
«Яндекс» запустил сервис закадрового перевода видео с YouTube и Vimeo — РБК
«Перевод происходит в несколько этапов. Сначала «Яндекс» распознает речь, превращает ее в текст и с помощью нейронных сетей разбивает на предложения. Потом определяет пол говорящего, переводит предложения на русский язык и синтезирует голос. Остается совместить перевод с видеорядом. Это совсем не тривиальная задача, потому что в русском языке предложения длиннее, чем в английском. Здесь на помощь снова приходят нейросети», — сообщили в компании.
Читайте на РБК Pro
Чтобы посмотреть видео в русской озвучке, пользователю необходимо нажать на кнопку в плеере и подождать какое-то время. Процесс перевода занимает несколько минут, после чего юзеру придет уведомление.
По словам руководителя «Яндекс.Браузера» Романа Иванова, автоматический перевод видео открывает перед людьми целый мир, который был недоступен из-за языкового барьера. «Полностью стереть языковые границы в интернете — одна из наших главных задач.
Иванов уточнил, что компания в дальнейшем будет добавлять в перевод видео новые языковые пары и голоса, помогая людям узнавать новое и получать от этого удовольствие.
«Яндекс» впервые показал прототип закадрового переводчика видео в середине июля. Тогда в компании говорили, что новая технология объединяет разработки «Яндекс.Переводчика», биометрии, распознавания и синтеза речи. Она определяет пол выступающего на видео и подбирает соответствующий голос. За темпом речи говорящего следит алгоритм, за счет чего переводчик делает паузы, замедляет или ускоряет речь, чтобы закадровый голос совпадал с картинкой.
Схожие технологии разрабатывают несколько зарубежных стартапов. Так, в конце июня сервис видеозвонков Zoom купил немецкий стартап Kites, который создает субтитры на других языках в режиме реального времени. Как заявили в Kites, технология, основанная на искусственном интеллекте, позволяет отображать стенограмму до того, как говорящий завершит предложение.
ЖК РФ Статья 22. Условия перевода жилого помещения в нежилое помещение и нежилого помещения в жилое помещение / КонсультантПлюс
Перспективы и риски споров в суде общей юрисдикции. Ситуации, связанные со ст. 22 ЖК РФ
1. Перевод жилого помещения в нежилое помещение и нежилого помещения в жилое помещение допускается с учетом соблюдения требований настоящего Кодекса и законодательства о градостроительной деятельности.
2. Перевод жилого помещения в нежилое помещение не допускается, если доступ к переводимому помещению невозможен без использования помещений, обеспечивающих доступ к жилым помещениям, или отсутствует техническая возможность оборудовать такой доступ к данному помещению, если переводимое помещение является частью жилого помещения либо используется собственником данного помещения или иным гражданином в качестве места постоянного проживания, а также если право собственности на переводимое помещение обременено правами каких-либо лиц.
(в ред. Федерального закона от 29.05.2019 N 116-ФЗ)
3. Перевод квартиры в многоквартирном доме в нежилое помещение допускается только в случаях, если такая квартира расположена на первом этаже указанного дома или выше первого этажа, но помещения, расположенные непосредственно под квартирой, переводимой в нежилое помещение, не являются жилыми.
3.1. Перевод жилого помещения в наемном доме социального использования в нежилое помещение не допускается.
(часть 3.1 введена Федеральным законом от 21.07.2014 N 217-ФЗ)
3.2. Перевод жилого помещения в нежилое помещение в целях осуществления религиозной деятельности не допускается.
(часть 3.2 введена Федеральным законом от 06.07.2016 N 374-ФЗ)
4. Перевод нежилого помещения в жилое помещение не допускается, если такое помещение не отвечает установленным требованиям или отсутствует возможность обеспечить соответствие такого помещения установленным требованиям либо если право собственности на такое помещение обременено правами каких-либо лиц.
Открыть полный текст документа
Можно ли вернуть деньги, переведенные на карту ошибочно
Способы аннулирования перевода денег
Моментальные перечисления платежа на карту стали привычными для каждого человека. Ежедневно по всему миру проходит миллионы операций перевода. Достаточно заполнить несколько полей в мобильном приложении на смартфоне, как деньги уже будут переведены на счет другого человека или организации. При этом часто возникают технические ошибки, как со стороны держателей карт, так и банка. Рассмотрим, как можно вернуть перечисленные деньги.
На выполнение денежных операций требуется, среднем, от пары минут до несколько часов. Если при переводе с карты через мобильный или интернет-банк была замечена ошибка, то пользователь может сразу отменить совершенное действие, где указана пометка «на исполнение».
Если нет приложения или денежный перевод уже был отправлен, то первое, что необходимо сделать, — это обратиться в банк, обслуживающий держателя пластиковой карты. Для отмены ошибочно совершенного платежа потребуется подать заявление. Если нет времени, чтобы приехать в офис банка, то стоит написать в онлайн-чат службы технической поддержки или позвонить оператору по горячей линии, телефон которой указан на оборотной стороне карты. Такие варианты помогут сэкономить время и оперативно решить вопрос. Самый надежный способ — написать заявление в отделение банка, где указать свои данные по счету, причину отмены перевода, доказать факт совершения ошибки, приложить копию чека при его наличии. Если при перечислении были указаны неправильные реквизиты, то деньги автоматически вернут владельцу.
Для отмены ошибочно совершенного платежа потребуется подать заявление. Если нет времени, чтобы приехать в офис банка, то стоит написать в онлайн-чат службы технической поддержки или позвонить оператору по горячей линии, телефон которой указан на оборотной стороне карты. Такие варианты помогут сэкономить время и оперативно решить вопрос. Самый надежный способ — написать заявление в отделение банка, где указать свои данные по счету, причину отмены перевода, доказать факт совершения ошибки, приложить копию чека при его наличии. Если при перечислении были указаны неправильные реквизиты, то деньги автоматически вернут владельцу.
Возможно лично обратиться к адресату, который по ошибке получил перевод. Возврат денег – это исключительно его волевое решение. Можно связаться с ним и убедить вернуть полученные деньги. Если человек не проигнорирует просьбу, то вопрос будет решен. В обратном случае – остается подать иск в суд.
Сроки возврата ошибочных перечислений на карту
Российское законодательство не предусматривает конкретные временные рамки, в течение которых должны будут возвращены деньги. Это напрямую зависит от банка.
Это напрямую зависит от банка.
- В случае если платеж еще не успел быть зачисленным, то в течение 5 рабочих дней сумма может быть возвращена обратно.
- Если деньги уже были перечислены физическому или юридическому лицу и составлен иск в суд, то получить возврат возможно в течение 7 суток с момента, когда ответчику будет доставлено письмо об ошибочном платеже.
Если процесс возвращения денежных средств затягивается, можно потребовать компенсацию в виде процентов за каждый день просрочки. Исковое заявление потребуется подать в судебные инстанции.
Можно ли вернуть отправленные мошеннику деньги
Возврат денежных средств, которые были ошибочно отправлены, происходит легче, чем в случае с незаконными действиями по счету. Банк не обязан компенсировать материальные потери людям, если они добровольно сообщили третьим лицам номер банковской карты и коды транзакции. По данным Центробанка, в 2019 года было возвращено только 15% от общего объема денежных средств, которые незаконно списаны со счетов пострадавших граждан.
Если вы самостоятельно совершили перевод мошенникам, то его можно вернуть, воспользовавшись описанной ниже схемой:
- Позвоните в банк или посетите его офис. Напишите заявление о возврате перечисленных денежных средств и прикрепите доказательства обмана. Если финансы еще не были отправлены, то их вернут на счет, а карту заблокируют. Перевыпуск нового платежного инструмента потребуется ждать в течение двух недель
- Подайте заявление в правоохранительные органы, если деньги уже были зачислены на интернет-кошелек, счет сторонней организации или в другом банке.
Для подтверждения факта незаконного снятия и перевода средств необходимо предоставить переписку, отправленные SMS-сообщения, имеющиеся данные о мошеннических действиях. Любой человек не должен терять бдительность и быть внимательным при заполнении формы перевода денежных средств на другой счет. Не стоит следовать инструкциям неизвестных лиц, которые пытаются получить реквизиты банковской карты. Проверяйте и контролируйте ее баланс, чтобы вовремя увидеть ошибку и нехватку денег.
Метод Translate переводчика – Azure Cognitive Services
- Чтение занимает 13 мин
Please rate your experience
Да Нет
Хотите оставить дополнительный отзыв?
Отзывы будут отправляться в корпорацию Майкрософт. Нажав кнопку “Отправить”, вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт.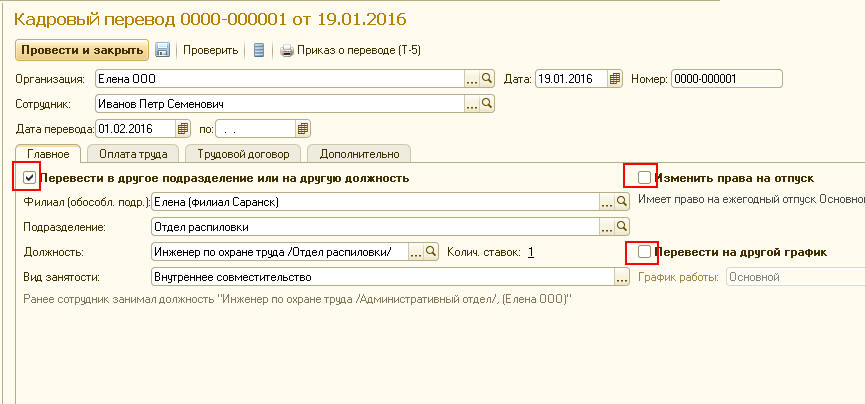 Политика конфиденциальности.
Политика конфиденциальности.
Отправить
Спасибо!
В этой статье
Этот интерфейс позволяет переводить текст.
URL-адрес запроса
Отправьте запрос POST на следующий адрес.
https://api.cognitive.microsofttranslator.com/translate?api-version=3.0
Параметры запроса
В таблице ниже приведены параметры, которые передаются в строке запроса.
