
Настройка конфигурации Adobe Scan — Adobe Scan для iOS
Доступ к странице параметров Adobe Scan можно получить из в левом верхнем углу. Возможно, потребуется коснуться , чтобы закрыть экран съемки. Для изменения конфигурации перейдите к необходимым настройкам в разделе О приложении Adobe Scan и/или в Настройках.
Отключение передачи данных по сотовой сети
По умолчанию передача данных по сотовой сети включена на устройствах с доступом к сотовой сети. Для выключения передачи данных по сотовой сети коснитесь > Установки > Разрешить передачу данных по сотовой сети.
При открытии экрана настроек устройства включите/выключите передачу данных по сотовой сети в Scan.
Отключение распознавания текста
По умолчанию приложение автоматически преобразует текст на изображении в полноценный текст при помощи технологии оптического распознавания символов (OCR). По умолчанию язык текста для распознавания — это язык устройства. Автоматическое распознавание текста позволяет сохранять, редактировать, рецензировать и выполнять другие действия с текстом.
Автоматическое распознавание текста позволяет сохранять, редактировать, рецензировать и выполнять другие действия с текстом.
Для изменения настроек OCR выполните следующие действия:
Коснитесь > Установки.
Отключите функцию Выполнять распознавание текста.
Чтобы изменить язык распознавания текста, коснитесь Язык текста для распознавания и выберите нужный язык.
Поддерживаемые языки: английский, голландский, японский, финский, норвежский, шведский, французский, испанский, бразильский португальский, итальянский, немецкий, традиционный китайский, упрощенный китайский, корейский, турецкий, русский, чешский и польский.
Примечание.
Оптическое распознавание символов не работает с документами длиной более 25 страниц для большинства пользователей. Однако при платной подписке можно применять OCR для отсканированных документов размером до 100 страниц.
Корректировка границ
Процесс съемки визитных карточек можно настроить таким образом, чтобы маркеры границ отображались после каждой съемки. Если эта функция включена, отображаются маркеры обрезки, и можно обрезать изображение в процессе редактирования (перед другим сканированием или просмотром всего скана).
Включите параметр Разрешить мне корректировать границы после каждого сканирования.
Распознание блоков текста в IOS-приложении с помощью Vision / Хабр
Работая над приложением, связанным с финансовыми операциями, возникла необходимость распознать и выделить суммы на чеках. Начиная с 11-ой версии в IOS-разработке появился нативный фреймворк Vision, который позволяет распознавать различные объекты на изображениях, без задействования сторонних сервисов.
В данной статье представлен личный опыт разработки приложения, использующего Vision.
Что такое Vision
Из документации Apple: “Vision применяет алгоритмы “компьютерного зрения” для выполнения множества задач с входными изображениями и видео. Фреймворк Vision выполняет распознание лиц, обнаружение текста, распознавание штрих-кодов, регистрацию изображений. Vision также позволяет использовать пользовательские модели CoreML для таких задач, как классификация или обнаружение объектов.”
Фреймворк Vision выполняет распознание лиц, обнаружение текста, распознавание штрих-кодов, регистрацию изображений. Vision также позволяет использовать пользовательские модели CoreML для таких задач, как классификация или обнаружение объектов.”
Анализируя документацию Apple, можно предположить, что Vision – это один из этапов подготовки таких продуктов как Apple glasses или шлем смешанной реальности. Забегая вперед, следует подчеркнуть, что данный фреймворк потребляет изрядное количество ресурсов. Обработка статичного изображения может занимать десятки секунд, следовательно, работа с видео в реальном времени будет предельно ресурсоемким процессом, над оптимизацией которого инженерам Apple еще предстоит поработать.
В рамках поставленной задачи, необходимо было решить следующую проблему: распознание блоков текста с помощью Vision.
Разработка
Проект построен на UIKit, который в данной статье детально рассматриваться не будет. Основное внимание уделяется блокам кода, связанным с фреймворком Vision. Приведенные листинги снабжены комментариями, позволяющими разработчикам детальнее понять принцип работы с фреймворком.
Приведенные листинги снабжены комментариями, позволяющими разработчикам детальнее понять принцип работы с фреймворком.
В MainViewController, который будет взаимодействовать с фреймворком Vision, нужно объявить две переменные:
//Recognition queue
let textRecognitionWorkQueue = DispatchQueue(label: "TextRecognitionQueue", qos: .userInitiated, attributes: [], autoreleaseFrequency: .workItem)
//Request for text recognition
var textRecognitionRequest: VNRecognizeTextRequest?Очередь для задач Vision не вызывает никаких затруднений у разработчиков. Именно в ней будут выполняться все задачи фреймворка.
Объявляется переменная типа VNRecognizeTextRequet. Инициализируется объект из ViewDidLoad (или из init), так как он должен быть активен на протяжении всей жизни ViewController. Этот объект отвечает за работу с Vision, поэтому необходимо разобрать его инициализацию подробнее:
//Set textRecognitionRequest from ViewDidLoad func setTextRequest() { textRecognitionRequest = VNRecognizeTextRequest { request, error in guard let observations = request.results as? [VNRecognizedTextObservation] else { return } var detectedText = "" self.textBlocks.removeAll() for observation in observations { guard let topCandidate = observation.topCandidates(1).first else { continue } detectedText += "\(topCandidate.string)\n" //Text block specific for this project if let recognizedBlock = self.getRecognizedDoubleBlock(topCandidate: topCandidate.string, observationBox: observation.boundingBox) { self.textBlocks.append(recognizedBlock) } } DispatchQueue.main.async { self.textView.text = detectedText self.removeLoader() self.drawRecognizedBlocks() } } //Individual recognition request settings textRecognitionRequest!.minimumTextHeight = 0.011 // Lower = better quality textRecognitionRequest!.recognitionLevel = .accurate }
Настройки объекта textRecognitionRequest.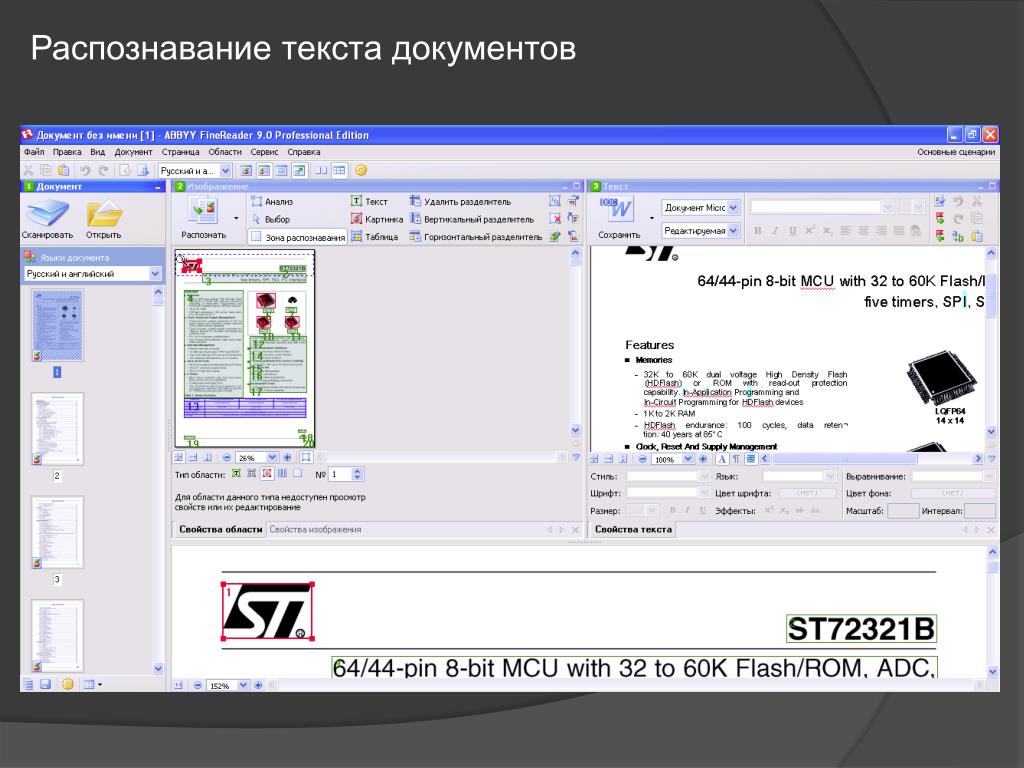 Описание всех доступных настроек можно найти в документации. Наиболее важным является параметр minimumTextHeight. Именно этот параметр отвечает за сочетание быстродействия и точности распознания текста. Для каждого проекта необходимо найти индивидуальное значение данного параметра, оно зависит от того, какие данные будет обрабатывать приложение.
Описание всех доступных настроек можно найти в документации. Наиболее важным является параметр minimumTextHeight. Именно этот параметр отвечает за сочетание быстродействия и точности распознания текста. Для каждого проекта необходимо найти индивидуальное значение данного параметра, оно зависит от того, какие данные будет обрабатывать приложение.
