
Цензурированная регрессия
Цензурированная регрессия (англ. Censored regression) — регрессия, с зависимой переменной, наблюдаемой с ограничением (цензурированием) возможных значений. При этом модель может быть цензурирована только с одной стороны (справа или слева) или с обеих сторон. Цензурированная регрессия отличается от усеченной регрессии (англ. truncated regression), тем что значения факторов, в отличие от зависимой переменной, наблюдаются без ограничений.
Каноническая цензурированная регрессия, цензурированная снизу нулевым значением, носит название тобит (по аналогии с пробит, логит и т. д.), названная в честь лауреата премии имени Нобеля по экономике Джеймса Тобина. Собственно исследования цензурированных моделей начались с работы Дж. Тобина в 1958 году, в которой рассматривались расходы семей на автомобили. Для оценки эластичности спроса на автомобили по доходу необходимо оценить модель зависимости логарифма расходов на логарифм доходов. Однако, как показал Тобин такая оценка будет смещенной и несостоятельной, так как для семей с низким доходом (ниже некоторого порога) величина расходов равна нулю независимо от конкретной величины дохода и других факторов. {T}b+sigma varepsilon } , однако фактически наблюдается другая переменная, которая определяется в общем случае следующим образом:
{T}b+sigma varepsilon } , однако фактически наблюдается другая переменная, которая определяется в общем случае следующим образом:
y = { y m i n , y ∗ ⩽ y m i n y ∗ , y m i n < y ∗ < y m a x y m a x , y ∗ ⩾ y m a x {displaystyle y={egin{cases}y_{min},y^{*}leqslant y_{min}y^{*},y_{min}<y^{*}<y_{max}y_{max},y^{*}geqslant y_{max}end{cases}}}
Если y m i n = 0 , y m a x = ∞ {displaystyle y_{min}=0,y_{max}=infty } , то имеем каноническую цензурированную модель (тобит):
y = { 0 , y ∗ ⩽ 0 y ∗ , y ∗ > 0 {displaystyle y={egin{cases}0,y^{*}leqslant 0y^{*},y^{*}>0end{cases}}}
Рассмотрим математическое ожидание наблюдаемой зависимой переменной на примере тобит-модели с нормально распределенной ошибкой:
E ( y ) = P ( y ∗ ⩽ 0 ) E ( y | y ∗ ⩽ 0 ) + P ( y ∗ > 0 ) E ( y | y ∗ > 0 ) = P ( y ∗ ⩽ 0 ) ⋅ 0 + P ( ε > − x T b / σ ) ( x T b + σ E ( ε | ε > − x T b / σ ) ) {displaystyle E(y)=P(y^{*}leqslant 0)E(y|y^{*}leqslant 0)+P(y^{*}>0)E(y|y^{*}>0)=P(y^{*}leqslant 0)cdot 0+P(varepsilon >-x^{T}b/sigma )(x^{T}b+sigma E(varepsilon |varepsilon >-x^{T}b/sigma ))}
Если ϕ {displaystyle phi } -плотность, а Φ {displaystyle Phi } -интегральная функция распределения случайной ошибки, то
P ( ε > − x T b / σ ) = Φ ( x T b / σ ) {displaystyle P(varepsilon >-x^{T}b/sigma )=Phi (x^{T}b/sigma )} E ( ε | ε > − x T b / σ ) = ϕ ( − x T b / σ ) / Φ ( x T b / σ ) {displaystyle E(varepsilon |varepsilon >-x^{T}b/sigma )=phi (-x^{T}b/sigma )/Phi (x^{T}b/sigma )}
Следовательно, окончательно имеем
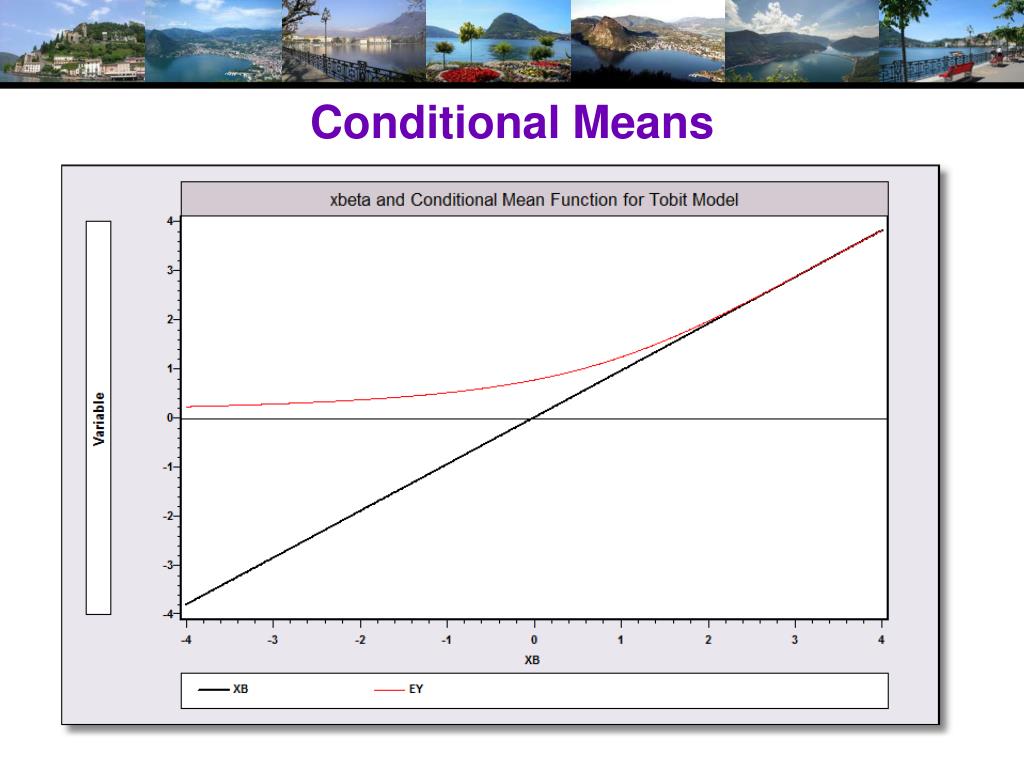
E ( y ) = Φ ( x T b / σ ) ⋅ x T b + σ ⋅ ϕ ( x T b / σ ) {displaystyle E(y)=Phi (x^{T}b/sigma )cdot x^{T}b+sigma cdot phi (x^{T}b/sigma )}
Очевидно, это выражение не равно x T b {displaystyle x^{T}b} , следовательно построение обычной регрессии приведет к смещенным и несостоятельным оценкам.
