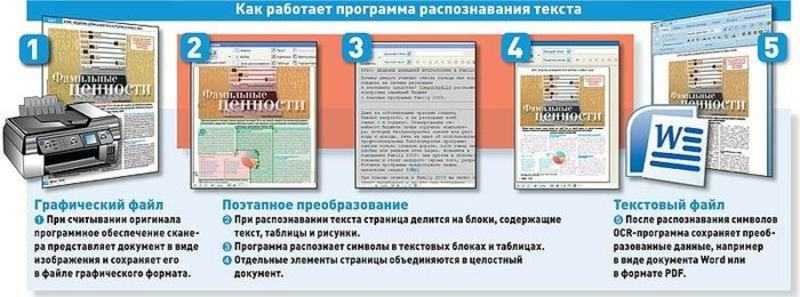
Системы перевода и распознавания текста кратко
4.2
Средняя оценка: 4.2
Всего получено оценок: 173.
4.2
Средняя оценка: 4.2
Всего получено оценок: 173.
Основные приемы работы с текстом заключаются не только в создании, редактировании и оформлении текстового материала, которые реализуют текстовые редакторы. Существует ряд специальных приложений, автоматизирующих действия по обработке текстов. Кратко о системах перевода и распознавания текста можно прочитать в данной статье.
Что такое системы перевода и распознавания текста
Для упрощения работы с текстом разработчики программного обеспечения создали специальные приложения, позволяющие автоматизировать ввод больших объемов текстовых данных. Также текст большими объемами можно не только вводить, но и переводить. Для автоматизации процессов работы с текстом используются системы перевода и распознавания текста.
Системы распознавания текста
Вводить информацию в компьютер можно не только с клавиатуры, но и с помощью специального устройства – сканера.
Процесс распознавания происходит так. Программа анализирует полученное изображение, выделяя в нем текстовые, табличные и графические области. Затем строки в текстовых блоках разбиваются на отдельные слова, слова – разбиваются на символы. И затем каждый символ сравнивается с имеющимся в базе изображением букв, цифр или специальных символов. Найдя оптимальный вариант, программа выдает его пользователю в виде распознанного текста.
Самым популярным программным продуктом, выполняющим распознавание текста, является Fine Reader от компании ABBYY.
Компания ABBYY на современном рынке программных продуктов является лидером мирового масштаба в разработке программных решений, использующих технологию распознавания документов. Более 1000 компаний в 150 странах сотрудничают с ABBYY, включая таких мировых лидеров, как Fujitsu, Panasonic, Microsoft, Sharp, Samsung, Xerox.
Более 1000 компаний в 150 странах сотрудничают с ABBYY, включая таких мировых лидеров, как Fujitsu, Panasonic, Microsoft, Sharp, Samsung, Xerox.
Приложение Fine Reader конвертирует изображения в электронные редактируемые форматы. В качестве графических объектов могут быть фотографии, PDF-файлы, а также полученные в результате сканирования копии бумажных документов. После преобразования результаты можно сохранить в форматах приложений Microsoft Word, Excel, Powerpoint, а также в текстовом формате RTF и в формате разметки гипертекста HTML. Самые новые версии этого программного продукта позволяют сохранять результаты распознавания в формате DJVU.
Достоинством данного программного продукта является распознавание более чем на 190, а также встроенная проверка орфографии.
Рис. 2. Интерфейс программного приложения ABBYY Fine Reader.Системы перевода

Программа переводчик представляет собой программный продукт, который позволяет осуществлять перевод с одного языка на другой отдельных слов, словосочетаний и предложений. Действие таких систем перевода строится на применении правил построения словосочетаний и предложений естественного языка. Переводчик анализирует текст на исходном языке, а затем составляет такой же текст на новом языке.
Как правило, такие программные продукты можно устанавливать на свой персональный компьютер как отдельные приложения (например, ABBYY Lingvo), но чаще их используют в режиме on-line в сети интернет. Свои услуги по переводу предлагают Яндекс-переводчик, Google-переводчик. Объем переводимого текста в Google может достигать до 5000 знаков, программа позволяет осуществлять перевод с 103 языков.
С 2017 года компания Google использует технологию перевода, основанную на применении нейросетей. Такой механизм позволяет предлагать более точные по смыслу, с учетом различных тонкостей языков, варианты слов.
Что мы узнали?
Тест по теме
Доска почёта
Чтобы попасть сюда – пройдите тест.