Так как основной поставленной задачей являлось считывание текста с квитанций, для вычисления значения параметра minimumTextHeight в приложение были добавлены различные типы квитанций в различном состоянии (в том числе и основательно помятые). В результате тестирования было определено значение равное 0.011. В случае распознания текста с квитанций, это значение лучшим образом сочетает в себе быстродействие и точность. Однако нужно отметить, что текст с одного изображения распознается в среднем за пять секунд. Подобной скорости недостаточно для обработки информации в реальном времени и ее следует значительно оптимизировать инженерам Apple.
На основе представленного кода можно сделать вывод, что после операции распознания, объект типа VNRecognizeTextRequet получает блоки текста.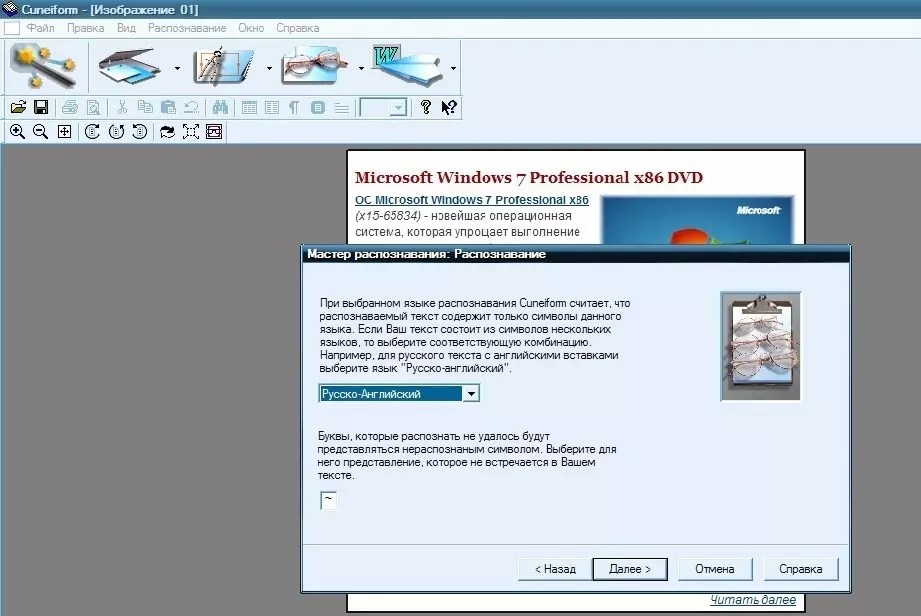 Именно с ними и ведется дальнейшая работа, в зависимости от функций приложения. В рассматриваемом примере, каждый распознанный фрагмент текста был внесен в текстовое поле. Так как особенностью задействованного приложения является выделение суммы на квитанции, следовательно, сохранялись только блоки текста, которые можно преобразовать в тип Double. Помимо распознанного текстового значения сохраняются и координаты блока текста на изображении.
Именно с ними и ведется дальнейшая работа, в зависимости от функций приложения. В рассматриваемом примере, каждый распознанный фрагмент текста был внесен в текстовое поле. Так как особенностью задействованного приложения является выделение суммы на квитанции, следовательно, сохранялись только блоки текста, которые можно преобразовать в тип Double. Помимо распознанного текстового значения сохраняются и координаты блока текста на изображении.
Представленный ниже метод отвечает за запуск работы запроса на распознание:
//Call text recognition request handler func recognizeImage(cgImage: CGImage) { textRecognitionWorkQueue.async { let requestHandler = VNImageRequestHandler(cgImage: cgImage, options: [:]) do { try requestHandler.perform([self.textRecognitionRequest!]) } catch { DispatchQueue.main.async { self.removeLoader() print(error) } } } }
В метод передается объект CGImage, в котором необходимо распознать текст. Вся работа по распознанию ведется в созданной для этого очереди. Создается объект VNImageRequestHandler, в который передается распознаваемый объект CGImage. В блоке do/try/catch запускается работа инициализированного объекта типа VNRecognizeTextRequet.
Вся работа по распознанию ведется в созданной для этого очереди. Создается объект VNImageRequestHandler, в который передается распознаваемый объект CGImage. В блоке do/try/catch запускается работа инициализированного объекта типа VNRecognizeTextRequet.
Описанные выше функции отвечают за распознание текста в приложении. Однако стоит еще остановится на методах, связанных с выделением нужных блоков текста.
func drawRecognizedBlocks() { guard let image = invoiceImage?.image else { return } //transform from documentation let imageTransform = CGAffineTransform.identity.scaledBy(x: 1, y: -1).translatedBy(x: 0, y: -image.size.height).scaledBy(x: image.size.width, y: image.size.height) //drawing rects on cgimage UIGraphicsBeginImageContextWithOptions(image.size, false, 1.0) let context = UIGraphicsGetCurrentContext()! image.draw(in: CGRect(origin: .zero, size: image.size)) context.setStrokeColor(CGColor(srgbRed: 1, green: 0, blue: 0, alpha: 1)) context.setLineWidth(4) for index in 0 ..< textBlocks.count { let optimizedRect = textBlocks[index].recognizedRect.applying(imageTransform) context.addRect(optimizedRect) textBlocks[index].imageRect = optimizedRect } context.strokePath() let result = UIGraphicsGetImageFromCurrentImageContext() UIGraphicsEndImageContext() invoiceImage?.image = result }

В данной статье рисование на изображении не рассматривается, так как при работе с разделом рисование у разработчиков не возникает никаких трудностей. При этом, стоит обратить внимание на особенности работы с координатами распознанных блоков текста. Для сохранения необходимых данных была использована следующая структура:
struct RecognizedTextBlock { let doubleValue: Double let recognizedRect: CGRect var imageRect: CGRect = .zero }
При распознании блоков текста фреймворк Vision вычисляет ряд важных параметров в объекте VNRecognizedTextObservation. Для нужд рассматриваемого проекта необходимо было получить только значение типа Double и его координаты на изображении, сохраняемые в константе recognizedRect.
Для нужд рассматриваемого проекта необходимо было получить только значение типа Double и его координаты на изображении, сохраняемые в константе recognizedRect.
Для выделения блока текста на изображении, следует применить трансформацию к координатам из константы recognizedRect. Полученные координаты так же сохраняются в объекте RecognizedTextBlock в переменной imageRect, необходимой для обработки нажатий на выделенные блоки текста.
После сохранения точных координат выделяемых блоков на изображении, обработку нажатий на выделенные области можно осуществить несколькими способами:
Добавить необходимое количество невидимых кнопок на изображение, при помощи трансформации сохраненного объекта imageRect;
При каждом нажатии на изображение проверять массив блоков текста и искать совпадение координат нажатия с сохраненным объектом imageRect и др.
Чтобы не перегружать ViewController дополнительными элементами, был использован второй способ.
//UIImageView tap listener
@objc func onImageViewTap(sender: UITapGestureRecognizer) {
guard let invoiceImage = invoiceImage, let image = invoiceImage. image else {
return
}
//get tap coordinates on image
let tapX = sender.location(in: invoiceImage).x
let tapY = sender.location(in: invoiceImage).y
let xRatio = image.size.width / invoiceImage.bounds.width
let yRatio = image.size.height / invoiceImage.bounds.height
let imageXPoint = tapX * xRatio
let imageYPoint = tapY * yRatio
//detecting if one of text blocks tapped
for block in textBlocks {
if block.imageRect.contains(CGPoint(x: imageXPoint, y: imageYPoint)) {
showTapAlert(doubleValue: block.doubleValue)
break
}
}
}
image else {
return
}
//get tap coordinates on image
let tapX = sender.location(in: invoiceImage).x
let tapY = sender.location(in: invoiceImage).y
let xRatio = image.size.width / invoiceImage.bounds.width
let yRatio = image.size.height / invoiceImage.bounds.height
let imageXPoint = tapX * xRatio
let imageYPoint = tapY * yRatio
//detecting if one of text blocks tapped
for block in textBlocks {
if block.imageRect.contains(CGPoint(x: imageXPoint, y: imageYPoint)) {
showTapAlert(doubleValue: block.doubleValue)
break
}
}
}Использование представленного метода позволяет вычислить координаты нажатия на объект ImageView с сохранением его пропорций и поиска полученных координат в массиве сохранных распознанных блоков текста.
Выводы
Представленная статья позволяет разработчикам IOS-приложений ознакомиться с фреймворком Vision, прежде всего с его функцией распознания текста. Тестовое приложение, полученное в результате работы с распознанием текста в Vision, является ключом к пониманию работы с такими возможностями фреймворка как распознание лиц, текста, штрих-кодов и др.
Тестовое приложение, полученное в результате работы с распознанием текста в Vision, является ключом к пониманию работы с такими возможностями фреймворка как распознание лиц, текста, штрих-кодов и др.
Cкриншоты полученного приложения для распознавания цифровых значений на различных изображениях представлены ниже:
Приложение распознающее блоки текста с помощью VisionДля ознакомления проект можно скачать из репозитория.
Какие программы для распознавания текста использовать в офисе — Сводные таблицы Excel 2010
Меня часто спрашивают: «Отсканировали (сфотографировали) страничку, файл открывается, читается. Как теперь внести в этот документ исправления?» Ответ: просто так — никак! То, что вы отсканировали — изображение, картинка, набор разноцветных точек. Редактировать можно только документ, состоящий из знаков (символов).
