
2.1.3. Проблема качества социально-психологического исследования
Однако самой крупной проблемой социальной психологии является проблема качества той информации, которую мы получаем в социально-психологическом исследовании. В самом общем виде проблема качества информации в любой науке решается путем обеспечения принципа репрезентативности1, а также путем проверки сособов получения данных на надежность. В социальной психологии эти общие проблемы приобретают специфическое содержание. Ведь в нашей науке существуют объективные и субъективные параметры качества информации. Поэтому повышение уровня надежности возможно лишь по тем характеристикам, которые являются субъективными. Для преодоления ошибок такого рода и вводится ряд требований относительно надежности информации.
Надежность
информации достигается прежде всего
проверкой на надежность того инструмента,
посредством которого побраны
социально-психологические данные. В
каждом случае обеспечиваются как минимум
три характеристики надежности:
обоснованность (валидность), устойчивость,
точность.
Обоснованность (валидность) инструмента – это его способность измерить именно те характеристики, которые и нужно измерить. Социальный психолог, строя какую-либо шкалу, должен быть уверен, что эта шкала измерит именно те свойства личности, которые он намеревался измерить. Существует несколько способов проверки инструмента на обоснованность. Например, можно прибегнуть к методу экспертов. Если те свойства личности, которые они распределили, лягут в той же последовательности как и результаты, полученные по шкале, значит можно говорить об обоснованности шкалы. Другой вариант – использование дополнительного интервью и сравнение полученных ответов с параметрами шкалы.
Устойчивость
информации.
Эта характеристика говорит о том, что
информация, полученная в разных условиях,
должна быть идентичной. Существует
несколько способов проверки информации
на устойчивость. Основных способов три.
Во-первых, это повторное измерение.
Во-вторых, это измерение одного и того
же свойства разными наблюдателями. В-третьих, это прием расщепления шкалы,
когда шкала проверяется по частям.
В-третьих, это прием расщепления шкалы,
когда шкала проверяется по частям.
Точность информации измеряется тем, насколько дробной являются применяемые метрики, то есть, насколько чувствителен инструмент. Следовательно, речь идет о том, насколько результаты измерения приближаются к истинному значению измеряемой величины. Перефразируя К. Роджерса, можно сказать, что мы пытаемся максимально приблизить точность карты к параметрам территории. Эта достаточно трудная задача и далеко не каждая методика ее успешно решает. Но, с другой стороны, надо понимать, что класс задач бывает разным, что влияет на задаваемый уровень точности. Вовсе не всегда требуется максимально возможная точность.
Нарушение хотя бы
одного из требований автоматически
уничтожает и все остальные. Кроме того,
существует проблема самого исследователя.
Ведь, в любом случае, измеряет не шкала,
измеряет исследователь. В руках неопытного
и/или малоквалифицированного специалиста
данные, полученные любой самой совершенной
методикой, будут ошибочными и приведут
к несостоятельным утверждениям.
Во многом
трудности социальной психологии
порождены спецификой самого источника
информации, то есть – человека. Ряд этих
трудностей в отечественном подходе
особо усилены. Как мы уже говорили выше,
П. Шихирев подчеркивал чрезмерную
приверженность российской социальной
психологии тестам, анкетам, опросникам,
интервью. Но тогда во весь рост встает
задача правильного понимания инструкции.
Позволяет ли интеллектуальный уровень
испытуемого адакватно понять тот вопрос,
который задает ему исследователь? Мы,
исходя из опыта собственной полевой
практики, можем честно сказать – не
всегда. И это только начало трудностей.
Французы говорят: «Даже самая красивая
женщина не может дать больше того, чем
она имеет. В лучшем случае, она может
повторить». Мы задаем вопрос испытуемому
и ждем от него определенной
социально-психологической информации,
а есть ли она у него? Мы просим испытуемого
описать свои ощущения от первого
сексуального опыта, полагая, что в 25 лет
он, такой опыт, у него есть. Но испытуемый
девственник, но социум иронично и
критично относится к двадцатипятилетним
девственником.