Оценка параметров
Оценка параметров осуществляется методом максимального правдоподобия. Логарифмическая функция правдоподобия цензурированной модели равна:
l ( b , σ ) = ∑ y t = y m i n ln F ( ( y m i n − x t T b ) / σ ) + ∑ y m i n < y t < y m a x ln f ( ( y t − x t T b ) / σ ) + ∑ y t = y m a x ln ( 1 − F ( ( y m a x − x t T b ) / σ ) ) {displaystyle l(b,sigma )=sum _{y_{t}=y_{min}}ln F((y_{min}-x_{t}^{T}b)/sigma )+sum _{y_{min}<y_{t}<y_{max}}ln f((y_{t}-x_{t}^{T}b)/sigma )+sum _{y_{t}=y_{max}}ln(1-F((y_{max}-x_{t}^{T}b)/sigma ))}
где f , F {displaystyle f,F} — плотность и интегральная функция распределения случайной ошибки ε {displaystyle varepsilon } .
Максимизация данной функции по неизвестным параметрам позволяет найти их оценки.
Модель Хекмана
Модель Тобина имеет один недостаток. Дело в том, что значение y=0 может означать выбор «не участвовать» (в расходах на отдых, например), а значения y > 0 {displaystyle y>0} , можно интерпретировать как «интенсивность участия». В тобит-модели и выбор «участвовать-не участвовать» и «интенсивность участия» определяются одними и теми же факторами и факторы действуют в одном направлении. Классический пример фактора и ситуации неоднозначного влияния — количество детей как фактор, влияющий на расходы семьи. Очевидно, что большое количество детей может негативно влиять на решение «отдыхать или нет» (из-за больших расходов), однако, если принято такое решение, то величина расходов (интенсивность участия) на отдых прямо зависит от количества детей.
Хекман предложил разделить модель на две составляющие — модель бинарного выбора для участия, и линейную модель для интенсивности участия и факторы этих двух моделей вообще говоря могут быть разными.
Случайные ошибки моделей предполагаются нормально распределенными. Вторая латентная переменная определяет выбор «участвовать/не участвовать» в рамках стандартной модели бинарного выбора (например, пробит-модели). Первая модель — это модель интенсивности участия при условии выбора «участвовать». Если выбирается «не участвовать», то y {displaystyle y} не наблюдается (равна нулю).
g = { 1 , g ∗ > 0 0 , g ∗ ⩽ 0 {displaystyle g={egin{cases}1,g^{*}>0 ,g^{*}leqslant 0end{cases}}}
y = { y ∗ , g = 1 0 , g = 0 {displaystyle y={egin{cases}y^{*},g=1 ,g=0end{cases}}}
Такую модель называют тобит II (соответственно исходная тобит-модель называется тобит I), иногда по аналогии хекит (модель Хекмана). {T}b)}
{T}b)}
Предполагая, что случайные ошибки моделей латентных переменных коррелированы и связаны соотношением
ε = σ ε u u + ν {displaystyle varepsilon =sigma _{varepsilon u}u+ u }
Следовательно
E ( y | g = 1 ) = x T b + σ ε u E ( ε | u > − z T b ) = x T b + σ ε u ϕ ( z T b ) Φ ( z T b ) = x T b + σ ε u λ ( z T b ) {displaystyle E(y|g=1)=x^{T}b+sigma _{varepsilon u}E(varepsilon |u>-z^{T}b)=x^{T}b+sigma _{varepsilon u}{frac {phi (z^{T}b)}{Phi (z^{T}b)}}=x^{T}b+sigma _{varepsilon u}lambda (z^{T}b)}
где λ ( z T b ) {displaystyle lambda (z^{T}b)} — так называемая «лямбда Хекмана». {T}b+sigma _{varepsilon u}lambda _{t}+eta _{t}}
{T}b+sigma _{varepsilon u}lambda _{t}+eta _{t}}
Полученные оценки являются неэффективными, но вполне могут быть использованы в качестве начальных значений в методе максимального правдоподобия.
Tobit-модель: olegchagin — LiveJournal
- Общество
- Образование
- Психология
- Cancel
В работе 1999 года Джастин Крюгер и Дэвид Даннинг описали эксперимент, в ходе которого исследователи попросили студентов пройти тесты, оценивающие их чувство юмора, логическое мышление и знание грамматики английского языка, а также предположить, насколько хорошо они справились по сравнению с остальными.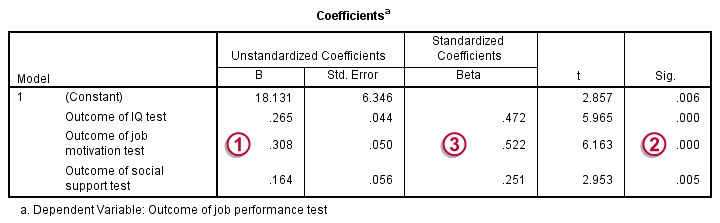 Участники в целом значительно переоценили свои способности (в среднем они считали, что выполнили задание лучше 66 процентов однокурсников), причем чем ниже был результат теста, тем сильнее предполагаемая оценка отличалась от реальной; недооценивали себя только наиболее сильные участники. Авторы статьи объяснили это тем, что люди с низкими способностями не только хуже справляются с заданиями, но и неадекватно оценивают свои знания.