Самое большее, что вы можете сделать с картинкой — в графическом редакторе (Paint, GIMP и т. п.) закрасить или вырезать на ней отдельные участки и нарисовать буквы и цифры. Редактируемым документом от этого изображение не станет!
Редактируемым документом от этого изображение не станет!
Однако решение есть: оптическое распознавание символов (optical character recognition, OCR). Программа анализирует изображение, выделяет из него характерные очертания букв и цифр, а потом создает настоящий редактируемый документ. Примерно то же самое делаете вы, когда читаете написанное и набираете прочитанное на клавиатуре. Правда, в распознавании символов компьютеру еще очень далеко до человека. Люди безошибочно разбирают любые каракули, а программы OCR пока хорошо справляются только с четкими изображениями печатных букв. С технологией OCR тесно связан рукописный ввод, который используется в планшетах и смартфонах. Пользователь пальцем или стилусом рисует на сенсорном экране буквы и цифры, а смартфон распознает их. Вы могли заметить, что устройство верно воспринимает только аккуратно начерченные символы, а криво или косо нарисованные приводят его в замешательство.
Весьма эффективное средство распознавания входит в состав пакета Microsoft Office.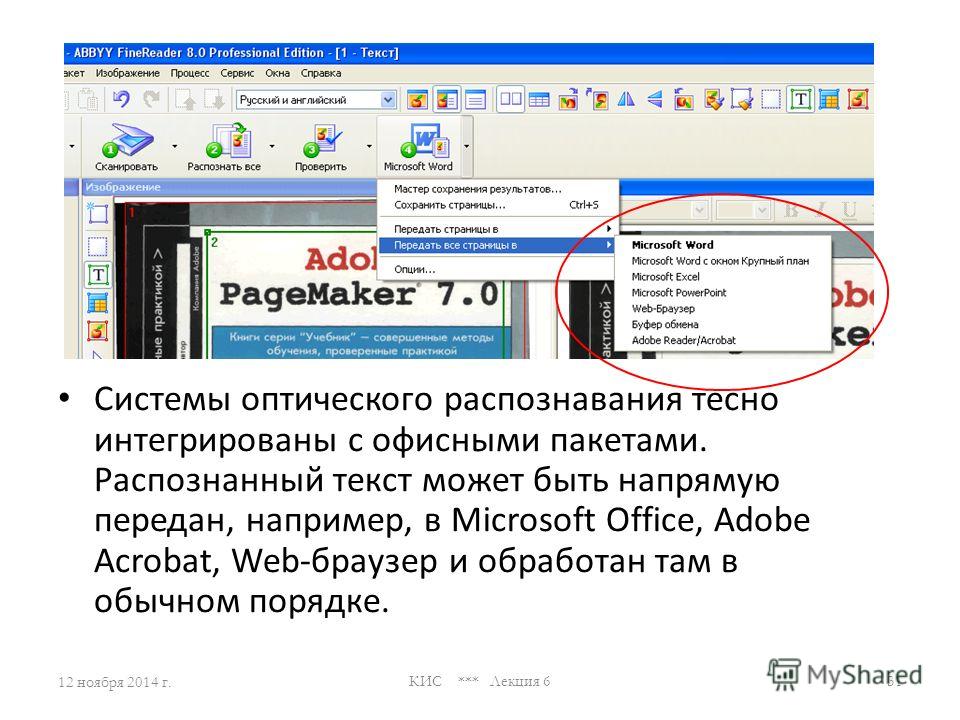 В предыдущих версиях пакета этим занималось отдельное приложение Microsoft Office Document Imaging (MODI). В Microsoft Office 2010 задача распознавания возложена на компонент OneNote. Примечательно, что теперь эта функция скромно именуется поиском и копированием текста в рисунках и вызывается «как бы между прочим». Как ею пользоваться?
В предыдущих версиях пакета этим занималось отдельное приложение Microsoft Office Document Imaging (MODI). В Microsoft Office 2010 задача распознавания возложена на компонент OneNote. Примечательно, что теперь эта функция скромно именуется поиском и копированием текста в рисунках и вызывается «как бы между прочим». Как ею пользоваться?
Распознавание символов с помощью OneNote
- Изображение, текст с которого нужно распознать, любым образом вставьте в заметку OneNote. Например, перетащите мышью файл рисунка в окно OneNote или на ленте воспользуйтесь кнопками Вставка → Рисунок — как вам удобнее.
- В окне OneNote щелкните на рисунке правой кнопкой мыши и в контекстном меню выберите команду Копировать текст из рисунка (см. рис.). Весь текст, который программа сумеет распознать в изображении, будет скопирован в буфер обмена.
- Вставьте скопированный текст в любой документ. Пункт Поиск текста в рисунках в контекстном меню служит для выбора языка распознавания.
 Эта настройка позволяет точнее определить набор символов, ведь многие буквы разных алфавитов похожи по начертанию.
Эта настройка позволяет точнее определить набор символов, ведь многие буквы разных алфавитов похожи по начертанию.
Одно из лучших приложений для распознавания документов и таблиц — ABBYY FineReader. Программа легко обрабатывает изображения документов со сложной структурой и очень точно воспроизводит ее в распознанном документе. Хотя в FineReader предусмотрено множество гибких настроек, с большинством типичных задач программа прекрасно справляется «на полном автомате». За простым и интуитивно понятным интерфейсом скрывается мощный интеллектуальный «движок». По умолчанию при запуске предлагается выбрать один из готовых сценариев.
Запуск программы ABBYY FineReader
Например, если вы выберете сценарий Сканировать в Microsoft Word, сначала откроется диалоговое окно сканирования. После сканирования первой страницы программа запрашивает, нужно ли сканировать следующую, либо можно переходить к следующему шагу. Когда получены изображения всех страниц, начинается их обработка и распознавание. Ход и результаты распознавания отображаются в главном окне программы. В левой части окна показаны эскизы страниц, а в рабочей области вы видите исходное изображение и рядом с ним — уже распознанный документ.
Ход и результаты распознавания отображаются в главном окне программы. В левой части окна показаны эскизы страниц, а в рабочей области вы видите исходное изображение и рядом с ним — уже распознанный документ.
Главное окно ABBYY FineReader
Результат распознавания FineReader в соответствии со сценарием передает в другую программу или сохраняет. Например, в данном случае автоматически откроется окно Microsoft Word с новым документом. Как правило, в созданном документе заголовки, абзацы и другие составляющие оформления выглядят почти так же, как на исходном изображении. Подбирается даже наиболее похожий шрифт! Другие сценарии позволяют отправить результат распознавания в Microsoft Excel — это удобно, если на оригинале изображена таблица, сохранить его в виде документа Adobe Reader (PDF), вместо сканирования открыть сделанное раньше фото оригинала и т. д.
Кроме того, программу можно запустить в пошаговом режиме. Для этого на панели инструментов нажмите кнопку Новое задание. Окно выбора сценариев закроется. Нажимая кнопки на панели инструментов, вы сможете последовательно и под полным контролем отсканировать документ или открыть готовое изображение, при необходимости исправить его дефекты и искажения, проанализировать и выделить то, что нужно распознавать, проверить и сохранить результат.
Окно выбора сценариев закроется. Нажимая кнопки на панели инструментов, вы сможете последовательно и под полным контролем отсканировать документ или открыть готовое изображение, при необходимости исправить его дефекты и искажения, проанализировать и выделить то, что нужно распознавать, проверить и сохранить результат.
К сожалению, программа FineReader передает документы лишь в приложения Microsoft Office (если они установлены), а с пакетом OpenOffice.org она не знакома. В таком случае очевидный выход — сохранять результаты распознавания в универсальном формате RTF, который прекрасно «понимают» любые редакторы документов. Очень качественное, но коммерческое ПО ABBYY FineReader подходит тем, кто распознает текст с бумажных оригиналов часто и регулярно.
Существуют ли бесплатные альтернативы?
Давний конкурент ABBYY — компания Cognitive Technologies в 2007 г. выпустила бесплатную версию программы CuneiForm и открыла ее исходные тексты. С тех пор поддержкой проекта (www. cuneiform.ru) занялось сообщество программистов, а сама программа сегодня работает на платформах Windows, Linux, FreeBSD и Mac OS X. Другой полностью свободный проект — Tesseract. Бесплатная программа COCR2 примечательна тем, что распознает китайские иероглифы. В связке с электронным переводом, например Переводчиком Google, это приложение дает удивительную возможность прочитать и понять документацию на китайском прямо «с листа»! Коммерческими программами Readiris и CrystalOCR комплектуются многие МФУ. Для конечного пользователя OEM-лицензия является бесплатной — фактически она была оплачена при покупке аппарата.
cuneiform.ru) занялось сообщество программистов, а сама программа сегодня работает на платформах Windows, Linux, FreeBSD и Mac OS X. Другой полностью свободный проект — Tesseract. Бесплатная программа COCR2 примечательна тем, что распознает китайские иероглифы. В связке с электронным переводом, например Переводчиком Google, это приложение дает удивительную возможность прочитать и понять документацию на китайском прямо «с листа»! Коммерческими программами Readiris и CrystalOCR комплектуются многие МФУ. Для конечного пользователя OEM-лицензия является бесплатной — фактически она была оплачена при покупке аппарата.
