
Как изменить код текста
Студенты очень страдают при разработке научных работ, ведь им зачастую необходимо изменить код текста, чтобы обойти антиплагиат. Сделать это бывает намного сложнее, чем может показаться с первого взгляда. Но если подойти к этому процессу с умом и не давать панике охватить вас, то вы увидите, что все проще, чем могло показаться.
Очень часто этот нехитрый прием помогает повысить процент уникальности текста. Справиться с задачей под силу даже гуманитариям, не имеющим глубоких знаний в компьютерных технологиях. Здесь главное – четко следовать всплывающим подсказкам и придерживаться последовательности при выполнении команд. В случае неудачи всегда можно вернуться к первоначальной точке. Итак, разберемся, как же изменять код текста.
Меняем код в ворде
Задать текстовому документу можно не только определенный формат, но и кодировку. Для этого вам необходимо проделать следующее:
- Выбираем необходимый файл
- Нажимаем команду «Сохранить как»
- Указываем место сохранения
- Устанавливаем необходимую кодировку
- Обязательно меняем имя нового файла, чтобы сохранить оба варианта текста
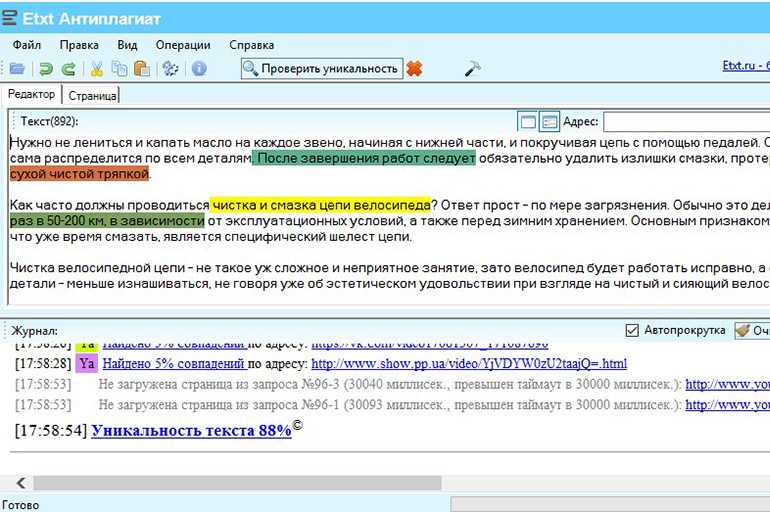
Как правило, сохраняем документы в форматах docx или docx. Затем проверяем на плагиат оба варианта.
Затем проверяем на плагиат оба варианта.
В ворде 10 смена кодировки немного отличается. Поэтому проще всего преобразовывать текст в третьем или седьмом ворде. Для этого исходный документ сохраните первоначально в этих версиях, а затем уже смените кодировку.
Меняем кодировку в блокноте
Иногда обойти антиплагиат удается с помощью переноса текста из ворда в блокнот, а затем возвращение его обратно. Для этого выполняем такие действия:
- В блокнот вставляем нужный текст
- Выбираем команду «сохранить как»
- Указываем имя файла и тип
- Выбираем необходимую кодировку
- Сохраняем
- Сохраненный файл переносим в ворд
Работаем с изображением
- Если вы попытаетесь открыть изображение в ворд, на страничке появятся непонятные символы.
- Чтобы получить читаемый документ делаем так:
- Открываем документ
- Выбираем параметры с помощью вкладки «файл»
- В строке «дополнительно» находим раздел «Общие»
- Подтверждаем преобразование файла
- Выбираем команду «Кодированный текст»
- Выбираем нужную кодировку и подтверждаем действие
Иногда при смене кодировки можно поменять шрифт, что тоже положительно скажется на качестве кодированного текста..jpg)
Заключение
Для чего же нужна смена кодировки? Текстовые процессоры в ПК автоматически выбирают кодировку, при которой документы отображаются наиболее корректно. Но ведь перед нами стоит задаче не просто удобного распознавания текста, а обход системы антиплагиат. Поэтому нам необходимо заставить эту коварную компьютерную программу отойти от привычных шаблонов и принять нашу работу за уникальную.
Алгоритм каждой версии антиплагиата работает по-своему. Но принцип, в общем-то, у всех одинаковый. Любой незнакомый программе документ она не сможет распознать, а, значит, пропустит без проверки.
Ваша главная задача при смене кодировки – сохранять все документы, присваивая им новые имена. В противном случае ранние версии текста будут утеряны. Как вы сами смогли убедиться, изменить код текста, чтобы обойти антиплагиат не так уж и сложно.
В этом процессе главное не торопиться и следовать согласно инструкции.
Ввиду того, что текстовый редактор “Майкрософт Ворд” является самым популярным на рынке, именно форматы документов, которые присущи ему, можно чаще всего встретить в сети. Они могут отличаться лишь версиями (DOCX или DOC). Но даже с этими форматами программа может быть несовместима или же совместима не полностью.
Они могут отличаться лишь версиями (DOCX или DOC). Но даже с этими форматами программа может быть несовместима или же совместима не полностью.
Случаи некорректного отображения текста
Конечно, когда в программе наотрез отказываются открываться, казалось бы, родные форматы, это поправить очень сложно, а то и практически невозможно. Но, бывают случаи, когда они открываются, а их содержимое невозможно прочесть. Речь сейчас идет о тех случаях, когда вместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, “перевести” которые невозможно.
Эти случаи чаще всего связаны лишь с одним – с неверной кодировкой текста. Точнее, конечно, будет сказать, что кодировка не неверная, а просто другая. Не воспринимающаяся программой. Интересно еще то, что общего стандарта для кодировки нет. То есть, она может разниться в зависимости от региона. Так, создав файл, например, в Азии, скорее всего, открыв его в России, вы не сможете его прочитать.
В этой статье речь пойдет непосредственно о том, как поменять кодировку в Word. Кстати, это пригодится не только лишь для исправления вышеописанных “неисправностей”, но и, наоборот, для намеренного неправильного кодирования документа.
Кстати, это пригодится не только лишь для исправления вышеописанных “неисправностей”, но и, наоборот, для намеренного неправильного кодирования документа.
Определение
Перед рассказом о том, как поменять кодировку в Word, стоит дать определение этому понятию. Сейчас мы попробуем это сделать простым языком, чтобы даже далекий от этой тематики человек все понял.
Зайдем издалека. В “вордовском” файле содержится не текст, как многими принято считать, а лишь набор чисел. Именно они преобразовываются во всем понятные символы программой. Именно для этих целей применяется кодировка.
Кодировка – схема нумерации, числовое значение в которой соответствует конкретному символу. К слову, кодировка может в себя вмещать не только лишь цифровой набор, но и буквы, и специальные знаки. А ввиду того, что в каждом языке используются разные символы, то и кодировка в разных странах отличается.
Как поменять кодировку в Word. Способ первый
После того, как этому явлению было дано определение, можно переходить непосредственно к тому, как поменять кодировку в Word./2a1d62915c54ffa.ru.s.siteapi.org/img/536800d6c86d5828a04295618432ef075a8c91aa.png) Первый способ можно осуществить при открытии файла в программе.
Первый способ можно осуществить при открытии файла в программе.
В том случае, когда в открывшемся файле вы наблюдаете набор непонятных символов, это означает, что программа неверно определила кодировку текста и, соответственно, не способна его декодировать. Все, что нужно сделать для корректного отображения каждого символа, – это указать подходящую кодировку для отображения текста.
Говоря о том, как поменять кодировку в Word при открытии файла, вам необходимо сделать следующее:
- Нажать на вкладку “Файл” (в ранних версиях это кнопка “MS Office”).
- Перейти в категорию “Параметры”.
- Нажать по пункту “Дополнительно”.
- В открывшемся меню пролистать окно до пункта “Общие”.
- Поставить отметку рядом с “Подтверждать преобразование формата файла при открытии”.
- Нажать”ОК”.
Итак, полдела сделано. Скоро вы узнаете, как поменять кодировку текста в Word. Теперь, когда вы будете открывать файлы в программе “Ворд”, будет появляться окно.
Выполните следующие действия:
- Откройте двойным кликом файл, который необходимо перекодировать.
- Кликните по пункту “Кодированный текст”, что находится в разделе “Преобразование файла”.
- В появившемся окне установите переключатель на пункт “Другая”.
- В выпадающем списке, что расположен рядом, определите нужную кодировку.
- Нажмите “ОК”.
Если вы выбрали верную кодировку, то после всего проделанного откроется документ с понятным для восприятия языком. В момент, когда вы выбираете кодировку, вы можете посмотреть, как будет выглядеть будущий файл, в окне “Образец”. Кстати, если вы думаете, как поменять кодировку в Word на MAC, для этого нужно выбрать из выпадающего списка соответствующий пункт.
Способ второй: во время сохранения документа
Суть второго способа довольно проста: открыть файл с некорректной кодировкой и сохранить его в подходящей. Делается это следующим образом:
- Нажмите “Файл”.

- Выберите “Сохранить как”.
- В выпадающем списке, что находится в разделе “Тип файла”, выберите “Обычный текст”.
- Кликните по “Сохранить”.
- В окне преобразования файла выберите предпочитаемую кодировку и нажмите “ОК”.
Теперь вы знаете два способа, как можно поменять кодировку текста в Word. Надеемся, что эта статья помогла вам в решении вопроса.
Когда человек работает с программой «MS Word», у него редко возникает потребность вникать в нюансы кодировки. Но как только появляется необходимость поделиться документом с коллегами, существует вероятность того, что отправленный пользователем файл может просто-напросто не быть прочитан получателем. Это случается из-за несовпадения настроек, а конкретно кодировок в разных версиях программы.
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений.
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Справка! Некоторые кодировки применяются к определенным языкам. Для японского языка специально была разработана кодировка «Shift JIS», для корейского – «EUC-KR», а для китайского «ISO-2022» и «EUC».
Изменение кодировки текста в «Word 2013»
Первый способ изменения кодировки в «Word»
Для исправления текстового документа, которому была неправильно определена изначальная кодировка, необходимо:
Шаг 1. Запустить текстовый документ и открыть вкладку «Файл».
Шаг 2. Перейти в меню настроек «Параметры».
Шаг 3. Выбрать пункт «Дополнительно» и перейти к разделу «Общие».
Шаг 4. Активируем нажатием по соответствующей области настройку в графе «Подтверждать преобразование формата файла при открытии».
Шаг 5. Сохраняем изменения и закрываем текстовый документ.
Шаг 6. Повторно запускаем необходимый файл. Перед пользователем появится окно «Преобразование файла», в котором необходимо выбрать пункт «Кодированный текст», и сохранить изменения нажатием «ОК».
Шаг 7. Всплывет еще одна область, в которой необходимо выбрать пункт кодировки «Другая» и выбрать в списке подходящую. Поле «Образец» поможет пользователю подобрать необходимую кодировку, отображаемую изменения в тексте. После выбора подходящей сохраняем изменения кнопкой «ОК».
Второй способ изменения кодировки в «Word»
- Производим запуск файла, кодировку текста которого необходимо произвести.
- Переходим во вкладку «Файл».
Читайте полезную информацию, как работать в ворде для чайников, в новой статье на нашем портале.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого. Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.
Важно! Перед началом работы в «Notepad ++» в первую очередь рекомендуется проверить установленную кодировку. При необходимости ее нужно изменить при помощи инструкции, приведенной ранее.
Корректировка кодировки веб-страниц
Кодировка символов – неотъемлемая часть работы браузеров для серфинга в интернете. Поэтому каждому из пользователей просто необходимо уметь ее настраивать. Чтобы быстро изменить кодировку «Google Chrome», необходимо будет установить дополнительное расширение, так как разработчики убрали возможность изменения данного параметра.
Чтобы быстро изменить кодировку «Google Chrome», необходимо будет установить дополнительное расширение, так как разработчики убрали возможность изменения данного параметра.
Для того, чтобы сменить кодировку на необходимую, нужно:
- Запустить браузер.
- Перейти по ссылке chrome://extensions/.
Как поменять кодировку в «Mozilla Firefox»
Для этого пользователю потребуется:
Шаг 1. Запустить браузер и открыть меню, нажав по иконке трех линий левой клавишей мыши в правом верхнем углу страницы.
Шаг 2. В контекстном меню запустить «Настройки».
Шаг 3. Перейти во вкладку «Содержимое».
Шаг 4. В разделе «Шрифты и цвета» нажать на блок «Дополнительные».
Шаг 5. Перед пользователем отобразится специальная панель, на которой будет указана использующаяся кодировка. Для ее изменения потребуется нажать на название кодировки и выбрать нужную.
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот» , будет полезно знать о том, что изменить кодировку можно следующим образом:
- Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Видео — Как изменить кодировку в Word
Понравилась статья?
Сохраните, чтобы не потерять!
Как закодировать текст в Word от плагиата: эффективные методы
Большинство контента на российских ресурсах проходит проверку уникальности различными сервисами. По тому, как закодирован текст в Word от плагиата, судят о его оригинальности.
По тому, как закодирован текст в Word от плагиата, судят о его оригинальности.
Из-за ошибок и несовершенства систем проверки ученикам, студентам и людям, занимающимся наполнением сайтов, приходится многократно переделывать часть контента. Ведь некоторые сервисы анализа уникальности часто бракуют всю работу, даже если она написана самостоятельно.
Даже самый ответственный автор может столкнуться с низким показателем уникальности текста.
Как работают современные антиплагиаты
Системы, которые проверяют уникальность, с помощью специально разработанного алгоритма сравнивают загруженный word-файл, какой-либо графический или текстовый документ с открытым контентом в интернете. Они анализируют полученный материал и выдают результат проверки в виде отчета, где указывается процент заимствования и ссылки на первоисточники.
Алгоритмы таких систем похожи. Они различаются лишь числом проверяемых за 1 проход слов или фраз и расстоянием между ними.
Большинство программ анализирует только текстовые файлы.

Но есть и такие сервисы, которые могут определить оригинальность картин, фотографий и даже целых сайтов.
Способы обхода систем проверки следующие:
- перестановка некоторых слов и фраз или замена их на синонимы, подходящие по смыслу;
- изменение кодировки текста;
- вставка в текст иностранных букв или невидимых знаков.
Антиплагиат- это система для проверки текста на уникальность.
Принцип замены
Раньше некоторые пользователи обходили системы распознавания антиплагиата путем перестановки фраз, предложений, а иногда даже абзацев. Главное, чтобы не терялся смысл. Другие заменяли синонимом каждое 3-5 слово, и уникальность поднималась до приемлемого уровня.
Но эти методы уже устарели и не действуют. Алгоритмы обновили, появилась необходимость найти и использовать новые способы снижения процента заимствования.
Сейчас для повышения оригинальности путем замены пользуются специально разработанными программами-синонимайзерами.

Они могут подобрать одинаковые по значению слова и фразы к любому фрагменту текста. Но часто эти системы выдают полную бессмыслицу. Поэтому иногда приходится прогонять через подобные программы один и тот же контент по несколько раз.
Для ускорения процесса замены слов на синонимы можно воспользоваться синонимайзером.
Действенно ли менять кодировку в Word
Есть множество других методов повышения процента оригинальности. Один из них — смена кодировки в Word. Его цель — запутать систему анализа, обмануть ее. Такой прием является сложным процессом, который заставляет программу проверки считать, что полностью или частично скачанный материал имеет высокий процент уникальности.
Этот вариант считается хорошим, ведь в результате изменения кода какого-либо контента текст или графический файл визуально не меняется.
А его оригинальность при проверке на антиплагиат оказывается нормальной. Найти и обезвредить такой уникальный алгоритм кодировки нельзя.
Часто он состоит из множества программных строк и ключей, подобрать их почти невозможно. Даже если они будут найдены, достаточно поменять всего 1 строку шифра и системы антиплагиата опять покажут высокий уровень оригинальности.
Но иногда после этого процесса пользователь получает нечитаемый текст. Поэтому приходится тратить время, чтобы подыскать подходящий вариант кодировки.
Поднимет ли уникальность замена букв на символы иностранного алфавита
Иногда пользователи, пишущие контент, повышают процент антиплагиата следующим способом. Они просто меняют часть символов на похожие латинские знаки. Например, вписывают вместо А, В, О, Р и т. д. одинаковые по написанию буквы английского алфавита.
Этот метод не новый, и большинство программ давно научилось выискивать подобные изменения текста и снижать за это уровень его оригинальности.
Такие знаки легко можно увидеть и в Word. Если скопировать в него скачанный контент, то эти символы будут подчеркнуты красным или другим цветом.
Но большинство программ нацелено на проверку только английских букв в русскоязычных текстах. Поэтому если взять похожие знаки других стран с алфавитом, отличным от латинского, то система может не распознать подмены и процент окажется высоким.
Программа может распознать замену некоторых символов латиницей.
Что делать, если в документе «Word» открываются иероглифы?
Первым долгом нам нужно проверить расширение файла, который мы открываем. Если это документ «Word», то он может быть представлен в двух форматах – «doc» и «docx». Расширение «doc» привязано к программе «Word» ниже версии 2007 года, а «docx» — соответственно, используется в «Word 2007/2010/2013/2016».
Если вы в более старой версии «Word» откроете файл с расширением «docx», то увидите эти самые непонятные иероглифы. То есть новые файлы не поддерживаются более ранней версией текстового редактора. И что в этом случае нужно сделать? Просто установить новую версию от 2007 года.
Если вам нужно проверить, какое расширение имеет тот или иной документ «Word», то кликните по нему правой кнопкой мышки, зайдите в контекстном меню в «Свойства» и в открывшемся окне на вкладке «Подробно» обратите внимание на имя файла:
Узнаем расширение файла
Также при открытии непонятного документа программа «Word» (официальной непиратской версии) должна спросить, в какой кодировке следует представить текст:
Программа «Word» должна спросить, в какой кодировке следует представить текст
Обычно кодировка определяется автоматически, но возможны и случаи исключения. Если программа предлагает вам выбрать кодировку, то тут могут возникнуть некоторые проблемы. Дело в том, что иногда сделать правильный выбор придется при помощи «метода тыка», хотя по умолчанию следует выбирать «Windows (по умолчанию)», если вы не открываете какой-то редкий документ:
Если программа предлагает вам выбрать кодировку, то тут могут возникнуть некоторые проблемы. Дело в том, что иногда сделать правильный выбор придется при помощи «метода тыка», хотя по умолчанию следует выбирать «Windows (по умолчанию)», если вы не открываете какой-то редкий документ:
Выбираем кодировку вручную
Добавление скрытых символов в текст
Студенты придумали следующий оригинальный вариант увеличения уникальности. Они вставляют символы, написанные самым мелким шрифтом, или буквы, окрашенные в белый цвет. Такие знаки не видны в тексте, визуально не выделяются на общем фоне, а программы-анализаторы показывают высокую оригинальность.
