OCR, функция которой заключается в оптическом распознавании символов. Данное ПО сравнивает символы в отсканированном файле с теми символами, которые имеются в его БД. После этого, программа данной категории производит конвертацию файла в удобный текстовый формат. Однако примите во внимание, что далеко не все OCR способны работать на бесплатной основе – среди них есть немало и платных вариантов. Также учтите, что в зависимости от того, насколько качественно вам удастся выполнить сканирование оригинала, вы можете столкнуться с различными ошибками, редактируя готовый скан. Чтобы решить непосредственно задачу связанную с тем, как редактировать сканированный текст следуйте следующей инструкции:
Данное ПО сравнивает символы в отсканированном файле с теми символами, которые имеются в его БД. После этого, программа данной категории производит конвертацию файла в удобный текстовый формат. Однако примите во внимание, что далеко не все OCR способны работать на бесплатной основе – среди них есть немало и платных вариантов. Также учтите, что в зависимости от того, насколько качественно вам удастся выполнить сканирование оригинала, вы можете столкнуться с различными ошибками, редактируя готовый скан. Чтобы решить непосредственно задачу связанную с тем, как редактировать сканированный текст следуйте следующей инструкции:
- Загрузите программу OCR с официального сайта разработчика или любого надежного веб-ресурса и установите ее.
- Откройте редактируемый файл в окне программы. Данный процесс может отличаться для каждого ПО подобного типа, но в целом от вас потребуется открыть файл, после чего запустить процесс конвертации. Во многих таких программах можно выбирать подходящий формат выходного файла.
 Главное, чтобы измененный тип документ был удобен для вас.
Главное, чтобы измененный тип документ был удобен для вас. - После произведенной конвертации вам нужно будет удалить из готового файла форматирование, если с ним возникли какие-то проблемы. Дело в том, что ПО может учесть форматирование, к примеру, шрифты, межстрочные интервалы, если сканируемый файл отсканируется недостаточно ровно. Чтобы удалить форматирование используйте любой текстовый редактор, к примеру, обычный «Блокнот». Он, как правило, не способен распознавать форматирование, благодаря чему вставить текст в него можно без лишнего кода.
- В конце вам нужно открыть новый документ в любом удобном редакторе и приступить к такому процессу, как редактирование сканированных документов. Обязательно воспользуйтесь функцией проверки орфографии, чтобы вовремя найти все ошибки и устранить их. Но ошибки, связанные с форматированием, придется исправлять ручным образом.
Но прежде чем включить сканер и отсканировать тот или иной текст, вам стоит изначально определиться с удобной для вас программой оптического распознавания символов. Далее можно ознакомиться с одними из самых популярных и распространенных среди них:
Далее можно ознакомиться с одними из самых популярных и распространенных среди них:
- Одной из самых известных программ категории OCR, является ABBYY FineReader, работающая на платной основе. Данное ПО используется для конвертирования сканов в текстовые файлы с помощью запатентованных алгоритмов, которые позволяют распознавать даже текст, имеющий не очень высокое качество. В целом преимущества программы заключаются в высокой точности распознавания текста, способности преобразовывать всю структуру и внешний вид отсканированного текста. Следовательно, она оставит на своих местах не только текст, но также таблицы, рисунки и прочее.
- Readiris Pro — также является довольно распространенной программой с функцией OCR, которая обладает очень удобным интерфейсом. С ее помощью можно сохранить распознанный текст в таких форматах, как XPS, OpenOffice, PDF, Word и Excel. Следует добавить, что эта программа позволяет работать с более чем сотней языков мира и форматом DjVu.
- Freemore OCR представляет собой программу, распространяемую абсолютно бесплатно.
 С ее помощью можно достаточно оперативно извлекать графику и текст с отсканированных изображений. Извлеченный текст можно сохранить в виде документа Word. Помимо этого, она обладает функцией многостраничного распознавания. Но учтите, что интерфейс программы выполнен только на английском языке. Однако данное обстоятельство не влияет на удобство ее использования.
С ее помощью можно достаточно оперативно извлекать графику и текст с отсканированных изображений. Извлеченный текст можно сохранить в виде документа Word. Помимо этого, она обладает функцией многостраничного распознавания. Но учтите, что интерфейс программы выполнен только на английском языке. Однако данное обстоятельство не влияет на удобство ее использования.
Как отсканировать документ перед редактированием?
Чтобы успешно манипулировать файлом в дальнейшем, важно правильно перевести его в формат “картинки”, а также учесть несколько простых, но полезных нюансов в самом процессе. Для этого:
- Разгладьте все заломы и складки, чтобы они не отобразились на скане и не привели к трудностям в распознавании букв.
- Для удобства обращения сохраните файл в формате PDF, JPG или TIFF.
- PDF-документ можно будет открыть и редактировать программой Adobe Acrobat (или любой другой, предназначенной для подобных целей).
- Зайдите на сайт компании-создателя сканера, либо поищите фирменную программу на прилагавшемся диске (часто известные бренды имеют собственные приложения для изменения отсканированных страниц).

- Для последующего использования файла в MS Office 2003 или 2007, установите утилиту Microsoft Office Document Scanning. Она производит конвертацию сканируемого файла автоматически, переводя его сразу в текст (программа не работает с более “свежими” версиями Офиса).
- Рекомендуется сканировать в черно-белой гамме, а не в цветной – это упрощает анализ текста.
- TIFF формат лучше всего применять для OCR конвертеров, то есть программ, производящих оптическое распознавание.
Способ открыть скан сразу в Ворде
PDF-скан
- Убедитесь точно, что Ваш файл сохранен в PDF формате и открывается в программе просмотра таких документов по двойному щелчку мыши.
- Кликните по нему правой кнопкой для вызова контекстного меню. Среди доступных вариантов выберите «Открыть с помощью», а там в перечне программ — Microsoft Word.
- После предложения конвертации файла, ничего не меняя, кликните на «OK».
- Ворд начнет «переводить» PDF документ в текстовый «doc».
 Это может занять от нескольких секунд до минут, в зависимости от размера источника.
Это может занять от нескольких секунд до минут, в зависимости от размера источника. - Когда конвертация закончиться Вам станет доступным результат, но вверху может появиться желтая или красная полоса с предупреждением о редактировании. Разрешите внесение изменений кнопкой на ней.
- Проверьте текст на наличие ошибок и других проблем. При необходимости исправьте под свои требования.
- Теперь можно сохранить документ. Используйте закладку «Файл» в главном меню или комбинацию клавиш CTRL+S на клавиатуре. Укажите требуемое имя и папку для сохранения на диске.
Изображение
- Найдите в интернете сервис преобразования изображений в PDF файлы. Одним из лучших в этой области является New OCR (https://www.newocr.com/).
- Откройте сайт по ссылке выше. Нажмите на кнопку «Обзор» и выберите свое сканированное изображение. Дождитесь загрузки, а затем нажмите на «Просмотр». Увидите предварительный результат.
- Для получения текста, который можно вставить в Word или другой редактор, кликните на кнопку «OCR».
- Таким же образом можно конвертировать PDF файлы в DOCX.
Как отредактировать отсканированный документ – работа с OCR-утилитами
Принцип метода Optical Character Recognition — считывание имеющихся на бумаге символов, их последующее сравнение с элементами из собственной базы данных. Таким образом происходит преобразование сплошной картинки в редактируемый текст. Яркие примеры программ, справляющихся с данной задачей – Adobe Acrobat и Evernote. Чтобы внести исправления в имеющийся скан, просто откройте его одним из таких приложений, весь последующий процесс произойдет автоматически. Когда программа закончит распознавание, то предложит пользователю сохранить документ в одном из доступных форматов.
Если отсканированный документ сохранен в файле PDF, мы с легкостью сможем отредактировать его в программе Acrobat DC. Для этого:
- открываем меню “Инструменты” -> “Редактировать PDF”;
- программа запускает процесс редактирования, показывая меню подсказок в правом углу сверху;
- щелкнув на ней и выбрав “Параметры”, можно указать язык распознавания;
- что внести изменения, просто щелкните на любой строке документа;
- документ, открытый для редактирования через OCR, сопровождается особой панелью с настройками, размещенной в правой стороне экрана;
- в разделе “Настройки”, кроме языка, также удобно выбирать отображаемый шрифт, отмечать страницы, которые необходимо редактировать (все или по одной).

Во всемирной сети существует доступная альтернатива устанавливаемым программам-конвертерам. Это онлайновые OCR, которые без труда переведут полученное изображение в любой текстовый формат. К примеру, сайт pdfonline.com позволит за несколько минут из отсканированного PDF-документа сделать обычный файл MS Word.
Решение задачи с помощью онлайн-сервисов
Если вас интересует ответ на вопрос о том, как изменить отсканированный документ, не устанавливая специальных программных приложений, то воспользуйтесь любым онлайн-сервисом, предлагающим конвертирование изображений в текст. Обычно все эти ресурсы работают по одной схеме. Вам нужно лишь загрузить скан документа, предварительно сохранив его в PDF-формате, после чего следуя рекомендации выбрать нужное задание и нажать на что-то типа «Конвертировать» (везде по-разному). Затем сервис выдаст вам готовый файл в виде документа Word.
- Одним из самых удобных и лучших сервисов, предлагающих конвертирование PDF в Word с целью редактирования скана, является smallpdf.
 com . Его преимущества заключаются в простом интерфейсе, быстрой работе, отличном качестве результата, поддержке работы с Dropbox и Google-диском и массой дополнительных функций. Бесплатно воспользоваться им можно только два раза в час. При необходимости вы можете приобрести платный Pro-аккаунт, в результате чего список функций будет заметно расширен.
com . Его преимущества заключаются в простом интерфейсе, быстрой работе, отличном качестве результата, поддержке работы с Dropbox и Google-диском и массой дополнительных функций. Бесплатно воспользоваться им можно только два раза в час. При необходимости вы можете приобрести платный Pro-аккаунт, в результате чего список функций будет заметно расширен. - Также довольно удобным онлайн-сервисом конвертации является zamzar.com. Он отличается возможностью пакетной обработки файлов, большим количеством вариантов конвертирования и быстротой. При этом использовать этот ресурс можно абсолютно бесплатно. Однако здесь имеются ограничения по размеру – не больше 50 мб. Чтобы снять этот лимит, вам придется оплатить соответствующий тариф. Кроме того, результат можно получить только на e-mail, который придется предварительно ввести перед загрузкой файла.
Инструкция
Если сканирование осуществлялось в режиме распознавания текста, то содержимое полученного документа можно изменить еще до его сохранения — большинство программ, предназначенных для сканирования и распознавания, имеют встроенные редакторы текста. Например, в популярной среди русскоязычных пользователей сканеров FineReader каждая страница отсканированного и переведенного в текстовый формат документа открывается в отдельном окне, имеющем меню редактирования, функциональные возможности которого схожи с функциями обычного текстового редактора. Если же отсканированный и распознанный текст был сохранен в файл, то изменить его можно стандартным текстовым редактором. Воспользуйтесь для этого, например, Microsoft Word — этот текстовый процессор способен прочесть большинство форматов, используемых для сохранения текстов OCR-программами.
Например, в популярной среди русскоязычных пользователей сканеров FineReader каждая страница отсканированного и переведенного в текстовый формат документа открывается в отдельном окне, имеющем меню редактирования, функциональные возможности которого схожи с функциями обычного текстового редактора. Если же отсканированный и распознанный текст был сохранен в файл, то изменить его можно стандартным текстовым редактором. Воспользуйтесь для этого, например, Microsoft Word — этот текстовый процессор способен прочесть большинство форматов, используемых для сохранения текстов OCR-программами.
Если отсканированный документ был сохранен в формате изображения, то для его правки следует использовать какой-либо графический редактор. В некоторых случаях будет достаточно стандартного приложения Paint, устанавливаемого по умолчанию вместе с операционной системой Windows. Откройте в нем файл, содержащий изображение , выделите участок картинки, который следует заменить, и залейте его цветом, совпадающим с фоном документа. Затем подберите размер, цвет и шрифт, соответствующий тексту, и напечатайте новый фрагмент поверх залитого участка. Однако в большинстве случаев для замены текста требуется более тщательная работа с изображением — копирование фоновых участков и помещение копий поверх текста в несколько слоев, деформация набранного текста в соответствии с состоянием исходного документа, копирование и вставка отдельных букв и слов текста и т.д. Поэтому намного больше подходит для этой работы более продвинутый графический редактор — например, Adobe Photoshop.
