
Распознавание рукописного текста. Какие программы в этом помогут?
Предисловие
Как известно, задача распознавания непрерывного рукописного текста в режиме off-line пока считается нерешённой. Мне удалось решить эту задачу теоретически и практически. Практическая часть сейчас имеет вид демонстрационной версии программы. Решение общее, оно не ограничивается какой-либо областью применения, языком или размером словаря.
О программе
Программа полностью обучаемая. Процесс обучения выглядит просто: вы пишете символы в режиме on-line, программа их обобщает и выделяет алгоритм написания. Это первый этап обучения. Второй этап происходит во время работы. Если встречается символ, общий алгоритм написания которого совпадает с одним из имеющихся в наличии, а значения некоторых свойств выходят за рамки вычисленных на первом этапе диапазонов, то диапазоны расширяются. Конечно, только после подтверждения пользователем общего результата распознавания. К слову сказать, на первом этапе достаточно от трёх до семи предъявлений символа, и алгоритм готов.
Теория
Немного о теории. Существует несколько подходов к решению указанной задачи. Их обычно делят на два вида: структурные и эталонные. Первый основан на выделении и анализе различных структурных элементов символа и их признаков, свойств. Второй предполагает сравнение распознаваемого символа с набором заданных эталонов. Эти методы не позволяют решить задачу в общем виде. Задача рукописного ввода в режиме on-line полностью и успешно решена. Это решение основано, в любом случае, на создании алгоритмов написания символов, учитывающих траекторию движения пера. То есть, последовательность смены его координат. Были предложения свести задачу распознавания в off-line режиме к распознаванию в режиме on-line. Для этого достаточно правильно считать линии с графической копии текста. Но сделать это принципиально невозможно. Можно считать отрезки линий между пересечениями, но чтобы их правильно соединить, уже нужна интерпретация. Остаётся только одно решение — восстанавливать символы в процессе интерпретации отрезков, полученных на этапе считывания с цифровой графической копии текста.
Практика

Коммерция
Заключение
И ещё один важный момент – показатели эффективности, а именно, время и процент распознавания. Конечно, в демоверсии основное внимание уделялось второму критерию. Сейчас достигнут уровень не ниже 70%. В готовом варианте этот показатель можно сформулировать так: если человек сможет прочитать текст, то и программа тоже. О времени распознавания пока можно сказать только то, что его удастся довести до приемлемых величин. Если всё пойдёт хорошо, будут ещё статьи о некоторых технических аспектах распознавания текста и об ИИ. Благодарю за внимание. ____________
 В целом топик был встречен положительно, что не может не радовать. Негодующим личностям хотелось бы сказать: уважаемые, мы не ярмарочные фокусники. Мы отдаём отчёт в своих словах. Если мы написали, что в готовом продукте точность распознавания будет стремиться к 100%, значит мы в этом уверены. Эту статью можете считать анонсом, у неё не было цели подробно раскрыть все технические подробности. Однако учитывая проявленный интерес, через некоторое время будет ещё одна статья, более подробно описывающая процесс распознавания. Также будет доступная для скачивания демонстрационная версия программы.
В целом топик был встречен положительно, что не может не радовать. Негодующим личностям хотелось бы сказать: уважаемые, мы не ярмарочные фокусники. Мы отдаём отчёт в своих словах. Если мы написали, что в готовом продукте точность распознавания будет стремиться к 100%, значит мы в этом уверены. Эту статью можете считать анонсом, у неё не было цели подробно раскрыть все технические подробности. Однако учитывая проявленный интерес, через некоторое время будет ещё одна статья, более подробно описывающая процесс распознавания. Также будет доступная для скачивания демонстрационная версия программы.Если вам необходимо перевести ранее напечатанный текст в электронную форму, то сегодня вам не потребуется набирать его на клавиатуре. Современные технологии существенно упрощают этот процесс. Достаточно отсканировать его или сфотографировать, и обработать специальной программой — распознавателем текста.
Давно прошло то время, когда для получения электронной копии печатного текста, приходилось набирать его на клавиатуре, символ за символом, буква за буквой.
Системы распознавания текста или OCR-системы (Optical Character Recognition) предназначены для автоматического ввода документов в компьютер. Это может быть страница книги, журнала, словаря, какой-то документ — все, что угодно, что было уже напечатано, и должно быть преобразовано обратно в электронную форму.
OCR-системы распознают текст и различные его элементы (картинки, таблицы) с электронного изображения. Изображение получается обычно путем сканирования документа и реже — его фотографированием. Поступившее изображение обрабатывается алгоритмом OCR-программы, выделяются области текста, изображений, таблиц, отделяется мусор от нужных данных.
На следующем этапе каждый символ сравнивается со специальным словарем символов, и если находится соответствие, то этот символ считается распознанным. В итоге вы получаете набор распознанных символов, то есть искомый текст.
В итоге вы получаете набор распознанных символов, то есть искомый текст.
Современные OCR-системы представляют собой достаточно сложные программные решения. Ведь текст может быть замусорен, искажен, загрязнен, и программа должна это учитывать и уметь правильно обрабатывать такие ситуации. Кроме того, современные OCR-системы позволяют также получить копию печатного документа в электронном виде с сохранением форматирования, стилей, размеров текста и видов шрифтов и т.д.
Содержание
- ABBYY FineReader 9.0 Home Edition
- ABBYY FineReader 9.0 Professional Edition
- ABBYY FineReader 9.0 Corporate Edition
- ABBYY Business Card Reader
- Readiris 12 Pro
- Readiris 12 Corporate
- SimpleOCR
- Ввод китайских иероглифов при помощи мыши или планшета
- rite Pen
- ArioForm
- MyScript Studio
- Распознавание рукописного текста MyScript Stylus
- PenOffice
- CalliGrapher
- 1. Office Lens
- 2.
 Adobe Scan
Adobe Scan - 3. Free OCR to Word
- 4. FineReader Online
- 5. Online OCR
- 6. Free OCR
- 7. Microsoft OneNote
- Джентльменский набор XXI века — нож, мультитул, фонарь и термос
- Моддер превратил Skyrim в динамичный ролевой экшен
- Вот вы и дошутились. Как интернет отреагировал на анонс новой Half-Life
- Павел Дуров: «Вы должны удалить WhatsApp со смартфонов»
- Раскрыт заработок российских блогеров от рекламы на YouTube
ABBYY FineReader 9.0 Home Edition
| Разработчик: | ABBYY |
| Тип лицензии: | Trial, только для домашнего использования |
| Требования: | Windows 2000/XP/Vista, 250-512 Mb свободного места, сканер |
Система распознавания текста ABBYY FineReader — это многофункциональная программа для перевода бумажных документов, pdf-файлов, фотографий в редактируемые форматы. Эта версия известной программы для распознавания текста специально предназначена для домашнего пользователя, простая и удобная в использовании. В ней отсутствуют лишние функции и сложные настройки, а интерфейс рассчитан даже на неподготовленного пользователя. Если вам нужно время от времени быстро получать электронные копии страниц каких-то учебников, книг, документов — эта версия OCR-программы для вас. Подробнее о FineReader 9.0 Home Edition ?
В ней отсутствуют лишние функции и сложные настройки, а интерфейс рассчитан даже на неподготовленного пользователя. Если вам нужно время от времени быстро получать электронные копии страниц каких-то учебников, книг, документов — эта версия OCR-программы для вас. Подробнее о FineReader 9.0 Home Edition ?
Скачать ABBYY FineReader 9.0 Home Edition
ABBYY FineReader 9.0 Professional Edition
| Разработчик: | ABBYY |
| Тип лицензии: | Trial |
| Требования: | Windows 2000/XP/Vista, 250-512 Mb свободного места, сканер |
Эта версия программы ABBYY FineReader для распознавания текста подойдет для использования в офисе или в учебном заведении, а также для продвинутых пользователей, кто хотел бы иметь возможность задавать множество настроек и активно участвовать в процессе распознавания текста. Возможности программы позволяют вам отсканировать и распознать документы, проверить результат распознавания на ошибки, исправить их автоматически или вручную, и сохранить документ в одном из множества форматов (txt, doc, pdf и др. ). Программа умеет работать с сетью: пересылать документы по электронной почте, размещать их в хранилища информации, использовать сетевое оборудование (сканеры и МФУ). Подробнее о FineReader 9.0 Professional Edition ?
). Программа умеет работать с сетью: пересылать документы по электронной почте, размещать их в хранилища информации, использовать сетевое оборудование (сканеры и МФУ). Подробнее о FineReader 9.0 Professional Edition ?
Скачать ABBYY FineReader 9.0 Professional Edition
ABBYY FineReader 9.0 Corporate Edition
| Разработчик: | ABBYY |
| Тип лицензии: | для корпоративного использования |
| Требования: | Windows 2000/XP/Vista, 250-512 Mb свободного места, сканер |
Специальная версия программы ABBYY FineReader для распознавания текста, предназначенная для использования в крупных фирмах, для организации электронных архивов документов. Система позволяет организовать полноценную работу по распознаванию текста внутри большой компании, размещение результатов в электронных хранилищах, использование сетевого оборудования. Подробнее о FineReader 9.0 Corporate Edition ?
ABBYY Business Card Reader
| Разработчик: | ABBYY |
| Тип лицензии: | Trial 1 день |
| Требования: | Nokia (модели N73, N78, N79, N82, N85, N86 8MP, N93, N93i, N95, N95-3 NAM, N95 8GB, N96, N96-3, E90 Communicator, 6210 Navigator, E71, E66, E63, E75, 6220 classic, 6720 classic, 5730 XpressMusic, 6710 Navigator, 5800 XpressMusic) |
Эта программа предназначена для мобильных устройств (смартфонов), позволяющая быстро вводить в записную книжку контактную информацию с визитных карточек. ABBYY Business Card Reader будет удобна для деловых людей, бизнесменов, менеджеров, всех, кто часто сталкивается с визитными карточками. Программа поддерживает 16 языков. Подробнее о ABBYY Business Card Reader ?
ABBYY Business Card Reader будет удобна для деловых людей, бизнесменов, менеджеров, всех, кто часто сталкивается с визитными карточками. Программа поддерживает 16 языков. Подробнее о ABBYY Business Card Reader ?
Скачать ABBYY Business Card Reader
Readiris 12 Pro
| Разработчик: | I.R.I.S. s.a. |
| Тип лицензии: | Trial |
| Требования: | Windows 200/XP/Vista или Mac, 256 Mb RAM, 150-250 Mb свободного места, сканер |
Readiris Pro — многофункциональная OCR-система, которая подойдет как домашним пользователям, так и профессионалам. При помощи этой программы вы можете быстро преобразовать любой документ, PDF-файл, изображение в редактируемый текст, и затем сохранить его в один из множества популярных форматов. Программа имеет простой и приятный интерфейс со множеством дополнительных возможностей и полезных инструментов: сжатие файлов, работа с изображениями, функции экспорта, и др. Подробнее о Readiris 12 Pro ?
Подробнее о Readiris 12 Pro ?
Скачать Readiris 12 Pro
Readiris 12 Corporate
| Разработчик: | I.R.I.S. s.a. |
| Тип лицензии: | Trial |
| Требования: | Windows 200/XP/Vista или Mac, 256 Mb RAM, 150-250 Mb свободного места, сканер |
Readiris Corporate — OCR-система, которая специально предназначена для использования в крупных компаниях, офисах, а также для создания электронных архивов. Программа обладает теми же возможностями, что и версия Readiris Pro, плюс еще дополнительные инструменты и настройки для работы с сетью и сетевым оборудованием. Поддерка азиатских языков, иврита, фарси устанавливается отдельно. Подробнее о Readiris 12 Corporate ?
Скачать Readiris 12 Corporate
SimpleOCR
| Разработчик: | SimpleSoftware |
| Тип лицензии: | Freeware |
| Требования: | Windows 95/98/NT4/2000/XP/Vista, 50 Mb свободного места, сканер, TWAIN driver |
SimpleOCR — OCR-система, которая распространяется совершенно бесплатно. Программа обладает множеством возможностей, практически не уступая коммерческим версиям. В данный момент SimpleOCR умеет распознавать тексты на английском и французском языках. Подробнее о SimpleOCR ?
Программа обладает множеством возможностей, практически не уступая коммерческим версиям. В данный момент SimpleOCR умеет распознавать тексты на английском и французском языках. Подробнее о SimpleOCR ?
Скачать SimpleOCR
Ввод китайских иероглифов при помощи мыши или планшета
| Разработчик: | NJStar Software Corp. |
| Тип лицензии: | trial на 30 дней |
NJStar Chinese Pen — полезная программа для тех, кто работает с китайским языком. NJStar Chinese Pen позволяет вводить китайские иероглифы простым рисования их при помощи мыши или планшета. Это намного быстрее и удобнее, чем набирать иероглифы на клавиатуре по определенным правилам.
Программа поддерживает как китайский традиционный, так и китайский упрощенный. Набранный текст можно озвучивать (произносить) при помощи встроенного speech-движка. Все параметры программы полностью настраиваются.
NJStar Chinese Pen поддерживает все версии операционной системы Windows. Для работы программы требуется примерно 50 Мб свободного места на жестком диске.
Для работы программы требуется примерно 50 Мб свободного места на жестком диске.
Скачать NJStar Chinese Pen
rite Pen
| Разработчик: | Evernote Corp. |
| Тип лицензии: | trial на 30 дней |
rite Pen — программа для ускорения ввода текста в текстовые редакторы, формы, для быстрого заполнения форм и сохранения заметок. Вы можете вводить текст, просто рисуя рукописные символы при помощи мыши или планшета в любом месте экрана. Программа автоматически их распознает и введет в указанную программу или форму, или просто сохранит в своей базе данных. Вы также можете добавлять заметки прямо на экран, выделять области экрана, и сохранять их для дальнейшего использования. Еще одна полезная возможность — создание меток. Запрограммируйте определенное слово или рисунок (метку) за вводом определенного текста, и как только вы нарисуете эту метку на экране, тут же будет вставлен нужный текст. Подробнее о rite Pen ?
Подробнее о rite Pen ?
Скачать rite Pen
ArioForm
| Разработчик: | Ariolis |
| Тип лицензии: | trial на 30 дней |
ArioForm — решение для обработки большого объема данных, оформленных по определенному шаблону (таких как результаты тестов и опросов, бланки, отчеты, различные формы). Возможности программы позволяют вам создавать и распознавать формы практически любой сложности, содержащие печатный текст, поля ввода рукописного текста, поля выбора одного или нескольких параметров, графические элементы. Программа также имеет набор уже созданных шаблонов. Подробнее о ArioForm ?
Скачать ArioForm
MyScript Studio
| Разработчик: | Vision Objects |
| Тип лицензии: | trial на 30 дней |
MyScript Studio — решение для оцифровки документов и заметок, созданных «от руки». Программа будет полезна всем деловым людям, менеджерам, журналистам, и всем остальным, кто часто делает рукописные заметки. При помощи этой программы вы сможете быстро перевести в электронную форму все ваши заметки, записи и рукописные документы, распознать текст и организовать электронный архив. Подробнее о MyScript Studio ?
Программа будет полезна всем деловым людям, менеджерам, журналистам, и всем остальным, кто часто делает рукописные заметки. При помощи этой программы вы сможете быстро перевести в электронную форму все ваши заметки, записи и рукописные документы, распознать текст и организовать электронный архив. Подробнее о MyScript Studio ?