Участники в целом значительно переоценили свои способности (в среднем они считали, что выполнили задание лучше 66 процентов однокурсников), причем чем ниже был результат теста, тем сильнее предполагаемая оценка отличалась от реальной; недооценивали себя только наиболее сильные участники. Авторы статьи объяснили это тем, что люди с низкими способностями не только хуже справляются с заданиями, но и неадекватно оценивают свои знания.
Работы с критикой выводов Даннинга и Крюгера стали появляться уже через несколько лет после публикации оригинального исследования. Многие авторы подтверждали существование эффекта, но не соглашались с предложенным объяснением. В одной из первых таких статей эффект Даннинга — Крюгера объяснялся склонностью людей в целом довольно высоко оценивать свои знания и регрессией к среднему. Регрессию впервые описал Фрэнсис Гальтон в 1886 году: он заметил, что у высоких отцов сыновья в среднем были ниже их, а у низких — наоборот, то есть значения «стремятся к среднему».
Профессор-исследователь факультета экономических наук ВШЭ Анатолий Пересецкий и его соавтор Ян Магнус из Амстердамского университета также предложили объяснение эффекта Даннинга — Крюгера с помощью статистики, а не психологии. Дело в том, что в экспериментах, в ходе которых изучался этот эффект, за тест можно было получить оценки, лежащие в строго оговоренном интервале, например от 0 до 10 или от 0 до 100. В двух работах этот факт отмечался, но развития идея ранее не получала.
Предположим, что люди могут угадывать свой результат с некоторой погрешностью, но в целом верно (то есть с равной вероятностью недо- и переоценивают себя). Но из-за того, что нельзя получить меньше 0 или больше 100 баллов, две группы участников ограничены в своих предположениях: написавшие очень плохо не могут сказать, что выполнили задания на –5 или –10, а решившие все правильно — что рассчитывают на 110. Получается, что предполагаемые оценки первых будут в среднем выше, а вторых — ниже, чем могли бы быть, если бы шкала не была ограничена.
Предположение авторы проверили на данных 665 студентов ВШЭ, которые сдавали экзамен по статистике в 2016–2019 годах. В середине экзамена студентов просили написать, какую оценку они ожидают получить в итоге (за верное предположение был обещан небольшой бонус). Результаты показали наличие эффекта Даннинга — Крюгера.
Чтобы проверить, можно ли получить такие же отклонения ожидаемых оценок от фактических, используя только законы статистики, авторы предложили простую статистическую модель (обобщающую хорошо известную в экономике Tobit-модель), учитывающую ограниченность прогноза — число от 0 до 100. Форма графика, который можно построить на основе модели, зависит от трех параметров: от того, насколько могут ошибаться участники в своих предположениях, и от двух случайных величин, характеризующих отклонение прогноза оценки от 0 и 100 баллов (с их помощью выполняется требование об ограничении оценок сверху и снизу). Исследователи показали, что при реалистичных значениях этих параметров можно получить график, почти идеально описывающий реальные данные.
«Эффект Даннинга — Крюгера действительно существует, но является статистическим артефактом и не требует для своего объяснения концепций из области психологии и когнитивной науки.
Вопрос, почему “психологические” объяснения этого эффекта до сих пор популярны в психологической литературе, пожалуй, может являться предметом исследования психологов», — подытожил соавтор работы Анатолий Пересецкий.
моделей Тобит | Примеры анализа данных R
Тобит-модель, также называемая цензурированной регрессионной моделью, предназначена для оценки
линейные отношения между переменными при цензуре слева или справа
в зависимой переменной (также известная как цензура снизу и сверху,
соответственно). Цензура сверху имеет место, когда случаи со значением в или
выше некоторого порога, все принимают значение этого порога, поэтому
что истинное значение может быть равно порогу, но может быть и выше.
В случае цензурирования снизу значения, которые попадают на или ниже некоторого
порог подвергается цензуре.
На этой странице используются следующие пакеты. Убедитесь, что вы можете загрузить
их, прежде чем пытаться запустить примеры на этой странице. Если у вас нет
пакет установлен, запустите: install.packages("packagename") , или
если вы видите, что версия устарела, запустите: update.packages() .
требуется (ggplot2) требуют (GGally) требуется (VGAM)
Информация о версии: Код для этой страницы был протестирован в R В разработке (нестабильно) (2012-11-16 r61126)
От: 2012-12-15
С: VGAM 0.9-0; GGally 0.4.2; изменить форму 0.8.4; слой 1,8; ggplot2 0.9.3; вязальщица 0,9
Обратите внимание: Целью этой страницы является показать, как использовать различные команды анализа данных.
Он не охватывает все аспекты исследовательского процесса, которыми должны заниматься исследователи. В
в частности, он не охватывает очистку и проверку данных, проверку предположений, моделирование
диагностика и возможные последующие анализы.
Примеры анализа тобитов
Пример 1. В 1980-х годах был федеральный закон, ограничивающий показания спидометра не выше 85 миль в час. Так что если вы хотели попытаться предсказать максимальную скорость транспортного средства по сочетанию лошадиных сил и объема двигателя, вы получите показание не выше 85, независимо от того, насколько быстро транспортное средство действительно двигалось. Это классический случай правой цензуры (цензуры сверху) данных. Единственное, в чем мы уверены, это то, что эти автомобили двигались со скоростью не менее 85 миль в час.
Пример 2. Исследовательский проект изучает уровень содержания свинца в домашней питьевой воде в зависимости от возраста дом и семейный доход. Набор для тестирования воды не может обнаружить свинец концентрации ниже 5 частей на миллиард (ppb). EPA считает уровни выше 15 частей на миллиард, чтобы быть опасным. Эти данные являются примером левой цензуры (цензурирование снизу).
