
Что такое научная статья: ✏️ виды, особенности
Какие бывают научные статьи?
Научный журнал
Написание научных статей – это процесс, который должен осуществляться в соответствии с установленными правилами. Поэтому перед тем как приступить к работе, необходимо ознакомиться с требованиями, предъявляемыми к трудам данного типа.
Печать научных статей является обязательным условием для ведения научной деятельности. Именно по количеству и качеству печатных работ оцениваются качественные характеристики ученого. Основной целью для публикации является доведение до общественности результатов исследования ученого.
Что такое научная статья?
Научная статья – это работа, содержащая основные результаты исследования, проведенного с использованием научных методов.
Объем статьи зависит от конкретных требований издания. Как правило, объем текста должен составлять не менее 5 машинопечатных страниц.
Виды научных статей
Статьи принято разделять по следующим критериям:
1. Предмет и метод исследования:
- научно-теоретическая – содержит описание теоретических разработок в доступной для обывателя форме;
- научно-практическая – содержит описание экспериментальных исследований и опытов;
- обзорные исследования – анализ взглядов ученых по тому или иному вопросу;
2. Стиль:
- аналитические – применяется исключительно строгий научный стиль, с употреблением специализированных определений и терминологии;
- научно-публицистические – сочетают в себе как научный стиль, так и публицистический.
 Характерен более свободный стиль подачи, с эмоциональным подтекстом, а терминология преобразована в доступную для широкой аудитории;
Характерен более свободный стиль подачи, с эмоциональным подтекстом, а терминология преобразована в доступную для широкой аудитории; - научно-практические – содержат результаты, полученные в ходе исследования.
3. Тип публикации:
- cтатья в журнале из перечня ВАК – по правилам Высшей аттестационной комиссии, каждый соискатель ученой степени в обязательном порядке должен иметь необходимое число статей в соответствующих изданиях. Требования в журналах ВАК практически не отличаются от требований других изданий. За исключением того, что уникальность текста должна быть не менее 75%, а также работа должна обладать оригинальностью и новизной. Помимо этого, требуется строгое соблюдение точности при цитировании и составлении библиографических списков;
- статья, индексируемая в РИНЦ, – это актуальный способ повышения статусности ученого. Российский индекс научного цитирования позволяет отслеживать активность автора. Поэтому многие стремятся публиковаться именно в данных изданиях.

Структура статьи для публикации включает в себя:
- Название;
- Аннотацию;
- Ключевые слова;
- Введение;
- Основную часть;
- Заключение;
- Список источников и используемой литературы.
Основа научной статьи заключается в значимости работы, актуальности поставленной цели и задач, а также научной новизне.
Создание научной статьи – это процесс, требующий не только четкого соблюдения правил относительно содержания и оформления текста работы, но и логического изложения материала и грамотности.
Характерной особенностью научной статьи является то, что в ее состав входит значительное количество фактов, которые должны быть подкреплены ссылками на первоисточники или же на результаты собственных исследований.
При изложении текста следует придерживаться научного стиля речи и избегать неаргументированных оценочных суждений. Текст работы должен придерживаться объективности, логичности и точности. Знание и выполнение основных требований написания статьи позволит ученому без лишних сложностей опубликовать свой труд в желаемом издании.
Текст работы должен придерживаться объективности, логичности и точности. Знание и выполнение основных требований написания статьи позволит ученому без лишних сложностей опубликовать свой труд в желаемом издании.
Автор: СибАК
Читайте также
Импакт-фактор журнала в научных базах
Перечень журналов, рекомендованных ККСОН МОН РК
Что такое ISBN и ISSN? Зачем они нужны?
Форма обратной связи о взаимодействии с сайтом
Укажите Ваше имя *
Адрес Вашей электронной почты *
Оставьте свой комментарий, если у вас возникли проблемы при работе с сайтом
Согласие *
Я согласен (-на) с условиями Публичной Оферты и даю свое Согласие на обработку персональных данных
Как читать научные статьи
Ироничный текст Адама Рубена о типичных затруднениях и разочарованиях, возникающих при чтении научных статей, вызвал большой резонанс среди читателей журнала Science Careers. Многие из вас приходят к нам за советом (и каждый раз все более серьезным), как разбираться в научной литературе, поэтому мы попросили нескольких специалистов из разных областей, находящихся на разных этапах карьеры, рассказать, как же им это удается. Всем хорошо известно, что легкость прочтения научных статей приходит с опытом, но, несмотря на это, препятствия реальны, и задача каждого ученого состоит в том, чтобы найти и применить наиболее удачную технику прочтения. Ответы прошли редакцию для большей лаконичности и ясности речи.
Многие из вас приходят к нам за советом (и каждый раз все более серьезным), как разбираться в научной литературе, поэтому мы попросили нескольких специалистов из разных областей, находящихся на разных этапах карьеры, рассказать, как же им это удается. Всем хорошо известно, что легкость прочтения научных статей приходит с опытом, но, несмотря на это, препятствия реальны, и задача каждого ученого состоит в том, чтобы найти и применить наиболее удачную технику прочтения. Ответы прошли редакцию для большей лаконичности и ясности речи.
Я начинаю с изучения абстракта. Затем смотрю вступление и бегло просматриваю статью целиком, чтобы задержаться на схемах и рисунках. Я стараюсь найти 1-2 наиболее значимых рисунка и убеждаюсь, что могу понять, что на них изображено. Затем я читаю заключение (summary). Лишь после того, как все это сделано, я возвращаюсь к техническим деталям для поиска ответов на появившиеся вопросы.
— Jesse Shanahan, магистрант астрономии Уэслианского Университета, Мидделтаун, штат Коннектикут.
Общее представление я получаю при чтении абстракта и заключения. Заключение помогает мне понять, была ли достигнута цель, обозначенная в абстракте, и может ли описанная работа оказаться полезной для моего собственного исследования. Я всегда смотрю на графики и рисунки — они помогают мне получить первое впечатление от статьи. Затем я обычно читаю всю статью от начала до конца, и таким образом могу следовать заданному авторами порядку работы.
Если вы хотите читать статьи как можно более продуктивно, вам нужно четкое представление о том, какая именно информация вам необходима в первую очередь, а затем следует сфокусироваться на этом аспекте. Например, это может быть сравнение ваших результатов с результатами авторов: поместите ваш анализ в контекст или расширьте его, используя недавно опубликованные данные. Является ли статья для вас важной, поможет понять список цитирований: он даст актуальную информацию о том, как коллеги по вашей теме применяют эту статью в своих исследованиях.
— Cecilia Tubiana, исследователь в Институте исследований Солнечной системы Общества Макса Планка, Гёттинген, Германия.
Если я буду стремиться понять основные моменты, то прочитаю абстракт, далее перескочу на рисунки и просмотрю главные пункты в дискуссии. Мне кажется, иллюстрации являются самой важной частью статьи, потому что c абстрактом и основной частью можно «сыграть» для того, чтобы создать убедительную историю. Затем все, что мне непонятно, я разбираю в методах.
Если я хочу копнуть в статью поглубже, для начала читаю ее целиком, а затем отыскиваю несколько предшествующих статей этой научной группы или другие материалы на эту же тему. Если после утверждения, которое мне показалось особенно интересным или противоречивым, есть ссылка, то я смотрю и её. Если вдруг требуется больше деталей, я заглядываю в репозитории с предоставленными данными или смотрю дополнительную информацию (приложения к статье).
Затем, если исследование авторов статьи похоже на мое, я смотрю, совпадает ли релевантная информация с нашими данными или есть какие-то противоречия. Если они есть, анализирую, что же могло их вызвать. Кроме этого, я думаю, что могло бы произойти с нашей моделью, если бы мы использовали такие же, как в статье, методы, и какие выводы из этого можно сделать. Иногда важно уделить внимание тому, почему авторы решили провести эксперимент именно таким образом. Может быть, они использовали малоизвестный тест вместо общепринятого анализа, тогда почему они это сделали?
Если они есть, анализирую, что же могло их вызвать. Кроме этого, я думаю, что могло бы произойти с нашей моделью, если бы мы использовали такие же, как в статье, методы, и какие выводы из этого можно сделать. Иногда важно уделить внимание тому, почему авторы решили провести эксперимент именно таким образом. Может быть, они использовали малоизвестный тест вместо общепринятого анализа, тогда почему они это сделали?
— Jeremy C. Borniger, аспирант в области нейробиологии, Университет штата Огайо, Колумбус
Я всегда начинаю с названия и абстракта. Это позволяет мне понять, заинтересован ли я в этой статье и, вообще говоря, способен ли ее понять – как с научной, так и с лингвистической точки зрения. Затем я читаю вступление, чтобы понять, какой вопрос сформулирован, и перескакиваю на рисунки и таблицы для того, чтобы разобраться в данных. Далее читаю обсуждение, чтобы получить представление о том, как статья соотносится с общей научной картиной.
