
Распознать сканированный текст в Word – Какие программы для распознавания текста использовать в офисе
Мы уже рассматривали с Вами программу для распознавания текста с картинки . Но распознавать текст можно не только с помощью программы. Это можно делать с помощью онлайн сервисов, не имея никаких программ на своем компьютере.И действительно, зачем устанавливать какие-то программы, если Вам нужно распознать текст один раз, и в дальнейшем Вы не собираетесь эту программу использовать? Или Вам нужно делать это раз в месяц? В этом случае лишняя программа на компьютере не нужна.
Давайте рассмотрим несколько сервисов, при помощи которых можно распознавать текст с картинки бесплатно, легко и быстро.
Free Online OCR
Очень хорошим сервисом для распознавания текста с картинки онлайн является сервис Free Online OCR. Он не требует регистрации, распознает текст с картинки практически любого формата. работает с 58 языками.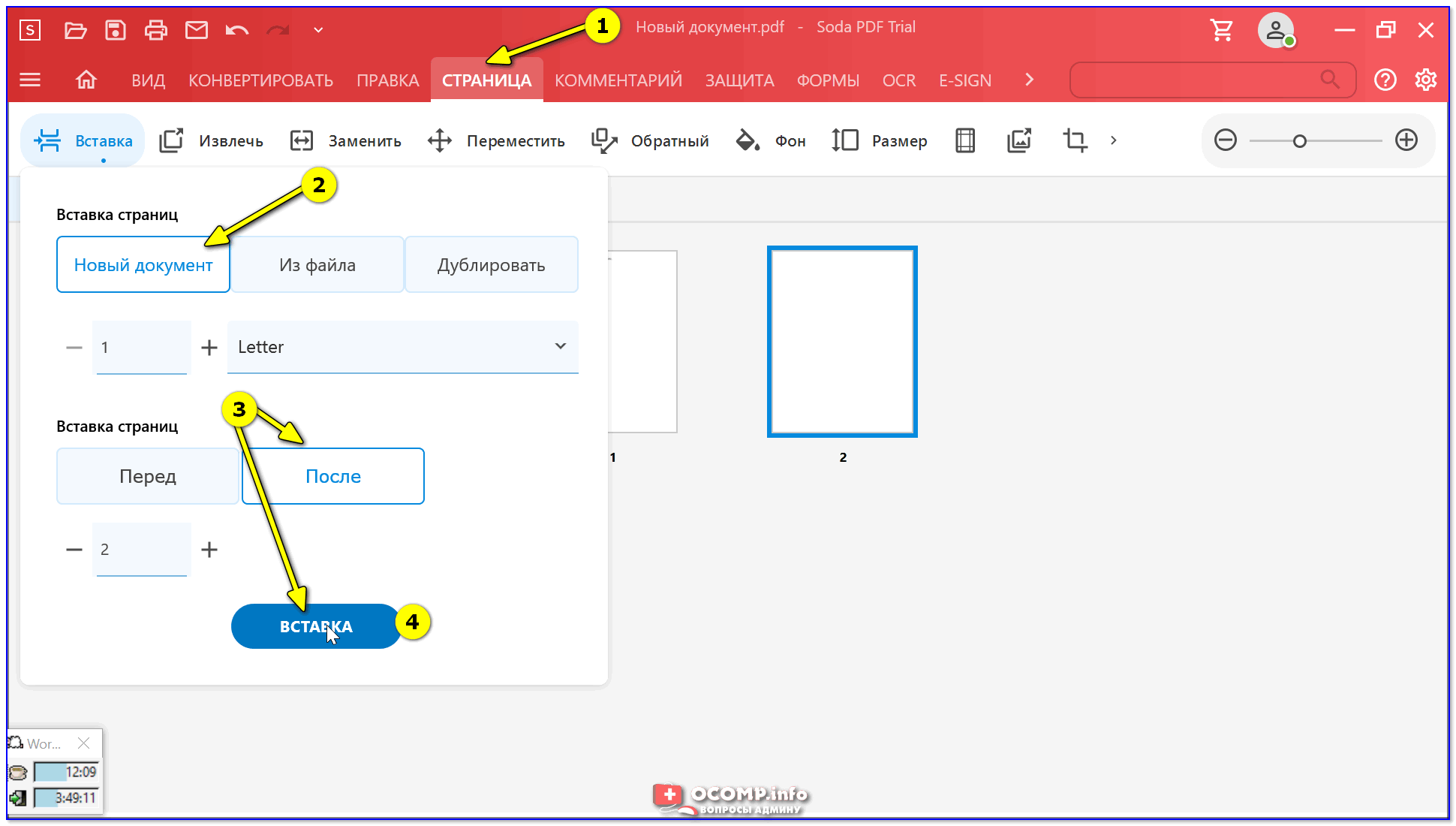
Пользоваться этим сервисом просто. Когда Вы на него зайдете, перед Вами будет всего два варианта: загрузить файл с компьютера, или вставить URL-адрес картинки, если она находится в Интернете.
Если Ваше изображение находится на компьютере, нажимаете на кнопку Выберите файл, затем выбираете свой файл, и нажимаете на кнопку Upload. Вы увидите свой графический файл ниже, а над ним кнопку OCR. Жмете эту кнопку, и получаете текст, который Вы можете найти в нижней части страницы.
Online OCR Net
Также довольно неплохой сервис, который позволяет распознавать тексты с картинок онлайн бесплатно, и без регистрации. Поддерживает он 48 языков, включая русский, китайский, корейский и японский. Чтобы начать с ним работать, заходите на 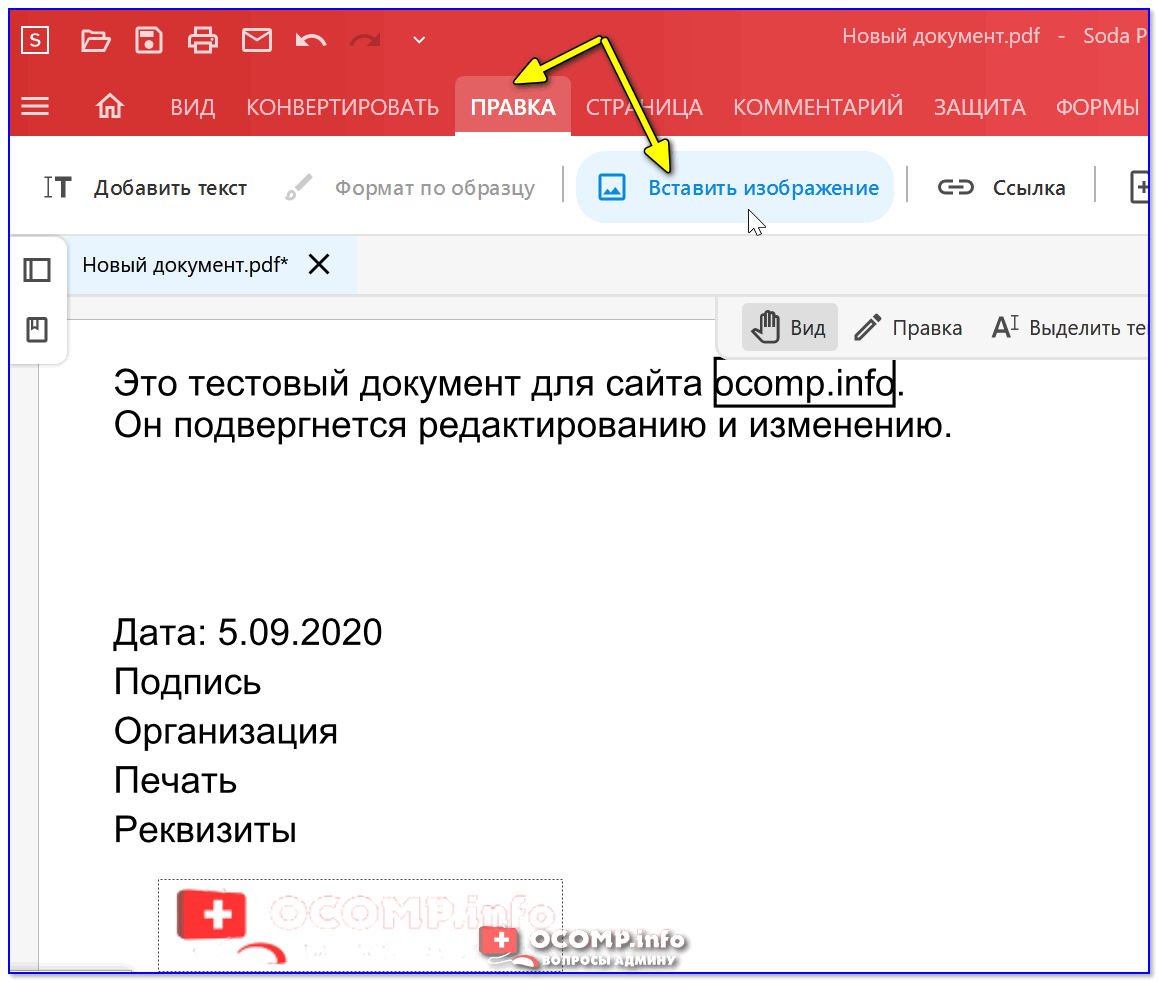
В соседних полях выбираете язык и расширение текстового документа, в котором будет полученный из картинки текст. После этого вводите капчу внизу, и нажимаете на кнопку Convert справа.
