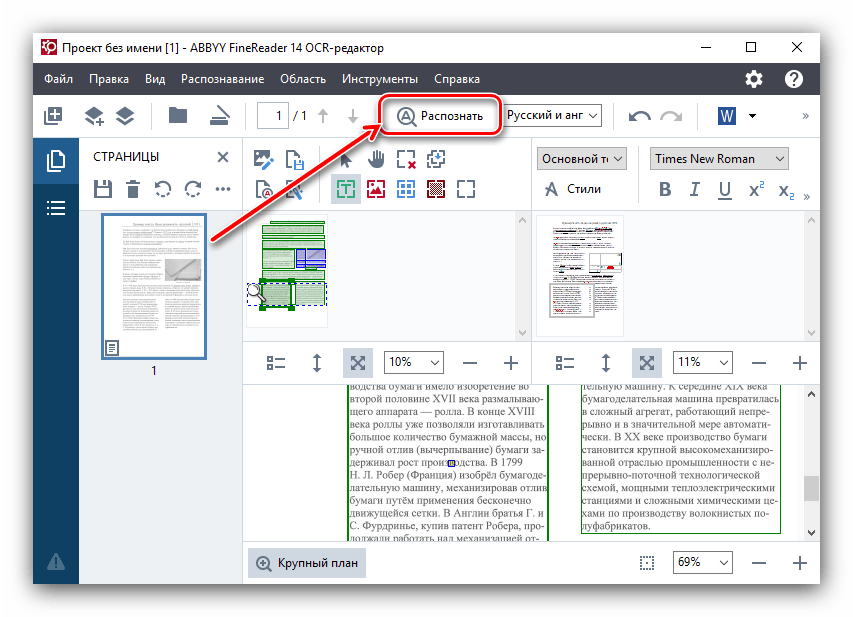
Онлайн распознавание текста — ТОП-3 сервиса
Онлайн распознавание текста – это процедура извлечения символов из сканированного документа или изображения с помощью веб-программ.
Распознавание слов позволяет пользователю существенно сэкономить время, ведь их не нужно печатать самостоятельно.
Сегодня с помощью оптической технологии распознавания текста OCR массово конвертируется огромное количество отсканированных книг журналов, которые потом можно читать на компьютере.
Оптическое распознавание стало популярным, ведь после процедуры определения символов, текст можно не только прочитать, но и перевести с помощью автоматического переводчика, внести правки и форматировать его, применяя различные стили.
Содержание:
К сожалению, данная технология не может распознать информацию из PDF со стопроцентной точностью.
1. Онлайн-словарь для распознавания текста ABBYY
Самая популярная программа-словарь, которая имеет функцию определения текста с изображений и других типов документов.
Данное приложение позволяет пользователю моментально получить тестовый вариант фотографии и перевести его на более чем на 50 языков мира.
Чтобы распознать текст с помощью данного сервиса, следуйте инструкции:
- Зайдите на официальный сайт веб-приложения и нажмите на кнопку «Распознать», которая находится в центре страницы. Официальная ссылка на сервис: https://finereaderonline.com/ru-ru
- Загрузите файл, с которого необходимо распознать инфо;
Процесс добавления картинки, с которой будет определяться текст
- Следующим шагом необходимо выбрать язык конечного документа.

Даже если вам не нужно переводить текст, выберите необходимый язык, ведь для каждого из них программа выбирает соответствующую кодировку символов, что позволяет более точно отображать символы;
Выбор языка конечного документа
- Последний шаг – необходимо выбрать формат конечного файла. Список доступных форматов указан на картинке ниже.
Список доступных форматов файлов для исходящего документа
С помощью данного сервиса можно переводить текст с PDF в Word, а также с форматов djvu и jpg.
к содержанию ↑2. Сервис Online-Ocr
Данный сервис позволяет без регистрации создать текстовый документ из отсканированного файла или из самой обычной картинки.
Данный сервис был первым, кто использовал технологию оптического определения машинного текста.