Иван Черных
5/5
Алла Дубровских
4/5
Егор Гаврилов
5/5
Влад Пешков
5/5
Александр Степанов
5/5
Виктория Грановская
5/5
Полина Коржиц
4/5
Арина Цыкарева
5/5
Оценка статьи
4. 2
2
Средняя оценка: 4.2
Всего получено оценок: 173.
А какая ваша оценка?
%d1%80%d0%b0%d1%81%d0%bf%d0%be%d0%b7%d0%bd%d0%b0%d0%b2%d0%b0%d0%bd%d0%b8%d0%b5%20%d1%82%d0%b5%d0%ba%d1%81%d1%82%d0%b0 – перевод на английский
Пример переведенного предложения: Его сбила машина 20 декабря прошлого года. ↔ Died in a traffic accident on December 20.
Glosbe Translate
Google Translate
+ Добавить перевод Добавить
Добавить пример Добавить
Склонение Основа
4.3. 2 [20] <4.1, 4.2> Покажите, как может быть реализован этот блок.
2 [20] <4.1, 4.2> Покажите, как может быть реализован этот блок.
4.3.2 [20] <4.1, 4.2> Show how this block can be implemented.
Коэффициент применения кесарева сечения в Италии заметно вырос за последние 20 лет с 11,2 процента (1980 год) до 33,2 процента (2000 год), и его значение превысило рекомендованные показатели ВОЗ на 10–15 процентов и показатели других европейских стран (например, 21,5 процента в Великобритании и Уэльсе, 17,8 процента в Испании, 15,9 процента во Франции).
Caesarean section rate in Italy has remarkably increased in the last 20 years, from 11.2% (1980) to 33.2% (2000), a value exceeding WHO suggestions by 10 to 15% and other European Countries’ values (i.e. 21.5% in Great Britain and Wales, 17.8% in Spain, 15.9% in France).
Кроме того, в статье 20 Конституции говорится, что начальное образование в государственных школах является обязательным и бесплатным.
Article 20 also provides that basic education is compulsory and is free of charge in Government schools.
Поверхность между верхней частью шипа и верхней поверхностью вставки выполнена плоской с наклоном таким образом, что между верхней поверхностью вставки и указанной поверхностью образуется двугранный угол 80-89,9 градусов.
The surface between the upper portion of the tongue and the upper surface of the insert is flat and is inclined in such a way that a dihedral angle of between
В 20 ч. 40 м. два вражеских израильских боевых самолета нарушили воздушное пространство Ливана над Марджаюном.
At 2040 hours, two enemy Israeli warplanes violated Lebanese airspace over Marjaayoun, flying north.
Песня Pokemon Mezase PokeMon Master Aim To Be A PokeMon Master представлена вам Lyrics-Keeper. Flash-фичу можно использовать в качестве караоке к песне Mezase PokeMon Master Aim To
Flash-фичу можно использовать в качестве караоке к песне Mezase PokeMon Master Aim To
The Pokemon Mezase PokeMon Master Aim To Be A PokeMon Master lyrics are brought to you by Lyrics-Keeper.
Common crawlЕго сбила машина 20 декабря прошлого года.
Died in a traffic accident on December 20.
OpenSubtitles2018.v3Если содержимое чувствительно к нагреву или если аэрозольные распылители изготовлены из пластмассы, которая размягчается при такой испытательной температуре, температуру воды следует поддерживать в пределах 20-30°C; однако, в дополнение к этому, один из 2 000 аэрозольных распылителей должен быть испытан при более высокой температуре.
If the contents are sensitive to heat or if the aerosol dispensers are made of plastics material which softens at this test temperature, the temperature of the bath shall be set at between 20 °C and 30 °C but, in addition, one aerosol dispenser in 2000 shall be tested at the higher temperature.
Конструкция 273 Еще раз повторяю: to be, а не to be eaten.
Êîíñòðóêöèÿ 273 Åùå ðàç ïîâòîðÿþ: to be, à íå to be eaten.
LiteratureНасколько же это было уместно, ведь выпускники назначались служить в 20 стран мира!
(Matthew 28:19, 20) How appropriate that was, since the graduates are being sent to serve in 20 different countries!
jw2019В обоснование своей претензии АББ представила письменное показание от 11 мая 2001 года, которое было дано под присягой бывшим руководителем отделения АББ в Ираке и в котором последний подтверждал, что 2 августа 1990 года в Ираке находилось 8 итальянских, 4 филиппинских и 80 таиландских сотрудников.
