Передовой опыт автоматизации распознавания изображений и текста
Распознавание изображений и текста составляет основу автоматизации приложений виртуального рабочего стола. В этой статье рассматриваются некоторые основы работы с распознаванием изображений и текста. Мы также представим передовые методы и решения для решения некоторых проблем, связанных с распознаванием изображений и текста.
Leapwork поставляется с двумя категориями строительных блоков для автоматизации распознавания изображений и текста:
Мышь и клавиатура
Найди и получи
Как работает распознавание изображений Leapwork?
Распознавание изображений — это «искусство» нахождения одного изображения внутри другого изображения. Как правило, у вас будет одно изображение, определенное во время разработки (захваченное в ваши потоки автоматизации Leapwork), и одно изображение, которое является снимком экрана фактического приложения во время выполнения потока автоматизации. Что Leapwork будет делать, когда поток автоматизации запущен, так это искать захваченное изображение на снимках экрана и действовать в соответствии с определенным потоком.
Что Leapwork будет делать, когда поток автоматизации запущен, так это искать захваченное изображение на снимках экрана и действовать в соответствии с определенным потоком.
Зарегистрируйтесь на веб-семинар: Автоматизация тестирования без кода с Leapwork
Технически распознавание изображений сравнивает матрицу чисел с другой матрицей чисел и возвращает результат, если первая матрица является частью второй матрицы. Одна из проблем заключается в том, что две матрицы могут меняться при изменении разрешения экрана. Например. если поток автоматизации выполняется на другой машине или изменилось разрешение, то точность нахождения захваченного изображения на снимке экрана может снизиться, что может привести к менее надежным потокам автоматизации.
Распознавание изображений ищет изображение в изображении или матрицу в матрице.
Как работает распознавание текста Leapwork?
Распознавание текста основано на распознавании образов, что означает, что Leapwork ищет в области экрана образец, соответствующий буквам. Буквы могут быть разных шрифтов, цветов и размеров, а фон текста может быть изображением или градиентным узором, что затрудняет распознавание реальных букв и цифр на экране.
Буквы могут быть разных шрифтов, цветов и размеров, а фон текста может быть изображением или градиентным узором, что затрудняет распознавание реальных букв и цифр на экране.
Далее мы представим передовые методы решения распространенных проблем, связанных с работой с распознаванием текста и изображений. Адрес передового опыта:
- Как захватывать значки при смене фона
- Как найти движущиеся изображения
- Определение части экрана в качестве области фокусировки для ускорения процесса распознавания
- Использование коллекций изображений для более надежного распознавания
- Дистанционная конструкция и исполнение
- Настройка точности распознавания изображений
- Настройка модуля OCR для лучшего распознавания текста
Следуя этим советам, вы значительно улучшите качество процессов автоматизации, основанных на распознавании изображений и текста.
Захват значков при смене фона
Цвет фона за значком может меняться, поэтому не включайте части фона при захвате значка.
Эффект “наведения” может изменить внешний вид значка при наведении указателя мыши, например сделать его более ярким или темным. Обычно это можно решить, закрыв все открытые окна в ходе выполнения теста, установив для свойства «Действие» в стандартном блоке «Пуск» значение «Закрыть все окна».
Эффект «выбрано» или «открыто» может изменить внешний вид значка при выборе. Например, значок Chrome на панели задач Windows до открытия Chrome выглядит иначе, чем когда экземпляры браузера уже открыты. Обычно это можно решить с помощью функции коллекции изображений (см. далее).
Нет открытых браузеров:
Открыт хотя бы один браузер:
Поиск движущихся изображений
Одна из ситуаций, которая может возникнуть для всех типов приложений, заключается в том, что изображение сначала отображается в одном месте, а затем перемещается в другое. Например, на некоторых веб-сайтах все ресурсы сначала загружаются на страницу, а затем “загружаются” на нужное место. Другим примером может быть диалоговое окно в настольном приложении, которое отображается и центрируется на экране.
Другим примером может быть диалоговое окно в настольном приложении, которое отображается и центрируется на экране.
В обоих случаях Leapwork может найти изображение в исходной позиции, а затем продолжить выполнение теста. Однако, если изображение изменит положение в рамках приложения, автоматизация завершится ошибкой.
Проверка свойства «Ждать отсутствия движения» в стандартном блоке «Изображение клика» решает эту проблему. Это сообщит механизму распознавания изображений подождать, пока экран не изменится в течение определенного периода времени, прежде чем начать поиск изображения.
Определение части экрана как области фокусировки
Для распознавания изображений — и особенно для распознавания текста — лучше всего и настоятельно рекомендуется использовать «Области». «Область» – это часть всего экрана, которая используется для указания системе распознавания изображений/текста ограничить поиск захваченного изображения или определенного текстового/текстового шаблона в указанной области. Обычно вы определяете область в той части экрана, где вы ожидаете появление изображения или текста, включая некоторое поле.
