
Экстраполяция в Excel
Существуют случаи, когда требуется узнать результаты вычисления функции за пределами известной области. Особенно актуален данный вопрос для процедуры прогнозирования. В Экселе есть несколько способов, с помощью которых можно совершить данную операцию. Давайте рассмотрим их на конкретных примерах.
Использование экстраполяции
В отличие от интерполяции, задачей которой является нахождения значения функции между двумя известными аргументами, экстраполяция подразумевает поиск решения за пределами известной области. Именно поэтому данный метод столь востребован для прогнозирования.
В Экселе можно применять экстраполяцию, как для табличных значений, так и для графиков.
Способ 1: экстраполяция для табличных данных
Прежде всего, применим метод экстраполяции к содержимому табличного диапазона. Для примера возьмем таблицу, в которой имеется ряд аргументов (X) от 5 до 50 и ряд соответствующих им значений функции (f(x)).
- Выделяем ячейку, в которой будет отображаться результат проведенных вычислений. Кликаем по значку «Вставить функцию», который размещен у строки формул.
- Запускается окно Мастера функций. Выполняем переход в категорию «Статистические» или «Полный алфавитный перечень». В открывшемся списке производим поиск наименования «ПРЕДСКАЗ». Найдя его, выделяем, а затем щелкаем по кнопке «OK» в нижней части окна.
- Мы перемещаемся к окну аргументов вышеуказанной функции. Она имеет всего три аргумента и соответствующее количество полей для их внесения.
В поле «X» следует указать значение аргумента, функцию от которого нам следует вычислить. Можно просто вбить с клавиатуры нужное число, а можно указать координаты ячейки, если аргумент записан на листе.
 Второй вариант даже предпочтительнее. Если мы произведем внесение именно таким способом, то для того, чтобы просмотреть значение функции для другого аргумента нам не придется менять формулу, а достаточно будет изменить вводную в соответствующей ячейке. Для того, чтобы указать координаты этой ячейки, если был выбран все-таки второй вариант, достаточно установить курсор в соответствующее поле и выделить эту ячейку. Её адрес тут же отобразится в окне аргументов.
Второй вариант даже предпочтительнее. Если мы произведем внесение именно таким способом, то для того, чтобы просмотреть значение функции для другого аргумента нам не придется менять формулу, а достаточно будет изменить вводную в соответствующей ячейке. Для того, чтобы указать координаты этой ячейки, если был выбран все-таки второй вариант, достаточно установить курсор в соответствующее поле и выделить эту ячейку. Её адрес тут же отобразится в окне аргументов.В поле «Известные значения y» следует указать весь имеющийся у нас диапазон значений функции. Он отображается в колонке «f(x)». Следовательно, устанавливаем курсор в соответствующее поле и выделяем всю эту колонку без её наименования.
В поле «Известные значения x» следует указать все значения аргумента, которым соответствуют внесенные нами выше значения функции. Эти данные находятся в столбце «x». Точно так же, как и в предыдущий раз выделяем нужную нам колонку, предварительно установив курсор в поле окна аргументов.
После того, как все данные внесены, жмем на кнопку «OK».
- После этих действий результат вычисления путем экстраполяции будет выведен в ячейку, которая была выделена в первом пункте данной инструкции перед запуском Мастера функций. В данном случае значение функции для аргумента 55 равно 338.
- Если все-таки был выбран вариант с добавлением ссылки на ячейку, в которой содержится искомый аргумент, то мы легко сможем его поменять и просмотреть значение функции для любого другого числа. Например, искомое значение для аргумента
 Второй вариант даже предпочтительнее. Если мы произведем внесение именно таким способом, то для того, чтобы просмотреть значение функции для другого аргумента нам не придется менять формулу, а достаточно будет изменить вводную в соответствующей ячейке. Для того, чтобы указать координаты этой ячейки, если был выбран все-таки второй вариант, достаточно установить курсор в соответствующее поле и выделить эту ячейку. Её адрес тут же отобразится в окне аргументов.
Второй вариант даже предпочтительнее. Если мы произведем внесение именно таким способом, то для того, чтобы просмотреть значение функции для другого аргумента нам не придется менять формулу, а достаточно будет изменить вводную в соответствующей ячейке. Для того, чтобы указать координаты этой ячейки, если был выбран все-таки второй вариант, достаточно установить курсор в соответствующее поле и выделить эту ячейку. Её адрес тут же отобразится в окне аргументов.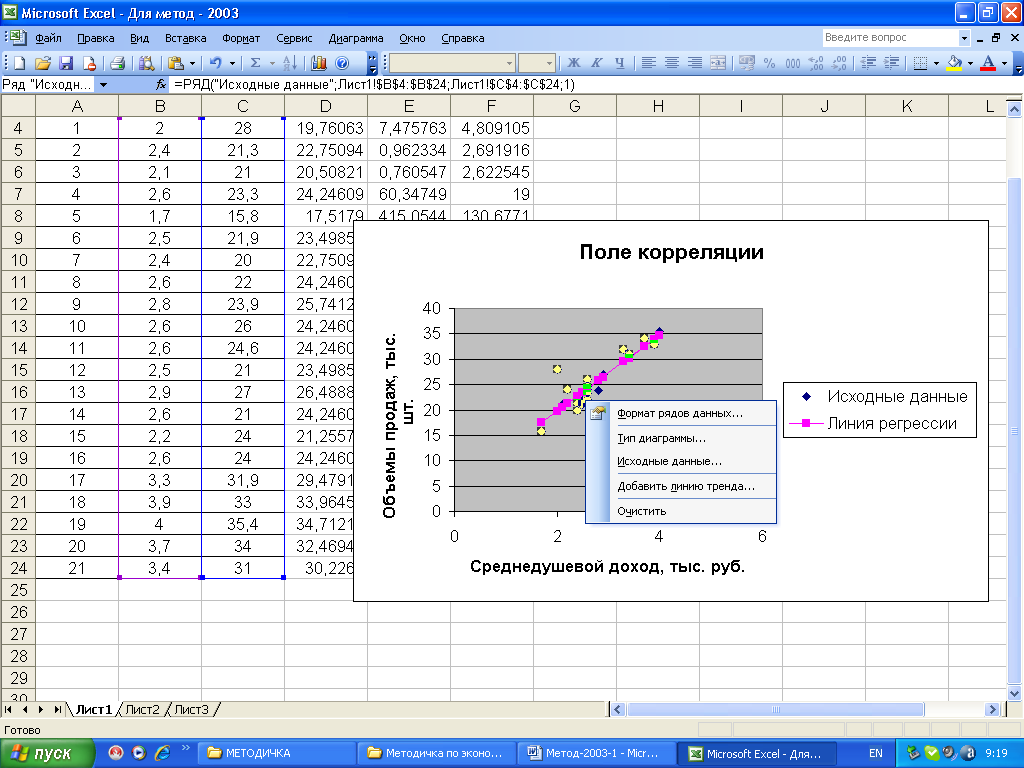
Урок: Мастер функций в Excel
Способ 2: экстраполяция для графика
Выполнить процедуру экстраполяции для графика можно путем построения линии тренда.
- Прежде всего, строим сам график. Для этого курсором при зажатой левой кнопке мыши выделяем всю область таблицы, включая аргументы и соответствующие значения функции. Затем, переместившись во вкладку «Вставка», кликаем по кнопке «График». Этот значок расположен в блоке «Диаграммы» на ленте инструментов. Появляется перечень доступных вариантов графиков. Выбираем наиболее подходящий из них на свое усмотрение.
- После того, как график построен, удаляем из него дополнительную линию аргумента, выделив её и нажав на кнопку Delete на клавиатуре компьютера.
- Далее нам нужно поменять деления горизонтальной шкалы, так как в ней отображаются не значения аргументов, как нам того нужно. Для этого, кликаем правой кнопкой мыши по диаграмме и в появившемся списке останавливаемся на значении «Выбрать данные».
- В запустившемся окне выбора источника данных кликаем по кнопке «Изменить» в блоке редактирования подписи горизонтальной оси.
- Открывается окно установки подписи оси. Ставим курсор в поле данного окна, а затем выделяем все данные столбца
- После возврата к окну выбора источника данных повторяем ту же процедуру, то есть, жмем на кнопку «OK».
- Теперь наш график подготовлен и можно, непосредственно, приступать к построению линии тренда. Кликаем по графику, после чего на ленте активируется дополнительный набор вкладок – «Работа с диаграммами». Перемещаемся во вкладку «Макет» и жмем на кнопку «Линия тренда» в блоке «Анализ». Кликаем по пункту «Линейное приближение»
- Линия тренда добавлена, но она полностью находится под линией самого графика, так как мы не указали значение аргумента, к которому она должна стремиться. Чтобы это сделать опять последовательно кликаем по кнопке «Линия тренда», но теперь выбираем пункт «Дополнительные параметры линии тренда».
- Запускается окно формата линии тренда. В разделе «Параметры линии тренда» есть блок настроек «Прогноз». Как и в предыдущем способе, давайте для экстраполяции возьмем аргумент 55. Как видим, пока что график имеет длину до аргумента
- Как видим, график был продлен на указанную длину с помощью линии тренда.
 Затем, переместившись во вкладку «Вставка», кликаем по кнопке «График». Этот значок расположен в блоке «Диаграммы» на ленте инструментов. Появляется перечень доступных вариантов графиков. Выбираем наиболее подходящий из них на свое усмотрение.
Затем, переместившись во вкладку «Вставка», кликаем по кнопке «График». Этот значок расположен в блоке «Диаграммы» на ленте инструментов. Появляется перечень доступных вариантов графиков. Выбираем наиболее подходящий из них на свое усмотрение. Затем жмем на кнопку «OK».
Затем жмем на кнопку «OK». Как и в предыдущем способе, давайте для экстраполяции возьмем аргумент 55. Как видим, пока что график имеет длину до аргумента
Как и в предыдущем способе, давайте для экстраполяции возьмем аргумент 55. Как видим, пока что график имеет длину до аргумента Урок: Как построить линию тренда в Excel
Итак, мы рассмотрели простейшие примеры экстраполяции для таблиц и для графиков. В первом случае используется функция ПРЕДСКАЗ, а во втором – линия тренда. Но на основе этих примеров можно решать и гораздо более сложные задачи прогнозирования.
Опишите, что у вас не получилось.
 Наши специалисты постараются ответить максимально быстро.
Наши специалисты постараются ответить максимально быстро.Помогла ли вам эта статья?
ДА НЕТПрогнозирование значений в рядах – Excel
Если вам нужно спрогнозировать расходы на следующий год или проецировать ожидаемые результаты для ряда в научном эксперименте, вы можете использовать Microsoft Office Excel для автоматического создания будущих значений на основе существующих данных или для автоматического получения экстраполированных значений, основанных на линейных или ростовых трендах.
Вы можете заполнить ряд значений, которые соответствуют простому линейному или экспоненциальному тренду, с помощью маркер заполнения или последовательности. Для расширения сложных и нелинейных данных можно использовать функции или инструмент регрессионный анализ надстройки “Надстройка анализа”.
В линейном ряду значение шага или разность между первым и следующим значением последовательного ряда добавляется к начальному значению, а затем добавляется к каждому последующему значению.
Начальное значение | Расширенный линейный ряд |
|---|---|
|
1, 2 |
3, 4, 5 |
|
1, 3 |
5, 7, 9 |
|
100, 95 |
90, 85 |
Чтобы заполнить ряд для линейного тренда, сделайте следующее:
-
Выделите не менее двух ячеек, содержащих начальные значения для тренда.
Если вы хотите повысить точность ряда трендов, выберите дополнительные начальные значения.
-
Перетащите его в нужном направлении.
Например, если в ячейках C1:E1 выбраны начальные значения 3, 5 и 8, перетащите его вправо, чтобы заполнить значениями тенденций, или влево, чтобы заполнить значениями убывания.

Совет: Чтобы вручную управлять тем, как создается ряд, или заполнять ряд с помощью клавиатуры, выберите команду “Ряд”(вкладка “Главная”, группа “Редактирование”, кнопка “Заполнить”).
В рядах роста начальное значение умножается на шаг, чтобы получить следующее значение в ряду. Результат и каждый последующий результат умножаются на шаг.
Начальное значение | Расширенный цикл роста |
|---|---|
|
1, 2 |
4, 8, 16 |
|
1, 3 |
9, 27, 81 |
|
2, 3 |
4.5, 6.75, 10.125 |
Чтобы заполнить ряд для тенденции роста, сделайте следующее:
-
Выделите не менее двух ячеек, содержащих начальные значения для тренда.
Если вы хотите повысить точность ряда трендов, выберите дополнительные начальные значения.
-
Удерживая нажатой правую кнопку мыши, перетащите указатель заполнения в том направлении, в каком вы хотите заполнить значениями, увеличив или убывнув значения, отпустите кнопку мыши, а затем нажмите кнопку “Рост” на контекстное меню.

Например, если в ячейках C1:E1 выбраны начальные значения 3, 5 и 8, перетащите его вправо, чтобы заполнить значениями тенденций, или влево, чтобы заполнить значениями убывания.
Совет: Чтобы вручную управлять тем, как создается ряд, или заполнять ряд с помощью клавиатуры, выберите команду “Ряд”(вкладка “Главная”, группа “Редактирование”, кнопка “Заполнить”).
При нажатии кнопки “Ряд” можно вручную управлять тем, как создается линейный или рост тренда, а затем заполнять значения с помощью клавиатуры. x).
x).
