
Как перевести иероглифы с картинки • Buycraft – покупки в Китае. Taobao – 1688
Описания товаров, размерные таблички и прочая информация, очень часто указаны на картинке, откуда ее с помощью “выделил-скопировал” не достать.
Такой метод оформления картинками используют оптовые продавцы. В целях удобства распространения среди розничных магазинов. “Оптовик” формирует готовые пакеты с описанием, фотографиями, прочей информацией и продает либо бесплатно раздает магазинам. Розничный продавец загружает пакет себе на Taobao, меняет цены на свои – магазин готов.
Поэтому в большинстве случаев, на просьбу прислать “эти же фото, но без текста или вотермарков” продавец отвечает отказом, у него их нет.
Иероглифы в размерных табличках можно запомнить или сохранить образцы с рисунками, где подписаны мерки на манекене, но что делать с описанием ткани и другими полезными характеристиками.
Как один из способов перевести иероглифы с картинки – онлайн распознавание текста.
Раньше я рассказывал об интересном плагине для браузера Google Chrome – Project Naptha, который «на лету» распознает иероглифы. К сожалению плагин развития не получил.
Процесс перевода иероглифов с картинки:
Сохранить фотографию на сайте 1688 можно с помощью скриншота, в Window 7 и 10 есть приложение Ножницы, вполне удобное и ничего устанавливать дополнительно не надо. Можно просто перетащить картинку, на Рабочий стол к примеру. Кликаете на картинку и не отпуская левую кнопку мышки “перетаскиваете” картинку на Рабочий стол или другую папку, обычно это работает, но есть исключения. С Таобао таких проблем нет, там можно через меню “правой мышки”сохранить картинку, в 1688 такая опция заблокирована. Изображение для перевода иероглифов подготовлено. Открываем NewOCR
По умолчанию в Recognition language(s) указан Английский, меняем на Chinese-Simplified.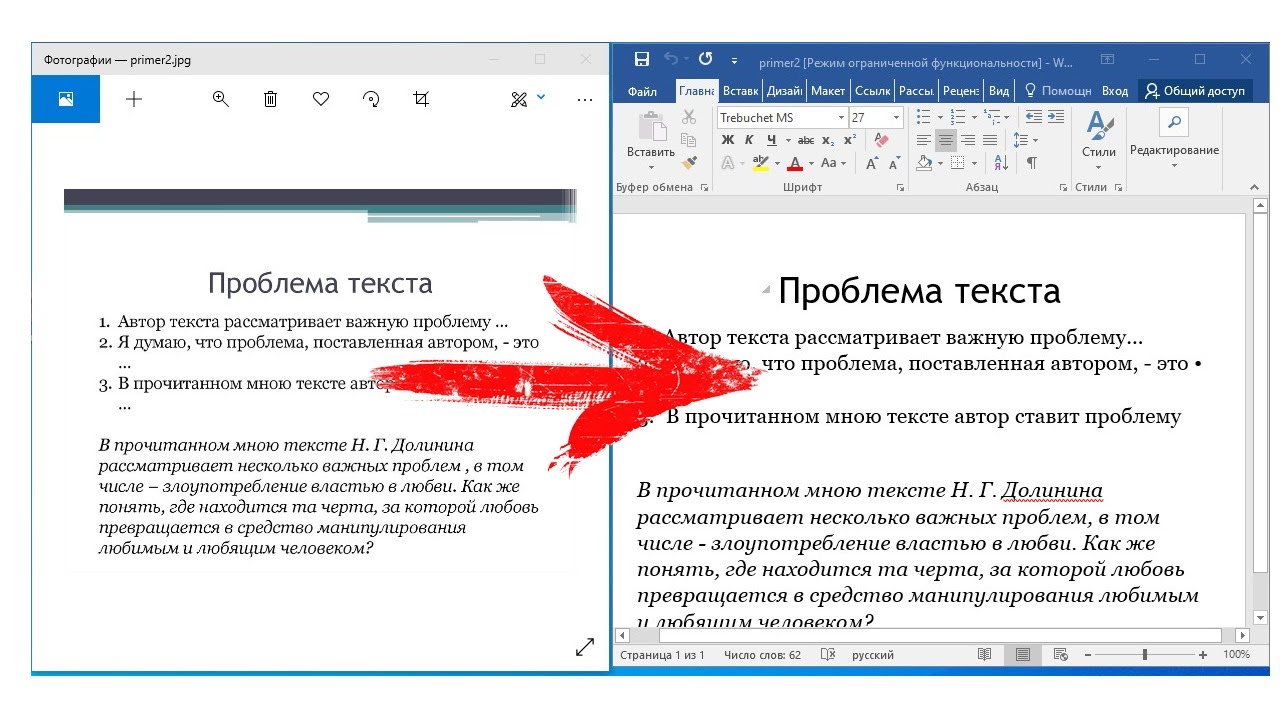 Если картинка с гонконгского сайта или тайваньского, лучше выбрать “Китайский – традиционный” или оба варианта сразу.
Если картинка с гонконгского сайта или тайваньского, лучше выбрать “Китайский – традиционный” или оба варианта сразу.
Выбираем фото для загрузки Select your file, жмем кнопку Choose File и выбираем нашу картинку для перевода и жмем
Ожидаем загрузки картинки на сайт. После чего отмечаем область, в которой расположены, необходимы нам иероглифы.
Можно конечно оставить и все подряд, но тогда будет “каша” из иероглифов со всей картинки, придется сортировать, где какие были.
После того как выделили область, нажимам OCR – кнопка выше картинки находится. Ожидаем несколько секунд/минут пока пройдет распознавание текста. Внизу картинки появится поле с текстом, который распознал сайт. Я выбрал только китайский язык, поэтому латиницу пытались распознать как иероглифы, вышло так себе.
Теперь можно нажать кнопку вверху Google Translate и перейти в Гугл.
Светлый текст на светлом фоне или темный на темном распознает плохо, с большими погрешностями. Понять смысл из того что получилось – можно.
Простое и практичное OCR распознавание китайских символов на основе Python на платформе Windows (с кодом)
Основная среда
Операционная система: 64-битная система win7
Версия Python: 3.6
2. Установка поддерживающей среды
(1) Сначала установите библиотеку распознавания символов OCR Tesseract Download URL:https://digi.bib.uni-mannheim.de/tesseract/
Загрузите соответствующую версию ниже
После загрузки дважды щелкните для установки. Поскольку мы хотим распознавать китайские символы, вам необходимо проверить дополнительный язык в интерфейсе установки и развернуть Дополнительные языковые данные.
Затем проверьте это, как показано ниже
Затем нажмите «Далее» для установки (Примечание. При выборе пути установки китайский язык не должен отображаться, и вы должны запомнить этот путь установки). Мой путь:
При выборе пути установки китайский язык не должен отображаться, и вы должны запомнить этот путь установки). Мой путь:
D:\toolplace\OCR\Tesseract-OCR
Затем настройте переменные среды.
Найдите интерфейс конфигурации переменных среды через панель управления следующим образом (вы не можете найти конфигурацию переменных среды самостоятельно, Baidu):
Только что добавьте каталог установки в пользовательскую переменную PATH и системную переменную Path D: \ toolplace \ OCR \ Tesseract-OCR; обратите внимание, что каждая переменная разделяется точкой с запятой на английском языке.
После изменения переменных среды убедитесь, что установка прошла успешно. Откройте инструмент командной строки cmd и введите команду:
Tesseract -vСледующий интерфейс показывает успех
(2) Установите среду Python
pip install Pillow==5.2.0
pip install pytesseract==0.2.43. Тест
Написать скрипт на Python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pytesseract
from PIL import Image
# open image
image = Image. open('2.jpg')
code = pytesseract.image_to_string(image, lang='chi_sim')
print(code)
open('2.jpg')
code = pytesseract.image_to_string(image, lang='chi_sim')
print(code)Здесь мы читаем на изображении 2.jpg, а затем распознаем текст на изображении. Диаграмма эффекта выглядит следующим образом:
Следует сказать, что весь эффект распознавания хорош для стандартизированного (включая печать и сканирование) распознавания на китайском языке (удобный сценарий применения – использовать мобильный телефон для фотосъемки, а затем снимать qq снимки экрана для распознавания, что может спасти работу от многократного набора большого количества текста).
Позже я попробовал распознавание почерка. Эффект распознавания для почерка все еще нуждается в улучшении.
Полный тестовый скрипт и вспомогательный установочный пакет можно скачать по следующему адресу:
https://download.csdn.net/download/qianbin3200896/10694840
Google запустил онлайн-убийцу FineReader. Разработчики FineReader не испугались
| Поделиться Протестировав «онлайн-распознавалку», эксперты Abbyy заявили, что Google еще есть над чем поработать, но похвалили поисковик за пропаганду OCR-технологий.
Протестировав «онлайн-распознавалку», эксперты Abbyy заявили, что Google еще есть над чем поработать, но похвалили поисковик за пропаганду OCR-технологий. Google добавил в свой «облачный» сервис Docs функцию распознавания текстов на 29 языках. Строго говоря, «онлайн-распознавалка» Google была впервые анонсирована и интегрирована в Docs еще в июне 2010 г. Тогда ее способности читать текст ограничивались поддержкой основных языков Европы и Америки: английского, испанского, итальянского, немецкого и французского.