Кроме того,
существует проблема человеческой
памяти. Она слаба и изменчива. Особенно
это характерно для женщин, ведь то
эмоциональное состояние, которое
испытывает женщина в момент опроса,
искажает ее восприятие прошлого в те
же эмоциональные тона, которые она
переживает сейчас. У американцев есть
одна характерная, но точная фраза: «Врет
как очевидец». Дело в том, что те участки
мозга, которые руководят нашими действиями
– одни, а те, с помощью которых мы
описывает эти самые действия – другие.
Поэтому-то наши установки и наши описания
действительности никогда не совпадают!!!
Искренность ответов испытуемого вовсе
не является показателем их надежности!!
В свое время в США прокатилась волна
многомиллионных специфических судебных
исков. Повзрослевшие дочери, как правило
30 – 40 лет, подавали в суд на собственных
отцов, обвиняя их в сексуальном
домогательстве, которому они, дочери,
якобы подвергались в детстве.
Есть и еще одно важное обстоятельство. Мы задаем испытуемому вопрос, ждем от него некой социально-психологической информации, а хочет ли он нам ее предоставить? Заинтересован ли сам испытуемый в том, чтобы мы получили надежную социально-психологическую информацию? Вопрос отнюдь не праздный, если мы, например, изучаем межличностные отношения у заключенных какой-либо колонии или тюрьмы.
Поэтому наряду с
обеспечением надежности данных особо
остро стоит в социальной психологии
вопрос и об их репрезентативности. Ее
решение возможно лишь через построение
выборки.
Проблема качества данных и возможности его повышения.
Сравнительный анализ качественного и количественного подхода к методам исследования.
Преимущества и ограничения качественных и количественных методов исследования.
История развития качественных и количественных методов в психологии.
По-иному
эта проблема может быть сформулирована
как проблема получения надежной
информации. В общем виде проблема
качества информации решается путем
обеспечения принципа
репрезентативности,
а также путем проверки способа получения
данных на
надежность.
В психологии эти общие проблемы
приобретают специфическое содержание.
Будь то экспериментальное или
корреляционное исследование, информация,
которая в нем собрана, должна удовлетворить
определенным требованиям. Учет специфики
неэкспериментальных исследований не
должен обернуться пренебрежением к
качеству информации. Для социальной
психологии, как и для других наук о
человеке, могут быть выделены
В общем виде проблема
качества информации решается путем
обеспечения принципа
репрезентативности,
а также путем проверки способа получения
данных на
надежность.
В психологии эти общие проблемы
приобретают специфическое содержание.
Будь то экспериментальное или
корреляционное исследование, информация,
которая в нем собрана, должна удовлетворить
определенным требованиям. Учет специфики
неэкспериментальных исследований не
должен обернуться пренебрежением к
качеству информации. Для социальной
психологии, как и для других наук о
человеке, могут быть выделены
Надежность информации достигается прежде всего проверкой на надежность инструмента, посредством которого собираются данные. В каждом случае обеспечиваются как минимум три характеристики надежности: обоснованность (валидность), устойчивость и точность (Ядов, 1995).
Обоснованность
(валидность) инструмента – это его
способность измерять именно те
характеристики объекта, которые и нужно
измерить.
Устойчивость информации – это ее качество быть однозначной, т.е. при получении ее в разных ситуациях она должна быть идентичной. (Иногда это качество информации называют «достоверностью»). Способы проверки информации на устойчивость следующие:
а) повторное измерение;
б) измерение одного и того же свойства разными наблюдателями;
в) так называемое «расщепление шкалы», т.е. проверка шкалы по частям.
Качественное
исследование будет
пониматься как исследование, где данные
получены путем наблюдения, интервью,
анализа личных документов (текстовых,
реже визуальных – фото- и видео-источников).
Зачастую это свидетельства, собранные
несколькими разными способами. Первичными
являются данные
о субъективных мнениях людей,
выраженные чаще всего пространными
высказываниями, реже – жестами, символами,
отражающими их взгляды.