Затем подберите размер, цвет и шрифт, соответствующий тексту, и напечатайте новый фрагмент поверх залитого участка. Однако в большинстве случаев для замены текста требуется более тщательная работа с изображением — копирование фоновых участков и помещение копий поверх текста в несколько слоев, деформация набранного текста в соответствии с состоянием исходного документа, копирование и вставка отдельных букв и слов текста и т.д. Поэтому намного больше подходит для этой работы более продвинутый графический редактор — например, Adobe Photoshop.
Есть и еще один способ замены фрагмента исходного текста в сохраненном как изображение отсканированном документе. Его можно использовать, если есть возможность сканирования нового фрагмента с отредактированным текстом. Нужный текст можно напечатать на такой же (или той же самой) бумаге, что и исходный документ, поэтому внешний вид исходного и исправленного фрагментов будет совпадать в большей мере, чем этого можно добиться в графическом редакторе. Отсканированную часть текста затем надо наложить на редактируемый документ с помощью любого графического редактора — такая операция предусмотрена практически во всех приложениях этого рода.
Отсканированную часть текста затем надо наложить на редактируемый документ с помощью любого графического редактора — такая операция предусмотрена практически во всех приложениях этого рода.
- какой программой можно редактировать документ
Сканирование текста производится для того, чтобы перевести его из «аналогового» формата в цифровой. В процессе данной конвертации в текст зачастую закрадываются ошибки. Поэтому текст иногда приходится редактировать. Сделать это можно несколькими способами.
Инструкция
Обратите внимание
Используйте онлайновые сервисы для распознавания текста в случае, если вам необходимо распознать небольшое количество страниц. Если вы постоянно занимаетесь сканированием и распознаванием текста — приобретите мощную платную программу.
Очень часто случается так, что требуется отредактировать текст, содержащийся только в бумажном варианте. Для распознавания и на данный момент имеется немало программ, которые различаются не только качеством результатов, но и расширенным функционалом. Fine Reader является одним из лучших существующих приложений для выполнения этих целей.
Fine Reader является одним из лучших существующих приложений для выполнения этих целей.
Вам понадобится
- — текстовый редактор;
- — программа Fine Reader.
Инструкция
Скачайте и установите программу распознавания , например, Fine Reader. Ознакомьтесь с функционалом программы – многие современные версии поддерживают интеграцию отсканированного текста прямо в Word, если такая функция имеется в вашей копии программы, выполните операцию, пропустив следующие пункты.
Если у вас старые версии программы, отсканируйте нужный для редактирования документ при помощи стандартной программы вашего копировального оборудования, которым вы обычно пользуетесь, и сохраните его в формате.jpg на вашем е.
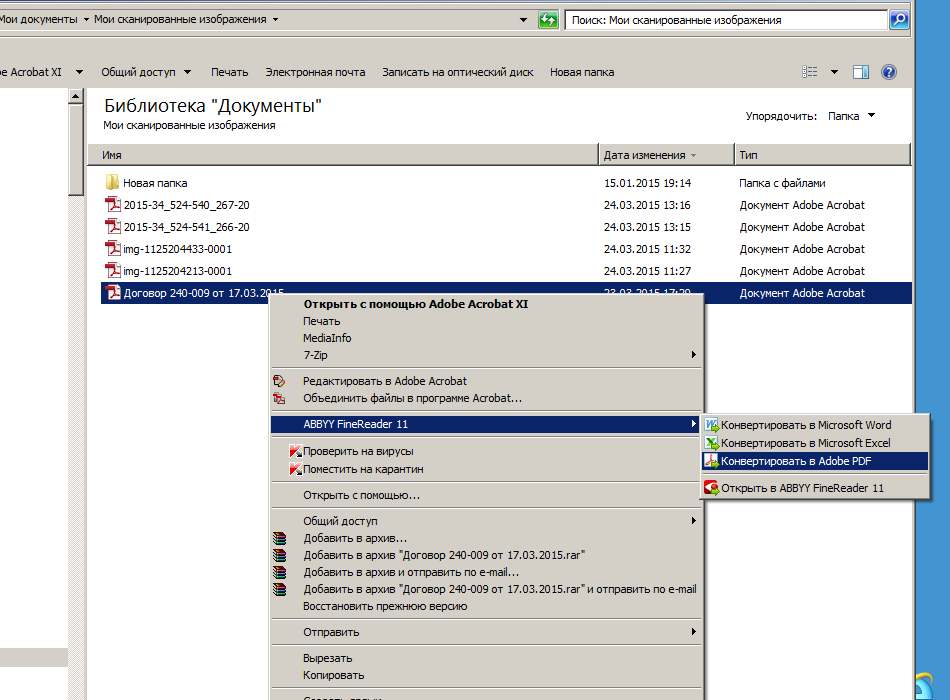
Щелкните один раз правой кнопкой мыши по сохраненному изображению, выберите пункт «Открыть с помощью…» и в появившемся списке программ выберите недавно установленный вами Fine Reader. Если нужно, отметьте флажком пункт «Использовать для всех данных для файлов этого типа.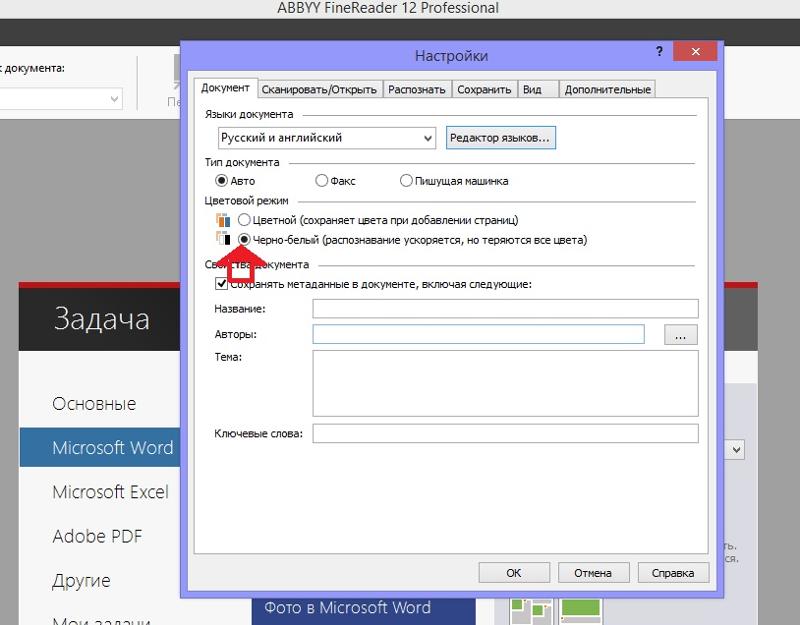 Также вы можете просто отсканировать изображение при помощи уже открытой программы, выбрав пункт “Scan and Read”, при этом изображение с устройства импортируется прямиком в рабочую область. Для этого предварительно в настройках укажите параметры работы сканера в режиме программы Fine Reader.
Также вы можете просто отсканировать изображение при помощи уже открытой программы, выбрав пункт “Scan and Read”, при этом изображение с устройства импортируется прямиком в рабочую область. Для этого предварительно в настройках укажите параметры работы сканера в режиме программы Fine Reader.
В открывшемся окне программы выберите пункт «Распознать текст». Подождите, пока программа выполнит чтение документа. Если результаты операции не будут соответствовать вашим требованиям, измените настройки сканирования и распознавания и повторите процедуру заново.
Сохраните получившийся документ в любом формате, который поддерживается программой Microsoft Office Word. Закройте Fine Reader, перейдите в папку, в которую был сохранен ваш документ.
Откройте файл при помощи MS Office Word или любого другого текстового редактора, в котором вам удобно работать. Произведите нужные изменения в файле, сохраните результаты.
Обратите внимание
Обратите особое внимание на настройки сканирования, лучше всего заранее выставить нужные параметры.
Полезный совет
Скачивайте программу только с официального сайта Abbyy.
Графический редактор Adobe Photoshop позволяет наносить новые слои на фон, в числе которых могут быть и текстовые слои. После заполнения текстового слоя на изображении появляется надпись, редактирование которой становится возможным после совершения определенных действий.
Вам понадобится
- Программное обеспечение Adobe Photoshop.
Инструкция
Добавьте на изображение текстовый слой. Для этого перейдите к панели инструментов, которая находится в левой части открытого окна, и щелкните левой кнопкой мыши на значке с изображением буквы «Т». Затем щелкните мышью на любом участке вашего изображения, на панели слоев появится новый текстовый слой.
Новый слой получает название от первых букв вводимых слов или фраз. Начните вводить любой текст. Для перемещения этого слоя используйте специальный маркер, находящийся в середине текущего выделения — захватите его левой кнопкой мыши и перетащите форму ввода в другое место.
Чтобы изменить форму блока текстового слоя, нажмите верхнее меню «Редактирование» и выберите пункт «Свободное трансформирование». Зацепите любой край изображения (квадратный маркер) и потяните в сторону. С помощью этого инструмента вы можете выполнить любое искажение текстового блока, а, соответственно, и самого текста.
При работе с бумажными документами, рукописями или книгами зачастую возникает необходимость перевести всё в электронный формат. Это открывает гораздо больше возможностей и существенно облегчает процесс редактирования. При наличии сканера или цифрового фотоаппарата с высоким разрешением сделать это не составит труда, но дальше возникает вопрос, как отсканированный документ перевести в формат Word? Чтобы не пришлось всё перепечатывать вручную, следует воспользоваться специализированным программным обеспечением.
Послесловие
Пакет Office представляет собой широкий набор инструментов для решения самых разнообразных задач. У каждой из входящих в него программ есть своя функциональность, и они дополняют друг друга при выполнении офисных работ.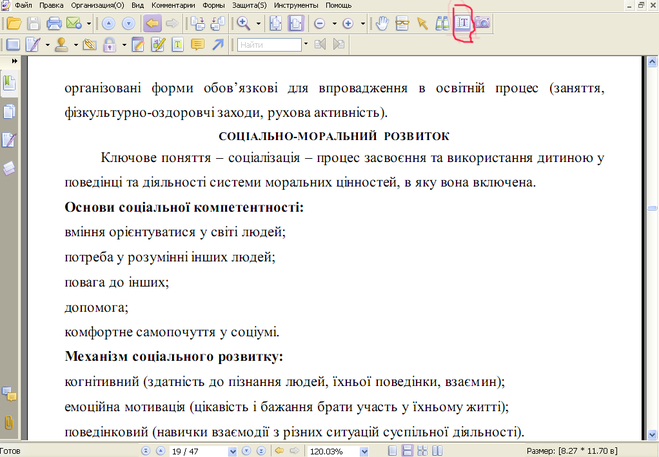 В частности, для редактирования отсканированных документов в Word потребуется программа распознавания, и в пакете она представлена. Такая структура «Всё-в-одном» весьма удобна, так как не приходится думать, где найти и как установить сторонний софт, не нужно разбираться с особенностями его интерфейса: есть решения, выполненные в едином стиле. Поэтому Office был и остаётся стандартом де-факто для офисной работы.
В частности, для редактирования отсканированных документов в Word потребуется программа распознавания, и в пакете она представлена. Такая структура «Всё-в-одном» весьма удобна, так как не приходится думать, где найти и как установить сторонний софт, не нужно разбираться с особенностями его интерфейса: есть решения, выполненные в едином стиле. Поэтому Office был и остаётся стандартом де-факто для офисной работы.
Что же касается возможности вставить изображение напрямую в Word и редактировать его прямо оттуда, то пока что такой режим не поддерживается. Однако учитывая тенденции на объединение программ внутри пакета и уход в онлайн (мы имеем в виду Office365), стоит этого вскоре ожидать. Сейчас же нужно будет установить требуемый компонент (если он ещё не был установлен) и работать именно так.
С помощью программы FineReader можно легко преобразовать текст с бумажного носителя в файл формата Ворд и отредактировать его при необходимости.
Узнать все этапы проведения данной процедуры можно в представленной статье.