С сегодняшнего дня OCR-сервис (Optical Character Recognition, оптическое распознавание текстов) Google начал в дополнение к прежним понимать наборы символов нескольких европейских алфавитов, русского, китайского и некоторых азиатских. В числе добавленных языков есть греческий, несколько кириллических (болгарский, сербский и украинский), корйеский, индонезийский и японский. Распознавание китайских текстов ограничивается документами с упрощенным набором иероглифов, принятым сейчас в КНР.
Для использования «онлайн-распознавалки» от пользователя требуется загрузить в Google Docs графическое изображение документа (или его PDF-версию), указав вручную формат документа и установив на странице загрузки опцию преобразования изображений и PDF-файлов в формат Google Docs. Функциональность доступна как в оригинальной, так и в русской локализации «Документов Google».
Программист Google Джейрон Шеффер (Jaron Schaeffer) предупреждает в корпоративном блоге, что сервис «лучше всего работает с высоким разрешением изображения».
«Онлайн-распознавалка» Google не очень хорошо прочитала Бродского, но зато сама подчеркнула ошибки
CNews протестировал «облачную распознавалку» на двух экзотических для Google языках: русском и китайском. Русский текст с качественного изображения (скриншот 72 пикселя на дюйм) система прочитала весьма средне. Претензии к распознаванию китайского в упрощенном написании свелись к артефактам и добавлению лишних пробелов.
Ошибки в прочитанном и распознанном тексте Google позволяет исправить средствами сервиса Google Docs либо скопировать в буфер и продолжить редактуру в оффлайновом редакторе.
Число потенциальных пользователей OCR-сервиса Google равно аудитории сервиса Google Docs, которое компания не сообщает. Это число должно быть близко количеству пользователей Gmail, поскольку сейчас почтового аккаунта достаточно для доступа ко всем сервисам Google.
Как цифровые технологии в промышленности дополняют бизнес
БизнесНа днях во время инцидента с пропажей переписки пользователей Gmail общее число ее подписчиков оценивалось примерно в 200 млн человек. В это число входят все пользователи, когда-либо зарегистрировавшие аккаунт в Gmail вне зависимости от того, посещали ли они почту в дальнейшем.
Отечественного разработчика OCR-систем Abbyy новый сервис Google не напугал даже невзирая на размер своей потенциальной аудитории. Генеральный директор «Abbyy Россия» Григорий Липич, ознакомившись с возможностями распознавания текстов в Google Docs высказал CNews мнение, что «с анонсированием недостаточно развитой возможности оптического распознавания текстов Google повторяет прошлогоднюю ошибку с Google Maps. Тогда компания объявила о запуске сервиса пробок по Москве, но практической ценности данный сервис не приносил ни во время запуска, ни сейчас, так как пока его качество предоставления информации о движении в городе далеко от аналогичного сервиса от компании Яндекс».
Генеральный директор «Abbyy Россия» Григорий Липич, ознакомившись с возможностями распознавания текстов в Google Docs высказал CNews мнение, что «с анонсированием недостаточно развитой возможности оптического распознавания текстов Google повторяет прошлогоднюю ошибку с Google Maps. Тогда компания объявила о запуске сервиса пробок по Москве, но практической ценности данный сервис не приносил ни во время запуска, ни сейчас, так как пока его качество предоставления информации о движении в городе далеко от аналогичного сервиса от компании Яндекс».
Григорий Липич подверг критике функциональность «онлайн-распознавалки» Google, заявив, что специалистам поисковика «есть над чем поработать в смысле качества распознавания текстов на русском, так и на английском и других языках», а также «в части сохранения оформления исходного документа». В отсутствие такой возможности пользователь будет тратить на редактуру документа после распознавания такое значительное время, что наличие OCR девальвируется, заметил Липич.
Однако, заметил глава Abbyy, «хорошо, когда такие известные компании как Google добавляют возможности распознавания текста в свои продукты. Это работает на повышение информированности рынка о технологиях распознавания текстов», которые известны не всем покупателям МФУ, фотокамер и сканеров.
Abbyy владеет собственным сервисом онлайн-распознавания документов FineReader Online, который, по данным на июль 2010 г., посещали около 70 тыс. пользователей. Хотя при регистрации пользователи FineReader Online получают право распознать несколько страниц документов бесплатно, использование сервиса происходит на платной основе.
Владислав Мещеряков
Распознавание удостоверяющих документов 193 стран — компания Smart Engines
Smart ID Engine
— высокоточное и безопасное программное обеспечение для распознавания данных более 1834 типов удостоверяющих документов 210 юрисдикций мира.
Smart ID Engine (ранее Smart IDReader) работает автономно на конечном устройстве: смартфоне, планшете, умной камере, терминале, персональном компьютере, сервере, — автоматически распознавая видео, фотографии или скан образы документов удостоверяющих личность (ДУЛ): паспорта, удостоверения личности (ID карты), водительские удостоверения, визы, виды на жительства, разнообразные свидетельства и др.
Программное обеспечение НЕ передает личные данные ваших клиентов на обработку в сторонние сервисы и/или третьим лицам для ручного ввода, НЕ сохраняет данные — все обработка ведется в локальной оперативной памяти устройства, НЕ требует сетевого соединения.
При использовании Smart ID Engine (Smart IDReader) НЕ требуется выполнять дополнительных действий, связанных с получением согласия субъекта на обработку его персональных данных (юридическое заключение).
Smart ID Engine — инструмент цифровой трансформации процессов дистанционного привлечения и обслуживания клиентов банков, страховых компаний, операторов связи, микрофинансовых организаций, брокеров, туроператоров, риэлтеров, игорного бизнеса, финансовых супермаркетов, онлайн торговли и других отраслей электронной коммерции. С его помощью просто наладить удобное, быстрое, безопасное и бесконтактное обслуживание посетителей банковских и страховых офисов и внесение данных в CRM системы, обеспечив распознавание текста по фото российского паспорта или удостоверений личности других стран. Продукт позволяет организовать продажу финансовых, страховых, транспортных услуг и продуктов, билетов и сим карт в вендинговых машинах и терминалах.
С его помощью просто наладить удобное, быстрое, безопасное и бесконтактное обслуживание посетителей банковских и страховых офисов и внесение данных в CRM системы, обеспечив распознавание текста по фото российского паспорта или удостоверений личности других стран. Продукт позволяет организовать продажу финансовых, страховых, транспортных услуг и продуктов, билетов и сим карт в вендинговых машинах и терминалах.
Разработанная нашими специалистами технология оптического распознавания текста: GreenOCR® позволяет точно распознавать текст на 100 языках, включая арабский, персидский, урду, японский (кандзи, катакана и хирагана), и специально оптимизирована для минимизации воздействия на окружающую среду в рамках подхода Green AI. А наши технологии Edge OCR и 4D OCR обеспечивают быстрое и автономное распознавание текста в видеопотоке на мобильных устройствах.
Smart ID Engine помогает выявлять и предотвращать попытки мошенничества с документами в процессе оказания услуг, защищая как организацию, так и клиента. Важными преимуществами использования Smart ID Engine являются: соблюдение прав и свобод личности, высокие стандарты безопасности обработки персональных данных (ФЗ-152, GDPR, CCPA), выполнение требований регуляторов (KYC/AML), формирование передового пользовательского опыта и минимизация воздействия на окружающую среду (Green AI).
Важными преимуществами использования Smart ID Engine являются: соблюдение прав и свобод личности, высокие стандарты безопасности обработки персональных данных (ФЗ-152, GDPR, CCPA), выполнение требований регуляторов (KYC/AML), формирование передового пользовательского опыта и минимизация воздействия на окружающую среду (Green AI).
Поставка Smart ID Engine осуществляется в виде автономного SDK (software developer kit): семейство Mobile SDK, семейство Server SDK, семейство Desktop SDK и семейство Web SDK. Комплект поставки SDK содержит все необходимые описания API (application programmable interface) и примеры по интеграции на разных языках программирования.
Подробные сведения о функциональных возможностях, архитектуре, совместимости с различными архитектурами ЭВМ и операционными системами представлены в спецификации.
Заказать продукт
Фото переводчик с китайского на русский онлайн
До чего же интерес китайский язык, и как же он сложен для понимания. Но трудности, с которыми сталкивается человек в процессе его изучения, никак не отменяют факта его востребованности. В современном мире китайский язык всё набирает обороты, а значит, услуги онлайн-переводчиков актуальны как никогда. Давайте рассмотрим приложения, которые помогут вам распознать текст по фотографии.
Но трудности, с которыми сталкивается человек в процессе его изучения, никак не отменяют факта его востребованности. В современном мире китайский язык всё набирает обороты, а значит, услуги онлайн-переводчиков актуальны как никогда. Давайте рассмотрим приложения, которые помогут вам распознать текст по фотографии.
Яндекс.Переводчик — поможет перевести по фото
Кроме уже привычного нам всем текстового перевода, замечательные веб-переводчики поддерживают и распознавание текста с изображений. Это очень удобно: будь то учебная работа или необходимость в работе. Напимер, программы всегда выручат и приблизят к пониманию загадочного языка прекрасного Китая.
