
Оптическое распознавание текста онлайн для Word
Онлайн-распознавание текста (оптическое распознавание символов) для PDF, изображений, Word, Excel и PowerPoint
Powered by aspose.com and aspose.cloud
Перетащите файл(ы) сюда
By uploading your files or using our service you agree with our Terms of Service and Privacy Policy
Язык
EnglishArabicCatalanChinese (Simplified)Chinese (Traditional)CzechDanishDutchGermanGreekFilipino (Philippines)FrenchHebrewHindiIndonesianItalianJapaneseKazakhKoreanMalayPersian (Farsi)PolishPortugueseRomanianRussianSpanishSwedishThaiTurkishUkrainianVietnameseHungarianBulgarian
О распознавании текста
Приложение
OCR может анализировать текст в любом изображении, PDF, Word, PowerPoint, особенно во встроенных изображениях документов, после чего вы можете легко редактировать извлеченный текст на своем компьютере. С помощью приложения OCR вам не придется повторно вводить весь контент для работы с документами. Сделайте свои печатные контракты, счета, квитанции, страницы журналов доступными для поиска и компактными бесплатно с любой ОС, которую вы используете Windows, macOS, Linux, мобильные Android и iOS.
Если вы хотите извлечь изображения из Word программно, проверьте документацию Aspose.PDF .
С помощью приложения OCR вам не придется повторно вводить весь контент для работы с документами. Сделайте свои печатные контракты, счета, квитанции, страницы журналов доступными для поиска и компактными бесплатно с любой ОС, которую вы используете Windows, macOS, Linux, мобильные Android и iOS.
Если вы хотите извлечь изображения из Word программно, проверьте документацию Aspose.PDF .
Важно! Мы придерживаемся политики конфиденциальности. Ваши документы обрабатываются API Aspose. Мы не используем ваши документы с личным имуществом и не передаем их третьим лицам. Ваши документы хранятся в безопасном хранилище Aspose.PDF в течение 24 часов, а затем удаляются. Чтобы немедленно удалить документы, просто нажмите кнопку ” DELETE ” в окне загрузки.
Как это работает
#01
Введите веб-сайт PDF
Откройте бесплатное приложение OCR и выберите Word для сканирования.
#02
Загрузить файлы
Щелкните внутри области перетаскивания файлов, чтобы загрузить Word файлов или перетащите Word файлов.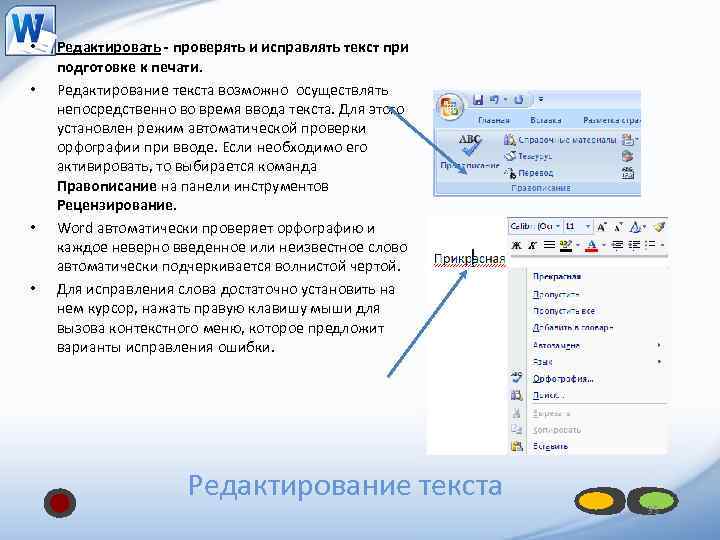
#03
Соблюдайте ограничения
Для операции можно загрузить максимум 10 Word файлов.
#04
Запустите сканирование
Нажмите кнопку «Сканировать». Ваши файлы Word будут загружены и распознаны в формате Word.
#05
Получите результаты
Ссылка на скачивание файлов результатов будет доступна сразу после сканирования.
#06
Отправить по электронной почте
Вы также можете отправить ссылку на файл Word на свой адрес электронной почты.
#07
Не забудьте получить результат
Обратите внимание, что файл будет удален с наших серверов через 24 часа, а ссылки для скачивания перестанут работать по истечении этого периода времени.
Часто задаваемые вопросы
❓ Как использовать OCR для Word?
Сначала вам нужно добавить файл для OCR: перетащите файл Word или щелкните внутри белой области, чтобы выбрать файл и выбрать язык. Затем нажмите кнопку «СКАНИРОВАТЬ».
⏱️ Сколько времени нужно, чтобы распознать Word?
Это приложение для распознавания текста работает быстро. Вы можете распознать Word за несколько секунд.
🛡️ Безопасно ли распознавать Word с помощью бесплатного приложения для распознавания текста?
💻 Могу ли я распознать Word в Mac OS, Android или Linux?
Наше распознавание Word работает онлайн и не требует установки программного обеспечения.
🌐 Какой браузер следует использовать для распознавания Word?
Вы можете использовать любой современный браузер для распознавания Word, например Google Chrome, Firefox, Opera, Safari.
Особенности
Быстрое и простое распознавание текста документов
Загрузите документ, выберите формат сохранения и нажмите кнопку «Сканировать». Вы получите ссылку для скачивания, как только изображения файлов будут распознаны
Распознавание текста с помощью OCR из любого места
Он работает на всех платформах, включая Windows, Mac, Android и iOS. Все файлы обрабатываются на наших серверах. Вам не требуется установка плагинов или программного обеспечения
Качество распознавания текста
Все файлы обрабатываются с помощью API Aspose, которые используются многими компаниями из списка Fortune 100 в 114 странах.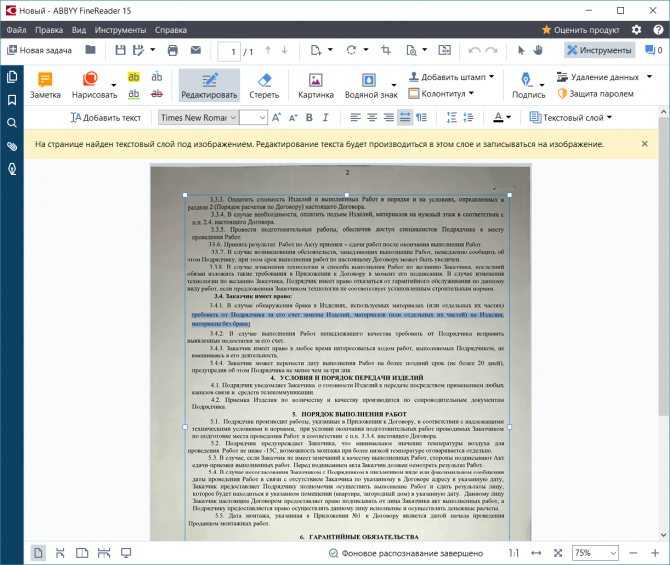
Распознавание pdf в word. OCR технология оптического распознавания текста
1. Выберите один PDF файл или файл изображения для распознавания.
2. Нажмите кнопку Распознать .
7. Пользуйтесь на здоровье
1. Выберите один ZIP файл содержащий изображения для распознавания. Только 20 файлов
могут быть распознаны одновременно.
2. Нажмите кнопку Распознать .
3. Файл отсылается на наш сервер и распознавание начинается немедленно.
5. Когда распознавание закончено, файл возвращается в то же самое окно браузера (не закрывайте Ваш браузер).
6. В случае невозможности распознавания, причина будет указана красным цветом.
7. Пользуйтесь на здоровье
Выберите PDF или файл изображение для распознавания Поддерживаются только PDF/JPG/JPEG/PNG/BMP/GIF/TIF/TIFF файлы
Русский English German French Spanish Italian Belgium Arabic Chinese Simplified Chinese Traditional Hindi Indonesian Tamil Telugu Portuguese Malaysian Ukranian
Идет распознавание
Это может занять несколько минут
На данной странице возможно распознавание только PDF JPG JPEG PNG BMP GIF TIF .
- Для конвертирования MS Word (DOC DOCX) в PDF воспользуйтесь ссылкой Word в PDF .
- Для конвертирования RTF ODT MHT HTM HTML TXT FB2 DOT DOTX XLS XLSX XLSB ODS XLT XLTX PPT PPTX PPS PPSX ODP POT POTX в PDF воспользуйтесь ссылкой Другие документы в PDF .
- Для конвертирования JPG JPEG PNG BMP GIF TIF TIFF в PDF воспользуйтесь ссылкой Изображение в PDF .
- Для извлечения текста из PDF документа воспользуйтесь ссылкой PDF в TXT .
- Для конвертирования DOC DOCX RTF ODT MHT HTM HTML TXT FB2 DOT DOTX в DOC DOCX DOT ODT RTF TXT или XLS XLSX XLSB XLT XLTX ODS в XLS XLSX или PPT PPTX PPS PPSX ODP POT POTX в PPT PPTX PPS PPSX JPG TIF PNG GIF BMP воспользуйтесь ссылкой Другие форматы .
- Для конвертирования DOC DOCX DOT DOTX RTF ODT MHT HTM HTML TXT в FB2 воспользуйтесь ссылкой Документы в FB2 .
- Для конвертирования JPG JPEG JFIF PNG BMP GIF TIF ICO в другие форматы, воспользуйтесь ссылкой Конвертировать изображение .
- Для конвертирования PDF в MS Word (DOC, DOCX), воспользуйтесь ссылкой Конвертировать PDF в Word .

- Для конвертирования PDF в JPG, воспользуйтесь ссылкой Конвертировать PDF в JPG .
- Для конвертирования DJVU в PDF, воспользуйтесь ссылкой Конвертировать DJVU в PDF .
Выберите ZIP архив для распознавания Поддерживаются только ZIP файлы
Русский English German French Spanish Italian Belgium Arabic Chinese Simplified Chinese Traditional Hindi Indonesian Portuguese Malaysian Ukranian
В режиме онлайн или офлайн
Создавайте файлы PDF в любом приложении, в любое время и в любом месте! Работайте в режиме онлайн с помощью Soda PDF Online или офлайн, загрузив Soda PDF Desktop на свой компьютер.
Запустите функцию OCR
Выполняйте больше операций с вашими документами PDF! Воспользуйтесь возможностями функции OCR для преобразования текста в документе PDF в обычный текст, который вы можете копировать, вставлять и редактировать.
Отправка по электронной почте
После создания файла PDF вы можете загрузить его на свой компьютер и просмотреть его в браузере.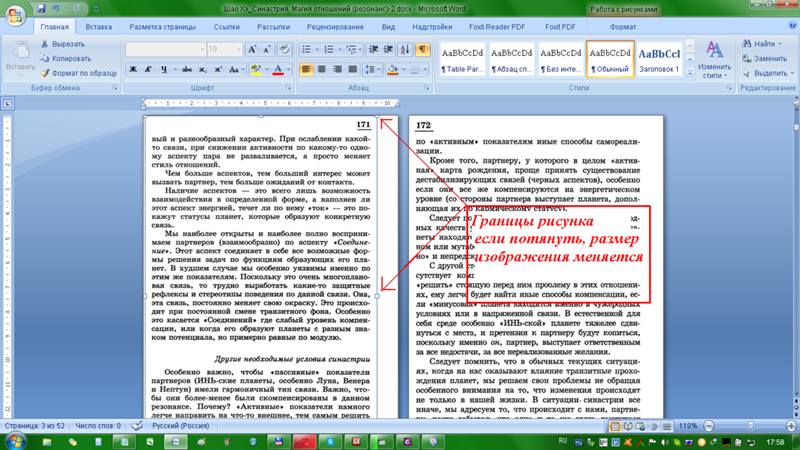
ЗНАЕТЕ ЛИ ВЫ?
Функция OCR – это ключевой инструмент для оцифровки документов
OCR – это программное обеспечение для оптического распознавания. Самая ранняя версия технологии OCR была изобретена в 1914 году задолго до изобретения PDF или других цифровых форматов документов. Эта функция использовалась для чтения строк текста и их преобразования в телеграфный код. Теперь технология OCR используется везде – от ввода данных до распознавания номерных знаков – и стала ключевым инструментом для распознавания и оцифровки рукописных и отсканированных документов.
Дополнительная информация о функции OCR
Слишком много информации?
У вас много файлов для распознавания и конвертирования с помощью функции OCR? Не беспокойтесь! Soda PDF позволяет выполнять пакетное распознавание текста из нескольких файлов одновременно!
Сканирование и распознавание
Нужно оцифровать бумажные документы? OCR выполнит эту задачу за вас! Отсканируйте документ, распознайте в нем текст при помощи функции OCR и преобразуйте файл в формат PDF.
Совершенно новый PDF
Попробуйте наш удобный онлайн-инструмент PDF для создания новых файлов PDF с изображениями, документами или даже таблицами Excel!
Пришло время рассказать, как произвести обратное действие.
Рассмотрим, как вытащить из PDF-документа текст, так чтобы можно было потом его редактировать в Word и подобных ему текстовых редакторах. То есть, попросту говоря, будем конвертировать PDF-файлы в Word.
Adobe Reader и аналоги
Самый простой, быстрый и бесплатный вариант:
Открываем нужный PDF-документ в Adobe Reader. Заходим в меню Редактировать, потом выбираем команду “Копировать файл в буфер обмена”
Все, можно спокойно редактировать полученный текст.
Обратите внимание, при использовании данного метода не сохраняется форматирование текста и нет возможности вытащить изображения!!!
Если вам, все таки, во что бы то ни стало нужно извлечь изображение из PDF-документа,чтобы не использовать какие-нибудь программы, сделайте скриншот с экрана на котором открыт PDF-файл, из которого вы скопировали текст, но не получилось скопировать картинку.
И полученное изображение вставьте в Word. Должно получиться вот так:
Понятно, что качество изображения будет оставлять желать лучшего, но как запасной вариант вполне подойдет.
В других просмотрщиках нужно будет сделать несколько иное действие.
Вот так в Foxit Reader (меню инструменты –> команда Выделить текст):
А вот так в PDF-XChange Viewer (меню Инструменты –> Основные –> Выделение):
Затем выделяем нужный текст и производим стандартные действия с буфером обмена, для тех кто не догадался: Копировать (Ctrl+C) и в Word — Вставить (Ctrl+V).
Система оптического распознавания текста (OCR)
При всей прелести этой методики у нее есть недостаток. Конвертировать PDF в Word не получиться, если PDF-документ создан сканированием с бумажного носителя или защищен от редактирования.
Поэтому будем использовать другой метод. А имено, с помощью специальной программы оптического распознавания текста.
Программа называется ABBYY FineReader и, к сожалению, является платной. Но зато функционал этой программы позволит перекрыть любые требования по созданию и конвертированию PDF-файлов.
Вот, например, имеем отсканированный текст в PDF формате
Запускаем ABBYY FineReader и в стартовом окне выбираем Файл в Microsoft Word
И все! Система сама распознает текст и отправляет его в Word
И опять же, ни один из онлайн-сервисов не работает с изображениями, и если текст у вас отсканирован и сохранен в формате PDF, то ничего не получится. Необходимо будет рассматривать вариант OCR.
Резюмируем
Как обычно, самым удобным оказался платный вариант, но остальные имеют право на существование, потому что не каждый день требуется преобразовывать файлы PDF. А на один раз можно или скачать демо-версию или воспользоваться онлайн-сервисом.
Если нельзя, но сильно надо, то способ всегда найдется.
Да, и еще, если Вы знаете еще какой-нибудь способ преобразования PDF-файлов, напишите мне в комментариях.
Спасибо за внимание!
P.S. Лирическое отступление :
1. Выберите один PDF файл или файл изображения для распознавания.
2. Нажмите кнопку Распознать .
7. Пользуйтесь на здоровье
1. Выберите один ZIP файл содержащий изображения для распознавания. Только 20 файлов
могут быть распознаны одновременно.
2. Нажмите кнопку Распознать .
3. Файл отсылается на наш сервер и распознавание начинается немедленно.
4. Скорость распознавания зависит от размера файла, скорости Вашего интернет соединения
и доступных ресурсов на наших серверах.
5. Когда распознавание закончено, файл возвращается в то же самое окно браузера
(не закрывайте Ваш браузер).
6. В случае невозможности распознавания, причина будет указана красным цветом.
7. Пользуйтесь на здоровье
Выберите PDF или файл изображение для распознавания Поддерживаются только PDF/JPG/JPEG/PNG/BMP/GIF/TIF/TIFF файлы
Русский English German French Spanish Italian Belgium Arabic Chinese Simplified Chinese Traditional Hindi Indonesian Tamil Telugu Portuguese Malaysian Ukranian
Идет распознавание
Это может занять несколько минут
На данной странице возможно распознавание только PDF JPG JPEG PNG BMP GIF TIF .
- Для конвертирования MS Word (DOC DOCX) в PDF воспользуйтесь ссылкой Word в PDF .
- Для конвертирования RTF ODT MHT HTM HTML TXT FB2 DOT DOTX XLS XLSX XLSB ODS XLT XLTX PPT PPTX PPS PPSX ODP POT POTX в PDF воспользуйтесь ссылкой Другие документы в PDF .
- Для конвертирования JPG JPEG PNG BMP GIF TIF TIFF в PDF воспользуйтесь ссылкой Изображение в PDF .
- Для извлечения текста из PDF документа воспользуйтесь ссылкой PDF в TXT .
- Для конвертирования DOC DOCX RTF ODT MHT HTM HTML TXT FB2 DOT DOTX в DOC DOCX DOT ODT RTF TXT или XLS XLSX XLSB XLT XLTX ODS в XLS XLSX или PPT PPTX PPS PPSX ODP POT POTX в PPT PPTX PPS PPSX JPG TIF PNG GIF BMP воспользуйтесь ссылкой Другие форматы .
- Для конвертирования DOC DOCX DOT DOTX RTF ODT MHT HTM HTML TXT в FB2 воспользуйтесь ссылкой Документы в FB2 .
- Для конвертирования JPG JPEG JFIF PNG BMP GIF TIF ICO в другие форматы, воспользуйтесь ссылкой Конвертировать изображение .
- Для конвертирования PDF в MS Word (DOC, DOCX), воспользуйтесь ссылкой Конвертировать PDF в Word .

- Для конвертирования PDF в JPG, воспользуйтесь ссылкой Конвертировать PDF в JPG .
- Для конвертирования DJVU в PDF, воспользуйтесь ссылкой Конвертировать DJVU в PDF .
Выберите ZIP архив для распознавания Поддерживаются только ZIP файлы
Русский English German French Spanish Italian Belgium Arabic Chinese Simplified Chinese Traditional Hindi Indonesian Portuguese Malaysian Ukranian
Иногда пользователям необходимо получить из сканированной странички, такой например как PDF, текстовый файл Word. В этих случаях часто используют программу ABBYY FineReader. Но программа не бесплатная, хотя имеет большой функционал, который полностью удовлетворит ваши потребности. Если вам не подходит данный способ, давайте подробно рассмотрим основные онлайн и оффлайн сервисы и ответим на вопрос о распознавании текста из ПДВ в Ворд, волнующий многих.
Большим плюсом данного сервиса является то, что здесь можно загружать файлы до 50 Мб. В отличие от других сервисов – это действительно много. В редких случаях бывают участки в готовом тексте, где необходима ваша корректировка, но в основном текст получается нормального качества.
В отличие от других сервисов – это действительно много. В редких случаях бывают участки в готовом тексте, где необходима ваша корректировка, но в основном текст получается нормального качества.
Сервис-конвертер PDF в Word pdf2doc.com/ru
В первую очередь подобные сервисы намного уменьшают время труда студентам и другим людям, чьи профессии соприкасаются со сканированными файлами. ПДФ-файлы имеют большой размер и занимают много места на флешках, дисках, в памяти разных устройств. Сюда можно добавить процесс передачи таких файлов по электронной почте. После преобразования файлы теряют первичный вес минимум на 10 – 20 %.
Попадая на главную страницу pdf2doc.com, вы увидите подсказки – как производить конвертацию. Посредине экрана, в верхней части вы можете выбрать язык. Можно выбрать английский и основные европейские языки. Ниже подсказок расположена панель по всей ширине сайта, на которой вы можете выбрать, что именно нужно конвертировать – PDF to DOC, PDF to JPG, JPG to PDF и т. д. Еще ниже этой панели, расположено рабочее окно, в котором и происходит конвертация.
д. Еще ниже этой панели, расположено рабочее окно, в котором и происходит конвертация.
Плюсами сервиса pdf2doc.com являются:
- Для работы не требуется регистрироваться на сайте.
- Поддержка основных популярных языков.