Но разработчики систем антиплагиата знают эти способы и борются с ними. Тем более что при внесении этого контента в Word и нажатии кнопки «Очистить формат» большинство скрытых символов становятся видимыми.
В 2021 г. СМИ писали о студенте, который додумался создать в дипломной работе между 2 словами невидимый объект типа «Надпись» размером с 1 букву. Юноша вставил в него более 20 тыс. знаков контента, состоящего из 40 фрагментов одного и того же оригинального текста по 500 символов каждый.
Юноша вставил в него более 20 тыс. знаков контента, состоящего из 40 фрагментов одного и того же оригинального текста по 500 символов каждый.
Программа проверила материал и выдала отчет о высокой уникальности.
Эти знаки определялись как рисунок и не были видны в Word. Но программа-анализатор приняла их за необрабатываемый текст, прибавила все знаки к общему количеству и вывела приемлемый процент оригинальности.
Данный способ часто применяют студенты в своих работах.
Скрытые знаки форматирования
Список непечатаемых знаков и то, как элементы форматирования отображаются найти нетрудно, здесь же рассказывается о том, как можно использовать невидимые знаки пробела, табуляции и другие основные символы в работе.
Невидимый знак абзаца и перевод строки
Непечатаемый знак абзаца, а точнее конца абзаца отображается значком….
Этот значок помогает определить, где заканчивается один абзац и начинается другой. Например, визуально в тексте видно два абзаца, но при установке отступа или выделении одного из них двойным кликом мыши текст форматируется и выделяется как один абзац.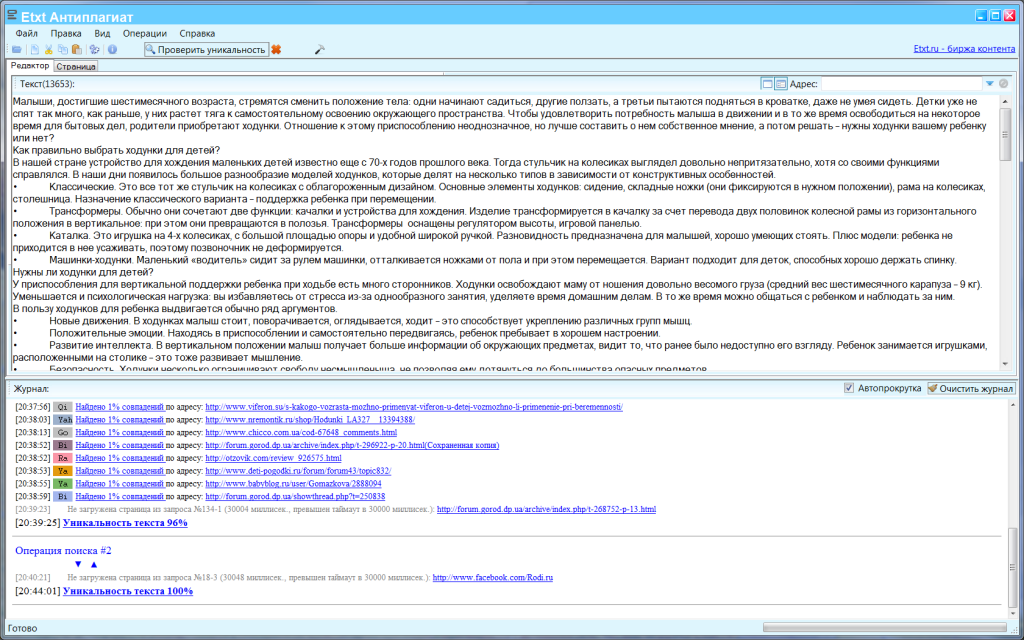 За второй абзац мы приняли начало новой строки (перевод строки), такое постоянно наблюдается при сканировании документов и обработке их программами OSR. Простой перевод строки обозначается значком
За второй абзац мы приняли начало новой строки (перевод строки), такое постоянно наблюдается при сканировании документов и обработке их программами OSR. Простой перевод строки обозначается значком
Пробел и неразрывный пробел
Пробел между словами показывается на экране значком точки . Часто многие пользователи компьютера красную строку абзаца делают несколькими нажатиями пробела. При распечатке такого документа текст может быть неровным. Этот значок также поможет узнать, добросовестно ли ваш исполнитель выполнил задание, не увеличил ли объем текста лишними пробелами.
Неразрывный пробел ставится в тех случаях, когда разрывать два слова по разным строкам нельзя, например это инициалы и фамилия. Обозначается неразрывный пробел значком похожим на символ процента
Скрытый текст
В программе Word Office есть возможность часть текста или весь текст сделать скрытым. В этом случае отображаться на экране такой текст будет только при включении функции непечатаемые символы Word.
Разрыв раздела, разрыв страницы
Для разных частей текста можно установить различные настройки, например нумерацию страниц, размеры полей и некоторые другие, но для этого текст должен быть разделен на разделы. В каждом разделе применяются свои соответствующие настройки. Поэтому, например, установка нумерации страниц в одной части документа необязательно приведет к их правильному расположению ее во всем документе. Такой разрыв нужно обнаружить и устранить. Убираются разрывы, так же как и любые другие символы, клавишей Del.
Таким образом, несмотря на то, что при первом взгляде на эти значки у неопытного пользователя возникает легкое недоумение: «Зачем это», непечатаемые символы форматирования, со временем, становятся полезным и незаменимым инструмент редактирования текстов.
Как самому перекодировать текст
Сервисы по выявлению процента уникальности уже могут обнаружить большинство ухищрений, на которые идут пользователи. Но эти системы пока не научились распознавать метод кодирования текста.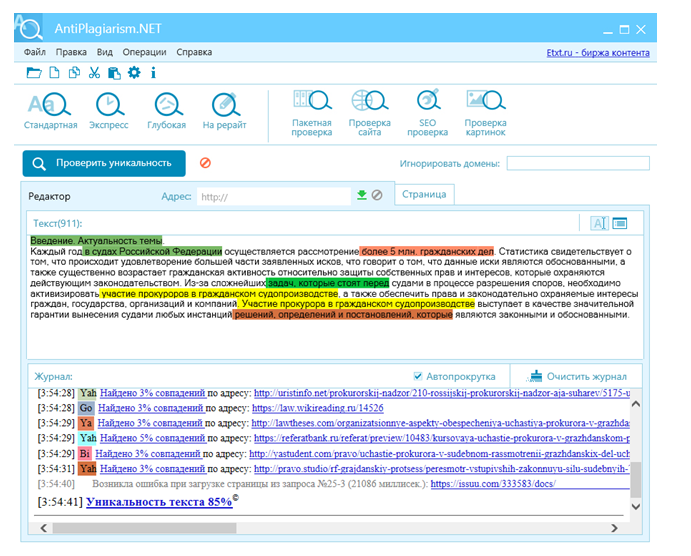 Поэтому есть смысл применить его при написании текста.
Поэтому есть смысл применить его при написании текста.
Программист может изменить внутренний код.
Каждый документ имеет какую-либо раскладку (KOI8-U, Windows-1251, ASCII и т. д.) со своим внутренним кодом. Если научиться модифицировать его правильно, то можно получить на выходе текст, визуально не отличающийся от первоисточника. Но профессиональную кодировку может сделать лишь программист.
Самому изменить его сложно, т. к. при его открытии появляется бессмысленный набор знаков, назначение которых понимает только профессионал. Простому пользователю, чтобы разобраться в них, потребуется несколько недель или месяцев.
Но можно попробовать сделать псевдошифрование. Метод заключается в следующем. Чтобы текст прошел антиплагиат, необязательно менять внутренний код, достаточно сменить его раскладку. Этот метод хуже, но большинство систем показывают высокую уникальность.
Смена кода в Word
В этой программе тексту можно придать не только нужный формат (docx или doc), но и задать любую раскладку. Нужно только правильно выполнить приведенную последовательность действий.
Нужно только правильно выполнить приведенную последовательность действий.
Для смены кода нужно:
- Найти нужный документ и открыть его.
- Войти в пункт меню «Файл» и нажать на кнопку «Сохранить как».
- Выбрать любое имя.
- В поле «Тит файла» отыскать надпись «Простой текст» и кликнуть по ней.
- Нажать кнопку «Сохранение».
- В появившемся окне выбрать нужную кодировку и записать файл в ПК.
Если все сделано правильно, то появится текст. При неверном написании символов или слов процедуру повторяют до получения читабельного варианта.
Некоторые кодировки применяются к определенным языкам.
Замена кодировки в блокноте
Иногда обойти систему анализа оригинальности удается с помощью перемещения контента из Word в текстовый редактор «Блокнот», а затем вставки его обратно.
Смена кодировки.
Чтобы сменить кодировку, надо сделать следующее:
- Открыть word-файл и скопировать текст.

- Вставить его в блокнот.
- В меню нажать на «Файл» и выбрать «Сохранить как».
- Указать в нижнем поле открывшегося окна раскладку контента, а в остальных — его тип и имя.
- Сохранить текстовый файл.
- Перенести его в Word.
Работа с изображениями
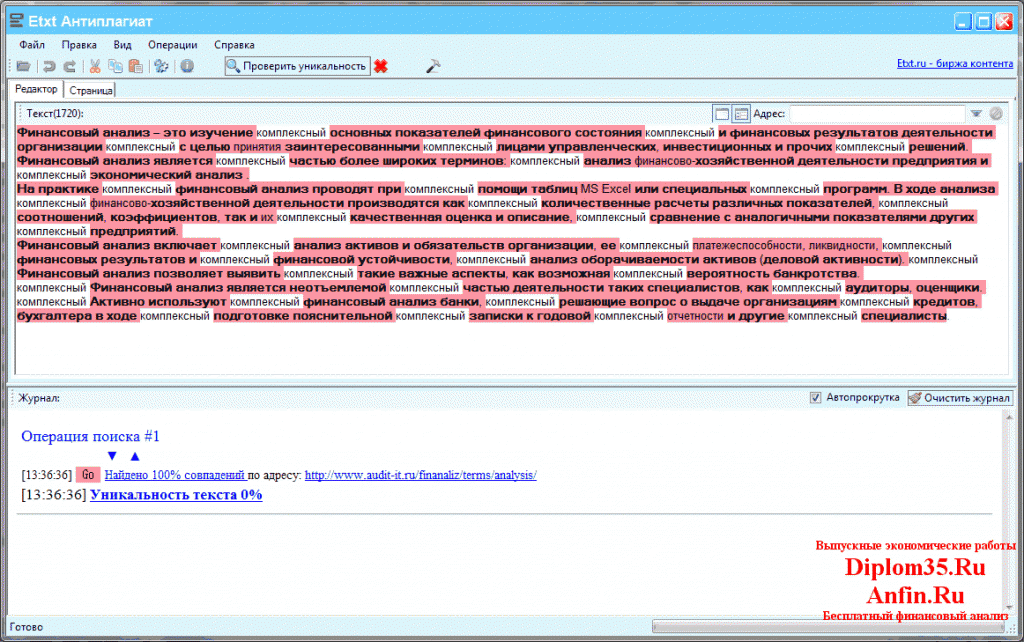
Кодирование рисунка или фотографии требует навыка. При попытке зашифровать графический файл, а затем открыть его в редакторе, в тексте появится абракадабра из непонятных символов и программа антиплагиата откажется принимать контент.
Чтобы все было корректно распознано, рекомендуется поступить так:
- Открыть документ.
- С помощью меню «Файл» выбрать необходимые параметры.
- Перейти в пункт «Дополнительно» и кликнуть по полю «Общие».
- Согласиться с методом преобразования.
- Выбрать надпись «Кодированный текст».
- Подобрать кодировку и нажать на кнопку «Сохранить».
Наглядная инструкция по изменению кодировки рисунку.
Иероглифы вместо русских букв, вместо текста квадратики, что делать?
Иногда при открытии скачанного или скопированного с другого ПК текстового файла, он не подлежит прочтению. Все буквы заменяются на иероглифы, символы, квадратики или иные нечитаемые знаки.
Все буквы заменяются на иероглифы, символы, квадратики или иные нечитаемые знаки.
Бывает, что буквы и цифры узнаваемы, но стоят на произвольных местах, что делает текст бессвязным и не читаемым. Такая проблема возникает не только в документах, но и в браузерах при открытии некоторых страниц.
Дело тут в кодировке, ее нужно либо снять, либо изменить.
Текстовые документы
Именно в документах Ворда, Блокнота и т.п. такая кодировка встречается чаще всего. Кодировка – набор знаков, благодаря которым происходит печать текста на определенном алфавите. Теоретически, любой документ сохраняется в различных шифрованиях, но пользователи почти никогда не прибегают к таким действиям.
Потому, если Вы видите вместо букв вопросительные знаки и т.п., то маловероятно, что это сделано намеренно. Скорее всего, ввиду системного сбоя у пользователя, создавшего документ, он сохранился не в той кодировки. Кроме того, дело может быть и в сбои на Вашем ПК, в результате чего файл не открывается правильно.
Наиболее часто проблема возникает при использовании Блокнота. Также встречается в файлах php, css, info и подобных текстовых. Гораздо реже в Ворде. Кроме того, путаница с шифрованием встречается в браузере, там Вы также можете увидеть кракозябры вместо русских букв. В последнем случае избавиться от нее особенно трудно.
Notepad +++
Самый простой способ открыть документ Блокнот, где вместо букв квадратики – применить сторонний софт. Популярен Notepad+++. Это тот же Блокнот, но обладающий дополнительными функциями. Имеет следующие преимущества:
- Распространяется бесплатно;
- Как и Ворд, имеет кнопку отмены последнего действия;
- Поддерживает одновременную работу с несколькими файлами;
- Позволяет изменить или выбрать шифрование.
- Автоматически дописывает тексты;
Чтобы иероглифы вместо русских букв преобразовались, откройте документ Блокнота в данной программе. В ленте меню сверху найдите вкладку Кодировки. Нажмите на нее. Откроется меню с перечислением всех их типов. Не всегда очевидно, какой именно тип шифрования применялся, потому, чтобы выбрать правильный для перекодировки, нужно попробовать несколько. Текст пред этим выделите.
Нажмите на нее. Откроется меню с перечислением всех их типов. Не всегда очевидно, какой именно тип шифрования применялся, потому, чтобы выбрать правильный для перекодировки, нужно попробовать несколько. Текст пред этим выделите.
По мере применения кодировок, символы в документе могут меняться (по одному нажатию в меню) или оставаться неизменными. В результате, после применения определенной, текст станет читаемым.
Bred 3
Программа аналогична предыдущей. Представляет собой Блокнот с расширенными возможностями. Успешно применяется вместо стандартного Блокнота Виндовс. Кодировки представлены в отдельной вкладке в верхнем меню. Откройте документ, в котором видны лишь текстовые значки или иероглифы, выделите текст, и пробуйте менять шифрования по очереди. В результате текст станет читаемым.
Поддерживает множество, даже редких, форматов. Работает со старой DOS- кодировкой, которую не открывают современные программы. Работает на Windows 8, 8.1, 10.
Word
Иногда кодировка появляется и в документах Ворд. Иногда причиной того, что в ворде появились непонятные символы, является то, что у Вас на ПК установлен старый Ворд (до 2007 года), а документ создан в более поздних версиях софта.
Иногда причиной того, что в ворде появились непонятные символы, является то, что у Вас на ПК установлен старый Ворд (до 2007 года), а документ создан в более поздних версиях софта.
Чаще всего, такие «новые» файлы просто не открываются в старой версии, но иногда открываются в странной кодировке. Чтобы понять, так ли это, посмотрите в Свойствах файла, какой он имеет формат. «Новые» документы имеют формат docx. Преобразование файла в word до старого формата невозможно.
Лучше установить обновление на MS Word. Изменить формат текстового документа на читаемый не сложно.
- Еще до открытия файла, софт «понимает», что в нем проблема. При двойном клике на него Ворд откроет окно, где спросит – в какой кодировке открыть файл. Чтобы изменить кодировку текста в word, выполните алгоритм;
- Попробуйте кодировку, предложенную программой;
- Если не сработало, кликайте по очереди на предлагаемые типы;
- Пробуйте менять типы кодировки и алфавит, типы кириллицы;
- Как только текст станет читаемым нажмите ОК.

Иногда возникает проблема другого характера. Вы набираете текст в Ворде или Блокноте и замечаете, что на клавиатуре вместо букв печатаются цифры. Проблема связана с режимом Num Look и возникает на некоторых ноутбуках. Посмотрите на клавиатуру.
Если на кнопках в правой части, кроме букв написаны и цифры, а вверху присутствует кнопка num lk, значит ноутбук оснащен данным режимом и Вы случайно включили. Для отключения нажмите кнопку Num Look или Fn+F11.
Набор цифр прекратится, появятся буквы в привычном виде.
Иероглифы в браузере
Иногда при открытии страницы в браузере Вы видите текст в кодировке. Это квадратики вместо букв в Опере, непонятные символы в Хроме и т.п. Причина – нарушение кодировки в браузере. Сбои происходят редко и виноваты в них разработчики. Но устранить сбой можно самостоятельно.
Если у Вас Хром, то пройдите по пути Настройки — Инструменты — Кодировки. Наведите на него указатель, откроется меню с кодировками. Если установлен параметр «Автоматически», измените на «Windows 1251». Если установлен другой параметр, замените на Windows 1251. Если он не помог открыть, установите «Автоматически» или перепробуйте кодировки по очереди.
Если установлен другой параметр, замените на Windows 1251. Если он не помог открыть, установите «Автоматически» или перепробуйте кодировки по очереди.