ABBYY FineReader Online
Очень хороший сервис в плане своей многофункциональности. На
На этом сервисе есть регистрация, но можно обойтись и входом с помощью социальной сети Facebook, сервисов Google+, или Microsoft Account.
Преимущество такого подхода в том, что созданные документы будут храниться в Вашем аккаунте в течении 14 дней, и даже если Вы их удалите из компьютера, можно будет вернуться на сервис, и опять их скачать.
Online OCR Ru
Сервис, похожий на предыдущий, с информацией на русском языке.
Кроме распознавания текста из картинок, сервис предоставляет возможность перевода изображений в форматы PDF, Excel, HTML и другие, причем структура и разметка документа будет соответствовать той, которая была на картинке.
На этом сервисе также есть регистрация, и файлы, созданные Вами с его помощью, будут храниться в Вашем личном кабинете.
Конвертирование отсканированного PDF в редактируемый текст
Испытываете сложности при работе с отсканированными PDF-файлами? Ищете способ быстро преобразовывать отсканированные PDF в текст? Мы предлагаем два эффективных решения данной проблемы. Сначала мы поговорим о том, как распознавать текст в Google Drive, а затем я представлю вам лучшее решение этой задачи – PDFelement.
Как использовать альтернативы Google Диска для распознавания текста
PDFelement сочетает функции создания, редактирования, аннотирования и преобразования файлов в одной программе. Функция OCR в данной программе позволяет с легкостью распознавать ваши отсканированные или основанные на изображениях PDF-документы и превращать их в редактируемый текст. Функция распознавания текста поддерживает широкий спектр языков, таких как английский, корейский, немецкий, румынский, итальянский, португальский, испанский и другие.
Шаг 1. Открытие отсканированного PDF-файла
После установки PDFelement откройте отсканированный PDF-документ с помощью этой программы. Для этого вы можете нажать кнопку «Открыть файл…» и ваш файл будет открыт прямо в PDFelement.
Шаг 2. Распознавание текста PDF без конвертирования
Программа напомнит вам выполнить распознавание текста после загрузки отсканированного PDF. Нажмите кнопку «Распознать текст» в верхней информационной панели и выберите нужный язык. Через некоторое время отсканированный PDF будет преобразован в редактируемый формат. Если вам нужно внести изменения в получившийся документ, нажмите «Редактировать» в левом верхнем углу экрана.
Нажмите кнопку «Распознать текст» в верхней информационной панели и выберите нужный язык. Через некоторое время отсканированный PDF будет преобразован в редактируемый формат. Если вам нужно внести изменения в получившийся документ, нажмите «Редактировать» в левом верхнем углу экрана.
Шаг 3. Конвертирование PDF в текст с помощью функции распознавания текста
Если вам нужно экспортировать отсканированный PDF в текстовый формат, перейдите во вкладку «Главная», нажмите кнопку «В другие формату» и выберите опцию «Преобразовать в текст». Затем установите флажок «Настройки» > «Включить распознавание» во всплывающем окне. Нажмите «Сохранить», чтобы запустить процесс распознавания.
Чтобы установить язык распознавания, перейдите в меню «Файл > Настройки» и выберите нужный язык во вкладке «Распознавание (OCR)».
Благодаря мощному функционалу вы можете редактировать текст PDF, менять изображения и размечать контент с легкостью.
Как использовать Google Диск для распознавания текста
Шаг 1. Импортирование PDF-файла, созданного на основе изображений
После входа в учетную запись Google Диск вы можете загрузить в нее свое изображение или отсканированный файл.
Шаг 2. Распознавание текста в Google Документах
Выберите загруженный файл и откройте его с помощью Google Документы. При открытии файла в Google Документах подключается опция распознавания символов Google Drive OCR. Текст в файле с изображениями теперь можно редактировать.
Шаг 3. Сохранение файла
Нажмите кнопку «Файл» > «Скачать», чтобы выбрать формат его сохранения на своем компьютере.
Вот как можно использовать функцию распознавания символов Google Docs для преобразования отсканированного PDF в текст. Это достаточно удобно, но в Google Документах нельзя сохранить форматирование и конфигурацию PDF-файла. После работы с Google Drive OCR вы можете обнаружить, что текст исходного файла было изменен. Если вы хотите сохранить исходное форматирование и конфигурацию PDF, попробуйте Wondershare PDFelement.
Это достаточно удобно, но в Google Документах нельзя сохранить форматирование и конфигурацию PDF-файла. После работы с Google Drive OCR вы можете обнаружить, что текст исходного файла было изменен. Если вы хотите сохранить исходное форматирование и конфигурацию PDF, попробуйте Wondershare PDFelement.
Как распознать текст в Word
Все мы уже привыкли фотографировать расписание, документы, страницы книг и многое другое, но по ряду причин «извлечь» текст со снимка или картинки, сделав его пригодным для редактирования, все же требуется.
Особенно часто с необходимостью преобразовать фото в текст сталкиваются школьники и студенты. Это естественно, ведь никто не будет переписывать или набирать текст, зная, что есть более простые методы. Было бы прям идеально, если бы преобразовать картинку в текст можно было в Microsoft Word, вот только данная программа не умеет ни распознавать текст, ни конвертировать графические файлы в текстовые документы.
Единственная возможность «поместить» текст с JPEG-файла (джипег) в Ворд — это распознать его в сторонней программе, а затем уже оттуда скопировать его и вставить или же просто экспортировать в текстовый документ.
Содержание
Распознавание текста
ABBYY FineReader по праву является самой популярной программой для распознавания текста. Именно главную функцию этого продукта мы и будем использовать для наших целей — преобразования фото в текст. Из статьи на нашем сайте вы можете более подробно узнать о возможностях Эбби Файн Ридер, а также о том, где скачать эту программу, если она еще не установлена на у вас на ПК.