Я уделяю внимание адекватному восприятию ограничений и правильности выводов. Тревожным сигналом для меня служит преувеличение авторами значимости своих аргументов. Как эпидемиолог, я могу попробовать удостовериться в том, что дизайн исследования был адекватен для того, чтобы действительно протестировать заявленную гипотезу.
Погружаясь глубже в формирование аргументов, рисунков и дискуссий, я думаю, какие части являются волнующими и новыми, какие биологически или логически релевантны, а какие больше всего поддерживаются литературой. Я всегда обдумываю, какие части статьи соответствуют моим гипотезам и вопросам в исследовательской деятельности.
— Kevin Boehnke, докторант в области гигиены окружающей среды, Мичиганский университет, Энн-Арбор.
Моя стратегия чтения зависит от статьи. Иногда я начинаю с беглого просмотра, чтобы оценить количество релевантной информации. Если статья полностью соответствует моей нынешней теме, то прочитаю ее внимательно, за исключением вступления, которое наверняка и так хорошо знакомо. Я всегда стараюсь выяснить, если ли в статье такие части текста и рисунки, на которые мне стоит обратить больше внимания; затем читаю сопроводительную информацию в результатах и обсуждение.
Я всегда стараюсь выяснить, если ли в статье такие части текста и рисунки, на которые мне стоит обратить больше внимания; затем читаю сопроводительную информацию в результатах и обсуждение.
Я также проверяю наличие ссылок, которые могли бы быть мне интересны. Иногда любопытно посмотреть, какой специалист из данной научной сферы был процитирован, или скорее, какой процитирован не был, чтобы узнать, не проигнорировали ли авторы некоторые аспекты исследования. Я неоднократно замечал, что дополнительные иллюстрации всегда содержат наиболее любопытные и интересные результаты, особенно если они относятся к части исследования, которую авторы не комментируют, или если эти результаты неоднозначно или нерадиво интерпретируют весь материал.
— Gary McDowell, постдок в области биологии развития, университет Тафтса, Медфорд, Массачусетс, приглашенный научный сотрудник в Бостонском колледже.
В чтении статей мне помогает наличие письменного задания, поэтому я остаюсь активным читателем, вместо того, чтобы позволить глазам остекленело просматривать горы текста для того, чтобы сразу забыть все, что я только что прочитал. Например, при чтении справочной информации я сохраняю информативные предложения из каждой статьи в определенный документ в Word. Заодно и пишу комментарии о новых идеях или вопросах, которые мне следует изучить в дальнейшем. В будущем мне понадобится прочитать только этот документ вместо того, чтобы перечитывать все отдельные статьи.
Например, при чтении справочной информации я сохраняю информативные предложения из каждой статьи в определенный документ в Word. Заодно и пишу комментарии о новых идеях или вопросах, которые мне следует изучить в дальнейшем. В будущем мне понадобится прочитать только этот документ вместо того, чтобы перечитывать все отдельные статьи.
Аналогично, когда требуется выяснить, как провести определенный эксперимент, я создаю удобную табличку в Excel, в которой собираю информацию о том, как поступили разные команды исследователей, проделывая его.
— Lina A. Colucci, докторант по программе Harvard-MIT Health Sciences and Technology program
Обычно я начинаю с абстракта – он дает краткое описание исследования. Затем читаю статью целиком, оставляя методы напоследок: сначала разбираю результаты и эксперименты, если они мне непонятны.
Разделы с результатами и методами позволяют оторваться от статьи, чтобы удостовериться в том, что она выдерживает проверку на научную строгость. Всегда нужно думать о типе проведенных экспериментов: действительно ли они способны ответить на поставленный вопрос. Необходимо удостовериться, что авторы включили актуальную информацию и необходимое количество контролей. Часто заключения могут быть основаны на небольшом числе образцов, что ограничивает их значимость.
Всегда нужно думать о типе проведенных экспериментов: действительно ли они способны ответить на поставленный вопрос. Необходимо удостовериться, что авторы включили актуальную информацию и необходимое количество контролей. Часто заключения могут быть основаны на небольшом числе образцов, что ограничивает их значимость.
Мне нравится распечатывать статьи и выделять наиболее важную информацию, чтобы при беглом прочтении можно было вспомнить основные моменты. Наиболее значимыми будут те вещи, которые помогают вам изменить ход мыслей о собственном исследовании или дают новые идеи и направления работы.
— Lachlan Gray, заместитель начальника лаборатории HIV Neuropathogenesis Lab института Бюрне и ассистент кафедры инфекционных болезней университета Монаша, Мельбурн, Австралия.
Статьи для чтения я выбираю на основании их близости к области моих исследований, а также беру те статьи, которые порождают уйму заинтересованности и дискуссий, потому что они ведут психологию или, если взять шире, науку целиком, в новых направлениях. Зачастую то, что я пытаюсь вычленить из статей – это проблемы методологии, дизайн экспериментов и статистический анализ. На мой взгляд, наиболее значимые разделы — это, во-первых, что авторы сделали (методы) и, во-вторых, что они обнаружили (результаты).
Зачастую то, что я пытаюсь вычленить из статей – это проблемы методологии, дизайн экспериментов и статистический анализ. На мой взгляд, наиболее значимые разделы — это, во-первых, что авторы сделали (методы) и, во-вторых, что они обнаружили (результаты).
Также бывает интересно понять, почему авторы решили работать именно над этим исследованием (вступление) и как они интерпретируют результаты (обсуждение). Обычно, если это область, в которой я хорошо ориентируюсь, я не забочусь об этих разделах, потому что чаще всего они отражают предпочтения авторов и являются одним из множества способов интерпретации метода и результатов. Но если тема мне малознакома, то я читаю эти разделы внимательно, потому что таким образом узнаю многое о предположениях и подходах к истолкованию результатов в этой области знаний.
— Brian Nosek, профессор кафедры физиологии Университета Виргинии и исполнительный директор центра Center for Open Science в Шарлоттсвиле.
Сначала я читаю очень быстро: цель первого прочтения — просто посмотреть, интересна ли статья для меня. Если да, то я читаю ее второй раз, медленнее, и уделяя больше внимания деталям.
Если да, то я читаю ее второй раз, медленнее, и уделяя больше внимания деталям.
Если статья крайне необходима для моего исследования и если она теоретическая – я сам пройду по пути исследователей, писавших статью: возьму начальную точку и затем проработаю все остальное самостоятельно, не заглядывая в материал. Иногда это мучительно медленный процесс. Иногда я злюсь на авторов, если они недостаточно понятно все написали, пренебрегли важными моментами и зациклились на всяких глупостях. Иногда остаюсь очень взволнованным статьей.
— Ulf Leonhardt, профессор физики института Вейцмана в Реховоте, Израиль.
Почти всегда начинаю с абстракта и продолжаю читать статью, только если он говорит о том, что статья обладает некой ценностью для меня. Затем, если тема статьи мне хорошо известна, я пропускаю вступление, читая последний параграф, чтобы удостовериться, что осведомлен о конкретном вопросе, рассматриваемом в статье. Затем смотрю иллюстрации и таблицы и читаю или бегло просматриваю результаты, а далее поступаю так же с обсуждением.
Если тема мне не очень хорошо известна, я читаю вступление гораздо тщательнее, чтобы исследование поместилось в определенный контекст, понятный мне. Затем просматриваю рисунки и таблицы и читаю результаты.
— Charles W. Fox, профессор кафедры энтомологии в Университете Кентукки, Лексингтон.
Важно осознавать, что рациональные методы чтения статей нужны для того, чтобы оставалось время и на другую работу, например: написание статей, проведение исследований, посещение конференций, преподавание и оценку статей. Начиная как студент-философ, я читала лишь заключения и методы статей в академических журналах и главы, а не книги целиком.
— Rima Wilkes, профессор кафедры социологии Университета Британской Колумбии, Ванкувер.
Как главный редактор журнала Science, я все время должна читать и понимать статьи за пределами моего поля деятельности. Как правило, начинаю с соответствующих отчетов редакторов, которые сделаны для людей вроде меня: ученых широкого профиля, интересующихся всем, но глубоко погруженных лишь в одну тему. Затем я проверяю, написал ли кто-нибудь новостную заметку по поводу этой статьи. После этого проверяю, есть ли обзор на статью (perspective) другого ученого. Основной целью подобного обзора является распространение идеи статьи, но зачастую авторы проделывают огромную работу, адаптируя основные ее идеи для неспециалистов.
Затем я проверяю, написал ли кто-нибудь новостную заметку по поводу этой статьи. После этого проверяю, есть ли обзор на статью (perspective) другого ученого. Основной целью подобного обзора является распространение идеи статьи, но зачастую авторы проделывают огромную работу, адаптируя основные ее идеи для неспециалистов.
Затем я берусь за абстракт, который написан для контакта с широкой читательской аудиторией. В конце концов, перемещаюсь непосредственно к статье и читаю ее в таком порядке: вступление, заключение, иллюстрации, а затем и остальной текст.
— Marcia K. McNutt, главный редактор Science.
Что вы делаете, обнаружив в статье что-то непонятное?