В количественном исследовании на вопросы: как часто? как долго? мы получаем достаточно объективный ответ, фиксирующий количество (в единицах счета: много-мало). В качественном исследовании на вопрос: как вам понравился фильм? мы получаем номинальный ответ, обозначающий качество отношения или, другими словами, субъективную ценность, значимость данного предмета для индивида в его собственных словах, исходя из его социального опыта (например, фильм скучный, интересный, любопытный и т. д.).
Такие данные анализируются не математически, а путем аналитического раскрытия их субъективного смысла.
Качественное
исследование проводится прежде всего
для изучения индивидуального аспекта
социальной практики – реального опыта
жизни конкретных людей в конкретных
обстоятельствах. Но через анализ
индивидуального могут исследоваться
и более широкие социальные проблемы,
касающиеся социальных групп, движений
или даже характера функционирования
социальных институтов в конкретной
социальной ситуации. Дополнительными
источниками информации могут служить
и количественные данные (например,
статистика), но их анализ также будет
осуществлен на основе аналитического
подхода.
Дополнительными
источниками информации могут служить
и количественные данные (например,
статистика), но их анализ также будет
осуществлен на основе аналитического
подхода.
7 Наиболее распространенные проблемы с качеством данных
Организации, работающие с данными, зависят от современных технологий и искусственного интеллекта, чтобы получить максимальную отдачу от своих активов данных. Но они постоянно борются с проблемами качества данных. Неполные или неточные данные, проблемы с безопасностью, скрытые данные — список бесконечен. Несколько опросов показывают масштабы убытков по многим вертикалям из-за проблем, связанных с качеством данных.
Некоторые примеры низкого качества данных в бизнесе включают:
- Неверное написание имени клиента, что приводит к упущенным возможностям общения с клиентом и получения дохода.
- Неполная или устаревшая информация о региональных предпочтениях приводит к невозможности открыть новые деловые рынки.

- Отсутствующие или старые номера экстренных служб пациентов приводят к невозможности получить согласие на неотложную медицинскую помощь.
Влияние качества данных напрямую проявляется в снижении доходов и повышении операционных расходов, что приводит к финансовым потерям. Качество данных существенно влияет на организационные усилия по управлению и соответствию требованиям, что приводит к дополнительным доработкам и задержкам. Исследование рынка качества данных, проведенное Gartner, показало, что среднегодовые финансовые затраты на некачественные данные составляют около 15 миллионов долларов. Опрос также показал, что неудовлетворительное качество данных подрывает цифровые инициативы, ослабляет конкурентоспособность и снижает доверие клиентов.
Каковы наиболее распространенные проблемы с качеством данных?
Низкое качество данных — враг номер один для широкого и прибыльного использования машинного обучения. Если вы хотите, чтобы такие технологии, как машинное обучение, работали на вас, вам необходимо уделять особое внимание качеству данных. В этом сообщении блога давайте обсудим некоторые из наиболее распространенных проблем с качеством данных и способы их решения.
В этом сообщении блога давайте обсудим некоторые из наиболее распространенных проблем с качеством данных и способы их решения.
1. Дубликаты данных
Современные организации сталкиваются с натиском данных со всех сторон — локальные базы данных, облачные озера данных и потоковые данные. Кроме того, они могут иметь разрозненные приложения и системы. В этих источниках обязательно будет много дублирования и дублирования. Дублирование контактных данных, например, значительно влияет на качество обслуживания клиентов. Маркетинговые кампании страдают, если некоторые потенциальные клиенты упускаются, а с некоторыми связываются снова и снова. Повторяющиеся данные увеличивают вероятность искажения аналитических результатов. В качестве обучающих данных он также может создавать искаженные модели машинного обучения.
Управление качеством данных на основе правил может помочь вам контролировать повторяющиеся и перекрывающиеся записи. При прогнозирующем DQ правила генерируются автоматически и постоянно совершенствуются путем изучения самих данных. Predictive DQ идентифицирует нечеткие и точно совпадающие данные, количественно оценивает вероятность дублирования и помогает обеспечить постоянное качество данных во всех приложениях.
Predictive DQ идентифицирует нечеткие и точно совпадающие данные, количественно оценивает вероятность дублирования и помогает обеспечить постоянное качество данных во всех приложениях.