- Сервис прост в использовании, незаменим для школьников, студентов и педагогов различных уровней.
- Быстро работает с преобразованием PDF-документов в DOC и обратно.
Для того чтобы начать работу с сервисом, перейдите на сайт — http://pdf2doc.com/ru/ .
- Выберите файл для загрузки с вашего жесткого диска и нажмите загрузить. Можно также выбирать несколько файлов одновременно, но при этом скорость закачки заметно снизится.
- Чтобы начать конвертирование, нажмите «Скачать» и подождите некоторое время.
- Далее сохраним полученный файл в виде WORD.
Текст, как и в других подобных сервисах, можно преобразовывать как в одну сторону (PDF в WORD), так и в другую. Чтобы это сделать выберите в меню ссылку «Any to PDF», а далее уже по плану, описанному выше.
Распознать текст PDF в WORD при помощи сервиса ABBYY FineReader
В начале статьи было сказано об этом сервисе. Давайте ближе познакомимся с его возможностями и принципами работы.
Сервис позволяет работать с расширенными возможностями при помощи , а также используя дополнительные форматы при конвертировании и редактировании документов. Тарифные пакеты измеряются в конвертируемых страницах. Так пакет на 1 месяц в 200 страниц готового текста можно приобрести за 5 долларов. При покупке на следующий месяц того же пакета, остаток с предыдущего месяца прибавляется к существующему. Для тех пользователей, которые не хотят платить есть также отличная новость – до 10 страниц в месяц вы можете конвертировать абсолютно бесплатно.
При переходе на сайт пользователь увидит качественный дизайн сайта, а также грамотное расположение блоков. На первой же странице сервис предлагает нам преобразовать PDF и JPG в Microsoft WORD или Excel при помощи нажатия на зеленую кнопку – «Распознать».
Возможности сервиса ABBYY FineReader
- Создание книги FB2 или ePub из сканированных документов или PDF-файлов. Сервис позволяет это сделать максимально быстро, через несколько минут вы будете наслаждаться любимой книгой, читая ее на планшете или телефоне.
- Конвертирование PDF в документы WORD. После обработки сервисом ПДФ вы сможете редактировать материал по своему усмотрению, включая работу с таблицами и картинками.
- FineReader Online преобразует любой скан или картинку с текстом в один из поддерживаемых файлов (WORD, PowerPoint, Excel). Кроме рукописных текстов.
- Преобразованный документ можно легко экспортировать в любое облачное хранилище: OneDrive, Evernote, Google Drive и т.д.
- Поддержка более чем 190 языков мира.
- Конвертируемые документы могут оставаться на хранении сервиса в течении 14 дней, после они удалятся без возможности восстановления. Поэтому необходимо успеть за этот период их скачать на свой компьютер.
Чтобы воспользоваться сервисом ABBYY FineReader перейдите на официальный сайт сервиса – https://finereaderonline. com/ru-ru .
com/ru-ru .
Как распознать текст с картинки в word
Как распознать текст с картинки в Word: лучшие способы и ресурсы
Бывало ли у вас такое, что, например, партнеры по бизнесу прислали какую-то документацию или проект договора о сотрудничестве в виде файла графического формата (обычной картинки или документа PDF)? По всей видимости, с этим сталкивались, если не все, то очень многие. А ведь документ вам бывает нужно срочно изменить, а чаще всего это касается редактирования текстовой части, которая может содержаться в исходном файле. Как распознать текст с картинки, чтобы затратить на это минимум времени и избежать возможного появления всевозможных ошибок и опечаток? Об этом и многом другом далее и пойдет речь. Способов «вытаскивания» текста из файлов графических типов или универсального формата PDF на сегодняшний день существует много, однако при рассмотрении некоторых из них будем отталкиваться от наиболее интересных, простых и понятных любому пользователю методов.
Как распознать текст с картинки в Word?
Начать стоит с одного из самых простых методов, который подойдет всем без исключения пользователям. Если речь идет о том, чтобы «вытащить» текст из PDF-документа, а затем отредактировать его и сохранить в «родном» формате текстового редактора Word, далеко ходить не нужно, поскольку все последние версии этого приложения, начиная с «Офиса» 2010 года выпуска, поддерживают работу с файлами PDF и позволяют их редактировать точно так же просто, как если бы это был самый обычный документ Word.
Чтобы в «Ворде» распознать текст с картинки формата PDF, который, если кто не знает, относится именно к графическим типам файлов, достаточно задать открытие документа, а в типе файла выбрать именно формат PDF. После этого текст можно будет и отредактировать, и сохранить повторно в виде «родного» формата редактора, выбрав в том же поле нужный тип (например, DOC или DOCX).
Дополнительные инструменты для Office 2003
Если же проблема состоит в том, как распознать текст с картинки в редакторе, входящем в состав офисного пакета, скажем, 2003 года, в котором формат PDF не поддерживается, то и в этом случае ничего сложного нет.
В довесок к самому текстовому редактору дополнительно можно установить инструмент в виде интегрируемого в Word расширения под названием File Format Converters, который добавит возможностей редактору в том плане, что он сможет работать и с файлами PDF, и с документами обновленных форматов вроде DOCX.
Как распознать текст с картинки в PDF?
Еще один способ извлечения текста непосредственно из графического объекта в PDF-формате состоит в том, чтобы воспользоваться любым из известных редакторов, рассчитанных на работу с такими документами. Одним из наиболее универсальных и практичных приложений можно назвать небезызвестную программу Reader от Adobe. Обратите внимание, что в данном случае речь идет именно о приложении «Ридер», а не об аналогичном просмотрщике «Акробат», который поддерживает только чтение документов (просмотр без возможности редактирования).
В самой программе вам нужно будет просто выделить нужный фрагмент текста, скопировать его в буфер обмена, а затем вставить в документ Word и сохранить в нужном конечном формате.
Использование приложения OneNote
Если разбираться в тонкостях того, как распознать текст с картинки без использования вышеописанных приложений, можно посоветовать воспользоваться еще одним уникальным апплетом, входящим в состав последних модификаций и сборок самих офисных пакетов, под названием OneNote, о возможностях которого многие пользователи в большинстве своем или забывают, или не знают вовсе. В программе потребуется для удобства работы всего лишь создать пустой документ, используя меню вставки поместить в него изображение с текстом из графического файла (любого формата), а затем настроить язык распознавания.
После этого останется только скопировать текст в буфер обмена, для чего используется специальный пункт «Копировать текст с картинки», после чего его можно будет вставить из буфера в любую другую программу.
Примечание: если вопросы касаются того, как с картинки распознать китайский текст или содержимое, представленное на любом другом неподдерживаемом для отображения языке, вам потребуется установить дополнительный языковой пакет, загрузив его, например, из официального источника Microsoft и интернете.
Система распознавания ABBYY Finereader
Естественно, если речь идет исключительно о том, как распознать текст с картинки в графических форматах, лучше всего применять для этого специализированные OCR-системы. Одной из самых мощных и популярных является программа ABBYY Finereader, а также ее онлайн-аналог в виде официального интернет-портала.
Это приложение работает по типу виртуального сканера, в котором нужно всего лишь задать направление распознавания, а иногда может потребоваться указать язык исходного документа (это относится к устаревшим версиям пакета). Когда сканирование текста на том же печатном листе или в графическом файле будет закончено, он будет автоматически перенаправлен, например, в Word или в любой другой офисный редактор.
Конвертеры форматов
Пока это были самые простые приложения, позволяющие распознать текст с картинки. Программы для выполнения таких действий включают в себя и еще одну категорию ПО, называемого конвертерами. Они интересны тем, что выполнять именно распознавание текстового содержимого графического файла в них не нужно. Суть состоит в том, чтобы переконвертировать исходный графический формат в выбранный текстовый, после чего преобразованный файл и можно будет открыть в нужном редакторе. Кроме того, очень часто именно такие приложения оказываются максимально эффективными, когда вам требуется обработать несколько десятков однотипных документов. Это называется пакетным режимом. Что же до самих программ, их в том же интернете можно найти огромное количество.
Суть состоит в том, чтобы переконвертировать исходный графический формат в выбранный текстовый, после чего преобразованный файл и можно будет открыть в нужном редакторе. Кроме того, очень часто именно такие приложения оказываются максимально эффективными, когда вам требуется обработать несколько десятков однотипных документов. Это называется пакетным режимом. Что же до самих программ, их в том же интернете можно найти огромное количество.
Среди наиболее востребованных приложений можно отметить утилиты для преобразования PDF-файлов в любые другие форматы, конвертеры PDF или JPG в Word, универсальные преобразователи любого типа графики в текстовые файлы и т. д.
Онлайн-сервисы: нюансы использования и возможные ограничения
Наконец, если ни одно из предложенных решений вам не подходит, заниматься преобразованиями вручную просто лень или нет времени, пожалуйста, в интернете представлено огромное количество ресурсов, на которых все эти операции будут выполнены без вашего прямого участия. От вас потребуется только загрузить исходный графический файл, дождаться окончания извлечения текста и скачать готовый текстовый файл на собственный компьютер (или даже просто скопировать текст из окна с результатом). Правда, неудобство некоторых таких сервисов состоит только в том, что зачастую могут устанавливаться ограничения по количеству одновременно загружаемых для обработки файлов и лимиты, касающиеся их размера, не говоря уже и о том, что некоторые сервисы являются отнюдь не бесплатными. Зато многие из таких ресурсов определяют используемый в тексте язык автоматически, что избавляет вас от дополнительных ненужных действий по переводу.
От вас потребуется только загрузить исходный графический файл, дождаться окончания извлечения текста и скачать готовый текстовый файл на собственный компьютер (или даже просто скопировать текст из окна с результатом). Правда, неудобство некоторых таких сервисов состоит только в том, что зачастую могут устанавливаться ограничения по количеству одновременно загружаемых для обработки файлов и лимиты, касающиеся их размера, не говоря уже и о том, что некоторые сервисы являются отнюдь не бесплатными. Зато многие из таких ресурсов определяют используемый в тексте язык автоматически, что избавляет вас от дополнительных ненужных действий по переводу.
Как распознать текст с картинки в Word
Представьте себе функцию, позволяющую извлечь текст из изображения и быстро вставить его в другой документ. На самом деле это возможно. Вам больше не нужно терять время, набирая все, потому что есть программы, которые используют оптическое распознавание символов (OCR) для анализа букв и слов в изображении, а затем конвертируют их в текст.
В наши дни существует так много бесплатных и эффективных опций, позволяющих извлечь текст из изображения, а не печатать его вручную. Ниже представлены самые удобные и эффективные программы и их сравнение.
Видео — распознавание текста с картинки в WORD
Извлечение текста с помощью OneNote
OneNote OCR уже на протяжении нескольких лет остается одной из самых лучших программ для распознавания текста. Однако, распознавание это одна из тех менее известных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть. Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Это стандартная программа, скорее всего вам не придется устанавливать ее самостоятельно. Найдите ее на компьютере в папке Microsoft Office или же с помощью поиска на панели «Пуск». Запустите программу.
Инструкции по извлечению текста:
- Шаг 1.
 Откройте любую страницу в OneNote, желательно пустую.
Откройте любую страницу в OneNote, желательно пустую.Теперь вы можете вставить его куда угодно. Удалите вставленное изображение, если оно вам больше не нужно.
На заметку! Это быстрый и удобный способ извлечения текста из картинки, но есть одно «но» — One Note работает подобным образом лишь с латиницей. Он не распознает русский текст.
Использование онлайн-сервисов
Онлайн-сервисы по распознаванию текста с изображения работают примерно по одному и тому же принципу. В примере ниже использовался Free Online OCR. На этом сайте стоит ограничение. Регистрация даст вам доступ к дополнительным функциям, недоступным для гостей: конвертировать многостраничный PDF (более 15 страниц) в текст, большие изображения и ZIP-архивы, выбирать языки распознавания, конвертировать в редактируемые форматы и многое другое. Распознать короткий тест можно и без регистрации.
- Шаг 1. Откройте сайт бесплатного OCR. Выберите изображение посредством кнопки «Select File». Это может быть и PDF файл.
Текст появится в поле ниже. Вы также можете скачать в формате Microsoft Word.
Этот способ имеет ряд преимуществ:
- Вам не придется скачивать и устанавливать стороннее программное обеспечение.
- Итог можно скачать в виде текстового документа.
- Это быстро.
- Более того на сайте можно распознавать текст на одном из множества предложенных языков.
Видео — Как распознавать текст с картинки, фотографии или PDF файла
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
- Шаг 1. Перейдите на сайт FineReader.
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
- Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.
Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Видео — Как распознать PDF в Word
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
|---|---|---|---|
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы.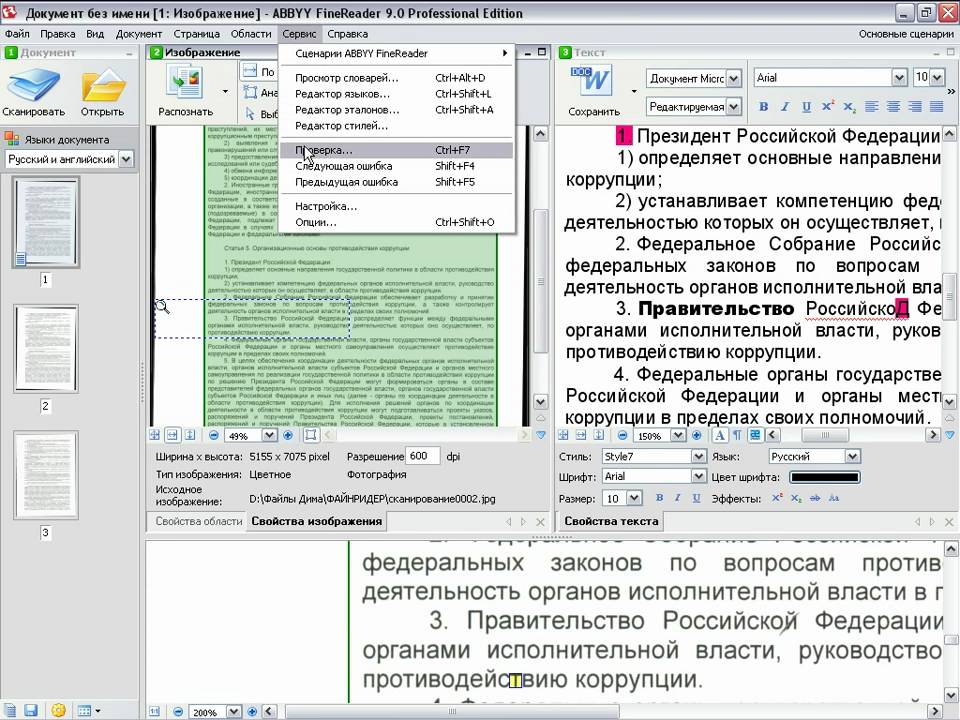 До 5 страниц бесплатно при регистрации До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование | Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат |
Хотя рынок заполнен программным обеспечением OCR, которое может извлекать текст из изображений, хорошая программа OCR должна делать больше, чем просто распознавание текста. Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Сервисы для распознавания текста — подборка лучших
Заказчик прислал сканы рабочих документов, в университете скинули фотку конспекта? Когда-то тексты умели распознавать только сканеры и то далеко не все. Сейчас же даже приложения на смартфоне могут перевести визуальный текст в редактируемый документ. А в этом материале ищем лучшие сервисы по распознаванию текста для вашего компьютера и смартфона тоже.
Finereaderonline.com
Компания ABBYY идет в плане распознавания текстов и обработки цифровых документов впереди всех. В арсенале их софта даже цифровые подписи, которые почти невозможно отличить от настоящих. Finereaderonline поддерживает почти 200 языков, работает быстро и онлайн — ничего не надо устанавливать. Можно выбрать разные форматы для сохранения текста, обработка текста происходит очень быстро и достаточно точно. Единственный нюанс — лимит на загрузку файлов до 100 Мб. Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Sodapdf.com
Еще один неплохой сервис, хотя тут нам предлагают скачать прогу отдельно. Правда, чуть менее обученный, чем софт от ABYYY — Sodapdf знает только 46 языков. Впрочем, если вам не нужно переводить с ацтекского или зулу, то проблем не возникнет. Программа условно бесплатная — есть триальная версия, полный функционал стоит от 7 до 17 евро в месяц в зависимости от пакета. Soda умеет конвертировать разные форматы, распознавать тексты, ставить электронные подписи и имеет большой набор инструментов для работы с PDF файлами и изображениями.
WinScan2PDF
Элементарная, простая маленькая утилита, которая состоит из трех кнопок: «выбрать источник», «сканировать» и подтвердить или отменить операцию. Поддерживает 23 языка, работает с многостраничными файлами и сохраняет обработанный файл в формате PDF. У этой программы есть одна особенность — она не работает с готовыми файлами и считывает документы только с подключенного сканера.
Free Online OCR
Не такой симпатичный, как Finereader, но тоже вполне умелый онлайн-сервис. Англоязычный, слегка устаревший интерфейс, в котором, впрочем, несложно разобраться. Free Online OCR поддерживает 106 языков и распознает текст с большинства самых популярных форматов файлов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сохранять готовые доки может не только в PDF, но и в стандарных doc и txt. Кроме текста, может распознать математические уравнения, правильно форматировать текст в колонках и столбцах или обработать только выделенный фрагмент. Качество распознавания довольно высокое даже c картинок низкого качества.
Microsoft OneNote
Распознавание текста здесь скорее дополнительная фича, а не основная задача. Вы можете вставить картинку в текущую запись OneNote и правой кнопкой мыши выбрать «Копировать текст из рисунка». Цифровая записная книжка от Microsoft однозначно не подойдет для обработки больших файлов, документов и постоянной работы с файлами. Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.
Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.
Readiris
Мощный и удобный конкурент ABBYY FineReader. Быстро и очень чисто распознает даже едва различимые тексты, при этом поддерживает 137 языков, включая русский. Работает очень быстро и легко обрабатывает даже большие объемы текста. Сохраняет исходное форматирование, не игнорируя кавычки, размеры шрифта и стиль написания. Может почистить текст от помарок и предложить исправления в словах. Знает символы, уравнения. Контактирует со сканерами, облачными сервисами, поддерживает кучу форматов. В общем, полноценный и удобный сервис, который не умеет разве что редактировать итоговый файл PDF. Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.
Img2txt.
 com
comПриятный дизайн, понятный интерфейс и высокая скорость обработки текста — что еще нужно для работы? Продвинутые алгоритмы распознавания помогают считывать документы даже плохого качества. Молниеносно конвертирует большие объемы текста, но при желании можно выбрать отдельную область файла для работы. Есть интеграция с Google Documents, хороший инструментарий для работы с документами PDF. Маловато языков — всего 35, но для основных задач этого может вполне хватить.
OCR CuneiForm
Шустро и тщательно распознает сфотографированные или отсканированные тексты, графические файлы. Старается сохранить исходную структуру текста, элементов и шрифты. Переводит все в редактируемые форматы на выбор. В общем, стандартный набор функционала. И, что самое главное, полностью бесплатный.
TextGrabber 6
Полностью бесплатное приложение для смартфонов за авторством компании ABBYY. Собственно, этим все сказано — в TextGrabber 6 все хорошо с распознаванием текста, есть встроенный модуль переводчика.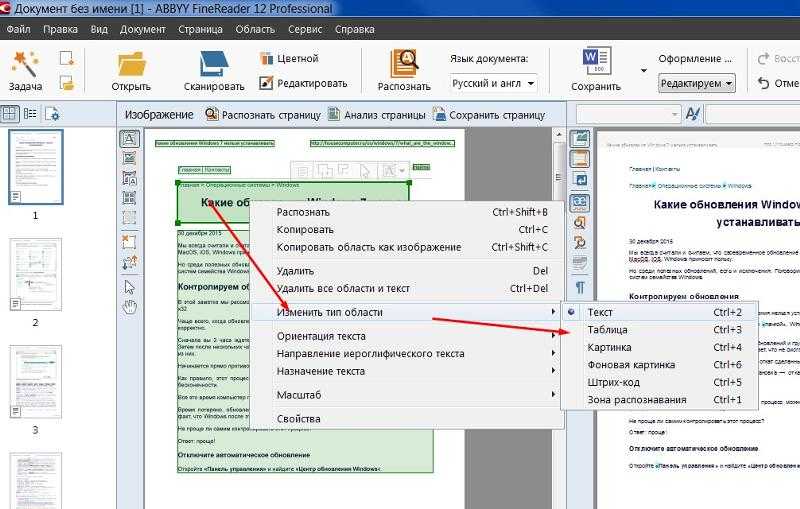 Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
Как преобразовать DJVU в Word
DjVu – достаточно известный формат файла, который, как правило, используется для хранения учебников и часто художественной литературы в электронном виде (чаще где преобладают изображения). В том случае, если вам необходимо «вытащить» из DjVu текстовую часть и сохранить ее в документ Word, вам пригодится один из конвертеров, приведенных ниже.
