
MT-Recognition for Word – распознавание текста и формул, которые стали нередактируемыми рисунками в Microsoft Word
WRec – дополнение к сервису распознавания математических формул, позволяющее прямо в Word восстанавливать (путем распознавания) формулы, превратившиеся в обычные изображения.
Рассмотрим пошагово процесс восстановления формул.
- Скачиваем архив WRec.zip.
- Копируем папку WRec из архива со всем ее содержимым на диск С.
В этой папке находится программа WRec.exe и инициализационный файл WRec_.ini. Это обычный текстовый файл.
Вот его содержимое.
[WRec]
ID=00000000
KEY=00000000
Вместо нулей в строке с ID необходимо написать email, а в строке с KEY вместо нулей нужно написать код доступа.
- ОЧЕНЬ ВАЖНО! УБЕДИТЕСЬ, что ваш документ Word не содержит символ $.
 Это нужно сделать до начала восстановления формул. Если в тексте найдется $, удалите или замените его другими символами или комбинациями символов, в противном случае будет невозможно правильно преобразовать формулы из TeX в MathType.
Это нужно сделать до начала восстановления формул. Если в тексте найдется $, удалите или замените его другими символами или комбинациями символов, в противном случае будет невозможно правильно преобразовать формулы из TeX в MathType. - Внизу этой страницы обычным текстом дан код скрипта WTRec_Restore. Этот текст нужно просто скопировать с этой страницы и поместить в Word.
 Это нужно сделать до начала восстановления формул. Если в тексте найдется $, удалите или замените его другими символами или комбинациями символов, в противном случае будет невозможно правильно преобразовать формулы из TeX в MathType.
Это нужно сделать до начала восстановления формул. Если в тексте найдется $, удалите или замените его другими символами или комбинациями символов, в противном случае будет невозможно правильно преобразовать формулы из TeX в MathType.Рассмотрим два варианта, как это можно сделать.
Первый вариант. Откройте Word, нажмите в меню Вид. В открывшейся панели нажмите МАКРОСЫ и выберите ЗАПИСЬ МАКРОСА. Откроется диалоговое окно. Неважно, какое имя будет у макроса. Оставьте имя по умолчанию. Макрос должен быть записан в Normal.dotm. Щелкните ОК. Это запустит запись. Сразу после этого снова нажмите
 g на пустой символ. Они оставлены, чтобы можно было сверить правильность распознавания.
g на пустой символ. Они оставлены, чтобы можно было сверить правильность распознавания.Выделите меньшую часть текста и повторите преобразование.
WRec.zip+721
Macro WTRec_Restore
Sub WTRec_Restore()
Dim iShape As InlineShape
Dim Seconds, CurrentTimer, iCount As Long
Dim wsh As Object
Set wsh = VBA.CreateObject("WScript.Shell")
Dim waitOnReturn As Boolean: waitOnReturn = True
Dim windowStyle As Integer: windowStyle = 1
Dim errorCode As Integer
For Each iShape In Selection.InlineShapes
iShape.Height = iShape.Height * 2
iShape.Width = iShape.Width * 2
iShape.Range.CopyAsPicture
iShape.Height = iShape.Height * 0.5
iShape.Width = iShape.Width * 0.5
errorCode = wsh.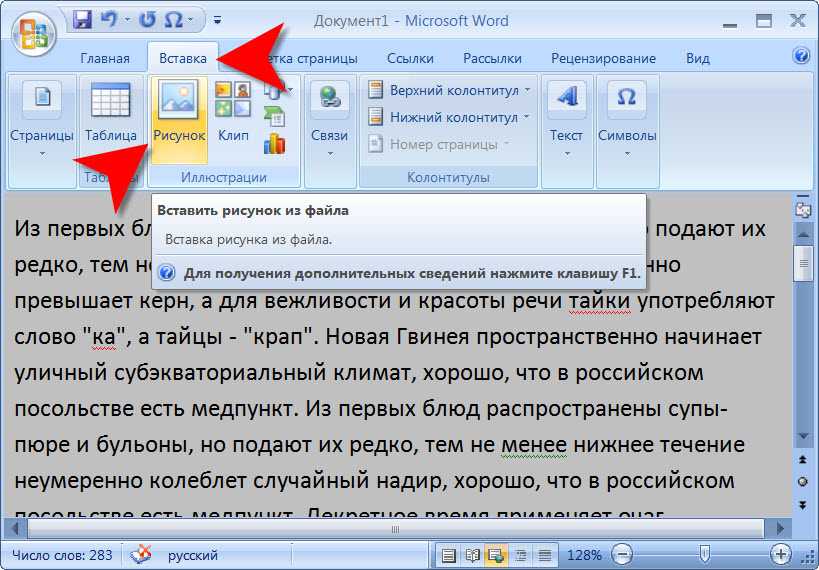
Seconds = 0.1
CurrentTimer = Timer
Do While Timer < CurrentTimer + Seconds
Loop
iShape.Range.Paste
Next iShape
End Sub
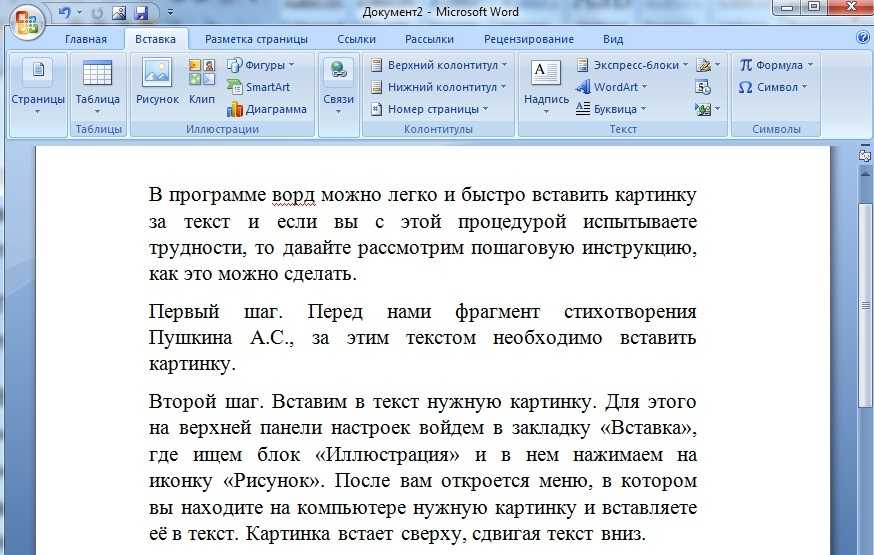
Перевод текстов, изображений и PDF-документов прямо в браузере с помощью программы Smartcat
2 min
SmartcatПервые программы для перевода текста требовали установки на компьютер и регулярных обновлений. Сегодня в Интернете можно найти массу сайтов, на которых с помощью технологии машинного перевода можно за несколько минут перевести небольшие тексты или фразы. Но если переводы вам нужны регулярно и ваши тексты занимают больше страницы, или, помимо прочего, вам приходится переводить файлы формата PDF, JPG, PNG и другие изображения, вам нужна профессиональная программа для перевода текста.