Обычно вы определяете область в той части экрана, где вы ожидаете появление изображения или текста, включая некоторое поле.
Указание области преследует две основные цели:
- Вы убедитесь, что ищете правильный экземпляр захваченного изображения/текста. Если слово появляется на экране несколько раз, вы можете получить список вхождений вместо «правильного».
- Скорость выполнения значительно выше, если механизм распознавания изображений/текста Leapwork должен искать только часть экрана, а не весь экран.
Дополнительная информация об использовании и определении областей.
Коллекции изображений
Функция “Коллекция изображений” позволяет захватывать два или более изображений в коллекцию, а затем использовать коллекцию при поиске изображения. Это означает, например, что вы можете захватить одну и ту же кнопку в разных состояниях (без фокуса, в фокусе, наведена, нажата и т. д.), добавить все захваченные изображения в одну коллекцию, а затем просто щелкнуть поток автоматизации или найти кнопку независимо от состояния кнопки. Это повышает надежность и устойчивость к изменениям в потоке.
Это повышает надежность и устойчивость к изменениям в потоке.
В приведенном ниже примере мы захватили кнопку поиска — «Перейти» — из настольного приложения Windows.
Кнопка может иметь четыре разных вида в зависимости от фокуса и эффекта наведения:
Все четыре состояния были захвачены, и изображения теперь расположены как ресурсы в потоке в меню ресурсов:
В В приведенном выше примере изображения переименованы, чтобы их было легче идентифицировать. При наведении курсора на изображение в меню ресурсов появится миниатюра изображения.
Чтобы создать коллекцию изображений, нажмите «Создать» + «Захват» + «Коллекция изображений». Это создаст новую пустую коллекцию изображений в меню активов. Также можно просто щелкнуть правой кнопкой мыши папку, в которой должна находиться коллекция изображений, и выбрать «Захват» + «Коллекция изображений».
Коллекции изображений можно узнать по этому логотипу в меню ресурсов:
После добавления рекомендуется переименовать коллекцию изображений во что-то осмысленное, чтобы упростить обслуживание и повторное использование коллекции изображений в нескольких потоках.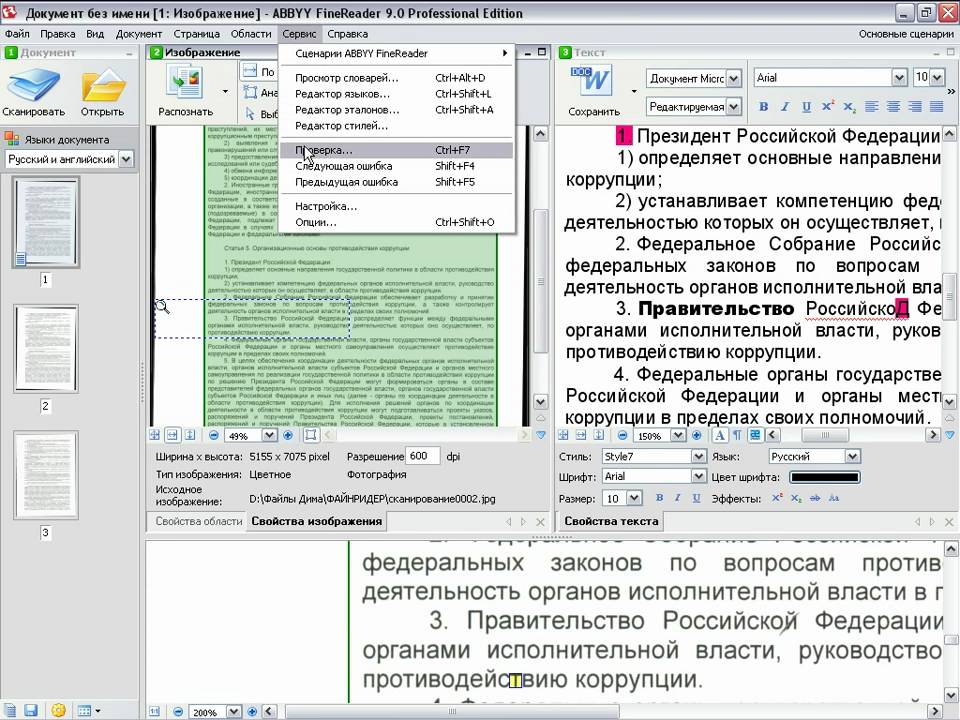
Добавить изображения в коллекцию изображений очень просто: просто перетащите изображения из любого места в меню ресурсов поверх коллекции изображений. Чтобы просмотреть изображения в коллекции, дважды щелкните коллекцию, чтобы открыть диалоговое окно «Редактировать коллекцию изображений».
В диалоговом окне можно редактировать и изменять изображения по отдельности, если это необходимо.
