
5 бесплатных программ для сканирования и распознавания текста
Программы для распознавания текста позволяют конвертировать сфотографированные или отсканированные документы непосредственно в предложения.
Дело в том, что текст на изображении представлен в виде растра, набора точек. Упомянутый софт осуществляет превращение набора точек в полноценный текст, доступный для редактирования и сохранения.
Распознавание букв призвано оптимизировать процесс оцифровки бумажных печатных или рукописных книг, документов.
Такой метод оцифровки на порядки превосходит скорость ручного набора с изображения. Широко применяется при оцифровке библиотек и архивов. Далее рассмотрим пятерку лучших представителей семейства подобных программ.
FineReader безоговорочный лидер среди всех программ, распознающих текст на изображении. В частности, софта, более четко обрабатывающего кириллицу нет. Вообще в активе FineReader 179 языков, текст на которых распознается чрезвычайно успешно.
Единственное обстоятельство, которое может разочаровать пользователей, состоит в том, что программа платная. Бесплатно распространяется только пробная версия на 15 дней. За этот период разрешено сканирование 50-ти страниц.
Дальше за пользование программой придется платить. FineReader легко «кушает» любое более-менее качественное изображение. Источник при этом совершенно неважен. Будь то фотография, скан страницы или любая картинка с буквами.
Достоинства:
- точное распознавание;
- огромное количество языков чтения;
- толерантность к качеству изображения-источника.
Недостаток:
- пробная версия на 15 дней.
Бесплатная программа для считывания текстовой информации с изображений. Точность распознавания на порядок ниже, чем у предыдущей рассматриваемой программы. Но как для бесплатной утилиты, функционал все-таки на высоте.
Интересно! CuneiForm распознает блоки текста, графические изображения и даже различные таблицы.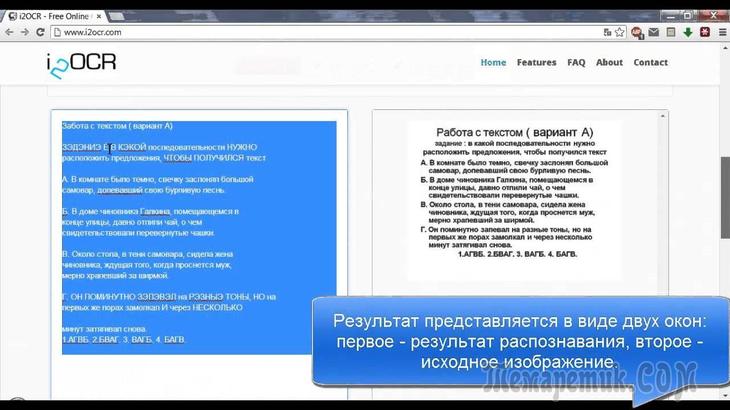 Более того, считыванию поддаются даже неразлинованные таблицы.
Более того, считыванию поддаются даже неразлинованные таблицы.
Программа может прочитать и сохранять шрифт и кегль распознаваемого текста. В базе шрифтов содержится большинство используемых печатных шрифтов. Поддерживается даже распознавание текста вышедшего из печатной машинки.
Для обеспечения точности к процессу распознавания подключаются специальные словари, которые пополняют словарный запас из сканируемых документов.
Достоинства:
- бесплатное распространение;
- использование словарей для проверки правильности текста;
- сканирование текста с ксерокопий плохого качества.
Недостатки:
- относительно небольшая точность;
- небольшое количество поддерживаемых языков.
WinScan2PDF
Это даже не полноценная программа, а утилита. Установка не потребуется, а исполнительный файл весит всего в несколько килобайт. Процесс распознавания происходит предельно быстро, правда, полученные в его результате документы сохраняются исключительно в формате PDF.
Фактически весь процесс выполняется при нажатии трех кнопок: выбор источника, места назначения и, собственно, запуска программы.
Утилита предназначена для быстрой пакетной обработки множества файлов. Для удобства пользователей предусмотрен большой языковой пакет интерфейса.
Достоинства:
- портативность;
- быстрая работа;
- простота в использовании.
Недостатки:
- минимальный размер;
- единственный формат файлов на выходе.
Отличная небольшая программа для распознавания текстов с изображений. Поддерживает даже чтение рукописей. Беда в том, что русский не входит ни в языковой пакет интерфейса, ни в список поддерживаемых для распознавания языков.
Однако если необходимо отсканировать английский, датский или французский, то лучшего бесплатного варианта не найти.
В своей области программа обеспечивает точную расшифровку шрифтов, удаление шума и извлечение графических изображений. К тому же в интерфейс программы встроен текстовый редактор, практически идентичный WordPad, что значительно повышает удобство использования программы.
К тому же в интерфейс программы встроен текстовый редактор, практически идентичный WordPad, что значительно повышает удобство использования программы.
Достоинства:
- точное распознавание текста;
- удобный текстовый редактор;
- удаление шума с изображения.
Недостатки:
- полное отсутствие русского языка.
Программа позволяет оперативно извлекать текст и графику с изображений. Софт поддерживает работу с несколькими сканерами без потери производительности. Извлеченный текст может быть сохранен в формате текстового документа или документа MS Office.
Кроме того предусмотрена функция многостраничного распознавания.
Распространяется Freemore OCR бесплатно, однако, интерфейс только на английском. Но это обстоятельство никак не влияет на удобство пользования, потому как организованы элементы управления интуитивно понятным образом.
Достоинства:
- бесплатное распространение;
- возможность работы с несколькими сканерами;
- достойна точность распознавания.


Недостатки
- Отсутствие русского языка в интерфейсе;
- Необходимость загрузки русского языкового пакета для распознавания.