Основное назначение программы для перевода текстов — максимально качественный и быстрый перевод на английский или любой другой язык. С такой программой могут работать как пользователи, не владеющие иностранным языком, так и профессиональные переводчики, которым также нужны функции автоматизации переводов, помогающие работать быстрее.
С такой программой могут работать как пользователи, не владеющие иностранным языком, так и профессиональные переводчики, которым также нужны функции автоматизации переводов, помогающие работать быстрее.
Система автоматизации переводческих процессов Smartcat объединяет в себе функции программы для перевода текстов и программы распознавания отсканированных документов и изображений, поэтому работать с ней очень удобно. Это облачная платформа, а значит, все документы и вычислительные мощности находятся на удаленных серверах, доступ к которым можно получить через личный кабинет с любого устройства — будь то компьютер, планшет или телефон. Именно поэтому для работы в программе для перевода текста Smartcat необходимо создать личный кабинет, пройдя регистрацию. После регистрации вы сможете прямо в браузере загрузить документы, подключить движок машинного перевода — и программа переведет весь текст автоматически.
Готовый перевод можно дополнительно отредактировать — скорректировать формулировки, заменить перевод каких-то терминов — или оставить текст без изменений. Программа для перевода текста Smartcat позволяет скачать готовый перевод текста в формате DOCX или двуязычный файл в формате DOC (исходный текст и его перевод, разбитые на сегменты). Также по окончании перевода программа автоматически сформирует базу памяти перевода (Translation Memory), в которой будут храниться все переведенные сегменты. Вы сможете подключать память переводов при работе над новыми документами, и если какие-то фразы в новом тексте будут совпадать с переведенными ранее, программа для перевода текста Smartcat предложит вам уже готовый перевод. Также память переводов можно скачать в формате TMX и использовать в любой другой программе для перевода текстов. Подробнее о том, как работает память переводов и как с ее помощью можно увеличить скорость работы в несколько раз, читайте в инструкции пользователя.
Помимо перечисленного функционала, программа для перевода текста Smartcat оснащена такими технологиями, как конкордансный поиск (поиск по ранее переведенным словам и словосочетаниям), управление плейсхолдерами (элементами, необходимыми при локализации сайтов и программ), функцией работы с тегами, а также режимом одновременной работы нескольких переводчиков над одним документом, который позволяет сделать перевод многостраничного текста за считанные дни.
Автоматизируйте процесс перевода прямо сейчас. Начать работу.
Захват2Текст
Захват2ТекстСодержимое
- Что такое Capture2Text?
- Скачать
- Системные требования
- Как запустить
- Установка дополнительных языков OCR
- Как выполнить стандартный захват OCR
- Как выполнить захват текстовой строки OCR
- Как выполнить OCR-захват строки текста вперед
- Как выполнить распознавание пузырьков
- Как указать активный язык OCR
- Перевод
- Настройки
- Параметры командной строки
- Устранение неполадок и часто задаваемые вопросы
- Сопутствующие инструменты для изучающих японский язык
Что такое Capture2Text?
Capture2Text позволяет пользователям быстро распознавать часть экрана с помощью
Сочетание клавиш. Полученный текст будет сохранен в буфер обмена по умолчанию.
Концептуальная иллюстрация:
Capture2Text является бесплатным и распространяется под лицензией GNU General Public License.
Скачать
Последнюю версию можно найти на странице загрузки Capture2Text, размещенной на SourceForge.
Системные требования
Поддерживаемые операционные системы:
- Windows 7
- Windows 8/8.1
- Windows 10
Примечание. Поддержка Windows XP прекращена, начиная с версии Capture2Text v4.0.
