
Как распознать и перевести текст по фото онлайн – 19 октября 2021
Распознавание текста по фото — это процесс перевода графического изображения символов (букв) в текстовые символы. Сделать это можно имея качественную цифровую копию оригинального текста и набор современных компьютерных программ для распознавания текста. Если вам необходимо перевести текст с фотографии на другой язык, то необязательно перепечатывать его в окно переводчика.
Как распознать и перевести текст по фото с ПК
Яндекс.Переводчик
Популярный в России способ — это переводчик от Яндекса. сервис, который умеет распознавать текст с изображения и затем переводить его на любой из множества языков. Пользоваться им можно бесплатно. Открыть можно на ПК по ссылке. Перевод по картинке осуществляется простым способом через переход на соответствующий раздел и выбор необходимого языка. Перевод текста по фото можно осуществлять по файлам следующих форматов: JPG, PNG, GIF, BMP, TIFF.
Соответственно можно сформулировать простую и ясную инструкцию как распознать текст с картинки:
- Переход на сайт Яндекс.
 Переводчика
Переводчика - Переключить его в режим «Картинка»
- Переащить изображение в окно браузера или выбрать файл через проводник.
- Выбрать языки.
Отличительной особенностью Яндекс.Переводчика также является автоматическое определение языка источника по картинке. Даже такая приятная мелочь может ускорить работу и облегчить восприятие переводчика онлайн по фото. Также можно увеличивать и уменьшать изображение, чтобы сфокусироваться на его отдельных частях при возможном использовании мелкого шрифта. После подготовки изображения останется кликнуть по кнопке «Открыть в переводчике», после чего появится новая вкладка с привычным интерфейсом. Слева будет исходный текст, а справа его перевод.
Яндекс.Переводчик — это удобный переводчик онлайн по фото, но не единственный доступный к использованию. Если результат его работы чем-то не устрооил, всегда можно попробовать и другие сервисы.
img2txt
img2txt — это сервис, который позволяет получить набранный текст из изображения путем оптического распознавания символов (OCR) и Вам не требуется устанавливать дополнительные программы на свой компьютер или смартфон. Для распознавания текста необходимо подготовить нужное изображение и загрузить его, далее следует выбрать язык на котором написан текст, после чего Вы получите результат.
Для распознавания текста необходимо подготовить нужное изображение и загрузить его, далее следует выбрать язык на котором написан текст, после чего Вы получите результат.
Текст с картинки в текст онлайн можно перевести за достаточно быстрое время и к тому же появится возможность сохранить результат перевода в удобный формат. Перевести по фото можно типовые форматы файлов-изображений: jpg, jpeg, png. Также поддерживаются и мульти-страничные документы pdf, что для многих может оказаться очень важной возможностью. Онлайн переводчик по фото работает довольно быстро и выдает результат в удобном для последующей обработке виде.
Free Online OCR
Free Online OCR — еще один популярный онлайн переводчик по фото. Функция перевода в этом сервисе реализована через сервис Google Translate. Главное достоинство сервиса — поддержка большого количества графических форматов. Загрузить на перевод по фотографии можно практически любую картинку одного из форматов: JPEG, JFIF, PNG, GIF, BMP, PBM, PGM, PPM, PCX. Вот только язык на картинке сервис может автоматически не определить, а потому придется его указать вручную.
Вот только язык на картинке сервис может автоматически не определить, а потому придется его указать вручную.
Таким образом, перевод по фото онлайн в данном сервисе можно осуществить довольно просто, следуя такому порядку действий:
- На главной странице сервиса нажать «Выберите файл».
- Через проводки указать файл с изображением.
- Нажать «Preview» и дождаться результата обработки.
- Нажать «OCR», чтобы получить из картинки текст.
Далее получившийся текст можно при необходимости подправить вручную и также воспользоваться кнопкой «Google Translate» для перевода.
iOS и Android приложения для перевода текста по фото
Большинство приложений, позволяющих осуществить распознавание текста по фото качественно реализованы одновременно и для iOS, и для Android устройств, потому имеет смысл рассматривать их вместе.
Google Translate
Google Translate — самое популярное приложение для перевода на Android. Среди его возможностей есть и функция распознавания текста с фотографий и любых других изображений. Распознавание текста с картинки можно осуществлять прямо в интерфейсе камеры. Чтобы понять, что написано на вывеске или в меню не нужно даже делать снимок — главное, чтобы было подключение к интернету.
Распознавание текста с картинки можно осуществлять прямо в интерфейсе камеры. Чтобы понять, что написано на вывеске или в меню не нужно даже делать снимок — главное, чтобы было подключение к интернету.
Можно распознать скриншот с текстом, запустить переводчик по картинке, выбирая изображение из памяти телефона. Запустить переводчик через камеру можно также нажатием на значок с камерой. После этого выбрать язык с которого осуществить перевод и язык на который нужно перевести. Затем навести объектив на текст и дождаться появления перевода на экране прямо поверх изображения.
Есть и другие возможности у Google Translate, которые могут вам пригодиться: поддержка более 100 языков для перевода, режим разговора с озвучиванием перевода, рукописный и голосовой ввод, разговорник для сохранения слов на разных языках.
Google Translate iOS
Google Translate Android
Microsoft Translator
Компания Microsoft также старается не отставать от конкурентов и позаботилась об удостве своих пользователей, добавив функционал распознавания текста с фотографий в свой переводчик, который поддерживает уже более 60 языков.
Для перевода текста с изображения достаточно придерживаться простого алгоритма действий:
- Нажать на значок камеры
- Выбрать языки оригинала и результата перевода
- Навести камеру на нужный текст и сфотографировать его.
- Дождаться завершения обработки.
Кроме новых фото, можно преобразовать старую картинка в текст, воспользовавшись выбором изображения из памяти телефона. Среди другиз возможностей программы также присутсвтуют режим разговора с синхронным переводом речи и режим многопользовательского общения (до 100 собеседников на разных языках). Переводчи от Microsoft пока не славится такой же эффективность, как от Google, но для простых задач пользоваться им уже вполне можно.
Microsoft Translator iOS
Microsoft Translator Android
Translate.ru
Приложение Translate.ru от PROMT имеет важное преимущество над конкурентами, оно может переводить текст из фото, осуществлять перевод по фото с английского на русский без подключения к интернету. Правда, для работы такой функции нужно предварительно скачать языковой пакет OCR. Выбирать следует тот язык, с которого вы планируете переводить.
Правда, для работы такой функции нужно предварительно скачать языковой пакет OCR. Выбирать следует тот язык, с которого вы планируете переводить.
Для работы с приложением достаточно придерживаться простого алгоритма действий:
- Выбрать значок камеры в главном окне приложения.
- Нажать Ок при появлении собщения об отсутсвии пакетов для распознавания текста.
- Выбрать язык с которого нужно переводить и установить пакет при наличии интернета.
Далее можно уже наводить камеру на нужный текст, фотографировать и ожидать результата распознавания текста. Как и в других приожениях тут поддерживается возможность перевести текст с фото сохраненного в галерее мобильного устройства. Также есть функции голосового и рукописного ввода, отображения транскрипции и воспроизведение оригинала текста носителем языка, режим диалога для общения собеседников на разных языках.
Translate.ru iOS
Translate.ru Android
Как распознать текст картинки
Как распознать вырезать, вытащить, перевести, конвертировать, преобразовать текст с картинки фото или изображение?
Распознавание текста с картинки производиться очень легко. Сделать это можно двумя способами: онлайн и скачав специальную программу.
Сделать это можно двумя способами: онлайн и скачав специальную программу.
Для чего это может понадобиться? Причин много, например перевод скана в текст или вытащить текст с картинки.
Хорошо если это только несколько строчек, их можно переписать в ручную (хотя и это не всегда хочется делать), а если целая книга и вам нужно четвертую часть заменить своим текстом.
Тогда в ручном режиме, коптеть продеться неделями, а так несколько часов и все готово.
На мой взгляд, если преобразование рисунка в текст, происходит не регулярно, то можно пользоваться онлайн сервисом, а если постоянно, то воспользоваться программой намного лучше.
Экономиться время, ведь в первом случае перевод с картинки в текст производиться загрузкой изображения на онлайн сервис.
Если скорость интернета большая то еще можно мериться, а вот если маленькая, то возня на нервы будет действовать, несомненно.
Как перевести текст с картинки
Распознавание текста с изображения можно выполнить любого. Даже если сервис не поддерживает ваш формат картинки, то его очень быстро можно перевести в другой.