Я люблю читать онлайн, поэтому могу с легкостью вырезать и вставлять незнакомые слова в браузер, чтобы уточнить, что они обозначают.
— McNutt
Если непонятного совсем немного, сделаю заметку, чтобы поискать попозже. Если я действительно испытываю трудности по ходу материала, то стараюсь посмотреть обзорную статью или главу в учебнике для получения необходимых базовых знаний по теме, в целом, я нахожу это весьма эффективным.
Встречается множество аббревиатур и профессиональных терминов, специфических для данной научной области, поэтому я обычно не зацикливаюсь на таких деталях, если, конечно, это не касается моего собственного исследования. Однако всегда стараюсь выделить побольше времени на понимание используемых авторами методов.
— Shanahan
Как правило, я немедленно останавливаюсь, чтобы выяснить моменты, которых не понимаю. Остаток чтения не имеет смысла, если я не понял ключевую фразу или термин. В свою очередь, это может дать обратный эффект: после поиска какой-либо информации я постоянно обрастаю не имеющими конца трудностями (Что такое Х? О, оно влияет на Y… Хм, а что такое Y? И так далее…). Изучение того, как все взаимосвязано, может оказаться особым развлечением, но если вы оказываетесь загружены на долгое время, это будет отвлекать от поставленной задачи.
Иногда обилие терминов в статье может “спрятать” всю суть эксперимента. В таких случаях стоит спросить себя: «На какой вопрос пытались ответить авторы?». После этого можно понять, пришли ли они к успеху или нет.
После этого можно понять, пришли ли они к успеху или нет.
— Borniger
Зависит от количества сложных для понимания частей, которые препятствуют улавливанию смысла основных идей статьи. Обычно я не пытаюсь понять детали всех разделов во время первого прочтения. Если непонятные части оказываются важными для моего исследования, я расспрашиваю коллег или контактирую с главным автором напрямую. Возвращение к оригинальным ссылкам для попытки понять всю сопроводительную информацию, на мой взгляд, является последней инстанцией, потому что время может быть ограничено, а личное общение и сотрудничество окажутся гораздо более эффективными в решении проблем подобного рода.
— Tubiana
Иногда можно просто пробежать глазами всю статью, а термины, с которыми вы не очень знакомы, станут понятнее в конце. Остановитесь и поищите дополнительную информацию, если материал идет тяжело, — обычно это помогает продвинуться дальше. Я часто гуглю тему, проблему, методы, термины и т. д. Порой, если это очень насыщенная статья, необходимо несколько раз просмотреть её, пока всё не станет понятным.
д. Порой, если это очень насыщенная статья, необходимо несколько раз просмотреть её, пока всё не станет понятным.
— Gray
Вопрос, который я задаю себе: «Нужно ли мне понять, что это значит, с целью получить необходимое из этой статьи?». Сейчас я читаю статьи из области исследований, выходящих далеко за пределы моей компетенции, и часто нужны лишь поверхностные знания основного содержания. Если я ничего не могу сделать с материалом до того, как не пойму всю его глубину, приходится проводить больше дополнительных исследований.
— Nosek
В последнее время мне нужно было прочесть несколько статей не по моей специализации с большим количеством непонятных терминов. В некоторых случаях я в состоянии вытащить необходимую информацию непосредственно из результатов или рисунков и таблиц. В других случаях я использую Гугл для того, чтобы понять термины и идеи написанного, или читаю цитированный материал для лучшего понимания особенностей сделанной работы. Временами статьи настолько непонятны (во всяком случае, для меня), что я и не пытаюсь их читать.
Временами статьи настолько непонятны (во всяком случае, для меня), что я и не пытаюсь их читать.
— Fox
Такое происходит постоянно. Если статья имеет отношение к проблеме, которую я стараюсь решить, можете не сомневаться, что в ней есть ключевые моменты, которые я не понимаю. Это замешательство не является негативным фактором, напротив — возможностью. Я малокомпетентна, и я хочу стать менее несведущей. Эта статья мне поможет.
В то же время некоторые статьи написаны ужасно, и дело того не стоит. Кто-то иной несомненно описал концепт исследования понятнее, поэтому можно задержаться на понимании сути происходящего, а не на понимании неадекватной грамматики.
— Nosek
Особенно сложно справиться со статьей, если она не вписывается в область моей работы, тем более, если она длинная и пестрит техническими терминами. Когда это случается, я разделяю статью на фрагменты и читаю ее в течение нескольких дней, если это возможно. Что касается действительно трудных статей, то помогает посидеть и проработать их с коллегой.
— Shanahan
Да, много раз. Поэтому я разработала собственную стратегию чтения, методом проб и ошибок, а также общаясь с другими учеными. Бывало, что из-за расстройства у меня опускались руки, и я отбрасывала неприятные статьи, никогда больше к ним не возвращаясь.
— Boehnke
Да, и в этих случаях вы должны понимать, что некоторые статьи являются результатом нескольких лет работы многих ученых. Ожидать усвоения материала и понимания статьи всего за 1 вечер – притянутая за уши идея.
— Borniger
Мне всегда кажется, что я не в состоянии справиться! Но некоторые разделы не нуждаются в таком глубоком понимании, как другие. Вы также должны осознавать собственные границы возможного: может, в статье есть части, которые вы бы хотели “превзойти”, но они не в вашей компетенции и могут стать «доступными» посредством коллабораций?
— Tubiana
Если я понимаю, что статья очень важна для моей работы, я оставляю ее на какое-то время и возвращаюсь к ней несколько раз. Но если она совсем мне не по силам, оставляю ее в стороне до того момента, пока кто-нибудь из моих коллег не сможет ее объяснить.
Но если она совсем мне не по силам, оставляю ее в стороне до того момента, пока кто-нибудь из моих коллег не сможет ее объяснить.
— McDowell
Если есть оригинальная статья, которую я хочу как следует понять, я найду способ рассказать презентацию о ней на семинаре по разбору публикаций. Обсуждение конкретной статьи и ответы на вопросы – для меня лучший способ закрепить материал.
Кроме того, заведите хорошую библиографическую базу. Mendeley помогает делать мне исследования, читать литературу и писать статьи.
— Colucci
В начале новым читателям академических текстов это занятие покажется медленным, потому что у них нет системы взглядов на проблему, о которой они читают. Но есть способы использовать чтение для создания интеллектуальной библиотеки, и после нескольких лет становится всё легче складывать статьи на интеллектуальные полочки. В дальнейшем вы можете быстро просмотреть статью, чтобы оценить ее вклад.
— Wilkes
Будьте терпеливы. Не стоит бояться или стыдиться использовать Википедию или другие ресурсы, больше направленные на непрофессиональную аудиторию (например, посты в блогах), для того, чтобы получше разобраться в теме. Задавайте много, очень много вопросов. Если у вас не получается понять материал, поговорите с людьми вашего круга деятельности. Если вы все еще озадачены, но понять концепт статьи действительно важно, напишите авторам.
Не стоит бояться или стыдиться использовать Википедию или другие ресурсы, больше направленные на непрофессиональную аудиторию (например, посты в блогах), для того, чтобы получше разобраться в теме. Задавайте много, очень много вопросов. Если у вас не получается понять материал, поговорите с людьми вашего круга деятельности. Если вы все еще озадачены, но понять концепт статьи действительно важно, напишите авторам.
— Boehnke
Не стесняйтесь разговаривать с более опытными учеными. Вы сделаете ИМ любезность, позволив объяснить вам в понятных для вас выражениях суть этой сложной статьи. Всем ученым необходимо приобретать больше опыта перевода сложных понятий в общепринятые термины.