Российский «Яндекс», знакомый нам всем, способен разобрать великое многообразие иероглифов даже с неровно отснятой или отсканированной картинки. От других переводчиков его отличает максимальная художественная точность и адекватность при переводе на русский язык. Конечно погрешность в работе с китайским — минимальна, а простота в использовании приложения — абсолютна. Разберёмся, как получить перевод от продукта наших соотечественников пошагово.
Разберёмся, как получить перевод от продукта наших соотечественников пошагово.
- Первый шаг — установка бесплатного приложения Яндекс.Переводчика. Вы можете скачать его из Play Маркет или AppStore, в зависимости от операционной системы Вашего устройства.
- Авторизуйтесь в приложении, используя учётную запись Яндекс Переводчика. Ваш телефон может войти в аккаунт сам, если он подключён к другим вспомогательным службам от Яндекс.
- Выберите язык.
- Следуя подсказкам интерфейса, загрузите изображение или сделайте мгновенный снимок. Не переживайте за качество.
- Готово — Вам не нужно переживать из-за того, что Вы не поняли важные для Вас материалы, ведь Яндекс с лёгкостью адаптировал их под Ваш родной язык.
«Яндекс» рушит все стереотипы и уверенно идёт в темпе со временем, а значит в будущем нас ждут новые любопытные «плюшки» от разработчиков!
Google Переводчик — приложение для перевода по картинке
Сложно сомневаться в качестве авторитетного Google Переводчик, который вырывает самых разных людей из пучины непонимания незнакомого языка. Лидер мирового рынка предлагает множество полезных, прогрессивных функций, в том числе и фотоперевод. Как и с любым языком, подвластным Google Переводчик, не приходится погружаться в сомнения насчёт качества перевода с китайского языка: он гарантирует правильное толкование и точное распознание материалов с изображения. Не верите? Убедитесь сами.
Лидер мирового рынка предлагает множество полезных, прогрессивных функций, в том числе и фотоперевод. Как и с любым языком, подвластным Google Переводчик, не приходится погружаться в сомнения насчёт качества перевода с китайского языка: он гарантирует правильное толкование и точное распознание материалов с изображения. Не верите? Убедитесь сами.
- Скачайте бесплатное приложение Google Переводчик, источником может стать Play Market или AppStore.
- Войдите в свой Google-аккаунт.
- Выберете перевод с китайского языка на русский.
- Загрузите изображение, или же снимите его сразу.
- Получите мгновенный перевод текста с изображения, которому если и нужна корректировка, то лишь минимальная. Как и при работе с любым искусственным интеллектом.
Google — интернациональная компания, и их переводчик — отличный выбор при работе с китайским языком!
Microsoft Translator — сможет перевести китайские иероглифы на русский
Все знают Microsoft как автора набора одноимённых офисных программ. Какие бы соперники не появлялись на рынке, этой компании не грозит спад, ведь она всегда уверенно стоит на вершине. Microsoft — один из первооткрывателей функции фотоперевода, а значит, в переводчике данного производства используются надёжные, проработанные технологии, что гарантирует тщательный и качественный анализ изображения.
- Скачайте или установите бесплатный Microsoft Translator, который без труда найдётся в PlayMarket или AppStore.
- Авторизируйтесь в учётную запись Microsoft, или же создайте новую. Это быстрый процесс, обеспечивающий сохранение информации и сведений.
- Отметьте перевод с китайского на русский в поле выбора.
- Нажмите на иконку фотоаппарата, сделайте фотографию или загрузите уже готовую.
- Готово!
Microsoft — отличная служба, чей профессионализм подчёркивает умение искусственного интеллекта. Между тем ориентироваться в сложных сплетениях иероглифов и точно угадывать используемые значения непросто.
Camera Translator Free — удобный фотопереводчик
Как и подразумевает название, Camera Translator Free не только комфортный в использовании сервис, но ещё и доступный для любого потребителя — при соблюдении ограничений (не более 5 фотопереводов в сутки) он абсолютно бесплатный. В отличие от своих конкурентов, Camera Translator Free специализируется на распознавании текста с фото: не придётся тратить время на поиск нужной кнопки.
В отличие от своих конкурентов, Camera Translator Free специализируется на распознавании текста с фото: не придётся тратить время на поиск нужной кнопки.
- Установите приложение. Его скачивание из Гугл Плей — абсолютно бесплатно.
- Выберите язык: с китайского на русский.
- Загрузите изображение с помощью кнопки «Альбом», или сделайте свежее, нажав на «Камера».
- Считанные секунды, и автоматический перевод нужного текста — на экране Вашего смартфона.
Прежде всего при работе с таким узкоспециализированным приложением как Camera Translator Free возрастает уверенность. В том, насколько эффективно оно распознаёт загруженный текст. Оно не так известно, как другие, но не менее замечательно!
Заключение
В заключение, Китай — важный экономический и образовательный партнёр.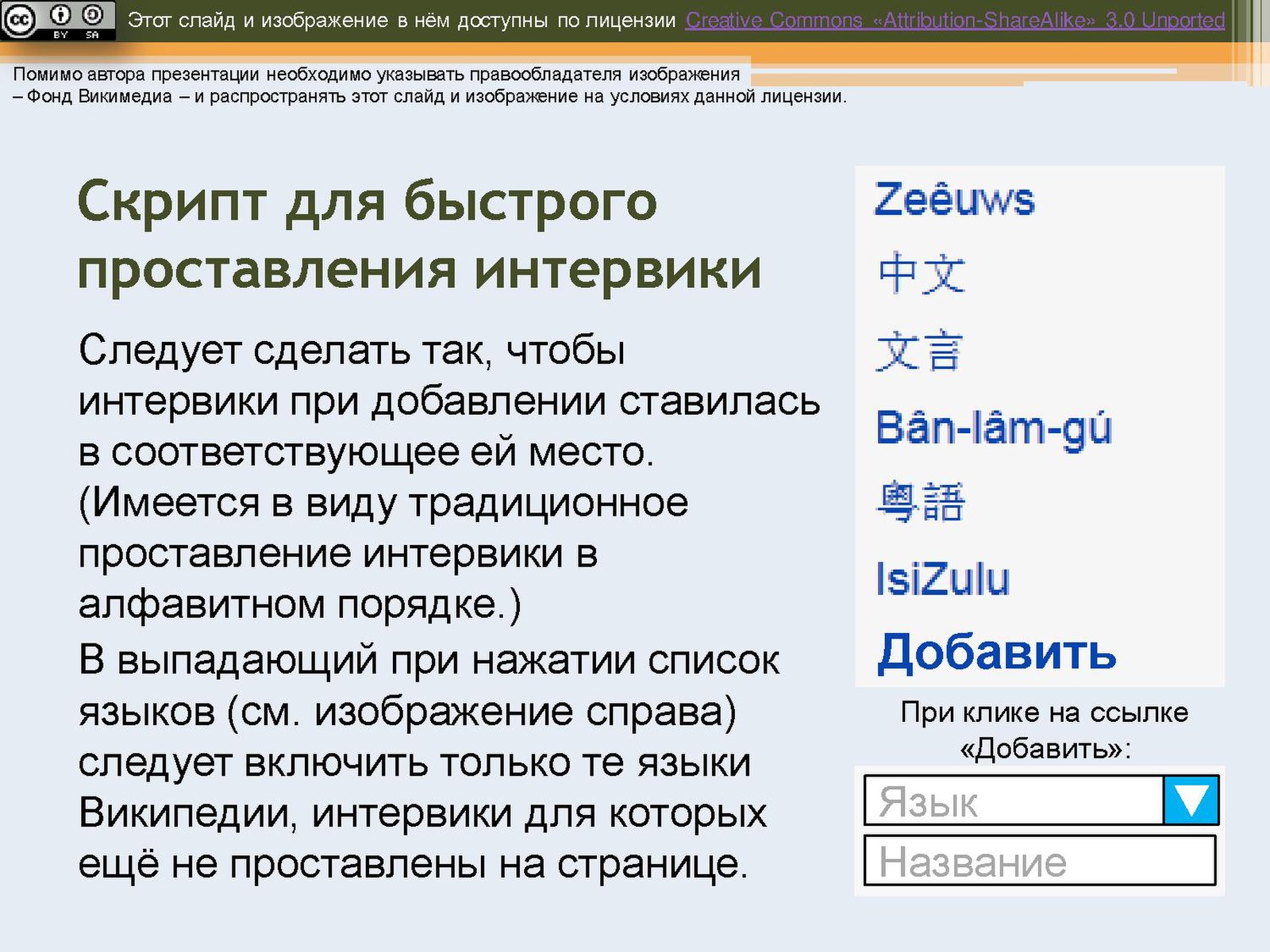 Изучение языка — отличное вложение в будущее, хоть и требует огромных усилий. Фотоперевод — замечательный способ мгновенно приблизиться к смыслу слов и речей.
Изучение языка — отличное вложение в будущее, хоть и требует огромных усилий. Фотоперевод — замечательный способ мгновенно приблизиться к смыслу слов и речей.