Большое количество пользователей, работающих с документами, нередко сталкиваются с необходимостью копирования текста с бумажного носителя в Word. В этом случае самым оптимальным выбором будет сканирование текста и его дальнейшее редактирование.
Сделать это возможно с помощью современной программы FineReader, она успешно преобразует обычную фотографию, полученную со скана, в осмысленный набор слов.
Сканирование в Microsoft Word
С помощью стартового окна вы можете создавать документы Word при помощи сканера или фотоаппарата.
- На закладке Сканировать нажмите Сканировать в Microsoft Word.
- Выберите устройство и задайте параметры сканирования.
- Нажмите кнопку Просмотр или в любом месте области сканирования.
- Просмотрите полученное изображение, при необходимости измените параметры и снова нажмите Просмотр.
- Укажите настройки выбранного формата.Внешний вид и свойства полученного документа будут зависеть от выбранных вами настроек.

- Сохранять форматирование. Выбор режима сохранения форматирования зависит от того, как вы будете использовать созданный документ в дальнейшем:
- Точная копияВозможность редактирования выходного документа ограничена, но при этом максимально точно сохраняется внешний вид документа.
- Редактируемая копияОформление выходного документа может незначительно отличаться от оригинала. Полученный документ легко редактируется.
- Форматированный текстСохраняются только шрифты, их размеры и начертание, разбиение на абзацы. Полученный документ содержит сплошной текст, записанный в одну колонку.
- Простой текстСохраняется только разбиение на абзацы. Весь текст форматируется одним шрифтом и располагается в одной колонке.
- Языки распознавания — необходимо правильно указать языки документа. Подробнее см. «Языки распознавания».
- Сохранять картинки — отметьте эту опцию, если вы хотите сохранять иллюстрации в полученном документе.
- Сохранять колонтитулы и номера страниц — в полученном документе будут сохранены колонтитулы и номера страниц.

- Настройки предобработки изображений… — вы можете задать настройки обработки файлов изображений, включая определение ориентации страницы и автоматическую обработку изображений. Эти настройки позволяют значительно улучшить исходное изображение и получить более точные результаты конвертации. Подробнее см. «Параметры обработки изображений».
- Другие настройки… — позволяет открыть Настройки форматов на закладке DOC(X)/RTF/ODT диалога Настройки (меню Инструменты > Настройки…) и задать дополнительные настройки.
- Нажмите Сканировать в Microsoft Word.
- После запуска на экране появится панель выполнения задачи, содержащая индикатор выполнения и подсказки.
- После завершения сканирования текущей страницы на экране появится диалог выбора дальнейшего действия. Нажмите Сканировать снова, чтобы запустить процесс сканирования следующих страниц с текущими настройками, или Завершить сканирование, чтобы закрыть диалог.
- Укажите папку для сохранения полученного Word-документа.

По завершении задачи документ Microsoft Word будет создан в указанной папке. Кроме того, все изображения будут добавлены в OCR-редактор и доступны для обработки.
help.abbyy.com
Загрузка и сканирование
Для запуска процесса:
Данная программа автоматом выделит фрагменты документа, рисунки и таблицы, при необходимости повернет сканированный текст по нужному направлению. После завершения сканирования, в данной программе требуется выбрать язык для расшифровки написанного.Выбрать его можно в выпадающем окне «Язык документа», если загруженный скан будет написан на нескольких иностранных языках – следует выбрать автоматический режим.
Редактирование
Конвертирование в формат Word
compsch.com
Как вырезать подпись из отсканированного документа?
Сделать это можно несколькими способами. Если вы не знаете, как осуществить подключение вашего устройства к компьютеру, то обратитесь в службу поддержки его производителя. Ситуация может существенно различаться от модели к модели.
Ситуация может существенно различаться от модели к модели.
- Сканирование картинок
- Как разместить отсканированный текст?
- Как перенести отсканированную подпись в другой документ?
- Как осуществляется сканирование и вставка подписи?
- Создание подписи
- Вставка подписи
- Как добавить к подписи текст?
- Как вставить рукописную подпись вместе с машинописным текстом?
- Добавление путем подчеркивания пробелов
- Как добавить строку с помощью подчеркивания пробелов?
Сканирование картинок
В данном случае вам подойдет не только сканер, но и копировальный принтер (не любая модель), МФУ. Также можно сделать снимок с помощью цифровой камеры или смартфона. Изображение должно быть в одном из 3 форматов: GIF, PNG, JPEG. Поместите курсор в ту часть документа, где хотите разместить контент. Отыщите в панели управления пункт «Вставка» и выберите «Рисунок».
Как разместить отсканированный текст?
Для сканирования текстовых материалов можно воспользоваться утилитой Office Lens.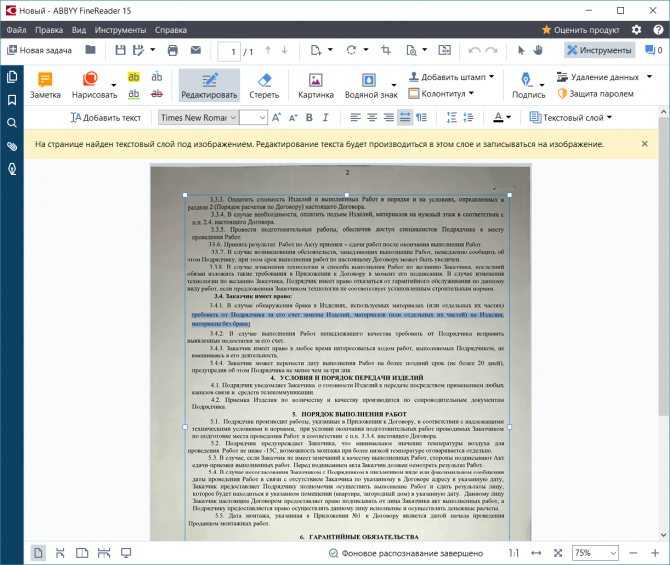 Она бесплатная, работает как на смартфонах, так и планшетах. Программа отлично функционирует на всех популярных операционных системах (как мобильных, так и стационарных).
Она бесплатная, работает как на смартфонах, так и планшетах. Программа отлично функционирует на всех популярных операционных системах (как мобильных, так и стационарных).
Лучше всего выбрать формат PDF. В Word вам необходимо выбрать пункт «Файл» и «Открыть». Перед вам откроется диалоговое окно, которое попросит подтвердить желание вставить PDF-документ.
Помните о том, что многое зависит от точности сканирования. Лучше всего работать с печатными материалами. У вам может быть сканер, который распознает документы, так что обязательно просмотрите инструкцию производителя.
Как перенести отсканированную подпись в другой документ?
Для решения данной задачи чаще всего используется «Фотошоп». Конечно, вы можете воспользоваться Paint, но это менее удобный и функциональный инструмент. В «Фотошопе» вы просто откроете документ, выделите нужную область, скопируете ее, а после перенесете в другой файл.
В «Adobe Photoshop» воспользуйтесь «Прямоугольной областью». Выделите необходимое место по контуру.
Как осуществляется сканирование и вставка подписи?
В Microsoft Word имеется весь необходимый функционал для проведения таких операций. При этом, работать можно как с печатными, так и рукописными подписями. Далее все узнаете, как осуществить все действия, сможете подготовить место.
Создание подписи
Предварительно необходимо создать подпись. Для этого вам потребуется белая бумага, а также сканер.
Вставка подписи
- Возьмите лист и распишитесь на нем.
- Отсканируйте подпись и сохраните ее в одном из ранее упомянутых форматов. Если у вас нет сканера, то воспользуйтесь цифровой камерой. Она есть в любом смартфоне.
- Теперь добавьте файл в документ.
- Вполне возможно, что вставленное изображение придется обрезать, менять размер.
- Вы можете легко разместить подпись в необходимом месте.
 Необходимо лишь переставить ее мышью.
Необходимо лишь переставить ее мышью.
Как добавить к подписи текст?
Обычно в документе необходимо также разместить фамилию, должность, номер телефона. Текстовые сведения можно отсканировать вместе с подписью. Но есть и другой вариант.
- Разместите курсор перед подписью или под ней. Далее начните вводить нужный текст.
- Выделите подпись вместе с текстом.
- Отправьтесь во вкладку «Вставка» и выберите в ней «Экспресс-блоки». Они находятся в подпункте «Текст».
- В открывшемся меню нажмите на «Сохранить выделенный фрагмент…».
- В появившемся окне заполните необходимее поля. Важно ввести имя и выбрать «Автотекст».
- Созданная подпись и текст будут сохранены в виде автотекста. Теперь их можно использовать и в других документах.
Как вставить рукописную подпись вместе с машинописным текстом?
Для решения этой задачи вам необходимо открыть ранее созданный «Автотекст».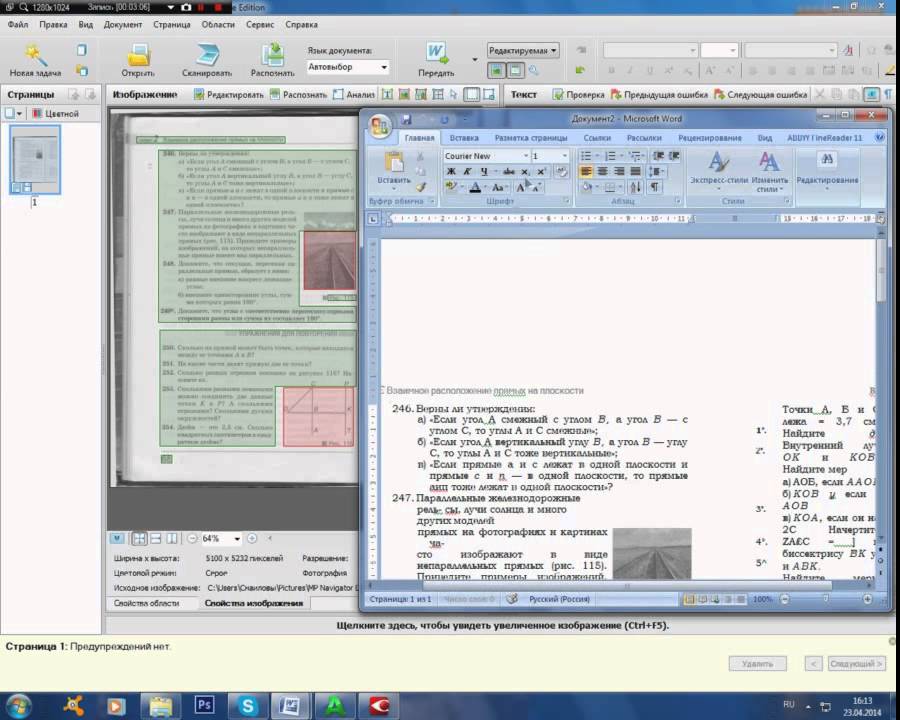
- Кликните на месте размещения и нажмите на «Вставка».
- Выберите «Экспресс-блоки».
- Кликните на «Автотекст».
- Выберите подходящий блок и вставьте его в документ.
- Рукописная подпись вместе с текстом появятся в файле.
Как вставить строку для подписи?
Она часто требуется в официальных документах. Существует несколько способов для решения этой задачи.
Добавление путем подчеркивания пробелов
Для упрощения задачи рекомендуется пользоваться знаками табуляции.
- Кликните на место, где должна располагаться строка.
- Нажимайте на TAB. Количество нажатий будет зависеть от длины строки.
- Кликните на «Главную» и выберите группу «Абзац». Здесь нажмите на символ «пи».
- Выделите знаки табуляции, которые требуется подчеркнуть. Они появятся в виде стрелок.
- После этого нужно нажать на «CTRL + U».
 Либо воспользуйтесь специальным символом с подчеркиванием. Он есть во вкладке «Шрифты».
Либо воспользуйтесь специальным символом с подчеркиванием. Он есть во вкладке «Шрифты».
Стандартное подчеркивание может вас не устроить. Тогда перейдите в меню «Шрифт» и выберите подходящий стиль линий.
- На выбранном вами месте появится полоса.
- Теперь можно отключить режим отображения символов.
Как добавить строку с помощью подчеркивания пробелов?
