Как работает распознавание рукописного текста — Machine learning на vc.ru
В повседневной жизни мы почти перестали писать от руки, ведь у многих работа и общение связаны со смартфоном, компьютером, и куда быстрее напечатать, нежели написать ручкой или стилусом. Тем не менее, иногда эта возможность не была бы лишней. Сейчас много разговоров про искусственный интеллект, машинное обучение, и кажется, что это можно дать на откуп девайсам. В этой статье мы разберем, как работают алгоритмы распознавания рукописного текста, какие есть проблемы, ведь до сих пор ввод текста на клавиатуре считается более надежным и быстрым, чем написание с помощью стилуса.
8138 просмотров
Введение
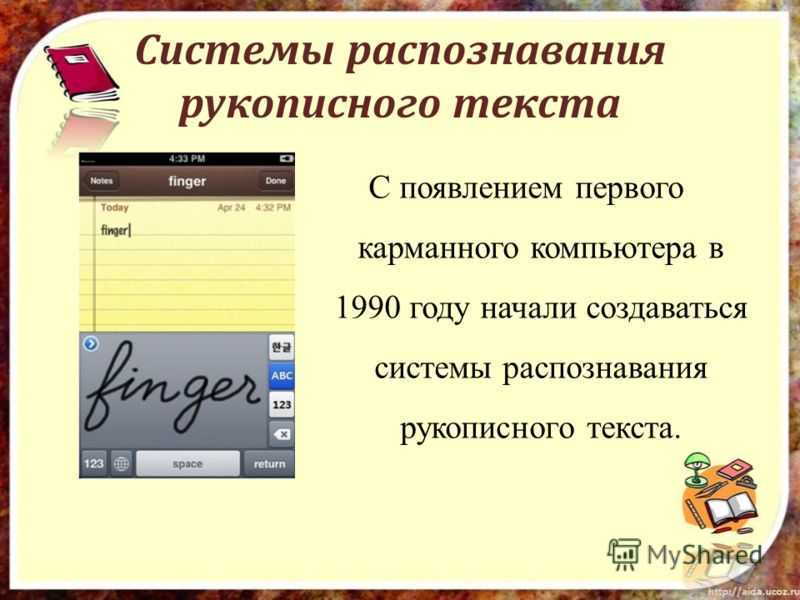
В качестве результата распознавания мы должны получить текст в цифровом формате. Существует два вида распознавания: — онлайновый и оффлайновый. Онлайновый — распознавание текста при написании стилусом или пальцем на экране или планшете. Сразу понятно, где написано слово, а где полотно. Первым КПК, который мог распознавать рукописный текст — Apple Newton (1993 год).
Первым КПК, который мог распознавать рукописный текст — Apple Newton (1993 год).
Занятная заметка тех времён.
Оффлайновый — распознавание уже написанного текста на бумаге. Текст предоставляется в виде скана или фотографии документа, страницы книги и т.п. Является более сложным способом, т.к. в случае онлайн-метода можно проследить процесс написания текста и на этом факте построить алгоритм распознавания. Сложность задачи распознавания рукописного текста — это большое разнообразие почерков, форм, размеров букв и многообразие языков. Так же бумага с текстом может содержать “шумы” — дефекты бумаги, посторонние пятна, что так же усложняет весь процесс.
Подходы распознавания
Существует по крайней мере два подхода, которые дают приемлемый результат: с использованием скрытой марковской модели и искусственной нейронной сети (ИНС). На практике так же применяется гибридный подход с использованием одновременно двух подходов.
Процесс
Подготовка
Подготовка включает выпрямление, пороговую бинаризацию, удаление шумов.
- Пороговая бинаризация — процесс отделения фона от объекта, в данном случае текст. В результате получаем чёрный текст на белом фоне.
- Удаление шумов — удаление артефактов с изображения, не затрагивая написанный текст.
