
Online сервисы распознавание текста. Просто. Бесплатно и удобно. | Учи Урок информатики
Онлайн распознавание текста – это процесс преобразования символов из сканированного документа или изображения с помощью специальных алгоритмов машинного обучения (веб-программ в случае использования online сервисов). Распознавание текста позволяет нам существенно сэкономить время, ведь их не нужно печатать самостоятельно. Сегодня с помощью оптической технологии распознавания текста OCR в большом количестве создается огромное количество отсканированных книг журналов, которые потом можно читать на компьютере. Оптическое распознавание текста завоевало себе место на рынке информационных услуг и стало популярным, ведь после процедуры определения символов, текст можно не только прочитать, но и перевести с помощью автоматического переводчика, внести правки и форматировать его, применяя различные стили.
К сожалению, данная технология не может распознать информацию из PDF со стопроцентной точностью, поэтому после завершения распознавания текста на изображении необходимо сравнивать результат и исходные документы (если форматируется большой документ или книга).
1. Онлайн-словарь для распознавания текста ABBYY
Самая популярная программа-словарь, которая имеет функцию определения текста с изображений и других типов документов. Данное приложение позволяет пользователю моментально получить тестовый вариант фотографии и перевести его на более чем на 50 языков мира. Чтобы распознать текст с помощью данного сервиса, следуйте инструкции:
- Зайдите на официальный сайт веб-приложения и нажмите на кнопку «Распознать», которая находится в центре страницы. Официальная ссылка на сервис: https://finereaderonline.com/ru-ru
- Загрузите файл, с которого необходимо распознать инфо;
- Следующим шагом необходимо выбрать язык конечного документа. Даже если вам не нужно переводить текст, выберите необходимый язык, ведь для каждого из них программа выбирает соответствующую кодировку символов, что позволяет более точно отображать символы;
Последний шаг – необходимо выбрать формат конечного файла. С помощью данного сервиса можно переводить текст с PDF в Word, а также с форматов djvu и jpg.
С помощью данного сервиса можно переводить текст с PDF в Word, а также с форматов djvu и jpg.
2. Сервис Online-Ocr
Данный сервис позволяет без регистрации создать текстовый документ из отсканированного файла или из самой обычной картинки. Данный сервис был первым, кто использовал технологию оптического определения машинного текста. Приведем пример распознавания с ПДФ в Ворд:
- Зайдите на сайт сервиса: http://www.onlineocr.net/
- Нажмите на клавишу «выбрать файл» и найдите на своем компьютере необходимый пдф документ, с которого будет определен текст. Максимальный размер входящего документа равен пяти мегабайтам;
- Выберите язык входящего документа и формат конечного файла из предложенного списка поддерживаемых форматов.
- Нажмите кнопку «Конвертировать»;
Процесс конвертации занимает максимум 5 минут, данный показатель зависит от размера входящего файла, от его кодировки и сложности визуального оформления.
3. Веб-приложение Free-OCR
Главное преимущество данного сервиса – возможность работы практически со всеми форматами картинок. К примеру, большинство сервисов распознавания текста не поддерживают такие форматы, как gif, bmp или tif.
Внешний вид сайта очень простой, таким образом каждый пользователь сможет справиться с поставленной задачей.
Ссылка на сервис: www.free-ocr.com
Удобнее всего переводить текст в Word, ведь данная программа способна отобразить огромное количество различных текстовых кодировок, а также элементы дизайна входящего файла. Данный сервис является абсолютно бесплатным и не требует пользовательской регистрации. Единственное ограничение — размер входящего файла должен быть меньше, чем 6 мегабайт, поэтому распознавать большие документы с помощью данной программы не получиться. Самое точное направление распознавания – с формата JPEG в ворд.
Источник: http://geek-nose.com/onlajn-raspoznavanie-teksta/
Пожалуйста, оцените статью
4. 2 из 5. (Всего голосов:259)
2 из 5. (Всего голосов:259)
Все статьи раздела
Сервисы для распознавания текста — подборка лучших | Сканеры | Блог
Заказчик прислал сканы рабочих документов, в университете скинули фотку конспекта? Когда-то тексты умели распознавать только сканеры и то далеко не все. Сейчас же даже приложения на смартфоне могут перевести визуальный текст в редактируемый документ. А в этом материале ищем лучшие сервисы по распознаванию текста для вашего компьютера и смартфона тоже.