2. Неточные данные
Точность данных играет решающую роль в строго регулируемых отраслях, таких как здравоохранение. Глядя на недавний опыт, необходимо улучшить качество данных для COVID-19и последующие пандемии очевидны как никогда. Неточные данные не дают вам правильной реальной картины и не могут помочь спланировать соответствующий ответ. Если ваши данные о клиентах неточны, персонализированный клиентский опыт разочаровывает, а маркетинговые кампании неэффективны.
Неточности данных могут быть связаны с несколькими факторами, включая человеческие ошибки, дрейф данных и испорченность данных. Gartner говорит, что каждый месяц около 3% данных во всем мире устаревают, что очень тревожно. Качество данных может со временем ухудшаться, а данные могут терять свою целостность при перемещении между различными системами. Автоматизация управления данными может помочь вам в некоторой степени, но специализированные инструменты качества данных могут обеспечить гораздо большую точность данных.
Автоматизация управления данными может помочь вам в некоторой степени, но специализированные инструменты качества данных могут обеспечить гораздо большую точность данных.
С помощью прогностического, непрерывного и самообслуживающегося DQ вы можете обнаруживать проблемы с качеством данных на ранних этапах жизненного цикла данных и заранее устранять их для обеспечения надежной аналитики.
3. Неоднозначные данные
В больших базах данных или озерах данных некоторые ошибки могут появиться даже при строгом контроле. Эта ситуация становится более сложной для потоковой передачи данных на высокой скорости. Заголовки столбцов могут вводить в заблуждение, с форматированием могут возникнуть проблемы, а орфографические ошибки могут остаться незамеченными. Такие неоднозначные данные могут привести к многочисленным ошибкам в отчетности и аналитике.
Непрерывный мониторинг с автоматически генерируемыми правилами, прогнозирующий DQ быстро устраняет неоднозначность, отслеживая проблемы, как только они возникают. Он обеспечивает высококачественные конвейеры данных для аналитики в реальном времени и надежных результатов.
Он обеспечивает высококачественные конвейеры данных для аналитики в реальном времени и надежных результатов.
4. Скрытые данные
Большинство организаций используют только часть своих данных, а остальные могут быть потеряны в хранилищах данных или сброшены на кладбище данных. Например, данные о клиентах, доступные в отделе продаж, могут не передаваться службе поддержки клиентов, что лишает возможности создавать более точные и полные профили клиентов. Скрытые данные означают упущение возможностей для улучшения услуг, разработки инновационных продуктов и оптимизации процессов.
Если скрытые данные являются проблемой качества данных для вашей организации, доверьтесь интеллектуальному DQ для автоматического обнаружения, а также возможности обнаружения скрытых взаимосвязей (таких как аномалии между столбцами и «неизвестные неизвестные») в ваших данных. Подумайте также об инвестировании в решение для каталога данных. По данным недавнего опроса, лучшие в своем классе компании имеют на 30 % больше шансов иметь специализированное решение для каталогов данных.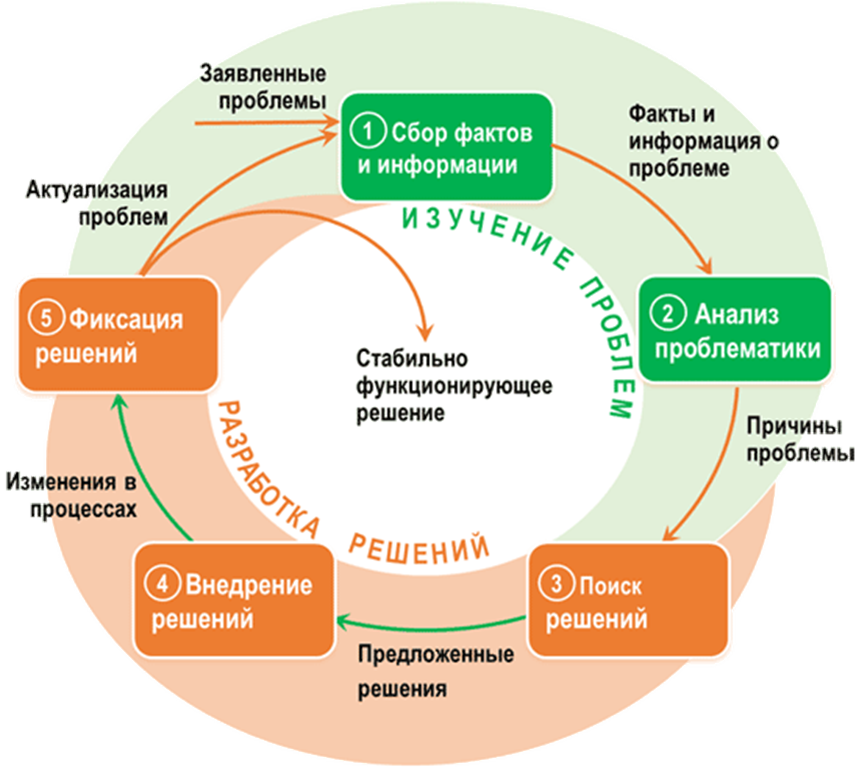
