
5 лучших онлайн-инструментов для преобразования фотографий в текстовые файлы – Print Peppermint
Онлайн-инструменты OCR сегодня являются замечательным дополнением к арсеналу любого писателя. Итак, как и какие из них использовать в 2022 году?
Преобразование фотографий в редактируемые тексты — замечательное дополнение к любой деловой или писательской заначке. Эти инструменты могут облегчить жизнь, преобразовывая изображения в редактируемые тексты для будущего использования и т. д.
Согласно информации эксперты, именно благодаря этому преимуществу эта технология станет еще более известной в 2022 году. Вот почему это императив и необходимая технология для использования почти всеми. Почему?
- Писателям это нужно
- Бизнесу это нужно
- Маркетологи это обожают
- Студенты приветствуют это как спасательный круг
- Академии используют его для хранения данных
Это лишь часть преимуществ инструментов OCR, которые мы подробно обсудим чуть позже. Но если вы используете инструменты OCR Google, вы получите столько же результатов, как это:
Но если вы используете инструменты OCR Google, вы получите столько же результатов, как это:
Это слишком много. Итак, как выбрать тот, который подходит вам лучше всего? Или какие из них лучше всего подходят для OCR? Давайте покопаемся и узнаем:
Как работает распознавание текста?OCR имеет различные элементы, которые работают вместе для получения конечного результата. Вот почему крайне важно понять, как все это работает. Это почему? Потому что тогда это может помочь вам понять, как выбрать хороший инструмент, о чем мы немного поговорим.
Итак, вот три основных элемента инструмента OCR:
СканированиеРаздел сканирования инструмента OCR может помочь вам понять, насколько он хорош. Например, этот инструмент сообщает вам, что он делает, как он это делает:
Этот инструмент сканирует его таким образом, а затем представляет вам текст позже. Таким образом, можно с уверенностью сказать, что он будет использовать технологии IWR, OCR или ICR, которые мы также немного объясним.
НЛП или естественный язык обработки является критической практикой в сегодняшнем инструменте для письма или сканирования. Это помогает машинам читать человеческие языки, то есть наши языки, такие как английский, испанский и так далее. Это язык, который преобразует отсканированный текст обратно в язык, на котором был отсканирован документ.
Редактируемый текстПоследним шагом любого инструмента OCR является предоставление вам редактируемого текста. Например:
Это тот же инструмент, который мы использовали ранее. Как видите, текст выделен курсором, что указывает на то, что теперь он доступен для редактирования. Это последний раздел, который вы увидите в любом инструменте OCR. В этой части, как указано выше, у вас будут варианты:
- Копирование вручную
- Копирование в буфер обмена
- Сохранение как документ
- Сохраненные документы, скорее всего, имеют формат TXT или DOCX.
Итак, вот как работает инструмент OCR и извлекает текст из изображений. Затем он может сохранить извлеченный текст по своему вкусу. Однако большинство инструментов предлагают только два формата, т. е. TXT или DOCX.
Затем он может сохранить извлеченный текст по своему вкусу. Однако большинство инструментов предлагают только два формата, т. е. TXT или DOCX.
Инструменты OCR сегодня имеют в себе все необходимые элементы. Некоторые извлекают текст из изображений, другие извлекают его из PDF-файлов, а некоторые предпочитают и то, и другое. Однако все эти инструменты используют различные технологии для выполнения таких задач.
Вот фоновая технология, используемая такими инструментами OCR:
ИВР и ИКРIWR или интеллектуальное распознавание слов — это элемент OCR с энтузиазмом AI, который извлекает текст как из рукописных, так и из машинописных текстов или документов. Это основная технология, которую сегодня используют большинство OCR-инструментов.
Младшим братом этой технологии является ICR, или интеллектуальное распознавание слов. Этот инструмент поглощает содержимое рукописей, идентифицируя каждый из символов, присутствующих на изображении или бумаге.
Обе эти технологии сегодня являются основным ядром любого OCR-инструмента, поскольку они извлекают тексты, написанные машинами и людьми.
ОМР и ООРOMR, также известное как оптическое распознавание меток, сегодня является одним из основных устройств любого OCR-инструмента. Эта технология идентифицирует знаки или фигуры в тексте, т. е. математические уравнения, знаки препинания и т. д.
OWR, с другой стороны, представляет собой оптическое распознавание слов и является расширением самого OCR. Однако вместо идентификации символов он распознает слова, написанные на изображении или бумаге.
Стандарт выбора инструмента OCRКак выбрать инструмент OCR? Это не ракетостроение, или нет? Инструмент OCR предоставляет вам множество возможностей, но некоторые инструменты OCR не предоставляются бесплатно. Более того, если вы хотите сканировать несколько изображений, вам нужно знать, позволяет ли это инструмент.
Более того, что, если инструмент вообще не позволяет сканировать изображения? Что, если он идеально подходит для PDF или других документов в стиле буклетов? Это все жизнеспособные вопросы и стандарт, который мы использовали для составления этого списка. Итак, вот четыре важные вещи, которые следует учитывать:
Итак, вот четыре важные вещи, которые следует учитывать:
Если инструмент платный, стоит ли его использовать? Если вы студент, вы не можете позволить себе инструмент для сканирования 100 изображений в месяц. С другой стороны, если вы занимаетесь бизнесом, вы не можете платить сотни долларов за инструмент, позволяющий сканировать несколько изображений в месяц. Вот почему бесплатное использование было главным приоритетом при выборе этих инструментов.
Количество изображений, отсканированных за разНекоторые инструменты позволяют сканировать по одному изображению за раз, в то время как другие могут сканировать до 5, 10 или даже 50 за раз. Вот почему приоритетом при выборе этих инструментов было найти что-то, что позволяет одновременно обрабатывать как можно больше — без ущерба для качества отсканированных изображений.
Качество извлеченного текстаКак упоминалось выше, снижение качества извлеченного текста означает, что использование такого инструмента недопустимо; даже из самых размытых изображений инструменты, которые мы выбрали, эффективно извлекали изображения. Вот почему эти инструменты будут лучшими, которые вы можете использовать сегодня.
Вот почему эти инструменты будут лучшими, которые вы можете использовать сегодня.
Как упоминалось выше, не все инструменты могут извлекать текст из размытых или неровных изображений. Эти инструменты имеют возможность сделать именно это. Таким образом, независимо от типа изображений, которые вы извлекаете, вы можете использовать их все соответствующим образом.
5 лучших онлайн-инструментов для преобразования фотографий в текстовые файлы в 2022 годуУ нас есть информация по OCR, мы знаем, как это работает, а также информация по выбору таких инструментов. Поэтому, без дальнейших проволочек, давайте прямо сейчас и поговорим о 5 лучших онлайн-инструментах для преобразования фотографий в текстовые файлы в 2022 году:
Prepostseo.com Конвертер изображений в текст — лучший в целомВ PrePostSEO есть множество инструментов для писателей, маркетологов, предприятий. Таким образом, само собой разумеется, что их конвертер изображений в текст возглавляет этот список как лучший инструмент, доступный сегодня. Он имеет простой UI<, как показано здесь:
Таким образом, само собой разумеется, что их конвертер изображений в текст возглавляет этот список как лучший инструмент, доступный сегодня. Он имеет простой UI<, как показано здесь:
Кроме того, инструмент не предлагает каких-либо особых сложностей, т.е. нежелательных проверок по капче и т. д. Вам нужно только перетащить файл в редактор для сканирования изображений. Затем подтвердите, что вы не робот, например:
На этом этапе ваше изображение готово к извлечению, и инструменту не потребуется много времени, чтобы скопировать из него текст. Вскоре вы увидите свой редактируемый текст, например:
Инструмент молниеносно извлекает текст из изображений, как показано здесь. Кроме того, вы можете скопировать текст или извлечь текст в виде файла TXT или DOCX.