В Опере нужно пройдите в главное меню в верху окна и оттуда – в Настройки. Нажмите на Веб – сайты и найдите раздел Отображение. Кликайте по Настройке шрифтов и внизу открывшегося окна находите чек – бокс. В нем выбирайте Windows 1251. Это универсальный параметр отображении русских шрифтов, какой бы браузер не использовался.
В Firefox пройдите по пути Главное меню браузера — Настройки — Содержимое — Дополнительно. Как и для Оперы, в чек — боксе внизу открывшегося окна, выбирайте нужную кодировку.
Теперь вы знаете, что делать, если вместо текста иероглифы.
Источник: https://pcyk.ru/windows/chto-delat-kogda-v-dokumente-poyavlyayutsya-neponyatnye-simvoly-i-ieroglify/
Альтернативные методы повышения уникальности
Чтобы тексты прошли проверку, лучше писать их самостоятельно. Но это возможно, когда человек знает тему. Другой способ — сделать пересказ контента. Для этого потребуется прочитать его и написать своими словами.
Другой способ — сделать пересказ контента. Для этого потребуется прочитать его и написать своими словами.
Часть пользователей повышает оригинальность с помощью программ-переводчиков.
При написании темы они вводят ее название на иностранном языке в поисковую строку. Интернет выдает сайты, посвященные этой теме.
Пользователь переводит любой из них и получает оригинальный текст. Но из-за несовершенства программ-переводчиков иногда приходится исправлять часть контента.
Вместо текста иероглифы, квадратики и крякозабры (в браузере, Word, тексте, окне Windows)
Вопрос пользователя
Здравствуйте.
Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Заранее спасибо…
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные “крякозабры” (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из Википедии), а браузер пытается открыть его в другой. Из-за такого рассогласования, вместо текста — непонятный набор символов.
Попробуем исправить это…
*
Обход антиплагиата с «невидимым символом» и его обнаружение
Я, помнится, уже писал, что работаю техническим редактором в научном журнале. Причем одно из требований к материалам, которые мы принимаем — это оригинальность. На самом деле статьи проходят довольно сложную проверку, однако один из начальных ее рубежей — это известная многим система Антиплагиат. Мы уже сталкивались с попытками эту систему обмануть, я писал об этом в статье О попытке обхода системы Антиплагиат. Ну а это, выходит, вторая часть.
На этот раз был использован более хитрый (но такой же очевидный) способ. Однако шансы на успех у него, возможно, даже и были. Ибо статья прошла предварительную проверку, верстку (а прошлую попытку, как мы помним, удалось заметить именно на верстке), и была изобличена уже в последний момент, попав ко мне.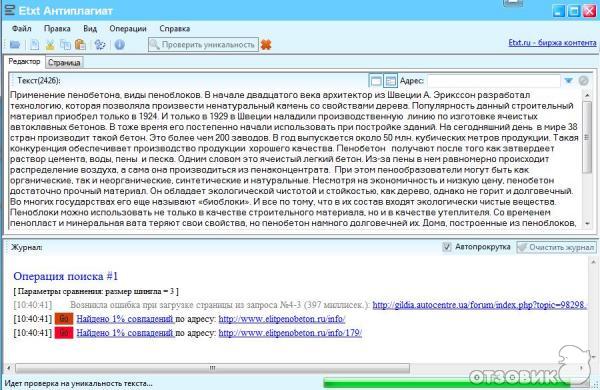
Что же натолкнуло меня на мысль о том, что требуется дополнительная проверка? На самом деле, существует масса косвенных признаков того, что текст не оригинальный.
Поначалу все было вообще хорошо и красиво, однако после того, как я придал заголовку нужное форматирование (в частности — размер шрифта 18), он стал выглядеть примерно так:
Если вы еще не поняли, что меня насторожило, внесу конкретику:
Да. Вот эти вот интервалы. Мелочь, казалось бы, но когда в день через твои руки проходит по нескольку статей, всякие необычности становятся особенно заметны. Поигравшись с продвинутыми настройками шрифта, от интервалов я не избавился, и стал копать дальше. Начал я с того, что скопировал заголовок в блокнот. Вышло вот что:
Ну вот, казалось бы и все ясно. Пробелы. Так-то оно так, да не так. Путем нехитрых манипуляций довольно быстро удалось установить, что это не пробелы. Для начала я выделил этот символ в Word. И он выделился:
При этом Word в статусбаре выдал такой вот интересный вердикт:
Мда. Не знаю, производственная ли это необходимость, или юмор тех, кто придумал этот способ (речь об албанском языке). Но между тем… Разумеется, следующее что я сделал, это попробовал «покрасить» символ в черный цвет, в надежде на то, что сейчас он белый, а после применения цвета станет видим. Однако это мне благополучно не удалось. Он так и остался невидимым. Поэтому пришлось взяться за
Не знаю, производственная ли это необходимость, или юмор тех, кто придумал этот способ (речь об албанском языке). Но между тем… Разумеется, следующее что я сделал, это попробовал «покрасить» символ в черный цвет, в надежде на то, что сейчас он белый, а после применения цвета станет видим. Однако это мне благополучно не удалось. Он так и остался невидимым. Поэтому пришлось взяться за скальпель инструмент поиска и замены. Скопировав паразитный символ в буфер обмена, я вставил его в строку «найти» этого инструмента. В строку «заменить на» я забил сочетание символов, которое вряд ли встретится в статье. Не мудрствуя лукаво — qweqwe.
Получилось вот так:
Пусть Вас не смущает, что верхняя строка пуста. Символ там есть. Если установить в нее курсор, и подвигать стрелочками, это станет очевидно. Ну а добавит уверенности нажатие кнопки «Заменить все»:
Ого! Да эти символы, похоже, были чуть ли не в каждом втором слове! После проведения экзекуции, заголовок стал выглядеть так:
Ну что же, выведем его на чистую воду! Выделяю весь текст, устанавливаю цвет шрифта черный и размер — 18. Получается вот что:
Получается вот что:
Вот так. Наши qweqwe появились во многих словах по всему тексту. Не удивительно, что Антиплагиат оценил текст как на 100% оригинальный. Почему? Да потому, что для системы невидимый паразитный символ все равно существует, разделяя слова. И при сравнении с базами данных, Антиплагиат бодро рапортует, что текст оригинальный. Конечно оригинальный — ведь в базе данных сохранен нормальный текст, без невидимых символов.
Прибегнем снова к инструменту поиска и замены, только по-другому. В верхнюю строку мы скопируем нашего албанского героя, а нижнюю просто оставим пустой. Совсем пустой. После нажатия кнопки «Заменить все» — лишние символы будут удалены. И мы сможем-таки узнать оригинальный результат предложенного текста при проверке через Антиплагиат. В нашем случае он составил 58%. Большой впрос — стоила ли игра свеч? Ведь для публикации в журнале надо хотя бы 70 — не такая уж и великая разница. Изменив немного текст, можно было добиться нужного результата.
На этом, казалось бы, можно и закончить, однако я хочу обратить внимание на некоторые интересные особенности этого метода. Начнем с простого. Обратите внимание, заголовок (а скриншоты сделаны в Word), не подчеркнут красным. Мы с Вами отлично знаем, что если в слово вставить лишнюю букву или пробел, это непременно произойдет, если только проверка орфографии включена. Я пока еще не разобрался, как добиться такого эффекта. Все оказалось совсем просто. Помните, я упоминал албанский язык? Если поменять язык документа на такой, средства проверки орфографии для которого не установлены, то и характерных подчеркиваний не будет.
Далее. Если вы читали первую статью, то помните, что ту попытку обхода системы можно было раскусить, просто открыв текст прямо на «Антиплагиате». Припрятанный уникальный, но бессмысленный кусок текста там был виден. Здесь же все более серьезно. Не видно не только сам символ, но и даже пробел вместо него, как мы с Вами наблюдали это в блокноте.
Ну а теперь возьмемся за скальпель и полезем в XML.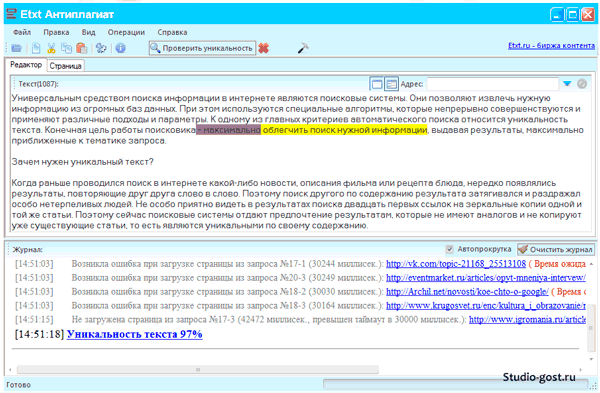 Если кто не в курсе — для того, чтобы добраться до внутренностей вордовского файла, надо изменить его расширение на zip, и получившийся архив разархивировать. Внутри будет несколько папок, содержащих различные объекты, имеющиеся в файле, и собственно текст в формате XML, где и можно увидеть что-нибудь занятное в такой ситуации. Поехали:
Если кто не в курсе — для того, чтобы добраться до внутренностей вордовского файла, надо изменить его расширение на zip, и получившийся архив разархивировать. Внутри будет несколько папок, содержащих различные объекты, имеющиеся в файле, и собственно текст в формате XML, где и можно увидеть что-нибудь занятное в такой ситуации. Поехали:
Вот он, наш герой. Если честно, я надеялся найти нечто более конкретное, поэтому полез еще глубже, то есть в шестнадцатеричный код:
Где и удалось узнать, что загадочному символу соответствует код 0A20 в таблице Unicode. Символ какого-то мудреного алфавита, которого, видимо, просто-напросто нет в тех шрифтах, которые мы используем. Кстати, по ссылке этот символ в Unicode от 1993 года. В современной таблице кода 0A20 нет вообще. Вот все и встало на свои места. То есть с точки зрения большинства программ… Символ как бы есть, но в то же время, его как бы и нет.
Хитро, кончено, что сказать… Я отлично понимаю, что все мы одарены разными талантами. И вот так взять и написать полтора десятка страниц уникального текста — некоторым сложно. Если вы относитесь к таковым — попробуйте вот это. Не бесплатно конечно. Зато честно. Ну, почти.
И вот так взять и написать полтора десятка страниц уникального текста — некоторым сложно. Если вы относитесь к таковым — попробуйте вот это. Не бесплатно конечно. Зато честно. Ну, почти.
Закончить статью, как и предыдущую, я хочу мыслями собственно об «Антиплагиате». Да, система не совершенна, однако же, приятно видеть, что она не стоит на месте. Статья, о которой идет речь выше, попала к нам около месяца назад, и тогда «Антиплагиат» ее проглотил запросто. Теперь же, после загрузки, рядом с ней загорается восклицательный знак — «подозрительный документ». Уже ради интереса я попробовал загрузить туда текст из первой статьи и получил такой же результат. Уже неплохо.
Только вот… Многие ли докопаются до таких тонкостей, даже получив предупреждение? Боюсь, что нет.
PS. Комментарии к этой записи отключены ввиду большого количество желающих порекламировать свои услуги по обходу антиплагиата. Статья-то вроде как о том, как это дело обнаружить.
Если Вам ну очень хочется донести что-то до автора — пишите на мыло.
PS. PS. Не пишите мне, чтобы я выслал «волшебный символ». Я с другой стороны баррикад 😉
Обход антиплагиата «со спрятанным текстом» и его обнаружение
В этой статье я хотел бы рассказать об одном очень интересном случае, с которым мне пришлось столкнуться недавно. О попытке «обмануть» систему «Антиплагиат».
О самой системе последнее время можно довольно часто услышать, как хорошее так и плохое. Как технический редактор научного журнала я с ней сталкивался не раз. Львиная доля недовольства, на мой взгляд вызвана некоторым недопониманием принципа ее работы. В частности, общаясь с пожилыми учеными, я довольно часто видел, что они ожидают от системы обнаружения «плагиата идеи». По их мнению, если кто-то попытается присвоить себе их научные достижения, пусть и переписав текст «на свой лад», система должна отреагировать – поймать и съесть виновных. Когда же выясняется, что в сферу возможностей «Антиплагиата» это не входит – наступает разочарование.
Система находит заимствования в чистом виде, и это на мой взгляд уже не мало и тоже важно. Если кто-то возьмет кусочек чужой статьи, книги, диссертации, диплома – и вставит в свой текст, система на это укажет. При этом не только указав долю заимствований в тексте, но и перечислив источники, откуда эти заимствования сделаны. Конечно, если переписать заимствованный кусочек «своими словами», то есть сделать рерайт, «Антиплагиат» будет молчать. Однако, очень многие сегодня не утруждают себя и рерайтом.
Есть и обратная сторона медали. Если опубликовать сперва научную статью, а затем ее содержимое, включить, скажем, в диссертацию, то «Антиплагиат» может принять последнее за заимствование, и то, что оба текста принадлежат «перу» одного и того же человека, для него значения не имеет. Ничего плохого в этом нет. Просто на это надо обращать внимание. И если в отношении какого-либо текста система рапортует о высоком проценте плагиата, прежде чем «казнить» автора, стоит посмотреть, что же она там нашла – может быть его же труды, опубликованные где-либо еще.
В любом случае, «Антиплагиат» заставляет потрудится ленивых, делая хотя бы рерайт заимствованного текста. Основные «плагиатчики» у нас, как водится, студенты. Уж сколько я наслушался жалоб о том, что долю оригинального текста в дипломе никак не получается вывести на приемлемый уровень… Но студенты народ находчивый.
Вот и мне недавно пришлось столкнуться со статьей аспиранта одного из подмосковных ВУЗов. В статье меня ждал сюрприз – попытка обмануть «Антиплагиат». Здесь надо сказать, что обмануть «Антиплагиат» аспиранту удалось, но не удалось обмануть редакцию, так что считать ли попытку успешной – вопрос открытый. Если бы речь шла о дипломной или курсовой работе хитрость могла бы и не «всплыть». Однако, выводы оставлю на потом, а сейчас расскажу о самой попытке.
Обнаружить ее удалось лишь на стадии форматирования статьи, однако некоторые сомнения возникли у меня с самого начала. Через мои руки прошло около тысячи научных статей, что позволило выработать некоторые закономерности. Поэтому, едва увидев файл со статьей, объем которого составлял почти 700 килобайт, я сразу отметил для себя: «с картинками». Однако внутри оказалась лишь пара черно-белых схем, которые ну никак не могли придать файлу такой солидный «вес».
Поэтому, едва увидев файл со статьей, объем которого составлял почти 700 килобайт, я сразу отметил для себя: «с картинками». Однако внутри оказалась лишь пара черно-белых схем, которые ну никак не могли придать файлу такой солидный «вес».
Просмотрев весь текст и внеся некоторые поправки в форматирование, я запустил один из макросов, которыми пользуюсь для автоматизации верстки статей. В его задачи входит установка шрифта, его размера, интервала, отступов и т. п. Разумеется, я сильно удивился, когда увидел, что после прогона макроса статья вдруг выросла раз в десять, и стала занимать не 12, а 110 страниц. А произошло именно это. В конце статьи, после списка литературы, появилось еще несколько десятков пустых страниц.
Исходная статья в минимальном масштабе
А вот что стало после применения макроса…
Довольно быстро стало ясно, что страницы вовсе не пустые. Они заполнены текстом, который был «покрашен» в белый цвет. Вернув тексту цвет, я увидел несколько абзацев из статьи, которые повторялись много-много раз.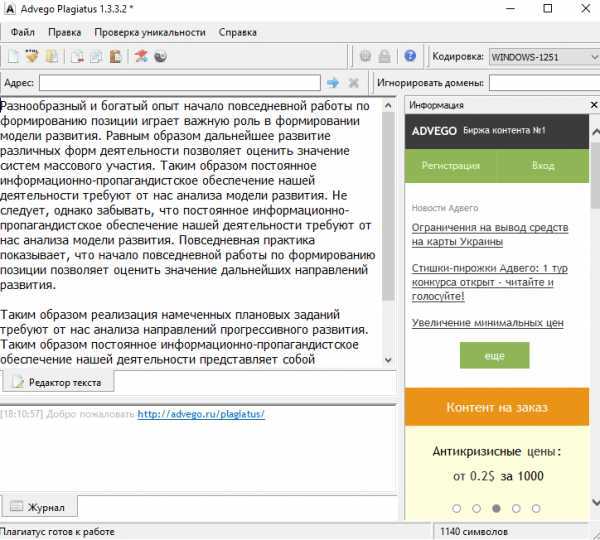 А «отрезав» этот своеобразный «хвост» понял зачем это было нужно, да и все остальное встало на свои места.
А «отрезав» этот своеобразный «хвост» понял зачем это было нужно, да и все остальное встало на свои места.
… и наконец, окончательный вариант
Например, файл со статьей похудел до 100 килобайт, а результат проверки файла системой «Антиплагиат» показал 59% оригинального текста. Хотя изначально выдавалась оценка 96%. Ну а для того, чтобы опубликовать статью в журнале, надо обеспечить не менее 70% оригинального текста (остальные 30 отводятся на цитирование, выдержки из каких-либо документов и т. п.).
То есть, фактически, бдительность «Антиплагиата» была усыплена увеличением в статье доли оригинального, пусть и бессмысленного (а также скрытого от глаз обычных читателей) текста. Ниже для наглядности я попробовал изобразить смысл сделанного графически.
Итак, мы с вами разобрались зачем. Осталось понять, как? Действительно, как же лишняя сотня страниц была спрятана в документе? И как можно обнаружить такой «припрятанный» текст?
Разумеется, недостаточно добавить большой кусок текста в конец и перекрасить его в белый цвет – это будет сразу заметно. Однако, изначально в статье было 12 страниц… Изучение исходного вариант показало, что текст был не только перекрашен в белый цвет, но и уменьшен до такого размера, что все 200 000 символов на экране выглядели как всего один. Вот ниже на рисунке можно увидеть перекрашенный в черный цвет «паразитный» текст в оригинальном размере.