Для этого следует добавить ячейки таблицы. В них должна отображаться исключительно нижняя граница. В данном случае созданная линия будет оставаться на одном месте при печати. Она может сопровождаться вводным текстом, к примеру, подписью или датой.
Поделиться с друзьями:
Как вытащить картинку из PDF — 5 способов
Когда возникает необходимость извлечь картинку из PDF файла, многие пользователи испытывают трудности. Дело в том, что PDF файлы не так просто редактировать.
Формат PDF (Portable Document Format), разработанный компанией Adobe Systems, широко распространен и используется для хранения документов, инструкций, электронных книг. Преимуществами формата является то, что документ, созданный в формате PDF, одинаково отображается на любом устройстве.
Преимуществами формата является то, что документ, созданный в формате PDF, одинаково отображается на любом устройстве.
Содержание:
- Как извлечь изображение из PDF — 1 способ
- Как достать картинку из PDF — 2 способ
- Как вытащить изображение из PDF — 3 способ
- Извлекаем изображения из PDF на PDF Candy — 4 способ
- Вытаскивание картинки из PDF на iLovePDF — 5 способ
- Выводы статьи
Как из PDF файла вытащить картинки? Для этого, существуют продвинутые платные программы для редактирования PDF файлов. В этой статье мы рассмотрим способы извлечения изображений из PDF, без использования платных инструментов.
Вы познакомитесь с несколькими самыми простыми способами для извлечения картинок из PDF. Файл в формате PDF может иметь разные свойства. Поэтому для решения проблемы: извлечения картинки из PDF, мы будем применять разные способы.
Для этого, нам понадобится бесплатная программа Adobe Acrobat Reader — просмотрщик PDF файлов, приложение для создания скриншотов, или веб-приложение на онлайн сервисе в интернете. Вы можете использовать программу на компьютере или удаленный сервис, которым доступен в любой операционной системе с разных устройств.
Вы можете использовать программу на компьютере или удаленный сервис, которым доступен в любой операционной системе с разных устройств.
Если вам, наоборот, нужно сделать PDF файл из изображений, прочитайте подробную статью на моем сайте.
Подробнее: Как сделать из изображений PDF файл — 7 примеров
Как извлечь изображение из PDF — 1 способ
Сначала рассмотрим самый простой способ, при котором файл в формате PDF состоит текста и изображений. В данном случае, мы осуществим копирование изображения непосредственно из PDF файла.
Откройте PDF файл в программе Adobe Acrobat Reader. На странице документа нажмите на нужное изображение, картинка выделится в голубом фоне. Далее кликните по изображению правой кнопкой мыши, в открывшемся контекстном меню нажмите на «Копировать изображение».
Картинка из PDF файла скопирована в буфер обмена. Вставьте изображение в другой текстовый редактор, например, в Word, или откройте картинку в графическом редакторе, для сохранения файла в нужном графическом формате (JPEG, PDF, BMP, GIF и т.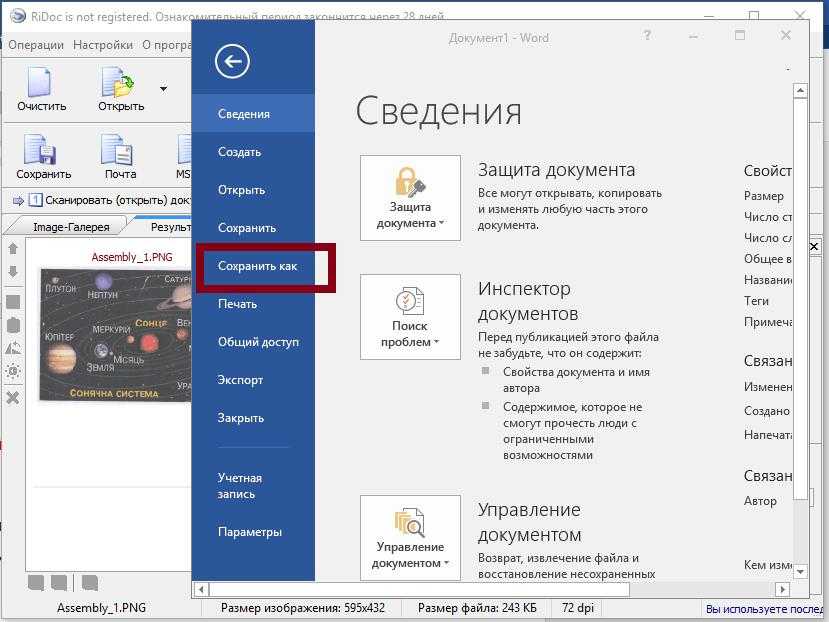 д.).
д.).
Откройте графический редактор Paint, встроенный в операционную систему, который вы найдете в меню «Пуск», в Стандартных программах Windows.
В программе Paint нажмите на меню «Файл», в контекстном меню выберите пункт «Сохранить как». Выберите необходимый графический формат для данного изображения, место сохранения, изображение на компьютер.
Как достать картинку из PDF — 2 способ
Во многих случаях файлы в формате PDF создаются из изображений, особенно это касается электронных книг. В таком файле целая страница является одним изображением, а нам необходимо извлечь только определенную картинку (на странице может быть много картинок) из данной страницы. Первый способ, в этом случае, нам не подойдет.
Для копирования картинки в программе Adobe Reader, мы воспользуемся встроенным в программу инструментом «Снимок».
Откройте нужную страницу в Adobe Acrobat Reader. Выделите картинку в PDF файле вручную с помощью курсора мыши. Войдите в меню «Редактирование», в выпадающем контекстном меню нажмите на пункт «Сделать снимок».
В окне программы Adobe Reader появится сообщение о том, что выделанная область скопирована в буфер обмена.
Теперь изображение можно открыть в Paint, в другом графическом редакторе, или вставить в текстовый редактор, поддерживающий вставку изображений.
Как вытащить изображение из PDF — 3 способ
В некоторых случаях, у пользователей возникают затруднения, когда они пытаются вытащить картинку из PDF первыми двумя способами, а ничего не получается.
Файл в формате PDF может быть защищен. Поэтому, извлечь картинки из PDF файла такими способами не удается.
В некоторых ситуациях, необходимо скопировать картинку из PDF, которая не имеет четких прямоугольных границ. Давайте усложним задачу. Как быть, если из защищенного PDF файла нужно скопировать изображение, не имеющее четких границ (обрамленное текстом или другими элементами дизайна)?
Можно очень легко обойти эти препятствия. Решение очень простое: необходимо воспользоваться программой для создания снимков экрана.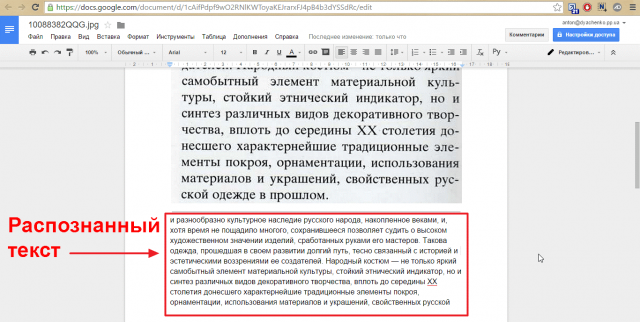 Потребуется всего лишь сделать скриншот (снимок экрана) необходимой области, которую входит интересующее нас изображение.
Потребуется всего лишь сделать скриншот (снимок экрана) необходимой области, которую входит интересующее нас изображение.
Откройте PDF файл в программе Adobe Acrobat Reader. Затем запустите программу для создания скриншотов. Для этого подойдет стандартная программа «Ножницы», входящая в состав операционной системы Windows, или другая подобная более продвинутая программа.
Я открыл в Adobe Reader электронную книгу в формате PDF, которая имеет защиту. Я хочу скопировать изображение, которое не имеет четких прямоугольных границ.
Для создания снимка экрана, я использую бесплатную программу PicPick (можно использовать встроенное в Windows приложение Ножницы). В программе для создания скриншотов, нужно выбрать настройку «Захват произвольной области».
Далее с помощью курсора мыши аккуратно обведите нужную картинку в окне программы, в данном случае, Adobe Acrobat Reader.
После захвата изображения произвольной области, картинка откроется в окне программы для создания скриншотов. Теперь изображение можно сохранить в необходимый графический формат на компьютере. В настройках приложения выберите сохранение картинки в соответствующем формате.
Теперь изображение можно сохранить в необходимый графический формат на компьютере. В настройках приложения выберите сохранение картинки в соответствующем формате.
Извлекаем изображения из PDF на PDF Candy — 4 способ
PDF Candy — бесплатный сервис с большим количеством инструментов для работы с фалами в формате PDF. На сайте имеется средство для извлечения изображений из PDF.
Извлеченные изображения будут сохранены без потери качества, в том виде, в котором они находились внутри документа PDF. Картинки будут сохранены как отдельные изображения, их можно скачать по отдельности или сразу все в ZIP-архиве.
Пройдите последовательные шаги:
- Перейдите по ссылке https://pdfcandy.com/ru/extract-images.html на страницу сайта PDFCandy.
- Перетащите PDF файл с компьютера в специальную форму, добавьте файл из облачных хранилищ Google, Drive Dropbox, или нажмите на кнопку «Добавить файл».
- После завершения обработки нажмите на кнопку «Скачать файл», чтобы загрузить все извлеченные картинки в ZIP-архиве, скачайте изображения по отдельности, или отправьте их в облачные хранилища.

Вытаскивание картинки из PDF на iLovePDF — 5 способ
iLovePDF — онлайн инструменты для работы с файлами формата PDF. На сервисе имеется веб-приложение способное извлекать изображения из файлов ПДФ.
Выполните следующие действия:
- Откройте веб-страницу https://www.ilovepdf.com/ru/pdf_to_jpg на сайте iLovePDF.
- Нажмите на кнопку «Выбрать PDF файл», перетащите документ в специальную область, или загрузите из облачных хранилищ Google Диск и Dropbox.
- На следующей странице, в опции «Параметры PDF в JPG» выберите параметр «Извлечение изображений», а затем нажмите на кнопку «Конвертация в JPG».
- Скачайте все извлеченные картинки в формате JPG на свой компьютер в ZIP-архиве, отправьте изображения в облачные хранилища, поделитесь ссылкой на скачивание или отсканируйте QR-код.
Выводы статьи
С помощью нескольких простых способов можно легко извлечь картинки из PDF файла, используя бесплатные программы на компьютере или веб-приложения в интернете. Картинки будут вытащены из PDF, даже в том случае, если на файле PDF стоит защита, или нужное изображение на странице документа PDF не имеет четких прямоугольных границ.
Картинки будут вытащены из PDF, даже в том случае, если на файле PDF стоит защита, или нужное изображение на странице документа PDF не имеет четких прямоугольных границ.
Нажимая на кнопку, я даю согласие на обработку персональных данных и принимаю политику конфиденциальности
Как извлечь текст из PDF за считанные секунды
Извлечь текст из PDF (Portable Document Format) непросто. Не многие программы чтения PDF могут извлекать текст из изображений PDF или отсканированных PDF-файлов. Проблема усугубляется, если в PDF-файле есть графики, таблицы или любые другие нелинейные данные, которые нельзя просто скопировать и вставить. В этой статье мы обсудим, как можно легко извлечь текст из PDF за считанные секунды.
Вы хотите убедиться, что правильный текст извлекается из PDF каждый раз без ошибок. Лучший способ сделать это — использовать программное обеспечение для извлечения данных, такое как Docparser.
Извлечение текста из PDF за секунды
Извлекайте данные быстрее с помощью Docparser.
Попробуйте Docparser бесплатно. Кредитная карта не требуется.
Содержание
- Введение
- Как извлечь текст из PDF
- Что такое OCR?
- Кому может быть полезна технология OCR?
- Чем мне может помочь программа OCR?
- Что такое PDF?
- Какой тип текста можно извлечь из PDF-файлов?
- Зачем использовать облачный подход?
Как извлечь текст из PDF-файла
Шаг 1. Загрузите PDF-файл
Войдите в наш инструмент OCR и выберите PDF-файл для загрузки. Вы можете автоматизировать этот процесс или загружать по одному документу за раз.
Шаг 2. Добавьте правила синтаксического анализа
Прежде чем отделять текст от PDF-файла, добавьте правила для автоматизации и ускорения процесса. Таким образом, наша система будет знать, как обрабатывать такие вещи, как электронные письма и телефонные номера.