Источник
Программы для распознавания текста – Androfon.ru
Последнее обновление: 12/07/2022
Часто в рабочих или личных целях пользователи сталкиваются с необходимостью распознавания текста, с целью извлечения, редактирования или сохранения в другом формате. Наиболее чаще с необходимостью распознавания текста сталкиваются студенты и офисные работники, а ещё переводчики журналов, комиксов и манги. В статье мы рассмотрим настольные и мобильные, а так же облачные сервисы, что помогут быстро и качественно распознать текст.
Содержание
Программы для компьютера
Настольные программы предназначены для ПК и ноутбука. Такие приложения оптимально держать при регулярном использовании функции распознавания текста.
Такие приложения оптимально держать при регулярном использовании функции распознавания текста.
Читайте также:
Как конвертировать pdf в word
Программа для чтения PDF
ABBYY FineReader
Официальная страницаДанная утилита – лидер в области оптического распознавания текста. Программа рассчитана на распознание отсканированных файлов в реальном времени, а так же готовых документов. В процессе конвертирования сохраняется точный размер, цвет и шрифт текста. Готовый документ легко сохранить в PDF или другом формате.
Подробный обзор программы читайте в нашем отдельном материале.
Основные преимущества:
- Наличие модуля для сравнения и поиска отличий двух документов.
- Распознание текста на более 170 языках.
- Отправка отредактированного документа по электронной почте или сохранение в популярных офисных форматах.
- Возможность сканирования текста стационарным сканером, МФУ или камерой.
- Полноценное редактирование PDF файлов: добавление или удаление страниц, изменение текста, установка водяного знака и т.
- Поддержка актуальных версий Windows: 7, 8 и 10.
- Дружелюбный интерфейс.
- 30-дневная бесплатная версия для ознакомления.

Основные недостатки:
- Программа нуждается в покупке лицензионного ключа на год или на постоянной основе. На стоимость влияет версия программы.
- Некоторые функции не доступны в базовой версии.
- Высокая стоимость отдельных модулей. Например, модуль для сравнения двух документов на постоянной основе обойдется примерно в 500 USD.
- Иногда текст распознается некорректно и нуждается в ручном редактировании.
- При работе с DOC форматом документ обязательно конвертируется в PDF, после чего требуется обратно сохранять отредактированный файл.
Scanitto Pro
Официальная страницаПрограмма предназначена для сканирования документов и изображений, при этом поддерживает функцию оптического распознавания текста с последующим редактированием. Модель распространения условно-бесплатная. После ознакомления с 30-дневной пробной версией требуется купить лицензионный ключ на год – 500 RUB или же купить программу на постоянной основе за 5500 RUB. Последний вариант позволяет устанавливать программ на любое количество компьютеров в пределах организации.
Последний вариант позволяет устанавливать программ на любое количество компьютеров в пределах организации.
Основные возможности:
- Настройка параметров сканирования – разрешение, цветность, выбор области сканирования, формат сохранения отсканированных файлов.
- Возможность сохранения файлов в формате PDF.
- Копирование документов со сканера на принтер.
- Оптическое распознавание текста, включая быстрое распознание при использовании многоядерных процессоров.
- Распознание популярных языков: Английский, Итальянский, Русский, Немецкий, Французский, Испанский.
- Загрузка информации в облачное хранилище.
Основные преимущества:
- Совместимость со всеми популярными сканерами.
- Настройка качества сканирования.
- Поддержка облачных дисков.
- Функция оптического распознавания текста с сохранением в DOCX, RTF или TXT.
- Сохранение отсканированных документов в популярные форматы файлов.
- Поддержка устаревших и актуальных версий ОС Windows.

Основные недостатки:
- Необходимость покупки лицензии или полной версии программы.
- Пробная версия действует 30 дней.
- Мало распознаваемых языков.
OCR CuneiForm
Бесплатная программа для распознания текста отсканированных или сфотографированных документов. Причем в процессе распознания сохраняется исходная структура документа и печатные шрифты. Так же поддерживается редактирование распознанных текстов.
Основные возможности:
- Сканирование документов при помощи сканера.
- Оптическое распознавание и редактирование электронных документов/изображений.
- Пакетная обработка документов.
- Адаптивное распознавание контента.
- Периодическое обновление алгоритмов распознавания.
Основные преимущества:
- Бесплатная модель распространения.
- Распознавание и редактирование текста.
- Совместимость с устаревшими версиями ОС Windows — XP, Vista и Se7en.
- Достойное качество распознания текста и графики.
- Периодический выход обновлений.
Основные недостатки:
- В процессе распознания текста возможны подвисания программы.
- Посредственный интерфейс.
Readiris
Официальная страницаПриложение предназначено для создания и редактирования PDF файлов. Так же для конвертации документов в другие форматы, а ещё конвертирования бумажных вариантов в цифровой формат за счет оптического распознания текста. Правда рукописный текст с обычной тетради распознать не удается.
После короткой регистрации разработчики предлагают бесплатную версию программы для ознакомления. Цена базовой версии на 1 ПК – 49 USD, расширенная – 99 USD, корпоративная – 199 USD. При покупке ключей на несколько ПК предоставляется скидка.
Основные возможности:
- Создание, редактирование, объединение, сжатие и прочие операции с PDF файлами.
- Функция оптического распознавания текста.
- Поддержка 30 языков в базовой версии программы, 138 языков в расширенной и корпоративной версии.
- Преобразование документов в файлы Microsoft Office .
- Пакетная обработка документов.
Основные преимущества:
- Набор необходимых инструментов для работы с PDF файлами.
- Оптическое сканирование и редактирование изображений/документов.
- Возможность прослушивания книг и других документов.
- Преобразование документов в популярные форматы файлов.
Основные недостатки:
- Необходимость покупки лицензионного ключа.
- Разграничение возможностей для каждой версии программы. Наиболее функциональна только корпоративная версия.
- Сложности с распознанием рукописного текста.
Онлайн сервисы
Использование облачных технологий актуально в редких случаях распознания текста и небольшого объема. В таком случае не требуется устанавливать настольную программу, где для нормального функционирования требуется приобрести дорогостоящую лицензию.
