
App Store: Распознавание текста OCR
Описание
* Умный и функциональный сканер позволяет преобразовать любой документ в редактируемый текст.
С помощью этого инструмента вы сможете извлечь текстовое содержимое заметок, квитанций, счетов и визиток, чтобы работать с ними с максимальным комфортом.
* Это приложение работает с различными форматами – JPG, BMP, TIFF.
Функция распознавания текста позволяет извлечь текст и символы из сканов документов и снятых на цифровую камеру изображений.
* Редактор границ изображения.
Вы можете обрезать картинку до нужного размера перед сканированием.
* Возможность обмена файлами.
Итоговые текстовые файлы можно не только редактировать, но и отправлять по почте и через соцсети.
* Программа понимает и распознает тексты на нескольких языках:
Английский, французский, русский, немецкий, испанский, португальский, итальянский.
Удобный, быстрый и точный сканер всегда выручит, если нужно срочно использовать или отредактировать печатный текст, ведь с ним извлечь документы в текст быстро, одним кликом.
Приложение предлагает подписку с доступом к дополнительным функциям:
– Сканирование и хранение QR кодов
– Отсутствие ограничения на сканирование файлов
– Пополнение базы языков распознавания
– Отсутствие рекламы
Privacy policy: https://anycasesolutions.com/privacy
Terms of use: https://anycasesolutions.com/tos
Версия 1.2.5
Мы исправили небольшие ошибки, которые могли доставить неудобства при использовании приложения. Эта версия – лучшая версия для вас.
Оценки и отзывы
Оценок: 14
денег не стоит
Зачем писать бесплатная, если пробный период 3 дня?! За это 2 звезды.

Распознает боле-мене, где-то 80-90% текста, для платной подписки маловато.
На маке с чипом М1 работает норм.

Приложение не работает
Вместо текста выдает тарабарщину. Фото документа хорошего качества.
списание денег
скачала приложение, не понравилось, в итоге оформилась подписка, которая не отменяется, приложением даже не пользовалась сразу удалила, возможно оформила пробный период подписки, но потом отменила, но куда списалось то, верните деньги !
Добрый день! Приложение не может снимать деньги без вашего подтверждения. Скорее всего, была оформлена подписка. Управлять подписками можно в настройках вашего аккаунта iTunes. С уважением, команда Any Case Solutions
Подписки
Скан текста и распознание
Сканирование без ограничений
2 990,00 ₽
Редактор и конвертор текста
Неограниченное количество сканов в день!
Пробная подписка
Разработчик Any Case Solutions указал, что в соответствии с политикой конфиденциальности приложения данные могут обрабатываться так, как описано ниже.
Не связанные с пользователем данные
Может вестись сбор следующих данных, которые не связаны с личностью пользователя:
- Геопозиция
- Идентификаторы
- Данные об использовании
- Диагностика
- Другие данные
Конфиденциальные данные могут использоваться по-разному в зависимости от вашего возраста, задействованных функций или других факторов. Подробнее
Подробнее
Информация
- Провайдер
- Any Case Solutions, OOO
- Размер
- 224 МБ
- Категория
- Утилиты
- Возраст
- 4+
- Copyright
- © Any Case Solutions
- Цена
- Бесплатно
- Поддержка приложения
- Политика конфиденциальности
Другие приложения этого разработчика
Вам может понравиться
Лучшие бесплатные OCR-сервисы для распознавания и конвертации PDF / Информационная безопасность, Законы, Программы, ПО, сайты / iXBT Live
Привет всем! Я расскажу о сервисах для распознавания текста или OCR.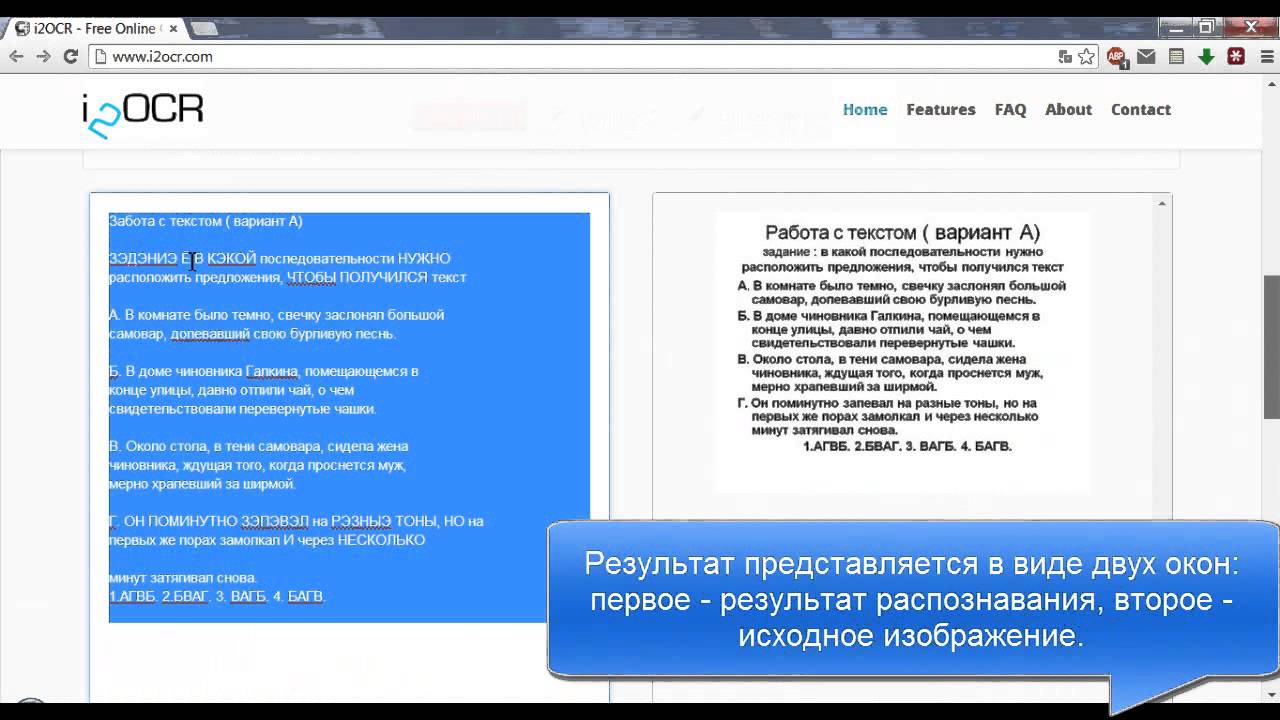 Считайте это небольшим рейтингом лучших OCR-утилит.
Считайте это небольшим рейтингом лучших OCR-утилит.
Оптическое распознавание символов (OCR – Optical Character Recognition) – механизм электронного или механического конвертирования изображения или печатного текста, например, с отсканированного документа, фотографии и т.д.