Распознавание текста с помощью ABBYY FineReader
Скачав программу, установите ее на компьютер и запустите. Добавьте в окно изображение, текст на котором необходимо распознать. Сделать это можно простым перетаскиванием, а можно нажать кнопку «Открыть», расположенную на панели инструментов, а затем выбрать необходимый графический файл.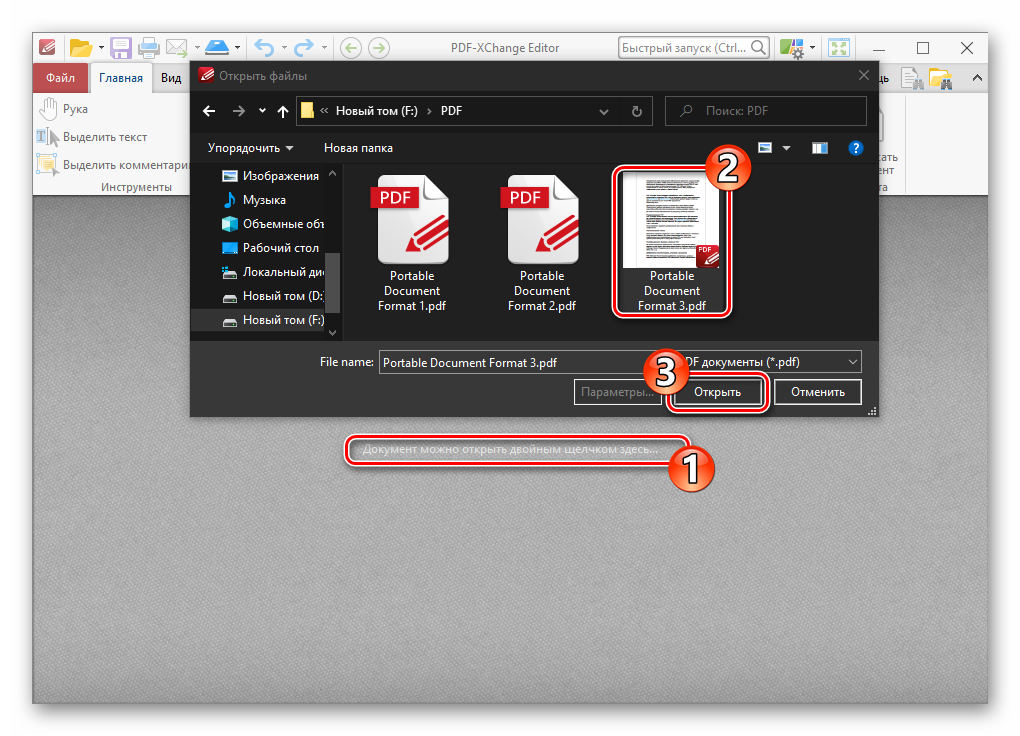
Теперь нажмите на кнопку «Распознать» и дождитесь, пока Эбби Файн Ридер просканирует изображение и извлечет из него весь текст.
Вставка текста в документ и экспорт
Когда FineReader распознает текст, его можно будет выделить и скопировать. Для выделения текста используйте мышку, для его копирования нажмите «CTRL+С».
Теперь откройте документ Microsoft Word и вставьте в него текст, который сейчас содержится в буфере обмена. Для этого нажмите клавиши «CTRL+V» на клавиатуре.
Урок: Использование горячих клавиш в Ворде
Помимо просто копирования/вставки текста из одной программы в другую, Эбби Файн Ридер позволяет экспортировать распознанный им текст в файл формата DOCX, который для MS Word является основным. Что для этого требуется сделать? Все предельно просто:
- выберите необходимый формат (программу) в меню кнопки «Сохранить», расположенной на панели быстрого доступа;
- кликните по этому пункту и укажите место для сохранения;
- задайте имя для экспортируемого документа.

После того, как текст будет вставлен или экспортирован в Ворд, вы сможете его отредактировать, изменить стиль, шрифт и форматирование. Наш материал на данную тему вам в этом поможет.
Примечание: В экспортированном документе будет содержаться весь распознанный программой текст, даже тот, который вам, возможно, и не нужен, или тот, который распознан не совсем корректно.
Урок: Форматирование текста в MS Word
Видео-урок по переводу текста с фотографии в Word файл
Преобразование текста на фото в документ Ворд онлайн
Если вы не хотите скачивать и устанавливать на свой компьютер какие-либо сторонние программы, преобразовать изображение с текстом в текстовый документ можно онлайн. Для этого существует множество веб-сервисов, но лучший из них, как нам кажется, это FineReader Online, который использует в своей работе возможности того же программного сканера ABBY.
ABBY FineReader Online
Перейдите по вышеуказанной ссылке и выполните следующие действия:
1. Авторизуйтесь на сайте, используя профиль Facebook, Google или Microsoft и подтвердите свои данные.
Примечание: Если ни один из вариантов вас не устраивает, придется пройти полную процедуру регистрации. В любом случае, сделать это не сложнее, чем на любом другом сайте.
2. Выберите пункт «Распознать» на главной странице и загрузите на сайт изображение с текстом, который нужно извлечь.
3. Выберите язык документа.
4. Выберите формат, в котором требуется сохранить распознанный текст. В нашем случае это DOCX, программы Microsoft Word.
5. Нажмите кнопку «Распознать» и дождитесь, пока сервис просканирует файл и преобразует его в текстовый документ.
6. Сохраните, точнее, скачайте файл с текстом на компьютер.
Примечание: Онлайн-сервис ABBY FineReader позволяет не только сохранить текстовый документ на компьютер, но и экспортировать его в облачные хранилища и другие сервисы. В числе таковые BOX, Dropbox, Microsoft OneDrive, Google Drive и Evernote.
В числе таковые BOX, Dropbox, Microsoft OneDrive, Google Drive и Evernote.
После того, как файл будет сохранен на компьютер, вы сможете его открыть и изменить, отредактировать.
На этом все, из данной статьи вы узнали, как перевести текст в Ворд. Несмотря на то, что данная программа не способна самостоятельно справиться с такой, казалось бы, простой задачей, сделать это можно с помощью стороннего софта — программы Эбби Файн Ридер, или же специализированных онлайн-сервисов.
Онлайн-сканер PDF OCR – Преобразование PDF в редактируемый текст
Как распознать PDF?
Используйте конвертер OCR в pdfFiller, чтобы извлекать и систематизировать данные из любых ваших файлов.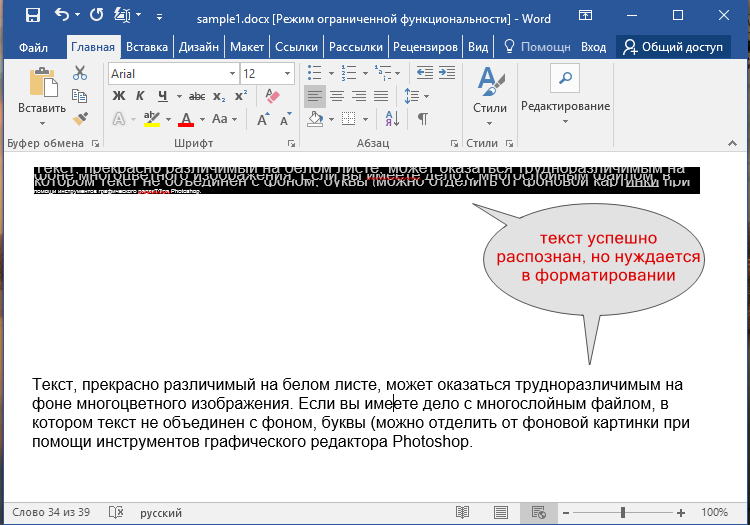
В своих документах выберите файл, который вы будете использовать в качестве шаблона, и используйте функцию извлечения в Bulk .
Добавляйте и редактируйте поля с извлеченными вами данными. Добавляйте имена в поля для облегчения соответствия столбцу в электронной таблице.
Загрузите документы, изображения или отсканированные файлы, которые необходимо распознать, и нажмите Старт .