Convertio
Официальная страницаСервис позволяет бесплатно распознать до 10 страниц в день.
Основные возможности:
- Анализ и распознание текста из PDF и популярных графических форматов файлов – PDF, JPG, BMP, GIF, JP2, JPEG, PBM, PCX, PGM, PNG, PPM, TGA, TIFF и WBMP.
- Пакетная обработка файлов, добавленных с ПК, облачного диска DropBox/Google Drive или по ссылке.
- Распознание до двух языков. Поддержка 74 языков.
- Выбор одного и 10 выходных форматов.
- Настройка распознавания: все страницы или определенный диапазон.
- Возможность скачать или сохранить результат на облачном диске – DropBox или Google Drive.
Основные преимущества:
- Распознавание текста из 2 двух форматов, суммарно 15 расширений файлов.
- Возможность загрузить и обрабатывать несколько файлов сразу.
- Указание файла с ПК, из облачного диска или по ссылке.
- Выбор выходного формата распознанного текста.
- Одновременное распознавание двух языков из 74.
- Сохранение готового результата на ПК или в облачный диск.
Основные недостатки:
- Суточное ограничение при распознании – 10 страниц.
- Что бы распознать больше страниц требуется купить предоплаченный пакет.
- Одновременно распознаются только 2 языка.
- Часто не удается распознать страницу.
img2txt
Официальная страницаБесплатный сервис для распознания текста из PDF и графических файлов.
Основные возможности:
- Локальная загрузка файла или с указанием по ссылке.
- Поддержка распознания 37 языков.
- Неограниченное количество запросов.
- Формат загружаемых файлов: pdf, jpg, jpeg, png и bmp.
Основные преимущества:
- Сервис бесплатный.
- Нет ограничений на количество распознаний.
- Не требуется регистрация.
- Указание до 37 языков при распознавании текста.
- 5 форматов загружаемых файлов.
Основные недостатки:
- Максимальный размер файла для распознания – 8 МБ.
- Ограничение на распознание в 50 страниц за один раз.
- Невозможно скачать распознанный документ.
- Мало поддерживаемых форматов для распознания.
Мобильные приложения
Программы для смартфона/планшета позволят отсканировать и оцифровывать текст с изображений на мобильном устройстве. Удобный вариант, когда под рукой нет компьютера или затруднено использование интернета. В качестве примера рассмотрим распознание текста в программе Office Lens. В качестве альтерантивы вам стоит так же обратить внимание на Adobe Scan и Simple OCR.
Microsoft Office Lens — PDF Scanner
СКАЧАТЬ БЕСПЛАТНОНаиболее функциональное приложение для сканирования и распознания текста. Для оптического распознания требуется сделать фотографию, обрезать участок при необходимости, а затем выбрать вариант – Word (OCR Document). Что бы посмотреть оцифрованный документ на мобильное устройство необходимо установить Word или другой офисный редактор.
Что касается потребления оперативной памяти, система сообщает о 71 МБ, поэтому программа хорошо сойдет для маломощных устройств. А вот если использовать дополнительно программу Microsoft Word для просмотра распознанного текста, тогда суммарный объем ОЗУ двух программ составит 321 МБ. Минимальная версия Android для установки Office Lens – 5.0 или выше.
Вывод
Представленные в статье программы позволяют произвести распознавание текста из PDF и графического файла, с целью извлечения текста. Программы для ПК целесообразно держать при регулярном извлечении текста. Так же настольные версии демонстрируют наилучший результат обработки. Облачные сервисы рационально использовать при нечастой обработке. А мобильные программы пригодятся при оцифровке в дорожных условиях или при отсутствии мобильного интернета.
А как часто вы пользуетесь оцифровкой документов? Какой предпочитаете софт? Поделитесь своим мнением в комментариях под статьей.
Связанные записи
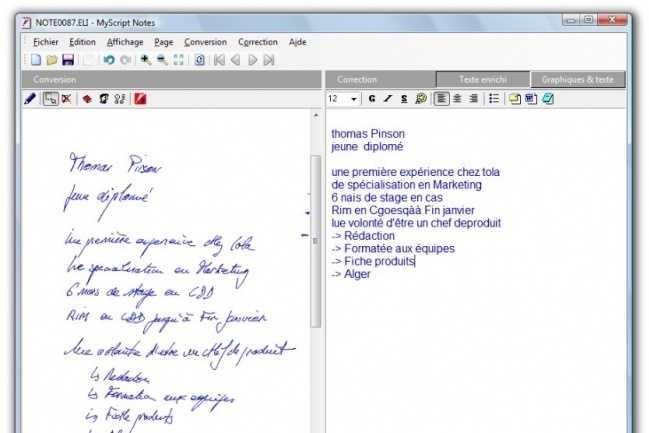
Распознавание рукописного ввода
Mathpix является лидером отрасли в области распознавания рукописного текста на изображениях и предлагает лучшее на рынке решение для расширенного распознавания математических данных и других научных материалов.
Рукописная математика (включая продвинутую математику)
Рукописный хинди и все языки латинского алфавита
Рукописные химические диаграммы
Начало работы
Лучшее распознавание рукописного ввода для математики и естественных наук STEM с длинным хвостом функциональности.
Простая математика
Продвинутая математика
Рукописный текст
Химические диаграммы
ДЛЯ СТУДЕНТОВ
Единственное приложение, которое может превратить изображения вашей тетради по линейной алгебре в красиво оформленный документ.
Мгновенно оцифровывайте рукописные математические и научные заметки в Markdown. Делитесь в Интернете или экспортируйте в документы LaTeX, DOCX, PDF или HTML.
Перейти к Snip
Используйте объединенную мощь цифровых чернил и распознавания рукописного текста на основе изображения, чтобы соответствовать рабочему процессу ведения заметок.