Однако, изначально в статье было 12 страниц… Изучение исходного вариант показало, что текст был не только перекрашен в белый цвет, но и уменьшен до такого размера, что все 200 000 символов на экране выглядели как всего один. Вот ниже на рисунке можно увидеть перекрашенный в черный цвет «паразитный» текст в оригинальном размере.
Так вот. Теперь давайте посмотрим его свойства.
Вроде ничего необычного. Если попробовать проделать обратное преобразование ничего не выйдет. Скажу забегая вперед, что у меня так и не получилось штатными средствами Word уплотнить текст до исходного состояния. Возможно, кунг-фу того, кто это сделал изначально, круче моего кунг-фу, однако я все-таки склоняюсь в сторону мысли о том, что для этого было использовано специальное ПО. Дело в том, что любой «вордовский» файл в формате .docx – это просто-напросто архив, внутри которого можно найти текст, содержащийся в файле, в формате XML, а так же изображения и т. п. Ради интереса можете попробовать самостоятельно, просто изменив расширение файла c . docx на .zip и разархивировав получившееся.
docx на .zip и разархивировав получившееся.
Так вот, анализ XML показал два интересных факта – во-первых многие параметры, касающиеся интервалов в файле, имеют отрицательное значение. Ну а во-вторых присвоены они всему «хвосту» целиком, в то время как Word, как правило, записывает параметры для каждого абзаца… Так что возвращаемся к исходному – файл был изготовлен с помощью специального ПО, или же, как промежуточный вариант XML редактировался вручную.
Остается последний вопрос – как же обнаружить спрятанный текст? Тут все довольно просто. Во-первых, если открыть статью после загрузки в систему «Антиплагиат», его там можно увидеть. Однако, скажем положа руку на сердце – кто это делает? Вот именно. Никто.
Обнаружить текст можно и прямо в Word – для этого надо выполнить команду «выделить» все, а затем установить параметры шрифта – масштаб – 100%, интервал – обычный.
Наконец, текст можно просто-напросто скопировать в любой простой текстовый редактор, не поддерживающий форматирование («Блокнот» например), там всё будет видно.
Ну а поводом заподозрить неладное может стать несопоставимый с содержимым объем файла.
Для себя я выбрал второй способ (проверка в Word) – тем более, написав макрос, такую проверку можно свести к одному клику мышью (а у меня он и так есть).
Ну а в качестве заключения хотелось бы сказать, что этой статьей я вовсе не выдал студентам инструкцию к обходу «Антиплагиата». Ибо в сети имеют место быть совершенно реальные инструкции, которым, судя по количеству комментариев, многие пользуются и вполне успешно.
Как проверяют студенческие работы? Их кучей загружают в «Антиплагиат», а затем смотрят лишь процентное соотношение оригинального и неоригинального текста, не вдаваясь в детали.
Если в ближайшее время на это не будет обращено внимания как пользователями системы, так и ЗАО «Анти-Плагиат», утверждения о том, что система изжила себя, которые можно увидеть на форуме «Антиплагиата», можно будет считать верными.
Кстати, некоторое время спустя история с обходом антиплагиата повторилась.
PS. В статье описан «ранний» способ модификации. Впоследствии описанный способ «обхода» был усовершенствован. Рекомендую прочесть статью «как обнаружить модификацию текстового файла с целю искусственного повышения уникальности«.
PS. PS. Комментарии к этой записи отключены ввиду большого количество желающих порекламировать свои услуги по обходу антиплагиата. Статья-то вроде как о том, как это дело обнаружить.
Если Вам ну очень хочется донести что-то до автора — пишите на мыло.
ПОВЫСИТЬ АНТИПЛАГИАТ PDF
Повысить Антиплагиат PDF реально или это миф?
Если Вас заинтересовала тема «как перевести документ из Word в PDF?», «как пройти антиплагиат пдф?» или «алгоритмы обнаружения антиплагиата в текстовых документах PDF» значит данная информация пойдет на пользу. Для чего студентам переводить работу в формат pdf? Многие преподаватели проверяют уникальность в формате pdf в программе антиплагиат вуз. С каждым годом проверка усложняется и ужесточается, а в данном формате преподавателю проще проверять текстовый документ. Современный студент пользуется такими программами как Word, PowerPoint и PDF. Преподаватели часто просят перевести документ в тот или другой формат. Многие учащиеся не знают как обычный документ в Word и PowerPoint можно перевести в ПДФ. Чтобы это понять? необходимо разобраться как перевести текст и проверить антиплагиат пдф.
Современный студент пользуется такими программами как Word, PowerPoint и PDF. Преподаватели часто просят перевести документ в тот или другой формат. Многие учащиеся не знают как обычный документ в Word и PowerPoint можно перевести в ПДФ. Чтобы это понять? необходимо разобраться как перевести текст и проверить антиплагиат пдф.
Если вы находитесь в программе Word и хотите этот документ преобразовать в pdf, для этого нужно зайти в верхнее меню документа, выбирать вкладку файл из выпадающего окошка выбираем позицию «сохранить как». Открывается еще одно окошко, в котором необходимо указать папочку где будем хранить свой документ, прописываем имя файла, указываем его тип. Также его можно оставить в той папке, в которой хранится определенный набор документов. Если нужна новая папочка, тогда вы выбираете в меню определенную позицию диска, на котором нужно сохранить, после выбираем папочку, и соответственно прописываем путь хранения. Название файла рекомендуется прописывать на латыни потому, что когда вы его переведете формат PDF его название не будет читаться, оно будет прописано в виде «кракозябры». Поэтому на латыни пропишите название своего документа, в строчке тип файла, нажимаем на выпадающее меню выбираем нужный нам формат PDF, нажимаем кнопочку «сохранить». Вот процесс преобразования уже проходит к концу, и нужный документ открывается уже в pdf формате.
Поэтому на латыни пропишите название своего документа, в строчке тип файла, нажимаем на выпадающее меню выбираем нужный нам формат PDF, нажимаем кнопочку «сохранить». Вот процесс преобразования уже проходит к концу, и нужный документ открывается уже в pdf формате.
В pdf формате рассматриваем свой документ, смотрим всё ли получилось.
Точно также открываем свой документ в программе PowerPoint и проделываем те же действия. Заходим в раздел файл сохранить как, во выпадающем окне прописываем название файла на латыни. Выбираем тип файла PDF и нажимаем сохранить. Далее пойдет процесс преобразования. Он немножко дольше занимает времени и документ откроется уже в формате pdf. Вот так всё просто. Только есть один важный момент, если при нажатии меню файл сохранить как у вас нет позиции «сохранить как» это говорит о том что у вас не установлено приложение EPS публикаций (формат файла, в котором могут содержаться векторные 2D-данные, текст и рисунки). Для этого сначала его нужно скачать, установить, а потом проводить преобразование ваших документов.
Следующие вопросы, которые чаще всего задают студенты это «повышение антиплагиат пдф», «проверка на антиплагиат в формате PDF» и «как обмануть антиплагиат пдф». Если перед студентом возникла задача создания оригинального текста и прохождения antiplagiat.ru и антиплагиат вуз, значит настала пора действовать. Для того, чтобы знать как пройти антиплагиат PDF, необходимо знать, чего не следует делать, что бы не получить от своего руководителя «пинка».
Первый способ повышения антиплагиат пдф онлайн – замена кириллицы латиницей. Метод замена русских букв на английские, которые имеют одинаковое написание, это как а, о, у, с, р. Этот способ мог бы прокатить в начале появления системы антиплагиат вуз, а на современном этапе это кроме как бурного гнева преподавателя не вызовет. После такой корректировки текст будет густо подчеркнут красной волнистой линией. Преподаватели люди неглупые, они быстро раскроют хитрый план студента, в следствии чего уникальность pdf не будет пройдена.
Метод второй – применение онлайн переводчиков. Сама по себе идея взять непроиндексированный текст на иностранном языке для своей работы – неплохой, однако, если студент загонит данный текст просто в переводчик, то на выходе можно получить слабо читаемый, либо нечитаемый текст, который будет состоять из разрозненных слов. Оригинальность пдф файла будет конечно высокой, но если преподаватель решит почитать вашу работу, у студента могут быть большие проблемы.
Третий «гениальный» вариант обмана антиплагиат пдф это перевод текста с русского на английский и затем обратно. В таком случае вновь переведенный материал будет иметь довольно высокий % уникальности. Однако можно столкнуться с той же проблемой, что и при использовании предыдущего способа повышения антиплагиат пдф файлов. В данном случае есть 10% «надежды», что руководитель текст читать не будет.
Метод номер три заключается в бездумном перемещении слов и предложений. Он однозначно плох в том случае, если учащийся этим будет заниматься вслепую и бездумно. В таком случае студент получит такой же результат, что и в предыдущих способах. Набор бессмысленных предложений. Этот метод позволит не только уничтожить уйму времени но и снизить оригинальность pdf.
В таком случае студент получит такой же результат, что и в предыдущих способах. Набор бессмысленных предложений. Этот метод позволит не только уничтожить уйму времени но и снизить оригинальность pdf.
Четвертый метод – применение синонимайзеров. Данный способ повышения антиплагиат pdf онлайн приведет к тому, что студент лишит смысла свою работу. Такой метод предусматривает дальнейшие доработки и возвращение смысла текстовому документу. В противном случае студент получит негативный отзыв от преподавателя.
Пятый метод подразумевает внедрение дополнительных символов и якорей. Иногда студенты пытаются включить в работу каких-то дополнительных иконок. Если преподаватель решит перевести работу в формат тхт или посмотреть отчет системы антиплагиат, он увидит очень занятную картину. Студенты, которые попадались с таким методом повышения, переписывали работу еще раз. В худшем случае могут исключить из высшего учебного заведения. Это очень плохая идея с повышением % оригинальности.
Шестой метод – вставка скриншотов вместо текста. Результат такого повышения уникальности будет довольно неприятным. Преподаватель без затруднений это увидит и у учащегося могут быть проблемы.
Как обойти антиплагиат pdf, какой способ применить лучше, решать только студенту. Каждый сам в праве решать, какой выбрать путь, а какой нет: «колхоз дело добровольное». Если вы решили самостоятельно повысить антиплагиат пдф лучше применить рерайт (переписывание текстового документа своими словами). Если проверка антиплагиат PDF показала маленькую оригинальность не стоит отчаиваться. Найдите время и перепишите работу еще раз или найдите специалиста, у которого будет болеть голова за вашу уникальность. Конечно это стоит больших денег, зато, как говорится, «результат на лицо». Обход антиплагиат пдф – дело тонкое и сложное, требует больших затрат времени и финансов.
Если возникли вопросы «как проверить pdf?», «как повысить антиплагиат пдф?», «сколько длится повышение антиплагиат PDF?», можно обратится за консультацией к преподавателям нашей фирмы. Сотрудники помогут проверить файл pdf. Проверка pdf формата в системе антиплагиата осуществляется в течении короткого времени. Проверка антиплагиат PDF дает возможность студентам исправить ошибки и убрать плагиат в работе.
Сотрудники помогут проверить файл pdf. Проверка pdf формата в системе антиплагиата осуществляется в течении короткого времени. Проверка антиплагиат PDF дает возможность студентам исправить ошибки и убрать плагиат в работе.
Обращайтесь в любую минуту! Будем рады помочь вам в любой ситуации!
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
-
Общие сведения о кодировке текста
-
Выбор кодировки при открытии файла
-
Выбор кодировки при сохранении файла
-
Поиск кодировок, доступных в Word
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке “Кириллица (Windows)” знаку “Й” соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка “Кириллица (Windows)”, компьютер считывает число 201 и выводит на экран знак “Й”.
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка “Западноевропейская (Windows)”, знак “Й” из исходного текстового файла на основе кириллицы будет отображен как “É”, поскольку именно этому знаку соответствует число 201 в данной кодировке.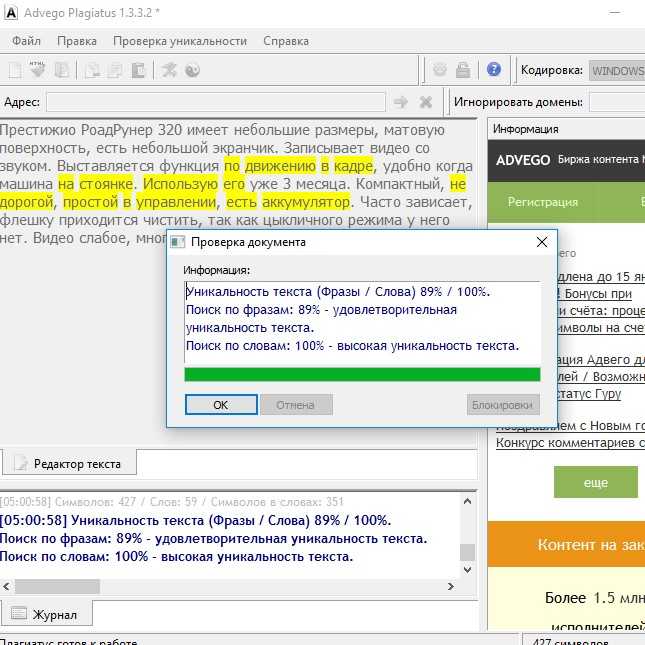
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
К началу страницы
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
-
Откройте вкладку Файл.
-
Нажмите кнопку Параметры.
-
Нажмите кнопку Дополнительно.
-
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM).
 Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось. -
Закройте, а затем снова откройте файл.
-
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
-
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
-
Нажмите кнопку Пуск и выберите пункт Панель управления.
-
Выполните одно из указанных ниже действий.
В Windows 7
-
На панели управления выберите раздел Удаление программы.
 org/ListItem”>
org/ListItem”>
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
-
На панели управления щелкните элемент Установка и удаление программ.
-
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
 org/ItemList”>
org/ItemList”> -
-
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
-
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
-
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
К началу страницы
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке “Китайская традиционная (Big5)”. В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке “Кириллица (Windows)”, текст на иврите не отобразится, а если сохранить его в кодировке “Иврит (Windows)”, то не будет отображаться кириллический текст.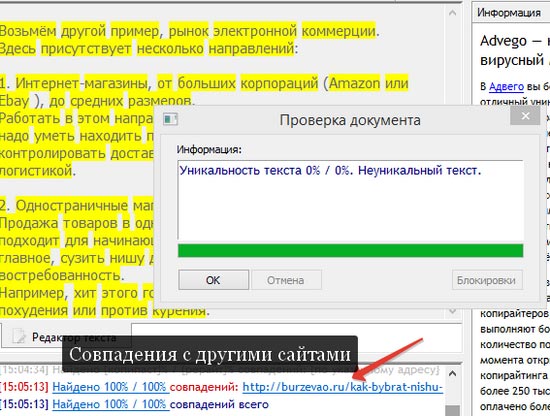
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
-
Откройте вкладку Файл.
-
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
 org/ListItem”>
org/ListItem”>
В поле Имя файла введите имя нового файла.
-
В поле Тип файла выберите Обычный текст.
-
Нажмите кнопку Сохранить.
-
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
-
В диалоговом окне Преобразование файла выберите подходящую кодировку.
 org/ListItem”>
org/ListItem”>
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
-
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
-
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
-
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.

Если появилось сообщение “Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке”, можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
К началу страницы
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
|
Система письменности |
Кодировки |
Используемый шрифт |
|---|---|---|
|
Многоязычная |
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7) |
Стандартный шрифт для стиля “Обычный” локализованной версии Word |
|
Арабская |
Windows 1256, ASMO 708 |
Courier New |
|
Китайская (упрощенное письмо) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
SimSun |
|
Китайская (традиционное письмо) |
BIG5, EUC-TW, ISO-2022-TW |
MingLiU |
|
Кириллица |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
Courier New |
|
Английская, западноевропейская и другие, основанные на латинице |
Windows 1250, 1252-1254, 1257, ISO8859-x |
Courier New |
|
Греческая |
Windows 1253 |
Courier New |
|
Иврит |
Windows 1255 |
Courier New |
|
Японская |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
MS Mincho |
|
Корейская |
Wansung, Johab, ISO-2022-KR, EUC-KR |
Malgun Gothic |
|
Тайская |
Windows 874 |
Tahoma |
|
Вьетнамская |
Windows 1258 |
Courier New |
|
Индийские: тамильская |
ISCII 57004 |
Latha |
|
Индийские: непальская |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: конкани |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: хинди |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: ассамская |
ISCII 57006 |
|
|
Индийские: бенгальская |
ISCII 57003 |
|
|
Индийские: гуджарати |
ISCII 57010 |
|
|
Индийские: каннада |
ISCII 57008 |
|
|
Индийские: малаялам |
ISCII 57009 |
|
|
Индийские: ория |
ISCII 57007 |
|
|
Индийские: маратхи |
ISCII 57002 (деванагари) |
|
|
Индийские: панджаби |
ISCII 57011 |
|
|
Индийские: санскрит |
ISCII 57002 (деванагари) |
|
|
Индийские: телугу |
ISCII 57005 |
-
Для непальского, ассамского, бенгальского, гуджарати, малаялам и ория доступна только ограниченная поддержка.
Для использования индийских языков необходима их поддержка в операционной системе и наличие соответствующих шрифтов OpenType.
К началу страницы
Создайте средство проверки на плагиат с помощью машинного обучения | Тайлер Хокинс
Фото Кристофера Бернса на Unsplash Плагиат свирепствует в Интернете и в классе. С таким большим количеством контента иногда трудно понять, когда что-то было плагиатом. Авторы, пишущие сообщения в блогах, могут захотеть проверить, не украл ли кто-то их работу и не разместил ли ее в другом месте. Учителя могут захотеть сверить работы студентов с другими научными статьями на предмет скопированных работ. Новостные агентства могут захотеть проверить, не украла ли контент-ферма их новостные статьи и не объявила ли контент своим.
Итак, как защититься от плагиата? Было бы неплохо, если бы программное обеспечение делало всю тяжелую работу за нас? Используя машинное обучение, мы можем создать собственную программу проверки на плагиат, которая ищет украденный контент в обширной базе данных. В этой статье мы сделаем именно это.
Мы создадим приложение Python Flask, которое использует Pinecone — службу поиска по сходству — для поиска возможно плагиата.
Давайте посмотрим на демонстрационное приложение, которое мы будем создавать сегодня. Ниже вы можете увидеть краткую анимацию приложения в действии.