Шаг 3: экспортируйте и сохраните текст.
Вот и все. Наше приложение извлекает ваш текст прямо из изображения или PDF-файла, чтобы вы могли использовать его по своему усмотрению. Мы даже структурируем его для вас, как того требуют ваши правила.
Как облачное решение, Docparser доступен, где бы вы ни находились. Используйте любой компьютер или мобильное устройство и извлекайте текст из pdf за 30 секунд.
Извлечение текста из PDF за секунды
Находите данные быстрее с помощью Docparser.
Попробуйте Docparser бесплатно. Кредитная карта не требуется.
Избранные статьи
Что такое OCR?
OCR расшифровывается как оптическое распознавание символов. OCR — это интеллектуальная технология, которая считывает и извлекает текст из изображений и PDF-файлов. Это самый быстрый, дешевый и умный способ извлечь текст из любого счета, отсканированного PDF-файла или изображения. Вы можете сделать это на компьютерах с Linux, Windows или Mac и Python.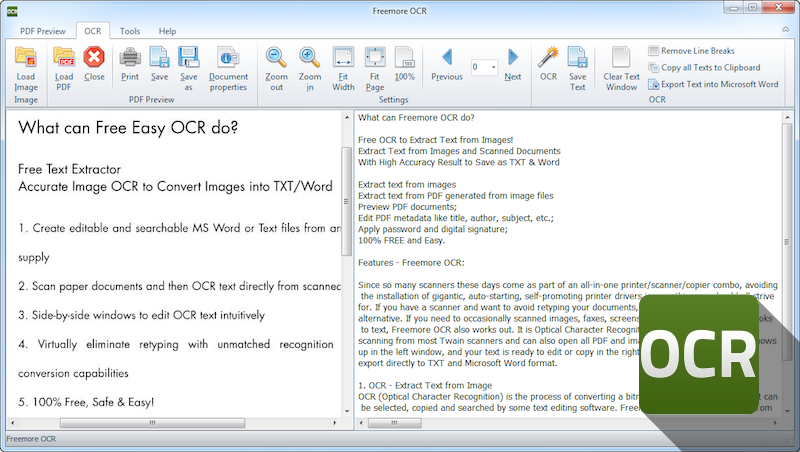
Кому может быть полезна технология OCR?
Любая компания любого размера может использовать ввод данных OCR. Как мы рассмотрели, OCR можно использовать для преобразования неизменяемых бумажных документов в редактируемые. Кроме того, документы можно передавать на компьютеры, смартфоны, планшеты и другие электронные устройства.
Практически любое предприятие извлекает выгоду из технологии OCR, но особенно:
- Банки и другие финансовые учреждения
- Любая компания, ориентированная на клиента
- Libraries
- Schools
- Medical practitioners
- And others
Some documents that are the best candidates for digitalization include:
- Invoices
- Research articles
- Tax documents
- Payroll information
- Contact information
- Данные клиента
- Юридические документы
- Финансовые инвестиции
- Среди прочего
Примеры ситуаций, в которых можно использовать технологию OCR:
Допустим, вы находитесь в дороге и достаете свой мобильный телефон, чтобы отсканировать документ клиента.
Или у вашей команды есть дамп данных. Вы хотите анализировать важные данные.
Или, возможно, клиент отправляет отсканированную копию счета в формате JPEG вместо PDF.
Или, может быть, вашему бизнесу необходимо оцифровать записи.
Независимо от области применения, технология оптического распознавания символов делает возможным все.
Чем мне может помочь программа OCR?
Технология OCR имеет ряд преимуществ. Это позволяет:
1. Сделайте ваши файлы доступными для поиска
Как правило, в PDF-файлах и текстовых электронных изображениях текстовая информация является неизменной. В результате у вас заморожен текст, который вы не можете найти или отредактировать, что делает поиск медленным и неэффективным. Таким образом, технология OCR преобразует этот неизменяемый текст в машиночитаемый и доступный для поиска текст.
Этот доступный для поиска текст также можно копировать и вставлять для других целей. Документы, недоступные для поиска, по сути бесполезны, особенно когда у вас есть сотни страниц материала, который нужно просеять, чтобы найти то, что нужно увидеть.
2. Сделайте редактирование проще
Компании постоянно меняются и развиваются. Изменения неизбежны. Каждый аспект вашей компании должен быть достаточно гибким, чтобы приспосабливаться к этим колебаниям. OCR повышает адаптивность ваших изменений. Ваши негибкие документы превращаются в легко редактируемые документы.
OCR требуется для преобразования PDF-файлов в редактируемые документы. В результате вам не нужно копировать, вставлять и создавать новый документ каждый раз, когда вносятся изменения. Вместо этого OCR позволяет вам изменить только ту часть, которую вам нужно изменить.
3. Предотвратить ошибки
Ошибаться свойственно человеку, а человеческие ошибки неизбежны. Из-за этого наличие редактируемых документов является обязательным требованием. Более того, вы хотите, чтобы технология обнаруживала ошибки в вашем документе. Человеческие ошибки могут быть устранены в кратчайшие сроки с помощью технологии OCR.
4. Экономьте время и деньги
Технология оптического распознавания символов сокращает объем бумажной работы в вашем бизнесе. Некоторые предприятия придерживаются устаревшей практики, например, продолжают хранить документы в бумажной форме. OCR значительно сокращает время и деньги, затрачиваемые на ручной ввод данных в ваш компьютер. Используйте технологию OCR для сканирования печатных документов, содержащих текст, и оцифровывайте их один за другим.
Некоторые предприятия придерживаются устаревшей практики, например, продолжают хранить документы в бумажной форме. OCR значительно сокращает время и деньги, затрачиваемые на ручной ввод данных в ваш компьютер. Используйте технологию OCR для сканирования печатных документов, содержащих текст, и оцифровывайте их один за другим.
5. Экономьте место в офисе
Бумаги занимают много места в вашем офисе: пространство, которое можно использовать для чего угодно, кроме бумажных документов.
Храните счета, квитанции, инвентарные списки и другие документы, требующие места и ручной обработки. Организуйте свое пространство с помощью оцифрованных документов.
6. Повышение производительности
Технология оптического распознавания текста помогает вашему бизнесу повысить эффективность за счет более быстрого поиска данных. Документы доступны для редактирования, поиска и легко доступны на вашем компьютере или сервере. Не тратьте время своих сотрудников, заставляя их без устали рыться в картотеках. Вместо этого попросите их направить свою энергию на другие продуктивные действия в вашем офисе.
Вместо этого попросите их направить свою энергию на другие продуктивные действия в вашем офисе.
7. Повышение безопасности данных
Да, хакеры есть, но бумажные документы тоже подвержены потере. Например, бумажные документы могут быть утеряны, украдены, сожжены или уничтожены стихийными бедствиями и другими способами, такими как наводнения или грызуны. Кроме того, доступ к файлам можно свести к минимуму, чтобы предотвратить неправильное обращение или предотвратить получение доступа нежелательными пользователями.
8. Улучшение обслуживания клиентов
Большинству колл-центров входящей связи необходимо предоставлять быстродоступные данные своим клиентам. Быстрый доступ к данным имеет важное значение для предприятий, полагающихся на поиск информации о клиентах. OCR систематически сохраняет и извлекает документы в цифровом виде с высокой скоростью. В результате время ожидания сокращается, клиенты остаются довольными, улучшается удержание клиентов и даже конверсия в будущем.
9. Восстановление после сбоев
Аварийное восстановление и избыточность данных являются значительными преимуществами технологии OCR. Когда данные оцифровываются в надежном месте, они остаются в безопасности в любой ситуации. Имейте в виду, что вы хотите распространять эти документы, создавая их резервные копии на нескольких серверах в разных местах. Природные катаклизмы, хотя и маловероятны, случаются.
10. Простота
Распознавание текста и, в частности, Зональное распознавание символов позволяет извлекать текст из определенных мест или зон в отсканированном документе. Обе эти технологии упрощают загрузку ваших документов.
Docparser, в частности, позволяет вам пакетно загружать ваши документы. Вы можете перетаскивать документы с локального диска или использовать наш API или облачную интеграцию для автоматического импорта важных документов.
Итак, что такое PDF-файлы?
PDF, переносимые форматы документов, были созданы Adobe в 1990-х годах. Это открытый формат файла, используемый для обмена электронными документами. Документы, формы, изображения и веб-страницы в формате PDF легко доступны и корректно отображаются на любом устройстве.
Это открытый формат файла, используемый для обмена электронными документами. Документы, формы, изображения и веб-страницы в формате PDF легко доступны и корректно отображаются на любом устройстве.
Если вы ничего не помните о PDF-файлах, помните, что они сохраняют макет. Независимо от того, какое устройство вы используете, целостность документа сохраняется.
Несколько забавных и интересных фактов о PDF-файлах
- Первоначальная стоимость Adobe Acrobat Reader составляла всего 50 долларов США.
- PDF-файлы можно защитить паролем.
- PDF-файлы — наиболее широко используемое расширение файлов в Интернете.
- Счета
- Формы заявлений
- Стандартизированные контракты
- Заказы на доставку
- Накладные о доставке
- Заказы на работу
- Сгенерированный отчет
- Банковские выписки
- Заполняемая PDF-форма
Docparser позволяет не только легко и удобно извлекать данные из PDF, но и может сделать это запрограммированным и автоматическим. Кроме того, он также может извлекать текст из PDF-файлов с помощью командной строки.
Кроме того, он также может извлекать текст из PDF-файлов с помощью командной строки.
После загрузки документа вы можете извлечь текст из PDF-файлов, чтобы преобразовать PDF-файлы в электронные таблицы, MS Word, JSON, XML и CSV-файлы.
Наш превосходный механизм синтаксического анализа содержит предустановки для синтаксического анализа, которые можно настроить в соответствии с требованиями вашего бизнеса. Например, если ваш PDF содержит табличные или графические данные, используйте наш механизм синтаксического анализа. После того, как вы настроите правила парсинга, Docparser позаботится обо всем остальном. Он запоминает ваши настройки для одного и того же типа документов и файлов, поэтому вам не нужно настраивать его снова и снова.
Предположим, у вас есть пакет файлов, из которых вам нужно извлечь текст — не беспокойтесь! Вы также можете загружать коллекцию файлов и обрабатывать их одновременно, что экономит ваше время и усилия.
Docparser также можно интегрировать с сотнями приложений во внешнем или внутреннем интерфейсе вашего бизнес-процесса. Эти интеграции делают процесс извлечения данных автоматическим. Вы можете импортировать документы с помощью интеграции и извлекать из них текст, или вы можете извлекать данные и экспортировать их в любое приложение или формат, который вам нравится.
Эти интеграции делают процесс извлечения данных автоматическим. Вы можете импортировать документы с помощью интеграции и извлекать из них текст, или вы можете извлекать данные и экспортировать их в любое приложение или формат, который вам нравится.
В общем, если ваш бизнес имеет дело с огромным количеством PDF-файлов любого типа, т. е. с изображениями, отсканированными файлами, вы можете безопасно и надежно использовать Docparser для автоматизации своего бизнес-процесса. После настройки извлечение данных из PDF-файлов происходит автоматически без ручного вмешательства.
Зачем использовать облачный подход для извлечения текста PDF?
Мобильность
В облачных средах ваша информация не хранится на одном компьютере. Вместо этого он хранится в «облачных пространствах». Конечно, мы не говорим о реальном облаке, но оно позволяет вам получать доступ к данным на мобильных устройствах, таких как смартфоны, планшеты, ноутбуки и другие. В результате бизнес-файлы и другие данные могут быть легко доступны кому угодно и где угодно.
Использование облачных решений, таких как Docparser, позволяет удаленным командам получать доступ к данным. В результате повышается производительность и эффективность бизнеса.
Скорость
PDF или другая обработка файлов происходит на наших серверах. Не нужно беспокоиться о совместимости вашего программного обеспечения или устройств. Вам также не нужно беспокоиться о том, чтобы просеивать бесконечные картотеки в поисках нужного файла. Загрузка документов в формате PDF повышает скорость доступа.