Прежде нам доводилось подробнее рассказывать об особенностях файла DjVu и о том, какими программами данный файл можно открыть на компьютере. В том случае, если в текстовую составляющую файла DjVu вам необходимо вносить коррективы или требуется чтение документа практически на любом современном устройстве, то самым оптимальным решением будет выполнение процедуры конвертирование из DjVu в Docx.
Как конвертировать DjVu в Docx?
Вариант 1: конвертирование с помощью онлайн-сервиса Convertio
В том случае, если вам не требуется регулярное конвертирование DjVu-файлов, то лучше всего для процедуры преобразования файла в Word воспользоваться онлайн-конвертером, работа с которым будет выполняться прямо в окне браузера.
Для начала преобразования перейдите на страницу сервиса и щелкните по кнопке «С компьютера». На экране появится проводник Windows, в котором вам потребуется указать имеющийся DjVu-файл на компьютере.
При необходимости, вы можете добавить на страницу сервиса дополнительные DjVu-файлы. Теперь, чтобы приступить к конвертированию, вам потребуется щелкнуть по кнопке «Преобразовать».
Начнется процесс конвертирования, который займет некоторое время (продолжительность может растянуться в зависимости от размера и количества загруженных файлов). Как только процедура будет завершена, вам будет предложено скачать файл на компьютер.
К сожалению, сервису далеко не всегда удается распознать текст в файле, поэтому он внезапно может выдать ошибку работы.
Перейти на страницу сервиса Convertio
Вариант 2: конвертирование с помощью онлайн-сервиса NewOCR
Данный онлайн-сервис специализируется на распознавании текста различных форматов файлов. Суть в том, что с помощью данного онлайн-сервиса можно распознать текст в формат TXT, а затем лишь скопировать получившийся текст и вставить его в формат Doc.
Суть в том, что с помощью данного онлайн-сервиса можно распознать текст в формат TXT, а затем лишь скопировать получившийся текст и вставить его в формат Doc.
Нюанс заключается в том, что в простеньком формате TXT будет полностью утеряно форматирование, но распознавание выполняется на очень высоком уровне.
Чтобы воспользоваться данным сервисом, вам потребуется загрузить в него DjVu-файл, а затем щелкнуть по кнопке «Preview».
Через некоторое время на экране отобразится окно настройки, в котором вам потребуется указать с какой страницы документа будет выполняться распознавание. Щелкните по кнопке «OCR».
Спустя мгновение, на экране отобразится текст документа, который можно скопировать и вставить в файл Docx и в последующем уже самостоятельно его отформатировать.
Перейти на страницу сервиса NewOCR
Вариант 3: конвертирование с помощью онлайн-сервиса PDF to DOCX
Формат DjVu по своей сути очень схож с форматом PDF, но в пользу второго стоит заметить, что он является самым популярным форматом документа в мире. К сожалению, найти онлайн-сервис или программу, которая бы позволила конвертировать DjVU в Docx практически невозможно, поэтому в данном случае мы пойдем обходным путем – конвертируем DjVu в PDF, а PDF, в свою очередь, в формат Docx.
К сожалению, найти онлайн-сервис или программу, которая бы позволила конвертировать DjVU в Docx практически невозможно, поэтому в данном случае мы пойдем обходным путем – конвертируем DjVu в PDF, а PDF, в свою очередь, в формат Docx.
Для начала пройдите на страницу сервиса DjVu to PDF по этой ссылке и щелкните по кнопке «Загрузить». На экране отобразится проводник Windows, в котором вам потребуется выбрать исходный DjVu-файл.
Сервис сразу начнет обработку загруженного файла. Как только обработка будет завершена, вам будет предложено загрузить результат на компьютер щелчком по кнопке «Скачать все».
На ваш компьютер будет загружен ZIP-архив, который для дальнейшей нашей работы потребуется распаковать. Теперь пройдите на страницу того же сервиса (ссылка ниже), который позволит перевести PDF в Docx. Точно таким же образом щелкните по кнопке «Загрузить», а затем укажите PDF-файл.
Сервис сразу начнет процедуру обработки. Снова ждем некоторое время, отслеживая процесс выполнения конвертирования.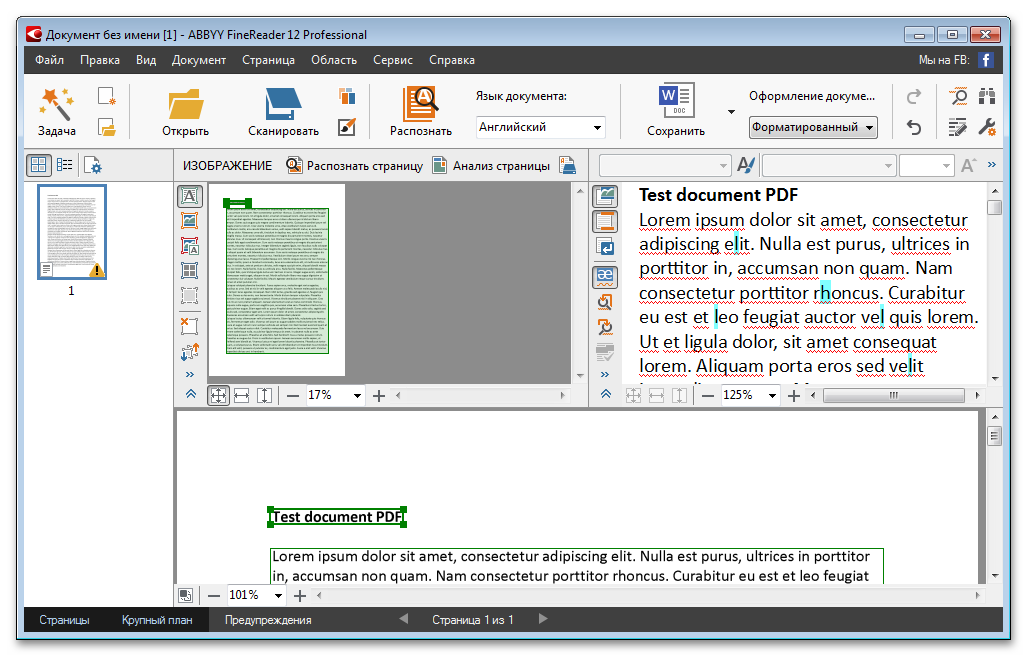 Данный тип конвертирования уже несколько сложнее, поскольку системе потребуется распознать весь текст документа, поэтому придется подождать несколько дольше.
Данный тип конвертирования уже несколько сложнее, поскольку системе потребуется распознать весь текст документа, поэтому придется подождать несколько дольше.
Как только обработка будет завершена, щелкните по кнопке «Скачать все».
Собственно, на этом все. На ваш компьютер будет загружен ZIP-архив, который лишь остается разархивировать, «вытащив» требуемый файл Docx.
Перейти на страницу сервиса PDF to DOCX
Что в итоге
В данной статье были рассмотрены лишь онлайн-сервисы для конвертирования DjVu в Docx, но были упущены компьютерные программы. Если у вас есть на примете программы-конвертеры, идеально выполняющие поставленную в этой статье задачу, обязательно поделитесь ими в комментариях.
Распознавание текста ocr, распознать текст из pdf в word, распознать текст с картинки или фото
Распознавание текста OCR
Настраиваем «под ключ» роботов для распознавания текста.
АВТОМАТИЗАЦИЯ МАРКЕТИНГАПредварительный заказ распознавания текста OCR
Как используется OCR на сайтах?
Для определения наличия ключевых слов на определенных страницах вашего сайта можно использовать роботов с применением технологии OCR. В таком случае вам не придется тратить много человеческого труда для поиска текста на сайте.
В таком случае вам не придется тратить много человеческого труда для поиска текста на сайте.
Обращаем ваше внимание, что для того, чтобы распознать текст из pdf в word вам понадобятся стандартные онлайн-сервисы. RPA роботы предназначены для работы именно с такими сервисами, но не заменяют их.
Зачем использовать OCR в интернете?
Если вам нужно автоматизировать какие-либо действия и отталкиваться от текста на сайте, тогда скорее всего вам нужны услуги по оптическому распознаванию текстов (ocr) для больших объемов текста.
В таком случае вы сможете использовать робота, который будет не просто понимать текст на сайте, но и действовать в соответствии с этим текстом, автоматизируя вашу деятельность на вашем сайте или на других сайтах.
Как используется OCR для распознавания документов?
При автоматизации документооборота практически всегда требуется распознавать текст различных документов. В таком случае, кроме того, что нужно реализовать распознавание текст в пдф в ворд, часто требуется поиск текста по документу.
RPA робот может распознать текст по картинке или фотографии, или распознать текст из jpg в word, при этом такие действия могут быть только частью одного большого алгоритма робота, обрабатывающего документы.
Зачем нужно OCR для мессенджеров?
Распознавание текста по аудио не является технологией OCR, но мы можем использовать роботов для автоматизации процесса распознавания отдельных аудио записей, или всего разговора в текст. Распознать звук из видео в текст может много разных сервисов.
Задача роботов будет в таком случае только записывать необходимые разговоры, переводить голос в текст при помощи готовых сервисов, после чего робот сможет находить необходимые ключевые слова в подготовленном тексте.
Как работает OCR с приложениями?
Если вам нужно распознать отсканированный текст в большом объеме, на постоянной основе, тогда имеет смысл сделать робота, который будет отправлять тексты в приложения, например, сканера, принтера, abbyy, после чего будет взаимодействовать с ними.
Задача распознать рукописный текст с фото может быть только одной из списка задач, которые выполняет робот при работе с приложениями, поэтому просто помните, что RPA роботы работают с любыми приложениями.
Автономность процессов
Программа для распознавания текста работает без участия человека.
Повышение качества
Автоматическое распознавание текста с фото эффективнее человека.
Избавление от рутины
OCR найдет нужную информацию за несколько минут, в зависимости от сложности задачи.
Экономия времени
Поиск текста на картинках уменьшает объем ручного труда.
Обработка данных
Помогает автоматизировать обработку и сбор информации с любых источников в интернете.
Многозадачность
OCR робот работает с несколькими ресурсами одновременно.
ЕСТЬ ВОПРОСЫ?У нас есть ответы как использовать OCR
Что такое OCR?
OCR — это автоматическое распознавание текста с любых ресурсов в интернете — картинок, сайтов, видео.
Для чего нужно распознавание текста?
Автоматическое распознавание информации позволяет экономить огромное количество времени. Распознавание текста онлайн позволяет искать нужную информацию по всему интернету, независимо от формата.
Как можно автоматизировать решение каптчи?
Роботизировать решение каптчи, поиск данных на картинках и в интернете можно с помощью технологии OCR. Например, при выполнении проекта с оказанием услуги массовой коммуникации используется эта технологию при построении процессов общения с клиентами.
Что дает автоматизация OCR?
Использование OCR в роботах увеличивает их эффективность. Например, поиск информации используется при парсинге или скрапинге, чтобы робот понимал где в карточке товара находятся определенные характеристики товара.
В чем выгода роботизации OCR?
Роботизация OCR позволяет оптимизировать затраты на человеческий ресурс при поиске текста на компьютере локально, или в интернете. Например, если вы решите заказать email рассылку и вам нужно будет собрать базу — в этом вам поможет, в том числе, технология OCR. Таким образом, вы используете сразу 2 технологии при выполнении 1 задачи при помощи роботизации.
Таким образом, вы используете сразу 2 технологии при выполнении 1 задачи при помощи роботизации.
• НАШ БЛОГНовые статьи и кейсы
Полезная информация для тех, кто интересуется автоматизацией бизнес-процессов, внедрением программных роботов RPA, а также продажами и маркетингом.
Бесплатная консультация
Объяснение роботизированной автоматизации процессов: все, что вам нужно знать
Dmitriy Makarenko 14.02.2022
В этой статье мы подробнее обсудим основные преимущества автоматизации процессов и познакомим вас с ее историей, чтобы показать, как мы достигли того, что имеем сегодня. Но перед этим давайте рассмотрим краткий пример роботизированной автоматизации процессов:
Читать далее »
3 вещи, которые следует учитывать перед внедрением автоматизации бизнес-процессов
Dmitriy Makarenko 05.02.2022
Третья компания сэкономила сотни часов ручной работы и получила своевременные и точные финансовые отчеты, после чего добилась пятикратного увеличения количества транзакций после внедрения решения по автоматизации между своими системами ERP и CRM.
Читать далее »
Как выбрать программное обеспечение RPA: 8 вещей, которые следует принять
Dmitriy Makarenko 30.01.2022
Чтобы помочь вам решить, какое программное обеспечение RPA выбрать, мы попросили инженеров-программистов и бизнес-лидеров поделиться своими лучшими идеями.
Читать далее »
20 Лучших Бесплатных И Платных Программ Для Оптического Распознавания Символов (OCR)
Каждый день в мире создаются триллионы документов, которые необходимо сканировать, оцифровывать и хранить.
Они бывают разных форматов, например, PDF, изображения и текстовые файлы.
Одним из способов оцифровки документа является использование программного обеспечения для оптического распознавания символов (OCR).
Программное обеспечение OCR сканирует бумажный или цифровой документ для получения информации – это позволяет вам сэкономить время на офисной работе, сократить ручной ввод и работать более эффективно.
Важное раскрытие информации: мы являемся гордыми партнерами некоторых инструментов, упомянутых в этом руководстве. Если вы перейдете по партнерской ссылке и впоследствии совершите покупку, мы получим небольшую комиссию без дополнительных затрат с вашей стороны (вы ничего не платите дополнительно).
Что Такое Программное Обеспечение Для Оптического Распознавания Символов?
Оптическое распознавание символов – это автоматизированный процесс, который преобразует отсканированные изображения текста в цифровой текст.
Владельцы бизнеса используют программное обеспечение OCR для оцифровки бумажных документов и даже целых офисов, сканируя их для получения информации, чтобы работать более эффективно, экономить время, улучшать управление бизнес-процессами и сокращать бумажную работу.
Существует три типа программного обеспечения OCR:
- Оффлайн: программное обеспечение, которое вы загружаете
- Semi-Offline: программное обеспечение, которое работает на вашем локальном компьютере
- Онлайн: программное обеспечение, которое работает в режиме онлайн через окно веб-браузера
После того как программное обеспечение OCR преобразует физический документ или изображение документа в цифровые данные, которые могут редактировать текстовые процессоры или программы электронных таблиц, пользователи могут осуществлять поиск в текстах с помощью обычных редакторов.
В настоящее время существуют инструменты OCR, которые могут повысить эффективность бизнеса практически в любой отрасли: ведение медицинской документации, правоохранительные органы, юридические сводки и многое другое.
via GIPHY
Когда дело доходит до выбора между бесплатным и платным программным обеспечением OCR, преимущества есть у обоих.
Платное программное обеспечение предлагает поддержку и обновления.
Бесплатные инструменты OCR могут быть не такими современными и точными в своих преобразованиях, но они предлагают более экономичный вариант для малых предприятий с ограниченным бюджетом.
Выбирая между платными и бесплатными вариантами OCR, очень важно соизмерять свои потребности с бюджетными ограничениями. Например, предположим, что у вас налаженный бизнес с большим количеством сотрудников, от которых зависит его повседневная работа.
В этом случае покупка первоклассного программного обеспечения для конвертации стоит инвестиций, поскольку без функций быстрого и эффективного сканирования документов ваш рабочий процесс может значительно замедлиться, что приведет к снижению производительности (и недовольству сотрудников).
С другой стороны, если вы начинаете и не нуждаетесь в крупномасштабном программном обеспечении, бесплатных инструментов OCR будет более чем достаточно для ваших нужд.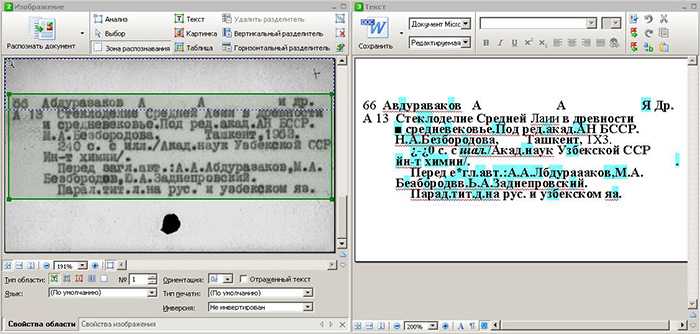
Как Выбрать Программу Для Оптического Распознавания Символов 📝
При выборе программного обеспечения OCR необходимо учитывать несколько факторов.
Прежде всего, необходимо решить, какие варианты вам нужны: офлайн, полуофлайн или онлайн (или все три).
Далее подумайте о потребностях и бюджете вашей компании – соответствуют ли они минимальным требованиям для платного варианта? Если нет, то, возможно, бесплатного варианта будет “достаточно”.
Наконец, решите, какие ключевые характеристики имеют наибольшее значение: точность преобразования или дополнительные возможности, такие как шаблоны оптического распознавания символов для стандартных форматов файлов и т.д.
Ниже мы подробно рассмотрим некоторые популярные инструменты OCR, чтобы вы могли принять обоснованное решение.
Основные характеристики, на которые следует обратить внимание при выборе инструмента OCR:
- Обнаружение Текста – поиск текста на изображениях с помощью алгоритмов и программирования.
 Это также известно как оптическое распознавание символов.
Это также известно как оптическое распознавание символов. - Функция Поиска – возможность поиска слов или фраз в документе для перехода непосредственно к ним.
- Перевод Текста – программа может переводить текст с одного языка на другой.
- Анализ Макета – программное обеспечение OCR анализирует макет документа и автоматически извлекает из него текст.
- Сегментация Текста – способ сегментации текста на слова для редактирования и поиска.
- Поддержка Форматов – программа распознает форматы файлов стандартных офисных документов, таких как Word, Excel и PowerPoint.
- Цифровая Подпись – программа может создавать цифровые подписи для ваших документов.
- Определение Макета – программа определяет макет документа и автоматически извлекает из него текст.
- Обнаружение Штрих-Кодов – программа может распознавать штрих-коды на бумаге.

Теперь, когда вы знаете, на что следует обратить внимание, давайте приступим к работе с нашей первой программой OCR: Adobe Acrobat
Лучшие Бесплатные И Платные OCR 💯
- Adobe Acrobat Pro DC
- Nanonets
- PDF Reader
- OmniPage Ultimate
- ABBYY FineReader PDF
- Readiris
- SimpleOCR
- Tesseract
- Amazon Textract
- Rossum
- Klippa
- Docparser
- Veryfi
- Google Document AI
- ABBYY FlexiCapture
- IBM Datacap
- FineReader
- Softworks OCR
- Microsoft OneNote
- Soda PDF
1. Adobe Acrobat Pro DC
Источник изображения: Adobe AcrobatAdobe Acrobat Pro DC – это программное обеспечение, позволяющее конвертировать файлы PDF в Word, Excel и другие форматы.
Он также имеет функцию OCR для преобразования отсканированных документов в редактируемый текст, что позволяет копировать/вставлять преобразованные тексты непосредственно в Office 365 или Google Docs.
Единственным существенным недостатком Adobe Acrobat DC является то, что он не бесплатный; однако, если ваша компания производит большие объемы бумажной документации, плата за лицензию может стоить инвестиций для снижения долгосрочных затрат, связанных с ручным вводом данных.
Adobe Acrobat Pro DC – не самый удобный вариант, поскольку это настольное приложение, но его функциональность компенсирует это.
Вы можете использовать Adobe Acrobat DC для преобразования отсканированных документов в редактируемый текст, а затем копировать/вставлять эти тексты непосредственно из PDF-файла в Office 365 или Google Docs.
Плюсы
- Простой в использовании
- Редактирование текста и изображений
- Изменение порядка и удаление страниц в PDF
- Легко конвертируйте другие форматы файлов в PDF
- Хороший инструмент для совместной работы
- Добавьте безопасность и защитите PDF-файлы паролем
- Подписывайте документы в цифровом формате своей собственной подписью
- Удобные вкладки рабочего процесса
- Простой пользовательский интерфейс
Минусы
- Функция редактирования текста неудобна
- Модель подписки Adobe может отталкивать
- Настольное приложение
Ценообразование
$14,99 в месяц, а Acrobat Standard DC – $12,99 в месяц.