Необходимые параметры
| Параметр запроса | Описание |
|---|---|
| api-version | Обязательный параметр. Версия API, запрошенная клиентом. Необходимое значение: 3.0. |
| значение | Обязательный параметр. Определяет язык выходного текста.  Целевой язык должен быть одним из поддерживаемых языков, включенных в область Целевой язык должен быть одним из поддерживаемых языков, включенных в область translation. Например, используйте параметр to=de, чтобы перевести на немецкий. Вы можете одновременно переводить на различные языки, использовав этот параметр в строке запроса несколько раз. Например, используйте параметр to=de&to=it, чтобы перевести на немецкий и итальянский. |
Необязательные параметры
| Параметр запроса | Описание |
|---|
| Параметр запроса | Описание |
|---|---|
| из | Необязательный параметр. Определяет язык оригинального текста. Чтобы просмотреть, какие языки доступны для перевода, выполните поиск поддерживаемых языков, используя область translation. Если параметр from не указан, исходный язык определяется автоматически.При использовании функции динамического словаря необходимо использовать параметр |
| textType | Необязательный параметр. Определяет, является ли текст перевода обычным или HTML-текстом. Любой код HTML должен быть полным элементом с правильным форматом. Возможные значения: plain (по умолчанию) или html. |
| категория | Необязательный параметр. Строка, где указано категорию (домен) перевода. Этот параметр позволяет получить переводы из пользовательской системы, созданной с помощью Custom Translator. Добавьте в этот параметр идентификатор категории из сведений о проекте пользовательского переводчика, чтобы использовать развернутую настроенную систему. Значение по умолчанию: general. |
| profanityAction | Необязательный параметр. Указывает способ обработки нецензурной лексики в переводе. Возможные значения: NoAction (по умолчанию), Marked или Deleted. Способы работы с нецензурной лексикой см. в этом разделе. в этом разделе. |
| profanityMarker | Необязательный параметр. Указывает, каким образом нецензурная лексика должна помечаться в переводе. Возможные значения: Asterisk (по умолчанию) или Tag. Способы работы с нецензурной лексикой см. в этом разделе. |
| includeAlignment | Необязательный параметр. Указывает, следует ли применять выравнивание из оригинального текста в переводе. Возможные значения: true или false (по умолчанию). |
| includeSentenceLength | Необязательный параметр. Указывает, следует ли включать границы предложения оригинального и переведенного текста. Возможные значения: true или false (по умолчанию). |
| suggestedFrom | Необязательный параметр. Указывает автоматический язык, если не удается определить язык оригинального текста. Автоопределение языка применяется при опущении параметра from. Если обнаружение завершается сбоем, используется язык Если обнаружение завершается сбоем, используется язык suggestedFrom. |
| fromScript | Необязательный параметр. Указывает сценарий оригинального текста. |
| toScript | Необязательный параметр. Указывает скрипт переведенного текста. |
| allowFallback | Необязательный параметр. Указывает, что службе разрешено откатиться к общей системе, когда настраиваемая система не существует. Возможные значения: true (по умолчанию) или false.
|
Заголовки запроса:
| Заголовки | Описание |
|---|---|
| Заголовки для проверки подлинности | Обязательный заголовок запроса. См. описание доступных способов аутентификации. |
| Content-Type | Обязательный заголовок запроса. Указывает тип содержимого для полезных данных. Допустимое значение: application/json; charset=UTF-8. |
| Content-Length | Обязательный заголовок запроса. Длина текста запроса. |
| X-ClientTraceId | Необязательно. Созданный клиентом идентификатор GUID, позволяющий уникально идентифицировать запрос. Этот заголовок можно опустить, если в строке запроса указан идентификатор трассировки в параметре с именем ClientTraceId. |
Текст запроса
Текст запроса является массивом в формате JSON. Каждый элемент этого массива представляет собой объект JSON со строковым свойством Text, который являет собой строку для перевода.
[
{"Text":"I would really like to drive your car around the block a few times."}
]
Действительны следующие ограничения.
- Массив может содержать не более 100 элементов.
- Полный текст, включенный в запрос, не может превышать 10 000 знаков, включая пробелы.
Текст ответа
Успешный ответ возвращается в формате массива JSON с одним результатом для каждой строки входного массива. Объект результата содержит следующие свойства.
detectedLanguage— объект, описывающий распознанный язык с помощью следующих свойств:language— строку, которая представляет код обнаруженного языка.score— значение с плавающей запятой, обозначающее достоверность результата. Может принимать ноль или единицу, где низкая оценка обозначает низкую достоверность.
Может принимать ноль или единицу, где низкая оценка обозначает низкую достоверность.
Свойство
detectedLanguageприсутствует в объекте результата исключительно при запросе автоопределения языка.translations— массив результатов перевода. Размер массива совпадает с количеством языков, указанных с помощью параметра запросаto. Каждый элемент массива содержит:to— строка, которая содержит код целевого языка.text— строка с текстом перевода.transliteration— объект, который возвращает переведенный текст в сценарии, указанном в параметреtoScript.script— строка, которая указывает целевой сценарий.text— строка, которая возвращает целевой текст в целевом сценарии.
Если не выполняется транслитерация, объект
transliterationне включается.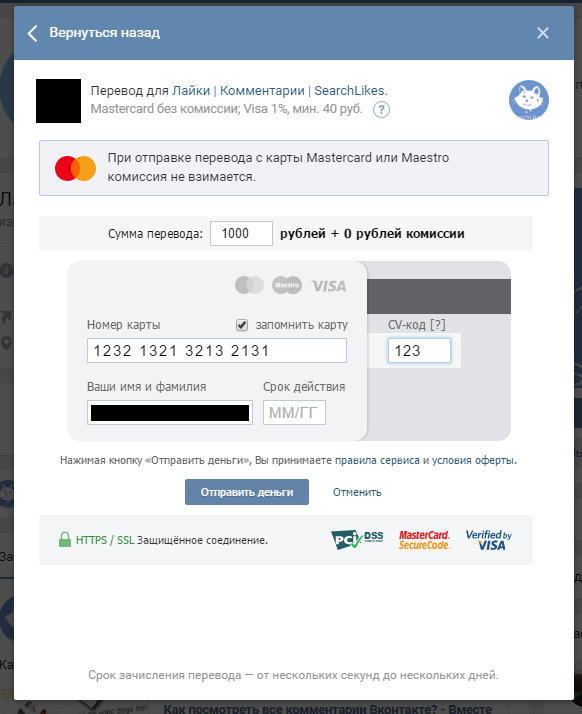
alignment— объект с одним свойством строкиproj, который преобразовывает оригинальный текст в переведенный. Сведения о выравнивании предоставляются, только когда параметр запросаincludeAlignmentимеет значениеtrue. Сведения о выравнивании возвращаются в виде строкового значения в следующем формате:[[SourceTextStartIndex]:[SourceTextEndIndex]–[TgtTextStartIndex]:[TgtTextEndIndex]]. Двоеточие разделяет начальный и конечный индексы, дефис — языки, а пробел — слова. Одно слово может соответствовать нулю, одному или нескольким словам другого языка. При этом сопоставленные слова могут не располагаться рядом. Если сведения о выравнивании недоступны, элемент Alignment будет пустым. Примеры и ограничения см. в разделе Получение сведений о выравнивании.sentLen— объект, возвращающий границы предложения в оригинальном и переведенном текстах.srcSentLen— массив целых чисел, представляющих значения длины предложений в оригинальном тексте. Длина массива соответствует количеству предложений, а значения — длине каждого предложения.
Длина массива соответствует количеству предложений, а значения — длине каждого предложения.transSentLen— массив целых чисел, представляющих значения длины предложений в переведенном тексте. Длина массива соответствует количеству предложений, а значения — длине каждого предложения.
Границы предложения включены только тогда, когда параметр запроса
includeSentenceLengthимеет значениеtrue.sourceText— объект с одним свойством строкиtext, который возвращает оригинальный текст в сценарии по умолчанию исходного языка.sourceTextсвойство присутствует только в том случае, если входные данные выражаются в сценарии, который не является обычным для этого языка. Например, если входные данные были на арабском языке, но написаны латинским алфавитом, тогда параметрsourceText.textвернет текст на арабском языке, преобразованным в арабский сценарий.
Примеры ответов JSON приведены в разделе примеры.
Заголовки ответов
| Заголовки | Описание |
|---|---|
| X-RequestId | Сформированное службой значение для идентификации запроса. Оно используется для устранения неполадок. |
| X-MT-System | Указывает тип системы, который использовался для перевода каждого целевого языка, запрошенного для перевода. Это значение представляет собой список строк, разделенных запятыми. Каждая строка обозначает тип: * Пользовательский – запрос включает пользовательскую систему, и при переводе использовалась как минимум одна пользовательская система. |
Коды состояния ответа
Ниже приведены возможные коды состояния HTTP, которые возвращает запрос.
| ProfanityAction | Действие |
|---|---|
NoAction | NoAction – алгоритм действий по умолчанию. Ненормативная лексика оригинального текста сохранится в переводе. Ненормативная лексика оригинального текста сохранится в переводе.Пример исходного текста (японский). 彼はジャッカスです。 |
Deleted | Оскорбительные слова будут удалены из выходных данных без замены. Пример исходного текста (японский). 彼はジャッカスです。 |
Marked | Нецензурную лексику в выходных данных заменяют маркеры. Маркер зависит от параметра ProfanityMarker.Если установлен параметр Если установлен параметр |
 彼はジャッカスです。
彼はジャッカスです。 Если возникнет ошибка, запрос также вернет ответ JSON с ошибкой. Код ошибки представляет собой число из 6 знаков, первые 3 из которых являются кодом состояния HTTP, а оставшиеся 3 цифры определяют категорию ошибки. Коды распространенных ошибок можно найти на справочной странице переводчика версии 3.
Примеры
Перевод отдельного элемента
В этом примере показано, как перевести одно предложение с английского языка на упрощенный китайский.
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=zh-Hans" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'Hello, what is your name?'}]"
Текст ответа:
[
{
"translations":[
{"text":"你好, 你叫什么名字?","to":"zh-Hans"}
]
}
]
Массив translations содержит один элемент, который обеспечивает перевод одного элемента текста в оригинальных данных.
Перевод одного ввода с автоопределением языка
В этом примере показано, как перевести одно предложение с английского языка на упрощенный китайский. В запросе не указан язык ввода. Вместо этого используется автоматическое определение исходного языка.
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&to=zh-Hans" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'Hello, what is your name?'}]"
Текст ответа:
[
{
"detectedLanguage": {"language": "en", "score": 1.0},
"translations":[
{"text": "你好, 你叫什么名字?", "to": "zh-Hans"}
]
}
]
Ответ похож на ответ из предыдущего примера. Поскольку было запрошено автоматическое определение языка, ответ также включает информацию о языке, обнаруженном для входящего текста. Функция автоопределения языка лучше работает при вводе более длинного текста.
Перевод методом транслитерации
Давайте расширим предыдущий пример, добавив метод транслитерации. В следующем запросе используется китайский текст, написанный латинским алфавитом.
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&to=zh-Hans&toScript=Latn" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'Hello, what is your name?'}]"
Текст ответа:
[
{
"detectedLanguage":{"language":"en","score":1.0},
"translations":[
{
"text":"你好, 你叫什么名字?",
"transliteration":{"script":"Latn", "text":"nǐ hǎo , nǐ jiào shén me míng zì ?"},
"to":"zh-Hans"
}
]
}
]
Результат перевода теперь включает свойство transliteration, которое возвращает переведенный текст, написанный символами латиницы.
Перевод нескольких фрагментов текста
Одновременный перевод нескольких строк — это просто вопрос задания массива строк в тексте запроса.
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=zh-Hans" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'Hello, what is your name?'}, {'Text':'I am fine, thank you.'}]"
Ответ содержит перевод всех фрагментов текста в том же порядке, что и в запросе. Текст ответа:
[
{
"translations":[
{"text":"你好, 你叫什么名字?","to":"zh-Hans"}
]
},
{
"translations":[
{"text":"我很好,谢谢你。","to":"zh-Hans"}
]
}
]
Перевод на несколько языков
В этом примере показано, как перевести одинаковый оригинальный текст на несколько языков в одном запросе.
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=zh-Hans&to=de" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'Hello, what is your name?'}]"
Текст ответа:
[
{
"translations":[
{"text":"你好, 你叫什么名字?","to":"zh-Hans"},
{"text":"Hallo, was ist dein Name?","to":"de"}
]
}
]
Работа с нецензурной лексикой
Обычно служба переводов сохраняет в переводе ненормативную лексику, которая присутствует в источнике. Степень нецензурности и оскорбительность контекста отличаются в разных культурах и в результате этого степень нецензурности в переводе может вырасти или уменьшится.