Начало работы
ДЛЯ КОМПАНИЙ ED TECH
Mathpix обеспечивает распознавание рукописного ввода для крупнейших компаний Ed Tech в мире благодаря нашей уникально надежной
поддержке смешанного текста и математического почерка.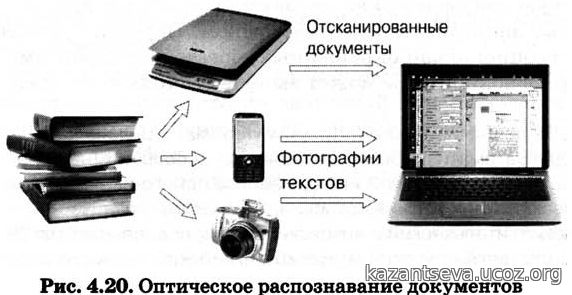 Наши API-интерфейсы обработки изображений просты в реализации и работают на всех платформах.
Наши API-интерфейсы обработки изображений просты в реализации и работают на всех платформах.
API-запрос
{ “src”: “https://mathpix.com/examples/limit.jpg”, “форматы”: [“текст”, “данные”, “html”], “параметры_данных”: { “include_asciimath”: правда, “include_latex”: правда } } 9{2}+9}{x-3}\\ справа) \\)” }
Наши партнеры выбирают Mathpix, а не AWS Textract, Google Vision API и Azure Computer Vision для обработки изображений рукописного ввода. Документы для разработчиков
Подробнее
2021-09-20
Преобразование печатных и рукописных химических диаграмм в SMILES
Сфотографируйте свои заметки по химии через мобильное приложение Snip, синхронизируйте их с компьютером, а затем вставьте SMILES в такие приложения, как ChemDraw.
Подробнее
03.03.2020
Рисование математических уравнений: рисование в приложениях поддерживается в приложениях Mathpix MS Word, LaTeX и другие форматы.
Подробнее
Как распознавать рукописный текст на изображении
Людям может быть проще получать доступ к текстам и использовать их не только для чтения, например, для быстрого поиска информации, если они оцифрованы. Со времен изобретения бумаги накопилось огромное количество текстов. Поэтому к концу ХХ века, после того как людям стало ясно, что задача распознавания при оцифровке может быть решена только с применением автоматических методов, стала активно развиваться технология оптического распознавания символов (OCR).
OCR проверяет отсканированные изображения печатного текста и преобразует эти изображения в цифровой текст. Хотя самые сложные модели OCR могут распознавать почти все типы шрифтов, они работают только с печатным текстом и игнорируют рукописные данные.
Нужны данные, помеченные человеком, для вашего проекта машинного обучения?
Ознакомьтесь с платформой маркировки данных Толока.
- Глобальное сообщество: более 40 языков, более 100 стран
- Любой тип данных: текст, изображение, видео, аудио и т. д.
Свяжитесь с нами
Чтобы распознавать рукописный текст на изображениях, используйте программное обеспечение OCR. Попробуйте распознать рукописный текст с помощью мобильного приложения, в котором есть функции OCR. Другим решением является сканирование рукописного текста и использование настольных или онлайн-приложений на базе OCR. И, наконец, некоторые сканеры также имеют какое-либо программное обеспечение для оптического распознавания символов, которое вы можете использовать, будь то встроенное программное обеспечение или загружаемый инструмент, предоставляемый производителем оборудования.
Распознавание рукописного текста (HTR) описывает автоматизированный компьютерный подход к расшифровке письменных записей. Этот тип распознавания рукописного ввода предоставит прекрасную возможность автоматизировать рабочий процесс многих предприятий, тем самым упростив работу человека. Обе технологии очень похожи, но OCR уже находится в продвинутом состоянии, тогда как HTR все еще находится на ранней стадии.
Обе технологии очень похожи, но OCR уже находится в продвинутом состоянии, тогда как HTR все еще находится на ранней стадии.
Самый простой и до сих пор широко используемый процесс распознавания текста включает сопоставление матриц: каждая буква в исходном изображении разлагается на пиксельные матрицы, а затем соотносится с матрицами, хранящимися в компьютере. Как только они совпадают, отдельный символ считается распознанным. Этот метод называется сопоставлением с образцом и в основном используется для распознавания печатных текстов. Чтобы было понятнее, OCR распознает все символы один за другим, применяя этот метод.
Для рукописного текста и других редких или нестандартных шрифтов обычное сравнение пиксельных матриц может вообще не применяться. В этом случае используется несколько видоизмененный подход, а именно распознавание отдельных признаков, таких как линии, кривые и другие участки букв. Такой метод также называется извлечением признаков или обнаружением признаков и используется для идентификации как печатных, так и письменных текстов.
Современные технологии распознавания текста
Оптическое распознавание символов
OCR — это процесс извлечения текста из изображения. Изображение страницы представляет собой цифровую копию текста и другого возможного содержимого. Их можно получить, отсканировав или сфотографировав бумажные документы, книги, письма и так далее.
Такие изображения еще не содержат текста, доступного для редактирования. Вместо этого они представляют собой набор пикселей, которые вместе образуют шаблон текста. При распознавании изображение преобразуется в текст, который можно редактировать на ПК без необходимости перепечатывать его вручную. Изображения преобразуются в текст с помощью технологии оптического распознавания.
Такие технологии, как интеллектуальное распознавание символов (ICR) и интеллектуальное распознавание слов (IWR), являются расширенными подтипами стандартных систем оптического распознавания символов (OCR). Они нацелены на рукописный, а не на печатный текст и включены в большинство современных систем распознавания.
Интеллектуальное распознавание символов
ICR — это улучшенный OCR или, точнее, тип распознавания рукописного текста. Он занимается распознаванием отдельных рукописных печатных символов. Программное обеспечение для распознавания ICR работает с отдельными символами, разбивая символы на элементы, такие как линии, кривые или петли, чтобы точно определить, какой это символ.