— McNutt
Если это вообще возможно, читайте чаще. Постарайтесь завести файл с библиографией, где содержатся все статьи, важные заметки, даже некоторые рисунки и информация о ссылках. Уделяйте внимание разным способам структуризации статьи и разным стилям написания.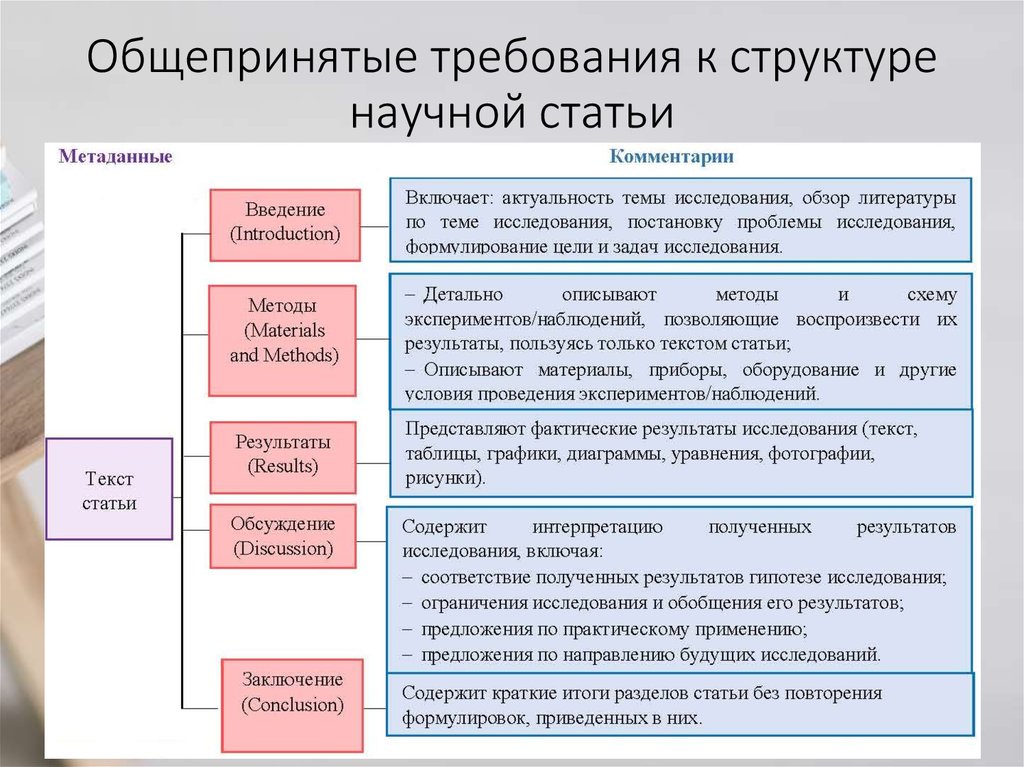 Это поможет вам разработать собственный стиль, который будет эффективным и в то же время уникальным.
Это поможет вам разработать собственный стиль, который будет эффективным и в то же время уникальным.
— Shanahan
Юридический и почтовый адрес организации-издателя: САФУ, редакция журнала «Вестник САФУ. Серия “Гуманитарные и социальные науки”», наб. Северной Двины, 17, г. Архангельск, Россия, 163002 Тел: (818-2) 21-61-21 | Научная статья имеет четкую структуру и, как правило, состоит из следующих частей:
Рассмотрим особенности составных элементов научной статьи и основные требования, которые необходимо соблюдать при работе над ними. Название Название (заголовок) — обозначение структурной части основного текста произведения (раздела, главы, параграфа, таблицы и др.) или издания. Основное требование к названию статьи — краткость и ясность. Максимальная длина заголовка — 10-12 слов. Заголовок статьи должен: — быть информативным, — привлекать внимание читателя, — соответствовать научному стилю речи, — отражать главную тему исследования и не вводить читателя в заблуждение относительно рассматриваемых в статье вопросов, — содержать некоторые из ключевых слов, отражающих суть статьи. В заголовке можно использовать только общепринятые сокращения. При переводе заглавия статьи на английский язык не должно использоваться никаких транслитераций с русского языка, кроме непереводимых названий собственных имен, приборов и др. объектов, имеющих собственные названия; также не используется непереводимый сленг, известный только русскоговорящим специалистам. Резюме (аннотация) Резюме – это не зависимый от статьи источник информации. Ее пишут после завершения работы над основным текстом статьи. Резюме выполняет следующие функции: — позволяет определить основное содержание статьи, его релевантность и решить, следует ли обращаться к полному тексту публикации; — используется в информационных, в том числе автоматизированных системах для поиска документов и информации. Резюме должны быть оформлены по международным стандартам и включать следующие моменты.
В резюме излагаются существенные факты работы, здесь не должно содержаться материала, который отсутствует в самой статье. Предмет, тема, цель работы указываются, если они не ясны из заглавия статьи; метод или методологию проведения работы имеет смысл описывать в том случае, если они отличаются новизной или представляют интерес с точки зрения данной работы. Результаты работы описывают предельно точно и информативно. Приводятся основные теоретические и экспериментальные результаты, фактические данные, обнаруженные взаимосвязи и закономерности. При этом отдается предпочтение новым результатам, важным открытиям, выводам, которые опровергают существующие теории, а также данным, имеющим практическое значение. Выводы могут сопровождаться рекомендациями, оценками, предложениями, гипотезами, описанными в статье. В тексте резюме следует употреблять синтаксические конструкции, свойственные языку научных и технических документов, избегать сложных грамматических конструкций. Он должен быть лаконичен и четок, без лишних вводных слов, общих формулировок. Ключевые слова Ключевыми являются слова и словосочетания, выражающие основное смысловое содержание статьи, служащие ориентиром для читателя и использующиеся для поиска статей в электронных базах, по этой причине среди них не должно быть общеупотребительных – это может усложнить поиск. Размещаются после аннотации в количестве 4–8 слов, приводятся на русском и английском языках. Одно ключевое слово должно выражать одно понятие: например, ценностно-смысловые ориентации, школы рабочей молодежи, этничность, северный эпос, экзистенциальная детерминация, северные конвои. Введение Введение призвано дать вводную информацию, касающуюся темы статьи, объяснить, с какой целью предпринято исследование. Во введении в обязательном порядке четко формулируются: — цель и объект предпринятого автором исследования. Работа должна содержать определенную идею, ключевую мысль, раскрытию которой она посвящена. Чтобы сформулировать цель, необходимо ответить на вопрос: «Что вы хотите создать в итоге проведенного исследования?» Этим итогом могут быть новая методика, классификация, алгоритм, структура, новый вариант известной технологии, методическая разработка и т. д. Формулировка цели любой работы, как правило, начинается с глаголов: выяснить, выявить, сформировать, обосновать, проверить, определить и т. п. Объект – это материал изучения. — актуальность и новизна. Актуальность темы – степень ее важности в данный момент и в данной ситуации. Это способность результатов работы быть применимыми для решения достаточно значимых научно-практических задач. Новизна – это то, что отличает результат данной работы от результатов, полученных другими авторами. — исходные гипотезы, если они существуют. Также в этой части работы читателя при необходимости знакомят со структурой статьи. После написания введения его необходимо проанализировать по следующим ключевым пунктам: — четко ли сформулированы цели, объект и исходные гипотезы, если они существуют;· — нет ли противоречий;· — указана ли актуальность и новизна работы.· Обзор литературы Обзор литературы представляет собой теоретическое ядро исследования. Его цель – изучить и оценить существующие работы по данной тематике. Предпочтительным является не просто перечисление предшествующих исследований, но их критический обзор, обобщение основных точек зрения. Основная часть Методология В данном разделе описывается последовательность выполнения исследования и обосновывается выбор используемых методов. Он должен дать возможность читателю оценить правильность этого выбора, надежность и аргументированность полученных результатов. Смысл информации, излагаемой в этом разделе, заключается в том, чтобы другой ученый достаточной квалификации смог воспроизвести исследование, основываясь на приведенных методах. Отсылка к литературным источникам без описания сути метода возможна только при условии его стандартности. Результаты В этой части статьи должен быть представлен авторский аналитический, систематизированный материал. Результаты проведенного исследования необходимо описывать достаточно полно, чтобы читатель мог проследить его этапы и оценить обоснованность сделанных автором выводов. По объему эта часть занимает центральное место в научной статье. Это основной раздел, цель которого заключается в том, чтобы при помощи анализа, обобщения и разъяснения данных доказать рабочую гипотезу (гипотезы). В зависимости от уровня знаний – теоретического или эмпирического – различают теоретические и эмпирические статьи. Теоретические научные статьи включают результаты исследований, выполненных с помощью таких методов познания, как абстрагирование, синтез, анализ, индукция, дедукция, формализация, идеализация, моделирование. Если статья имеет теоретический характер, чаще всего она строится по следующей схеме: автор вначале приводит основные положения, мысли, которые в дальнейшем будут подвергнуты анализу с последующим выводом. Результаты исследования должны быть изложены кратко, при этом содержать достаточно информации для оценки сделанных выводов, также должно быть очевидно, почему для анализа выбраны именно эти данные. Заключение, выводы Заключение содержит краткую формулировку результатов исследования. В нем в сжатом виде повторяются главные мысли основной части работы. Всякие повторы излагаемого материала лучше оформлять новыми фразами, новыми формулировками, отличающимися от высказанных в основной части статьи. В этом разделе необходимо сопоставить полученные результаты с обозначенной в начале работы целью. В заключении суммируются результаты осмысления темы, делаются выводы, обобщения и рекомендации, которые вытекают из работы, подчеркивается их практическая значимость, а также определяются основные направления для дальнейшего исследования в этой области. | Отправить материал Arctic Environmental Research Журнал медико-биологических Лесной журнал “Арктика и Север” |

 Название должно быть содержательным, выразительным, отражать содержание статьи.
Название должно быть содержательным, выразительным, отражать содержание статьи.  Она включает характеристику основной темы, проблемы, объекта, цели работы и ее результаты. В ней указывают, что нового несет в себе данный документ в сравнении с другими, родственными по тематике и целевому назначению. Рекомендуемый объем — 200–250 слов на русском и английском языках.
Она включает характеристику основной темы, проблемы, объекта, цели работы и ее результаты. В ней указывают, что нового несет в себе данный документ в сравнении с другими, родственными по тематике и целевому назначению. Рекомендуемый объем — 200–250 слов на русском и английском языках.