Также выполняется сегментация строк, слов, символов. Это разделение текста на строки, слова и символы, чтобы в дальнейшем распознавать их с помощью ИНС. Чем меньше строки в тексте похоже на прямые, тем хуже будет работать алгоритм сегментации на строки. Элементарная сегментация на слова работает по принципу, что расстояние между словами больше, чем между буквами.
Сегментация строк, слов и букв
Рассмотрим подробнее несколько из шагов.
Выпрямление
Угол наклона — угол между вертикалью и направлением письма.
Слово до выпрямления
Слово после выпрямления
Сегментация слов
Не во всех алгоритмах требуется сегментация. Тем не менее, рассмотрим несколько способов разбиения текста на слова.
- Страница текста разбивается на строки, затем строка разбивается на слова, где пробел является их разделителем. Для этого на текст последовательно накладываются фильтры для удаления шумов и определения границ слов.
- Текст разбивается на составные части — компоненты и рассчитывается расстояние между их центрами. В качестве параметра алгоритма принимается какое-то пороговое значение расстояния, которое в дальнейшем можно подобрать исходя из успешности результатов.
- Следующий подход тоже основан на расчете расстояний. С помощью метода опорных векторов находится плоскость, которая разделяет два разных типа данных (символа), а затем с помощью порогового значения текст разбивается на слова.


Опорные вектора отмечены окружностями
- Последний подход использует несколько способов расчета расстояния между и их комбинация.
a — исходный кусок текста, b — ограничивающий прямоугольник, с — Евклидово расстояние, d — горизонтальное расстояние
Языковая модель
Языковая модель помогает алгоритму распознавания улучшить результат с помощью известных языковых словосочетаний. Языковая модель может предсказывать следующее слово на основании предыдущих и предлагать варианты с различной степенью вероятности. Например, более вероятной считается словосочетание «There are» по сравнению с «Their are». Такую модель можно тренировать на основании большого количества текста с расчетом повторений одного слова за другими. Конечно, нет сильной уверенности, что языковая модель сможет во всех случаях предсказывать следующее слово для любого текста, поэтому модель тренируют на тексте той же тематики, что и распознаваемый.
Префиксное дерево
Алгоритм поиска слова по префиксу достаточно быстрый и простой для понимания. Как можно догадаться, используется структура дерево, где рёбра — буквы, а вершина содержит признак слова. Таким образом, слово представляется в виде пути от корневого узла (первой буквы слова) через рёбра — составные буквы слова к вершине с признаком слова.
На иллюстрации можно увидеть представление слов to, too, a, this, that.
Классификация
На вход классификатора может поступать как изображения отдельных слов, так и целых строк. ИНС состоит из слоёв. Именно здесь и происходит вся магия и математека: сначала используются свёрточные нейронные сети (СНС) — операции свёртки и пулинга, и рекуррентные нейронные сети (РНС), а именно один из типов типы LSTM, mdlstm, IDCN. Суть свёртки в том, что каждый фрагмент изображения умножается на матрицу (ядро) свёртки поэлементно, а результат суммируется и записывается в аналогичную позицию выходного изображения (формируется карта признаков — feature map).
Пост-обработка
Текст после классификации может быть проверен на орфографию. На данном этапе в нашем распоряжении только текстовая информация без исходных графических данных. Например, текст разбивается на слова, затем проверяется на наличие в словаре. Если в словаре нет слова, но оно похоже на какое-то, предлагается вариант для исправления. Исправления можно так же тренировать параллельно от классификатора.
Заключение
Максимальная точность распознавания рукописного текста на английском, результаты которого удалось найти в открытых источниках, достигает величины от 55 до 75%.
Не забывайте, что большое значение имеет датасет. Каких-то данных про точность инструментов для распознавания русского языка я найти не смог. Тем не менее, на данный момент задача не выглядит нерешаемой, и при серьезном подходе к созданию модели, ее обучению, можно достигнуть высоких результатов распознавания.
Если вас заинтересовала тема глубокого обучения, советую для прочтения эту книгу. Пример реализации алгоритма для распознавания рукописного текста можно найти на GitHub, например, у этого автора.
