
Метод проекции градиента – Энциклопедия по экономике
Метод проекции градиента [c.140]МЕТОД ПРОЕКЦИИ ГРАДИЕНТА 141 [c.141]
МЕТОД ПРОЕКЦИЙ ГРАДИЕНТА 143 [c.143]
Задача”(11)— (13) в принципе решается, и возможный алгоритм ее решения не так уж сложен, однако сам метод в целом уже не имеет той степени обоснованности, которой обладает метод проекции градиента в точной постановке ведь мы не учитываем связанных с нелинейностью задачи величин, имеющих формально порядок 0(Ц м а). Следующие простые теоремы содержат грубое обоснование метода, основанного на линеаризации. [c.143]
МЕТОД ПРОЕКЦИИ ГРАДИЕНТА 145 [c.145]
Эта задача легко решается с любой необходимой точностью. Подробно да этом мы не останавливаемся, так как все эти элементы алгоритма входят в применявшийся в расчетах метод решения задачи (11) — (13) и описаны в 49. Хотя сходимость алгоритма доказана, попытка использования его в практических расчетах оказалась неудачной из-за крайне медленной сходимости.
Таким образом, задача (11) — (13) оказалась не столь уж простой, и хотя общая идея метода проекции градиента сформулирована очень давно, ее реализация применительно к достаточно общей задаче оптимального управления осуществлена, видимо, впервые в работе автора [96]. Решение конкретных задач описано в 34, 37.

Однако для частных классов задач метод проекции градиента был предложен намного раньше. Эти частные классы выделяются тем, что задача проектирования, аналогичная задаче (11) — (13), оказывается более простой и решается привычными вычислительными методами. Можно выделить два класса таких задач. [c.146]
МЕТОД ПРОЕКЦИИ ГРАДИЕНТА 147 [c.147]
Варианты. Метод проекции градиента настолько естествен, что предлагался многими авторами независимо друг от друга. Иногда эти предложения отличались только формой описания, иногда — деталями, не имеющими, видимо, принципиального значения. Полезно указать, хотя бы в общих чертах, эти внешне различные варианты метода, [c.147]
МЕТОД ПРОЕКЦИИ ГРАДИЕНТА 151 [c.151]
МЕТОД ПРОЕКЦИИ ГРАДИЕНТА 153 [c.153]
МЕТОД ПРОЕКЦИИ ГРАДИЕНТА 155 [c.155]
Метод проекции градиента и скользящие режимы. Следует особо отметить те задачи, в которых конструкция (45) будет иметь значительное преимущество перед методом проекции градиента в форме (46), (43).

МЕТОД ПРОЕКЦИИ ГРАДИЕНТА 157 [c.157]
Метод проекции градиента в задачах с конечными связями. Рассмотрим задачу, в которой, кроме перечисленных в (7) условий, добавлена еще конечная связь между х (t) и u (t) вида [c.157]
МЕТОД ПРОЕКЦИИ ГРАДИЕНТА 159 [c.159]
МЕТОД ПРОЕКЦИИ ГРАДИЕНТА 161 [c.161]
МЕТОД ПРОЕКЦИИ ГРАДИЕНТА [c.163]
Решение этой задачи может быть осуществлено простейшим вариантом метода проекции градиента (см. 18). Разумеется, в общем случае речь идет о приближенном решении. В силу предположения о строгой выпуклости D min (z, g) достигается в един-
[c.189]
В силу предположения о строгой выпуклости D min (z, g) достигается в един-
[c.189]
Сравнение с решением задачи методом проекции градиента было проведено для другого варианта, отличающегося следующим [c.245]
Эти данные были взяты из работы [99], где задача решалась классическим вариантом метода проекции градиента, применимость которого обеспечивалась ликвидацией условия и (t) U при помощи замены и на неограниченное и [c.246]
Величина Т была фиксирована, однако затем решалась серия задач с разными Т, что позволило найти и оптимальное Т. В [70] использовался метод проекции градиента на данной траектории (и(-), ( ) вычислялась производная функционала F0 [и ( )] [c.256]
Мы не будем подробно объяснять физический смысл задачи. Ограничимся лишь указанием, что уравнения (1) описывают вращение твердого тела (спутника), снабженного тремя реактивными двигателями, F0 есть расход топлива, условия (3) — суть условия отсутствия вращения (стабилизация). Эта задача была решена аналитически в [33], точное решение ее известно, и она представляет собой удобный методический пример.
Решение задачи методом проекции градиента было проведено в целях сравнения двух методов и иллюстрации возможностей метода проекции градиента. Результаты опубликованы в [96] здесь они воспроизводятся. Заметим, что задачи (6) и (8) решались и методом последовательной линеаризации ( 19), но результаты мы приводить не будем, так как они практически те же самые. [c.278]
Решение задачи методом проекции градиента. Задачи 1 и 2 были решены методом проекции градиента, подробно описанным в 18. Схема вычислений в этом случае в основном совпадает со схемой вычислений методом последовательной линеаризации. Основное отличие в том, что вариация управления находится решением задачи квадратичного программирования.