Степень нецензурности и оскорбительность контекста отличаются в разных культурах и в результате этого степень нецензурности в переводе может вырасти или уменьшится.
Если необходимо избежать появления ненормативной лексики при переводе (независимо от наличия ненормативной лексики в источнике), можно использовать параметр фильтрации ненормативной лексики. Этот параметр позволяет выбрать, что нужно делать с нецензурной лексикой: удалить, пометить ее соответствующими тегами (что дает возможность добавить собственный метод постобработки) или ничего не предпринимать. Допустимые значения ProfanityAction: Deleted , Marked и NoAction(по умолчанию).
| ProfanityAction | Действие |
|---|---|
NoAction | NoAction – алгоритм действий по умолчанию. Ненормативная лексика оригинального текста сохранится в переводе. Пример исходного текста (японский). 彼はジャッカスです。 |
Deleted | Оскорбительные слова будут удалены из выходных данных без замены. Пример исходного текста (японский). 彼はジャッカスです。 |
Marked | Нецензурную лексику в выходных данных заменяют маркеры. Маркер зависит от параметра ProfanityMarker.Если установлен параметр Если установлен параметр |
 Он — придурок.
Он — придурок.
Пример:
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=de&profanityAction=Marked" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'This is an <expletive> good idea.'}]"
Данный запрос возвращает:
[
{
"translations":[
{"text":"Das ist eine *** gute Idee.","to":"de"}
]
}
]
Сравнение:
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=de&profanityAction=Marked&profanityMarker=Tag" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'This is an <expletive> good idea.'}]"
Последний запрос возвращает:
[
{
"translations":[
{"text":"Das ist eine <profanity>verdammt</profanity> gute Idee. ","to":"de"}
]
}
]
","to":"de"}
]
}
]
Перевод содержимого с исправлениями и определение переведенного текста
Обычно переводят содержимое, которое включает разметку, например содержимое HTML-страницы или содержимое XML-документа. Включите параметр запроса textType=html при переводе содержимого с тегами. Кроме того, иногда бывает полезно исключить из перевода конкретное содержимое. С помощью атрибута class=notranslate можно указать содержимое, которое должно остаться не переведенным. В следующем примере содержимое внутри первого элемента div не будет переведено, в то время как содержимое во втором элементе div будет переведено.
<div>This will not be translated.</div>
<div>This will be translated. </div>
Пример запроса приведен ниже.
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=zh-Hans&textType=html" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'<div class=\"notranslate\">This will not be translated. </div><div>This will be translated.</div>'}]"
</div><div>This will be translated.</div>'}]"
Ответ:
[
{
"translations":[
{"text":"<div class=\"notranslate\">This will not be translated.</div><div>这将被翻译。</div>","to":"zh-Hans"}
]
}
]
Получить сведения о выравнивании
Сведения о сопоставлении возвращаются в виде строкового значения в следующем формате для каждого слова источника. Сведения о каждом слове разделяются пробелом, в том числе в языках (системах письменности) без разделения пробелами, таких как китайский:
[[SourceTextStartIndex]:[SourceTextEndIndex]–[TgtTextStartIndex]:[TgtTextEndIndex]] *
Пример строки со сведениями о сопоставлении: 0:0-7:10 1:2-11:20 3:4-0:3 3:4-4:6 5:5-21:21.
Иными словами, двоеточие разделяет начальный и конечный индексы, дефис — языки, а пробел — слова. Одно слово может соответствовать нулю, одному или нескольким словам другого языка. При этом сопоставленные слова могут не располагаться рядом. Если сведения о сопоставлении недоступны, элемент Alignment будет пустым. В этом случае метод не возвращает ошибку.
Если сведения о сопоставлении недоступны, элемент Alignment будет пустым. В этом случае метод не возвращает ошибку.
Чтобы получить сведения о выравнивании, укажите параметр includeAlignment=true в строке запроса.
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=fr&includeAlignment=true" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'The answer lies in machine translation.'}]"
Ответ:
[
{
"translations":[
{
"text":"La réponse se trouve dans la traduction automatique.",
"to":"fr",
"alignment":{"proj":"0:2-0:1 4:9-3:9 11:14-11:19 16:17-21:24 19:25-40:50 27:37-29:38 38:38-51:51"}
}
]
}
]
Сведения о выравнивании начинаются со строки 0:2-0:1. Это значит, что первые три символа в исходном тексте (
Это значит, что первые три символа в исходном тексте (The) сопоставляются с двумя первыми символами в переведенном тексте (La).
Ограничения
Получение информации о согласовании представляет собой экспериментальную функцию, которую мы включили для исследования прототипов и опыта с потенциальными сопоставлениями фраз. В дальнейшем мы можем отказаться от поддержки данной функции. Вот некоторые из заметных ограничений, при которых выравнивания не поддерживаются:
- Функция выравнивания недоступна для текста в формате HTML, т. е. TextType = html
- Сведения о выравнивании возвращаются только для группы языковых пар:
- С английского на любой другой язык, за исключением традиционного китайского, кантонского (традиционного) или сербского (кириллица).
- с японского на корейский или с корейского на японский.
- с японского на упрощенный китайский и на японский с упрощенного китайского.
- с упрощенного китайского на традиционный китайский и с традиционного китайского на упрощенный китайский.

- Вы не получите сведения о выравнивании, если предложение является законченным переводом. Примеры таких переводов — “Это тест”, “Я люблю тебя” и другие предложения, встречающиеся с высокой частотой.
- Функция выравнивания недоступна, если вы применяете любой из подходов для предотвращения перевода, как описано здесь
Установка границ предложения
Чтобы получать сведения о длине предложения в исходном тексте и переводе, укажите параметр includeSentenceLength=true в строке запроса.
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=fr&includeSentenceLength=true" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'The answer lies in machine translation. The best machine translation technology cannot always provide translations tailored to a site or users like a human. Simply copy and paste a code snippet anywhere. '}]"
'}]"
Ответ:
[
{
"translations":[
{
"text":"La réponse se trouve dans la traduction automatique. La meilleure technologie de traduction automatique ne peut pas toujours fournir des traductions adaptées à un site ou des utilisateurs comme un être humain. Il suffit de copier et coller un extrait de code n’importe où.",
"to":"fr",
"sentLen":{"srcSentLen":[40,117,46],"transSentLen":[53,157,62]}
}
]
}
]
Перевод с помощью динамического словаря
Если вы уже знаете перевод, который хотите применить к слову или фразе, вы можете указать его в запросе как исправление. Динамический словарь безопасен только для имен собственных, таких как личные имена и названия продуктов.
В разметке используется следующий синтаксис:
<mstrans:dictionary translation="translation of phrase">phrase</mstrans:dictionary>
Например, рассмотрим следующее русское предложение: “Слово “словоматик” — это словарная запись”. Чтобы сохранить при переводе слово словоматик, необходимо отправить запрос:
Чтобы сохранить при переводе слово словоматик, необходимо отправить запрос:
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=de" -H "Ocp-Apim-Subscription-Key: <client-secret>" -H "Content-Type: application/json; charset=UTF-8" -d "[{'Text':'The word <mstrans:dictionary translation=\"wordomatic\">word or phrase</mstrans:dictionary> is a dictionary entry.'}]"
Результат:
[
{
"translations":[
{"text":"Das Wort \"wordomatic\" ist ein Wörterbucheintrag.","to":"de"}
]
}
]
Эта возможность работает одинаково как с textType=text, так и с textType=html. Компонент должен использоваться только в случае необходимости. Соответствующий и гораздо лучший способ настройки перевода — это использование концентратора Custom Translator. Custom Translator обеспечивает полное использование контекста и статистические значения вероятности. Если вы имеете или можете позволить себе создавать учебные данные, которые показывают вашу работу или фразу в контексте, вы получите гораздо лучшие результаты. Узнайте больше о Custom Translator.
Если вы имеете или можете позволить себе создавать учебные данные, которые показывают вашу работу или фразу в контексте, вы получите гораздо лучшие результаты. Узнайте больше о Custom Translator.
Попробуйте Microsoft переводчик бесплатно-Microsoft переводчик для бизнеса
Производительность текста и перевода речи тест-переводчика
Существует несколько способов проверить текст переводчика и исполнение речевого перевода прямо сейчас бесплатно.
На простейшем уровне вы можете попробовать перевод сразу через Интернет или в продуктах Office без установки каких-либо новых программ. Если вы хотите присмотреться, вы можете установить приложения, такие как приложения Microsoft Translator для вашего смартфона.
Чтобы увидеть, как работает переводчик, мы предлагаем бесплатные примеры приложений на GitHub для Текст И Речи, в комплекте с открытым исходным кодом, чтобы вы могли просмотреть код в действии. Чтобы использовать примеры приложений, сначала необходимо зарегистрировать Бесплатная подписка на текстовый или речевой API.
Если вы хотите перейти непосредственно к тестированию переводчика в ваших собственных приложениях, зарегистрируйтесь на бесплатная подписка на услугу Переводчика или Речи на Azure.
Просмотр цен для Translator И Речевая служба на Лазурном берегу.
Попробуйте в веб-приложениях и в Microsoft Word
Переводчик для Bing
Перевод текста
Мгновенный перевод текста с одного языка на другой с помощью переводчика для Bing. На базе Microsoft Translator, сайт предоставляет бесплатный перевод на любой из поддерживаемых Языки перевода текста.
Перейти к Bing.com/Translator
Переводчик слов
Перевод текста
Подписчики Microsoft Office 365 могут переводить документы Word на любой из языков и диалектов с помощью Word Translator, интеллектуальной службы, доступной через облако. Встроенный переводчик Word можно использовать, если вы хотите перевести выбранные слова в документе или перевести весь документ. Подробнее
Получить Office 365
Установка приложений и плагинов для переводчиков
Приложение для переводчиков Майкрософт
Перевод текстаПеревод речи
Microsoft Translator — это бесплатное персональное приложение для перевода текста, голоса, разговоров, фотографий с камеры и снимков экрана. Подробнее
Подробнее
Переводчик для надстройки Outlook
Перевод текстаПеревод речи
Переводчик поможет вам читать сообщения на вашем предпочтительном языке на устройствах. Подробнее
Загрузка из магазина Office
Тестовые примеры приложений
Следующие приложения требуют подписки на Translator или API речи переводчика. Посмотреть, как зарегистрироваться ниже.
Переводчик документов
Перевод текста
Переводчик документов Microsoft позволяет быстро и легко перевести Word, PDF, PowerPoint, обычный текст или документы Excel. Вы также можете Настроить и тонкой настройки ваших переводов. Исходный код этого примера приложения также доступен на GitHub.
Скачайте приложение на GitHub
Голосовой переводчик
Перевод текстаПеревод речи
Перевести, как вы говорите, и показать переводы в окне субтитров отображается на экране. В этом примере приложения показано использование в режиме реального времени перевода и транскрипции. Исходный код этого примера приложения также доступен на GitHub.
Исходный код этого примера приложения также доступен на GitHub.
Скачайте приложение на GitHub
Разработка собственного приложения
Выполните следующие 4 шага, чтобы начать использовать Translator, чтобы начать разработку собственного приложения.
Если вы находитесь в Китае, вы можете подписаться на бесплатную пробную версию на Azure.cn. Просмотр шагов для подписки на Azure.cn.