Даже если сервис не поддерживает ваш формат картинки, то его очень быстро можно перевести в другой.
Для этого достаточно открыть фото, картинку или изображение в любом редакторе (фотошоп, паинт, джим…) и сохранить в другом.
Если даже у вас нет фото-редактора, хотя паинт есть у всех, это можно сделать программой преобразования форматов или с картинки сделать скриншот и сохранить уже в другом формате.
Как видите распознавание текста с изображения или преобразование рисунка в текст задача не сложная.
Теперь, когда вы знаете (как это сделать, подробно описано по ссылкам вначале статьи), как вырезать текст из картинки то можете спокойно на сайтах, защищенных от копирования, делать скриншоты и быстро их переводить в редактируемый вид.
Уметь перевести картинку в текст — значит переложить множество работы пальцев на плечи программ или онлайн-сервисов.
Программы «переводчик картинок в текст» делают возможным производить нарушение авторских прав, ведь «писатели» на сайтах или в книгах специально защищают свои «творения» от копирования.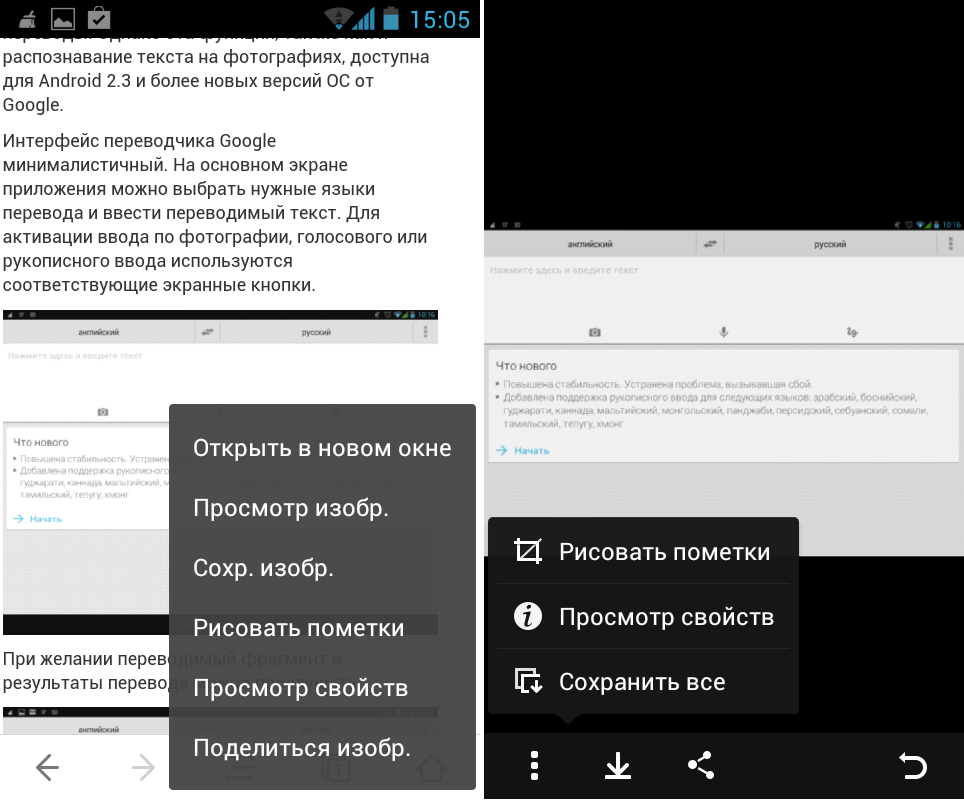
Хотя все это можно сделать в ручном режиме без них — они просто процесс ускоряют.
Мне однажды такой распознаватель текстов помог в работе со своей собственной книгой. После компиляции, скопировать содержимое — невозможно, а все, что было написано на обычном текстовом листке — потерялось.
Вот и пришлось делать каждой страницы скриншот и используя распознаватель преобразовать фото в текст.
В целом преобразование рисунка в текст занятие даже увлекательное, только при помощи программы, а не онлайн.
Красиво смотреть, как происходит перевод фотографии в текст — как по мановению палочки строчки выстраиваться в редактируемый вид.
В заключение лишь скажу, что я преобразование рисунка в текст всегда выполняю при помощи программ, хотя онлайн ничем по качеству не хуже, если конечно интернет скоростной.
Я просто привык все иметь под руками, а вдруг в нужный момент интернет пропадет, а так работу можно продолжать.
Как распознать текст с картинки
В последнее время можно все чаще столкнуться с ситуацией, когда нужно перевести какой-либо текст, содержащийся на изображениях, в электронную текстовую форму.
 Для того чтобы сэкономить время и не перепечатывать вручную, следует использовать специальные компьютерные приложения для распознавания текста, о чем мы и расскажем сегодня.
Для того чтобы сэкономить время и не перепечатывать вручную, следует использовать специальные компьютерные приложения для распознавания текста, о чем мы и расскажем сегодня.Как оцифровать текст
На рынке представлено немало приложений для оцифровки текста, поэтому каждый пользователь найдёт решение, соответствующее требованиям.
Способ 1: ABBYY FineReader
Это условно-бесплатное приложение от российского разработчика обладает огромнейшим функционалом и позволяет не только распознавать текст, но и производить его редактирование, сохранение в различных форматах и сканирование бумажных исходников.
Скачать ABBYY FineReader
- Чтобы распознать текст на картинке, прежде всего, нужно загрузить её в программу. Для этого после запуска ABBYY FineReader жмем на кнопку
После выполнения данного действия открывается окно выбора источника, где вы должны найти и открыть нужное изображение. Поддерживаются следующие популярные форматы: JPEG, PNG, GIF, TIFF, XPS, BMP и др.
 , а также файлы PDF и DjVU.
, а также файлы PDF и DjVU. - После загрузки в ABBYY FineReader автоматически начинается процесс распознавания текста на картинке без вашего вмешательства.
В случае если вы хотите произвести повторную процедуру распознавания, достаточно просто нажать кнопку «Распознать» в верхнем меню. - Иногда не все символы программа может распознать корректно. Это может быть в том случае, если изображение на исходнике не слишком качественное, очень мелкий шрифт, в тексте используется несколько разных языков, применяются нестандартные символы. Но это не беда, так как ошибки можно исправить вручную, с помощью текстового редактора и набора инструментов, которые в нем содержатся.
Для облегчения поиска неточностей оцифровки программа по умолчанию выделяет возможные ошибки бирюзовым цветом.
- Закономерным окончанием процесса распознавания является сохранение его результатов. Для этого жмем кнопку «Сохранить» на верхней панели меню.

ABBYY FineReader представляет собой самое продвинутое решение, но однозначно рекомендовать именно его мешают платная модель распространения и ограничения пробной версии.
Способ 2: Readiris
Приложение Readiris укрепилось на рынке как ближайший конкурент упомянутого выше Файн Ридер – оно предоставляет подобный функционал, некоторые аспекты исполняет несколько лучше, чем продукция ABBYY.
Скачать Readiris
- После запуска приложения выберите источник данных для оцифровки – со сканера или же с готового графического файла.
В примере мы будем использовать последний вариант – для него следует воспользоваться кнопкой «Из файла».
- Откроется диалоговое окно «Проводника», в котором следует выбрать нужные документы. Поддерживается большинство графических форматов, а также PDF.
- Подождите, пока документ будет загружен в программу, после чего следует настроить распознавание текста. Первым делом нужно установить основной язык – выберите его из выпадающего меню.
Также рекомендуем отметить опцию «Анализ текста», благодаря которой значительно повыситься качество оцифровки. - Далее обратитесь к меню «Инструменты» — имеющиеся в нём параметры помогут решить некоторые проблемы сканирования, такие как искажение перспективы, недостаточная контрастность картинки или смещение текста относительно полотна.
Из этого меню также можно подкорректировать текст, если распознавание сработало неправильно. - После внесения изменений в распознанный текст следует задать выходной формат полученных данных через одноименное меню в панели инструментов.

Все возможные форматы экспорта сгруппированы в пункте «Другое». Кроме упомянутых выше типов файлов, оцифрованный текст можно сохранить в виде данных OpenOffice, гипертекстовых файлов или обычных TXT. - После выбора формата откроется окошко Мастера по экспорту. В нём можно настроить те или иные параметры полученного файла (зависят от выбранного формата) и вариант сохранения (локальный или в облачный сервис). После внесения всех требуемых изменений нажмите
Снова появится окно «Проводника», в котором следует выбрать желаемый конечный каталог сохранения.