Скопировать защищенный текст, если он не копируется на сайте
Вам необходимо скопировать информацию с сайта, но у вас не получается ее сохранить? Скорее всего, это некопируемый или защищенный от копирования текст. Веб-ресурс запрещает его выделять в целях соблюдения авторских прав. Для того чтобы скачать не копирующийся текст, воспользуйтесь этим онлайн-сервисом. Все что вам потребуется сделать – это указать ссылку на web-страницу, где нельзя копировать материал, запустить сканирование содержимого, найти и выделить заблокированные строчки статьи.
Все что вам потребуется сделать – это указать ссылку на web-страницу, где нельзя копировать материал, запустить сканирование содержимого, найти и выделить заблокированные строчки статьи.
ГлавнаяИнструментыСохранение текста с защищенного от копирования сайта
Сервис для сохранения не копирующегося текста
Если текст на сайте не получается или невозможно копировать, то воспользуйтесь онлайн-сканером текста. Он поможет вам обойти блокировку и скопировать любой заблокированный от копирования материал. При этом, скачать содержимое вы сможете не только на компьютере или ноутбуке, но и на телефоне.
Сохраните текстовую информацию, как на Айфоне, так и на любом смартфоне с операционной системой Андроид. Для этого вам больше не потребуются специальные программы и приложения. Вам достаточно будет открыть стандартный браузер, скопировать ссылку на сайт и воспользоваться онлайн-сервисом.
«Почему на некоторых сайтах невозможно скопировать и сохранить текст?» – спросите вы. Все дело в том, что правообладатели этих интернет-ресурсов заботятся о сохранении авторских прав на свои статьи, новости и другие информационные материалы и поэтому всяческими способами защищают их от копирования.
Все дело в том, что правообладатели этих интернет-ресурсов заботятся о сохранении авторских прав на свои статьи, новости и другие информационные материалы и поэтому всяческими способами защищают их от копирования.
Ознакомьтесь с простой инструкцией и воспользуйтесь быстрым онлайн-поиском содержимого, чтобы обойти защиту любого web-сайта и скачать не копирующийся текст с его web-страниц. После чего, вам останется выделить нужные строчки и сохранить их в Ворде, блокноте или любом другом текстовом документе.
Скопируйте текст по ссылке на сайт
Скачайте некопируемый текс с любого защищенного от копирования web-ресурса, где не получается выделить его содержимое. Для этого из адресной строки браузера скопируйте URL-ссылку на интернет-страницу сайта. Далее, вставьте гиперссылку в поле ниже и запустите копирование.
Как копировать ссылку на сайт?
Сканирование web-страницы…
Не обновляйте и не покидайте страницу! Идет сканирование содержимого web-ресурса.
Ошибка!
Возможно ссылка указана не верно, а может что-то пошло не так. Повторите сканирование или обратитесь за помощью к специалисту!
Выделите и скопируйте содержимое
В результате сканирования найден текст, который вы можете выделить и сохранить на компьютере или телефоне. Внимательно ознакомьтесь с найденным материалом, пролистав содержимое окна ниже.
Как скопировать текст из окна?
Пожалуйста поддержите работу сервиса, если он оказался вам полезен.
Как скачать некопируемый материал
Копируем ссылку на защищенный web-сайт
Итак, чтобы скопировать защищенный текст вам, в первую очередь, потребуется открыть интернет-страницу сайта, где он содержится. Сделать это вы можете, как через компьютер, так и через телефон. При этом не играет роли iPhone у вас или смартфон с Android. При открытии веб-страницы, в адресной строке вашего браузера появится ссылка. Скопируйте ее, она вам в дальнейшем потребуется для того, чтобы сохранить необходимый материал.
Ищем весь текст на интернет-странице
После того, как ссылка на интернет-ресурс скопирована, вам необходимо будет воспользоваться онлайн-сканером текста. Вставьте адрес web-страницы в поле для ссылки и запустите копирование, нажав на кнопку «Скопировать». В результате этих действий начнется сканирование страницы сайта и поиск всей текстовой информации, содержащейся на ней. Это не займет у вас много времени.