Пример 3. Рассмотрим ситуацию, в которой у нас есть мера академического
способности (в масштабе 200-800), которые мы хотим смоделировать с помощью теста на чтение и математику
баллы, а также тип
программы, в которой обучается студент (академическая, общая или профессиональная). Проблема здесь в том, что студенты, которые отвечают на все вопросы по
тест академических способностей правильно получает 800 баллов, хотя вполне вероятно, что эти
студенты не «действительно» равны по способностям. То же самое относится и к студентам, которые
ответить на все вопросы неправильно. Все такие студенты будут иметь оценку
200, хотя не все они могут иметь одинаковые способности.
Проблема здесь в том, что студенты, которые отвечают на все вопросы по
тест академических способностей правильно получает 800 баллов, хотя вполне вероятно, что эти
студенты не «действительно» равны по способностям. То же самое относится и к студентам, которые
ответить на все вопросы неправильно. Все такие студенты будут иметь оценку
200, хотя не все они могут иметь одинаковые способности.
Описание данных
Для нашего анализа данных, приведенного ниже, мы расширим пример 3 выше. Мы сгенерировали гипотетические данные, которые можно получить с нашего веб-сайта из R. Обратите внимание, что R требует косой черты, а не обратной косой черты. при указании местоположения файла, даже если файл находится на жестком диске.
дат <- read.csv("https://stats.idre.ucla.edu/stat/data/tobit.csv")
Набор данных содержит 200 наблюдений. Переменная академических способностей равна 9.0005 apt
чтение и математика соответственно. Переменная
Переменная прога это тип программы, в которой учится студент, это категориальная (номинальная) переменная, которая принимает три
ценности, академические ( prog = 1), общие ( prog = 2) и
профессиональный ( прог =3). Переменная id является идентификационной переменной. Теперь давайте посмотрим на данные описательно. Обратите внимание, что в этом наборе данных самый низкий
значение
резюме(дата)
## id читать математическую прогу ## Мин. : 1,0 мин. :28,0 мин. :33.0 академический :45 ## 1-й кв.: 50,8 1-й кв.: 44,0 1-й кв.: 45,0 общий: 105 ## Медиана: 100,5 Медиана: 50,0 Медиана: 52,0 профессиональное: 50 ## Среднее значение: 100,5 Среднее значение: 52,2 Среднее значение: 52,6 ## 3-й кв.: 150,2 3-й кв.: 60,0 3-й кв.: 59.0 ## Макс. :200,0 Макс. :76,0 Макс. :75,0 ## подходит ## Мин. :352 ## 1-й квартал: 576 ## Медиана: 633 ## Среднее: 640 ## 3-й кв.:705 ## Макс. :800
# функция, которая дает плотность нормального распределения
# для заданного среднего и стандартного отклонения, масштабированного для метрики подсчета
# для гистограммы: количество = плотность * размер выборки * ширина ячейки
f <- function(x, var, bw = 15) {
dnorm(x, среднее = среднее(var), sd(var)) * длина(var) * bw
}
# настроить базовый сюжет
p <- ggplot (dat, aes (x = apt, fill = prog))
# гистограмма, раскрашенная по пропорциям в разных программах
# с наложением нормального распределения
p + stat_bin (ширина_бина = 15) +
stat_function (удовольствие = f, размер = 1,
аргументы = список (вар = dat $ apt))
Глядя на приведенную выше гистограмму, мы можем
видим цензуру в значениях apt , то есть там далеко
больше случаев с баллами от 750 до 800, чем
можно было бы ожидать, глядя на остальную часть распределения. Ниже представлена альтернативная гистограмма
это еще больше подчеркивает избыток случаев, когда
Ниже представлена альтернативная гистограмма
это еще больше подчеркивает избыток случаев, когда apt = 800. в
гистограммы ниже, опция breaks создает гистограмму, где каждый
уникальное значение apt имеет свой собственный бар (путем установки разрывов, равных вектору
содержащие значения от минимума apt до максимум apt является непрерывным, большинство значений apt уникальны в наборе данных,
хотя ближе к центру распределения есть несколько значений apt которые имеют два или три случая. Шип в крайнем правом углу
гистограмма — столбец для случаев, когда apt =800, высота этого столбца
относительно всех остальных отчетливо видно избыточное количество случаев с этим значением.
p + stat_bin(binwidth = 1) + stat_function(fun = f, size = 1, args = list(var = dat$apt,
чб = 1))
Далее мы рассмотрим двумерные отношения в нашем наборе данных.
cor(dat[ c("read", "math", "apt")])
## чтение математики ## чтение 1,0000 0,6623 0,6451 ## математика 0,6623 1,0000 0,7333 ## ап 0,6451 0,7333 1,0000
# матрица графика
ggpairs(dat[ c("read", "math", "apt")])
В первой строке матрицы диаграммы рассеяния, показанной выше, мы видим
диаграммы рассеяния, показывающие взаимосвязь между чтением и ап ,
а также math и apt . Обратите внимание на сбор дел в
верхние эти две диаграммы рассеяния, это связано с цензурой в
дистрибутив ап .
Методы анализа, которые вы можете рассмотреть
Ниже приведен список некоторых методов анализа, с которыми вы могли столкнуться. Некоторые из перечисленных методов вполне разумны, в то время как другие либо вышли из моды или имеют ограничения.
- Тобит-регрессия, в центре внимания этой страницы.
- Регрессия МНК. Вы можете анализировать эти данные с помощью регрессии МНК.
 ОЛС
регрессия будет рассматривать 800 как фактические значения, а не как нижний предел верхней академической
способность. Ограничение этого подхода заключается в том, что когда переменная подвергается цензуре, МНК обеспечивает противоречивые данные.
оценки параметров, а это означает, что коэффициенты из анализа
не обязательно будет приближаться к «истинным» параметрам генеральной совокупности, так как размер выборки
увеличивается. См. Long (1997, глава 7) для более подробного обсуждения проблем
с использованием регрессии OLS с цензурированными данными.
ОЛС
регрессия будет рассматривать 800 как фактические значения, а не как нижний предел верхней академической
способность. Ограничение этого подхода заключается в том, что когда переменная подвергается цензуре, МНК обеспечивает противоречивые данные.