-
1. Войти на портал Azure
-
2. Создать подписку на переводчика
После вступления на портал можно создать подписку на Translator следующим образом:
- Выбирать – Создание ресурса.
- В Поиск на рынке окно поиска, введите Translator а затем выбрать Translator из результатов.
- Выбирать Создать для определения деталей подписки.

- Из Уровень ценообразования список, выберите ценовой уровень, который наилучшим образом соответствует вашим потребностям.
- Каждая подписка имеет бесплатный уровень. Бесплатный уровень имеет те же функции и функции, что и платные планы, и не истекает.
- Вы можете иметь только одну бесплатную подписку на свой аккаунт.
- Выбирать Создать для завершения создания подписки.
-
3. ключ аутентификации
Зарегистрируйся в Translator вы получаете персонализированный ключ доступа, уникальный для вашей подписки. Этот ключ требуется при каждом вызове переводчику.
- Извлеките ключ проверки подлинности, сначала выбрав соответствующую подписку.
- Выбирать Ключи В Управление ресурсами раздела данных вашей подписки.
- Копируйте любой из ключей, перечисленных для подписки.
-
4.
 Учитесь, тестируйте и получайте поддержку
Учитесь, тестируйте и получайте поддержку
Настройте свои переводы и создайте систему перевода, настроенную на собственную терминологию и стиль с помощью пользовательского переводчика
Подробнее
%d0%bd%d0%b5%d1%81%d0%ba%d0%be%d0%bb%d1%8c%d0%ba%d0%be — со всех языков на все языки
Все языкиРусскийАнглийскийИспанский────────Айнский языкАканАлбанскийАлтайскийАрабскийАрагонскийАрмянскийАрумынскийАстурийскийАфрикаансБагобоБаскскийБашкирскийБелорусскийБолгарскийБурятскийВаллийскийВарайскийВенгерскийВепсскийВерхнелужицкийВьетнамскийГаитянскийГреческийГрузинскийГуараниГэльскийДатскийДолганскийДревнерусский языкИвритИдишИнгушскийИндонезийскийИнупиакИрландскийИсландскийИтальянскийЙорубаКазахскийКарачаевскийКаталанскийКвеньяКечуаКиргизскийКитайскийКлингонскийКомиКомиКорейскийКриКрымскотатарскийКумыкскийКурдскийКхмерскийЛатинскийЛатышскийЛингалаЛитовскийЛюксембургскийМайяМакедонскийМалайскийМаньчжурскийМаориМарийскийМикенскийМокшанскийМонгольскийНауатльНемецкийНидерландскийНогайскийНорвежскийОрокскийОсетинскийОсманскийПалиПапьяментоПенджабскийПерсидскийПольскийПортугальскийРумынский, МолдавскийСанскритСеверносаамскийСербскийСефардскийСилезскийСловацкийСловенскийСуахилиТагальскийТаджикскийТайскийТатарскийТвиТибетскийТофаларскийТувинскийТурецкийТуркменскийУдмурдскийУзбекскийУйгурскийУкраинскийУрдуУрумскийФарерскийФинскийФранцузскийХиндиХорватскийЦерковнославянский (Старославянский)ЧеркесскийЧерокиЧеченскийЧешскийЧувашскийШайенскогоШведскийШорскийШумерскийЭвенкийскийЭльзасскийЭрзянскийЭсперантоЭстонскийЮпийскийЯкутскийЯпонский
Все языкиРусскийАнглийскийИспанский────────АймараАйнский языкАлбанскийАлтайскийАрабскийАрмянскийАфрикаансБаскскийБашкирскийБелорусскийБолгарскийВенгерскийВепсскийВодскийВьетнамскийГаитянскийГалисийскийГреческийГрузинскийДатскийДревнерусский языкИвритИдишИжорскийИнгушскийИндонезийскийИрландскийИсландскийИтальянскийЙорубаКазахскийКарачаевскийКаталанскийКвеньяКечуаКитайскийКлингонскийКорейскийКрымскотатарскийКумыкскийКурдскийКхмерскийЛатинскийЛатышскийЛингалаЛитовскийЛожбанМайяМакедонскийМалайскийМальтийскийМаориМарийскийМокшанскийМонгольскийНемецкийНидерландскийНорвежскийОсетинскийПалиПапьяментоПенджабскийПерсидскийПольскийПортугальскийПуштуРумынский, МолдавскийСербскийСловацкийСловенскийСуахилиТагальскийТаджикскийТайскийТамильскийТатарскийТурецкийТуркменскийУдмурдскийУзбекскийУйгурскийУкраинскийУрдуУрумскийФарерскийФинскийФранцузскийХиндиХорватскийЦерковнославянский (Старославянский)ЧаморроЧерокиЧеченскийЧешскийЧувашскийШведскийШорскийЭвенкийскийЭльзасскийЭрзянскийЭсперантоЭстонскийЯкутскийЯпонский
Услуги профессионального письменного перевода в бюро переводов онлайн по доступным ценам
Оказание услуг письменного перевода
Человек, владеющий разговорным английским, может быть абсолютно беспомощен, когда дело доходит до необходимости на этом языке что-либо написать. То же самое можно сказать о немецком, французском языке, и о любом другом. Многие достаточно быстро осваивают разговорную часть, так как она более интуитивна и позволяет понимать друг друга даже с ошибками. Но с письменной частью дело обстоит сложнее.
То же самое можно сказать о немецком, французском языке, и о любом другом. Многие достаточно быстро осваивают разговорную часть, так как она более интуитивна и позволяет понимать друг друга даже с ошибками. Но с письменной частью дело обстоит сложнее.
Если вам нужно перевести какой-либо документ с русского на иностранный язык и наоборот, не обойтись без услуг профессионального письменного перевода. Особенно это касается случаев с узкоспециализированными темами (медицина, технические или юридические документы и т.д.). Компания TRANSLATION STATION поможет вам решить вопрос с письменным переводом любой сложности.
Стоимость профессионального письменного перевода документов и как можно сэкономить
Профессиональный письменный перевод – удовольствие не из дешевых. Но мы предложим вам несколько путей получить эту услугу и не уйти в минус при ограниченном бюджете.
- Если у вас есть форматируемый файл для перевода (Word, Excel и т.д.), отсылайте нам именно его. Если вы пришлете исходник в формате PDF (или хуже – сканированный PDF), нам придется затратить дополнительное время на разверстку (распознавание файла, приведение его в соответствие с оригиналом, подготовку к переводу), что увеличит итоговую цену услуги.

- Если сроки позволяют, лучше отправляйте документы на письменный перевод заранее, поскольку расценки на срочный перевод значительно выше.
- Если вам нужно перевести несколько похожих или шаблонных документов, в письменный перевод можно передать только один, а остальные вычитать.
Письменный перевод документов на иностранные языки и наоборот от бюро TRANSLATION STATION
Специалисты компании TRANSLATION STATION работают со 150 языками. Отлично разбираются в текстах юридических, технических, медицинских, финансовых и других тематик. Переводчики тщательно подыскивают термины, уместные для конкретного контекста, чтобы текст в итоге получился максимально понятным и точным.
После перевода тексты проходят редакторскую и корректорскую проверку, что позволяет гарантировать их высокое качество. Внимание уделяется не только содержанию текста, но и его формату, который мы приводим в строгое соответствие с исходным документом.
Мы беремся за работу любой сложности – от письменного перевода личных документов до перевода литературных произведений и технической документации для узкоспециализированного оборудования. При этом в любом случае заказчик может быть уверен в высоком качестве работы, а также в том, что мы сдадим ее в установленный договором срок.
При этом в любом случае заказчик может быть уверен в высоком качестве работы, а также в том, что мы сдадим ее в установленный договором срок.
Искусство перевода: много английского, много китайцев
После недавней конференции переводчиков молодой коллега поднял интересный вопрос: «Я все время слышу, как люди говорят, что они переводят с испанского, они переводят с французского. Почему – это ? »
Действительно. Об этом спросили множество людей, и лучшее, что мы смогли придумать вместе, было: «Это попытка звучать более профессионально, более формально». После этого я задавался вопросом, не происходит ли что-то еще, бессознательное желание преобразовать язык в единое целое.«Испанский», как будто испанцев не так много, как много регионов, где на нем говорят. Наверное, больше. То, что Грегори Рабасса, переводивший работы Габриэля Гарсиа Маркеса, Марио Варгаса Льосы, Кларис Лиспектор и многих других перед своей смертью в 2016 году, назвал «диким разнообразием значений, тонких и прямых, которые цепляются за слова», вариациями, которые являются достаточно широкие в пределах одного сообщества, не говоря уже о размножении по территориям.
Я перевожу с китайского на английский, языки, которые я нахожу полными разнообразия и противоречий.На обоих говорят в огромных частях земного шара, огромное количество людей, что затрудняет их сдерживание: английский с его пористой готовностью впитывать в себя всевозможные местные вариации, китайский с буквальными и метафорическими границами, разделяющими его различные области. В настоящее время я работал над почти двадцатью книгами – художественной и документальной в различных жанрах – и с равным количеством пьес, продаваемых из десяти стран и в них, и обнаружил, что обладаю множеством разных ушей и голосов, чтобы использовать их в нужное время. стык.
Нам знакома шутка Джорджа Бернарда Шоу о том, что Англию и Америку разделяет общий язык. Об этом часто говорят банально при выборе слова: тротуар или тротуар , лифт или лифт . Тем не менее, выполнить перевод между британским и американским языком не так просто, как найти и заменить кабачков и кабачков . (Однако многие люди считают, что это просто. «Это не наука о рукколе», – плачут они.) Даже после полувека, проведенного в этой стране, я постоянно открываю для себя новые отличия, которые никогда не мог вообразить. Недавно меня упрекали за то, что я сказал «в выходные» – все знают, что это «в выходные».
(Однако многие люди считают, что это просто. «Это не наука о рукколе», – плачут они.) Даже после полувека, проведенного в этой стране, я постоянно открываю для себя новые отличия, которые никогда не мог вообразить. Недавно меня упрекали за то, что я сказал «в выходные» – все знают, что это «в выходные».
Эти различия, стратегически развернутые, могут быть инструментом. Один британский редактор сообщает мне, что многие британские читатели на самом деле предпочитают триллеры на американском английском – что-то в быстро меняющихся каденциях как-то более, ну, захватывающе. И наоборот, я иногда опираюсь на британский словарь классовых различий, когда разные слои общества должны быть разными.Одно предостережение: при переводе произведений для театра я считаю, что лучше всего использовать английский, который наиболее естественен для актеров, если нет веских причин поступить иначе. Одно дело – требовать гибкости голоса в голове читателя, совсем другое дело – вкладывать слова в уста другого артиста.
Итак, остается вопрос: на какой английский мы переводим? Ответ может зависеть от желаемого эффекта, как указано выше, или может быть еще более четким: версия, требуемая издателем.В конце концов, при капитализме потребности торговли превыше всего, и читатели хотят того, чего хотят. (Да, я говорю здесь как практикующий; когда переводят на оплату аренды, искусство должно идти рука об руку с определенными прагматическими проблемами.) А, но что, если бы у вас был выбор, и ничего из этого не применимо? Тогда, вероятно, вы перевели бы на свой собственный английский. Это подводит меня к вопросу, на который я часто не могу ответить: какая версия английского языка принадлежит мне?