В обоих случаях шаг игнорируется. Созданный ряд эквивалентен значениям, которые возвращаются функцией ТЕНДЕНЦИЯ или функцией РОСТ.
Чтобы заполнить значения вручную, сделайте следующее:
-
Вы выберите ячейку, с которой нужно начать ряд. Ячейка должна содержать первое значение в ряду.
При выборе команды “Ряд” итоговые ряды заменяют исходные выбранные значения. Если вы хотите сохранить исходные значения, скопируйте их в другую строку или столбец, а затем создайте ряд, выбирая скопированные значения.
-
На вкладке Главная в группе Редактирование нажмите кнопку Заполнить и выберите пункт Прогрессия.
-
Выполните одно из указанных ниже действий.
-
Чтобы заполнить ряд вниз по столбцам, щелкните “Столбцы”.
-
Чтобы заполнить ряды на всем телефоне, щелкните “Строки”.
-
-
В поле “Шаг” введите значение, на которое нужно увеличить ряд.

Тип ряда | Результат шага |
|---|---|
|
Линейная |
Шаг добавляется к первому начальному значению, а затем к каждому последующему значению. |
|
Геометрическая |
Первое начальное значение умножается на шаг. Результат и каждый последующий результат умножаются на шаг. |

-
В области “Тип”выберите “Линейный” или “Увеличение”.
-
В поле “Остановить значение” введите значение, для чего нужно остановить ряд.
Примечание: Если ряд имеет несколько начальных значений и необходимо, чтобы приложение Excel формирует тенденцию, выберите его.
Если у вас есть данные, для которых необходимо спрогнозировать тенденцию, можно создать линия тренда диаграмме.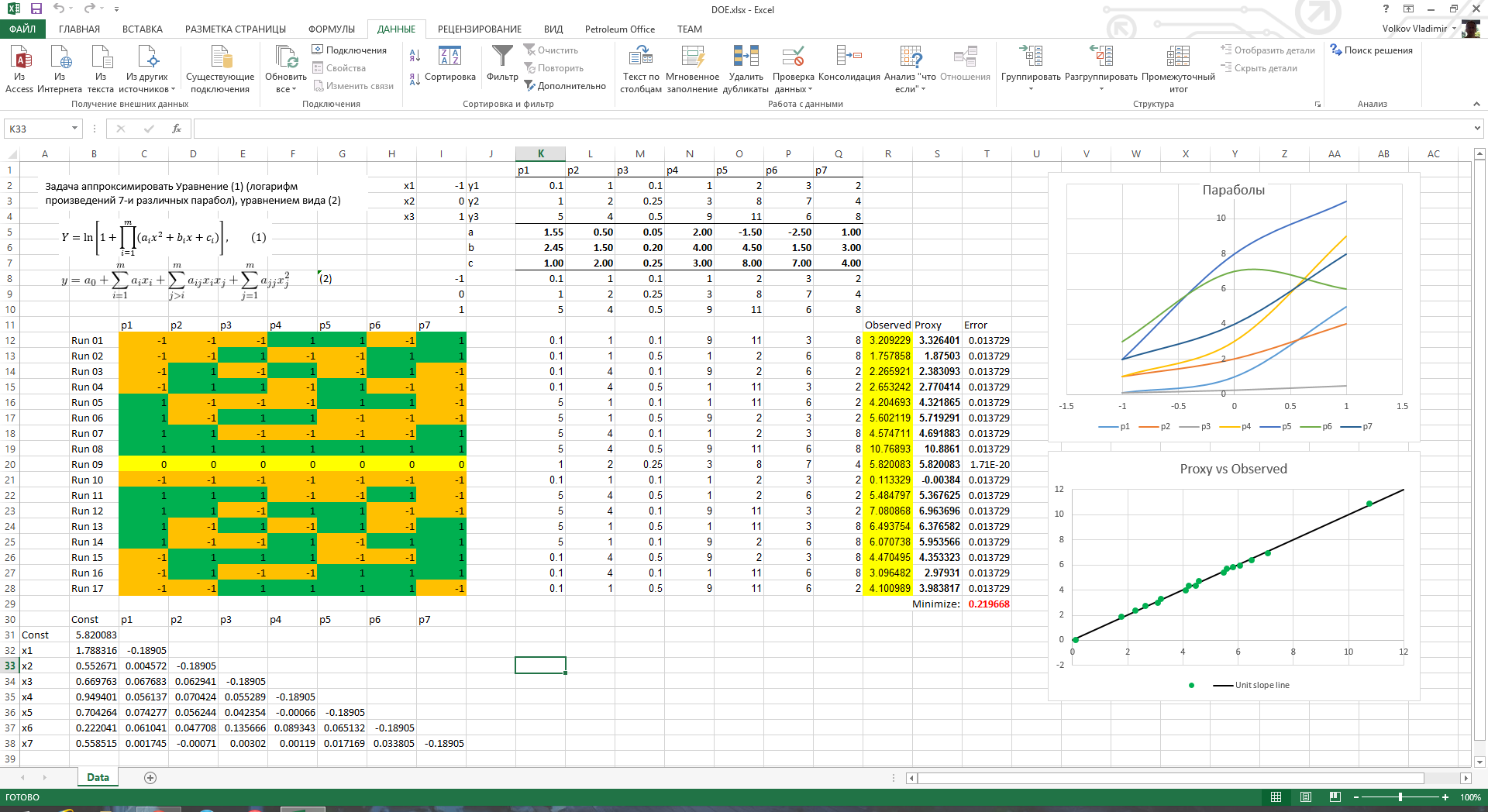 Например, если в Excel есть диаграмма с данными о продажах за первые несколько месяцев года, вы можете добавить на нее линию тренда, которая отображает общую тенденцию продаж (увеличение или убываю или неплоскую) либо отображает прогнозируемый тренд на месяцы вперед.
Например, если в Excel есть диаграмма с данными о продажах за первые несколько месяцев года, вы можете добавить на нее линию тренда, которая отображает общую тенденцию продаж (увеличение или убываю или неплоскую) либо отображает прогнозируемый тренд на месяцы вперед.
В этой процедуре предполагается, что вы уже создали диаграмму, основанную на существующих данных. Если это не так, см. раздел “Создание диаграммы”.
-
Щелкните диаграмму.
-
Щелкните ряд данных, к которому вы хотите добавить линия тренда или скользящее среднее.
-
На вкладке “Макет” в группе “Анализ” нажмите кнопку “Линия тренда” и выберите нужный тип линии тренда или скользящего среднего.
-
Чтобы настроить параметры и отформать линию тренда или линию скользящего среднего, щелкните линию тренда правой кнопкой мыши и выберите в shortcut-меню пункт “Формат линии тренда”.
-
Выберите нужные параметры линии тренда, линии и эффекты.
-
Если выбрана полиномиальная,введите в поле “Порядок” наивысшую мощность для независимой переменной.
-
При выборе скользящегосреднего введите в поле “Период” количество периодов, используемых для расчета скользящего среднего.
-

Примечания:
-
В поле «На основе ряда» перечислены все ряды данных на диаграмме, поддерживают линии тренда. Чтобы добавить линию тренда к другому ряду, щелкните имя в поле и выберите нужные параметры.
-
При добавлении скользящего среднего на точечная диаграмма скользящие средние значения будут основаны на порядке, в том числе в значении X, относящегося к диаграмме.
Чтобы получить нужный результат, перед добавлением скользящего среднего может потребоваться отсортировать значения X.
 Чтобы получить нужный результат, перед добавлением скользящего среднего может потребоваться отсортировать значения X.
Чтобы получить нужный результат, перед добавлением скользящего среднего может потребоваться отсортировать значения X.Если вам нужно выполнить более сложный регрессивный анализ, в том числе вычислить оставшиеся остаток и отсчитать оставшиеся остаток, используйте инструмент анализа регрессии в надстройке “Надстройка “Надстройка анализа”. Дополнительные сведения см. в подзагонке “Загрузка предоплаченного анализа”.
В Excel в Интернете можно проецировать значения ряда с помощью функций или перетащить его, чтобы создать линейный тренд чисел. Но создать тенденцию роста с помощью этого хи2-го нельзя.
Чтобы создать линейный тренд чисел в Excel в Интернете, используйте его Excel в Интернете:
-
Выделите не менее двух ячеек, содержащих начальные значения для тренда.
Если вы хотите повысить точность ряда трендов, выберите дополнительные начальные значения.
-
Перетащите его в нужном направлении.
Интерполяция графика и табличных данных в Excel
Интерполяция – это своего рода «латание» графиков в тех местах, где возникают обрывы линий из-за отсутствия данных по отдельным показателям. Термин интерполяция подразумевает «латание» внутренних обрывов на графике. А если бы «латались» внешние обрывы, то это была-бы уже экстраполяция графика.
Как построить график с интерполяцией в Excel
При работе в Excel приходится сталкиваться с интерполяцией графиков различной сложности. Но для первого знакомства с ней рассмотрим сначала самый простой пример.
Если в таблице еще нет всех значений показателей, но уже нужно сформировать по ним отчет и построить графическое представление данных. Тогда на графике мы наблюдаем обрывы в местах, где отсутствуют значения показателей.
Тогда на графике мы наблюдаем обрывы в местах, где отсутствуют значения показателей.
Заполните таблицу как показано на рисунке:
Выделите диапазон A1:B4 и выберите инструмент: «Вставка»-«Диаграммы»-«График»-«График с маркерами».
Чтобы устранить обрывы на графике, то есть выполнить интерполяцию в Excel, можем использовать 2 решения для данной задачи:
- Изменить параметры в настройках графика выбрав соответствующую опцию.
- Использовать функцию: =НД() – возвращает значение ошибки #Н/Д.
Оба эти способа рассмотрим далее на конкретных примерах.
Способ 1:
- Сделайте график активным щелкнув по нему левой кнопкой мышки и выберите инструмент: «Работа с диаграммами»-«Конструктор»-«Выбрать данные».
- В появившемся диалоговом окне «Выбор источника данных» кликните на кнопку «Скрытые и пустые ячейки»
- В появившемся диалоговом окне «Настройка скрытых и пустых ячеек» выберите опцию «линию». И нажмите ОК во всех открытых диалоговых окнах.

Как видно на рисунках сразу отображены 2 варианта опций «линию» и «нулевые значения». Обратите внимание, как ведет себя график при выборе каждой из них.
Методы интерполяции табличных данных в Excel
Теперь выполним интерполяцию данных в таблице с помощью функции: =НД(). Для этого нужно предварительно сбросить выше описанные настройки графика, чтобы увидеть как работает данный способ.
Способ 2. В ячейку B3 введите функцию =НД(). Это автоматически приведет к интерполяции графика как показано на рисунке:
Примечание. Вместо функции =НД() в ячейку можно ввести просто значение: #Н/Д!, результат будет тот же.
Линейная экстраполяция онлайн с решением и графиком
- Подробности
Калькулятор линейной экстраполяции позволяет вычислить значение линейной функции если абсцисса (Х) искомой точки лежит за пределами отрезка интерполяции [X1, X2].
Дано:
округление до 12345знаков после запятой
Решение:
Формула линейной экстраполяции
расчет линейной экстраполяции по двум точкам
Помощь на развитие проекта premierdevelopment.ru
Send mail и мы будем знать, что движемся в правильном направлении.Спасибо, что не прошели мимо!
I. Порядок действий при расчете линейной экстраполяции онлайн калькулятором:
- Для проведения экстраполяции требуется ввести значения координат 2 точек ([X1, Y1]; [X2, Y2]) и абсциссу (Х) той точки, значение которой необходимо вычислить.
- График справа позволяет визуализировать полученный линейной экстраполяцией результат.
II. Для справки:
- интерполяция
- — способ нахождения промежуточных значений величины по имеющемуся дискретному набору известных значений.
- линейная интерполяция
- — нахождение промежуточного значения функции по двум точкам (условно проведя прямую между ними).
- квадратичная интерполяция
- — нахождение промежуточного значения функции по трем точкам (интерполирующая функция многочлен второго порядка – парабола).
- экстраполяция
- — способ нахождения значений функции по уже известным нескольким ее значениям.
4. Построение прогнозов в Excel
Прогнозирование– это метод научного исследования, ставящей своей целью предусмотреть возможные варианты тех процессов и явлений, которые выбраны в качестве предмета анализа.
Одним
из методов прогнозирования является
метод экстраполяции. Метод экстраполяции заключается в нахождении значений,
лежащих за пределами данного статистического
ряда: по известным значениям статистического
ряда находятся другие значения, лежащие
за пределами этого ряда.
При экстраполяции переносится выводы, сделанные при изучении тенденций развития явления в прошлом и настоящем, на будущее, т.е. в основе экстраполяции лежит предположение об определенной стабильности факторных признаков, влияющих на развитие данного явления.
Чем более устойчивый характер носит прогнозируемые процессы и тенденции, тем дальше может быть отодвинут горизонт прогнозирования. Как показывает практика, интервал наблюдения должен быть в три и более раз длиннее интервала упреждения. Как правило, этот период – довольно короткий. Метод экстраполирования не работает при скачкообразных процессах.
Метод экстраполяции легко реализуется на персональном компьютере. Использование современных табличных процессоров, таких как MSExcelпозволяет оперативно проводить прогнозирование различных процессов с использованием экстраполяционного метода.