Поддерживаемые Платформы:
Windows и Mac
2. Nanonets
Источник изображения: NanonetsNanonets – это программное обеспечение OCR на основе искусственного интеллекта, которое автоматизирует извлечение данных из документов/изображений. Извлекайте необходимые данные из PDF-файлов или изображений и экспортируйте их в настроенные файлы CSV, Excel, JSON или XML.
Nanonets – это отличный способ оцифровки документов и извлечения данных “из коробки”. Идеально подходит для автоматизации целых рабочих процессов, связанных с бизнес-документами.
Nanonets может понимать все виды документов, на разных языках и независимо от шаблонов. ИИ Nanonets непрерывно обучается и постоянно повышает свою точность по мере извлечения/проверки данных из ваших документов.
Извлекайте и экспортируйте данные из счетов-фактур, налоговых форм, заказов на поставку, банковских выписок, страховых форм, медицинских форм, удостоверений личности и многого другого. Захватывайте только нужные данные/информацию из всех видов документов.
Захватывайте только нужные данные/информацию из всех видов документов.
Плюсы
- Бесплатная пробная версия
- Возможность поиска в PDF
- Простой интерфейс
- Простой в использовании
- Повышение производительности
- Быстрое время отклика API
- Интеграция с ERP и базами данных
- Соответствует требованиям GDPR
- Работает в автономном режиме (в премиум-версии)
Минусы
- Аннотирование может отнимать много времени
Ценообразование
- Доступна бесплатная пробная версия
- 499 долларов США за модель в месяц после пробной версии
Поддерживаемые платформы
- Web
3. PDF Reader
Источник изображения: KdanMobileKdan Mobile’s PDF Reader – это комплексное решение для работы с PDF-файлами, которое может преобразовать отсканированный документ в читаемый текст всего за один клик. Он также позволяет просматривать и редактировать оригинальный файл PDF-документа на мобильном телефоне или планшете и делиться им с другими.
Это приложение поддерживает 20 языков, включая английский, французский, португальский, немецкий и испанский.
Сфотографируйте текст с помощью мобильного телефона или планшета, чтобы использовать это приложение, и произойдет мгновенное преобразование. Самое приятное, что вы можете отредактировать результат, чтобы его было легче читать другим.
Это приложение имеет множество потенциальных применений в деловой и академической среде. Например, представьте, как было бы здорово, если бы вы могли конвертировать заметки в документы PDF на своем устройстве.
Это программное обеспечение также предлагает другие функции, такие как фотосъемка из приложения, просмотр документов по главам и экспорт файлов в Google Drive.
Плюсы
- Простой в использовании
- Мобильные возможности – подписывайте PDF-документы на ходу
- Дополнительные языковые возможности
- Простые возможности экспорта
- Функция синхронизации
- Особенности аннотирования
- Единовременная покупка программного обеспечения (без ежемесячной платы)
- Возможность отправки документов по факсу
- Возможность создавать и заполнять формы
Минусы
- Из-за большого количества функций интерфейс немного перегружен.
- Иногда медленное время загрузки
Ценообразование
Бесплатная пробная версия, затем $89,99 за PDF Reader Standard и $119,99 за PDF Reader Pro. Это одноразовая покупка, и в настоящее время на нее действует скидка
Поддерживаемые Платформы:
Устройства iOS, Mac, Android и Windows
4. OmniPage Ultimate
Источник изображения: OmniPage UltimateOmniPage Ultimate, одна из самых популярных OCR-программ в списке PCWorld, является мощной и простой в использовании программой, которая может сделать хорошие предположения о том, какой текст может быть в отсканированном документе.
Она также включает функции для редактирования документов PDF путем устранения ошибок печати. Программа поставляется с тремя лицензиями для отдельных компьютеров или устройств: вы можете установить ее на трех ПК (только Windows) или Mac, если все они являются вашей собственностью.
В дополнение к трем лицензиям вы получаете 14-дневную бесплатную пробную версию.

OmniPage также поставляется с пользовательским интерфейсом на английском языке, поэтому не возникнет проблем с чтением всех его функций и опций, что очень удобно, если ваш основной язык не английский или вы пока не владеете им в совершенстве.
Программное обеспечение также поддерживает более 100 языков, включая французский, немецкий и испанский, и это лишь несколько примеров.
Плюсы
- Дополнительные языки
- Бесплатная пробная версия
- Поддерживает более 100 языков
- Простой в использовании
- Устранение ошибок печати
- Возможность сканирования и создания заполняемых документов
Минусы
- Запутанный и непоследовательный интерфейс
- Дорого
Ценообразование
$499.00 единовременная плата
Поддерживаемые Платформы
Windows и Mac
5. ABBYY FineReader PDF
Источник изображения: Abbyy FineReader PDFABBYY FineReader, одна из самых популярных программ OCR в списке PCWorld, – это мощная и простая в использовании программа, которая может угадать, какой текст может быть в отсканированном документе.
Она также включает функции для редактирования PDF-файлов путем устранения ошибок печати. Программа поставляется с тремя лицензиями для отдельных компьютеров или устройств: вы можете установить ее на трех ПК (только Windows) или Mac, если все они являются вашей собственностью.
Механизм OCR может распознавать до 99% печатного текста независимо от уровня распознавания символов, начиная со шрифтов размером 18 пт и заканчивая шрифтом размером 11 пт (ширина символа). Точность выше при больших размерах точек.
Механизм основан на последних научных достижениях в области распознавания образов, компьютерного зрения и искусственного интеллекта. Он был разработан с использованием обширного набора данных отсканированных документов из различных источников: книг, журналов, дневников и т.д.
Плюсы
- Редактор для ручных исправлений
- Простой интерфейс
- Экспорт в различные форматы
- Функция сравнения документов
- Простой в использовании
Минусы
- Отсутствует полнотекстовое индексирование
Ценообразование
$199 за Стандартную версию или $299 за Корпоративную версию.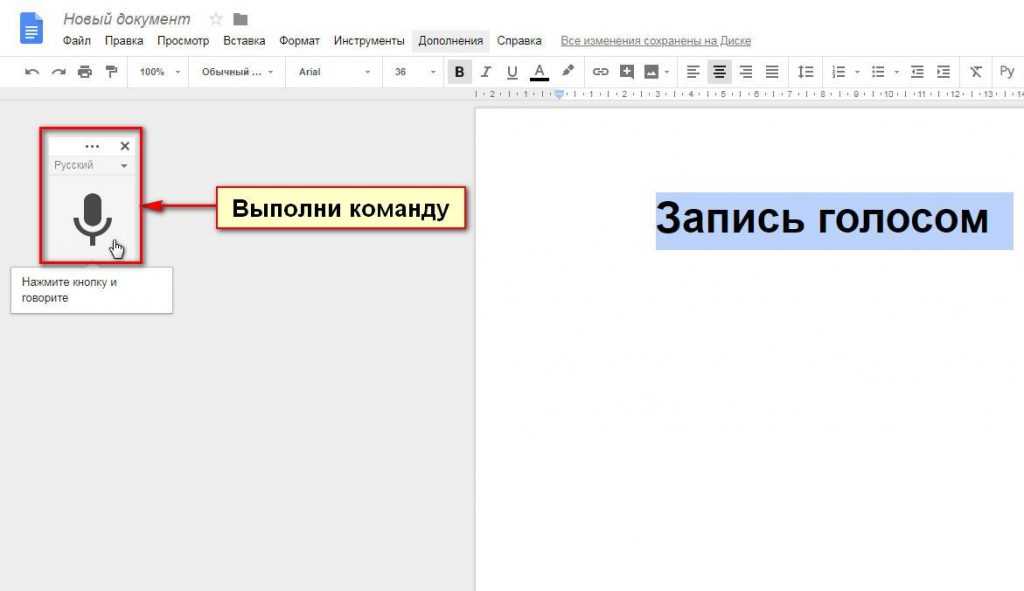
Единовременная покупка для обоих вариантов
Поддерживаемые Платформы
Windows и Mac
6. Readiris
Источник изображения: ReadirisReadiris 200 – это превосходное программное обеспечение для распознавания символов, позволяющее создавать высококачественные PDF-файлы из отсканированных изображений.
К сожалению, процесс сканирования документов и их импорта в программу Readiris для преобразования в цифровые файлы может занять много времени. Тем не менее, с Readiris 200 все стало доступнее, чем когда-либо прежде.
Он состоит из двух основных режимов редактирования:
- Режим Просмотра: в нем все отсканированные данные отображаются в виде уменьшенных изображений на одной странице.
- Режим Редактора: который дает вам контроль над каждым аспектом процесса преобразования, включая настройки извлечения текста, параметры векторизации, такие как толщина линий или цвета, и т.д., и многое другое
У вас также будет доступ к инструментам для создания аннотаций и комментариев к отдельным страницам.
Вам может пригодиться этот бесплатный инструмент OCR для преобразования сканов старых фотографий в цифровой формат.
Преимущества, которые дает эта программа, трудно игнорировать – Readiris 200 не только бесплатна, но и оснащена функциями, которые стоили бы как рука и нога, будь они доступны у других поставщиков.
Недостаток? Если у вас нет времени на изучение работы каждой функции, возможно, стоит подумать о предоплате.
Плюсы
- Бесплатно
- Создание высококачественных PDF-файлов из отсканированных изображений
- Возможность делать аннотации и комментарии
- Режим просмотра и режим редактора
Минусы
- Занимает много времени
- Меньше функций, чем у других вариантов в этом списке
Ценообразование
Бесплатно
Поддерживаемые Платформы
Windows и Mac
7. SimpleOCR
Источник изображения: SimpleOCRSimpleOCR – это бесплатный онлайн-инструмент, не требующий загрузки. Он может преобразовывать изображения и PDF в редактируемый текст, который можно скопировать или сохранить в другом формате, например CSV.
Он может преобразовывать изображения и PDF в редактируемый текст, который можно скопировать или сохранить в другом формате, например CSV.
Вы загружаете изображение (или документ) и нажимаете кнопку “Конвертировать! ” Результат откроется в новом окне, где вы можете выбрать тип файла (DOCX/DOC/PDF или TXT) для создания.
Также есть возможность сохранения в виде изображения (PNG), текстового файла (CSV) или файла Word (.docx).
Это программное обеспечение конвертирует все документы из отсканированных фотографий, рукописных документов, факсов и полностью поддерживает цветные и полутоновые форматы изображений, такие как JPEG, TIFF и PNG.
SimpleOCR также поддерживает преобразование PDF в текст (OCR), преобразование PDF в редактируемые файлы Word, включая оглавление, и экспорт в документы DOCX или TXT с сохранением форматирования.
SimpleOCR – это бесплатный онлайн-инструмент, который может конвертировать отсканированные изображения и PDF-файлы в форматы текстового процессора, такие как DOCX или TXT.
Плюсы
- Бесплатно
- Распознавание рукописного текста
- Поддерживает все типы форматов документов
- Поддерживает цветные и полутоновые форматы изображений
Минусы
- Только онлайн
Ценообразование
Бесплатно
Поддерживаемые Платформы
Web
8. Tesseract
Источник изображения: GlitchymeTesseract – это OCR-движок с открытым исходным кодом, поддерживающий 100+ языков. Это инструмент командной строки, но он также имеет интерфейсы API и GUI, чтобы разработчикам было проще использовать его в своих проектах.
Движок Tesseract был разработан в Hewlett Packard Laboratories с 1985 по 1995 год Артуром К. Эллисом, Джимом Плакско, Дэвидом Халмом и другими специалистами для исследования технологии понимания изображений документов, направленной на распознавание с помощью компьютера (CARE).
В 1996 году HP выпустила код под ограничением “без коммерческого использования” – документы могут быть созданы из отсканированных изображений с текстом с помощью этого программного обеспечения без покупки лицензий или выплаты авторских отчислений после 1991 года.
Этот проект с открытым исходным кодом продолжает развиваться и сегодня без каких-либо ограничений на использование.
Это один из лучших OCR-движков, поддерживающий более 100 языков. Однако он не так удобен в использовании, как другие варианты на рынке.
Плюсы
- Бесплатно
- С открытым исходным кодом
- Поддерживает 100+ языков
- Доступны интерфейсы API и GUI
Минусы
- Тессеракт может быть сложным в использовании, если вы не знаете основ кодирования или языка программирования
Ценообразование
Бесплатно
Поддерживаемые Платформы
Linux, Windows и Mac
9. Amazon Textract
Источник изображения: Amazon TextractTextract – это облачный сервис машинного обучения на Amazon’s AWS Marketplace. Textract преобразует бумажные документы в редактируемый текст с помощью искусственного интеллекта (ИИ) и глубоких нейронных сетей.
Она может конвертировать отсканированные изображения или PDF-файлы, извлекая из них текст без вмешательства человека. На выходе получается точная версия документа в формате DOCX, ODT или TXT, которую можно открыть как редактируемый документ.
На выходе получается точная версия документа в формате DOCX, ODT или TXT, которую можно открыть как редактируемый документ.
Этот процесс преобразования также позволяет пользователям экспортировать содержимое обратно в различные форматы изображений, такие как JPEG, TIFF, PNG и другие, выбрав “формат экспортируемого файла” в левом нижнем углу экрана в разделе опций.
Недостатков немного, один из них заключается в том, что он не распознает изображения (только pdf-файлы). В нем также отсутствуют некоторые более продвинутые функции, такие как проверка орфографии и т.д.
Textract подходит для тех, кому нужно просто конвертировать документы в форматы текстового процессора, не заботясь об их последующем редактировании.
Плюсы
- Облачный
- Использует искусственный интеллект и глубокие нейронные сети
- Поддерживает все типы форматов документов
- Технология глубокого обучения
- Идентифицирует рукописные документы
- Создает интеллектуальный поисковый индекс
Минусы
- Не распознает изображения
Ценообразование
Бесплатный аккаунт с 1 000 бесплатных страниц в месяц
$0,01 за страницу за первый миллион страниц и $0,008 за страницу за более чем 1 миллион страниц
Поддерживаемые Платформы
Web
10.
 RossumИсточник изображения: Rossum
RossumИсточник изображения: RossumRossum предлагает бесплатное программное обеспечение OCR, которое можно использовать для преобразования отсканированных изображений текста в редактируемые форматы текстового процессора, такие как DOCX или TXT.
Он также поддерживает преобразование PDF в текст (OCR) – преобразование PDF в редактируемые файлы Word, включая оглавление; экспорт в виде документов DOCX или TXT с сохранением форматирования.
Это один из немногих доступных онлайн-инструментов для конвертирования цветных изображений в форматы JPEG, TIFF и PNG.
Эта программа конвертирует все типы документов из отсканированных фотографий, рукописных страниц, факсов и т.д., полностью поддерживая цветные и полутоновые форматы изображений, такие как JPEG, TIFF и PNG.
Интерфейс этой программы понятен и прост в использовании. Она не занимает много процессорной мощности или оперативной памяти, а значит, вам не придется беспокоиться о замедлении работы компьютера при ее использовании.
Кроме того, Rossum – это программное обеспечение с открытым исходным кодом, что означает, что его разработали добровольцы и сообщество. Однако Rossum был создан добровольцами, и качество этого программного обеспечения не гарантируется.
Возможно, вам придется использовать его некоторое время, прежде чем вы сможете настроить его параметры в соответствии со своими потребностями.
Плюсы
- Простая и быстрая обработка документов
- Бесплатно
- С открытым исходным кодом
- Простой в использовании
- Интеграция с третьими сторонами
- Управление рабочими процессами
- Расширенное извлечение данных
- Поддерживает преобразование PDF в текстовые файлы или файлы Word
- Позволяет конвертировать форматы цветных изображений
Минусы
- Качество программного обеспечения не гарантируется
Ценообразование
Бесплатно
Поддерживаемые Платформы
Web, Android, iPhone и iPad
11.
 KlippaИсточник изображения: Klippa
KlippaИсточник изображения: KlippaKlippa – это программное обеспечение OCR, которое позволяет бизнес-пользователям извлекать данные из неструктурированных документов, включая отсканированные и отправленные по факсу бумажные формы, файлы PDF или изображения TIFF.
Интерфейс Klippa не только извлекает форматированный текст, но и автоматически разбирает его в виде таблиц.
Эта программа сканирования поддерживает более 20 языков, включая английский (США), испанский, французский, итальянский, немецкий, китайский и др.
Klippa предлагает широкий спектр функций для решения ваших задач по извлечению данных. Например, он может за считанные секунды преобразовать отсканированные и отправленные по факсу бумажные формы, файлы PDF или изображения TIFF в редактируемый текст.
Он быстр в использовании – просто перетащите документ в окно Klippa и нажмите на кнопку “Извлечь“, чтобы мгновенно извлечь редактируемый текст с собственным форматированием в виде таблиц.
Klippa – это мощное программное обеспечение OCR с множеством функций, которые делают его универсальным. Это программное обеспечение, несомненно, станет отличным помощником на вашем цифровом рабочем месте.
Однако недостатком использования Klippa является то, что вам нужно платить за каждую добычу.
Плюсы
- Позволяет редактировать документы PDF
- Поддерживает более 20 языков
- Создание таблиц из форматированного текста
- Широкий спектр возможностей
- Идеально подходит для извлечения данных
- Быстрота и простота в использовании
- Хорошее обслуживание клиентов
- Мобильные приложения
- Пакетная обработка
Минусы
- Платите за каждое извлечение
Ценообразование
Klippa Basic – бесплатно, $4,68/месяц или $41,05/год для плана Klippa Pro
Поддерживаемые Платформы
Web, iPhone и Android
12. Docparser
Источник изображения: DocparserDocparser – это бесплатное программное обеспечение с открытым исходным кодом для распознавания отсканированных документов. Она может использоваться для извлечения текста из личных или рабочих сканов, pdf-файлов, факсов и т.д.
Она может использоваться для извлечения текста из личных или рабочих сканов, pdf-файлов, факсов и т.д.
Выходные данные DocParser включают извлеченный текст в формате Unicode и файл изображения с оригинальным сканом, содержащим только изображения букв, которые Doc Parser исправил. Таким образом, тексты остаются документами, пригодными для поиска, даже если вы отредактируете их в Microsoft Word.
Имеется поддержка клиентов на всех языках, а программное обеспечение доступно для Windows, Mac OS X и Linux.
Некоторые недостатки заключаются в том, что может быть трудно извлечь текст из изображений с большим количеством шума или искажений, но результаты будут более точными для сканов лучшего качества, чем у других бесплатных инструментов OCR.
Этот инструмент PDF также не поддерживает языки, использующие право-левостороннее письмо, например, арабский шрифт – это означает, что вы не можете использовать Doc Parser для этих шрифтов.
Программное обеспечение предлагает множество преимуществ для личного использования.
Если вы заинтересованы в извлечении текста из отсканированных документов, стоит обратить внимание на Doc Parser, который может оказаться подходящим инструментом для ваших нужд.
Плюсы
- Документы с возможностью поиска
- Простота в использовании и настройке
- Интеграция с Zapier
- Бесплатное программное обеспечение с открытым исходным кодом
- Поддержка всех языков
Минусы
- Отсутствует поддержка языков, использующих правостороннее левостороннее движение
- Сложность извлечения текста из изображений с искажениями
- Несоответствие при разборе информации.
Ценообразование
Бесплатно
Поддерживаемые Платформы
Windows, Mac OS X и Linux
13. Veryfi
Источник изображения: VeryfiПлатформа Veryfi – это служба преобразования, редактирования и контроля качества документов. Она помогает компаниям без проблем конвертировать документы в цифровые форматы для хранения или распространения.
Она помогает компаниям без проблем конвертировать документы в цифровые форматы для хранения или распространения.
Veryfi конвертирует бумажные документы в формат PDF с извлечением текста и использует новейшую технологию OCR для распознавания отсканированных изображений рукописных данных, таких как подписи, и выделения их из фонового шума для преобразования в редактируемые символы на экране.
Он также предлагает такие функции, как пакетная обработка, позволяющая пользователям обрабатывать большое количество файлов одновременно, чтобы они загружались быстрее, чем если бы обрабатывались по отдельности.
Verify имеет инструменты автоматического форматирования для быстрого улучшения изображений, услуги по удалению и редактированию метаданных, корректуру одним щелчком мыши и услуги машинного перевода документов на любой язык.
Veryfi – отличный вариант для компаний, которым нужна помощь в организации документооборота и управления документами.

Плюсы
- Преобразование документов в редактируемые файлы
- Обеспечение качества
- Распознает отсканированные изображения рукописных данных
- Пакетная обработка
- Услуги по сокращению
- Доступна бесплатная пробная версия
- Способности к переводу
- Пробный оттиск одним щелчком мыши
Минусы
- Интерфейс может быть сложным для навигации
Ценообразование
Бесплатный план, $15.00/месяц за подписку
Поддерживаемые Платформы
Web, iPhone и Android
14. Google Document AI
Источник изображения: Google Document AIGoogle Document AI – это функция Google Drive, которая автоматически преобразует любые отсканированные или загруженные PDF-файлы в документы с возможностью текстового поиска.