Перейдем к результатам. Первый расчет проводился при /7=10 и ограничении на вариацию управления u(t) [c.340]
Не видно и способов, которыми можно было бы добиваться выполнения (15). Попытки использовать замену (14) действительно привели к бессмысленной эволюции v(t) в процессе поиска минимума. Впервые регуляризация численного решения задачи оптимального управления была осуществлена в работе 181], причем использовался именно функционал F0 [и ( ), а] (6). Решалась, кстати, задача, совпадающая с (1), однако в более простой ситуации решение искалось только на интервале ( , 2) (оптимальные значения t и tz можно искать подбором, причем каждый акт подбора связан с решением вариационной задачи на (t1 t2).) Поэтому ограничение О и U отсутствовало, и применялся метод проекции градиента (классический вариант, 18). В этом случае вариация 8u (t) имеет вид [c.354]
Разумеется, и здесь можно применить метод проекции градиента, но мы считаем (и это соответствует положению дел в прикладных задачах такого сорта), что проектирование на множество X, определяемое системой нелинейных уравнений / (z)=0, i=l, 2,. . . . . ., т, является слишком сложной операцией. Алгоритм поиска условного минимума состоит в том, что для каждой точки х нужно уметь строить улучшающую вариацию аргумента ох. При этом приходится иметь в виду не только понижение f (х), но и восстановление условий / (ж)=0, если они оказываются нарушенными. Итак, пусть есть некоторая точка xk, причем условия / (xk)=0 могут и не выполняться. Считая искомую вариацию Ьх малой и ограниченной условием Ьх S, где S — шаг процесса, поставим следующую естественную задачу для определения Ьх [c.400]
. . . . ., т, является слишком сложной операцией. Алгоритм поиска условного минимума состоит в том, что для каждой точки х нужно уметь строить улучшающую вариацию аргумента ох. При этом приходится иметь в виду не только понижение f (х), но и восстановление условий / (ж)=0, если они оказываются нарушенными. Итак, пусть есть некоторая точка xk, причем условия / (xk)=0 могут и не выполняться. Считая искомую вариацию Ьх малой и ограниченной условием Ьх S, где S — шаг процесса, поставим следующую естественную задачу для определения Ьх [c.400]
Реализация метода проекции градиента в 18 привела к необходимости решения следующей вспомогательной задачи найти числа sn, п=1, 2,. . ., N из условий [c.453]
Предостережение. Опыт решения задач оптимального управления методом проекции градиента еще не очень велик, и некоторые детали не совсем ясны. Автор хотел бы предупредить читателя о”возможных осложнениях. Прежде всего, не очень ясен вопрос о назначении величины rj, задающей требуемую относительную точность решения по значению минимизируемой формы (1). В задаче линейного программирования (при S= o) форма (1) имеет простой содержательный смысл — это значение F0 [Su ( )], и назначение ] =0,1 (0,2 или 0,05, если угодно) в особых разъяснениях не нуждается. В задаче квадратичного программирования форма (1) уже не имеет такого простого значения, часто ее значение
[c.458]
В задаче линейного программирования (при S= o) форма (1) имеет простой содержательный смысл — это значение F0 [Su ( )], и назначение ] =0,1 (0,2 или 0,05, если угодно) в особых разъяснениях не нуждается. В задаче квадратичного программирования форма (1) уже не имеет такого простого значения, часто ее значение
[c.458]
Ф е д о р е н к о Р. П. Метод проекции градиента в задачах оптимального управления. — М. ИПМ АН СССР, 1975, № 5. [c.483]
Итерационный метод работы с неравенствами, как с равенствами, был предложен в [51]. Суть дела поясним на самом простом примере. Пусть в задаче есть одно условие-неравенство 9 1и (t)] 0. Тогда на этом интервале условие 9 0 заменяется условием-равенством 9 [и ( )]=0, и находится новая вариация 8ц (t) в задаче, поставленной только в терминах равенств, снова проверяется условие 9 0 и т. д. Однако этот эрзац операции проектирования теоретически несостоятелен в простых ситуациях он может привести к 8u (i)=0, хотя варьируется траектория очевидным образом неоптимальная, и правильное проектирование градиента привело бы, конечно, к 8ц ( ) 0. [c.162]
[c.162]
Итак, мы имеем большое число возможных типов вариационных задач, некоторое число основных идей численного их решения и достаточно большое число возможных технологических оформлений. И каждый из элементов этих трех уровней может сочетаться если и не с каждым, то с большим числом элементов соседнего уровня. Вот эта-то комбинаторика и создает (в значительной мере) видимое разнообразие методов приближенного решения. Однако в этих комбинациях могут содержаться и очень ценные предложения, когда есть достаточно веские основания утверждать, что для данного специального класса задач следует выбрать именно данный подход и дополнить его именно одним конкретным вариантом технологии, а при других комбинациях получатся заметно менее эффективные или трудно реализуемые методы. Этой трехслойной структуре проблемы приближенного решения задач оптимального управления и соответствуют первые три главы книги. Во второй главе каждый возможный подход описан достаточно подробно, но самый низший уровень — технология вычислений — естественно, не излагается это уже материал третьей главы. Выше мы отмечали, что основных конструкций приближенных методов оказалось не так уж много. Автор надеется, что читатель, разобравшийся в этом материале, без труда убедится, например, в том, что очень большое число предложенных в разное время и в разных странах методов являются несущественными модификациями простейших вариантов метода проекции градиента.