Хотя этот метод имеет свои ограничения, инструменты ICR распознают сильно структурированные, т. е. равномерно расположенные символы. Примеры включают такие формы, как анкета, в которой человек записывает информацию в поля, зарезервированные для отдельных писем. Такой вид анкеты встречается, например, в тестах, когда правильный ответ или букву нужно вписать в специальные квадратики.
Современное программное обеспечение ICR часто имеет функцию самообучения: нейронная сеть, которая автоматически обновляет базу данных распознавания на основе новых стилей почерка. Он расширяет возможности обработки документов OCR и HTR. Тем не менее, ICR не выполняет распознавание курсивного рукописного ввода, поскольку пока может распознавать только каждый отдельно написанный символ.
Тем не менее, ICR не выполняет распознавание курсивного рукописного ввода, поскольку пока может распознавать только каждый отдельно написанный символ.
Интеллектуальное распознавание слов
ICR также претерпел своего рода эволюцию, которая называется интеллектуальным распознаванием слов. Он используется для распознавания символов с неструктурированным, рукописным или курсивным почерком. Он пытается различить все слово, а не отдельные символы.
Этот процесс наиболее применим для распознавания рукописных заметок произвольной формы, поскольку идентифицируются не отдельные символы, а целые связные фразы или слова. IWR не задумывался как замена ICR и OCR, напротив, сегодняшние приложения сочетают в себе все три подхода.
IWR предназначен для распознавания реальных текстов, написанных людьми курсивом, который часто трудно распознать. Эти рукописные заметки не могут быть распознаны ICR из-за характера метода. IWR значительно минимизирует ошибки, возникающие в типичных системах распознавания, поскольку сопоставляет написанные от руки или напечатанные слова с заданным пользователем словарем.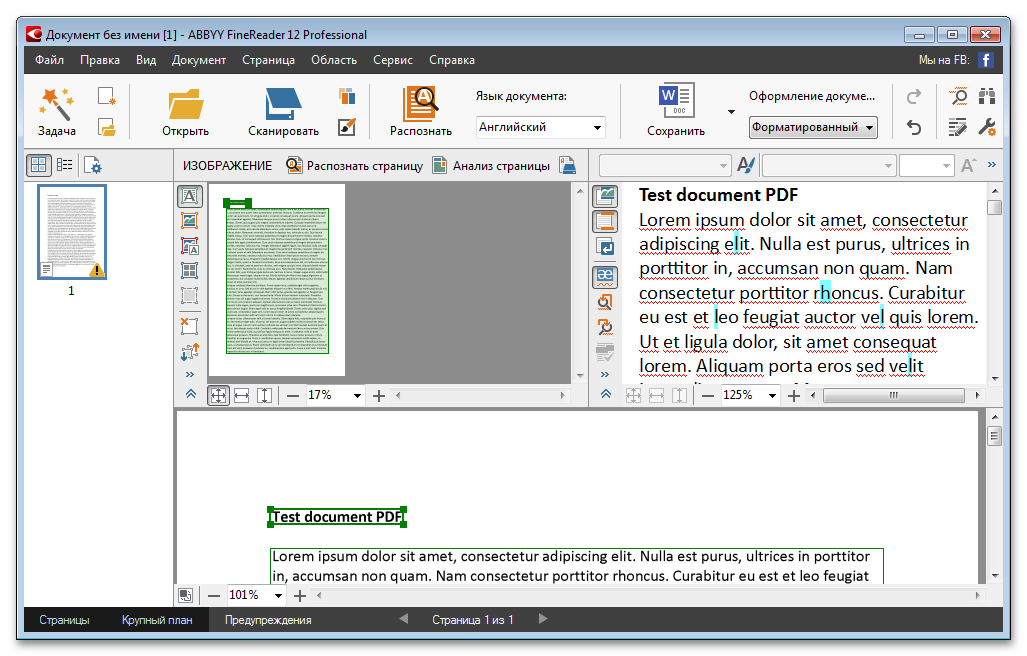
Методы распознавания текстов, написанных человеком
Каждое рукописное письмо, несмотря на то, что оно написано каждым человеком по-разному, тем не менее состоит из одних и тех же частей. Однако существует гораздо больше вариантов того, как могут выглядеть рукописные символы, а не печатные. Таким образом, каждый отдельный символ представляет собой характерный признак буквы, и основная задача состоит в том, чтобы найти его в исходном тексте, чтобы распознать.
Такие задачи обрабатываются нейронными сетями. Нейронные сети — это тип процесса машинного обучения, состоящий из множества простых математических вычислений одинакового характера. Сегодня они активно используются для преобразования отсканированного рукописного текста в печатный текст.
Нейронные сети полагаются на машинное обучение, но сначала им нужно научиться эффективно распознавать текст. Они учатся находить закономерности, используя размеченные данные. Алгоритмы непрерывно обрабатывают входные данные, классифицируя их снова и снова, пока не будут найдены четкие закономерности.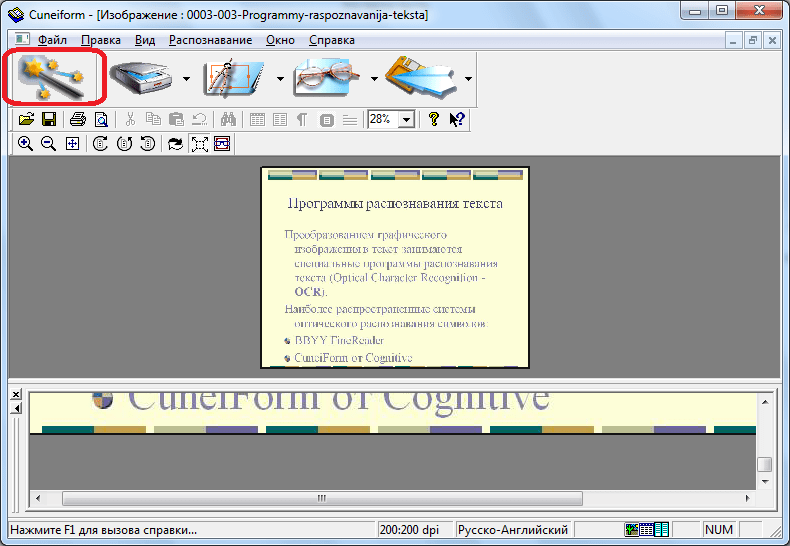
Модели машинного обучения, которые могут справиться с такой задачей, требуют значительного объема обучающих данных. Во многих случаях такие входные данные уже обработаны и доступны уже сегодня. Например, набор данных MNIST, в частности, включает около 70 000 изображений рукописных цифр, при этом точность распознавания алгоритмов на его основе очень высока, достигая более 99% для сверточных нейронных сетей.