Пользовательский интерфейс имеет простую текстовую область ввода, в которую пользователь может вставить текст из статьи. Когда пользователь нажимает кнопку Submit , этот ввод используется для запроса базы данных статей. Результаты и их очки соответствия затем отображаются для пользователя. Чтобы уменьшить количество шума, приложение также включает ползунок, в котором пользователь может указать порог сходства, чтобы отображались только очень сильные совпадения.
Как вы можете видеть, когда в качестве входных данных для поиска используется исходный контент, показатели совпадения для статей, возможно, являющихся плагиатом, относительно низкие. Однако, если бы мы скопировали и вставили текст одной из статей в нашей базе данных, результаты для статьи с плагиатом вернутся с 99,99% совпадений!
Итак, как мы это сделали?
При создании приложения мы начинаем с набора данных новостных статей из Kaggle. Этот набор данных содержит 143 000 новостных статей из 15 крупных изданий, но мы используем только первые 20 000. (Полный набор данных, из которого получен этот, содержит более двух миллионов статей!)
Затем мы очищаем набор данных, переименовывая пару столбцов и удаляя несколько ненужных. Затем мы пропускаем статьи через модель встраивания для создания векторных вложений — это метаданные для алгоритмов машинного обучения, чтобы определить сходство между различными входными данными. Мы используем модель среднего вложения слов. Наконец, мы вставляем эти векторные вложения в векторную базу данных, управляемую Pinecone.
После того, как векторные изображения добавлены в базу данных и проиндексированы, мы готовы начать поиск похожего контента. Когда пользователи отправляют текст своей статьи в качестве входных данных, делается запрос к конечной точке API, которая использует SDK Pinecone для запроса индекса векторных вложений. Конечная точка возвращает 10 похожих статей, которые, возможно, были плагиатом, и отображает их в пользовательском интерфейсе приложения. Вот и все! Достаточно просто, не так ли?
Если вы хотите попробовать это сами, вы можете найти код этого приложения на GitHub. README содержит инструкции по локальному запуску приложения на вашем компьютере.
Мы рассмотрели внутреннюю работу приложения, но как мы его создали? Как отмечалось ранее, это приложение Python Flask, в котором используется SDK Pinecone. HTML использует файл шаблона, а остальная часть внешнего интерфейса построена с использованием статических ресурсов CSS и JS. Для простоты весь внутренний код находится в файле app.py , который мы полностью воспроизвели ниже:
Давайте рассмотрим важные части файла app.py , чтобы понять его.
В строках 1–14 мы импортируем зависимости нашего приложения. Наше приложение опирается на следующее:
-
Dotenvдля переменных среды чтения от. EnvФайл -
Flaskдля настройки веб -приложения -
JSONдля работы с JSON 49999999999259. -
Pandasдля работы с набором данных -
Pineconeдля работы с Pinecone SDK -
REдля работы с регулярными выражениями (REGEX) -
Запросыдля API для загрузки на наш для некоторых удобных методов статистики -
предложение_трансформеровдля нашей модели встраивания -
более быстрыйдля работы с кадром данных pandas
для работы для работы с JSON99999999992566666666666666666 6. . получение переменных окружения В строке 16 мы предоставляем шаблонный код, чтобы сообщить Flask имя нашего приложения.
В строках 18–20 мы определяем некоторые константы, которые будут использоваться в приложении. К ним относятся имя нашего индекса Pinecone, имя файла набора данных и количество строк для чтения из файла CSV.
В строках 22–25 наш метод initialize_pinecone получает наш ключ API из файла .env и использует его для инициализации Pinecone.
В строках 27–29 наш delete_existing_pinecone_index ищет в нашем экземпляре Pinecone индексы с тем же именем, что и тот, который мы используем («Проверка на плагиат»). Если существующий индекс найден, мы удаляем его.
В строках 31–35 наш метод create_pinecone_index создает новый индекс, используя выбранное нами имя («Проверка плагиата»), метрику близости «косинус» и только один сегмент.
В строках 37–40 наш метод create_model использует библиотеку Offering_transformers для работы со средней моделью встраивания слов. Мы будем кодировать наши векторные вложения, используя эту модель позже.
В строках 62–68 наш метод process_file читает CSV-файл, а затем вызывает для него методы prepare_data и upload_items . Эти два метода описаны далее.
В строках 42–56 наш метод prepare_data корректирует набор данных, переименовывая первый столбец «id» и удаляя столбец «date». Затем он объединяет заголовок статьи с содержанием статьи в одно поле. Мы будем использовать это комбинированное поле при создании векторных вложений.
В строках 58–60 наш метод upload_items создает векторное вложение для каждой статьи, кодируя ее с помощью нашей модели. Затем мы вставляем векторные вложения в индекс Pinecone.
В строках 70–74 наши методы map_titles и map_publications создают несколько словарей заголовков и названий публикаций, чтобы потом было легче находить статьи по их идентификаторам.
Каждый из описанных нами методов вызывается в строках 95–101 при запуске серверного приложения. Эта работа подготавливает нас к последнему шагу — фактическому запросу индекса Pinecone на основе пользовательского ввода.
В строках 103–113 мы определяем два маршрута для нашего приложения: один для домашней страницы и один для конечной точки API. Домашняя страница обслуживает файл шаблона index.html вместе с ресурсами JS и CSS, а конечная точка API предоставляет функцию поиска для запроса индекса Pinecone.
Наконец, в строках 76–93 наш метод query_pinecone принимает введенные пользователем данные о содержании статьи, преобразует их в векторное вложение, а затем запрашивает индекс Pinecone, чтобы найти похожие статьи. Этот метод вызывается, когда /api/search конечная точка попадает, что происходит каждый раз, когда пользователь отправляет новый поисковый запрос.
Для визуальных учеников вот схема, показывающая, как работает приложение:
Архитектура приложения и взаимодействие с пользователем Итак, сложив все это вместе, как выглядит взаимодействие с пользователем? Давайте рассмотрим три сценария: исходный контент, точная копия плагиата и контент, написанный «заплаткой».
При отправке оригинального контента приложение отвечает некоторыми, возможно, связанными статьями, но оценки соответствия довольно низкие. Это хороший знак, так как контент не является плагиатом, поэтому мы ожидаем низкие оценки соответствия.
Когда отправляется точная копия плагиата, приложение отвечает практически идеальным совпадением для одной статьи. Это потому, что содержание идентично. Хорошая находка, проверка на плагиат!
Теперь, для третьего сценария, мы должны определить, что мы подразумеваем под «содержимым, написанным патчем». Написание исправлений — это форма плагиата, при которой кто-то копирует и вставляет украденный контент, но затем пытается замаскировать факт плагиата, изменяя некоторые слова здесь и там. Если в предложении из оригинальной статьи говорится: «Он был вне себя от радости, когда нашел свою потерянную собаку», кто-то может изменить содержание, чтобы вместо этого сказать: «Он был счастлив вернуть свою пропавшую собаку». Это несколько отличается от перефразирования, потому что структура основного предложения содержания часто остается неизменной на протяжении всей плагиатной статьи.
А вот и самое интересное: наша программа проверки на плагиат очень хорошо справляется с идентификацией контента, написанного с исправлениями! Если бы вы скопировали и вставили одну из статей в базу данных, а затем изменили некоторые слова здесь и там и, возможно, даже удалили несколько предложений или абзацев, результат совпадения все равно будет почти идеальным! Когда я попытался сделать это со скопированной и вставленной статьей, которая имела оценку совпадения 99,99%, контент, «написанный патчем», по-прежнему возвращал оценку совпадения 99,88% после моих правок!
Не так уж и плохо! Наша проверка на плагиат работает хорошо.
Теперь мы создали простое приложение Python для решения реальной проблемы. Подражание может быть высшей формой лести, но никому не нравится, когда его работу крадут. В растущем мире контента такая проверка на плагиат была бы очень полезна как для авторов, так и для преподавателей.
Это демонстрационное приложение имеет некоторые ограничения, так как это всего лишь демонстрационная версия. База данных статей, загруженных в наш индекс, содержит всего 20 000 статей из 15 крупных новостных изданий. Однако существуют миллионы или даже миллиарды статей и сообщений в блогах. Подобная проверка на плагиат полезна только в том случае, если она проверяет ваш ввод по всем местам, где ваша работа могла быть плагиатом. Это приложение было бы лучше, если бы в нашем указателе было больше статей и если бы мы постоянно добавляли его.
Тем не менее, на данный момент мы продемонстрировали надежное доказательство концепции. Pinecone, как управляемый сервис поиска по сходству, сделал за нас тяжелую работу, когда дело дошло до аспекта машинного обучения. С его помощью мы смогли создать полезное приложение, которое довольно легко использует обработку естественного языка и семантический поиск, и теперь мы можем быть спокойны, зная, что наша работа не является плагиатом.
Обнаружение и предотвращение плагиата: пособие для исследователей
Ревматология. 2021; 59(3): 132–137.
Опубликовано онлайн 2021 мая 13. DOI: 10.5114/reum.2021.105974
1 и 2
Информация о том, что Статья о качественном, аниболе. и достоверность научных публикаций. Повышение осведомленности исследователей о плагиате слов, идей и графики имеет важное значение для предотвращения неприемлемой практики написания. Глобальные редакционные ассоциации опубликовали свои заявления о стратегиях очистки литературы от избыточной, украденной и вводящей в заблуждение информации. Рекомендуется ознакомиться с соответствующими документами для обновления инструкций для авторов и предупреждения плагиаторов об академических и других последствиях неэтичного поведения. Считается, что отсутствие творческого мышления и плохие навыки академического английского языка усугубляют большинство случаев избыточного письма и «копирования и вставки». Программное обеспечение для обнаружения плагиата в значительной степени зависит от сообщения о сходстве текста. Однако требуется ручная проверка для выявления неуместных ссылок, нарушений авторских прав и некачественного английского письма.
Медицинские исследователи и авторы могут улучшить свои навыки письма и избежать тех же ошибок, ознакомившись со списком отзывов из-за плагиата, которые отслеживаются на платформе PubMed и обсуждаются в блоге Retraction Watch.
Ключевые слова: плагиат, публикации, публикационная этика, ревматология
Плагиат – одна из частых форм нарушения публикационной этики. Исследователи со всего мира могут стать свидетелями такого нарушения в своей академической среде, а некоторые из них могут намеренно или ненамеренно повторно использовать свою или чужую интеллектуальную собственность без надлежащей обработки и указания [1, 2].
Напоминаем исследователям в области медицины и смежных областях здравоохранения, что термин Медицинских предметных рубрик (MeSH) определяет плагиат как «выдачу за свою работу другого без указания авторства» (https://www. ncbi.nlm.nih.gov/mesh /?term=плагиат). Этот термин был введен еще в 1990 году. С тех пор глобальное понимание плагиата эволюционировало, отражая различные неэтичные повторные использования идей, текстов и графических материалов [3].
Глобальное движение за открытый доступ позволило легко выявить большинство случаев плагиата, включая копирование текстов и графики из оцифрованных старых и новых источников. Возникшие в результате опровержения ошибочных и неэтичных статей в основном коснулись биомедицинских авторов из Китая, Индии и Ирана, особенно тех, кто публикуется в журналах с низким импакт-фактором [4]. Оцифровка редакционного управления и регулярное сканирование бесчисленных онлайн-платформ позволили обнаружить неэтичное повторное использование рукописей, проходящих рецензирование [5]. Оцифровка рецензирования также позволила выявить случаи кражи идей и материалов, предназначенных для конфиденциальной и привилегированной оценки рецензентами [6].
Интеллектуальное воровство все чаще рассматривается как серьезное нарушение этических норм в странах, вступающих в глобальную академическую конкуренцию и приводящих свою политику исследований и разработок в соответствие с общепризнанными нормами. Осведомленность о различных формах плагиата растет благодаря международному исследовательскому сотрудничеству и качественным публикациям, в которых участвуют ученые с разными языками и культурными традициями. Однако проблема плагиата в глобализованном мире науки усложняется из-за по-разному воспринимаемых определений неэтичного поведения, повторного использования собственных опубликованных материалов, недопустимого дублирования идентичной научной информации на разных языках [7].
Глобальные редакционные рекомендации содержат ряд пунктов, инструктирующих редакторов журналов, как поступать с подозрениями на плагиат и повторяющимися/перекрывающимися материалами на этапах до и после публикации. Основные практики Комитета по этике публикаций (COPE) побуждают редакторов определять плагиат в своих инструкциях и четко указывать читателям, как повторно использовать опубликованные ими статьи [8]. Также все авторы рукописей и опубликованных статей с незаконным присвоением интеллектуальной собственности должны осознавать свою полную ответственность за любые правонарушения на любом этапе. В случае подозрения редакторы могут допросить всех соавторов и соответствующие органы [9].].
Совет научных редакторов (CSE) определяет пиратство и плагиат как связанные нарушения публикационной этики с несанкционированным воспроизведением идей, данных, методов и графических материалов, в том числе принадлежащих плагиату (самоплагиат и дублирование публикации) [10] . CSE рассматривает плагиат, фальсификацию и фальсификацию как различные формы неправомерного поведения в исследованиях, которые могут оправдать академические санкции, налагаемые соответствующими национальными органами и профессиональными сообществами. Во избежание каких-либо обвинений в плагиате авторам необходимо правильно обрабатывать первичную литературу и указывать генераторы идей и другую интеллектуальную собственность. Редакторы, в свою очередь, должны уметь выявлять скопированные и повторяющиеся материалы с помощью передового программного обеспечения и различных других средств.
Наконец, Всемирная ассоциация медицинских редакторов (WAME) подтверждает редакционную нетерпимость к плагиату в неопубликованных и опубликованных рукописях и предлагает по-разному относиться к самоплагиату, особенно в случае лингвистически избыточного описания методов и других неизбежных и непреднамеренных дублирований [11]. ].
Плагиат часто выявляется в произведениях начинающих неанглоязычных авторов, находящихся в консервативной образовательной среде, поощряющей копирование и запоминание и отвергающей творческое мышление [12, 13]. Пробелы в обучении методологии исследования, этичному письму и приемлемой поддержке редактирования также рассматриваются как препятствия для нацеливания влиятельных журналов на студентов-медиков и выпускников [14].
Простота доступа к качественным онлайн-статьям опытных авторов, неосведомленность о плагиате и неопределенная политика этики исследований могут подтолкнуть исследователей в некоторых академических учреждениях к копированию, повторному использованию и выпуску неэтичных публикаций [15, 16].
Большой опрос студентов бакалавриата и магистратуры Западной и Восточной Европы ( n = 1757) выявил диаметрально противоположные подходы к повышению осведомленности о плагиате и организации антиплагиатных курсов, при этом польские студенты не имеют подготовки в этих областях [17]. Кроме того, опрос 1100 студентов-медиков в Пакистане показал высокий процент неосведомленности о плагиате (87%) и случаев плагиата (71%) [18]. Наконец, общенациональный опрос 706 иранских выпускников медицинских вузов и преподавателей показал, что большинство опрошенных (74%) не проходили никакой подготовки по вопросам плагиата [19].]. Тот же опрос показал, что 11% даже не слышали о таком этическом нарушении.
Существование многочисленных редактирующих и копировальных агентств, охотящихся за начинающими исследователями, студентами и авторами, может еще больше усложнить проблему и негативно сказаться на научных публикациях в Китае и некоторых других неанглоязычных странах [9].
Несколько форм плагиата можно отличить на основе вмешивающихся факторов этого неправомерного поведения (). В зависимости от замысла автора плагиат подразделяется на преднамеренный и непреднамеренный (случайный) формы [20]. Первое является преднамеренным неэтичным действием, направленным на введение читателей в заблуждение опытными авторами, которые воруют идеи, тексты и графику и выдают украденные материалы за свои собственные. Его обнаружение сопровождается академическими санкциями и другими наказаниями. Непреднамеренная форма может появиться из-за неправильного перефразирования и ссылки на ранее опубликованные работы [21].
Table I
Common instances of plagiarism
| Ethical misconduct | Involved individuals |
|---|---|
| Plagiarism of ideas | Reviewers of scholarly works, researchers copying unpublished hypotheses, published methodologies, and ideas |
| Прямое (дословное) копирование | Неопытные авторы, не подозревающие о плагиате и копирующие тексты со ссылкой или без ссылки |
| Парафрагиат | Авторы, которые копируют отрывки текста со ссылками или без них, а затем заменяют несколько слов синонимами, перетасовывают слова, предложения и абзацы, чтобы намеренно запутать антиплагиатное программное обеспечение |
| Повторное использование текста | Авторские права правообладатели, которые считают, что нет проблем с повторным использованием их собственной интеллектуальной собственности |
| Переводческий плагиат | Авторы, которые переиздают одни и те же произведения на разных языках без ведома и согласия первичных и вторичных издателей |
| Плагиат графики | Авторы обзоров и других статей, повторно использующие изображения, таблицы и другие графические материалы без официального разрешения и в нарушение авторских прав |
| Плагиат с манипулированием цитированием цитирование для сокрытия существенного плагиата | |
| Составной плагиат | Лица (редакторы), занимающиеся кражей, переводом и редактированием опубликованных материалов, чтобы избежать тревожных сигналов программного обеспечения для борьбы с плагиатом |
Открыть в отдельном окне
Неопытных авторов часто обвиняют в таких нарушениях, связанных с неавторизованным копированием отрывков текста, научных фактов и чужих идей. В случае непреднамеренного плагиата может быть достаточно надлежащего редактирования и ссылки на такие рукописи до подачи в журнал, а также исправления ошибочных статей путем публикации извинений перед читателями [22].
Эксперты различают плагиат идей, слов (текстов) и изображений (график) [3]. Идеи могут быть украдены неэтичными оценщиками грантовых проектов, журнальных рукописей или других научных материалов во время рецензирования, которое намеренно откладывается, чтобы позволить плагиатору сначала опубликовать свою собственную статью с незаконно присвоенными идеями. Незаконное присвоение идей и методологий является более серьезным и незаметным проступком, чем копирование слов [23].