Для
повышения точности прогноза, необходимо
учитывать зависимость
прогнозируемой величины Y, от внешних
факторов Х.Совокупность изучаемых
величин подвержена, как правило,
воздействию случайных факторов. В связи
с этим зависимость прогнозируемой
величины Y, от внешних факторов Х чаще
всего статистическая, или – корреляционная.
В связи
с этим зависимость прогнозируемой
величины Y, от внешних факторов Х чаще
всего статистическая, или – корреляционная.
Статистическойназывается зависимость случайных величин, при которой каждому значению одной их них соответствует закон распределения другой, то есть изменение одной из величин влечет изменение распределения другой.
Корреляционнойназывается статистическая зависимость случайных величин, при которой изменение одной из величин влечет изменение среднего значения другой.
Мерой корреляционной зависимости двух случайных величин Х и Y служит коэффициент корреляции r, который является безразмерной величиной, и поэтому он не зависит от выбора единиц измерения изучаемых величин.
Свойства коэффициента корреляции:
1) Если две случайные величины Х и Y независимы, то их коэффициент корреляции равен нулю, т.е. r=0.
2) Модуль коэффициента корреляции не превышает единицы, т.е. |r|1, что эквивалентно двойному неравенству:1r1.
3)
Равенство коэффициента -1 или +1 показывает
наличие функциональной (прямой) связи. Знак «+» указывает на связь прямую
(увеличение или уменьшение одного
признака сопровождается аналогичным
изменением другого признака), знак «-»
– на связь обратную (увеличение или
уменьшение одного признака сопровождается
противоположным по направлению изменением
другого признака).
Знак «+» указывает на связь прямую
(увеличение или уменьшение одного
признака сопровождается аналогичным
изменением другого признака), знак «-»
– на связь обратную (увеличение или
уменьшение одного признака сопровождается
противоположным по направлению изменением
другого признака).
После определения наиболее существенных факторных признаков влияющих прогнозируемую величину, не менее важно установить их математическое описание (уравнение), дающее возможность численно оценивать результативный показатель через факторные признаки.
Уравнение, выражающее изменение средней величины результативного показателя в зависимости от значений факторных признаков, называется уравнение регрессии.
Линии на координатной плоскости, соответствующие уравнениям регрессии называются линиями регрессии.
Корреляционные зависимости могут выражаться уравнениями регрессии различных видов: линейной, параболической, гиперболической, показательной и т.д.
Линейная регрессия
Уравнением
линейной регрессии(выборочным)YнаХназывается зависимость от
наблюдаемых значений величины Х,
выраженная линейной функцией: , где
величина называется коэффициентом линейной
регрессии YнаХ, b– константа.
Линейная аппроксимация хорошо описывает изменение величин, происходящее с постоянной скоростью.
Если коэффициент корреляции двух величин ХиYравенr=1, то эти величины связаны линейной зависимостью. Коэффициент корреляции служит мерой силы (тесноты) линейной зависимости измеряемых величин. На практике, если коэффициент корреляции двух величинХиY|r|>0.5, то считают, что есть основания предполагать наличие линейной зависимости между этими величинами. Однако ориентироваться при выборе типа линии регрессии (линейной или нелинейной) лучше по виду эмпирической зависимости величинХиY.
Параболическая и полиномиальная регрессии.
Параболическойзависимостью величиныYот величиныХназывается зависимость,
выраженная квадратичной функцией
(параболой 2-ого порядка):. Это
уравнение называетсяуравнением
параболической регрессииYнаХ. Параметрыа,b,сназываютсякоэффициентами
параболической регрессии.
Уравнение параболической регрессии является частным случаем более общей регрессии, называемой полиномиальной. Полиномиальнойзависимостью величиныYот величиныХназывается зависимость, выраженная полиномомn-ого порядка: ,где числааi(i=0,1,…,n) называютсякоэффициентами полиномиальной регрессии.
Полиномиальная аппроксимация используется для описания величин, попеременно возрастающих и убывающих.
Степенная регрессия.
Степеннойзависимостью величиныYот величиныХназывается зависимость вида: . Это уравнение называетсяуравнением степенной регрессииYнаХ. Параметрыаиbназываютсякоэффициентами степенной регрессии.
Степенная
аппроксимация полезна для описания
монотонно возрастающей либо монотонно
убывающей величины, например расстояния,
пройденного разгоняющимся автомобилем.
Использование степенной аппроксимации
невозможно, если данные содержат нулевые
или отрицательные значения.
Показательная регрессия.
Показательной(илиэкспоненциальной) зависимостью величиныYот величиныХназывается зависимость вида: (или )
Это уравнение называется уравнениемпоказательной(илиэкспоненциальной)регрессииYнаХ. Параметрыа(илиk) иbназываютсякоэффициентами показательной(илиэкспоненциальной)регрессии.
Экспоненциальная аппроксимация полезна в том случае, если скорость изменения данных непрерывно возрастает. Однако для данных, которые содержат нулевые или отрицательные значения, этот вид приближения неприменим.
Логарифмическая регрессия.
Логарифмическойзависимостью величиныYот величиныХназывается зависимость
вида:.Это уравнение называетсяуравнением логарифмической регрессииYнаХ. Параметрыаиbназываютсякоэффициентами логарифмической
регрессии.
Логарифмическая аппроксимация полезна для описания величины, которая вначале быстро растет или убывает, а затем постепенно стабилизируется. Логарифмическая аппроксимация использует как отрицательные, так и положительные величины.
Гиперболическая регрессия.
Гиперболическойзависимостью величиныYот величиныХназывается зависимость вида: . Это уравнение называетсяуравнением гиперболической регрессии YнаХ. Параметрыаиbназываютсякоэффициентами гиперболической регрессии.
Проведение регрессионного анализа можно разделить на три этапа: выбор формы зависимости (вида уравнения) на основе статистических данных, вычисление коэффициентов выбранного уравнения, оценка достоверности выбранного уравнения.
Использование табличного процессора позволяет легко выполнить все этапы регрессионного анализа.
Использование функции ТЕНДЕНЦИЯ
Для
прогнозирования процессов, изменение
которых носит линейный характер можно
использовать функцию ТЕНДЕНЦИЯ.
Эта функция позволяет находить значения в соответствии с линейным трендом. Она аппроксимирует прямой линией (по методу наименьших квадратов) массивы известных значений Yи известных значения Х. Находит новые значенияY, в соответствии с этой прямой для новых значений Х. Например, если у нас есть данные изменения цены на энергоносители за несколько последних лет, то с помощью функции ТЕНДЕНЦИЯ мы можем получить прогноз на цену на энергоносители на будущий год. При этом если зависимость цены от времени близка к линейной, то результат будет удовлетворительным.
Предварительно, перед использованием функции ТЕНДЕНЦИЯ необходимо ввести (в столбец или в строку) массивы XиY, взаимосвязанных величин, а также значенияXдля которых будет спрогнозирована величинаY.
Затем,
вызываем статистическую функцию
ТЕНДЕНЦИЯ. Для этого необходимо вызвать
Мастер функций, щелкнув на кнопке строки
формул или отдав команду Вставка/Функция.В окне Мастера функций выберите категориюСтатистическиеи в полеВыберите
функцию выберите из списка функцию
ТЕНДЕНЦИЯ. В появившемся диалоговом
окнеАргументы функции (рис.5.8) в
соответствующие поля внесите ссылки
на диапазоны ячеек в которых хранятся
известные значения величинYиX, новые значения Х, для
которых ТЕНДЕНЦИЯ возвращает
соответствующие значенияY.
С помощью поляКонст можно
указать вычислять ли константу b или
принять равной 0. Если это поле имеет
значение ИСТИНА или опущено, то b
вычисляется обычным образом, если ЛОЖЬ
– то b полагается равным 0, и значенияподбираются
таким образом, чтобы выполнялось
соотношениеy = x.
В появившемся диалоговом
окнеАргументы функции (рис.5.8) в
соответствующие поля внесите ссылки
на диапазоны ячеек в которых хранятся
известные значения величинYиX, новые значения Х, для
которых ТЕНДЕНЦИЯ возвращает
соответствующие значенияY.
С помощью поляКонст можно
указать вычислять ли константу b или
принять равной 0. Если это поле имеет
значение ИСТИНА или опущено, то b
вычисляется обычным образом, если ЛОЖЬ
– то b полагается равным 0, и значенияподбираются
таким образом, чтобы выполнялось
соотношениеy = x.
Рис. 8. Фрагмент диалогового окна Аргументы функции.
После ввода всех необходимых аргументов функции необходимо нажать на кнопке ОК.
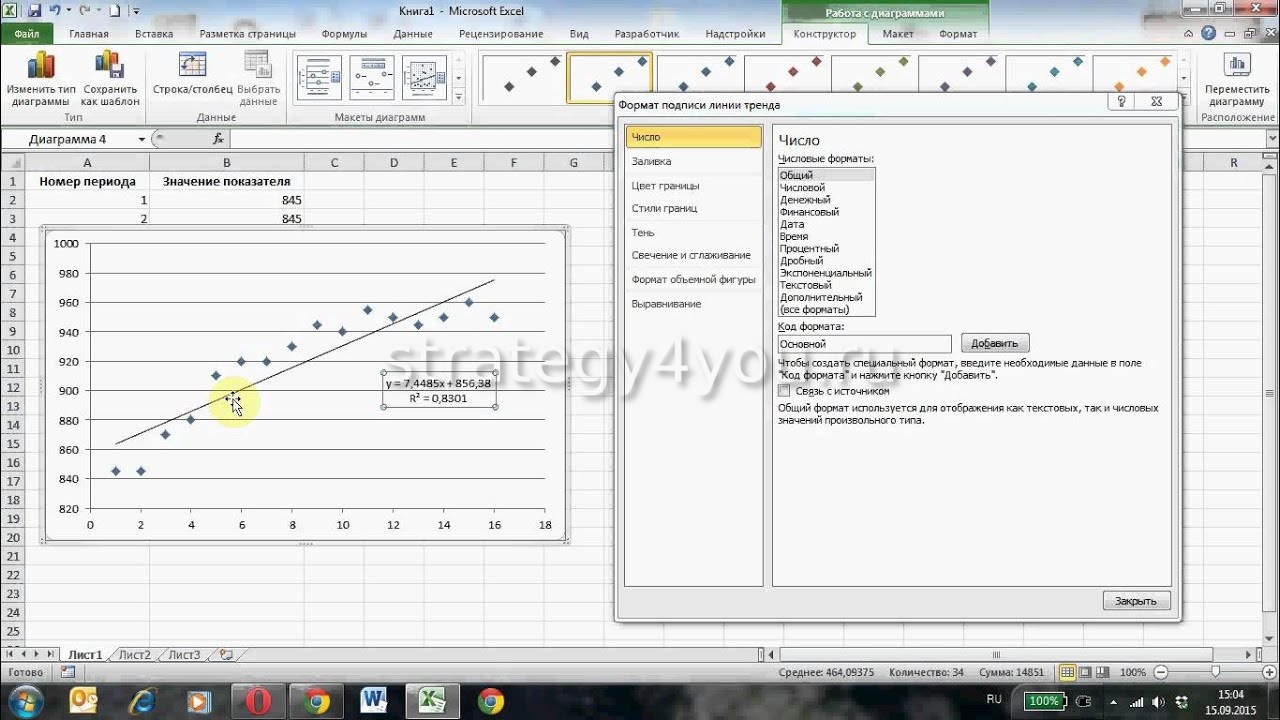
Быстрое построение линий регрессии в Excel: линия тренда.
В Excel имеется быстрый и удобный способ построить график линейной регрессии, а также основных видов нелинейных регрессий. Это можно сделать следующим образом:
Выделить
столбцы с данными X и Y (они должны располагаться именно в таком
порядке!).
Вызвать Мастер диаграмм (используя инструмент или команду Вставка/Диаграмма) и в открывшемся окне Мастер диаграмм выбрать в группе Тип – Точечная и сразу нажать Готово.
Не сбрасывая выделения с диаграммы, выбрать появившейся пункт основного меню Диаграмма, в котором следует выбрать пункт Добавить линию тренда.
В
открывшемся диалоговом окне Линия
тренда во вкладке Тип выбрать тип. Можно
выбрать одну из шести зависимостей:
линейная, степенная, логарифмическая,
экспоненциальная, полиномиальная и
линейная фильтрация. Для полиномиальной
аппроксимации можно указать степень.
При линейной фильтрации (скользящее
среднее) элементы данных усредняются,
и полученный результат используется в
качестве среднего значения для
приближения. Так, если шаг линейной
фильтрации равен 2, первая точка
сглаживающей кривой определяется как
среднее значение первых двух элементов
данных, вторая точка – как среднее
следующих двух элементов и так далее.
Рис.5.9. Вкладка Линия тренда.
.
Интерполяция промежуточных значений для произвольных данных в Excel
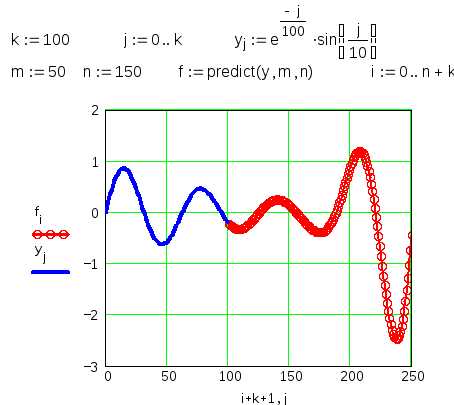
читая ваши комментарии и изменения к вопросу, есть несколько вещей, которые вы хотите сделать, которые на самом деле не рассматриваются в моем предыдущем ответе. Этот ответ будет иметь дело с этими элементами, и я включил пошаговое пошаговое руководство о том, как вы выполните весь процесс интерполяции.