Finereaderonline.com
Попробовать тут
Компания ABBYY идет в плане распознавания текстов и обработки цифровых документов впереди всех. В арсенале их софта даже цифровые подписи, которые почти невозможно отличить от настоящих. Finereaderonline поддерживает почти 200 языков, работает быстро и онлайн — ничего не надо устанавливать. Можно выбрать разные форматы для сохранения текста, обработка текста происходит очень быстро и достаточно точно. Единственный нюанс — лимит на загрузку файлов до 100 Мб. Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Единственный нюанс — лимит на загрузку файлов до 100 Мб. Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Sodapdf.com
Попробовать тут
Еще один неплохой сервис, хотя тут нам предлагают скачать прогу отдельно. Правда, чуть менее обученный, чем софт от ABYYY — Sodapdf знает только 46 языков. Впрочем, если вам не нужно переводить с ацтекского или зулу, то проблем не возникнет. Программа условно бесплатная — есть триальная версия, полный функционал стоит от 7 до 17 евро в месяц в зависимости от пакета. Soda умеет конвертировать разные форматы, распознавать тексты, ставить электронные подписи и имеет большой набор инструментов для работы с PDF файлами и изображениями.
WinScan2PDF
Попробовать тут
Элементарная, простая маленькая утилита, которая состоит из трех кнопок: «выбрать источник», «сканировать» и подтвердить или отменить операцию. Поддерживает 23 языка, работает с многостраничными файлами и сохраняет обработанный файл в формате PDF. У этой программы есть одна особенность — она не работает с готовыми файлами и считывает документы только с подключенного сканера.
Поддерживает 23 языка, работает с многостраничными файлами и сохраняет обработанный файл в формате PDF. У этой программы есть одна особенность — она не работает с готовыми файлами и считывает документы только с подключенного сканера.
Free Online OCR
Попробовать тут
Не такой симпатичный, как Finereader, но тоже вполне умелый онлайн-сервис. Англоязычный, слегка устаревший интерфейс, в котором, впрочем, несложно разобраться. Free Online OCR поддерживает 106 языков и распознает текст с большинства самых популярных форматов файлов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сохранять готовые доки может не только в PDF, но и в стандарных doc и txt. Кроме текста, может распознать математические уравнения, правильно форматировать текст в колонках и столбцах или обработать только выделенный фрагмент. Качество распознавания довольно высокое даже c картинок низкого качества.
Microsoft OneNote
Попробовать тут
Распознавание текста здесь скорее дополнительная фича, а не основная задача. Вы можете вставить картинку в текущую запись OneNote и правой кнопкой мыши выбрать «Копировать текст из рисунка». Цифровая записная книжка от Microsoft однозначно не подойдет для обработки больших файлов, документов и постоянной работы с файлами. Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.
Вы можете вставить картинку в текущую запись OneNote и правой кнопкой мыши выбрать «Копировать текст из рисунка». Цифровая записная книжка от Microsoft однозначно не подойдет для обработки больших файлов, документов и постоянной работы с файлами. Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.
Readiris
Попробовать тут
Мощный и удобный конкурент ABBYY FineReader. Быстро и очень чисто распознает даже едва различимые тексты, при этом поддерживает 137 языков, включая русский. Работает очень быстро и легко обрабатывает даже большие объемы текста. Сохраняет исходное форматирование, не игнорируя кавычки, размеры шрифта и стиль написания. Может почистить текст от помарок и предложить исправления в словах. Знает символы, уравнения. Контактирует со сканерами, облачными сервисами, поддерживает кучу форматов. В общем, полноценный и удобный сервис, который не умеет разве что редактировать итоговый файл PDF. Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.
В общем, полноценный и удобный сервис, который не умеет разве что редактировать итоговый файл PDF. Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.
Img2txt.com
Попробовать тут
Приятный дизайн, понятный интерфейс и высокая скорость обработки текста — что еще нужно для работы? Продвинутые алгоритмы распознавания помогают считывать документы даже плохого качества. Молниеносно конвертирует большие объемы текста, но при желании можно выбрать отдельную область файла для работы. Есть интеграция с Google Documents, хороший инструментарий для работы с документами PDF. Маловато языков — всего 35, но для основных задач этого может вполне хватить.
OCR CuneiForm
Попробовать тут
Шустро и тщательно распознает сфотографированные или отсканированные тексты, графические файлы. Старается сохранить исходную структуру текста, элементов и шрифты. Переводит все в редактируемые форматы на выбор. В общем, стандартный набор функционала. И, что самое главное, полностью бесплатный.
И, что самое главное, полностью бесплатный.
TextGrabber 6
iOS, Android
Полностью бесплатное приложение для смартфонов за авторством компании ABBYY. Собственно, этим все сказано — в TextGrabber 6 все хорошо с распознаванием текста, есть встроенный модуль переводчика. Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
Распознавание текста с картинки онлайн бесплатно
Мы уже рассматривали с Вами
И действительно, зачем устанавливать какие-то программы, если Вам нужно распознать текст один раз, и в дальнейшем Вы не собираетесь эту программу использовать? Или Вам нужно делать это раз в месяц? В этом случае лишняя программа на компьютере не нужна.
Давайте рассмотрим несколько сервисов, при помощи которых можно распознавать текст с картинки бесплатно, легко и быстро.