In support of its claim, ABB provided an affidavit dated 11 May 2001 sworn by ABB’s former branch manager in Iraq confirming that there were eight Italian, four Filipino and 80 Thai employees present in Iraq on 2 August 1990.
Совет управляющих Программы Организации Объединенных Наций по окружающей среде (ЮНЕП) в своем решении 25/10 от 20 февраля 2009 года отметил итоги первого специального межправительственного совещания с участием многих заинтересованных сторон, посвященного межправительственной научно-политической платформе по биоразнообразию и экосистемным услугам, состоявшегося 10–12 ноября 2008 года в Путраджайе, Малайзия, а также признал и подчеркнул необходимость укрепления и усиления научно-политического взаимодействия в области биоразнообразия и экосистемных услуг в интересах благосостояния людей и устойчивого развития на всех уровнях.
The Governing Council of the United Nations Environment Programme (UNEP), by its decision 25/10 of 20 February 2009, noted the outcomes of the first ad hoc intergovernmental and multi-stakeholder meeting on an intergovernmental science-policy platform on biodiversity and ecosystem services, held in Putrajaya, Malaysia, from 10 to 12 November 2008, and recognized and emphasized the need to strengthen and improve the science-policy interface for biodiversity and ecosystem services for human well-being and sustainable development at all levels.
Еще 10 минут на 20 подъемов.
10 more minutes you got two 20s.
OpenSubtitles2018.v3Тебе останется 20 процентов, как агенту, а я возьму 80 процентов.
You keep 20 percent of the royalties, like an agent.
OpenSubtitles2018.v3Я знала, как высоко Бог ценит человека и его тело, но даже это не останавливало меня. Дженнифер, 20 лет
I knew of God’s high regard for the human body, but even this did not deter me.” —Jennifer, 20.
jw2019Внедрение расширенной беспроводной сети в целях обеспечения более полного охвата всех основных помещений МООНЛ (залов заседаний) и мест, в которых находятся 20 или более пользователей из числа сотрудников МООНЛ, включая жилые помещения.
Implementation of extended wireless system to cover all main UNMIL facilities (conference rooms) and areas where 20 or more UNMIL users are present, including residences.
Если вы готовы принять небольшой совет друга – отдохните, поспите”20.
If you will now accept some advice from a friend—get some rest, get some sleep.”
LiteratureВ 1998 г. постановлением Кабинета Министров Украины N 513 от 20 апреля ей присвоено имя выдающегося государственного деятеля и ученого профессора Платона Лукича Шупика (1907-1986), который дважды занимал должность министра здравоохранения Украины (1952-1954, 1956-1969), внес весомый вклад в развитие материальной, учебной и научной базы академии, на протяжении 14 лет (1965-1979) заведовал кафедрой социальной медицины и организации здравоохранения (теперь кафедра управления здравоохранением).
The Institute got a new qualification in 1996, in the year of the 5th anniversary of Ukrainian independence. On the 13th of May 1996 the Resolution of the Cabinet of Ministers “On the Formation of Kyiv Medical Academy of Post-graduate Education” was issued, according to it the Academy was considered to be an educational institution of a new type and higher (IV) level of accreditation.
Одним из основных социальных изменений, которые произошли в Латинской Америке начиная с 80‐х годов, было возникновение движений коренных народов на местном, национальном и международном уровне.
One of the principal social changes that have taken place in Latin America since the early 1980s is the emergence of indigenous movements at the local, national and international levels.
парламент Венгрии принял Международную конвенцию о борьбе с бомбовым терроризмом (10 сентября 2002 года) и Международную конвенцию о борьбе с финансированием терроризма (20 декабря 2002 года).
The Hungarian Parliament promulgated the International Convention for the Suppression of Terrorist Bombings (on 10 September 2002) and the International Convention for the Suppression of the Financing of Terrorism (on 20 December 2002).
К 20-м числам сентября крупная группировка советских войск, включая 42-ю дивизию, оказалась запертой в киевском «котле».
By 20 September a large group of Soviet troops, including the 42nd Division, was locked in Kiev cauldron.
WikiMatrixРабочая группа согласилась с тем, что текст проекта статьи 92, как он содержится в документе A/CN.9/WG.III/WP.81, является приемлемым и будет дополнен необходимыми данными.