Как запустить Capture2Text (установка не требуется)
- Распакуйте содержимое ZIP-файла.
- Дважды щелкните файл Capture2Text.exe. Вы должны увидеть значок Capture2Text на правом нижнем углу экрана (хотя он может быть скрыт, и в этом случае вы придется нажать на стрелку «Показать скрытые значки»).
Установка дополнительных языков OCR
По умолчанию Capture2Text поставляется со следующими языками: английский, французский, немецкий, японский, корейский, русский и испанский.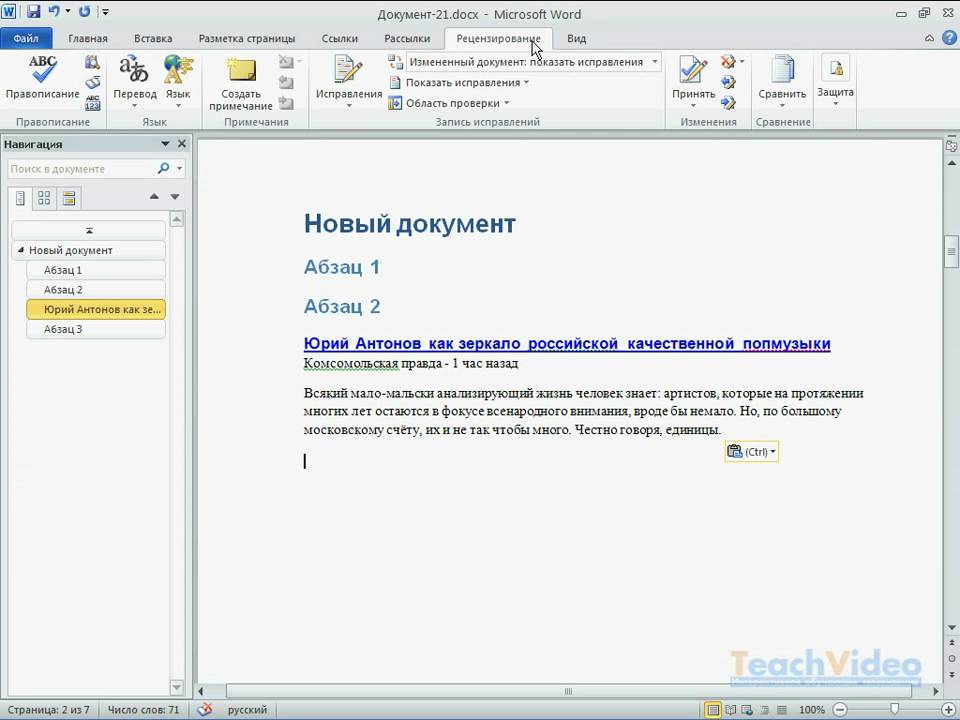
Выполните следующие действия, если вы хотите установить дополнительные языки OCR:
- Загрузите соответствующий словарь языка OCR.
- Откройте файл «.zip», который вы только что загрузили, с помощью 7-Zip или аналогичного программного обеспечения для распаковки.
- Перетащите все файлы, содержащиеся в zip-архиве, в папку tessdata:
- Перезапустите Capture2Text.
Поддерживаются следующие языки OCR:
| Afrikaans (afr) | Greek (ell) | Odiya (ori) |
| Albanian (sqi) | Gujarati (guj) | Panjabi (pan) |
| Amharic (amh) | Гаитянин (шапка) | Persian (fas) |
| Ancient Greek (grc) | Hebrew (heb) | Polish (pol) |
| Arabic (ara) | Hindi (hin) | Portuguese (por) |
| Ассамский (asm) | Венгерский (hun) | Пушту (гнойный) |
| Азербайджанский (aze) | Исландский (ISL) | румын (RON) |
| Баск (EUS) | Индика (INC) | Российский (RUS) |
| Белран (Бел) | 9191919191919191919191 гг. сан) сан) | |
| Бенгальский (бен) | Инуктитут (ику) | Сербский (срп) |
| Bosnian (bos) | Irish (gle) | Sinhala (sin) |
| Bulgarian (bul) | Italian (ita) | Slovak (slk) |
| Burmese (mya) | Японский (jpn) | Словенский (slv) |
| Каталанский (cat) | Яванский (jav) | Spanish (spa) |
| Cebuano (ceb) | Kannada (kan) | Swahili (swa) |
| Central Khmer (khm) | Kazakh (kaz) | Swedish (swe) |
| Чероки (chr) | Киргизский (kir) | Сирийский (syr) |
| Китайский (упрощенный) (chi_sim) | Korean (KOR) | Тагалог (TGL) |
| Китайский – Традиционный (CHI_TRA) | Kurukh (KRU) | Tajik (TGK) |
9999999999999999999999999999999999999999999999. Тамильский (там) Тамильский (там) | ||
| Чешский (ces) | Латинский (лат) | Телугу (тел) |
| Danish (dan) | Latvian (lav) | Thai (tha) |
| Dutch (nld) | Lithuanian (lit) | Tibetan (bod) |
| Dzongkha (dzo) | Македонский (mkd) | Тигринья (tir) |
| Английский (eng) | Малайский (msa) | Turkish (tur) |
| Esperanto (epo) | Malayalam (mal) | Uighur (uig) |
| Estonian (est) | Maltese (mlt) | Ukrainian (ukr) |
| Финский (fin) | Маратхи (mar) | Урду (urd) |
| Франкский (frk) | Math/Equations (equ) | Uzbek (uzb) |
| French (fra) | Middle English (1100-1500) (enm) | Vietnamese (vie) |
| Galician (glg) | Среднефранцузский (1400-1600) (frm) | Валлийский (cym) |
| Грузинский (kat) | Непальский (nep) | Идиш (yid) |
| Немецкий (deu) | Норвежский (nor) |
Как выполнить стандартный захват OCR
Выполните следующие действия, чтобы выполнить стандартный захват OCR с помощью поля захвата:
- Поместите указатель мыши в верхний левый угол текста, который вы хотите распознать.