Загрузите электронную таблицу, содержащую извлеченные данные из вашего шаблона.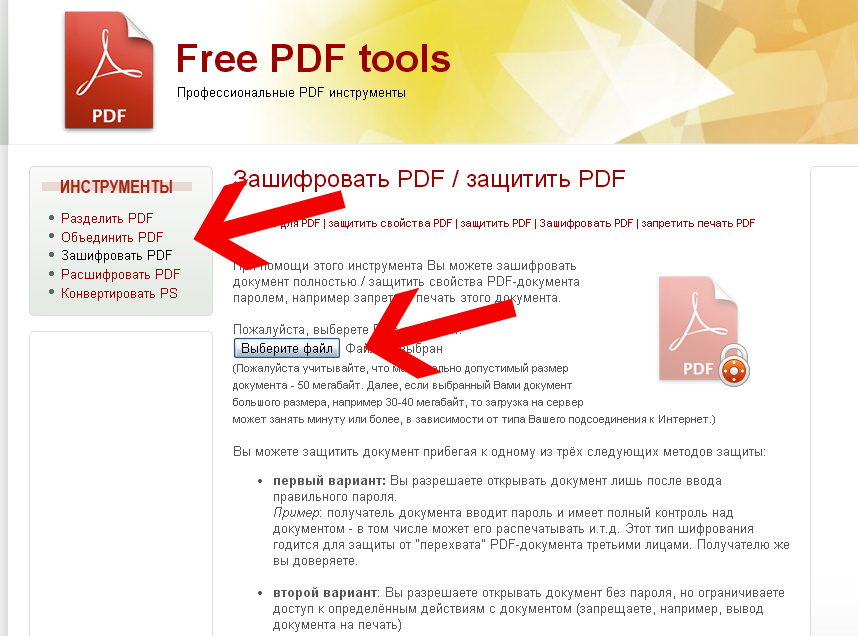
Как использовать технологию распознавания текста PDF с pdfFiller:
1
Откройте файл, который вы будете использовать в качестве шаблона, и определите в нем поля данных.
2
Загрузите любые похожие документы, из которых вам нужно извлечь данные.
3
Распознайте текст в файлах и экспортируйте его.
4
Загрузите электронную таблицу, содержащую извлеченные данные.
OCR Text Recognition – Преобразование отсканированного PDF в текст для редактирования
OCR или оптическое распознавание символов – это процесс преобразования нередактируемого текстового документа, такого как файл PDF, созданный из сканированных изображений книги, в редактируемый текст, который можно изменять и искать.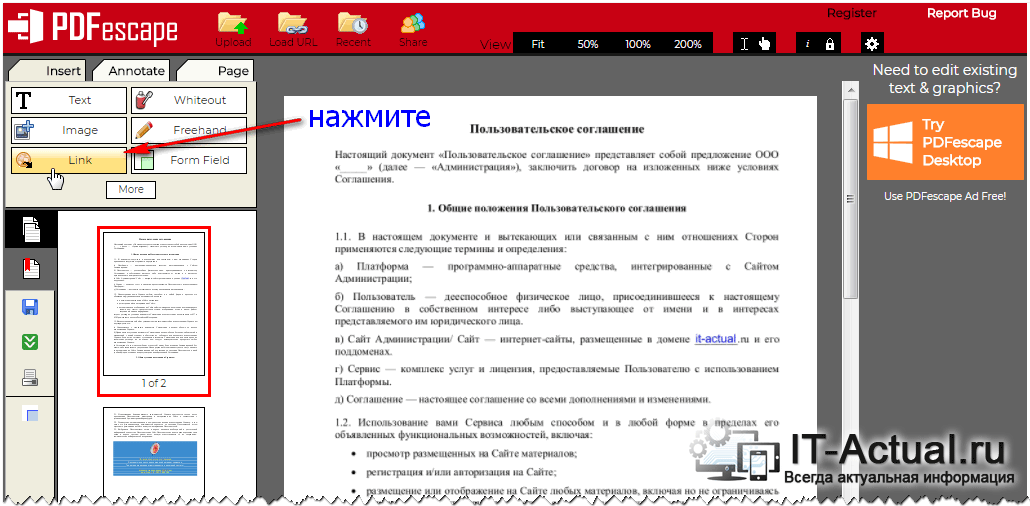 Для многих приложений это может быть невероятно полезно, например, возможность поиска в отсканированной книге определенных фраз может значительно сократить время исследования для студентов. В общем, наличие файла текста, которым можно манипулировать, гораздо полезнее, чем наличие, по сути, фиксированных изображений, получаемых при сканировании, что делает OCR обычным процессом для файлов PDF. В этой статье я покажу вам, как преобразовать отсканированный PDF в текст за несколько шагов.
Для многих приложений это может быть невероятно полезно, например, возможность поиска в отсканированной книге определенных фраз может значительно сократить время исследования для студентов. В общем, наличие файла текста, которым можно манипулировать, гораздо полезнее, чем наличие, по сути, фиксированных изображений, получаемых при сканировании, что делает OCR обычным процессом для файлов PDF. В этой статье я покажу вам, как преобразовать отсканированный PDF в текст за несколько шагов.
Часть 1. Лучшее программное обеспечение для извлечения текста из отсканированного PDF-файла.
Отсканированные документы PDF может быть очень сложно редактировать, если у вас нет подходящего редактора PDF с функцией распознавания текста, который поможет вам преобразовать отсканированный PDF в текст.Лучший инструмент, который поможет вам преобразовать отсканированный PDF-файл в текст, – это PDFelement Pro, простой в использовании, но универсальный PDF-редактор, который поможет вам редактировать все аспекты любого PDF-документа. Его функция OCR особенно проста в использовании и, в отличие от большинства других инструментов OCR, этот профессиональный редактор PDF не изменит структуру преобразованного файла. Он также поставляется с множеством других функций редактирования PDF, которые помогут вам полностью отредактировать документ PDF после его преобразования в текст.
Его функция OCR особенно проста в использовании и, в отличие от большинства других инструментов OCR, этот профессиональный редактор PDF не изменит структуру преобразованного файла. Он также поставляется с множеством других функций редактирования PDF, которые помогут вам полностью отредактировать документ PDF после его преобразования в текст.
Как превратить отсканированный PDF в текст на Mac (включая macOS High Sierra)
Возможно, выдающейся особенностью PDFelement Pro для Mac является то, насколько легко его использовать и получать отличные результаты.Всего несколько шагов, чтобы получить идеальный текстовый файл OCR из вашего PDF-файла с помощью этого отсканированного PDF-конвертера в текст. Следуйте этому руководству, чтобы распознать текст с помощью OCR. Пользователи Windows, пожалуйста, загрузите и установите PDFelement Pro, а затем выполните те же действия.
Шаг 1. Импортируйте отсканированные файлы PDF.
Он начинается с простого импорта PDF-файла для преобразования в программу путем нажатия кнопки «Открыть файл».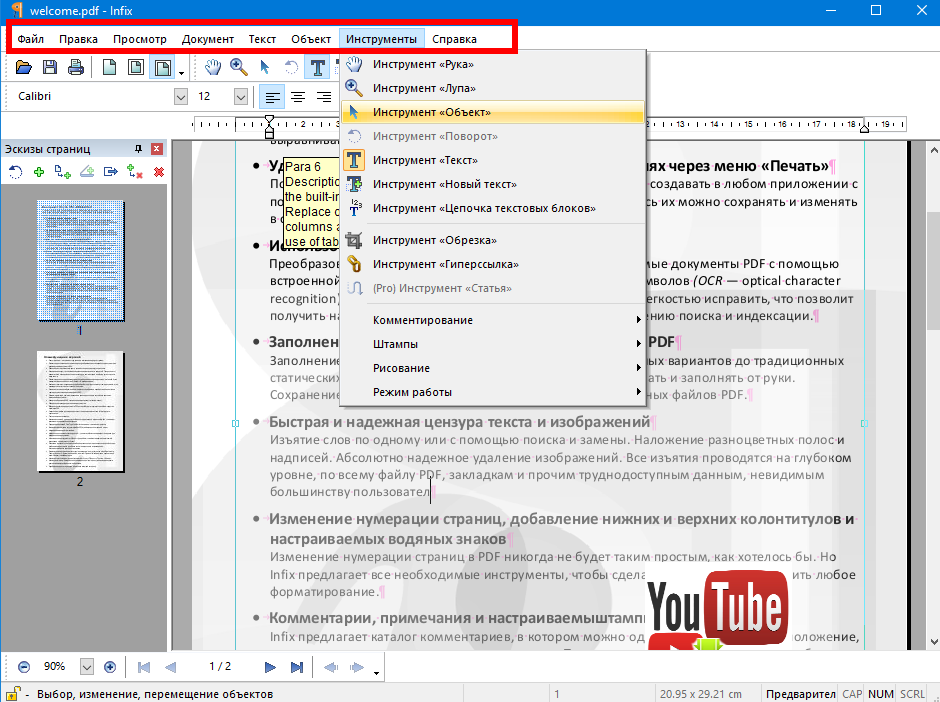 После этого ваш файл появится в списке во всплывающем окне.