Я родился и вырос в Сингапуре в семье малазийских китайцев и тамилов из Шри-Ланки.Я поступил в университет в Великобритании, где прожил тогда десять лет. Я живу в Соединенных Штатах уже шесть лет. Из всех этих влияний, где мне найти «свой собственный» английский? В эпоху повышенной мобильности, когда иммигранты и ранее колонизированные люди стремятся заявить права на свои культурные пространства, я осмелюсь предположить, что мы увидим все больше и больше людей с таким же трудным для классификации опытом, выполняющих эту работу по переводу – и, возможно, Учитывая водоворот языков и культур внутри меня, жизнь в переводе была неизбежна.
Что-то особенно интересное происходит, когда акт перевода происходит в ранее колонизированном пространстве между двумя языками, на которые переводчик может претендовать. Я имею в виду такие территории, как Индия или Нигерия, Гонконг или Сингапур, где широко распространен английский язык. Выросший в англоязычном Сингапуре, я нахожу неприятным, когда американский переводчик переводит сингапурский китайский текст на своем собственном идиоме, наполняя его лифтами и средними школами , словами, которые мы бы никогда не использовали.Это похоже на то, что тебя снова колонизируют, когда приходят люди с Запада и накладывают свой словарный запас на наш.
Каким бы постколониальным оно ни было, в Сингапуре используется не простой британский английский, а локализованная версия, которую иногда называют синглиш. Помимо двоичного выбора баклажан или баклажан , у нас есть местное слово brinjal . Мы не используем ни мобильных телефонов , ни мобильных телефонов , а мобильных телефонов .
Итак, мы возвращаемся к вопросу о том, на какой английский переводить – и в этих случаях я бы сказал, что ответ будет не «ваш собственный», а «наш собственный», то есть английский язык места, с которого переводится и на него, или «Свои», если переводчик не принадлежит к культуре. Может ли переводчик, не являющийся сингапурским, работать с сингапурским текстом? Конечно, но я бы сказал, что в этом случае необходимо провести дополнительный уровень исследования как целевой, так и исходного языка и культуры.В идеале должен быть задействован сингапурский редактор – вторая пара глаз, способная указать, что мы используем кашу для обозначения рисового отвара , а не овсяных хлопьев .
Недавно я работал с британским редактором над переводом сингапурского романа, и у нас возникли разногласия, которые меня удивили. Персонаж в книге жалуется, что ее ребенок «игриво». Замечание редактора для меня было: «Разве не хорошо шутить?» На что я ответил: «Только не в Сингапуре! Развлечение – это отвлечение от учебы.Этот обмен напомнил мне, как культура формирует язык – мы думаем, что можем согласиться со значением слова игривый , но коннотации сильно различаются в Азии и на Западе. Мы можем согласиться только в том случае, если мы разделяем одно и то же мышление, но через определенные промежутки времени будут возникать непримиримые разногласия.
Замечание редактора для меня было: «Разве не хорошо шутить?» На что я ответил: «Только не в Сингапуре! Развлечение – это отвлечение от учебы.Этот обмен напомнил мне, как культура формирует язык – мы думаем, что можем согласиться со значением слова игривый , но коннотации сильно различаются в Азии и на Западе. Мы можем согласиться только в том случае, если мы разделяем одно и то же мышление, но через определенные промежутки времени будут возникать непримиримые разногласия.
У меня также был опыт редактирования сингапурских книг. В данном случае переводчик был британцем, и нам нужно было найти словарный запас, который казался ей естественным, но совместимым с сингапурской лексикой.Одно из слов, на котором мы застряли, было ass , которое я выделил как слишком британский. Должны ли мы тогда пойти в Америку с задницей ? Но нет, это тоже было неправильно. После долгих переговоров мы остановились на bum как на слове, которое в Сингапуре показалось бы «правильным», и она могла бы с комфортом использовать его.![]()
(Если можно еще немного понизить тон, я хотел бы процитировать Грегга Барнса, художника по костюмам из Красотка: мюзикл на Бродвее . В недавнем интервью он говорил о трудностях работы с началом девяностых. временной период.«Вы хотите чувствовать парня красивым и сексуальным, а не персонажем в неструктурированном мешковатом костюме, который был привлекательным более тридцати лет назад. Мы старались, чтобы форма и ткани соответствовали нашему [современному] глазу, но многие детали взяты из той эпохи ». Я не часто нахожу идеальную аналогию для перевода, когда читаю афишу , но это именно то, что иногда необходимо – не сама вещь, а ее воспроизведение.)
Кажется, это немного вовлеченный? Я считаю, что это цена существования на периферии.Как далеко мы можем зайти в этом принципе, прежде чем текст будет помечен как слишком недоступный, слишком незнакомый или слишком чуждый? Есть методы, которым можно научиться, способы предоставления контекста, который указывает: Да, я делаю это намеренно; это литературный выбор, а не недостаток моего английского . Вам следует переводить только на свой родной язык, нам снова и снова говорят. Но родной ли мне этот язык? Что ж, это так, и это не так, и есть определенная перформативность в том, чтобы претендовать на это без полного подчинения гегемонии центра.
Вам следует переводить только на свой родной язык, нам снова и снова говорят. Но родной ли мне этот язык? Что ж, это так, и это не так, и есть определенная перформативность в том, чтобы претендовать на это без полного подчинения гегемонии центра.
И все же дело того стоит. У одного есть ограниченное количество времени, и поэтому ограниченное количество книг, которые можно перевести. Меня привлекают в мир те, которые имеют наибольшее значение, и часто это те, которые меньше всего похожи на существующую литературу. (По прискорбному совпадению, это те самые книги, которые труднее всего продать.) Расширяя диапазон английского языка, предлагаемого в печатном виде, мы растягиваем умы.
Установив, что существует много разных английских языков в целевой части этого обмена, можно было бы ожидать аналогичной истории у источника – но нет, здесь маятник качается еще шире.Внутри Китая уже есть вариации, которые можно ожидать от очень большой страны с населением более миллиарда человек. При переводе романа из Чэнду я узнал от автора, который, к счастью, прекрасно говорит по-английски, что bihu (귿빪; буквально «настенный тигр») может означать «геккон» в остальной части Китая, но в Сычуани это означает «плющ». В этом было гораздо больше смысла – мне было интересно, почему так много гекконов бегают по внешней стороне здания. Эти множественные значения являются замечательной особенностью региональных вариаций, способствуют богатству языка и, кстати, значительно усложняют работу переводчика.
При переводе романа из Чэнду я узнал от автора, который, к счастью, прекрасно говорит по-английски, что bihu (귿빪; буквально «настенный тигр») может означать «геккон» в остальной части Китая, но в Сычуани это означает «плющ». В этом было гораздо больше смысла – мне было интересно, почему так много гекконов бегают по внешней стороне здания. Эти множественные значения являются замечательной особенностью региональных вариаций, способствуют богатству языка и, кстати, значительно усложняют работу переводчика.
Конечно, китайский язык – это не только мандарин. Мы могли бы целый день спорить о том, являются ли кантонский, хоккинский, хакка, шанхайский и т. Д. «Диалектами», как это было бы в официальной версии, или это фактически разные языки. Однако на странице они имеют общую систему письма – благодаря первому императору Китая, который унифицировал китайскую письменность в третьем веке до нашей эры. В широком смысле это означает, что они действуют как один язык для переводчика, но только в самых общих чертах. Когда я перевожу книгу из среды, говорящей на мандаринском диалекте, языковой мир, который я вижу на странице, достаточно ясно написан. Однако часто я оказываюсь на одном месте, зная, что читаю текст на мандаринском, но автор написал его, имея в виду другого китайца.
Когда я перевожу книгу из среды, говорящей на мандаринском диалекте, языковой мир, который я вижу на странице, достаточно ясно написан. Однако часто я оказываюсь на одном месте, зная, что читаю текст на мандаринском, но автор написал его, имея в виду другого китайца.
Насколько это важно? Даже с моим рудиментарным кантонским диалектом я знаю, что звуки совершенно другие. В кантонском диалекте больше тонов, и он кажется мне более мелодичным по сравнению с ритмами стаккато мандарина.Я работаю с поэтессой из Макао и считаю полезным, чтобы она читала мне ее сочинение на кантонском диалекте, а я изо всех сил стараюсь следить за ним, чтобы я мог удерживать звук в своей голове во время работы, даже когда я извлекаю значения из моего китайского понимания персонажей.
Таким образом, удовольствия и подводные камни нефонетического языка – мы с говорящим на кантонском языке смотрим на одну и ту же идеограмму и говорим на ней совершенно по-разному. Более того, кантонский диалект не полностью соответствует системе письма китайского языка, известной как 蝎 충 刀 ( shumianyu ) – «язык книжной поверхности». Продолжая читать, я замечаю, что говорящий на кантонском диалекте иногда меняет порядок слов, чтобы соответствовать синтаксису кантонского диалекта, или вообще заменяет другие слова. Мандарин 청 唐 ( meiyou ; «не иметь») произносится на кантонском диалекте как один звук ( mou ), но по-прежнему записывается как два символа.
Продолжая читать, я замечаю, что говорящий на кантонском диалекте иногда меняет порядок слов, чтобы соответствовать синтаксису кантонского диалекта, или вообще заменяет другие слова. Мандарин 청 唐 ( meiyou ; «не иметь») произносится на кантонском диалекте как один звук ( mou ), но по-прежнему записывается как два символа.
– это кантонский алфавит с собственным набором символов для всех слов и звуков, которых нет в мандаринском диалекте. Mou представлен буквой «冇» – иероглифом «иметь», 唐, с вынутыми внутренностями.Это не так широко используется, особенно за пределами Гонконга. Однако недавно мне посчастливилось поработать над книгой Йенг Пуэй Нгон, сингапурского писателя семидесяти с лишним лет, чей роман Костюм (Balestier Press, 2019) знаменует собой болезненный эпизод, который он пережил – стирание того, что нет. Китайцы-мандаринки из Сингапура. Это произошло в 1970-х годах, когда правительство Сингапура решило, что будущее страны лежит за мандаринским языком, языком, который почти ни для кого не является родным. В своих мемуарах Взрослея в эпоху Ли Куан Ю (Lingzi Media, 2014) сингапурский писатель Ли Хуэй Мин вспоминает, как однажды пришел домой и включил телевизор, но обнаружил все те же люди, которые говорили Кантонский диалект накануне превратился в мандаринский; их окрестили.Вот почему многие люди моего поколения не могут разговаривать с нашими родителями или бабушками и дедушками на любом языке, кроме английского, а если они не говорят по-английски, то вообще не говорят на языке. Это насилие и потеря, которыми отмечен текст Йэна, и багаж, который несут его языки.
В своих мемуарах Взрослея в эпоху Ли Куан Ю (Lingzi Media, 2014) сингапурский писатель Ли Хуэй Мин вспоминает, как однажды пришел домой и включил телевизор, но обнаружил все те же люди, которые говорили Кантонский диалект накануне превратился в мандаринский; их окрестили.Вот почему многие люди моего поколения не могут разговаривать с нашими родителями или бабушками и дедушками на любом языке, кроме английского, а если они не говорят по-английски, то вообще не говорят на языке. Это насилие и потеря, которыми отмечен текст Йэна, и багаж, который несут его языки.