Я испытаю следующие программы и сервисы:
- PDF – Adobe Acrobat Pro – эталон всех распознавателей.
- PDF24 tools – богатый инструментарий для работы с PDF-документами, включает OCR.
- NewOCR – заявляют себя как сервис конвертации в текст форматов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu.
- Img2txt – сервис отличается красивым интерфейсом, но спасёт ли его это?
- Free Online OCR – простецкий онлайн-сервис для распознавания.
Чтобы результат был наглядным и достоверным, нужно протестировать. Для этого я подготовил специальные документы:
- Фрагмент статьи “8 бесплатных аналогов платных программ для переводчиков”.
- Тот же фрагмент, но без текстового слоя – скрин, завёрнутый в PDF. Базовые сложности те же, только к ним ещё добавляется необходимость распознавания всего остального текста и необходимость сохранить форматирование.
- Рекламная брошюра масел. Сложное и разное форматирование, местами текстовый слой есть, местами его нет. Отнюдь не простой документ. Посмотрим, справятся ли конкурсанты.

Я попробую сравнить качество распознавания при конвертировании в редактируемый формат между бесплатными сервисами и эталоном – Adobe Acrobat DC.
Adobe Acrobat DC идёт первым как эталон, созданный для одной задачи – для работы с pdf-файлами.
Простой файл с текстовым слоем:
Ожидаемо. Никаких трудностей. Полная конвертация в редактируемый формат. Изображение по центре осталось нетронутым, но это невеликая проблема, можно подписать или обработать в Paint.
Изображение по центре осталось нетронутым, но это невеликая проблема, можно подписать или обработать в Paint.
Простой файл без текстового слоя:
Нестандартный шрифт не распознался, но мелкий шрифт под звёздочкой распознался достаточно хорошо. Ещё пару букв пропустил, но допустимая погрешность для последующего ручного редактирования.
Сложный файл с непостоянным текстовым слоем:
Как сказать. Результат ожидаемо плохой, потому что файл очень сложный. Впрочем, отредактировать всё равно можно, лучше, чем ничего.
Почему я не взял на тест больше программ для ПК? А их нет. Существует несколько простых программ, которые распознают только изображения или устанавливают на компьютер мусор. Я пробовал: Free OCR, Simple OCR, CuneiForm OCR, Freemore OCR. Вторая категория – это титаны вроде Abbyy или Adobe, которых мы стараемся избежать в этой статье.
Итак, перейдём к онлайн-сервисам.
PDF24 tools – многогранный сервис. Он может распознать текст в PDF, но в результате всё равно выдаст PDF. На наше счастье среди утилит этого сайта есть и конвертер в Word. Они даже расположены рядом.
На наше счастье среди утилит этого сайта есть и конвертер в Word. Они даже расположены рядом.
Простой файл с текстовым слоем:
Получилось очень плохо, но текст типа сохранён полностью. Изображение вырезано и половина страницы пустая. Ладно, сочтём, что так и должно быть.
Простой файл без текстового слоя:
С задачей сервис не справился. После распознавания и конвертации в ворд, я увидел пустой лист.
Сложный файл с непостоянным текстовым слоем:
Результат оказался таким же – пустой лист. Но сервис предлагает три режима конвертации:
Я попробовал все три, лучший результат выдал третий режим “только текст”:
Распознался даже сложный шрифт!
Брошюра тоже распозналась, но легче мне от этого не стало:
Вердикт:
Спорный сервис. Конвертирует и распознаёт быстро и удобно, много разных утилит. Пусть будет, конечно, на крайняк покатит.
NewOCR – нашёл в одной из статей про лучшие сервисы распознавания символов на просторах интернета. Говорят, что сервис хороший.
Говорят, что сервис хороший.
Простой файл с текстовым слоем:
Текст распозанёт хорошо, но предлагает выбрать только формат .txt, не распознаёт картинку и даже не пытается сохранить форматирование.
Простой файл без текстового слоя:
Неплохо распознал основной язык – русский, но ужасно справился с английским. Вся латиница превратилась в какую-то кашу. С другой стороны распознать получилось даже нестандартный шрифт с картинки. Не без ошибок, нор всё же. А ещё удалось получить формат Word. От чего это зависит – не знаю.
Сложный файл с непостоянным текстовым слоем:
Брошюра тоже распозналась косячно. Вместо многих символов ужасные кракозябры, слова собрались в кашу, формат только .txt. Зачем мне нужно вот это? Легче отредактировать скриншоты в paint, чем так.
Вердикт:
Сервис неплохо справляется с распознаванием текста, но что-нибудь сложнее, чем абзацы текста ему не под силу. Если в тексте встречается несколько языков, то один из них обязательно будет воспринят неправильно. Даже если указать два языка в поле перед распознанием. Про форматирование можно забыть, его здесь не будет. А ещё мне не понравилось, что каждую страницу многостраничного документа придётся распознавать и скачивать отдельно. Документ на 50 страниц? Простите, но придётся выкачивать по одной странице за раз. А ещё придётся подождать 5 секунд перед распознанием очередной страницы. Не больше ни меньше. Если попытаетесь распознать быстрее, получите ошибку. А ещё не всегда с первого раза точно прицеливается в страницу, иногда выхватывает маленький фрагмент страницы и пытается его распознать.
Даже если указать два языка в поле перед распознанием. Про форматирование можно забыть, его здесь не будет. А ещё мне не понравилось, что каждую страницу многостраничного документа придётся распознавать и скачивать отдельно. Документ на 50 страниц? Простите, но придётся выкачивать по одной странице за раз. А ещё придётся подождать 5 секунд перед распознанием очередной страницы. Не больше ни меньше. Если попытаетесь распознать быстрее, получите ошибку. А ещё не всегда с первого раза точно прицеливается в страницу, иногда выхватывает маленький фрагмент страницы и пытается его распознать.
Сервис Img2txt. Нашёл его где-то на просторах интернета в комментариях к статье о лучших сервисах.
Простой файл с текстовым слоем:
Крупный текст распознал, мелкий превратил в кашу. Решил, забить на текстовый слой и распознал только картинку. Странное решение. Зато предлагает много форматов.
Простой файл без текстового слоя:
Не сказать, что плохо, но и не сказать, что хорошо. Некоторые буквы перепутал, латиницу не распознал. Но по крайней мере можно скачать в вордовском формате.
Некоторые буквы перепутал, латиницу не распознал. Но по крайней мере можно скачать в вордовском формате.
Сложный файл с непостоянным текстовым слоем:
Слева оригинал, справа результат распознанияКуцый результат. Распозналось плохо, большая часть текста пропущена, слова в кашу превратились. Получилась бесполезная белиберда.
Вердикт:
Ещё один сервис, который распознаёт неплохо простые документы с большими абзацами текста. Раздражает, что сначала нужно загрузить файл, выбрать для него язык, потом файл обработается сервером, нужно снова выбрать для него язык и запустить распознавание. Я как-то ожидал, что загружая я уже достаточно чётко выражаю намерение распознать файл.