Оценка статьи:
Загрузка…Камера Bixby Vision | Приложения и службы
* Bixby распознает только некоторые акценты и диалекты британского английского, американский английский, французский (Франция), немецкий (Германия), итальянский (Италия), корейский (Южная Корея) языки, а также мандаринский диалект китайского языка (Китай), испанский (Испания), и португальский (Бразилия). Поддержка других языков будет добавлена позже.
* Использование приложения Bixby может быть ограничено в некоторых ситуациях, например при записи мультимедийного содержимого (видео, игр, речи), во время вызова (включая исходящие вызовы), при подключении к DeX Station, в режиме DeX, в максимальном режиме энергосбережения, в аварийном режиме и в Samsung Kids.
* Изображения устройства и экрана имитируются с иллюстративной целью.
* В данный момент доступно в Galaxy S21/S21+/S21 Ultra/Note20/Note20 Ultra/S20/S20+/S20 Ultra/Z Flip/Fold/Note10/Note10+/Note10 Lite/S10/S10+/S10e/S10 Lite/Note9/S9/S9+/Note8/S8/S8+/S8 Active/A71/A51/A90/A80/A70/A70s/A60/A50/A50s/A8s/A9 2018/A9 Star/Tab S6/Tab S5e/Tab S4/Tab A 10.5”/Tab Active Pro/Watch Active2/Watch Active/Watch/W20 5G/W2019/W2018.Active/A71/A51/A90/A80/A70/A70s/A60/A50/A50s/A8s/A9 2018/A9 Star/Tab S7/Tab S7+/Tab S6/Tab S5e/Tab S4/Tab A 10.5″/Tab Active Pro/Watch4/Watch Active2/Watch Active/Watch.
* Доступность службы зависит от страны, оператора, языка, модели устройства и версии ОС.
* Доступность функций Bixby и поставщиков содержимого может отличаться в зависимости от страны или языка.
* Приложение Bixby управляет лишь некоторыми приложениями. Поддержка других приложений будет добавлена в будущем.
* Необходим вход в учетную запись Samsung Account и подключение к сети (Wi-Fi или сети передачи данных).
* Пользовательский интерфейс может изменяться и различаться в разных устройствах.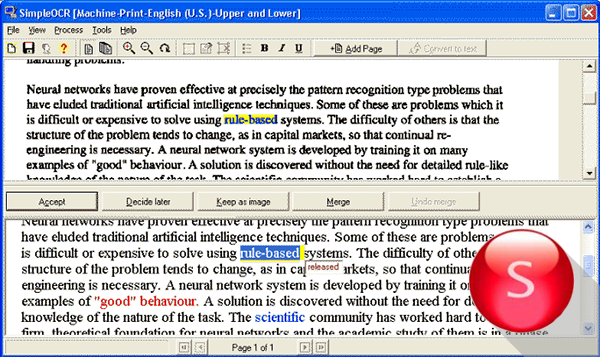
* Чтобы управлять другими устройствами с помощью Bixby, необходимо все эти устройства зарегистрировать в приложении SmartThings. Дополнительные сведения см. на веб-сайте SmartThings (www.samsung.com/smartthings)
.
Большой набор данных на китайском языке в дикой природе
В этой статье мы представляем очень большой набор текстовых данных на китайском языке в дикой природе. Хотя оптическое распознавание символов (OCR) в изображениях документов хорошо изучено и доступно множество коммерческих инструментов, обнаружение и распознавание текста в естественных изображениях по-прежнему является сложной проблемой, особенно для некоторых более сложных наборов символов, таких как китайский текст. Отсутствие обучающих данных всегда было проблемой, особенно для методов глубокого обучения, которые требуют массивных обучающих данных.В этой статье мы предоставляем подробную информацию о недавно созданном наборе данных китайского текста с примерно 1 миллионом китайских иероглифов из 3850 уникальных, аннотированных экспертами на более чем 30000 изображениях улиц. Это сложный набор данных с хорошим разнообразием, содержащий плоский текст, выпуклый текст, текст при плохом освещении, удаленный текст, частично скрытый текст и т. Д. Помимо набора данных, мы даем базовые результаты, используя современные методы для трех задач: распознавание символов (точность топ-1 80,5%), обнаружение символов (AP 70.9%) и обнаружение текстовых строк (22,1 AED). Набор данных, исходный код и обученные модели общедоступны.
Это сложный набор данных с хорошим разнообразием, содержащий плоский текст, выпуклый текст, текст при плохом освещении, удаленный текст, частично скрытый текст и т. Д. Помимо набора данных, мы даем базовые результаты, используя современные методы для трех задач: распознавание символов (точность топ-1 80,5%), обнаружение символов (AP 70.9%) и обнаружение текстовых строк (22,1 AED). Набор данных, исходный код и обученные модели общедоступны.
- 32 285 изображений с высоким разрешением
- 1018 402 экземпляра символов
- 3850 категорий символов
- 6 видов атрибутов
(Нажмите, чтобы открыть изображение в исходном разрешении)
Учебник
Для получения последнего руководства посетите наш репозиторий git.
Часть-1: основы
- разделение набора данных
- формат аннотации
- примеров аннотаций
Узнать больше >>
Часть-2: классификация
- базовые модели поездов
- формат подачи
- оценка API
(можно найти в репозитории git)
Часть-3: обнаружение
- базовые модели поездов
- формат подачи
- оценка API
(можно найти в репозитории git)
Файлы
Оценочный сервер
- Оценочный сервер доступен в CodaLab.

- Вы должны отправить файл
.zip, который содержит один файл.jsonlв каталоге верхнего уровня. Форматы отправки и показатели оценки для задачи классификации и задачи обнаружения описаны в части 2 и части 3 руководства, соответственно. - Образцы заявок можно загрузить из «открытых заявок» соответствующего конкурса на CodaLab. Перед загрузкой вам может потребоваться войти в CodaLab.
- Подробные результаты представлены по ссылке «Просмотреть подробные результаты» для каждой заявки.
Контакты
Если у вас есть какие-либо вопросы о наборе данных или коде, свяжитесь с Tai-Ling Yuan (yuantailing [at] gmail.com).
Бибтекс:
@article {yuan2019ctw,
author = {Тай {-} Лин Юань и Чжэ Чжу, Кунь Сю и Чэн {-} Цзюнь Ли и Тай {-} Цзян Му и Ши {-} Мин Ху},
title = {Большой набор китайских текстовых данных в дикой природе},
journal = {Journal of Computer Science and Technology},
объем = {34},
число = {3},
pages = {509-521},
год = {2019},
} История изменений
- 17.
 06.2019 (GMT + 8): замените бумагу на Большой набор данных на китайском языке в дикой природе
06.2019 (GMT + 8): замените бумагу на Большой набор данных на китайском языке в дикой природе - 07/04/2018 (GMT + 8): набор данных перемещен в OneDrive
- 17.03.2018 (GMT + 8): доступен оценочный сервер
- 15.03.2018 (GMT + 8): набор данных выпущен на WeiYun и Google Drive
- 28.02.2018 (GMT + 8): сайт открыт
Условия использования
Посмотрите китайские иероглифы по картинке
Вы только что видели броскую восточную футболку или загадочную азиатскую татуировку? И вы хотите найти китайский иероглиф, чтобы знать, что он означает, не так ли?Как найти китайский иероглиф, если я вижу его на картинке? Сначала сделайте снимок.Затем попробуйте медленно разделить китайский иероглиф на несколько небольших компонентов и щелкнуть по ним один за другим. Выше доступно множество компонентов для упрощенного китайского языка.
***** Быстрый пример! Нажмите 又, 爫, , затем, наконец, 冖 , и вы найдете 爱. А этот символ означает ЛЮБОВЬ *****
А этот символ означает ЛЮБОВЬ *****
Поздравляю! Вы сделали это. Найдите китайские иероглифы по картинкам, найдя их в таблице, и щелкните любые компоненты китайских иероглифов, чтобы собрать свой иероглиф из набора экзамена HSK (2644 популярных упрощенных китайских иероглифа, составляющих более 5 тысяч слов).
Итак, начните находить и нажимать части китайского иероглифа, которые вы хотите ввести и перевести.
И снова хорошие новости! Вам не нужно ничего быстро рисовать с помощью мыши или пальца. Это может быть круто (доступны приложения для iOS и Android), но нелегко с китайскими иероглифами, такими как 泰 , для новичков, которые не хотят сходить с ума, пытаясь нарисовать правильный набросок на лету.
Начните поиск китайского иероглифа, когда увидите его на картинке, собирая китайские иероглифы из его частей прямо сейчас, как наборы LEGO, только простым щелчком по строительным блокам выше! Ниже вы найдете несколько важных правил, которые помогут вам искать китайские иероглифы по картинкам:
1. Снова! Эти правила помогают ориентироваться в таблице, они предназначены для абсолютных новичков, – © Дэвид Боуи, – , как и мы с вами. Я просто программист, который любит китайский язык и хочет помочь другим людям искать китайские иероглифы по картинкам без словарей, зная порядок мазков кистью (да, это из китайской каллиграфии), 214 радикалов кандзи и изучая пиньинь ( звук и набор текста)
Снова! Эти правила помогают ориентироваться в таблице, они предназначены для абсолютных новичков, – © Дэвид Боуи, – , как и мы с вами. Я просто программист, который любит китайский язык и хочет помочь другим людям искать китайские иероглифы по картинкам без словарей, зная порядок мазков кистью (да, это из китайской каллиграфии), 214 радикалов кандзи и изучая пиньинь ( звук и набор текста)
2. Наши сердца часто заставляют нас ошибаться! И 心 работает точно так же! Итак, если вы ищете что-то вроде 思 с этой необычной нижней частью или с таким же рисунком в 忽 или 息, сначала коснитесь символа 心, а затем любых верхних частей.Я сделал сердечко красным (как напоминание).