Ключевая особенность:- Перетаскивания
- Поддержка Google Диска
- вставка URL
- Быстрее, чем любой другой инструмент, доступный сегодня
- Просмотр или импорт файлов
- В бесплатной версии много рекламы
 Информация – Легко и удобно
Информация – Легко и удобно ImageToText.Info использует самые передовые элементы IWR и ICR, и это очевидно в его инструменте. Когда вы открываете веб-сайт, вас приветствует упрощенный дизайн пользовательского интерфейса, такой как этот:
Цветовые оттенки и все остальное в этом инструменте приятны для глаз. Итак, если вы работаете допоздна, этот инструмент идеально вам подойдет. Он поддерживает ту же опцию перетаскивания, или вы можете найти изображение, из которого хотите извлечь контент.
Как только вы это сделаете, изображение будет загружено, и вам нужно еще раз подтвердить, что вы не робот. После этого инструменту требуется всего 10 секунд, чтобы извлечь текст даже из самых длинных изображений. Вот что вы видите дальше:
Вы можете либо скопировать содержимое в буфер обмена, либо сохранить его как документ. Или вы можете пойти еще раз, если у вас есть больше документов для сканирования. Этот жизнеспособный https://hotcanadianpharmacy.com/ инструмент предлагает больше, чем несколько подходов, по крайней мере. Поэтому он идеально подходит для простого и быстрого использования.
Поэтому он идеально подходит для простого и быстрого использования.
- Привлекательный интерфейс
- Идеально подходит для использования в одном изображении
- Дизайн приятный для глаз
- Никто до сих пор
FreeOnline.OCR или OCR.best — замечательный инструмент для писателей, маркетологов и предприятий. Это также один из первых инструментов в этом списке, который поддерживает Dropbox. Дизайн инструмента выглядит прямо как на постмодернистской съемочной площадке, как показано здесь:
И снова мы видим те же основы, что и в предыдущих инструментах. Тем не менее, этот делает его лучше, так как он уделяет внимание деталям. Как только вы загрузите изображение, вы увидите красивую анимацию:
Затем инструмент показывает вам прогресс, который действительно трудно зафиксировать, потому что инструмент делает это очень быстро:
Он изменяется от 1% до 100% за одно мгновение, так что спасибо, что сделали этот снимок экрана. Затем вы получаете извлеченный текст в такой форме:
Затем вы получаете извлеченный текст в такой форме:
Еще раз, инструмент предлагает вам скачать файл в виде файла doc или txt. Это делает этот инструмент идеальным компаньоном для пользователей, которые хотят быстро извлекать текст.
Ключевая особенность:- Быстрое извлечение
- Простой в использовании интерфейс
- Извлечение с энтузиазмом ИИ
- Тщательно использует IWR
- Спортивный простой и привлекательный пользовательский интерфейс
- Привлекательный пользовательский интерфейс может замедлить работу на некоторых компьютерах.
OCR SodaPDF Online идеально подходит для извлечения изображений или PDF-файлов. Этот инструмент отлично подходит для таких применений, как копирование текста из более длинных форматов, таких как PDF или отсканированные документы. Вот что вы видите при посещении сайта:
Вот что вы видите при посещении сайта:
Хотя инструмент отдает приоритет файлам PDF, он также может сканировать изображения. Когда вы выберете один, вот что вы увидите дальше:
Затем требуется менее нескольких секунд, прежде чем вы увидите редактируемый текст.
Ключевая особенность:- Надежный конвертер PDF
- Легко конвертирует большие файлы PDF
- Поддерживает изображения тоже
- Иногда может глючить
Бесплатный онлайн-сканер OCR от DocSumo подойдет вам, если вы хотите извлечь текст из сложных изображений и сделать это быстро. Вот как выглядит инструмент:
Как только вы передаете изображение инструменту, он показывает вам таймер перед извлечением текста, например:
Это очень удобно, так как говорит вам, что это займет много времени.
Вы видите эту опцию после того, как текст вашего файла был извлечен. Нажав на «Копировать ссылку» и открыв ее, вы увидите следующее:
Текст представлен в онлайн-редакторе. Что делает его очень удобным инструментом для быстрого использования и редактирования.
Ключевая особенность:- Встроенный редактор
- Таймер
- Позволяет редактировать или загружать текст
- Замечательный пользовательский интерфейс
- Никто до сих пор
Все, кому нужны изображения для текста, могут и должны использовать инструменты OCR. Однако каждый конкретный аспект жизни сегодня требует того или иного типа редактируемого текста. Поэтому, чтобы помочь вам понять эту идею, вот четыре типа людей, которые должны использовать инструменты OCR:
КомпанииОдним из основных преимуществ использования OCR для бизнеса сегодня является то, что оно может помочь им повысить эффективность работы. Сотрудникам, у которых есть все необходимые инструменты для создания контента, OCR может помочь повысить моральный дух.
Сотрудникам, у которых есть все необходимые инструменты для создания контента, OCR может помочь повысить моральный дух.
Это избавляет от ненужной бумажной работы и улучшает доступ к критически важным элементам, таким как онлайн-хранилище и виртуальные центры обработки данных. Это упрощает автоматизацию данных и повышает эффективность на мили.
МаркетологиМаркетологам нужно быстрое и удобное создание контента. Для этого они, как правило, используют изображения или рукописи других видов. Вот когда OCR пригодится, так как он предоставляет им редактируемый текст для маркетинговых целей.
СтудентыСтуденты, пожалуй, получают больше всего преимуществ от использования OCR. Это может позволить им улучшить качество обучения и помочь им быстро и эффективно создавать контент. Более того, OCR делает использование текста из книг и других учебных материалов еще проще.
Профессиональные писателиПрофессиональные писатели, например, специалисты по поисковой оптимизации или онлайн-маркетингу, могут в значительной степени использовать инструмент OCR. От использования недоступных данных до извлечения информации из маловероятных рукописей возможности для профессионала безграничны.
От использования недоступных данных до извлечения информации из маловероятных рукописей возможности для профессионала безграничны.
Итак, у вас есть пять лучших инструментов, которые вы можете использовать сегодня, и то, как они могут принести пользу каждому из следующих аспектов жизни. Поэтому выберите инструмент, который предлагает то преимущество, которое вы ищете, и извлекайте текст по своему усмотрению.
Как определить монтаж на фото :: Разоблачаем фейки, фотошоп и ретушь :: Блог Вастрик.ру
В 1855 году пионер портретной фотографии Оскар Рейландер сфотографировал себя несколько раз и наложил негативы друг на друга при печати. Получившееся двойное селфи считается первым фотомонтажом в истории. Наверное лайков тогда собрал, уух…
Теперь же каждый подросток с фотошопом, смартфоном и интернетом сможет даже лучше. Правда чаще всего эти коллажи неимоверно доставляют. А вот профессионалы научились скрывать свою работу весьма качественно. Это был вызов.
Это был вызов.
Совокупность методов анализа модифицированных изображений назвали Image Forensics, что можно перевести как «криминалистика изображений». В интернете существует куча сервисов, заявляющих, что они за два клика помогут определить подлинность фото. Особенно доставляют самые тупые, которые идут смотреть EXIF и если там нет оригинальных метаданных камеры начинают громко вопить «вероятно фото было модифицировано». И про них даже в New York Times пишут (а про тебя нет).
Я пересмотрел около десятка сервисов и остановился на одном: Forensically. В нём реализовано большинство описанных в статье алгоритмов, я буду часто на него ссылаться. Все описанные методы названы оригинальными английскими названиями, чтобы не было путаницы.
Однако возможность загрузить свою фотку в какой-то сервис и посмотреть на красивые шумы не сделает из вас сыщика. Поначалу может быть трудно и непонятно, а первые эксперименты точно окажутся неудачными. У меня так же было. Тут как в спорте — нужен намётанный глаз и опыт как должно и не должно быть. Умение не просто смотреть на шумные картинки, а видеть еле заметные искажения в них.
У меня так же было. Тут как в спорте — нужен намётанный глаз и опыт как должно и не должно быть. Умение не просто смотреть на шумные картинки, а видеть еле заметные искажения в них.