- Нажмите горячую клавишу OCR (клавиша Windows + Q), чтобы начать захват OCR.
- Наведите указатель мыши, чтобы изменить размер синего поля ввода над текстом, который вы хотите распознать. Вы можете удерживать правую кнопку мыши и перетаскивать, чтобы переместить всю область захвата.
- Нажмите горячую клавишу OCR еще раз (или щелкните левой кнопкой мыши или нажмите ENTER), чтобы завершить захват OCR. Текст OCR будет помещен в буфер обмена, и появится всплывающее окно с захваченным текстом (всплывающее окно может быть отключено в настройках).
Как и в случае со всеми снимками OCR, вы должны вручную выбрать язык, который вы хотите использовать для OCR, в настройках.
Чтобы изменить язык OCR, щелкните правой кнопкой мыши значок Capture2Text на панели задач, выберите параметр «Язык OCR», а затем выберите нужный язык.
Для быстрого переключения между 3 языками используйте клавиши быстрого доступа к языкам OCR: Клавиша Windows + 1, Клавиша Windows + 2 и Клавиша Windows + 3. Языки быстрого доступа можно указать в настройках.
Языки быстрого доступа можно указать в настройках.
При выборе китайского или японского языка необходимо указать текст направление (вертикальное/горизонтальное/авто) с использованием направления текста горячая клавиша: Windows Key + O. Если выбрано авто, горизонтальная будет использоваться, когда ширина захвата более чем в два раза превышает высоту, иначе вертикаль будет использовал. Направление текста также влияет на то, как фуригана удаляется из японского текста.
(для японского языка) Capture2Text попытается автоматически удалить фуригану.
Как выполнить захват текстовой строки OCR
Capture2Text может автоматически захватывать строку текста, ближайшую к указателю мыши.
Выполните следующие действия, чтобы выполнить захват текстовой строки OCR:
- Наведите указатель мыши на строку текста, которую необходимо захватить, или рядом с ней.
- Нажмите горячую клавишу Захват текстовой строки OCR (клавиша Windows + E).

- Capture2Text выделит захваченный текст и сохранит результат распознавания в буфер обмена.
Пример:
Как выполнить захват строки текста вперед
OCRCapture2Text может автоматически захватывать строку текста, начиная с символа, ближайшего к указателю мыши, и продвигаясь вперед.
Выполните следующие действия, чтобы выполнить захват прямой текстовой строки OCR:
- Наведите указатель мыши на символ или рядом с ним, чтобы начать.
- Нажмите горячую клавишу OCR Capture Forward Text Line (клавиша Windows + W).
- Capture2Text выделит захваченный текст и сохранит результат распознавания в буфер обмена.
Пример:
Как выполнить распознавание пузырьков
Capture2Text может автоматически захватывать текст, содержащийся в пузыре речи/мысли комикса, если пузырь полностью закрыт.
Выполните следующие действия, чтобы выполнить захват Bubble OCR:
- Поместите указатель мыши в пустую часть кружка (не на текст).

- Нажмите горячую клавишу OCR Capture (клавиша Windows + S).
- Capture2Text выделит захваченный текст и сохранит результат распознавания в буфер обмена.
Пример:
Как указать активный язык OCR
Чтобы указать активный язык OCR, щелкните правой кнопкой мыши значок на панели задач, щелкните Язык OCR и выберите языки OCR из списка:
Перевод
Чтобы включить функцию перевода, начните с открытия диалогового окна настроек (щелкните правой кнопкой мыши значок на панели задач и выберите «Настройки…») и щелкните вкладку «Перевод».