После этого ваш файл появится в списке во всплывающем окне.
Перед преобразованием PDF-файла с изображениями в редактируемый текст вы можете установить язык для распознавания текста.Для этого вы можете открыть касание «Инструмент», а затем нажать кнопку «Распознавание текста OCR» и выбрать идеальный язык.
Шаг 2. Редактировать PDF отсканированный PDF
После того, как вы выполнили OCR для отсканированных файлов PDF, вы можете использовать несколько инструментов редактирования PDF, чтобы с легкостью редактировать отсканированные файлы PDF. Чтобы отредактировать файл, нажмите кнопку «Редактировать», после чего вы сможете легко редактировать изображения, тексты, страницы и ссылки в PDF-документах.
Шаг 3.Распознать текст в отсканированном PDF-файле
Затем нужно выбрать формат файла, необходимый для результирующего текстового файла. Нажмите кнопку «Экспорт в» в разделе «Файл», чтобы установить выходной формат для ваших PDF-файлов.
Настройка занимает несколько секунд и достаточно проста, чтобы любой желающий мог ее использовать и получать отличные результаты.
Почему стоит выбрать PDFelement Pro для Mac для преобразования отсканированного PDF в текст
Для выполнения оптического распознавания текста и создания текстового документа с возможностью поиска и редактирования требуется специальное программное обеспечение, и лучшим из доступных является PDFelement Pro.Это фантастическая программа с широким спектром функций, которые делают распознавание текста в PDF-файле очень простым и понятным процессом.
Он может выводить текст в различных форматах, включая Word, Excel, epub в формате электронной книги, HTML, Rich Text Files и, конечно же, простой текст. Имея более 20 языков на выбор и простой для понимания интерфейс, он идеально подходит для любой работы и любого пользователя. В дополнение к функциям распознавания текста PDFelement для Mac также является отличным редактором PDF, который может полностью удовлетворить ваши различные требования к редактированию PDF.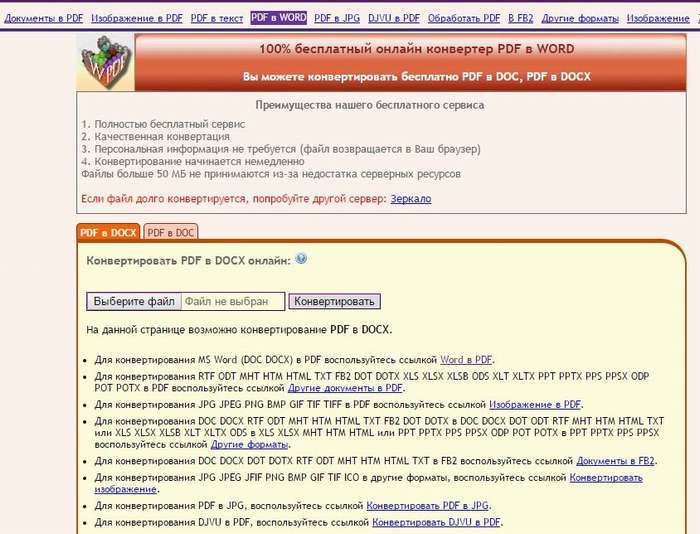
Почему стоит выбрать этот экстрактор данных PDF:
- Легко извлекайте текст, таблицы и другие данные из файлов PDF.
- Конвертируйте PDF в другие форматы и конвертируйте несколько PDF-документов в пакетном режиме.
- С легкостью редактируйте тексты, изображения, ссылки в PDF-документах.
- Помечайте и комментируйте PDF-файлы с помощью нескольких инструментов разметки.
- Объедините несколько файлов в PDF и разделите PDF на несколько файлов.
- Добавьте водяной знак, подпись и пароль в PDF.
Часть 2. Полезные советы и рекомендации по распознаванию текста
Есть также несколько бесплатных онлайн-конвертеров отсканированного PDF в текст, которые вы можете использовать для бесплатного преобразования отсканированного PDF в текст. Некоторые из них лучше всего включают следующее.
№1. Онлайн OCR
Online OCR – один из самых популярных бесплатных онлайн-конвертеров отсканированных PDF-файлов в текст, который вы можете использовать для онлайн-преобразования отсканированных PDF-файлов в текст. Он очень прост в использовании и поддерживает широкий спектр типов входных и выходных файлов. Помимо преобразования отсканированного PDF в текст, вы также можете использовать его для преобразования изображений в текстовые форматы, такие как Word и TXT.
Он очень прост в использовании и поддерживает широкий спектр типов входных и выходных файлов. Помимо преобразования отсканированного PDF в текст, вы также можете использовать его для преобразования изображений в текстовые форматы, такие как Word и TXT.
Плюсы:
- Это совершенно бесплатно и легко доступно.
- Он поддерживает до 46 языков.
Минусы:
- Вы не можете использовать его для редактирования полученного файла.
№2. Бесплатное онлайн-распознавание текста
Free Online OCR – это бесплатный онлайн-конвертер отсканированных PDF-файлов в текст, который также предоставляет простое и бесплатное решение для бесплатного онлайн-преобразования отсканированных PDF-файлов в текст. Он очень прост в использовании. Все, что вам нужно сделать, это загрузить документ, который нужно преобразовать, а затем выбрать выходной формат.
Плюсы:
- Он может конвертировать отсканированные PDF-файлы и другие изображения.
- Он поддерживает широкий спектр выходных форматов.
Минусы:
- Его нельзя использовать для редактирования текста в результирующем файле.
№3. Конвертер в текст
Вы можете использовать To-Text Converter для извлечения текста из любого отсканированного PDF-документа, а также из множества других файлов изображений. Как и большинство бесплатных онлайн-конвертеров отсканированных PDF-файлов в текст, он очень прост в использовании и легко доступен.
Плюсы:
- Он поддерживает несколько языков.
- Он поддерживает несколько форматов изображений для преобразования.
Минусы:
- Вы можете преобразовать только отсканированный PDF-файл в формат TXT; он не поддерживает другие типы файлов, такие как Word.
- Вы не можете использовать его для редактирования PDF-документов.
Часть 3. Полезные советы и рекомендации по распознаванию текста
PDF Converter Pro для Mac дает отличные результаты прямо из коробки, будучи очень точным и выдающим отличные результаты, однако, как и все программное обеспечение OCR, есть несколько вещей, которые вы можете сделать, чтобы обеспечить наилучший вывод текста из вашего процесса OCR.
- Первое, на что следует обратить внимание при использовании любого процесса OCR, – это всегда проверять результаты, все время нет 100% точных данных, а иногда случаются ошибки, поэтому очень важно проверять любой вывод, чтобы убедиться, что ничего не было пропущено или добавлено неправильно. Вам следует избегать использования результатов любого OCR без предварительной проверки окончательного текстового файла на наличие ошибок.
- Процесс оптического распознавания символов наиболее эффективен и точен, если для его работы необходимы четкие и высококачественные отсканированные изображения.Очевидно, что это не всегда то, что вы можете контролировать.Если у вас есть только PDF-файл с низким разрешением или плохой PDF-файл старой книги, советовать вам найти лучший отсканированный файл – не лучший совет, однако в ситуациях, когда качество оригинального файла, который у вас есть, находится под вашим контролем, простой ответ – чем выше качество, тем лучше.
- Для больших книг или томов текстов, где нужно преобразовать много страниц, может быть проще разбить их на более управляемые части, главу или даже отдельные страницы.
 Это может не только помочь произвести более точные преобразования, но также может помочь программе быстрее получать результаты.
Это может не только помочь произвести более точные преобразования, но также может помочь программе быстрее получать результаты.