Нейронные сети способны анализировать огромное количество информации, которую человек не смог бы обработать. Они фильтруют массивные потоки данных на высокой скорости, фиксируя закономерности, которые в противном случае ускользнули бы от внимания. В нейросетевом подходе существует множество методов. Наиболее популярными являются сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN), сети Хопфилда и многие другие.
Напрямую запрограммировать поведение нейронных сетей невозможно, они лишь проходят процесс обучения, что можно назвать их основным преимуществом. Это связано с тем, что они могут делать прогнозы с определенной степенью уверенности, не говоря человеку-программисту, что делать в каждой конкретной ситуации.
Это связано с тем, что они могут делать прогнозы с определенной степенью уверенности, не говоря человеку-программисту, что делать в каждой конкретной ситуации.
На сегодняшний день создано значительное количество библиотек для распознавания текста. Применение этих библиотек значительно упрощает разработку моделей распознавания рукописного ввода. Чтобы повысить точность распознавания, набор данных может быть собран для определенных целей, таких как характеристики изображений или определенный язык.
Распознавание рукописного текста
Современные модели распознавания печатного текста дают достаточно качественные результаты, демонстрируя относительно безошибочное преобразование входного изображения в текст. Однако эти результаты обусловлены ограниченным набором шрифтов, которые должны быть максимально понятными для человека.
Все типографские шрифты имеют несколько одинаковый контур. Чаще всего они хорошо читаются и имеют лишь небольшие стилистические отличия, например, некоторые люди не видят различий в шрифтах Arial и Calibri, хотя стилистически они не совпадают. Однако технически легче научить компьютер распознавать шрифты этого типа, потому что формы и символы, из которых состоят буквы этих шрифтов, в основном схожи.
Однако технически легче научить компьютер распознавать шрифты этого типа, потому что формы и символы, из которых состоят буквы этих шрифтов, в основном схожи.
Распознавание рукописного текста — дело более сложное. У каждого свой почерк, который со временем может даже измениться. Вариативность рисунков почерка весьма значительна. У одного человека может сформироваться привычка писать тот или иной персонаж определенным образом на протяжении всей жизни, и только один человек может написать его таким образом.
Помимо того, что обучение модели распознавания рукописного текста предполагает создание набора данных, как упоминалось ранее, что само по себе уже непростая задача, существует также сложность маркировки такой собранной информации.
Например, иногда для распознавания исторического документа требуется специалист, хорошо разбирающийся в способах письма. Если рукописный текст очень сложный, может потребоваться два или более человека, чтобы интерпретировать его и правильно обозначить каждую букву. Однако даже для простых наборов данных должно существовать несколько аннотаций, сделанных несколькими людьми, чтобы можно было исправить ошибки, которые часто делают аннотаторы при попытке пометить рукописный текст.
Однако даже для простых наборов данных должно существовать несколько аннотаций, сделанных несколькими людьми, чтобы можно было исправить ошибки, которые часто делают аннотаторы при попытке пометить рукописный текст.
Как преобразовать отсканированный почерк?
С помощью соответствующего программного обеспечения вы можете легко преобразовать рукописный текст в печатный. Такое распознавание включает в себя следующие этапы преобразования отсканированных изображений или фотографий в текст:
Обработка изображения
Для преобразования отсканированного рукописного текста в печатный текст входное изображение с текстом, которое вводится в систему, должно быть очищено от шума и преобразовано в форма, которая позволяет эффективно извлекать и обнаруживать символы. Как правило, изображение улучшается, контрастируется, выпрямляется и преобразуется в формат, используемый системой.
Важную роль играет пороговая бинаризация, которая представляет собой преобразование изображения в черно-белое из цветного или в оттенках серого. Такое преобразование позволяет отчетливо отделить текст от фона, упрощает дальнейшее применение многих алгоритмов, а также убирает с изображения некоторые шумы.
Такое преобразование позволяет отчетливо отделить текст от фона, упрощает дальнейшее применение многих алгоритмов, а также убирает с изображения некоторые шумы.
Выделение интересующей области
На этом шаге выделяется область изображения, содержащая распознаваемый текст. Иными словами, специалист должен определить почерк на изображении, отбрасывая при этом элементы, не являющиеся текстом. К ним относятся такие объекты, как подтеки и пятна на бумаге, которые не были удалены в процессе бинаризации.
Сегментация на строки и символы
Текстовое изображение должно быть разделено на строки, затем строки разделены на слова, а затем на символы, прежде чем система оптического распознавания символов сможет обрабатывать каждый символ в отдельности.
Поскольку рукописный текст, в отличие от машинописного, обычно пишется по определенной кривой, при разделении ввода могут возникнуть трудности.