оценки параметров, а это означает, что коэффициенты из анализа
не обязательно будет приближаться к «истинным» параметрам генеральной совокупности, так как размер выборки
увеличивается. См. Long (1997, глава 7) для более подробного обсуждения проблем
с использованием регрессии OLS с цензурированными данными. - Усеченная регрессия — иногда возникает путаница в отношении различий
между усеченными данными и цензурированными данными. С цензурой
переменные, все наблюдения есть в наборе данных, но мы не знаем «истинного»
значения некоторых из них. При усечении некоторые наблюдения не
включены в анализ из-за значения переменной. Когда
переменная подвергается цензуре, регрессионные модели для усеченных данных дают противоречивые оценки параметров.

Тобит-регрессия
Ниже мы запускаем тобит-модель, используя функцию vglm пакета VGAM.
summary(m <- vglm(apt ~ read + math + prog, tobit(Upper = 800), data = dat))
## ## Вызов: ## vglm(formula = apt ~ read + math + prog, family = tobit(Upper = 800), ## данные = дата) ## ## Остатки Пирсона: ## Мин. 1 кв. Медиана 3 кв. Макс. ## мю -2,6 -0,76 -0,051 0,79 4,1 ## log(sd) -1,1 -0,62 -0,3690,25 5,4 ## ## Коэффициенты: ## Оценить стандарт. Значение ошибки z ## (перехват):1 209,6 32,457 6,5 ## (Перехват):2 4,2 0,053 79,4 ## прочитано 2,7 0,618 4,4 ## математика 5,9 0,705 8,4 ## проггенерал -12,7 12,355 -1,0 ## прогпрофессиональный -46,1 13,770 -3,4 ## ## Количество линейных предикторов: 2 ## ## Имена линейных предикторов: mu, log(sd) ## ## Параметр дисперсии для семейства тобитов: 1 ## ## Логарифмическая вероятность: -1041 на 394 степени свободы ## ## Количество итераций: 4
- В выводе выше первое, что мы видим, это вызов, это R
напоминая нам, какую модель мы использовали, какие параметры мы указали и т.
 д.
д. - В таблице с пометками коэффициенты приведены коэффициенты, их стандартные ошибки,
и z-статистика. В сводную таблицу не включены p-значения, но мы покажем, как рассчитать
их ниже. Тобит-коэффициенты регрессии интерпретируются аналогичным образом.
отношение к коэффициентам регрессии МНК; тем не менее, линейный эффект на
скрытая переменная без цензуры, а не наблюдаемый результат. См. McDonald и Moffitt (1980) для более подробной информации.
- Для увеличения на одну единицу числа
читать, есть2,6981точка увеличения прогнозируемого значенияapt. - Увеличение на одну единицу в
математикесвязано с5,9146увеличение на единицу прогнозируемого значенияapt. - Термины для
прогимеют немного другую трактовку. Прогнозируемое значениеaptравно-46,1419 напунктов ниже для студентов в профессиональной программе, чем для студентов в академической программе.
- Коэффициент с пометкой «(Intercept):1» является точкой пересечения или константой для модели.
- Коэффициент с пометкой «(Intercept):2» является вспомогательной статистикой. Если мы
возведя это значение в степень, мы получим статистику, аналогичную квадрату
корень остаточной дисперсии в регрессии МНК. Значение
65,6773можно сравнить со стандартным отклонением академических способностей, которое составляло 99,21, существенное сокращение.
- Для увеличения на одну единицу числа
- Окончательная логарифмическая вероятность,
-1041.0629, показано ближе к концу вывода, его можно использовать для сравнения вложенных моделей.
Ниже мы вычисляем p-значения для каждого из коэффициентов в модели. Мы
рассчитать значение p для каждого коэффициента, используя значения z, а затем отобразить в
таблица с коэффициентами. Коэффициенты для читать , математика ,
и прог = 3 (профессиональные) статистически значимы.
ctable <- coef(summary(m)) pvals <- 2 * pt(abs(ctable[ "значение z"]), df.residual(m), lower.tail = FALSE) cbind(ctable, pvals)
## Расчетный стандарт. Ошибка значения z pval ## (Перехват):1 209,555 32,45655 6,456 3,157e-10 ## (Перехват):2 4,185 0,05268 79,432 1,408e-244 ## чтение 2,698 0,61808 4,365 1,625e-05 ## математика 5,915 0,70480 8,392 8,673e-16 ## proggeneral -12.716 12.35467 -1.029 3.040e-01 ## прогпрофессиональный -46.142 13.76971 -3.351 8.831e-04
Мы можем проверить значимость типа программы в целом, подобрав модель без программы и с использованием теста отношения правдоподобия.
м2 <- vglm(apt ~ чтение + математика, тобит(Верхний = 800), данные = dat) (p <- pchisq(2 * (logLik(m) - logLik(m2)), df = 2, lower.tail = FALSE))
## [1] 0,003155
LRT с двумя степенями свободы связан с
p-значение 0,0032 , что указывает на то, что общий эффект
из прог является статистически значимым.