Недостоверные Сведения
вы описываете процесс, который сгенерировал данные, как снятие показаний за интервал времени, а числа округляются. Тот уравнение так же хорошо, как и данные. В вашем фактическом анализе вы должны использовать самые точные доступные числа (возможно, вы просто сохраняли свой пример простым, показывая округленные времена).
Однако, данные, которые вы показываете, точно не соответствуют виду кривой, которую вы обычно видите для физического процесса.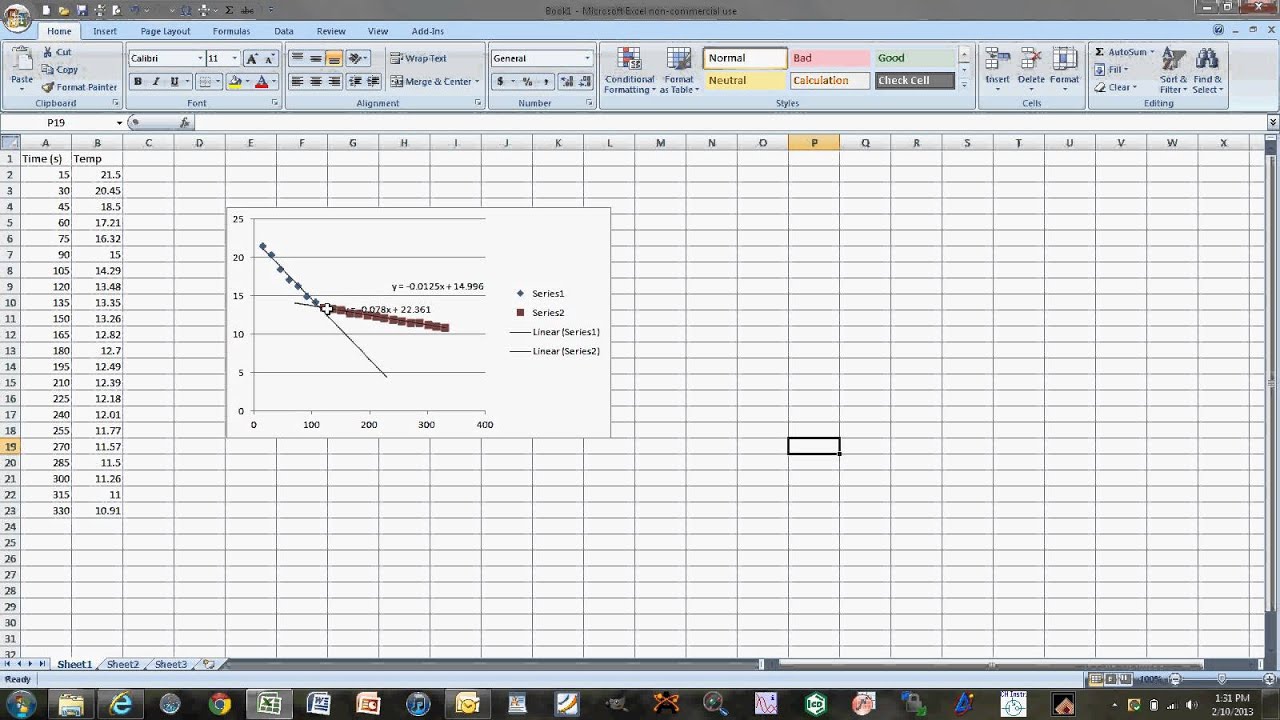 Теоретические кривые, как правило, гладкие, когда есть только одна движущая переменная и нет шума. Если вы используете очень точное оборудование и для того чтобы вызвать чтение на preset интервал и обеспечить точное измерение, вы можете принимать результаты как точные. Однако, если вы вручную приурочиваете чтение и вручную принимаете чтение, то
Теоретические кривые, как правило, гладкие, когда есть только одна движущая переменная и нет шума. Если вы используете очень точное оборудование и для того чтобы вызвать чтение на preset интервал и обеспечить точное измерение, вы можете принимать результаты как точные. Однако, если вы вручную приурочиваете чтение и вручную принимаете чтение, то X значения могут быть неточными, порой даже если показания, сами по себе, являются точными. Сдвиг персонажа X значения немного так или иначе введут виды небольших неровностей, которые вы видите на кривой ваших данных (если пример не является просто числами, которые вы составили для целей образец.)
если это так, вы можете воспользоваться регрессией для оценки наилучшего соответствия.
используя Y как X
в вашей задаче вы хотите определить значения для Y (целочисленные значения от 1 до 37 в данном примере), и поиска соответствующего значения x. Это было достаточно легко сделать в вашей Y=2^X проблема, потому что это простое уравнение можно легко обратить к X=log(Y)/log(2), и вы можете сразу рассчитать любое значение вы хотите. Если уравнение не что-то простое, часто нет практического способа инвертировать его. “Злоупотребленный” регрессионный подход в моем предыдущем ответе дает вам уравнение высокого порядка, но это “однонаправленное”, часто непрактичное решение для обратного уравнения.
Если уравнение не что-то простое, часто нет практического способа инвертировать его. “Злоупотребленный” регрессионный подход в моем предыдущем ответе дает вам уравнение высокого порядка, но это “однонаправленное”, часто непрактичное решение для обратного уравнения.
самый простой подход-просто обратить X и Y С самого начала. Это дает уравнение можно использовать с целочисленными значениями введут (анализ дает coeficients уравнения, как описано в предыдущем ответ.)
это никогда не повредит, чтобы увидеть, если простая кривая будет работать. Вот обратные данные, и вы можете видеть, что нет полезной подгонки:
Итак, попробуйте полиномиальную подгонку. Однако это случай, как я описал в предыдущем ответе. Значения от 1 до 8 подходят хорошо, но 9 дает ему несварение. Многочлен 3-го порядка дает вам bump:
это становится все более “интересным” по мере увеличения порядка уравнения. По 7-м порядка, вы получите это:
он проходит почти точно через каждую точку, но кривая между 8 и 9 не полезно. X пример, вы можете рассчитать любое значение, которое вы хотите.
X пример, вы можете рассчитать любое значение, которое вы хотите.
если известно, что процесс генерации данных следует простой кривой, и вы уверены в подгонке, вы можете проецировать значения за пределы диапазона данных и даже получить значимый доверительный интервал для диапазона, в котором могут быть значения (на основе того, сколько вариаций между данными и кривой внутри диапазона данных).
если вы принудительно подгоняете уравнение высокого порядка к данным, проекции вне диапазона данных обычно бессмысленны.
если вы используете сплайны, нет оснований для проецирования за пределы диапазона данных.
какие бы проекции вы ни делали за пределами диапазона ваших данных, они хороши только как уравнение, которое вы используете, и если вы не используете точное уравнение, чем дальше вы получаете от своих данных, тем более неточным оно будет.
глядя на кривую журнала на первом графике, вы можете видеть, что она будет проецировать совсем другое значение чем вы и ожидали.
для полиномиальных уравнений коэффициент нулевой мощности является константой, и это значение, которое будет получено для X стоимостью 0. Это простой способ посмотреть, куда пойдет кривая в этом направлении.
обратите внимание, что в 4-м или 5-м порядке точки с 1 по 8 довольно точны. Но как только вы выходите за пределы диапазона, уравнения могут вести себя очень иначе.
экстраполяция с использованием ограниченных данных
один из способов улучшить ситуацию-подогнать только точки На этом конце и включить столько последовательных точек, сколько следует за формой кривой на этом конце. Точка 9-это явно. Перед этим на кривой есть несколько перегибов, один из которых находится вокруг точки 5 или 6, поэтому точки выше этого следуют другой кривой. Используя только точки от 1 до 5, вы приближаетесь к идеальной подгонке с полиномом 3-го порядка. Это уравнение будет нулевой точки 0.12095 (сравните таблицу выше), а для X стоимостью 1,0.. 3493
3493
что произойдет, если просто подогнать прямую к первым пяти точкам:
что проектов с нулевой точки -0.5138 и X на 1,-0.0071.
этот диапазон возможных результатов указывает на уровень неопределенности за пределами диапазона ваших данные. Нет правильного ответа. И это было на” хорошем ” конце твоей кривой. The Y значение X на 9 is 36.7. Ты хочешь пойти в 37. Сплайны предполагают, что кривая асимптотична при 9. Проецирование прямой линии в необработанных данных приведет к значению чуть больше, чем 9 (то же самое с полиномом 4-го порядка). Полином 3-го порядка предлагает значение меньше 9 (как сделать 5 и 6 заказов). Многочлен 7-го порядка предлагает значение существенно выше 9. Таким образом, все, что находится за пределами диапазона данных, является предположением или чем-то другим.
собираем все вместе
Итак, давайте шаг через то, что фактическое решение будет выглядеть. Мы предположим, что вы уже пытались найти точное уравнение и протестировали общие кривые с помощью линии тренда. Следующим шагом будет попробовать регрессию, потому что это дает вам формулу для кривой, и вы можете подключить целочисленные значения.
Мы предположим, что вы уже пытались найти точное уравнение и протестировали общие кривые с помощью линии тренда. Следующим шагом будет попробовать регрессию, потому что это дает вам формулу для кривой, и вы можете подключить целочисленные значения.
I нет готового доступа к Excel 2013 или инструментарию анализа. Для иллюстрации я буду использовать LibreOffice Calc. Он не идентичен, но достаточно близок, чтобы вы могли следить за ним в Excel. В LO Calc это фактически бесплатное расширение, которое необходимо загрузить. Я использую CorelPolyGUI, которую можно скачать здесь. Насколько я помню, инструментарий анализа не включал сплайны. Если это все еще так, и вы хотите сделать это в Excel, я наткнулся это бесплатное дополнение (который я не проверял). Альтернативой будет использование Lo Calc, который будет работать в Windows и является бесплатным.
здесь я ввел значения X и Y (реверсированные) в Столбцах A и B и открыл диалоговое окно анализа. Выделение значений X и нажатие кнопки X загружает диапазоны данных, и я выбрал полином.
на следующей вкладке я указываю, что хочу использовать 0 to 7 Градусы (многочлен 7-го порядка со всеми порядками).
чтобы указать вывод, я выбираю C1 и нажимаю столбцы, и он регистрирует столбцы, необходимые для вывода. Я выбираю, что я хочу, чтобы он выводил исходные данные, вычисленные результаты, и я выбрал добавьте три промежуточные точки между каждой исходной точкой данных. И я говорю, что хочу график результатов на новом графике. Затем перейдите в меню calculate и нажмите calculate.
и вот оно. Если вы посмотрите на вычисленные значения, вы можете заметить проблему. Это станет очевидным на следующем этапе.
вот, я добавил 1 через 37 значения. На данный момент мы хотим иметь дело только с интерполяцией, поэтому я добавил формулу для вычисления только значений 3 через 36. Формула просто расширяет коэффициенты, перечисленные в результатах (значения a (n)). 7
7
это просто каждый коэффициент, умноженный на соответствующую мощность значения X. Перетащите это вниз, и у вас есть результаты. Ну не совсем; Вы должны смотреть на него, чтобы увидеть, если он проходит здравомыслие испытание. Мы знали, что между 8 и 9, но это оказывается половина значений, которые вы хотите. Мы могли бы использовать значения из 3 через 20, но нет смысла объединять так много значений из другого метода. Так что давайте просто использовать сплайны для всего этого.
снова откройте диалоговое окно анализ и измените метод на “сплайны” на вкладке ввод (здесь не показано). Дайте ему новое выведите наружу ряд и скажите, что он высчитал. Это все, что для этого нужно.
у нас есть новые результаты в работе. Разделение диапазона данных на это множество сегментов делает каждый сегмент коротким, поэтому линейная интерполяция должна быть довольно хорошей (лучше, чем использовать ее на исходных данных).
процесс подгонки кривой или интерполяции включает в себя создание точек данных; используя свое собственное суждение о том, что кривая “должна” (или не должна) выглядеть (регрессия предполагает, что даже исходные данные неточны).
проверка правильности этих данных показывает, что даже сплайны создают соединительную кривую с выпуклостью; одно значение немного превышает 9, который скорее артефакт, нежели отражение процесса вы были измерения. В этом случае кривая асимптотика при 9 более вероятно, поэтому я произвольно назначил высокую точку a значение, что волос меньше!–24 — > глядя на него. Предположение не в том, что моя ценность точна, только в том, что это улучшение. Для этой иллюстрации я создал новый столбец со значениями, которые будут использоваться.
я добавил столбец с вашими номерами 1 через 37. Из предыдущего обсуждения у нас нет надежной основы для проектирования значений для 1 и 2, поэтому я оставил их пустыми. Для
Для 37, я пошел с асимптотическим предположением и сделал это 9. Значения для 3 через 36 найдены линейной интерполяцией (и это формула, которую вы могли бы адаптировать к другим данным). Формула в Q3:
=TREND(OFFSET($M,MATCH(P3,M:M)-1,2,2),OFFSET($M,MATCH(P3,M:M)-1,0,2),P3)
функция TREND просто интерполирует, когда диапазон равен двум точкам. Синтаксис команды:
TREND(Y_range, X_range, X_value)
функция смещения используется для каждого диапазона. В каждом случае функция MATCH используется для поиска первой строки диапазона, содержащего целевое значение. The -1 значения, потому что это смещения, а не местоположения; совпадение в первой строке является смещением 0 из исходной строки. И обратите внимание, что Y столбец смещен на 2, в данном случае, потому что я добавил дополнительный столбец для ручной настройки значения. Параметры смещения выбирают столбец, содержащий значения Y или X, и выбирают высоту диапазона 2, которая дает вам значения ниже и выше цели.