Теперь вы можете использовать коллекцию в стандартном блоке, перетащив коллекцию на поле изображения в стандартном блоке:
Когда блок Найти изображение выполняется, он будет искать на экране изображения в коллекции одно за другим. Если он находит одно из изображений, он щелкает его, а затем останавливает поиск и передает выполнение следующему строительному блоку в потоке.
Коллекцию изображений также можно использовать для обработки одного и того же значка/изображения в разных разрешениях, если вы знаете, что будете запускать один и тот же процесс автоматизации в разных разрешениях. Его также можно использовать для обработки различных состояний значков.
Его также можно использовать для обработки различных состояний значков.
Ресурсы изображений совместно используются в рамках проекта, поэтому коллекции можно использовать в нескольких потоках автоматизации. Это означает, что вы можете создать, например. коллекцию «Значок Chrome», которая содержит все соответствующие состояния значка Chrome на панели задач Windows, а затем использовать эту коллекцию во всех потоках автоматизации, которые работают с Chrome. Преимуществом этого является то, что вам нужно поддерживать коллекцию изображений только в одном месте, а не во всех потоках автоматизации.
Дистанционная конструкция и исполнение
Типичная конфигурация Leapwork состоит из нескольких рабочих станций с установленной Leapwork Studio, контроллера, установленного на общем/разделяемом сервере для упрощения совместного использования, а затем одной или нескольких машин, полностью используемых для выполнения потоков автоматизации. Когда потоки автоматизации используют распознавание изображений и текста, они будут взаимодействовать с реальным экраном. Это означает, что если вы запускаете распознавание изображений и текста на своем локальном компьютере, вы не можете работать над ним одновременно. По этой причине для запуска процессов автоматизации используются «удаленные компьютеры».
Это означает, что если вы запускаете распознавание изображений и текста на своем локальном компьютере, вы не можете работать над ним одновременно. По этой причине для запуска процессов автоматизации используются «удаленные компьютеры».
Чтобы ваши потоки автоматизации не зависели от различий в разрешении экрана между машинами, на которых могут выполняться потоки, вы можете определить Среду, указывающую на «удаленный компьютер». Затем вы можете использовать «удаленный компьютер» для захвата изображений вместо вашей локальной рабочей станции. Таким образом, вы в конечном итоге будете захватывать изображения непосредственно на машине, где вы будете выполнять поток автоматизации, гарантируя, что разрешение экрана всегда будет одинаковым.
Чтобы создать «удаленный компьютер», вам необходимо установить Leapwork Agent на выделенную рабочую станцию, доступную как из Leapwork Studio, так и из Leapwork Controller. Как только удаленная машина запущена и работает, вы можете определить среду в Studio, указывающую на эту машину. Дополнительную информацию можно найти здесь.
Дополнительную информацию можно найти здесь.
Когда среда создана, вы можете выбрать ее в «Предварительном просмотре среды» на холсте дизайна. В приведенном ниже примере «Amazon Cloud Remote» — это среда, указывающая на сервер, размещенный в облаке (Amazon), на котором установлен агент Leapwork Agent.
Когда «Среда предварительного просмотра» указывает на удаленный компьютер, при захвате новых изображений появляется всплывающее окно «терминала», позволяющее захватывать непосредственно на удаленном компьютере, а не на локальном.
Настройка точности распознавания изображений
Стандартные блоки, использующие распознавание изображений, имеют свойство с именем Точность. Эта конфигурация доступна путем расширения строительных блоков. Свойство Точность имеет два подсвойства:
- Пиксели: Уровень допустимой точности распознавания изображений.
- Цвет: Это свойство определяет чувствительность к изменениям плотности цвета.
 Плотность цвета одного и того же набора пикселей может меняться в зависимости от используемого оборудования.
Плотность цвета одного и того же набора пикселей может меняться в зависимости от используемого оборудования.
В этом разделе можно установить допустимый уровень точности распознавания изображений. По умолчанию используется значение “Pixel perfect”, что означает, что должно быть идеальное совпадение, пиксель за пикселем, прежде чем захваченное изображение будет считаться найденным на экране. В некоторых случаях требуется более высокий уровень толерантности. Рекомендуется начать с параметра “Pixel Perfect” для обоих свойств, а затем изменять их по одному уровню за раз, пока распознавание изображений не будет работать должным образом.
Настройка модуля OCR
Для стандартных блоков, использующих OCR (распознавание текста), вы можете изменить настройки механизма OCR, чтобы оптимизировать распознавание символов.
Выбор ядра
Вы можете выбрать один из двух встроенных модулей OCR в конфигурациях строительных блоков:
- «По умолчанию» : основан на Tesseract версии 3.
 5, который является механизмом с открытым исходным кодом. используется буквально всеми двигателями OCR.
5, который является механизмом с открытым исходным кодом. используется буквально всеми двигателями OCR. - “По умолчанию (новое)” : Этот движок основан на Tesseract версии 4.0, в которой для оптимизации движка используется архитектура нейронной сети (LSTM). Эта архитектура считается будущим для всех типов программного обеспечения для распознавания (изображения, речь, видео, текст и т. д.)