В костюме Йенг описывает слабые отношения между стариком, говорящим на кантонском диалекте, и его внучкой, говорящей на мандаринском диалекте, пропасть между ними, по крайней мере частично, вызвана их разными вариантами китайского языка.Радикальное вмешательство автора состоит в том, чтобы оставить все кантонские диалоги в книге на кантонском языке, а не услужливо переводить их на письменный язык – шумянью – мандаринского, таким образом делая его непрозрачным для некантонских читателей. (В качестве уступки, в конце книги у него есть глоссарий с кантонского на мандаринский, но даже необходимость обращаться к нему – это напоминание говорящему на мандаринском диалекте, что не все должно быть сразу же читаемым для нас, в отличие от обычного гегемония.)
(В качестве уступки, в конце книги у него есть глоссарий с кантонского на мандаринский, но даже необходимость обращаться к нему – это напоминание говорящему на мандаринском диалекте, что не все должно быть сразу же читаемым для нас, в отличие от обычного гегемония.)
У меня возникла трудность в том, чтобы придумать, как передать эту двойственность в переводе.По опыту я знаю, что попытка сопоставить диалекты английского языка с другими языками редко срабатывает – любая попытка представить кантонский диалект как шотландский или техасский в широком смысле будет сочтена надуманной. Некоторое время я размышлял над идеей транслитерации кантонского диалекта или даже оставить его в оригинальных иероглифах, чтобы имитировать эффект оригинала – но оставит ли это меня заброшенным в моих обязанностях? В конце концов, я перевожу с китайского, а не только с мандаринского. Кроме того, достаточно сложно заставить американских читателей взять переведенную книгу, не говоря уже о сингапурской.Если они столкнутся с неразборчивым диалогом, они, вероятно, так же быстро заставят их снова отказаться от него.
В конце концов, я принял близко к сердцу изречение «Если у тебя не получается делать это хорошо, делай это быстро» и принял простейший метод: установив в качестве соглашения, что кантонская речь будет отмечена курсивом, и добавив примечание переводчика в конец объясняет, что я сделал и почему, добавляя некоторую предысторию Сингапура, чтобы любой желающий мог найти его здесь. Все заметки моего переводчика представляют собой смесь словесной болтовни ( здесь все лингвистические нюансы, интересует только 1 процент читателей) и извинений ( это то, что я не смог передать, извините, mea culpa , Пробовал ).
Чтобы сделать свою жизнь намного более сложной, я постарался уйти от центральной роли Китая, переводя больше работ из Тайваня, Гонконга, Макао, Малайзии и Сингапура. Это потребовало расширения моей системы взглядов и выхода из зоны комфорта «стандартного» китайского языка. Снова вознаграждение и снова трудность. Человек должен быть постоянно начеку, готовый бросить вызов предположениям о том, что «нормально», в том числе и о собственном. Я напоминаю себе, что эти вещи вызывают дискомфорт из-за стирания, и решение состоит в том, чтобы заново сосредоточиться, заново познакомиться и, таким образом, расширить диапазон моих знаний, а не оставаться в пределах знакомого.
Я напоминаю себе, что эти вещи вызывают дискомфорт из-за стирания, и решение состоит в том, чтобы заново сосредоточиться, заново познакомиться и, таким образом, расширить диапазон моих знаний, а не оставаться в пределах знакомого.
Переводчики не просто используют язык – мы его формируем. Это верно для всех, но больше, чем у большинства, у нас есть возможность вырезать язык в новых формах, перенять его из других культур. Язык – это не статичное явление, и мы не являемся его пассивными потребителями. Выбор, который мы делаем, усиливается по мере того, как мы создаем объем работы, когда мы обучаем и передаем свой процесс.
Пара примеров из Китая: Хотя идея о том, что китайское общество основывается на системе отношений под названием guanxi , стала обычным явлением, я выступаю против этого использования, потому что сохранение непереведенного слова порождает идею, что это что-то эзотерическое или эзотерическое. даже зловещий, а не старый добрый нетворкинг.Имена также являются еще одной горячей точкой – двусмысленность китайских иероглифов не может существовать в английском языке, что вынуждает переводчика выбирать между, скажем, кантонским Au Siu-Man или мандаринским Ou Xiaoman. Я слышал, как некоторые заявляли, что та или иная система транслитерации является «стандартной», и что, например, пиньинь, производный от китайского языка, – единственный выход. Мое личное правило состоит в том, что персонажей называют так, как они сами себя называют, даже если это иногда означает, что у них есть фамилии, отличные от фамилий их собственных родителей. Мандарин Хуанг становится кантонским Вонгом.
Я слышал, как некоторые заявляли, что та или иная система транслитерации является «стандартной», и что, например, пиньинь, производный от китайского языка, – единственный выход. Мое личное правило состоит в том, что персонажей называют так, как они сами себя называют, даже если это иногда означает, что у них есть фамилии, отличные от фамилий их собственных родителей. Мандарин Хуанг становится кантонским Вонгом.
Это некрасиво, но я не думаю, что перевод заключается в предоставлении изящных решений. Конечно, есть определенное удовольствие в элегантном обороте фраз или в ловком переложении, но в целом я не верю, что эти грубые пятна нужно отшлифовать, оставив работу без трения. Существует модель перевода, напоминающая воронку – все, начиная с исходного языка, движется к одному открытию, и все получается одинаково. Я предпочитаю кухонный инвентарь – сито, позволяющее как можно большему количеству просыпаться, падать сколько угодно, разбивать комки, чтобы облегчить поток.
Перевод – это искусство, да, но не декоративное. Дело не в красивой линии, а в грубом значении, которое формирует мир. Переводчики должны противостоять гегемонии и отказываться от центра для периферии, где в любом случае происходит самое интересное.
Дело не в красивой линии, а в грубом значении, которое формирует мир. Переводчики должны противостоять гегемонии и отказываться от центра для периферии, где в любом случае происходит самое интересное.
В переводе Transhumance (Feminist Press, 2017), переведенном Рос Шварц, Мирей Гансель пишет о передвижении людей и движении слов как о «путях перевода, медленном и терпеливом пересечении стран, границы стерты, движение огромных скоплений слов через все жаргоны «зонтичного» языка поэзии.Перевод становится актом слушания, своего рода свидетельством. «Меня внезапно осенило, – пишет она, – что незнакомец был не другим, это был я. Я был тем, кому нужно было всему научиться, все понять от другого ».
И это, я думаю, ключ к переводу – мы влияем на язык, но в гораздо большей степени на него воздействуем. Оставаясь восприимчивым и настроенным на разнообразие языков; охватывая многие английские, многие китайские, многие другие языки; запачкая руки в неизбежно беспорядочной и неточной навигации по этим безграничным территориям, мы расширяем, а не сужаем возможности перевода, позволяем себе быть решетом, а не воронкой, и все ближе подходим к нашему истинному призванию переводчиков – к сделать мир немного более открытым, чем он есть.
Версия этого эссе была представлена в Принстонском институте международных и региональных исследований при Принстонском университете 19 ноября 2018 года.
Переводы Джереми Тианг с китайского включают романы Су Вэя -Чен, Чжан Юэран, Чан Хо-Кей, Йенг Пуэй Нгон и Ли Эр, а также документальная литература Ю Цюю и Джеки Чана. Он также пишет и переводит пьесы и является лауреатом гранта PEN / Hein Grant, награды Mao-Tai Cup за перевод и стипендии NEA по литературным переводам.Тианг является автором сборника рассказов В национальный день не бывает дождя (Epigram Books, 2015) и романа State of Emergency (Epigram Books, 2017), получившего литературную премию Сингапура. Он является управляющим редактором Pathlight и одним из основателей Cedilla & Co., коллектива литературных переводчиков.
трансляция / трансляция РНК | Изучайте науку в Scitable
Перевод
это процесс, посредством которого белок синтезируется из информации, содержащейся
в молекуле информационной РНК (мРНК). Во время трансляции последовательность мРНК
читать с помощью генетического кода, который представляет собой набор правил, определяющих, как мРНК
последовательность должна быть переведена в 20-буквенный код аминокислот, которые
строительные блоки белков. Генетический код представляет собой набор из трех букв.
комбинации нуклеотидов, называемые кодонами, каждый из которых соответствует
специфическая аминокислота или стоп-сигнал. Перевод происходит в структуре, называемой
рибосома, которая является фабрикой по синтезу белков. Рибосома
имеет малую и большую субъединицу и представляет собой сложную молекулу, состоящую из нескольких
молекулы рибосомной РНК и ряд белков.Трансляция мРНК
молекула рибосомы происходит в три стадии: инициация, удлинение и
прекращение. Во время инициации малая субъединица рибосомы связывается с началом
последовательности мРНК. Затем молекула транспортной РНК (тРНК), несущая амино
кислотный метионин связывается с так называемым стартовым кодоном последовательности мРНК.
Стартовый кодон во всех молекулах мРНК имеет последовательность AUG и кодирует
метионин. Затем большая рибосомная субъединица связывается, образуя полный
комплекс инициации. На стадии удлинения рибосома продолжает расти.
переводить каждый кодон по очереди.Каждая соответствующая аминокислота добавляется к
растущая цепь и связаны через связь, называемую пептидной связью. Удлинение продолжается
пока не будут прочитаны все кодоны. Наконец, обрыв происходит, когда рибосома
достигает стоп-кодона (UAA, UAG и UGA). Поскольку нет молекул тРНК
которые могут распознавать эти кодоны, рибосома распознает, что трансляция
полный. Затем высвобождается новый белок, и появляется комплекс трансляции.
отдельно.
Во время трансляции последовательность мРНК
читать с помощью генетического кода, который представляет собой набор правил, определяющих, как мРНК
последовательность должна быть переведена в 20-буквенный код аминокислот, которые
строительные блоки белков. Генетический код представляет собой набор из трех букв.
комбинации нуклеотидов, называемые кодонами, каждый из которых соответствует
специфическая аминокислота или стоп-сигнал. Перевод происходит в структуре, называемой
рибосома, которая является фабрикой по синтезу белков. Рибосома
имеет малую и большую субъединицу и представляет собой сложную молекулу, состоящую из нескольких
молекулы рибосомной РНК и ряд белков.Трансляция мРНК
молекула рибосомы происходит в три стадии: инициация, удлинение и
прекращение. Во время инициации малая субъединица рибосомы связывается с началом
последовательности мРНК. Затем молекула транспортной РНК (тРНК), несущая амино
кислотный метионин связывается с так называемым стартовым кодоном последовательности мРНК.
Стартовый кодон во всех молекулах мРНК имеет последовательность AUG и кодирует
метионин. Затем большая рибосомная субъединица связывается, образуя полный
комплекс инициации. На стадии удлинения рибосома продолжает расти.
переводить каждый кодон по очереди.Каждая соответствующая аминокислота добавляется к
растущая цепь и связаны через связь, называемую пептидной связью. Удлинение продолжается
пока не будут прочитаны все кодоны. Наконец, обрыв происходит, когда рибосома
достигает стоп-кодона (UAA, UAG и UGA). Поскольку нет молекул тРНК
которые могут распознавать эти кодоны, рибосома распознает, что трансляция
полный. Затем высвобождается новый белок, и появляется комплекс трансляции.
отдельно.
Трудности перевода: некоторые сомалийские лидеры сообщают о трудностях с поиском информации о вакцинах в Гранд-Форкс
.Это, по словам Юсуфа, связано с тем, что она не знала, где ей сделают прививку в Гранд-Форксе.