The Working Group agreed that the text of draft article 92 as contained in A/CN.9/WG.III/WP.81 was acceptable and would be supplemented as needed.
Это предписание указано в виде замечания 35 в колонке 20 таблицы С главы 3.2.
This requirement is indicated by remark 35 in column (20) of Table C of Chapter 3.2;
Согласно национальному обзору культивирования коки за 2015 год, проведенному в Многонациональном Государстве Боливия, площадь культивирования кокаинового куста в 2015 году практически не изменилась и составила 20 200 га, что является самым низким с 2001 года показателем.
According to the 2015 national coca monitoring survey in the Plurinational State of Bolivia, the level of cultivation of coca bush remained stable, at 20,200 ha in 2015, the lowest level recorded since 2001.
Бог требует поклонения себе и возвещает, что Он — Бог–ревнитель (Исх 20:5, Втор 5:9).
God demands worship and announces himself to be a jealous God (Ex 20:5; Deut 5:9).
Literature Список самых популярных запросов: 1K, ~2K, ~3K, ~4K, ~5K, ~5-10K, ~10-20K, ~20-50K, ~50-100K, ~100k-200K, ~200-500K, ~1MОбнаружение, распознавание и перевод текста | по Манси Сарда | Analytics Vidhya
ICDAR-2015 Изображение для обнаружения текста- Введение в проблему.
- Глубокое обучение Формулировка бизнес-задачи.
- Бизнес-ограничения.
- Источник данных.
- Исследовательский анализ данных.
- Окончательное создание данных для использования моделей машинного обучения и глубокого обучения.

- Модели, используемые для обнаружения и распознавания.
- Перевод текста.
- Окончательный конвейер с использованием лучшей модели.
- Развертывание с использованием flask
- Будущая работа.
- Профиль Github и LinkedIn.
- Ссылки.

Чтение текста в естественных изображениях привлекает все большее внимание в сообществе компьютерного зрения из-за его многочисленных практических применений в анализе документов, понимании сцен, навигации роботов и поиске изображений. Хотя в предыдущих работах был достигнут значительный прогресс как в обнаружении текста, так и в распознавании текста, это все еще сложно из-за большого разнообразия текстовых шаблонов и очень сложного фона.
Наиболее распространенный способ чтения текста сцены — разделить его на обнаружение текста и распознавание текста, которые обрабатываются как две отдельные задачи. Подходы, основанные на глубоком обучении, становятся доминирующими в обеих частях.
Обнаружение текста: Обнаружение текста — это метод, при котором изображение передается модели, а текстовая область обнаруживается путем построения ограничивающей рамки вокруг нее.
Распознавание текста: после обнаружения текста следует распознавание текста, при котором обнаруженные текстовые области дополнительно обрабатываются для распознавания текста.
Перевод текста: здесь, в моем блоге, распознанный английский текст затем переводится на язык хинди.
Для выполнения вышеуказанных задач на каждом этапе используются разные модели глубокого обучения, которые мы обсудим позже в этом блоге.
Изображения могут быть размытыми, шумными, низкого качества или разнонаправленными (повернутыми/искривленными) со сложным фоном. Это затрудняет обнаружение текстовых областей.
Низкая задержка необходима, если модель развертывается для обнаружения, распознавания и перевода текста на изображениях в режиме реального времени.
1. Данные предоставлены ICDAR 2015. Это Задача 4 конкурса ICDAR 2015 Robust Reading Competition, который обычно используется для обнаружения и обнаружения ориентированного текста сцены. Этот набор данных включает 1000 обучающих изображений с носимых камер. Для задачи определения текста он предоставляет 3 конкретных списка слов:
Это Задача 4 конкурса ICDAR 2015 Robust Reading Competition, который обычно используется для обнаружения и обнаружения ориентированного текста сцены. Этот набор данных включает 1000 обучающих изображений с носимых камер. Для задачи определения текста он предоставляет 3 конкретных списка слов:
- 100 слов на изображение, включая слова, появляющиеся на изображении, а также отвлекающие факторы.
- Словарь всех слов (слова из 3 символов или более, состоящие только из букв), встречающихся в обучающем наборе.
- 1000 текстовых файлов с локализацией на уровне слов и транскрипцией.
2. ИКДАР 2013 состоит из 229 обучающих изображений. В отличие от приведенного выше, он состоит из горизонтального текста.