И “По умолчанию”, и “По умолчанию (новый)” являются рабочими ядрами, но из-за различных технологий для некоторых приложений может лучше подходить одно ядро. Если стандартные блоки OCR работают не так, как ожидалось, один из вариантов — попытаться перейти на другое ядро.
Если встроенный в Leapwork модуль OCR не соответствует вашим требованиям, можно изменить модуль на ABBYY .
ABBYY — ведущая в мире система распознавания текста, но для этого требуется отдельная лицензия ABBYY. Также имейте в виду, что ABBYY сама требует настройки инфраструктуры, поэтому в большинстве случаев лучше всего использовать встроенные механизмы.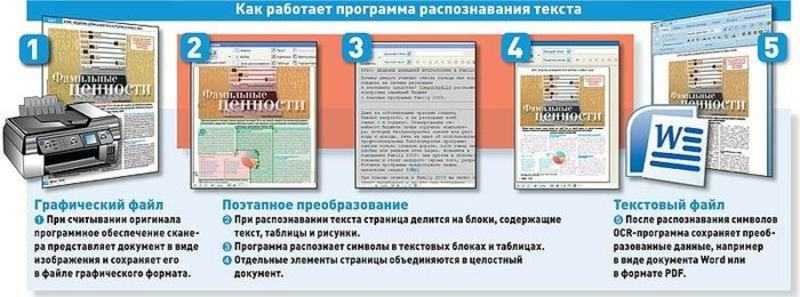
Свяжитесь с нашей командой по работе с клиентами, чтобы начать работу с ABBYY.
Выбор режима OCR:
Вы можете выбрать один из двух режимов OCR. Короче говоря, это выбор между скоростью и качеством.
- Высокая скорость: Модуль OCR выполняет два параллельных цикла распознавания: один в обычной цветовой схеме (черный текст на белом фоне) и один с инвертированными цветами. Этот режим работает быстрее, чем параметр “Высокое качество”, поэтому, если символы найдены правильно, просто продолжайте использовать этот параметр.
- Высокое качество: Модуль OCR выполняет четыре цикла распознавания параллельно: два в обычной цветовой схеме и два в инвертированных цветах. Этот параметр работает медленнее, чем параметр «Быстрая скорость», но может потребоваться, если модуль OCR неправильно возвращает символы.
Настройка уровней точности OCR:
Точность OCR устанавливает точность результатов распознавания на уровне символов. Это означает, что более высокий уровень точности OCR требует большей уверенности в механизме OCR, прежде чем будет найден определенный символ.
Это означает, что более высокий уровень точности OCR требует большей уверенности в механизме OCR, прежде чем будет найден определенный символ.
С высокой точностью вы можете быть уверены, что найденные символы являются правильными.
С другой стороны, высокая точность может привести к тому, что некоторые символы не будут найдены. Установка более низкой точности означает, что, как правило, обнаруживается больше символов, но уверенность в том, что это правильные символы, ниже, чем при высокой точности. Таким образом, правильная настройка — это баланс между поиском всех нужных символов и отсутствием слишком большого количества символов, которые могут исказить результаты. Правильная настройка будет зависеть от шрифта, цветов, фона и размера текста.
Точность может быть установлена по шкале от 0 до 100. 0 вернет все, что распознано механизмом OCR, а 100 вернет наилучший возможный распознанный результат.
Уровни точности по умолчанию:
- Высокий: Это самый высокий коэффициент достоверности или точность, при которой пользователь уверен, что символ достаточно большой и видимый (не размытый или сжатый), чтобы его можно было распознать механизмом OCR.
 Предустановленное значение равно 70.
Предустановленное значение равно 70. - Средний: Это средний коэффициент достоверности, который пользователь может выбрать, когда он думает, что символ может или не может быть распознан механизмом OCR, поэтому он устанавливает это. Это говорит движку искать возможные символы в определенной области. Предустановленное значение равно 50.
- Низкий: Это фактор низкой достоверности, который пользователь может выбрать, когда он менее уверен, что символ может быть распознан механизмом OCR, поэтому он устанавливает его. Это указывает движку искать относительно возможные символы в словаре и за его пределами в определенной области, где точность идентификации низкая. Предустановленное значение равно 30.
- Очень низкий: Это фактор самой низкой достоверности, который пользователь может выбрать, когда он меньше всего уверен, что символ может быть распознан механизмом OCR, поэтому он устанавливает его. Это говорит движку искать относительно все возможные символы в словаре и за его пределами в определенной области, где точность идентификации наименьшая.

- Пользовательский: Может использоваться для установки пользовательского значения точности/коэффициента достоверности. Он находится в диапазоне от 0 до 100.
Узнайте больше о Leapwork и автоматизации тестирования без кода на нашем вебинаре.