В целом Readiris представляет собой удобное и современное решение для оцифровки текста, однако весомым его недостатком можно назвать платную модель распространения.
Способ 3: RiDoc
Ещё одно приложение, ориентированное на работу со сканерами, однако умеющее работать и с локальными файлами в разных форматах.
Скачать RiDoc
- Откройте приложение. Для начала работы используйте на панели инструментов кнопки «Открыть»
- В окне «Проводника» перейдите к документу, из которого требуется получить текст, и выберите его. Доступна также пакетная обработка документов.
- Если требуется, можно обработать полученный файл: обрезать картинку, установить область распознавания, исправить огрехи сканирования.
Отдельным пунктом стоит возможность склейки – в этом случае мультистраничный документ будет сохранён единым файлом. Можно выбрать значение DPI и формат вывода (доступны только файлы изображений). - Для распознавания текста в правой части окна найдите вкладку «OCR» и откройте её. Доступных опций не много – можно выбрать только язык документа.
 После смены пакета нажмите на кнопку «Распознать» на панели инструментов.
После смены пакета нажмите на кнопку «Распознать» на панели инструментов.
Отсюда же можно подправить результаты оцифровки. - Сохранение документов доступно в двух вариантах – прямое или экспорт в офисные приложения. Для выполнения первого способа следует использовать кнопку «Сохранить». Откроется окно, в котором можно выбрать место сохранения, а также тип (единичные файлы или один многостраничный). Формат сохраняемого файла зависит от выбранного на этапе склейки.
Экспорт результатов возможен в текстовые процессоры офисных пакетов Microsoft или OpenOffice, в виде электронного письма (кнопка «Почта»), в формат PDF или же печати на принтере. Для экспорта в офисные программы они должны быть установлены на компьютере, тогда как сохранение в ПДФ возможно даже без соответствующих приложений.
Как видим, РиДок представляет собой небогатое возможностями решение, но для несложных вариантов оцифровки вполне подойдёт.
Способ 4: Capture2Text
Небольшая утилита, которая позволяет распознавать текст из любой области на экране компьютера, полностью бесплатная и удобная в использовании.
Скачать Capture2Text с официального сайта
- Загрузите архив с программой и распакуйте его в любое удобное место. Затем перейдите к полученному каталогу и запустите исполняемый файл.
Далее откройте системный трей – в нём должна появится иконка утилиты.
Для изменения языка распознавания кликните правой кнопкой мыши по значку Capture2Text в системном трее, затем в настройках выберите пункт «OCR Language» и установите нужный язык.
- Откройте файл, текст с которого требуется оцифровать, например, документ DjVU без текстового слоя. Когда файл будет открыт, нажмите сочетание клавиш Win+Q и выделите область распознавания.
- Появится окошко утилиты с результатами распознавания. Полученные данные можно скопировать в любое приложение, поддерживающее ввод пользовательского текста.
Приложение невероятно простое, но это оборачивается ограниченным функционалом и, порой, некорректным распознаванием русского текста. Также к недостаткам можем отнести отсутствие локализации на русский язык. Впрочем, для некоторых пользователей эти минусы несущественны, а основных возможностей будет вполне достаточно.
Также к недостаткам можем отнести отсутствие локализации на русский язык. Впрочем, для некоторых пользователей эти минусы несущественны, а основных возможностей будет вполне достаточно.
Способ 5: CuneiForm
Ещё одно решение для оцифровки текста, созданное на постсоветском пространстве. Несмотря на прекращение разработки, по-прежнему актуально.
Скачать CuneiForm
- Как и многие другие представленные в этой статье программы, КунейФорм умеет работать как с готовыми изображениями, так и получать данные напрямую со сканера. Воспользуемся первым вариантом – для этого откройте меню «Файл» и выберите в нём пункт «Открыть».
- Посредством «Проводника» выберите требуемый файл или файлы.
- После загрузки данных в программу используйте пункты «Распознавание» – «Авторазметка».
Это позволит выбрать области с текстом для более корректной работы модуля OCR. Если автоматические алгоритмы неправильно разметили страницу, области с текстом можно подправить вручную или вообще убрать. - Далее можно заниматься непосредственно оцифровкой. Снова откройте меню «Распознавание» и выберите вариант с таким же наименованием.
- Распознанный текст будет открыт в окне приложения, где его также можно редактировать. Возможности довольно обширные, и соответствуют полноценному текстовому редактору. В случае если на компьютере установлен MS Word, полученные данные будут открыты через его интерфейс.
- Сохранение результатов работы доступно по пунктам «Файл» – «Сохранить».
В открывшемся «Проводнике» выберите местоположение полученного файла и его формат. Поддерживаются не много вариантов: TXT, RTF, внутренний формат FED, а также экспорт в приложения Microsoft Office (Word и Excel).
Как видим, CuneiForm представляет собой простой и в то же время мощный инструмент для оцифровки текста. Весомым его преимуществом будет свободная модель распространения, однако недостатки в виде окончания поддержки и отсутствия формата PDF могут заставить обратиться к альтернативам.
Заключение
Как видим, распознать текст с картинки довольно просто, если использовать для этого специализированные приложения. Данная процедура не потребует от вас много усилий, а польза будет в огромной экономии времени.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТКак распознать и перевести текст с фото на Айфоне без установки приложений
Среди всех новинок iOS 15 функция Live Text кажется наиболее востребованной. Работает она также и в iPadOS 15, и в macOS Monterey. Суть этой функции заключается в том, что она извлекает (распознает) слова из изображений, а потом вставляет их в заметки, электронные письма и т.д. Пользователи уже оценили возможности Live Text как на iPhone, так и на iPad, найдя опыт действительно удивительным.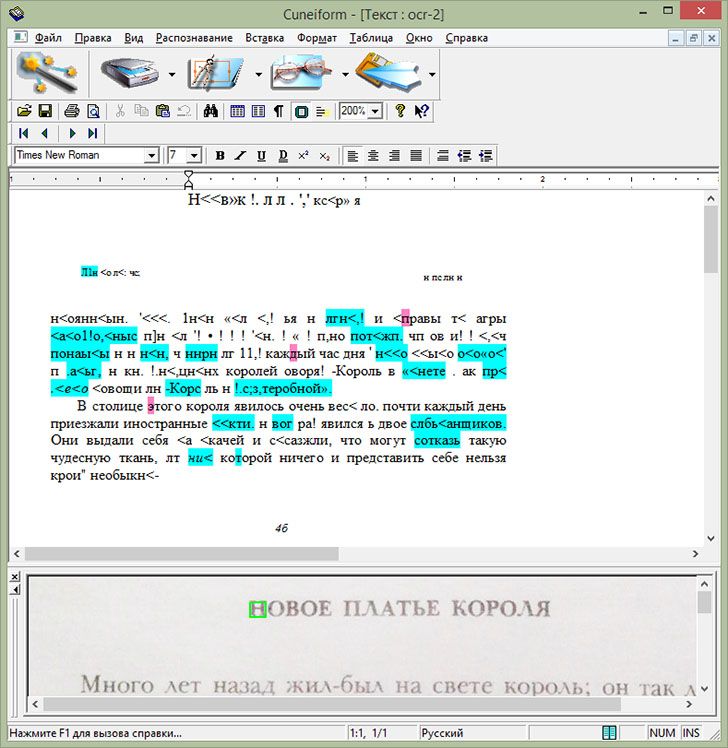
♥ ПО ТЕМЕ: Как снизить фоновый шум в видеозвонках на iPhone (выделить голос).
Для чего нужна функция Live Text?
У многих людей сформировалась привычка – не запоминать, а просто фотографировать ту информацию, которая понадобится позже. Но Live Text делает эту процедуру еще более полезной. Вместо того, чтобы сохранять изображение целиком, можно превратить текст в нем в заметку или напоминание.
Например, прогуливаясь, вы можете сразу же считать название интересующего вас ресторана на вывеске. А затем можно осуществить поиск этого заведения в Интернете. Или же, предположим, администрация заведения написала пароль от Wi-Fi на доске. Можно не вводить его побуквенно, а использовать камеру iPhone для захвата текста, через пару секунд его можно будет вставить в настройки своего устройства для подключения к общественной сети.
Студенты же могут копировать написанное на доске (функция распознает даже рукописный текст), чтобы потом вставлять в свои заметки. Эта функция должна пригодиться людям, которым на собраниях или лекциях что-то пишут на досках.
Эта функция должна пригодиться людям, которым на собраниях или лекциях что-то пишут на досках.