Приведем пример распознавания с ПДФ в Ворд:
- Зайдите на сайт сервиса: http://www.onlineocr.net/
- Нажмите на клавишу «выбрать файл» и найдите на своем компьютере необходимый пдф документ, с которого будет определен текст.

Внешний вид сервиса ONLINE OCR
- Выберите язык входящего документа и формат конечного файла из предложенного списка поддерживаемых форматов. Нажмите кнопку «Конвертировать»;
Процесс конвертации занимает максимум 5 минут, данный показатель зависит от размера входящего файла, от его кодировки и сложности визуального оформления.
к содержанию ↑3. Веб-приложение Free-OCR
Главное преимущество данного сервиса – возможность работы практически со всеми форматами картинок.
К примеру, большинство сервисов распознавания текста не поддерживают такие форматы, как gif, bmp или tif.
Внешний вид сайта очень простой, таким образом каждый пользователь сможет справиться с поставленной задачей.
Ссылка на сервис: www.free-ocr.com
Внешний вид веб-приложения
Удобнее всего переводить текст в Word, ведь данная программа способна отобразить огромное количество различных текстовых кодировок, а также элементы дизайна входящего файла.
Данный сервис является абсолютно бесплатным и не требует пользовательской регистрации.
Единственное ограничение — размер входящего файла должен быть меньше, чем 6 мегабайт, поэтому распознавать большие документы с помощью данной программы не получиться.
Самое точное направление распознавания – с формата JPEG в ворд.
Тематические видеоролики:
Распознание текста онлайн
Онлайн распознавание текста — ТОП-3 сервиса
Распознавание текста онлайн. Вытаскиваем текст с картинок и PDF
Онлайн распознавание текста — ТОП-3 сервиса
Как распознать текст с картинки онлайн – Google Диск
Как распознать текст с картинки, фотографии или PDF документа онлайн, бесплатно с помощью Google Диска или Документов Гугл
8 Рейтинг
Краткий обзор
Весьма простые сервисы для онлайн-распознавания текста с изображений. На их освоение даже не нужно время, ведь там все элементарно и просто. Огромным плюсом является отсутствие необходимости вкладывать в работу с этими сервисами деньги.
Сложность использования
7
Время на освоение
7
Стоимость
10
Максим Wood
Развитие цифровых технологий требует непрестанного получения новых знаний и расширения кругозора.
OCR online / Хабр
С технологией оптического распознавания текста я познакомился где-то в 1997 года, когда купил свой первый, тогде ещё ручной, чёрно-белый сканер Genius ScanMate 256 (кстати, всё ещё рабочий). К сканеру прилагалась программа Direct OCR на 3х дюймовой дискете (блин, откуда-то из подсознания все эти названия всплывают), которая всеми своими силами пыталась доказать, что можно быстро и почти без ошибок текст из книги ввести в компьютер. Ну, доказательства были не очень. FineReader, с которым я познакомился позже, делал это качественнее. Тема распознавания меня заинтересовала, я потратил довольно много времени на научно-популярные статьи о технологиях OCR.
В 2001 году я готовил дипломную работу по web-технологиям. Долго думал о том, куда приложить знания. Поскольку меня интересовала технология OCR, я задумал совместить WEB и распознавание текстов. За само распознавание у меня должен был отвечать FineReader. С друзьями мы «разобрали» FineReader на отдельные DLL и выяснили, как вызывать отдельные функции этих библиотек, передавая двоичные данные изображений, и как получать обратно распознанный вариант текста. Над этим всем был построен простейший веб-интерфейс, чтобы загружать картинки, запускать распознавание и получать результат.
Поскольку меня интересовала технология OCR, я задумал совместить WEB и распознавание текстов. За само распознавание у меня должен был отвечать FineReader. С друзьями мы «разобрали» FineReader на отдельные DLL и выяснили, как вызывать отдельные функции этих библиотек, передавая двоичные данные изображений, и как получать обратно распознанный вариант текста. Над этим всем был построен простейший веб-интерфейс, чтобы загружать картинки, запускать распознавание и получать результат.