Скачать MyScript Studio
Распознавание рукописного текста MyScript Stylus
| Разработчик: | Vision Objects |
| Тип лицензии: | trial на 30 дней |
| Требования: | Windows, Mac или Linux, 400 Мб свободного места |
MyScript Stylus — программа для распознавания рукописного текста. Текст можно вводить при помощи мыши или планшета. Программа распознает текст по технологии, применяющейся в кпк, и может использоваться там, где нет возможности использовать стандартную клавиатуру или ее использование затруднено (например, если компьютер используется как терминал для ввода/вывода информации, как платежный терминал).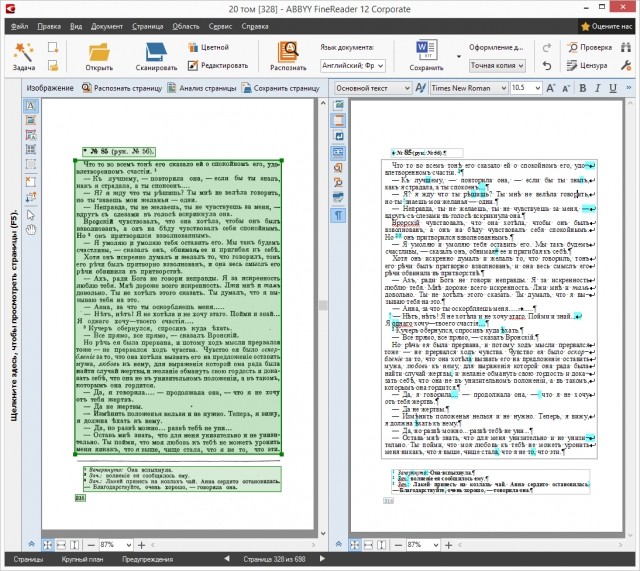 Вы можете закрепить MyScript Stylus за определенной программой, и весь распознаваемый текст будет передаваться ей, как-будто текст вводится стандартным способом. MyScript Stylus поддерживает 26 языков. Подробнее о MyScript Stylus ?
Вы можете закрепить MyScript Stylus за определенной программой, и весь распознаваемый текст будет передаваться ей, как-будто текст вводится стандартным способом. MyScript Stylus поддерживает 26 языков. Подробнее о MyScript Stylus ?
Скачать MyScript Stylus
PenOffice
| Разработчик: | PhatWare Corporation |
| Тип лицензии: | trial на 30 дней |
| Требования: | Windows XP/Vista, 50 Мб свободного места |
PenOffice — программа для распознавания рукописного текста. PenOffice был специально создан для интеграции с программами пакетов Microsoft Office и OpenOffice, но позволяет вводить распознанный текст также и в другие программы. Программа позволяет распознавать 9 языков: английский, испанский, итальянский, голландский, французский, немецкий, норвежский, португальский и шведский. Подробнее о PenOffice ?
Скачать PenOffice
CalliGrapher
| Разработчик: | PhatWare Corporation |
| Тип лицензии: | trial на 30 дней |
| Требования: | Windows Mobile 4/5/6/6. 1, 3.8 Мб свободного места, ActiveSync 4.0 1, 3.8 Мб свободного места, ActiveSync 4.0 |
CalliGrapher — программа ввода рукописного текста для кпк и смартфонов под управлением Windows Mobile. Программа распознает рукописный текст и сразу же вводит его в текстовый редактор в выбранном стиле. Вы можете писать текст в любом месте экрана. CalliGrapher имеет встроенную виртуальную клавиатуру, систему проверки правописания и многоязыковую поддержку. Подробнее о CalliGrapher ?
Скачать CalliGrapher
1. Office Lens
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в мощный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы можно редактировать в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens.
2.
 Adobe Scan
Adobe Scan- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Результаты удобно экспортировать в кросс-платформенный сервис Adobe Acrobat, который позволяет редактировать PDF-файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.
3.
 Free OCR to Word
Free OCR to Word- Распознаёт: JPG, TIF, BMP, GIF, PNG, EMF, WMF, JPE, ICO, JFIF, PCX, PSD, PCD, TGA и другие форматы.
- Сохраняет: DOC, DOCX, TXT.
Настольная программа Free OCR to Word распознаёт выбранные пользователем изображения, извлекая из них чистый текст без форматирования. Его можно копировать в буфер обмена, сохранять в формате TXT или экспортировать в Word.
Воспользоваться Free OCR to Word →
4. FineReader Online
- Распознаёт: JPG, TIF, BMP, PNG, PCX, DCX, PDF (не защищённые паролем).
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A.
Онлайновый сервис, который конвертирует не только тексты, но и таблицы. Увы, бесплатные возможности FineReader Online ограничены. После регистрации вам позволят распознать без оплаты всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Поэтому сервис больше подойдёт тем, кто не нуждается в услугах распознавания слишком часто.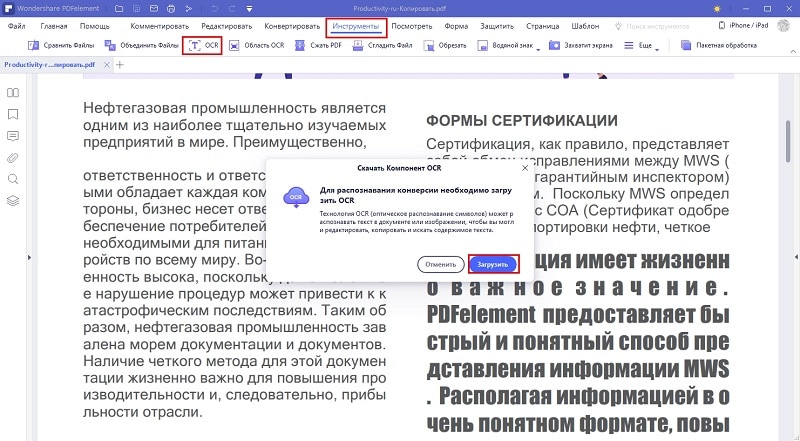
Воспользоваться FineReader Online →
5. Online OCR
- Распознаёт: JPG, BMP, TIFF, GIF, PDF.
- Сохраняет: DOCX, XLSX, TXT.
Ещё один сайт, с помощью которого можно распознать тексты и таблицы. В отличие от FineReader, в Online OCR вполне можно обойтись без регистрации. Хотя она может понадобиться, если вы планируете загружать несколько файлов для распознавания за один раз. В то же время FineReader поддерживает больше форматов.
Воспользоваться Online OCR →
6. Free OCR
- Распознаёт: JPG, GIF, TIFF BMP, PNG, PDF.
- Сохраняет: TXT.
Free OCR — простейший онлайн-сервис, извлекающий текст из PDF-файлов и изображений. Результат распознавания — чистый текст без форматирования. Кроме того, сервис может уступать по точности вышеперечисленным аналогам. Зато Free OCR не требует регистрации и справляется с мультиязычными документами.
Воспользоваться Free OCR →
7. Microsoft OneNote
- Распознаёт: популярные форматы изображений.
- Сохраняет: файлы OneNote.
В настольной версии популярного заметочника OneNote тоже есть функция распознавания текста, которая работает с загруженными в сервис изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Рисунок» → «Текст», то всё текстовое содержимое будет скопировано в буфер обмена.
Если вы не нашли подходящей программы, взгляните на наши предыдущие подборки приложений для Android и iOS.
9 августа французская компания MyScript выпустила приложение Nebo — записную книжку с возможностью распознавать рукописный текст и выполнять простые задачи, например, для конспектирования лекций или записи формул. Приложение работает лишь на узкой прослойке устройств с особыми стилусами — планшетах Microsoft и iPad Pro. Главный редактор TJ потестировал его и пришёл к выводу, что Nebo оказалось интересным, но скорее как рабочий концепт.
В закладки
У меня очень плохой почерк. Я не умел красиво или хотя бы разборчиво писать ни в школе, когда я практиковался в этом ежедневно, ни сейчас, когда я пишу от руки хорошо если пару строк в неделю — на столе лежит ежедневник для записей «Не забыть бы» и зарисовок.
Не могу сказать, что я страдаю от своего почерка: в конце концов, по работе и в личной жизни я в 99% случаев использую клавиатуру, реальную или виртуальную. Кнопки не требуют от меня аккуратно выводить дуги у букв «з» и «ш», чтобы читатели их разобрали с первого раза.
Тем сильнее было моё удивление, когда мои каракули смог разобрать впервые встретившийся с ними алгоритм Nebo. Перечитывая спустя пару часов то, что я ввёл на экране, я и сам уже не мог понять, что там было написано — а Nebo расшифровал это в машинописный текст.
С Nebo я столкнулся случайно, увидев трансляцию в Periscope одного из западных журналистов, почему-то посчитавшего, что это продукт Microsoft. На самом деле, в MyScript даже подтрунивали над Microsoft над тем, как медленно корпорация движется на рынке распознавания текста. Из крупных изданий, насколько мне известно, Nebo заметило только PC World, да и то из-за того, что приложение выпущено для платформы Windows.
MyScript, разработчик приложения, не самая известная компания, хотя и выпустила уже не одну технологию вокруг рукописного ввода. Одна из впечатляющих — Interactive E-Ink, которая и легла в основу Nebo. Она на лету превращает вводимые с помощью активного стилуса данные в векторную графику и анализирует её, распознавая, скажем, геометрические фигуры и текст.
Nebo умеет немного — всего лишь очень хорошо распознавать ваши каракули.
В первые несколько недель после релиза Nebo можно скачать бесплатно, однако версия есть только для планшетов Microsoft и Apple с активным стилусом — то есть Surface и iPad Pro. Пальцем набирать текст нельзя: разработчики объясняют это тем, что у активного стилуса (вроде Apple Pencil) меньше лаг, и поэтому ввод и обработка текста удаются лучше. Кроме того, активный стилус защищает от непредумышленного рисования рукой, лежащей на экране — по-другому вводить большой объём рукописного текста не получается.
Тот самый западный журналист, о котором я писал выше, отзывался о Nebo как об идеальном инструменте для школьников или студентов. На лекциях можно делать заметки и одновременно записывать текст, лишь при острой необходимости переключаясь на клавиатуру, а потом использовать распознавание прописи для поиска по тому, что написал за время занятий.
Функций в Nebo немного: это скорее очень примитивная демонстрация возможностей технологии, чем реальный и необходимый для ежедневного использования продукт. В приложении можно писать от руки, редактируя текст интуитивными жестами: провёл черту по слову сверху вниз — разделил его пополам, снизу вверх — соединил два слова в одно.
В приложении можно писать от руки, редактируя текст интуитивными жестами: провёл черту по слову сверху вниз — разделил его пополам, снизу вверх — соединил два слова в одно.
Обвёл слово — при конвертации в печатный текст оно выделится маркером. Заштриховал текст — он удалился. Можно быстро помогать программе исправлять распознанный текст, выбирая корректный вариант из списка (чаще всего он есть).
Количество языков, которые поддерживаются Nebo, огромно: помимо стандартных английского, немецкого, французского и прочих популярных есть русский, украинский, татарский, польский и несколько вариантов китайского.
Что удивительно, даже в случае моих далеко не самых разборчивых писмен Nebo удавалось распознавать их корректно. Более того, Nebo правильно понимает англоязычные слова в русском тексте и наоборот.
Помимо текста, в Nebo можно рисовать блок-схемы и править их на лету, перемещая блоки и редактируя текст внутри. Есть и функция распознавания формул, которая в том числе позволяет решать несложные арифметические примеры.
Разница между приложениями для iOS и Windows только в том, что в версии для Windows присутствует экспорт в Microsoft Word. В iOS экспортировать можно либо в обычный текст (тогда не сохранится графика), либо в HTML: в этом случае графика представлена в векторном виде, однако распознанные математические формулы скопировать в документ не получится — придётся делать скриншоты или сохранять весь файл в PDF.
В целом Nebo сложно удивить человека, плотно работающего с OCR: технологии распознавания текста давно встроены в массовые продукты вроде Evernote, а для промышленного использования есть специальные программные пакеты. Однако здесь текст распознаётся на лету, и не печатный, а рукописный, и в отличие от многих продуктов — с поддержкой русского языка.
Естественно, как продукт Nebo популярным стать не может. Уж слишком нишевая прослойка эти планшеты с активными стилусами, iPad Pro запредельно дорогой, а Microsoft Surface вообще официально в России не продаётся. Но приятно осознавать, что распознавание твоих закорючек — задача, посильная роботу, и когда-нибудь технология окажется встроена в более популярные продукты.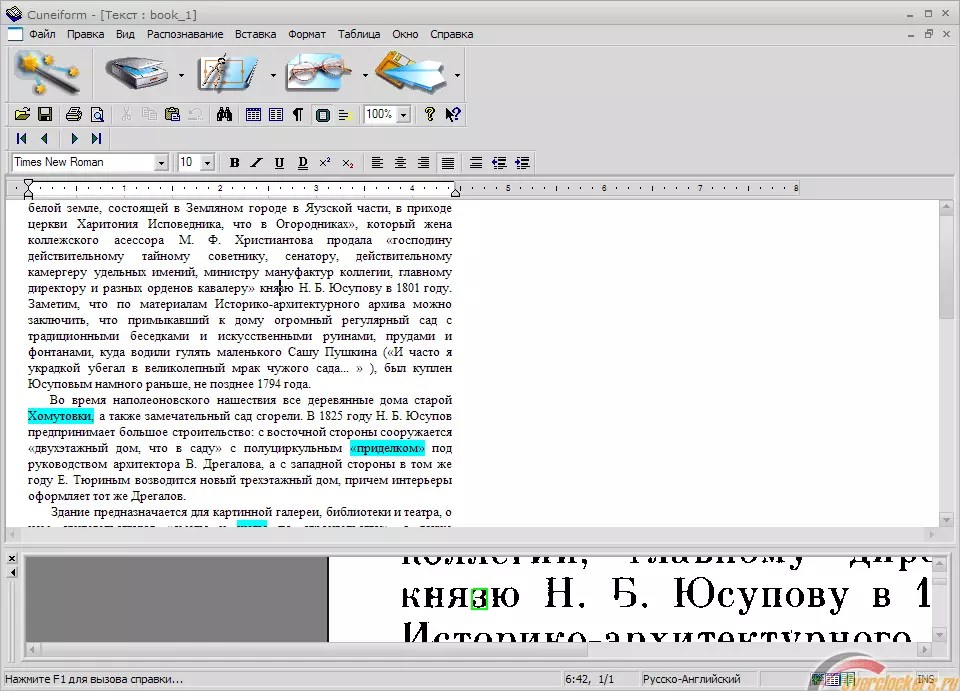
Джентльменский набор XXI века — нож, мультитул, фонарь и термос
Всех ситуаций не предусмотришь, но к некоторым можно подготовиться заранее. Мелкий домашний ремонт, поход в компании друзей, выезд на дачу или рыбалку станут проще, если под рукой имеются необходимые инструменты и аксессуары. Выясняем, что пригодится человеку, ведущему активный образ жизни, но не желающему захламлять жильё и таскать с собой лишнее.
В далее
31 25.11.19Моддер превратил Skyrim в динамичный ролевой экшен
ОдноВ из самых серьёзных преимуществ и одновременно главный недостаток TES V: Skyrim — её невероятно казуальная боевая система. Это хорошо, когда речь об охвате максимальной аудитории, но плохо, когда за дело берутся опытные геймеры: им будет скучно. Спустя 8 лет после выхода TES V появился мод, превращающий Skyrim в куда более хардкорную игру.
В далее
79 19.11.19Вот вы и дошутились. Как интернет отреагировал на анонс новой Half-Life
Что ж, это случилось: Valve наконец-то анонсировала новую игру в серии Half-Life. Правда, ей оказалась не долгожданная третья часть, а некая «флагманская игра для VR». Возможно, Valve готовит что-то стоящее, но как бы то ни было, мало у кого есть доступ к этой чудной, сырой и дорогой технологии. Поэтому и реакция интернета была, как обычно, едкой и язвительной.
Правда, ей оказалась не долгожданная третья часть, а некая «флагманская игра для VR». Возможно, Valve готовит что-то стоящее, но как бы то ни было, мало у кого есть доступ к этой чудной, сырой и дорогой технологии. Поэтому и реакция интернета была, как обычно, едкой и язвительной.
В далее
321 21.11.19Павел Дуров: «Вы должны удалить WhatsApp со смартфонов»
Вскоре после того, как в WhatsApp была обнаружена крупная уязвимость, свою характеристику популярному мессенджеру дал создатель Telegram Павел Дуров. Он раскритиковал детище Facebook за несоответствие требованиям безопасности и предложил пользователям свой способ решения проблемы с приватностью гаджетов.