Ниже мы вычисляем верхний и нижний 95% доверительные интервалы для коэффициентов.
b <- коэфф(м) se <- sqrt(diag(vcov(m))) cbind(LL = b - qnorm(0,975) * se, UL = b + qnorm(0,975) * se)
## LL UL ## (Перехват):1 145,941 273,169 ## (Перехват):2 4,081 4,288 ## прочитано 1,487 3,909 ## математика 4,533 7,296 ## проггенерал -36,930 11,499 ## профессиональный -73.130 -19.154
Мы также можем проверить, насколько хорошо наша модель соответствует данным. В одну сторону начать с графиков остатков, чтобы оценить их абсолютные значения, а также как относительные (пирсоновские) значения и предположения, такие как нормальность и однородность дисперсии.
dat$yhat <- установлен(м)[1]
dat$rr <- resid(m, type = "ответ")
dat$rp <- resid(m, type = "pearson")[1]
пар (mfcol = с (2, 3))
с (дата, {
plot(yhat, rr, main = "Подгонка против остатков")
qqнорма(рр)
plot(yhat, rp, main = "Подгонка по сравнению с остатками Пирсона")
qqнорма(рп)
plot(apt, rp, main = "Фактическое против остатков Пирсона")
plot(apt, yhat, main = "Фактическое против приспособленного")
})
График в правом нижнем углу представлял собой предсказанные или подобранные значения
построено против фактического. Это может быть
особенно полезно при сравнении конкурирующих моделей. Мы можем рассчитать
корреляция между этими двумя, а также квадрат корреляции,
чтобы понять, насколько точно наша модель предсказывает данные и как
большая часть дисперсии результатов объясняется моделью. 92
Это может быть
особенно полезно при сравнении конкурирующих моделей. Мы можем рассчитать
корреляция между этими двумя, а также квадрат корреляции,
чтобы понять, насколько точно наша модель предсказывает данные и как
большая часть дисперсии результатов объясняется моделью. 92
## [1] 0,6123
Корреляция между прогнозируемыми и наблюдаемыми значениями apt равна 0,7825 . Если мы возведем это значение в квадрат, мы получим кратное квадрату
корреляция, это указывает на долю прогнозируемых значений 61,23% их дисперсии с apt .
Ссылки
Лонг, Дж. С. 1997. Модели регрессии для категориальных и ограниченных зависимых переменных. Таузенд-Оукс, Калифорния: Sage Publications.
Макдональд, Дж. Ф. и Моффит, Р. А. 1980. Использование тобит-анализа. Обзор экономики и статистики Том 62 (2): 318-321.
Тобин, Дж. 1958. Оценка отношений для ограниченных зависимых переменных. Эконометрика 26: 24-36.
Эконометрика 26: 24-36.
Тобит-анализ | Примеры анализа статистических данных
Информация о версии: Код для этой страницы был протестирован в Stata 12.
Тобит-модель, также называемая цензурированной регрессионной моделью, предназначена для оценки линейные отношения между переменными при цензуре слева или справа в зависимой переменной (также известная как цензура снизу и сверху, соответственно). Цензура сверху имеет место, когда случаи со значением в или выше некоторого порога, все принимают значение этого порога, поэтому что истинное значение может быть равно порогу, но может быть и выше. В случае цензурирования снизу значения, которые попадают на или ниже некоторого порог подвергается цензуре.
Обратите внимание: Целью этой страницы является показать, как использовать различные команды анализа данных.
Он не охватывает все аспекты исследовательского процесса, которыми должны заниматься исследователи. В
в частности, он не охватывает очистку и проверку данных, проверку предположений, моделирование
диагностика и возможные последующие анализы.
Примеры тобит-регрессии
Пример 1.
В 1980-х годах федеральный закон ограничивал показания спидометра не более 85 миль в час. Так что если вы хотели попытаться предсказать максимальную скорость транспортного средства по сочетанию лошадиных сил и объема двигателя, вы получите показание не выше 85, независимо от того, насколько быстро транспортное средство действительно двигалось. Это классический случай правой цензуры (цензуры сверху) данных. Единственное, в чем мы уверены, это то, что эти автомобили двигались со скоростью не менее 85 миль в час.
Пример 2. Исследовательский проект изучает уровень содержания свинца в домашней питьевой воде в зависимости от возраста дом и семейный доход. Набор для тестирования воды не может обнаружить свинец концентрации ниже 5 частей на миллиард (ppb). EPA считает уровни выше 15 частей на миллиард, чтобы быть опасным. Эти данные являются примером левой цензуры (цензурирование снизу).
Пример 3. Рассмотрим ситуацию, в которой у нас есть мера академического
способности (в масштабе 200-800), которые мы хотим смоделировать с помощью теста на чтение и математику
баллы, а также тип
программы, в которой обучается студент (академическая, общая или профессиональная). Проблема здесь в том, что студенты, которые отвечают на все вопросы по
тест академических способностей правильно получает 800 баллов, хотя вполне вероятно, что эти
студенты не «действительно» равны по способностям. То же самое относится и к студентам, которые
ответить на все вопросы неправильно. Все такие студенты будут иметь оценку
200, хотя не все они могут иметь одинаковые способности.
Проблема здесь в том, что студенты, которые отвечают на все вопросы по
тест академических способностей правильно получает 800 баллов, хотя вполне вероятно, что эти
студенты не «действительно» равны по способностям. То же самое относится и к студентам, которые
ответить на все вопросы неправильно. Все такие студенты будут иметь оценку
200, хотя не все они могут иметь одинаковые способности.
Описание данных
Давайте продолжим Пример 3 сверху.
У нас есть гипотетических файлов данных, tobit.dta с 200 наблюдениями. Переменная академических способностей — apt , результаты тестов по чтению и математике — чтение и математика соответственно. Переменная prog - это тип программы студент, это категориальная (номинальная) переменная, которая принимает три ценности, академические ( прог = 1), общий ( прог. = 2) и профессиональный ( прог. ) = 3).
Посмотрим на данные.
Обратите внимание, что в этом наборе данных самый низкий
значение apt равно 352. Ни один учащийся не получил 200 баллов (т.е.
возможная оценка), а это означает, что хотя цензура снизу была возможна, она
не встречается в наборе данных.
Ни один учащийся не получил 200 баллов (т.е.
возможная оценка), а это означает, что хотя цензура снизу была возможна, она
не встречается в наборе данных.
используйте https://stats.idre.ucla.edu/stat/stata/dae/tobit, очистите
суммировать apt читать математику
Переменная | Набл. Среднее ст. Дев. Мин Макс
----------------------------+------------------------------------ --------------------
подходящий | 200 640,035 99,21903 352 800
читать | 200 52,23 10,25294 28 76
математика | 200 52,645 9,368448 33 75
табулировать прог
тип |
программа | Частота Процент спермы.