UPD: Отныне нижняя часть также доступна как.
Кстати, китайский иероглиф 心, пересеченный «一», означает 必 (должен). Что ж, иногда нам приходится делать что-то, что нам не нравится.
3. При обработке китайского символа
Эффекты нормализации формы и извлечения признаков
[7] К.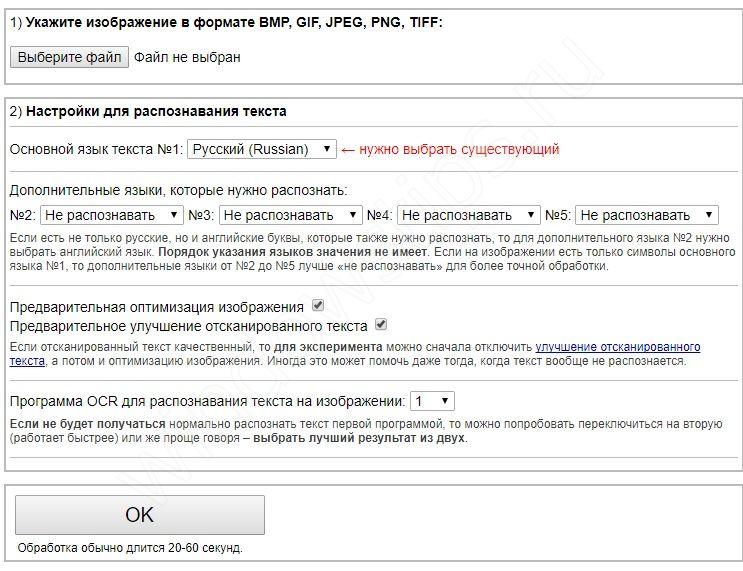 Фукунага, Введение в статистический патент
Фукунага, Введение в статистический патент
распознавание тернов, 2-е издание (Academic Press,
1990).
[8] R.O. Дуда, П. Харт и Д. Аист, образец
Классификация, 2-е издание (Wiley Interscience,
2001).
[9] А.К. Джайн, Р. Дуин и Дж. Мао, Statisti-
распознавание образов: обзор, IEEE Trans.
Образец Анал. Мах. Intell. 22 (1) (2000) 4-37.
[10] I.-J. Ким и Дж. Ким, Статистический характер
Моделирование структурыи его применение для распознавания письменных китайских символов
, IEEE
Пер.Pattern Anal. Мах. Intell. 25 (11)
(2003) 1422-1436.
[11] Т. Иидзима, Х. Генчи и К. Мори, Теоретическое исследование
идентификации паттернов методом сопоставления
, Proc. Первая конференция USA-JAPAN Computer
, октябрь 1972 г., стр. 42–48.
[12] М. Ясуда и Х. Фудзисава, Улучшение
метода корреляции для распознавания символов,
Пер. IEICE Japan J62-D (3) (1979) 217-224
(на японском языке).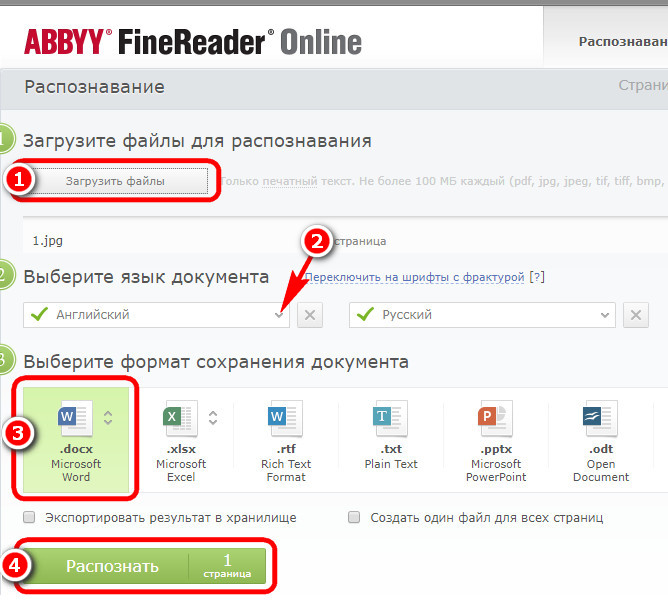
[13] Ю.Ямасита, К. Хигучи, Ю. Ямада и
Ю. Хага, Классификация напечатанных вручную символов кандзи
методом сопоставления структурированных сегментов
, Письма о распознавании образов 1 (1983)
475-479.
[14] Х. Фудзисава и К.-Л. Лю, Направленный шаблон
соответствие для распознавания символов еще раз, в
Proc. 7-я Международная конф. on Document Analysis and
Recognition, Edinburgh, Scotland, 2003, 794-
798.
[15] J.Цукумо и Х. Танака, Классификация
отпечатанных вручную китайских иероглифов с использованием методов линейной нормализации и корреляции, отличных от
,
в Proc. 9-я Международная конф. по распознаванию образов,
Рим, 1988, 168–171.
[16] Х. Ямада, К. Ямамото и Т. Сайто, A
Метод нелинейной нормализациидля отпечатанных вручную
Распознавание символов кандзи – равная плотность линий –
ization, Pattern Recognition 23 (9) (1990) 1023-
1029.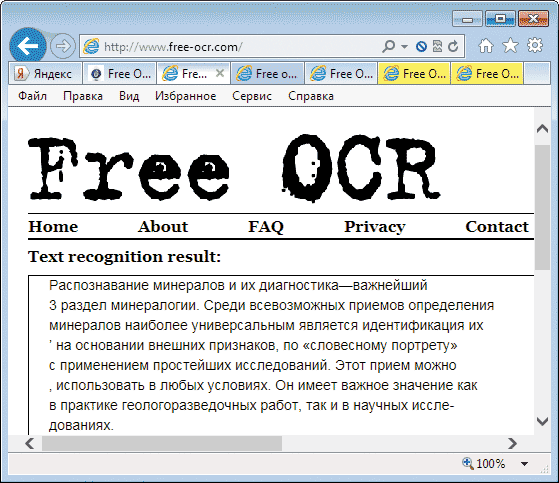
[17] Ф. Кимура, К. Такашина, С. Цуруока и Ю.
Мияке, Модифицированные квадратичные дискриминантные функции
и приложение к распознаванию китайских иероглифов
, IEEE Trans. Pattern Anal. Мах.
Intell. 9 (1) (1987) 149-153.
[18] Ф. Кимура, Т. Вакабаяси, С. Цуруока,
и Ю. Мияке, Улучшение рукописного распознавания японских символов
с использованием взвешенной гистограммы кода направления
, Распознавание образов
30 (8) (1997 ) 1329-1337.
[19] Н. Като, М. Абэ, Ю. Немото, Система распознавания десяти знаков рукописного текста
с использованием модифицированного расстояния Махаланобиса
, Пер. IEICE Япония
J79-D-II (1) (1996) 45-52.
[20] R.G. Кейси, Нормализация момента руки –
печатного символа, IBM J. Res. Развивать. 14
(1970) 548-557.
[21] C.-L. Лю, Х. Сако и Х. Фудзисава, Handwrit-
Распознавание десяти китайских символов: альтернативы
нелинейной нормализации, в Proc. 7-я Международная
7-я Международная
конф. по анализу и распознаванию документов,
Эдинбург, Шотландия, 2003 г., 524-528.
[22] C.-L. Лю и К. Марукава, Глобальная нормализация форм
для рукописного китайского иероглифа
распознавание: новый метод, в Proc. 9-й международный семинар
на границах распознавания почерка –
nition, Токио, Япония, 2004 г., 300–305.
[23] Т. Хориучи, Р. Харуки, Х. Ямада и К. Я.
mamoto, Двумерное расширение метода нормализации уха nonlin-
с использованием линейной плотности для распознавания символов
, в Proc.4-я Международная конф.
по анализу и распознаванию документов, Ульм,
Германия, 1997, 511-514.
[24] C.-L. Лю и К. Марукава, Псевдо-два –
методов нормализации формы для
распознавания рукописных китайских символов,
Распознавание образов 38 (12) (2005) 2242-2255.
[25] М. Хаманака, К. Ямада и Дж. Цукумо,
Извлечение признаков с помощью нормализации
Метод распознавания отпечатанных вручную символов кандзи –
, в Proc. 3-й международный семинар по вопросам распознавания почерка
3-й международный семинар по вопросам распознавания почерка
, Бушало, Нью-Йорк, 1993,
343-348.
[26] C.-L. Лю, К. Накашима, Х. Сако и Х. Фу –
дзисава, Распознавание рукописных цифр: стенд –
маркировка новейших технологий, Образец
Распознавание 36 (10) (2003) 2271 -2285.