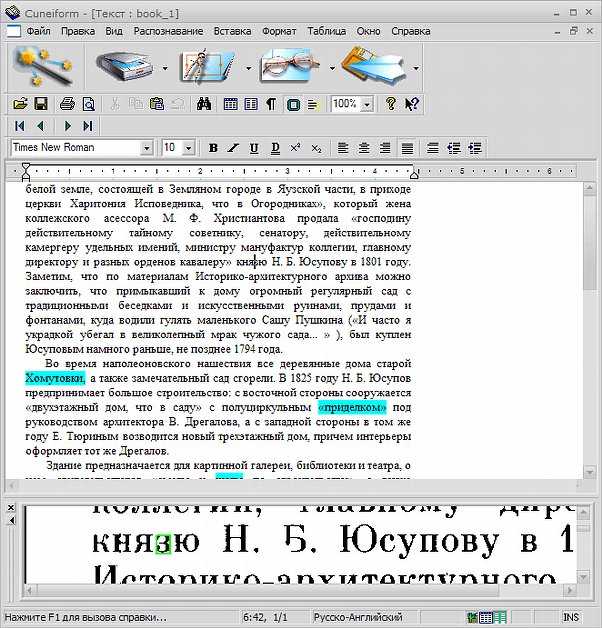
8 лучших программ для распознавания текста в 2023 году: бесплатные и дешевые
Используя лучшее программное обеспечение для распознавания текста, вы можете быстро сканировать статьи, формы и другие тексты, чтобы сохранять их в формате PDF. OCR расшифровывается как оптическое распознавание символов, поэтому такие программы удобны, когда вам нужно оптимизировать рабочий процесс и сократить количество бумажной работы за счет преобразования счетов, отчетов и других офисных документов в цифровые файлы, которые легче хранить и делиться с коллегами.
- Adobe Acrobat — большой выбор вариантов преобразования
- ABBYY FineReader – поддерживает широкий выбор форматов
- OmniPage Ultimate — передовые технологии распознавания текста
- PDFelement — интегрированный PDF-редактор профессионального уровня
- Readiris — лучший облачный выбор для резервного копирования
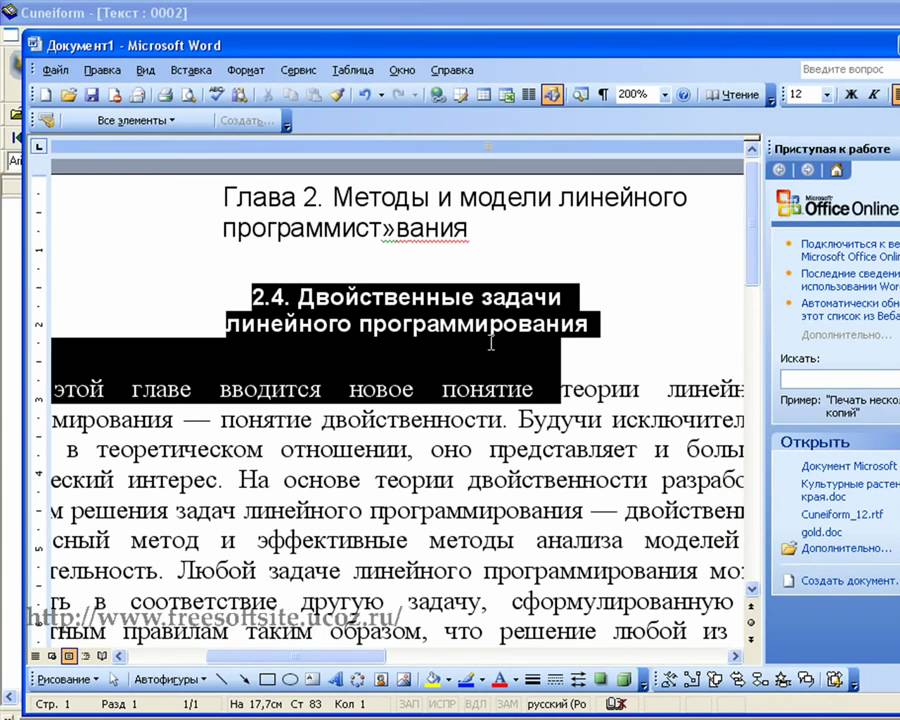
- Tesseract – лучшая бесплатная программа для оптического распознавания символов
- SimpleOCR — пакетный процесс
- SimpleOCR — предназначен для коммерческого использования
За последние годы программы OCR стали более совершенными, теперь они могут решать любую сложную задачу с большей точностью.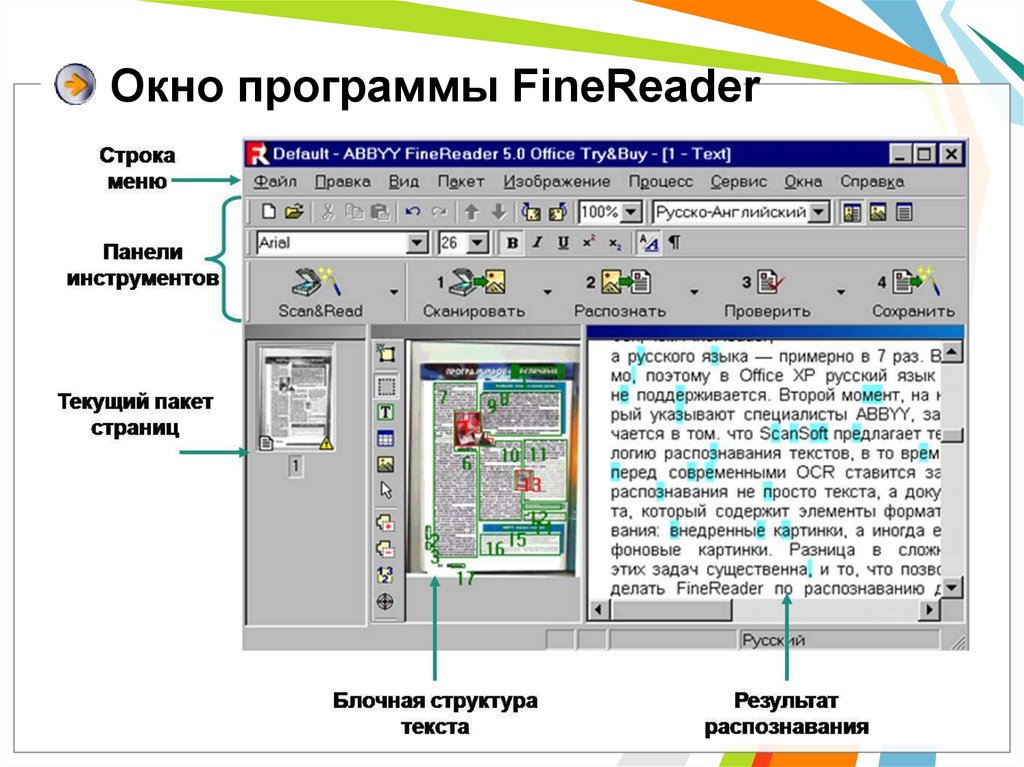 Даже если ваши документы старые, рукописные или плохого качества, такое программное обеспечение отлично распознает все текстовые элементы и создаст отформатированный документ, используя алгоритмы шумоподавления. Это сэкономит ваше время, так как вам не нужно будет набирать тексты вручную. Кроме того, цифровые копии легче хранить и искать.
Даже если ваши документы старые, рукописные или плохого качества, такое программное обеспечение отлично распознает все текстовые элементы и создаст отформатированный документ, используя алгоритмы шумоподавления. Это сэкономит ваше время, так как вам не нужно будет набирать тексты вручную. Кроме того, цифровые копии легче хранить и искать.
1. Adobe Acrobat – наш выбор
Большой выбор вариантов преобразования
- Индексация текста
- Делится файлами через облако
- Создает документы без особого шума
- Оптимизирует размер файла
- Слишком дорого
Адобе Акробат