Параметры смещения выбирают столбец, содержащий значения Y или X, и выбирают высоту диапазона 2, которая дает вам значения ниже и выше цели.
в результат:
мастер анализа делает тяжелую работу, и независимо от того, используете ли вы полиномиальную регрессию или сплайны, для генерации результата требуется всего одна формула.
Определение промежуточного значения методом линейной интерполяции
Это глава из книги Билла Джелена Гуру Excel расширяют горизонты: делайте невозможное с Microsoft Excel.
Задача: некоторые инженерные проблемы проектирования требуют использования таблиц для вычисления значений параметров. Поскольку таблицы являются дискретными, дизайнер использует линейную интерполяцию для получения промежуточного значения параметра. Таблица (рис. 1) включает высоту над землей (управляющий параметр) и скорость ветра (рассчитываемый параметр). Например, если надо найти скорость ветра, соответствующую высоте 47 метров, то следует применить формулу: 130 + (180 – 130) * 7 / (50 – 40) = 165 м/сек.
Рис. 1. Высота над землей (управляющий параметр) и скорость ветра (рассчитываемый параметр)
Скачать заметку в формате Word или pdf, примеры в формате Excel
Как быть, если существует два управляющих параметра? Можно ли выполнить вычисления с помощью одной формулы? В таблице (рис. 2) показаны значения давления ветра для различных высот и величин пролета конструкций. Требуется вычислить давление ветра на высоте 25 метров и величине пролета 300 метров.
Рис. 2. Исходная таблица для интерполяции по двум управляющим параметрам
Решение: проблему решаем путем расширения метода, используемого для случая с одним управляющим параметром. Выполните следующие действия.
Начните с таблицы, изображенной на рис. 2. Добавьте исходные ячейки для высоты и пролета в J1 и J2 соответственно (рис. 3).
Рис. 3. Формулы в ячейках J3:J17 объясняют работу мегаформулы
Для удобства использования формул определите имена (рис. 4).
Рис. 4. Определенные имена
4. Определенные имена
Проследите за работой формулы последовательно переходя от ячейки J3 к ячейке J17.
Путем обратной последовательной подстановки соберите мегаформулу. Скопируйте текст формулы из ячейки J17 в J19. Замените в формуле ссылку на J15 на значение в ячейке J15: J7+(J8-J7)*J11/J13. И так далее. Получится формула, состоящая из 984 символов, которую невозможно воспринять в таком виде. Вы можете посмотреть на нее в приложенном Excel-файле. Не уверен, что такого рода мегаформулы полезны в использовании.
Резюме: линейная интерполяция используется для получения промежуточного значения параметра, если табличные значения заданы только для границ диапазонов; предложен метод расчета по двум управляющим параметрам.
Как экстраполировать в Excel
Экстраполяция – это математический метод, который используется для прогнозирования за пределами определенного диапазона путем программирования и расширения прошлых известных данных. Так что это разновидность анализа и визуализации данных Excel.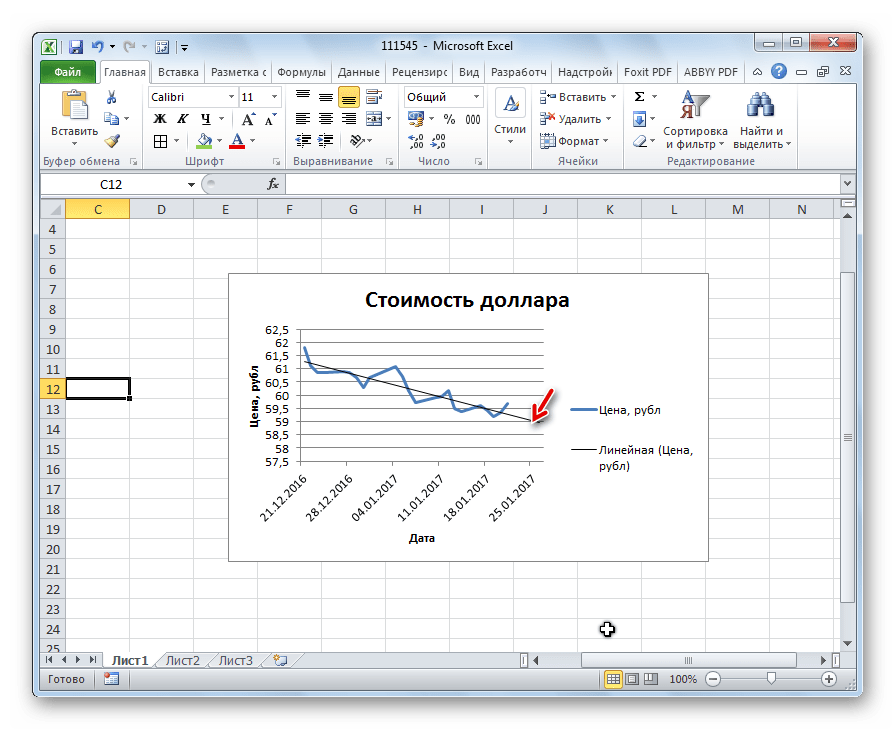 В этом руководстве мы узнаем, как экстраполировать данные в Excel.
В этом руководстве мы узнаем, как экстраполировать данные в Excel.
Чтобы экстраполировать данные по формуле, нам нужно использовать две точки линейной диаграммы, которую мы построили ранее.
Формула линейной экстраполяции:
Y (x) = b + (x-a) * (d-b) / (c-a)
Вы можете ввести формулу в соответствии с двумя точками значений данных и экстраполировать целевое значение.
Рисунок 1 – Формула линейной экстраполяции в Excel Как экстраполировать график по линии тренда
Экстраполяция графика по линии тренда помогает отображать тенденции визуальных данных. Здесь мы узнаем, как добавить линию тренда на наши диаграммы:
Здесь мы узнаем, как добавить линию тренда на наши диаграммы:
- Выберите диапазон данных.
- Перейдите на вкладку Вставьте с ленты.
- В разделе диаграмм щелкните диаграмму Line (вы также можете выбрать диаграмму разброса.)
- Щелкните значок Элемент диаграммы и установите флажок Линия тренда.
- Дважды щелкните линию тренда на графике, чтобы открыть панель Format Trendline и применить свои пользовательские настройки.
Рисунок 2 – Как добавить линию тренда к графику Экстраполяция данных функцией прогноза
Если вам нужна функция для прогнозирования данных без создания диаграмм и графиков (внутренняя ссылка), используйте функцию Excel Forecast .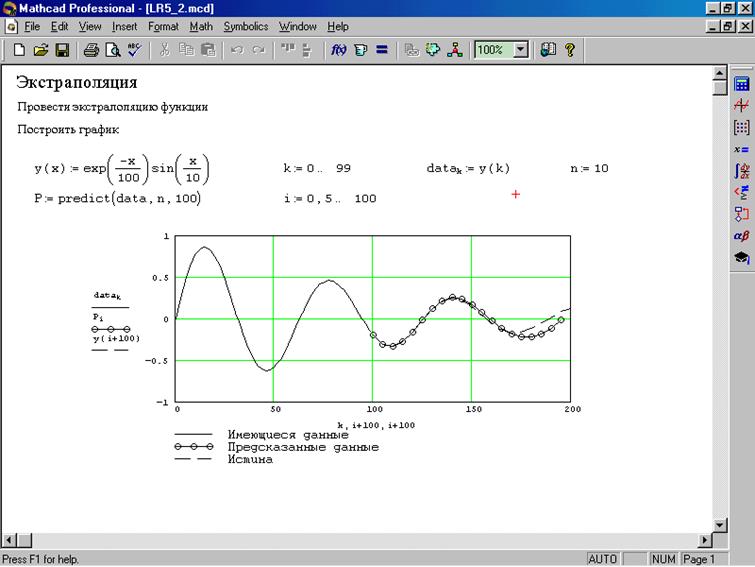 Функция прогноза помогает экстраполировать числовые данные на линейный тренд. Кроме того, вы можете экстраполировать шаблон периодического издания или даже экстраполировать лист.
Функция прогноза помогает экстраполировать числовые данные на линейный тренд. Кроме того, вы можете экстраполировать шаблон периодического издания или даже экстраполировать лист.
Здесь мы узнаем, как использовать функции Forecast.linear и Forecast.ETS и как экстраполировать лист.
Прогноз. ЛинейныйЭкстраполяция определяет, что взаимосвязь между известными значениями применима и к неизвестным значениям. Эта функция помогает экстраполировать данные, содержащие два набора числовых значений, которые соответствуют друг другу.
Ниже приведен синтаксис функции Forecast.Linear:
= ПРОГНОЗ.ЛИНЕЙНЫЙ (x ؛ известное Ys ؛ известное Xs)
Предположим, у нас есть набор данных, показывающий количество продаж за девять месяцев. Нам нужно спрогнозировать продажи на ближайшие три месяца. Чтобы использовать эту функцию, выполните следующие действия:
- Выберите пустую ячейку.
- Введите = прогноз или = прогноз.линейный в строке формул .
- Щелкните значение x , которое вы хотите предсказать для себя, и введите точку с запятой или запятую (в соответствии с вашей версией Excel.)
- Выберите все известных Y , введите точку с запятой, а затем выберите все известные X .
- Нажмите Введите .

Рисунок 3 – Синтаксис функции Forecast.Linear Прогноз.ETS
В некоторых случаях у вас есть сезонный шаблон, и этот шаблон периодического издания требует определенной функции для прогнозирования будущего. Здесь у нас есть объем продаж за год, и нам нужно спрогнозировать первые три месяца следующего года.
Здесь у нас есть объем продаж за год, и нам нужно спрогнозировать первые три месяца следующего года.
Синтаксис функции Forecast.ETS:
= FORECAST.ETS (целевая_дата ؛ значения ؛ временная шкала ؛ [сезонность], [data_complation]; [агрегирование])
Target_date : точка, которую нужно спрогнозировать.
Значения : Здесь указаны все известные суммы продаж.
Временная шкала : В данном случае количество месяцев.
[ сезонность ]: длина сезонной модели (необязательный аргумент).
[data_complation] : Хотя временная шкала требует постоянного шага между точками данных, ПРОГНОЗ.ETS поддерживает до 30% отсутствующих данных и автоматически корректирует их (необязательный аргумент).
[ агрегирование ]: параметр агрегирования – это числовое значение, указывающее, какой метод будет использоваться для агрегирования нескольких значений с одной и той же меткой времени (необязательный аргумент).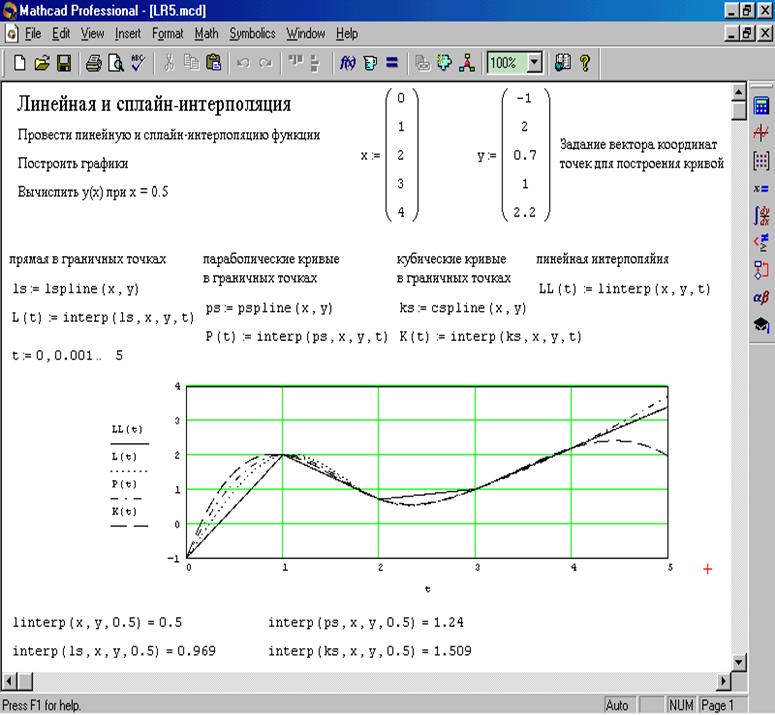
Теперь выполните следующие действия, чтобы спрогнозировать целевые значения:
- Выберите пустую ячейку, в которой вы хотите представить результат.
- Введите синтаксис функции и введите аргументы, как мы уже упоминали.
- Нажмите Enter.
Рисунок 4 – Синтаксис функции Forecast.ETS Листы экстраполяции
Excel 2016 и более поздние версии предоставляют инструмент для прогнозирования таблицы. Этот инструмент создает таблицу в соответствии с вашими данными и определяет нижнюю и верхнюю доверительные границы.