В далее
148 24.11.19Раскрыт заработок российских блогеров от рекламы на YouTube
В далее
Эксперимент в распознавании рукописных текстов на кириллице / Хабр
Введение
Распознавание рукописного текста (англ. Handwritten Text Recognition, HTR) – это автоматический способ расшифровки записей с помощью компьютера. Оцифрованный вид рукописных записей позволило бы автоматизировать бизнес процессы множества компаний, упростив работу человека. В данной работе рассматривается модель распознавания рукописного текста на кириллице на основе искусственной нейронной сети. В исследовании использовалась система SimpleHTR разработана Гаральдом, а также LineHTR, расширенной версией системы Simple HTR. Подробнее о SimpleHTR можно почитать здесь.
Handwritten Text Recognition, HTR) – это автоматический способ расшифровки записей с помощью компьютера. Оцифрованный вид рукописных записей позволило бы автоматизировать бизнес процессы множества компаний, упростив работу человека. В данной работе рассматривается модель распознавания рукописного текста на кириллице на основе искусственной нейронной сети. В исследовании использовалась система SimpleHTR разработана Гаральдом, а также LineHTR, расширенной версией системы Simple HTR. Подробнее о SimpleHTR можно почитать здесь.
Датасет
В этом разделе опишу два типа наборов данных: Первый набор данных содержит рукописные цитаты на кириллице. Он содержит 21 000 изображений из различных образцов почерка (названия стран и городов). Мы увеличили этот набор данных для обучения, собрав 207 438 изображений из доступных форм или образцов.
Второй HKR для рукописной казахско-русской базы данных состоял из отдельных слов (или коротких фраз), написанных на русском и казахском языках (около 95% русского и 5% казахского слова/предложения, соответственно). Обратите внимание, что оба языка являются кириллическими написаны и разделяют одни и те же 33 символа. Кроме этих символов, в казахском алфавите есть еще 9 специфических символов. Некоторые примеры набора данных HKR показаны ниже:
Обратите внимание, что оба языка являются кириллическими написаны и разделяют одни и те же 33 символа. Кроме этих символов, в казахском алфавите есть еще 9 специфических символов. Некоторые примеры набора данных HKR показаны ниже:
Этот окончательный набор данных был затем разделен на обучающие (70%), валидация (15%) и тестовые (15%) наборы данных. Сам тестовый набор данных был разделен на два субданных (по 7,5% каждый): первый набор данных был назван TEST1 и состоял из слов, которые не были включены в обучающий и проверочный наборы данных; другой субдатасет был назван TEST2 и состоял из слов, которые были включены в обучение набор данных, но полностью различные стили почерка. Основная цель разбиения тестового набора данных на наборы данных TEST1 и TEST2 нужно было проверить разница в точности между распознаванием невидимых слов и слов, видимых на стадии обучения, но с невидимыми стилями почерка.
SimpleHTR модель
Предлагаемая система использует ANN, при этом для извлечения объектов используются многочисленные слои CNN с входной фотографии. Затем выход этих слоев подается в RNN. RNN распространяет информацию через последовательность. Вывод RNN содержит вероятности для каждого символа в последовательности. Для прогнозирования конечного текста реализуются алгоритмы декодирования в выход RNN. Функции CTC отвечают за декодирование вероятностей в окончательный текст. Для повышения точности распознавания декодирование может также использовать языковую модель. CTC используется для получения знаний; выход RNN представляет собой матрицу, содержащую вероятности символов для каждого временного шага. Алгоритм декодирования CTC преобразует эти символические вероятности в окончательный текст. Затем, чтобы повысить точность, используется алгоритм, который продолжает поиск слов в словаре. Однако время, необходимое для поиска фраз, зависит от размеров словаря, и он не может декодировать произвольные символьные строки, включая числа.
Затем выход этих слоев подается в RNN. RNN распространяет информацию через последовательность. Вывод RNN содержит вероятности для каждого символа в последовательности. Для прогнозирования конечного текста реализуются алгоритмы декодирования в выход RNN. Функции CTC отвечают за декодирование вероятностей в окончательный текст. Для повышения точности распознавания декодирование может также использовать языковую модель. CTC используется для получения знаний; выход RNN представляет собой матрицу, содержащую вероятности символов для каждого временного шага. Алгоритм декодирования CTC преобразует эти символические вероятности в окончательный текст. Затем, чтобы повысить точность, используется алгоритм, который продолжает поиск слов в словаре. Однако время, необходимое для поиска фраз, зависит от размеров словаря, и он не может декодировать произвольные символьные строки, включая числа.
Операции: CNN: входные изображения подаются на слои CNN. Эти слои отвечают за извлечение объектов. Есть 5х5 фильтры в первом и втором слоях и фильтры 3х3 в последних трех слоях. Они также содержат нелинейную функцию RELU и максимальный объединяющий слой, который суммирует изображения и делает их меньше, чем входные данные. Хотя высота изображения уменьшается в 2 раза в каждом слое, карты объектов (каналы) добавляются таким образом, чтобы получить выходную карту объектов (или последовательность) размером от 32 до 256. RNN: последовательность признаков содержит 256 признаков или симптомов на каждом временном шаге. Соответствующая информация распространяется РНН через эти серии. LSTM-это один из известных алгоритмов RNN, который переносит информацию на большие расстояния и более эффективное обучение, чем типичные РНН. Выходная последовательность RNN сопоставляется с матрицей 32х80.
Есть 5х5 фильтры в первом и втором слоях и фильтры 3х3 в последних трех слоях. Они также содержат нелинейную функцию RELU и максимальный объединяющий слой, который суммирует изображения и делает их меньше, чем входные данные. Хотя высота изображения уменьшается в 2 раза в каждом слое, карты объектов (каналы) добавляются таким образом, чтобы получить выходную карту объектов (или последовательность) размером от 32 до 256. RNN: последовательность признаков содержит 256 признаков или симптомов на каждом временном шаге. Соответствующая информация распространяется РНН через эти серии. LSTM-это один из известных алгоритмов RNN, который переносит информацию на большие расстояния и более эффективное обучение, чем типичные РНН. Выходная последовательность RNN сопоставляется с матрицей 32х80.
CTC: получает выходную матрицу RNN и прогнозируемый текст в процессе обучения нейронной сети, а также определяет величину потерь. CTC получает только матрицу после обработки и декодирует ее в окончательный текст. Длина основного текста и известного текста не должна превышать 32 символов
Длина основного текста и известного текста не должна превышать 32 символов
Данные: Входные данные: это файл серого цвета размером от 128 до 32. Изображения в наборе данных обычно не имеют точно такого размера, поэтому их исходный размер изменяется (без искажений) до тех пор, пока они не станут 128 в ширину и 32 в высоту. Затем изображение копируется в целевой образ размером от 128 до 32. Затем значения серого цвета стандартизируются, что упрощает процесс нейронной сети.
LineHTR модель
Модель LineHTR – это просто расширение предыдущей модели SimpleHTR, которая была разработана для того, чтобы позволить модели обрабатывать изображения с полной текстовой строкой (а не только одним словом), таким образом, чтобы еще больше повысить точность модели. Архитектура модели LineHTR очень похожа на модель SimpleHTR, с некоторыми различиями в количестве слоев CNN и RNN и размере входных данных этих слоев: она имеет 7 слоев CNN и 2 слоя Bidirectinal LSTM (BLSTM) RNN.
Ниже кратко представлен конвейер алгоритма LineHTR:
На входе изображение в градациях серого фиксированного размера 800 x 64 (Ш x В).
Слои CNN сопоставляют это изображение в градациях серого с последовательностью элементов размером 100 x 512.
Слои BLSTM с 512 единицами отображают эту последовательность признаков в матрицу размером 100 x 205: здесь 100 представляет количество временных шагов (горизонтальных позиций) в изображении с текстовой строкой; 205 представляет вероятности различных символов на определенном временном шаге на этом изображении)
Слой CTC может работать в 2 режимах: режим LOSS – чтобы научиться предсказывать правильного персонажа на временном шаге при обучении; Режим ДЕКОДЕР – для получения последней распознанной текстовой строки при тестировании
размер партии равен 50
Экспериментальные Материалы
Все модели были реализованы с использованием Python и deep learning библиотеки Tensorflow. Tensorflow позволяет прозрачно использование высоко оптимизированных математических операций на графических процессорах с помощью Python. Вычислительный граф определяется в скрипте Python для определения всех операций, необходимых для конкретных вычислений. Графики для отчета были сгенерированы с помощью библиотеки matplotlib для Python, а иллюстрации созданы с помощью Inkscape-программы векторной графики, аналогичной Adobe Photoshop. Эксперименты проводились на машине с 2-кратным ” Intel ® Процессоры Xeon(R) E-5-2680”, 4x ” NVIDIA Tesla k20x” и 100 ГБ памяти RAM. Использование графического процессора сократило время обучения моделей примерно в 3 раза, однако это ускорение не было тщательно отслежено на протяжении всего проекта,поэтому оно могло варьироваться.
Tensorflow позволяет прозрачно использование высоко оптимизированных математических операций на графических процессорах с помощью Python. Вычислительный граф определяется в скрипте Python для определения всех операций, необходимых для конкретных вычислений. Графики для отчета были сгенерированы с помощью библиотеки matplotlib для Python, а иллюстрации созданы с помощью Inkscape-программы векторной графики, аналогичной Adobe Photoshop. Эксперименты проводились на машине с 2-кратным ” Intel ® Процессоры Xeon(R) E-5-2680”, 4x ” NVIDIA Tesla k20x” и 100 ГБ памяти RAM. Использование графического процессора сократило время обучения моделей примерно в 3 раза, однако это ускорение не было тщательно отслежено на протяжении всего проекта,поэтому оно могло варьироваться.
SimpleHTR эксперименты
SimpleHTR модель-это обучение, валидация и тестирование на двух различных датасетах. Для того чтобы запустить процесс обучения модели на наших собственных данных, были предприняты следующие шаги:
• Создан словарь слов файлов аннотаций
• Файл DataLoader для чтения и предварительного владения набором данных изображений и чтения файла аннотаций принадлежит изображениям
• Набор данных был разделен на два подмножества: 90% для обучения и 10% для проверки обученной модели. Для повышения точности и снижения частоты ошибок мы предлагаем следующие шаги: во-первых, увеличить набор данных, используя данные увеличение; во-вторых, добавьте больше информации CNN слоев и увеличение ввода размера; в-третьих, удалить шум на изображении и в скорописи стиле; В-четвертых, заменить ЛСТМ двусторонними ГРУ и, наконец, использование декодера передача маркера или слово поиска луча декодирование, чтобы ограничить выход в словарь слова.
Для повышения точности и снижения частоты ошибок мы предлагаем следующие шаги: во-первых, увеличить набор данных, используя данные увеличение; во-вторых, добавьте больше информации CNN слоев и увеличение ввода размера; в-третьих, удалить шум на изображении и в скорописи стиле; В-четвертых, заменить ЛСТМ двусторонними ГРУ и, наконец, использование декодера передача маркера или слово поиска луча декодирование, чтобы ограничить выход в словарь слова.
Первый Набор Данных: Для обучения на собранных данных была обработана модель SimpleHTR, в которой есть 42 названия стран и городов с различными узорами почерка. Такие данные были увеличены в 10 раз. Были проведены два теста: с выравниванием курсивных слов и без выравнивания. После изучения были получены значения по валидации данных, представленных в Таблице ниже.
Алгоритм | выравнивание скорописи | нет выравнивания | ||
CER | WAR | CER | WAR | |
bestpath | 19. | 52.55 | 17.97 | 57.11 |
beamsearch | 18.99 | 53.33 | 17.73 | 58.33 |
wordbeamsearch | 16.38 | 73.55 | 15.78 | 75.11 |
 13
13Эта таблица показывает точность распознавания SimpleHTR для раличных методов декодирования (bestpath, beamsearch, wordbeamsearch). Декодирование наилучшего пути использует только выход NN и вычисляет оценку, принимая наиболее вероятный символ в каждой позиции. Поиск луча также использует только выход NN, но он использует больше данных из него и, следовательно, обеспечивает более детальный результат. Поиск луча с character-LM также забивает символьные последовательности, которые еще больше повышают исход.
Результаты обучения можно посмотреть на рисунке ниже:
Результаты эксперимента с использованием SimpleHTR (lr=0,01): точность модели. Результаты эксперимента с использованием SimpleHTR (lr=0,01): погрешность модели.
Результаты эксперимента с использованием SimpleHTR (lr=0,01): погрешность модели.На рисунке ниже показано изображение с названием региона, которое было представлено на вход, а на другом рисунке мы видим узнаваемое слово ” Южно Казахстанская” с вероятностью 86 процентов.
Пример изображения с фразой ” Южно-Казахстанская” на русском языкеРезультат распознаванияВторой набор данных (HKR Dataset): Модель SimpleHTR показала в первом тесте набора данных 20,13% символьной ошибки (CER) и второго набора данных 1,55% CER. Мы также оценили модель SimpleHTR по каждому показателю точности символов(рисунок ниже). Частота ошибок в словах (WER) составил 58,97% для теста 1 и 11,09% для теста 2. Результат например TEST2 показывает что модель может распознавать слова которые существуют в обучающем наборе данных но имеют полностью различные стили почерка. Набор данных TEST1 показывает, что результат не является хорошим, когда модель распознает слова, которые не существуют в обучении и наборы данных проверки.
Следующий эксперимент проводился с моделью LineHTR, обученной на данных за 100 эпох. Эта модель продемонстрировала производительность со средним CAR 29,86% и 86,71% для наборов данных TEST1 и TEST2 соответственно (рисунок ниже). Здесь также наблюдается аналогичная тенденция переобучения обучающих данных.
Заключение
Эксперименты по классификации рукописных названий городов проводились с использованием SimpleHTR и LineHTR на тестовых данных были получены следующие результаты по точности распознавания: 57,1% для SimpleHTR рекуррентного CNN с использованием алгоритмов декодирования с наилучшим путем, 58,3% для Beamsearch и 75,1% wordbeamsearch. Лучший результат был показан для Wordbeamsearch, который использует словарь для окончательной коррекции текст при распознавании.
App Store: Сканер текста
Описание
Сканер документов в MS Word
Сканер таблиц и форм в MS Excel
Сканер-переводчик до 20 страниц с аудио поддержкой
Сканер чеков
Распознавайте рукописный текст из заметок, писем, эссе, досок, бланков и других источников.
Сканируйте до 20 страниц за раз в один текстовый файл!
Будьте более продуктивны, фотографируя рукописные заметки, а не расшифровывая их. Распознавание рукописного текста работает с различными поверхностями и фонами, такими как белая бумага, желтые стикеры и доски. Рукописный ввод в текст одним касанием!
Возможности текстового сканера:
– Сканер документов в MS Word (docx формат)
– Сканер таблиц и форм в MS Excel (xlsx, csv форматы)
– Сканер переводчик до 20 страниц с аудио поддержкой
– Сканер текста до 20 страниц с аудио поддержкой
– Неограниченное использование
– Сканировать до 20 страниц за раз
– Опечатки и обработка исключений
– До 100% точность, включая пунктуацию
– Аудиоплеер. Воспроизведение звука при заблокированном экране
– Обрезка изображений перед распознаванием
– Не требуется регистрация
– Сохраняет ваши данные в безопасности
– Поддержка 122 языков распознавания и шрифтов
– Многоязычное распознавание
Поддерживаемые языки: рукописное распознавание текста поддерживает в общей сложности 122 языка для текста в стиле печати.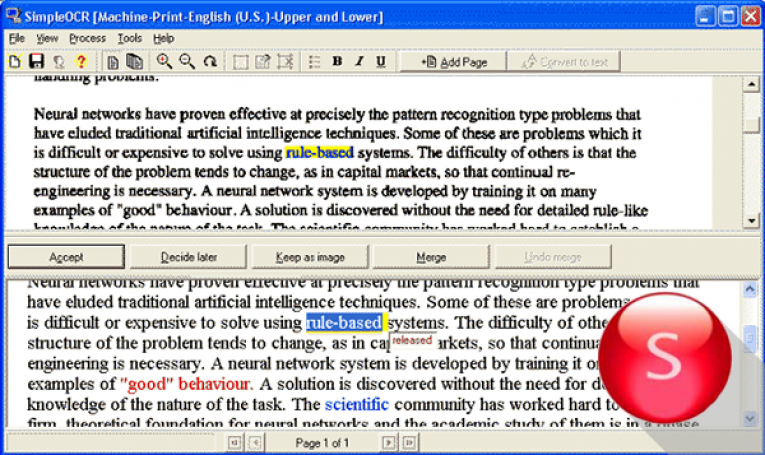 Распознавание рукописного текста поддерживается исключительно для английского, упрощенного китайского, французского, немецкого, итальянского, португальского, японского, корейского и испанского языков.