Ещё одна беда – это постраничное распознавание. Как и в случае с NewOCR каждая страница распознаётся отдельно, скачивается отдельным документом. Только тут ещё необходимо для каждой новой страницы повторно выбирать язык.
А ещё это единственный сервис с ограничением размера файла. Максимум – 8 мб.
Максимум – 8 мб.
Online OCR – сервис с самым непримечательным названием. Я упоминал этот сервис в статье про 8 бесплатных аналогов платных программ.
Простой файл с текстовым слоем:
Ого. Результат удивляет. Почти идеальный. Мало того, что распознание прошло почти мгновенно, так ещё и латиница распозналась там, где надо. Даже мои опечатки были распознаны правильно. То что текст вокруг картинки – это ерунда. Чуть-чуть не дотянул до уровня Adobe.
Простой файл без текстового слоя:
Снова в яблочко! В этот раз побольше промахов, но результат достойный. Хотя бы картинка сохранилась и часть мелкого текста с неё удалось распознать.
Сложный файл с непостоянным текстовым слоем:
Ух ты! Сервис справился с распознаванием и этого документа! Удивительно, но факт. Есть некоторые недочёты, но это очень хороший результат. С редактированием такого файла в ворде придётся очень сильно помучиться, зато распознаны все таблички, большинство надписей. Если в ваши обязанности не входит вёрстка, то это именно то, что нужно.
Если в ваши обязанности не входит вёрстка, то это именно то, что нужно.
Я бы назвал это самым большим успехом. Даже Adobe по сравнению с этим меркнет:
Adobe слева, Online OCR справаВердикт:
Это лучший сервис! К сожалению, без регистрации он не даст распознать PDF больше 15 страниц, большие изображения, ZIP-архивы и ещё что-то. Но после регистрации сервис даёт только 50 бесплатных страниц.
Я слышу слово “абьюз” или мне кажется? Раскрою секрет, как сделать сервис абсолютно бесплатным. Создатели сайта не придумали подтверждение почты при регистрации. Можно указать любой вымышленный адрес. Как только заканчиваются страницы, переезжаем на новый аккаунт и пользуемся 50 бесплатными. Забавно получается.
Читайте другие статьи переводческого цикла:
Распознавание текста из изображения: Преобразователь изображения в текст
Распознавание текста из изображения имеет решающее значение, когда изображения повсюду в Интернете и могут появляться в различных форматах. Но ваши пользователи не смогут отличить их только по цвету. Вот почему вам нужен API-интерфейс OCR, чтобы гарантировать, что веб-доступность встроена в ваш цифровой контент по дизайну.
Но ваши пользователи не смогут отличить их только по цвету. Вот почему вам нужен API-интерфейс OCR, чтобы гарантировать, что веб-доступность встроена в ваш цифровой контент по дизайну.
Создатели контента должны помнить о том, как их пользователи взаимодействуют с веб-сайтами, взаимодействуя с элементами на веб-странице. Лучше всего добавлять описания к изображениям, оставляя замещающий текст в HTML или подписи в соседнем абзаце. Однако изображения текста не индексируются поисковыми системами, и программы чтения с экрана не могут их обнаружить.
Функциональность имеет большое значение, когда пользователям необходимо перетаскивать, загружать или вставлять изображения в определенную область. Если вы хотите извлечь текст из изображений, вам понадобится конвертер изображений в текст .
Содержание
Что означает распознавание преобразования изображения в текст?
Распознавание текста в изображение — это преобразование изображения в читаемый текст для взаимодействия с вспомогательными технологиями. Этот термин описывает бесплатное онлайн-программное обеспечение оптического распознавания символов (OCR) для перевода слов на изображении в электронные символы.
Этот термин описывает бесплатное онлайн-программное обеспечение оптического распознавания символов (OCR) для перевода слов на изображении в электронные символы.
Отличным примером является случай, когда пользователь выделяет фрагмент текста для копирования и вставки в поле. Это часто относится к конвертерам PDF, изображениям, содержащим текст, и электронным книгам с ограниченным доступом. Настоящей проблемой является попытка прочитать сморщенные или размытые PDF-документы на небольших экранах. Аналогичная проблема — невозможность извлечь текст из исходного материала при цитировании цитаты или статистики.
При этом документы должны быть переведены в понятный формат, иначе скан останется текстовым изображением без возможности поиска определенных фраз. Для работы с областями, которые отключают выделение текста, OCR онлайн может переопределить встроенные сценарии для захвата текста из меню или всплывающих окон.
Чтобы узнать больше о типах файлов изображений , в этом посте объясняются различия между растровыми и векторными изображениями и как сохранить качество версий с измененным размером.
Как работает оптическое распознавание символов (OCR)?
OCR — это API на основе машинного зрения, который обнаруживает и извлекает текст из изображений в пределах границ рамки. Затем текст преобразуется в строку JSON, которая может охватывать целые страницы или абзацы, разделенные разрывами. Это показано в Google Cloud Vision для выполнения рабочих нагрузок.
API Vision отлично справляется с обнаружением функций файла изображения в облачном хранилище, даже не отправляя этот файл в тело запроса. Наиболее универсальные OCR могут определять язык текста с помощью нескольких подсказок, предоставляя вам контроль над тем, где размещать ресурсы, устанавливая конечную точку. Следовательно, вам нужно указать только значения для изображений, источников, URI и объектов функций в файле JSON.
Последней разработкой является онлайн-система оптического распознавания текста, которая позволяет тщательно изучить фотографию и определить значение любых написанных, напечатанных или напечатанных слов.![]() Как только это будет сделано, вы можете перевести или использовать текст в своем текстовом процессоре или издательском программном обеспечении для распространения среди более широкой аудитории. Извлечение текста из изображения удобно для вставки в другую программу, например Outlook или OneNote.
Как только это будет сделано, вы можете перевести или использовать текст в своем текстовом процессоре или издательском программном обеспечении для распространения среди более широкой аудитории. Извлечение текста из изображения удобно для вставки в другую программу, например Outlook или OneNote.
Вот 5 лучших API OCR , о которых вы должны знать, если вам нужна помощь в выборе того, которому доверяют эксперты и который имеет все нужные функции.
Распознавание текста с изображения: 7 способов преобразования изображений в текст с помощью удобного оптического распознавания символов
В век цифровых технологий большинству пользователей приходится извлекать текст из изображения, чтобы с легкостью редактировать его. Это особенно верно из-за нашей зависимости от бумажных документов и программного обеспечения OCR для их цифровой модификации. Преобразователь изображения в текст сэкономит ваше время на поиск исходного документа.
Через онлайн-конвертер
Все, что вам действительно нужно, это браузер и подключение к Интернету, чтобы начать перевод блоков текста. Это довольно простой метод, который мы рассмотрим в этой статье. Успех, которого вы добились с OCR, полностью зависит от качества загруженных вами изображений.