Это доступный и удобный способ превратить бумагу в цифровой контент одним нажатием кнопки.
Если вы уже используете Google Docs и набор продуктов Google, использование этого OCR будет невероятно удобным и улучшит ваш документооборот.
При загрузке документа Google Диск извлекает текст из изображений с помощью технологии OCR. После обработки и индексации Google Docs вернет извлеченный контент в виде цифровой копии для редактирования.
Самое лучшее в этом решении для автоматизации документооборота то, что вам не нужно ничего делать – все делается автоматически. Еще одним преимуществом является то, как быстро он конвертирует большие партии PDF-файлов.
Единственный недостаток, который я обнаружил, заключается в том, что извлеченный контент не может быть каким-либо образом отредактирован. Это означает, что если отсканированный документ содержит текст с обеих сторон, то эти слова не будут доступны для поиска.
Плюсы
- Программное обеспечение для распознавания текста на основе искусственного интеллекта
- Преобразование PDF-файлов в редактируемые PDF-документы с возможностью текстового поиска
- Извлечение текста из файлов изображений популярных форматов
- Интеллектуальное распознавание символов
- Легкость в использовании и простая настройка
- Хорошее хранение информации
- Доступный
Минусы
- Извлеченный контент нельзя редактировать
- Дорого (затраты на API могут быстро увеличиться)
Ценообразование
Бесплатно при наличии лицензии Office 365 Персональный или Бизнес
Поддерживаемые Платформы
Web
15.
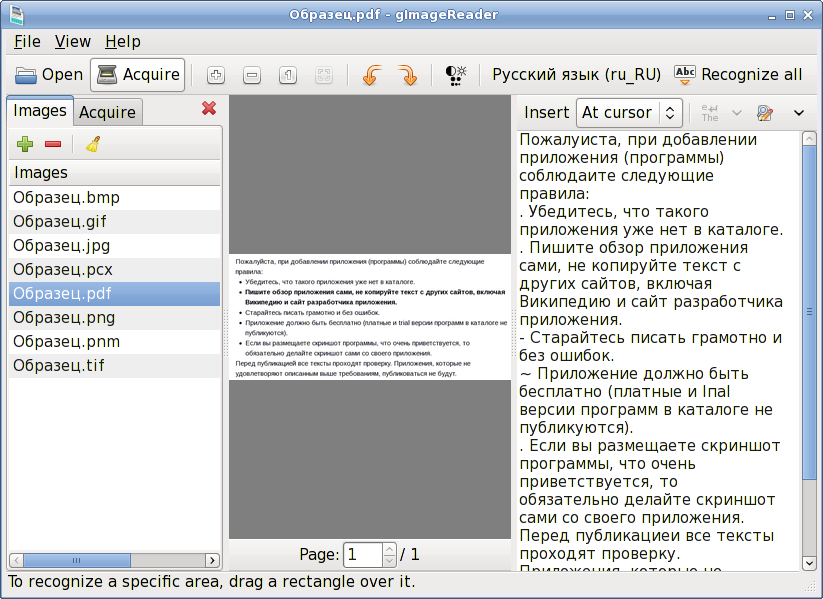 ABBYY FlexiCaptureИсточник изображения: ABBYY FlexiCapture
ABBYY FlexiCaptureИсточник изображения: ABBYY FlexiCaptureABBYY FlexiCapture – это простая и удобная в использовании программа для распознавания текста, которую можно использовать для работы с любыми типами документов.
Это решение для автоматизации документооборота имеет чистый интерфейс и несколько отличных инструментов, которые помогают в управлении документами.
Он предлагает следующие возможности:
- Возможность сканирования оригинального документа в формате DOCX, PDF или изображения для извлечения текста
- Возможность поиска по слову или фразе с использованием подстановочного знака
- Возможность экспорта только в виде файлов TXT, любых отсканированных форматов, таких как JPG/PNG/BMP, и многое другое.
ABBYY FlexiCapture прост в использовании. Однако ограничения ABBYY FlexiCapture заключаются в том, что вы не можете импортировать форматы, отличные от TXT (например, DOCX).
Кроме того, отсутствует возможность пакетной обработки, что означает, что это не идеальный вариант, если вы ищете инструмент для быстрого сканирования больших объемов бумаги.
Плюсы
- Простой в использовании
- Простой интерфейс
- PDF-файлы с возможностью поиска
- Извлечение текста из бумаги, DOCX, PDF или изображений
- Текст с возможностью поиска
- Технология обработки естественного языка
- Мобильные приложения
- Доступна бесплатная пробная версия
Минусы
- Невозможно импортировать форматы, отличные от TXT
- Нет пакетного преобразования или пакетной обработки
Ценообразование
Цены начинаются от $169.00
Поддерживаемые Платформы
Windows, Mac, iPad, iPhone и Android
16. IBM Datacap
Источник изображения: IBM DatacapIBM Datacap – еще одна отличная программа для распознавания текста, которую стоит рассмотреть.
Он имеет множество функций и может использоваться людьми с любым уровнем опыта.
Некоторые недостатки этого программного обеспечения заключаются в том, что время регистрации не включено в базовый пакет, а за пакет премиум-класса взимается ежегодная плата, которая включает неограниченное количество часов обучения в течение одного года.
Единственное различие между этими пакетами заключается в том, что в базовом пакете вам придется регистрироваться каждый час. В отличие от него, в пакет Enterprise время регистрации включено, поэтому он обеспечивает некоторую экономию на этом.
Плюсы
- Простой в использовании
- Ручная или автоматическая сегментация
- Распознавание текста любой ориентации, размера и типа шрифта
- Поиск текста на отсканированных изображениях с помощью подстановочных знаков
- Многоязыковая поддержка
- Настраиваемые правила
Минусы
- Время регистрации не включено в базовый пакет
- Ежегодная плата, взимаемая с пакетом премиум-класса
- Пользовательский интерфейс кажется устаревшим
Ценообразование
По данным IMB, стоимость Datacap определяется на основе целого ряда факторов. Свяжитесь с представителем IBM для получения информации о ценах.
Поддерживаемые Платформы
Windows
17. FineReader
Источник изображения: FineReaderПрограммное обеспечение FineReader (ранее FineScanner) имеет два режима работы.
- Сканирование бумажных документов
- Сканирование изображений с экрана компьютера, например, PDF-файлов или фотографий
FineReader – единственный инструмент OCR, который может сканировать бумажные документы в цвете с помощью автоматического устройства подачи документов (ADF).
Он также предлагает множество функций для улучшения качества документов и облегчения создания PDF-файлов с возможностью поиска.
FineReader также может преобразовывать отсканированные бумажные документы в редактируемые электронные форматы, такие как файлы Microsoft Word и Excel, страницы HTML или изображения в формате JPEG.
Однако FineReader не предлагает способ сканирования изображений из Интернета, поэтому их нельзя преобразовать в редактируемые форматы.
Плюсы
- Единственный инструмент OCR, который может сканировать бумажные документы в цвете с помощью автоподатчика.
- Улучшение качества документов
- PDF-файлы с возможностью поиска
- Возможность редактировать и организовывать PDF-файлы
- Инструменты для совместной работы
- Функции безопасности
- Бесплатная пробная версия
- Создание заполняемых форм
Минусы
- Не предлагает способ сканирования изображений из Интернета
Ценообразование
Стандартные тарифные планы стоят 199 долларов для Windows и 129 долларов для Mac, а корпоративный тарифный план – 299 долларов.
Все планы предлагаются на основе единовременной оплаты
Поддерживаемые Платформы
Windows, Mac, Android, iPhone
18. Softworks OCR
Источник изображения: Softworks OCRSoftworks OCR – это мощный и простой в использовании инструмент для сканирования и распознавания текста на изображениях в формате PDF.
Это программное обеспечение может легко преобразовать отсканированные файлы в редактируемые форматы, такие как Word, Excel или PowerPoint. Кроме того, она преобразует отсканированные слайд-шоу в формат PDF, которым легко поделиться с другими в Интернете.
Softworks OCR также доступен для операционных систем Windows и Mac с 30-дневным бесплатным пробным периодом, поэтому вы можете сначала попробовать программу, чтобы узнать, подходит ли она вам.
Однако один минус заключается в том, что вы не сможете сканировать большие документы или книги из-за ограничения их размера.
Кроме того, Softworks является одним из самых дорогих вариантов программного обеспечения, что может отпугнуть некоторых, поскольку существует более чем несколько бесплатных вариантов.
Плюсы
- Простой в использовании
- Изменение отсканированных файлов в редактируемые форматы
- Бесплатная пробная версия
- Преобразование отсканированных слайд-шоу в формат PDF
- Искусственный интеллект и машинное обучение
- Специализируются на ипотечных кредитах и финансовых документах
Минусы
- Ограничение по размеру
- Дорого
Ценообразование
Цены варьируются; свяжитесь с Softworks для получения подробной информации о ценах
Поддерживаемые Платформы
Windows и Mac
19.
Microsoft OneNoteИсточник изображения: Microsoft OneNoteOneNote – это мощное приложение, которое предлагает множество функций бесплатно. Оно имеет интуитивно понятный интерфейс, что облегчает его использование и организацию заметок из различных источников.
OneNote также поддерживает возможность создания блокнотов с маркированными вкладками и страницами для разных предметов, что делает его идеальным для студентов, которым нужны заметки для занятий в одном месте.
Это отличный вариант для тех, кто хочет избавиться от всех этих PDF, загромождающих жесткий диск, или найти альтернативу приложению по умолчанию на своем телефоне.
Однако некоторые функции требуют подписки на Office 365, например, совместная работа с другими людьми и использование Office Lens для съемки фотографий или документов.
Плюсы
- Расширенные возможности
- Бесплатно
- Интуитивно понятный интерфейс
- Создавайте блокноты
- В соавторстве
- Офис позволяет делать фотоснимки
Минусы
- Некоторые функции требуют подписки на Office 365
Ценообразование
Бесплатно, но для некоторых функций требуется подписка на Office 365
Поддерживаемые Платформы
Windows, Mac, iPad, iPhone, Android, web
20.
Soda PDFИсточник изображения: Soda PDFБесплатная версия Soda PDF отлично подходит для задач быстрого преобразования.
Это программное обеспечение также предлагает тарифный план Pro с неограниченным количеством ежемесячных конвертаций, отсутствием водяных знаков на конвертированных документах и возможностью конвертировать файлы из форматов Microsoft Office, таких как DOCX, в популярные форматы изображений, такие как JPEG или PNG.
Существует несколько способов использования Soda PDF для решения повседневных задач. Например, предположим, вам нужно заполнить онлайн-форму, но вы не хотите вводить информацию вручную.
В этом случае вы можете сфотографировать документ на телефон и преобразовать его в текст с помощью программы OCR, например Snap & Convert или Image Converter Plus.
Кроме того, сервис не требует создания учетной записи пользователя, что делает работу еще быстрее. Он также позволяет конвертировать PDF-файлы в форматы JPEG или PNG для большего удобства.
Недостатком является то, что существуют ограничения на количество конверсий, которые вы можете сделать за месяц с бесплатными аккаунтами, и вы будете видеть логотип компании на любом конвертированном документе.
Плюсы
- Простой в использовании
- Быстрое преобразование
- Бесплатная версия
- Возможность создания персонализированных форм
- Возможности электронной подписи
- Регистрация не требуется
Минусы
- Ограничения для бесплатного аккаунта, например, количество конверсий
- В бесплатной версии логотип включается в конвертированные документы
Ценообразование
Бесплатный план, Стандартный план за $4,15/месяц, Pro план $7,50/месяц
Поддерживаемые Платформы
Web
Готовы Выбрать Новое Программное Обеспечение Для Распознавания Текста? 💁🏻♀️
Когда речь идет о перечисленных выше вариантах программного обеспечения, важно провести исследование и найти продукт, который наилучшим образом отвечает вашим потребностям.
Владельцы бизнеса могут использовать программное обеспечение OCR для повышения эффективности бизнеса и управления бизнес-процессами.
Лучшим вариантом для владельцев бизнеса является тот, который отвечает всем требованиям, когда речь идет о выполнении задач, которые вам необходимы. Поначалу это может быть сложной задачей, но по мере изучения всех существующих вариантов она будет становиться все проще!
Сканирование документов в PDF, Adobe Acrobat
- Руководство пользователя Acrobat
- Знакомство с Acrobat
- Доступ к Acrobat с рабочего стола, мобильного устройства, Интернета
- Что нового в Acrobat
- Горячие клавиши
- Системные требования
- Рабочее пространство
- Основы рабочего пространства
- Открытие и просмотр PDF-файлов
- Открытие PDF-файлов
- Навигация по страницам PDF
- Просмотр настроек PDF
- Настройка просмотра PDF
- Включить предварительный просмотр эскизов PDF-файлов
- Отображение PDF в браузере
- Работа с учетными записями онлайн-хранилища
- Доступ к файлам из ящика
- Доступ к файлам из Dropbox
- Доступ к файлам из OneDrive
- Доступ к файлам из SharePoint
- Доступ к файлам с Google Диска
- Acrobat и macOS
- Уведомления Acrobat
- Сетки, направляющие и измерения в PDF-файлах
- Азиатский текст, кириллица и текст с письмом справа налево в PDF-файлах
- Основы рабочего пространства
- Создание PDF-файлов
- Обзор создания PDF-файлов
- Создание PDF-файлов с помощью Acrobat
- Создание PDF-файлов с помощью PDFMaker
- Использование принтера Adobe PDF
- Преобразование веб-страниц в PDF
- Создание PDF-файлов с помощью Acrobat Distiller
- Настройки преобразования Adobe PDF
- PDF-шрифты
- Редактирование PDF-файлов
- Редактирование текста в PDF-файлах
- Редактировать изображения или объекты в PDF
- Поворот, перемещение, удаление и перенумерация страниц PDF
- Редактировать отсканированные файлы PDF
- Улучшение фотографий документов, снятых с помощью мобильной камеры
- Оптимизация PDF-файлов
- Свойства PDF и метаданные
- Ссылки и вложения в PDF-файлах
- PDF-слоя
- Миниатюры страниц и закладки в PDF-файлах
- Мастер действий (Acrobat Pro)
- PDF-файла, преобразованные в веб-страницы
- Настройка PDF-файлов для презентации
- Статьи в формате PDF
- Геопространственные файлы PDF
- Применение действий и сценариев к файлам PDF
- Изменить шрифт по умолчанию для добавления текста
- Удалить страницы из PDF
- Сканирование и распознавание символов
- Сканирование документов в PDF
- Улучшение фотографий документов
- Устранение неполадок сканера при сканировании с помощью Acrobat
- Формы
- Основы форм PDF
- Создание формы с нуля в Acrobat
- Создание и распространение PDF-форм
- Заполнение PDF-форм
- Свойства поля формы PDF
- Заполнение и подписание PDF-форм
- Настройка кнопок действий в формах PDF
- Публикация интерактивных веб-форм PDF
- Основные сведения о полях формы PDF
- Поля формы штрих-кода PDF
- Сбор и управление данными формы PDF
- О трекере форм
- Справка по PDF-формам
- Отправка PDF-форм получателям по электронной почте или на внутренний сервер
- Объединение файлов
- Объединение или объединение файлов в один PDF
- Поворот, перемещение, удаление и перенумерация страниц PDF
- Добавить верхние и нижние колонтитулы и нумерацию Бейтса в PDF-файлы
- Обрезать страницы PDF
- Добавление водяных знаков в PDF-файлы
- Добавление фона в PDF-файлы
- Работа с файлами компонентов в портфолио PDF
- Публикация и совместное использование портфолио PDF
- Обзор портфолио PDF
- Создание и настройка портфолио PDF
- Публикация, рецензирование и комментирование
- Публикация и отслеживание PDF-файлов в Интернете
- Разметить текст с правками
- Подготовка к просмотру PDF
- Запуск обзора PDF
- Размещение общих обзоров на сайтах SharePoint или Office 365
- Участие в проверке PDF
- Добавить комментарии к PDF-файлам
- Добавление штампа в PDF
- Рабочие процессы утверждения
- Управление комментариями | просмотреть, ответить, распечатать
- Импорт и экспорт комментариев
- Отслеживание и управление обзорами PDF
- Сохранение и экспорт PDF-файлов
- Сохранение PDF-файлов
- Преобразование PDF в Word
- Преобразование PDF в JPG
- Преобразование или экспорт PDF-файлов в файлы других форматов
- Параметры формата файла для экспорта PDF
- Повторное использование содержимого PDF
- Безопасность
- Расширенная настройка безопасности для PDF-файлов
- Защита PDF-файлов с помощью паролей
- Управление цифровыми идентификаторами
- Защита PDF-файлов с помощью сертификатов
- Открытие защищенных PDF-файлов
- Удаление конфиденциального содержимого из PDF-файлов
- Настройка политик безопасности для PDF-файлов
- Выбор метода защиты для PDF-файлов
- Предупреждения системы безопасности при открытии PDF-файла
- Защита PDF-файлов с помощью Adobe Experience Manager
- Функция защищенного просмотра для PDF-файлов
- Обзор безопасности в Acrobat и PDF-файлах
- JavaScripts в PDF-файлах как угроза безопасности
- Вложения как угроза безопасности
- Разрешить или заблокировать ссылки в PDF-файлах
- Электронные подписи
- Подписание PDF-документов
- Сохраните свою подпись на мобильном телефоне и используйте ее везде
- Отправка документов на электронные подписи
- О подписях сертификатов
- Подписи на основе сертификата
- Проверка цифровых подписей
- Утвержденный список доверия Adobe
- Управление доверенными удостоверениями
- Печать
- Основные задачи печати PDF
- Буклеты для печати и портфолио в формате PDF
- Расширенные настройки печати PDF
- Печать в PDF
- Печать цветных PDF-файлов (Acrobat Pro)
- Печать PDF-файлов нестандартных размеров
- Специальные возможности, теги и перекомпоновка
- Создание и проверка доступности PDF
- Специальные возможности в PDF-файлах
- Инструмент порядка чтения для PDF-файлов
- Чтение PDF-файлов с функциями перекомпоновки и специальных возможностей
- Редактирование структуры документа с помощью панелей «Содержимое» и «Теги»
- Создание доступных PDF-файлов
- Поиск и индексирование
- Создание индексов PDF
- Поиск PDF-файлов
- Мультимедийные и 3D-модели
- Добавление аудио-, видео- и интерактивных объектов в PDF-файлы
- Добавление 3D-моделей в файлы PDF (Acrobat Pro)
- Отображение 3D-моделей в PDF-файлах
- Взаимодействие с 3D-моделями
- Измерение 3D-объектов в PDF-файлах
- Настройка 3D-видов в PDF-файлах
- Включить 3D-контент в PDF
- Добавление мультимедиа в PDF-файлы
- Комментирование 3D-проектов в PDF-файлах
- Воспроизведение видео, аудио и мультимедийных форматов в PDF-файлах
- Добавлять комментарии к видео
- Инструменты для печати (Acrobat Pro)
- Обзор инструментов для печати
- Следы от принтера и линии роста волос
- Предварительный просмотр вывода
- Сведение прозрачности
- Преобразование цвета и управление чернилами
- Цвет захвата
- Предпечатная проверка (Acrobat Pro)
- Файлы, совместимые с PDF/X, PDF/A и PDF/E
- Предполетные профили
- Расширенные предполетные проверки
- Предполетные отчеты
- Просмотр результатов предварительной проверки, объектов и ресурсов
- Цели вывода в PDF-файлах
- Исправление проблемных областей с помощью инструмента Preflight
- Автоматизация анализа документов с помощью дроплетов или предпечатных действий
- Анализ документов с помощью инструмента Preflight
- Дополнительные проверки в Preflight tool
- Предполетные библиотеки
- Переменные предварительной проверки
- Управление цветом
- Поддержание согласованности цветов
- Настройки цвета
- Документы с управлением цветом
- Работа с цветовыми профилями
- Понимание управления цветом
Отсканируйте бумажный документ в PDF и с помощью Acrobat превратите его в интеллектуальный PDF-файл с возможностью поиска и возможностью выбора текста.
Вы можете создать файл PDF непосредственно из бумажного документа, используя сканер и Acrobat. В Windows Acrobat поддерживает драйверы сканера TWAIN и драйверы Windows Image Acquisition (WIA). В Mac OS Acrobat поддерживает TWAIN и функцию захвата изображений (ICA).