Распознавание рукописного текста поддерживается исключительно для английского, упрощенного китайского, французского, немецкого, итальянского, португальского, японского, корейского и испанского языков.
Сканер документов и форм – незаменимый помощник в работе!
Optional Handwritten OCR Subscription:
– $4.49 weekly plan for unlimited text recognition subscription will be applied to your iTunes account at the end of the 3 day free trial.
– $9.49 monthly plan for unlimited text recognition subscription will be applied
– $44.49 annual plan for unlimited text recognition subscription will be applied
– Payment will be charged to iTunes Account at confirmation of purchase- Subscription automatically renews unless auto-renew is turned off at least 24-hours before the end of the current period
– Account will be charged for renewal within 24-hours prior to the end of the current period, and identify the cost of the renewal
– Subscriptions may be managed by the user and auto-renewal may be turned off by going to the user’s Account Settings after purchase
– No cancellation of the current subscription is allowed during active subscription period
– Privacy policy and Terms of Use:
https://www. freeprivacypolicy.com/privacy/view/c733a8a4a0590ca277bdad005e200758
freeprivacypolicy.com/privacy/view/c733a8a4a0590ca277bdad005e200758
Версия 6.3
Улучшение пользовательского опыта
Оценки и отзывы
Оценок: 6
Отвратительное приложение
Вообще не переводит текст, не распознаёт рукописные тексты.
Норм
У всех вроде бы так плохо но у меня нормально работает. Хоть и непонятный почерк не разбирает но обычный хороший почерк переведёт на печатные буквы запросто
Отвратительно
Вылезает в рекламе, в самой первой ссылке по поиску приложений по распознаванию рукописного текста.
Но ничего не работает. Каждые 5 секунд вылезают подряд две рекламы. Но даже после них ничего не происходит. Хорошая идея, отвратительное исполнение. Если вы хотите, что приложение покупали, то покажите хотя бы что оно может.
Подписки
One year unlimited photo scan
Document scanner app. Save 80%!
1 150,00 ₽
Разработчик Global Business Ltd указал, что в соответствии с политикой конфиденциальности приложения данные могут обрабатываться так, как описано ниже. Подробные сведения доступны в политике конфиденциальности разработчика.
Данные, используемые для отслеживания информации
Следующие данные могут использоваться для отслеживания информации о пользователе в приложениях и на сайтах, принадлежащих другим компаниям:
- Идентификаторы
- Данные об использовании
- Диагностика
Не связанные с пользователем данные
Может вестись сбор следующих данных, которые не связаны с личностью пользователя:
- Идентификаторы
- Данные об использовании
- Диагностика
Конфиденциальные данные могут использоваться по-разному в зависимости от вашего возраста, задействованных функций или других факторов. Подробнее
Подробнее
Информация
- Провайдер
- GLOBAL BUSINESS LTD.
- Размер
- 49,9 МБ
- Категория
- Производительность
- Возраст
- 4+
- Copyright
- © GBSoftware.BIZ
- Цена
- Бесплатно
- Сайт разработчика
- Поддержка приложения
- Политика конфиденциальности
Поддерживается
Другие приложения этого разработчика
Вам может понравиться
5 бесплатных веб-сайтов OCR, которые позволяют бесплатно конвертировать изображения в текст
OCR становится все более распространенным инструментом в Интернете для преобразования изображений в текст. Это полезно для самых разных целей и ситуаций, но для большинства из них требуются специальные программы, чтобы максимально использовать их.
Это полезно для самых разных целей и ситуаций, но для большинства из них требуются специальные программы, чтобы максимально использовать их.
К счастью, вам не нужно ничего скачивать или устанавливать, если вы хотите максимально использовать эту технологию. Вот пять лучших бесплатных онлайн-инструментов OCR, которые вы можете использовать для бесплатного преобразования изображений в текст.
Что такое OCR?
OCR или оптическое распознавание символов — это процесс, с помощью которого программы извлекают полезную информацию из печатного или письменного текста. Как правило, это отсканированный документ или какая-либо фотография.
Что это значит? По сути, OCR — это инструмент, который вы можете использовать для извлечения простого, простого в использовании и обработки текста из изображения, написанного от руки или напечатанного.
Связано: Как преобразовать изображение с рукописным вводом в текст с помощью OCR
Например, если у вас есть фотография документа или письма, которое вы хотите преобразовать в документ Microsoft Word, вы сможете использовать для этого OCR.
Первым в этом списке идет OCRSpace, полностью бесплатная онлайн-служба OCR. В OCRSpace доступно множество различных опций, поэтому он подойдет любому из вас, кто любит возиться с различными настройками.
Использование OCRSpace очень просто. У вас есть возможность загрузить файл со своего компьютера или использовать URL-адрес веб-сайта с изображением. Вы также можете перетащить файл. Он принимает наиболее часто используемые форматы изображений.
Здесь можно включить или отключить множество полезных параметров. Если ваше изображение неправильно ориентировано, OCRSpace может переориентировать изображение за вас, а если изображение низкого качества или маленькое, OCRSpace может автоматически улучшить его для вас.
Интересно, что если вы пытаетесь включить информацию, которая лучше подходит в виде таблицы, OCRSpace также включает в себя функциональные возможности для этого. Скажем, если вы пытаетесь загрузить квитанции для налоговых документов, эта функция будет наиболее полезной.
OCRSpace также поддерживает впечатляющий набор различных языков, поэтому вы не ограничены извлечением информации из документов только на английском языке.
Для OCRSpace доступны премиум-планы, но в большинстве случаев вам не понадобятся функции, которые он предоставляет. Однако, если вы обнаружите, что загружаете особенно большие документы, вам может потребоваться обновление.
Если вы ищете что-то, что должно работать просто и легко, независимо от ваших целей, NewOCR может вам подойти.
NewOCR может похвастаться простым пользовательским интерфейсом. Есть одна кнопка для загрузки вашего файла и все. После загрузки вы можете выбрать языки распознавания и повернуть изображение, если оно обращено не в ту сторону.
Отличие NewOCR заключается не в дизайне, а в функциях. Нет никаких ограничений на то, сколько вы можете загрузить, и нет необходимости в учетной записи или регистрации.
Связано: Лучшие бесплатные инструменты OCR для преобразования ваших файлов обратно в редактируемые документы
Кроме того, NewOCR способен распознавать значительное количество различных форматов входных файлов и языков. Существует очень мало файлов, которые NewOCR не может обработать, в том числе несколько больших документов с изображениями, упакованных в zip-архивы.
Существует очень мало файлов, которые NewOCR не может обработать, в том числе несколько больших документов с изображениями, упакованных в zip-архивы.
Однако более впечатляющим является диапазон языков, доступных для перевода. NewOCR может понимать 122 различных языка, в том числе многие, которые вы вряд ли найдете где-либо еще. Среди выдающихся предметов — древнегреческий, среднеанглийский и математические уравнения.
Далее у нас есть Soda PDF Online. Как следует из названия, Soda PDF Online — это, прежде всего, пакет для обработки PDF. Но он также включает в себя функции OCR для изображений, отсканированных документов и PDF-файлов.
Soda PDF Online позволяет загружать документы вручную или с Google Диска и Dropbox. После загрузки и обработки Soda PDF Online предоставит вам редактируемый PDF-файл, который вы можете использовать для прямого копирования и редактирования информации.
Естественно, это наиболее полезно, если у вас есть документ в формате PDF. В противном случае другие варианты позволяют достичь того же результата с меньшим количеством шагов.
В противном случае другие варианты позволяют достичь того же результата с меньшим количеством шагов.
Soda PDF Online также включает в себя множество премиальных функций. Однако большинство из них не имеют прямого отношения к своей функциональности OCR, как к их пакету обработки PDF.
Если вы не уверены, что именно ищете, или надеетесь на небольшую помощь, OCR2Edit может подойти.
OCR2Edit отличается от других служб OCR в этом списке простотой использования. Он разбивает каждую из своих различных функций на уникальные категории и роли, чтобы вы могли найти именно то, что хотите сделать.
Связано: бесплатное и платное программное обеспечение для оптического распознавания текста: сравнение Microsoft OneNote и Nuance OmniPage
Например, если вы хотите преобразовать изображение в документ Microsoft Word, OCR2Edit может направить вас на страницу, посвященную этой службе. Если вы хотите сделать PDF доступным для поиска, для этого также есть страница.
Эта разбивка на категории позволяет легко найти именно то, что вы ищете, вместо того, чтобы гадать и надеяться, что вы достигнете желаемого результата.
Наконец-то у нас есть img2txt. img2txt — отличный сервис OCR, если вы хотите что-то простое и простое, но просто работающее.
img2txt позволяет загружать файл, перетаскивая его или перемещаясь по компьютеру. Вы также можете предоставить ему текстовую ссылку на веб-страницу с изображением, и он сможет обнаружить ее содержимое.
Интерфейс прост в использовании, а img2txt также поддерживает более 35 языков для распознавания текста. Нет необходимости ни в какой форме регистрации, ни в ограничении запросов, поэтому вы сможете использовать img2txt всякий раз, когда возникнет такая необходимость.
Онлайн — не единственный способ конвертировать изображения в текст
OCR — невероятно полезный инструмент, который можно использовать, когда возникает необходимость, и, надеюсь, где-то в этом списке вы нашли правильный инструмент для работы, которую ищете.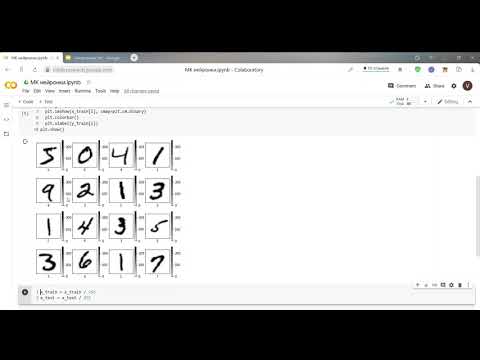
Однако существует множество других инструментов, которые вы можете использовать в случае необходимости. Часто они могут быть даже более удобными, чем онлайн-решения, при условии, что они подходят для работы.
Как всегда, разнообразие и широкий выбор альтернатив — самый полезный инструмент, который вы можете иметь. Итак, почему бы не осмотреться?
Лучшее программное обеспечение для распознавания рукописного текста
Перейти к содержимомуПоиск:
Найдите лучшее программное обеспечение для распознавания рукописного текста.
Обработка корпоративных форм для захвата данных из рукописных форм и автоматического ввода данных для любого приложения.
Облачные решения OCR, такие как Google Vision и Amazon Textract, способны обеспечить точное распознавание рукописного ввода для всех типов документов.
Вывод распознанного текста в CSV, Excel, XML, JSON, базу данных SQL или любые другие форматы данных.
Используйте роботизированную автоматизацию процессов (RPA), чтобы упростить интеграцию с любым приложением или веб-сайтом.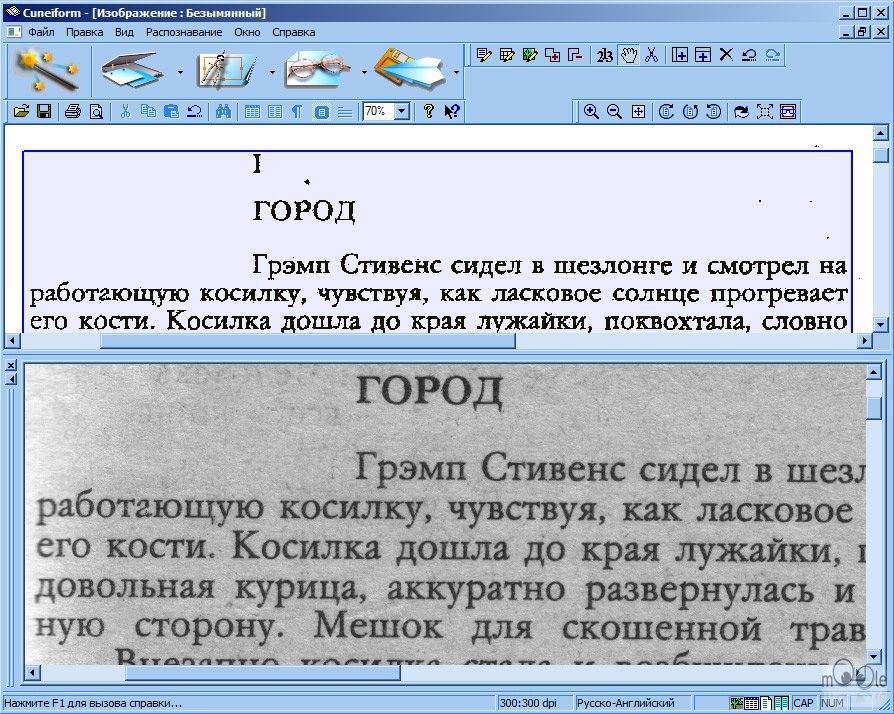
Специалисты компании SimpleOCR помогут вам найти лучшее программное обеспечение для распознавания рукописного текста!
Свяжитесь с нами для получения консультации или узнайте больше о наших решениях здесь:
- Руководство по преобразованию отпечатка руки в текст
- Руководство по обработке форм
- Создание форм, оптимизированных для преобразования отпечатка руки в текст
- Преобразование отпечатка руки в текст в ABBYY Vantage и FlexiCapture
OCR Решения, преобразующие отпечатки пальцев в текст:
- SimpleIndex Cloud OCR
- ABBYY Vantage
- ABBYY FlexiCapture
- Digitech PaperVision Capture Forms Magic
- IRIS Xtract
- Remark Office OMR
OCR SDK and API products for developers looking to convert handprint to text in custom applications:
- ABBYY FineReader SDK
- ABBYY Cloud OCR SDK
- ABBYY FlexiCapture SDK
- Amazon Textract Cloud API
- Google Vision Cloud API
Приложения для распознавания отпечатков пальцев могут давать совершенно разные результаты с точки зрения точности в зависимости от того, предназначена ли форма для интеллектуального распознавания символов (ICR).
Приложения для обработки форм, такие как ABBYY FlexiCapture, имеют встроенный инструмент для создания форм с оптимизированными для ICR элементами макета полей и правилами, которые проверяют, используются ли в вашей форме передовые методы распознавания. Эти формы могут быть автоматически преобразованы в шаблоны распознавания для сканирования с целью сбора данных. Это сэкономит вам десятки часов проб и ошибок в процессе проектирования и даже больше при вводе данных после того, как заполненные формы будут собраны.