♥ ПО ТЕМЕ: На домашнем экране iOS 15 можно размещать одно и то же приложение несколько раз.
На каких iPhone, iPad и Mac работает LiveText?
Для работы функции LiveText вам понадобится относительно новое «железо». Функция потребует как минимум процессор A12 Bionic (выпущен в 2018 году) в вашем iPhone или iPad. К тому же Live Text работает только на компьютерах Mac с процессором серии M, но не на компьютерах предыдущих поколений с процессорами Intel.
♥ ПО ТЕМЕ: Нужно ли вынимать зарядку с розетки, когда ничего не заряжается.
Как распознавать текст на фото при помощи функции Live Text в iOS 15?
Функцией Live Text пользоваться очень просто. По сути, никакого обучения и не потребуется.
Рассмотрим пример. Допустим, вы нашли в каком-то журнале понравившийся рецепт. Достаньте свой iPhone или iPad, откройте встроенное приложение «Камера» и действуйте так, как будто собираетесь сфотографировать текст. Подождите секунду или две, и в правом нижнем углу появится небольшой значок. Нажмите на него, и появится всплывающее окно с текстом в нем.
Тут вы можете выбрать слова, предложения и прочее, что вам требуется скопировать. Нажмите поделиться во всплывающем меню.
Выберите приложение, в которое вы бы хотели экспортировать выделенный текст.
Аналогичный процесс работает с изображениями в приложении «Фото». В этом случае весь текст будет сразу показан на картинке. Затем вы можете выбрать нужные его части. Иногда специальный значок не отображается. В этом случае нажмите и удерживайте текст, который хотите выделить. Он будет выбран, если символы не окажутся слишком искаженными.
Также Live Text зачастую может вытягивать слова из изображений на веб-страницах. В ходе тестирований этот вариант пока показал себя не слишком надежным, но надо понимать, что работа велась с первыми бета-версиями iOS 15 и iPadOS 15. У Apple есть достаточно времени, чтобы улучшить Live Text к выходу финальных версий своих операционных систем.
Но даже на этой ранней стадии Live Text работает почти потрясающе. При копировании чего-либо напечатанного точность часто составляет 100%! И даже в плохих условиях обычно удается захватить почти весь текст.
Функция работает и с почерком, в том числе написанными курсивом словами. Точность распознавания зависит от того, насколько ясен текст, но он не обязательно должен быть идеальным.
Конечно, если слова написаны знаменитым «почерком врачей», то могут возникнуть проблемы. Функцию опробовали на нескольких заметках, результаты оказались правильными на 95%.
♥ ПО ТЕМЕ: Как размыть фон во время видеозвонков на iPhone (WhatsApp, FaceTime, Instagram, Telegram и т.д.).
С какими языками работает Live Text?
К огромному сожалению, функция Live Text пока поддерживает только семь языков: английский, китайский (как упрощенный, так и традиционный), французский, итальянский, немецкий, испанский и португальский. Мы очень надеемся, что поддержка русского языка появится в ближайших обновлениях операционных систем Apple.
Но даже сейчас русскоязычные пользователи могут воспользоваться этой функцией, например, в путешествиях – Live Text умеет переводить текст на русский и другие языки.
♥ ПО ТЕМЕ: 20 функций iPhone, которые можно отключить большинству пользователей.
Как переводить текст при помощи функции Live Text
Live Text, вероятно, пригодится путешественникам, потому что функция тесно связана со службой переводов Apple. Есть простой вариант использования – сделать снимок меню, затем открыть его, нажать и удерживать фразу, чтобы выбрать ее. Во всплывающем окне следует выбрать пункт Перевод, который и позволит перевести текст на необходимый язык (в том числе русский).
Первый опыт взаимодействия с такой связкой оказывается интересным и достаточно полезным. Да, перевод, неидеален. Но, находясь в чужой стране без знания местного языка, поможет и такой инструмент для формирования заказа.
♥ ПО ТЕМЕ: Как изменить метаданные местонахождения, даты и т.д. на фото в iPhone.
LiveText – это система распознавания текста для всех и везде
Live Text – это, конечно, всего лишь приложение для оптического распознавания символов. Технология эта существует уже несколько десятилетий (обзор лучших приложений для распознавания текста для iOS и Android). Но iOS 15, macOS Monterey и iPadOS 15 неплохо интегрировали в себя эту функцию. Live Text оказалась удобной и работает очень быстро.
И поскольку разработчиком функции является Apple, процесс осуществляется с учетом конфиденциальности. Функция распознавания слов работает непосредственно на вашем устройстве. Изображение не загружается на некий удаленный сервер. Это не только хорошо с точки зрения конфиденциальности, но также означает, что вам не нужно быстрое подключение к Интернету или вообще какое-либо сетевое соединение.
Смотрите также:
Как распознать текст с фотографии на смартфонах Huawei и Honor
Чтобы получить копию документа необходимо потратить время и силы на поиски ксерокопии? А что если появилась необходимость перевести текст из бумажного в электронный вариант? Неужели сложной процедуры сканирования с применением громоздкой техники не избежать? Только не для владельцев смартфонов Huawei и Honor. Обладая современным устройством можно в считанные минуты сфотографировать, отсканировать и даже распознать текст для дальнейшей работы. Понадобится только смартфон, который и без этого всегда с собой.
Как сфотографировать текст для распознавания на смартфоне
Чтобы сделать бумажный документ доступным для работы на смартфоне достаточно правильно сфотографировать его и распознать его. Безошибочное распознавание текста зависит от следующих факторов:
- Фотография должна быть пропорциональная размерам оригинального документа;
- Текст на фото располагается строго горизонтально;
- Документ должен быть равномерно освещен без резких перепадов и пятен;
- Фотография в высоком разрешении с большей долей вероятности позволит точно распознать текст.
Для фотографирования документа не нужно устанавливать каких-либо специальных приложений, просто активируем стандартную камеру на своем смартфоне Honor или Huawei. Перед началом съемки открываем вкладку «Еще» и выбираем значок «Документы». Этот режим позволит сфотографировать текст в подходящем для распознавания и дальнейшей работы формате.
Наводим камеру на страницу с текстом. Ждем, пока программа подстроится под формат и обрежет все лишнее, на это может уйти до 30 секунд. В зависимости от модели смартфона. Граница документа будет очерчена голубой линией, значит можно нажимать «Съемка». В течение 1-2 секунд фото документа будет продемонстрировано и сохранено.
Чтобы просмотреть фото еще раз необходимо нажать на «Просмотр документа», если есть желание что-то исправить, кликаем по кнопке «Сканер». В открывшемся режиме редактирования можно переместить границы, подровнять или повернуть документ. Как только желаемый результат достигнут, нажимаем на галочку для сохранения последнего варианта.
Распознаем сфотографированный на камеру смартфона текст
Как только документ сфотографирован и сохранен, его можно распознать для дальнейшей работы в электронном виде. Для распознавания и работы с текстом смартфон использует инновационные программы Optical character recognition (OCR). Алгоритм узнает на фотографии кусочек, где находится какой-либо текст и воссоздает его в соответствующем формате.
За распознавание текста отвечает встроенная по умолчанию программа Google Lens, которая также используется для считывания QR-кодов и других штрих-кодов. Чтобы распознать текст из картинки папку Google и находим там стандартное приложение Google Фото.
Открываем фотографию, которую необходимо распознать, и кликаем по пункту меню «Google Lens». В течение пары секунд после запуска программа будет анализировать изображение, после чего выделит текст на экране.
Чтобы быстро выделить весь текст на документе, нажимаем в нижней части экрана «Текст документа» и кликаем по строке «Выбрать все».
Распознанный программой текст будет выделен синим цветом. Все, что нужно сделать для продолжения работы с ним и редактирования, скопировать его и перенести в текстовый редактор. Если исходный документ был на иностранном языке, перевести его можно, кликнув по активному значку в этой же программе.
Всего за несколько минут фотографирования, распознавания и копирования текста можно получить качественный документ в электронном виде и продолжить работу с ним по своему усмотрению.
Поделиться ссылкой:
Новости партнёров и реклама
Использование движка Tesseract OCR в R
Пакет tesseract предоставляет R-привязки Tesseract: мощный механизм оптического распознавания символов (OCR), поддерживающий более 100 языков. Движок имеет широкие возможности настройки для настройки алгоритмов обнаружения и получения наилучших возможных результатов.