Не существует 100% метода, позволяющего определить фейк. Но есть человеческие ошибки.
Найдет самые глупые косяки
Главный инструмент — наши глаза. Так что первым делом стоит открыть фото в любимом графическом редакторе или просмотрщике, поставить зум в 1000% внимательно втыкать в предположительное место монтажа. С этого начинается любой анализ. Чем более неопытный монтажер попался — тем проще будет найти косяки, артефакты и склейки. Иногда фейки настолько кривые, что можно нагуглить оригинал используя поиск по изображениям или заметив несоответствия в EXIF.
 Хотя по другим параметрам фейк сделан вполне неплохо.
Хотя по другим параметрам фейк сделан вполне неплохо.Помимо этого, в любом уважающем себя редакторе есть инструменты для цветокоррекции. В Preview.app на маке они спрятаны в меню Tools > Adjust Color… Вытягивание различных ползунков поможет лучше разглядеть детали.
Brightness and contrast.
Color adjustment. Увеличивая насыщенность или яркость разных цветов, можно заметить неестественные переливы и границы склейки.
Иногда фейк палится игрой с уровнями и контрастомInvert. Часто помогает увидеть скрытую информацию в однотонных объектах.
Sharpen and blur. Добавление резкости поможет прочитать надписи на табличках, есть целые сервисы, которые могут побороть заблюренные области.
Normalization and histograms.
Даже если определить фейковость сразу не удалось, у вас уже могли появиться полезные наблюдения, чтобы перейти к следующим методам с страшными математическими названиями.
Найдет свежую кисть, деформацию, клонирование и вставку чужеродных частей
Реальные фотографии полны шума. От матрицы камеры или фотосканера, от алгоритмов сжатия или по естественным природным причинам. Графические редакторы же этот шум не создают, их инструменты живут в «идеальном мире», потому чаще всего «размазывают» шум оригинального изображения. Кроме того, два изображения чаще всего обладают разной степенью зашумленности.
Заметить шум глазом не так-то просто, но можно взять любой инструмент Noise Reduction и инвертировать его действие, оставив от фотографии только шум. Хорошо работает для свежеобработанных изображений и в случаях, когда автор решил, что нашел очень подходящие на вид изображения. Но легко обманывается, если знать как.
Хорошо работает для свежеобработанных изображений и в случаях, когда автор решил, что нашел очень подходящие на вид изображения. Но легко обманывается, если знать как.
Поиграть самому можно здесь.
Добавить своего шума. Самый очевидный вариант. Хочешь скрыть свои косяки — навали на фото столько шума, чтобы забить оригинальный.
Пережать JPEG. Уменьшение качества изображение в два раза делает шумы неразличимыми (вот исследование).
</div>
Найдет свежие артефакты наложения изображений или текста
Каждый раз при сохранении картинки ваш редактор заново прогоняет её через кучу преобразований — конвертирует цвета, делит на блоки, усредняет значения пикселей, и. т.д. Он занимается этим даже если вы выбрали 100% качество при сохранении, так уж устроен алгоритм JPEG. Интересующиеся могут почитать про него глубокую статью полную косинусных преобразований.
т.д. Он занимается этим даже если вы выбрали 100% качество при сохранении, так уж устроен алгоритм JPEG. Интересующиеся могут почитать про него глубокую статью полную косинусных преобразований.
Так как JPEG — формат сжатия с потерями, то при каждом сохранении растет количество математических усреднений, ошибок или более популярный термин — «артефактов». Два сохранения с 90% сжатием примерно эквивалентно одному с 81% по количеству этих самых артефактов. На практике это может принести пользу. Даже если зоркий глаз не видит разницы между 80% и 85% сжатием, то наверное есть инструменты, которые наглядно покажут это различие? Да, Error Level Analysis или ELA.
Фейки с наложениями чаще всего делают подыскав нужные изображения где-нибудь в гугле. Вероятность, что найденные изображения будут с одинаковым уровнем артефактов, ну, крайне мала. Социальные сети или даже специализированные хранилища фотографий всё равно пережимают изображения под себя при загрузке, чтобы не платить за хранение гигабайтов ваших селфи из отпуска.
Простота и известность делает ELA самым популярным методом работы мамкиных интернет-сыщиков, от чего его начинают пихать везде, где только могут. Как будто других методов просто не существует и ELA может объяснить всё. Тот же Bellingcat использует его чуть ли не в каждом втором своём расследовании. Хотелось немного остудить пыл всех услышавших новую умную аббревиатуру.
ELA — не панацея. Сфотографируйте летящую чайку на фоне ровного синего неба (ага, особенно в Москве), сохраните её в jpg и прогоните через анализатор ошибок. Результат покажет просто огромное количество артефактов на чайке и их полное отсутствие на фоне, из чего начинающие сразу сделают вывод — чайка прифотошоплена. Да что там начинающие, сама команда Bellingcat с этим бывало глупо и по-детски наёбывалась. Алгоритм JPEG достаточно чисто работает на ровных цветовых областях и градиентах, и куда больше ошибается на резких переходах — отсюда такой результат, а не из-за ваших домыслов.
Да что там начинающие, сама команда Bellingcat с этим бывало глупо и по-детски наёбывалась. Алгоритм JPEG достаточно чисто работает на ровных цветовых областях и градиентах, и куда больше ошибается на резких переходах — отсюда такой результат, а не из-за ваших домыслов.
Из-за растущей популярности Error Level Analysis я уже слышал призывы запретить и не принимать его всерьез. Не буду столь категоричен, лишь посоветую не бежать писать разоблачения, если ELA показал вам какие-то шумы на краях. ОН НЕ ТАК РАБОТАЕТ. Думайте головой и помните как JPEG устроен внутри. Вот если ELA очертил четкий квадрат там, где его не должно быть, либо заметил разительную разницу в шумах при неотличимости на глаз — наверное стоит задуматься. Не уверены — проверяйте другими методами.
Поиграть с ELA можно тут.
Много раз пересохранить. Все свои манипуляции алгоритм JPEG делает внутри блоков максимум 8×8 пикселей. В теории нужно 64 раза пересохранить изображение, чтобы уровни ошибок стали неотличимы друг от друга. На практике же это происходит гораздо раньше, достаточно пересохранить картинку раз 10 и ELA, да и некоторые другие методы, больше не увидят ничего полезного.
Изменить размер. Чтобы не напрягаться с пересохранением можно поступить еще проще — отресайзить изображение на какой-нибудь коэффициент не кратный степени двойки. То есть в 2 раза (50%) уменьшить не подойдет, а вот что-нибудь типа на 83% — уже всё, никакой ELA больше не поможет.
Смонтировать из одного источника или из lossless-формата. Вы сфотографировали двух людей на свой фотоаппарат, или скачали фотографии из какого-нибудь блога, где автор скорее всего пересохранял их всего раз-два. Либо наложили друг на друга две PNG’шки. Во всех этих случаях ELA не покажет ничего интересного.
</div>
Найдет ретушь, компьютерную графику, хромакей, Liquify, Blur
В жизни свет никогда не падает на объекты абсолютно равномерно. Области ближе к источнику всегда ярче, дальше — темнее. Никакого расизма, только физика. Если разбить изображения на небольшие блоки, скажем 3×3 пикселя, то внутри каждого можно будет заметить переход от более темных пикселей к светлым. Примерно так:
Разбив картинку на блоки 3×3 можно нарисовать примерное направление к источнику светаНаправление этого перехода так и называется — градиент освещенности. Можно попробовать нарисовать кучу маленьких стрелочек на изображении и понаблюдать за их направлением.
На первом изображении свет падает сверху и стрелочки направлены хаотически — это характеризует рассеянный свет. Второе изображение — компьютерная графика, на ней свет падает слишком идеально, никаких шумов и отклонений как на настоящем фото. Третье изображение — фотография с резким переходом, в центре стрелочки массово смотрят в самую яркую сторону, а на фоне — рассеяны так же, как на первом фото.