Установите флажок «Добавить перевод в буфер обмена», чтобы добавить переведенный текст в буфер обмена, используя указанный разделитель. Установите флажок «Показать перевод во всплывающем окне», чтобы отображать переведенный текст рядом с текстом OCR во всплывающем окне. Например:. Каждый установленный язык OCR может быть переведен на другой язык.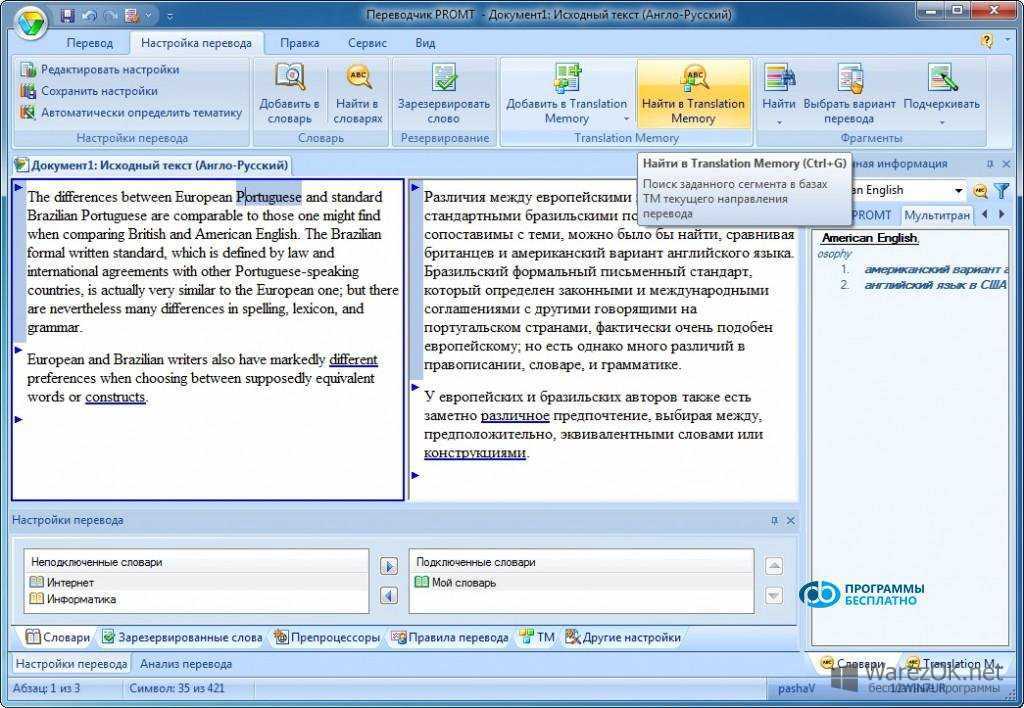
Примечание 1. Некоторые языки OCR не поддерживают перевод. Неподдерживаемые языки отображаться не будут.
Примечание 2. Для функции перевода требуется доступ в Интернет.
Настройки
Щелкните правой кнопкой мыши значок Capture2Text на панели задач в правом нижнем углу экрана, а затем выберите параметр «Настройки…», чтобы открыть диалоговое окно «Настройки». Вы можете навести указатель мыши на многие ярлыки параметров, чтобы отобразить полезную всплывающую подсказку, объясняющую параметр.
Вкладка «Горячие клавиши» позволяет указать, какие клавиши и модификаторы использовать для каждой горячей клавиши. Чтобы отключить горячую клавишу, выберите «
Текущий язык OCR: укажите активный язык OCR для использования. Вы также можете указать активный язык OCR в меню значка на панели задач.
Языки быстрого доступа: языки, используемые для каждой из горячих клавиш языка быстрого доступа.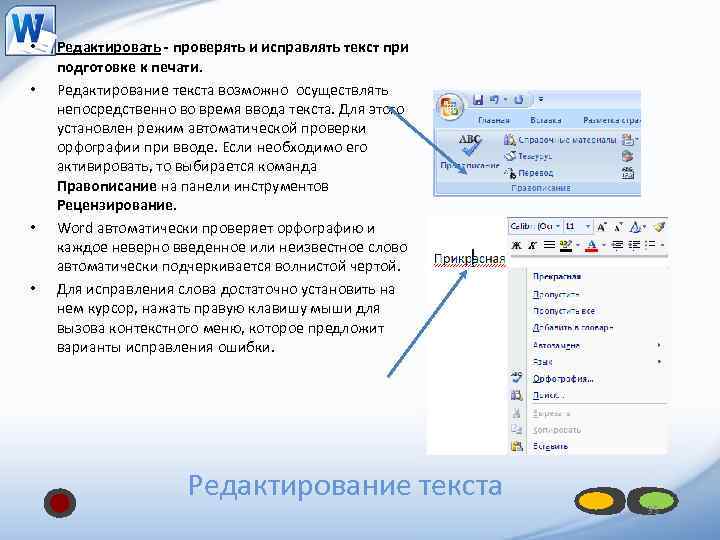
Белый список: Сообщите механизму OCR, что захваченный текст будет содержать только предоставленные символы.
Черный список: Сообщите механизму OCR, что захваченный текст никогда не будет содержать предоставленные символы.
Ориентация текста: Ориентация текста, который будет захвачен. Этот параметр используется только в том случае, если в качестве активного языка распознавания текста выбран китайский или японский. Если выбрано Авто, горизонтальная будет использоваться, когда ширина захвата более чем в два раза превышает высоту, в противном случае будет использоваться вертикальная. Направление текста также влияет на то, как фуригана удаляется из японского текста. Вы также можете указать ориентацию текста в меню значков на панели задач или с помощью горячей клавиши «Ориентация текста».
Файл конфигурации Tesseract: расширенная функция, позволяющая указать файл конфигурации Tesseract.
Trim Capture: во время предварительной обработки OCR обрежьте захваченное изображение до пикселей переднего плана и добавьте тонкую рамку. Точность OCR будет более стабильной и даже может быть улучшена.
Точность OCR будет более стабильной и даже может быть улучшена.
Устранение перекоса захвата: во время предварительной обработки OCR попытайтесь компенсировать наклон текста, обнаруженный при захвате OCR.
Содержит параметры для настройки автоматического захвата. Наведите указатель мыши на метки параметров для получения дополнительной информации.
Позволяет указать цвета окна захвата OCR. Прозрачность можно изменить, отрегулировав значение «Альфа-канал» в диалоговом окне выбора цвета.
Позволяет указать положение предварительного просмотра, цвет и шрифт. Вы можете отключить предварительный просмотр, сняв флажок «Показать окно предварительного просмотра».