[c.14]
Выше мы отмечали, что основных конструкций приближенных методов оказалось не так уж много. Автор надеется, что читатель, разобравшийся в этом материале, без труда убедится, например, в том, что очень большое число предложенных в разное время и в разных странах методов являются несущественными модификациями простейших вариантов метода проекции градиента.
[c.14]
Для решения задачи (1) давно предложен и обоснован (при определенных предположениях, обсуждать которые мы здесь не станем) метод проекции градиента. Он представляет собой алгоритм построения минимизирущей последовательности точек и. Пусть имеется некоторое и. Тогда в качестве следующего приближения берется точка [c.140]
В основу дальнейшего будет положен первый способ, хотя некоторые алгоритмы (они будут описаны) основаны на втором. Выше мы убедились, что проектирование на Q практически осуществить не удается. Однако можно построить алгоритм, основанный на проектировании не на Q, а на некоторое многообразие, которое условно можно считать касательным к и в точке и. Речь идет о следующем линеаризуем задачу в окрестности данной точки и и построим метод проекции градиента для линеаризованной задачи. Пусть wt (t) — функциональные производные входящих в задачу функционалов Ff [и ( )], z=0, 1,.. ., т. Будем искать вариацию управления Ьи ( ), решая вариационную задачу найти
[c.142]
Речь идет о следующем линеаризуем задачу в окрестности данной точки и и построим метод проекции градиента для линеаризованной задачи. Пусть wt (t) — функциональные производные входящих в задачу функционалов Ff [и ( )], z=0, 1,.. ., т. Будем искать вариацию управления Ьи ( ), решая вариационную задачу найти
[c.142]
Gradient-Restoration Algorithm [52], [53] (для задач классического типа). Разработанный в последние годы, метод основан на втором способе интерпретации задачи оптимального управления как общей задачи математического программирования и внешне существенно отличается от приведенных выше форм метода проекции градиента. Однако, кроме формального отличия, здесь есть и некоторое отличие по существу, влияние которого на алго- [c.148]
Паллиативы (метод проекции градиента в общем случае). Выше было показано, что проектирование градиента осуществляется достаточно просто (правда, в линеаризованной постановке, приводящей к проектированию на линейное подпространство) в двух случаях либо при отсутствии дополнительных условий (F(=ff), либо при отсутствии геометрического ограничения на значения и (t) (u( U). Однако большая часть прикладных задач оптимального управления содержит оба сорта условий, а в этом случае проектирование выполняется решением задачи квадратического программирования. К сожалению, идеи и алгоритмы, относящиеся к линейному и нелинейному программированию, мало известны среди специалистов по прикладной механике, которые особенно часто сталкиваются с необходимостью решения задач оптимального управления достаточно общего вида. Именно в этой среде были созданы многочисленные приемы, имеющие целью сформулировать общую задачу как задачу классического типа, либо как простейшую неклассическую задачу. Мы рассмотрим наиболее типичные из этих приемов. Их следует отнести к разряду паллиативов, так как они не снимают трудностей численного решения, а лишь отодвигают их, так сказать, в глубь проблемы. Создание алгоритма приближенного решения задачи оптимального управления можно условно разбить на два этапа [c.160]
Однако большая часть прикладных задач оптимального управления содержит оба сорта условий, а в этом случае проектирование выполняется решением задачи квадратического программирования. К сожалению, идеи и алгоритмы, относящиеся к линейному и нелинейному программированию, мало известны среди специалистов по прикладной механике, которые особенно часто сталкиваются с необходимостью решения задач оптимального управления достаточно общего вида. Именно в этой среде были созданы многочисленные приемы, имеющие целью сформулировать общую задачу как задачу классического типа, либо как простейшую неклассическую задачу. Мы рассмотрим наиболее типичные из этих приемов. Их следует отнести к разряду паллиативов, так как они не снимают трудностей численного решения, а лишь отодвигают их, так сказать, в глубь проблемы. Создание алгоритма приближенного решения задачи оптимального управления можно условно разбить на два этапа [c.160]
Для сравнения в табл. 4 подробно показан начальный этап решения той же задачи методом проекции градиента. Приведены следующие величины v — номер итерации, предсказанное значение х1 (Т), F т F” — значения Ф [х ( )] в двух точках локальных максимумов, среднее значение и( ) и К — число точек аппроксимации в формуле (35). Стоит отметить, что механизм постепенного увеличения К сработал с небольшим опозданием уже на 6-й итерации Ф [х (t) стала двугорбой , и следовало увеличить К с 1 до 2. Таким образом, терминальная задача была довольно легко решена, и уже с 9-й итерации начался процесс минимизации.
[c.345]
Приведены следующие величины v — номер итерации, предсказанное значение х1 (Т), F т F” — значения Ф [х ( )] в двух точках локальных максимумов, среднее значение и( ) и К — число точек аппроксимации в формуле (35). Стоит отметить, что механизм постепенного увеличения К сработал с небольшим опозданием уже на 6-й итерации Ф [х (t) стала двугорбой , и следовало увеличить К с 1 до 2. Таким образом, терминальная задача была довольно легко решена, и уже с 9-й итерации начался процесс минимизации.
[c.345]
Численные и вычислительные методы, оптимизация
Сообщения без ответов | Активные темы | Избранное
Правила форума
В этом разделе нельзя создавать новые темы.