5. Несогласованность данных
При работе с несколькими источниками данных вероятны несоответствия в одной и той же информации из разных источников. Расхождения могут быть в форматах или единицах измерения, а иногда и в написании. Несогласованные данные также могут быть введены во время миграции или слияния компаний. Если не согласовывать постоянно, несоответствия в данных имеют тенденцию накапливаться и разрушать ценность данных. Организации, ориентированные на данные, внимательно следят за согласованностью данных, потому что им нужны только надежные данные для их аналитики.
Непрерывный DQ автоматически профилирует наборы данных, выделяя проблемы с качеством при каждом изменении данных. Для DataOps всеобъемлющая информационная панель помогает быстро определить приоритеты сортировки с помощью ранжирования воздействия. Адаптивные правила постоянно изучают данные, гарантируя устранение несоответствий в источнике, а конвейеры данных предоставляют только надежные данные.
6. Слишком много данных
Хотя мы сосредоточены на аналитике на основе данных и ее преимуществах, слишком много данных не кажется проблемой качества данных. Но это. Когда вы ищете данные, относящиеся к вашим аналитическим проектам, вы можете потеряться в слишком большом количестве данных. Бизнес-пользователи, аналитики данных и специалисты по данным тратят 80 % своего времени на поиск нужных данных и их подготовку. Другие проблемы с качеством данных становятся более серьезными с увеличением объема данных, особенно с потоковыми данными и большими файлами или базами данных.
Если вы изо всех сил пытаетесь разобраться в огромном объеме и разнообразии данных, поступающих из различных источников, у нас есть ответ. Без перемещения или извлечения каких-либо данных прогнозный DQ может легко масштабироваться и обеспечивать постоянное качество данных из нескольких источников. Благодаря полностью автоматическому профилированию, обнаружению выбросов, обнаружению изменений схемы и анализу закономерностей вам не нужно беспокоиться о слишком большом количестве данных.
7. Время простоя данных
Компании, работающие с данными, полагаются на данные для принятия решений и операций. Но могут быть короткие промежутки времени, когда их данные ненадежны или не готовы (особенно во время таких событий, как слияния и поглощения, реорганизации, обновления инфраструктуры и миграции). Это время простоя данных может сильно повлиять на компании, включая жалобы клиентов и плохие аналитические результаты. Согласно исследованию, около 80% времени инженера данных тратится на обновление, обслуживание и обеспечение качества конвейера данных. Длительное операционное время перехода от сбора данных к анализу создает высокие предельные затраты для постановки следующего бизнес-вопроса.
Причины простоя данных могут варьироваться от изменений схемы до проблем миграции. Сложность и масштабы конвейеров данных также могут быть сложными. Важно постоянно отслеживать время простоя данных и минимизировать его с помощью автоматизированных решений.