ICDAR-2013Все вышеперечисленные данные состоят только из текста на английском языке. Большинство из них имеют горизонтальную ориентацию, а некоторые имеют разнонаправленные текстовые области.
ICDAR-2013–15
Функция для загрузки ограничивающих рамок и построения их вокруг текстовых областей на изображении ICDAR_2013–15.
- Приведенные выше изображения взяты из ICDAR 2013, состоящего из 229 обучающих изображений.
- Состоит из горизонтального текста.
- Содержит только текст на английском языке.
ИКДАР-2015
Аналогично пишется еще одна функция аналогично вышеописанному с исходником ИКДАР-2015 и получаются изображения.
ICDAR-2015- Вышеприведенные изображения взяты из данных ICDAR 2015 текста случайной сцены.
- Текст здесь представлен только на одном языке — английском, но текстовые области разнонаправлены, а некоторые из них также размыты.
Размер изображений
- Изображения имеют тот же размер, что и 1280 x 720 для текста случайной сцены ICDAR 2015.
Изображения имеют разные размеры для данных ICDAR_2013–15_Focussed_Scene_Text.
Высота и ширина печатаются для первых 10 изображений с использованием приведенного выше кода.
каждый фрейм данных содержит:
- путь изображения
- наземная истина
- Координаты ограничивающих прямоугольников.
- ориентация прямоугольника и центр прямоугольника. 9Метка 0004
- используется для обозначения того, какое изображение принадлежит какому набору данных. Поэтому необходимо равномерно разделить данные в тестовом разделении поезда. df_2013 имеет метку 1, а df_2015 имеет метку 2

- MSER (максимально стабильные экстремальные области):
MSER — это метод обнаружения пятен на изображениях. Алгоритм MSER извлекает из изображения ряд ковариантных областей, называемых MSER: MSER — это стабильно связанный компонент некоторых наборов уровней серого изображения. Его можно использовать для асинхронного обнаружения текста.
MSER на ICDAR-2013 imageMSER на ICDAR-2015 imageПриведенное выше не очень хорошо справляется с обнаружением текста. Хотя он работает достаточно хорошо для горизонтальных текстовых данных.
- Модель East и Pytesseract
EAST (эффективный точный детектор текста сцены):
Это очень надежный метод глубокого обучения для обнаружения текста, основанный на этой статье. Стоит отметить, что это всего лишь метод обнаружения текста. Он может находить горизонтальные и повернутые ограничивающие рамки. Его можно использовать в сочетании с любым методом распознавания текста.
Стоит отметить, что это всего лишь метод обнаружения текста. Он может находить горизонтальные и повернутые ограничивающие рамки. Его можно использовать в сочетании с любым методом распознавания текста.
Конвейер обнаружения текста в этом документе исключил избыточные и промежуточные этапы и имеет только два этапа.
В One используется полностью сверточная сеть для прямого прогнозирования на уровне слов или строк текста. Полученные прогнозы, которые могут быть повернутыми прямоугольниками или четырехугольниками, дополнительно обрабатываются на этапе подавления максимума, чтобы получить окончательный результат.
East Модель EAST может обнаруживать текст как на изображениях, так и на видео. Как упоминалось в документе, он работает почти в реальном времени со скоростью 13 кадров в секунду на изображениях 720p с высокой точностью обнаружения текста. Еще одним преимуществом этого метода является то, что его реализация доступна в OpenCV 3.4.2 и OpenCV 4. Мы увидим эту модель EAST в действии вместе с распознаванием текста.
Pytesseract Модель для распознавания текста:
Pytesseract — это оболочка для Tesseract-OCR Engine. Он также полезен в качестве автономного сценария вызова для tesseract, поскольку он может читать все типы изображений, поддерживаемые библиотеками обработки изображений Pillow и Leptonica, включая jpeg, png, gif, bmp, tiff и другие.
Некоторые выходные изображения из ICDAR-2013 после использования East с Pytesseract:
Некоторые выходные изображения из ICDAR-2015 после использования East с Pytesseract:
Приведенная выше модель очень хорошо обнаруживает горизонтальный текст, который не размыт. Он не очень хорошо справляется с распознаванием текста для размытых изображений.
Обнаружение текста хорошо подходит для размытых изображений, так как оно обнаруживает размытую текстовую область, но не может понять текст.