Если Вы хотите задать новый вопрос, то не дописывайте его в существующую тему, а создайте новую в корневом разделе “Помогите решить/разобраться (М)”.
Если Вы зададите новый вопрос в существующей теме, то в случае нарушения оформления или других правил форума Ваше сообщение и все ответы на него могут быть удалены без предупреждения.
Не ищите на этом форуме халяву, правила запрещают участникам публиковать готовые решения стандартных учебных задач. Автор вопроса обязан привести свои попытки решения и указать конкретные затруднения.
Обязательно просмотрите тему Правила данного раздела, иначе Ваша тема может быть удалена или перемещена в Карантин, а Вы так и не узнаете, почему.
| Karoed |
| ||
29/10/09 |
| ||
| |||
 …
…
| Karoed |
| ||
29/10/09 |
| ||
| |||

| MaximVD |
| ||
14/07/10 |
| ||
| |||
 Так?
Так?| мат-ламер |
| |||
30/01/09 |
| |||
| ||||
 03.2011, 20:20
03.2011, 20:20  Во-вторых, попробуйте применить к исходной задаче метод барьеров. При этом, на каждом шаге получается задача нелинейного программирования без ограничений, к которой можно применить метод Ньютона. Получим мы при этом полиномиальную сходимость – не знаю.
Во-вторых, попробуйте применить к исходной задаче метод барьеров. При этом, на каждом шаге получается задача нелинейного программирования без ограничений, к которой можно применить метод Ньютона. Получим мы при этом полиномиальную сходимость – не знаю.| Karoed |
| ||
29/10/09 |
| ||
| |||
 Самая обыкновенная система ограничений:
Самая обыкновенная система ограничений:| мат-ламер |
| |||
30/01/09 |
| |||
| ||||

| Показать сообщения за: Все сообщения1 день7 дней2 недели1 месяц3 месяца6 месяцев1 год Поле сортировки АвторВремя размещенияЗаголовокпо возрастаниюпо убыванию |
| Страница 1 из 1 | [ Сообщений: 6 ] |
Модераторы: Модераторы Математики, Супермодераторы
Кто сейчас на конференции |
Сейчас этот форум просматривают: нет зарегистрированных пользователей |
| Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете добавлять вложения |
| Найти: |
лекция4
Страница курса EE227C
Загрузить файл ipynb
В этой заметке мы решим некоторые задачи оптимизации, используя рассмотренные ранее методы градиента.
- Прогнозируемый градиентный спуск
- Разминка: Квадратика
- Метод наименьших квадратов
- Регуляризация
- Неявная регуляризация
- ЛАССО
- Машины линейных опорных векторов
- Оценка обратной разреженной ковариации
- Градиентное безумие
Игнорировать следующее поле кода.
В [1]:
%matplotlib встроенный
импортировать numpy как np
импортировать matplotlib
импортировать matplotlib.pyplot как plt
np.random.seed(1337)
# загрузить пользовательское форматирование ipython (игнорируйте это)
из отображения импорта IPython.core.display, HTML
дисплей (HTML (открыть ('custom.html'). читать ()))
kwargs = {'ширина линии': 3,5}
шрифт = {'вес': 'нормальный', 'размер': 24}
matplotlib.rc('шрифт', **шрифт)
def error_plot (ys, yscale = 'log'):
plt.figure(figsize=(8, 8))
plt.xlabel('Шаг')
plt.ylabel('Ошибка')
plt.yscale(yscale)
plt.plot(диапазон(len(ys)), ys, **kwargs)
Спроектированный градиентный спуск¶
Начнем с базовой реализации спроецированного градиентного спуска.
В [2]:
def gradient_descent(init, steps, grad, proj=lambda x: x):
"""Проецируемый градиентный спуск.
Входы:
начальная: отправная точка
steps: список скалярных размеров шагов
grad: точки сопоставления функций с градиентами
proj (необязательно): функция сопоставления точек с точками
Возвращает:
Список всех точек, вычисленных методом прогнозируемого градиентного спуска.
"""
хз = [инициализация]
для шага по шагам:
xs.append(proj(xs[-1] - шаг * град(xs[-1])))
вернуть хз
92,$$, который имеет карту градиента $\nabla f(x)=x.$ В [3]:
def quadratic(x):
вернуть 0,5 * х.точка (х)
определение квадратичный_градиент (х):
вернуть х
Обратите внимание, что функция является $1$-гладкой и $1$-сильно выпуклой. Тогда наши теоремы подразумевают, что мы используем постоянный размер шага $1.$ Если подумать, при таком размере шага алгоритм фактически найдет оптимальное решение всего за один шаг.
В [4]:
x0 = np.random.normal(0, 1, (1000))
_, x1 = градиент_спуск (x0, [1.0], квадратичный_градиент)
Так и есть.
В [5]:
x1.all() == 0
Out[5]:
Допустим, у нас нет нужной скорости обучения.
В [6]:
xs = градиент_спуск(x0, [0,1]*50, квадратичный_градиент)
error_plot([квадратный(x) для x в xs])
Ограниченная оптимизация¶
Допустим, мы хотим оптимизировать функцию внутри некоторого аффинного подпространства. Напомним, что аффинные подпространства являются выпуклыми множествами. Ниже мы выбираем случайное аффинное подпространство малой размерности $b+U$ и определяем соответствующий оператор линейного проектирования.