СКАЧАТЬ
Вердикт: Adobe Acrobat DC — отличная программа для создания PDF-файлов. С ним вы сможете работать с PDF-документами с любого устройства и быстро отправлять их коллегам на подпись. Помимо создания и преобразования PDF-файлов, программа поставляется со встроенным редактором, который позволяет вам проверять отсканированные документы, сравнивать различные версии, оставлять комментарии, предлагать изменения и исправлять ошибки.
С ним вы сможете работать с PDF-документами с любого устройства и быстро отправлять их коллегам на подпись. Помимо создания и преобразования PDF-файлов, программа поставляется со встроенным редактором, который позволяет вам проверять отсканированные документы, сравнивать различные версии, оставлять комментарии, предлагать изменения и исправлять ошибки.
Ключевым преимуществом этого лучшего программного обеспечения для распознавания текста является то, что его можно установить на устройства с разными экранами. Кроме того, он позволяет быстро оценить качество процесса оптического распознавания, сравнить входные и выходные файлы, сохранить документы в поддерживаемых форматах. Все PDF-файлы, созданные с помощью этой программы, можно редактировать, подписывать и защищать паролем. Они также полностью доступны для поиска, что позволяет без проблем найти любую информацию.
2. ABBYY FineReader
Поддерживает широкий выбор форматов
 8″> Полезные сочетания клавиш
8″> Полезные сочетания клавиш- Сохраняет файлы в нескольких форматах
- Позволяет сравнивать документы
- Оптимизированный интерфейс
- Отсутствует полнотекстовое индексирование
ABBYY FineReader
СКАЧАТЬ
Вердикт: ABBYY FineReader по праву считается лучшей читалкой PDF, способной решать задачи любой сложности. Независимо от типа документа, который вам нужно отсканировать, будь то обзор, заполненная форма или многостраничный отчет, эта программа создаст бесшовно отформатированный файл в любом формате по вашему выбору. Более того, он позволяет пользователям редактировать любой текст, чтобы PDF-файлы было легче читать. Будучи одним из самых известных программ для оптического распознавания символов, FineReader широко используется различными компаниями и организациями.