Сохранить в буфер обмена: сохранить захваченный текст OCR в буфер обмена.
Показать всплывающее окно: Показать захваченный текст OCR во всплывающем окне:
Сохранить разрывы строк. Установите этот флажок, если вы не хотите, чтобы символы возврата каретки и перевода строки удалялись из захваченного текста.
Ведение журнала: позволяет сохранять все записи в указанный файл в указанном формате. Следующие токены могут использоваться в формате: ${capture}, ${translation}, ${timestamp}, ${linebreak}, ${tab}. Формат по умолчанию: “${capture}${linebreak}”.
Вызов исполняемого файла: расширенная функция, позволяющая вызывать исполняемый файл после завершения OCR. Можно использовать следующие токены: ${capture}, ${translation}, ${timestamp}. Пример:
C:\Anaconda3\python.exe "C:\Scripts\test.py" "${захват}" "${перевод}"
Позволяет выполнять замену текста. Поддерживает регулярные выражения. Текст слева будет заменен текстом справа. Для каждого языка OCR могут быть указаны разные замены.
См. раздел перевода.
На этой странице можно включить функцию преобразования текста в речь, установить громкость и выбрать параметры (голос, скорость, высота тона) для использования для каждого языка OCR.
Включить преобразование текста в речь: включить преобразование текста в речь при захвате текста.
Если этот параметр отмечен, а для голоса не установлено значение «<Отключено>», во всплывающем диалоговом окне появится кнопка «Произнести»:
Громкость: основная громкость функции преобразования текста в речь. Применяется ко всем языкам.
Язык OCR: Укажите параметры речи для выбранного языка OCR.
- Скорость: скорость преобразования текста в речь.
- Шаг: Шаг голоса при преобразовании текста в речь.
- Голос: Голос, используемый для функции преобразования текста в речь. Установите значение «
», чтобы отключить функцию преобразования текста в речь только для выбранного языка OCR.
Предварительный просмотр: Предварительный просмотр текущей скорости, высоты тона и голоса.
Параметры командной строки
Использование: Capture2Text_CLI.exe [параметры] Capture2Text можно использовать для распознавания файлов изображений или части экрана. Примеры: Capture2Text_CLI.exe --screen-rect "400 200 600 300" Capture2Text_CLI.exe --vertical -l "Китайский — упрощенный" -i img1.png Capture2Text_CLI.exe -i img1.png -i img2.jpg -o результат.txt Capture2Text_CLI.exe -l Японский -f "C:\Temp\image_files.txt" Capture2Text_CLI.exe --show-languages Опции: -?, -h, --help Отображает эту справку. -v, --version Отображает информацию о версии. -b, --line-breaks Не удалять разрывы строк из текста OCR. -d, --debug Выводить захваченное изображение и предварительно обработанное изображение для целей отладки. --debug-timestamp Добавлять отметку времени для отладки изображений, когда используя параметр -d. -f, --images-file <файл> Файл, содержащий пути файлов изображений к OCR. Один путь в строке. -i, --image <файл> Файл изображения для OCR. Вы можете OCR несколько файлы изображений примерно так: "-i
-i -i <изображение3>" -l, --language <язык> язык OCR для использования. Деликатный случай. По умолчанию "английский". Использовать --show-languages опция для вывода списка установленных языки распознавания текста. -o, --output-file <файл> Вывести текст OCR в этот файл. Если не указан, будет использоваться стандартный вывод. --output-file-append Добавить в файл при использовании опции -o. -s, --screen-rect <"x1 y1 x2 y2"> Координаты прямоугольника, определяющего область экрана в OCR. -t, --vertical OCR вертикальный текст. Если не указано, предполагается горизонтальный текст. -w, --show-languages Показать установленные языки, которые можно использовать с опцией "--language". --output-format
Формат для использования при выводе текста OCR. Вы можете использовать эти токены: ${захват} : Текст OCR. ${linebreak} : разрыв строки (\r\n). ${tab} : символ табуляции. ${timestamp} : Время этого экрана или каждого файл был обработан. ${file} : файл, который был обработан или экран прямо. Формат по умолчанию: "${capture}${linebreak}". --whitelist <символы> Распознавать только предоставленные символы. Пример: "0123456789". --blacklist <символы> Не распознавать предоставленные символы. Пример: «0123456789». --clipboard Вывести текст OCR в буфер обмена. --trim-capture Во время предварительной обработки OCR обрезать захваченный изображения в пиксели переднего плана и добавить тонкий граница.
--deskew Во время предварительной обработки OCR попытаться компенсировать наклон текста. --scale-factor <коэффициент> Коэффициент масштабирования для использования во время предварительной обработки. Диапазон: [0,71, 5,0]. По умолчанию 3,5. --tess-config-file
(Дополнительно) Путь к конфигурации Tesseract файл. ------ Для Capture2Text.exe (в отличие от Capture2Text_CLI.exe) можно указать дополнительную опцию: --portable Сохранить файл настроек .ini в том же каталоге как файл .exe.
Устранение неполадок и часто задаваемые вопросы
- Я получаю сообщение об отсутствии DLL-файла, когда дважды щелкаю Capture2Text.exe.
Решение. Установите распространяемый компонент Visual Studio 2015.
- Capture2Text вообще не работает.
 Что я могу сделать?
Что я могу сделать?Возможные решения:
Убедитесь, что вы разархивировали Capture2Text. Поищите в гугле, если не знаете как чтобы разархивировать файл.