Аварийное восстановление и резервное копирование
Бедствия непредсказуемы и неизбежны. Никто не знает, когда произойдет бедствие, и мало что можно сделать, чтобы предотвратить его.
Сбои в ИТ могут привести к финансовым потерям и непродуктивным часам. Облачное программное обеспечение обеспечивает быстрое аварийное восстановление за счет удаленного резервного копирования всех ваших бизнес-данных. В результате вам не нужно вкладывать средства в дорогостоящие резервные копии или другие системы восстановления (хотя мы все равно рекомендуем это делать).
Масштабируемость
Облачные приложения легко масштабируются вверх или вниз. Они быстро адаптируются к постоянно меняющимся потребностям компании. Такие вещи, как емкость хранилища данных, скорость обработки и работа в сети, можно масштабировать с помощью облачных приложений. Масштабирование также может быть выполнено быстро, практически без простоев.
Обновления программного обеспечения
Поставщик услуг часто обновляет облачное программное обеспечение. Автоматические обновления экономят время вашего внутреннего ИТ-отдела и любые затраты, связанные с внешними консультациями.
Как облачное решение, Docparser доступен, где бы вы ни находились. Используйте любой компьютер или мобильное устройство и извлекайте текст из PDF за 30 секунд.
Некоторые ключевые преимущества Docparser включают:
- Пакетное преобразование PDF-файлов в Excel, CSV, JSON или XML
- Извлечение данных из PDF-файлов, как мы узнали сегодня
- Полностью автоматизированные рабочие процессы на основе документов
- Устранение необходимости ручного ввода данных
Технология OCR — это настоящее и будущее PDF.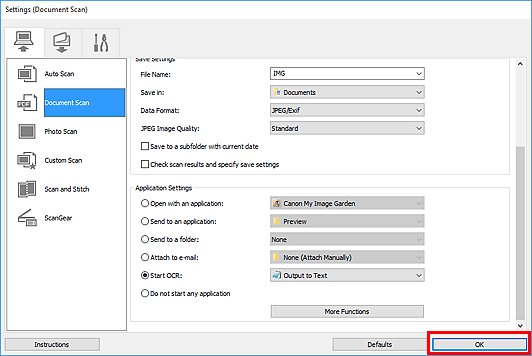 OCR повышают производительность, безопасность данных, улучшают обслуживание клиентов, аварийное восстановление, предотвращают ошибки и экономят ваше время и деньги.
OCR повышают производительность, безопасность данных, улучшают обслуживание клиентов, аварийное восстановление, предотвращают ошибки и экономят ваше время и деньги.
Извлечение текста из ваших документов и преобразование их в PDF-файлы спасает вашу компанию от катастрофических сбоев данных и ускоряет доступ к документам. Повысьте производительность и прибыль компании, перенеся бумажные документы в облачное приложение OCR.
Есть ли у вас какие-либо индивидуальные бизнес-требования? Не знаете, как встроить Docparser в свой рабочий процесс? Нужно извлечь данные из ваших пользовательских PDF-файлов? Дайте нам знать, и мы свяжемся с вами, чтобы помочь.
Извлечение текста из PDF за секунды
Быстрый поиск данных с помощью Docparser.
Попробуйте Docparser бесплатно. Кредитная карта не требуется.
Как извлечь данные из отсканированных изображений/документов
По умолчанию файлы PDF редко редактируются, кроме как автором. У большинства пользователей нет доступа к инструментам, которые сделали бы PDF редактируемым. Наряду с этим распространенной проблемой при работе с PDF-файлами является проблема со встроенными шрифтами. Текст в PDF часто нельзя выделить. Проблема в том, что PDF-файл никогда не может быть текстом, а может быть фотографией физической страницы, преобразованной в PDF-файл. С той же проблемой приходится сталкиваться при извлечении данных из изображений, поскольку текст в изображениях нельзя выделить.
У большинства пользователей нет доступа к инструментам, которые сделали бы PDF редактируемым. Наряду с этим распространенной проблемой при работе с PDF-файлами является проблема со встроенными шрифтами. Текст в PDF часто нельзя выделить. Проблема в том, что PDF-файл никогда не может быть текстом, а может быть фотографией физической страницы, преобразованной в PDF-файл. С той же проблемой приходится сталкиваться при извлечении данных из изображений, поскольку текст в изображениях нельзя выделить.
Итак, как решить эти проблемы?
В этой статье мы обсудим, как можно извлечь текст из отсканированных/неотсканированных PDF-файлов и изображений.
Давайте сразу к делу.
Извлечение текста из PDF/изображений с оптическим распознаванием символов (OCR) Технология OCR помогает сканировать документ, независимо от того, состоит ли он из текста или изображений, на наличие признаков текста. Он использует алгоритмы распознавания образов, чтобы определить, может ли какая-либо часть документа быть алфавитом, цифрой или символом. После того, как это распознавание было выполнено, средство извлечения OCR преобразует это изображение в текст в самом документе или извлекает этот текст из документа в отдельную среду. Средство извлечения OCR является важной частью технологии во многих областях и приложениях.
После того, как это распознавание было выполнено, средство извлечения OCR преобразует это изображение в текст в самом документе или извлекает этот текст из документа в отдельную среду. Средство извлечения OCR является важной частью технологии во многих областях и приложениях.
При отсутствии экстракторов OCR все извлечение данных из отсканированных документов должно выполняться вручную. Если ваши данные доступны в формате PDF, вам нужно будет воспроизвести те же данные на листе Excel, прежде чем вы сможете их проанализировать. Как вы можете себе представить, этот ручной ввод данных занимает очень много времени и подвержен всякого рода ручным ошибкам. Часто у высшего руководства не было времени на ручную обработку данных, поэтому им приходилось нанимать кого-то для этого или отдавать весь процесс на аутсорсинг. Кроме того, данные нельзя отслеживать в режиме реального времени.
Экстрактор OCR — универсальное решение всех этих проблем. Хорошо обученный экстрактор OCR может извлечь все необходимые данные за считанные секунды с минимальной ошибкой.
Хорошо обученный экстрактор OCR может извлечь все необходимые данные за считанные секунды с минимальной ошибкой.
Обработка документов становится препятствием для развития вашего бизнеса?
Присоединяйтесь к Docsumo, чтобы быть в курсе последних тенденций IDP и советов по автоматизации. Docsumo является партнером Document AI для ведущих кредиторов и страховых компаний в США.
Проблемы при извлечении данных из PDF-документовДаже если у вас есть средство извлечения OCR, часто оно имеет несколько ограничений. Вот лишь некоторые из проблем, с которыми вы можете столкнуться при извлечении OCR:0005
1. Документ никогда не был текстовым Если документ, который сканирует программа OCR, был изначально создан как текстовый документ, программа OCR, скорее всего, столкнется с легкой задачей, поскольку символы будут разборчивый. Однако, если документ никогда не был текстовым, а представляет собой изображение, преобразованное в PDF, большинству приложений OCR будет сложно извлечь данные.
Если вы извлекаете данные из PDF, не все экстракторы OCR справятся с этой задачей. Интуитивно понятно, что экстракторы OCR имеют тенденцию обрабатывать горизонтально выровненный текст как строку. В результате у него могут возникнуть значительные трудности с распознаванием таблиц, представляющих собой блоки отдельных фрагментов текста. Это может стать еще более трудным, если документ содержит вложенные таблицы — таблица внутри таблицы.
В Docsumo мы разработали специальный бесплатный инструмент, чтобы обойти это ограничение. С помощью бесплатного инструмента для извлечения таблиц Docsumo вы можете извлекать таблицы из любого отсканированного и неотсканированного документа PDF вместе с изображениями. Идите вперед и убедитесь сами.3. Четкость изображения
Четкость изображения также является важным фактором, влияющим на производительность экстрактора OCR. Только OCR-экстрактор, хорошо обученный работе с множеством различных типов изображений, сможет извлекать текст из изображений, снятых при различных типах освещения.
Только OCR-экстрактор, хорошо обученный работе с множеством различных типов изображений, сможет извлекать текст из изображений, снятых при различных типах освещения.
Оптическое распознавание символов (OCR) идентифицирует образцы света и тени в документах, которые составляют буквы, знаки и символы. В то время как ранние системы OCR были разработаны для работы с ограниченным количеством шрифтов, современная интеллектуальная технология OCR способна распознавать несколько шрифтов в документах, рукописных заметках и рукописных текстах.
Принцип работы технологии оптического распознавания символов заключается в том, что пользователи сначала загружают в системы отсканированные изображения своих документов. Технология распознает тексты и строки в этих документах посимвольно, тщательно просматривая весь документ. Как только алгоритмы OCR считывают данные, они извлекают и преобразуют документы в редактируемый текст. Пользователи могут экспортировать свои документы в виде электронных таблиц PDF, JSON, CSV, Excel или конвертировать в различные форматы файлов.
Современное распознавание символов работает с использованием обнаружения признаков вместо распознавания образов, при котором анализируются отдельные компоненты символов, букв и символов вместо обнаружения общих шрифтов. Например, правило, указывающее, что программа должна обнаруживать A как штрихи под двумя углами, имеющие заостренный конец наверху и пересекающиеся между ними горизонтальные линии — независимо от того, каким типом шрифта или стилем написан A, программа может обнаружить это.
Распознавание рукописного ввода — это эксклюзивная функция интеллектуального оптического распознавания текста, при которой программы могут считывать данные из комбинированных полей в документах и использовать распознавание функций сенсорного экрана, при этом программное обеспечение может обнаруживать пользователей, пишущих символы построчно, и распознавать определенные особенности стилей рукописного ввода, что упрощает извлекать тексты после начального чтения. Повседневное распознавание символов используется для сканирования машинописных текстов, рукописных документов и символов с фотоизображений на фото.
Сложные решения для оптического распознавания символов также способны выполнять анализ макета, когда программы выходят за рамки обычного распознавания текста и могут сканировать таблицы, макеты, столбцы и различные типы данных в документах.
Одним из важных факторов, который следует учитывать, является то, что, хотя OCR может обеспечить точность данных от 95% до 99,5%, оно далеко не идеально и требует определенной корректуры человеком после автоматического извлечения данных. Интеллектуальное OCR или ICR принимает другой оборот, поскольку модели ИИ лучше распознают различные шрифты и стили почерка из отсканированных изображений, PDF-файлов и документов, а это означает, что количество необходимых человеческих проверок становится меньше по мере того, как в системы поступает больше данных.
Некоторые программы OCR могут обеспечивать функции исправления ошибок и поддержку преобразования извлеченных данных на несколько языков, что полезно для пользователей. Технология OCR используется с начала 1920-х годов, и для оптимальной работы лучших решений пользователям важно получать четкие изображения отсканированных документов. Это должно помочь API зафиксировать точное форматирование и упростить процесс извлечения данных.
Технология OCR используется с начала 1920-х годов, и для оптимальной работы лучших решений пользователям важно получать четкие изображения отсканированных документов. Это должно помочь API зафиксировать точное форматирование и упростить процесс извлечения данных.
Предприятиям, а также отдельным пользователям требуется программа OCR, которая решает эти проблемы и помогает извлекать данные быстрее и с большей точностью. Бесплатный OCR-сканер Docsumo — это бесплатный и хорошо обученный инструмент для извлечения данных из любого документа. Попробуйте сегодня и убедитесь сами!
Как извлечь данные из отсканированных документов
Хотите извлечь данные из отсканированных документов? Try Nanonets ™ advanced AI-based OCR Scanner to extract and organize information from scanned documents automatically .
Введение
По мере того, как мир для удобства перешел от бумаги и рукописного текста к цифровым документам, важность преобразования изображений и отсканированных документов в значимые данные резко возросла.
Чтобы удовлетворить потребность в высокоточном извлечении данных из документов, многочисленные исследовательские центры и корпорации (например, Google, AWS, Nanonets и т. д.) глубоко сосредоточились на технологиях в области компьютерного зрения и обработки естественного языка (NLP). .
Расцвет технологий глубокого обучения обеспечил гигантский скачок в том, какие данные можно извлекать; мы больше не ограничены только извлечением текста, но и других структур данных, таких как таблицы и пары ключ-значение. В настоящее время многие решения предлагают различные продукты для удовлетворения потребностей частных лиц и владельцев бизнеса в извлечении данных из документов.