В [7]:
# U — ортонормированный базис случайного 100-мерного подпространства.
U = np.linalg.qr(np.random.normal(0, 1, (1000, 100))[0]
б = np.random.normal (0, 1, 1000)
деф проект(х):
"""Проекция x на аффинное подпространство"""
return b + U. n$, который минимизирует следующую цель: 9\верх А)$. В [10]:
определение наименьших квадратов (A, b, x):
"""Цель наименьших квадратов."""
возврат (0,5/м) * np.linalg.norm(A.dot(x)-b)**2
определение наименьшего_квадрата_градиента (A, b, x):
"""Целевой градиент метода наименьших квадратов в точке x."""
вернуть A.T.dot(A.dot(x)-b)/m
Переопределенный случай $m\gen n$¶
В [11]:
m, n = 1000, 100
A = np.random.normal(0, 1, (m, n))
x_opt = np.random.normal (0, 1, n)
шум = np.random.normal (0, 0,1, м)
b = A.dot(x_opt) + шум
цель = лямбда x: наименьшие_квадраты (A, b, x)
градиент = лямбда x: наименьший_квадрат_градиент (A, b, x)
Сходимость по цели¶
В [12]:
x0 = np.random.normal(0, 1, n)
xs = градиент_спуск (x0, [0,1] * 100, градиент)
error_plot([цель(x) для x в xs])
plt.plot (диапазон (длина (xs)), [np.linalg.norm (шум) ** 2] * длина (xs),
label='уровень шума', **kwargs)
plt. plot (диапазон (длина (xs)), [наименьшие_квадраты (A, b, x_opt)] * длина (xs),
label='оптимальный', **kwargs)
_ = plt.legend()
Конвергенция в домене¶
В [13]:
error_plot([np.linalg.norm(x-x_opt)**2 for x in xs])
9\top A)=0.$ В [14]:
м, n = 100, 1000
A = np.random.normal(0, 1, (m, n))
б = np.random.normal (0, 1, м)
# Решение с наименьшей нормой дается псевдообратным
x_opt = np.linalg.pinv(A).dot(b)
цель = лямбда x: наименьшие_квадраты (A, b, x)
градиент = лямбда x: наименьший_квадрат_градиент (A, b, x)
x0 = np.random.normal (0, 1, n)
xs = градиент_спуск (x0, [0,1] * 100, градиент)
error_plot([цель(x) для x в xs])
plt.plot (диапазон (длина (xs)), [наименьшие_квадраты (A, b, x_opt)] * длина (xs),
label='оптимальный', **kwargs)
_ = plt.legend()
92$$
Примечание: С этой модификацией цель снова становится $\alpha$-сильно выпуклой.
В [16]:
def наименьшие_квадраты_l2(A, b, x, альфа=0,1):
вернуть наименьшие_квадраты (A, b, x) + (альфа/2) * x. dot (x)
def наименьшие_квадраты_l2_градиент (A, b, x, альфа = 0,1):
вернуть наименьший_квадратный_градиент (A, b, x) + альфа * x
Давайте создадим экземпляр метода наименьших квадратов.
В [17]:
м, n = 100, 1000
A = np.random.normal(0, 1, (m, n))
b = A.dot (np.random.normal (0, 1, n))
цель = лямбда х: наименьшие_квадраты_l2 (A, b, x)
градиент = лямбда х: наименьшие_квадраты_l2_градиент (A, b, x)
9\top b.$ Убедитесь, что эта точка действительно оптимальна. В [18]:
x_opt = np.linalg.inv(A.T.dot(A) + 0,1*np.eye(1000)).dot(A.T).dot(b)
Вот как работает градиентный спуск.
В [19]:
x0 = np.random.normal(0, 1, n)
xs = градиент_спуск (x0, [0,1] * 500, градиент)
error_plot([цель(x) для x в xs])
plt.plot (диапазон (длина (xs)), [наименьшие_квадраты_l2 (A, b, x_opt)] * длина (xs),
label='оптимальный', **kwargs)
_ = plt.legend()
Вы видите, что ошибка не снижается ниже определенного уровня из-за члена регуляризации. Это неплохая вещь. На самом деле член регуляризации равен сильная выпуклость , которая снова приводит к сходимости в области:
В [20]:
xs = градиент_спуск(x0, [0,1]*500, градиент)
error_plot([np.linalg.norm(x-x_opt)**2 для x в xs])
plt.plot (диапазон (длина (xs)), [np.linalg.norm (x_opt) ** 2] * длина (xs),
label='квадрат нормы $x_{\mathrm{opt}}$', **kwargs)
_ = plt.legend()
Магия неявной регуляризации¶
Иногда простой запуск градиентного спуска из подходящей начальной точки сам по себе оказывает регуляризующий эффект без введения явного члена регуляризации .
Мы увидим это ниже, когда вернемся к нерегуляризованной цели метода наименьших квадратов, но инициализируем градиентный спуск из начала координат, а не из случайной гауссовой точки.