Сервисы распознавания символов появились и в Интернете: FineReaderOnline.ru, Onlineocr.ru, Liveocr.com и некоторые другие. С помощью формы на веб-странице указывается путь к файлу изображения на вашем компьютере, а результат распознавания выдается опять же через Интернет. В принципе, сервисы работают на коммерческой основе: нужно зарегистрироваться на сайте и оплатить услугу. Однако ограниченное число страниц в течение суток они обрабатывают бесплатно.
Однако ограниченное число страниц в течение суток они обрабатывают бесплатно.
Разработка мобильного приложения детектирования и распознавания текстов на изображениях для платформы IOS
Please use this identifier to cite or link to this item: http://earchive.tpu.ru/handle/11683/48069
| Title: | Разработка мобильного приложения детектирования и распознавания текстов на изображениях для платформы IOS |
| Authors: | Осина, Полина Максимовна |
| metadata.dc.contributor.advisor: | Болотова, Юлия Александровна |
| Keywords: | детектирование текста; распознавание текста; неи?ронные сети; iOS; обработка изображении?; text detection; text recognition; neural network; iOS; image processing |
| Issue Date: | 2018 |
| Citation: | Осина П. М. Разработка мобильного приложения детектирования и распознавания текстов на изображениях для платформы IOS : магистерская диссертация / П. М. Осина ; Национальный исследовательский Томский политехнический университет (ТПУ), Инженерная школа информационных технологий и робототехники (ИШИТР), Отделение информационных технологий (ОИТ) ; науч. рук. Ю. А. Болотова. — Томск, 2018. М. Разработка мобильного приложения детектирования и распознавания текстов на изображениях для платформы IOS : магистерская диссертация / П. М. Осина ; Национальный исследовательский Томский политехнический университет (ТПУ), Инженерная школа информационных технологий и робототехники (ИШИТР), Отделение информационных технологий (ОИТ) ; науч. рук. Ю. А. Болотова. — Томск, 2018. |
| Abstract: | В процессе исследования проводился анализ существующих методов и алгоритмов детектирования, распознавания текста, методов по улучшению качества изображения, а также основных принципов разработки под iOS. В результате исследования было разработано приложение под платформу iOS для детектирования и распознавания текста. The study analyzed the existing methods and algorithms for detection, recognition text, methods for improving the image quality, and also the basic principles of iOS development. As a result of the study, the iOS application was developed for detecting and recognizing text.  |
| URI: | http://earchive.tpu.ru/handle/11683/48069 |
| Appears in Collections: | Магистерские диссертации |
Items in DSpace are protected by copyright, with all rights reserved, unless otherwise indicated.
Scan – Adobe Scan для iOS
Вы можете использовать приложение Adobe Scan для мгновенного сканирования различных типов документов, захвата новых изображений или использования существующих изображений и преобразования их в цифровые копии. Приложение Scan конвертирует изображения в PDF и сохраняет их в Adobe Document Cloud. Благодаря оптическому распознаванию символов (OCR) приложение поддерживает автоматическое распознавание текста, которое автоматически преобразует текст изображения в реальный текст.
Для функции сканирования требуется доступ к вашей камере. При появлении запроса выберите Разрешить .Для получения дополнительной информации см. Настройка Adobe Scan.
Для быстрого сканирования документа в режиме автоматического захвата:
Откройте приложение и дождитесь захвата.
После того, как приложение захватит документ, нажмите на миниатюру, чтобы просмотреть и / или отредактировать сканированное изображение.
Отсканировать документ
Для сканирования документа из окна захвата:
Откройте приложение и коснитесь
Выберите тип документа.Дополнительные сведения см. В разделе «Быстрые действия».
При желании нажмите, чтобы изменить настройки вспышки. Дополнительные сведения см. В разделе «Быстрые действия».
Вызвать сканирование, используя один из следующих режимов захвата:
Автозахват (по умолчанию): приложение отображает экран захвата и обнаруживает документ. В режиме автоматического захвата приложение использует определение границ живого края, которое отображает синие точки для определения углов документа.

Захват вручную : отцентрируйте документ в окне и коснитесь кнопки захвата.
Следуйте сообщениям на экране, чтобы завершить рабочий процесс сканирования:
Ищет документ : приложение ищет документ и пытается определить его границы.
Захват… удерживать неподвижно : Обнаружение краев позволяет видеть весь документ.
Документов не найдено. Захват вручную : приложение не может обнаружить края документа.
Приложение использует автоматическое кадрирование и очистку изображения для улучшения качества сканирования. Захваченное сканирование появится на эскизе в правом нижнем углу.
Нажмите Продолжить , чтобы захватить другие документы. Вы можете нажать Retake , если хотите повторно захватить этот документ.
Нажмите на эскиз документа, чтобы открыть его в режиме редактирования, и измените его по своему усмотрению.Дополнительные сведения см. В разделе «Редактировать отсканированное изображение».
Нажмите Сохранить PDF . Он автоматически преобразует сканированное изображение в PDF и сохраняет его в Adobe Document Cloud.
Примечание
Приложение «Сканирование» использует обнаружение границ в реальном времени для автоматического определения границ документа в режиме автоматического захвата.
Выполнение быстрых действий
Adobe Scan теперь позволяет выполнять стандартные действия на основе сканирования. Например, когда приложение распознает адрес электронной почты или номер телефона, на экране захвата вы можете напрямую отправить электронное письмо, позвонить или скопировать захваченный текст.Вы можете использовать эту функцию, чтобы быстро связаться с человеком по отсканированным изображениям визиток.
Для выполнения быстрых действий:
Отсканируйте документ с текстом. Можно выбрать тип сканирования «Документ», «Белая доска» или «Форма». Если приложение «Сканирование» распознает адрес электронной почты или номер телефона, на экране захвата появятся кнопки.
Нажмите одну из кнопок быстрого действия: электронная почта, звонок, выбор текста или другое.
Выберите действие.Вы можете позвонить или отправить электронное письмо.
Настройка захвата сканирования
Используйте параметры на экране захвата, чтобы управлять сканированием:
Товар | Описание |
|---|---|
Тип сканирования | Оптимизируйте рабочий процесс, выбрав один из типов документов. |
Если на вашем устройстве есть вспышка, вы можете установить ее на всегда включенную, всегда выключенную или автоматическую (использовать только в темноте). | |
Включение и выключение автоматического захвата. | |
Добавить существующую фотографию или документ в текущую коллекцию отсканированных изображений | |
Нажмите и удерживайте эскиз, чтобы просмотреть 3 последних эскиза сканирования – вы можете удалить эти снимки сейчас или позже. Коснитесь миниатюры, чтобы завершить сеанс сканирования и просмотреть / отредактировать файл. |
Типы документов
При выборе типа сканирования изменяется имя сканирования, а также то, как приложение фиксирует сканирование. Например, приложение захватывает весь вид камеры для доски, но использует определение границ при захвате визитной карточки.
Параметры меню по умолчанию, доступные на экране предварительного просмотра и эскизах документов, могут различаться в зависимости от контекста. Например, в форме отображается пункт меню «Заполнить и подписать» , а на визитной карточке – пункт меню «Сохранить в контактах» .
Примечание
Вы можете настроить имя файла по умолчанию на экране настроек приложения.
Доска:
Форма:
Документ:
Визитная карточка:
Создавать отсканированные изображения из цифровых фотографий или документов
ИнтеграцияScan с фото-библиотекой устройства позволяет создавать отсканированные изображения из существующих фотографий или цифровых документов. При сканировании используется функция обнаружения документов, чтобы отличать документы от селфи, иллюстраций и других фотографий, не являющихся документами.
Для сканирования фотографий или документов:
Кран. Он открывает галерею изображений.
Коснитесь одного или нескольких изображений, чтобы выбрать их.
При желании включите Показать только документы , чтобы просматривать только документы. Коснитесь одного или нескольких документов, чтобы выбрать их.
Нажмите, чтобы сделать снимок / изображения в виде отсканированных изображений.
При необходимости отредактируйте сканированное изображение и нажмите Сохранить PDF .
Вы также можете напрямую импортировать изображения из вашей галереи. Для этого откройте галерею, нажмите, а затем нажмите. Когда изображение откроется в приложении для сканирования, отредактируйте, переименуйте и сохраните сканированное изображение как обычно.
Отредактируйте сканированное изображение
Когда вы закончите сканирование, коснитесь эскиза в правом нижнем углу, чтобы войти в Режим просмотра . Отсюда вы можете нажать Сохранить PDF или изменить отсканированные изображения, нажав и выбрав один из параметров редактирования в нижнем меню.
Эти параметры позволяют:
Добавить фотографии к существующим отсканированным изображениям
На устройстве можно просматривать изображения и документы, которые можно добавить к текущему отсканированному изображению:
Метчик
Сделайте еще одну фотографию или выберите файл на своем устройстве.