Выделяем и сохраняем содержимое
По завершению сканирования, в специальном окне будет выведен весь текст, найденный на веб-странице сайта. Вам останется совершить последнее действие – это скачать необходимую текстовую информацию себе на ПК или мобильный. Для этого, сначала внимательно ознакомьтесь с содержимым окна. Далее, найдите необходимые строчки текста. После чего, выделите их, скопируйте и сохраните в Ворде, блокноте или любом другом текстовом документе.
Самые популярные вопросы
Почему нельзя скопировать текстовую информацию на сайте?
Если у вас не получается сохранить текст на сайте, то не стоит думать, что это сбой в работе вашего браузера. Возможно вы удивитесь, но это достаточно распространены мера защиты авторских прав. Дело в том, что с помощью такого рода защиты, владелец интернет-ресурса борется с копированием информационных материалов, содержащихся на веб-странице. Чаще всего, за это отвечают специально написанный код, который и не дает вам скопировать содержимое.
Возможно вы удивитесь, но это достаточно распространены мера защиты авторских прав. Дело в том, что с помощью такого рода защиты, владелец интернет-ресурса борется с копированием информационных материалов, содержащихся на веб-странице. Чаще всего, за это отвечают специально написанный код, который и не дает вам скопировать содержимое.
Этот онлайн-сервис позволяет копировать материалы бесплатно?
Да, конечно, с помощью этого онлайн-сервиса вы сможете разблокировать текст не только быстро, но и бесплатно. По статистике скачать некопируемый материал можно на 99% web-ресурсах. При этом, не важно какой у них протокол, HTTP или защищенный HTTPS. Кроме того, сохранить необходимую текстовую информацию вы сможете не только на компьютере, но на любом мобильном устройстве, где есть браузер и выход в Интернет.
Как выгрузить некопируемую информацию на компьютер?
Если сайт не даёт скачать информацию, а вам необходимо сохранить ее у себя на компьютере, то следуйте простой инструкции.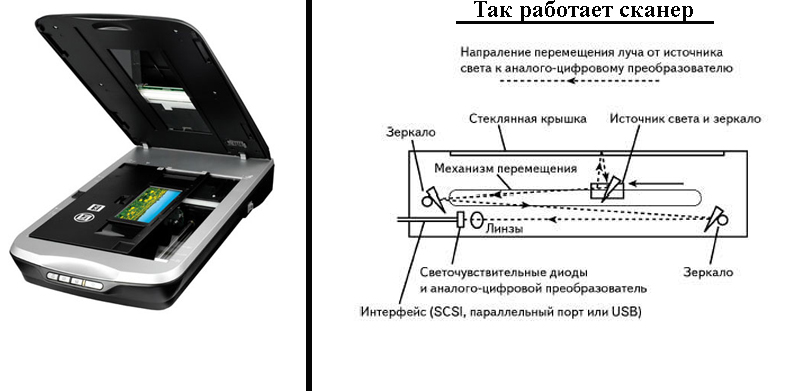 Для этого вам не потребуется устанавливать специальные программы на ваш ПК и дополнительные расширения для браузера. Просто откройте необходимую интернет-страницу, скопируйте ссылку на нее и воспользуйтесь поиском текста.
Для этого вам не потребуется устанавливать специальные программы на ваш ПК и дополнительные расширения для браузера. Просто откройте необходимую интернет-страницу, скопируйте ссылку на нее и воспользуйтесь поиском текста.
Можно ли скачать не копирующийся текст на телефон?
Да, разумеется. Вы можете обойти запрет копирования текста не только на компьютере, но и на любом телефоне. Для того чтобы это сделать, вам не нужно будет устанавливать специальные приложения на ваш смартфон. Обход блокировки защищённого текста на мобильном абсолютно идентично процедуре на ПК. Для этого вам потребуется всего лишь запустить браузер и воспользоваться этим онлайн-сервисом.
Возможно ли сохранить защищённую статью на Айфоне и Андроиде?