 При написании введения автор прежде всего должен заявить общую тему исследования. Далее необходимо раскрыть теоретическую и практическую значимость работы и описать наиболее авторитетные и доступные для читателя публикации по рассматриваемой теме. Во введении автор также обозначает проблемы, не решенные в предыдущих исследованиях, которые призвана решить данная статья.
При написании введения автор прежде всего должен заявить общую тему исследования. Далее необходимо раскрыть теоретическую и практическую значимость работы и описать наиболее авторитетные и доступные для читателя публикации по рассматриваемой теме. Во введении автор также обозначает проблемы, не решенные в предыдущих исследованиях, которые призвана решить данная статья.

 Результаты при необходимости подтверждаются иллюстрациями – таблицами, графиками, рисунками, которые представляют исходный материал или доказательства в свернутом виде. Важно, чтобы проиллюстрированная информация не дублировала текст. Представленные в статье результаты желательно сопоставить с предыдущими работами в этой области как автора, так и других исследователей. Такое сравнение дополнительно раскроет новизну проведенной работы, придаст ей объективности.
Результаты при необходимости подтверждаются иллюстрациями – таблицами, графиками, рисунками, которые представляют исходный материал или доказательства в свернутом виде. Важно, чтобы проиллюстрированная информация не дублировала текст. Представленные в статье результаты желательно сопоставить с предыдущими работами в этой области как автора, так и других исследователей. Такое сравнение дополнительно раскроет новизну проведенной работы, придаст ей объективности. Эмпирические научные статьи, используя ряд теоретических методов, в основном опираются на практические методы измерения, наблюдения, эксперимента и т. п.
Эмпирические научные статьи, используя ряд теоретических методов, в основном опираются на практические методы измерения, наблюдения, эксперимента и т. п. В заключительную часть статьи желательно включить попытки прогноза развития рассмотренных вопросов.
В заключительную часть статьи желательно включить попытки прогноза развития рассмотренных вопросов.Editorial: Mining Scientific Papers: NLP-Enhanced Bibliometrics
1. Введение
Тема исследования «NLP-Enhanced Bibliometrics» направлена на содействие междисциплинарным исследованиям в библиометрии, обработке естественного языка (NLP) и компьютерной лингвистике с целью улучшения способы, которыми библиометрия может извлечь выгоду из крупномасштабной текстовой аналитики и анализа документов. Цели таких исследований заключаются в том, чтобы дать представление о научном письме и открыть новые перспективы для понимания как природы цитирования, так и природы научных статей и их внутренней структуры. Возможность обогащения метаданных путем полнотекстовой обработки статей открывает новую область исследований, где основные проблемы возникают вокруг организации и структуры текста, извлечения информации и ее представления на уровне метаданных.
Цели таких исследований заключаются в том, чтобы дать представление о научном письме и открыть новые перспективы для понимания как природы цитирования, так и природы научных статей и их внутренней структуры. Возможность обогащения метаданных путем полнотекстовой обработки статей открывает новую область исследований, где основные проблемы возникают вокруг организации и структуры текста, извлечения информации и ее представления на уровне метаданных.
В последнее время постоянно растущая доступность наборов данных и статей в полном тексте и в машиночитаемых форматах сделала возможным изменение перспективы в области библиометрии. От баз данных препринтов до движения Open Access и Open Science развитие онлайн-платформ, таких как ArXiv, CiteSeer или PLoS и т. д., в значительной степени облегчает экспериментирование с наборами данных статей, позволяя выполнять библиометрические исследования не только с учетом метаданные статей, но и их полное текстовое содержание.
Область НЛП предлагает методологические рамки и инструменты для полнотекстовой обработки документов, которые могут облегчить библиометрические исследования. Некоторые из инструментов с открытым исходным кодом для обработки текста, которые недавно применялись для таких задач, включают NLTK, Mallet, OpenNLP, CoreNLP, Gate, CiteSpace, AllenNLP и другие. Многие наборы данных в настоящее время находятся в свободном доступе для сообщества: например, PubMed OA, CiteSeerX, JSTOR, ISTEX, Microsoft Academic Graph, антология ACL и т. д. Дальнейшие разработки в этой области исследований требуют создания аннотированных корпусов и общих протоколов оценки, чтобы позволить сравнение различных инструментов и методов. Разработка таких ресурсов является важным шагом к тому, чтобы сделать возможной научную воспроизводимость.
Некоторые из инструментов с открытым исходным кодом для обработки текста, которые недавно применялись для таких задач, включают NLTK, Mallet, OpenNLP, CoreNLP, Gate, CiteSpace, AllenNLP и другие. Многие наборы данных в настоящее время находятся в свободном доступе для сообщества: например, PubMed OA, CiteSeerX, JSTOR, ISTEX, Microsoft Academic Graph, антология ACL и т. д. Дальнейшие разработки в этой области исследований требуют создания аннотированных корпусов и общих протоколов оценки, чтобы позволить сравнение различных инструментов и методов. Разработка таких ресурсов является важным шагом к тому, чтобы сделать возможной научную воспроизводимость.
2. Статьи по этой теме исследования
Все семь статей, опубликованных по этой теме исследования, были проанализированы двумя независимыми рецензентами.
В статье «Является ли реферат простым тизером? Оценка щедрости рефератов статей в науках об окружающей среде», Ермакова и др. рассматривает рефераты научных работ. На самом деле аннотация указывает на информацию, которая является наиболее важной для читателя и часто используется в качестве заменителя содержания статьи. Авторы предлагают шкалу GEM, которая измеряет репрезентативность реферата или его «щедрость». Чтобы получить этот балл, разделы статей были взвешены в соответствии с их важностью для читателя, а предложения в аннотациях были отнесены к разным разделам на основе их сходства с содержанием разделов. Было обработано более 36 000 статей по наукам об окружающей среде, извлеченных из базы данных ISTEX, для наблюдения за тенденциями в оценке GEM за 80-летний период времени. Результаты показывают, что тезисы, как правило, более обширны в недавних публикациях, и, по-видимому, нет никакой корреляции между оценкой GEM и уровнем цитирования статей.
На самом деле аннотация указывает на информацию, которая является наиболее важной для читателя и часто используется в качестве заменителя содержания статьи. Авторы предлагают шкалу GEM, которая измеряет репрезентативность реферата или его «щедрость». Чтобы получить этот балл, разделы статей были взвешены в соответствии с их важностью для читателя, а предложения в аннотациях были отнесены к разным разделам на основе их сходства с содержанием разделов. Было обработано более 36 000 статей по наукам об окружающей среде, извлеченных из базы данных ISTEX, для наблюдения за тенденциями в оценке GEM за 80-летний период времени. Результаты показывают, что тезисы, как правило, более обширны в недавних публикациях, и, по-видимому, нет никакой корреляции между оценкой GEM и уровнем цитирования статей.
В статье «Термолатор: распознавание терминологии на основе группирования, статистических и поисковых оценок» Meyers et al. предложить высокопроизводительную систему извлечения терминологии с открытым исходным кодом под названием Termolator, в которой используется сочетание основанных на знаниях и статистических компонентов. Инструмент Termolator включает в себя фрагментацию, которая отдает предпочтение фрагментам, содержащим слова, не входящие в словарь, номинализации, технические прилагательные и другие специализированные классы слов, а также поддерживает ранжирование фрагментов терминов. Авторы анализируют эффективность всех задействованных компонентов по отношению к общей производительности системы и сравнивают свою систему Termolator с системой извлечения терминологии под названием Termostat. Они используют золотой стандарт, состоящий из аннотированных вручную экземпляров встроенных терминов (номинальных выражений из нескольких слов) различных типов документов (например, патентов, журнальных статей).
Инструмент Termolator включает в себя фрагментацию, которая отдает предпочтение фрагментам, содержащим слова, не входящие в словарь, номинализации, технические прилагательные и другие специализированные классы слов, а также поддерживает ранжирование фрагментов терминов. Авторы анализируют эффективность всех задействованных компонентов по отношению к общей производительности системы и сравнивают свою систему Termolator с системой извлечения терминологии под названием Termostat. Они используют золотой стандарт, состоящий из аннотированных вручную экземпляров встроенных терминов (номинальных выражений из нескольких слов) различных типов документов (например, патентов, журнальных статей).
В статье «Углубленный анализ научной литературы по искусству и гуманитарным наукам» Rodrigues Alves et al. работа над архитектурой глубокого обучения для обнаружения, извлечения и классификации ссылок в полном тексте научных публикаций. Авторы исследуют встраивание слов на уровне слов и символов, различные уровни прогнозирования (Softmax и Conditional Random Fields) и многозадачность по сравнению с однозадачными компонентами обучения. Их эксперименты основаны на опубликованном наборе аннотированных ссылок из корпуса публикаций по историографии Венеции (книги и журнальные статьи на итальянском, английском, французском, немецком, испанском и латинском языках), опубликованных с девятнадцатого века до 2014 года. авторы показывают относительный положительный вклад их вложений слов на уровне символов. Авторы выпускают две реализации архитектуры в Keras и TensorFlow вместе со всеми данными для обучения и тестирования. Их результаты решительно поддерживают использование методов глубокого обучения для общей задачи интеллектуального анализа данных.