Это довольно простой метод, который мы рассмотрим в этой статье. Успех, которого вы добились с OCR, полностью зависит от качества загруженных вами изображений.
Щелчок правой кнопкой мыши для копирования должен предоставить опции для выбора между копированием только одной страницы или всех страниц в документе PDF. Щелкните место, куда вы хотите вставить текст, и нажмите 9.0007 Ctrl+V , чтобы вставить его из многостраничной распечатки.
Для сканирования текста в системе Windows или Mac начните с создания снимка экрана с текстом на странице PDF. Вы можете либо нажать клавишу печати экрана, чтобы получить все это, либо использовать инструмент Snipping Tool в своих программах.
В Snipping Tool нажмите кнопку New — это позволит вам щелкнуть и перетащить, пока рамка не закроет нужную область. Вы можете пометить изображение некоторыми аннотациями или просто сохранить его в свои файлы, нажав кнопку дискета значок.
Если вы работаете на Mac, вам нужно нажать клавиши Shift+Command+3 , чтобы открыть весь экран. Или нажмите Shift+Command+4 , чтобы изменить размер выделения. Вы даже можете сузить его до определенного окна, нажав после этого клавишу пробела.
Когда вы увидите значок камеры, перетащите его к окну, чтобы запечатлеть, что внутри. Изображения должны быть видны на рабочем столе. Теперь перейдите к предпочитаемому OCR и откройте этот файл в интерфейсе редактора. Щелкните правой кнопкой мыши и выберите параметр «захватить текст», чтобы отобразить его в новом окне.
В Google Docs
Если вы уже сохранили свои документы в Google Docs, вам больше не придется покупать другие инструменты для исследовательских целей. Его OCR преобразует текст из изображения для любого файла, который соответствует стандартам размера и разрешения. Он также имеет функцию определения языка и шрифта для обеспечения максимальной читабельности.
В Windows
Опять же, если вы предпочитаете конвертировать изображения непосредственно на ПК, на рынке доступно множество OCR. Для бесплатного программного обеспечения OCR возможности безграничны с OCRSpace, OnlineOCR, Nanonets, Adobe Acrobat Pro, LightPDF и другими. Эти приложения автоматически преобразуют изображения в машиночитаемые копии.
Для бесплатного программного обеспечения OCR возможности безграничны с OCRSpace, OnlineOCR, Nanonets, Adobe Acrobat Pro, LightPDF и другими. Эти приложения автоматически преобразуют изображения в машиночитаемые копии.
На Android
Если у вас есть Android, существуют приложения для преобразования изображений в обычный текст, которые позволяют сканировать изображения на ходу с помощью встроенной камеры. Приложения OCR создают редактируемую электронную копию, чтобы помочь оцифровать архивные документы и облегчить ввод данных. Примеры включают Office Lens, CamScanner и Text Fairy.
На Mac
Плохая новость заключается в том, что для macOS не так много заслуживающих доверия инструментов распознавания текста. Если вам нужно надежное программное обеспечение для распознавания текста на вашем MacBook, вам придется приобрести платную версию. На сегодняшний день лучшим вариантом является Adobe Acrobat Pro DC для скорости и точности. Для инструментов сканирования попробуйте FineReader или PDFpen.
Через расширение Chrome OCR
Для изображений браузера установите расширение Chrome, чтобы захватывать и переназначать текст. Чтобы найти OCR Chrome, щелкните правой кнопкой мыши, чтобы открыть изображение в новой вкладке. Затем выберите «Поиск изображения с помощью Google Lens», чтобы он распознавал каждый сегмент текста. Теперь вы можете прослушать или перевести слова.
Приложение OCR для iOS
Scanner Pro — одно из лучших приложений для распознавания текста и сканирования документов для устройств iOS. Но если вы хотите ходить по магазинам, самые высокие отзывы получают ABBYY FineReader, Scanner for Me, Scanbot и объектив Microsoft Office, потенциальные облачные сервисы, поддержка Office 365 и инструменты для рукописного ввода.
Как конвертер фото в текст экономит время и усилия
Короче говоря, конвертер фото в текст решит ваши проблемы с анализом текста. Помимо обычных действий поиска и масштабирования, он позволяет вам составить оглавление. Кроме того, он изменяет положение текста для просмотра на мобильных устройствах и воспроизводит звук преобразования текста в речь.
Кроме того, он изменяет положение текста для просмотра на мобильных устройствах и воспроизводит звук преобразования текста в речь.
Одним из преимуществ является возможность собирать текст из каталога файлов и включать важные сведения, такие как имя файла, размер, местоположение или дата изменения. Эта функция очень полезна, когда вы берете текст со скриншотов веб-сайта, и вам больше не нужно перепечатывать текст с нуля.
С помощью бесплатного онлайн-OCR ваша команда может преобразовать статическое изображение в цифровой текст за считанные минуты. Программное обеспечение выполняет электронный поиск для получения нужной информации с мгновенными результатами у вас на глазах.
Помимо всего прочего, у вас есть множество онлайн-инструментов, из которых можно выбирать на множестве устройств. Функциональность OCR не ограничивается только файлами Word. Он умеет вставлять текст со скриншотов в Slack, Microsoft Teams и множество других инструментов.
Распознавание текста из изображения и преобразование изображения в текст с помощью стека файлов
В настоящее время существует множество бесплатных онлайн-программ для распознавания текста или конвертеров изображений в текст. В результате их легко обнаружить с результатами, которые различаются по качеству. Если вы ищете исключительный конвертер изображений в текст, то специальная команда Filestack предоставит вам все необходимое.
В результате их легко обнаружить с результатами, которые различаются по качеству. Если вы ищете исключительный конвертер изображений в текст, то специальная команда Filestack предоставит вам все необходимое.
Распознавание текста из изображения и преобразование изображения в текст — это распознавание и преобразование изображения в читаемый текст. И есть много способов преобразовать изображение в текст. Но для качественной обработки изображений вы можете рассчитывать на Filestack. Filestack извлекает ключевой текст из изображений на многочисленных устройствах вплоть до сети. И он использует расширенный интеллект ML (машинное обучение). В результате мы можем использовать его OCR для расшифровки плотных символов или трудноразличимых точек интереса в ваших документах, лицензиях и других типах изображений. Это поможет вам правильно определить аспекты изображения, если вам нужно отсортировать их в каталоге.
Подробнее →
8 лучших программ для оптического распознавания символов на 2022 год [бесплатные и платные]
Время от времени мы получаем изображение из отрывка из книги или PDF-файла с большим содержанием, которое мы хотим отредактировать или найти. Иногда нам приходится извлекать таблицы из изображений для редактирования и добавлять их в Microsoft Excel или файл CSV. В таких случаях нам нужно программное обеспечение OCR, которое может точно распознавать символы и преобразовывать их в текст. Это сэкономит вам много времени и хлопот от ручного ввода всего документа. Поэтому, чтобы упростить вам задачу, мы составили список лучших программ для распознавания текста (бесплатных и платных), которые могут преобразовывать изображения и PDF-файлы в текст с почти идеальной точностью. На этой ноте давайте продолжим и найдем лучшее программное обеспечение для распознавания текста, подходящее для ваших нужд.