- Easy OCR:
Часть обнаружения использует алгоритм CRAFT, а модель распознавания — CRNN. Он состоит из 3 основных компонентов: извлечения признаков (в настоящее время мы используем Resnet), маркировки последовательностей (LSTM) и декодирования (CTC). EasyOCR не имеет большого количества программных зависимостей, его можно использовать напрямую с его API.
EasyOCR не имеет большого количества программных зависимостей, его можно использовать напрямую с его API.
EasyOCR может обрабатывать несколько языков одновременно, если они совместимы друг с другом.
Класс Reader — это базовый класс для EasyOCR, который содержит список кодов языков и других параметров, таких как GPU, для которого по умолчанию установлено значение True. Это нужно запустить только один раз, чтобы загрузить необходимые модели. Вес модели загружается автоматически или может быть загружен вручную.
Затем следует метод readtext, который является основным методом класса Reader.
В выходных данных отображаются 4 координаты ограничивающей рамки (x, y) текста вместе с идентифицированным текстом и оценкой достоверности.
В коде я установил язык как «en», что означает английский.
- Приведенный выше алгоритм довольно хорошо распознает текст не только для горизонтального текста, но и для различных ориентаций текстовых областей.
- Распознавание текста очень хорошо для четкого горизонтального текста. Точность падает в случае размытых и разнонаправленных текстовых областей.
 Точность падает в случае размытых и разнонаправленных текстовых областей.
Точность падает в случае размытых и разнонаправленных текстовых областей.EasyOCR во многих аспектах работает лучше, чем tesseract (другой механизм OCR, созданный Google, используемый с пакетом Python Pytesseract). Он прост в использовании, для его реализации требуется всего несколько строк кода, он имеет достаточную точность для большинства протестированных изображений и поддерживает широкий спектр языков.
Я использую модуль englisttohindi для перевода английского слова на хинди.
- Вышеупомянутая модель использует легкое распознавание и обнаружение текста и библиотеку Python EngtoHindi для перевода английских слов в слова хинди.
- Модель хорошо работает для высокого разрешения (четкие текстовые области), но не так хороша для размытых текстовых областей.
- Некоторые слова распознаются с небольшими орфографическими ошибками
Вышеприведенный конвейер также развернут с использованием flask:
- Мы можем изучить больше и попытаться построить модель, которая лучше работает для размытых изображений с разнонаправленными текстовыми областями.
- Далее можно попробовать перевести язык не только на хинди, но и на другие популярные языки.
- Попробуйте построить модель, которая определяет текстовые регионы на любом языке, а не только на английском.

для полного учебного кода вы найдете на GitHub здесь
Mansi Sarda – Maulana Abul Kalam Azad Университет Технологии, West Bengal, прежний WBUT INSINMIN
www.linkedin.com
- https://analyticsindiamag.com/hands-on-tutorial-on-easyocr-for-scene-text-detection-in-images/
- https://jaafarbenabderrazak-info.medium.com/opencv-east -model-and-tesseract-for-detection-and-recognition-of-text-in-natural-scene-1fa48335c4d1
- https://www.geeksforgeeks. org/build-an-application-to-translate-english- to-hindi-in-python/
- https://www.geeksforgeeks.org/text-detection-and-extraction-using-opencv-and-ocr/
- https://github.com/oyyd/frozen_east_text_detection. pb/blob/master/frozen_east_text_detection.pb
- https://stackoverflow.com/questions/13928155/spell-checker-for-python/48280566#:~:text=The%20best%20way%20for%20spell,%20fastest%20one%20is%20SymSpell
- https://www.geeksforgeeks.org/python-opencv-cv2-puttext-method/
- https://www.geeksforgeeks.org/python-opencv-cv2-puttext-method/
- https://www.geeksforgeeks.org/python-opencv-cv2-puttext-method/ прикладной курс. язык в текст и перевести его на несколько языков. Простой подход для извлечения текста в минутах.
Ну, тебе когда-нибудь было сложно прочитать почерк друга? или Заинтересованы в изучении нового языка? или Чтобы перевести ваши статьи на разные языки? или Заинтересованы в чтении статей, опубликованных на разных языках? Считайте, что вам повезло, так как большая часть нашей жизни компьютеризирована, жизненно важно, чтобы машины и люди могли понимать друг друга и передавать информацию туда и обратно.