В [21]:
# Мы инициализируем с 0
х0 = np.zeros(n)
# Обратите внимание, что это градиент w.r.t. нерегулируемая цель!
градиент = лямбда x: наименьший_квадрат_градиент (A, b, x)
xs = градиент_спуск (x0, [0,1] * 50, градиент)
error_plot([np. 2 + \alpha\|x\|_1$$
Мы увидим, что LASSO может определить разреженных решений, если они существуют. Это распространенная причина использования $\ell_1$-регуляризатора.
В [22]:
по лассо (A, b, x, альфа = 0,1):
вернуть наименьшие_квадраты (A, b, x) + альфа * np.linalg.norm (x, 1)
защита ell1_subgradient(x):
"""Субградиент нормы ell1 в точке x."""
g = np.ones (x.shape)
г [х < 0.] = -1,0
вернуть г
def lasso_subgradient (A, b, x, альфа = 0,1):
"""Субградиент цели лассо в точке x"""
вернуть наименьший_квадратный_градиент (A, b, x) + alpha * ell1_subgradient (x)
В [23]:
м, n = 100, 1000
A = np.random.normal(0, 1, (m, n))
x_opt = np.zeros (n)
х_опт[:10] = 1,0
b = A.dot(x_opt)
x0 = np.random.normal (0, 1, n)
xs = градиент_спуск (x0, [0,1] * 500, лямбда x: lasso_subgradient (A, b, x))
error_plot ([лассо (A, b, x) для x в xs])
В [24]:
plt.figure(figsize=(14,10))
plt.title('Сравнение начальной, оптимальной и вычисленной точки')
idxs = диапазон (50)
plt. plot(idxs, x0[idxs], '--', color='#aaaaaa', label='initial', **kwargs)
plt.plot(idxs, x_opt[idxs], 'r-', label='optimal', **kwargs)
plt.plot(idxs, xs[-1][idxs], 'g-', label='final', **kwargs)
plt.xlabel('Координата')
plt.ylabel('Значение')
plt.legend()
Out[24]:
Как и было обещано, LASSO правильно определяет значимые координаты оптимального решения. Вот почему на практике LASSO является популярным инструментом для выбора признаков.
Поэкспериментируйте с этим графиком, чтобы проверить другие точки по пути, например, точку, которая достигает наименьшего целевого значения. Почему объективная ценность растет, хотя мы продолжаем получать лучшие решения?
Машины опорных векторов¶
В задаче линейной классификации нам дано $m$ помеченных точек $(a_i, y_i)$, и мы хотим найти гиперплоскость, заданную точкой $x$, которая их разделяет так, чтобы

 n$, который минимизирует следующую цель: 9\верх А)$.
n$, который минимизирует следующую цель: 9\верх А)$.  plot (диапазон (длина (xs)), [наименьшие_квадраты (A, b, x_opt)] * длина (xs),
label='оптимальный', **kwargs)
_ = plt.legend()
plot (диапазон (длина (xs)), [наименьшие_квадраты (A, b, x_opt)] * длина (xs),
label='оптимальный', **kwargs)
_ = plt.legend()
 dot (x)
def наименьшие_квадраты_l2_градиент (A, b, x, альфа = 0,1):
вернуть наименьший_квадратный_градиент (A, b, x) + альфа * x
dot (x)
def наименьшие_квадраты_l2_градиент (A, b, x, альфа = 0,1):
вернуть наименьший_квадратный_градиент (A, b, x) + альфа * x
 Это неплохая вещь. На самом деле член регуляризации равен сильная выпуклость , которая снова приводит к сходимости в области:
Это неплохая вещь. На самом деле член регуляризации равен сильная выпуклость , которая снова приводит к сходимости в области: 2 + \alpha\|x\|_1$$
2 + \alpha\|x\|_1$$
 plot(idxs, x0[idxs], '--', color='#aaaaaa', label='initial', **kwargs)
plt.plot(idxs, x_opt[idxs], 'r-', label='optimal', **kwargs)
plt.plot(idxs, xs[-1][idxs], 'g-', label='final', **kwargs)
plt.xlabel('Координата')
plt.ylabel('Значение')
plt.legend()
plot(idxs, x0[idxs], '--', color='#aaaaaa', label='initial', **kwargs)
plt.plot(idxs, x_opt[idxs], 'r-', label='optimal', **kwargs)
plt.plot(idxs, xs[-1][idxs], 'g-', label='final', **kwargs)
plt.xlabel('Координата')
plt.ylabel('Значение')
plt.legend()
- $\langle a_i , x\rangle \ge 1$ при $y_i=1$ и
- $\langle a_i, x\rangle \le -1$ при $y_i = -1$
Чем меньше норма $\|x\|$, тем больше отступ между положительными и отрицательными экземплярами. Поэтому есть смысл добавить регуляризатор, штрафующий большие нормы. Это приводит к цели. 92$$
Поэтому есть смысл добавить регуляризатор, штрафующий большие нормы. Это приводит к цели. 92$$
В [25]:
деф шарнир_лосс(г):
вернуть np.maximum (1.-z, np.zeros (z.shape))
def svm_objective (A, y, x, альфа = 0,1):
"""Цель SVM."""