Рисовать стрелочки хоть и наглядно, но мы физически не сможем изобразить все градиенты освещенности для каждого блока поверх картинки. Стрелочки займут всё изображение и мы не увидим ничего. Потому для большей наглядности придумали не рисовать их, а использовать цветовое кодирование. Для направления вектора понадобится две координаты, и еще одна для его длины — а у нас как раз есть для этого три цветовых компоненты — R, G, B. В итоге получатся вот такие карты освещенности.
Вместо стрелочек наглянее изобразить направление света с помощью цветового кодирования. Некоторые вещи становятся нагляднее: например на компьютерной графике (по центру) видны четкие границы объектов и целые плоскости ровной освещенности. На реальных фото такого не бывает.
Некоторые вещи становятся нагляднее: например на компьютерной графике (по центру) видны четкие границы объектов и целые плоскости ровной освещенности. На реальных фото такого не бывает.В реальной жизни нас окружает ограниченное число источников света. В помещении это лампы, вспышки, окна. В ясный день на улице чаще всего источник света только один — это Иисус, спаситель наш солнце. Если на карте освещенности находящиеся рядом объекты сильно отличаются по направлению падения света — у нас есть главный кандидат на монтаж.
Но еще лучше карты освещенности справляются с определением ретуши. Surface Blur, Liquify, Clone Stamp и другие любимые инструменты фотографов начинают светиться на картах освещенности как урановые ломы тихой весенней ночью. Нагляднее всего выглядит анализ фотографий из журналов или рекламных плакатов — там ретушеры не жалеют блюра и морфинга, а это непаханное поле для практики.
Нагляднее всего выглядит анализ фотографий из журналов или рекламных плакатов — там ретушеры не жалеют блюра и морфинга, а это непаханное поле для практики.
Лично я считаю карты освещенности одним из самых полезных методов, потому что он чаще всего срабатывает и мало кто знает как его обмануть. Поиграться можно здесь.
Не знаю. Говорят помогает изменение яркости и насыщенности цветов по отдельности, но на бытовых фотографиях такие вещи всегда будут заметны глазу. Если вы знаете простой и действующий метод — расскажите в комментах под этим абзацем, всем будет интересно.
</div>
 Палится Liquify на обоих руках модели, замазанная какуля на плече, ремень нарисован почти заново, а вся кожа лица и рук подверглась сильному блюру. Силуэт на стене передаёт привет ретушеру и фотографу — кто-то косячит со светом 🙂
Палится Liquify на обоих руках модели, замазанная какуля на плече, ремень нарисован почти заново, а вся кожа лица и рук подверглась сильному блюру. Силуэт на стене передаёт привет ретушеру и фотографу — кто-то косячит со светом 🙂Найдет копипаст, вытягивание и несоотвествие цветов, Healing Brush, Clone Stamp
Метод PCA или на русском «метод главных компонент». Чтобы ко мне не придрались, мол, слишком просто всё рассказываешь и наверное не шаришь, вот описание PCA для рептилоидов.
Метод главных компонент осуществляет переход к новой системе координат y1,…,ур в исходном пространстве признаков x1,…,xp которая является системой ортонормированных линейных комбинаций. Линейные комбинации выбираются таким образом, что среди всех возможных линейных нормированных комбинаций исходных признаков первая главная компонента обладает наибольшей дисперсией. Геометрически это выглядит как ориентация новой координатной оси у1 вдоль направления наибольшей вытянутости эллипсоида рассеивания объектов исследуемой выборки в пространстве признаков x1,. ..,xp. Вторая главная компонента имеет наибольшую дисперсию среди всех оставшихся линейных преобразований, некоррелированных с первой главной компонентой. Она интерпретируется как направление наибольшей вытянутости эллипсоида рассеивания, перпендикулярное первой главной компоненте. Следующие главные компоненты определяются по аналогичной схеме.
..,xp. Вторая главная компонента имеет наибольшую дисперсию среди всех оставшихся линейных преобразований, некоррелированных с первой главной компонентой. Она интерпретируется как направление наибольшей вытянутости эллипсоида рассеивания, перпендикулярное первой главной компоненте. Следующие главные компоненты определяются по аналогичной схеме.
А теперь для людей: представьте, что цветовые компоненты R, G и B мы взяли как оси координат — каждая от 0 до 255. И на этом трехмерном графике точками отметили все пиксели, которые есть на нашем изображении. Получится что-то похожее на картинку ниже.
Линия вдоль и поперек колбасятины и есть главные компоненты этой колбасятиныМожно заметить, что наши пиксели не рассосались по графику равномерно, а вытянулись в округлую колбасятину. Все реальные изображения так устроены, потому что science, bitches. Теперь мы можем построить новые оси — вдоль колбасятины (это самая главная) и две поперек — это и будут те самые «главные компоненты». Для каждого изображения набор цветов будет разным, колбасятина и главные компоненты будут направлены по-своему.
Так что вся эта математика нам дает? Дело в том, что если какие-то цвета на изображении стоят «не на своих местах» — они будут сильно выделяться из этого облака пикселей, то есть на карте PCA начнут светиться ярким белым цветом. Это может означать локальную цветокоррекцию или же полную вклейку. Диаграммы PCA может построить тот же Forensically. На них будет изображено расстояние от каждого пикселя картинки до плоскости 1, 2 и 3 главной компоненты. Так как расстояние — это число, то изображения будут черно-белыми.
PCA против Healing Brush. На фотографии действительно была замазана муха и даже несмотря на пережаты JPEG это место ярко видно на диаграмме.Но еще более полезным свойством PCA является то, что он превращает JPEG-артефакты в очень заметные «квадраты». Даже если вы обманули ELA из предыдущего пункта пережатиями и ресайзом, то PCA этим не проведешь — он работает с цветом. Иногда артефакты сразу видно, например если исходное изображение увеличивали для вклейки. В других случаях сматриваться придется чуть более внимательно, чтобы заметить разницу в квадратах на изображении.
Как видно из примеров, PCA не очень наглядный и требует ну уж очень сильно присматриваться к таким мелким косякам, которые вполне могут оказаться случайностями. Потому PCA редко используется в одиночку, его применяют как дополнение к другим.
Самому поиграться можно здесь.
Заблюрить. Любой блюр смазывает соседние цвета и делает «колбасятину» более округлой. Хороший блюр сильно затруднит исследование по методу PCA.
Еще хитрее изменить размер. Хотя PCA и более устойчив к изменение размеров изображения, говорят можно попробовать подобрать такой процент, чтобы обмануть даже его.
</div>

Найдет различия в резкости, отклонения в фокусе, ресайз
Дискретное вейвлет-преобразование очень чувствительно к резкости объектов в кадре. Если фотографии сняты на разные объективы, использовался зум или просто немного отличалась точка фокусировки — после DWT эти отличия будут намного виднее. То же самое произойдет, если у какого-то объекта в кадре изменяли размер — резкость таких частей будет заметно ниже.
Без лишних погружений в теорию сигналов, вейвлет — это такая простенькая волнушка, как на картинке ниже.
Их придумали лет 100 назад, чтобы приблизительно описывать аналоговые сигналы. Одну большую длинную волну представляли набором мелких вейвлетов, тогда некоторые её характеристики внезапно становилось проще анализировать, да и места чтобы хранить надо было меньше. На вейвлет-сжатии например был построен формат JPEG-2000, который к нашему времени (к счастью) сдох.
Картинка — это тоже двухмерный сигнал из цветных пикселей, а значит её можно разложить на вейвлеты. Для достаточно точного приближения изображения 800×600 требуется до 480000 вейвлетов на цветовой канал. Если уменьшать это количество — будет сильно падать резкость и цветопередача. Но что это даёт, кроме сжатия?
Для достаточно точного приближения изображения 800×600 требуется до 480000 вейвлетов на цветовой канал. Если уменьшать это количество — будет сильно падать резкость и цветопередача. Но что это даёт, кроме сжатия?