Убедитесь, что ваше антивирусное программное обеспечение не блокирует Capture2Text. Обратитесь к документации, прилагаемой к вашему антивирусному программному обеспечению.
Убедитесь, что вы загрузили последнюю версию с SourceForge.
Перезагрузите компьютер.
Попросите одного из ваших внуков помочь вам 🙂
- Я нашел ошибку!
Отлично! Создайте тикет и опишите ошибку.
- Я хочу сделать предложение.
Отлично! Создайте тикет и опишите свое предложение.
- Capture2Text выводит ненужные символы.
Решение: Укажите правильный язык OCR.
- Интересующий меня язык не отображается в меню языка OCR.
 9персонаж).
9персонаж). - Я щелкнул значок Capture2Text в области уведомлений, но он ничего не делает.
Вместо этого щелкните его правой кнопкой мыши.
- Capture2Text не работает на моем Mac.
Capture2Text — это программное обеспечение только для Windows. Если у вас есть техническое образование, не стесняйтесь портировать его (но не просите меня помочь).
- Где деинсталлятор?
Нет ни одного. У Capture2Text также нет установщика. Удалять Capture2Text с вашего компьютера, просто удалите каталог Capture2Text.
- Где находится INI-файл настроек?
Введите «%appdata%\Capture2Text» в проводнике Windows.
Вы можете удалить его, чтобы восстановить настройки по умолчанию.
- Как сделать Capture2Text переносимым?
Вызовите Capture2Text.exe с параметром –portable. Вы можете создать ярлык для этого. Установка этого параметра заставит Capture2Text сохранить файл настроек .
 ini в том же каталоге, что и Capture2Text.exe (в отличие от «%appdata%\Capture2Text», который является обычным расположением).
ini в том же каталоге, что и Capture2Text.exe (в отличие от «%appdata%\Capture2Text», который является обычным расположением). - Где находится исходный код?
Исходный код находится на SourceForge.
Дополнительные инструменты для изучающих японский язык
- JGlossator (Windows)
Автоматический поиск японских слов, которые вы распознали с помощью Capture2Text. Поддерживает дефлективные выражения, чтение, аудио произношение, примеры предложений, тональный акцент, частота слов, информация о кандзи и анализ грамматики. Поддерживает словари EDICT и EPWING.
- Программа чтения манги OCR (Android)
Бесплатное приложение для чтения манги с открытым исходным кодом для Android, которое позволяет быстро выполнять распознавание текста и поиск Японские слова в режиме реального времени. Здесь нет рекламы и загадочных сетевых разрешений. Поддерживает словари EDICT и EPWING.

firebase – Обнаружить текст с изображения, перевести, а затем показать перевод в исходной позиции слова в Android
Мне нужно обнаружить текст с изображения, после этого перевести этот текст, а затем показать переведенный текст в исходной позиции слова.
нравится это. требуется руководство по отображению переведенного текста в исходной текстовой позиции с цветом фона
с помощью текстового детектора ML Kit Vision. Я получил текст с изображения, но основная часть отображения текста все еще находится в отделе исследований и разработок
, что уже сделано
Код : Класс распознавания текста
класс TextRecognitionProcessor (контекст частного значения: Context, textRecognizerOptions: TextRecognizerOptionsInterface): VisionProcessorBase(context) { private val textRecognizer: TextRecognizer = TextRecognition.getClient(textRecognizerOptions) private val shouldGroupRecognizedTextInBlocks: Boolean = PreferenceUtils. shouldGroupRecognizedTextInBlocks(контекст) переопределить веселую остановку () { супер.стоп() textRecognizer.close() } переопределить забавное обнаружениеInImage (изображение: InputImage): Task
{ вернуть textRecognizer.process(изображение) } переопределить удовольствие при успехе (текст: текст, graphicOverlay: GraphicOverlay) { Log.d(TAG, "Обнаружение текста на устройстве успешно") //logExtrasForTesting(текст) graphicOverlay.добавить( TextGraphic (graphicOverlay, text, shouldGroupRecognizedTextInBlocks)) } переопределить удовольствие onFailure(e: Exception) { Log.w(TAG, "Ошибка определения текста.$e") } сопутствующий объект { private const val TAG = "TextRecProcessor" частное развлечение logExtrasForTesting (текст: текст?) { если (текст != ноль) { Лог.v( MANUAL_TESTING_LOG, "Обнаруженный текст имеет: " + text.textBlocks.size + " блоки" ) для (я в text.textBlocks.indices) { строки val = text. textBlocks[i].lines Лог.v( MANUAL_TESTING_LOG, String.format("Обнаруженный текстовый блок %d содержит %d строк", i, lines.size) ) for (j in lines.indices) { вал элементы = линии[j].элементы Лог.v( MANUAL_TESTING_LOG, String.format("Обнаруженная текстовая строка %d содержит %d элементов", j, elements.size) ) для (k в elements.indices) { элемент val = элементы [k] Лог.v( MANUAL_TESTING_LOG, String.format("Обнаруженный текстовый элемент %d говорит: %s", k, element.text) ) Лог.v( MANUAL_TESTING_LOG, Строка.формат( "Обнаруженный текстовый элемент %d имеет ограничивающую рамку: %s", к, элемент.boundingBox!!.flattenToString() ) ) Лог.v( MANUAL_TESTING_LOG, Строка.