Текстовый плагиат проявляется в различных формах, которые могут быть обнаружены передовыми поисковыми системами и программным обеспечением, анализирующим сходство значительного количества оцифрованных публикаций. Прямые, или дословные, и переводные формы плагиата относительно легко обнаружить с помощью поисковых систем и программного обеспечения для борьбы с плагиатом [24, 25]. Перефразирование и лоскутный плагиат могут сбить с толку системы обнаружения плагиата попытками плагиаторов заменить несколько слов в исходном тексте и неправильно использовать фразы и предложения. Тщательная ручная проверка и анализ ключевых слов и ссылок может помочь правильно интерпретировать отчеты о сходстве, созданные программным обеспечением.
Плагиаторы могут умышленно увеличивать список литературы путем цитирования несуществующих источников или некорректно цитировать первоисточники, взятые из вторичных (систематические обзоры), с единственной целью ввести читателей в заблуждение и скрыть плагиат вторичных публикаций [20]. Сообщается также о форме манипуляции («троянское цитирование») в связи со ссылками на соответствующие элементы, чтобы скрыть существенный плагиат и ввести в заблуждение редакторов журналов и программное обеспечение для борьбы с плагиатом [26].
Текущее программное обеспечение для борьбы с плагиатом может обнаруживать непризнанные переработанные (самосплагиатные) тексты, так называемые салями (данные, полученные в результате одного исследования, разбросанного по нескольким статьям) и дополненные (в отличие от салями) тексты. Обвинения в плагиате в таких случаях требуют тщательной ручной проверки всех подобных частей, особенно экспертами в профессиональной области.
Обнаружение идентичных тезисов требует особого внимания из-за сходства некоторых полных текстов с тезисами и препринтами конгресса, которые являются неопубликованными материалами и не учитывают плагиат. Таким образом, авторам следует рекомендовать предоставлять примечания в своих рукописях, ссылаясь на ранее опубликованные тезисы конгресса и повторно опубликованные препринты.
Концентрируясь на текстовых сходствах, редакторы, использующие антиплагиатное программное обеспечение, часто упускают из виду графические совпадения, которые могут выявить сложные формы нарушения этических норм и авторских прав [27, 28]. Тщательный графический анализ особенно необходим для рукописей с таблицами, рисунками, изображением технологических процессов и химическими формулами [29].]. Опрос авторов относительно подлинности всех материалов, запрос официальных разрешений на повторное использование у правообладателей и ссылки на первоисточники повторно используемой или измененной графики могут помочь избежать неэтичного поведения и нарушения авторских прав [30].
С появлением программного обеспечения для защиты от плагиата некоторые редакторы журналов установили ограничения на незначительное, умеренное и неприемлемое копирование и повторное использование текста. Они утверждают, что менее 10% дословного копирования, особенно в разделе «Методы», могут быть допущены при условии отсутствия языковых вариантов перефразирования [31]. Соответственно, 15–20 % текстового перекрытия оцениваются как менее приемлемые, а более 30 % — как неприемлемые. Хотя такая количественная классификация помогает стратифицировать меры по борьбе с плагиатом, большинство экспертов выступают за политику нулевой терпимости, поскольку даже небольшой процент копирования может выявить сложные и скрытые нарушения этики [32].
Исследователи должны знать, что представляет собой плагиат и как его обнаружить (). Те авторы, которые владеют академическим английским языком, знакомятся с библиографическим поиском и совершенствуют свои навыки графического дизайна, могут избежать большинства случаев плагиата, дублирования и нарушения авторских прав. Тем, кто использует инструменты для борьбы с плагиатом, следует сочетать программное обеспечение и средства обнаружения человека.
Таблица II
Стратегии обнаружения плагиата
| Обработанные элементы | Стратегии обнаружения | Инструменты обнаружения и индивидуумы | |||
|---|---|---|---|---|---|
| Текстовые пассажи | Соответствующие идентичные проходы | . | Ключевые слова и логические слова | Выявление семантических совпадений | Поисковые системы, такие как PubMed, отображающие похожие статьи с перекрывающимися ключевыми словами |
| Стили написания | Авторы, смешанные отрывки с американским и британским английским стилями | Авторы, читатели и редакторы | |||
| Методологии | Выявление сходства, редакторы 9031 и 9031 тесты и порядок тестов | ||||
| Ссылки | Сравнение сходств в списках и порядке отдельных ссылок | Антиплагиат, авторы, читатели, и редакторы | |||
| Гипотезы | Сравнение сходств и эпизодов отчетности привилегированной экспозиции | , читатели и редакторы | |||
| , графики и редакторы | |||||
| , графики и редакторы | |||||
| , рисунки и редакторы | |||||
| , читатели и редакторы | |||||
| , читатели и редакторы | |||||
| , читатели и редакторы | |||||
| . Движок Google Images и новое передовое программное обеспечение для защиты от плагиата |
Открыть в отдельном окне
Хотя ни одна из доступных в настоящее время систем защиты от плагиата не является идеальной [33], игнорирование важности соответствующих редакционных проверок может повлиять на подлинность научных публикаций и приводят к так называемым хищническим практикам [34, 35]. Как правило, использование популярных онлайн-платформ, таких как Google Scholar, Grammarly и PlagScan, позволяет улучшить качество ссылок, удобочитаемость и лингвистический стиль научных рукописей и повысить вероятность их принятия влиятельными журналами [36]. Роль обработки рукописей с помощью свободно доступных средств обнаружения плагиата трудно переоценить, поскольку у большинства исследователей и преподавателей, особенно в развивающихся странах, нет доступа к проприетарному программному обеспечению [37].
Предварительные данные свидетельствуют о том, что существуют различия в распространенности текстового плагиата в академических дисциплинах, что требует тщательной проверки представленных материалов в журналах по науке, технологиям, инженерии и математике [38]. Кроме того, в эпоху оцифровки и открытого доступа рецензии с большей вероятностью будут содержать письменные разделы типа «копировать-вставить», что указывает на особую необходимость проверок такого рода статей [39].
Обнаружение и проверка плагиата в значительной степени основаны на поисковых системах по текстовому сопоставлению и компьютерном программном обеспечении, которые сообщают о показателях сходства. Усовершенствованное программное обеспечение интегрировано с многочисленными издателями и онлайн-платформами, что позволяет сканировать потенциальные совпадения среди бесчисленного количества литературы в открытом доступе и по подписке [40]. Возможно, самой продвинутой системой защиты от плагиата является iThenticate, которая используется большинством авторитетных издателей для сообщения общей оценки сходства и оценки сходства из одного источника [41]. Система предлагает варианты фильтрации прямых цитат, библиографий и методологий, чтобы свести к минимуму вероятность ошибочных отчетов [42]. Высокие общие оценки сходства (> 35%) часто указывают на плагиат, требующий прямого отклонения или опровержения [43].
Регулярные проверки iThenticate позволили минимизировать, но не исключить неэтичные публикации [44]. Сообщаемые оценки сходства не должны заменять редакционные решения и должны сопровождаться тщательным чтением и проверкой ссылок [45].
По сравнению с обнаружением текстового сходства обнаружение плагиата изображений является более сложной задачей, поскольку часто требует как обработки изображений, так и методов семантического сопоставления [46, 47]. Google Images — это широко доступная поисковая система, которую можно использовать для выявления идентичных или измененных изображений, обработанных Google [48]. Однако этот движок не может обнаружить скопированные и измененные графические материалы. Семантический анализ особенно полезен в таком сценарии модификации изображения. Фактически, обработка легенд изображений с помощью тестов на текстовое сходство может указывать на неправомерные действия с измененными изображениями.
Предпринимаются попытки предложить усовершенствованную систему отслеживания плагиата графики [49]. Тем временем редакторы журналов, особенно заинтересованные в публикации графических изображений, должны проинструктировать своих авторов о том, что представляет собой плагиат изображений и как этично повторно использовать связанный контент [50].
Хотя отзыв опубликованных статей, как правило, случается нечасто, их анализ может выявить различия в редакционных стратегиях, политике предотвращения неправомерных действий и принудительных мерах, связанных со страной и дисциплиной [51, 52]. Изучение деталей отозванных статей, которые публично обсуждаются в блоге Retraction Watch, также может определить приоритетность тем этики для последипломного образования [53, 54].
Благодаря широкому использованию iThenticate и другого программного обеспечения для обнаружения плагиата за последнее десятилетие было получено множество связанных отзывов. При сравнении уведомлений об отзыве в PubMed одинаковый процент плагиата (около 20%) был отмечен в образцах 2008 и 2016 годов [55]. Количество отзывов из-за плагиата варьируется в зависимости от страны и академической дисциплины: на США, Китай, Германию, Японию и Великобританию приходится 3 из 4 отзывов в выборке из 130 статей по хирургии [51]. То же исследование оценило уровень плагиата в этих статьях в 16%. Также анализ 176 ретракций по акушерству и гинекологии выявил 40 случаев плагиата (23%) [56]. В реабилитационных и спортивных науках опровержения из-за плагиата были зарегистрированы в 11 (26%) и 7 (13%) случаях соответственно [57]. И, наконец, анализ 22 ретракций по ревматологии выявил 7 (32%) случаев плагиата в обзорных статьях [58].
Плагиат продолжает влиять на достоверность научных публикаций во всем мире. Оцифровка и открытый доступ открывают многочисленные возможности для доступа и распространения научной информации. Тем не менее, некоторые исследователи и авторы намеренно или непреднамеренно прибегают к упрощениям и строят свои статьи с скопированными и неавторизованными текстами, графикой и идеями. Возможно, обучение авторов тому, как систематически получать доступ к литературе и обрабатывать ее, а также овладевать академическим английским языком, может предотвратить большинство случаев современного плагиата. Систематические поиски необходимы для выбора новых тем и избежания дублирования. Обработка извлеченных статей, соответствующие ссылки на опубликованные научные факты и написание своими словами могут еще больше улучшить этический статус новых рукописей.
Как исследователям, так и руководителям исследований необходимо больше узнать о общепринятых практиках написания статей, регулярно анализировать отказы от статей из-за плагиата и избегать связанных с этим ошибок в своей практике. Знание глобальных редакционных рекомендаций и стратегий обнаружения и предотвращения плагиата необходимо для успешного написания статей и работы с влиятельными журналами, посвященными этике. Редакторы журналов должны применять политику «доверяй, но проверяй», проводя проверки на плагиат, запрашивая информацию о писательской практике авторов и запрашивая отказ от ответственности, если подозрения в плагиате сохраняются.
Авторы заявляют об отсутствии конфликта интересов.
1. Бувиль М. Плагиат: слова и идеи. Научно-инженерная этика. 2008; 14: 311–322. doi: 10.1007/s11948-008-9057-6. [PubMed] [CrossRef] [Google Scholar]
2. де Васконселос С.М., Роиг М. Предыдущие публикации и избыточность в современной науке: авторы и редакторы на распутье? Научно-инженерная этика. 2015;21:1367–1378. doi: 10.1007/s11948-014-9599-8. [PubMed] [CrossRef] [Google Scholar]
3. Роиг М. Избегайте неэтичных методов письма. Пищевая химическая токсикол. 2012;50:3385–3387. doi: 10.1016/j.fct.2012.06.043. [PubMed] [CrossRef] [Академия Google]
4. Wang T, Xing QR, Wang H, Chen W. Изъятые публикации в биомедицинской литературе из журналов открытого доступа. Научно-инженерная этика. 2019;25:855–868. doi: 10.1007/s11948-018-0040-6. [PubMed] [CrossRef] [Google Scholar]
5. Heaven D. Экспертные рецензенты на основе искусственного интеллекта упростили процесс публикации. Природа. 2018; 563: 609–610. doi: 10.1038/d41586-018-07245-9. [PubMed] [CrossRef] [Google Scholar]
6. Мехреган М. Этические рецензенты необходимы научным журналам для своевременной обработки материалов и предотвращения отзывов. J Korean Med Sci. 2019;34:e41. doi: 10.3346/jkms.2019.34.e41. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
7. Yi N, Nemery B, Dierickx K. Восприятие плагиата биомедицинскими исследователями: онлайн-опрос в Европе и Китае. Медицинская этика BMC. 2020;21:44. doi: 10.1186/s12910-020-00473-7. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
8. Основные практики Доступно по адресу: https://publicationethics.org/core-practices [Доступ 27.01.2021]
9. Misra DP, Agarwal V ● Целостность проведения клинических исследований, отчетности, публикации и продвижения после публикации в ревматологии. Клин Ревматол. 2020;39: 1049–1060. doi: 10.1007/s10067-020-04965-0. [PubMed] [CrossRef] [Google Scholar]
10. Белая книга CSE о содействии добросовестности в публикациях научных журналов. -050618.pdf [Дата обращения: 27.01.2021]
11. Рекомендации по этике публикаций в медицинских журналах. Доступно по ссылке: https://wame.org/recommendations-on-publication-ethics-policies-for-medical-journals#Plagiarism [Дата обращения: 27.01.2021]
12. Гаспарян А.Ю., Нурмашев Б., Сексенбаев Б. и соавт. Плагиат в контексте образования и развития стратегий обнаружения. J Korean Med Sci. 2017;32:1220–1227. doi: 10.3346/jkms.2017.32.8.1220. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
13. Sun X, Hu G. Что ученые знают и знают о плагиате? Интервью с преподавателями английского языка в китайских университетах. Этика поведения. 2020; 30: 459–479. doi: 10.1080/10508422.2019.1633922. [Перекрестная ссылка] [Академия Google]
14. Мастера К. Этика в цифровом образовании медицинского образования: Руководство AMEE № 134. Med Teach. 2020; 42: 252–265. doi: 10.1080/0142159X.2019.1695043. [PubMed] [CrossRef] [Google Scholar]
15. Coughlin PE. Плагиат в пяти университетах Мозамбика: масштабы, методы обнаружения и меры контроля. Int J Educ Integr. 2015;11:2. doi: 10.1007/s40979-015-0003-5. [CrossRef] [Google Scholar]
16. Джонсон Д.Р., Эклунд Э.Х. Этическая двусмысленность в науке. Научно-инженерная этика. 2016;22:989–1005. doi: 10.1007/s11948-015-9682-9. [PubMed] [CrossRef] [Google Scholar]
17. Махмуд С., Бретаг Т., Фолтынек Т. Восприятие студентами политики плагиата в высшем образовании: сравнение Великобритании, Чехии, Польши и Румынии. J Академическая этика. 2019;17:271–289. doi: 10.1007/s10805-018-9319-0. [CrossRef] [Google Scholar]
18. Джавид А., Хан А.С., Хан С.Х., Гаури С.К. Восприятие плагиата среди студентов-медиков в Равалпинди, Пакистан. Пак J Med Sci. 2019;35:532–536. doi: 10.12669/pjms.35.2.33. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
19. Рокни М.Б., Бижани Н., Хабибзаде Ф. и соавт. Всесторонний обзор плагиата в Иране. Пак J Med Sci. 2020;36:1441–1448. doi: 10.12669/pjms.36.7.3456. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
20. Шарма Х., Верма С. Взгляд на современный плагиат: наука о псевдоисследованиях. Ци Цзи И Сюэ За Чжи. 2019;32:240–244. doi: 10.4103/tcmj.tcmj_210_19. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
21. Дас Н. Преднамеренный или непреднамеренный плагиат никогда не бывает нормальным: примечание о том, как индийским университетам рекомендуется бороться с плагиатом. Перспект Клин Рез. 2018;9:56–57. doi: 10.4103/picr.PICR_140_17. [Статья PMC бесплатно] [PubMed] [CrossRef] [Google Scholar]
22. Роиг М. Поощрение редакционной гибкости в случаях повторного использования текста. J Korean Med Sci. 2017; 32: 557–560. doi: 10.3346/jkms.2017.32.4.557. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
23. Вессал К., Хабибзаде Ф. Правила игры в научное письмо: честная игра и плагиат. Ланцет. 2007;369:641. doi: 10.1016/S0140-6736(07)60307-9. [PubMed] [CrossRef] [Google Scholar]
24. Ахмед С., Анирван П. Истинное значение плагиата. Индийский J Ревматол. 2020;15:155–158. doi: 10.4103/injr.injr_178_20. [CrossRef] [Google Scholar]
25. Рустаи М., Фахрахмад С.М., Садреддини М.Х. Выравнивание текста на разных языках: предлагаемая схема двухуровневого сопоставления для обнаружения плагиата. Приложение Expert Syst. 2020;160:113718. doi: 10.1016/j.eswa.2020.113718. [CrossRef] [Академия Google]
26. Мемон А.Р. Сходство и плагиат в публикациях научных журналов: внесение ясности в концепцию для авторов, рецензентов и редакторов. J Korean Med Sci. 2020;35:e217. doi: 10.3346/jkms.2020.35.e217. [бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
27. Байдик О.Д., Гаспарян А.Ю. Как действовать, когда недобросовестное исследование обнаружено не программным обеспечением, а раскрыто автором статьи, ставшей объектом плагиата. J Korean Med Sci. 2016;31:1508–1510. doi: 10.3346/jkms.2016.31.10.1508. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
28. Хонг ул. Плагиат продолжает влиять на научные журналы. J Korean Med Sci. 2017; 32:183–185. doi: 10.3346/jkms.2017.32.2.183. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
29. Zhang XX, Huo ZL, Zhang YH. Обнаружение и (не) борьба с плагиатом в технической статье: помимо CrossCheck — тематическое исследование. Научно-инженерная этика. 2014;20:433–443. doi: 10.1007/s11948-013-9460-5. [PubMed] [CrossRef] [Google Scholar]
30. Misra DP, Ravindran V. Неправомерные действия, связанные с публикацией авторских прав: действуйте осторожно, чтобы не упасть. JR Coll Physicians Edinb. 2020; 50:3–5. дои: 10.4997/JRCPE.2020.101. [PubMed] [CrossRef] [Google Scholar]