Что отличает его от своих аналогов, так это то, что он позволяет пользователям конвертировать файлы, распознавать документы на разных языках и вносить изменения. Он предназначен для бесшовной обработки изображений документов и создания PDF-файлов с высокой точностью. Помимо текстов, FineReader умеет распознавать диаграммы, таблицы и изображения. Он поставляется со встроенным редактором PDF, который можно использовать для исправления ошибок или заполнения форм.
3. OmniPage Ultimate
Передовые технологии распознавания текста
- Автоматическое распознавание символов
- Интегрируется с облачными службами
- Преобразование текста в речь
- Высокая точность
- Запутанный пользовательский интерфейс
OmniPage Ultimate
СКАЧАТЬ
Вердикт: Это комплексное программное обеспечение, состоящее из нескольких сервисов. Основным элементом является сама программа OmniPage Ultimate, разработанная для оптического распознавания символов. Его пользовательский интерфейс отличается от интерфейсов других программ, входящих в полный пакет. Недавно разработчики предложили новое решение под названием Launchpad, ускоряющее преобразование файлов. Он был создан для облегчения вашего рабочего процесса, так как большинство задач выполняются автоматически. С ним вам больше не нужно настраивать все параметры вручную, что поможет вам работать эффективнее.
Основным элементом является сама программа OmniPage Ultimate, разработанная для оптического распознавания символов. Его пользовательский интерфейс отличается от интерфейсов других программ, входящих в полный пакет. Недавно разработчики предложили новое решение под названием Launchpad, ускоряющее преобразование файлов. Он был создан для облегчения вашего рабочего процесса, так как большинство задач выполняются автоматически. С ним вам больше не нужно настраивать все параметры вручную, что поможет вам работать эффективнее.
Благодаря помощнику по обнаружению электронных данных вы можете быстро проверить все свои документы и решить, какие из них вы хотите сделать полностью доступными для поиска. Это повысит вашу продуктивность и поможет достичь большего за меньшее время. Единственным недостатком является то, что вы можете сделать PDF-файлы доступными для поиска, только если они не редактировались каким-либо образом.
4. Элемент PDF
Встроенный PDF-редактор профессионального уровня
 8″> Пользовательский интерфейс в офисном стиле
8″> Пользовательский интерфейс в офисном стиле- Уменьшает размер файлов
- Массовая обработка
- Параметры редактирования
- Часто вылетает
PDFэлемент
СКАЧАТЬ
Вердикт: PDFelement имеет хорошо продуманный пользовательский интерфейс, который проще в использовании, чем замысловатые интерфейсы в стиле Office, характерные для других программ сопоставимой функциональности. Это первоклассное программное обеспечение OCR идеально подходит для большинства рабочих задач. Владельцы малого бизнеса оценят, что это значительно дешевле, чем другие варианты профессионального уровня в этом списке.
Многие пользователи считают его лучшим конвертером PDF в Word, поскольку он поддерживает огромное количество форматов. Например, вы можете экспортировать файлы в XLS, RTF, PPT, EPUB, HTML и многих других форматах. Он позволяет конвертировать изображения, веб-страницы и текстовые документы. Для большего удобства он позволяет добавлять комментарии и настраиваемые формы, редактировать текст, защищать документы паролем и устанавливать ограничения, определяющие, какие пользователи получат полный доступ к вашему файлу.
Он позволяет конвертировать изображения, веб-страницы и текстовые документы. Для большего удобства он позволяет добавлять комментарии и настраиваемые формы, редактировать текст, защищать документы паролем и устанавливать ограничения, определяющие, какие пользователи получат полный доступ к вашему файлу.
5. Readiris
Лучшее облачное решение для резервного копирования
- Простой экспорт
- Полезная поддержка
- Быстрая производительность
- Простые в использовании инструменты PDF
- Ограниченная функциональность бесплатной версии
Readiris
СКАЧАТЬ
Вердикт: Readiris Pro — лучшее программное обеспечение для распознавания текста для тех, кто ищет оптимальное решение для своего бизнеса. Он был создан I.R.I.S. и предлагает впечатляющий выбор расширенных опций OCR, некоторые из которых нельзя найти в других программах. Еще одним преимуществом является то, что даже стандартные функции доведены до совершенства, что делает его отличным решением для компаний, которые ценят свое время. Кроме того, он поддерживает 130 языков.
Он был создан I.R.I.S. и предлагает впечатляющий выбор расширенных опций OCR, некоторые из которых нельзя найти в других программах. Еще одним преимуществом является то, что даже стандартные функции доведены до совершенства, что делает его отличным решением для компаний, которые ценят свое время. Кроме того, он поддерживает 130 языков.