изображений рукописного текста в строки, что не позволяет применять алгоритмы, подходящие для машинописных текстов, напрямую.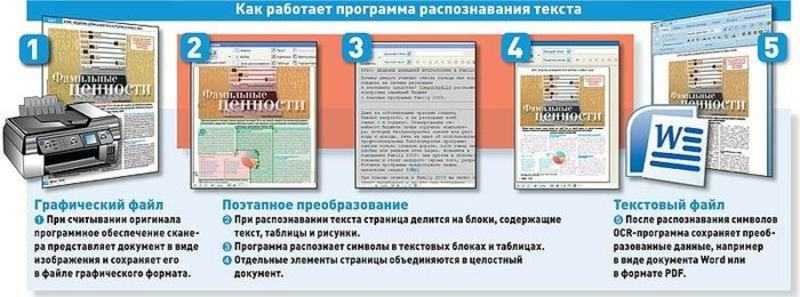 Линии могут изгибаться или располагаться слишком близко друг к другу, а текстовые элементы, принадлежащие разным строкам, могут перекрываться.
Линии могут изгибаться или располагаться слишком близко друг к другу, а текстовые элементы, принадлежащие разным строкам, могут перекрываться.
Методы извлечения базовой линии пытаются проследить некоторую воображаемую линию, вдоль которой пишет человек, а затем реконструировать линию по ней. После этого шага разные системы распознавания используют свои уникальные алгоритмы.
Обработка символов
Изображение символа может быть обработано целиком путем сравнения его с имеющимися шаблонами. В качестве альтернативы извлекаются характеристики изображенного символа: соответствующие признаки выбираются и классифицируются в соответствии с критериями, присутствующими в приложении.
Результат распознавания
В качестве вывода выводятся возможные варианты письма. Однако, как правило, система распознавания продолжает работать другими методами, уточняя достигнутый результат. Механизм распознавания не всегда может следовать всем упомянутым шагам, однако основные действия процесса распознавания являются общими для всех алгоритмов.
Создание модели распознавания рукописного ввода
Чтобы все шаги, описанные выше, были возможны с рукописным текстом, необходимо создать обученную модель распознавания рукописного ввода. Ниже приведены основные шаги для создания такой модели.
Сбор данных
Первое, что необходимо сделать специалистам, это собрать обучающий набор данных, содержащий изображения со словами с разным почерком на языке, с которым они планируют работать. Это могут быть фотографии, сканы рукописных заметок, отсканированные документы, письма и так далее.
Разработчики моделей могут использовать готовые наборы данных, которых сейчас существует большое количество и многие находятся в свободном доступе. Кроме того, они могут создавать свои собственные наборы данных. Например, они могут распространять специальные формы для написания слов среди большой группы людей, таких как студенты или коллеги, чтобы охватить как можно больше почерков.
Более быстрым решением будет сбор обучающих данных с помощью краудсорсинга. Этот относительно новый подход является эффективным инструментом для сбора огромных объемов данных. На краудсорсинговых платформах заказчик дает задание большой группе людей, чаще всего фрилансерам, которые за небольшую плату отправляют изображения рукописного текста.
Этот относительно новый подход является эффективным инструментом для сбора огромных объемов данных. На краудсорсинговых платформах заказчик дает задание большой группе людей, чаще всего фрилансерам, которые за небольшую плату отправляют изображения рукописного текста.
Аннотация
Графические изображения документа, в том числе написанные от руки, еще не являются текстовым документом. Человеческий мозг устроен таким образом, что достаточно просто посмотреть на лист бумаги с текстом, чтобы понять, что на нем написано (в зависимости от почерка конечно, некоторые непонятны даже человеку). С точки зрения компьютера отсканированный документ представляет собой просто набор цветных точек и совсем не похож на текстовый документ. Модель не может извлекать соответствующие признаки сама по себе.
Таким образом, собранные данные необходимо аннотировать, поскольку модель не может самостоятельно научиться распознавать буквы на изображении. Вместо этого ему нужно показать, как рукописный символ соответствует печатной букве, чтобы в дальнейшем он мог извлекать текст из рукописных заметок и помогать людям распознавать похожие символы. Как уже упоминалось, требуется более одного человека, чтобы получить лучший результат и избежать ошибок аннотации.
Как уже упоминалось, требуется более одного человека, чтобы получить лучший результат и избежать ошибок аннотации.
Здесь снова пригодится краудсорсинг. Окончательное решение о присвоении изображению той или иной буквы принимается по согласованию волонтеров, разбросанных по всему миру. Для отсеивания недобросовестных участников необходимо создавать качественные контрольные задания, по которым можно будет оценить компетентность человека.
Обучение модели
После того, как все фотографии, сканы и документы, содержащие текст, написанный человеком, будут промаркированы, специалисты могут начать обучение модели. В качестве конечного результата обучения модель распознавания должна обеспечить надежный вывод: текстовый файл в цифровом формате.
Причем текст должен быть качественным, то есть просто набор бессвязных букв не подойдет. В этом случае специалисты по машинному обучению могут сделать вывод, что либо набор данных был плохого качества, либо он был неправильно размечен, либо процесс обучения был ошибочным. В идеале должны быть решены все случаи повторяющихся символов, повторяющихся символов и нераспознанных символов.
В идеале должны быть решены все случаи повторяющихся символов, повторяющихся символов и нераспознанных символов.
Так или иначе, при обнаружении проблем с распознаванием специалистам придется начинать заново, тщательно изучая все этапы подготовки модели, чтобы точно вычислить, на каком этапе произошел сбой в подготовке модели.
Обеспечение качества и мониторинг моделей
Достигнув качественного распознавания написанного текста моделью, разработчики не должны забывать о постоянном контроле качества. Этот шаг необходим, чтобы гарантировать, что работа модели всегда будет отличного качества и что она обеспечивает наилучший возможный результат в течение длительного периода времени.
Кроме того, этот этап работы может указывать команде разработчиков на необходимость дальнейшего обучения модели с использованием дополнительных наборов данных, содержащих новые изображения различных почерков.