Передовые практические рекомендации для форм ICR и OCR включают:
- Большое расстояние между элементами формы и этикетками, не менее 0,5 см / 0,25 дюйма
- Используйте выпадающие цвета для фона формы, когда это возможно
- Напечатанные от руки символы должны быть ограничены рамками или гребенками, чтобы заполнитель писал разборчиво, раздельно , печатные символы
- По возможности используйте флажки вместо отпечатков рук, поскольку они почти на 100 % точны
- По возможности используйте цифровые коды вместо буквенно-цифрового текста, чтобы уменьшить количество возможных символов и повысить точность
- Используйте правила проверки для проверки возможных значений и отмечайте данные с неправильными значениями
- Поля флажков можно использовать для проверки наличия подписи
Цены на программное обеспечение OCR варьируются от бесплатных до десятков тысяч долларов . Чем объясняется разница между этими приложениями? Вот разбивка:
Чем объясняется разница между этими приложениями? Вот разбивка:
- Бесплатное ПО OCR использует механизмы SimpleOCR или Tesseract и предоставляет ограниченные возможности сканирования и форматирования вывода. Качество распознавания, как правило, низкое, за исключением изображений документов самого высокого качества.
- Преобразователи PDF OCR предоставляют высококачественные механизмы распознавания текста, такие как ABBYY, IRIS и OmniPage, но ограничивают вывод доступными для поиска PDF-файлами. Они стоят менее 100 долларов.
- Стандартные приложения оптического распознавания символов стоят от 100 до 200 долл. США и обеспечивают все возможности оптического распознавания символов, включая преобразование отсканированных изображений в Word, Excel, HTML и другие редактируемые форматы.
- Корпоративные приложения OCR добавляют дополнительные функции, такие как автоматическая обработка горячих папок, параллельное лицензирование и другие функции, полезные для бизнес-приложений.
 Цена на них 200-500$.
Цена на них 200-500$. - Серверы OCR предоставляют масштабируемые корпоративные службы OCR для обработки очень больших объемов документов или предоставляют возможности OCR пользователям во всей организации. Цены начинаются примерно с 1500 долларов и растут в зависимости от объема обработки.
- Корпоративные приложения для сбора данных и обработки форм используются для сбора структурированных данных из сложных документов, таких как формы медицинских заявлений и счета-фактуры, которые включают в себя такие элементы, как таблицы, рукописный ввод, флажки и подвижные зоны. Эти решения могут стоить от 1000 до сотен тысяч долларов в зависимости от объема документов и сложности проекта.
aaron2021-01-24T18:39:02-05:00Теги: Автоматизация кредиторской задолженности, Распознавание кредиторской задолженности, Сканирование счетов AP, Автоматический ввод данных, Распознавание штрих-кода, Пакетное распознавание текста, Пакетное распознавание текста PDF, Лучшее программное обеспечение для распознавания рукописного ввода, Преобразование Изображения в PDF с возможностью поиска, Преобразование изображений в Word, Преобразование PDF в редактируемый Word, Преобразование PDF в Excel, Преобразование PDF в HTML, Преобразование PDF в текст, Преобразование изображения в текст, Сбор данных, Извлечение данных, Управление документами, Программное обеспечение для обработки документов, Извлечение Текст из изображения, обработка форм, распознавание отпечатков рук, ICR, распознавание изображений, программное обеспечение для автоматизации счетов, захват счетов, визуализация счетов, OCR счетов, распознавание счетов, программное обеспечение для сканирования счетов, программное обеспечение рабочего процесса счетов, точность OCR, распознавание символов OCR, обработка счетов OCR, OCR PDF, сканер OCR, оптическое распознавание символов, извлечение данных PDF, OCR PDF, сканирование счета-фактуры, OCR сервера, простое программное обеспечение счета-фактуры, распознавание текста |
Подробнее
ICR – Интеллектуальное распознавание персонажаИнтеллектуальное распознавание характера
I NTELLIGENT CLENCLICKEN IS EXTERNED ANTERNED (IS EXTERNED (IS EXTERNED (IS EXTERNED ).
 ). В то время как технология OCR предназначена для извлечения машинно-печатных символов, технология ICR извлекает информацию, предоставленную в виде символов, напечатанных вручную
). В то время как технология OCR предназначена для извлечения машинно-печатных символов, технология ICR извлекает информацию, предоставленную в виде символов, напечатанных вручную
Технология ICR может извлекать напечатанные от руки символы, которые разделены и записаны как отдельные символы в областях/зонах – эти области/зоны должны быть указаны как фиксированные поля машиночитаемых форм. В качестве альтернативы они должны быть обнаружены автоматически.
Пример формы, содержащей символы, напечатанные от руки:
Важное примечание: ICR не может извлекать тексты, написанные «курсивным почерком» как в этом примере:
- В большинстве случаев технология ICR связана с распознаванием полей/зон и обработкой форм.
- Для повышения точности распознавания ICR рекомендуется использовать метаданные , например, регулярные выражения, словари или поиск в базе данных.
ICR в ABBYY SDK
Следующие ABBYY SDK и продукты поддерживают ICR
FineReader Engine
Начиная с версии 12, Release 3, ICR также включен в версию для Linux. Начиная с Релиза 4 версии 12, он также включен в версию FineReader Engine для Mac (в более ранних версиях технология ICR поддерживалась только в версии для Windows). для обработки форм и извлечения данных ICR и сопоставление шаблонов для фиксированных форм являются частью набора функций по умолчанию. Кроме того, ABBYY предлагает эту технологию в качестве продукта в форме FlexiCapture.
Cloud OCR SDK – служба ABBYY OCR, позволяющая считывать зоны, содержащие напечатанные от руки разделенные символы. Этот онлайн-сервис OCR […]
Екатерина2022-06-21T14:44:09-04:00Теги: Автоматический ввод данных, Лучшее программное обеспечение для распознавания рукописного текста, Лучшее программное обеспечение для оптического распознавания символов, Лучшее программное обеспечение для создания форм, Распознавание галочек , Распознавание флажков, Преобразование отпечатка руки в текст, Распознавание курсивного рукописного ввода, Сбор данных, Извлечение данных, Программное обеспечение для обработки документов, Обработка форм, Распознавание отпечатков пальцев, Распознавание рукописного ввода, Распознавание счетов, NLP, Распознавание символов OCR, Форма OCR, Программное обеспечение OCR Form, OMR, Оптическое распознавание символов, оптическое распознавание меток, чтение рукописного текста, сканирование рукописного текста в текст, сканирование, тестовое сканирование, распознавание текста, зональное распознавание символов, зональное распознавание символов |
Подробнее
Оптическое распознавание символов Во время своего знакомства с миром сканирования документов вы, вероятно, встречали термин « OCR » и, возможно, даже знаете, что он означает « Оптическое распознавание символов ». . Но что такое OCR и как лучше всего использовать этот сложный и ценный инструмент?
. Но что такое OCR и как лучше всего использовать этот сложный и ценный инструмент?
Мы здесь, чтобы дать вам краткое изложение того, что вам нужно знать об оптическом распознавании символов, ответить на любые ваши вопросы и порекомендовать лучшее программное решение OCR для вашего проекта сканирования.
Содержание:
- Что такое OCR?
- OCR Output Types
- Limitations of OCR
- OCR for Business
- Levels of OCR Software
- Improving OCR Accuracy
- Desktop OCR Software Comparison
- Feature Comparison Chart
- OCR Apps and Descriptions
Основная цель оптического распознавания символов — быстрое и автоматическое преобразование отсканированных или сфотографированных изображений документов в машиночитаемый текст, который можно искать по ключевым словам или редактировать в текстовом процессоре.
Как правило, механизм OCR анализирует пиксельные данные отсканированных изображений и ищет шаблоны, напоминающие буквы, цифры и другие символы, для создания оцифрованной записи символов.
Крупнейшие механизмы OCR используют огромные модели искусственного интеллекта (ИИ) и машинного обучения (МО), которые были обучены на миллиардах документов, собранных за десятилетия разработки.
Хотя точная механика этого процесса может быть сложной, механизмы оптического распознавания символов являются ключевым инструментом автоматизации в эпоху цифровых технологий. Это устраняет разрыв между знаниями, хранящимися в физических документах, и цифровыми данными, которые можно редактировать, искать или анализировать в структурированные данные для автоматизации задач ввода данных.
Типы вывода OCROCR на всю страницу преобразует весь документ в один из следующих форматов:
- […]
aaron2022-06-24T14:29:13-04:00Tags: AI OCR Training, Apple OCR, Пакетное распознавание, Пакетное распознавание PDF, Программное обеспечение для пакетного распознавания, Лучшая загрузка для распознавания текста, Лучшее программное обеспечение для распознавания текста, Лучшее программное обеспечение для распознавания рукописного текста, Облачное распознавание символов, Сравните программное обеспечение для распознавания текста, Преобразование отпечатка руки в текст, Преобразование изображений в PDF с возможностью поиска, Преобразование изображений в Word , Преобразование PDF в редактируемый Word, Преобразование PDF в Excel, Преобразование PDF в HTML, Распознавание курсивного рукописного ввода, Распознавание текста на рабочем столе, Распознавание электронной почты, Распознавание Excel, Распознавание отпечатков пальцев, Распознавание рукописного ввода, ICR, Распознавание изображений, Распознавание MAC-адресов, Программное обеспечение оптического распознавания символов MAC, Точность распознавания текста , OCR Engine, OCR Library, OCR PDF, OCR SDK, OCR Solution, OCR to Excel, OCR Training, Optical Character Recognition, PDF Converters, PDF Data Extraction, PDF OCR, PDF Text Extraction, PDF to TXT Converter, Read Handwriting, Scan Рукописный ввод в текст, сканирование в Excel, Te хт Признание|
Подробнее
При сканировании документа, содержащего текстовые или числовые данные, вы можете прочитать и понять, что написано на отсканированном изображении.
 Однако для компьютера полученный файл изображения представляет собой такой же бессмысленный набор пикселей, как и пейзажная фотография. Чтобы преобразовать эту информацию в редактируемый формат, который вы можете искать, копировать и изменять без повторного ввода вручную, вам потребуется программное обеспечение для оптического распознавания символов (OCR).
Однако для компьютера полученный файл изображения представляет собой такой же бессмысленный набор пикселей, как и пейзажная фотография. Чтобы преобразовать эту информацию в редактируемый формат, который вы можете искать, копировать и изменять без повторного ввода вручную, вам потребуется программное обеспечение для оптического распознавания символов (OCR).Существует множество доступных программ для оптического распознавания текста. Хотя все они имеют общую способность преобразовывать изображения машинопечатного (не рукописного) текста или чисел в редактируемый формат, различное программное обеспечение часто имеет разные функции, точность, цены и языковые параметры.
Вы можете найти различные типы программного обеспечения OCR с описанием каждого из них ниже.
Пользователи одного отдела, работающие из дома или имеющие малый бизнес, могут просто сканировать свои документы в общую папку. В этом «специальном» сценарии вам понадобится только базовое программное обеспечение для сканирования документов, чтобы упростить и обеспечить согласованность вашей файловой системы.

Если вы хотите перейти на следующий уровень, есть варианты Desktop Document Management, которые предоставляют универсальные средства для захвата, хранения, поиска и извлечения документов. Кроме того, они обеспечивают безопасность, расширенные возможности и простоту использования по сравнению со специальными методами.
Вам нужно простое решение для оптического распознавания символов без излишеств, не тратя сотни долларов на профессиональное программное обеспечение? Не смотрите дальше. Существует бесплатное, добровольное пожертвование, бесплатное решение OCR для […]
aaron2022-06-21T12:06:06-04:00Теги: Автоматизация кредиторской задолженности, OCR кредиторской задолженности, Классификация AI, Сканирование счетов AP, Автоматический ввод данных, Программное обеспечение для автоматической обработки счетов, Автоматическая классификация, Автоматическое разделение документов, OCR штрих-кода, Пакетное распознавание текста, Пакетное распознавание PDF, Программное обеспечение пакетного распознавания текста, BCR, Лучшее программное обеспечение для распознавания рукописного ввода, Лучшее программное обеспечение для создания форм, Распознавание визитных карточек, Распознавание галочек, Распознавание флажков, Облачное распознавание символов, Преобразование отпечатка руки в текст, Преобразование изображений в PDF с возможностью поиска, Преобразование изображений в Word, Преобразование PDF в редактируемый Word, Преобразование PDF в Excel, Преобразование PDF в HTML, Преобразование PDF в текст, Преобразование изображения в текст, Распознавание курсивного рукописного ввода, Сбор данных, Извлечение данных, Управление документами, Программное обеспечение для обработки документов, Электронные данные Захват, Excel OCR, обработка форм, распознавание отпечатков пальцев, распознавание рукописного ввода, здравоохранение OCR, ICR, программное обеспечение для автоматизации счетов, захват счетов, отображение счетов, OCR счетов, распознавание счетов, Программное обеспечение для сканирования счетов, программное обеспечение для обработки счетов, роботизированная автоматизация процессов в Ноксвилле, решения для распознавания текста в Ноксвилле, штат Теннесси, машинное обучение, НЛП, форма для распознавания текста, программное обеспечение для форм для распознавания текста, обработка счетов для распознавания текста, сканер для распознавания текста, решение для распознавания текста, распознавание текста в Excel, OMR, распознавание оптических меток, Извлечение данных PDF, извлечение текста PDF, конвертер PDF в TXT, чтение рукописного текста, сканирование чеков, роботизированная автоматизация процессов, RPA, сканирование рукописного ввода в текст, сканирование счета-фактуры, сканирование в Excel, Scantron, программное обеспечение для простого счета-фактуры, оптическое распознавание налоговых форм, тестовое сканирование |
Подробнее
aaron2022-06-21T10:50:47-04:00Теги: Пакетное распознавание текста, Пакетное распознавание текста в формате PDF, Программное обеспечение для пакетного распознавания текста, Лучшая загрузка для распознавания текста, Лучшее программное обеспечение для распознавания текста, Лучшее программное обеспечение для распознавания рукописного текста, Лучшее программное обеспечение для оптического распознавания символов , Лучшее программное обеспечение для создания форм, Сравнение программного обеспечения OCR, Преобразование изображений в PDF с возможностью поиска, Преобразование изображений в Word, Преобразование PDF в редактируемое слово, Преобразование PDF в Excel, Преобразование PDF в HTML, Преобразование PDF в текст, Преобразование изображения в текст, Excel OCR , Извлечение текста из изображения, Распознавание изображений, OCR PDF, OCR в Excel, Оптическое распознавание символов, Преобразователи PDF, Извлечение данных PDF, OCR PDF, Извлечение текста PDF, Преобразование PDF в TXT, Сканирование в Excel |
Подробнее
ABBYY — одна из ведущих компаний в мире по оптическому распознаванию символов. Они предлагают широкий спектр продуктов для ввода и автоматизации документов, начиная с FineReader Pro для индивидуальных или малых компаний и FineReader Corporate . Если вам нужно обработать много тысяч или миллионов страниц, ABBYY имеет FineReader Server для полнотекстового распознавания текста и FlexiCapture для ввода данных OCR. Многие компании используют свои продукты из-за их гибкости и масштабируемости, всегда есть возможность настроить продукты ABBYY OCR в соответствии с вашими потребностями в автоматизации.
Они предлагают широкий спектр продуктов для ввода и автоматизации документов, начиная с FineReader Pro для индивидуальных или малых компаний и FineReader Corporate . Если вам нужно обработать много тысяч или миллионов страниц, ABBYY имеет FineReader Server для полнотекстового распознавания текста и FlexiCapture для ввода данных OCR. Многие компании используют свои продукты из-за их гибкости и масштабируемости, всегда есть возможность настроить продукты ABBYY OCR в соответствии с вашими потребностями в автоматизации.