Конечно можно! Нет никакой разницы в том через какое устройство вы пытаетесь сохранить некопируемый текст. Будь то iPhone или смартфоне с операционной системой Android. Вам больше не потребуются специальные приложения для этой цели. Скачать заблокированный текст можно абсолютно на любом мобильном устройстве, где есть браузер. Просто скопируйте адрес web-страницы и воспользуйтесь онлайн-поиском для того, чтобы сохранить текст, которой ранее было невозможно копировать.
Просто скопируйте адрес web-страницы и воспользуйтесь онлайн-поиском для того, чтобы сохранить текст, которой ранее было невозможно копировать.
Получится ли скопировать содержимое без фона?
Да, разумеется. Весь найденный текст будет доступен в исходном, стандартном формате. В том виде, если бы вы набирали его в текстовом документе. Все дело в том, что фон, шрифты и другие стили сайта, при копировании текста, сбрасываются до значений по умолчанию. Поэтому при сохранении текстовой информации, например в Ворде, у вас не появится лишнего оформления и случайно скопированного дизайна веб-страницы.
Запрещённые строчки текста можно сохранить в Word?
Да, безусловно. При этом, вам не потребуется самостоятельно искать текстовую информацию в коде. Любой текст, находящийся на веб-странице, вы можете не только разблокировать, но сохранить в Ворде, блокноте или обычном текстовом документе. Для этого вам сначала потребуется воспользоваться онлайн-сканером, а затем выделить и скопировать необходимые строчки текста. После чего нужно будет вставить и сохранить их в текстовом файле.
После чего нужно будет вставить и сохранить их в текстовом файле.
Что будет, если я скопирую статью на чужом web-ресурсе?
Вам стоит знать, что копирование чужих материалов не совсем хорошая идея, если вы хотите выкладывать их на своем сайте. Дело в том, что не только закон, но и поисковики борются за соблюдение авторских прав и крайне негативно относятся к копиям. Поэтому, если вы не хотите, чтобы ваш ресурс был понижен в поисковой выдаче или попал в бан, то вам не следует скачивать чужую информацию и размещать ее на своем ресурсе. Другое дело будет, если вы перепишите скопированные статьи, тем самым сделав их уникальными. В этом случае можно будет не беспокоится за продвигаемый web-сайт и избежать санкций от поисковиков. Если же копирование не подразумевает размещение информации в интернете, то можете не беспокоиться и пользоваться онлайн-сервисом.
Качественная копия сайта делается прямо здесь
Оставьте заявку удобным для вас способом
Выберете удобный для вас способ связи
Вконтакте
Telegram
Эл. почта
почта
Telegram
Если данная ссылка не активна, найдите нас, введя в поле поиска Telegram @sitecopypro
Telegram
Заявка на почту
Выберете удобный для вас способ связи
Закажите шаблон удобным для вас способом
Выберете удобный для вас способ связи
ВконтактеTelegram
Эл. почта
Заявка на почту
Шаблон придёт вам на почту
Заявка отправлена
Ваша заявка отправлена! Ожидайте, в ближайшее время мы ознакомимся с ней. Если вы не хотите ждать, то свяжитесь с нами другим способом.
Помогите сервису
Ваша маленькая финансовая помощь – большой вклад в поддержание работы и в развитии сервиса.
На карту
ЮMoney
Перевод на карту
Перевод можно произвести на номер карты, указанный ниже. Назначение платежа просьба оставить пустым.
Перевод на ЮMoney
Перевод можно произвести на кошелёк ЮMoney, указанный ниже. Назначение платежа просьба оставить пустым.
Номер скопирован
Спасибо вам за то, что решили поддержать сервис!
Заявка отправлена
Ваша заявка отправлена! Ожидайте, в ближайшее время мы ознакомимся с ней. Если вы не хотите ждать, то свяжитесь с нами другим способом.
Помочь скопировать?
Нужна помощь?
Вы самостоятельно хотите скопировать сайт или вам нужна помощь специалиста?
Успехов!