А вот что: вейвлеты приближают области с разной резкостью по-разному. Чем плавнее переходы — тем проще плавному по своей природе вейвлету его воспроизвести, а чтобы приблизить резкий переход — надо больше вейвлетов. Это как пытаться сделать из кучи шариков идеальный куб.
Вейвлет-сжатие на динозаврах. Верхняя левая — оригинал. На правой использовался лишь 1% вейвлетов. Критические цвета, как черный и белый, очень сложно передать таким количеством. Левый нижний — 5% вейвлетов, средний динозавр становится более резким, чем уменьшенный (он четкий на 3%) и увеличенный (он на 8%). Больше 10% ставить не имеет смысла, вейвлеты начинают приближать цвета, а не резкость. Последняя картинка тому доказательство, на ней использовано 20% вейвлетов.Если части изображения были смонтированы с изначально разной резкостью — это можно будет заметить. Увеличили картинку — проиграли в резкости, уменьшили — наоборот всё стало слишком резким. Даже если взять две фотографии снятые на камеру с автофокусом из одной точки — они будут отличаться по резкости из-за погрешности автофокуса. DWT устойчив даже перед блюром, ведь редакторы ничего не знают про резкость исходных частей изображения.
Увеличили картинку — проиграли в резкости, уменьшили — наоборот всё стало слишком резким. Даже если взять две фотографии снятые на камеру с автофокусом из одной точки — они будут отличаться по резкости из-за погрешности автофокуса. DWT устойчив даже перед блюром, ведь редакторы ничего не знают про резкость исходных частей изображения.
На практике полезно рассматривать приближения с помощью 1%, 3% или 5% вейвлетов. На этом количестве перепады в резкости становятся достаточно заметны глазу, как видно на примере одного из участников соревнования по фотомонтажу, который не определяется другими методами, но заметен при вейвлет-преобразовании.
Фотошоп с Клинтон с одного из контестов по монтажу, который не палится большинством методов. Приненив 5% вейвлет-преобразование можно заметить небольшую разницу в резкости: торс становится резким, а лицо всё еще размытым. Объектив камеры не мог дать такого сильного смещения плоскости фокуса, так что скорее всего лицо не отсюда.Сделать фотографии с одной точки, одним объективом с фиксированным фокусом и сразу обработать в RAW. Редкие студийные условия, но всё может быть. Сколько вон лет разбирали всякие видео с Усамой Бен-Ладеном, целые книги писали.
Редкие студийные условия, но всё может быть. Сколько вон лет разбирали всякие видео с Усамой Бен-Ладеном, целые книги писали.
Изображение очень маленькое. Чем меньше изображение — тем сложнее его анализировать вейвлетами. Картинки меньше 200х200 пикселей можно даже не пытаться прогонять через DWT.
Погружаясь в тему Image Forensics начинаешь понимать, что любой из методов можно обмануть. Одни легко обходятся с помощью пережатых до 10 шакалов JPEG’ов, другие цветокоррекцией, блюром, ресайзом или поворотом изображения на произвольные углы. Оцифровка журнала или TV-сигнала тоже добавляет ошибок в исходник, усложняя анализ. И тут вы начинаете понимать:
Вполне возможно отфотошопить изображение так, что никто не докажет обратное. Но для этого надо не быть глупеньким.
Зная эти методы, можно скрыть монтаж настолько, чтобы потом сказать в стиле пресс-секретаря президента: «эти картинки — лишь домыслы ангажированной кучки людей, мы не видим на них ничего нового». И такое вполне вероятно.
И такое вполне вероятно.
Но это не значит, что занятие полностью бесполезно. Здесь как в криптографии: пока те, кто делает фейки не знают матчасти так же глубоко — сила на стороне знаний, математики и анализа.
Приглашаю экспертов высказаться в комментарии. При подготовке поста я написал нескольким разбирающимся в теме профессионалам в лички, но ответа до сих пор не получил.
_Ну а чтобы стимулировать новые посты, подпишитесь на рассылку или пошарьте этот пост у себя. Специльно сделал удобные кнопочки чуть ниже. Так я буду видеть, что всё это хоть кому-то интересно.
Терминология онлайн-изображений, которую нужно знать • Дастин Стаут
Что такое мем ? Как произносится gif ? Что считается инфографикой ? В чем разница между gif и синемаграфом ?
Поскольку мы начинаем погружаться в сложный мир обмена изображениями в Интернете, я подумал, что важно сначала пройтись по онлайн-терминологии изображений . Я хочу, чтобы мы могли общаться более эффективно или, по крайней мере, иметь точку отсчета, когда мы говорим о различных типах изображений, которыми делятся в Интернете. Это сделает наши разговоры более эффективными, и вы будете звучать как супер-сообразительная онлайн-рок-звезда, которой вы и являетесь.
Я хочу, чтобы мы могли общаться более эффективно или, по крайней мере, иметь точку отсчета, когда мы говорим о различных типах изображений, которыми делятся в Интернете. Это сделает наши разговоры более эффективными, и вы будете звучать как супер-сообразительная онлайн-рок-звезда, которой вы и являетесь.
Думайте об этом посте как о своем официальном терминологическом онлайн-словаре изображений . (Скажите это в пять раз быстрее!)
Существует множество различных типов и форматов онлайн-изображений . Ниже я определил наиболее часто используемые форматы и даже ввел пару новых слов, которые помогают классифицировать типы изображений, которым еще предстоит найти свое собственное имя.
Это часть моей серии основных руководств по обмену изображениями в Интернете. Остальные посты из этой серии вы можете посмотреть здесь.
Фото
Наиболее распространенным типом изображения является классическое фото. Это статичное (неподвижное) изображение, снятое камерой. Он не разработан художником-графиком с нуля — это реальный захват из реального мира. Возможно, над ним была проделана некоторая работа, чтобы его украсить, но предмет взят через объектив камеры.
Он не разработан художником-графиком с нуля — это реальный захват из реального мира. Возможно, над ним была проделана некоторая работа, чтобы его украсить, но предмет взят через объектив камеры.
Например:
Держитесь, ребята, мы должны начать с основ!
Gif
GIF (произносится как JIF , марка арахисового масла (не то, что в «подарке» без буквы «т») — это формат изображения, который позволяет использовать анимацию. Это дает возможность создавать «движущиеся» изображения, которые воспроизводятся в бесконечном цикле. (из Википедии) GIF может быть статичным, но этот формат чаще всего используется для создания анимации.
Например:
Анимированные GIF-файлы, кажется, довольно популярны и, как правило, получают много репостов в социальных сетях, когда они юмористические. [Изображение предоставлено SBNation]
И, чтобы было ясно, правильный способ произносить GIF — мягкий звук «г». Как в джин , жираф и генерал .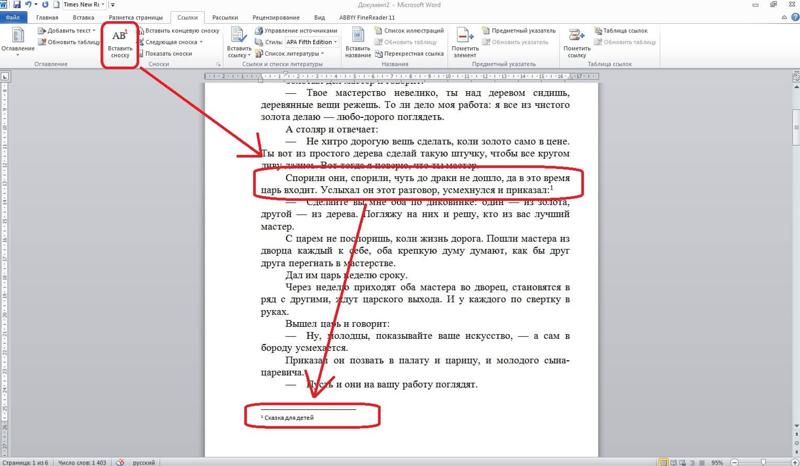
Синемаграф
Синемаграф — это неподвижные фотографии, на которых происходит незначительное и повторяющееся движение. Синемаграфы, которые обычно публикуются в анимированном формате gif, могут создать иллюзию того, что зритель смотрит видео. (из Википедии)
Например:
Это как модная форма гифок. Великие могут быть совершенно очаровательными или действительно жуткими, как этот:
[Изображение предоставлено Cinemagraphs.com]
Селфи
Селфи — это тип фотографии автопортрета, обычно сделанный с помощью ручной цифровой камеры или телефона с камерой. Это также одно из самых часто используемых слов в 2013 году.