Подотчетность и соблюдение соглашений об уровне обслуживания могут помочь контролировать время простоя данных. Но что вам действительно нужно, так это комплексный подход к обеспечению постоянного доступа к надежным данным. Прогностический DQ может отслеживать проблемы для непрерывной доставки высококачественных конвейеров данных, всегда готовых к операциям и аналитике.
Но что вам действительно нужно, так это комплексный подход к обеспечению постоянного доступа к надежным данным. Прогностический DQ может отслеживать проблемы для непрерывной доставки высококачественных конвейеров данных, всегда готовых к операциям и аналитике.
В дополнение к вышеперечисленным проблемам организации также борются с неструктурированными данными, недействительными данными, избыточностью данных и ошибками преобразования данных.
Наиболее распространенные формулировки проблемы качества данных| Формулировка проблемы качества данных | Описание |
| Сообщите мне, если что-то вдруг изменится в моих данных | Любое значение столбца, схемы или ячейки, которое внезапно выходит за пределы прежней тенденции. Потребуются тысячи условных операторов и их постоянное управление, если только вы не используете поведенческую аналитику для автоматического контроля изменений. |
| Сколько форматов телефонных номеров в этом столбце? | Эта проблема DQ распространена в полях STRING или VARCHAR, где вы можете получить много разных форматов. Например – почтовый индекс или номер телефона или SSN например. Полезно найти большинство форматов и показать формы данных topN, которые составляют значения столбца. Это помогает выявлять опечатки и странные форматы. Например – почтовый индекс или номер телефона или SSN например. Полезно найти большинство форматов и показать формы данных topN, которые составляют значения столбца. Это помогает выявлять опечатки и странные форматы. |
| Уменьшилось ли количество строк в каком-либо наборе данных? | Может быть важно знать, уменьшается ли объем набора данных, что также известно как уменьшение количества строк. Когда в наборе данных внезапно становится меньше строк, чем обычно, это может означать, что данные отсутствуют в файле или таблице. |
| Проблема значений NULL | Проверка нуля создается на основе прошлого поведения столбцов или описательной статистики. |
| Мне нужно обнаружить выбросы по некоторой группе. | Иногда выбросы на уровне базовых столбцов не решают проблему. Это применяется, когда пользователь хочет найти вопиющие числовые значения относительно населения. |
Мне нужно DQ в конвейере данных. | У меня уже есть конвейер данных на Python, Scala или Spark, и я хочу управлять операциями DQ. Некоторые называют это конвейером ETL, что делает этот ETLQ. |
| Билл Гейтс, проблема нечеткого соответствия Уильяма Гейтса | Эта проблема не подходит для условных операторов. Вам нужно выбрать любую группу столбцов и найти точные или похожие записи (нечеткое соответствие). Это можно сделать на уровне столбца или записи. Выявляйте повторяющиеся или избыточные данные в наборе данных с помощью нечеткого или точного сопоставления. |
| Мне нужно сравнить две таблицы. | Обычно требуется проверка при загрузке данных из файла в таблицу базы данных или из исходной базы данных в целевую базу данных для выявления отсутствующих записей, значений и нарушенных связей между таблицами или системами. |
| Я хотел бы увидеть тепловую карту всех моих ошибок данных. | Визуализируйте тепловую карту слепых зон по времени, подразделениям и запланированным заданиям. |
| Штат и почтовый индекс не принадлежат друг другу в моем наборе данных. | Определите взаимосвязи, выявляя аномалии между столбцами. Обычно используется для иерархических и родительских/дочерних несоответствий. |
Как устранить проблемы с качеством данных?
Качество данных является критическим аспектом жизненного цикла данных. Организации часто сталкиваются с трудностями при решении проблем с качеством данных, потому что не существует быстрого решения. Если вы хотите решить проблемы с качеством данных в источнике, лучший способ — определить их приоритетность в стратегии данных организации. Следующим шагом является привлечение и предоставление всем заинтересованным сторонам возможности внести свой вклад в качество данных.
Наконец, инструменты. Выбирайте инструменты с интеллектуальными технологиями, чтобы повысить качество и раскрыть ценность данных. Включите метаданные для описания и обогащения данных в контексте того, кто, что, где, почему, когда и как. Подумайте об анализе данных, чтобы понять и правильно использовать данные вашей организации.