Их эксперименты основаны на опубликованном наборе аннотированных ссылок из корпуса публикаций по историографии Венеции (книги и журнальные статьи на итальянском, английском, французском, немецком, испанском и латинском языках), опубликованных с девятнадцатого века до 2014 года. авторы показывают относительный положительный вклад их вложений слов на уровне символов. Авторы выпускают две реализации архитектуры в Keras и TensorFlow вместе со всеми данными для обучения и тестирования. Их результаты решительно поддерживают использование методов глубокого обучения для общей задачи интеллектуального анализа данных.
В статье «Временные представления цитат для понимания изменяющихся ролей научных публикаций» Хе и Чен предлагают анализ временных характеристик цитат, чтобы представить динамическую роль научных публикаций. Для этого они изучают и сравнивают разные типы контекстов цитирования, чтобы выявить статьи, играющие важную роль в развитии науки. Предлагаемые методы могут иметь различное применение, например, для улучшения методов цитирования на индивидуальном или коллективном уровне, а также для улучшения систем рекомендаций, предназначенных для поиска информации путем определения важных или представляющих интерес статей.
В статье «Разрешение ссылок цитирования с помощью нейронных сетей» Номото представляет новый способ решения проблемы цитирования посредством применения моделей нейронных сетей и определения некоторых операционных факторов, влияющих на их поведение. Автор вводит понятие приблизительно правильных целей , которое представляет собой «идею о том, что мы должны рассматривать предложения, встречающиеся вблизи истинных целей, как одинаково правильные, посредством чего мы пытаемся идентифицировать область, которая, вероятно, включает в себя истинную цель, а не найти его точное местоположение». Эксперименты в статье проводятся с использованием трех наборов данных, разработанных с помощью общей задачи CL-SciSumm (репозиторий ACL), и настройки стиля перекрестной проверки.
Два документа «Корпус NLP4NLP (I и II): 50 лет публикации, сотрудничества и цитирования в обработке речи и языка» Мариани и др. и Мариани и др. представляют результаты обширного исследования набора данных в области обработки естественного языка (NLP) и обработки разговорного языка (SLP) за период 1956–2015 гг. Авторы исследуют различные тенденции, которые можно наблюдать в публикациях в этой конкретной области исследований. Исследование представлено в двух сопутствующих документах, в каждом из которых представлена своя точка зрения на анализ. В первой статье описывается корпус и представлен общий анализ количества статей, авторов, гендерного распределения, соавторства, моделей сотрудничества и моделей цитирования. Во второй статье исследуются темы исследований и их эволюция с течением времени, ключевые инновационные темы и авторы, которые их представили, а также повторное использование статей и плагиат. Вместе эти две статьи представляют собой обзор литературы по НЛП и СЛП, а также данные, позволяющие понять тенденции и эволюцию исследований в этом исследовательском сообществе. Это исследование также можно рассматривать как методологическую основу для проведения аналогичных обзоров для других научных областей. Авторы сообщают об основных препятствиях, возникающих при такой обработке. К первой относятся ошибки, связанные с автоматической обработкой полного текста статей и, в частности, отсканированного контента.
Авторы исследуют различные тенденции, которые можно наблюдать в публикациях в этой конкретной области исследований. Исследование представлено в двух сопутствующих документах, в каждом из которых представлена своя точка зрения на анализ. В первой статье описывается корпус и представлен общий анализ количества статей, авторов, гендерного распределения, соавторства, моделей сотрудничества и моделей цитирования. Во второй статье исследуются темы исследований и их эволюция с течением времени, ключевые инновационные темы и авторы, которые их представили, а также повторное использование статей и плагиат. Вместе эти две статьи представляют собой обзор литературы по НЛП и СЛП, а также данные, позволяющие понять тенденции и эволюцию исследований в этом исследовательском сообществе. Это исследование также можно рассматривать как методологическую основу для проведения аналогичных обзоров для других научных областей. Авторы сообщают об основных препятствиях, возникающих при такой обработке. К первой относятся ошибки, связанные с автоматической обработкой полного текста статей и, в частности, отсканированного контента. Вторым препятствием является отсутствие последовательной и единообразной идентификации авторов, организаций, названий конференций и т. д., которые требуют ручной корректировки экспертами в исследуемой области исследований.
Вторым препятствием является отсутствие последовательной и единообразной идентификации авторов, организаций, названий конференций и т. д., которые требуют ручной корректировки экспертами в исследуемой области исследований.
3. Заключение
Большое количество исследований по использованию научных документов с библиометрическими приложениями показывает растущий интерес библиометрического сообщества к этой теме. С 2016 года мы поддерживаем «Библиографию с расширенной библиометрией IR 1 », которая представляет собой библиографию всех научных статей (семинаров и журналов) по этой теме исследования. В 2018 году вышло два специальных выпуска, тесно связанных с данной темой исследования. Первый — это специальный выпуск «Библиометрически расширенный поиск информации и обработка естественного языка для цифровых библиотек (BIRNDL)» в 9-м выпуске.0023 Международный журнал цифровых библиотек (Mayr et al., 2018). Второй — «Библиометрический поиск информации и наукометрия» в Scientometrics (Cabanac et al. , 2018).
, 2018).
Статьи, опубликованные в этой теме исследований, вносят свой вклад в развитие науки благодаря теоретическим открытиям, практическим методам и технологиям обработки научных корпусов, включая полнотекстовую обработку, классификацию цитат, а также их временное представление, семантический анализ, анализ текста, и смежные темы. В совокупности эти документы определяют некоторые из новых проблем в этой области и прокладывают путь для будущих теоретических основ.
В этой области развиваются методы глубокого обучения с подходами, основанными на моделях нейронных сетей, которые могут сыграть фундаментальную роль в использовании цитат и их контекстов в научной литературе. В то время как разработка моделей нейронных сетей требует больших ресурсов, растущее количество наборов данных, доступных сегодня, позволяет реализовать этот тип технологии для анализа цитирований. Действительно, две статьи в этой теме исследования посвящены реализации моделей нейронных сетей для анализа цитирования (Rodrigues Alves et al. и Nomoto), а две другие — созданию и эксплуатации большого корпуса статей (Mariani et al. , и Мариани и др.).
и Nomoto), а две другие — созданию и эксплуатации большого корпуса статей (Mariani et al. , и Мариани и др.).
Вклад авторов
Все перечисленные авторы внесли существенный, непосредственный и интеллектуальный вклад в работу и одобрили ее для публикации.
Финансирование
Работа, выполненная PM, частично финансировалась Программой обмена персоналом (PPP) DST-DAAD под номером проекта DAAD: 57318047 Номер проекта DST: DST/INT/FRG/DAAD/P-28/2017 .
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов. 9https://github.com/PhilippMayr/Bibliometric-enhanced-IR_Bibliography/
Ссылки
Кабанак Г., Фромхольц И. и Майр П. (2018). Библиометрический поиск информации: предисловие. Наукометрия 116, 1225–1227. doi: 10.1007/s11192-018-2861-0
CrossRef Full Text | Google Scholar
Mayr, P. , Frommholz, I., Cabanac, G., Chandrasekaran, M.K., Jaidka, K., Kan, M.-Y., et al. (2018). Введение в специальный выпуск по расширенному библиометрическому поиску информации и обработке естественного языка для цифровых библиотек (BIRNDL). Международный журнал цифровых библиотек , 19, 107–111.
, Frommholz, I., Cabanac, G., Chandrasekaran, M.K., Jaidka, K., Kan, M.-Y., et al. (2018). Введение в специальный выпуск по расширенному библиометрическому поиску информации и обработке естественного языка для цифровых библиотек (BIRNDL). Международный журнал цифровых библиотек , 19, 107–111.
Google Scholar
Ресурсы для поиска и доступа к научным статьям
Соревнования по передовым наукам
Введение
Чтение научной литературы является важной частью планирования и реализации успешного научного проекта. Руководство «Как читать научную статью» может помочь вам получить максимальную отдачу от каждой прочитанной вами статьи — конечно, сначала вы должны взять ее в руки! Вот тут-то и пригодится это руководство. Ниже вы найдете советы и ресурсы по поиску и приобретению бесплатных копий научных статей для чтения.
Академические поисковые системы: ресурсы для поиска ссылок на научные статьи
Когда вы начинаете свое фоновое исследование, одним из первых шагов является поиск и чтение научной литературы, связанной с вашим научным проектом (см. Дорожная карта: Как начать работу над продвинутым статью «Научный проект» для более подробной информации об этапах проекта). Наставники — отличный ресурс для рекомендаций о том, какие научные статьи имеют решающее значение для вас, и вам обязательно следует обратиться за советом к своему наставнику или другому эксперту в этой области. Но также будут случаи, когда ваш наставник занят или не в курсе конкретного экспериментального метода, и в этом случае вам нужно будет проявлять инициативу и искать документы самостоятельно. Оказывается, простое включение условий поиска в обычную поисковую систему, такую как Google, Yahoo или MSN, не очень эффективно. Страницы, которые вы получите, будут представлять собой множество веб-сайтов, и очень немногие из них будут содержать ссылки на рецензируемые научные статьи. Для поиска научной литературы лучше всего использовать академический поисковик.