В Windows можно либо использовать режим автоматического определения цвета и позволить Acrobat определить тип содержимого бумажного документа, либо использовать другие предустановки (черно-белый документ, документ в градациях серого, цветное изображение и цветной документ) на свое усмотрение. Вы можете настроить предустановки сканирования или использовать параметр «Выборочное сканирование» для сканирования с выбранными вами параметрами.
Предустановленное сканирование доступно только для драйверов сканера, поддерживающих режим скрытого интерфейса сканера. Предустановки сканирования недоступны в Mac OS.
В Windows, если для вашего сканера установлен драйвер WIA, вы можете использовать кнопку «Сканировать» на вашем сканере для создания PDF-файла. Нажмите кнопку «Сканировать», а затем в Windows выберите Adobe Acrobat из списка зарегистрированных приложений. Затем в интерфейсе сканирования Acrobat выберите сканер и предустановку документа или пользовательское сканирование.
Чтобы отсканировать бумажный документ в PDF с помощью Acrobat, выберите Инструменты > Создать PDF . Отображается интерфейс Создать PDF из любого формата . Выберите Сканер , чтобы просмотреть доступные параметры.
В Windows:
Создавайте PDF-файлы из интерфейса сканера; при нажатии на значок настроек или шестеренки отображаются все настройки для выбранного параметра.На Mac:
Создавайте PDF-файлы из интерфейса сканера; выберите сканер и нажмите «Далее», чтобы просмотреть настройки для выбранного сканера.Сканирование бумажного документа в PDF с помощью Автоопределение цветового режима (Windows)
Выберите Инструменты > Создать PDF > Сканер > Автоопределение цветового режима .
Если вы хотите добавить сканируемый документ к существующему файлу, выполните следующие действия:
- Установите флажок Добавить к существующему файлу .
- Если файлы открыты в Acrobat, выберите соответствующий файл из раскрывающегося списка или нажмите Просмотрите и выберите соответствующий файл.
Если вы хотите отсканировать несколько файлов в PDF, щелкните значок Настройки . Отображается интерфейс выборочного сканирования. Установите флажок Запрашивать сканирование дополнительных страниц .
Нажмите Сканируйте .
При появлении запроса на сканирование дополнительных страниц выберите Сканировать дополнительные страницы , Сканировать оборотные стороны или Сканирование завершено и нажмите OK .
Сканирование бумажного документа в PDF с помощью предустановка (Windows)
Выберите Инструменты > Создать PDF > Сканер > [ предустановка документа ].
Если вы хотите добавить сканируемый документ к существующему файлу, выполните следующие действия:
- Установите флажок Добавить к существующему файлу .
- Если файлы открыты в Acrobat, выберите соответствующий файл из раскрывающегося списка или нажмите Просмотрите и выберите соответствующий файл.
Если вы хотите отсканировать несколько файлов в PDF, щелкните значок Настройки . Отображается интерфейс выборочного сканирования. Установите флажок Запрашивать сканирование дополнительных страниц .
Нажмите Сканируйте .
При появлении запроса на сканирование дополнительных страниц выберите Сканировать дополнительные страницы , Сканировать оборотные стороны или Сканирование завершено и нажмите OK .
Сканирование бумажного документа в PDF без предустановки
Выберите Инструменты > Создать PDF > Сканер > Настройки по умолчанию или Мои пользовательские настройки .
Если вы хотите добавить сканируемый документ к существующему файлу, выполните следующие действия:
- Установите флажок Добавить к существующему файлу .
- Если файлы открыты в Acrobat, выберите соответствующий файл из раскрывающегося списка или нажмите Просмотрите и выберите соответствующий файл.
Если вы хотите изменить настройки, щелкните значок Настройки . Отображается интерфейс выборочного сканирования. При необходимости выберите параметры сканирования.
Если вы хотите отсканировать несколько файлов в PDF, установите флажок Запрашивать сканирование дополнительных страниц .
Если вы укажете, что хотите использовать Показать пользовательский интерфейс сканера вместо пользовательского интерфейса Acrobat, появятся другие окна или диалоговые окна. Информацию о доступных параметрах см. в документации сканера. В Mac OS всегда отображается пользовательский интерфейс сканера.
Нажмите Отсканируйте .
При появлении запроса на сканирование дополнительных страниц выберите Сканировать дополнительные страницы , Сканировать оборотные стороны или Сканирование завершено и нажмите OK .
Улучшение или оптимизация отсканированного файла PDF
Откройте PDF-файл, созданный на основе отсканированного документа.
Выберите Tools > Scan & OCR > Enhance > Отсканированный документ .
Выберите параметры на дополнительной панели инструментов — щелкните значок Параметры и выберите соответствующие параметры в диалоговом окне «Улучшить отсканированный PDF», затем нажмите OK .
Дополнительные сведения о параметрах, отображаемых в диалоговом окне, см.
в разделе Диалоговое окно «Улучшить отсканированный PDF».
Настройка предустановок сканирования (Windows)
Выберите инструменты > Создать PDF > Сканер .
Выберите предустановку: Автоопределение цветового режима, Черно-белый документ, Цветной документ, Документ в оттенках серого или Цветная фотография.
Щелкните значок Настройки рядом с предустановкой. В зависимости от вашего выбора отображается интерфейс Custom Scan или Configure Predefined Settings for .
При необходимости измените настройки.
Если вы хотите отсканировать несколько файлов в PDF, установите флажок Запрашивать сканирование дополнительных страниц .
Нажмите «Сохранить настройки», чтобы сохранить предустановку, а затем нажмите кнопку с крестиком ( X ), чтобы закрыть.
Параметры сканирования
После выбора сканера вы можете выбрать или настроить различные параметры сканирования в соответствии со своими требованиями.
Сканер
Выберите установленный сканер. На вашем компьютере должно быть установлено программное обеспечение для сканирования производителя. Только в Windows: нажмите кнопку «Параметры», чтобы указать параметры сканера.
Показать пользовательский интерфейс сканера
Выберите этот параметр, только если вы хотите просмотреть настройки с помощью окон и диалоговых окон, предоставленных производителем сканера. Если этот параметр не выбран, сканирование начинается непосредственно с параметрами, указанными в интерфейсе Custom Scan или Configure Predefined Settings.
Страницы
Укажите одностороннее или двустороннее сканирование. Если вы выберете «Обе стороны» и настройки сканера предназначены только для одной стороны, настройки сканера переопределяют настройки Acrobat.
Обе стороны страниц можно сканировать даже на сканерах, которые сами по себе не поддерживают двустороннее сканирование. Если выбран параметр Обе стороны, диалоговое окно появляется после сканирования первых сторон. Затем вы можете перевернуть исходные бумажные документы в лотке и выбрать в этом диалоговом окне параметр Сканировать обратную сторону (Поместить обратную сторону листов). Этот метод создает PDF-файл со всеми страницами в правильной последовательности.
Цветовой режим (только для Windows)
Выберите основной цветовой режим (Автоопределение, Цветной, Черно-белый или Оттенки серого), который поддерживает ваш сканер. Этот параметр включен, если в параметрах сканера установлено использование диалогового окна сканирования Acrobat вместо приложения сканера.
Разрешение (только для Windows)
Выберите разрешение, которое поддерживает ваш сканер. Этот параметр включен, если в параметрах сканера установлено использование диалогового окна сканирования Acrobat вместо приложения сканера.
Если выбран параметр «Цветовой режим» или «Разрешение», не поддерживаемый вашим сканером, появится сообщение и откроется окно приложения сканера. Выберите различные параметры в окне приложения сканера.
Размер бумаги (только для Windows)
Выберите размер бумаги или укажите пользовательские ширину и высоту.
Запрос на сканирование дополнительных страниц
При выборе диалоговое окно с предложением сканировать дополнительные страницы появляется после каждого сеанса сканирования.
Качество > Оптимизировать изображение
Выберите этот параметр, чтобы запустить процесс оптимизации PDF-файла. Этот параметр используется для сжатия и фильтрации изображений в отсканированном PDF-файле. Нажмите Настройки значок для настройки оптимизации с помощью определенных параметров сжатия и фильтрации файлов.
Качество > Оптимизация изображения > Малый размер/Высокое качество
Перетащите ползунок, чтобы установить баланс между размером файла и качеством.
Вывод > Добавить к существующему файлу
Добавляет преобразованный скан в существующий PDF-файл. Выберите открытый файл из раскрывающегося списка или просмотрите и выберите файл PDF.
Вывод > Создать новый PDF
Создает PDF-файл.
Вывод > Сохранить несколько файлов
Создает несколько файлов из нескольких бумажных документов. Щелкните значок Настройки и укажите, следует ли создавать портфолио PDF из файлов, количество страниц для каждого файла и префикс имени файла.
Распознавание текста (OCR)
Выберите этот параметр, чтобы преобразовать текстовые изображения в формате PDF в текст с возможностью поиска и выбора. Этот параметр применяет к текстовым изображениям оптическое распознавание символов (OCR), а также распознавание шрифтов и страниц. Нажмите Настройки значок укажите настройки в диалоговом окне Распознавание текста — Настройки. См. Распознавание текста в отсканированных документах.
Добавить метаданные
При выборе диалоговое окно «Свойства документа» появляется после сканирования. В диалоговом окне «Свойства документа» вы можете добавить метаданные или информацию об отсканированном документе в файл PDF. Если вы создаете несколько файлов, вы можете ввести общие метаданные для всех файлов.
Сделать PDF/A совместимым
Выберите этот параметр, чтобы привести файл PDF в соответствие со стандартами ISO для PDF/A-1b.
Диалоговое окно «Оптимизация отсканированного PDF»
Диалоговое окно «Улучшить отсканированный PDF» управляет параметрами изображения, которые определяют фильтрацию и сжатие отсканированных изображений для PDF. Настройки по умолчанию подходят для широкого диапазона страниц документа, но вы можете настроить параметры для изображений более высокого качества, файлов меньшего размера или проблем со сканированием.
Применить адаптивное сжатие
Разделяет каждую страницу на черно-белые, оттенки серого и цветные области и выбирает представление, сохраняющее внешний вид при сильном сжатии каждого типа содержимого. Рекомендуемое разрешение сканирования составляет 300 точек на дюйм (dpi) для ввода в градациях серого и RGB или 600 dpi для черно-белого ввода.
Цветное сканирование/оттенки серого
При сканировании цветных страниц или страниц в оттенках серого выберите один из следующих вариантов:
JPEG2000
Применяет сжатие JPEG2000 к содержимому цветного изображения. (Этот параметр не рекомендуется использовать при создании файлов PDF/A. Вместо этого используйте JPEG.)
ZIP
Применяет сжатие ZIP к содержимому цветного изображения.
JPEG
Применяет сжатие JPEG к содержимому цветного изображения.
Сканер использует либо выбранный параметр «Цвет/оттенки серого», либо выбранный параметр «Монохромный». Какой из них используется, зависит от настроек, выбранных в диалоговом окне «Сканирование Acrobat» или в интерфейсе TWAIN сканера, который может открыться после нажатия кнопки «Сканировать» в диалоговом окне «Сканирование Acrobat». (По умолчанию диалоговое окно приложения сканера не открывается.)
Монохромные сканы
При сканировании черно-белых или монотонных изображений выберите один из следующих вариантов:
JBIG2 (без потерь) и JBIG2 (с потерями)
Применяет метод сжатия JBIG2 к черно-белым исходным страницам. Уровни самого высокого качества используют метод без потерь; при более низких настройках текст сильно сжимается. Текстовые страницы обычно на 60% меньше, чем сжатые страницы CCITT Group 4, но обработка происходит медленно. Совместимость с Acrobat 5.0 (PDF 1.4) и более поздними версиями.
Для совместимости с Acrobat 4.0 используйте метод сжатия, отличный от JBIG2.
МККТТ Группа 4
Применяет сжатие CCITT Group 4 к черно-белым изображениям исходной страницы. Этот быстрый метод сжатия без потерь совместим с Acrobat 3.0 (PDF 1.2) и более поздними версиями.
Малый размер/высокое качество
Устанавливает точку баланса между размером файла и качеством.
Исправить перекос
Поворачивает любую страницу, которая не совпадает со сторонами платформы сканера, чтобы выровнять страницу PDF по вертикали. Выберите Вкл. или Выкл.
Удаление фона
Отбеливает почти белые области оттенков серого и цветного ввода (не черно-белого ввода).
Для достижения наилучших результатов откалибруйте параметры контрастности и яркости сканера таким образом, чтобы при сканировании обычной черно-белой страницы был темно-серый или черный текст и белый фон. Тогда Off или Low должны дать хорошие результаты. При сканировании не совсем белой бумаги или газетной бумаги выберите «Средний» или «Высокий», чтобы очистить страницу.
Дескринировать
Удаляет полутоновую точечную структуру, которая может уменьшить сжатие JPEG, вызвать муар и затруднить распознавание текста. Подходит для ввода с разрешением 200–400 dpi в оттенках серого или RGB или, для адаптивного сжатия, для черно-белого ввода с разрешением 400–600 dpi. Параметр «Вкл.» (рекомендуется) применяет фильтр для оттенков серого с разрешением 300 dpi или выше и входа RGB. Выберите Выкл. при сканировании страницы без изображений или заполненных областей или при сканировании с разрешением, превышающим эффективный диапазон.
Повышение резкости текста
Повышает резкость текста отсканированного PDF-файла. Значение по умолчанию низкое и подходит для большинства документов. Увеличьте его, если качество распечатываемого документа низкое, а текст нечеткий.
Распознавание текста — диалоговое окно настроек
Язык документа
По умолчанию язык OCR выбирается из локали по умолчанию. Чтобы изменить язык, нажмите «Изменить» и выберите другой язык.
Выход
Либо изображение с возможностью поиска, либо редактируемый текст и изображения.
Сканирование Acrobat принимает изображения с разрешением от 10 до 3000 dpi. Если для стиля вывода PDF выбрано изображение с возможностью поиска или ClearScan, требуется входное разрешение 72 dpi или выше. Кроме того, входное разрешение выше 600 dpi уменьшается до 600 dpi или ниже.
Сжатие без потерь можно применять только к монохромным изображениям. Чтобы применить к отсканированному изображению сжатие без потерь, выберите один из следующих параметров в разделе «Параметры оптимизации» диалогового окна «Оптимизация отсканированного PDF»: CCITT Group 4 или JBIG2 (без потерь) для монохромных изображений.
Если это изображение добавляется к документу PDF и вы сохраняете файл с помощью параметра «Сохранить», отсканированное изображение остается несжатым. Если вы сохраните PDF-файл с помощью команды «Сохранить как», отсканированное изображение может быть сжато.Для большинства страниц при черно-белом сканировании с разрешением 300 dpi текст лучше всего подходит для преобразования. При разрешении 150 dpi точность распознавания немного ниже, и возникает больше ошибок распознавания шрифтов; при разрешении 400 dpi и выше обработка замедляется, а сжатые страницы больше. Если на странице много нераспознанных слов или мелкого текста (9 пунктов или меньше), попробуйте отсканировать с более высоким разрешением. По возможности сканируйте в черно-белом режиме.
Когда распознавание текста с помощью OCR отключено, можно использовать полный диапазон разрешений от 10 до 3000 dpi, но рекомендуемое разрешение — 72 dpi и выше. Для адаптивного сжатия рекомендуется 300 dpi для ввода в оттенках серого или RGB или 600 dpi для черно-белого ввода.
Страницы, отсканированные в 24-битном цвете, с разрешением 300 точек на дюйм и размером 8 1/2 на 11 дюймов (21,59 на 27,94 см), перед сжатием дают большие изображения (25 МБ). Вашей системе может потребоваться 50 МБ виртуальной памяти или больше для сканирования изображения. При разрешении 600 dpi и сканирование, и обработка обычно выполняются примерно в четыре раза медленнее, чем при разрешении 300 dpi.
Избегайте настроек сглаживания или сканирования полутонов. Эти настройки могут улучшить внешний вид фотографий, но затрудняют распознавание текста.
Для текста, напечатанного на цветной бумаге, попробуйте увеличить яркость и контрастность примерно на 10 %. Если ваш сканер имеет функцию цветной фильтрации, рассмотрите возможность использования фильтра или лампы, которые пропускают фоновый цвет. Или, если текст нечеткий или выпадает, попробуйте отрегулировать контрастность и яркость сканера, чтобы сделать отсканированное изображение более четким.
Если ваш сканер имеет ручную регулировку яркости, отрегулируйте ее так, чтобы символы были четкими и правильными. Если символы соприкасаются, используйте более высокую (яркую) настройку. Если символы разделены, используйте более низкую (темную) настройку.
Чтобы устранить ошибки или проблемы со сканером, см. следующие документы по устранению неполадок:
- Ошибка: Acrobat не удалось получить доступ к службе распознавания.
- Ошибка: Acrobat не может выполнить распознавание (OCR) на этой странице, так как эта страница содержит отображаемый текст.
- Устранение других проблем со сканером.
Вы можете использовать Acrobat для распознавания текста в ранее отсканированных документах, которые уже были преобразованы в PDF. Программное обеспечение для оптического распознавания символов (OCR) позволяет искать, исправлять и копировать текст в отсканированном PDF-файле. Чтобы применить OCR к PDF-файлу, исходное разрешение сканера должно быть установлено на 72 dpi или выше.
Сканирование с разрешением 300 dpi дает наилучший текст для преобразование. При разрешении 150 dpi точность распознавания немного ниже.
Распознавание текста в одном документе
Откройте отсканированный файл PDF.
Выберите Инструменты > Сканирование и OCR > Распознать текст > В этом файле .
Параметры распознавания текста отображаются на дополнительной панели инструментов.
На дополнительной панели инструментов выберите диапазон страниц и язык для распознавания текста.
При необходимости щелкните Параметры , чтобы открыть диалоговое окно «Распознавание текста» и укажите нужные параметры.
Нажмите Распознать текст . Acrobat создает слой текста в вашем PDF-файле, который можно найти или скопировать и вставить в новый документ.
Распознавание текста в нескольких документах
Выберите Инструменты > Сканирование и распознавание символов > Распознать текст > В нескольких файлах с.
В диалоговом окне «Распознавание текста» нажмите Добавить файлы и выберите Добавить файлы , Добавить папки или Добавить открытые файлы . Затем выберите файлы или папку.
В диалоговом окне «Параметры вывода» укажите целевую папку для выходных файлов и настроек имени файла.
В диалоговом окне «Распознавание текста — общие параметры» укажите параметры, а затем щелкните ОК .
Acrobat создает слой текста в PDF-файле, который можно найти или скопировать и вставить в новый документ.
Распознавание текста — общие настройки диалоговое окно
Язык документа
Указывает язык, который модуль OCR будет использовать для идентификации символов.
Вывод (стиль вывода PDF)
Определяет тип создаваемого файла PDF. Все варианты требуют входного разрешения 72 dpi или выше (рекомендуется). Все форматы применяют OCR и распознавание шрифтов и страниц к текстовым изображениям и преобразовывают их в обычный текст.
Изображение с возможностью поиска
Обеспечивает возможность поиска и выбора текста. Этот параметр сохраняет исходное изображение, выравнивает его по мере необходимости и помещает на него невидимый текстовый слой. Выбор Downsample Images в этом же диалоговом окне определяет, будет ли изображение уменьшено и в какой степени.
Изображение с возможностью поиска (точное)
Обеспечивает возможность поиска и выбора текста. Этот параметр сохраняет исходное изображение и помещает на него невидимый текстовый слой. Рекомендуется для случаев, требующих максимальной точности исходного изображения.
Редактируемый текст и изображения
Синтезирует новый пользовательский шрифт, максимально приближенный к исходному, и сохраняет фон страницы, используя копию с низким разрешением.
Понизить дискретизацию до
Уменьшает количество пикселей в цветных, полутоновых и монохромных изображениях после завершения OCR. Выберите степень понижающей дискретизации для применения. Параметры с более высокими номерами уменьшают дискретизацию, создавая PDF-файлы с более высоким разрешением.
При выполнении оптического распознавания символов на отсканированном документе Acrobat анализирует растровые изображения текста и заменяет эти растровые области словами и символами. Если идеальная замена неясна, Acrobat помечает слово как подозрительное. Подозреваемые отображаются в PDF как исходное растровое изображение слова, но текст включается в невидимый слой за растровым изображением слова. Этот метод делает слово доступным для поиска, даже если оно отображается в виде растрового изображения.