[27] А. Кавамура, К. Юра, Т. Хаяма, Й. Хидаи,
Т. Минамикава, А. Танака, А. Танака и С. Ма –
suda, Распознавание свободного почерка онлайн –
десять японских иероглифов, использующих направленную плотность точек
, в Proc.11-я Международная конф. на Pat-
tern Recognition, Гаага, 1992, Том 2, 183-
186.
inria-00120408, версия 1 – 14 декабря 2006 г.
Ссылки по теме | Венлинь
Китайское OCR (оптическое распознавание символов)
Многие пользователи Wenlin спрашивали нас, как они могут сканировать китайские иероглифы с печатной страницы, а затем читать их как электронный текст. Для этого требуется китайское программное обеспечение OCR (оптическое распознавание символов). Мы не тестировали ни одну из этих программ, но если вы это сделаете, мы хотели бы услышать, что вы знаете об этих или других китайских продуктах OCR.Первый, IRIS (с необходимым «надстройкой азиатского распознавания текста»), как сообщил один пользователь Wenlin, «неплохо» работает в Windows XP; есть также IRIS для MacOS.
Мы не тестировали ни одну из этих программ, но если вы это сделаете, мы хотели бы услышать, что вы знаете об этих или других китайских продуктах OCR.Первый, IRIS (с необходимым «надстройкой азиатского распознавания текста»), как сообщил один пользователь Wenlin, «неплохо» работает в Windows XP; есть также IRIS для MacOS.
Интересные ссылки
- Журнал языков
- Language Log – один из самых популярных лингвистических блогов. Многие из его сообщений связаны с использованием языка в СМИ и популярной культурой, но темы охватывают весь спектр языковых исследований. Одна из специальностей Виктора Х. Мэра по языковому журналу – «Трудности перевода», но он также подчеркивал, как технологии влияют на китайскую речь и письмо.
- Китайско-платонические статьи
- Sino-Platonic Papers – научная монографическая серия, изданная Пенсильванским университетом. Основное внимание в сериале уделяется межкультурным отношениям Китая и Центральной Азии с другими народами.
 Журнал был основан в 1986 году Виктором Х. Мэйром, который остается редактором.
Журнал был основан в 1986 году Виктором Х. Мэйром, который остается редактором. - Марджори ChinaLinks Чана
- Аннотированные ссылки на сайты, посвященные Китаю и китайскому языку и лингвистике. “Связи с китайской лингвистикой отражают мой собственный исследовательский интерес к китайской диалектологии (включая кантонский диалект), фонетике и фонологии, как синхронной, так и диахронической.«
- Некоторые вспомогательные скрипты Python для Wenlin 3
- Сайлас С. Браун из Кембриджского университета.
- pinyin.info
- Руководство по написанию мандаринского китайского языка в Пиньине, написанное Марком Своффордом из Баньцяо, Тайвань.
- Председатели Бао
- Первая онлайн-газета на упрощенном китайском языке, написанная носителями китайского языка в строгом соответствии со списком слов HSK (Национальный тест на знание китайского языка). В каждой статье указывается целевой уровень HSK, а также предлагаются четкие грамматические объяснения, идиомы, ключевые слова и устная речь.

- Взлом Китая
- Сосредоточение внимания на том, как учиться, а не на том, чему учиться. Все, что вам нужно знать об изучении китайского, но никто вам не скажет.
- Юникод
- Консорциум Unicode
- Восточноазиатский Язык и мысль
- Чарльз Мюллер (Включает он-лайн словари буддийских терминов и т. Д.)
- А Образец китайского текста
- Сборник китайской литературы для студентов, организованный автор Clavis Sinica.
- Генеалогия китайских иероглифов Рика Харбо
- Этимологический словарь в Интернете для изучения китайских иероглифов – Потрясающе!
- An Интеллектуальная база данных для стандартных китайских компьютерных технологий
- Компьютерное общество Гонконга
- Словарь китайских иероглифов Варианты
- Тайвань Министерство образования
Если вы хотите порекомендовать ссылки, отправьте электронное письмо по адресу [email protected].
5 веб-сайтов для распознавания китайских иероглифов с помощью рисования с помощью мыши • Raymond.CC
Научиться писать по-китайски не так просто, как писать по-английски. Китайские иероглифы представляют собой комбинацию штрихов, которые требуют запоминания для изучения, в отличие от английского, где вы можете попытаться написать его с помощью алфавитов, и при этом все еще можно понять это правильно. В компьютерах ввод китайских иероглифов можно выполнять с помощью английской клавиатуры через систему пиньинь, которая использует латинские алфавиты для представления китайских звуков. Система пиньинь полезна для перевода алфавитов в китайские иероглифы, но не наоборот.
Допустим, вы где-то видели китайский иероглиф и хотите узнать, что он означает. Вы можете попробовать записать его на листе бумаги или сделать снимок с помощью смартфона, а затем нарисовать его с помощью Windows Paint со своего компьютера, когда вернетесь домой, сохранить его в формате изображения и загрузить на какой-нибудь китайский форум, чтобы попросить кого-нибудь перевести его. Или, возможно, вы столкнулись с проблемой заполнения формы, содержащей CAPTCHA на китайском языке, где вам необходимо ввести китайский иероглиф, который вы видите, но вы не знаете, что это означает или как они звучат.В то время пиньинь для вас совершенно бесполезен.
Или, возможно, вы столкнулись с проблемой заполнения формы, содержащей CAPTCHA на китайском языке, где вам необходимо ввести китайский иероглиф, который вы видите, но вы не знаете, что это означает или как они звучат.В то время пиньинь для вас совершенно бесполезен.
К счастью, у нас есть список веб-сайтов, на которых можно рисовать китайские иероглифы с помощью мыши.
1. nciku
nciku рекламируется как онлайн-словарь с английского на китайский, но это нечто большее. Вы найдете два поля в правом верхнем углу, где левое используется для рисования китайского иероглифа с помощью мыши, а в поле рядом с ним будут отображаться любые совпадающие китайские символы в соответствии с тем, который нарисован в левом поле.Щелчок по китайскому символу в окне результатов автоматически вставляет слово в поле поиска, где вы можете найти значение символа или просто скопировать и вставить его в другое место назначения.
Преимущество использования nciku заключается в том, что он может довольно точно распознавать китайские иероглифы, даже если вы не соблюдаете порядок штрихов.
Посетите nciku
2. MDBG
MDBG – популярный веб-сайт, предлагающий бесплатный англо-китайский онлайн-словарь, используемый во многих школах и университетах по всему миру.Поскольку у MDBG уже есть обширная база данных с английского на китайский в словаре, они интегрировали на свой веб-сайт бесплатное приложение Java под названием HanziLookup от Jordan Kiang, позволяющее посетителям искать китайские иероглифы с помощью мыши.
Чтобы включить рукописный ввод в MDBG, щелкните значок кисти рядом с кнопкой «Перейти», и в правой части страницы появится вертикальное поле, предлагающее активировать платформу Java. После активации Java вам необходимо разрешить запуск Java-апплета.Теперь вы можете начать рисовать китайский иероглиф в верхнем поле, а список символов, наиболее близких к тому, что вы нарисовали, будет отображаться внизу. Выбор символа мгновенно переместит его в окно поиска, где вы сможете найти слово или просто скопировать и вставить.
Обратите внимание, что распознавание китайских иероглифов мышью основано на порядке штрихов. Если вы не знакомы с порядком обводки китайских иероглифов, всегда помните общее правило письма сверху вниз и слева направо.
Посетите MDBG
3. YellowBridge
YellowBridge имеет распознаватель рукописного ввода, который очень похож на тот, что есть в nciku, за исключением того, что он не требует загрузки Adobe Flash Player. Просто щелкните значок кисти, чтобы загрузить дополнительное диалоговое окно, в котором вы можете нарисовать китайский иероглиф, используя правильный порядок штрихов.
Обратите внимание, что если у вас есть надстройка для блокировки рекламы, такая как Adblock Plus, установленная в вашем веб-браузере, YellowBridge сможет обнаружить его и запретить вам использовать их бесплатные онлайн-сервисы, пока вы не внесете их веб-сайт в белый список или не станете их платным подписчиком. .Еще одно простое решение – использовать другой веб-браузер, в котором не установлен модуль блокировки рекламы.
Посетите YellowBridge
4. Рукописный поиск по кандзи
Хотя кандзи – японское слово, слово кандзи на самом деле означает японскую систему письма с использованием китайских иероглифов. Что нам действительно понравилось в этой программе распознавания кандзи с рукописным вводом, так это возможность включать или отключать такие параметры, как просмотр вперед, отображение номеров штрихов, сохранение ввода и, самое главное, игнорирование порядка штрихов, что очень полезно для людей, которые не знают, как писать китайские иероглифы. в правильном порядке штрихов.
Однако есть небольшая проблема при попытке скопировать распознанное слово, соответствующее вашему рисунку. Вам нужно будет очень осторожно выделять слово, не нажимая на гиперссылку. Мы не могли рисовать, когда веб-страница загружалась из Internet Explorer 11, но отлично работает в Firefox и Chrome.