Первым ограничением на то время для нас оказалась смешная пропускная способность интернет. Страница A4, отсканированная в качестве 200 точек на дюйм и сохранённая в формате TIFF (который только и воспринимала программа FineReader) могла занимать несколько мегабайт в серых тонах, а если кто по ошибке или незнанию цветной вариант отсканирует, то объём увеличивался в три-четыре раза. Такой огромный по тем временам файл даже по локальной сети пересылался и обрабатывался с трудом, а через публичный Интернет — вообще трудно выполнимая задача.
Второй фактор — стоимость. При такой скорости пересылки файлов отсканированных страниц каждая страница стоила дорого. Мы также приняли во внимание, что обычно используются взломанные версии программ распознавания текстов, который достаются бесплатно или за копейки.
Третий фактор — востребованность. Чтобы человек стал пользоваться онлайн-сервисом по распознаванию текста, надо как минимум три фактора: наличие сканера, наличие Интернет и отсутствие возможности самостоятельно распознать текст. Было трудно представить себе большое количество таких «криворуких» и «глупых» пользователей.
Проект был реализован, но оставлен «под сукном» как бесперспективный.
Два года назад я предлагал своим коллегам по работе обдумать вариант повторной реализации проекта. Ситуация изменилась: интернет стал быстрее (файлы mp3 уже давно больше по объёму, чем отсканированная страница в формате JPG), сканеры стоят чуть ли не повсеместно (а ещё текст можно просто сфотографировать), пользователи стараются не нагружать себе голову всякими программами и пользуются онлайн-сервисами. У FineReader есть API, а FLASH позволяет сделать достаточно удобный web-интерфейс для управления загрузкой и распознаванием. Но мы не пришли к общему мнению и, можно сказать, упустили возможность сделать полезный и востребованный сервис который можно выгодно продать ABBYY или гуглю.
У FineReader есть API, а FLASH позволяет сделать достаточно удобный web-интерфейс для управления загрузкой и распознаванием. Но мы не пришли к общему мнению и, можно сказать, упустили возможность сделать полезный и востребованный сервис который можно выгодно продать ABBYY или гуглю.
Сейчас компания ABBYY уже сама реализовала онлайн-версию Fine Reader для распознавания текстов (поддерживает 6 языков, включая русский; понимает документы, написанные сразу на нескольких языках, поддерживает ввод в форматах TIFF (включая многостраничные файлы), JPEG, BMP, PNG, PCX, GIF, DjVu; поддерживает вывод в форматах Microsoft® Word, Excel®, Rich Text Format, TXT, searchable PDF).
А на днях хорошо известный сервис Google Docs API продоставил возможность проверить то же самое у себя на демо-странице. Гугль позволяет загрузить изображение в высоком разрешении (до 10 Мегабайт) в формате JPG, PNG или GIF. Распознавание длится около двух минут. Поддерживается пока только латинский алфавит.
Ссылки по теме:
- FineReader API
- ABBYY Fine Reader online
- Демо-страница распознавания текста Google Docs (требуется регистрация в Google Docs)
Покопавшись в поисковиках, я нашёл ещё несколько сервисов (некоторые созданы буквально в этом году) по распознаванию текстов в online. Вот некоторые из них:
Вот некоторые из них:
- OnlineOCR (28 языков, включая русский; поддерживает ввод в форматах TIFF (multi-page), JPEG/JPG, BMP, PCX, PNG, GIF, PDF (multi-page), файлы до 20 мб; вывод в PDF, MS Word, MS Excel, HTML, RTF, TXT)
- Free OCR (6 языков, русского нет; ввод в форматах PDF (только первая страница), JPG, GIF, TIFF or BMP, файл до 2х мегабайт; вывод в текстовом формате)
- OCR Terminal (6 языков, русского нет; ввод в форматах PNG, JPEG, GIF, BMP, multi-page TIFF and PDF; вывод в форматах DOC, TXT, RTF, PDF)
- Небольшой список бесплатных и коммерческих систем оптического распознавания в онлайн-режиме
P.S. Также хотел бы отметь удобство системы EverNote и тот факт, что эта система включает в себя распознавание надписей и текстов
P.S.S. Я бы хотел получить отзыв о работе таких сервисов от хабравцев. Есть ли среди вас те, кто пользовался распознаванием в online-finereader, google docs и других сервисах? Ваш отзыв (а лучше даже примеры распознавания и технические ограничения) я добавлю в пост.