Иногда нам приходится извлекать таблицы из изображений для редактирования и добавлять их в Microsoft Excel или файл CSV. В таких случаях нам нужно программное обеспечение OCR, которое может точно распознавать символы и преобразовывать их в текст. Это сэкономит вам много времени и хлопот от ручного ввода всего документа. Поэтому, чтобы упростить вам задачу, мы составили список лучших программ для распознавания текста (бесплатных и платных), которые могут преобразовывать изображения и PDF-файлы в текст с почти идеальной точностью. На этой ноте давайте продолжим и найдем лучшее программное обеспечение для распознавания текста, подходящее для ваших нужд.
Лучшее программное обеспечение OCR (2022)
Здесь мы добавили 8 лучших программ OCR, как бесплатных, так и платных для обычных пользователей и предприятий. Вы можете развернуть приведенную ниже таблицу, чтобы найти все программы OCR в одном месте.
Содержание
1. Tesseract
Tesseract — одно из лучших программ оптического распознавания текста, бесплатное и с открытым исходным кодом . Он разработан Google и имеет один из лучших движков для распознавания текстов из PDF-файлов и изображений. Я лично использовал это программное обеспечение OCR для преобразования выдержек из книг, архивов, PDF-файлов и многого другого. Самое приятное то, что он может обнаруживать символы даже из старых книг, где размер шрифта слишком мал, а текст почти неразборчив. Он восстанавливает тип и размер шрифта в соответствии с исходным текстом без особых ошибок.
Он разработан Google и имеет один из лучших движков для распознавания текстов из PDF-файлов и изображений. Я лично использовал это программное обеспечение OCR для преобразования выдержек из книг, архивов, PDF-файлов и многого другого. Самое приятное то, что он может обнаруживать символы даже из старых книг, где размер шрифта слишком мал, а текст почти неразборчив. Он восстанавливает тип и размер шрифта в соответствии с исходным текстом без особых ошибок.
Существует множество клиентов с графическим интерфейсом, созданных на основе проекта Tesseract. Если вы пользователь Windows, то gImageReader — лучшее программное обеспечение для распознавания текста, которое вы можете использовать. Пользователи Linux имеют OCRFeeder, а пользователи macOS могут использовать PDF OCR X. И если вы хотите конвертировать PDF-файлы и изображения в текст через веб-сайт, OCR.Space (веб-сайт) — это тот, который построен на Tesseract. Не говоря уже о том, что Tesseract поддерживает более 100 языков , включая глобальные и региональные языки. Подводя итог, если вам нужно лучшее бесплатное программное обеспечение для распознавания текста, не ищите ничего, кроме Tesseract.
Подводя итог, если вам нужно лучшее бесплатное программное обеспечение для распознавания текста, не ищите ничего, кроме Tesseract.
Pros
- Free and open-source
- Quite powerful and accurate
- Supports over 100 languages
- Can detect handwritten and illegible documents
- Quite lightweight
Cons
- Не для бизнес-пользователей
Цена : Бесплатно
Скачать : Windows (бесплатно), macOS (бесплатно), Linux (бесплатно), веб-браузер (бесплатно) , Командная строка (бесплатно)
2. Sejda
Пользователям, которые хотят быстро извлекать текст из PDF-файлов и изображений, я настоятельно рекомендую Sejda. Это бесплатное программное обеспечение для распознавания текста, которое доступно в браузере, а также предлагает настольный клиент для Windows, macOS и Linux.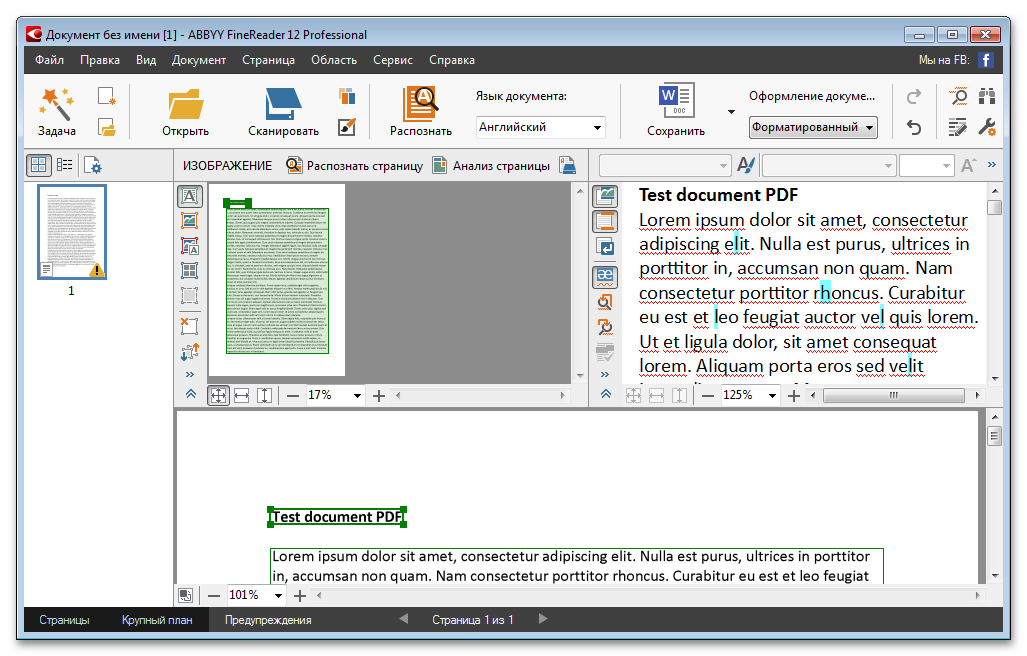 Для обычных пользователей я предлагаю использовать его веб-сайт, поскольку он бесплатный. Только платные пользователи могут загрузить настольный клиент. В любом случае, говоря о функциях, его PDF-редактор — один из самых простых и понятных инструментов. Вы можете редактировать PDF-файлы размером до 50 МБ в бесплатной версии.
Для обычных пользователей я предлагаю использовать его веб-сайт, поскольку он бесплатный. Только платные пользователи могут загрузить настольный клиент. В любом случае, говоря о функциях, его PDF-редактор — один из самых простых и понятных инструментов. Вы можете редактировать PDF-файлы размером до 50 МБ в бесплатной версии.