«Мне никто не сказал», – сказал Юсуф, управляющий Safari Market на Гейтвэй Драйв. По ее словам, многие из ее клиентов совершили такое же путешествие через Ред-Ривер, и они часто путешествовали вместе с Абдирисаком Дуале, директором Центра интеграции новых американцев.
Дуале сказал, что некоторые иммигранты из Гранд-Форкса, в основном сомалийцы, не знали, куда пойти, чтобы получить вакцину от COVID-19, потому что Служба здравоохранения Гранд-Форкса не переводила надлежащим образом материалы о вакцинах и не поддерживала связь с ним и другими лидерами иммигрантов, которые может передавать информацию о сайтах клиник и так далее.
Это расстраивает обычно кроткого Дуале, который отмечает, что многие иммигранты, которых на гражданском языке часто называют «новыми американцами», плохо говорят по-английски.
«Любой, кто не говорит по-английски, не может быть в курсе пандемии», – сказал он Herald. «Многие люди, когда они спрашивают меня, где мы можем получить вакцину, у меня нет информации о стороне Гранд-Форкса.
Так где же отключение?
Много материалов, мало переводов
В мобильных клиниках вакцинации, которые они открыли по всему городу этим летом, сотрудники общественного здравоохранения Гранд-Форкса были готовы раздать переведенные материалы о вакцинах.
«Мы поразили все районы», – сказал Хейли Брюн, возглавляющий отдел вакцинации департамента здравоохранения.
Они также открыли магазин на других встречах в Гранд-Форкс, таких как общественный пикник, организованный Глобальной коалицией друзей, и празднование Всемирного дня беженцев.Эта стратегия, как отметил Брюн, предполагает, что люди уже присутствуют в клинике вакцинации.
Сотрудники департамента здравоохранения развесили записки о вакцинах от COVID на дверях по всему Гранд-Форксу, в том числе, с помощью домовладельцев, внутри некоторых охраняемых многоквартирных домов. В продуктовых магазинах Хьюго сотрудники раздали листовки о вакцинах, чтобы они раздавали их покупателям. И они подготовили серию листовок, в которых излагалось еженедельное расписание мобильной клиники по вакцинации, чтобы сотрудники школьных обедов также передавали их посетителям.Они также опубликовали это еженедельное расписание в Интернете.
Но материалы, которые они распространяли таким образом, не были переведены с английского, по словам Тиффани Беспфлуг, руководителя группы по укреплению здоровья в Grand Forks Public Health. Она также сказала, что ей не было известно ни о каких запросах на перевод рекламных материалов министерства здравоохранения на другой язык.
Fliers, однако, имел QR-код, который направлял пользователей на городскую веб-страницу с информацией о вакцинах, также написанной на английском языке.Выпадающее меню в верхней части страницы позволяет посетителям использовать службу Google для перевода страницы на несколько других языков, включая испанский и арабский. У страницы нет готовой опции для перевода на сомалийский или непальский – два из наиболее распространенных языков, на которых говорят иммигранты из района Гранд-Форкс, – но городские власти заявили, что пользователи могут изменить настройки в своих веб-браузерах, чтобы добавить эти языки.
Точно так же сообщения министерства здравоохранения в Facebook о его усилиях по вакцинации остались на английском языке.Боэспфлуг отметил, что сайт иногда предлагает пользователям возможность создать переведенную версию данного сообщения на язык по своему выбору.
Листовка в Сомали, рекламирующая клинику по вакцинации в июле, созданную Общественным здравоохранением округа Полк. Принесено / Абдирисак Дуале.
Положитесь на другие организации
Брун сказал, что министерство здравоохранения полагалось на другие учреждения Гранд-Форкса и Северной Дакоты, такие как Global Friends и некоторые религиозные организации, для проведения разъяснительной работы.
«Мы знаем, что некоторые из этих работ уже выполняются другими группами, поэтому нам пока не нужно начинать дублировать их, потому что мы делаем то, что не могут делать другие группы», – сказал Брун. «Управление справедливости в отношении здоровья штата не может вакцинировать 30 000 человек в Центре Алерус, но они могут работать с этими подгруппами населения и пытаться им помочь».
Мэр Брэндон Боченски и другие сотрудники города также проводили регулярные встречи в мэрии Гранд-Форкса с Дуале и другими ведущими фигурами сообщества «NFI» – «новых американцев, иностранцев или иммигрантов».По словам менеджера по связям с общественностью Греты Силевски, цель этих встреч заключалась в том, чтобы довести опасения жителей до нужных людей.
Всякий раз, когда сотрудники системы здравоохранения города, округа и Альтру соглашались перевести округ Гранд-Форкс на следующий этап многоуровневой вакцинации прошлой весной, городские администраторы получали уведомления, в которых говорилось, что это было переведено на сомали, непали и несколько языков, что затем они отправлялись в Дуале и другим лидерам иммигрантов для дальнейшего распространения.
Когда прошлой весной вакцины были открыты для широкой публики, те же лидеры и Боченски объявили об этом на нескольких языках в видеоролике, подготовленном городскими властями. Некоторые также рассказали о причинах вакцинации.
В то время вакцины были доступны через объединенную городскую программу вакцинации в центре Alerus, которая требовала от жителей предварительной регистрации, позвонив по номеру телефона или воспользовавшись веб-страницей «MyChart» компании Altru.Эта страница также написана на английском языке и не имеет метода ее перевода. По словам представителя Кеннета Харви, больница перевела некоторые сообщения в Facebook на сомалийский и другие языки и предлагает бесплатные услуги устного перевода.
«Было бы хорошо, если бы они распространяли листовки в Сомали и распространяли их у нас», – сказал Herald Фейсал Али, проживающий в Гранд-Форкс с 2013 года через Мохамеда Мохамеда, главы Исламского центра Ист-Гранд-Форкс. .”Хорошая идея.”
Мохамед, который живет в Ист-Гранд-Форкс, не хотел говорить о состоянии охвата Гранд-Форкса, но он высоко оценил усилия общественного здравоохранения округа Полк.
«С моей стороны, они отлично работают», – сказал он.
Персонал округа Полк заказал переводы множества материалов о COVID-19, включая рекламу клиник по вакцинации, и у них были переводчики в этих клиниках.Эти материалы также распространяются через такие организации, как Duale’s.
Эти усилия, по оценке Дуале, означают, что отдел общественного здравоохранения округа Полк проделал большую работу в этом виде информационно-пропагандистской работы, чем их коллеги в Гранд-Форкс. На прошлой неделе семь жителей Гранд-Форкса направились в клинику вакцины Ист-Гранд-Форкс, заявил Дуале.
Сотрудники некоммерческой организации New Hope for Immigrants, расположенной в Ист-Гранд-Форкс, составляют свои собственные листовки на сомалийском и арабском языках, которые распространяют информацию о вакцинах от COVID-19.По словам исполнительного директора New Hope Илхама Хасана, с тех пор они сняли видео, которое делает то же самое совместно с Global Friends Coalition.
Хасан также сказала, что сама не слышала о трудностях, с которыми столкнулась Дуале.
«Может быть, еще в мае или апреле, – сказала она, – но не сейчас».
некоторые уроки, извлеченные из JSTOR
АбстрактныйРаспространение систем статистического машинного перевода (SMT) в индустрии профессиональных переводов все еще ограничивается недостаточной надежностью результатов SMT, качество которых сильно варьируется.Важной частью информации для систем машинного перевода будет автоматическая оценка их выходных переводов с помощью автоматически полученных показателей качества. Прогнозирование показателей качества действительно было целью совместной задачи на семинаре по SMT в 2012 году. В этой статье мы сначала сообщаем о наших результатах для этой общей задачи, подробно описывая функции, которые, по нашему мнению, наиболее предсказуемы для качества. Во второй части мы повторно исследуем общие данные и протокол задачи и показываем, что несколько факторов действительно способствовали сложности задачи, и обсуждаем альтернативные схемы оценки.
Информация о журналеMachine Translation публикует оригинальные исследовательские работы по всем аспектам машинного перевода и приветствует статьи с многоязычным аспектом из других областей компьютерной лингвистики и языковой инженерии, таких как компьютерный перевод, многоязычный корпус ресурсов, инструменты для переводчиков, роль технологий в подготовка переводчиков, машинный перевод и обучение языкам, оценка, описание и т. д. Машинный перевод регулярно фокусируется на проблемах, представляющих особый интерес, включает регулярный раздел рецензирования книг и приветствует другие материалы, представляющие интерес для широкой читательской аудитории журнала, такие как: составление и генерация текста, поиск информации, интерфейсы естественного языка, диалоговые системы, сообщения понимание систем, дискурсивных явлений, интеллектуального анализа текста, инженерии знаний, контрастивной лингвистики, морфологии, синтаксиса, семантики, прагматики, компьютерного обучения языку и локализации и интернационализации обучающего программного обеспечения.
Информация об издателеSpringer – одна из ведущих международных научных издательских компаний, издающая более 1200 журналов и более 3000 новых книг ежегодно, охватывающих широкий круг предметов, включая биомедицину и науки о жизни, клиническую медицину, физика, инженерия, математика, компьютерные науки и экономика.
Zero-Shot Translation с помощью многоязычной системы нейронного машинного перевода Google
Вот как это работает.Допустим, мы обучаем многоязычную систему на примерах японского, английского и корейского и английского языков, которые показаны сплошными синими линиями на анимации. Наша многоязычная система того же размера, что и одна система GNMT, разделяет свои параметры для перевода между этими четырьмя разными языковыми парами. Такое совместное использование позволяет системе передавать «знания о переводе» из одной языковой пары в другие. Такое переносное обучение и необходимость перевода между несколькими языками вынуждают систему лучше использовать свои возможности моделирования.Это побудило нас задать следующий вопрос: можем ли мы переводить между языковой парой, которую система никогда раньше не видела? Примером этого может быть перевод между корейским и японским языками, где примеры корейско-японского языка не были показаны системе. Впечатляюще, но ответ – да – он может генерировать разумные корейско-японские переводы, хотя его этому никогда не учили. Мы называем это «нулевым» переводом, что показано желтыми пунктирными линиями на анимации. Насколько нам известно, этот тип трансферного обучения работает в машинном переводе впервые.
Успех нулевого перевода поднимает еще один важный вопрос: изучает ли система общее представление, в котором предложения с одинаковым значением представлены одинаковым образом независимо от языка – то есть «интерлингва»? Используя трехмерное представление данных внутренней сети, мы смогли заглянуть в систему, поскольку она переводит набор предложений между всеми возможными парами японского, корейского и английского языков.
Часть (а) рисунка выше показывает общую геометрию этих переводов.Точки в этом представлении окрашены смыслом; предложение, переведенное с английского на корейский, имеющее то же значение, что и предложение, переведенное с японского на английский, имеет тот же цвет. С этого вида мы можем видеть отдельные группы точек, каждая из которых имеет свой цвет. Часть (b) увеличивает масштаб до одной из групп, а часть (c) окрашивает в соответствии с исходным языком. Внутри одной группы мы видим предложение с одинаковым значением, но на трех разных языках. Это означает, что сеть должна кодировать что-то о семантике предложения, а не просто запоминать переводы фразы в фразу.Мы интерпретируем это как признак наличия интерлингва в сети.В нашей статье мы приводим гораздо больше результатов и анализов и надеемся, что его результаты будут интересны не только для исследователей машинного обучения или машинного перевода, но также для лингвистов и других лиц, которым интересно, как несколько языков могут обрабатываться машинами с использованием единой системы. .