Примечание . Если вы попытаетесь выделить текст в отсканированном PDF-файле, к которому не применено распознавание текста, или попытаетесь выполнить операцию чтения вслух с файлом изображения, Acrobat спросит, хотите ли вы запустить распознавание текста. Если нажать кнопку “ОК”, откроется диалоговое окно “Распознавание текста”, в котором можно будет выбрать параметры, подробно описанные в предыдущем разделе.
Выберите Инструменты > Сканирование и оптическое распознавание > Распознавание текста > Исправить распознанный текст .
Acrobat выявляет предполагаемые текстовые ошибки и отображает изображение и текст рядом на дополнительной панели инструментов. (Все подозрительные слова на странице заключены в рамки.)
Щелкните выделенный объект или поле в документе, а затем исправьте его в поле Распознано как на дополнительной панели инструментов. Нажмите Принять .
Следующий подозреваемый выделен. Исправьте ошибки по мере необходимости. Нажмите Принять для каждого исправления.
Щелкните Закрыть на дополнительной панели инструментов после завершения задачи.
Больше подобных
- Редактирование отсканированных PDF-файлов
- Редактировать изображения или объекты в PDF
- Улучшение фотографий документов, снятых с помощью мобильной камеры
- Функция продукта: сканирование документов в PDF-файлы с помощью Acrobat
- Онлайн-инструменты PDF: преобразование JPG в PDF
- Используйте онлайн-заполнитель PDF
Онлайн-конвертер OCR | OCR распознавание PDF
Что делает наш сервис OCR
Вам когда-нибудь хотелось нажать «Ctrl + F» и искать в печатных материалах конкретную информацию, которую вы ищете? Или что вам нужно отредактировать содержимое журнала или документа PDF без необходимости перепечатывать весь документ?
Классическим решением во всех этих случаях было перепечатать весь контент и отредактировать его. Это по-прежнему нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или журнальных страниц. Но все мы знаем, насколько трудоемким и беспокойным может быть это решение. Бесплатный конвертер OCR, с другой стороны, может решить вашу проблему, сэкономить ваши деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько кликов.
С помощью нашего сервиса вы можете конвертировать документ Microsoft Word в формат PDF. В любое время вы можете преобразовать PDF в Word. Также, если вы хотите конвертировать книгу в формат DJVU, воспользуйтесь этой ссылкой Djvu to PDF. Наш сервис также позволяет конвертировать изображения в PDF. Чтобы подготовить PDF из электронной книги или документа Fb2, воспользуйтесь ссылкой ePub to PDF. Дополнительно разделение или объединение PDF можно выполнить на соответствующих страницах: Разделить PDF и Объединить PDF.
О распознавании символов
Оптическое распознавание символов или OCR — это технология, позволяющая преобразовывать печатные или рукописные документы в редактируемые текстовые файлы. Просто отсканировав печатные документы с помощью программного обеспечения для сканирования текста OCR, вы можете легко преобразовать файлы в электронные копии, которые можно редактировать, копировать или делиться в соответствии с вашими требованиями. Текстовые сканеры OCR очень универсальны и могут сканировать текст с изображений, печатных документов и файлов PDF. Программное обеспечение OCR можно загрузить или использовать в качестве онлайн-сервисов OCR.
Как работает OCR
Хотя понятие «машины», читающие «тексты», не ново и было введено еще в 1960-х годах. Хотя в то время компьютер мог прочитать только один тип шрифта, который назывался OCR-A. С развитием технологий текстовые сканеры OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два разных метода для захвата печатного текста и преобразования его в редактируемый формат.
Метод сопоставления матриц
Первый метод — это метод сопоставления матриц. Этот метод работает по принципу сопоставления печатного текста с базой данных шаблонов символов и шрифтов. Сканер текста OCR сканирует напечатанный текст, сравнивает его с существующей библиотекой шаблонов и, как только совпадение найдено, преобразует данные в соответствующий код ASCII. Затем вы можете манипулировать этими данными в соответствии с вашими требованиями. Этот метод быстро возвращает результаты, но из-за ограничений базы данных метод сопоставления матриц имеет свои ограничения. Метод терпит неудачу, когда он должен прочитать текст, отсутствующий в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может создавать ошибки, которые необходимо исправлять вручную.
Метод выделения признаков
Другой метод, используемый программным обеспечением OCR, — это метод извлечения признаков. Этот метод основан на искусственном интеллекте, где онлайн-программное обеспечение OCR предназначено для выявления общих точек в формах букв, таких как кривизна, наклон и пустые места в алфавите. Сканеры текста OCR ищут эти общие точки в тексте и возвращают результаты в коде символов ASCII после того, как будет найден определенный процент «совпадения».
Следовательно, этот метод ищет повторяющиеся шаблоны, которые представляют букву, и программное обеспечение может предсказать букву, просто сканируя общие точки, найденные в шаблоне. Метод более гибкий и может работать с большим количеством печатных или рукописных документов.
Кроме того, ИИ постоянно обновляет свои знания о различных почерках и шрифтах, что делает его более универсальным в использовании.
OCR онлайн
Самый простой способ преобразовать печатные файлы в редактируемую версию — использовать онлайн-сервисы OCR, предлагаемые нашим бесплатным OCR-конвертером. Пользоваться онлайн-сервисами OCR чрезвычайно просто, так как вам нужно только отсканировать документ, загрузить его, и файл будет преобразован в редактируемую версию для загрузки. Бесплатная услуга OCR — это отличная возможность для бизнеса сэкономить свое драгоценное время и деньги.
Использование бесплатных онлайн-сервисов оптического распознавания символов имеет множество преимуществ. Эти преимущества включают в себя:
- Время, затрачиваемое на весь процесс, значительно сокращается, а большие документы можно подготовить всего за несколько минут. Редактировать контракты, журнальные страницы и брошюры теперь стало очень просто.
- Упрощение процесса извлечения данных из сложных документов.
- Уменьшение вероятности человеческой ошибки, связанной с методом чтения и повторного ввода.
- Устранение затрат человеко-часов, необходимых для лихорадочного процесса ввода данных.
- Текстовые сканеры OCR сложны и могут также обнаруживать трудный почерк, для чтения и обработки которого человеческому глазу может потребоваться время.
Благодаря более быстрому времени обработки и усовершенствованным текстовым сканерам OCR эта технология может сэкономить значительное количество времени и средств для пользователей, которые могут использоваться для различных печатных документов или документов PDF.
Преимущества нашего онлайн-сервиса OCR
Исходные форматы OCR
Отсканированный PDF или другие форматы изображений
Без ограничений
Нет ограничений на количество распознаваемых страниц
Только ресурсы службы
Распознавание OCR выполняется только на наших серверах
404: Страница не найдена
Страница, которую вы пытались открыть по этому адресу, похоже, не существует. Обычно это результат плохой или устаревшей ссылки. Мы приносим свои извинения за доставленные неудобства.
Что я могу сделать сейчас?
Если вы впервые посещаете TechTarget, добро пожаловать! Извините за обстоятельства, при которых мы встречаемся. Вот куда вы можете пойти отсюда:
- Ознакомьтесь с последними новостями.
- Наша домашняя страница содержит самую свежую информацию об управлении корпоративным контентом.
- Наша страница «О нас» содержит дополнительную информацию о сайте, на котором вы находитесь, SearchContentManagement.
- Если вам нужно, свяжитесь с нами, мы будем рады услышать от вас.
Поиск по категории
ПоискБизнесАналитика
- Google запускает три новых инструмента для своего облака данных
Инструменты управления данными и аналитики, включая новые платформы обмена данными и озера данных, предназначены для предоставления пользователям доступа …
- Sisense добавляет три новых встроенных аналитических возможности
Новая интеграция с GitLab, многопользовательской средой и усовершенствования Extense Framework предназначены для дальнейшего .
.. - Дополнительная автоматизация, встроенная аналитика в планах Tableau
Новые возможности, запланированные к выпуску в рамках двух последних обновлений платформы поставщика в 2022 году, предназначены для ускорения …
SearchDataManagement
- Как создать эффективную команду DataOps
Все больше организаций обращаются к DataOps для поддержки своих операций по управлению данными. Узнайте, как построить команду с правильным …
- Как Lufthansa переносит свое хранилище данных в облако
Переход от локальной системы данных к облаку может быть сложной операцией. Lufthansa собирается убрать часть …
- Дебют бессерверной базы данных CockroachDB с инструментами миграции
После года предварительной версии поставщик базы данных делает бессерверное предложение общедоступным. Он обеспечивает новый .
..
ПоискERP
- 7 преимуществ RFID в управлении цепочками поставок и логистике
RFID может помочь компаниям в их операциях по цепочке поставок, помогая отслеживать продукты и потенциально улучшая их …
- Не так скучно: 50-летие SAP показывает, что он адаптируется к изменениям
Аналитик Винни Мирчандани, автор книги «SAP Nation 3.0», говорит, что адаптивность, лояльность клиентов и периодические перестановки в управлении являются …
- RFID или штрих-коды в цепочке поставок: что выбрать?
И RFID, и штрих-коды ценны в цепочке поставок, но каждый из них более полезен в определенных сценариях. Узнайте, что следует учитывать…
ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная .
.. - Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, в связи с чем …
ПоискSAP
- Сантандер присоединяется к SAP MBC, чтобы внедрить финансы в процессы
SAP Multi-Bank Connectivity добавил Santander Bank в свой список партнеров, чтобы помочь компаниям упростить внедрение …
- В 50 лет SAP оказалась на очередном распутье
За свою 50-летнюю историю компания SAP вывела бизнес и технологические тренды на вершину индустрии ERP, но сейчас она находится на перепутье .
.. - Сторонняя поддержка SAP обеспечивает гибкость миграции
Сторонние поставщики услуг поддержки заявляют, что они могут обеспечить большую гибкость при меньших затратах, но клиенты должны подумать …
Как распознавать текст в MS Office
На днях я получил задание от школьной учительницы напечатать некоторые прошлые экзамены, которые она собирала в книгу. Тестовых работ было довольно много, а точнее файл стоил.
Зная, что это будет проблемой с точки зрения времени и усилий, которые мне придется выделить, я решил найти более быстрое решение. первое что пришло в голову OCR (оптическое распознавание символов) .
OCR — это в основном идентификация текста из файлов изображений. С точки зрения непрофессионала, подумайте об этом как о преобразовании изображений в текст .
OCR может сэкономить вам время и деньги, которые вы в противном случае потратили бы на набор текста или на аутсорсинг профессионалам. В моем случае мне удалось снизить нагрузку на эту конкретную работу примерно на 70-80%, и она была бы выше, если бы не несколько неправильно идентифицированных символов и подкрашивание некоторых диаграмм.
Для оптического распознавания символов я выбрал MS Office. Я рассмотрел другие варианты, прежде чем остановиться на нем, например, многофункциональный редактор PDF-XChange, который объединяет OCR со своим средством просмотра PDF. В конечном итоге, однако, все они оказались менее способными по сравнению с механизмом распознавания текста в MS Office, который был более точным и быстрым.
Я полагаю, что это можно отнести к тому, что они использовали бесплатный механизм распознавания текста Tesseract, который, хотя и является мощным сам по себе, как правило, уступает коммерческим альтернативам.
1 Начало работы: параметры оптического распознавания символов Microsoft Office
2 1. Как распознавать с помощью OneNote
3
2. Как распознавать с помощью Microsoft Office Document Imaging (MODI)
3.1 Шаг 1. Установка MODI
3.2 Шаг 2: OCR с MODI
3.2.1 я. OCR изображения
3.2.2 II. OCR прямо со сканера
4 Языковая поддержка для MODI и OneNote
4.1 1. Установка языковых пакетов OCR для OneNote
4.2 2. Установка языковых пакетов OCR для MODI
Getting Started: Microsoft Office OCR Options
MS Office does OCR in two ways:
- Using OneNote
- Using Microsoft Office Document Imaging (MODI)
All MS Office versions of OneNote 2007 и позже будет делать для этой цели. Обратите внимание, однако, что, начиная с Office 2019, приложение OneNote для Windows 10 заменило прошлые версии Office, но не включает параметр OCR.
Для MODI дела обстоят немного иначе, так как он давно снят с производства. MS Office 2007 был последней версией, в которой он был реализован. Однако вам не обязательно иметь MS Office 2007, поскольку его можно установить отдельно и использовать с более новыми версиями MS Office.
Что вам понадобится
- OneNote (любая версия Office 2007-2016)
- Для автономной функции OCR вам потребуется SharePoint Designer 2007 для установки MODI. Вы можете получить его из двух источников:
- автономный SharePoint Designer 2007, который предоставляется в виде
бесплатной загрузки Microsoft. MS вытащила ссылку из своего центра загрузки; получить его от Softpedia вместо этого. - Если у вас уже есть лицензионная копия MS Office 2007, вы можете использовать ее вместо загрузки SharePoint Designer 2007.
- автономный SharePoint Designer 2007, который предоставляется в виде
- Изображение для оптического распознавания символов
- Сканер, если вы хотите использовать оптическое распознавание символов в процессе сканирования.
1. Как распознавать текст в OneNote
- Запустите OneNote и начните с создания новой заметки.
- На ленте перейдите на вкладку Вставка и вставьте изображение в OCR.
- Внутри заметки щелкните правой кнопкой мыши вставленное изображение и выберите Копировать текст с изображения .
- Откройте MS Word или текстовый редактор и вставьте распознанный текст.
- В качестве альтернативы вы можете искать текст в OneNote вместо того, чтобы копировать и вставлять его в другое место. Для этого щелкните правой кнопкой мыши вставленное изображение и выберите Сделать текст в изображении доступным для поиска, затем выберите язык, на котором находится текст.
- Затем вы можете использовать Ctrl+F для поиска текста внутри изображения. Если он найдет совпадение, оно будет выделено.
ПРИМЕЧАНИЕ. Если вам нужен другой язык, ознакомьтесь с разделом языков, чтобы узнать, как установить дополнительные языковые пакеты.
2. Как распознавать с помощью Microsoft Office Document Imaging (MODI)
Шаг 1. Установка MODI
- Запустите программу установки SharePoint Designer 2007 или MS Office 2007.
- Выберите вариант установки Настроить .
- Установите для всех доступных параметров значение Недоступно , затем разверните Инструменты Office и установите Microsoft Office Document Imaging на Запускать все с моего компьютера .
- Теперь оставьте его для установки.
Шаг 2: OCR с MODI
MODI может запустить OCR одним из двух способов:
- Запустив OCR на файлах изображений
- Подключившись к сканеру и автоматически запустив OCR после завершения сканирования документа
я.
OCR изображенияMODI только OCR изображения в формате TIFF (*.tif, *.tiff) . Если ваше изображение находится в другом формате (например, JPEG, PNG, GIF), вы можете использовать один из многих бесплатных графических редакторов, доступных в Интернете (XnView, IrfanView и т. д.), чтобы преобразовать их в TIFF.
Вы даже можете использовать Paint для преобразования. Просто откройте изображение с помощью Paint, выберите Сохранить как , затем выберите Другие форматы . В диалоговом окне сохранения выберите тип TIFF и сохраните изображение.
Получив изображения в этом формате, выполните следующие действия:
- Перейдите в меню «Пуск» программ и внутри Microsoft Office Tools откройте Microsoft Office Document Imaging .
- Внутри MODI нажмите кнопку Открыть и выберите изображение TIFF в диалоговом окне.
- После загрузки изображения в MODI нажмите кнопку Распознать текст с помощью OCR .
- Дайте ему время сделать OCR. Когда это будет сделано, нажмите кнопку Отправить текст в Word .
- Появится диалоговое окно с вариантами отправки текста. Если в TIFF было несколько страниц, обязательно выберите параметр All Pages . Если внутри изображения есть изображения/диаграммы, которые вы также хотите экспортировать, отметьте опцию Сохранить изображения в выводе . Нажмите кнопку OK .
- Распознанный текст и любые изображения, которые он может найти, будут экспортированы в файл HTML, открытый любой установленной версией Word.
ii. OCR непосредственно со сканера
- Подключите сканер и загрузите объект для сканирования.
- Перейдите к программам меню «Пуск» и в инструментах Microsoft Office откройте Сканирование документов Microsoft Office .
- В окне сканирования нажмите кнопку Scanner и выберите свой сканер.
- В зависимости от характера сканируемого объекта вы можете выбрать для него подходящую предустановку цвета, которая включает Цвет, Оттенки серого или Черно-белый .
- Нажмите кнопку Сканирование. Ваш элемент будет отсканирован, и после его завершения OCR запустится автоматически.
- Затем распознанный текст будет открыт в MODI. Завершите, нажав Отправить текст в Word 9Кнопка 1252 для переноса распознанного текста и любых изображений в Word.
ПРИМЕЧАНИЕ.
В папке сохранения по умолчанию вы найдете HTML-файл, содержащий информацию OCR. Проверьте в соответствующей папке HTML любые изображения, такие как диаграммы, которые будут экспортированы MODI.
Языковая поддержка для MODI и OneNote
Встроенная функция OCR в OneNote и MODI поддерживает только три языка: английский , французский и Испанский . По умолчанию он будет использовать язык, который использует ваш установленный MS Office.
Вы можете изменить язык, который MODI использует для OCR, выполнив следующие действия:
- Откройте Microsoft Office Document Imaging.
- Перейдите в Инструменты > Параметры…
- Выберите вкладку OCR , а затем выберите раскрывающийся список Язык OCR.
Для других языков, особенно тех, которые используют совершенно другой алфавит, чем тот, который используется в английском языке, например, греческий, корейский, китайский, японский, арабский, кириллица (славянские языки — русский, болгарский, сербский, украинский) и т. д. вам нужно будет установить соответствующий языковой пакет, чтобы он работал с OneNote или MODI.
1. Установка языковых пакетов OCR для OneNoteЧтобы установить языковой пакет для OneNote для OCR, выполните следующие действия:
- Откройте OneNote и выберите: Параметры > Язык
- Добавьте язык из раскрывающегося меню, затем, когда он появится в поле языков, щелкните ссылку Not Installed в столбце Проверка.
После этого вы попадете на сайт поддержки Microsoft Office, где сможете загрузить бесплатные языковые пакеты.
Убедитесь, что вы загрузили правильный языковой пакет для используемой вами версии MS Office, т. е. пакет 32 или 64-разрядный пакет вашей версии MS Office.
2. Установка языковых пакетов OCR для MODIДля MODI процесс немного сложен, но здесь есть отличное руководство по установке языковых пакетов.
Если все это кажется слишком трудоемким, вы можете использовать Tesseract, который имеет широкую поддержку различных языков. Однако Tesseract использует командную строку, но вы можете найти пару графических интерфейсов (версии с пользовательским интерфейсом) для него в Интернете.
Лучшее программное обеспечение для мобильного сканирования и оптического распознавания символов в 2022 году
Раньше я думал, что программное обеспечение для мобильного сканирования и оптического распознавания символов в основном используется для «официальных» документов — приложений, удостоверений личности и тому подобного. Но, проведя несколько недель с программным обеспечением OCR-сканера, я никогда больше не буду недооценивать возможности технологии, лежащей в основе этих приложений.
После тщательного тестирования около 30 мобильных инструментов сканирования и оптического распознавания символов я выбрал лучшие варианты. Они здесь.
The best mobile scanning and OCR software
Adobe Scan for the best free OCR software
CamScanner for the most detailed scans
Microsoft Lens for quick scanning (and Microsoft пользователей)
iScanner для OCR плюс уникальные функции
Tiny Scanner для точности
Pen to Print для рукописного распознавания текста
Google Lens для всех наворотов Google
Что делает приложение OCR для мобильного телефона отличным?
Если у вас нет сканера, вы все равно можете быстро оцифровать документы с помощью мобильного приложения для сканирования — все приложения из этого списка помогут вам. Но если вам нужно превратить свои страницы в файл, который вы можете редактировать, вам понадобится оптическое распознавание символов (OCR) как часть вашего мобильного приложения для сканирования. Это то, что превратит ваши мобильные сканы в редактируемые цифровые документы.
Имея это в виду, лучшее программное обеспечение для оптического распознавания символов с мобильным сканированием должно превосходить несколько ключевых областей. Не каждое приложение в этом списке соответствует всем этим критериям, но если вы собираетесь сканировать с помощью телефона, вам следует обратить внимание на эти функции — и это то, что я искал во время тестирования.
Автоматическое сканирование. Каждое приложение в этом списке включает какую-либо функцию сканирования, но я обратил внимание на то, какие приложения сделали процесс максимально безболезненным. Это включало проверку того, насколько хорошо каждое приложение фокусируется на документе, насколько точно датчик определяет границы и сколько времени требуется для захвата сканирования.
Точность. Приложение OCR должно быть точным, поэтому я обратил внимание на то, насколько точно каждое приложение воспроизводит оцифрованный текст из моих сканов.