Дорожная карта: Как начать работу над продвинутым статью «Научный проект» для более подробной информации об этапах проекта). Наставники — отличный ресурс для рекомендаций о том, какие научные статьи имеют решающее значение для вас, и вам обязательно следует обратиться за советом к своему наставнику или другому эксперту в этой области. Но также будут случаи, когда ваш наставник занят или не в курсе конкретного экспериментального метода, и в этом случае вам нужно будет проявлять инициативу и искать документы самостоятельно. Оказывается, простое включение условий поиска в обычную поисковую систему, такую как Google, Yahoo или MSN, не очень эффективно. Страницы, которые вы получите, будут представлять собой множество веб-сайтов, и очень немногие из них будут содержать ссылки на рецензируемые научные статьи. Для поиска научной литературы лучше всего использовать академический поисковик.
Существует множество различных академических поисковых систем. Некоторые сосредотачиваются на одной дисциплине, в то время как другие содержат цитаты из нескольких областей. Существует несколько бесплатных общедоступных академических поисковых систем, к которым можно получить доступ в Интернете; некоторые из них перечислены в таблице 1 ниже. Остальные, такие как ISI Web of Science, работают по подписке. Университеты и колледжи часто подписываются на академические поисковые системы. Если вы не можете найти то, что вам нужно, с помощью бесплатной поисковой системы, вы можете получить доступ к этим ресурсам с компьютеров в библиотеке университета или колледжа. Посетите веб-страницу школьной библиотеки или позвоните непосредственно в библиотеку, чтобы узнать, на какие академические поисковые системы они подписаны и разрешено ли вам входить в библиотеку для доступа к ним.
Существует несколько бесплатных общедоступных академических поисковых систем, к которым можно получить доступ в Интернете; некоторые из них перечислены в таблице 1 ниже. Остальные, такие как ISI Web of Science, работают по подписке. Университеты и колледжи часто подписываются на академические поисковые системы. Если вы не можете найти то, что вам нужно, с помощью бесплатной поисковой системы, вы можете получить доступ к этим ресурсам с компьютеров в библиотеке университета или колледжа. Посетите веб-страницу школьной библиотеки или позвоните непосредственно в библиотеку, чтобы узнать, на какие академические поисковые системы они подписаны и разрешено ли вам входить в библиотеку для доступа к ним.
Таблица 1: В этой таблице представлен список бесплатных академических онлайновых поисковых систем по различным научным дисциплинам.
Вот несколько советов, которые помогут вам начать работу с академическими поисковыми системами:
- Каждая поисковая система работает немного по-своему, поэтому стоит потратить время на чтение доступных справочных страниц, чтобы понять, как лучше всего использовать каждую из них.
 один.
один. - Когда вы начинаете поиск литературы, попробуйте несколько разных ключевых слов, как по отдельности, так и в комбинации. Затем, когда вы просматриваете результаты, вы можете сфокусировать свое внимание и выяснить, какие ключевые слова лучше всего описывают интересующие вас виды работ.
- Когда вы читаете литературу, вернитесь назад и попробуйте выполнить дополнительный поиск, используя жаргон и термины, которые вы усвоили во время чтения.
Примечание: Результаты академических поисковых систем приходят в виде аннотации, которую вы можете прочитать, чтобы определить, имеет ли статья отношение к вашему научному проекту, а также полного цитирования (автор, название журнала, том, номера страниц, год и т. д.), чтобы вы могли найти физическую копию статьи. Поисковые системы не обязательно содержат полный текст статьи для чтения. Некоторые из них, такие как PubMed, предоставляют ссылки на бесплатные онлайн-версии газеты, когда они доступны. Читайте дальше, чтобы найти полную версию статьи.
Как получить копию научной статьи
После того как вы нашли ссылку на статью, имеющую отношение к вашему продвинутому научному проекту, следующим шагом будет получение копии, чтобы вы могли ее прочитать. Как упоминалось выше, некоторые поисковые системы предоставляют ссылки на бесплатные онлайн-версии статьи, если таковые существуют. Если поисковая система этого не делает или если вы получили ссылку где-то еще, например, в библиографии другой научной статьи, которую вы читали, есть несколько способов найти копии.
Поиск новых статей (опубликованных в эпоху Интернета)
- Проверьте библиотеку местного колледжа или университета. Академические учреждения, такие как колледжи и университеты, часто подписываются на множество научных журналов. Некоторые из этих библиотек бесплатны для публики. Свяжитесь с библиотекой или посетите их веб-сайт, чтобы узнать, можете ли вы использовать их ресурсы и подписываются ли они на интересующие вас журналы.
 Часто библиотечный каталог фондов находится в Интернете и доступен для публичного поиска.
Часто библиотечный каталог фондов находится в Интернете и доступен для публичного поиска.- Примечание: Если вы идете в библиотеку университета или колледжа, чтобы копировать или печатать журнальные статьи, не забудьте взять с собой много сдачи, потому что у них ее не будет!
- Найдите бесплатную онлайн-версию. Попробуйте найти полное название статьи в обычной поисковой системе, такой как Google, Yahoo или MSN. Статья может появляться несколько раз, и одна из них может быть бесплатной копией для скачивания. Итак, если первая ссылка не загружается, попробуйте другую.
- Перейдите непосредственно на домашнюю страницу журнала , в котором была опубликована статья. Некоторые научные журналы имеют «открытый исходный код», что означает, что их контент всегда доступен в Интернете бесплатно для публики. Другие доступны бесплатно в Интернете (часто после регистрации на веб-сайте), если статья была опубликована более года назад.
 Справочник журналов открытого доступа также является хорошим местом для проверки того, какие журналы являются бесплатными в интересующей вас области. На веб-сайте журналы перечислены по тематике, а также по названию.
Справочник журналов открытого доступа также является хорошим местом для проверки того, какие журналы являются бесплатными в интересующей вас области. На веб-сайте журналы перечислены по тематике, а также по названию. - Найдите домашнюю страницу первого или последнего автора статьи и посмотрите, есть ли у него или нее документ в формате PDF на его или ее веб-сайте. Если это так, вы можете скачать его прямо оттуда. Как правило, стоит искать только первого автора (тот, кто внес наибольший вклад в статью) или последнего автора (обычно это профессор, в лаборатории которого выполнялась работа и который руководил научным проектом).
- Найдите статью (используя название или авторов) в научной базе данных, , как перечисленные ниже в таблице 2. Эти базы данных содержат бесплатные полнотекстовые версии научных статей, а также другую соответствующую информацию, например общедоступные наборы данных.
Таблица 2: Список баз данных, содержащих бесплатные полнотекстовые научные статьи и наборы данных.
- Купить копию. В зависимости от издателя научного журнала вы также можете столкнуться с предложениями о покупке копии статьи. Это дорогой вариант, особенно если у вас есть несколько статей, которые вы хотели бы прочитать; сначала попробуйте другие методы поиска
Поиск старых статей (опубликованных до эпохи Интернета)
Даже при использовании всех вышеперечисленных методов поиска вы не сможете найти бесплатную копию статьи в Интернете. Это особенно верно для старых научных статей, которые были опубликованы до того, как онлайн-контент стал обычным явлением. В этих случаях есть дополнительные способы получить бумагу бесплатно или с минимальными затратами.
- Свяжитесь с автором по электронной почте. Как упоминалось выше, лучше всего подходят первый и последний авторы. Кратко объясните свою ситуацию и запросите копию документа непосредственно у него или у нее. Если вы сделаете это, обязательно будьте вежливы и кратки в своем электронном письме.

- Загляните в библиотеку местного колледжа или университета. Академические учреждения, такие как колледжи и университеты, часто подписываются на множество научных журналов. Некоторые из этих библиотек бесплатны для публики. Свяжитесь с библиотекой или посетите их веб-сайт, чтобы узнать, можете ли вы использовать их ресурсы и подписываются ли они на интересующие вас журналы. Часто библиотечный каталог фондов находится в Интернете и доступен для публичного поиска.
- Примечание: Если вы идете в библиотеку университета или колледжа, чтобы копировать или печатать журнальные статьи, не забудьте взять с собой много сдачи, потому что у них их не будет!
- Свяжитесь со своим наставником и спросите, может ли он или она помочь вам приобрести копию статьи. Используйте это в крайнем случае, потому что вы можете обнаружить, что ваш запрос находится довольно далеко в длинном списке дел наставника.
Дизайн и производство автоматов
Хроматография конфет: какие цвета у ваших конфет?