Наконец, описанная многоязычная система нейронного машинного перевода Google уже запущена в производство для всех пользователей Google Translate.В настоящее время многоязычные системы используются для обслуживания 10 из недавно выпущенных 16 языковых пар, что приводит к повышению качества и упрощению производственной архитектуры.
Автор: Майк Шустер (Google Brain Team), Мелвин Джонсон (Google Translate) и Никхил Торат (Google Brain Team)За последние 10 лет Google Translate вырос с поддержки всего нескольких языков до 103, переводя более 140 миллиардов слов каждый. день. Чтобы сделать это возможным, нам нужно было создать и поддерживать множество различных систем для перевода между любыми двумя языками, что потребовало значительных вычислительных затрат.С нейронными сетями, реформирующими многие области, мы были убеждены, что можем еще больше повысить качество перевода, но это означало бы переосмысление технологии, лежащей в основе Google Translate.
В сентябре мы объявили, что Google Translate переходит на новую систему под названием Google Neural Machine Translation (GNMT), структуру сквозного обучения, которая учится на миллионах примеров и обеспечивает значительное улучшение качества перевода. Однако, хотя переход на GNMT улучшил качество для языков, на которых мы его тестировали, масштабирование до всех 103 поддерживаемых языков представляло серьезную проблему.
В статье «Многоязычная система нейронного машинного перевода Google: включение перевода с нулевым выстрелом» мы решаем эту проблему, расширяя нашу предыдущую систему GNMT, позволяя одной системе переводить между несколькими языками. Предлагаемая нами архитектура не требует изменений в базовой системе GNMT, но вместо этого использует дополнительный «токен» в начале входного предложения, чтобы указать требуемый целевой язык для перевода. Помимо улучшения качества перевода, наш метод также обеспечивает «нулевой перевод» – перевод между языковыми парами, который система не видит явно.
Это побудило нас задать следующий вопрос: можем ли мы переводить между языковой парой, которую система никогда раньше не видела? Примером этого может быть перевод между корейским и японским языками, где примеры корейско-японского языка не были показаны системе. Впечатляюще, но ответ – да – он может генерировать разумные корейско-японские переводы, хотя его этому никогда не учили. Мы называем это «нулевым» переводом, что показано желтыми пунктирными линиями на анимации. Насколько нам известно, этот тип трансферного обучения работает в машинном переводе впервые.
Успех нулевого перевода поднимает еще один важный вопрос: изучает ли система общее представление, в котором предложения с одинаковым значением представлены одинаковым образом независимо от языка – то есть «интерлингва»? Используя трехмерное представление данных внутренней сети, мы смогли заглянуть в систему, поскольку она переводит набор предложений между всеми возможными парами японского, корейского и английского языков.
Часть (а) рисунка выше показывает общую геометрию этих переводов.Точки в этом представлении окрашены смыслом; предложение, переведенное с английского на корейский, имеющее то же значение, что и предложение, переведенное с японского на английский, имеет тот же цвет. С этого вида мы можем видеть отдельные группы точек, каждая из которых имеет свой цвет. Часть (b) увеличивает масштаб до одной из групп, а часть (c) окрашивает в соответствии с исходным языком. Внутри одной группы мы видим предложение с одинаковым значением, но на трех разных языках. Это означает, что сеть должна кодировать что-то о семантике предложения, а не просто запоминать переводы фразы в фразу.Мы интерпретируем это как признак наличия интерлингва в сети.В нашей статье мы приводим гораздо больше результатов и анализов и надеемся, что его результаты будут интересны не только для исследователей машинного обучения или машинного перевода, но также для лингвистов и других лиц, которым интересно, как несколько языков могут обрабатываться машинами с использованием единой системы. .
Наконец, описанная многоязычная система нейронного машинного перевода Google уже запущена в производство для всех пользователей Google Translate.В настоящее время многоязычные системы используются для обслуживания 10 из недавно выпущенных 16 языковых пар, что приводит к повышению качества и упрощению производственной архитектуры.
несколько-ошибок-переводов-серьезных-последствий
Мы часто об этом не задумываемся, но простые ошибки перевода могут иметь серьезные последствия или привести к смешным ситуациям. Работа переводчика требует знаний и ноу-хау.
Вот некоторые из этих ошибок.
Французский «спрос»
В 1830-х годах Париж и Вашингтон вступили в конфликт из-за послания, полученного в Белом доме французским правительством.
Началом сообщения было: «Французское правительство требует …», что было переведено как «Французское правительство требует …».
Из-за этого фальшивого друга тогдашний американский президент Эндрю Джексон сердито ответил, что, если французское правительство осмелится «потребовать» что-либо, оно вообще ничего не получит.
К счастью, ошибка перевода была быстро исправлена, и напряжение вскоре улеглось.
“Марсианские каналы”
В 1877 году в Италии астроном Джованни Вирджинио Скиапарелли, не осознавая этого, выдвинул теорию марсианской жизни.
Действительно, он попытался нанести на карту Марс, отличая темные области от слабых мест красной планеты. Для простоты он назвал их «море» и «континент» и нарисовал разновидности «каналов», которые по-итальянски назывались «Канали». Только слово «канали» подверглось очень причудливому толкованию, вплоть до названия теории о жизни марсиан.
Это не шутка, потому что теория была серьезно воспринята американским астрономом Персивалем Лоуэллом, который нарисовал сотни «каналов» на Марсе, так что он опубликовал три книги по теории.Его работа вдохновила Х. Дж. Уэллса, автора «Войны миров» в 1897 году.
Слово имеет много значений
Если есть одна ошибка перевода, которая привела к серьезным последствиям, то это именно эта.
В июле 1945 года, когда союзники поставили японцам ультиматум о капитуляции. Японское правительство ответило в коммюнике, «что пока воздерживается от комментариев».
Проблема в том, что они использовали термин «Мокусатсу», слово, имеющее несколько значений, в том числе «игнорировать с презрением».
Этот неправильный перевод привел к тому, что Трумэн приказал запустить атомную бомбу на Хиросиму.
Таким образом, ошибки письменного или устного перевода являются частыми и имеют последствия.
Чтобы не сталкиваться с подобными ситуациями, Lingolet первым предлагает решение по запросу с более чем 4000 переводчиков и полную платформу управления для администраторов.
(PDF) Экономика художественного перевода: немного теории и свидетельства
Список литературы
Алесина, А., Девлишауэр, А., Истерли, В., Курлат, С., Вачциарг, Р., 2003. Фракционализация. Экономический журнал
Рост 8, 155–194.
Альтбах, П., Хошино, Э., 1995. Международное книгоиздание: энциклопедия. Издательство Гарленд, Нью-Йорк.
Biltereyst, D., 1991. Сопротивление американской гегемонии: сравнительный анализ восприятия национальной и американской фикции.
European Journal of Communication 6, 469–497.
Bossert, W., d’Ambrosio, C., La Ferrara, E., 2006. Обобщенный индекс дробления. Неопубликованная статья.
de Candolle, A., 1873. Histoire des Sciences et des savants depuis deux sie
`cles. Librarie Arthe
` me Fayard, Paris.
Каной, М., ван дер Плоег, Р., ван Оурс, Дж., 2006. Экономика книги. В: Ginsburgh, V., Throsby, D. (Eds.),
Справочник по экономике искусства и культуры. Эльзевир, Амстердам, стр. 720–761.
Casanova, P., 2002. Conse
«cration et Накопление капитала»
´raire: la traduction come e
´change ine
´gal.Actes de la
Recherche en Sciences Sociales 144, 7–20.
Казанова, П., 2008. La re
´publique mondiale des lettres. Сеуил, Париж.
Кэтфорд, Дж. К., 1967. Лингвистическая теория перевода. Издательство Оксфордского университета, Оксфорд, Великобритания.
Кавалли-Сфорца, Л.Л., 2000. Гены, народы и языки. Калифорнийский университет Press, Беркли, Калифорния.
Пещеры, Р., 2000. Творческие индустрии: контракты между искусством и коммерцией. Издательство Гарвардского университета, Кембридж, Массачусетс.
Козер, Л., Кадушин, К., Пауэлл, В., 1982. Книги: культура и коммерция издательского дела. Издательство Чикагского университета,
Чикаго.
Кристалл, Д., 2001. Словарь языков. Издательство Чикагского университета, Чикаго.
Де Сваан А., 1993. Слова мира. Polity Press, Кембридж, Великобритания.
Десмет, К., Ортуно-Ортин, И., Вебер, С., 2009. Языковое разнообразие и перераспределение. Журнал европейской экономики
Association 7, 1291–1318.
Дайен, И., Крускал, Дж. Б., Блэк, П., 1992. Индоевропейская классификация: лексикостатистический эксперимент. Транзакции
Американского философского общества 82 (5), 1–132, iii – iv.
Фрит, С., 1996. Музыка пересекает границы? В: van Hemel, A., Mommaas, H., Smithuijsen, C. (Eds.), Trading Culture.
Фонд Бёкмана, Амстердам, стр. 157–163.
Ганн В., Минон М., 1992. Ge
´ographies de la traduction. В: Баррет-Дюкрок, Ф.(Ред.), Traduire l’Europe. Payot, Paris,
pp. 55–96.
Ginsburgh, V., Weyers, S., 2008. Consensus ou diversite
´: Un mise en перспектива de la crisique litte
´raire en France. In:
Greffe, X., Sonnac, N. (Eds.), Cre
´ation, contenus e
´conomie nume
´rique. Dalloz, Paris, стр. 847–863.
Гинзбург, В., Вебер, С., 2011. Сколько языков нам нужно? Экономика языкового разнообразия. Princeton
University Press, Princeton, NJ.
Heilbron, J., 1999. К социологии перевода: переводы книг как культурная мировая система. Европейский журнал
Социальная теория 2, 429–444.
Heilbron, J., 2008. Реагируя на глобализацию: развитие книжного перевода во Франции и Нидерландах. В:
Pym, A., Schlesinger, M., Simeoni, D. (Eds.), Beyond Descriptive Translation Studies: Investigations in Homage to
Gideon Toury. Издательство Джона Бенджамина, Амстердам, стр.187–197.
Heilbron, J., Sapiro, G., 2002. La traduction litte
´raire, un objet sociologique. Actes de la Recherche en Sciences Sociales
144, 3–5.
Хейлброн, Дж., Сапиро, Г., 2007. Pour une sociologie de la traduction: bilan et перспектива. В: La traduction mess vecteur
des e
´changes culturels internationaux. Circulation des livres de litte
«Литература и социальные науки и др.»
«Эволюция
Плейс де ла Франс на марше
Мондиаль
» (1980–2002 гг.).
Хьорт-Андерсен, К., 2001. Модель переводов. Журнал экономики культуры 25, 203–217.
Хофстеде, Г., 1980. Последствия культуры. Сейдж, Беверли-Хиллз, Калифорния.
Хофстеде, Г., 1991. Культура и организации. Макгроу-Хилл, Лондон.
Хоскинс, К., Макфадьен, С., Финн, А., 1997. Глобальное телевидение и кино. Кларендон Пресс, Оксфорд, Великобритания.
Янссен С., 2009. Иностранная литература в национальных СМИ. Международный журнал литературных исследований «Аркадия» 44, 352–375.
Me
´litz, J., 2007. Влияние доминирования английского языка на литературу и благосостояние. Журнал экономического поведения и
Организация 64, 193–215.
Нида, Э., 1975. Языковая структура и перевод.