Чтобы использовать лист прогноза, перейдите на вкладку Data , из группы Forecast щелкните инструмент Forecast Sheet , чтобы открыть окно Create Forecast Worksheet . Вы можете выбрать линейную или столбчатую диаграмму по их значкам в правом верхнем углу поля.
Вы можете выбрать линейную или столбчатую диаграмму по их значкам в правом верхнем углу поля.
Рисунок 5 – Инструмент таблицы прогнозов в Excel
Если вам нужно настроить диаграмму прогноза, вы можете отредактировать, нажав на опции :
- Где начинается или заканчивается прогноз
- Измените доверительный интервал
- Добавьте статистику прогноза
- Измените временную шкалу и диапазон значений
- И объедините дубликат с помощью
Затем нажмите кнопку Create и посмотрите результат.
Рисунок 6 – Результат работы инструмента Таблица прогнозов Функция тренда Excel Еще одна функция экстраполяции данных без построения графиков – это функция тренда в Excel. Эта статистическая функция будет предсказывать будущие тенденции в соответствии с известными значениями.
Эта статистическая функция будет предсказывать будущие тенденции в соответствии с известными значениями.
Синтаксис функции тренда:
= ТЕНДЕНЦИЯ (известные_Y; [известные_X]; [новые_X]; [const])
Известный Ys : Значения Y, которые мы уже знаем.
Известные X : значения X, которые мы уже знаем (необязательный аргумент.)
Const : согласно Y = mX + b, если const ложно, b равно нулю, но если const истинно или пропущено, b вычисляется нормально.
Рисунок 7 – Функция тренда в Excel
Вы можете связаться с нами, задать вопросы нашим специалистам и получить дополнительную поддержку через службу поддержки Excel .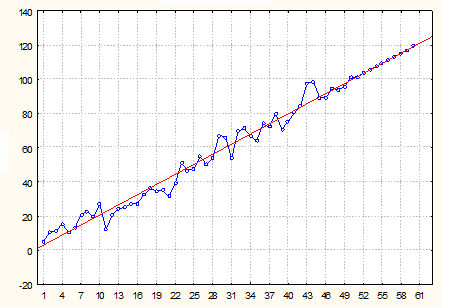
Кроме того, сокращайте расходы, ускоряйте выполнение задач и повышайте качество с помощью служб автоматизации Excel.
Функция ТЕНДЕНЦИЯ– как прогнозировать и экстраполировать в Excel
Функция ТЕНДЕНЦИЯ – Прогноз и экстраполировать в Excel
Функция ТЕНДЕНЦИЯ – это статистическая функция Excel ФункцииСписок наиболее важных функций Excel для финансовых аналитиков.Эта шпаргалка охватывает сотни функций, которые критически важно знать аналитику Excel, который будет вычислять линейную линию тренда для массивов известных значений y и x. Функция расширяет линейную линию тренда для вычисления дополнительных значений y для нового набора значений x. Это руководство покажет вам шаг за шагом, как экстраполировать в Excel с помощью этой функции.
Как финансовый аналитик Описание работы финансового аналитика Описание работы финансового аналитика, приведенное ниже, дает типичный пример всех навыков, образования и опыта, необходимых для работы аналитиком в банке, учреждении или корпорации. Выполняйте финансовое прогнозирование, отчетность и отслеживание операционных показателей, анализируйте финансовые данные, создавайте финансовые модели, эта функция может помочь нам в прогнозировании будущих тенденций. Например, мы можем использовать тенденции для прогнозирования будущих доходов конкретной компании. Это отличная функция прогнозирования
Выполняйте финансовое прогнозирование, отчетность и отслеживание операционных показателей, анализируйте финансовые данные, создавайте финансовые модели, эта функция может помочь нам в прогнозировании будущих тенденций. Например, мы можем использовать тенденции для прогнозирования будущих доходов конкретной компании. Это отличная функция прогнозирования
Формула
= ТЕНДЕНЦИЯ (известные_y, [известные_x], [новые_x], [const])
Функция TREND использует следующие аргументы:
- Known_y’s 9000 (обязательный аргумент) – это набор значений y, которые мы уже знаем в отношении y = mx + b.
- Known_x’s (необязательный аргумент) – это набор значений x. Если мы предоставим аргумент, он должен иметь ту же длину, что и набор known_y. Если опущено, набор [known_x’s] принимает значение {1, 2, 3,…}.
- New_x (необязательный аргумент) – предоставляет один или несколько массивов числовых значений, которые представляют значение new_x. Если аргумент [new_x’s] опущен, он устанавливается равным [known_x’s].
- Константа (необязательный аргумент) – указывает, нужно ли принудительно устанавливать константу b равной 0.Если const имеет значение ИСТИНА или опущено, b вычисляется нормально. Если false, b устанавливается равным 0 (нулю), а значения m корректируются так, чтобы y = mx.
 Если аргумент [new_x’s] опущен, он устанавливается равным [known_x’s].
Если аргумент [new_x’s] опущен, он устанавливается равным [known_x’s].Функция ТЕНДЕНЦИЯ использует метод наименьших квадратов для поиска линии наилучшего соответствия, а затем использует ИТ для вычисления новых значений y для предоставленных новых значений x.
Как использовать функцию ТЕНДЕНЦИЯ в Excel?
Чтобы понять использование функции ТЕНДЕНЦИЯ, давайте рассмотрим пример. Ниже мы выполним экстраполяцию в Excel с помощью функции прогноза.
Пример – прогноз и экстраполяция в Excel
Предположим, мы хотим построить прогноз или экстраполировать будущий доход компании. Приведенный набор данных показан ниже:
Для расчета будущих продаж мы будем использовать функцию ТЕНДЕНЦИЯ. Используемая формула будет следующей:
Это вернет массив значений для y, так как значения x, которые нужно вычислить, являются массивом x.Таким образом, его необходимо ввести как формулу массива, выделив ячейки, которые необходимо заполнить, введите свою функцию в первую ячейку диапазона и нажмите CTRL-SHIFT-Enter (то же самое для Mac). Получим результат ниже:
Что нужно помнить о функции ТРЕНД
- #REF! error – возникает, если массив known_x и массив new_x имеют разную длину.
- #VALUE! ошибка – возникает в следующих случаях:
- Нечисловые значения, указанные в известных_y, [известных_x] или [новых_x].
- Указанный аргумент [const] не является логическим значением.
Щелкните здесь, чтобы загрузить образец файла Excel
Дополнительные ресурсы
Спасибо за то, что прочитали руководство CFI по функции Excel TREND. Потратив время на изучение и освоение этих функций, вы значительно ускорите свое финансовое моделирование в Excel. Что такое финансовое моделирование? Финансовое моделирование выполняется в Excel для прогнозирования финансовых показателей компании. Обзор того, что такое финансовое моделирование, как и зачем его создавать.. Чтобы узнать больше, ознакомьтесь с этими дополнительными ресурсами CFI:
- Расширенный курс формул Excel
- Расширенные формулы Excel, которые вы должны знать Расширенные формулы Excel, которые необходимо знать Эти расширенные формулы Excel очень важно знать и выведут ваши навыки финансового анализа на новый уровень. Расширенные функции Excel
- Ярлыки Excel для ПК и MacExcel Ярлыки ПК MacExcel Ярлыки – Список наиболее важных и распространенных ярлыков MS Excel для пользователей ПК и Mac, специалистов в области финансов и бухгалтерского учета.Сочетания клавиш ускоряют ваши навыки моделирования и экономят время. Изучите редактирование, форматирование, навигацию, ленту, специальную вставку, обработку данных, редактирование формул и ячеек и другие краткие сведения.
- Станьте сертифицированным финансовым аналитиком. Станьте сертифицированным аналитиком финансового моделирования и оценки (FMVA) ®
Интерполировать с помощью Excel – Excel Off Сетка
Интерполяция – это процесс оценки точек данных в существующем наборе данных. Поскольку это блог об Excel, очевидно, что мы хотим ответить на следующий вопрос: можем ли мы выполнять интерполяцию с помощью Excel.Это частый вопрос. Фактически, следующий вопрос читателя впервые заставил меня изучить эту тему:
«У меня есть вопрос по Excel – есть ли способ интерполировать значение из таблицы? У меня есть X и Y, которых нет в таблице, но есть коррелированные данные, поэтому я хочу вычислить интерполированное значение ».
В качестве простого примера: если пройти 1 милю в понедельник за 15 минут, а во вторник – за 1 час, мы могли бы разумно оценить, что на прогулку 2 мили потребуется 30 минут.
Не следует путать с экстраполяцией, которая оценивает значения вне набора данных. Оценка того, что пройти 8 миль займет 2 часа, будет экстраполяцией, поскольку оценка выходит за рамки известных значений.
Excel – отличный инструмент для интерполяции, так как в конечном итоге это большой визуальный калькулятор.
Загрузите файл примера
Я рекомендую вам загрузить файл примера для этой публикации. Тогда вы сможете работать с примерами и увидеть решение в действии, а файл будет полезен для дальнейшего использования.
Загрузите файл: 0020 Interpolate with Excel.xlsx
Посмотрите видео
Посмотрите видео на YouTube.
Варианты интерполяции в Excel
С точки зрения ответа на вопрос, есть несколько сценариев, которые могут привести к различным решениям.
Во-первых, мы могли использовать простую математику. Это сработало бы, если бы результаты были абсолютно линейными (т.е. значения X и Y перемещались синхронно друг с другом).Но в противном случае мы могли бы получить немного искаженный результат.
В качестве альтернативы мы могли бы использовать функцию ПРОГНОЗ в Excel (или ПРОГНОЗ.ЛИНЕЙНЫЙ в Excel 2016 и последующих версиях). Судя по названию, функция ПРОГНОЗ кажется странным выбором. Казалось бы, это функция специально для экстраполяции; однако это также один из лучших вариантов линейной интерполяции в Excel. FORECAST использует все значения в наборе данных для оценки результата; поэтому он отлично подходит для линейных отношений, даже если они не полностью коррелированы.
Тогда еще одна мысль, а что, если отношения X и Y вообще не линейны? Как мы могли интерполировать значение, когда данные экспоненциальны?
Давайте рассмотрим все эти сценарии.
Интерполяция с использованием простой математики
Простая математика хорошо работает, когда есть только две пары чисел или когда отношения между X и Y совершенно линейны.
Вот базовый пример (посмотрите на вкладку Пример 1 в вспомогательном файле загрузки):
Формула в ячейке E4:
= B2 + (E2-A2) * (B3-B2) / (A3-A2)
Некоторым это может показаться немного сложным, поэтому вот краткий обзор формулы.
= B2 + (E2-A2) * (B3-B2) / (A3-A2)
В последнем разделе (выделенном зеленым цветом выше) вычисляется, насколько изменяется значение Y при изменении значения X на 1. В в нашем примере Y перемещается на 1,67 на каждый 1 из X.
= B2 + (E2-A2) * (B3-B2) / (A3-A2)
Во втором разделе (зеленом выше) вычисляется, как далеко интерполированный X находится далеко от первого X, затем умножается на значение, вычисленное выше. В нашем примере результат равен 17.5 (ячейка E2) минус 10 (ячейка A2), результат умножается на 1,67. Все это равно 12,5.
= B2 + (E2-A2) * (B3-B2) / (A3-A2)
Наконец, мы переходим к первой части формулы (выделенной зеленым цветом выше), которая складывает первое значение Y. В нашем примере это дает окончательный результат 77,5 (65 + 12,5). Для тех, кто помнит математику в средней школе, формула будет следующей:
Вот результат, наложенный на диаграмму.
Даже если вы не помните линейную интерполяцию в школе, хорошая новость заключается в том, что Excel предоставил нам более простой вариант – функцию ПРОГНОЗ.
Создавайте точный код VBA за секунды с помощью AutoMacro
AutoMacro – это мощный генератор кода VBA, который поставляется с обширной библиотекой кода и множеством других инструментов и утилит для экономии времени.
Если вы опытный программист, желающий сэкономить время, или новичок, просто пытающийся заставить вещи работать, AutoMacro – это инструмент для вас.
Интерполяция с использованием функции ПРОГНОЗ
В версии Excel 2016 года было добавлено множество новых статистических функций.Чтобы освободить место для этих новых функций, FORECAST был заменен функцией FORECAST.LINEAR. Хотя ПРОГНОЗ остается на данный момент с целью обратной совместимости с Excel 2013 и ранее.
Поскольку FORECAST и FORECAST.LINEAR фактически одно и то же, мы будем использовать эти термины как синонимы.
Интерполяция при идеальной линейности
Теперь давайте воспользуемся ПРОГНОЗОМ для интерполяции результата.
Используя те же числа из приведенного выше примера, формула в ячейке E6:
= ПРОГНОЗ (E2, B2: B3, A2: A3)
Функция ПРОГНОЗ имеет следующий синтаксис:
= ПРОГНОЗ (x, известные_y, известные_x)
Три аргумента функции:
- x – точка данных, для которой мы хотим спрогнозировать значение
- known_y’s – диапазон ячеек или массив значений содержащий известные значения Y
- известные_x – диапазон ячеек или массив значений, содержащий известные значения X
При использовании функции ПРОГНОЗ результат ячейки E6 также равен 77.5 (как и в математическом подходе).
Для полноты картины файл примера также содержит использование функции FORECAST.LINEAR. Как и следовало ожидать, результат идентичен устаревшей функции ПРОГНОЗ.