Подумайте об анализе данных, чтобы понять и правильно использовать данные вашей организации.
При оценке инструментов качества данных ищите инструменты, которые обеспечивают постоянное качество данных в любом масштабе. Наряду с ними используйте управление данными и каталог данных, чтобы обеспечить всем заинтересованным сторонам доступ к высококачественным, надежным, своевременным и актуальным данным.
Проблемы с качеством данных можно рассматривать как возможность устранить их в корне и предотвратить будущие потери. Благодаря общему пониманию качества данных используйте доверенные данные для повышения качества обслуживания клиентов, раскрытия инновационных возможностей и стимулирования роста бизнеса.
Что такое проверки качества данных?
Проверки качества данных начинаются с определения показателей качества, проведения тестов для выявления проблем с качеством и устранения проблем, если они поддерживаются системой. Проверки часто определяются на уровне атрибутов, чтобы обеспечить быстрое тестирование и решение проблем.
Общие проверки качества данных включают:
- Выявление дубликатов или перекрытий для обеспечения уникальности.
- Проверка обязательных полей, нулевых значений и отсутствующих значений для выявления и исправления полноты данных.
- Применение проверки форматирования на согласованность.
- Проверка диапазона значений на достоверность.
- Проверка того, насколько свежими являются данные или когда они были обновлены в последний раз, определяет недавность или свежесть данных.
- Проверка целостности строки, столбца, соответствия и значения.
Некоторые проверки качества данных можно рассматривать как бизнес-правила, позволяющие лучше сфокусироваться на предметной области. Например, поставщик страховых услуг может разработать диапазон оценки факторов риска и включить его в бизнес-правила.
Примеры проверки качества данных различаются в зависимости от вертикали. В здравоохранении актуальность данных о пациентах может проверяться на предмет последнего назначенного лечения или диагноза. С другой стороны, для торговли на рынке Форекс проверка свежести может основываться на времени тестирования.
В здравоохранении актуальность данных о пациентах может проверяться на предмет последнего назначенного лечения или диагноза. С другой стороны, для торговли на рынке Форекс проверка свежести может основываться на времени тестирования.
Collibra Data Quality & Observability заблаговременно выявляет проблемы качества в режиме реального времени с помощью автоматически адаптирующихся правил. Благодаря автоматизированным проверкам качества данных вы можете быть уверены в надежности данных, необходимых для принятия надежных бизнес-решений.
Чтобы узнать больше о Collibra Data Quality, запросите демонстрацию в реальном времени.
Хотите узнать больше о качестве данных Collibra?
Посмотрите демонстрацию качества данных по запросу!Анкур Гупта
Директор по маркетингу продукции
Анкур — страстный маркетолог, работающий с данными, и рассказчик историй, который любит помогать компаниям добиваться роста и совершенства. Он имеет степень магистра делового администрирования в Корнелле и инженера в Индийском технологическом институте в Дели.
Пять наиболее распространенных проблем с качеством данных и способы их решения
ДАТАБЕРГ
С появлением социализации данных многие организации эффективно собирают, обмениваются и делают данные доступными для всех сотрудников.
Хотя большинство компаний получают выгоду от широкого использования таких информационных ресурсов своими работниками, некоторые сталкиваются с проблемами точности используемых ими данных.
Поскольку в настоящее время большинство организаций также рассматривают возможность внедрения систем искусственного интеллекта или подключения своего бизнеса к Интернету вещей, это становится особенно важным.
Проблемы с качеством данных могут быть вызваны дублированием данных, неструктурированными данными, неполными данными, различными форматами данных или трудностями доступа к данным. В этой статье мы обсудим наиболее распространенные проблемы с качеством данных и способы их преодоления.
Дублирование данных Несколько копий одних и тех же записей мешают вычислениям и хранению, но могут также привести к искаженным или неправильным выводам, если их не обнаружить. Одной из критических проблем может быть человеческая ошибка — кто-то просто случайно вводит данные несколько раз — или алгоритм, который дал сбой.