В этой статье рассказывается о современной технологии, используемой для извлечения данных из отсканированных документов, после чего следует краткое практическое руководство по Python. Мы также рассмотрим некоторые из популярных в настоящее время решений, представленных на рынке и предлагающих лучшие предложения в этой области.
Мы также рассмотрим некоторые из популярных в настоящее время решений, представленных на рынке и предлагающих лучшие предложения в этой области.
Извлечение данных — это процесс преобразования неструктурированных данных в интерпретируемую информацию с помощью программ, чтобы обеспечить дальнейшую обработку данных людьми. Здесь мы перечисляем несколько наиболее распространенных типов данных, которые можно извлечь из отсканированных документов.
Текстовые данные
Наиболее распространенной и наиболее важной задачей при извлечении данных из отсканированных документов является извлечение текста. Этот процесс, кажущийся простым, на самом деле очень сложен, поскольку отсканированные документы часто представляются в формате изображений. Кроме того, методы извлечения сильно зависят от типов текста. Хотя в большинстве случаев текст присутствует в плотных печатных форматах, не менее важна возможность извлечения разреженного текста из менее тщательно отсканированных документов или из рукописных писем с резко отличающимся стилем. Такой процесс позволит программам преобразовывать изображения в машинно-кодированный текст, где мы можем дополнительно организовать их из неструктурированных данных (без определенного форматирования) в структурированные данные для дальнейшего анализа.
Такой процесс позволит программам преобразовывать изображения в машинно-кодированный текст, где мы можем дополнительно организовать их из неструктурированных данных (без определенного форматирования) в структурированные данные для дальнейшего анализа.
💡
Хотите понять алгоритмы глубокого обучения, лежащие в основе таких процессов? Загляните в наш блог LayoutLM Help
Таблицы
Табличные формы — самый популярный подход к хранению данных, поскольку формат легко интерпретируется человеческим глазом. Процесс извлечения таблиц из отсканированных документов требует технологии, выходящей за рамки распознавания символов — необходимо обнаруживать линии и другие визуальные особенности, чтобы выполнить правильное извлечение таблицы и преобразовать эту информацию в структурированные данные для дальнейших вычислений. Методы компьютерного зрения (подробно описанные в следующих разделах) широко используются для достижения высокой точности извлечения таблиц.
Извлечение таблиц из отсканированных документовПары ключ-значение
Альтернативный формат, который мы часто используем в документах для хранения данных, — это пары ключ-значение (KVP).
KVP – это, по сути, два элемента данных — ключ и значение — связанные вместе в одно целое. Ключ используется как уникальный идентификатор извлекаемого значения. Классическим примером KVP является словарь, где словари являются ключами, а соответствующие определения — значениями. Эти пары, обычно незамеченные, на самом деле очень часто используются в документах: такие вопросы в опросах, как имя, возраст и цены на товары в счетах-фактурах, — все они неявно являются KVP.
Однако, в отличие от таблиц, KVP часто существуют в неизвестных форматах и иногда даже частично написаны от руки. Например, ключи могут быть предварительно напечатаны в коробках, а значения вписаны от руки при заполнении формы. Таким образом, поиск базовых структур для автоматического извлечения KVP является постоянным исследовательским процессом даже для самых передовых объектов и лабораторий.
Рисунки
Наконец, также очень важно извлекать или захватывать данные из рисунков в отсканированном документе. Статистические индикаторы, такие как круговые диаграммы и гистограммы, часто содержат важную информацию для документов. Хороший процесс извлечения данных должен быть в состоянии делать выводы из легенд и чисел, чтобы частично извлекать данные из рисунков для дальнейшего использования.
Статистические индикаторы, такие как круговые диаграммы и гистограммы, часто содержат важную информацию для документов. Хороший процесс извлечения данных должен быть в состоянии делать выводы из легенд и чисел, чтобы частично извлекать данные из рисунков для дальнейшего использования.
Хотите автоматизировать извлечение данных из отсканированных документов? Дайте Nanonets ™ более высокую точность, большую гибкость, постобработку и широкий набор интеграций!
Извлечение данных вращается вокруг двух основных процессов: Оптическое распознавание символов (OCR) , за которым следует обработка естественного языка (NLP) .
Извлечение OCR — это процесс преобразования текстовых изображений в машинно закодированный текст, в то время как последний представляет собой анализ слов для определения значений. OCR часто сопровождается другими методами компьютерного зрения, такими как обнаружение прямоугольников и строк, для извлечения вышеупомянутых типов данных, таких как таблицы и KVP, для более полного извлечения.
Основные улучшения конвейера извлечения данных тесно связаны с достижениями в области глубокого обучения, которые внесли большой вклад в области компьютерного зрения и обработки естественного языка (NLP).
Что такое глубокое обучение?
Глубокое обучение играет важную роль в ажиотаже эпохи искусственного интеллекта и постоянно выдвигается на передний план во многих приложениях. В традиционной инженерии наша цель состоит в том, чтобы спроектировать систему/функцию, которая генерирует выходные данные из заданных входных данных; глубокое обучение, с другой стороны, опирается на входные и выходные данные, чтобы найти промежуточные отношения, которые могут быть расширены на новые невидимые данные через так называемые нейронная сеть .
Нейронная сеть или многоуровневый персептрон (MLP) — это архитектура машинного обучения, вдохновленная тем, как обучается человеческий мозг. Сеть содержит нейроны, которые имитируют биологические нейроны и «активируются» при получении другой информации. Наборы нейронов образуют слои, а несколько слоев складываются вместе, чтобы сформировать сеть, которая служит целям прогнозирования нескольких форм (например, классификации изображений или ограничивающих рамок для обнаружения объектов).
Наборы нейронов образуют слои, а несколько слоев складываются вместе, чтобы сформировать сеть, которая служит целям прогнозирования нескольких форм (например, классификации изображений или ограничивающих рамок для обнаружения объектов).
В области компьютерного зрения широко применяется разновидность нейронных сетей — сверточные нейронные сети (CNN) . Вместо традиционных слоев CNN использует сверточные ядра, которые скользят по тензорам (или многомерным векторам) для извлечения признаков. В конце концов, в сочетании с традиционными сетевыми уровнями, CNN очень успешно справляются с задачами, связанными с изображениями, и в дальнейшем сформировали основу для извлечения OCR и обнаружения других функций.
С другой стороны, НЛП зависит от другого набора сетей, который фокусируется на данных временных рядов. В отличие от изображений, где одно изображение не зависит друг от друга, прогнозирование текста может быть значительно улучшено, если также учитывать слова, предшествующие или следующие за ним.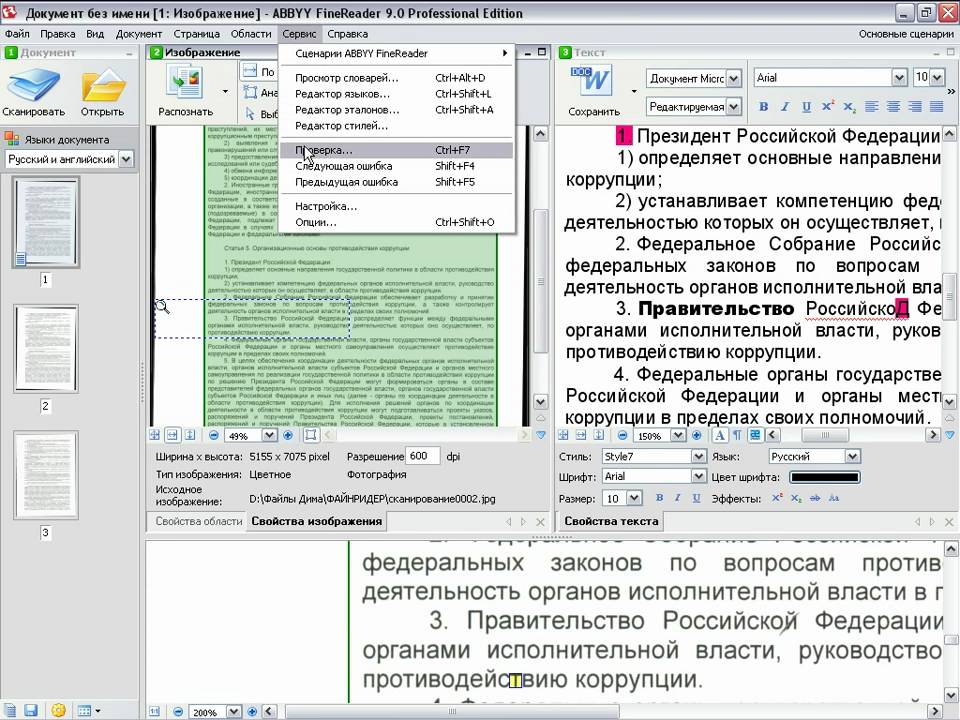 В последние несколько лет появилось семейство сетей, а именно долговременная кратковременная память 9.0003 (LSTM) , который использует предыдущие результаты в качестве входных данных для прогнозирования текущих результатов. Двусторонние LSTM также часто применялись для улучшения результатов прогнозирования, когда учитывались как результаты до, так и после. Однако в последние годы концепция преобразователей, использующих механизм внимания, начинает развиваться из-за ее более высокой гибкости, что приводит к лучшим результатам, чем традиционные сети, обрабатывающие последовательные временные ряды.
В последние несколько лет появилось семейство сетей, а именно долговременная кратковременная память 9.0003 (LSTM) , который использует предыдущие результаты в качестве входных данных для прогнозирования текущих результатов. Двусторонние LSTM также часто применялись для улучшения результатов прогнозирования, когда учитывались как результаты до, так и после. Однако в последние годы концепция преобразователей, использующих механизм внимания, начинает развиваться из-за ее более высокой гибкости, что приводит к лучшим результатам, чем традиционные сети, обрабатывающие последовательные временные ряды.
Основной целью извлечения данных является преобразование данных из неструктурированных документов в структурированные форматы, в которых высокоточный поиск текста, рисунков и структур данных может быть очень полезен для числового и контекстуального анализа. Эти анализы могут быть очень полезны, особенно для бизнеса:
Бизнес
Корпорации и крупные организации ежедневно имеют дело с тысячами документов в одинаковых форматах. Крупные банки получают множество одинаковых приложений, и исследовательским группам приходится анализировать горы форм для проведения статистического анализа. Таким образом, автоматизация начального этапа извлечения данных из документов значительно снижает избыточность человеческих ресурсов и позволяет работникам сосредоточиться на анализе данных и проверке приложений, а не на вводе информации.
Крупные банки получают множество одинаковых приложений, и исследовательским группам приходится анализировать горы форм для проведения статистического анализа. Таким образом, автоматизация начального этапа извлечения данных из документов значительно снижает избыточность человеческих ресурсов и позволяет работникам сосредоточиться на анализе данных и проверке приложений, а не на вводе информации.
- Проверка заявок — Компании получают массу заявок, как написанных от руки, так и только в форме заявок. В большинстве случаев эти приложения могут сопровождаться личными идентификаторами для целей проверки. Отсканированные документы, удостоверяющие личность, такие как паспорта или карты, обычно поставляются партиями в одинаковых форматах. Таким образом, хорошо написанный инструмент для извлечения данных может быстро преобразовывать данные (тексты, таблицы, рисунки, KVP) в машиночитаемые тексты, что может существенно сократить трудозатраты на выполнение этих задач и сосредоточиться на выборе приложений, а не на их извлечении.

- Сверка платежей — Сверка платежей – это процесс сравнения банковских выписок для обеспечения соответствия чисел между счетами, который в значительной степени связан с извлечением данных из документов — сложная задача для компании со значительными размерами и различными источниками поток доходов. Извлечение данных может упростить этот процесс и позволить сотрудникам сосредоточиться на ошибочных данных и изучить потенциальные мошеннические действия, связанные с денежным потоком.
- Статистический анализ — Отзывы клиентов или участников экспериментов используются корпорациями и организациями для улучшения своих продуктов и услуг, и для всесторонней оценки отзывов обычно требуется статистический анализ. Однако данные опроса могут существовать в различных форматах или быть скрыты между текстом в различных форматах. Извлечение данных может облегчить процесс, указав очевидные данные из документов в пакетах, упростить процесс поиска полезных процессов и, в конечном счете, повысить эффективность.