Имейте в виду, что OCR (распознавание образов в целом) – очень сложная проблема для компьютеров. Результаты редко бывают идеальными, а точность быстро снижается с увеличением качества входного изображения.Но если вы можете добиться приемлемого качества входных изображений, Tesseract часто может помочь извлечь большую часть текста из изображения.
Языковые данные
Механизм оптического распознавания текста tesseract использует данные для обучения языку в распознаваемых словах. Алгоритмы OCR склоняются к словам и предложениям, которые часто встречаются вместе на определенном языке, как это делает человеческий мозг. Поэтому наиболее точные результаты будут получены при использовании данных обучения на правильном языке.
Используйте tesseract_info () , чтобы вывести список языков, которые у вас в настоящее время установлены.
tesseract_info () $ путь к данным
[1] "/ Пользователи / jeroen / Library / Application Support / tesseract4 / tessdata /"
$ в наличии
[1] "chi_tra" "eng" "fra" "osd" "spa"
$ версия
[1] «4.1.1»
$ конфиги
[1] "альт" "ambigs.train" "api_config" "bigram" "box.train"
[6] "box.train.stderr" "цифры" "get.images" "hocr" "inter"
[11] "каннада" "строковый ящик" "файл журнала" "lstm.поезд "lstmbox"
[16] «lstmdebug» «makebox» «pdf» «тихий» «rebox»
[21] "strokewidth" "tsv" "txt" "unlv" "wordstrbox" По умолчанию в пакет R входят только данные для обучения английскому языку. Пользователи Windows и Mac могут установить дополнительные данные обучения с помощью tesseract_download () . Давайте сделаем OCR снимок экрана из Википедии на голландском (Нидерланды)
# Необходимо только один раз загрузить:
tesseract_download ("nld") # Теперь загружаем словарь
(голландский <- tesseract ("nld"))
текст <- ocr ("https: // jeroen.github.io/images/utrecht2.png ", двигатель = голландский)
кот (текст) Как сразу видно: почти идеально! (Хорошо, просто поверьте мне на слово).
Предварительная обработка с помощью Magick
Точность процесса распознавания текста зависит от качества входного изображения. Часто можно улучшить результаты, правильно масштабируя изображение, удаляя шум и артефакты или обрезая область, где есть текст. См. Вики по tesseract: улучшение качества для получения важных советов по улучшению качества входного изображения.
Пакет awesome magick R имеет множество полезных функций, которые можно использовать для улучшения качества изображения. Что стоит попробовать:
- Если ваше изображение перекошено, используйте
image_deskew ()иimage_rotate (), чтобы сделать текст горизонтальным. -
image_trim ()обрезает пробелы на полях. Увеличьте параметрfuzz, чтобы он работал для шумных пробелов. - Используйте
image_convert (), чтобы преобразовать изображение в оттенки серого, что может уменьшить количество артефактов и улучшить текст. - Если ваше изображение очень большое или маленькое, изменение размера с помощью
image_resize ()может помочь tesseract определить размер текста. - Используйте
image_modulate ()илиimage_contrast ()илиimage_contrast ()для настройки яркости / контрастности, если это проблема. - Попробуйте
image_reducenoise ()для автоматического удаления шума. Ваш пробег может отличаться. - С помощью
image_quantize ()вы можете уменьшить количество цветов в изображении.Иногда это помогает увеличить контраст и уменьшить количество артефактов. - Настоящие ниндзя, работающие с изображениями, могут использовать
image_convolve ()для использования собственных методов свертки.
Ниже приведен пример сканирования OCR из онлайн-курса искусственного интеллекта. Код преобразует его в черно-белое и изменяет размер + обрезает изображение перед подачей его в тессеракт, чтобы получить более точные результаты распознавания текста.
библиотека (магия) Связывание с ImageMagick 6.9.12.3
Включенные функции: cairo, fontconfig, freetype, heic, lcms, pango, raw, rsvg, webp
Отключенные функции: fftw, ghostscript, x11 input <- image_read ("https://jeroen.github.io/images/bowers.jpg")
текст <- input%>%
image_resize ("2000x")%>%
image_convert (type = 'Grayscale')%>%
image_trim (fuzz = 40)%>%
image_write (format = 'png', density = '300x300')%>%
тессеракт :: ocr ()
кот (текст) Жизнь и творчество
Фредсон Бауэрс
к
ГРАММ.ТОМАС ТАНСЕЛЛ
В КАЖДОЙ ОБЛАСТИ КОНЦЕПЦИИ ЕСТЬ НЕСКОЛЬКО ЦИФРОВ, КОТОРЫЕ
уступчивость и влияние делают их символами своего времени;
их карьера и творчество становятся ориентирами, по которым
поле измеряется и рассказывается его история. В родственных занятиях
аналитическая и описательная библиография, текстологическая критика и научная
редактирования, Фредсон Бауэрс был такой фигурой, доминирующей четыре десятилетия
после 1949 г., когда были опубликованы его «Принципы библиографического описания».
lished.К 1973 году этот период уже назывался «веком дач»:
в том же году Норман Сандерс, написавший главу о текстологической стипендии
для Шекспира Стэнли Уэллса: Избранные библиографии, дал это название
раздел его эссе. Для большинства людей этого было бы достаточно
подняться до такой позиции в такой сложной области, как шекспировские тексты.
исследования; но Дачи сыграли не менее важную роль и в других областях.
Например, редакторы американских авторов XIX века
также следует называть недавнее прошлое «веком дач», как писатели
описательных библиографий авторов и печатных изданий.Его повсеместность в
обширная область библиографического и текстологического исследования, его, казалось бы, ком-
полное владение им отличало его от его прославленных предшественников.
Сорса и сделал его олицетворением библиографической науки в
его время.
Когда в 1969 году Бауэрс был награжден Золотой медалью Библии.
графического общества в Лондоне, цитата Джона Картера относилась к
Принципы как «величественные» называют текущие проекты Бауэрса «грозными»,
сказал, что он «наложил критическую дисциплину» на тексты нескольких
авторы описали «Исследования в области библиографии» как «великий и продолжающийся
достижения »и включил в число своих характеристик« бескомпромиссное
серьезность цели »и« профессиональная напряженность.«Дач не было
не привык к такой энкомии, но он также испытал свою долю
нападки: его научные позиции не пользовались всеобщей популярностью, и он
выразил их с агрессивностью, которая казалась почти рассчитанной на Чтение из файлов PDF
Если ваши изображения хранятся в файлах PDF, их сначала необходимо преобразовать в соответствующий формат изображения. Мы можем сделать это в R, используя функцию pdf_convert из пакета pdftools. Используйте высокое разрешение для сохранения качества изображения.
pngfile <- pdftools :: pdf_convert ('https://jeroen.github.io/images/ocrscan.pdf', dpi = 600) Преобразование страницы 1 в ocrscan_1.png ... готово! текст <- tesseract :: ocr (pngfile)
кот (текст) | САПОРСКИЙ ПЕРЕУЛОК - БУЛ - СПОРТ - Bh35 8 ER
ТЕЛЕФОННЫЙ БУЛ (945 13) 51617 - ТЕЛЕКС 123456
Наш Ref. 350 / PJC / EAC 18 января 1972 г.
Доктор П.Н. Кандалл,
ООО "Майнинг Сюрвейз",
Холройд-роуд,
Чтение,
Беркс.
Дорогой Пит,
Разрешите познакомить вас со средством факсимильной связи.
коробка передач.В факсимильной связи фотоэлемент выполняет растровое сканирование
тематическая копия. Вариации плотности печати на документе
заставляют фотоэлемент генерировать аналогичный электрический видеосигнал.
Этот сигнал используется для модуляции несущей, которая передается на
удаленный пункт назначения по радио или кабельной линии связи.
На удаленном терминале демодуляция восстанавливает видео
сигнал, который используется для модуляции плотности печати, производимой
печатающее устройство. Это устройство сканирует в режиме растрового сканирования синхронизировано
с этим на передающем терминале.В результате факсимиле
создается копия тематического документа.
Вероятно, у вас есть использование этого средства в вашей организации.
Искренне Ваш,
44, ж
П.Дж. Кросс
Руководитель группы - факсимильные исследования
Зарегистрирован в Англии: № 2038.
Зарегистрированный офис № 1: GO Vicara Lane, Ilford. Eseex. Параметры управления Tesseract
Tesseract поддерживает сотни параметров управления, которые изменяют механизм распознавания текста. Используйте tesseract_params () , чтобы вывести список всех параметров с их значениями по умолчанию и кратким описанием.Он также имеет удобный аргумент filter для быстрого поиска параметров, соответствующих определенной строке.