Есть ли среди вас те, кто пользовался распознаванием в online-finereader, google docs и других сервисах? Ваш отзыв (а лучше даже примеры распознавания и технические ограничения) я добавлю в пост.
Updated: перенесено в Сервисы.
Бесплатное онлайн-распознавание текста — Функции
Особенности
Точное распознавание символов
Бесплатное онлайн-распознавание текста позволяет преобразовывать бумажные документы или изображения в редактируемые и доступные для поиска файлы. Программное обеспечение было специально разработано для достижения высокой точности распознавания. даже с документами низкого качества, такими как факсы и скриншоты.
Несколько форматов вывода
Онлайн-программа OCR может сохранить результат в любом из самых популярных форматов файлов:
DOC, PDF, RTF и TXT.
Несколько форматов ввода
Online OCR может обрабатывать изображения в любом из популярных форматов файлов изображений, таких как JPG, BMP, TIFF и PNG. Он также может обрабатывать файлы PDF.
Поддерживает отсканированные PDF-файлы
Файлы PDF часто содержат изображение отсканированного документа. Это делает невозможным
для поиска файла или индексации его содержимого. Наш онлайн OCR извлечет изображение из
PDF, преобразовать его в текст и сохранить результат в формате PDF, DOC, RTF или TXT с возможностью поиска.
Сохраняет макет и форматирование
Выходные файлы сохраняют исходный макет и форматирование обработанных документов, включая изображения, маркеры, шрифты, стили и размеры.
Встроенный словарь
Бесплатное онлайн-распознавание текста содержит встроенный словарь, повышающий точность распознавания. распознавание текста.
Автоповорот изображений
Часто при сканировании документа он немного поворачивается, что затрудняет его обработку. Служба Online OCR автоматически обнаружит такие страницы и предварительно обработает их.
чтобы выпрямить их перед процессом OCR.
Служба Online OCR автоматически обнаружит такие страницы и предварительно обработает их.
чтобы выпрямить их перед процессом OCR.
Создает PDF-файлы с возможностью поиска
Бесплатное онлайн-распознавание текста создает PDF-файлы, в которых текстовая информация вставляется в отдельный невидимый слой, позволяющий вам искать и индексировать файл. Оригинал изображение сохраняется как слой изображения в PDF.
Сканировать в текст
С помощью этого бесплатного онлайн-конвертера текста вы можете преобразовывать отсканированные изображения или отсканированные документы в текст. Извлекайте текст из отсканированных изображений с помощью OCR (оптического распознавания символов). Лучший способ сделать сканы доступными для поиска.
Загрузите отсканированный документ или изображение или введите ссылку. Конечно, вы также можете использовать облачное хранилище, такое как Dropbox или Google Drive.
Извлекайте текст из отсканированных изображений с помощью OCR (оптического распознавания символов). Лучший способ сделать сканы доступными для поиска.
Загрузите отсканированный документ или изображение или введите ссылку. Конечно, вы также можете использовать облачное хранилище, такое как Dropbox или Google Drive.
Конвертировать
…
к
…
Перетащите файлы сюда
300 000+ пользователей
22 000+ пользователей
Оставайтесь на связи:
Оцените этот инструмент 4,5 /5
Вам нужно преобразовать и загрузить хотя бы 1 файл, чтобы оставить отзыв
Отзыв отправлен
Спасибо за ваш голос
Пожалуйста, подождите.