Надеемся на этом сайте вы найдете много полезной информации о том, как скопировать сайт. Если не получится сделать копию, то обращайтесь.
Цены на приложение Text Scan
Цены на приложение Text ScanСканирование текста
ЛОГИН ЗАРЕГИСТРИРОВАТЬСЯ
Оставайтесь продуктивными. Оцифруйте свои знания с помощью лучшего механизма OCR.
Кол. сканов сканов | 5/сутки для посетителей, 10/день для зарегистрированных | неограниченно | неограниченно |
| Скорость | Быстро | Очень быстро (выделенный сервер, низкая нагрузка) | Самый быстрый (больше выделенных серверов, меньше нагрузка) |
| Корректность обнаруженного текста | Достаточно правильно | Наивысшая точность (достигнута с помощью Google Vision OCR) | Наивысшая точность (достигнута с помощью Google Vision OCR) |
| Обнаружение аннотаций | – | ||
| Личные заметки (скоро) | – | ||
| Текстовый поиск (скоро) | – | ||
| Сканирование многостраничных документов | – | – | |
| Полномасштабный преобразователь | – | – | |
| Служба поддержки | Через 24 часа | Приоритет | Прямой |
| Зарегистрироваться | Свяжитесь с нами |
ПРОДУКТ
- Сканер текста
- Возможности приложения
- Цены
КОМПАНИЯ
- О нас
- Связаться с
ЮРИДИЧЕСКАЯ ИНФОРМАЦИЯ
- Политика конфиденциальности
- Условия обслуживания
ПОДПИСЫВАЙТЕСЬ НА НАС
- Твиттер
- Фейсбук
Бесплатный онлайн-сканер OCR — высокая точность (от 95 до 100%), более 100 языков
Самый точный онлайн-сканер OCR, распознает символы на изображении с высокой точностью (от 95% до 100%).

Поддерживает более 100 языков
Если у вас возникнут какие-либо проблемы с онлайн-инструментом OCR, напишите нам по электронной почте.
Процесс использования Online OCR Now
Шаг 1
Загрузка изображений
Шаг 1
Язык и формат
Выберите язык, используемый в вашем документе.
Шаг 1
Конвертировать и скачать
Нажмите кнопку “Конвертировать” и загрузите файл с распознанным текстом.
Часто задаваемые вопросы
1 Какова функция OCR?
OCR используется для преобразования практически любых изображений, содержащих письменный текст, напечатанный, написанный от руки или напечатанный, в машиночитаемые текстовые данные.
2 Является ли OCR машинным обучением?
Да, OCR почти всегда реализуется с помощью машинного обучения.
3 В чем разница между OCR и ICR?
OCR более удобен, поэтому, если ваша офисная работа связана с цифровыми или бумажными копиями, OCR может быть предпочтительным инструментом. С другой стороны, ICR (интеллектуальное распознавание символов) специализируется на преобразовании многих типов рукописных символов в цифровые функции. Поэтому при обработке рукописных или рукописных заметок требуется интеллектуальное распознавание символов.
4 Безопасен ли онлайн-сканер OCR?
Всегда есть опасения при использовании онлайн-сервисов, особенно бесплатных онлайн-сканеров OCR, которые обрабатывают конфиденциальную информацию. Безопасно ли использовать? К счастью, да. Во-первых, OCR преобразует только текст из изображений, что означает, что оно не влияет на ваши документы или ваш компьютер. Пожалуйста, не беспокойтесь, что это испортит данные в ваших документах.
Сами по себе эти службы не хранят вашу информацию. Переведенный текст хранится в отдельном файле, а не в самой программе онлайн-сканирования OCR. Это означает, что ваша информация недоступна.
Переведенный текст хранится в отдельном файле, а не в самой программе онлайн-сканирования OCR. Это означает, что ваша информация недоступна.