Программа распознавания текста ABBYY FineReader помогает преобразовывать отсканированные бумажные документы, файлы PDF и цифровые фотографии в доступные для поиска и редактирования форматы. Непревзойденная точность распознавания текста и возможности преобразования документов практически исключают повторный ввод и переформатирование. Интуитивное использование и автоматическое преобразование одним щелчком мыши позволяют вам делать больше с этим программным обеспечением OCR за меньшее количество шагов.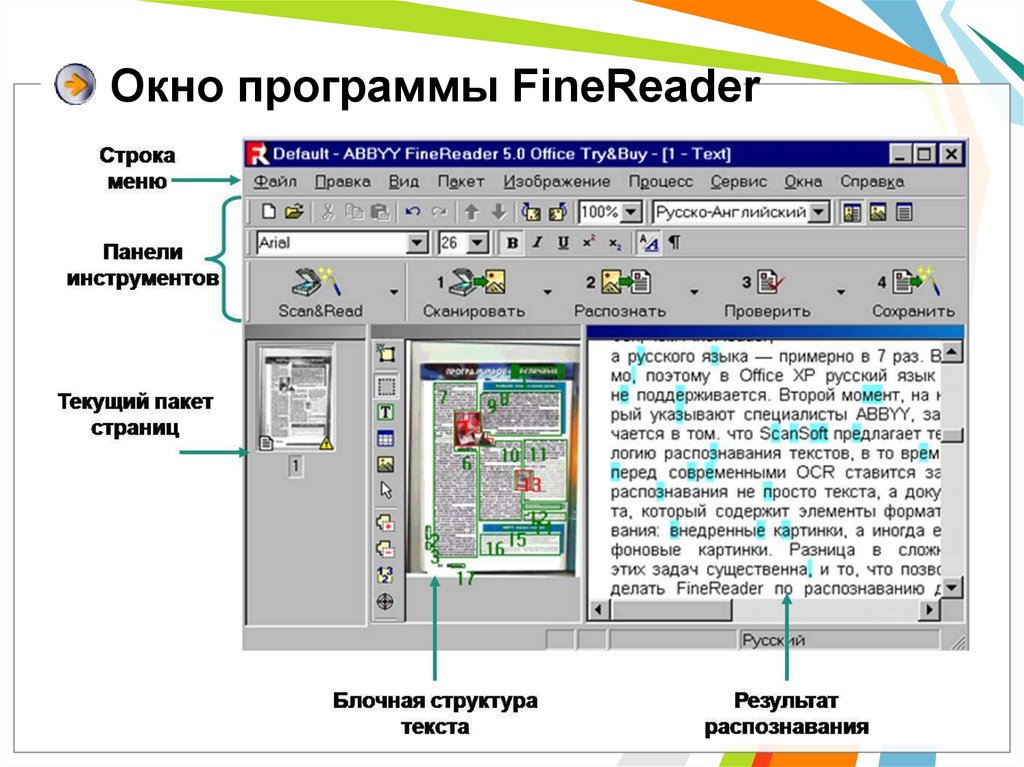 Поддержка до 190 языков для распознавания текста и преобразования документов — абсолютный рекорд на рынке программного обеспечения OCR/PDF!
Поддержка до 190 языков для распознавания текста и преобразования документов — абсолютный рекорд на рынке программного обеспечения OCR/PDF!
ABBYY FlexiCapture — мощное решение для сбора данных и обработки документов. Он предназначен для преобразования потоков документов любой структуры и сложности в готовые для бизнеса данные. Надежные технологии распознавания, автоматическая классификация документов и масштабируемая и настраиваемая архитектура позволят компаниям и организациям любого размера оптимизировать свои бизнес-процессы, повысить эффективность и сократить расходы.
Сервер ABBYY FineReader — это мощное серверное программное обеспечение для оптического распознавания текста, предназначенное для автоматического ввода документов и преобразования PDF. Разработанный для пакетной обработки средних и больших объемов, он позволяет организациям и поставщикам услуг сканирования внедрить экономичные процессы для преобразования бумажных документов, а также документов с изображениями в форматах TIFF, JPEG и PDF в электронные файлы, пригодные для полнотекстового поиска и длительного сканирования. -срочное цифровое архивирование.
-срочное цифровое архивирование.
ScanStore и SimpleSoftware — это опытных интеграторов ABBYY […]
aaron2022-06-21T10:36:04-04:00Теги: Автоматизация кредиторской задолженности, Распознавание кредиторской задолженности, Классификация AI, Сканирование счетов AP, Автоматический ввод данных, Программное обеспечение для автоматической обработки счетов, Автоматическая классификация, Лучший Загрузка OCR, Лучшее программное обеспечение OCR, Лучшее программное обеспечение OCR для рукописного ввода, Лучшее программное обеспечение для оптического распознавания символов, Лучшее программное обеспечение для создания форм, Распознавание галочек, Преобразование отпечатка руки в текст, Распознавание курсивного рукописного ввода, Сбор данных, Извлечение данных, Классификация документов, Электронный сбор данных , Обработка форм, Распознавание отпечатков пальцев, Распознавание рукописного ввода, ICR, Программное обеспечение для автоматизации счетов, Захват счетов, Изображение счетов, OCR счетов, Распознавание счетов, Программное обеспечение для сканирования счетов, Программное обеспечение рабочего процесса счетов, Форма OCR, Программное обеспечение для форм OCR, Обработка счетов OCR, Сканер OCR, OMR, оптическое распознавание меток, извлечение данных PDF, чтение рукописного текста, сканирование чека, сканирование рукописного текста в текст, сканирование счета-фактуры, сканирование в Excel, Scantron, Простое программное обеспечение для выставления счетов, тестовое сканирование |
Подробнее
Что такое ICR, обработка опросов и форм? ICR расшифровывается как Интеллектуальное распознавание символов и представляет собой технологию, которая позволяет программному обеспечению интерпретировать напечатанный от руки текст на отсканированных изображениях.
Программное обеспечение для обработки форм использует технологию ICR для автоматизации задач ввода данных, включая заполняемые вручную опросы, приложения и формы. Он предоставляет интерфейсы для сканирования, распознавания, проверки и экспорта данных, а также инструменты управления и мониторинга для отслеживания больших объемов документов и данных в рабочем процессе.
Forms Processing также включает технологию OCR (оптическое распознавание символов) для распознавания машинописного текста и OMR (оптическое распознавание меток) для флажков и всплывающих окон с несколькими вариантами выбора.
Эти приложения также можно использовать для автоматизации сбора данных из форм PDF, документов Word, электронных таблиц Excel и других форматов, используемых для электронного заполнения форм. Многие из них включают возможность одновременной публикации форм в бумажном виде, заполняемых PDF-файлов и веб-страниц для распространения и сбора данных из нескольких источников в один набор данных.
Любая организация, которая регулярно собирает данные в бумажных формах, опросах или приложениях, может получить очень высокую отдачу от инвестиций, автоматизировав ввод данных с помощью программного обеспечения для обработки форм.
Вам нужно иметь значительное количество форм, чтобы оправдать расходы – не менее сотни форм в месяц или больше, в зависимости от объема собираемых данных. Если задача ввода данных может быть выполнена менее чем за 100 человеко-часов, то это не лучший кандидат для автоматизации с помощью программного обеспечения ICR.
Организации, в которых есть много отдельных отделов, собирающих данные о формах, могут разделить бюджет на программное обеспечение для обработки форм, повторно используя его для других проектов. Ваш текущий проект может быть недостаточно большим, чтобы оправдать расходы, но в сочетании с одним или двумя другими он будет оправдан.
aaron2022-06-21T12:53:23-04:00Теги: Классификация AI, Автоматический ввод данных, Программное обеспечение для автоматической обработки счетов, Автоматическая классификация, Автоматическое разделение документов, Пакетное распознавание текста, Пакетное распознавание текста PDF, пакетное программное обеспечение OCR, лучшее программное обеспечение OCR для рукописного ввода, лучшее программное обеспечение для создания форм, распознавание флажков, распознавание флажков, преобразование отпечатка руки в текст, преобразование PDF в Excel, распознавание курсивного рукописного ввода, сбор данных, извлечение данных, классификация документов, обработка документов Программное обеспечение, электронный сбор данных, Excel OCR, обработка форм, распознавание отпечатков пальцев, распознавание рукописного ввода, Healthcare OCR, ICR, программное обеспечение для сканирования счетов, программное обеспечение для обработки счетов, решения Knoxville TN OCR, NLP, OCR Form, OCR Form Software, OCR Solution, OCR to Excel, OMR, оптическое распознавание меток, извлечение данных PDF, оптическое распознавание символов PDF, извлечение текста PDF, чтение рукописного текста, сканирование чеков, сканирование рукописного текста в текст, Scantron, серверное распознавание символов, налоговые формы OC R, тестовое сканирование, зональное распознавание, зональное распознавание |
Подробнее
Узнать больше Загрузить сейчас
Сканеры документови Детали сканера
Точное распознавание символов начинается с качественных изображений. Эффективное распознавание символов начинается с быстрого сканирования. Найдите сканеры документов , предназначенные для оптического распознавания символов, в ScanStore .
Эффективное распознавание символов начинается с быстрого сканирования. Найдите сканеры документов , предназначенные для оптического распознавания символов, в ScanStore .
Наша команда экспертов по OCR всегда готова помочь! SimpleOCR — это не просто Freeware , у нас есть все виды решений для оптического распознавания текста, от PDF Converters до 9.0179 Сбор корпоративных данных , OCR-серверы и Распознавание отпечатков пальцев для Форм и опросов . Прямой чат со специалистом по OCR прямо сейчас или по телефону . Свяжитесь с нами по телефону , чтобы получить консультацию по вашему проекту OCR.
SimpleOCR — это популярное бесплатное программное обеспечение OCR Software , которым пользуются сотни тысяч пользователей по всему миру. SimpleOCR также является бесплатным OCR SDK , который разработчики могут использовать в своих пользовательских приложениях.
SimpleIndex — это OCR, созданное для бизнеса, предлагающее мощное пакетное сканирование, сервер OCR и функции сбора данных с простым пользовательским интерфейсом и доступной лицензией.
Если вам нравятся бесплатные вещи, также доступны бесплатные версии нашего средства просмотра документов SimpleView (с Tesseract OCR), принтера штрих-кода SimpleCoversheet и конвертера SimpleExport CSV в XML.
Если у вас есть сканер и вы хотите избежать повторного набора документов, SimpleOCR — это быстрый и бесплатный способ сделать это. Бесплатное ПО SimpleOCR на 100 % бесплатно и не имеет никаких ограничений. Любой может бесплатно использовать SimpleOCR для домашних пользователей, образовательных учреждений и даже корпоративных пользователей.
Если ваши документы имеют многоколоночную компоновку, нестандартные шрифты, таблицы, плохое качество или изображения с цифровой камеры, вы не добьетесь большого успеха с приложениями, основанными на бесплатных механизмах с открытым исходным кодом, таких как SimpleOCR и Tesseract. Вам понадобится коммерческое приложение OCR, чтобы получить точное чтение. Наше руководство по распознаванию текста сравнивает настольные компьютеры и […]
Вам понадобится коммерческое приложение OCR, чтобы получить точное чтение. Наше руководство по распознаванию текста сравнивает настольные компьютеры и […]
aaron2022-06-21T12:40:50-04:00Теги: Автоматизация кредиторской задолженности, OCR кредиторской задолженности, Классификация AI, Обучение распознаванию AI, Сканирование счетов AP, Искусственный интеллект, Автоматизировать ввод данных, Программное обеспечение для автоматической обработки счетов, Автоматическая классификация, Автоматическое разделение документов, Распознавание штрих-кодов, Пакетное распознавание, Пакетное распознавание PDF, Программное обеспечение для пакетного распознавания, Лучшее программное обеспечение для оптического распознавания текста, Лучшее программное обеспечение для распознавания рукописного текста, Лучшее программное обеспечение для оптического распознавания символов, Лучшее программное обеспечение для создания форм, Распознавание галочек, Сравнение программного обеспечения для оптического распознавания символов, Преобразование отпечатков пальцев в текст, преобразование изображений в PDF с возможностью поиска, преобразование PDF в Excel, сбор данных, извлечение данных, электронный сбор данных, Excel OCR, обработка форм, распознавание отпечатков пальцев, распознавание рукописного ввода, здравоохранение OCR, ICR, программное обеспечение для автоматизации счетов, захват счетов, визуализация счетов , Invoice OCR, Invoice Recognition, Invoice Scanning Software, Invoice Workflow Software, Knoxville Robotic Process Automation, Knoxville RPA Consultants, Knoxville UiPa Консультанты, программное обеспечение MAC OCR, машинное обучение, NLP, механизм OCR, форма OCR, программное обеспечение формы OCR, обработка счетов OCR, библиотека OCR, OCR PDF, OCR Scanner, OCR SDK, OCR Solution, OCR to Excel, OMR, распознавание оптических меток , Преобразователи PDF, Извлечение данных PDF, OCR PDF, Извлечение текста PDF, Преобразователь PDF в TXT, Чтение рукописного текста, Сканирование чеков, Автоматизация роботизированных процессов, RPA, Сканирование рукописного ввода в текст, Сканирование счета-фактуры, Сканирование в Excel, SDK OCR, Simple Invoice Software , Налоговые формы OCR|
Подробнее
Что такое ICR, распознавание отпечатков пальцев?
ICR расшифровывается как Интеллектуальное распознавание символов и представляет собой технологию, которая позволяет программному обеспечению интерпретировать напечатанный от руки текст на отсканированных изображениях.
Программное обеспечение для обработки форм использует технологию ICR для автоматизации задач ввода данных, включая заполняемые вручную опросы, приложения и формы. Он предоставляет интерфейсы для сканирования, распознавания, проверки и экспорта данных, а также инструменты управления и мониторинга для отслеживания больших объемов документов и данных в рабочем процессе.
Forms Processing также включает технологию OCR (оптическое распознавание символов) для распознавания машинописного текста и OMR (оптическое распознавание меток) для флажков и всплывающих окон с несколькими вариантами выбора.
Традиционная обработка форм основана на ограниченном почерке , где поля в форме вынуждают заполнителя писать разделенными печатными печатными символами. Современная технология искусственного интеллекта значительно улучшила способность распознавать неограниченный почерк и рукописный шрифт. Напечатанные от руки заметки, блоки комментариев произвольной формы, несегментированные поля, исторические документы и многое другое теперь можно преобразовать в текст с приемлемой точностью, где это было невозможно всего несколько лет назад.
Кому может быть полезно программное обеспечение для распознавания рукописного текста?
Любая организация, которая регулярно собирает данные в бумажных формах, опросах или приложениях, может получить очень высокую отдачу от инвестиций, автоматизировав ввод данных с помощью программного обеспечения для обработки форм.
Вам необходимо иметь значительное количество форм, чтобы оправдать расходы, по крайней мере сто форм в месяц или больше, в зависимости от того, сколько данных собирается. Если задача ввода данных может быть выполнена менее чем за 25 рабочих часов, то, вероятно, это не лучший кандидат для автоматизации с помощью программного обеспечения ICR.
Организации, в которых есть много отдельных отделов, собирающих данные о формах, могут разделить бюджет на программное обеспечение для обработки форм, повторно используя его для других проектов. Ваш текущий проект может быть недостаточно большим, чтобы оправдать […]
Nikita2022-06-21T11:25:46-04:00Теги: Искусственный интеллект, Автоматический ввод данных, Лучшее программное обеспечение для распознавания рукописного текста, Лучшее программное обеспечение для создания форм, Облачное распознавание символов , Сравнение программного обеспечения OCR, Преобразование отпечатка руки в текст, Распознавание курсивного рукописного ввода, Сбор данных, Извлечение данных, Программное обеспечение для обработки документов, Электронный сбор данных, Обработка форм, Распознавание отпечатка руки, Распознавание рукописного ввода, ICR, Распознавание изображений, Решения Knoxville TN OCR, Машинное обучение, NLP, Точность OCR, Форма OCR, Программное обеспечение OCR Form, Извлечение данных PDF, Чтение рукописного ввода, Сканирование рукописного ввода в текст |
Подробнее
База знаний SimpleOCR содержит часто задаваемые вопросы и ответы, технические руководства и общую информацию о широком спектре оптического распознавания символов, распознавания отпечатков пальцев, захвата данных, оптического распознавания символов PDF, сканирования счетов AP и приложений OCR зон.