Посетите Рукописный поиск по кандзи
5. Google Translate
Неудивительно, что Google Translate, бесплатная онлайн-служба языкового перевода от технического гиганта, поддерживает рукописный ввод.Сначала выберите китайский в качестве основного языка, и в нижнем левом углу поля ввода появится дополнительный значок с китайскими символами. Щелкните стрелку, указывающую вниз, и выберите « Китайский (упрощенный) – Рукописный ввод ». Появится поле, в котором вы можете использовать мышь, чтобы нарисовать китайский иероглиф.
К счастью, рукописный ввод Google Translate с помощью мыши не ограничивает порядок штрихов. Если иероглиф нарисован так, чтобы он выглядел как настоящее китайское слово, его можно распознать без проблем.
Посетить Google Translate
Fujitsu достигает 96,7% скорости распознавания рукописных китайских иероглифов с использованием искусственного интеллекта, имитирующего человеческий мозг
Пекин, Китай и Кавасаки, Япония, 17 сентября 2015 г.
Fujitsu R&D Center Co., Ltd. и Fujitsu Laboratories Ltd. (совместно Fujitsu) сегодня объявили о разработке первой в мире технологии распознавания рукописного ввода с использованием технологии искусственного интеллекта, смоделированной на основе процессов человеческого мозга, чтобы превзойти уровень распознавания человеческого эквивалента 96.7%, установленный на конференции.
Fujitsu ранее достигала высочайшего уровня точности в этой области, что было продемонстрировано, заняв первое место с показателем распознавания 94,8% на конкурсе распознавания рукописных китайских символов (1) , проводившемся на Международной конференции по анализу и распознаванию документов. (ICDAR), конференция высшего уровня в области обработки изображений документов. Однако для дальнейшего повышения точности распознавания потребовался новый механизм изучения разнообразия деформаций знаков.
Теперь, сфокусировавшись на иерархической модели расширенных связей между нейронами, модели, основанной на человеческом мозге, которая улавливает особенности персонажей, Fujitsu разработала технологию для автоматического создания множества моделей деформации персонажа на основе базового рисунка персонажа, тем самым «тренируя» эту иерархическую нейронную модель. Используя этот метод, Fujitsu достигла уровня точности 96,7%, превзойдя уровень распознавания рукописных китайских иероглифов 96,1% для рукописных китайских иероглифов (2) .
Используя этот метод, Fujitsu достигла уровня точности 96,7%, превзойдя уровень распознавания рукописных китайских иероглифов 96,1% для рукописных китайских иероглифов (2) .
Fujitsu ожидает, что эта технология позволит автоматизировать компьютерный ввод и распознавание.
Предпосылки разработки
Обычно, хотя люди могут легко распознавать носители, такие как символы, изображения и звуки, для компьютеров это распознавание намного сложнее из-за множества вариаций формы, яркости и т. Д. Распознаваемого объекта, а также из-за наличие подобных объектов. Это стало центральной проблемой в исследованиях искусственного интеллекта.
Fujitsu имеет многолетний опыт распознавания символов, коммерциализированные технологии, используемые в таких областях, как финансы и страхование Японии для японского языка, а также китайская технология распознавания символов, используемая правительством Китая для создания 800 миллионов рукописных бланков переписи населения. Fujitsu начала исследования в области искусственного интеллекта на основе глубокого обучения для распознавания символов в 2010 году. В 2013 году технология распознавания символов, разработанная на основе этого искусственного интеллекта, заняла первое место (коэффициент распознавания 94.8%) в конкурсе по распознаванию рукописных символов китайского языка, проводимом в рамках международного конкурса высшего уровня в области обработки изображений документов, достигнув высочайшей точности в этой области.
Fujitsu начала исследования в области искусственного интеллекта на основе глубокого обучения для распознавания символов в 2010 году. В 2013 году технология распознавания символов, разработанная на основе этого искусственного интеллекта, заняла первое место (коэффициент распознавания 94.8%) в конкурсе по распознаванию рукописных символов китайского языка, проводимом в рамках международного конкурса высшего уровня в области обработки изображений документов, достигнув высочайшей точности в этой области.
Технические проблемы
С помощью технологии распознавания символов цель состоит в том, чтобы изучить и сохранить особенности многих шаблонов символов, которые, как считается, используются людьми при распознавании символов, с использованием модели связанных иерархий, основанных на человеческих нейронах. Когда вводится изображение персонажа, первый слой модели воспринимает простые черты персонажа, а затем следующий слой воспринимает сложные черты персонажа.Таким образом, признаки, эффективные для различения символов, извлекаются автоматически и иерархически, а затем накапливаются результаты процесса обучения, включая то, на какие особенности (нейроны) модель реагировала. При попытке распознать символ черты входящего символа извлекаются таким же образом, как и в процессе обучения, и персонаж идентифицируется, а результаты распознавания выводятся на основе того, какие функции (нейроны) отреагировали, как определено в процессе обучения. .
При попытке распознать символ черты входящего символа извлекаются таким же образом, как и в процессе обучения, и персонаж идентифицируется, а результаты распознавания выводятся на основе того, какие функции (нейроны) отреагировали, как определено в процессе обучения. .
Чтобы еще больше повысить точность распознавания, потребовались новые усилия по изучению разнообразия деформаций символов. Это связано с тем, что, хотя Fujitsu достигла наивысшего уровня точности в этой области, она не была на уровне, сопоставимом с распознаванием людей (уровень распознавания 96,1%).
Новые технологии
Теперь, увеличив количество связей между нейронами в иерархической модели более чем в пятьдесят раз, Fujitsu разработала технологию для автоматического создания множества разновидностей деформированных шаблонов символов для обучения.Используя этот метод, модель может учиться более тщательно и достигать уровня распознавания 96,7%, что превосходит показатель человеческого эквивалента 96,1% при распознавании рукописных китайских иероглифов. Ниже перечислены особенности этой недавно разработанной технологии.
Ниже перечислены особенности этой недавно разработанной технологии.
1. Расширение шкалы иерархической модели
Fujitsu расширила масштаб связей между нейронами в иерархической модели, используемой в процессе распознавания символов, повысив точность распознавания за счет увеличения количества связей с 2.От 8 миллионов, использованных в предыдущей технологии (коэффициент распознавания 94,8%) до 150 миллионов, чтобы точно настроить исследование деформаций (Рисунок 1, Рисунок 2).
Рисунок 1: Процесс распознавания символов и визуализация изученных функций между нейронами
Рисунок 2: Расширение масштаба соединений в иерархической модели для извлечения большего количества функций
Изображение большего размера (82 КБ)
2.Создание разнообразных образцов символов на основе случайной трехмерной деформации
Необходимо распознать около 3 800 китайских иероглифов (3) , что чрезвычайно затрудняет сбор реальных образцов деформации для каждого символа. Поэтому Fujitsu разработала технологию случайного деформирования существующих образцов символов для автоматического создания всевозможных образцов символов для обучения. Это позволило иерархической модели изучить множество различных типов деформированных паттернов персонажей (рис. 3).
Поэтому Fujitsu разработала технологию случайного деформирования существующих образцов символов для автоматического создания всевозможных образцов символов для обучения. Это позволило иерархической модели изучить множество различных типов деформированных паттернов персонажей (рис. 3).
Рисунок 3: Создание выборки для обучения персонажей на основе трехмерной рандомизированной деформации
В предыдущих методах, поскольку они рандомизировали положение персонажа только в двух измерениях, различия в яркости частей фона или частей персонажа (штрихи) и локальные различия создавали проблемы. Чтобы решить эту проблему, Fujitsu разработала технологию генерации выборки символов, основанную на случайных деформациях в трех измерениях.Добавляя значение серого каждого элемента изображения в качестве параметра оси Z к существующим осям X и Y изображения шаблона символа, они смогли создать множество деформированных шаблонов.
Результаты
С помощью этой недавно разработанной технологии Fujitsu достигла уровня распознавания рукописных китайских иероглифов 96,7%, что превышает показатель человеческого эквивалента 96,1%.
Планы на будущее
Fujitsu стремится к практическому применению этой технологии в 2015 финансовом году, а также к дальнейшему повышению точности технологии распознавания символов и расширению ее использования для распознавания носителей, отличных от письменных символов, таких как изображения и голос.
Кроме того, Fujitsu изучает возможности применения этой технологии распознавания символов для многих других языков, таких как японский, алфавитные языки и цифры.
Все упомянутые здесь названия компаний или продуктов являются товарными знаками или зарегистрированными товарными знаками соответствующих владельцев. Информация, представленная в этом пресс-релизе, актуальна на момент публикации и может быть изменена без предварительного уведомления.
Дата: 17 сентября 2015 г.
Город: Пекин, Китай и Кавасаки, Япония
Компания: Fujitsu R&D Center Co. , Ltd. / Fujitsu Laboratories Ltd.
, Ltd. / Fujitsu Laboratories Ltd.