---------------------------+-------------------------------------------------
академический | 45 22,50 22,50
общий | 105 52,50 75,00
профессиональный | 50 25.00 100.00
---------------------------+-------------------------------------------------
Итого | 200 100,00
гистограмма, нормальная ячейка (10) xline (800)
Глядя на приведенную выше гистограмму, показывающую распределение apt , мы можем
увидеть цензуру в данных, то есть случаев с десятками
от 750 до 800, чем
можно было бы ожидать, глядя на остальную часть распределения. Ниже представлена альтернативная гистограмма
это еще больше подчеркивает избыток случаев, когда apt = 800. в
гистограммы ниже, опция дискретных создает гистограмму, где каждый
уникальное значение кв имеет свой собственный бар. Опция freq заставляет ось Y
быть помечены частотой для каждого значения, а не плотностью. Потому что apt является непрерывным, большинство значений apt уникальны в наборе данных,
хотя ближе к центру распределения есть несколько значений apt с двумя или тремя корпусами. Шип в крайнем правом углу
гистограмма — столбец для случаев, когда apt =800, высота этого столбца
относительно всех остальных отчетливо видно избыточное количество случаев с этим значением.
Ниже представлена альтернативная гистограмма
это еще больше подчеркивает избыток случаев, когда apt = 800. в
гистограммы ниже, опция дискретных создает гистограмму, где каждый
уникальное значение кв имеет свой собственный бар. Опция freq заставляет ось Y
быть помечены частотой для каждого значения, а не плотностью. Потому что apt является непрерывным, большинство значений apt уникальны в наборе данных,
хотя ближе к центру распределения есть несколько значений apt с двумя или тремя корпусами. Шип в крайнем правом углу
гистограмма — столбец для случаев, когда apt =800, высота этого столбца
относительно всех остальных отчетливо видно избыточное количество случаев с этим значением.
гистограмма, дискретная частота
Далее мы рассмотрим двумерные отношения в нашем наборе данных.
корреляция чтения математики apt
(наб=200)
| уметь читать по математике
----------------------------+---------------------------
читать | 1. 0000
математика | 0,6623 1,0000
подходящий | 0,6451 0,7333 1,0000
графическая матрица чтения математических данных, половинный джиттер(2)
0000
математика | 0,6623 1,0000
подходящий | 0,6451 0,7333 1,0000
графическая матрица чтения математических данных, половинный джиттер(2)
В последней строке матрицы диаграммы рассеяния, показанной выше, мы видим диаграммы рассеяния, показывающие чтения и apt , а также математики и ап . Обратите внимание на набор случаев в верхней части каждой диаграммы рассеяния. из-за цензуры в раздаче apt .
Методы анализа, которые вы можете рассмотреть
Ниже приведен список некоторых методов анализа, с которыми вы могли столкнуться. Некоторые из перечисленных методов вполне разумны, в то время как другие либо вышли из моды или имеют ограничения.
- Тобит-регрессия, в центре внимания этой страницы.
- Регрессия МНК. Вы можете анализировать эти данные с помощью регрессии МНК. МНК-регрессия
будет рассматривать 800 как фактические значения, а не как верхний предел высшего академического
способность.
 Ограничение этого подхода заключается в том, что когда переменная подвергается цензуре, МНК обеспечивает противоречивые данные.
оценки параметров, а это означает, что коэффициенты из анализа
не обязательно будет приближаться к «истинным» параметрам генеральной совокупности, поскольку размер выборки
увеличивается. См. Лонг (1997, глава 7) для более подробного обсуждения проблем
с использованием регрессии OLS с цензурированными данными.
Ограничение этого подхода заключается в том, что когда переменная подвергается цензуре, МНК обеспечивает противоречивые данные.
оценки параметров, а это означает, что коэффициенты из анализа
не обязательно будет приближаться к «истинным» параметрам генеральной совокупности, поскольку размер выборки
увеличивается. См. Лонг (1997, глава 7) для более подробного обсуждения проблем
с использованием регрессии OLS с цензурированными данными. - Усеченная регрессия — иногда возникает путаница в отношении различий
между усеченными данными и цензурированными данными. С цензурой
переменные, все наблюдения есть в наборе данных, но мы не знаем «истинных»
значения некоторых из них. При усечении некоторые наблюдения не
включены в анализ из-за значения переменной. Когда
переменная подвергается цензуре, регрессионные модели для усеченных данных дают противоречивые оценки параметров. См. Длинный
(1997, глава 7) для более подробного обсуждения проблем использования
регрессионные модели для усеченных данных для анализа подвергнутых цензуре данных.

Тобит-регрессия
Ниже мы запускаем модель тобит , используя чтение , математику и prog для предсказания apt . Параметр ul() в команде tobit указывает значение, при котором начинается (т. е. верхний предел). Существует также ll( ) 9Опция 0015 для указания значения левой цензуры (нижний предел), который в этом примере не нужен. я. до prog указывает, что prog является фактором переменная (т.е. категориальная переменная), и что она должна быть включена в модель как ряд фиктивных переменных. Обратите внимание, что этот синтаксис был введен в Stata 11.