Если вы уже работали в офисе, оснащенном сканером документов, то наверняка не раз сталкивались с выражением «Оптическое распознавание символов» (OCR). Но что такое OCR и для чего он используется? В этой статье объясняется, что означает OCR, и связывается Google переводчик с OCR и переводит текст на несколько языков.Оптическое распознавание символов (OCR)
Проще говоря, OCR — это тип программного обеспечения (программы), которое может автоматически анализировать печатный текст и преобразовывать его в форму, более удобную для обработки компьютером. Это широко распространенная технология распознавания текста внутри изображений, таких как отсканированные документы и фотографии. Технология OCR использует методологию распознавания образов и обнаружения признаков для преобразования практически любых изображений, содержащих письменный текст (печатный, рукописный или печатный), в машиночитаемые текстовые данные.
Google Translate
Google Translate — это бесплатная многоязычная служба статистического и нейронного машинного перевода, разработанная Google для перевода текста и веб-сайтов с одного языка на другой.
Я буду использовать инструмент « R » с пакетами « Tesseract » и « TranslateR » вместе с Google API для достижения цели преобразования изображений/pdf-файлов в текст и перевода их в желаемый язык. [Будет использовать несколько языков, таких как английский, китайский, каннада, хинди… для достижения цели]
Основное внимание будет уделено:
- Преобразование изображения в текст на английском языке
- Изображение в текст с последующим переводом:
- Преобразование изображения с китайского языка в текст и перевод его на английский язык
- Преобразование и изображения с языка каннада в текст и его перевод на английский язык
- Преобразование изображения с языка хинди в текст и его перевод на английский язык
3. Обработка изображения с помощью пакета Magick
4. Преобразование pdf с китайского языка в текст и перевод его на английский язык
5.
Белый/черный список символовНеобходимые библиотеки на R
1. Преобразование изображения в текст – Английский
Буду преобразование изображения ниже в текст:
Шаг 1: Загрузка нужного языка и настройка словаря
Шаг 2: загрузка изображения и с помощью пакета tesseract извлечение текста
Результаты извлечения точно совпадают с текстом в изображение
Шаг 3: Проверка уровня достоверности извлеченного текста.
Из результатов видно, что в основном уровень достоверности выше 95% для всех текстов. Что говорит о том, что модель уверена в извлеченной информации.
2. Изображение в текст и затем перевод:
- Преобразование изображения с китайского языка в текст и перевод его на английский
Я буду преобразовывать приведенное ниже изображение в текст:
Шаг 1: Загрузка нужного языка и настройка словаря
Шаг 2: Загрузка изображения и с помощью пакета tesseract извлечение текста
Результаты извлечения точно совпадают с текстом на изображении
Шаг 3: Проверка Уровень достоверности извлеченного текста.
Шаг 4: Перевод текста на английский язык
По результатам мы видим, что изображение с традиционным китайским языком было точно переведено на английский язык
- Преобразование изображения с языка каннада в текст и его перевод на английский язык
Далее мы проверим, будет ли успешно выполняться распознавание текста, когда на изображении вместе с текстом присутствуют фоновые помехи.
Я преобразую приведенное ниже изображение в текст [у него есть текст, а также идол Будды]:
Шаг 1: Загрузка нужного языка и настройка словаря
Шаг 2: загрузка изображения и с помощью Пакет tesseract извлекает текст
Шаг 3: Перевод текста на английский язык
По результатам мы видим, что изображение на языке каннада было переведено на английский язык
- Преобразование изображения с языка хинди в текст и перевод его на английский язык
Я преобразую изображение ниже в текст [когда фон темный]:
Шаг 1: Загрузка необходимого языка и настройка словаря
‘tesseract_info()’ показывает доступные/загруженные языки
Шаг 2: загрузка изображения и с помощью пакета tesseract извлечение текста
Шаг 3: Проверка уровня достоверности извлеченного текста.
Шаг 4. Снижение уровня достоверности значения менее 50 %
Шаг 5. Перевод текста на английский язык
Из результатов видно, что изображение на языке хинди было переведено на английский язык
3. Обработка изображения с помощью пакета Magick
Я выбрал изображение с плохим качеством текста для проверки извлечения
Из результатов видно, что извлечение из пакета Magick в основном точное, даже если текст на изображении не соответствует требованиям.