Изменить порядок страниц
Чтобы изменить заказ страниц:
Метчик
Перетаскивайте страницы в новое место.
Метчик
Обрезка страниц
Для обрезки или корректировки границ отсканированных страниц:
Перейдите на страницу, которую хотите изменить.
Метчик
Перетащите маркеры обрезки, чтобы изменить размер области сканирования.
При желании нажмите, чтобы повернуть отсканированные изображения на 90 градусов по часовой стрелке.
Метчик
Повернуть страницы
Чтобы повернуть одну или несколько отсканированных страниц:
Перейдите на страницу, которую хотите изменить.
Метчик
При необходимости повторите для других страниц.
Применить фильтры
Вы можете применять фильтры для настройки цвета отсканированных страниц. Для этого:
Перейдите на страницу, которую вы хотите изменить.
Метчик
Выберите один из следующих вариантов фильтра:
Исходный цвет , чтобы цвета оставались неизменными.
Автоцвет , чтобы приложение для сканирования могло вносить изменения.
Светлый текст для выделения светлого текста или рисунков.
Оттенки серого для удаления цвета.
Доска для увеличения контрастности.
Чтобы применить настройку на нескольких страницах, включите Применить ко всем страницам .
Нажмите Сохранить .
Очистить изображение
В режиме просмотра вы можете стереть нежелательные артефакты, нечеткие изображения или любой другой нежелательный контент.Действие «стирания» по существу заполняет выбранную область выбранным вами цветом (таким образом скрывая эту область). Вы можете выполнить очистку изображения при новом сканировании или очистить изображение при существующем сканировании.
Перейдите на страницу, которую хотите изменить.
Метчик
Выберите цвет заливки:
При необходимости измените размер ластика.
Увеличивайте и уменьшайте изображение по мере необходимости.
Проведите пальцем по области, которую хотите стереть.
Метчик
Изменить размер страниц
Вы можете легко настроить размер страницы на экране просмотра. Например, вы можете выбрать A4 Книжный или другой размер, который соответствует вашим потребностям в печати. Для изменения размера страниц:
Метчик
Перейдите на страницу, размер которой нужно изменить.
Выберите нужный формат размера бумаги и при необходимости измените размер.Повторите этот шаг для любой страницы.
Метчик
Удалить страницы
В режиме просмотра вы можете удалить любое количество страниц.
Перейдите на страницу, которую хотите удалить.
Метчик
Подтвердите, что хотите удалить страницу.
Отменить сканирование или отредактировать
Отмените текущее сканирование, выполнив одно из следующих действий:
Нажмите Когда появится диалоговое окно «Отменить сканирование?», Выберите вариант или нажмите Отменить .
Нажмите и удерживайте значок предварительного просмотра эскиза и коснитесь красного X. Вы можете удалить одну или несколько страниц из текущего сканирования.
Нажмите Отменить на экране просмотра, чтобы отменить выполняемое сканирование.
Сохранить как PDF
Когда результат сканирования удовлетворителен, можно сделать следующее:
Нажмите или имя файла, чтобы изменить имя по умолчанию.
Нажмите Сохранить , чтобы автоматически преобразовать отсканированное изображение в PDF, а затем загрузить его в Adobe Document Cloud, чтобы вы могли получить доступ к файлу где угодно.
Оптическое распознавание символов (OCR) | Справочный центр AppSheet
OCR – это технология, которая позволяет вам получить доступ к тексту или письмам, которые появляются на изображении. С помощью функции OCR AppSheet вы можете ускорить ввод данных, автоматически заполняя формы с изображения. Смотрите видео ниже для демонстрации.
Функцию OCR AppSheet можно использовать, когда вам нужно отсканировать несколько документов с фиксированным макетом. Изображение может содержать печатный текст или почерк.Вот некоторые примеры:
Некоторые случаи, когда функция оптического распознавания текста в AppSheet не работает, включают:
Визитные карточки (которые не соответствуют стандартному формату)
Формы, в которых используются флажки
Приложения, которые нет подключения к Интернету
Функция распознавания текста в AppSheet в настоящее время находится на стадии бета-тестирования. Вы можете получить к нему доступ в редакторе AppSheet в разделе Intelligence> OCR.
Чтобы начать работу с OCR, вам потребуются как минимум четыре изображения-примера и значения, которые следует извлечь из них.AppSheet проверит приведенные примеры и предложит общий шаблон для сопоставления с новыми изображениями.
Когда у вас есть примеры, вы можете создать новую модель OCR на вкладке OCR в редакторе. Для модели OCR вам нужно будет выбрать:
Таблица, содержащая ваши примеры
Столбец изображения, из которого вы хотите извлечь
Выходные столбцы, содержащие извлеченные значения
Например, предположим, что мы извлекаем информацию из изображений значка конференции.Мы создадим новую модель OCR, которая будет работать с таблицей Badges, извлекая из столбца изображения значка и возвращая имя, фамилию, организацию, идентификатор Twitter и роль из изображения.
После сохранения изменений будет создана пользовательская модель распознавания текста. AppSheet покажет шаблоны, которые были обнаружены в каждом примере, и проинформирует вас о любых проблемах, которые произошли на этом пути.
Теперь, когда обучение вашей модели OCR завершено, она доступна для использования в вашем приложении.Ваши столбцы будут автоматически инициализированы с использованием значений, извлеченных из изображения.
За кулисами AppSheet добавил специальные формулы OCR для инициализации значений ваших столбцов:
Распознавание текста (OCR) | База знаний Scanner Pro
Оптическое распознавание символов (OCR) – это интеллектуальная технология распознавания текста, которая распознает текст на отсканированных изображениях и делает их доступными для поиска. После того, как отсканированное изображение или изображение проходят обработку OCR, их легко читать, выбирать и копировать в другие приложения.
Предварительные требования
Улучшенная технология распознавания текста, описанная в этой статье, доступна в Scanner Pro 8.0 или более поздних версиях. Для тех, кто ранее покупал Scanner Pro, эта функция бесплатна. Новые клиенты могут найти информацию о подписке здесь.
Выберите язык для распознавания текста
Scanner Pro по умолчанию распознает текст на автоматически выбранных языках на основе латиницы. Чтобы переключиться на другой язык для обработки отсканированных изображений, выполните следующие действия:
- Откройте настройки Scanner Pro и коснитесь Распознавание текста (OCR) .
- Убедитесь, что переключатель Автоматическое распознавание текста (OCR) включен.
- Отключите языков на основе латиницы Переключатель и выберите один язык из списка.
- Нажмите Сохранить .
Распознавать, копировать и передавать текст
- Откройте сканированное изображение в Scanner Pro и коснитесь Текст на нижней панели инструментов.
- Выберите вкладку Document или Text вверху.Вкладка «Документ» содержит отсканированное изображение с текстовым слоем на нем, а вкладка «Текст» содержит текст, извлеченный из отсканированного изображения.
- Если язык сканирования отличается от того, который обычно используется в тексте ваших сканированных изображений, нажмите Язык на нижней панели инструментов и убедитесь, что выбран правильный язык:
- Если язык этого сканирования , язык на основе латиницы , убедитесь, что включен переключатель языка на основе латиницы.
- Если язык сканирования не является латинским и отличается от того, который вы выбрали вручную в настройках, выберите новый язык из списка и нажмите Обработать .
Затем выберите и скопируйте необходимую часть текста, нажмите Копировать все на нижней панели инструментов или выберите Поделиться , чтобы экспортировать текстовый слой в другие приложения. Закончив работу с текстом, нажмите Готово в правом верхнем углу.
Отключить автоматическое распознавание текста
Автоматическое распознавание текста включено по умолчанию, и это позволяет быстро распознавать и искать содержимое ваших отсканированных изображений. Чтобы отключить его, откройте Настройки Scanner Pro> Text Recognition (OCR) и отключите переключатель Automatic Text Recognition (OCR) .После этого вас будут спрашивать, распознавать ли текст или нет, каждый раз, когда вы нажимаете Text на нижней панели инструментов или пытаетесь выполнить поиск в документе.
Конфиденциальность
Обратите внимание, что Scanner Pro использует модель OCR на устройстве. Это означает, что мы не загружаем распознанный текст в какое-либо облачное хранилище, и он безопасно хранится только на вашем устройстве. Чтобы узнать, как мы обрабатываем ваши данные, чтобы обеспечить их безопасность, ознакомьтесь с нашей Политикой конфиденциальности. Его можно найти на нашем веб-сайте или напрямую через Scanner Pro Settings> Privacy Policy .
Устранение неполадок
Если у вас возникли проблемы с функцией распознавания текста в Scanner Pro, убедитесь, что у вас установлено приложение версии 8.0 или более поздней. Затем попробуйте выйти из приложения и запустить его снова. Если на данный момент ситуация не решена, обратитесь в нашу службу поддержки, выполнив следующие действия:
- Запустите Scanner Pro и коснитесь значка «Настройки» в левом верхнем углу.
- Прокрутите вниз и коснитесь Поддержка > Отправить отзыв .
- Появится новое окно электронной почты. В своем сообщении опишите проблему.