Свяжитесь с нами для получения
БЕСПЛАТНОЙ консультации по вашему проекту OCR Программное обеспечение для обработки, автоматическая классификация, автоматическое разделение документов, пакетное распознавание текста, пакетное распознавание PDF, пакетное распознавание текста, лучшее программное обеспечение для распознавания рукописного ввода, распознавание флажков, распознавание флажков, преобразование отпечатка руки в текст, преобразование изображений в PDF с возможностью поиска, преобразование изображений в Word, Преобразование PDF в редактируемое слово, преобразование PDF в текст, распознавание курсивного рукописного ввода, сбор данных, извлечение данных, сбор электронных данных, распознавание отпечатков пальцев, распознавание рукописного ввода, ICR, программное обеспечение для автоматизации счетов, захват счетов, отображение счетов, оптическое распознавание счетов, распознавание счетов, счет Программное обеспечение для сканирования, Программное обеспечение для обработки счетов, Решения для оптического распознавания текста в Ноксвилле, штат Теннесси, Распознавание символов OCR, Обработка счетов OCR, OCR PDF, Сканер OCR, OMR, O оптическое распознавание символов, оптическое распознавание меток, конвертеры PDF, извлечение данных PDF, оптическое распознавание символов PDF, извлечение текста PDF, конвертирование PDF в TXT, чтение рукописного текста, сканирование чеков, сканирование рукописного текста в текст, сканирование счета-фактуры, сканирование в Excel, Scantron, серверное распознавание символов, Простое программное обеспечение для выставления счетов, тестовое сканирование, распознавание текста |Подробнее
Специалисты по распознаванию текста для любого проекта Наша уникальная команда специалистов по распознаванию текста готова помочь с проектами по распознаванию текста любого размера и сложности. У нас есть специалисты по поддержке, которые могут удаленно настроить настольные решения за считанные минуты, и опытные системные интеграторы с многолетним опытом программирования, проектирования баз данных и автоматизации роботизированных процессов.
У нас есть специалисты по поддержке, которые могут удаленно настроить настольные решения за считанные минуты, и опытные системные интеграторы с многолетним опытом программирования, проектирования баз данных и автоматизации роботизированных процессов.
Воспользуйтесь нашим интернет-магазином, чтобы заказать приложения OCR для настольных компьютеров, и наши сотрудники будут рады ответить на ваши вопросы по настройке по электронной почте или в веб-чате.
Услуги удаленной настройки и обучения с использованием GotoMeeting доступны по низкой почасовой ставке.
Позвольте нам OCR Это для васВы сделали разовое преобразование и не хотите возиться с программным обеспечением? Загрузите отсканированный документ к нам, и мы отправим обратно преобразованные файлы. Дополнительная служба проверки исправляет ошибки распознавания и проблемы с макетом за низкую почасовую ставку.
Обработка данных для форм, отчетов, справочников и других документов также доступна с выводом в CSV, Excel, XML, JSON, SQL и т.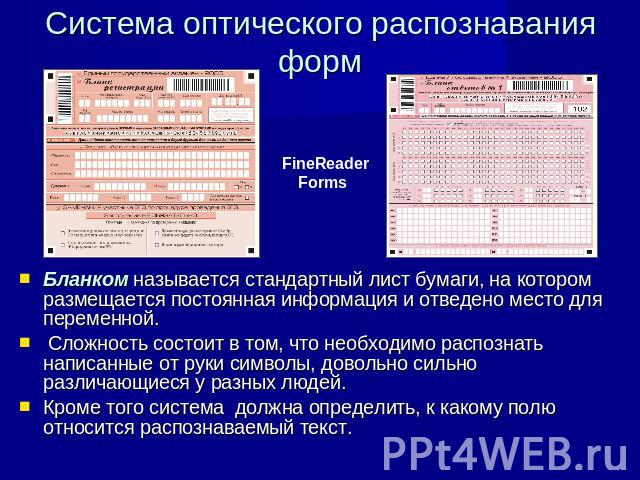 д.
д.
Свяжитесь с нами и, если возможно, предоставьте образец, общее количество страниц, желаемый результат и хотите ли вы, чтобы мы исправили результаты после OCR, и мы сразу же ответим вам с предложением. Цены начинаются от 50 долларов за объем до 1000 страниц.
Автоматизируйте процессы сканирования документов и архивирования цифровых документов, используя зональное распознавание символов, распознавание штрих-кодов, интеграцию с базами данных и другие технологии.
Системы для малого бизнеса и рабочие процессы с одним документом можно настроить удаленно через GotoMeeting, обычно всего за несколько часов. Напишите сейчас, если мы онлайн, или оставьте сообщение, чтобы назначить консультацию.
Передовые решения для извлечения данных, которые могут превратить самые сложные документы в готовые структурированные данные […]
aaron2022-06-23T16:16:20-04:00Теги: Автоматизация кредиторской задолженности, OCR кредиторской задолженности, Классификация AI, Сканирование счетов AP , Искусственный интеллект, Автоматический ввод данных, Программное обеспечение для автоматической обработки счетов, Автоматическая классификация, Автоматическое разделение документов, Распознавание штрих-кодов, Пакетное распознавание символов, Пакетное распознавание PDF, Пакетное распознавание символов, Лучшее программное обеспечение для распознавания рукописного ввода, Лучшее программное обеспечение для создания форм, Распознавание галочек, Распознавание флажков, облачное распознавание символов, преобразование отпечатка руки в текст, преобразование изображений в PDF с возможностью поиска, распознавание курсивного рукописного ввода, сбор данных, извлечение данных, управление документами, программное обеспечение для обработки документов, сбор электронных данных, извлечение текста из изображения, обработка форм, распознавание отпечатков пальцев, рукописный ввод Распознавание, ICR, программное обеспечение для автоматизации счетов, захват счетов, отображение счетов, оптическое распознавание счетов, распознавание счетов, программное обеспечение для сканирования счетов re, Программное обеспечение для обработки счетов, Автоматизация роботизированных процессов Knoxville, Консультанты по RPA в Ноксвилле, Решения для оптического распознавания символов в Ноксвилле, TN, Консультанты по UiPath в Ноксвилле, Машинное обучение, НЛП, Форма OCR, Программное обеспечение для форм OCR, Обработка счетов OCR, OCR PDF, Сканер OCR, OCR SDK, OMR , Оптическое распознавание меток, Преобразователи PDF, Извлечение данных PDF, OCR PDF, Извлечение текста PDF, Преобразователь PDF в TXT, Решения Procure to Pay для лабораторий, Чтение рукописного текста, Сканирование чеков, Роботизированная автоматизация процессов, RPA, Сканирование рукописного ввода в текст, Сканирование счета-фактуры , Scan to Excel, Scantron, Server OCR, Simple Invoice Software, тестовое сканирование, Zone OCR|
Подробнее
ABBYY FlexiCapture On-Premise — распределенная — бессрочная лицензия PPY 50K страниц
ABBYY FlexiCapture — это мощное решение для сбора данных и обработки документов от ведущего мирового поставщика технологий. Он предназначен для преобразования потоков документов любой структуры и сложности в готовые для бизнеса данные. А его отмеченные наградами технологии распознавания, автоматическая классификация документов, а также масштабируемая и настраиваемая архитектура означают, что он может помочь компаниям и организациям любого размера оптимизировать свои бизнес-процессы, повысить эффективность и сократить расходы.
Он предназначен для преобразования потоков документов любой структуры и сложности в готовые для бизнеса данные. А его отмеченные наградами технологии распознавания, автоматическая классификация документов, а также масштабируемая и настраиваемая архитектура означают, что он может помочь компаниям и организациям любого размера оптимизировать свои бизнес-процессы, повысить эффективность и сократить расходы.
Nikita2022-06-22T16:40:37-04:00Категории: ABBYY, ABBYY FlexiCapture, Скрипты на арабском и иврите, Азиатский CJK OCR, Программное обеспечение для пакетного оптического распознавания текста, Сбор корпоративных данных, Excel OCR, Обработка форм, Распознавание рукописного ввода, OMR , Zone OCR|Теги: Классификация AI, Обучение AI OCR, Сканирование счетов AP, Искусственный интеллект, Автоматический ввод данных, Автоматическая классификация, Автоматическое разделение документов, Лучшее программное обеспечение OCR, Лучшее программное обеспечение OCR для рукописного ввода, Лучшее программное обеспечение для оптического распознавания символов, Лучшее программное обеспечение для Создание форм, сбор данных, извлечение данных, классификация документов, сбор электронных данных, обработка форм, распознавание отпечатков пальцев, ICR, машинное обучение, форма OCR, программное обеспечение для форм OCR, таблицы OCR, извлечение данных PDF, чтение рукописного текста, извлечение таблиц, зональное распознавание символов, Зона OCR|
Подробнее
ABBYY FlexiCapture Cloud
ABBYY FlexiCapture Cloud предоставляет расширенные возможности платформы сбора данных ABBYY через REST API и веб-интерфейсы. Клиенты ABBYY FlexiCapture Cloud могут быстро настроить и предоставить свое решение Content IQ, используя преимущества наших облачных сервисов для автоматизации и ускорения своих процессов, связанных с документами. Усовершенствованное машинное обучение и ИИ на платформе улучшают результаты классификации и извлечения данных, позволяя основным процессам поддерживать более эффективные, разумные и быстрые решения.
Клиенты ABBYY FlexiCapture Cloud могут быстро настроить и предоставить свое решение Content IQ, используя преимущества наших облачных сервисов для автоматизации и ускорения своих процессов, связанных с документами. Усовершенствованное машинное обучение и ИИ на платформе улучшают результаты классификации и извлечения данных, позволяя основным процессам поддерживать более эффективные, разумные и быстрые решения.
FlexiCapture Cloud позволяет организациям ускорить цифровую трансформацию, дополняя свои системы автоматизации новыми расширенными когнитивными возможностями, которые высвобождают интеллект, запертый в их документах.
Nikita2022-06-22T16:41:07-04:00Категории: ABBYY, ABBYY FlexiCapture, Скрипты на арабском и иврите, Азиатский CJK OCR, Программное обеспечение для пакетного оптического распознавания символов, Облачное оптическое распознавание символов, Сбор корпоративных данных, Excel OCR, Обработка форм, Рукописный ввод Распознавание, OMR, Zone OCR|Теги: Классификация AI, Обучение AI OCR, Сканирование счетов AP, Искусственный интеллект, Автоматический ввод данных, Автоматическая классификация, Автоматическое разделение документов, Лучшее программное обеспечение OCR, Лучшее программное обеспечение OCR для рукописного ввода, Лучшее программное обеспечение для оптического распознавания символов, Лучшее программное обеспечение для создания форм, облачное распознавание символов, сбор данных, извлечение данных, классификация документов, сбор электронных данных, обработка форм, распознавание отпечатков пальцев, ICR, машинное обучение, форма распознавания текста, программное обеспечение форм распознавания текста, таблицы распознавания текста, извлечение данных PDF, чтение почерка, Извлечение таблицы, зональное распознавание, зональное распознавание |
Подробнее
PaperVision Capture Forms Magic добавляет шаблоны и бизнес-правила для распознавания рукописного ввода, обработки форм, обработки счетов или форм заявлений на медицинское обслуживание и бизнес-правила к своей платформе сканирования больших объемов документов и сбора данных.
aaron2022-06-26T10:19:51-04:00Категории: Программное обеспечение для пакетного оптического распознавания символов, Системы Digitech, Сбор корпоративных данных, Обработка форм, Обработка счетов, Зональное оптическое распознавание|Теги: Классификация ИИ, Обучение распознаванию ИИ, Сканирование счетов AP , Искусственный интеллект, Автоматический ввод данных, Автоматическая классификация, Автоматическое разделение документов, Лучшее программное обеспечение для распознавания текста, Лучшее программное обеспечение для распознавания рукописного текста, Лучшее программное обеспечение для оптического распознавания символов, Лучшее программное обеспечение для создания форм, Сбор данных, Извлечение данных, Классификация документов, Электронный сбор данных, Обработка форм, Распознавание отпечатков пальцев, ICR, Машинное обучение, Форма OCR, Программное обеспечение OCR Form, Таблицы OCR, Извлечение данных PDF, Чтение рукописного текста, Извлечение таблиц, Зональное распознавание, Зональное распознавание |
Подробнее
ABBYY FlexiCapture SDK позволяет разработчикам программного обеспечения быстро создавать приложения, извлекающие смысл из документов. FlexiCapture SDK идеально подходит для системных интеграторов, разработчиков и поставщиков услуг, которые хотят интегрировать мощные возможности сбора данных в свои решения. Благодаря использованию машинного обучения и искусственного интеллекта ABBYY конечные клиенты могут обрабатывать больше транзакций, быстрее и с меньшим количеством ошибок, улучшая обслуживание клиентов, сокращая затраты и принимая более взвешенные технологические решения.
FlexiCapture SDK идеально подходит для системных интеграторов, разработчиков и поставщиков услуг, которые хотят интегрировать мощные возможности сбора данных в свои решения. Благодаря использованию машинного обучения и искусственного интеллекта ABBYY конечные клиенты могут обрабатывать больше транзакций, быстрее и с меньшим количеством ошибок, улучшая обслуживание клиентов, сокращая затраты и принимая более взвешенные технологические решения.
FlexiCapture SDK, как вариант поставки платформы FlexiCapture, предоставляет разработчикам мощный и гибкий набор инструментов для беспрепятственной интеграции ведущих в отрасли технологий сбора данных ABBYY для улучшения их собственных продуктов и услуг в соответствии с потребностями вертикального рынка.
Лицензирование основано на количестве разработчиков для базового SDK, затем для бессрочной лицензии используется количество страниц в год. В лицензию включена вся функциональность, поддерживаемая ABBYY FlexiCapture, за некоторыми исключениями.
aaron2022-06-22T16:50:43-04:00Категории: ABBYY, ABBYY FlexiCapture, Скрипты на арабском и иврите, Азиатский CJK OCR, Обработка форм, Распознавание рукописного ввода, Обработка счетов, OCR SDK|Теги: Автоматизация расчетов с поставщиками, Счета к оплате OCR, сканирование счетов AP, автоматический ввод данных, пакетное распознавание текста, пакетное распознавание PDF, лучшее программное обеспечение для распознавания рукописного текста, сбор данных, извлечение данных, распознавание отпечатков пальцев, ICR, распознавание счетов, программное обеспечение рабочего процесса счетов, OCR Engine, OCR Library, OCR SDK, Извлечение данных PDF, простое программное обеспечение для выставления счетов |
Подробнее
ABBYY Vantage использует машинное обучение ИИ и огромную библиотеку «навыков» работы с документами, чтобы обеспечить готовый сбор данных для всех типов документов.
Vantage предлагает простой способ внедрения новых процессов сбора данных без необходимости в программистах.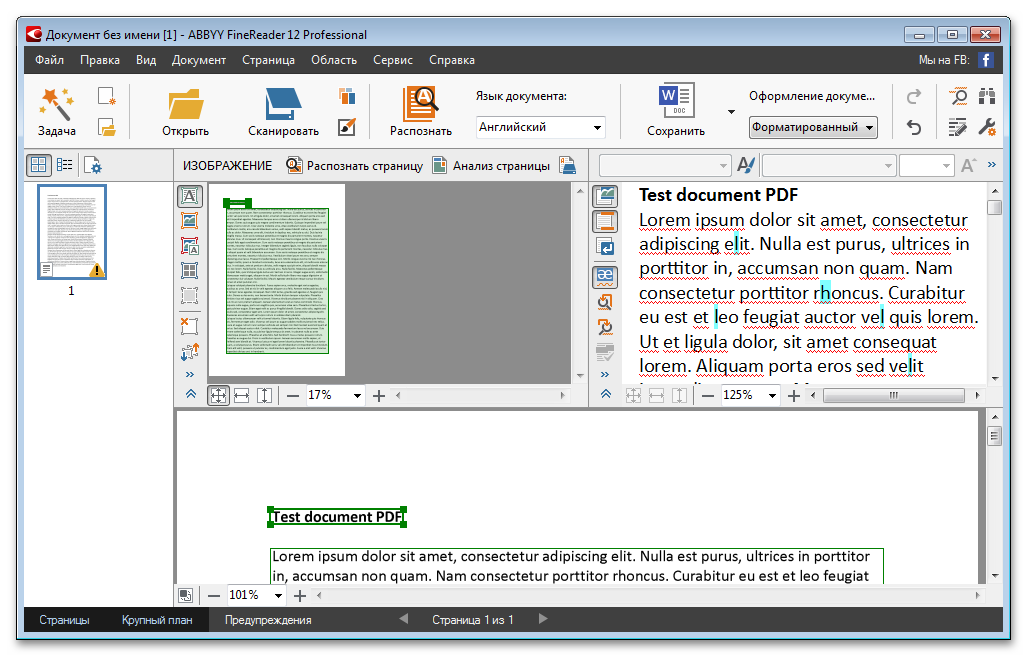
Он использует платформу FlexiCapture, размещает ее в облаке и значительно упрощает интерфейс. Тысячи настроек, которые вы можете использовать с FlexiCapture для создания шаблонов, управляются искусственным интеллектом, предоставляя вам простой интерфейс «укажи и щелкни» для создания новых рабочих процессов захвата документов.