# Вывести список всех параметров с * цветом * в названии или описании
tesseract_params ('цвет') # Тиббл: 3 × 3
param default desc
*
1 editor_image_word_bb_color 7 Цвет границы слова
2 editor_image_blob_bb_color 4 Цвет ограничивающей рамки Blob
3 editor_image_text_color 2 Правильный цвет текста Обратите внимание, что некоторые параметры управления изменились между Tesseract Engine 3 и 4.
tesseract :: tesseract_info () ['версия'] $ версия
[1] "4.1.1" Персонажи белого / черного списка
Одним из важных параметров является tessedit_char_whitelist , который ограничивает вывод ограниченным набором символов. Это может быть полезно для чтения, например, чисел, таких как банковский счет, почтовый индекс или счетчик газа.
Параметр белого списка работает для всех версий движка Tesseract 3, а также версий движка 4.1 и выше, но, к сожалению, в Tesseract 4.0 он не работал.
номеров <- tesseract (options = list (tessedit_char_whitelist = "$ .0123456789"))
cat (ocr ("https://jeroen.github.io/images/receipt.png", engine = numbers)) 90,52 долл. США
81,52 $
9,00 долларов США
90,52 долл. США Чтобы проверить, действительно ли это работает, посмотрите, что произойдет, если мы удалим $ из tessedit_char_whitelist :
# Не допускать никаких знаков доллара
числа2 <- tesseract (options = list (tessedit_char_whitelist = ".0123456789 "))
cat (ocr ("https://jeroen.github.io/images/receipt.png", engine = numbers2)) 90,52
81,52
9.00
90,52 Обратите внимание, как это заставляет tesseract определять число (3, 8 или 5), если мы исключаем знак доллара.
Как использовать Live Text в iOS 15 и iPadOS 15
Apple внесла в iOS 15 несколько интересных и замечательных улучшений. Но среди всех функций Live Text привлек мое внимание. В конце концов, встроенная функция OCR может помочь вам распознавать, копировать и использовать текст с изображений или сценариев в реальном времени.
Итак, что такое Live Text и как его можно использовать на iPhone и iPad. Присоединяйтесь ко мне, когда я углублюсь в эту новую функцию iOS и сравню ее с Google Lens.
Что такое Live Text в iOS 15?Live Text - это интеллектуальная интегрированная функция распознавания текста в iOS 15; он распознает и оцифровывает текст на фотографиях. Отсканированный текст можно использовать несколькими способами: от копирования и вставки до поиска в Интернете.
Кроме того, Live Text может похвастаться следующими особенностями:
Теперь все это открывает двери для множества вариантов использования, от оцифровки рукописных заметок до сканирования номера / адреса на ходу и записи рецептов или квитанций до получения дополнительной информации о ресторане на картинке.
Live Text iOS 15 поддерживаемые устройстваХотя это очень удобная функция, не все пользователи iOS, iPadOS или macOS могут ею воспользоваться. Для запуска функции Live Text на вашем устройстве у вас должно быть:
- iPhone и iPad с A12 Bionic или новее и под управлением iOS 15 / iPadOS 15 или новее
- iPhone XS и новее
- iPad Pro 2020 и новее
- iPad Mini 5-го поколения
- iPad Air 2019 или новее
- iPad 2020
- Mac с процессором M1 и macOS Monterey.
- Запустите приложение Camera и направьте его на текст, который вы хотите захватить.
- Коснитесь общей области текста . Вы увидите, как вокруг него образуется желтая скобка.
- Теперь нажмите значок Live Text (с желтыми скобками и текстом внутри) в правом нижнем углу страницы.
- Выберите нужный текст, и вы можете
- Скопировать текст в буфер обмена и вставить его при необходимости.
- Выбрать все , чтобы выделить весь текст и символы на изображении.
- Look Up для поиска выделенного текста в Интернете.
- Перевести , чтобы преобразовать текст на поддерживаемый язык.
- Поделиться … для отправки текста через Сообщения, электронную почту, WhatsApp или любое другое приложение.
- Откройте приложение Фото и выберите фотографию.
- Коснитесь значка Live Text в правом нижнем углу страницы.
- Проведите пальцами по тексту, чтобы выделить его.
- Теперь скопируйте и вставьте, найдите, переведите или поделитесь текстом.
- Запустите приложение по вашему выбору; Я, например, делал заметки.
- Нажмите и удерживайте экран, чтобы вызвать плавающее окно параметров.
- Выбрать текст из камеры ; экран разделится на две части с камерой внизу.
- Перенести объект с текстом в поле зрения камеры; Live View автоматически начнет распознавать текст и вставлять его в приложение.
- При необходимости выделите текст и нажмите Вставить , чтобы завершить процесс.
- Запустите приложение камеры и направьте его на номер телефона / адрес электронной почты или откройте приложение «Фото» и выберите изображение.
- Коснитесь значка Live View .
- Выберите
- Телефонный номер: вы можете позвонить, отправить сообщение, FaceTime или скопировать номер.
- Идентификатор электронной почты: Открывает почтовое приложение по умолчанию, чтобы вы могли быстро составлять и отправлять почту.
Примечание : Это также работает с адресами; просто отсканируйте изображение с помощью Live View и коснитесь адреса. он откроется в приложении "Карты".
Вы уже тестировали функцию Live Text? Поделитесь с нами своим мнением в разделе комментариев ниже.
Подробнее:
Как скопировать и вставить текст с фотографии
Apple представляет iPhone 13 в Великобритании в своем магазине на Риджент-стрит 24 сентября 2021 года в Лондоне, Англия.
Ming Yeung | Getty Images
Последняя версия операционной системы iPhone, iOS 15, имеет несколько новых функций, которые используют искусственный интеллект для анализа содержимого фотографии.
Хотя распознавание объектов существует уже некоторое время, Apple утверждает, что его реализация отличается, потому что это происходит на устройстве, а не на облачном сервере.Кроме того, он встроен в операционную систему.
Одним из самых удобных приложений этой новой технологии является возможность копировать и вставлять текст с фотографии - так, например, пользователи могут сделать снимок страницы в книге, а затем взять этот текст и поместить его в документ. или записку.
Он также позволяет пользователям более легко звонить или отправлять электронную почту, распознавая номера телефонов и адреса электронной почты, которые были записаны, как на визитной карточке.
Он также работает с рукописным текстом - пример Apple, когда она объявила об этой функции в июне, превращала каракули на доске в заметки.
Вот как это работает:
Копирование текста с фотографии
Увеличить значок Стрелки, указывающие наружу- Сделайте снимок с текстом, который вы хотите скопировать в документ. В этом примере мы используем рецепт из поваренной книги.
- Зайдите в приложение «Фото» и выберите фотографию с текстом, который вы хотите скопировать. Эта функция также работает из камеры в приложении камеры.
- Нажмите пальцем на текст, который хотите скопировать, так же, как в Apple Note или текстовом сообщении.На фотографии должны появиться две точки селектора текста.
- Растяните курсоры выделения текста, чтобы покрыть весь текст, который вы хотите скопировать. Нажмите "копировать".
- Зайдите в текстовый редактор по вашему выбору, нажмите на текстовое поле и вставьте.
Сделайте снимок текста и поместите его прямо в приложение Notes
Увеличить значок Стрелки, направленные наружуЖивой текст работает в текстовых процессорах
Снимок экрана
- Новая функция также работает непосредственно в текстовом процессоре, таком как приложение Notes.
- Нажмите на экран и выберите значок во всплывающем окне, который выглядит как три строки текста в квадратном поле. Это значок Live Text.
- Окно камеры поднимается вверх в нижней половине экрана. Наведите его на текст, и программа автоматически его распознает.
- Программное обеспечение Apple выделит текст, который нужно вставить в приложение внутри окна фотографии.
- Нажмите синюю кнопку «Вставить», когда программа выбрала правый фрагмент текста.
Сканировать текст прямо с камеры iPhone
Увеличить значок Стрелки, указывающие наружу- Вы также можете сканировать текст прямо из приложения камеры iPhone.
- Наведите камеру на слова, и если программа распознает текст, она отобразит значок из трех строк текста в правом нижнем углу видоискателя или в правом верхнем углу в альбомной ориентации.
- Нажмите кнопку. Он станет желтым, и появится окно, посвященное тексту на фотографии.
- Вы можете выделить этот текст и скопировать его в любой документ.