4. Преобразование pdf-файла с китайского языка в текст и его перевод на английский язык
Я буду преобразовывать прикрепленный выше pdf-файл в текст и буду переводить его на английский язык
Шаг 1: Буду конвертировать Файлы PDF в изображение
Шаг 2: Преобразование файла изображения в текст
Результаты: Заголовок 25 строк
Шаг 3. Перевод текста на английский язык
Из результатов видно, что извлечение и перевод из PDF-файла выполнены успешно.
 org/build-an-application-to-translate-english- to-hindi-in-python/
org/build-an-application-to-translate-english- to-hindi-in-python/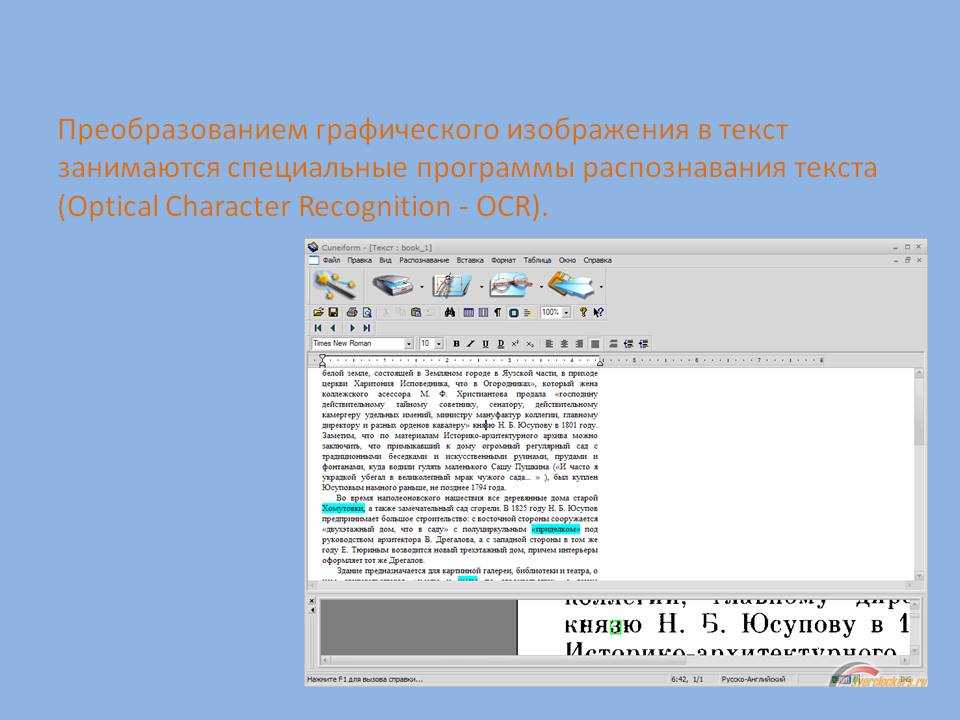 Если вы уже работали в офисе, оснащенном сканером документов, то наверняка не раз сталкивались с выражением «Оптическое распознавание символов» (OCR). Но что такое OCR и для чего он используется? В этой статье объясняется, что означает OCR, и связывается Google переводчик с OCR и переводит текст на несколько языков.
Если вы уже работали в офисе, оснащенном сканером документов, то наверняка не раз сталкивались с выражением «Оптическое распознавание символов» (OCR). Но что такое OCR и для чего он используется? В этой статье объясняется, что означает OCR, и связывается Google переводчик с OCR и переводит текст на несколько языков.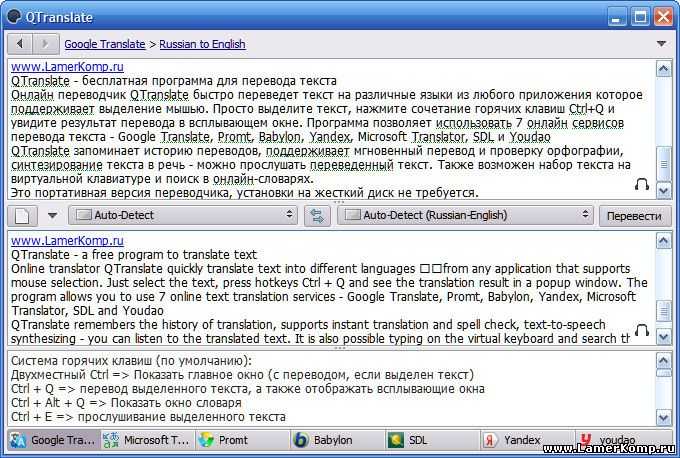
 Белый/черный список символов
Белый/черный список символов