Интерполяция, когда приблизительно линейна
Но … что, если наши данные не совсем линейны? Посмотрите на диаграмму ниже, данные явно имеют линейную зависимость, но она не идеальна. Посмотрите на вкладку Пример 2 во вспомогательном файле.
В этих обстоятельствах функция ПРОГНОЗ даже более полезна, поскольку она не просто интерполирует между первым и последним значениями.Вот данные, используемые в диаграмме.
Функция ПРОГНОЗ в ячейке E4 интерполирует значение Y на основе значения X, равного 17,5.
= ПРОГНОЗ (E2, B2: B11, A2: A11)
В этом сценарии ПРОГНОЗ оценивает значение на основе всех доступных точек данных, а не только начала и конца. Результат функции ПРОГНОЗ в ячейке E4 равен 77,3 (округлено до 1 десятичного знака), что в большинстве случаев будет более точным, чем простая линейная интерполяция, применяемая в математическом подходе.
Помните, что для оценки значений используется интерполяция. 77.3 может быть неточным результатом, но это разумная оценка, основанная на имеющейся у нас информации.
И снова FORECAST.LINEAR вычисляет тот же результат.
Интерполяция, когда данные не линейны
Но вот более сложный вопрос: что, если данные вообще не линейны? Тогда что?
Посмотрите на вкладку Example 3 во вспомогательном файле. Вот наш новый сценарий графика:
Если бы мы использовали простой линейный подход, это дало бы нам значение 77.5, который, как вы можете видеть ниже, довольно далеко от кривой. Использование функции ПРОГНОЗ даст результат 70,8, что лучше, но также далеко от кривой.
Есть еще два варианта для получения более точной оценки (1) интерполяция экспоненциальных данных с помощью функции РОСТА (2) вычисление внутренней линейной интерполяции
Интерполировать экспоненциальные данные
Функция РОСТА аналогична ПРОГНОЗУ, но может применяться к данным с экспоненциальным ростом.
Результат функции РОСТ в ячейке E10 равен 70,4. Опять же, это ближе к черте, но все же немного дальше.
Формула в ячейке E10:
= РОСТ (B2: B11, A2: A11, E2)
Функция РОСТ имеет следующий синтаксис:
= РОСТ (известные_y, [известные_x], [новые_x] , [const])
Четыре аргумента в функции РОСТ (только имейте в виду, что аргументы не в том же порядке, что и функция ПРОГНОЗ).
- известные_y – диапазон ячеек или массив значений, содержащих известные значения Y
- [известные_x] – диапазон ячеек или массив значений, содержащий известные значения X
- [новые_x] – точка данных, для которой мы хотим спрогнозировать значение
- [Const] – мера истина / ложь, чтобы указать, как формула должна рассчитывать. В нашем сценарии мы можем оставить этот последний аргумент.
Квадратные скобки указывают, какие аргументы являются необязательными для функции для вычисления результата.Нам нужны известные_y , известные_x , и новые_x , но мы проигнорировали аргумент const .
Хотя результат 70,4 является более близким приближением, мы не должны слепо использовать функцию РОСТ. Проверьте свои интерполяции, чтобы убедиться, что они разумны.
Внутренняя линейная интерполяция
Разумным вариантом может быть найти результат выше и ниже нового значения X, а затем применить линейную интерполяцию между этими двумя точками.Это было бы довольно близко.
В нашем примере значения по обе стороны от X, равного 17,5:
- X: 16 и 18
- Y: 66,3 и 68
Используя эти значения, теперь мы можем выполнить стандартную линейную интерполяцию .
Быстрый одноразовый метод
Если бы это было разовое действие, мы могли бы сделать это быстро, включив в формулу только основные ячейки.
= ПРОГНОЗ (E2, B6: B7, A6: A7)
Однако, как только мы изменим интерполированное значение, ПРОГНОЗ может вычислить неточный результат.Итак, перейдем к рассмотрению гибкого метода.
Гибкий подход
Чтобы создать гибкий подход, мы будем использовать функции ИНДЕКС, ПОИСКПОЗ и ПРОГНОЗ вместе. Это может показаться сложным, но не волнуйтесь, мы рассмотрим это медленно. В конечном итоге мы пытаемся достичь того же результата, что и описанный выше одноразовый метод, но автоматически корректируем диапазоны в зависимости от интерполируемого значения.
ПРИМЕЧАНИЕ. Для работы этого метода требуется, чтобы диапазон известных X был указан в порядке возрастания.
Функция ПОИСКПОЗ
Во-первых, мы используем функцию ПОИСКПОЗ, чтобы получить позицию значения ниже 17,5.
= ПОИСКПОЗ (E2, A2: A11,1)
Эта формула говорит, что найдите значение в ячейке E2 из диапазона ячеек A2-A11. 1 в конце формулы сообщает функции ПОИСКПОЗ, что мы хотим использовать приблизительное совпадение (т. Е. Ближайшее значение ниже искомого значения). 16 – ближайшее значение ниже 17,5. Поскольку 16 – это 5-й элемент в ячейках A2-A11, ПОИСКПОЗ возвращает значение 5.
Функция ИНДЕКС
Определив на предыдущем этапе, что 5-я позиция содержит значение ниже, мы можем использовать функцию ИНДЕКС, чтобы определить ссылку на ячейку для этого значения.
ИНДЕКС (A2: A11, MATCH (E2, A2: A11,1))
Это вернет ссылку на ячейку A6.
Чтобы найти указанное выше значение, мы можем использовать ту же функцию, но добавить 1 к функции ПОИСКПОЗ.
ИНДЕКС (A2: A11, ПОИСКПОЗ (E2, A2: A11,1) +1 )
Приведенная выше формула вернет ссылку на ячейку A7.
Динамический диапазон
Теперь все становится интереснее. Мы можем объединить эти функции с двоеточием (:) посередине, чтобы создать диапазон для двух значений X.
ИНДЕКС (A2: A11, ПОИСКПОЗ (E2, A2: A11,1)): ИНДЕКС (A2: A11, ПОИСКПОЗ (E2, A2: A11,1) +1)
Первая функция ИНДЕКС возвращает ссылку в ячейку A6 (результат выделенного зеленым цветом раздела). Вторая функция ИНДЕКС возвращает ссылку на ячейку A7 (результат выделенного фиолетовым цветом раздела).Они разделены двоеточием (:) (выделены красным), чтобы создать диапазон – A6: A7
Мы можем сделать то же самое, чтобы создать диапазон для двух значений Y. Единственная разница в том, что функции ИНДЕКС будут смотреть на ячейки B2-B11.
ИНДЕКС (B2: B11, ПОИСКПОЗ (E2, A2: A11,1)): ИНДЕКС (B2: B11, ПОИСКПОЗ (E2, A2: A11,1) +1)
Используя ячейки B2-B11 в ИНДЕКСЕ функция, она вычислит диапазон B6: B7.
ИНДЕКС СООТВЕТСТВИЕ И ПРОГНОЗ
Теперь у нас есть два диапазона; значения X A6: A7 и значения Y B6: B7.Давайте объединим все это в функции ПРОГНОЗ.
= ПРОГНОЗ (E2, ИНДЕКС (B2: B11; ПОИСКПОЗ (E2; A2: A11,1)): ИНДЕКС (B2: B11; ПОИСКПОЗ (E2; A2: A11,1) +1), ИНДЕКС (A2: A11, MATCH (E2, A2: A11,1)): INDEX (A2: A11, MATCH (E2, A2: A11,1) +1))
Это довольно большая формула, верно. Но, надеюсь, мне удалось объяснить это так, что это не слишком страшно.
Результатом внутренней линейной интерполяции с использованием функции ПРОГНОЗ составляет 67,6 (с точностью до 1 десятичного знака, как показано в ячейке E14). Взгляните на график еще раз; вы увидите, что 67.6 – разумная оценка, основанная на имеющихся данных.
ПРЕДУПРЕЖДЕНИЕ: В конечном счете, это все еще вычисление линейной интерполяции, основанное на двух значениях по обе стороны от значения X. Расстояние между значениями выше и ниже будет иметь прямое влияние на точность интерполяции.
Заключение
Первоначально то, что казалось простым вопросом, привело нас к множеству потенциальных решений для трех различных сценариев. Ключевым моментом является то, что вам необходимо знать свои данные, чтобы выбрать метод, обеспечивающий наиболее точные результаты.
В процессе мы рассмотрели функции FORECAST и FORECAST.LINEAR и убедились, что они полезны как для интерполяции, так и для экстраполяции.
Кроме того, в этом посте мы использовали ИНДЕКС и ПОИСКПОЗ для создания динамических диапазонов, что является очень мощным методом для сложных формул в Excel.
Если вам нужна дополнительная информация о методах прогнозирования в Excel, загляните в Engineer Excel (https://engineerexcel.com/blog). Хотя вы, возможно, не работаете в инженерном контексте, методы применимы во многих других обстоятельствах.
Не забудьте:
Если вы нашли этот пост полезным или у вас есть лучший подход, оставьте комментарий ниже.
Вам нужна помощь в адаптации этого к вашим потребностям?
Я полагаю, что примеры в этом посте не совсем соответствуют вашей ситуации. Все мы используем Excel по-разному, поэтому невозможно написать сообщение, которое удовлетворит потребности всех. Потратив время на то, чтобы понять методы и принципы, описанные в этом посте (и в других местах на этом сайте), вы сможете адаптировать их к своим потребностям.
Но, если вы все еще боретесь, вам следует:
- Прочитать другие блоги или посмотреть видео на YouTube на ту же тему. Вы получите гораздо больше, открыв свои собственные решения.
- Спросите «Excel Ninja» в своем офисе. Удивительно, что знают другие люди.
- Задайте вопрос на форуме, например в Mr Excel, или в сообществе ответов Microsoft. Помните, что люди на этих форумах обычно проводят свое время бесплатно. Так что постарайтесь сформулировать свой вопрос, сделайте его ясным и кратким.Составьте список всего, что вы пробовали, и предоставьте снимки экрана, фрагменты кода и примеры рабочих книг.
- Воспользуйтесь Excel Rescue, моим партнером-консультантом. Они помогают, предлагая решения небольших проблем с Excel.
Что дальше?
Не уходите, есть еще много чего узнать об Excel Off The Grid. Ознакомьтесь с последними сообщениями:
Значения проекта в серии
Если вам нужно спрогнозировать расходы на следующий год или спрогнозировать ожидаемые результаты для серии в научном эксперименте, вы можете использовать Microsoft Office Excel для автоматического генерирования будущих значений на основе существующих данных или для автоматического генерирования экстраполированных значений на основе по расчетам линейного тренда или тренда роста.
Вы можете ввести ряд значений, которые соответствуют простой линейной тенденции или тенденции экспоненциального роста, используя маркер заполнения или команду Series . Чтобы расширить сложные и нелинейные данные, вы можете использовать функции рабочего листа или инструмент регрессионного анализа в надстройке Analysis ToolPak.
В линейном ряду значение шага или разница между первым и следующим значением в ряду добавляется к начальному значению, а затем прибавляется к каждому последующему значению.
Первоначальный выбор | Расширенная линейная серия |
|---|---|
1, 2 | 3, 4, 5 |
1, 3 | 5, 7, 9 |
100, 95 | 90, 85 |
Чтобы заполнить ряд для линейного наиболее подходящего тренда, выполните следующие действия:
Выберите как минимум две ячейки, содержащие начальные значения для тенденции.
Если вы хотите повысить точность ряда трендов, выберите дополнительные начальные значения.
Перетащите маркер заполнения в том направлении, в котором вы хотите заполнить увеличивающимися или уменьшающимися значениями.
Например, если выбранные начальные значения в ячейках C1: E1 равны 3, 5 и 8, перетащите маркер заполнения вправо, чтобы заполнить увеличивающимися значениями тенденции, или перетащите его влево, чтобы заполнить уменьшающимися значениями.
Совет: Чтобы вручную управлять созданием серии или использовать клавиатуру для заполнения серии, щелкните команду Series (вкладка Home , группа Editing , кнопка Fill ).
В серии роста начальное значение умножается на значение шага, чтобы получить следующее значение в серии.Полученный продукт и каждый последующий продукт затем умножаются на значение шага.
Первоначальный выбор | Серия расширенного роста |
|---|---|
1, 2 | 4, 8, 16 |
1, 3 | 9, 27, 81 |
2, 3 | 4.5, 6,75, 10,125 |
Чтобы заполнить ряд для тенденции роста, выполните следующие действия:
Выберите как минимум две ячейки, содержащие начальные значения для тенденции.
Если вы хотите повысить точность ряда трендов, выберите дополнительные начальные значения.
Удерживая нажатой правую кнопку мыши, перетащите маркер заполнения в направлении, в котором вы хотите заполнить увеличивающимися или уменьшающимися значениями, отпустите кнопку мыши и затем щелкните Growth Trend в контекстном меню.
Например, если выбранные начальные значения в ячейках C1: E1 равны 3, 5 и 8, перетащите маркер заполнения вправо, чтобы заполнить его увеличивающимися значениями тренда, или перетащите его влево, чтобы заполнить уменьшающимися значениями.
Совет: Чтобы вручную управлять созданием серии или использовать клавиатуру для заполнения серии, щелкните команду Series (вкладка Home , группа Editing , кнопка Fill ).
Когда вы нажимаете команду Series , вы можете вручную управлять тем, как создается линейный тренд или тренд роста, а затем использовать клавиатуру для ввода значений.
В линейном ряду начальные значения применяются к алгоритму наименьших квадратов (y = mx + b) для создания ряда. x) для создания серии.