м, _ = А.форма
вернуть np.mean (петля_потеря (np.diag (y). dot (A.dot (x)))) + (альфа/2) * x.dot (x)
В [26]:
z = np.linspace(-2, 2, 100) plt.figure(figsize=(12,10)) plt.plot(z, шарнир_потеря(z), **kwargs)
Исходящий[26]:
[]
Входящий [27]:
определение шарнир_субградиент (г):
g = np.zeros (z.shape)
г[г < 1] = -1.
вернуть г
def svm_subgradient (A, y, x, альфа = 0,1):
g1 = шарнир_субградиент (np.diag (y).dot (A.dot (x)))
g2 = np.diag(y).dot(A)
вернуть g1.dot(g2) + альфа*х
В [28]:
plt.figure(figsize=(12,10)) plt.plot(z, шарнир_субградиент(z), **kwargs)
Исходящий[28]:
[lines.Line2D at 0x7f2f3de7da90>]
Входящий [29]:
м, n = 1000, 100
A = np.vstack([np.random.normal(0.1, 1, (m//2, n)),
np.random.normal (-0,1, 1, (м//2, п))])
y = np.hstack([np.ones(m//2), -1.*np.ones(m//2)])
x0 = np.random.normal (0, 1, n)
xs = градиент_спуск (x0, [0,01] * 100,
лямбда х: svm_subgradient (A, y, x, 0,05))
В [30]:
error_plot([svm_objective(A, y, x) для x в xs])
Посмотрим, даст ли усреднение решений улучшенное значение функции.
В [31]:
xavg = 0,0
для х в х:
среднее += х
svm_objective(A, y, xs[-1]), svm_objective(A, y, xavg/len(xs))
Out[31]:
(1,0714422960045327, 0,88151010653237649)
Мы также можем посмотреть на точность нашей линейной модели для прогнозирования меток. Из того, как мы определили данные, мы видим, что вектор всех единиц является классификатором с наивысшей точностью в пределе бесконечных данных (очень больших $m$). Для конечного набора данных точность может быть еще выше из-за случайных флуктуаций.
Для конечного набора данных точность может быть еще выше из-за случайных флуктуаций.
В [32]:
Точность определения (A, y, x):
вернуть np.mean(np.diag(y).dot(A.dot(x))>0)
В [33]:
plt.figure(figsize=(12,10))
plt.ylabel('Точность')
plt.xlabel('Шаг')
plt.plot(range(len(xs)), [точность(A, y, x) для x в xs], **kwargs)
plt.plot (диапазон (длина (xs)), [точность (A, y, np.ones (n))] * len (xs),
label='Оптимальная популяция', **kwargs)
_ = plt.legend()
Мы видим, что точность резко возрастает довольно рано и немного падает, когда мы слишком долго тренируемся. 9\Топ
$$
В этом примере также подчеркивается полезность автоматического дифференцирования, предоставляемого пакетом autograd , который мы будем регулярно использовать. В следующей лекции мы поймем, как именно работает автоматическая дифференциация. На данный момент мы просто рассматриваем его как черный ящик, который дает нам градиенты.
В [34]:
импортировать autograd.
 numpy как np
из автоград импорт град
np.random.seed(1337)
numpy как np
из автоград импорт град
np.random.seed(1337)
В [35]:
def sparse_inv_cov(S, X, альфа=0,1):
возврат (np.trace (STdot (X))
- np.log(np.linalg.det(X))
+ альфа * np.sum (np.abs (X)))
В [36]:
n = 5 A = np.random.normal (0, 1, (n, n)) S = A.dot(AT) цель = лямбда X: sparse_inv_cov (S, X) # autograd обеспечивает "градиент", ура! градиент = град (цель)
Нам также нужно побеспокоиться о проекции на положительно-полуопределенный конус, который соответствует усечению собственных значений.
В [37]:
проекция по умолчанию (X):
"""Проекция на положительно полуопределенный конус."""
е, U = np.linalg.eig(X)
эс[эс<0] = 0.
вернуть U.dot(np.diag(es).dot(UT))
В [38]:
A0 = np.random.normal(0, 1, (n,n)) X0 = A0.точка(A0.T) Xs = градиент_спуск (X0, [0,01] * 500, градиент, проекция) error_plot([цель(X) для X в Xs])
Просто для удовольствия, ниже мы рассмотрим сумасшедший пример. Мы можем использовать
Мы можем использовать autograd не только для получения градиентов для естественных целей, мы можем, в принципе, также использовать его для настройки гиперпараметров нашего оптимизатора, таких как расписание размера шага.
Ниже мы видим, как мы можем найти лучшие 10-шаговые графики скорости обучения для оптимизации квадратичного уравнения. Это в основном просто для иллюстративных целей (хотя некоторые исследователи более серьезно изучают такого рода идеи).