- Нажмите Отправьте , и наша служба поддержки свяжется с вами, чтобы решить проблему.
Мы будем благодарны за ваш отзыв, который поможет нам улучшить статью:
Спасибо! Расскажите подробнее о своем опыте работы со Scanner Pro. Справочный центр:
Программное обеспечениеReinvented – О распознавании текста в Keep It
Keep It будет выполнять распознавание текста в PDF-документах и изображениях (включая вложения, начиная с версии v1.7), используя технологии компьютерного зрения и машинного обучения, чтобы минимизировать трудозатраты и получить наиболее точные результаты.
Keep It не изменяет PDF-файлы и не преобразует изображения, чтобы сделать их доступными для поиска, а индексирует текст, чтобы его можно было снова найти, и сохраняет этот текст в iCloud, чтобы не повторять работу на других устройствах.
Keep It всегда была в состоянии индексировать текст в PDF-файлах, которые имеют выбираемый текст или для них уже было выполнено распознавание текста, и не выполняет ненужное распознавание текста на них или на изображениях, которые не содержат никакого текста.
В iOS Keep It будет временно загружать элементы для распознавания текста, пока приложение подключено к Wi-Fi (если не включен параметр «Использовать мобильные данные для индексирования»).
Распознавание текста может занять некоторое время – подробнее см. Ниже.
PDF-документы
Для PDF-файлов Keep It не будет выполнять распознавание текста, если в документе уже есть индексируемый текст. Вместо этого текст, хранящийся в документе, будет проиндексирован, чтобы его можно было искать.
После распознавания текста Keep It не изменяет PDF-документы, добавляя невидимый текстовый слой, а вместо этого индексирует этот текст, чтобы его можно было найти. Текст также сохраняется в iCloud, если он используется, чтобы избежать повторения этой работы на других устройствах. Эти данные занимают минимум места, обычно от 1 до 2 килобайт на страницу.
Для документов PDF большего размера и более сложных макетов может потребоваться некоторое время. В то время как распознавание текста на одной странице может занять несколько секунд, большие и более сложные документы могут занять несколько минут.
Keep It всегда выполняет распознавание текста в фоновом режиме (а на Mac – в совершенно отдельном процессе). Чтобы увидеть прогресс на Mac, выберите в меню «Окно»> «Действие» и проверьте, выполняет ли Keep It какие-либо операции «Извлечение информации». В iOS коснитесь строки состояния под любым из списков.
Изображения
Для изображений Keep It использует компьютерное зрение для обнаружения областей текста на изображении и выполняет распознавание текста только в любых найденных областях.Keep It предпримет шаги для улучшения качества текста, но только текст с высоким контрастом между цветами переднего плана и фона, вероятно, даст хорошие результаты.
Как и в случае с PDF-файлами, файлы изображений не изменяются, а текст индексируется, чтобы его можно было искать и сохранять в iCloud (если он используется), чтобы избежать дублирования работы на разных устройствах.
Распознавание текста для изображений может быть не таким точным в macOS High Sierra и iOS 11, как в Mojave и iOS 12 или новее, из-за достижений в технологии компьютерного зрения Apple.
Скриншоты
OCR лучше всего работает с изображениями с более высоким разрешением, такими как фотографии, и для текста, где есть высокий контраст между цветами переднего плана и фона. Снимки экрана могут дать хорошие результаты, если используются более крупные шрифты или снимок экрана был сделан с экрана с более высоким разрешением, например дисплея Retina.
Вложения
Keep It при необходимости выполнит распознавание текста для вложений в заметки, файлов RTFD и почтовых сообщений.
Рукописный ввод
Рукописный ввод вряд ли даст полезные результаты.
Увидеть распознанный текст
В приложении нет возможности увидеть распознанный текст, но он будет проиндексирован для поиска.
Языки и скрипты
Распознавание текста основывается на знании того, какой язык ему необходимо распознать.По умолчанию Keep It использует тот же язык, что и ваш Mac или устройство iOS. Его можно изменить на другой язык или сценарий, который охватывает многие родственные языки (например, латынь).
В macOS 11.0 или iOS 14 и более поздних версиях, если основным языком распознавания текста является английский, китайский, португальский, французский, итальянский, немецкий или испанский, Keep It также будет включать любой из ваших предпочтительных языков из этого списка. Предпочтительные языки можно установить в системных настройках «Язык и регион» на Mac или в общих настройках на устройстве iOS.Для других языков или сценариев будет использоваться только основной язык или сценарий. Однако большинство скриптов также включают поддержку английского языка, кроме кириллицы.
В случаях, когда языки могут быть написаны как по горизонтали, так и по вертикали (например, японский), вертикальная версия может использоваться как дополнительный язык.
Чтобы изменить язык или выбрать сценарий:
- На Mac выберите в меню «Сохранить»> «Настройки», затем нажмите «Поиск».Выберите язык или сценарий во всплывающем окне.
- В iOS коснитесь значка шестеренки над представлением «Списки», затем коснитесь «Распознавание текста» и выберите язык из списка.
Keep Предлагает переиндексировать документы при изменении языка.
Отключение распознавания текста
Распознавание текста можно включить или отключить для каждого устройства. Чтобы отключить распознавание текста:
- На Mac выберите в меню «Сохранить»> «Настройки», затем нажмите «Поиск».Отключите параметр «Распознавать текст в PDF-файлах и изображениях».
- На iOS коснитесь значка шестеренки над представлением «Списки», затем коснитесь «Распознавание текста» и выключите «Распознавать текст в PDF-файлах и изображениях».
TextSniper: Упрощенное распознавание текста: Apple World Today
Многие пользователи Mac привыкли получать текст с веб-сайтов и документов, просто выбирая и копируя его. К сожалению, это не работает для растущего числа интернет-СМИ. Сегодня мы познакомимся с TextSniper , приложением, которое делает запись невыбираемого текста такой же простой, как создание снимка экрана.
Пробная версия бесплатна: 6,99 долларов США за одну лицензию Mac с веб-сайта TextSniper, 8,99 долларов США за несколько компьютеров Mac в Mac App Store, и это часть подписки Setapp. Для работы приложения требуется macOS 11 Big Sur или macOS 10.15 Catalina.
TextSniper быстро захватывает текст с любого изображения.Что мы подразумеваем под «невыбираемым текстом»?
Невыбираемый текст – это любой текст, отображаемый на экране Mac, который нельзя выделить, перетащив на него текстовый курсор. Сюда входит текст от:
- YouTube vidos
- PDF-файлы
- Изображения, подобные показанному выше
- Онлайн-курсы
- Screencasts
- Presentations
- Photos
and more…
Пользователи Mac обычно остаются с одним решением – повторно набирать текст на текстовый редактор или текстовый редактор.
TextSniper спешит на помощь!
TextSniper избавляет от этой тяжелой работы. Просто нажмите Command (⌘) + Shift + 2 или выберите Capture Text в строке меню, выберите область экрана Mac, где находится текст, который нужно записать, затем нажмите Command (⌘) + V, чтобы вставить текст в другое приложение. .
Вот видео, показывающее приложение в действии:
Другие особенности TextSniper
Это не мешает, пока вам не понадобится его использовать.
Серьезно, в большинстве случаев владельцы Mac могут просто использовать настраиваемое сочетание клавиш или щелкнуть крошечный значок в строке меню. TextSniper не занимает места в Dock.
Невероятно точный
Я использую приложение почти каждый день по той или иной причине. Большая часть текста в Интернете и в документах распознается со 100% точностью. Даже невероятно мелкий текст и необычные шрифты не подходят для распознавания символов TextSniper. Символы, подобные тем, которые используются при кодировании, могут вызывать проблемы.
Супербыстрый
Вам никогда не придется ждать, пока TextSniper преобразует ваши отсканированные изображения в текст.
Считывание QR-кода / штрих-кода
QR-коды и штрих-коды содержат текст, веб-адреса и адреса электронной почты, даже vCard (адресные карты). Используйте команду «Прочитать QR / штрих-код» под значком строки меню, отсканируйте онлайн-код, и он немедленно преобразуется в читаемую информацию.
Преобразование текста в речь
TextSniper даже преобразует распознанный текст в слышимую речь.Эта функция идеально подходит для людей с проблемами зрения, для чтения небольшого текста на экранах и для тех, кто изучает иностранные языки (стоит отметить, что TextSniper поддерживает восемь языков при использовании с macOS Big Sur).
Функция преобразования текста в речь также является мощной вспомогательной технологией для людей с дислексией.
Кому может быть полезен TextSniper?
TextSniper может сэкономить почти любому пользователю Mac много времени.
Студенты , проводящие исследования, могут найти онлайн-курсы и презентации, а затем скопировать текст без ошибок для использования в своих заметках
Блогеры , которым необходимо захватить текст из рекламных видеороликов или рекламных объявлений, считают TextSniper полезным активом строки меню
Офисные работники , которым нужно извлекать текст из файлов PDF для использования при создании новых документов без обременительного повторного набора
Обычный вариант использования TextSniper
Я занимаюсь дизайном веб-сайтов для местной некоммерческой организации.Совет директоров хотел, чтобы на главной странице веб-сайта был размещен полный текст заявления о миссии группы. Они прислали мне PDF-файл документа без возможности скопировать текст.