Управление файлами. Приложение для сканирования телефона не должно иметь много наворотов, но я принял во внимание, насколько эффективно каждое приложение при организации, сохранении, совместном использовании, печати и экспорте оцифрованных файлов.
Персонализация. Сканирование и оцифровка документа может быть для вас только началом. Если ваша цель состоит в том, чтобы добавить больше текста, подписи или водяных знаков или защитить документы паролем, также важно иметь параметры настройки.
Режимы сканирования . Скорее всего, вы будете сканировать различные документы — от удостоверений личности и паспортов до книг и квитанций. Наличие различных вариантов режима сканирования может помочь с таким разнообразием.
Как мы тестировали мобильные OCR-приложения
Как мы оцениваем и тестируем приложения
Все наши обзоры лучших приложений написаны людьми, которые большую часть своей карьеры использовали, тестировали и писали о программном обеспечении. Мы тратим десятки часов на изучение и тестирование приложений, используя каждое приложение по назначению и оценивая его по критериям, которые мы установили для категории. Нам никогда не платят за размещение в наших статьях из какого-либо приложения или за ссылки на какой-либо сайт — мы ценим доверие, которое читатели оказывают нам, предлагая достоверные оценки категорий и приложений, которые мы просматриваем. Для получения более подробной информации о нашем процессе прочитайте полное изложение того, как мы выбираем приложения для размещения в блоге Zapier.
Для проверки производительности каждого приложения я использовал три очень разных документа:
Сертификат с некоторыми хитрыми шрифтами параграфы
Обратите внимание, что я не выбирал документы, которые были бы легкими. С любым приложением для сканирования вы получите наилучшие результаты при работе с плоскими, односторонними страницами стандартного размера с четким черным текстом и одним шрифтом (в идеале без засечек), расположенными в абзацах на белой бумаге. Выцветание, складывание, разрыв, книжные переплеты, вариации насыщенности чернил и другие факторы могут привести к срабатыванию оптического распознавания символов. Жизнь, однако, редко дает нам нетронутые документы.
5 вещей, которые вы должны автоматизировать сегодня
Начните автоматизировать
Все приложения из этого списка работают на iOS или Android, но я тестировал каждое приложение на iPhone 12 с iOS 15.4.1. Я использовал каждое приложение в одинаковых условиях естественного освещения на одном и том же фоне — деревянном полу. Когда это было возможно, я использовал любые функции автоматического сканирования в приложении, которые имели отношение к этому конкретному тексту. Например, у CamScanner есть специальный режим для сканирования страниц книги, поэтому я использовал его в учебнике, в то время как другие приложения не имеют таких настроек и заставляют вас выполнять быстрое сканирование.
Я начал этот эксперимент, думая, что могу увидеть тонкие различия в том, насколько хорошо каждое приложение обрабатывает цвет или сколько ошибок я могу насчитать в текстах OCR. И я предполагал, что у меня будет по крайней мере дюжина приложений, которые я мог бы легко порекомендовать. Это было не так. Когда пшеница отделилась от плевел, пшеницы осталось немного.
При сужении списка некоторые приложения не соответствовали базовым требованиям, а другие работали плохо. Например, у Evernote есть отличная функция сканирования, которая создает PDF-файлы с возможностью поиска практически из всего, что вы ему бросаете, но не дает вам редактируемый текст. Одному приложению не удалось отсканировать и правильно обрезать стандартную квитанцию (простой тест, который большинство других приложений прошли с честью). Другой смог идеально отсканировать только для получения неразборчивого, тарабарского текста.
В конце концов, лишь несколько приложений стали достойными и надежными вариантами. Вот семь лучших мобильных приложений для сканирования и распознавания текста.
Лучшее бесплатное программное обеспечение для распознавания текста
Adobe Scan
Adobe Scan предлагает несколько режимов сканирования, включая книги, документы, визитные карточки и даже электронные доски. Я начал со сканирования квитанции и был приятно удивлен, обнаружив, что приложение не только может определять телефонные номера и URL-адреса, но также делает номер или URL-адрес кликабельным. Это должно быть полезно, особенно если вы в пути и у вас нет времени записать номер или веб-сайт — вы можете просто сделать снимок и легко получить доступ к этой информации позже.
Что касается оцифровки, то с точностью были некоторые сбои, но в целом неплохо. Цены в квитанции, которые другие приложения справились с задачей, здесь были неверными. С другой стороны, сертификат показал себя намного лучше: Adobe уловила большую часть текста, за исключением заголовка «Certificate of Achievement» вверху. Что интересно, книга оказалась самой точной: в некоторых словах было несколько ошибок, но по большей части текст был достаточно правильным, чтобы его можно было расшифровать.
В целом, Adobe Scan — хороший вариант для тех, кто ищет бесплатное приложение для распознавания текста. Он поставляется с базовыми возможностями управления файлами и редактирования, что делает его более доступным, чем Microsoft Lens. А для тех, кто ищет еще несколько функций, таких как возможность экспорта в Word, сжатия и объединения PDF-файлов, защиты PDF-файлов паролем или оцифровки до 100 страниц, доступен премиум-план.
Стоимость Adobe Scan : Бесплатно; 9,99 долларов США в месяц или 69,99 долларов США в год за премиум-функции.
Smart Lens — настоятельно рекомендуемая альтернатива Adobe Scan для Android. Он работает аналогично для обнаружения телефонных номеров, адресов электронной почты и URL-адресов. С помощью Smart Lens вы можете пойти дальше и получить доступ к профилям Facebook, отправлять электронные письма или даже создавать контакты. Но приложение не является кросс-платформенным.
Лучшее приложение сканера OCR для детального сканирования1553 год стал первым глотком свежего воздуха. Мне ни разу не пришлось настраивать границы ни в одном из моих документов, а уровень детализации был на другом уровне. Он распознал почти весь текст на сертификате, включая хитрый заголовок «Сертификат достижений», который сбивал с толку все другие приложения. Он также разбил каждую часть текста на отдельные строки, что было приятно.
Еще одним приятным сюрпризом стало то, как CamScanner работал с книгой. Когда я экспортировал страницу как документ Word, она выглядела как реальная картинка, а не просто оцифрованное сканирование. Текст был организован почти так же, как в книге, включая расположение абзацев — и все это можно было полностью выделить.
При настройке документов вы можете добавить подпись, но, в отличие от других приложений, вы можете либо импортировать подпись, либо позволить приложению сканировать ее из другого места. (Большинство других приложений позволяли мне просто рисовать свою подпись на экране телефона.) Тем не менее, вы можете добавлять водяные знаки и устанавливать код доступа для защиты документов, а предложения по именованию при сохранении файлов и управлении ими были приятным штрихом.
Хотя цена CamScanner может показаться несколько завышенной, я думаю, что она того стоит, учитывая ее многофункциональность. Мало того, что OCR является точным, подробным и оптимизированным для удобства пользователя, но с премиальной подпиской вы можете искать текст в своих документах, создавать коллажи, сканировать неограниченное количество документов и получать до 10 ГБ облачного пространства.
Цена CamScanner : 9,99 долл. США в месяц, 69,99 долл. США в год, 299 долл. США на весь срок службы
Если вы ищете альтернативу CamScanner, я бы предложил Genius Scan . Как и CamScanner, он предлагал варианты заголовков на основе дат, местоположений и даже текста, распознанного в документе, а также очень точно оцифровывал его. Genius Scan не попал сюда, потому что OCR доступен только в премиальном плане. Начинающих пользователей это может раздражать, если они хотят сразу же использовать функцию распознавания текста.
Лучшее приложение OCR для быстрого мобильного сканирования (и пользователей Microsoft)
Microsoft Lens
Microsoft Lens простое — это то, что привлекло меня. Если вы попробуете другие приложения в этом списке, вы заметим, что многие из них требуют, чтобы вы зарегистрировались или провели экскурсию, прежде чем вы сможете даже отсканировать свой первый документ. Хотя в этом подходе нет ничего плохого, Microsoft Lens пропускает всю суету и позволяет сразу приступить к сканированию.
С другой стороны это означает, что приложение довольно простое. Microsoft Lens не уделяет особого внимания управлению файлами. Нет возможности создавать папки или сортировать и фильтровать сканы. На iPhone, как только я закончил редактирование своих документов, приложение перенаправило меня прямо к параметрам экспорта, которые включали либо сохранение документа в приложении iPhone Photos, либо в других совместимых приложениях. Тем не менее, пользователи Microsoft получат возможность сохранять документы и импортировать их в другие приложения Microsoft, включая OneDrive, OneNote, Word и PowerPoint.
Что касается OCR, квитанция и сертификат были в основном точными, с пропусками одной или двух строк. И хотя книга была чем-то вроде Final Boss для большинства приложений, Microsoft Lens смогла справиться с этой задачей. У него все еще были некоторые проблемы с точностью — несколько пропущенных слов и букв — но в основном он все еще был читабелен.
Цена: Бесплатно
Лучшее приложение OCR с дополнительными функциями
iScanner
У iScanner был мой любимый интерфейс из всех приложений OCR. Он предлагает множество функций, которые могли бы быть ошеломляющими, но он отлично справляется с организацией всего. Независимо от того, хотите ли вы отсканировать удостоверение личности, подписать документ или распознать текст, приложение делает функции очевидными, разделяя действия на следующие категории: Scan , Edit , Share и Other . А если вы чувствуете себя потерянным или любопытным, просто нажмите на круглые значки в верхней части экрана, и вы найдете видеоуроки по большинству функций.
Что касается моих стандартных тестовых документов, iScanner показал себя довольно хорошо. С сертификатом он по-прежнему пропускал заголовок вверху (что не редкость), но в основном это было точно. Книга и квитанция были немного лучше: пропущены некоторые буквы и слова, но в целом оцифрованный текст был разборчив и понятен.
Но уникальность этого приложения заключается в том, что оно может выполнять другие действия с обнаруженной информацией. Пример: iScanner может решать математические задачи. Чтобы протестировать эту функцию, я написал от руки простое уравнение — (4+8)/2 = — и приложение решило его за считанные секунды. Если вы действительно хотите увидеть, на что способно приложение, добавьте к нему более сложную алгебру, и вы должны получить аналогичные результаты.
Также умеет считать. Как вы можете видеть на скриншоте выше, я нацарапал девять точек на листе бумаги. После анализа и определения формы каждой точки приложение смогло сосчитать все девять. Если вам нужно быстро подсчитать или подтвердить сумму, это приложение будет палочкой-выручалочкой.
Еще одна маленькая деталь, которая мне понравилась, — это возможность размыть текст в документе. Большинство приложений OCR предлагают это в той или иной степени, но iScanner отличается тем, что размытие соответствует цвету фона документа, поэтому кажется, что вы полностью удалили текст. В целом, iScanner определенно является одним из лучших вариантов в этом списке.
Цена iScanner : 9,99 долл. США в месяц или 19,99 долл. США в год
Лучшее мобильное приложение для точного сканирования
Tiny Scanner
Tiny Scanner Функция автоматического сканирования сертификата и квитанции работала быстро и точно, но у меня возникли проблемы при попытке отсканировать обе страницы книги, поэтому мне пришлось делать это по отдельности. Однако, как только я преодолел этот сбой, я был впечатлен результатами OCR — я могу с уверенностью сказать, что это приложение было самым точным из всех в списке. CamScanner был на втором месте, но он немного боролся с орфографическими ошибками и пропущенными словами, в то время как Tiny Scanner был верен T.
Чтобы получить доступ к функциям OCR Tiny Scanner, лучше всего подписаться на платный план, но есть некоторая гибкость. Например, когда я повторно зашел в приложение после истечения срока действия бесплатной пробной версии и попытался включить распознавание текста, я первым получил предложение перейти на премиум-версию. Но когда я вышел из подсказки, появилось другое всплывающее окно с просьбой просто посмотреть рекламу для одноразового доступа к функции, которую я хотел. Видео могут быть короткими до пяти секунд, а самое длинное, которое мне приходилось смотреть, было 17 секунд. Я обнаружил, что это хороший компромисс для тех, кому нужно использовать приложение только время от времени, и, что удивительно, это единственное приложение из 30+ протестированных мной, которое предлагает такую гибкость.
Миниатюрный сканер цена : Доступен бесплатный план; Премиум-планы стоят 4,99 долл. США в месяц или 49,99 долл. США в год
Лучшее приложение для распознавания рукописного текста
Pen to Print
Даже в эпоху цифровых технологий рукописный ввод никогда полностью не выйдет из моды. Для тех из нас, кто любит ощущение прикосновения пера к бумаге, но также иногда нуждается в выводе этих надписей на экран, Pen to Print — отличное решение для распознавания рукописного текста OCR.
Чтобы проверить это, мне пришлось отказаться от книги, поэтому я составил базовый список продуктов. Я начал со своего обычного почерка: поначалу приложение с трудом определяло мой список, но после оцифровки все пункты оказались правильными. Во втором раунде я намеренно написал более беспорядочно и даже добавил немного курсива для ровного счета. Результат был все еще очень многообещающим: все получилось правильно, кроме двух пунктов. Это определенно надежный вариант распознавания рукописного текста.
Вы можете сохранять свои оцифрованные тексты в приложении, но если вы хотите экспортировать их на другие платформы — или копировать, вставлять и редактировать текст — вам необходимо подписаться на премиум-план. Однако варианты оплаты более чем разумны, начиная с 1,9 доллара.9/месяц.
Pen to Print price : For OCR features: $1.99/month, $9.99/yr, or $29.99 one-time
Best OCR app for Google bells and whistles
Google Lens
Google Lens становится мобильным приложением для сканирования и распознавания текста, когда вы используете его с другими приложениями, такими как Google Фото. Выберите фотографию из библиотеки Google Фото и щелкните значок линзы в нижней части экрана. Вы увидите, как на экране вспыхивают белые точки, когда Google Lens анализирует изображение, и через несколько секунд он выделяет весь ваш текст. Или вы можете отсканировать что-то с помощью Google Lens, а затем скопировать это в Google Docs— 9. 1552 Видео этого процесса от Google довольно эффектное. (Примечание: вы также можете преобразовывать изображения в текст с помощью Google Диска и Google Документов.)
Отсюда доступно множество вариантов, благодаря тому, что Google есть Google. Например, когда я нажал «перевести», приложение сразу же определило, что мой текст был английским, и предложило мне открыть Google Translate. А благодаря функции преобразования текста в речь я прочитал абзац из моей книги вслух с удивительно высокой точностью. Я даже взял этот список продуктов с неряшливым почерком, который я использовал для тестирования Pen to Print, и у Google Lens не было проблем с идентификацией слов.
Но возможности Google Lens идут еще дальше: он предлагает «визуальные совпадения», что означает, что он может анализировать изображение или документ и находить похожие результаты в Интернете (например, поиск изображений Google). Когда я протестировал его с сертификатом и списком продуктов, появились результаты по результатам сертификатов и списков продуктов. В том же примечании, когда я щелкнул вкладку «Покупки», я смог увидеть результаты для сертификатов в продаже вместе с ценами. Спасибо, Гугл!
Хотя Google Lens технически не имеет компонента сканирования (т. е. он не сохраняет ваши сканы), вы обнаружите, что на самом деле это не обязательно, если вашей целью является извлечение текста. Вы можете просто сфотографировать свой документ, позволить Google Lens сделать свое дело, скопировать текст и вставить его в другое место. Это может не сработать для хранения оцифрованных версий документов, особенно для профессиональных целей, но очень удобно иметь под рукой такой вариант.
Цена Google Lens: Бесплатно
Text Fairy — это надежная альтернатива Google Lens для Android для всех, кто хочет оцифровывать текст на разных языках (в базе данных более 110 языков). Как и Google Lens, он также имеет функцию преобразования текста в речь.
Как сканировать с помощью телефона?
Все приложения здесь будут сканировать текст и — либо изначально, либо путем его копирования в другое место — позволят вам редактировать этот текст по своему усмотрению. Честно говоря, это невероятно. Еще более впечатляющим является то, что в ваш телефон встроены некоторые из этих функций.
Если у вас iPhone или iPad, просто сделайте снимок или снимок экрана с текстом, и вы увидите всплывающую маленькую кнопку, позволяющую выделить, скопировать и вставить его. Я регулярно использовал эту функцию и обнаружил, что она чрезвычайно точна и хорошо справляется с захватом даже самого расплывчатого текста. Возможно, вам придется немного повозиться с форматированием — например, если вы копируете абзацы, будут неудобные разрывы строк, — но это до смешного удобно.
Дополнительные советы по сканированию см. в разделе лучшие сканеры визитных карточек и лучшие приложения для цифровой подписи файлов.
Эта статья была первоначально опубликована в сентябре 2018 г. Джилл Даффи. Последнее обновление было выпущено в мае 2022 года.
Преобразование JPG в Word — бесплатное распознавание текста онлайн
Преобразование JPG в Word — бесплатное распознавание текста онлайнПреобразование JPG в Word онлайн и бесплатно с распознаванием символов или без него
Конвертировать JPG в Word
OCR 1OCR 2Преобразовать
Как конвертировать JPG (JPEG) в Word
Шаг 1
Выберите одно из доступных приложений. Они немного отличаются по функционалу. Загрузите изображение в формате JPG или JPEG на сайт с помощью окна загрузки.
Шаг 2
После завершения загрузки выполните необходимые настройки. Обратите внимание, что конвертировать с OCR или без него можно с помощью различных приложений, в зависимости от того, что вам нужно.
Шаг 3
Через некоторое время преобразование будет завершено, и вы сможете загрузить файл Word на свое устройство. Проверьте результат и поделитесь нашим сайтом с друзьями.
Информация
Преобразование JPG в Word и как работает распознавание текста
OCR или оптическое распознавание символов — это система, которая преобразует изображения JPG/JPEG, например, фотографии печатного текста, файлы в формате PDF, а также отсканированные документы, в текстовые форматы Microsoft Word, DOC, DOCX с возможностью дальнейшего редактирования и наличием в них поиска. Сегодня нет необходимости перепечатывать существующий текст, тратя на это драгоценное время. Справиться с этой работой помогают многофункциональные устройства, которые выполняют ее в несколько этапов, освобождая человека от этой утомительной процедуры. Программное распознавание отсканированного текста и изображений позволяет быстро преобразовывать графические данные в цифровые. Полученные файлы можно редактировать.
OCR использует нейронные сети для поиска и распознавания текста на изображениях. Оптическое распознавание символов (OCR) позволяет преобразовывать фототекстовые изображения JPG в редактируемый текстовый формат, поддерживающий возможность поиска текста в документе, его копирования и редактирования. Наш сервис поможет вам извлечь текстовое содержимое изображений и документов, чтобы вам было удобнее работать с ними. Если вам не нужно распознавание текста, а только обычная конвертация, то выберите режим конвертации вверху сайта. В этом случае в результате преобразования JPG в Word вы получите файл Word, содержащий исходные изображения, растянутые на 100% для заполнения всей страницы.
Откройте конвертер
Особенности
Узнайте, почему преобразование JPG в Word на нашем веб-сайте является идеальным выбором
Converter
Вы можете преобразовать изображение или фотографию JPG / JPEG в документ Word. В результате этого преобразования у вас будет документ Word с вашим изображением на странице документа.
Распознавание текста
Вы сможете распознавать текст на изображениях и преобразовывать его в редактируемый формат Microsoft Word – DOC или DOCX. Для распознавания доступны все самые популярные языки мира.
Конфиденциальность
Мы гарантируем полную сохранность и конфиденциальность информации, содержащейся в ваших документах, которые вы загружаете через наш сервис и на серверы наших партнеров.
Любое устройство
Вы можете пользоваться нашим сервисом как со своего компьютера, так и со своего мобильного телефона – на iOS или Android. Вне зависимости от платформы вы получите одинаково качественный результат.
Удобство
Вы можете сами оценить удобство конвертации JPG в Word через наш сайт. Можем лишь отметить, что вам не нужно ничего устанавливать на свой компьютер.
Бесплатно
JPG2WORD всегда был, есть и будет абсолютно бесплатным для пользователей. Мы зарабатываем на рекламе, поэтому будем благодарны, если вы отключите блокировщик рекламы для нашего сайта.
Несколько фактов о JPG2WORD
При создании сайта jpg2word.com мы думали о вашем удобстве. Мы хотели создать максимально удобный со всех точек зрения продукт, и думаем, нам это удалось.
- Простой и интуитивно понятный интерфейс
- Современный и удобный дизайн
- Быстрое преобразование с распознаванием текста
260К
Преобразованные файлы
3 с
Скорость преобразования
100 млн+
Распознанные слова
150К
пользователей
Вам понравился наш сайт? Помогите нам расти.