- Обмен прошлыми записями — От здравоохранения до смены банковских услуг крупным отраслям часто требуется новая информация о клиентах, которая, возможно, уже существовала в другом месте. Например, пациент, меняющий больницу из-за переезда, может иметь ранее существовавшие медицинские записи, которые могут быть полезны для новой больницы. В таких случаях пригодится хорошее программное обеспечение для извлечения данных, поскольку все, что требуется, — это принести отсканированную историю записей в новую больницу, чтобы они автоматически заполнили всю информацию. Это было бы не только удобно, но и позволило бы избежать больших рисков, особенно в сфере здравоохранения, когда важные записи о пациентах были бы упущены из виду.
Хотите извлечь данные из отсканированных документов? Дайте Nanonets ™ более высокую точность, большую гибкость, постобработку и широкий набор интеграций!
Учебные пособия
Чтобы дать более четкое представление о том, как выполнять извлечение данных, мы покажем два набора методов извлечения данных из сканированных документов.
Строительство с нуля
Можно создать простой механизм OCR для извлечения данных с помощью механизма PyTesseract следующим образом:
попробуйте:
из изображения импорта PIL
кроме ошибки импорта:
импорт изображения
импортировать питессеракт
# Если у вас нет исполняемого файла tesseract в вашем PATH, включите следующее:
pytesseract.pytesseract.tesseract_cmd = r'<полный_путь_к_вашему_tesseract_executable>'
# Пример tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract'
# Простое изображение в строку
print(pytesseract.image_to_string(Image.open('test.png')))
# Список доступных языков
печать (pytesseract.get_languages (config = ''))
# текстовое изображение на французском языке в строку
print(pytesseract.image_to_string(Image.open('test-european.jpg'), lang='fra'))
# Чтобы обойти преобразование изображений pytesseract, просто используйте относительный или абсолютный путь к изображению
# ПРИМЕЧАНИЕ. В этом случае вы должны предоставить поддерживаемые tesseract изображения, иначе tesseract вернет ошибку
печать (pytesseract. image_to_string ('test.png'))
# Пакетная обработка с одним файлом, содержащим список путей к нескольким файлам изображений
печать (pytesseract.image_to_string ('images.txt'))
# Тайм-аут/завершение задания tesseract через определенный период времени
пытаться:
print(pytesseract.image_to_string('test.jpg', timeout=2)) # Тайм-аут через 2 секунды
print(pytesseract.image_to_string('test.jpg', timeout=0.5)) # Тайм-аут через полсекунды
кроме RuntimeError как timeout_error:
# Обработка тессеракта прекращена
проходить
# Получить оценки ограничивающей рамки
print(pytesseract.image_to_boxes(Image.open('test.png')))
# Получить подробные данные, включая поля, конфиденциальность, номера строк и страниц
print(pytesseract.image_to_data(Image.open('test.png')))
# Получить информацию об ориентации и обнаружении сценария
print(pytesseract.image_to_osd(Image.open('test.png')))
# Получить PDF с возможностью поиска
pdf = pytesseract.image_to_pdf_or_hocr('test.png', расширение='pdf')
с open('test.
image_to_string ('test.png'))
# Пакетная обработка с одним файлом, содержащим список путей к нескольким файлам изображений
печать (pytesseract.image_to_string ('images.txt'))
# Тайм-аут/завершение задания tesseract через определенный период времени
пытаться:
print(pytesseract.image_to_string('test.jpg', timeout=2)) # Тайм-аут через 2 секунды
print(pytesseract.image_to_string('test.jpg', timeout=0.5)) # Тайм-аут через полсекунды
кроме RuntimeError как timeout_error:
# Обработка тессеракта прекращена
проходить
# Получить оценки ограничивающей рамки
print(pytesseract.image_to_boxes(Image.open('test.png')))
# Получить подробные данные, включая поля, конфиденциальность, номера строк и страниц
print(pytesseract.image_to_data(Image.open('test.png')))
# Получить информацию об ориентации и обнаружении сценария
print(pytesseract.image_to_osd(Image.open('test.png')))
# Получить PDF с возможностью поиска
pdf = pytesseract.image_to_pdf_or_hocr('test.png', расширение='pdf')
с open('test. pdf', 'w+b') как f:
f.write(pdf) # тип pdf по умолчанию в байтах
# Получить вывод HOCR
hocr = pytesseract.image_to_pdf_or_hocr('test.png', extension='hocr')
# Получить вывод ALTO XML
xml = pytesseract.image_to_alto_xml('test.png')
pdf', 'w+b') как f:
f.write(pdf) # тип pdf по умолчанию в байтах
# Получить вывод HOCR
hocr = pytesseract.image_to_pdf_or_hocr('test.png', extension='hocr')
# Получить вывод ALTO XML
xml = pytesseract.image_to_alto_xml('test.png') Для получения дополнительной информации о коде вы можете проверить их официальную документацию.
Проще говоря, код извлекает данные, такие как текст и ограничивающие рамки, из заданного изображения. Несмотря на то, что движок довольно полезен, он далеко не так силен, как те, которые предоставляются передовыми решениями, из-за их значительной вычислительной мощности для обучения.
Использование API документов Google
def async_detect_document (gcs_source_uri, gcs_destination_uri):
"""OCR с PDF/TIFF в качестве исходных файлов в GCS"""
импортировать json
импортировать повторно
из google.cloud импортировать зрение
из хранилища импорта google.cloud
# Поддерживаемые mime_types: 'application/pdf' и 'image/tiff'
mime_type = 'приложение/pdf'
# Сколько страниц должно быть сгруппировано в каждый выходной файл json. /]+)/(.+)', gcs_destination_uri)
Bucket_name = match.group(1)
префикс = match.group(2)
ведро = storage_client.get_bucket(bucket_name)
# Список объектов с заданным префиксом.
blob_list = список (bucket.list_blobs (префикс = префикс))
print('Выходные файлы:')
для блоба в blob_list:
печать (имя BLOB-объекта)
# Обработать первый выходной файл из GCS.
# Так как мы указали batch_size=2, первый ответ содержит
# первые две страницы входного файла.
вывод = blob_list[0]
json_string = output.download_as_string()
ответ = json.loads(json_string)
# Фактический ответ для первой страницы входного файла.
first_page_response = ответ['ответы'][0]
аннотация = первая_страница_ответа['fullTextAnnotation']
# Здесь мы печатаем полный текст с первой страницы.
# Ответ содержит дополнительную информацию:
# аннотация/страницы/блоки/абзацы/слова/символы
# включая оценки достоверности и ограничивающие рамки
print('Полный текст:\n')
печать (аннотация ['текст'])
/]+)/(.+)', gcs_destination_uri)
Bucket_name = match.group(1)
префикс = match.group(2)
ведро = storage_client.get_bucket(bucket_name)
# Список объектов с заданным префиксом.
blob_list = список (bucket.list_blobs (префикс = префикс))
print('Выходные файлы:')
для блоба в blob_list:
печать (имя BLOB-объекта)
# Обработать первый выходной файл из GCS.
# Так как мы указали batch_size=2, первый ответ содержит
# первые две страницы входного файла.
вывод = blob_list[0]
json_string = output.download_as_string()
ответ = json.loads(json_string)
# Фактический ответ для первой страницы входного файла.
first_page_response = ответ['ответы'][0]
аннотация = первая_страница_ответа['fullTextAnnotation']
# Здесь мы печатаем полный текст с первой страницы.
# Ответ содержит дополнительную информацию:
# аннотация/страницы/блоки/абзацы/слова/символы
# включая оценки достоверности и ограничивающие рамки
print('Полный текст:\n')
печать (аннотация ['текст']) В конечном счете, искусственный интеллект Google для документов позволяет извлекать многочисленные данные из документов с высокой точностью. Кроме того, услуга предлагается и для определенных целей, включая извлечение текста как для обычных изображений, так и для изображений в дикой природе.
Кроме того, услуга предлагается и для определенных целей, включая извлечение текста как для обычных изображений, так и для изображений в дикой природе.
Подробнее см. здесь.
Помимо крупных корпораций с API-интерфейсами для извлечения данных из документов, существует несколько решений, обеспечивающих высокоточные услуги оптического распознавания символов PDF. Мы представляем несколько вариантов оптического распознавания символов PDF, которые специализируются на различных аспектах, а также некоторые недавние исследовательские прототипы, дающие многообещающие результаты*:
*Боковое примечание. Существует несколько служб OCR, которые предназначены для таких задач, как изображения в дикой природе. Мы пропустили эти службы, так как в настоящее время мы сосредоточены только на чтении PDF-документов.
- Google API — Являясь одним из крупнейших поставщиков онлайн-услуг, Google предлагает потрясающие результаты извлечения документов с помощью своей новаторской технологии компьютерного зрения.
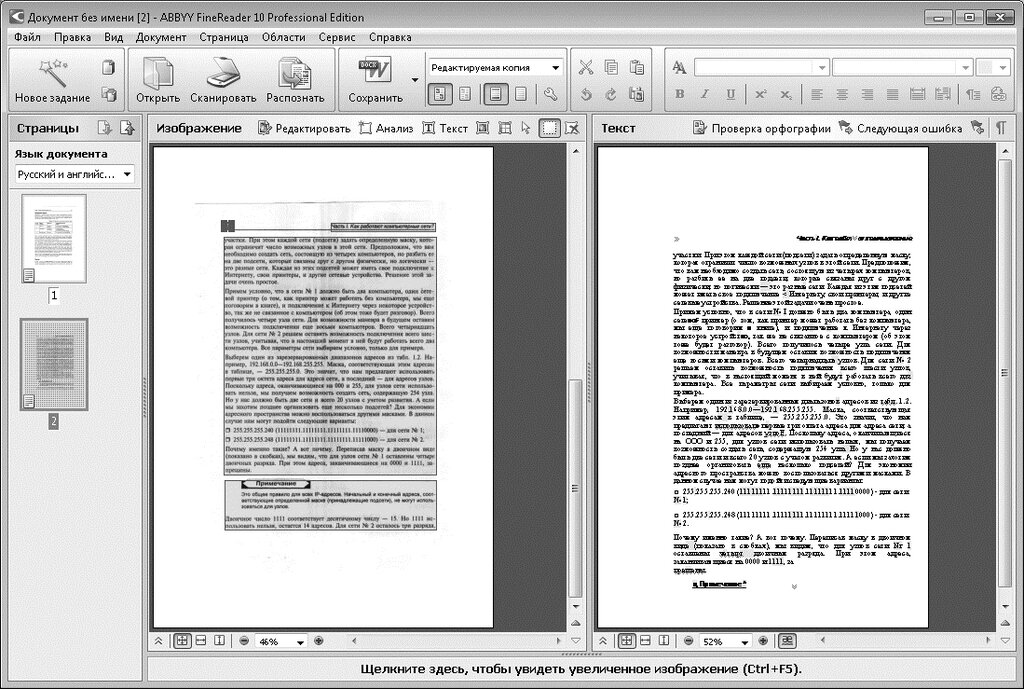 Можно использовать их услуги бесплатно, если использование довольно низкое, но цена увеличивается по мере увеличения вызовов API.
Можно использовать их услуги бесплатно, если использование довольно низкое, но цена увеличивается по мере увеличения вызовов API. - Deep Reader — Deep Reader — это исследовательская работа, опубликованная на конференции ACCV 2019. Она включает несколько современных сетевых архитектур для выполнения таких задач, как сопоставление документов, поиск текста и шумоподавление изображений. Существуют дополнительные функции, такие как таблицы и извлечение пар ключ-значение, которые позволяют извлекать и сохранять данные организованным образом.
- Nanonets™ — Благодаря высококвалифицированной команде глубокого обучения Nanonets™ PDF OCR полностью не зависит от шаблонов и правил. Таким образом, Nanonets™ может работать не только с определенными типами PDF-файлов, но также может применяться к любому типу документов для поиска текста.
Хотите извлечь данные из отсканированных документов? Дайте Nanonets ™ более высокую точность, большую гибкость, постобработку и широкий набор интеграций!
Заключение
В заключение в этой статье представлено подробное объяснение извлечения данных из отсканированных документов, включая связанные с этим проблемы и технологии, необходимые для этого процесса.