Нет проблем! Все, что мне нужно было сделать, это открыть PDF-файл, нажать Command + Shift + 2, перетащить PDF-файл и затем вставить преобразованный текст в инструмент веб-дизайна.
То, что мне потребовалось бы пять минут, чтобы перепечатать, с TextSniper заняло меньше пяти секунд.
TextSniper является частью замечательного пакета подписки на приложение SetappПопробуйте TextSniper Free
Вам нравится идея TextSniper, но вы хотите знать, действительно ли она так хороша, как я говорю? Попробуйте бесплатно в течение 7 дней в рамках бесплатной пробной версии Setapp .Вы получите доступ к более чем 210 другим замечательным приложениям для Mac одновременно.
После того, как вы убедились, насколько полезен TextSniper, либо продолжите подписку Setapp всего за 9,99 доллара США (плюс налог) в месяц, либо приобретите TextSniper отдельно.
Если вы решите приобрести TextSniper отдельно, одна лицензия доступна непосредственно у разработчика за 6,99 доллара США. При покупке в Mac App Store за 8,99 доллара TextSniper можно использовать на нескольких компьютерах Mac.
Это универсальное приложение, что означает, что TextSniper работает на компьютерах Mac Intel и Apple Silicon.
Как собирать важные данные с помощью приложений для сканирования и оптического распознавания символов
Приложение для сканирования с оптическим распознаванием символов (OCR) незаменимо для организации. Лучшие приложения для сканирования помогут вам захватить всевозможную информацию, такую как слайды презентации с собрания, заметки на белой доске, визитные карточки, не говоря уже о важных документах. Они пригодятся и для других целей: от оцифровки бумажных рецептов до сохранения гарантий.
Несколько лет назад мне пришлось получить новый паспорт и в тот же день сдать его на визу.Сразу после того, как я взял паспорт, я подумал: «Мне, наверное, нужно иметь его копию, прежде чем я его передам». Я достал телефон и отсканировал его. Конечно, на получение визы ушло больше двух недель, а тем временем мне понадобились данные моего паспорта для кучи документов. Хорошо, что у меня была разборчивая копия!
Как работают приложения для сканирования?
Когда вы используете мобильное приложение для сканирования, это мало чем отличается от фотографирования. В идеальной обстановке вы воспроизводите документ на контрастном фоне и наводите на него камеру телефона.
Затем приложение для сканирования проведет вас через весь процесс. Обычно вам предлагается выровнять края документа с метками обрезки на экране телефона. Держитесь крепче, но не волнуйтесь. Приложение подстраивается под легкие движения. Сканирование занимает секунду или две. Когда это будет сделано, вы обычно видите предварительный просмотр вашего документа. Затем приложение обычно спрашивает, хотите ли вы добавить дополнительные страницы или начать новое сканирование.
Возможно, вы думаете, что можете вообще пропустить приложение для сканирования и вместо этого сфотографировать любые документы, которые вы хотите сохранить в цифровом виде.Можно, но есть два недостатка. Во-первых, изображение вряд ли будет таким четким, как сканированное изображение, поэтому вы рискуете получить нечитаемый текст. Во-вторых, вы не можете выполнять поиск по тексту, что может значительно затруднить поиск того, что вам нужно позже.
Что следует сканировать с помощью приложения для сканирования?
Давайте рассмотрим примеры того, как вы можете использовать приложение для сканирования, чтобы оставаться организованным. После этого я объясню, какие функции вам следует искать в лучших приложениях для сканирования, и назову несколько приложений, в которых они есть.
Визитки
В следующий раз, когда кто-то вручит вам визитную карточку, воспользуйтесь приложением для сканирования, чтобы захватить контактную информацию этого человека, а затем верните карточку. Вы покажете, как легко быть безбумажным, а также собирать информацию о них в цифровом формате, чтобы вам не пришлось ничего вводить позже. Некоторые приложения для сканирования могут обнаруживать визитные карточки и создавать новую запись в приложении для контактов. Другие ищут в LinkedIn и предлагают подключиться там.
Доски и презентационные материалы
На собраниях большинство из нас хочет уделять каждому выступающему все свое внимание.Это сложно сделать, если мы смотрим на презентацию или доску, надеясь не упустить важную деталь. Отличное решение – быстро сканировать слайды или другие материалы по мере их появления, зная, что вы сможете просмотреть их более подробно позже.
Документы для электронной почты или резервного копирования
Несмотря на то, что многие люди и организации с удовольствием отправляют вам цифровые документы, все же существует множество случаев, когда мы сталкиваемся с бумажными документами. Допустим, ваш банк дает вам важный бумажный документ для подписи, но вы хотите, чтобы ваш юрист сначала его проверил.Это прекрасное время для использования вашего приложения для сканирования. Отсканируйте несколько страниц, чтобы отправить их по электронной почте. Некоторые приложения для сканирования включают инструмент, который также позволяет вам подписывать их цифровой подписью.
Другие важные документы, которые вы, возможно, захотите отсканировать и сделать резервную копию, включают записи о прививках, налоговые документы и юридические свидетельства (о рождении, браке, иммиграции и т. Д.).
На что обращать внимание в приложении для сканирования
Лучшие приложения для сканирования четко фиксируют ваши документы, обеспечивают возможность поиска по тексту и помогают сохранять готовые файлы в нужных местах.Вот что нужно искать:
Автоматическое определение края
Отличное приложение для сканирования и распознавания текста автоматически находит края ваших документов. Когда вы наводите камеру на бумагу, метки обрезки, которые вы видите на экране, должны самостоятельно искать край документа и подстраиваться под другие размеры. Итак, сканируете ли вы лист бумаги формата А4 или визитку, приложение распознает это автоматически.
Параметры сохранения и экспорта
Лучшие приложения для сканирования дают вам возможность сохранять или экспортировать недавно отсканированные тексты, например, Google Drive, Dropbox или другую службу хранения.Вам не нужно приложение, которое заставляет вас хранить документы в новом месте.
OCR
Я упомянул OCR в начале статьи. Когда у вас есть OCR, любые слова, которые вы сканируете, становятся текстом. Вы также можете скопировать и вставить текст или отредактировать его. Допустим, вы просматриваете рецепт и видите опечатку. С действительно хорошим приложением для сканирования и распознавания текста вы сможете исправить опечатку. Некоторые приложения могут преобразовать окончательный текст в знакомый формат обработки текста, например .docx. Другие позволяют изменять текст прямо в приложении, не открывая предварительно документ в текстовом редакторе.
OCR также позволяет выполнять поиск по тексту документов. Это означает, что если вы хотите найти свои записи о прививках, вы можете попробовать поискать по имени вашего врача, чтобы найти файл. Вам не нужно запоминать, как вы назвали файл. Если вы часто пользуетесь поиском для поиска файлов, то вам определенно понадобится OCR.
Функция поиска
Может быть, вы не очень организованы, когда дело доходит до экспорта и сохранения файлов в другом месте. В этом случае вы захотите иметь возможность искать в содержимом приложения для сканирования все, что вы когда-то сканировали и теперь нуждаетесь.В отличном приложении для сканирования будет собственная функция поиска.
Поддержка нескольких страниц
Действительно хорошие приложения для сканирования могут сканировать несколько страниц подряд. Затем они должны с легкостью сопоставить все страницы в один PDF-файл. Самые современные приложения для сканирования также корректируют искажение страницы, например, когда вы сканируете страницы из книги и не можете заставить ее лежать ровно.
Цена
Многие из лучших приложений для сканирования и распознавания текста имеют бесплатный уровень обслуживания и платный уровень премиум-класса.OCR иногда считается премиальной функцией. Цены на приложения для сканирования и распознавания текста немного сумасшедшие. Какое-то время вы могли рассчитывать заплатить от 4 до 7 долларов за достойное приложение. Сейчас единовременные платежи в десять раз выше. Хотя цены на подписку более разумные, некоторым людям требуется приложение для сканирования всего несколько раз в год.
Лучшие приложения для сканирования
Теперь, когда вы понимаете, что могут делать приложения для сканирования и почему они могут вам понадобиться, вот некоторые из лучших, которые вы можете найти. Я сосредоточился на приложениях, которые предлагают сканирование, а OCR и делают ваш текст редактируемым.Есть множество приложений, которые просто сканируют. Evernote Scannable и мобильное приложение Dropbox – два примера. Но они не дают вам окончательного текста, который вы можете скопировать, вставить или отредактировать. Эти приложения делают.
Независимо от того, какое приложение вы выберете, вы обнаружите, что наличие под рукой приложения для сканирования, которому вы доверяете, помогает вам оцифровывать ваши документы и оставаться организованным.