В большинстве случаев при съемке селфи принято делать странное, похожее на утку выражение лица, однако отсутствие такого выражения лица не дисквалифицирует его как селфи.
Например:
Заметьте, я воздержался от утиной морды. Я отказываюсь.
Мем
мем [mēm] (существительное) юмористическое изображение, видео, фрагмент текста и т.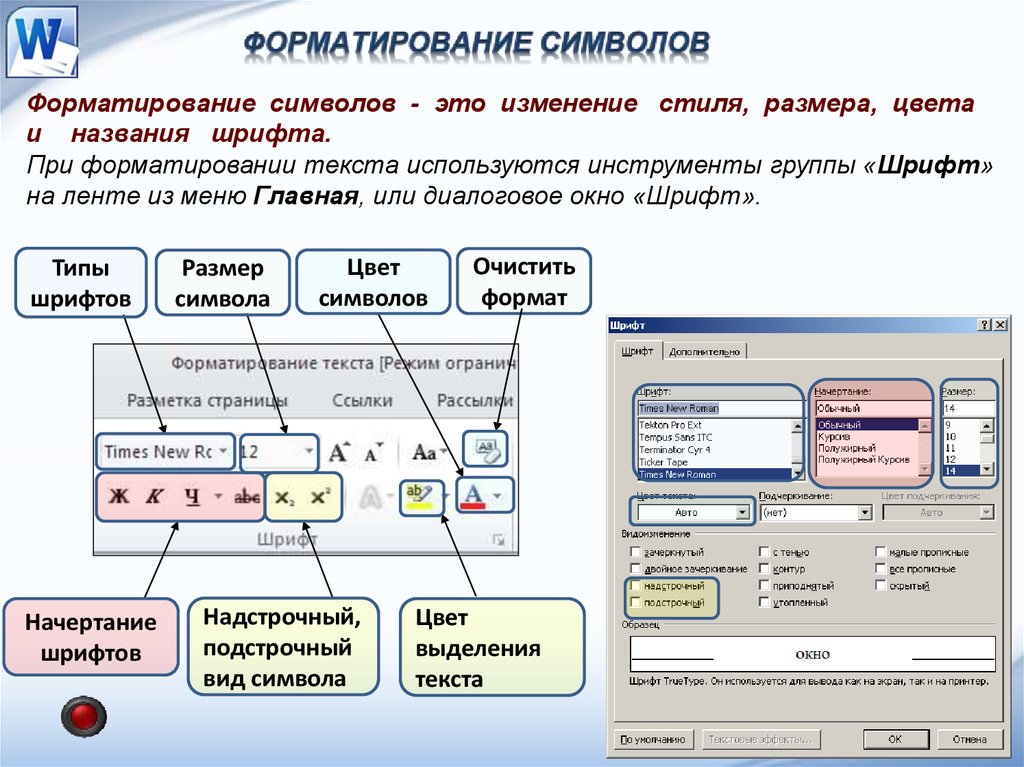 д., которые копируются (часто с небольшими вариациями) и быстро распространяются пользователями Интернета. (Как определено Google.)
д., которые копируются (часто с небольшими вариациями) и быстро распространяются пользователями Интернета. (Как определено Google.)
Для наших целей мы сосредоточимся на приложении «изображение». Мем чаще всего можно узнать по большой белой текстовой подписи поверх изображения, которое должно быть юмористическим.
Например:
А если вы хотите попробовать создать свой собственный, на SoVisual.co есть целая категория шаблонов мемов, которые безумно легко настроить.
Инфографика
инфографика [инфографик] (существительное) визуальное изображение, такое как диаграмма или диаграмма, используемая для представления информации или данных. (Как определено Google.)
Теперь я часто вижу, как люди ссылаются на любой тип графики со словами на ней как на инфографику. Я не думаю, что это точное представление о том, какой должна быть инфографика. На мой взгляд, инфографика — это любое графическое изображение, которое визуально передает несколько точек данных.
Например:
Инфографика — один из лучших способов передачи интересных данных таким образом, чтобы людям действительно нравилось читать. Ими можно поделиться (особенно на Pinterest), и при правильном подходе они могут стать одной из лучших форм контент-маркетинга.
Да, и, кстати, это одно из моих любимых занятий. Не стесняйтесь обращаться ко мне здесь, чтобы узнать больше.
Инфограмма
Инфограмма — это совершенно новая или краткая часть инфографики, которая работает как отдельный элемент контента. (определено NeoMam)
Например:
Это отличный способ перепрофилировать инфографику для разных носителей, которые могут не поддерживать очень длинные [высокие] изображения. Он может служить в качестве моментального снимка (или Заголовок Графика ) или как часть слайд-шоу.
Графика заголовка, графика заголовка, тематическое изображение, главное изображение
Для каждого сообщения в блоге я создаю один из этих типов изображений. Разные люди называют их по-разному, и для всех целей и задач каждое из перечисленных выше имен отлично работает.
Разные люди называют их по-разному, и для всех целей и задач каждое из перечисленных выше имен отлично работает.
Эти изображения созданы с явной целью стать визуальным заголовком для публикации в блоге, статьи или веб-страницы.
Например:
[Прокрутите страницу назад и посмотрите, что я сделал для этого сообщения.]
Это отличный способ привлечь внимание к сообщению в социальной сети, которое продвигает блог. после. Визуальные эффекты вызовут гораздо больше вовлеченности и кликов, чем просто отдельный текстовый пост. Я провел серьезное тестирование этого в Google+ и обнаружил, что обмен изображениями всегда приводит к большему взаимодействию.
Графика с цитатами
Графика с цитатами — это безумно популярные и широко распространяемые изображения, которые вы видите в потоках Google+, Facebook и Pinterest. Проще говоря, это цитата, созданная как изображение.
Например:
Хотя кажется, что Интернет наводнен изображениями такого типа, те, которые сделаны хорошо, могут очень быстро получить широкую известность.
Вот и все.
Итак, теперь, когда мы разобрались с базовой терминологией онлайн-изображений, мы можем приступить к разбору деталей, касающихся легальности обмена, курирования, создания, оптимальных размеров и отсутствия всасывания. Оставайтесь с нами для следующей части серии Essential Guide to Sharing Images Online.
А пока, какие форматы я упустил? Вы бы добавили/убрали что-нибудь из приведенных выше определений?
Как написать описание изображения | Алекс Чен
Я написал это практическое руководство, опираясь на чрезвычайно полезные советы и идеи от Бекс Леон и Робин Фаннинг, а также на основе онлайн-опроса слепых/слабовидящих/слабовидящих людей.
Темно-фиолетовый текст с надписью «Объект — действие — контекст» на светло-фиолетовом фоне.Описание изображения — это письменная подпись, описывающая основную информацию изображения.
Описания изображений могут определять фотографии, графику, гифки и видео — практически все, что содержит визуальную информацию. Предоставление описаний для изображений и видео требуется как часть WCAG 2.1 (для соответствия цифровым требованиям ADA).
Предоставление описаний для изображений и видео требуется как часть WCAG 2.1 (для соответствия цифровым требованиям ADA).
Иногда его называют замещающим текстом, поскольку атрибут alt является обычным местом для их хранения. Атрибут alt отображается в HTML-коде следующим образом:
Хотя замещающий текст и описание изображения иногда используются как синонимы, на самом деле это не одно и то же. Альтернативный текст относится к тексту, специально добавленному к атрибуту alt, и часто является коротким и лаконичным. Описание изображения можно найти в замещающем тексте, подписи или основной части веб-страницы, и оно часто бывает более подробным. Чтобы узнать больше об альтернативном тексте и описаниях изображений, посетите @higher_priestess в Instagram.