Обход препятствий: проект BlueBot №4
SciXGen: набор данных научной статьи для создания контекстно-зависимого текста
Хун Чен, Хироя Такамура, Hideki Nakayama
Abstract
Генерация текстов в научных статьях требует не только захвата содержания, содержащегося в данных входных данных, но также частого получения внешней информации, называемой контекстом. Мы продвигаем генерацию научного текста, предлагая новую задачу, а именно генерацию контекстно-зависимого текста в научной области, стремясь использовать вклад контекста в генерируемые тексты. С этой целью мы представляем новый сложный набор данных научных статей для контекстно-зависимой генерации текста (SciXGen), состоящий из хорошо аннотированных 205 304 статей с полными ссылками на широко используемые объекты (например, таблицы, рисунки, алгоритмы) в бумага. Мы всесторонне оцениваем, используя современные достижения, эффективность нашего недавно созданного набора данных SciXGen при создании описания и абзаца. Наш набор данных и эталонные тесты будут опубликованы, чтобы облегчить исследования по созданию научных текстов.
Мы продвигаем генерацию научного текста, предлагая новую задачу, а именно генерацию контекстно-зависимого текста в научной области, стремясь использовать вклад контекста в генерируемые тексты. С этой целью мы представляем новый сложный набор данных научных статей для контекстно-зависимой генерации текста (SciXGen), состоящий из хорошо аннотированных 205 304 статей с полными ссылками на широко используемые объекты (например, таблицы, рисунки, алгоритмы) в бумага. Мы всесторонне оцениваем, используя современные достижения, эффективность нашего недавно созданного набора данных SciXGen при создании описания и абзаца. Наш набор данных и эталонные тесты будут опубликованы, чтобы облегчить исследования по созданию научных текстов.- Anthology ID:
- 2021.findings-emnlp.128
- Volume:
- Findings of the Association for Computational Linguistics: EMNLP 2021
- Month:
- November
- Year:
- 2021
- Address:
- Пунта-Кана, Доминиканская Республика
- Места проведения:
- EMNLP | Выводы
- SIG:
- SIGDAT
- Издатель:
- Ассоциация компьютерной лингвистики
- Примечание:
- Pages:
- 1483–1492
- Language:
- URL:
- https://aclanthology.
 org/2021.findings-emnlp.128
org/2021.findings-emnlp.128 - DOI:
- 10.18653/v1/2021.findings- emnlp.128
- Bibkey:
- Cite (ACL):
- Хонг Чен, Хироя Такамура и Хидэки Накаяма. 2021. SciXGen: набор данных научной статьи для создания контекстно-зависимого текста. В выводах Ассоциации компьютерной лингвистики: EMNLP 2021 , страницы 1483–149.2, Пунта-Кана, Доминиканская Республика. Ассоциация компьютерной лингвистики.
- Ссылка (неофициальная):
- SciXGen: набор данных научной статьи для создания контекстно-зависимого текста (Chen et al., Findings 2021)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2021.findings-emnlp.128.pdf
- Данные
- S2ORC, unarXive
PDF Процитировать Поиск
- BibTeX
- МОДЫ XML
- Сноска
- Предварительно отформатированный
@inproceedings{chen-etal-2021-scixgen-scientific,
title = "{S}ci{XG}en: набор данных научной статьи для создания контекстно-зависимого текста",
автор = "Чен, Хун и
Такамура, Хироя и
Накаяма, Хидэки». booktitle = "Выводы Ассоциации компьютерной лингвистики: EMNLP 2021",
месяц = ноябрь,
год = "2021",
address = "Пунта-Кана, Доминиканская Республика",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2021.findings-emnlp.128",
doi = "10.18653/v1/2021.findings-emnlp.128",
страницы = "1483--1492",
abstract = "Генерация текстов в научных статьях требует не только захвата содержимого, содержащегося в данном вводе, но также частого получения внешней информации, называемой контекстом. Мы продвигаем генерацию научного текста, предлагая новую задачу, а именно генерацию контекстно-зависимого текста в научная область, стремясь использовать вклад контекста в сгенерированные тексты.С этой целью мы представляем новый сложный крупномасштабный набор данных научных статей для контекстно-зависимой генерации текста (SciXGen), состоящий из хорошо аннотированных 205 304 статей с полными ссылками на широко используемые объекты (например, таблицы, рисунки, алгоритмы) в документе.
booktitle = "Выводы Ассоциации компьютерной лингвистики: EMNLP 2021",
месяц = ноябрь,
год = "2021",
address = "Пунта-Кана, Доминиканская Республика",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2021.findings-emnlp.128",
doi = "10.18653/v1/2021.findings-emnlp.128",
страницы = "1483--1492",
abstract = "Генерация текстов в научных статьях требует не только захвата содержимого, содержащегося в данном вводе, но также частого получения внешней информации, называемой контекстом. Мы продвигаем генерацию научного текста, предлагая новую задачу, а именно генерацию контекстно-зависимого текста в научная область, стремясь использовать вклад контекста в сгенерированные тексты.С этой целью мы представляем новый сложный крупномасштабный набор данных научных статей для контекстно-зависимой генерации текста (SciXGen), состоящий из хорошо аннотированных 205 304 статей с полными ссылками на широко используемые объекты (например, таблицы, рисунки, алгоритмы) в документе. Мы всесторонне оцениваем, используя современные достижения, эффективность нашего недавно созданного набора данных SciXGen в создании описания и абзаца. Наш набор данных и эталонные показатели будут сделан общедоступным, чтобы облегчить исследование генерации научных текстов.",
}
Мы всесторонне оцениваем, используя современные достижения, эффективность нашего недавно созданного набора данных SciXGen в создании описания и абзаца. Наш набор данных и эталонные показатели будут сделан общедоступным, чтобы облегчить исследование генерации научных текстов.",
}
<моды> <информация о заголовке> SciXGen: набор данных научной статьи для создания контекстно-зависимого текста <название типа="личное">Гонконг Чен <роль>автор <название типа="личное">Хироя Такамура <роль>автор <название типа="личное">Хидеки Накаяма <роль>автор <информация о происхождении>2021-11 текст <информация о заголовке> Выводы Ассоциации компьютерной лингвистики: EMNLP 2021 <информация о происхождении>Ассоциация компьютерной лингвистики <место>Пунта-Кана, Доминиканская Республика публикация конференции Генерация текстов в научных статьях требует не только захвата содержимого, содержащегося в заданных входных данных, но также частого получения внешней информации, называемой контекстом. Мы продвигаем генерацию научного текста, предлагая новую задачу, а именно генерацию контекстно-зависимого текста в научной области, стремясь использовать вклад контекста в генерируемые тексты. С этой целью мы представляем новый сложный набор данных научных статей для контекстно-зависимой генерации текста (SciXGen), состоящий из хорошо аннотированных 205 304 статей с полными ссылками на широко используемые объекты (например, таблицы, рисунки, алгоритмы) в бумага. Мы всесторонне оцениваем, используя современные достижения, эффективность нашего недавно созданного набора данных SciXGen при создании описания и абзаца. Наш набор данных и эталонные тесты будут опубликованы, чтобы облегчить исследования в области генерации научных текстов.
chen-etal-2021-scixgen-scientific 10.18653/v1/2021.findings-emnlp.128 <местоположение>https://aclanthology.org/2021.findings-emnlp.128 <часть> <дата>2021-11 <единица экстента="страница">1483 <конец>1492
%0 Материалы конференции %T SciXGen: набор данных научной статьи для контекстно-зависимой генерации текста %А Чен, Хонг %A Такамура, Хироя %А Накаяма, Хидэки %S Выводы Ассоциации компьютерной лингвистики: EMNLP 2021 %D 2021 %8 ноябрь %I Ассоциация компьютерной лингвистики %C Пунта-Кана, Доминиканская Республика %F chen-etal-2021-scixgen-научный %X Генерация текстов в научных статьях требует не только захвата содержимого, содержащегося в заданных входных данных, но также частого получения внешней информации, называемой контекстом.Мы продвигаем генерацию научного текста, предлагая новую задачу, а именно генерацию контекстно-зависимого текста в научной области, стремясь использовать вклад контекста в генерируемые тексты. С этой целью мы представляем новый сложный набор данных научных статей для контекстно-зависимой генерации текста (SciXGen), состоящий из хорошо аннотированных 205 304 статей с полными ссылками на широко используемые объекты (например, таблицы, рисунки, алгоритмы) в бумага. Мы всесторонне оцениваем, используя современные достижения, эффективность нашего недавно созданного набора данных SciXGen при создании описания и абзаца. Наш набор данных и эталонные тесты будут опубликованы, чтобы облегчить исследования по созданию научных текстов. %R 10.18653/v1/2021.findings-emnlp.128 %U https://aclanthology.org/2021.findings-emnlp.128 %U https://doi.org/10.18653/v1/2021.findings-emnlp.128 %Р 1483-1492
Markdown (неофициальный)
[SciXGen: набор данных научной статьи для контекстно-зависимой генерации текста] (https://aclanthology.