Извлечение текста из изображения с помощью EasyOCR
# Изменение пути изображения IMAGE_PATH = 'Турецкий_текст.png '
# Здесь тот же код, только атрибут изменен с ['en'] на ['zh'] reader = easyocr.Reader (['tr']) result = reader.readtext (IMAGE_PATH, paragraph = "False") результат
Выход:
[[[[89, 7], [717, 7], [717, 108], [89, 108]] », ' Самый распространенный текстовый сленг на турецком языке '], [[[392, 234], [446, 234], [446, 260], [392, 260]], 'тест' ], [[[353, 263], [488, 263], [488, 308], [353, 308]], 'язык' ], [[[394, 380], [446, 380], [446, 410], [394, 410]], 'ссылка' ], [[[351, 409], [489, 409], [489, 453], [351, 453]], 'bağlantı' ], [[[373, 525], [469, 525], [469, 595], [373, 595]], 'tag etiket' ], [[[353, 674], [483, 674], [483, 748], [353, 748]], 'follov takip et' ]]
По вашему желанию я добавляю изображение, к которому я сделал это определение турецкого текста!
Факт
EasyOCR в настоящее время поддерживает 42 языка Я предоставил набор всех этих языков с их обозначениями. Удачи, ребята!
африкаанс (af), азербайджанский (az), боснийский (bs), чешский (cs), валлийский (cy), датский (da), немецкий (de), английский (en), испанский (es), эстонский (et) , Французский (fr), ирландский (ga), хорватский (hr), венгерский (hu), индонезийский (id), исландский (is), итальянский (it), японский (ja), корейский (ko), курдский (ku)) , Латинский (la), литовский (lt), латышский (lv), маори (mi), малайский (ms), мальтийский (mt), голландский (nl), норвежский (no), польский (pl), португальский (pt) , Румынский (ro), словацкий (sk), словенский (sl), албанский (sq), шведский (sv), суахили (sw), тайский (th), тагальский (tl), турецкий (tr), узбекский (uz) , Вьетнамский (vi), китайский (zh) – Источник: JaidedAI
EasyOCR обеспечивает достаточную гибкость, чтобы выбрать обнаружение текста с графическим процессором или без него.
Извлечение текста из изображения с помощью графического процессора
# Изменение пути изображения IMAGE_PATH = 'Turkish_text.png'
reader = easyocr.Reader (['ru']) результат = reader.readtext (IMAGE_PATH) результат
Выход:
[([[89, 7], [717, 7], [717, 75], [89, 75]],
«Самый распространенный текстовый сленг» ,
0,8411301022318493),
([[296, 60], [504, 60], [504, 108], [296, 108]],
'на турецком' ,
0.9992136162168752),
([[392, 234], [446, 234], [446, 260], [392, 260]], 'текст', 0,955612246445849),
([[353, 263], [488, 263], [488, 308], [353, 308]],
'язьмак' , г.
0,8339281200424168),
([[394, 380], [446, 380], [446, 410], [394, 410]],
'ссылка' ,
0,8571656346321106),
([[351, 409], [489, 409], [489, 453], [351, 453]],
'baglanti' , г.
0,9827189297769966),
([[393, 525], [446, 525], [446, 562], [393, 562]], 'тег', 0.999996145772132),
([[373, 559], [469, 559], [469, 595], [373, 595]],
'этикет' , г.
0,9999972515293261),
([[378, 674], [460, 674], [460, 704], [378, 704]],
'следовать' ,
0,9879666041306504),
([[353, 703], [483, 703], [483, 748], [353, 748]],
'takip et' ,
0,9987622244733467)] Извлечение текста из изображения
без графического процессора
# Изменение пути изображения IMAGE_PATH = 'Выполнить-OCR.jpg '
reader = easyocr.Reader (['ru'], gpu = False) результат = reader.readtext (IMAGE_PATH) результат
Выход:
[([[95, 71], [153, 71], [153, 107], [95, 107]], 'OCR' , 0,9
426051807 )] # Где 0,9904 .. - уровень достоверности обнаружения
Примечание: Если у вас нет GPU , но вы не устанавливаете его как False , то вы получите следующее предупреждение:
5.1. Нарисуйте результаты для однострочного текста – Пример 1
top_left = кортеж (результат [0] [0] [0]) bottom_right = кортеж (результат [0] [0] [2]) текст = результат [0] [1] font = cv2.FONT_HERSHEY_SIMPLEX
В приведенном выше фрагменте кода
- Мы пытаемся получить координаты с по , нарисовать ограничивающую рамку и текст поверх нашего изображения, на котором мы должны выполнить наше обнаружение.
- В переменной top_left мы получаем координату угла top_left в форме кортежа, доступ к которому осуществляется из результатов.Точно так же мы можем видеть это в координате bottom_right .
- Получение координаты текста из Формат двумерного массива
- Выбор шрифта текста как FONT_HERSHEY_SIMPLEX из пакета cv2.
img = cv2.imread (IMAGE_PATH) img = cv2.rectangle (img, top_left, bottom_right, (0,255,0), 3) img = cv2.putText (img, текст, bottom_right, font, 0,5, (0,255,0), 2, cv2.LINE_AA) plt.figure (figsize = (10,10)) plt.imshow (img) plt.показать ()
Теперь, как будто у нас есть координаты, давайте просто нанесем их на график!
- Чтение изображения с помощью функции cv2 imread ()
- Рисование прямоугольника с использованием координат top_left и bottom_right и определения цвета спуска (( 0,255,0 )) и толщины ( 3 ).
- Рисование текста поверх изображения с использованием координаты top_left ( непосредственно над прямоугольником, ограничивающим рамку )
- Отображение изображения
Выход:
5.2. Результаты рисования для однострочного текста – Пример 2
IMAGE_PATH = 'знак.png' reader = easyocr.Reader (['ru'], gpu = False) результат = reader.readtext (IMAGE_PATH) результат
Выход:
[([[19, 181], [165, 181], [165, 201], [19, 201]],
'ЗАЩИТА ГОЛОВКИ' ,
0,97782562963),
([[31, 201], [153, 201], [153, 219], [31, 219]],
"ДОЛЖНЫ НОСИТЬСЯ" ,
0,9719649866726915),
([[39, 219], [145, 219], [145, 237], [39, 237]],
'НА ЭТОМ САЙТЕ' ,
0.9683973478739152)] Получение координат
top_left = кортеж (результат [0] [0] [0]) bottom_right = кортеж (результат [0] [0] [2]) текст = результат [0] [1] font = cv2.FONT_HERSHEY_SIMPLEX
Рисование текста и ограничивающих рамок
img = cv2.imread (IMAGE_PATH) img = cv2.rectangle (img, top_left, bottom_right, (0,255,0), 3) img = cv2.putText (img, text, top_left, font, 0,5, (0,0,255), 2, cv2.LINE_AA) plt.figure (figsize = (10,10)) plt.imshow (img) plt.show ()
Выход:
Но держись! Что, если мы хотим видеть обнаружение всего текста на самом изображении?
Вот что я сделаю в этом разделе!
5.3. Результаты рисования для нескольких линий
img = cv2.imread (IMAGE_PATH)
spacer = 100
для обнаружения в результате:
top_left = кортеж (обнаружение [0] [0])
bottom_right = кортеж (обнаружение [0] [2])
текст = обнаружение [1]
img = cv2.прямоугольник (img, top_left, bottom_right, (0,255,0), 3)
img = cv2.putText (img, текст, (20, разделитель), font, 0,5, (0,255,0), 2, cv2.LINE_AA)
разделитель + = 15 plt. Рисунок (figsize = (10,10)) plt.imshow (img) plt.show ()
В приведенном выше фрагменте кода нам просто нужно сосредоточиться на нескольких моментах:
- Вместо того, чтобы обнаруживать однострочный текст, здесь мы перебираем все обнаружения, так как мы хотим построить несколько строк текста
- Пока даю координаты на cv2.putText мы используем дополнительную переменную «spacer» этот разделитель позже в коде увеличивается до +15 , что помогает ограничить текст, чтобы он сталкивался друг с другом.
- Эта переменная-разделитель поможет тексту оставаться отсортированным и равномерно распределенным.
Выход:
Заключение модели также завершает мое обсуждение на сегодня 🙂
Концевые сноскиСпасибо, что прочитали мою статью 🙂
Надеюсь, вам понравилась практическая реализация и построчное объяснение практического руководства EasyOCR
Я предоставляю здесь ссылку на код, чтобы вы, ребята, также могли изучить этот проект и внести свой вклад, чтобы сделать его еще лучше.
Вы никогда не захотите пропустить мою предыдущую статью «Обнаружение мошенничества с картами PAN », опубликованную в Analytics Vidhya как часть Data Science Blogathon-9. По этой ссылке
Также на, «Открытие лекарств с использованием машинного обучения». Перейдите по этой ссылке.
Если у вас есть какие-либо вопросы, вы можете связаться со мной в LinkedIn, перейдите по этой ссылке
Обо мне
Приветствую всех, в настоящее время я работаю младшим аналитиком по анализу данных в Zorba Consulting India. Помимо работы с частичной занятостью, я испытываю огромный интерес к той же области, то есть к науке о данных, а также к другим ее подмножествам искусственного интеллекта, таким как компьютерное зрение, машинное обучение и глубокое обучение. Не стесняйтесь сотрудничать со мной по любым вопросам. проект на вышеупомянутых доменах (LinkedIn).
Носители, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению автора.
.