31. Kravitz RL, Feldman MD. Из редакции: Самоплагиат и другие редакционные преступления и проступки. J Gen Intern Med. 2011;26:1. doi: 10.1007/s11606-010-1562-z. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
32. Park S, Yang SH, Jung E, et al. Анализ сходства корейской медицинской литературы и ее связи с усилиями по улучшению этики исследований и публикаций. J Korean Med Sci. 2017; 32: 887–892. doi: 10.3346/jkms.2017.32.6.887. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
33. Foltýnek T, Dlabolová D, Anohina-Naumeca A, et al. Тестирование вспомогательных инструментов для обнаружения плагиата. Int J Educ Technol High Educ. 2020;17:46. doi: 10.1186/s41239-020-00192-4. [CrossRef] [Google Scholar]
34. Оуэнс Дж.К., Николл Л.Х. Плагиат в грабительских публикациях: сравнительное исследование трех журналов по сестринскому делу. Стипендия J Nurs. 2019;51:356–363. doi: 10.1111/jnu.12475. [PubMed] [CrossRef] [Академия Google]
35. Палтридж Б. Написание статей для академических журналов в эпоху цифровых технологий. RELC J. 2020; 51: 147–157. doi: 10.1177/00336882198
36. Magulod GC, Capulso LB, Tabiolo CDL, et al. Использование технологических инструментов для обеспечения качества публикуемых журнальных статей. Int J Learn Teach Educ Res. 2020;19:145–162. [Google Scholar]
37. Мемон А.Р., Мавринац М. Знание, отношение и практика плагиата по сообщениям участников, завершающих MOOC Author AID по написанию исследований. Научно-инженерная этика. 2020;26:1067–1088. дои: 10.1007/s11948-020-00198-1. [PubMed] [CrossRef] [Google Scholar]
38. Sun YC. Занимаются ли авторы журналов плагиатом? Использование программного обеспечения для обнаружения плагиата для обнаружения совпадения текстов в разных дисциплинах. J Engl Acad Purp. 2013;12:264–272. doi: 10.1016/jeap.2013.07.002. [CrossRef] [Google Scholar]
39. Baskaran S, Agarwal A, Panner Selvam MK, et al. Есть ли плагиат в самых влиятельных изданиях в области андрологии? Андрология. 2019;51:e13405. doi: 10.1111/and.13405. [PubMed] [CrossRef] [Академия Google]
40. Ли Ю. Текстовый плагиат в научных публикациях: проблемы, разработки и образование. Научно-инженерная этика. 2013;19:1241–1254. doi: 10.1007/s11948-012-9367-6. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
41. Taylor DB. Плагиат в рукописях, представленных в AJR: разработка оптимального алгоритма проверки и путей управления. AJR Am J Рентгенол. 2017; 208:712–720. doi: 10.2214/AJR.17.18078. [PubMed] [CrossRef] [Google Scholar]
42. Миллер Б.Дж. Показатели сходства не одинаковы. J Psychiatr Res. 2020; 131:31–32. [PubMed] [Академия Google]
43. Эль-Тахан М.Р. Может ли индекс подобия предсказать причины ретракций в журналах по высокоэффективной анестезии? Библиометрический анализ. Сауди Джей Анаст. 2019;13(Приложение 1):S2–S8. doi: 10.4103/sja.SJA_709_18. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
44. Park S, Yang SH, Jung E, et al. Анализ сходства корейской медицинской литературы и ее связи с усилиями по улучшению этики исследований и публикаций. J Korean Med Sci. 2017; 32: 887–892. doi: 10.3346/jkms.2017.32.6.887. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
45. Weber-Wulff D. Детекторы плагиата — это костыль и проблема. Природа. 2019;567:435. doi: 10.1038/d41586-019-00893-5. [PubMed] [CrossRef] [Google Scholar]
46. Shen H. Познакомьтесь с этим супер-корректировщиком повторяющихся изображений в научных статьях. Природа. 2020; 581: 132–136. doi: 10.1038/d41586-020-01363-z. [PubMed] [CrossRef] [Google Scholar]
47. Eisa TAE, Salim N, Abdelmaboud A. Обнаружение плагиата научных фигур на основе содержания с использованием семантического сопоставления. В: Саид Ф., Мохаммед Ф., Газем Н., редакторы. Новые тенденции в интеллектуальных вычислениях и информатике. ИРИКТ 2019. Достижения в области интеллектуальных систем и вычислений. Том. 1073. Чам: Спрингер; 2020. С. 420–427. [CrossRef] [Google Scholar]
48. Thakur R, Rohilla R. Последние достижения в методах обнаружения манипулирования цифровыми изображениями: краткий обзор. Междунар. криминалистики. 2020;312:110311. doi: 10.1016/j.forsciint.2020.110311. [PubMed] [CrossRef] [Google Scholar]
49. Акшай С., Чайтанья Б.Н., Кумар Р. Обнаружение плагиата изображений с использованием сжатых изображений. ИДЖИТЕ. 2019; 8: 1423–1426. [Академия Google]
50. Калиядан Ф. Манипуляции с изображениями и плагиат изображений – что хорошо, а что нет? Индийский J Дерматол Венереол Лепрол. 2017; 83: 519–521. doi: 10.4103/ijdvl.IJDVL_521_17. [PubMed] [CrossRef] [Google Scholar]
51. Cassão BD, Herbella FAM, Schlottmann F, Patti MG. Отозванные статьи в хирургических журналах. Что хирурги делают не так? Операция. 2018; 163:1201–1206. doi: 10.1016/j.surg.2018.01.015. [PubMed] [CrossRef] [Google Scholar]
52. Айоделе Ф.О., Яо Л., Харон Х. Продвижение этики и честности в управленческих академических исследованиях: Инициатива опровержения. Научно-инженерная этика. 2019;25:357–382. doi: 10.1007/s11948-017-9941-z. [PubMed] [CrossRef] [Google Scholar]
53. Камали Н., Талеби Безмин Абади А., Рахими Ф. Плагиат, фальшивая рецензирование и дублирование: основные причины, лежащие в основе отзывов научных статей, связанных с Ираном. Научно-инженерная этика. 2020;26:3455–3463. doi: 10. 1007/s11948-020-00274-6. [PubMed] [CrossRef] [Google Scholar]
54. Rossouw TM, Matsau L, van Zyl C. Анализ отозванных статей с авторами или соавторами из Африканского региона: возможные последствия для обучения и повышения осведомленности. J Empir Res Hum Res Этика. 2020; 15: 478–493. doi: 10.1177/1556264620955110. [PubMed] [CrossRef] [Google Scholar]
55. Deculllier E, Maisonneuve H. Исправление литературы: тенденции улучшения, наблюдаемые в содержании уведомлений об отзыве. Примечания BMC Res. 2018;11:490. doi: 10.1186/s13104-018-3576-2. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
56. Чемберс Л.М., Миченер С.М., Фальконе Т. Плагиат и фальсификация данных являются наиболее распространенными причинами отзыва публикаций по акушерству и гинекологии. БЖОГ. 2019;126:1134–1140. дои: 10.1111/1471-0528.15813. [PubMed] [CrossRef] [Google Scholar]
57. Kardeş S, Levack W, Özkuk K, et al. Ретракции в журналах по реабилитации и спортивным наукам: систематический обзор. Arch Phys Med Rehabil. 2020;101:1980–1990. doi: 10.1016/j.apmr.2020.03.010. [PubMed] [CrossRef] [Google Scholar]
58. Гаспарян А.Ю., Айвазян Л., Акажанов Н.А., Китас Г.Д. Самокоррекция в биомедицинских публикациях и научное влияние. Croat Med J. 2014;55:61–72. doi: 10.3325/cmj.2014.55.61. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
Обнаружение плагиата
Обнаружение плагиатаОБНОВЛЕНИЯ
- 26 апреля 2021 г. Если у вас возникли проблемы с регистрацией, попробуйте использовать Gmail для отправки регистрационного сообщения.
- 10 апреля 2020 г. Резкое увеличение количества онлайн-курсов из-за
пандемия коронавируса, похоже, привела к соответствующему резкому увеличению
в использовании мха за последние несколько недель. (Непонятно, почему эти две вещи должны быть связаны,
но, похоже, они есть.) На общедоступном сервере есть
был перемещен на более крупную машину (больше ядер и больше памяти), что должно помочь
удовлетворить возросший спрос. Трудности с подключением к серверу или получением результатов являются признаком
что сервер в это время перегружен; Пожалуйста, попробуйте позже. Всех пользователей просят ограничить
заявок не более 100/день.
- 14 декабря 2018 г., Добавлен сценарий преобразования UTF8 в сообщения сообщества
- 1 февраля 2018 г. Добавлено еще больше вкладов сообщества!
- 9 ноября 2017 г. Ниже добавлено больше материалов сообщества ...
- 31 августа 2017 г. Спасибо Кристофу Троестлеру за клиент OCaml для Moss.
- 18 мая 2014 г. Вклады сообщества (включая графический интерфейс отправки Windows от Шейна Мэя, спасибо!) теперь находятся в отдельном разделе на этой странице.
- 14 мая 2014 г. А вот Java-версия скрипта отправки. Спасибо Бьорну Зилке!
- 2 мая 2014 г. Вот PHP-версия скрипта отправки. Большое спасибо Филиппу Ресу!
- 9 июня 2011 г. За последние пару дней было два отключения, которые длились не более часа каждое (кажется). Я внес некоторые изменения в программу управления дисками, чтобы предотвратить повторение этих проблем.
- 29 апреля 2011 г. Сегодня был сбой на несколько часов, первый с прошлого лета, но все восстановилось.
- 1 августа 2010 г. Все вернулось на круги своя.
- 27 июля 2010 г. Сервер Moss снова в сети. В ближайшие недели могут быть дополнительные настройки и, возможно, простои, но любые отключения должны быть краткими. Новые регистрации еще не работают, но люди с существующими учетными записями могут отправлять вакансии.
- 25 июля 2010 г. Как многие (многие!) заметили, сервер Moss не работал весь июль. К сожалению, оборудование вышло из строя, пока я был в отъезде. Я надеюсь, что он будет восстановлен в течение нескольких дней.
Что такое мох?
Moss (для измерения схожести программного обеспечения) — это автоматическая система для определения схожесть программ. На сегодняшний день основным применение Мосса было в обнаружении плагиата в программировании классы. С момента своего создания в 1994, Мосс был очень
эффективен в этой роли. Алгоритм, лежащий в основе moss, является значительным улучшением по сравнению с другими
алгоритмы обнаружения читерства (по крайней мере, над известными нам).Чем не мох?
Мох не система для полностью автоматически обнаруживая плагиат. Плагиат — это заявление о том, что кто-то скопировал код преднамеренно без указания авторства, и хотя Мосс автоматически определяет сходство программ, не имеет возможности зная , почему коды похожи. Это все еще зависит от человека пойти и посмотреть на части кода, которые Мосс выделяет, и сделать решение о том, есть ли плагиат или нет. Один из способов Думая о том, что предлагает Moss, так это то, что он экономит учителям и преподавательскому составу много времени за счет указание частей программы, которые заслуживают более подробного экспертиза. Но как только кто-то взглянул на эти части программы, не должно иметь значения, был ли подозрительный код впервые обнаружен Моссом. или человеком; дело о том, что имел место плагиат, должно стоять само по себе.В частности, полагаться исключительно на оценки сходства является неправильным использованием Мосса. Эти оценки полезны для оценки относительной степени совпадения между различными пар программ и для более легкого просмотра, какие пары программ выделяются необычное количество совпадений. Но оценки, конечно же, не являются доказательством плагиата. Кто-то все равно должен посмотреть код.
Языки
В настоящее время Moss может анализировать код, написанный на следующих языках:. C, C++, Java, C#, Python, Visual Basic, Javascript, FORTRAN, ML, Haskell, Lisp, Scheme, Pascal, Modula2, Ada, Perl, TCL, Matlab, VHDL, Verilog, Spice, сборка MIPS, сборка a8086, сборка а8086, HCL2.
Интернет-сервис
Moss предоставляется как интернет-услуга. Услуга была разработана таким образом, чтобы ее было очень легко использовать — вы предоставить список файлов для сравнения, а Мосс сделает все остальное.Текущий сценарий отправки Moss предназначен для Linux.
В ответ на запрос сервер Moss выдает список HTML-страниц. пары программ с похожим кодом. Мосс также выделяет отдельные отрывки в программах выглядят одинаково, что упрощает для быстрого сравнения файлов. Наконец, Мосс может автоматически исключить совпадения с кодом, который предполагается использовать совместно (например, библиотеки или код, предоставленный инструктором), тем самым устраняя ложные положительные стороны, возникающие в результате законного совместного использования кода.
Регистрация Мосса
Мох предоставляется в надежде, что он принесет пользу образовательное сообщество. Moss быстрый, простой в использовании и бесплатный. в Раньше доступ был ограничен инструкторами и сотрудниками курсов программирования. Это больше не так, и любой может получить учетную запись Moss. Однако Moss предназначен для некоммерческого использования. Если вас интересует коммерческое использование
Moss, свяжитесь с Similix Corporation.
Чтобы получить учетную запись Moss, отправьте сообщение по адресу мох@moss.stanford.edu. Текст сообщения должен выглядеть следующим образом:
registeruser
mail username@domain
где последний бит курсивом — это ваш адрес электронной почты.
Если у вас уже есть учетная запись, последний сценарий отправки можно скачать здесь.
Безопасность и юридические вопросы
Если вы используете Moss, результаты будут содержать копии кода, который вы отправлены, и они будут доступны любому, у кого есть URL-адрес результата. Стэнфорд не может нести никакой ответственности за ваши материалы. Приняты разумные меры предосторожности для защиты конфиденциальности
кода, который вы отправляете. Эти меры включают в себя: только вы получаете
URL-адрес результата и содержит случайное целое число, поэтому его нелегко
угадать URL-адрес результата. Кроме того, каталог с результатами не может
просматриваться или индексироваться роботами. Наконец, представления не
сохраняется на сервере на неопределенный срок; обычно результаты удаляются
через 14 дней, хотя их можно удалить раньше, чтобы освободить диск
пространство, когда сервер особенно занят. Если некоторые результаты, которые вам нужны,
были удалены, вы можете просто повторно отправить свою работу.
Вклад сообщества
Ряд пользователей Moss предоставили версии сценария отправки:- Версия скрипта отправки Moss в Ниме, предоставленная Дэвидом Эдвином.
- Скрипт для преобразования файлов в UTF8. Мосс в настоящее время не любит UTF16! (от Яна Скотта-Флеминга).
- Графический интерфейс Swing и соответствующий файл jar (от Мухаммета Алкана).
- Графический интерфейс Python (от Jeremiah Blanchard).
- Клиент Python (от Сайеда Чишти)
- Клиент OCaml (от Christophe Troestler).
- Утилита отправки Common Lisp (от Wojciech Gac).
- Java-версия (от Бьорна Зилке).
- Версия PHP (от Phillip Rehs).
- Графический интерфейс для Windows (от Шейна Мэя).
Эндрю Кейн написал для Мосса драгоценный камень Ruby.
Хьялти Магнуссион написал сценарий обобщения/визуализации.
Как это работает?
Статью об идеях, лежащих в основе Moss, можно найти здесь.Назад на домашнюю страницу Алекса Айкена
Плагиат и программирование: как программировать без плагиата
19 декабря 2019 г. Без комментариев
Tweet
Избранная статья Лизы Херд, Independent Technology Author
Плагиат быстро становится проблемой среди студентов, изучающих информатику. В недавнем прошлом в университете стали популярны курсы, основанные на технологиях, и все больше и больше студентов подают на них заявки. По мере увеличения числа студентов, изучающих программирование, плагиат в программировании постепенно становится нормой.
Программирование все еще является новым языком, который постоянно развивается. Это представляет собой проблему для студентов, поскольку в нем нет полностью разработанного стандарта общения, который помогает им цитировать работы других людей. Вот почему большинство студентов в университете борются с плагиатом в кодировании.
https://unsplash.com/photos/MSN8TFhJ0is
Распространение плагиата в коде и способы его предотвращения в собственном коде плагиат в кодировании и как его избежать. Это поможет вам найти некоторые из лучших инструментов проверки подобия кода, а также эссе с советами о том, как копировать и вставлять без плагиата.
Это поможет вам как студенту узнать, что такое плагиат и как его избежать. Вот несколько полезных советов о том, как избежать этого академического проступка в вашей работе.
1. Узнайте, когда использовать внешний код
Система образования США позволяет учащимся использовать внешний код при обучении программированию. Однако существуют правила, которым необходимо следовать при включении внешнего кода в задание. Понимание правил, регулирующих использование чужих работ по программированию, — лучший способ избежать плагиата в заданиях по информатике.
2. Найдите инструменты для проверки на плагиат в Интернете
Бесплатные онлайн-инструменты для проверки на плагиат очень полезны, когда вам нужно искать плагиат в эссе и научных работах. Такие веб-сайты, как https://phdessay.com/check-for-plagiarism/, предоставляют студентам бесплатный инструмент для поиска скопированных и нецитируемых работ в своих работах. Будучи студентом, вам также необходимо найти эффективные онлайн-инструменты для проверки кода на плагиат.
3. Понять правила сотрудничества
Специалист по проверке кода на плагиат может счесть вашу работу чистой и оригинальной, но ваш преподаватель все равно признает вас виновным в списывании только потому, что вы сотрудничали с другим студентом. Поэтому вам нужно знать, когда и как сотрудничать с другими учащимися в проекте, чтобы это не считалось списыванием. Вы даже можете использовать бесплатный инструмент проверки подобия кода, чтобы быть в безопасности.
4. Узнайте об ограничениях использования внешнего кода
С помощью детектора языка программирования ваш инструктор может сказать, откуда вы взяли весь свой код. Учащимся разрешается использовать внешний код только из утвержденных источников и проектов с открытым исходным кодом в своих академических целях. Это похоже на написание эссе или исследовательской работы; вы должны использовать точные и заслуживающие доверия источники.
5. Проконсультируйтесь со своим инструктором или руководителем
При работе над проектом по информатике всегда консультируйтесь с инструктором на каждом этапе пути. Это гарантирует, что вы получите руководство, необходимое для выполнения задачи без проблем. Ваш наставник подскажет, как подойти к задаче и как убедиться, что она идеальна в долгосрочной перспективе.
6. Научитесь комментировать свой код
Независимо от языка, который вы используете в своем коде, вы можете добавлять комментарии в свою работу. Это все равно, что оставить руководство для вашего руководителя о том, что является оригинальным, а что заимствовано. Это помогает избежать плагиата, поскольку вы признаете, что заимствовали код из внешних источников. Это разрешено.