В любом случае значение шага игнорируется. Создаваемый ряд эквивалентен значениям, возвращаемым функцией ТЕНДЕНЦИЯ или РОСТ.
Чтобы ввести значения вручную, выполните следующие действия:
Выберите ячейку, с которой вы хотите начать серию. Ячейка должна содержать первое значение в серии.
Когда вы нажимаете команду Series , полученная серия заменяет исходные выбранные значения.Если вы хотите сохранить исходные значения, скопируйте их в другую строку или столбец, а затем создайте серию, выбрав скопированные значения.
На вкладке Home в группе Editing щелкните Fill , а затем щелкните Series .
Выполните одно из следующих действий:
Чтобы заполнить ряды на листе, щелкните Столбцы .
Чтобы заполнить ряды на листе, щелкните строк .
В поле Шаг значение введите значение, на которое вы хотите увеличить ряд.
Серии тип | Результат значения шага |
|---|---|
Линейная | Значение шага добавляется к первому начальному значению, а затем добавляется к каждому последующему значению. |
Рост | Первое начальное значение умножается на значение шага. Полученный продукт и каждый последующий продукт затем умножаются на значение шага. |
В разделе Тип щелкните Линейный или Рост .
В поле Stop value введите значение, при котором вы хотите остановить серию.
Примечание: Если в ряду несколько начальных значений и вы хотите, чтобы Excel генерировал тренд, установите флажок Тренд .
Если у вас есть данные, для которых вы хотите спрогнозировать тренд, вы можете создать линию тренда на диаграмме.Например, если у вас есть диаграмма в Excel, на которой показаны данные о продажах за первые несколько месяцев года, вы можете добавить к диаграмме линию тренда, которая показывает общую тенденцию продаж (увеличение, уменьшение или фиксированное значение) или прогнозируемый тенденция на месяцы вперед.
Эта процедура предполагает, что вы уже создали диаграмму на основе существующих данных. Если вы еще не сделали этого, см. Раздел Создание диаграммы.
Щелкните диаграмму.
Щелкните ряд данных, к которому вы хотите добавить линию тренда или скользящее среднее.
На вкладке Макет в группе Анализ щелкните Линия тренда , а затем выберите нужный тип линии тренда регрессии или скользящего среднего.
Чтобы установить параметры и отформатировать линию тренда регрессии или скользящее среднее, щелкните линию тренда правой кнопкой мыши, а затем выберите Форматировать линию тренда в контекстном меню.
Выберите нужные параметры линии тренда, линии и эффекты.
Если вы выбрали Полином , введите в поле Порядок наибольшую степень для независимой переменной.
Если вы выбрали Moving Average , введите в поле Period количество периодов, которые будут использоваться для расчета скользящего среднего.
Примечания:
В поле на основе серии перечислены все ряды данных на диаграмме, которые поддерживают линии тренда. Чтобы добавить линию тренда в другую серию, щелкните имя в поле и выберите нужные параметры.
Если вы добавляете скользящее среднее на диаграмму xy (точечная диаграмма), скользящее среднее основывается на порядке значений x, нанесенных на диаграмму.Чтобы получить желаемый результат, вам может потребоваться отсортировать значения x перед добавлением скользящего среднего.
Если вам нужно выполнить более сложный регрессионный анализ, включая вычисление и построение остатков, вы можете использовать инструмент регрессионного анализа в надстройке Analysis ToolPak. Для получения дополнительной информации см. Загрузка пакета инструментов анализа.
В Excel в Интернете вы можете проецировать значения в ряд, используя функции рабочего листа, или вы можете щелкнуть и перетащить маркер заполнения, чтобы создать линейный тренд чисел. Но вы не можете создать тенденцию роста, используя маркер заполнения.
Вот как вы используете маркер заполнения для создания линейного тренда чисел в Excel в Интернете:
Выберите как минимум две ячейки, содержащие начальные значения для тенденции.
Если вы хотите повысить точность ряда трендов, выберите дополнительные начальные значения.
Перетащите маркер заполнения в том направлении, в котором вы хотите заполнить увеличивающимися или уменьшающимися значениями.
Линейная интерполяция в Excel – Dagra Data Digitizer
Как работает реализация Excel
Простую реализацию легче всего понять, проанализировав извне и работая внутри.Вот полное уравнение:
= ПРОГНОЗ ( NewX , OFFSET ( KnownY , MATCH ( NewX , KnownX , 1) -1,0,2), OFFSET ( KnownX , MATCH ( NewX) , KnownX , 1) -1,0,2))
Вкратце уравнение состоит из 3 частей:
- функция ПРОГНОЗ для вычисления линейной интерполяции,
- два вызова функции ПОИСКПОЗ, чтобы найти ближайшее табличное значение x, но меньше нового значения x, и
- два вызова функции СМЕЩЕНИЕ для ссылки на табулированные значения x и значения y чуть выше и чуть ниже нового значения x.
Более подробно, функция ПРОГНОЗ выполняет фактическую интерполяцию, используя уравнение линейной интерполяции, показанное выше. Его синтаксис: ПРОГНОЗ ( NewX , известная_y_pair , известная_x_pair ).
Первый параметр, NewX , – это просто значение для интерполяции. Следующие два параметра, известная_y_ пара и известная_x_ пара , являются значениями по обе стороны от NewX . То есть {x1, x2} и {y1, y2} на диаграмме выше.
Функция ПОИСКПОЗ используется для нахождения табличного значения x чуть ниже NewX . Его синтаксис: MATCH ( lookup_value , lookup_table , match_type ). ПОИСКПОЗ возвращает относительное положение элемента в отсортированном массиве. Итак, lookup_value – это значение для интерполяции, lookup_table – это массив значений KnownX , а match_type – 1, чтобы найти наибольшее значение в массиве, которое меньше или равно NewX .
Функция ПОИСКПОЗ возвращает индекс, но для функции ПРОГНОЗ требуется два диапазона ячеек: один для пары known_x_pair и один для пары known_y_pair . Таким образом, функция СМЕЩЕНИЕ используется дважды для создания этих диапазонов. Его синтаксис: OFFSET ( ссылка , row_offset , column_offset , row_count , column_count ). Он берет начальную точку, ссылку , и создает ссылку на ячейку с заданным смещением и размером.Для получения диапазона known_y_pair , ссылка устанавливается в таблицу значений KnownY ; для диапазона known_x_pair ссылка устанавливается на массив значений KnownX . Если табличные значения расположены вертикально, row_offset является результатом функции MATCH меньше 1, а row_count равно 2; column_offset равно 0, а column_count равно 1. Это дает нам ссылку на массив ячеек на 2 ячейки в высоту и 1 ячейку в ширину.Если табличные значения расположены горизонтально, строка и столбец переключаются в функции СМЕЩЕНИЕ.
Линейная интерполяция в Excel | EngineerExcel
До сих пор в сообщениях о поиске табличных данных в Excel я сосредоточился на том, как извлечь известные значения x и y из таблицы. Но что, если данные в таблице слишком «грубые» и вам нужна более высокая точность? Что ж, также можно выполнить линейную интерполяцию в Excel, которая позволяет вам оценить значение y для любого значения x, которое не указано явно в данных.
Чтобы выполнить линейную интерполяцию в Excel, мы будем использовать приведенное ниже уравнение, где x – независимая переменная, а y – значение, которое мы хотим найти:
Этот метод предполагает, что изменение y для данного изменения x является линейным.
В большинстве случаев это дает достаточно точные результаты. Однако, если вам нужна еще большая точность, вы можете рассмотреть более продвинутый метод, такой как кубические сплайны.
Как показано в приведенном выше уравнении, нам нужно найти значения x1, y1, x2 и y2.Чтобы найти их, мы воспользуемся функциями ПОИСКПОЗ и ИНДЕКС.
Я писал здесь о синтаксисе этих функций, поэтому, если вам нужно что-то напомнить, обязательно ознакомьтесь с этим. Но в основном MATCH возвращает местоположение значения (n) в столбце или строке данных. ИНДЕКС возвращает фактическое значение в позиции n -го строки или столбца данных.
Используя эти функции вместе, мы можем извлечь значения x1, y1, x2 и y2, которые нам нужны для интерполяции.
Давайте посмотрим, как выполнить этот анализ на реальных данных.
В таблице ниже приведена зависимость плотности воздуха от температуры с шагом 20 градусов Цельсия. Если мы хотим получить данные при любых температурах, кроме тех, что указаны в первом столбце, нам придется интерполировать.
Если мы хотим оценить плотность при 53 градусах Цельсия, нам понадобится Excel, чтобы найти в таблице значения x1 = 40, y1 = 1,127, x2 = 60 и y2 = 1,067. Затем мы можем использовать эти значения в приведенном выше уравнении.
Найдите значение x1 по следующей формуле:
В этом примере я дал ячейке C2 имя «x», создав именованную ячейку.Формула возвращает 40, что является максимальной температурой, которая меньше 53, нашего значения x.
Далее мы можем получить y1 по следующей формуле:
Это уравнение очень похоже на то, что используется для x1. Я использовал функцию ПОИСКПОЗ, чтобы вернуть положение наибольшего значения x, которое меньше «x», как и раньше. Но вместо того, чтобы искать значение в этой позиции данных температуры , я вместо этого вернул значение из столбца данных плотности .
Теперь, чтобы получить x2 и y2, мы будем использовать в основном те же самые формулы с небольшой разницей. Мы добавим 1 к значению, возвращаемому MATCH, чтобы получить 60 для x1 и 1,067 для y.
Теперь достаточно просто ввести формулу линейной интерполяции в соответствующую ячейку. Я снова использовал именованные диапазоны, чтобы сделать формулу более понятной.
Формула возвращает 1,088. В качестве быстрой проверки, чтобы увидеть, имеет ли это какой-либо смысл, мы можем построить график на кривой известных данных:
Выглядит хорошо!
Самое замечательное в настройке формул таким образом состоит в том, что вы можете правильно интерполировать между ЛЮБОЙ парой табличных значений x и y.
Итак, у вас есть метод для выполнения линейной интерполяции в Excel. Конечно, это не единственный метод, но я думаю, что это, пожалуй, самый простой. У вас есть предпочтительный метод? Позвольте мне знать в комментариях ниже.
Загрузите шаблон экстраполяции линейной интерполяции (Plus Tutorial)
Щелкните здесь, чтобы загрузить шаблон экстраполяции линейной интерполяции с диаграммой (бесплатный шаблон с полной функциональностью)
Определение из Википедии: В математике линейная интерполяция – это метод подбора кривой с использованием линейных полиномов.Для получения дополнительной информации: http://en.wikipedia.org/wiki/Linear_interpolation
Введение в шаблон Excel
Этот шаблон позволяет быстро выполнять линейную интерполяцию (и экстраполяцию) между гибким набором данных, максимум до 50 выборочных точек данных (строк). Говоря простым языком, этот шаблон Excel проводит прямую линию между каждой точкой в наборе данных. Кроме того, он вычисляет (или приближает) координаты точек, образующих эту прямую линию.
Рабочий лист является гибким, поэтому, если вы хотите внести определенные изменения, он может вместить гораздо больший набор данных.Пользователь может управлять тремя параметрами интерполяции:
- Начальное значение x
- Конечное значение x
- Размер приращения
Обратите внимание, что диаграмма может также экстраполировать данные за пределы указанного набора данных, предполагая, что такой же наклон применяется после последней точки данных.
Ниже приводится подробное объяснение того, как правильно использовать образец файла.
Существующий базовый шаблон
- Столбец A-C:
- Точка выборки данных для интерполяции.Все данные образца должны быть введены в соответствии с заголовками (ось x, ось y в соответствующей синей области)
- Важно:
- Числа в столбце A ДОЛЖНЫ быть в В возрастающем ПОРЯДКЕ , иначе НЕ будет работать.
- Все числа в столбце A должны быть разными (или уникальными). Ни один номер не может отображаться более одного раза.
- Рассчитан наклон в столбце C. Не редактируйте и не удаляйте ячейки.
- Формула наклона автоматически корректируется в зависимости от количества точек данных.
- Вам не нужно редактировать эту строку, поскольку количество точек данных остается на уровне 50 или ниже.
- Без каких-либо изменений файл диаграммы должен содержать 11 точек выборки данных или записей слева.
- Колонна E-F
- Здесь происходит вычисление интерполяции с помощью столбцов от H до K.
- Мы не будем здесь объяснять столбцы от H до K. Все, что вам нужно знать, это то, что это вспомогательные расчеты.
- Любой, кто интересуется формулой линейной интерполяции, должен уметь ее расшифровать!
- Столбец E начинается, увеличивается и заканчивается в зависимости от ввода пользователя в столбце O.
- Столбец F – это интерполированная ось Y. Обратите внимание, что для любого значения x, равного значению y выборки данных. В противном случае файл неправильный (или я ошибся :))
- Например, в исходном файле в демонстрационных данных (столбцы A и B): виджеты (ось x) = 100, время (ось y) = 1300. Если в столбцах E и F, когда виджеты (ось x) равно 100, но интерполированное время (ось Y) не 1300, тогда файл неверен .
- «Диаграмма с выборочными данными И интерполяцией (и экстраполяцией)» – синие маленькие точки (интерполяционная экстраполяция) должны хорошо совпадать с красными точками (выборочные данные).
- Здесь происходит вычисление интерполяции с помощью столбцов от H до K.