Приложения для обнаружения рукописного текста
Системы OCR и HTR используются во множестве областей.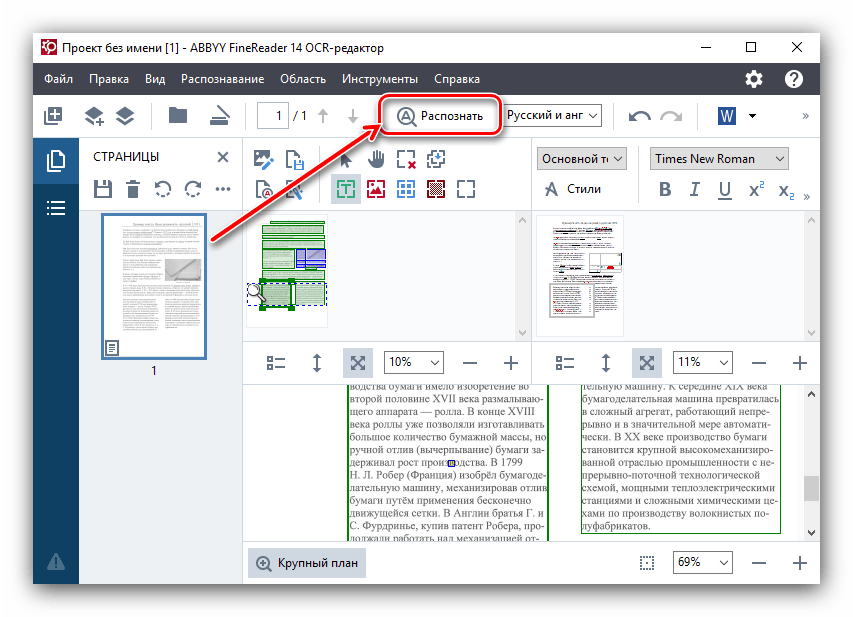 Вот некоторые из задач, которые решают системы распознавания текста:
Вот некоторые из задач, которые решают системы распознавания текста:
- Генерация цифровых версий печатных и рукописных документов.
- Считывание данных с форм и анкет.
- Автоматическое распознавание автомобильных номеров.
- Технология помощи слепым и слабовидящим.
- Распознавание данных документов, удостоверяющих личность.
- Извлечение информации с визитных карточек в списки контактов.
Распознавание рукописного текста также можно использовать для быстрого редактирования заметок и заметок. Когда вы пишете заметки в классе, вы можете сфотографировать их и создать текст на своем компьютере, который можно редактировать и изменять. Распознавание почерка упрощает и ускоряет оформление документов в больницах и государственных учреждениях, оказывающих услуги гражданам. Для писателей, которые пишут свои книги от руки на бумаге, а затем перепечатывают готовый текст, этот автоматизированный процесс может значительно облегчить работу.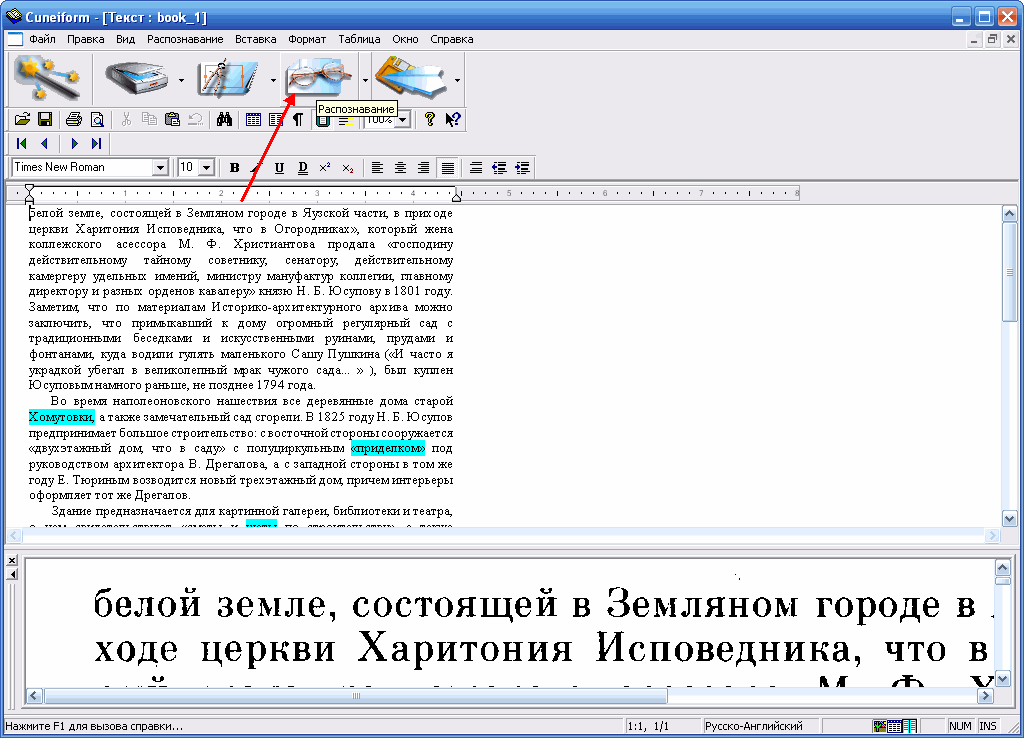
Такая технология может упростить работу историков, расшифровывающих исторические документы, написанные от руки. Некоторые проекты включают расшифровку старых книг и древних рукописей. Люди расшифровывают фотографии или сканы таких книг вручную, что часто является сложным процессом. Очень немногие знают, как это сделать. Если бы компьютер мог это сделать, он мог бы значительно ускорить процесс. Машинное обучение может значительно облегчить эту работу.
Это далеко не все области применения распознавания рукописного текста. Поэтому разработка технологий распознавания рукописного ввода, позволяющих значительно упростить процесс ввода данных, является актуальной задачей для многих пользователей.
Подведение итогов
В настоящее время существует довольно много типов систем распознавания текста. Однако только некоторые из них могут распознавать почерк. Системы распознавания с высокой скоростью и точностью, как правило, очень дороги в создании, что делает их малодоступными для массового внедрения онлайн-OCR, кроме существующих у крупных игроков.