Кроме того, описания изображений — это жест заботы и важная часть доступности. Без них контент был бы полностью недоступен для слепых/слабовидящих людей. Описывая изображения, мы демонстрируем поддержку солидарности между людьми с инвалидностью и движениями.
Описывая изображения, мы демонстрируем поддержку солидарности между людьми с инвалидностью и движениями.
Объект-действие-контекст
Кое-что, что я узнал из разговора с Бекс, это то, что в написании описаний есть аспект повествования. Не обязательно имеет смысл идти слева направо, описывая все на изображении, потому что это может привести к потере основного сообщения или создать чувство дезориентации. По этой причине я придумал структуру, которую рекомендую, под названием object-action-context .
Объект находится в центре внимания. Действие описывает, что происходит, обычно то, что делает объект. Контекст описывает окружающую среду.
Я рекомендую этот формат, поскольку он сохраняет описание объективным, кратким и описательным .
Это должно быть объективное , чтобы люди, использующие описание, могли составить собственное мнение о том, что означает изображение. Он должен быть кратким , чтобы людям не потребовалось слишком много времени, чтобы усвоить весь контент, особенно если есть несколько изображений. А должно быть описательный достаточно, чтобы описать все основные аспекты изображения.
Он должен быть кратким , чтобы людям не потребовалось слишком много времени, чтобы усвоить весь контент, особенно если есть несколько изображений. А должно быть описательный достаточно, чтобы описать все основные аспекты изображения.
То, что считается «необходимым», иногда может быть субъективным. В моем исследовании некоторые люди предпочитали очень краткие описания, в то время как другие предпочитали большое количество визуальных деталей (например, Робин и Бекс). Мой лучший совет в этой области — быть настолько описательным, насколько это необходимо вашей аудитории. Вы лучше всех знаете свою аудиторию и свой контент. Если ваша работа очень наглядна и ваша аудитория заинтересована, добавьте больше деталей. Если вы и ваша аудитория больше заботитесь о невизуальном контенте, оставьте его на более короткой стороне.
Пример:
Описание: Знак Black Lives Matter держат в толпе.
Объект: Знак Black Lives Matter
Действие: на руках
Контекст: в толпе
Мы можем добавить больше деталей к этому описанию, чтобы нарисовать более яркую картину. В большинстве случаев я рекомендую добавлять детали в формате объект-действие-контекст. Это делает описание более кратким.
В большинстве случаев я рекомендую добавлять детали в формате объект-действие-контекст. Это делает описание более кратким.
Краткий способ добавить детали: Раскрашенный картонный плакат Black Lives Matter анонимно держат в размытой толпе перед каменным зданием.
Избыточный способ добавить детали: Знак Black Lives Matter держится в толпе. За ними каменное здание. Толпа размыта. Знак нарисован на картоне. Лицо, держащее знак, анонимно.
Вы можете видеть, что избыточный пример повторяет много слов и перескакивает с одного на другое, что делает его более длинным и дезориентирующим. Формат объект-действие-контекст помогает зафиксировать основное внимание, а затем медленно расширяется, чтобы получить полную картину.
Однако иногда деталей так много, что добавление их приводит к созданию одного длинного предложения. В этом случае лучше сделать первое предложение коротким и в формате объект-действие-контекст. Таким образом, люди могут получить общее представление и пропустить остальные детали, если захотят.
Пример:
Описание: Татуированный человек с табличкой «Учите своих детей хорошо» в толпе людей. В середине знака есть изображение земли с двумя поднятыми кулаками с каждой стороны, на фоне которых изображен радужный квадратный фон, фон в виде круга транс-прайда и полосы коричневого оттенка кожи на кулаках.
Объект: человек
Действие: держит табличку
Контекст: толпа
Чтобы быть еще более наглядным, вы можете углубиться в смысл визуальных образов. Здесь описания изображений также полезны для зрячих людей, потому что они дают дополнительное объяснение вещам, которые в противном случае могли бы быть неочевидными.
Пример добавления значения: Поднятый кулак является символом солидарности и особенно силы черных, популяризированной партией Черных пантер в 1960-е годы. Радужный флаг гордости имеет радужные полосы и символизирует общую гордость ЛГБТК. Флаг транс-гордости имеет розовые, синие и белые полосы и прославляет гордость за трансгендерный и гендерно-неконформный зонтик.
Флаг транс-гордости имеет розовые, синие и белые полосы и прославляет гордость за трансгендерный и гендерно-неконформный зонтик.
Это, очевидно, более длительное обязательство и может не понадобиться, если вы написали другой контент в соседней статье или если вы предпочитаете приберечь свою энергию от объяснений и побуждать людей искать это самостоятельно. И, очевидно, если вы решите объяснить символизм, обязательно проведите надлежащее исследование.
(обновление за апрель 2021 г.)
Цифровые изображения не просто существуют в вакууме, они имеют окружающий контекст в любом приложении или на веб-сайте, где они находятся. Мы часто сталкиваемся с изображениями, когда читаем новости, пролистываем страницы друзей в социальных сетях, совершаем покупки в Интернете и т. д.
Пример:
Описание: собака сидит в поле с осенними листьями
Для изображения на новостная статья, это описание работает достаточно хорошо. Это объективно, лаконично и описательно, но в то же время довольно кратко.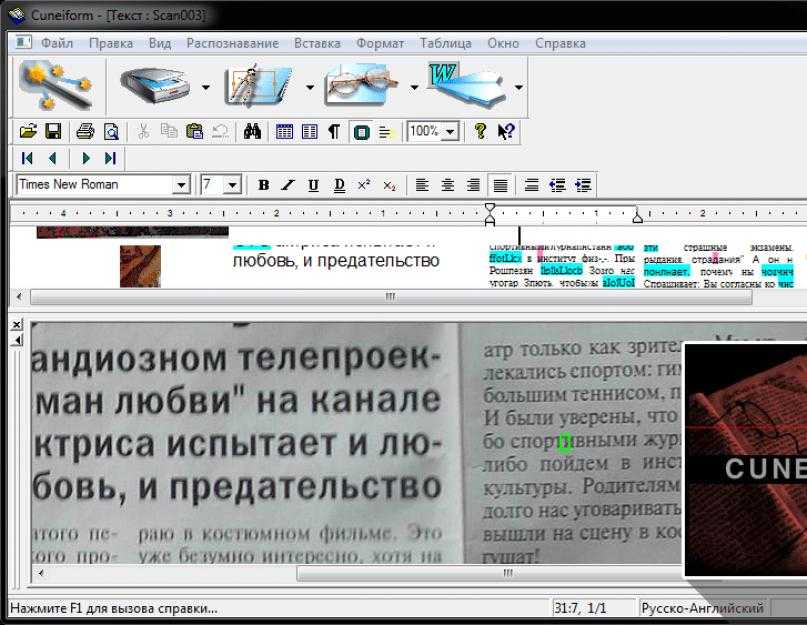 Однако, если фотография находится на веб-сайте собаководов, на котором есть изображения нескольких разных пород собак, на самом деле она не несет много полезной информации (особенно если в каждом описании указано просто «собака»). По этой причине я бы включил породу и больше визуальных описаний собаки.
Однако, если фотография находится на веб-сайте собаководов, на котором есть изображения нескольких разных пород собак, на самом деле она не несет много полезной информации (особенно если в каждом описании указано просто «собака»). По этой причине я бы включил породу и больше визуальных описаний собаки.
Описание веб-сайта собаковода: светло-коричневая собака породы питбуль с черным носом и короткими заостренными ушами
Если я художник, который сфотографировал собаку и хочет продемонстрировать свои навыки и вызвать эмоции, я г, вероятно, хотите добавить более подробные описания. Это, конечно, субъективно, в зависимости от того, какой я художник и как я хочу, чтобы публика восприняла мою работу.