7. Отделите вашу оригинальную работу от копии
При подготовке кода вы должны отделить свою оригинальную работу от того, что вы позаимствовали из других источников. Это позволяет легко цитировать заимствованные работы в вашем проекте. С помощью детектора языка программирования ваш руководитель всегда будет проверять и обнаруживать скопированные работы в вашем проекте. Что они найдут?
8. Примите творческий подход и доверьтесь своей интуиции
Программирование — это творчество и исследования. Поэтому нужно провести мозговой штурм и придумать оригинальный, уникальный код. Таким образом, вы не будете беспокоиться о том, что ваша работа пройдет проверку на плагиат кода, поскольку вы знаете, что она уникальна.
Заключительные замечания
Программирование становится очень популярным в современном образовании. Многие студенты выбирают технологические курсы, такие как разработка программного обеспечения и информатика. Поэтому правила и стандарты цитирования в языках программирования нуждаются в разработке и совершенствовании.
В то же время быть оригинальным — лучший способ избежать мошенничества при кодировании. Вместо того, чтобы учиться копировать и вставлять без плагиата, научитесь придумывать новые и уникальные коды в своих школьных проектах. Плагиат не должен быть проблемой, если вы достаточно креативны.
Избранные статьи
Как обнаружить плагиат в тексте с помощью Python
вступление
Привет, ребята,
В этом уроке мы узнаем, как сделать детектор плагиата на Python, используя методы машинного обучения , такие как word2vec и косинусное сходство 9001 всего за несколько строк2 кода.
Обзор
После завершения нашего детектора плагиата сможет загрузить задание учащегося из файлов, а затем вычислить сходство , чтобы определить, учащиеся скопировали друг друга.
Требования
Чтобы следовать этому руководству, на вашем компьютере должен быть установлен scikit-learn .
Монтаж
pip install -U scikit-learnВойти в полноэкранный режимВыйти из полноэкранного режима
Как мы анализируем текст?
Все мы знаем, что компьютеры могут понимать только 0s и 1s , и для того, чтобы выполнить некоторые вычисления над текстовыми данными, нам нужен способ преобразовать текст в 2 чисел.
Встраивание слов
Процесс преобразования текстовых данных в массив чисел обычно известен как встраивание слов .
Векторизация текстовых данных в векторы не является случайный процесс вместо этого следует определенным алгоритмам , в результате чего слова представляются как позиции в пространстве. для этого мы собираемся использовать встроенные функции scikit-learn .
Как мы обнаруживаем сходство в документах?
Здесь мы воспользуемся базовой концепцией вектора , скалярного произведения , чтобы определить, насколько близко два текста похожи, путем вычисления значения косинусного сходства между векторами представлений текстовых заданий учащихся.
Также необходимо иметь образцов текстовых документов по заданиям учащихся, которые мы будем использовать при тестировании нашей модели.
Текстовые файлы должны находиться в том же каталоге , что и ваш сценарий с расширением . txt . Если вы хотите использовать образцы текстовых файлов, которые я использовал для этого руководства, загрузите здесь
Каталог проекта должен выглядеть следующим образом
. ├── app.py ├── fatma.txt ├── изображение.png ├── john.txt └── juma.txtВойти в полноэкранный режимВыйти из полноэкранного режима
Теперь давайте создадим наш детектор плагиата.
- Давайте сначала импортируем все необходимые модули
импорт ОС из sklearn.feature_extraction.text импортировать TfidfVectorizer из sklearn.metrics.pairwise импортировать cosine_similarityВойти в полноэкранный режимВыйти из полноэкранного режима
мы будем использовать OS Module в путях загрузки текстовых файлов, а затем TfidfVectorizer для выполнения встраивания слов в наши текстовые данные и косинусного сходства для вычисления плагиата .
- Чтение всех текстовых файлов с использованием List Comprehension
Мы собираемся использовать концепцию понимания списка, чтобы загрузить все текстовые файлы пути в нашем каталоге проекта , как показано ниже.
student_files = [документ для документа в os.listdir(), если doc.endswith('.txt')]
Вход в полноэкранный режимВыход из полноэкранного режима- Лямбда-функция для векторизации и вычисления сходства
Нам нужно создать две лямбда-функции , одну для преобразования текста в массивы чисел, а другую для вычисления сходства между ними.
векторизация = лямбда Текст: TfidfVectorizer().fit_transform(Text).toarray() сходство = лямбда doc1, doc2: cosine_similarity([doc1, doc2])Войти в полноэкранный режимВыйти из полноэкранного режима
- Векторизация текстовых данных
добавление следующих двух строк для векторизации загруженных файлов учеников.
векторов = vectorize (student_notes) s_vectors = список (zip (студенческие_файлы, векторы))Войти в полноэкранный режимВыйти из полноэкранного режима
- Создание функции для вычисления сходства
Ниже представлена основная функция нашего скрипта, отвечающая за управление всем процессом вычисления сходства между учениками.
защита check_plagiarism():
plagiarism_results = установить ()
глобальные s_vectors
для student_a, text_vector_a в s_vectors:
новые_векторы =s_vectors.copy()
current_index = new_vectors.index((student_a, text_vector_a))
del new_vectors[current_index]
для student_b , text_vector_b в new_vectors:
sim_score = сходство (text_vector_a, text_vector_b)[0][1]
student_pair = отсортировано ((student_a, student_b))
оценка = (student_pair[0], student_pair[1],sim_score)
plagiarism_results.add(оценка)
вернуть plagiarism_results
Распечатаем результаты плагиата
для данных в check_plagiarism():
печать (данные)
Войти в полноэкранный режимВыйти из полноэкранного режима- Окончательный код
Когда вы скомпилируете все вышеперечисленные концепции, вы получите приведенные ниже полные сценарии, готовые к ** обнаружению плагиата** среди заданий учащихся.
импорт ОС из sklearn.Войти в полноэкранный режимВыйти из полноэкранного режима
- Вывод:
После того, как вы запустите указанный выше app.py , результат будет выглядеть, как показано ниже
$ python app.py
#__________РЕЗУЛЬТАТ ___________
('john.txt', 'juma.txt', 0.5465972177348937)
('fatma.txt', 'john.txt', 0.14806887549598566)
('fatma.txt', 'juma.txt', 0.18643448370323362)
Войти в полноэкранный режимВыйти из полноэкранного режимаПоздравляем вы только что создали свой собственный Детектор плагиата на Python. Теперь поделитесь им со своими коллегами, нажмите Tweet сейчас, чтобы поделиться им.
В случае каких-либо комментариев, предложений или трудностей, оставьте их в поле для комментариев ниже, и я свяжусь с вами как можно скорее.
Оригинал статьи можно найти на сайте kalebujordan. dev
Проект Python для проверки документов на плагиат на основе косинусного сходства
Этот репозиторий состоит из исходного кода скрипта Python для обнаружения плагиата в текстовом документе с использованием косинусное сходство
Как это делается?
Вам может быть интересно узнать, как выполняется обнаружение плагиата в текстовых данных, ну, это не так сложно, как вы думаете.
Все мы знаем, что компьютер хорошо справляется с числами, поэтому, чтобы вычислить сходство между двумя текстовыми документами, необработанные текстовые данные преобразуются в векторы => массивы чисел, а затем мы собираемся использовать базовые знания. вектор, чтобы вычислить сходство между ними.
Этот репозиторий содержит базовый пример того, как это сделать.
Начало работы
Чтобы начать работу с кодом в этом репозитории, вам необходимо либо клонировать , либо загрузить этот репозиторий на свой компьютер, как показано ниже;
git clone https://github.Войти в полноэкранный режимВыйти из полноэкранного режима
Зависимости
Прежде чем начать играть с…
Посмотреть на GitHub
Обнаруживает ли Turnitin перефразирование: как безопасно перефразировать
Если вам нужно отправить статью или эссе через Turnitin, у вас может возникнуть множество вопросов. Если вы скопировали какой-то контент, вы можете беспокоиться, не обнаружит ли Turnitin перефразирование.
Ответим на все это в посте. Мы также посоветуем, как безопасно перефразировать, чтобы ваше эссе или статья были хорошо сделаны. Но вы можете обратиться к нашим надежным экспертам по написанию эссе, если хотите, чтобы это было сделано профессионально.
Может ли Turnitin обнаруживать перефразирование?
Если все сделано правильно, Turnitin не сможет обнаружить перефразирование, поскольку новое перефразирование не похоже на исходный текст дословно . Однако, если он плохо перефразирован, Turnitin обязательно отсканирует текст и пометит его как плагиат. Чтобы избежать этого, вы должны научиться хорошо и безопасно перефразировать свои эссе, чтобы сойти за Turnitin.
Чтобы дать вам более полное объяснение этого вопроса, мы должны сначала понять, что такое перефразирование и чем оно отличается от плагиата.
В то время как плагиат — это непродуманное копирование работы другого человека, перефразирование — это переписывание или реструктуризация концепций или идей из другого источника.
Однако при перефразировании смысл останется схожим с исходным произведением с разницей в структуре и стиле.
Несмотря на то, что Turnitin может легко распознать дублирующийся текст между вашей статьей и другими источниками и интерпретировать его как плагиат, перефразирование остается недостижимым. Это потому, что люди придумали различные уловки, которые позволяют им избежать обнаружения.
Однако алгоритмы Turnitin постоянно совершенствуются для обнаружения перефразированного текста. Следовательно, да. Turnitin может обнаруживать перефразирование.
Получите оригинальное эссе сегодня
Вы обременены домашним заданием и вам нужна небольшая помощь? Позвольте нашим специалистам помочь вам в этом. Мы предоставим качественное эссе и
Разместим заказ
Как именно Turnitin обнаруживает перефразирование
Как мы уже отмечали, Turnitin может обнаруживать перефразирование, поскольку постоянно совершенствует алгоритм своей системы для преодоления новых приемов перефразирования, которые были разработаны людьми. чтобы избежать обнаружения.
Как это работает? Во-первых, в базе данных Turnitin есть обширные архивы, которые используются для сравнения ваших документов.
Такие архивы включают статьи, которые были ранее отправлены студентами, заархивированный и текущий онлайн-контент, доступный для общественности, и, наконец, газеты, журналы и книги.
Эти архивы используются для обнаружения подобия с помощью программы, известной как поисковый робот.
Поисковый робот может получать доступ к содержимому, доступному в Интернете, и автоматически включать его в базу данных Turnitin. Благодаря этому Turnitin может обнаруживать перекрывающийся текст и текст, который имеет тот же смысл, что и исходный текст.
Как упоминалось выше, вы должны цитировать текст или переворачивать текст, если вы не можете правильно и вдумчиво перефразировать. В противном случае, даже если мы рекомендуем перефразировать как один из способов обмана Turnitin, вы не сможете обмануть Turnitin.
Были случаи, когда учащиеся в результате применяли иностранные буквы, использовали белый текст, чтобы сделать их невидимыми для Turnitin, использовали разные символы и т. д., чтобы избежать обнаружения при перефразировании.
Компания Turnitin обновила алгоритм своей системы таким образом, что теперь такие читы можно обнаружить. В противном случае вы должны следовать правилам перефразирования и цитирования, чтобы избежать обнаружения и последующего наказания.
Проверяет ли Turnitin дословно?
Нет. Turnitin не проверяет дословно. Существуют различные методы, используемые программным обеспечением для поиска сходства. Один из них заключается в использовании анализа ключевых слов.
Это означает, что Turnitin будет использовать определенные ключевые слова для поиска сходства между вашей статьей и работами, доступными в ее базе данных.
Второй метод заключается в сканировании последовательностей или строк слов или групп слов вместо дословного сканирования. Любое сходство между вашей работой и другими работами будет обнаружено.
Другой метод — сканирование контента путем определения стиля написания, например фраз и смыслов в тексте.
Как Canvas обнаруживает и предотвращает мошенничество
Canvas может обнаруживать мошенничество и некоторые другие акты академической нечестности. Это связано с тем, что Canvas сравнивает задания или документы, которые вы отправляете, с теми, которые уже существуют в инструментах проверки на плагиат, которые включили его в свою систему.
Одним из основных таких инструментов является Turnitin. Однако следует отметить, что SafeAssign не поддерживает Canvas и поэтому здесь не применим.
Canvas также может помочь преподавателям отслеживать действия своих учеников, например, доступ к несанкционированным вопросам заданий. Таким образом, Canvas может обнаруживать такие формы мошенничества. Он обновляется для обнаружения других форм мошенничества.
Является ли повторное использование вашей собственной работы плагиатом
Ответ на этот вопрос зависит от взглядов вашего преподавателя на академические проступки. Некоторые могут воспринять повторную переработку своей работы как плагиат, в то время как другие не будут с этим мириться.
Для тех, кто поддерживает повторное использование ваших собственных работ, они используют определение плагиата, которое гласит, что неправильно использовать работу другого человека, не отдавая должное ему. Это потому, что это было бы кражей интеллектуальной собственности человека.
Что делать, если человек использует всю работу или часть своей предыдущей работы? Это не квалифицируется как плагиат, потому что человек не украл чью-либо работу, а использовал их работу для создания другой статьи.
Тем не менее, те, кто против повторного использования своих работ, приводят доводы, основанные на самоплагиате, когда автор повторно публикует свои ранее опубликованные работы. Это противоречит авторским правам издателя.
Цитаты могут быть использованы из предыдущих работ человека, но использование больших фрагментов неэтично. Исходя из этого, мы можем сделать вывод, что, хотя у некоторых преподавателей нет проблем с повторным использованием личной работы, в более широком контексте это следует рассматривать как самоплагиат.
Это показывает, что человек недостаточно заинтересован или посвящен, чтобы написать новую статью. Поэтому повторная подача собственных работ является плагиатом и неправомерна. Узнайте больше об этом и о том, как Turnitin проверяет ранее загруженные документы из этого поста.
Как безопасно перефразировать, чтобы избежать плагиата
Перефразирование — это повторное изложение смысла текста с использованием других слов и указанием источника информации. Перефразирование помогает упростить, уточнить и обобщить информацию. Это также помогает избежать плагиата и повторения при написании эссе.
Правила перефразирования
1. Изменение структуры предложения
Изменение синтаксической структуры предложения является способом перефразирования. Для этого нужно прочитать и понять смысл текста.
Изменение структуры предложения включает изменение предложения с действительного залога на пассивный залог и изменение частей речи в предложении.
Вы также можете использовать координатные выражения, сравнения, которые показывают сходства и различия, и относительные предложения, чтобы изменить структуру предложения.
2. Используйте синонимы по отдельности
Обычно при перефразировании важно заменять слова в тексте словами, имеющими одинаковое значение.
Такие слова не всегда просто различить.
Поэтому писатели должны тщательно выбирать синонимы, которые они намерены использовать.
Некоторые синонимы имеют несколько иные характеристики. Они могут различаться грамматическим или синтаксическим контекстом и уровнем уместности использования.
3. Используйте компенсаторные стратегии
Бывают случаи, когда мы забываем синонимы вместо слов и вынуждены придумывать конструктивные средства, чтобы помочь. Прилагательные могут быть заменены их противоположностями с включенным «не».
Глаголы с особым значением могут быть заменены общими глаголами. Существительные можно перефразировать, используя описания и объяснения. Они называются компенсаторными стратегиями
4. Эффективно цитируйте источник
При перефразировании учащиеся должны ссылаться на свою работу, включая источники информации в работе. Вы можете использовать различные форматы ссылок, такие как APA, MLA, Havard и Chicago, среди прочих, для цитирования перефразированного контента.
Избегайте обвинений в плагиате, ссылаясь на источники информации, даже если вам не нужно использовать прямые цитаты.
Запрещено перефразирования- Включая ваши соображения или чувства. При перефразировании смысл не должен отличаться от первого источника.
- Случайное изменение слов и оставление большей части работы без изменений. Это будет автоматически определено как плагиат.
- Не укорачивайте работу. Идеально заменяйте слова и идеи. Перефразирование — это не обобщение.
Задачи и проблемы перефразирования
Перефразирование никогда не бывает легкой задачей. Эффективное перефразирование сопряжено с различными проблемами. Вы должны хорошо владеть языком.
Перефразирование включает синонимы, антонимы, цитирование, цитаты, изменение структуры предложения и использование компенсационных предложений.
Все это должно быть под рукой у учащихся, чтобы они могли эффективно перефразировать. Это не вариант. Студенты должны быть экспертами по грамматике, чтобы эффективно справляться с перефразированием.
Учащиеся должны читать и перечитывать тексты, чтобы правильно перефразировать. Это помогает лучше понять данный текст. Поверхностное понимание текста приводит к неэффективному перефразированию.
Некоторые тексты имеют сложный словарный запас и сложные значения, и у учащегося нет другого выбора, кроме как тратить время на понимание текста.
Выражать свои мысли и идеи никогда не было легко. Вот что такое перефразирование. Это становится сложнее, потому что вы не должны изменять основной смысл исходного текста.
Почему перефразирование вредно для академического письма
Перефразирование считается плохим в следующих случаях:
В кои-то веки оно не является оригинальным. перефразирование предполагает представление уже представленных идей как собственных, чтобы избежать плагиата. Учащиеся, скорее всего, перефразируют существующую работу, если им поручили ту же работу.
Это становится формой жульничества, потому что преподаватели ожидали, что студенты будут выполнять работу, основываясь на своем мышлении. Перефразирование делает студентов ленивыми.
Перефразирование контента для размещения на веб-сайтах никогда не бывает хорошей идеей. Это может привести к тому, что ваш сайт потеряет доверие и упадет в рейтингах.
Перефразированный контент можно легко назвать тонким контентом. Например, если вы используете программное обеспечение для перефразирования, оно будет производить тонкий контент. Вот почему вращение как Quillbot считается читерством, поскольку оно не приводит к исходному контенту.
Перефразирование контента, доступного на том же веб-сайте, считается дублированием контента. Единственная ошибка, связанная с тем, что вы забыли указать источник информации, может привести к тому, что вас обвинят в плагиате.
Лучше написать свою работу с нуля, чем перефразировать уже существующую работу и рисковать наказанием за плагиат.