В [39]:
x0 = np.random.normal(0, 1, 1000)
В [40]:
def f(x):
вернуть 0,5 * np.dot (х, х)
Оптимизатор защиты (шаги):
"""Оптимизируйте квадратное число с заданными шагами."""
xs = градиент_спуск (x0, шаги, град (f))
вернуть f(xs[-1])
Функция оптимизатора является недифференцируемой функцией своих входных шагов . Тем не менее, autograd предоставит градиент, который мы можем использовать в градиентном спуске.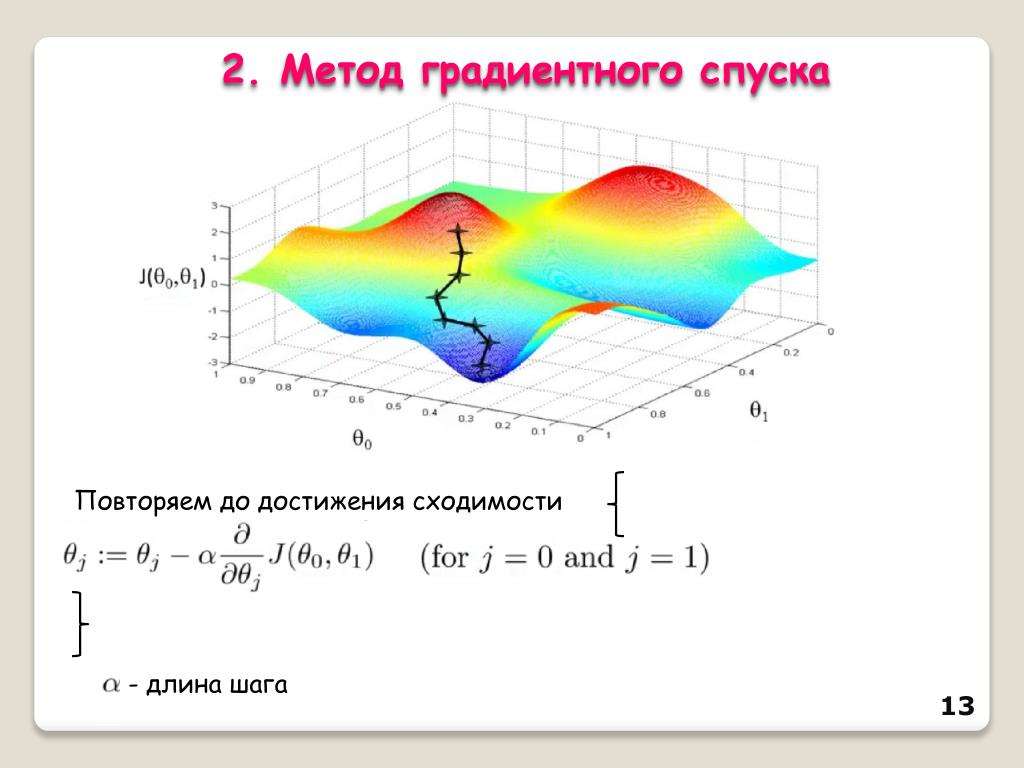 То есть мы настраиваем градиентный спуск с помощью градиентного спуска.
То есть мы настраиваем градиентный спуск с помощью градиентного спуска.
В [41]:
grad_optimizer = grad(оптимизатор)
В [42]:
initial_steps = np.abs(np.random.normal(0, 0,1, 10)) лучшие_шаги = градиент_спуск (начальные_шаги, [0,001] * 500, град_оптимизатор)
В [43]:
error_plot([оптимизатор(шаги) для шагов в better_steps])
Как мы видим, графики скорости обучения значительно улучшаются со временем. Конечно, мы уже знаем из первого примера, что существует график размера шага, который сходится за один шаг. Интересно, что последнее расписание, которое мы здесь нашли, совсем не похоже на то, что мы могли бы ожидать:
В [44]:
plt.figure(figsize=(12,6))
plt.xticks(диапазон(длина(better_steps[-1])))
plt.ylabel('Размер шага')
plt.xlabel('Номер шага')
plt.plot(диапазон(len(better_steps[-1])), better_steps[-1], **kwargs)
Out[44]:
[]
На сегодня все.
 градиентный спуск?
градиентный спуск?спросил
Изменено 1 год, 6 месяцев назад
Просмотрено 35 тысяч раз
$\begingroup$
Я только что прочитал о проецированном градиентном спуске, но я не увидел интуиции, чтобы использовать спроецированный вместо обычного градиентного спуска. Не могли бы вы рассказать мне причину и предпочтительные ситуации прогнозируемого градиентного спуска? Что дает эта проекция?
- оптимизация
- числовая оптимизация
- градиентный спуск
$\endgroup$
$\begingroup$
На базовом уровне прогнозируемый градиентный спуск — это просто более общий метод решения более общей задачи.
Градиентный спуск минимизирует функцию, перемещаясь в отрицательном направлении градиента на каждом шаге. На переменную ограничений нет. $$ \text{Задача 1:} \min_x f(x) $$ $$ x_{k+1} = x_k - t_k \nabla f(x_k) $$
С другой стороны, проецируемый градиентный спуск минимизирует функцию с ограничением. На каждом шаге мы движемся в направлении отрицательного градиента, а затем «проецируемся» на допустимое множество.
$$ \text{Задача 2:} \min_x f(x) \text{ при условии } x \in C $$
$$ y_{k+1} = x_k - t_k \набла f(x_k)\\ x_{k+1} = \text{arg} \min_{x \in C} \|y_{k+1}-x\| $$
$\endgroup$
1
$\begingroup$
Я нашел два подхода к алгоритму.
Подход 1:
- $d_k = Pr(x_k-\nabla f(x_k)) - x_k$ : направление поиска проецируется на допустимое множество
- $x_{k+1} = x_k + t_k d_k$
Подход 2: (То же, что ответ из p.