Описание сайта автора: фото светло-коричневой собаки с короткими ушами и высунутым розовым языком, сидящей в поле осенних листьев. Собака в фокусе, а солнечный свет отражается от светло-оранжевых и желтых листьев, сливаясь с фоном.
Если изображение находится на сайте или в приложении с несколькими сотнями изображений, например, для учебника по зоотехнике или приложения для карточек, то лучше оптимизировать его для быстрого и простого сканирования содержимого. Возможно, в этом контексте будет достаточно «собака в поле» или даже просто «собака».
Возможно, в этом контексте будет достаточно «собака в поле» или даже просто «собака».
Этот раздел является новым и активно развивается. Если у вас есть дополнительные мысли о том, как контекст влияет на описания изображений, не стесняйтесь обращаться к нам! (Контактная информация внизу.)
В общем, я рекомендую указывать расу и пол, если (1) это имеет отношение к изображению, (2) если вы знаете, кто они, и (3) если вы его описание согласуется с другими описаниями.
Это релевантно , если это важная часть сообщения — например, шутка конкретно об идентичности или прославление радикальной заметности маргинализированных людей. известно , если люди на фото подтвердили свою личность. Это соответствует , если вы описываете все расы, а не только цветных людей (предполагая, что белый по умолчанию).
Например, проект стоковых фотографий Disabled and Here создал библиотеку специально для инвалидов BIPOC (черных и цветных людей из числа коренного населения). Они также любезно предоставили описания изображений! Это пример описания релевантной, известной и последовательной идентичности.
Они также любезно предоставили описания изображений! Это пример описания релевантной, известной и последовательной идентичности.
Описание: Три чернокожих и инвалида (небинарный человек с тростью, женщина, сидящая в инвалидной коляске с электроприводом, и женщина, сидящая в кресле) частично улыбаются в камеру, в то время как радужный флаг прайда задрапирован на стена за ними.
Другие большие и разнообразные библиотеки фотографий включают The Gender Spectrum, Nappy и CreateHer Stock.
Во многих ситуациях упоминание расы или пола может вообще не иметь значения. И хотя может показаться заманчивым называть людей «женщинами» или «мужчинами», существует риск ошибочного определения их пола. На самом деле лучше говорить «человек» или «люди» и говорить о физических характеристиках более буквально, чем присваивать пол каждой презентации (например, говорить «человек с длинными волосами» вместо «женщина» или «человек, представляющий женщину»).
Пример:
Описание: Четыре человека сидят на скамейке у тротуара, большинство в темных очках и на каблуках, а один с большой коричневой собакой, в городе в солнечный день.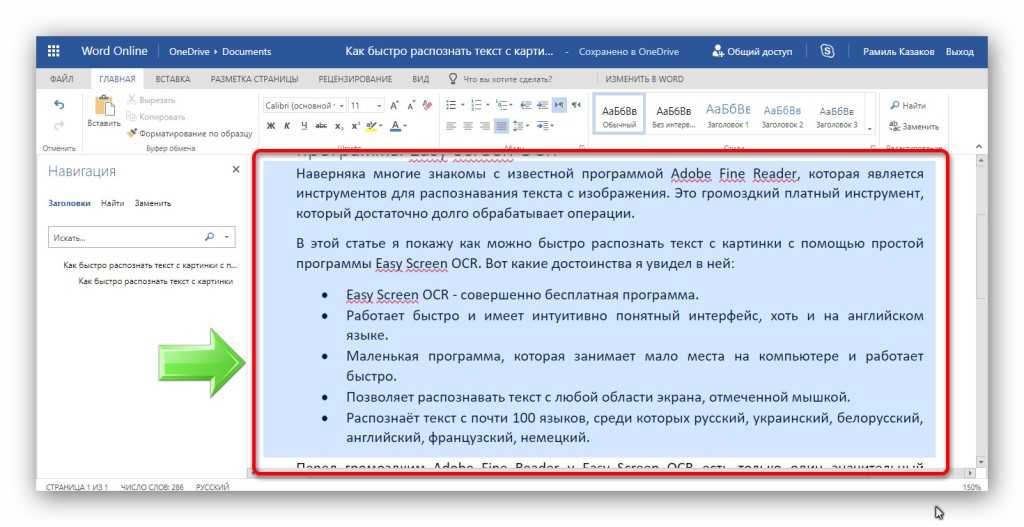
Имейте в виду, что эта статья написана небинарным человеком! Из-за того, что я испытал так много мисгендеринга, я склонен избегать гендерных различий в большинстве своих описаний. Тем не менее, я понимаю, что это не каждый опыт, и есть много ситуаций, когда гендерная принадлежность людей важна для видимости и репрезентации. По этой причине я призываю вас писать таким образом, который кажется вам наиболее искренним, и в то же время уважать других.
Если вы описываете диаграммы, инфографику или диаграммы более сложной сложности, я рекомендую разделить их на разделы и сосредоточиться на одном разделе за раз в логическом порядке.
Пример:
Описание: Графика с названием «Безопасный протест» вверху лиловым текстом на темно-фиолетовом фоне. Он состоит из 3 разделов: «Что надеть», «Что брать с собой» и «Не брать с собой», все с графическими иллюстрациями. В светло-фиолетовом разделе «Что надеть» написано: «невзрачная, однотонная, многослойная одежда; закройте идентификационные татуировки, очки и маску, запишите контакты для экстренных случаев, термостойкие перчатки и завяжите волосы». В средне-фиолетовом разделе «Что взять с собой» написано: «вода для питья и слезоточивый газ, закуски, наличные/сдача и удостоверение личности, мочалка, бинты и средства первой помощи, беруши и знаки протеста. В светло-красном разделе «Не брать с собой» говорится: «Мобильный телефон без предварительного отключения Face/Touch ID, перехода в режим полета и отключения данных, ювелирных изделий, всего, с чем вы не хотите, чтобы вас арестовали, и контактные линзы.”
В средне-фиолетовом разделе «Что взять с собой» написано: «вода для питья и слезоточивый газ, закуски, наличные/сдача и удостоверение личности, мочалка, бинты и средства первой помощи, беруши и знаки протеста. В светло-красном разделе «Не брать с собой» говорится: «Мобильный телефон без предварительного отключения Face/Touch ID, перехода в режим полета и отключения данных, ювелирных изделий, всего, с чем вы не хотите, чтобы вас арестовали, и контактные линзы.”
Я предпочитаю не вдаваться в подробности описания визуальных эффектов, если текст по существу уже описывает их и если описание уже довольно длинное. В данном случае целью изображения определенно является передача информации, поэтому я чувствовал, что описание графики будет отвлекать.
Поскольку изображения представляют собой просто набор пикселей и векторов, текст недоступен программам чтения с экрана (иногда программы чтения с экрана могут считывать текст, но это непостоянно). Убедитесь, что расшифруйте весь текст на изображении, если вы предоставляете описание.
Следует помнить о некоторых ограничениях программы чтения с экрана. Обязательно напишите хэштеги в заголовке #ForExampleLikeThis, чтобы программы чтения с экрана могли расшифровывать отдельные слова. Кроме того, избегает всех заглавных букв , потому что программы чтения с экрана иногда интерпретируют эти буквы по одной.
В настоящее время большинство социальных сетей предлагают альтернативный текст. Из того, что я слышал от сообщества, на самом деле лучше поместите описание в заголовок вместо этого. Таким образом, его также увидят пользователи экранной лупы и зрячие люди, которым может понадобиться описание или извлечь из него пользу. (На самом деле мне неясно, должны ли мы также добавлять полное описание или сокращенную версию в тег alt, если мы добавляем заголовок. Если у вас есть мысли или идеи по этому поводу, пожалуйста, обращайтесь! Контактная информация внизу).
Если вы описываете что-то, что требует определенных знаний в предметной области, полезно добавьте краткое пояснение для дополнительного контекста.