На первый взгляд ни одно из этих изменений не является серьезным, но все они вносят значительный вклад в точность, скорость или оба процесса распознавания текста, и на них стоит обращать внимание каждый раз, когда вы используете эти инструменты.
[ОФИЦИАЛЬНО] Cisdem PDF Converter OCR для Mac
Преобразование PDF в популярные форматы документов
PDF может идеально отображать содержимое на любом экране и легко читать, архивировать или распространять файлы, в то время как форматы Office необходимы для создания и редактирования документов, поэтому преобразование PDF становится обычным явлением для дальнейшего редактирования или повторного использования.Cisdem PDF Converter OCR поддерживает быстрое и плавное преобразование PDF в следующие форматы документов:
Microsoft Office
Word (docx, doc) Excel (xlsx) PowerPoint (pptx)
iWork
Страницы (страницы) Основная тема (ключ)
Изображения
5 изображений (jpeg, bmp, png, gif, tiff)
и др.

EPUB, HTML Rich text format (RTF) Обычный текст (txt)
Преобразованные документы выглядят точно так же, как оригиналы
Cisdem PDF Converter OCR постарается максимально точно сохранить текст, изображения, элементы таблиц и сохранить исходное форматирование и макеты.Например, он сохраняет оригинальный вид даже сложного файла PDF в документе Word, помещает табличные данные в правую ячейку электронной таблицы Excel и сохраняет макеты в PowerPoint. Вам не нужно тратить часы на настройку выходного файла.
Превратить отсканированный PDF-файл в PDF-файл с возможностью поиска и другие форматы
OCR (оптическое распознавание символов) применяется для распознавания текстовых символов на основе форм и внешнего вида, оно может помочь извлечь текстовое содержимое из отсканированного PDF-файла или файла изображения.Это обязательная функция для архивирования и повторного использования отсканированных PDF-файлов. Cisdem PDF Converter OCR не только позволяет быстро обрабатывать отсканированные PDF-файлы и файлы изображений в пакетном режиме за счет включения функции распознавания текста, но также позволяет точно настраивать прикладные области распознавания текста путем ручной пометки текста, изображений и таблиц для более точного распознавания. Cisdem PDF Converter OCR поддерживает более 200 языков, включая английский, китайский, испанский, арабский, французский, русский, португальский, немецкий, японский, корейский. Кроме того, он поддерживает многоязычное распознавание.
10 лучших онлайн-инструментов OCR для извлечения текста из изображения
Устали писать? Сталкиваетесь ли вы с трудностями при наборе текста, который уже был опубликован давно? Технологии дали нам такие инструменты, как OCR, чтобы сделать нашу рабочую жизнь более управляемой. Оптическое распознавание символов – лучший электронный инструмент для преобразования любого письменного текста или документа в легко читаемые текстовые данные.
Это помогло людям повысить эффективность их рабочего процесса. OCR идентифицирует текст на изображениях, отсканированных документах и фотографиях, избавляя вас от лишних часов работы и предоставляя вам свежий и качественный документ.
OCR был представлен в начале 1990-х годов и стал доступен в Интернете как облачный сервис. С тех пор это был самый популярный инструмент для распознавания изображений, документов и плавного извлечения идентифицируемых данных. За прошедшие годы OCR широко внедрили. Например, в 1940 году был изобретен отофон; он помогал слепым людям читать тексты с некоторой практикой.
Также прочтите – Как преобразовать запись голоса в текст на ПК и Android
Список лучших онлайн-инструментов OCR для извлечения текста из изображенияOCR сделало его более доступным благодаря многочисленным применениям, таким как распознавание данных, рукописный ввод в перьевые вычисления, извлечение информации из печатных текстов и т. Д.Мы также можем использовать это программное обеспечение в качестве словаря; он просто распознает слово, устраняет ошибки и перехватывает текст.
OCR стало достаточно универсальным, чтобы читать более сложный текст, почерк и печатные материалы в текущей ситуации.
1. Газировка PDF OCR В настоящее время OCR используется повсеместно; можно создавать PDF-файлы с опциями онлайн и офлайн, загрузив рабочий стол Soda Pdf на компьютеры. Вы можете распознать текст из нескольких файлов, используя содовый PDF-файл.OCR может преобразовывать текст в PDF-документах в обычный текст, который можно копировать, вставлять и редактировать.После завершения процесса вы можете получить доступ к своему pdf, загрузив его в свою систему. Доступно множество опций, таких как преобразование текста в PDF, преобразование из PDF, преобразование изображений в читаемый текст и управление файлами PDF.
Посетить веб-сайт
2. OCR в Интернете Позволяет преобразовывать отсканированные изображения, факсы, снимки экрана, документы PDF и электронные книги в текст.Он дает вам такие возможности, как неограниченное количество загрузок, сохраняет ваши данные в безопасности; вы можете скачать и отредактировать файл в Google docs, а затем перевести и опубликовать файл в Интернете на веб-сайтах.Доступны форматы входных и выходных файлов, такие как JPEG, JFIF, PNG, GIF, BMP, PBM, PGM, PPM, PCX, а также форматы выходных файлов, такие как обычный текст (TXT), Microsoft Word (DOC), Adobe Acrobat (PDF).
Посетить веб-сайт
Также читайте – Лучшие альтернативы CamScanner для Android и iOS
3.OCR Space С помощью оптического распознавания текста вы можете преобразовывать отсканированные изображения или текстовые документы со смартфона в легкодоступные файлы. Его можно использовать бесплатно, и ваши данные будут в безопасности. Вам нужно выполнить четыре простых шага: загрузить файл, запустить распознавание текста, получить результаты и проверить наложение определенных изображений / текстов.При загрузке файлов помните, что не загружайте изображения / pdf размером более 1 МБ, если вы пользуетесь бесплатным тарифным планом; с профессиональной версией вы можете увеличить свой лимит загрузки.Существует множество поддерживаемых языков OCR, таких как китайский, японский, немецкий, английский и т. Д. Однако он может обрабатывать только печатные документы.
Посетить веб-сайт
4. Отсканированный PDF-файл в Word Online Загрузка отсканированных файлов PDF и преобразование файлов Word для редактирования текста документа позволяет сэкономить время. Система распознавания текста может облегчить вам жизнь. Он предоставляет вам простой способ конвертировать отсканированные файлы PDF в доступные документы с точным извлечением текста.Нет никаких ограничений, так как они не запрашивают ваш адрес электронной почты для регистрации. После преобразования они удаляют ваши файлы, поэтому ваши файлы также в безопасности. Он может работать на любой машине, поэтому нет необходимости устанавливать инструмент для преобразования.
Посетить веб-сайт
5. Преобразование OCR так же просто, как это слово convertio. Просто загрузите отсканированные документы и изображения и преобразуйте их в легко читаемый файл. Вы можете выбрать различные форматы файлов, такие как PDF, JPG, PBM и т. Д.Вы можете выбрать разные языки и настройки вывода в соответствии с вашими требованиями. В конце концов, вы можете преобразовать и загрузить свой файл, нажав кнопку распознавания, и ваш файл готов к использованию.
Посетить веб-сайт
Также читайте – Лучшие бесплатные редакторы PDF с открытым исходным кодом для Windows и Mac
6. i2OCR Портал i2OCR предоставляет вам возможность загружать неограниченное количество документов / изображений без регистрации. Вы можете редактировать и форматировать текст с изображений, следуя функциям распознавания текста.Он может преобразовывать отсканированные книги в документы с возможностью поиска.Самое лучшее в i2ocr – это неограниченная загрузка и конвертация без какой-либо регистрации и сборов. Более того, более 100 языков распознавания могут улучшить результат.