После сканирования бумажного документа Readiris создаст цифровую копию с сохранением исходного форматирования. Если вы выберете план подписки «Корпоративный», вы сможете использовать функцию распознавания текста в речь и создавать резервные копии на таких сервисах, как Dropbox, Google Drive, Evernote. Программа также может похвастаться отличными инструментами индексации и позволяет оптимизировать размер файла.
6. Тессеракт
Лучшее бесплатное ПО для оптического распознавания символов
- 40 языков
 8″> Бесплатное использование
8″> Бесплатное использование- Создает текстовый слой поверх изображения
- Легко освоить
- Базовая обработка изображений
Тессеракт
СКАЧАТЬ
Вердикт: Tesseract — лучшее программное обеспечение для оптического распознавания символов, которое поставляется со встроенной библиотекой OCR. Это решение с открытым исходным кодом было разработано для расширенного распознавания символов и выводит сопоставление шаблонов на новый уровень. Используя адаптивное распознавание, он делает процесс OCR более эффективным, поскольку он был предварительно обучен для выполнения распознавания символов даже без предварительно определенных шаблонов. Проанализировав контекст, Tesseract автоматически находит шаблоны в символах, словах и предложениях.
Благодаря внедренной технологии глубокого обучения это хорошее программное обеспечение для оптического распознавания символов легко преобразует изображения, сохраненные в форматах BMP, PNG, JPEG, TIFF, PDF, в текст.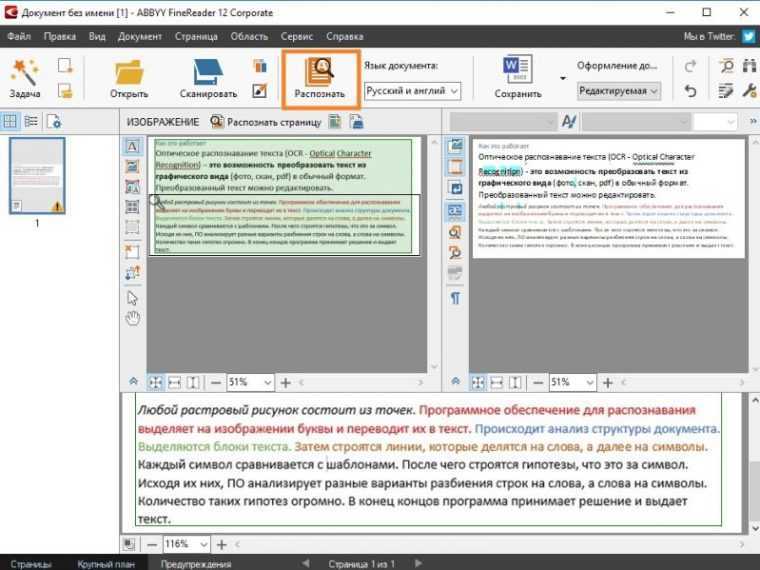 Он работает под самыми популярными ОС, такими как Windows, Linux и macOS. В отличие от дорогих продуктов ABBYY и Adobe, эта программа абсолютно бесплатна, что позволяет вам распознавать бесчисленное количество изображений и делать их доступными для поиска бесплатно.
Он работает под самыми популярными ОС, такими как Windows, Linux и macOS. В отличие от дорогих продуктов ABBYY и Adobe, эта программа абсолютно бесплатна, что позволяет вам распознавать бесчисленное количество изображений и делать их доступными для поиска бесплатно.
7. EasyScreenOCR
Пакетный процесс
- Удобно и быстро
- Бесплатное использование
- 100% конфиденциальность
- Работает на нескольких платформах
- Требуется стабильное подключение к Интернету
EasyScreenOCR
ИСПОЛЬЗОВАНИЕ
Вердикт: EasyScreenOCR — удобный и гибкий инструмент. Вам нужно всего лишь перетащить изображения и подождать несколько секунд. Ваши файлы будут загружены и обработаны с помощью передовой технологии OCR. Все загруженные файлы удаляются в течение 30 минут.
Ваши файлы будут загружены и обработаны с помощью передовой технологии OCR. Все загруженные файлы удаляются в течение 30 минут.
Программа принимает 5 изображений/загрузку для обработки OCR. Простой текст с каждого изображения будет сохранен в виде файла .txt. Кроме того, все файлы заархивированы, прежде чем вы сможете их скачать.
8. Простое распознавание символов
Предназначен для коммерческого использования
- Импорт файлов DOX
- Проверка орфографии
- Сохраняет файлы в оригинальном формате
- Бесплатный SDK OCR
- Плохая настройка
Простое распознавание символов
СКАЧАТЬ
Вердикт: Если вы хотите бесплатно использовать лучшее программное обеспечение для распознавания текста, эта программа станет идеальным решением для всех задач.