Распознанные языки
Online OCR Теперь поддерживает более 100 языков.
| Африкаанс | Эстонский |
| Албанский | Финский |
| Амхарский | французский |
| Арабский | Галисийский |
| Ассамский | Грузинский |
| Азербайджанский | Грузинский – Старый |
| Азербайджанский – Кириллица | немецкий |
| Басков | Немецкий фрактур |
| Белорусский | Греческий |
| Бенгальский | Гуджарати |
| боснийский | гаитянский; Гаитянский креольский |
| Болгарский | Иврит |
| Бирманский | Хинди |
| каталонский; Валенсия | Венгерский |
| Себуано | Исландский |
| Чероки | Индонезийский |
| Китайский — упрощенный | Инуктитут |
| Китайский — традиционный | итальянский |
| Хорватский | Итальянский – Старый |
| Чехия | ирландский |
| Датский | японский |
| Голландский; Фламандский | яванский |
| Дзонгка | Каннада |
| Английский | Казахский |
| Эсперанто | кхмерский; Центральный кхмерский |
| Киргизский; Киргизский | сингальский; сингальский |
| Корейский | Словацкий |
| Курдский | Словенский |
| Лаос | испанский; кастильский |
| Литовский | испанский; Кастильский – Старый |
| Латинский | Суахили |
| латышский | Шведский |
| Македонский | сирийский |
| малайский | Тагальский |
| Малаялам | Таджикский |
| Мальтийский | Тамильский |
| маратхи | Телугу |
| Непальский | тайский |
| Норвежский | Тибетский |
| Ория | Тигриня |
| Пенджаби; Пенджаби | Турецкий |
| персидский | уйгурский; уйгурский |
| польский | Украинский |
| Португальский | урду |
| Пушту; Пушту | узбекский |
| румынский; Молдавский | Узбекский – Кириллица |
| Русский | вьетнамский |
| Санскрит | валлийский |
| Сербский | Идиш |
| Сербский – Латинский |
Что такое OCR?
Оптическое распознавание символов (OCR) объясняет метод электронного или механического преобразования отсканированных изображений из печатного текста в машинно-кодированный текст. Думайте об этом как о процессе преобразования аналоговых и цифровых данных. Используя этот программный инструмент, вы можете быстро преобразовать отсканированные документы в текстовые файлы с возможностью поиска.
Думайте об этом как о процессе преобразования аналоговых и цифровых данных. Используя этот программный инструмент, вы можете быстро преобразовать отсканированные документы в текстовые файлы с возможностью поиска.
В настоящее время спрос на отсканированные документы неуклонно растет, поскольку их можно легко просмотреть при необходимости. Отсканированные документы также могут быть легко переданы через электронные носители. Чего OCR не делает, так это не учитывает фактическую природу сканируемого объекта. Он просто «видит» символы, которые вы хотите преобразовать в числовой формат. Например, когда вы сканируете слово, вы выучите и узнаете буквы, но не сможете определить значение слова.
Функции онлайн-распознавания текста Теперь
Эффективное преобразование изображения в текст
Online OCR Now — один из лучших инструментов для преобразования изображений в редактируемый текст без дополнительной работы. Вы просто выбираете изображение, и этот инструмент может эффективно распознавать несколько форматов и конвертировать быстро, легко и эффективно. Он поддерживает такие форматы, как JPG, JPEG, PNG и BMP.
Он поддерживает такие форматы, как JPG, JPEG, PNG и BMP.Быстрый и высокоточный
Одной из основных проблем ввода данных является точность. Инструменты автоматического ввода данных, такие как OCR, могут обеспечить быстрый и эффективный ввод данных. Online OCR Now — один из самых точных OCR-сканеров, способный распознавать символы на изображении с 9Точность от 5% до 100%.Простой в использовании и дружественный интерфейс
Online OCR Now имеет простой интерфейс и может даже преобразовать любое слово в изображение. Файлы могут быть извлечены и отредактированы в любое время, что выгодно большинству поддерживающих предприятий, отраслей и предприятий. Например, вы можете использовать технологию OCR, чтобы легко просматривать старые квитанции, записи, кредитную историю и другие документы.Изменить текст
После сканирования документа с помощью OCR онлайн вы можете отредактировать текст с помощью предпочитаемой вами программы текстового процессора.