Посетить веб-сайт
7. Abbyy FineReader Это бесплатный веб-сайт для преобразования любого PDF-файла, изображения или отсканированного документа в полностью редактируемый файл. Выбрав язык документа, вы можете конвертировать файлы в MS Word, MS Excel, MS Powerpoint и экспортировать файл в облачное хранилище, что является лучшей функцией Abby Finereader.Кроме того, он предоставляет вам лимит загрузки 100 Мб, чего вполне достаточно.Загрузить Abbyy Finereader
8. Бесплатная OCR Ищете бесплатный инструмент для извлечения текста из любых изображений, тогда Free OCR – это то, что вам нужно. Он поддерживает многоязычное преобразование. Максимальный размер – 7 МБ, что вполне достаточно, потому что он конвертирует только первую страницу, что является недостатком этого инструмента. Но тем не менее, его стоит использовать, потому что для преобразования файла не требуется регистрация.Вам понравится этот инструмент благодаря своей простоте. Скачать бесплатно OCR
Также прочтите – Как преобразовать документ в PDF с помощью Google Chrome
9. Новое оптическое распознавание символов – бесплатное онлайн-оптическое распознавание символов Этот сайт выглядит очень просто, и на нем нет дополнительных функций, которые вас отвлекают. Просто зайдите на сайт, и вы увидите, что там есть кнопка просмотра. Загрузите эти изображения и нажмите кнопку OCR. Затем он извлечет текст из изображения.Вы можете в любое время загрузить на этот сайт текстовые изображения, и он предоставит вам необработанный текст этих изображений, который вы можете легко скопировать и использовать.Вы можете конвертировать JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu в текст.
Посетить веб-сайт
10. Adobe Acrobat DC Adobe – один из самых популярных инструментов распознавания текста, доступных на рынке. Легко редактируйте отсканированный PDF-файл с помощью расширенных инструментов Adobe OCR. Кроме того, Adobe предоставляет вам бесплатную пробную версию, которую вы можете использовать для проверки ее функциональности.Самое лучшее в Adobe – это то, что вы можете работать с Adobe на нескольких платформах, таких как мобильная, настольная и веб-платформа, что может помочь вам повысить вашу продуктивность.Мы любим Adobe за его простоту и расширенные функции. Так что стоит попробовать.
Скачать Adobe Acrobat
Преобразование ваших документов в PDF
Советы по созданию файлов PDF в заявках Grants.Gov
- PDF – это стандартный формат для обмена данными, и можно преобразовать многие распространенные форматы файлов (Microsoft Word, Corel WordPerfect и т. Д.) В PDF, используя широкий спектр приложений для создания PDF-файлов, иногда называемых дистилляторами.Фактически, преобразование PDF встроено в Microsoft Office с 2007 года. Некоторые сторонние преобразователи PDF бесплатны, многие довольно недороги, а некоторые лучше, чем другие. Если вы используете одно из этих приложений, обязательно проверьте результаты – убедитесь, что вы и другие пользователи можете открывать и просматривать полученные PDF-файлы с помощью бесплатного программного обеспечения Adobe Acrobat Reader.
- Если вы что-то сканируете для создания файла PDF, не сканируйте его с более высоким разрешением, чем вам нужно.Рецензенты и участники дискуссии обычно читают приложения NEH в режиме онлайн, поэтому изображение или буква, отсканированные с разрешением 100 dpi (точек или пикселей на дюйм), будут четко отображаться на мониторе компьютера или планшете. Изображение, отсканированное с более высоким разрешением (300+ dpi), приведет к гораздо большему размеру файла, но обычно не дает лучшего качества при просмотре на мониторе или планшете. Кроме того, эти большие файлы могут вызвать проблемы при просмотре или загрузке вашего приложения. Это верно как для фотографий, рисунков и чертежей, так и для писем, резюме и т. Д.Короче говоря, избегайте высоких разрешений при сканировании чего-либо, чтобы превратить это в PDF.
- Если вы сканируете текст – например, письмо, резюме или биографию – не сканируйте его как изображение, даже изображение с относительно низким разрешением. Текст следует сканировать как текст с использованием приложения оптического распознавания символов (OCR), поскольку текстовые данные намного компактнее, чем данные изображения. Сканирование текста с помощью программного обеспечения OCR позволяет редактировать текст после того, как он был отсканирован, и позволяет вам (и тем, кто читает ваше приложение) искать текст в документе.Ничего из этого нельзя сделать, если вы отсканируете текст и сохраните его как изображение.
- Если вы конвертируете изображения в PDF (фотографии, архитектурные чертежи, карты и т. Д.), Убедитесь, что они не больше, чем должны быть. Как упоминалось выше, приложения обычно читаются онлайн, поэтому нет необходимости, чтобы ваши изображения были больше, чем они будут отображаться на мониторе компьютера или планшете. А большие изображения могут вызвать проблемы при просмотре или загрузке вашего приложения.Если ваше изображение должно быть просмотрено с очень высоким разрешением, сделайте его доступным в Интернете и вставьте ссылку на него в файл PDF, а не включайте его в свое приложение (см. Следующий маркированный элемент).
- Если вам необходимо включить в приложение большие медиафайлы – изображения с высоким разрешением, видео- или звуковые файлы или яркие многоцветные отчеты – рассмотрите возможность встраивания ссылок на эти ресурсы в свои файлы PDF, а не их включения в свое приложение. . Конечно, это означает, что эти ресурсы должны быть доступны через Интернет – на вашем веб-сайте или в другом месте, доступном с помощью веб-браузера.Тогда ваш PDF-файл будет содержать ссылки на эти ресурсы, а не на сами ресурсы. Поскольку заявки обычно просматриваются в Интернете, ресурсы будут легко доступны для рецензентов и участников группы, когда они прочитают вашу заявку.
- Программное обеспечение, необходимое для просмотра и печати файлов PDF (Adobe Acrobat Reader), находится в свободном доступе, но не у всех есть самая последняя версия этого программного обеспечения. А стандарт PDF с годами развивался – новые функции добавляются с каждой версией.Помните эти факты при создании файлов PDF. Не создавайте файлы PDF, которые можно прочитать только с помощью самых последних версий бесплатного Acrobat Reader. Более совершенные приложения для создания PDF-файлов позволяют указать версию PDF-файла, которую будет создавать программное обеспечение. Текущая версия – 1.7 (поддерживается Acrobat Reader 10.x и выше).
- Не включайте никаких средств защиты в ваши файлы PDF. Убедитесь, что файлы не предназначены только для чтения, не зашифрованы и не защищены паролем.
- Не прикрепляйте портфолио в формате PDF к заявке на grants.gov. Это функция, добавленная в стандарт PDF с версии 1.6, и она позволяет вам включать или прикреплять дочерние файлы PDF в родительский файл. Это может быть удобный способ объединения файлов, но портфолио вызывает проблемы у многих программ чтения PDF. Если вы хотите объединить два или более PDF-файлов в один файл, используйте функцию «Объединить файлы в один PDF-файл» в Acrobat и выберите «Один файл PDF», а не «Портфолио» в качестве вывода.
jbarlow83 / OCRmyPDF: OCRmyPDF добавляет текстовый слой OCR к отсканированным файлам PDF, что позволяет выполнять поиск по ним
OCRmyPDF добавляет текстовый слой OCR к отсканированным файлам PDF, позволяя выполнять поиск по ним или копировать-вставку.
ocrmypdf # это программа командной строки с поддержкой сценариев -l eng + fra # поддерживает несколько языков --rotate-pages # может исправить неправильно повернутые страницы --deskew # он может выровнять искаженные PDF-файлы! --title "My PDF" # может изменять выходные метаданные --jobs 4 # по умолчанию использует несколько ядер --output-type pdfa # по умолчанию создает PDF / A input_scanned.pdf # принимает ввод PDF (или изображения) output_searchable.pdf # производит проверенный вывод PDF
Подробнее о последних изменениях см. В примечаниях к выпуску.
Основные характеристики
- Создает доступный для поиска файл PDF / A из обычного PDF
- Размещает текст OCR точно под изображением, чтобы облегчить копирование / вставку.
- Сохраняет точное разрешение исходных встроенных изображений
- По возможности вставляет информацию оптического распознавания символов как операцию “без потерь”, не нарушая никакого другого содержимого.