Если у вас есть снимок экрана или отрывок из книги, Сейда может мгновенно преобразовать PDF-файл или изображение. Он поддерживает различных форматов изображений , таких как JPEG, PNG, TIFF и другие. Что мне особенно нравится в Sejda, так это то, что он предлагает функцию точной проверки, где вы можете узнать, где, по мнению программного обеспечения, может потребоваться ручная коррекция. Вы можете экспортировать текст в PDF-документ с возможностью поиска, а также в обычный текстовый файл.
Единственный недостаток в том, что он позволяет только 3 задачи в час для бесплатных пользователей, но думаю это справедливое ограничение. Мы написали подробное руководство о том, как бесплатно редактировать PDF в Windows 10, поэтому ознакомьтесь с подробными инструкциями. В заключение, Sejda входит в число лучших бесплатных программ для распознавания текста, и вам обязательно стоит попробовать.
Мы написали подробное руководство о том, как бесплатно редактировать PDF в Windows 10, поэтому ознакомьтесь с подробными инструкциями. В заключение, Sejda входит в число лучших бесплатных программ для распознавания текста, и вам обязательно стоит попробовать.
Плюсы
- Быстрое и простое распознавание символов
- По большей части бесплатно
- Без водяных знаков
- Довольно точно
- Строгая политика конфиденциальности
Минусы
- 3 задачи в час для бесплатных пользователей
- Ограничение документа 50 МБ
Цена : Бесплатно, Платный план начинается с 7,5 долларов США в месяц
Платформы : Windows, macOS, Linux, веб-браузер
Загрузка : Веб-сайт
3. Microsoft Word / Excel / OneNote
Если вы являетесь пользователем Microsoft Office, вам не нужно загружать отдельное программное обеспечение OCR для преобразования PDF-файлов и изображений в текст. Microsoft добавила в свое программное обеспечение мощный механизм OCR, включающий Microsoft Word, Excel и OneNote. В Microsoft Word вам просто нужно открыть файл PDF с помощью Microsoft Word, и он автоматически конвертирует PDF в редактируемый файл Word. Насколько это удивительно? Если у вас есть изображение, добавьте его в Word и сохраните в формате PDF. Затем откройте файл PDF с помощью Word, и все готово! Он даже пытается сохранить форматирование и цвета с почти идеальной точностью.
Microsoft добавила в свое программное обеспечение мощный механизм OCR, включающий Microsoft Word, Excel и OneNote. В Microsoft Word вам просто нужно открыть файл PDF с помощью Microsoft Word, и он автоматически конвертирует PDF в редактируемый файл Word. Насколько это удивительно? Если у вас есть изображение, добавьте его в Word и сохраните в формате PDF. Затем откройте файл PDF с помощью Word, и все готово! Он даже пытается сохранить форматирование и цвета с почти идеальной точностью.
Что касается Excel, он пригодится, если у вас много таблиц на изображении. Послушайте, я перепробовал множество программ OCR для извлечения таблиц, но ни одна из них не работала так хорошо, как Excel. Просто откройте Excel и перейдите к Данные -> Получить данные -> Из файла -> Из PDF . И именно так вы можете легко извлекать таблицы с правильным расположением строк и столбцов, цветовой кодировкой и т. д. Так проще извлекать таблицы из PDF-файлов и изображений. Обратите внимание, что эта функция доступна только подписчикам Office 365.
Обратите внимание, что эта функция доступна только подписчикам Office 365.
Что касается OneNote, просто добавьте изображение, щелкните его правой кнопкой мыши и выберите « Копировать текст из изображения ». Вы сделали. Чтобы довести до конца, нет лучшего программного обеспечения для оптического распознавания символов, чем Microsoft Office, если вы уже являетесь пользователем Office.
Pros
- Лучшее программное обеспечение OCR для пользователей Office
- Поддерживает изображения, PDF-файлы
- Поддержка нескольких языков
- Извлечение таблиц в Excel
- Добавление текста непосредственно в заметки
- Cons2
- Для извлечения таблицы требуется подписка на Office 365
- Распознавание текста недоступно в веб-версии MS Office
Цены : Платный план начинается с 6,99 долларов США в месяц
Платформы : Windows и macOS
Скачать : Веб-сайт
4.
Adobe Acrobat DCПоскольку Adobe является компанией, создавшей PDF, она предлагает непревзойденный механизм оптического распознавания символов, который может редактировать любой PDF-файл, который вы ему подбрасываете. Это, безусловно, один из мощных механизмов распознавания текста в отрасли, и если вам нужно отредактировать больших томов PDF-файлов , Adobe Acrobat DC — это то, что вам нужно. Вы можете с большой точностью конвертировать как текстовые, так и графические PDF-файлы прямо в его программное обеспечение. Самое приятное в этом программном обеспечении то, что оно сохраняет шрифт исходного документа, используя свой метод генерации пользовательского шрифта.
Так как Adobe имеет огромный репозиторий проприетарных и дизайнерских шрифтов, она автоматически подбирает стиль шрифта исходного документа, а затем преобразует PDF-файл в этот конкретный шрифт. И в случае, если шрифт недоступен, он генерирует пользовательский шрифт, используя аналогичную типографику .
Это та функция, которую может использовать только Adobe. Проще говоря, если вы хотите преобразовать тысячи страниц отсканированных изображений в файлы PDF (например, книги), тогда Adobe Acrobat Pro DC — лучшее программное обеспечение для оптического распознавания символов, которое вы можете выбрать.Плюсы
- Точное определение символов
- Добавляет текст к невидимым символам
- Широкая поддержка шрифтов
- Использует проприетарную типографику
Минусы
- Дорого для обычных пользователей
Цены : Бесплатная пробная версия на 7 дней, платный план начинается с 14,99 долларов США в месяц
Платформы : Windows и macOS
Скачать : Веб-сайт
5. ABBYY FlexiCapture
Если вы занимаетесь бизнесом, возможно, нет лучшего программного обеспечения для оптического распознавания символов, чем ABBYY FlexiCapture.
Это многофункциональное программное обеспечение, поддерживающее более 200 языков и обеспечивающее интеллектуальное сканирование документов, не имеющее аналогов в отрасли. Он использует искусственный интеллект , машинное обучение и передовые технологии распознавания для точного распознавания символов из изображений и PDF-файлов. Кроме того, ABBYY FlexiCapture добавляет бесшовный рабочий процесс с инструментами автоматизации, если вы хотите выполнять пакетные задания и преобразовывать сложные документы с большим объемом содержимого с таблицами, графиками, фотографиями и многим другим.ABBYY FlexiCapture также использует свой NLP (обработка естественного языка) для идентификации и извлечения данных из неструктурированных документов, что позволяет легко редактировать документ, который можно импортировать куда угодно. Одно можно сказать наверняка: если вы собираетесь использовать ABBYY FlexiCapture, потребность в ручной обработке значительно сократится.