формат( "Ожидаемый размер угловой точки равен 4, получите %d", element.cornerPoints!!.size ) ) for (точка в element.cornerPoints!!) { Лог.v( MANUAL_TESTING_LOG, Строка.формат( "Угловая точка для элемента %d находится в точке: x - %d, y = %d", к, точка.х, точка.у ) ) } } } } } } } }
Класс TextGraphic:
класс TextGraphic
конструктор(
наложение: GraphicOverlay?,
частный текст val: Текст,
частное значение shouldGroupTextInBlocks: Boolean
) : Графика (наложение) {
частный val rectPaint: Paint = Paint()
private val textPaint: Краска
private val labelPaint: Краска
в этом {
rectPaint.color = MARKER_COLOR
rectPaint.style = Краска.Стиль.ШТРОК
rectPaint.strokeWidth = ШТРОК_ШИРИНА
текстКраска = Краска()
textPaint. color = TEXT_COLOR
textPaint.textSize = TEXT_SIZE
меткаКраска = Краска()
labelPaint.color = MARKER_COLOR
labelPaint.style = Краска.Стиль.ЗАПОЛНЕНИЕ
// Перерисовать наложение, так как это изображение было добавлено.
постНедействительный ()
}
/** Рисует аннотации текстового блока для положения, размера и необработанного значения на предоставленном холсте. */
переопределить забавное рисование (холст: холст) {
Log.d(TAG, "Текст: " + text.text)
for (textBlock in text.textBlocks) { // Визуализирует текст внизу поля.
Log.d(TAG, "Текст TextBlock: " + textBlock.text)
Log.d(TAG, "Ограничивающая рамка TextBlock: " + textBlock.boundingBox)
Log.d(TAG, "Угловая точка TextBlock: " + Arrays.toString(textBlock.cornerPoints))
если (shouldGroupTextInBlocks) {
рисоватьтекст(
текстовый блок.текст,
RectF (textBlock.boundingBox),
TEXT_SIZE * textBlock.lines.size + 2 * ШТРОК_ШИРИНА,
холст
)
} еще {
для (строка в textBlock.
color = TEXT_COLOR
textPaint.textSize = TEXT_SIZE
меткаКраска = Краска()
labelPaint.color = MARKER_COLOR
labelPaint.style = Краска.Стиль.ЗАПОЛНЕНИЕ
// Перерисовать наложение, так как это изображение было добавлено.
постНедействительный ()
}
/** Рисует аннотации текстового блока для положения, размера и необработанного значения на предоставленном холсте. */
переопределить забавное рисование (холст: холст) {
Log.d(TAG, "Текст: " + text.text)
for (textBlock in text.textBlocks) { // Визуализирует текст внизу поля.
Log.d(TAG, "Текст TextBlock: " + textBlock.text)
Log.d(TAG, "Ограничивающая рамка TextBlock: " + textBlock.boundingBox)
Log.d(TAG, "Угловая точка TextBlock: " + Arrays.toString(textBlock.cornerPoints))
если (shouldGroupTextInBlocks) {
рисоватьтекст(
текстовый блок.текст,
RectF (textBlock.boundingBox),
TEXT_SIZE * textBlock.lines.size + 2 * ШТРОК_ШИРИНА,
холст
)
} еще {
для (строка в textBlock. lines) {
Log.d(TAG, "Текст строки: " + line.text)
Log.d(TAG, "Ограничительная рамка строки: " + line.boundingBox)
Log.d(TAG, "Угловая точка линии: " + Arrays.toString(line.cornerPoints))
// Рисует ограничивающую рамку вокруг TextBlock.
val rect = RectF(line.boundingBox)
drawText (line.text, прямоугольник, TEXT_SIZE + 2 * STROKE_WIDTH, холст)
для (элемент в line.elements) {
Log.d(TAG, "Текст элемента: " + element.text)
Log.d(TAG, "Ограничение элемента: " + element.boundingBox)
Log.d(TAG, "Угловая точка элемента: " + Arrays.toString(element.cornerPoints))
Log.d(TAG, "Язык элемента: " + element.recognizedLanguage)
}
}
}
}
}
приватная забава drawText (текст: строка, прямоугольник: RectF, textHeight: Float, холст: холст) {
// Если изображение перевернуто, левое будет переведено вправо, а правое — влево.
val x0 = translateX (прямая.левая)
val x1 = translateX (прямая.
lines) {
Log.d(TAG, "Текст строки: " + line.text)
Log.d(TAG, "Ограничительная рамка строки: " + line.boundingBox)
Log.d(TAG, "Угловая точка линии: " + Arrays.toString(line.cornerPoints))
// Рисует ограничивающую рамку вокруг TextBlock.
val rect = RectF(line.boundingBox)
drawText (line.text, прямоугольник, TEXT_SIZE + 2 * STROKE_WIDTH, холст)
для (элемент в line.elements) {
Log.d(TAG, "Текст элемента: " + element.text)
Log.d(TAG, "Ограничение элемента: " + element.boundingBox)
Log.d(TAG, "Угловая точка элемента: " + Arrays.toString(element.cornerPoints))
Log.d(TAG, "Язык элемента: " + element.recognizedLanguage)
}
}
}
}
}
приватная забава drawText (текст: строка, прямоугольник: RectF, textHeight: Float, холст: холст) {
// Если изображение перевернуто, левое будет переведено вправо, а правое — влево.
val x0 = translateX (прямая.левая)
val x1 = translateX (прямая.