Доступность
Программное обеспечение для оптического распознавания текста в Интернете — это удобный и удобный инструмент. Пользователи с нарушениями зрения могут сканировать входящие факсы, книги, журналы или другие документы в программу обработки текстов для использования вместе с голосовой утилитой компьютера.Простой в использовании и дружественный интерфейс
Online OCR Now имеет простой интерфейс и может даже преобразовать любое слово в изображение. Файлы могут быть извлечены и отредактированы в любое время, что выгодно большинству поддерживающих предприятий, отраслей и предприятий. Например, вы можете использовать технологию OCR, чтобы легко просматривать старые квитанции, записи, кредитную историю и другие документы.Изменить текст
После сканирования документа с помощью OCR онлайн вы можете отредактировать текст с помощью предпочитаемой вами программы текстового процессора.Доступность
Программное обеспечение для оптического распознавания текста в Интернете — это удобный и удобный инструмент. Пользователи с нарушениями зрения могут сканировать входящие факсы, книги, журналы или другие документы в программу обработки текстов для использования вместе с голосовой утилитой компьютера.
Пользователи с нарушениями зрения могут сканировать входящие факсы, книги, журналы или другие документы в программу обработки текстов для использования вместе с голосовой утилитой компьютера.Эффективное преобразование изображения в текст
Online OCR Now — один из лучших инструментов для преобразования изображений в редактируемый текст без дополнительной работы. Вы просто выбираете изображение, и этот инструмент может эффективно распознавать несколько форматов и конвертировать быстро, легко и эффективно. Он поддерживает такие форматы, как JPG, JPEG, PNG и BMP.Быстрота и высокая точность
Одной из основных проблем ввода данных является точность. Инструменты автоматического ввода данных, такие как OCR, могут обеспечить быстрый и эффективный ввод данных. Online OCR Now — один из самых точных OCR-сканеров, способный распознавать символы на изображении с точностью от 95% до 100%.Как работает
оптическое распознавание символов?
Давайте рассмотрим три основных этапа оптического распознавания символов: предварительная обработка изображения, распознавание символов и постобработка вывода.

Предварительная обработка изображения в OCR
Программное обеспечение OCR обычно предварительно обрабатывает изображения, чтобы увеличить шансы на успешное распознавание. Цель предварительной обработки — улучшить фактические данные изображения. Таким образом подавляются нежелательные искажения и улучшаются некоторые характеристики изображения. Эти два процесса важны на следующих этапах.Распознавание символов в OCR
Чтобы эффективно распознавать символы, важно понимать, что такое «извлечение признаков». Если входные данные слишком велики для обработки, будет выбрано лишь небольшое количество функций. Функции являются важными, но подозреваемые избыточные функции будут проигнорированы.
Использование меньшего набора данных вместо первого более обширного набора данных позволяет повысить производительность. Это важно для процесса оптического распознавания символов, поскольку алгоритм должен обнаруживать определенную часть или форму отсканированного изображения.
Распознавание символов в OCR
Чтобы эффективно распознавать символы, важно понимать, что такое «извлечение признаков». Если входные данные слишком велики для обработки, будет выбрано лишь небольшое количество функций. Функции являются важными, но подозреваемые избыточные функции будут проигнорированы.
Использование меньшего набора данных вместо первого более обширного набора данных позволяет повысить производительность. Это важно для процесса оптического распознавания символов, поскольку алгоритм должен обнаруживать определенную часть или форму отсканированного изображения.
Постобработка в OCR
Постобработка — еще одна технология исправления ошибок, которая может обеспечить высокую точность оптического распознавания символов. Если словарь ограничивает вывод, точность может быть дополнительно улучшена. Таким образом, алгоритм может вернуться к списку слов, отображаемому в отсканированном документе. Чтобы лучше обрабатывать различные типы входных данных OCR, некоторые поставщики начали разрабатывать системы OCR, которые более эффективно обрабатывают определенные типы входных данных.