Поэтому, если вы ищете лучшее программное обеспечение для оптического распознавания символов для предприятий, обратите серьезное внимание на ABBYY FlexiCapture.Плюсы
- Особенности, упакованные в Brim
- Best для бизнес -пользователей
- Использование AI, ML и NLP для OCR
- . обычные пользователи
Цены : Бесплатная пробная версия на 30 дней, платный план начинается с 29,99 долларов США в месяц
Платформы : Windows и macOS
Скачать : Веб-сайт
6. OmniPage Ultimate от Kofax
OmniPage Ultimate — это профессиональное программное обеспечение для преобразования изображений (JPG и PNG), документов и PDF-файлов в цифровые файлы. Если у вас крупная компания и вам нужна надежная программа OCR , то я настоятельно рекомендую OmniPage Ultimate от Kofax. Однако для частных лиц это программное обеспечение будет слишком дорогим.
Что касается функций, OmniPage может точно оцифровывать изображения и документы , делая их редактируемыми и доступными для поиска . Он также поддерживает длинный список форматов изображений, поэтому независимо от расширения файла вы можете легко преобразовать его в любой формат файла. По возможностям, я бы сказал, очень близко к ABBYY FlexiCapture.
Кроме того, OmniPage Ultimate использует собственную технологию определения расположения изображений и автоматически поворачивает документ в правильном направлении. Кроме того, вы можете запланировать пакетную обработку больших объемов PDF-файлов, используя его инструмент автоматизации.
Не говоря уже о том, что он может обнаруживать более 125 языков и соответственно обрабатывать изображения и документы. Что касается форматов выходных файлов, он поддерживает PDF, DOC, EXCL, PPT, CDR, HTML, ePUB и другие. Учитывая все аспекты, OmniPage Ultimate кажется надежным решением для распознавания текста для корпоративных пользователей.
Плюсы
- Многофункциональное распознавание текста
- Поддержка более 125 языков
- Поддержка PDF-файлов и различных форматов изображений
- Простая автоматизация и пакетная обработка
- Экспорт в различные форматы
Минусы
- Точность ниже, чем у ABBYY
Цена: Бесплатная пробная версия на 15 дней, платная версия за 149 долларов США
Скачать : Веб-сайт
7. Readiris
Ищете чрезвычайно мощное программное обеспечение для оптического распознавания текста с множеством функций, но не требующее особых усилий для начала работы? Взгляните на Readiris, возможно, это то, что вам нужно. А приложение профессионального уровня , Readiris обладает обширным набором функций, во многом идентичным ранее рассмотренному ABBYY FlexiCapture. Readiris поддерживает множество форматов изображений, от BMP до PNG и от PCX до TIFF.
Помимо этого, файлы PDF и DJVU также могут обрабатываться. Изображения можно получать со сканеров, и приложение также позволяет задавать пользовательские параметры обработки для исходных файлов/изображений, такие как сглаживание и настройка DPI, перед их анализом. Хотя Readiris может нормально обрабатывать изображения с более низким разрешением, оптимальное разрешение должно быть не менее 300 dpi.
По завершении анализа Readiris определяет текстовые разделы (или зоны), и текст может быть извлечен либо из определенных зон, либо из всего файла . Извлеченный текст доступен для редактирования и поиска и может быть сохранен в различных форматах, таких как PDF, DOCX, TXT, CSV и HTM.
Более того, функция сохранения в облаке Readiris Pro позволяет напрямую сохранять извлеченный текст в различные облачные службы хранения, такие как Dropbox, OneDrive, Google Диск и другие. Также имеется множество функций редактирования / обработки текста, и даже штрих-коды можно сканировать.
В целом, вам следует использовать Readiris, если вам нужны надежные функции извлечения/редактирования текста в простом в использовании пакете с расширенной поддержкой форматов ввода/вывода. Однако Readiris немного колеблется, когда дело доходит до обработки документов со сложными макетами, такими как несколько столбцов, таблиц и т. д.
Плюсы
- Отличный вариант для предприятий
- Надежный набор функций
- Поддерживает длинный список файлов
- Довольно высокая точность
- Пакетная обработка
Минусы
- Низкая точность рукописного текста
Цена: Бесплатная пробная версия на 10 дней, платная версия за 129 долларов США
Скачать : Веб-сайт
В 2019 году Amazon запустила свое программное обеспечение для распознавания текста под названием Textract, которое основано на модели машинного обучения и было обучено с использованием миллионов документов.
Он может автоматически обнаруживать печатный текст из изображений (JPG и PNG) и файлов PDF и может преобразовывать их в цифровую форму с помощью почти идеальная точность . Хотя Textract в основном доступен в веб-браузере, вы также можете загрузить его и использовать службу через командную строку.Кроме того, Textract кажется довольно мощным программным обеспечением для распознавания текста, поскольку он может извлекать не только тексты, но также таблицы, поля, числа и ключевые значения. Мне особенно нравится извлечение таблицы из отсканированных изображений, так как это значительно упрощает редактирование текста. Textract хранит данные таблицы, используя предопределенную схему, где он извлекает все данные в виде строк и столбцов.
Сказав все это, Amazon Textract предлагает свои услуги как для частных лиц, так и для компаний. Как домашний пользователь, вы можете зарегистрировать учетную запись уровня бесплатного пользования AWS и использовать сервис, но имейте в виду, что вы можете преобразовать только 1000 страниц в месяц .
В целом, Amazon Textract представляет собой отличное программное обеспечение для оптического распознавания символов, которое может использоваться как обычными пользователями, так и предприятиями.Плюсы
- Поддерживает PDF-файлы и несколько форматов изображений
- Бесплатно на 3 месяца
- Поддерживает извлечение таблицы
- Довольно мощный инструмент для распознавания символов
Минусы
- Нежелательный вариант для обычных пользователей
Цена: Бесплатно для 1000 страниц в месяц в течение 3 месяцев, Премиум-план начинается с 1,50 доллара США за 1000 страниц
Платформа: Интернет, Windows, macOS, Linux
Скачать : Веб-сайт
БОНУС: Google Keep и Google Docs
Если вы хотите конвертировать изображения и PDF-файлы на лету, я рекомендую Google Keep и Google Docs.
Google Keep может извлекать тексты из изображений за считанные секунды, а также поддерживает региональные языки. Самое приятное в этом решении — насколько безупречен процесс оптического распознавания символов, и все это доступно бесплатно. Просто добавьте изображение в Google Keep, нажмите на меню с тремя точками и выберите « Захватить текст изображения », и вот оно. Через несколько секунд весь текст будет скопирован под изображение. Вы также можете сделать это в Интернете и в мобильном приложении. Единственная проблема заключается в том, что он плохо работает с таблицами, но это понятно.Переходя к Google Docs, если вы хотите конвертировать PDF-файлы, Google Docs позволяет вам делать это так же, как Microsoft Word. Но в отличие от Word, это совершенно бесплатно. Просто загрузите PDF-файл на Google Диск и откройте его с помощью Google Docs. Он автоматически преобразует PDF в редактируемый и доступный для поиска документ за считанные секунды.