Библиотека «Навыки» предоставляет предварительно настроенные рабочие процессы захвата для сотен наиболее распространенных документов. Просто подключите их к местам назначения импорта и экспорта, и вы готовы к работе, что сэкономит вам часы или даже дни времени разработки.
aaron2022-06-22T16:52:51-04:00Категории: ABBYY, ABBYY FlexiCapture, Скрипты на арабском и иврите, Азиатский CJK OCR, Программное обеспечение пакетного оптического распознавания символов, Облачное оптическое распознавание символов, Сбор корпоративных данных, Excel OCR, Обработка форм, Рукописный ввод Распознавание, Обработка счетов, OMR, Роботизированная автоматизация процессов, OCR сервера, OCR зоны|Теги: Автоматизация кредиторской задолженности, Классификация AI, Обучение распознаванию AI, Сканирование счетов AP, Искусственный интеллект, Автоматический ввод данных, Программное обеспечение для автоматической обработки счетов, Автоматическая классификация, Автоматический Разделение документов, Лучшее программное обеспечение OCR, Лучшее программное обеспечение OCR для рукописного ввода, Лучшее программное обеспечение для оптического распознавания символов, Лучшее программное обеспечение для создания форм, Облачное распознавание символов, Сбор данных, Извлечение данных, Классификация документов, Электронный сбор данных, Обработка форм, Распознавание отпечатков пальцев, Оптическое распознавание символов в здравоохранении, ICR, программное обеспечение для автоматизации счетов, захват счетов, визуализация счетов, оптическое распознавание счетов, распознавание счетов, программное обеспечение для сканирования счетов, программное обеспечение для обработки счетов, машинное обучение ing, Точность OCR, Форма OCR, Программное обеспечение для форм OCR, Обработка счетов OCR, Таблицы OCR, Извлечение данных PDF, Чтение рукописного текста, Сканирование чеков, Автоматизация роботизированных процессов, RPA, Сканирование счетов, Простое программное обеспечение счетов, Извлечение таблиц, Налоговые формы OCR, Зональное OCR, Зона OCR|
Подробнее
Автоматически извлекайте рукописный текст, обычный текст или данные формы из любого документа с помощью крупнейшей в мире модели машинного обучения OCR, основанной на миллиардах образцов документов.
Amazon Textract — это облачная служба OCR, которая автоматически обнаруживает и извлекает текст и данные из отсканированных документов и файлов PDF. Он выходит за рамки простого оптического распознавания символов (OCR) и позволяет также идентифицировать содержимое полей в формах и информацию, хранящуюся в таблицах.
API Amazon Textract также позволяет внедрять распознавание символов в рабочие процессы RPA. UiPath и другие боты предлагают коннекторы, которые позволяют включать OCR Textract в процесс RPA.
Textract не является «готовым к использованию» продуктом. Для его внедрения в ваши системы требуются навыки программирования, опыт работы с системами AWS и достаточное количество кода, особенно если вы добавите пользовательские интерфейсы для сканирования и проверки данных.
Простое программное обеспечение разработчиков обладают необходимыми навыками и опытом для интеграции Textract в ваши пользовательские приложения. Свяжитесь с нами или нажмите кнопку «Запросить цену», чтобы получить предложение по вашему индивидуальному проекту разработки приложений.
Simple Software также предлагает готовое к использованию приложение SimpleIndex, которое включает Textract в полнофункциональное приложение для сканирования, индексирования и обработки документов.
Никита2022-06-22T18:17:00-04:00Категории: Облачное распознавание текста, Распознавание рукописного текста, Обработка счетов, OCR SDK, Услуги распознавания текста, Роботизированная автоматизация процессов|Теги: Обучение распознаванию текста на основе ИИ, Искусственный интеллект, Лучшее программное обеспечение для распознавания текста, Лучшее средство распознавания текста Программное обеспечение для рукописного ввода, облачное распознавание текста, преобразование рукописного текста в текст, курсивное распознавание рукописного ввода, распознавание отпечатков пальцев, распознавание рукописного ввода, распознавание счетов, машинное обучение, точность распознавания текста, модуль оптического распознавания символов, обработка счетов оптического распознавания символов, библиотека оптического распознавания символов, SDK оптического распознавания символов, чтение рукописного ввода, сканирование чеков, Сканирование рукописного ввода в текст, SDK OCR, распознавание текста |
Подробнее
Компания Grooper была создана с нуля компанией BIS, имеющей 35-летний опыт разработки и внедрения новых технологий. Grooper — это интеллектуальное решение для обработки документов и интеграции цифровых данных, которое позволяет организациям извлекать важную информацию из бумажных/электронных документов и других форм неструктурированных данных.
Grooper — это интеллектуальное решение для обработки документов и интеграции цифровых данных, которое позволяет организациям извлекать важную информацию из бумажных/электронных документов и других форм неструктурированных данных.
Платформа сочетает в себе запатентованную и сложную обработку изображений, технологию захвата, машинное обучение, обработку естественного языка и оптическое распознавание символов, чтобы обогатить и внедрить человеческое понимание в данные. Решая сложные задачи, которые не могут решить другие системы, Grooper стала основой для многих передовых решений в области здравоохранения, финансовых услуг, нефти и газа, образования и правительства.
- Single platform
- Patented OCR
- Image processing
- Machine learning
- Natural language processing
- Zero code
- Zero templates
- Open architecture
Nikita2022-06-22T16:56:44-04 :00Категории: Программное обеспечение для пакетного оптического распознавания символов, Сбор корпоративных данных, Обработка форм, Распознавание рукописного ввода, Обработка счетов, OMR, Зональное оптическое распознавание символов|Теги: Автоматизация расчетов с поставщиками, Сканирование счетов AP, Автоматический ввод данных, Программное обеспечение для автоматической обработки счетов, Лучшее программное обеспечение для оптического распознавания символов, Лучшее программное обеспечение для оптического распознавания символов Программное обеспечение для рукописного ввода, Лучшее программное обеспечение для создания форм, Сбор данных, Извлечение данных, Электронный сбор данных, Обработка форм, Распознавание отпечатков пальцев, ICR, Программное обеспечение для автоматизации счетов, Захват счетов, Изображение счетов, OCR счетов, Распознавание счетов, Программное обеспечение для сканирования счетов, Рабочий процесс счетов Программное обеспечение, Точность OCR, Форма OCR, Программное обеспечение формы OCR, Обработка счетов OCR, Таблицы OCR, Извлечение данных PDF, Rea d Рукописный ввод, сканирование счета-фактуры, программное обеспечение для простого счета-фактуры, извлечение таблиц, оптическое распознавание налоговых форм, зональное распознавание символов, зональное распознавание символов |
Подробнее
Ссылка для загрузки страницыПерейти к началу
Программное обеспечение для распознавания рукописного текста для безопасного вождения
Бизнес-задача
Команда Intellias завершила научно-исследовательский проект приложения автомобильной клавиатуры Android с несколькими премиальными функциями, включая распознавание рукописного ввода. Это был ответ нашей компании на рыночный спрос на решение, которое решит некоторые из наиболее распространенных проблем и потребностей в инклюзивности, с которыми ежедневно сталкиваются водители:
Это был ответ нашей компании на рыночный спрос на решение, которое решит некоторые из наиболее распространенных проблем и потребностей в инклюзивности, с которыми ежедневно сталкиваются водители:
- Сложные и отвлекающие интерфейсы ставят под угрозу безопасность
- Шумная обстановка в автомобиле заглушает голосовых помощников
- Ограничения скорости устанавливают ограничения на использование ввода текста с клавиатуры
- Вибрация автомобиля затрудняет нажатие клавиш и искажает качество рукописного текста
- Удобство ввода для левшей и слабослышащих водителей часто упускается из виду
Учитывая все эти болевые точки водителей, мы составили контрольный список жестких требований к нашему продукту. Intellias успешно провела научно-исследовательский проект, который демонстрирует наши сильные технологические возможности и опыт в области нейронных сетей, машинного обучения и искусственного интеллекта. После серии совещаний и семинаров мы подтвердили, что наше решение предлагает эффективный метод ввода.
Решение доставлено
Наша команда разработчиков Android и машинного обучения, специалистов по безопасности и обслуживанию, дизайнеров и инженеров по обеспечению качества приступила к работе над нашим продуктом R&D.
Специальное приложение для клавиатуры Android поддерживает несколько режимов пользовательского ввода: стандартный, смахивание и распознавание рукописного ввода. Он может понимать текст, написанный от руки, и позволяет водителям эффективно общаться с информационно-развлекательной системой автомобиля, не отрывая глаз от дороги. Это решение чрезвычайно интуитивно понятно, оно распознает любой естественный почерк: прописные, строчные, курсив, блочный и даже наложенный текст.
Благодаря интеграции системы с пользовательской информацией водители могут вводить пункт назначения, просматривать достопримечательности на карте, изменять настройки климат-контроля, включать свою любимую музыку и звонить или отправлять сообщения своим контактам — и все это одним движением пальца. Возможность приложения захватывать рукописный текст из отсканированных изображений и даже предлагать и предсказывать слова на основе привычек и стиля письма пользователя обеспечивает удобство для водителей и повышает безопасность.
Возможность приложения захватывать рукописный текст из отсканированных изображений и даже предлагать и предсказывать слова на основе привычек и стиля письма пользователя обеспечивает удобство для водителей и повышает безопасность.
Распознавание рукописного ввода
Наше программное обеспечение для распознавания рукописного ввода, реализованное с помощью платформы TensorFlow, преобразует изображения слов в цифровой текст. Мы построили сверточную нейронную сеть (CNN) и обучили ее на автономном наборе данных IAM изображений слов. Входное изображение, представленное векторами и временными дельтами, подается в модель CNN, которая извлекает соответствующие функции. Затем выходные данные карты объектов обрабатываются, алгоритм выявляет корреляции со словами и генерируется цифровой текст. Эта модель распознает рукописный текст на изображениях со значительной точностью.
Многосимвольное распознавание (MCR)
Для реализации модели многосимвольного распознавания мы использовали MXNet и ResNet в качестве опорных нейронных сетей, а также специальные функции предварительной и постобработки для обработки движений пальцев во время вождения. Наш подход MCR состоит из трех шагов:
- Обнаружение текстовых областей путем выделения признаков с помощью сверточной нейронной сети
- Распознавание символов с помощью сверточной нейронной сети
- Применение языковой модели для исправления ошибок
Исправление и подсказка слов
Мы разработали модели исправления слов и подсказки/прогноза слов, используя классические подходы машинного обучения.
Вычисляя расстояние Левенштейна, модель исправления слов исправляет неправильно идентифицированные слова и повышает точность обнаружения слов.
Кроме того, мы внедрили подход к обучению с подкреплением, основанный на образцах почерка водителей в тестовых автомобилях, чтобы улучшить модели с помощью отзывов о взаимодействии с пользователем. Текстовые исправления при вводе пользователем будут собраны, и модель будет соответствующим образом обновлена.
Текстовые исправления при вводе пользователем будут собраны, и модель будет соответствующим образом обновлена.
Модель предложения слов предсказывает следующее слово или фразу, чтобы свести к минимуму объем требуемого ввода. Эта модель основана на извлечении биграмм и n-грамм, а также на статистике из исторических пользовательских данных. Он учитывает контекст написания, словари языка и местонахождения и даже поведенческие и орфографические предпочтения пользователя.
Решение также включает механизм подсказок на основе местоположения, чтобы подсказывать пользователю при поиске определенного адреса или места. В зависимости от местоположения пользователя система извлекает запрошенную информацию из базы данных карты NDS и предлагает местоположение или название улицы. Имея многолетний опыт создания решений для определения местоположения и картографирования, наши инженеры обладают всеми необходимыми знаниями для создания и обновления баз данных о местоположении и их интеграции с приложениями автомобильной клавиатуры.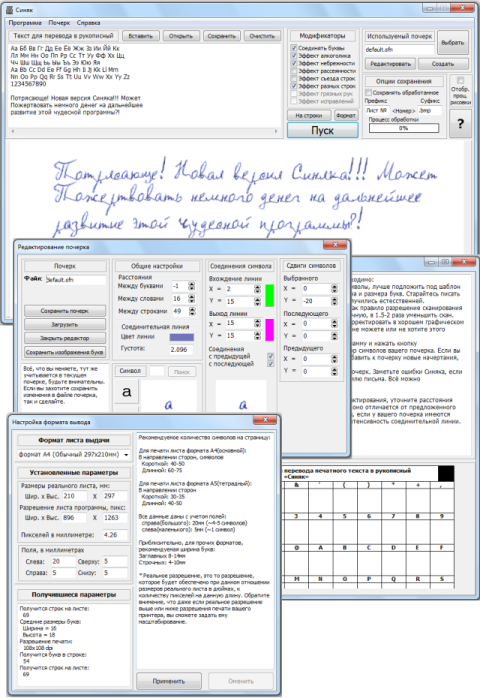
Помимо разработки технического решения, включающего в себя саму клавиатуру и серверную часть, позволяющую достичь высокой точности распознавания, мы также решили другие проблемы, связанные с машинным обучением:
- Обновление моделей
Наше решение включает в себя службу обновления по беспроводной сети (OTA), которая позволяет легко распространять только что обученные модели машинного обучения для распознавания рукописного ввода на транспортные средства. Таким образом, точность распознавания автомобилей на дороге может со временем повышаться.
- Получение достаточных обучающих данных
Мы использовали самые современные технологии для увеличения данных, чтобы расширить набор обучающих данных, дополняя данные распознавания нескольких символов смесью реальных и искусственных данных. Для этого мы придерживались подходов Autoencoder и GAN и использовали только данные реального почерка для создания расширенных образцов данных. Кроме того, мы использовали классические подходы к дополнению, включая вращение данных, масштабирование, сдвиг и искажения для учета движения транспортного средства.
Кроме того, мы использовали классические подходы к дополнению, включая вращение данных, масштабирование, сдвиг и искажения для учета движения транспортного средства.
Бизнес-результат
Поскольку автомобильные гиганты во всем мире продолжают поднимать планку безопасности, комфорта и эффективности вождения, автомобильным компаниям важно оставаться на шаг впереди перед лицом жесткой конкуренции. Разработанное нами приложение для клавиатуры позволит автопроизводителям поддерживать уровень удовлетворенности клиентов выше среднего по отрасли и даже повышать его со временем. Наше быстродействующее решение предлагает интуитивно понятное взаимодействие и практически не требующий усилий ввод данных. Он инклюзивен по своей природе и может похвастаться впечатляющей точностью распознавания слов. Это приложение является фундаментальным шагом к изменению опыта вождения для пользователей.
Инженеры Intellias привнесли в этот проект большой отраслевой опыт и важные навыки, в том числе компетентность в области автомобилестроения, опыт работы с системами определения местоположения и навигации, навыки разработки программного обеспечения для Android и знания в области машинного обучения.