tobit apt read math i.prog, ul(800)
Тобит-регрессия Количество наблюдений = 200
LR хи2(4) = 188,97
Вероятность > хи2 = 0,0000
Логарифмическая вероятность = -1041,0629 Псевдо R2 = 0,0832
-------------------------------------------------- ----------------------------
подходящий | Коэф. стандарт Ошиб. т П>|т| [95% конф. интервал]
----------------------------+------------------------------------ ----------------------------
читать | 2,697939 ,618798 4,36 0,000 1,477582 3,918296
математика | 5,914485 .7098063 8,33 0,000 4,514647 7,314323
|
прог |
2 | -12,71476 12,40629 -1,02 0,307 -37,18173 11,7522
3 | -46,1439 13,72401 -3,36 0,001 -73,2096 -19,07821
|
_против | 209,566 32,77154 6,39 0,000 144,9359 274,1961
----------------------------+------------------------------------ ----------------------------
/сигма | 65,67672 3,481272 58,81116 72,54228
-------------------------------------------------- ----------------------------
Обс. резюме: 0 наблюдений с левой цензурой
183 наблюдения без цензуры
17 правых цензурированных наблюдений при apt>=800
стандарт Ошиб. т П>|т| [95% конф. интервал]
----------------------------+------------------------------------ ----------------------------
читать | 2,697939 ,618798 4,36 0,000 1,477582 3,918296
математика | 5,914485 .7098063 8,33 0,000 4,514647 7,314323
|
прог |
2 | -12,71476 12,40629 -1,02 0,307 -37,18173 11,7522
3 | -46,1439 13,72401 -3,36 0,001 -73,2096 -19,07821
|
_против | 209,566 32,77154 6,39 0,000 144,9359 274,1961
----------------------------+------------------------------------ ----------------------------
/сигма | 65,67672 3,481272 58,81116 72,54228
-------------------------------------------------- ----------------------------
Обс. резюме: 0 наблюдений с левой цензурой
183 наблюдения без цензуры
17 правых цензурированных наблюдений при apt>=800 - Окончательная логарифмическая вероятность (-1041,0629) показана в верхней части выходных данных,
его можно использовать при сравнении вложенных моделей, но мы не будем показывать пример
из того здесь.

- Также в верхней части вывода мы видим, что все 200 наблюдений в нашем наборе данных были используемые в анализе (было бы использовано меньше наблюдений, если бы какие-либо из наших переменных имели пропущенные значения).
- Отношение правдоподобия хи-квадрат 188,97 (df=4) с p-значением 0,0001 говорит нам о том, что наша модель в целом подходит значительно лучше, чем пустая модель (т. е. модель без предикторов).
- В таблице мы видим коэффициенты, их стандартные ошибки, t-статистику,
связанные p-значения и 95% доверительный интервал коэффициентов.
Коэффициенты для чтения и математики статистически значимы, как и
коэффициент для прог =3. Коэффициенты регрессии Тобита
интерпретируются аналогично коэффициентам регрессии МНК; однако линейный эффект
относится к скрытой переменной без цензуры, а не к наблюдаемому результату. См. McDonald и Moffitt (1980) для более подробной информации.
- При увеличении на одну единицу числа , прочитанного как , прогнозируемое значение увеличивается на 2,7 пункта.
 значение apt .
значение apt . - Увеличение на одну единицу в математике связано с увеличением на 5,91 единицы прогнозируемого значение apt .
- Термины для прог имеют немного другую трактовку. Прогнозируемое значение ап на 46,14 балла ниже у студентов профессиональной программы ( прог =3), чем для учащихся академическая программа ( prog =1).
- При увеличении на одну единицу числа , прочитанного как , прогнозируемое значение увеличивается на 2,7 пункта.
- Вспомогательная статистика /сигма аналогична квадратному корню из остаточная дисперсия в регрессии МНК. Значение 65,67 можно сравнить со стандартным отклонением академических способностей, которое составляло 99,21, что является существенным снижением. Выходные данные также содержат оценку стандарта ошибка /сигма, а также 95% доверительный интервал.
- Наконец, выходные данные содержат сводку о количестве цензурированных по левому краю, без цензуры и по правому краю. ценности.
Мы можем проверить общий эффект prog с помощью команды test . Ниже мы видим, что общий эффект прог является статистически значимым.
Ниже мы видим, что общий эффект прог является статистически значимым.
тест 2.прог 3.прог
( 1) [модель]2.prog = 0
( 2) [модель]3.prog = 0
F(2, 196) = 5,98
Вероятность > F = 0,0030 Мы также можем проверить дополнительные гипотезы о различиях в коэффициенты для разных уровней прог . Ниже мы проверить, что коэффициент для прог =2 равен коэффициенту для прог =3. В выводе ниже мы видим, что коэффициент для прог =2 равен существенно отличается от коэффициента для прог =3.
тест 2.прог = 3.прог
( 1) [модель]2.прог - [модель]3.прог = 0
F(1, 196) = 6,66
Вероятность > F = 0,0106 Мы также можем захотеть увидеть, насколько хорошо подходит наша модель. Это может быть
особенно полезно при сравнении конкурирующих моделей. Один из способов сделать это
сравнить предсказанные значения на основе тобитной модели с наблюдаемыми значениями в
набор данных. 2 = 0,6123) своей дисперсии с ап . Кроме того,
мы можем использовать написанную пользователем команду fitstat для получения разнообразной статистики соответствия. Вы можете найти дополнительную информацию
на fitstat , введя search fitstat (см.
Как я могу использовать
команда поиска для поиска программ и получения дополнительной помощи? для большего
информация об использовании поиска ).
2 = 0,6123) своей дисперсии с ап . Кроме того,
мы можем использовать написанную пользователем команду fitstat для получения разнообразной статистики соответствия. Вы можете найти дополнительную информацию
на fitstat , введя search fitstat (см.
Как я могу использовать
команда поиска для поиска программ и получения дополнительной помощи? для большего
информация об использовании поиска ).
фитстат
Меры соответствия для tobit of apt
Только перехват Log-Lik: -1135.545 Полная модель Log-Lik: -1041.063
Д(193): 2082,126 LR(4): 188,965
Вероятность > LR: 0,000
McFadden's R2: 0,083 McFadden Adj R2: 0,077
ML (Кокса-Снелла) R2: 0,611 Cragg-Uhler (Nagelkerke) R2: 0,611
R2 Маккелви и Завойны: 0,616
Дисперсия y*: 11230,171 Дисперсия ошибки: 4313,432
АИК: 10,481 АИК*n: 2096.126
БИК: 1059,550 БИК': -167,772
BIC, используемый Stata: 2113.916 AIC, используемый Stata: 2094.126 См.