Всякий раз, когда мне нужно преобразовать изображения и PDF-файлы в текст, оба этих инструмента очень удобны, и я думаю, что вы тоже должны их использовать.Плюсы
- Быстрое и простое программное обеспечение OCR для обычных пользователей
- Бесплатное использование
- Поддержка изображений и PDF-файлов
- Поддержка мобильных приложений
- Доступно почти на всех платформах
Минусы
- Документы Google не могут конвертировать PDF-файлы отсканированных изображений
Скачать : Google Keep (Интернет, Android, iOS), Документы Google (Интернет)
Найдите лучшее программное обеспечение для оптического распознавания символов из нашего списка
Вот наш выбор лучшего программного обеспечения для оптического распознавания символов. Мы добавили программное обеспечение OCR как для обычных пользователей, так и для предприятий. Если вы обычный пользователь, то бесплатных инструментов достаточно, и вам не нужно ничего платить за редактирование PDF-файлов и преобразование изображений в текст с возможностью поиска.
 Adobe Acrobat DC
Adobe Acrobat DC Это та функция, которую может использовать только Adobe. Проще говоря, если вы хотите преобразовать тысячи страниц отсканированных изображений в файлы PDF (например, книги), тогда Adobe Acrobat Pro DC — лучшее программное обеспечение для оптического распознавания символов, которое вы можете выбрать.
Это та функция, которую может использовать только Adobe. Проще говоря, если вы хотите преобразовать тысячи страниц отсканированных изображений в файлы PDF (например, книги), тогда Adobe Acrobat Pro DC — лучшее программное обеспечение для оптического распознавания символов, которое вы можете выбрать. Это многофункциональное программное обеспечение, поддерживающее более 200 языков и обеспечивающее интеллектуальное сканирование документов, не имеющее аналогов в отрасли. Он использует искусственный интеллект , машинное обучение и передовые технологии распознавания для точного распознавания символов из изображений и PDF-файлов. Кроме того, ABBYY FlexiCapture добавляет бесшовный рабочий процесс с инструментами автоматизации, если вы хотите выполнять пакетные задания и преобразовывать сложные документы с большим объемом содержимого с таблицами, графиками, фотографиями и многим другим.
Это многофункциональное программное обеспечение, поддерживающее более 200 языков и обеспечивающее интеллектуальное сканирование документов, не имеющее аналогов в отрасли. Он использует искусственный интеллект , машинное обучение и передовые технологии распознавания для точного распознавания символов из изображений и PDF-файлов. Кроме того, ABBYY FlexiCapture добавляет бесшовный рабочий процесс с инструментами автоматизации, если вы хотите выполнять пакетные задания и преобразовывать сложные документы с большим объемом содержимого с таблицами, графиками, фотографиями и многим другим. Поэтому, если вы ищете лучшее программное обеспечение для оптического распознавания символов для предприятий, обратите серьезное внимание на ABBYY FlexiCapture.
Поэтому, если вы ищете лучшее программное обеспечение для оптического распознавания символов для предприятий, обратите серьезное внимание на ABBYY FlexiCapture.


 Он может автоматически обнаруживать печатный текст из изображений (JPG и PNG) и файлов PDF и может преобразовывать их в цифровую форму с помощью почти идеальная точность . Хотя Textract в основном доступен в веб-браузере, вы также можете загрузить его и использовать службу через командную строку.
Он может автоматически обнаруживать печатный текст из изображений (JPG и PNG) и файлов PDF и может преобразовывать их в цифровую форму с помощью почти идеальная точность . Хотя Textract в основном доступен в веб-браузере, вы также можете загрузить его и использовать службу через командную строку. В целом, Amazon Textract представляет собой отличное программное обеспечение для оптического распознавания символов, которое может использоваться как обычными пользователями, так и предприятиями.
В целом, Amazon Textract представляет собой отличное программное обеспечение для оптического распознавания символов, которое может использоваться как обычными пользователями, так и предприятиями.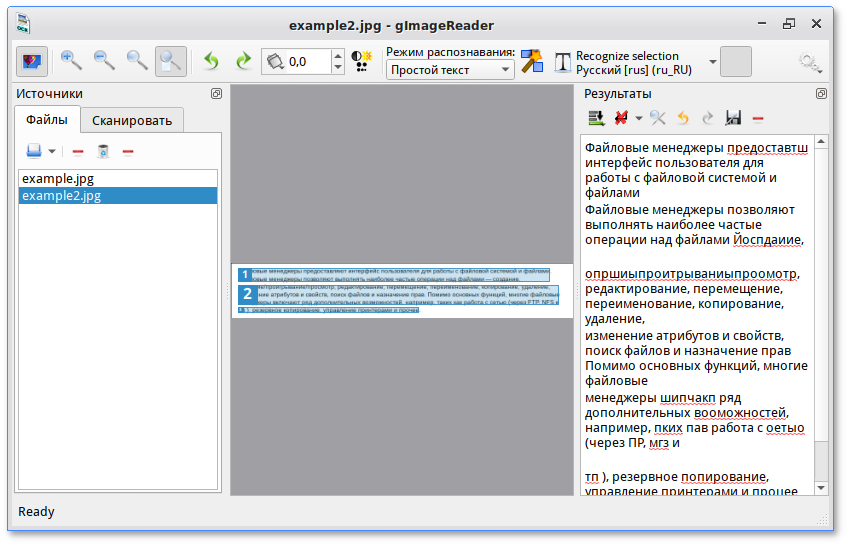 Google Keep может извлекать тексты из изображений за считанные секунды, а также поддерживает региональные языки. Самое приятное в этом решении — насколько безупречен процесс оптического распознавания символов, и все это доступно бесплатно. Просто добавьте изображение в Google Keep, нажмите на меню с тремя точками и выберите « Захватить текст изображения », и вот оно. Через несколько секунд весь текст будет скопирован под изображение. Вы также можете сделать это в Интернете и в мобильном приложении. Единственная проблема заключается в том, что он плохо работает с таблицами, но это понятно.
Google Keep может извлекать тексты из изображений за считанные секунды, а также поддерживает региональные языки. Самое приятное в этом решении — насколько безупречен процесс оптического распознавания символов, и все это доступно бесплатно. Просто добавьте изображение в Google Keep, нажмите на меню с тремя точками и выберите « Захватить текст изображения », и вот оно. Через несколько секунд весь текст будет скопирован под изображение. Вы также можете сделать это в Интернете и в мобильном приложении. Единственная проблема заключается в том, что он плохо работает с таблицами, но это понятно. Всякий раз, когда мне нужно преобразовать изображения и PDF-файлы в текст, оба этих инструмента очень удобны, и я думаю, что вы тоже должны их использовать.
Всякий раз, когда мне нужно преобразовать изображения и PDF-файлы в текст, оба этих инструмента очень удобны, и я думаю, что вы тоже должны их использовать.