ABBYY FineScanner (посетите сайт ABBYY)
Бесплатно; Pro за 4,99 доллара в месяц, 19,99 доллара в год или 59 долларов.99 единоразовая плата
ABBYY FineScanner, возможно, лучший и самый мощный сканер и приложение OCR для мобильных устройств. Он экспортирует файлы в различные форматы, позволяет сохранять файлы в большинстве основных служб хранения и даже выполняет распознавание текста на более чем 40 языках. Чтобы получить OCR, вам понадобится премиум-аккаунт, который стоит 4,99 доллара в месяц, 19,99 доллара в год или 59,99 доллара за единовременную плату.
Доступно на Android, iOS
Объектив Microsoft Office (посетите сайт ABBYY)
Бесплатно
Microsoft Office Lens – одно из немногих совершенно бесплатных приложений для сканирования.Он немного медленнее и неуклюже, чем другие приложения с обнаружением краев и обрезкой, но выполняет свою работу. В приложении есть специальные режимы для сканирования визиток и доски. Чтобы отредактировать отсканированный текст, вы должны экспортировать текст через Microsoft OneDrive, а затем открыть его в Word.
Доступно на Android, iOS, Windows
Scanbot 9 (посетите сайт ABBYY)
Бесплатно; Pro за 4,49 доллара в первый год, затем за 22,49 доллара в год; или 69,99 долларов США единовременно на iOS
Scanbot – отличное приложение для сканирования и распознавания текста.При этом компания недавно изменила свою модель ценообразования с недорогой единовременной платы на годовую подписку или более дорогую единовременную плату (69,99 доллара США). Кроме того, очень сложно отследить цены. В любом случае стоит подумать о версии Pro Scanbot, если вам нужно быстрое и точное приложение для сканирования практически любого типа документа. Он имеет хорошие инструменты цветокоррекции и оптимизации, а также другие функции сканирования, такие как считыватель QR-кода и сканер штрих-кода. Вы также можете использовать его для подписи документов, используя только палец и телефон или планшет.
Доступно для Android и iOS
Apple Fan?
Подпишитесь на нашу еженедельную сводку Apple , чтобы получать последние новости, обзоры, советы и многое другое прямо на ваш почтовый ящик.
Этот информационный бюллетень может содержать рекламу, предложения или партнерские ссылки. Подписка на информационный бюллетень означает ваше согласие с нашими Условиями использования и Политикой конфиденциальности. Вы можете отказаться от подписки на информационные бюллетени в любое время.
Новый пример приложения – блог TensorFlow
https: // blog.tenorflow.org/2021/09/blog.tensorflow.org202109optical-character-recognition.html
https://1.bp.blogspot.com/-evZXm9aNW_A/YUt5gmbBJ8I/AAAAAAAAEgE/LS3Li9WxxmobhGAE9lqQQvY8-b65ZjYHACLcBGAsYHQ/s0/demo.gif
Автор: Вэй Вэй, адвокат разработчиков TensorFlow
Как гласит старая пословица, «картинка стоит тысячи слов». Изображения богаты визуальной информацией, но иногда ключ кроется в тексте внутри. Хотя грамотным людям легко читать слова, встроенные в изображения, как мы можем использовать компьютерное зрение и машинное обучение, чтобы научить компьютеры делать это?
Сегодня мы покажем вам, как использовать TensorFlow Lite для извлечения текста из изображений на устройствах Android.Мы проведем вас через ключевые шаги приложения для Android с оптическим распознаванием символов (OCR), исходный код которого мы недавно открыли здесь, и вы можете обратиться к нему за полным кодом. На анимации ниже вы можете увидеть, как приложение извлекает названия продуктов из трех логотипов продуктов Google.
Процесс распознавания текста на изображениях называется оптическим распознаванием символов и широко используется во многих областях. Например, Google Maps использует технологию OCR для автоматического извлечения информации из географических изображений для улучшения Google Maps.
Вообще говоря, OCR – это конвейер с несколькими шагами. Обычно они состоят из обнаружения текста и распознавания текста:
- Используйте модель обнаружения текста, чтобы найти ограничивающие рамки вокруг текста;
- Выполните некоторую пост-обработку для преобразования ограничивающих рамок;
- Преобразуйте изображения в этих ограничивающих прямоугольниках в оттенки серого, чтобы модель распознавания текста могла отображать слова и числа.
В нашем случае мы собираемся использовать модели обнаружения и распознавания текста из TensorFlow Hub.Существует несколько различных версий моделей для компромисса между скоростью и точностью; здесь мы используем квантованные модели float16. Для получения дополнительной информации о квантовании модели, пожалуйста, обратитесь к разделу квантования TensorFlow Lite. Мы также используем OpenCV, широко используемую библиотеку компьютерного зрения для подавления без максимума (NMS) и преобразования перспективы (мы расскажем об этом позже) для результатов обнаружения постобработки. Кроме того, мы используем библиотеку поддержки TFLite для градации серого и нормализации изображений.
| Конвейер OCR от обнаружения текста, преобразования перспективы до распознавания. |
Для обнаружения текста, поскольку модель обнаружения принимает фиксированный размер 320×320, мы используем библиотеку поддержки TFLite для изменения размера и нормализации входного изображения:
val imageProcessor =
ImageProcessor.Builder ()
.add (ResizeOp (высота, ширина, ResizeOp.ResizeMethod.BILINEAR))
.add (NormalizeOp (означает, stds))
.строить()
var tensorImage = TensorImage (DataType.FLOAT32)
tenorImage.load (bitmapIn)
tenorImage = imageProcessor.process (tensorImage) Затем мы используем TFLite для запуска модели обнаружения:
detectionInterpreter.runForMultipleInputsOutputs (обнаружение входов, обнаружение выходов) Результатом модели обнаружения является количество повернутых ограничивающих рамок, которые содержат текст на изображении. Мы запускаем Non-Maximum Suppression, чтобы идентифицировать одну ограничивающую рамку для каждого текстового блока с OpenCV:
NMSBoxesRotated (
boundingBoxesMat,
обнаруженConfidencesMat
обнаружениеConfidenceThreshold.держаться на плаву(),
обнаружениеNMSThreshold.toFloat (),
индексы
) Иногда текст внутри изображений искажается (например, наклейка «kubernetes» на моем ноутбуке) с перспективным углом:
| Демонстрация перспективного преобразования |
Если мы просто введем необработанную повернутую ограничивающую рамку в модель распознавания, модель вряд ли сможет правильно идентифицировать символы. В этом случае нам нужно использовать OpenCV для преобразования перспективы:
val RotationMatrix = getPerspectiveTransform (srcPtsMat, targetPtsMat)
warpPerspective (
srcBitmapMat,
распознаваниеBitmapMat,
RotationMatrix,
Размер (распознаваниеImageWidth.toDouble (), распознаваниеImageHeight.toDouble ())
) После этого мы снова используем библиотеку поддержки TFLite для изменения размера, оттенков серого и нормализации преобразованных изображений внутри ограничивающих рамок:
val imageProcessor =
ImageProcessor.Builder ()
.add (ResizeOp (высота, ширина, ResizeOp.ResizeMethod.BILINEAR))
.add (TransformToGrayscaleOp ())
.add (NormalizeOp (среднее, стандартное))
.build () Наконец, мы запускаем модель распознавания текста, отображаем символы и числа из выходных данных модели и обновляем пользовательский интерфейс приложения:
распознавание Переводчик.запустить (распознаваниеTensorImage.buffer, распознаваниеResult)
вар признанныйТекст = ""
for (k in 0 до распознаванияModelOutputSize) {
var алфавитIndex = распознаваниеResult.getInt (k * 8)
если (алфавитный индекс в 0..alphabets.length - 1)
распознанный текст = распознанный текст + алфавиты [алфавитный индекс]
}
Log.d ("Результат распознавания:", распознанный текст)
if (распознанный текст! = "") {
ocrResults.put (распознанный текст, getRandomColor ())
} Вот и все. Теперь мы можем извлекать текст из входных изображений с помощью TFLite в нашем приложении.
Наконец, если вам просто нужен готовый к использованию OCR SDK, Google также предлагает функции OCR на устройстве с помощью ML Kit, который использует TFLite внизу и должен быть достаточным для большинства случаев использования OCR. Есть несколько ситуаций, в которых вы можете захотеть создать собственное решение OCR с TFLite, например:
- У вас есть собственные модели TFLite для обнаружения / распознавания текста, которые вы хотели бы использовать;
- У вас есть особые бизнес-требования (например, распознавание перевернутого текста) и вам необходимо настроить конвейер OCR;
- Вы хотите поддерживать языки, не входящие в ML Kit;
- Ваши целевые пользовательские устройства, на которых не обязательно установлены сервисы Google Play;
- Вы хотите контролировать аппаратные серверные части (ЦП / ГП и т. Д.) используется для запуска ваших моделей.
В этих случаях я надеюсь, что это руководство и наш пример реализации могут помочь вам приступить к созданию собственных функций распознавания текста в вашем приложении.
Вы можете узнать больше об оптическом распознавании текста, используя приведенные ниже ресурсы.
Автор хотел бы поблагодарить Тиан Линь за полезные отзывы и участников сообщества @ Tulasi123789 и @risingsayak за их предыдущую работу над OCR с использованием TFLite (создание и загрузка моделей в TF Hub, предоставление сопровождающих записных книжек и т. Д.)).
.