Одной из критических проблем может быть человеческая ошибка — кто-то просто случайно вводит данные несколько раз — или алгоритм, который дал сбой.
Предлагаемое решение этой проблемы называется “дедупликация данных”. Это сочетание человеческой интуиции, анализа данных и алгоритмов для обнаружения возможных дубликатов на основе случайных оценок и здравого смысла для определения того, где записи выглядят как близкие совпадения.
Неструктурированные данныеВо многих случаях, если данные были введены в систему неправильно или некоторые файлы могли быть повреждены, оставшиеся данные содержат много отсутствующих переменных. Например, если адрес вообще не содержит почтового индекса, остальные детали могут не представлять большого интереса, поскольку будет сложно определить географическое измерение.
С помощью инструмента интеграции данных вы можете преобразовать неструктурированные данные в структурированные. А также перемещать данные из разных форматов в одну непротиворечивую форму.
Помимо отраслевых и нормативных стандартов, таких как HIPAA или PCI Data Security Standards (PCI DSS), требования к безопасности данных и соответствию требованиям исходят из разных источников и включают организационные требования. Несоблюдение этих правил может обернуться большими штрафами и, что еще дороже, потерей лояльности клиентов. Руководящие принципы, предусмотренные такими нормативными актами, как HIPAA и PCI, также являются убедительным аргументом в пользу надежной системы управления качеством данных.
Консолидация управления конфиденциальностью и обеспечением безопасности в рамках общей программы управления данными дает значительное преимущество. Это может включать в себя интегрированное управление данными и проверенные аудиторами процедуры контроля качества данных, что дает бизнес-руководителям и ИТ-специалистам уверенность в том, что их компания соответствует критическим требованиям конфиденциальности и обеспечивает защиту от возможных утечек данных. Защищая целостность данных клиентов с помощью единой программы качества данных, клиенты поощряются к установлению прочных и длительных связей с брендом.
Защищая целостность данных клиентов с помощью единой программы качества данных, клиенты поощряются к установлению прочных и длительных связей с брендом.
Большинство компаний используют только около 20% своих данных при принятии решений бизнес-аналитики, оставляя 80% в метафорическом мусорном баке. Скрытые данные наиболее полезны в отношении поведения клиентов. Клиенты взаимодействуют с компаниями сегодня в различных средах, от личного общения по телефону до онлайн. Данные о том, когда, как и почему клиенты взаимодействуют с компанией, могут иметь неоценимое значение, но они редко используются.
Сбор скрытых данных с помощью такого инструмента, как Datumize Data Collector (DDC), может дать гораздо больше информации о скрытых данных, которые вы получили.
Неточные данные Наконец, нет смысла проводить аналитику больших данных или связываться с клиентами на основе данных, которые просто неверны. Данные могут быстро стать неточными. Если вы не соберете все скрытые данные, ваши данные будут неполными и ограничивают вас в принятии решений на основе полных и точных наборов данных. Более очевидный путь для неточных данных — это данные в системах, заполненных человеческими ошибками, такими как тип или неправильная информация, предоставленная клиентом, или ввод данных в неправильное поле.
Данные могут быстро стать неточными. Если вы не соберете все скрытые данные, ваши данные будут неполными и ограничивают вас в принятии решений на основе полных и точных наборов данных. Более очевидный путь для неточных данных — это данные в системах, заполненных человеческими ошибками, такими как тип или неправильная информация, предоставленная клиентом, или ввод данных в неправильное поле.
Это может быть одной из самых сложных проблем с качеством данных, которые можно обнаружить, в основном, если кодировка все еще соответствует требованиям — например, ввод неточного, но законного номера социального страхования может остаться незамеченным базой данных, которая проверяет достоверность только изолированно. информация.
Человеческая ошибка неизлечима, но для начала неплохо убедиться, что у вас есть четкие процедуры, которые последовательно соблюдаются. Инструменты автоматизации, позволяющие сократить объем ручной работы при перемещении данных между системами, также чрезвычайно полезны для снижения риска ошибок со стороны уставших или скучающих сотрудников.