Apple Live Text позволяет взаимодействовать с текстом на фотографиях - TechCrunch
Apple представила новую функцию в своей системе камеры, которая автоматически распознает и расшифровывает текст на ваших фотографиях, от номера телефона на визитной карточке до доски, полной заметок. Live Text, как называется функция, не требует никаких подсказок или специальной работы со стороны пользователя - просто нажмите значок, и все готово.
Объявленный Крейгом Федериги на виртуальной сцене WWDC, Live Text появится на iPhone с iOS 15.Он продемонстрировал это с помощью пары изображений, одной из которых была доска после встречи, и пары снимков, на которых были вывески ресторанов на заднем плане.
При нажатии кнопки «Живой текст» в правом нижнем углу обнаруженный текст слегка подчеркивается, а затем смахивание позволяет выделить и скопировать его. В случае с доской он собрал несколько предложений с заметками, включая маркеры, и с помощью одной из табличек ресторана он получил номер телефона, по которому можно было позвонить или сохранить.
Некоторые типы текстовых строк также могут быть распознаны: код отслеживания будет рассматриваться как таковой, и ссылка на URL отслеживания будет доступна немедленно. Перевод может быть выполнен быстро на любой язык или с любого языка, поддерживаемого другими инструментами перевода Apple.
Эта функция напоминает многие функции давно разработанного Google приложения Lens, а Pixel 4 в 2019 году добавил более надежные возможности сканирования. Разница в том, что текст захватывается более или менее пассивно на каждой фотографии, сделанной iPhone с новым система - вам не нужно входить в режим сканера или запускать отдельное приложение.
Это хорошая вещь для всех, но она может быть особенно полезна людям с нарушениями зрения. Один или два снимка позволяют продиктовать или сохранить любой текст, который иначе трудно читать.
Весь процесс происходит по телефону, поэтому не беспокойтесь, что эта информация отправляется куда-то в центр обработки данных. Это также означает, что это происходит довольно быстро, хотя, пока мы не проверим это на себе, мы не сможем сказать, является ли это мгновенным или, как некоторые другие функции машинного обучения, чем-то, что происходит в течение следующих нескольких секунд или минут после того, как вы сделаете снимок.Тем не менее, ваш задний каталог фотографий будет отображаться в режиме реального времени в режиме реального времени, когда ваш телефон простаивает.
3 шага для обнаружения текста на изображении
2021-08-24 09:19:46 • Отправлено по адресу: OCR Solution • Проверенные решения
Вы можете спросить, как определить текст на изображении? В этом случае вам необходимо использовать технологию оптического распознавания символов.PDFelement - одна из лучших и наиболее продвинутых опций, которые можно использовать для обнаружения текста на изображении с помощью распознавания текста. Для обнаружения слов в изображении эта программа заботится о внедрении новейших технологий с осторожностью и безупречностью. Здесь мы познакомим вас с двумя методами точного и безупречного обнаружения текста на изображениях.
Обнаружение текста в изображении с помощью PDFelement
Шаг 1. Импортируйте изображение
Нажмите кнопку «Создать PDF» в главном интерфейсе, чтобы выбрать изображение для импорта.
Шаг 2. Обнаружение OCR
Нажмите кнопку «Выполнить OCR», в новом всплывающем окне выберите «Редактируемый текст» и нажмите кнопку «Язык», чтобы выбрать правильный язык содержания изображения, после чего вы можете начать процесс обнаружения OCR.
Шаг 3. Преобразование изображения в текст
После процесса обнаружения OCR текст во вновь открытом файле PDF уже доступен для редактирования. Вы можете выделить текст для копирования и вставки или отредактировать текст непосредственно в PDFelement.Вы можете обратиться к статье о том, как редактировать PDF-текст.
Если вы хотите получить текстовый файл, вы также можете использовать PDFelement для его преобразования. После обнаружения OCR щелкните вкладку «Преобразовать», затем щелкните значок «Word» или «Текст», чтобы преобразовать файл в текстовый или текстовый файл.
Обнаружение слов в изображении с помощью PDFelement
Шаг 1. Импортируйте изображение
Нажмите кнопку «Создать PDF» в главном интерфейсе, чтобы выбрать изображение для импорта.
Шаг 2.Обнаружение слов по изображению
Щелкните «Форма»> «Извлечение данных»> «Извлечь данные из помеченного PDF-файла», чтобы убедиться, что данные вручную обнаруживаются в PDF-файле. Вы можете использовать мышь, чтобы указать поля файла, в которых требуется обнаружение данных.
Шаг 3. Получите текст с изображения
Нажмите кнопку «Далее» в интерфейсе, чтобы начать обнаружение. После этого нажмите кнопку «Да» на синей панели уведомлений, чтобы полностью завершить процесс и назвать свое обнаружение данных.Нажмите «Пуск» во всплывающих окнах. Вы получите текст в формате .csv в выходной папке.
Лучшее программное обеспечение для обнаружения текста на изображении
Для автоматического обнаружения и распознавания текста в естественных изображениях PDFelement - один из лучших способов убедиться, что работа выполнена. Это один из лучших способов не выполнять работу с легкостью. Программа получила высокие оценки пользователей, и все это из-за удобства использования и жизнеспособности, которые она представляет.С помощью PDFelement вы можете быть уверены, что идея обнаружения текста в изображениях в Интернете никогда не используется, поскольку это небезопасный метод. С PDFelement OCR еще никогда не было таким простым, как эта программа. Выполняйте работу с PDFelement и сделайте свои документы точными. Программа настоятельно рекомендуется заинтересованным пользователям во всем мире.
PDFelement - одна из лучших программ, которую следует использовать, чтобы убедиться, что задачи, связанные с PDF, выполняются легко и безупречно.Сделать PDF-файлы удобными для пользователя - одна из лучших вещей, которые делает эта программа. Настоятельно рекомендуется использовать эту программу в качестве программного обеспечения для управления PDF, которое гарантирует, что вы никогда не застрянете в какой-либо задаче, связанной с PDF.
Безопасное редактирование PDF-файлов
С помощью программы можно редактировать не только файлы PDF, но и изображения, водяные знаки, ссылки, страницы, фон и заголовки. Это один из лучших способов убедиться, что вы никогда не будете использовать сложные программы, которые позволят вам застрять в трудную минуту.PDFelement был разработан таким образом, чтобы вы могли редактировать изображения, применяя несколько методологий. Он также позволяет аккуратно и безупречно обрезать изображения PDF. Вы также можете редактировать текст и следить за тем, чтобы у вас никогда не было проблем.
PDF Аннотация
АннотацииPDF - это относительно новая идея, которая была добавлена в PDFelement. Это один из лучших способов легко и с удовольствием комментировать файлы PDF. С помощью элемента PDF очень легко убедиться, что выполняется аннотация любого типа.Это гарантирует, что вы никогда не столкнетесь с проблемами. Его можно использовать для добавления заметок, текстовых полей и штампов в файлы PDF. Вы можете использовать персонализированные инструменты, чтобы быть уверенным, что лучший результат достигается с осторожностью и безупречностью.
Преобразование и создание PDF
С помощью PDFelement вы можете выполнять преобразование PDF в другие форматы. Это очень простая задача, и вы никогда не попадете в неприятности. С PDFelement вы можете пользоваться мощным инструментом для создания PDF-файлов, а также можете быть уверены, что PDF-файл преобразован в форму файла, которую можно легко и безупречно редактировать.С PDFelement управление PDF становится простым и понятным. Сделав эту программу вашим партнером, вы получите лучший результат, связанный с файлами PDF. PDFelement также можно использовать для извлечения данных.
Защита PDF
С помощью PDFelement вы можете легко убедиться, что ваши файлы PDF никогда не будут доступны посторонним лицам. Это можно сделать с помощью различных механизмов, которые встроены в программу и могут использоваться для защиты файлов PDF.Вы также можете использовать программу для цифровой подписи файлов PDF, что означает, что они подписаны вашим именем. Вы также получаете разрешения, чтобы гарантировать получение наилучшего и наиболее продвинутого результата. Благодаря расширенным функциям печати вы можете быть уверены, что файлы PDF защищены наилучшим образом.
Другие особенности PDFelement
- Для распознавания текста на изображении лучше всего подходит эта программа. Это гарантирует, что OCR выполняется наиболее точно.
- С помощью PDFelement вы можете аккуратно добавлять, удалять, изменять размер и вращать графические элементы в PDF.
- PDFelement можно использовать для цифрового утверждения и подписи документов.
Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
Как применить OCR для распознавания текста на любом изображении с помощью Python | от Ivy Professional School
Недавно меня осенила интригующая мысль.При всей автоматизации и технологическом прогрессе, с которыми мы сталкиваемся каждый день, я начал задаваться вопросом, можно ли в электронном виде прочитать текст с любого изображения. Я обратился к всеведущему гуглу за ответами и вуаля! Благодаря Google я понял, что эта мысль пришла мне в голову с опозданием на несколько десятилетий. Для начала я наткнулся на такие термины, как «Компьютерное зрение» и «Оптическое распознавание символов». Тем не менее, я решил шагнуть в этот новый мир компьютерного зрения и попробовать себя.Моя цель в этом посте - дать вам представление о компьютерном зрении и оптическом распознавании символов (OCR). Будет очень интересно посмотреть, как мы можем извлекать текст из изображения с помощью Python.
Компьютерное зрение - это область компьютерных наук, в которой мы хотим позволить компьютерам идентифицировать и обрабатывать изображения и объекты так же, как это делаем мы, люди. Это также включает предоставление полезных результатов, основанных на наблюдении. Позвольте мне уточнить некоторые практические примеры.
- Одной из наиболее заметных областей применения является медицинское компьютерное зрение.Мы извлекаем информацию из данных изображения, которая помогает диагностировать пациента. Примером этого является обнаружение опухолей, атеросклероза или других злокачественных изменений.
- Сканер текста - еще одно широко используемое приложение для компьютерного зрения. Благодаря этому мы можем сканировать любой текст с изображения с помощью оптического распознавания символов, отображать текст на экране и выполнять любые дальнейшие операции / задачи.
OCR - это раздел компьютерного зрения. Несмотря на то, что это не требует пояснений, это метод распознавания текста внутри цифрового изображения физического документа, например, отсканированного документа, а также его можно напрямую преобразовать в редактируемый текстовый редактор.
Объяснив эти термины, перейдем к выбору двух изображений, с которых мы хотим прочитать текст. Иногда от нас требуется прочитать изображение по URL-адресу. Я выбрал изображение, доступное как URL. Другой - текстовое изображение, которое я взял в Google. Я поделился обоими ниже.
Давайте перейдем к Python и к коду для извлечения текста из этих изображений. Предоставленный код написан на Google Colab.
Во-первых, нам нужно установить и / или импортировать необходимые библиотеки. Кратко рассмотрим используемые библиотеки.
Pytesseract - Python-tesseract - это инструмент оптического распознавания символов (OCR) для Python. Он может распознавать и читать текст, встроенный в изображения.
IO - Модуль io предоставляет основные возможности Python для работы с различными типами ввода-вывода.
BytesIO - Двоичный ввод-вывод (также называемый буферизованным вводом-выводом ) ожидает байтовые объекты и создает байтовые объекты. Кодирование, декодирование или перевод новой строки не выполняется. Эта категория потоков используется для всех видов нетекстовых данных.
Запросы - Запросы позволяют отправлять обычных HTTP / 1.1-запросов без ручного труда. Это помогает получить HTML-код любого веб-сайта.
PIL - Библиотека изображений подушек - это бесплатная библиотека для языка программирования Python, которая добавляет поддержку для открытия, управления и сохранения множества различных форматов файлов изображений.
Ниже приведен код -
1
2
3
4
5
6
7
8
9
10
11
12
12 sudo & nbsp; apt & nbsp; install & nbsp; tesseract-ocr
! pip & nbsp; install & nbsp; pytesseract
import & nbsp; pytesseract
: ; Nbsp; 9000 & nbsp; Nbsp; 9000 & nbsp; ; ImportError:
import & nbsp; Image
Давайте выберем наше первое изображение с URL-адресом.Нам нужно связаться с URL-адресом, получить его исходный код с помощью команды requests.get. Поскольку это изображение, мы откроем и сохраним это изображение как переменную. Наконец, мы прочитаем текст на изображении, используя команду image_to_string от tesseract, а затем распечатаем содержимое. Команды представлены ниже.
1
2
3
4
5
6
7
8
9
10
11
12
13
nbs ; io & nbsp; import & nbsp; BytesIO
url = "https: // i.oodleimg.com/item/5528750302u_0x424x360f?1570301166 "
response & nbsp; = & nbsp; request.get (url)
img1 & nbsp; = & nbsp; Image.open & nbsp; ; = & nbsp; pytesseract.image_to_string (img1)
print (extractInformation)
Результат выглядит следующим образом.
Теперь давайте выберем второе изображение. Это файл, а не URL.Следовательно, наша команда изменится соответствующим образом, что вы можете найти ниже.
1
2
3
4
5
img2 = & nbsp; (Image.open ('Text_paragraph.png'))
extractInformation & nbsp; = & nbspimage_tes_tes )
print (extractInformation)
Сгенерированный вывод выглядит следующим образом.
Самым популярным приложением OCR является распознавание рукописного текста.С преобразованием рукописного текста в цифровой, единообразие и удобство использования многократно увеличиваются. Тем не менее, недостатком OCR является неточность на 100%. Как вы, возможно, уже заметили, он не может правильно распознать веб-сайт по первому изображению. Существуют способы повышения точности распознавания текста с помощью OCR, которые выходят за рамки данной статьи.
Мы хотели бы побудить вас опробовать эту интересную концепцию оптического распознавания символов из мощного мира компьютерного зрения и разместить свои комментарии и замечания.
Parallels ToolBox 5.0 Инструмент распознавания текста
Инструмент «Распознать текст» - один из новых инструментов в Parallels® Toolbox 5.0, выпущенный 27 июля 2021 года. Этот инструмент «извлекает» текст из фотографии или изображения. Несмотря на то, что функция «Распознать текст» была доступна чуть больше месяца, она быстро стала моим вторым по популярности инструментом в Parallels Toolbox. (К вашему сведению, мой наиболее часто используемый инструмент - это загрузка видео.)
Я обнаружил несколько приемов для получения наилучших результатов от инструмента «Распознать текст», и я представляю эти и несколько других предостережений в отношении этого инструмента в этом сообщении в блоге.
Основные операцииКак и все инструменты в Parallels Toolbox, основная операция инструмента Распознать текст проста и понятна: перетащите изображение в инструмент, выберите язык и извлеките текст. В моем предыдущем сообщении в блоге показано, как это работает.
Получение наилучших результатовСовет №1 Сканирование с более высоким разрешением обычно дает наилучшие результаты.
Если у вас есть опция разных точек на дюйм (dpi), например, если вы сканируете фотографию, более высокое значение dpi обычно дает лучшие результаты. См. Рисунок 1. (Изображение на рисунках 1, 2 и 3 - это задняя обложка книги «Объектно-ориентированное программирование для Macintosh», изображение любезно предоставлено автором).
Рисунок 1_ Повышенный DPI может улучшить результатыСовет № 2 Выбор определенных частей изображения может улучшить результаты.
Если текст, который вы хотите извлечь, окаймлен графикой, выделение только текстовой области может улучшить результаты. См. Рисунок 2
Рис. 2_Выбор части сложного макета может улучшить результатыСовет № 2.5. Увеличьте окно «Распознать текст», чтобы получить изображение большего размера и упростить выбор части.
Не можете выбрать область для сканирования? Просто сначала увеличьте окно «Распознать текст». См. Рисунок 3.
Рис. 3. При изменении размера окна «Распознать текст» эскиз увеличится.Совет № 3 Выпрямление текста по горизонтали может улучшить результаты.
См. Рис. 4. (Изображение на рис. 4 и рис. 6 любезно предоставлено фотографом.) Я выпрямил текст на этом изображении с помощью инструментов обработки изображений в Microsoft PowerPoint.
Рис. 4_Поворот изображения так, чтобы текст располагался горизонтально, может улучшить результатыСовет № 4 Вертикальный текст
Некоторые языки, например , японский и китайский, часто пишутся вертикально. В настоящее время функция распознавания текста не поддерживает вертикальный текст.Однако команда инженеров Parallels знает, что вертикальный текст очень важен, и они уже начали работу над добавлением этой поддержки в инструмент распознавания текста. Следите за обновлениями в этом сообщении в блоге. (См. Рис. 5 из 眞 月 - 二 十五 周年 を 迎 え て, 眞 月 会, 1994)
Рисунок 5_Currently Recognize Text не поддерживает вертикальный текстСовет № 5 Текст на нескольких, смешанных языках - даже не пытайтесь.
Совет № 6 Необычные, богато украшенные каллиграфические шрифты или почерк - даже не пытайтесь.
(См. Рисунок 6. Изображение на этом рисунке взято из BiblioficDesigns.)
Надеюсь, эти советы помогут вам в использовании инструмента «Распознать текст».