- Оптимизирует изображения PDF, часто создавая файлы меньшего размера, чем входной файл
- Если требуется, выравнивает и / или очищает изображение перед выполнением OCR
- Проверяет файлы ввода и вывода
- Распределяет работу по всем доступным ядрам ЦП
- Использует движок Tesseract OCR для распознавания более 100 языков
- Правильно масштабируется для обработки файлов с тысячами страниц
- Проверено в боевых условиях на миллионах PDF-файлов
Подробнее: обратитесь к документации.
Мотивация
Я поискал в Интернете бесплатный инструмент командной строки для распознавания PDF-файлов: я нашел много, но ни один из них не удовлетворил:
- Либо они создали PDF-файлы с неправильно размещенным текстом под изображением (что делает невозможным копирование / вставку)
- Или не обрабатывали акценты и многоязычные символы
- Или меняли разрешение встроенных изображений
- Или они создали смехотворно большие файлы PDF
- Или они вылетели при попытке OCR
- Или они не создали действительные файлы PDF
- Кроме того, ни один из них не создавал файлы PDF / A (формат, предназначенный для длительного хранения)
… поэтому я решил разработать свой собственный инструмент.
Установка
ПоддерживаютсяLinux, Windows, macOS и FreeBSD. Также доступны образы Docker как для x64, так и для ARM.
| Операционная система | Установить команду |
|---|---|
| Debian, Ubuntu | apt install ocrmypdf |
| Подсистема Windows для Linux | apt install ocrmypdf |
| Fedora | dnf установить ocrmypdf |
| macOS | brew install ocrmypdf |
| LinuxBrew | brew install ocrmypdf |
| FreeBSD | pkg install py37-ocrmypdf |
| Конда | conda установить ocrmypdf |
Для всех остальных, см. Нашу документацию по шагам установки.
языков
OCRmyPDF использует Tesseract для распознавания текста и полагается на свои языковые пакеты. Для пользователей Linux часто можно найти пакеты с языковыми пакетами:
# Показать список всех языковых пакетов Tesseract APT-кеш поиск в tesseract-ocr # Пользователи Debian / Ubuntu apt-get install tesseract-ocr-chi-sim # Пример: установка языкового пакета для упрощенного китайского языка # Пользователи Arch Linux pacman -S tesseract-data-eng tesseract-data-deu # Пример: установка пакетов английского и немецкого языков # brew для пользователей macOS brew install tesseract-lang
Затем вы можете передать аргумент -l LANG в OCRmyPDF, чтобы указать, какие языки следует искать.Могут быть запрошены несколько языков.
OCRmyPDF поддерживает Tesseract 4.0 и бета-версии Tesseract 5.0. Так и будет
автоматически использовать ту версию, которую он найдет первой в среде PATH Переменная. В Windows, если PATH не предоставляет двоичный файл Tesseract, мы используем
самый высокий номер версии, установленной в соответствии с реестром Windows.
Документация и поддержка
После установки OCRmyPDF встроенную справку, объясняющую синтаксис команды и параметры, можно получить по адресу:
Наша документация размещена на сайте Read the Docs.
Пожалуйста, сообщайте о проблемах на нашей странице проблем GitHub и следуйте шаблону проблемы для быстрого ответа.
Требования
Помимо требуемой версии Python (3.6+), OCRmyPDF требует установки внешних программ Ghostscript, Tesseract OCR, QPDF и Leptonica. OCRmyPDF – это чистый Python, но он использует CFFI для переносимой генерации привязок библиотек. OCRmyPDF работает практически со всем: Linux, macOS, Windows и FreeBSD.
Пресса и СМИ
Деловые запросы
OCRmyPDF не был бы таким программным обеспечением, каким оно является сегодня, если бы компании и пользователи не хотели оказывать поддержку при разработке функций и консультировать запросы.Мы рады обсудить все запросы, будь то расширение существующего набора функций или интеграция OCRmyPDF в более крупную систему.
Лицензия
Программное обеспечение OCRmyPDF находится под лицензией Mozilla Public License 2.0. (МПЛ-2.0). Эта лицензия разрешает интеграцию OCRmyPDF с другим кодом, включен коммерческий и закрытый исходный код, но просит вас опубликовать исходный код изменения, которые вы вносите в OCRmyPDF.
Некоторые компоненты OCRmyPDF имеют другие лицензии, как указано в этих файлах и файл debian / copyright .Большинство файлов в misc / используют лицензию MIT, а
документация и тестовые файлы обычно находятся под лицензией Creative Commons
ShareAlike 4.0 (CC-BY-SA 4.0).
Заявление об ограничении ответственности
Программное обеспечение распространяется на УСЛОВИЯХ «КАК ЕСТЬ», БЕЗ ГАРАНТИЙ ИЛИ УСЛОВИЙ ЛЮБОГО РОДА, явных или подразумеваемых.
Одним из наиболее распространенных вариантов использования коннектора Encodian Power Automate является выполнение OCR (оптического распознавания символов) в файлах PDF.Затем эти документы становятся доступными для поисковых систем, таких как поиск SharePoint, и вы также можете начать работу с данными, содержащимися в документах. Но что делать, если у вас уже есть большие репозитории SharePoint файлов PDF, в которых нет текстового слоя? или может иметь текстовый слой, но вы не уверены!
Один из вариантов – использовать действие OCR PDF Document, предоставляемое соединителем Encodian Power Automate. Можно создать поток для извлечения документов из библиотеки, применения текстового слоя, а затем либо обновления существующего файла, либо сохранения в альтернативном месте.Это вполне приемлемое решение, но оно может стать слишком дорогостоящим для требований массового распознавания текста. Power Automate хорош для повседневной автоматизации распознавания текста, но как вы справляетесь с массовым распознаванием текста в больших репозиториях SharePoint?
Представляем Encodian Indxr!
Приложение Encodian Indxr может быть установлено и запущено на рабочем столе Windows (или сервере), и при простой настройке оно может автоматически обнаруживать и распознавать PDF-документы, хранящиеся в библиотеке документов SharePoint или в определенной папке.Обработанные документы могут быть добавлены в исходный или альтернативный пункт назначения SharePoint, и доступны дополнительные параметры для копирования метаданных, копирования разрешений, принудительного распознавания текста, перезаписи исходного файла и префиксов имен файлов:
По умолчанию Encodian Indxr проверяет наличие текстового слоя в PDF перед обработкой документа и будет пропущено, если текстовый слой присутствует. Однако при выборе параметра «Принудительное распознавание текста» новый текстовый слой всегда будет создаваться с помощью распознавания текста.
В качестве быстрого примера; Рассмотрим библиотеку документов SharePoint, содержащую три файла: один документ Word и два PDF-файла, один PDF-файл уже имеет текстовый слой, а один – нет.Также есть еще одна папка, содержащая те же три файла (всего шесть файлов):
Если я открою PDF-файл без текстового слоя в браузере и найду какой-то текст, результат не будет:
Тот же поиск в PDF-файле с текстовым слоем дает результаты:
В этом примере целью является распознавание требуемых PDF-документов и сохранение обновленных файлов (OCR’d) в новом расположении SharePoint.
Можно создать новую конфигурацию, которая определяет исходную и целевую библиотеки SharePoint; мы не собираемся копировать метаданные или разрешения и не будем принудительно распознавать текст.Цель состоит в том, чтобы просто распознать те PDF-файлы, в которых в настоящее время нет текстового слоя, и скопировать результат в библиотеку «Целевые документы»:
При запуске приложение Indxr обрабатывает все PDF-файлы, содержащиеся в исходной библиотеке, идентифицируя и выполняя OCR по мере необходимости. Indxr предоставляет визуальную подсказку, выделяя зеленым цветом те документы, которые были распознаны. В том маловероятном случае, если во время обработки возникнет проблема, файл будет выделен красным цветом:
Во время и после завершения выполнения пользователь может просматривать файлы журнала и экспортировать выходные данные сетки для дальнейшего анализа.
Давайте исследуем целевую библиотеку. Мы видим, что был создан файл «PDF без текстового слоя.