Free Online OCR
Очень хорошим сервисом для распознавания текста с картинки онлайн является сервис Free Online OCR. Он не требует регистрации, распознает текст с картинки практически любого формата. работает с 58 языками. Распознаваемость текста у него отличная.
Пользоваться этим сервисом просто. Когда Вы на него зайдете, перед Вами будет всего два варианта: загрузить файл с компьютера, или вставить URL-адрес картинки, если она находится в Интернете.
Если Ваше изображение находится на компьютере, нажимаете на кнопку Выберите файл, затем выбираете свой файл, и нажимаете на кнопку Upload. Вы увидите свой графический файл ниже, а над ним кнопку
Online OCR Net
Также довольно неплохой сервис, который позволяет распознавать тексты с картинок онлайн бесплатно, и без регистрации. Поддерживает он 48 языков, включая русский, китайский, корейский и японский. Чтобы начать с ним работать, заходите на Online OCR, нажимаете кнопку Select file, и выбираете файл на своем компьютере. Существуют ограничения по размеру — файл не должен весить больше 5 Мбайт.
Чтобы начать с ним работать, заходите на Online OCR, нажимаете кнопку Select file, и выбираете файл на своем компьютере. Существуют ограничения по размеру — файл не должен весить больше 5 Мбайт.
В соседних полях выбираете язык и расширение текстового документа, в котором будет полученный из картинки текст. После этого вводите капчу внизу, и нажимаете на кнопку
ABBYY FineReader Online
Очень хороший сервис в плане своей многофункциональности. На ABBYY FineReader Online можно не только распознавать текст с картинки, но также и переводит документы из формата PDF в формат Word, переводить таблицы из картинок в Excel, и создавать документы PDF из сканов.
На этом сервисе есть регистрация, но можно обойтись и входом с помощью социальной сети Facebook, сервисов Google+, или Microsoft Account.
Преимущество такого подхода в том, что созданные документы будут храниться в Вашем аккаунте в течении 14 дней, и даже если Вы их удалите из компьютера, можно будет вернуться на сервис, и опять их скачать.
Online OCR Ru
Сервис, похожий на предыдущий, с информацией на русском языке. Принцип работы сервиса Online OCR такой же, как и всех остальных — нажимаете на кнопку Выберите файл, загружаете картинку, выбираете язык и выходной формат текстового документа, и нажимаете на кнопку Распознать текст.
Кроме распознавания текста из картинок, сервис предоставляет возможность перевода изображений в форматы PDF, Excel, HTML и другие, причем структура и разметка документа будет соответствовать той, которая была на картинке.
На этом сервисе также есть регистрация, и файлы, созданные Вами с его помощью, будут храниться в Вашем личном кабинете.
Данные сервисы распознавания текста с картинок, на мой взгляд, самые лучшие. Надеюсь, они и Вам принесут пользу. Также, возможно, я не все хорошие сервисы осветил. Жду Ваших комментариев, насколько эти сервисы Вам понравились, какими сервисами пользуетесь Вы, и какие из них являются, на Ваш взгляд, самыми удобными.
Также, возможно, я не все хорошие сервисы осветил. Жду Ваших комментариев, насколько эти сервисы Вам понравились, какими сервисами пользуетесь Вы, и какие из них являются, на Ваш взгляд, самыми удобными.
Более подробные сведения Вы можете получить в разделах “Все курсы” и “Полезности”, в которые можно перейти через верхнее меню сайта. В этих разделах статьи сгруппированы по тематикам в блоки, содержащие максимально развернутую (насколько это было возможно) информацию по различным темам.
Также Вы можете подписаться на блог, и узнавать о всех новых статьях.
Это не займет много времени. Просто нажмите на ссылку ниже:
Подписаться на блог: Дорога к Бизнесу за Компьютером
Проголосуйте и поделитесь с друзьями анонсом статьи на Facebook:
Как распознать текст в Word – Онлайн сервисы для бесплатного распознавания текста
Все мы уже привыкли фотографировать расписание, документы, страницы книг и многое другое, но по ряду причин «извлечь» текст со снимка или картинки, сделав его пригодным для редактирования, все же требуется.
Особенно часто с необходимостью преобразовать фото в текст сталкиваются школьники и студенты. Это естественно, ведь никто не будет переписывать или набирать текст, зная, что есть более простые методы. Было бы прям идеально, если бы преобразовать картинку в текст можно было в Microsoft Word, вот только данная программа не умеет ни распознавать текст, ни конвертировать графические файлы в текстовые документы.
Единственная возможность «поместить» текст с JPEG-файла (джипег) в Ворд — это распознать его в сторонней программе, а затем уже оттуда скопировать его и вставить или же просто экспортировать в текстовый документ.
Содержание
Распознавание текста
ABBYY FineReader по праву является самой популярной программой для распознавания текста. Именно главную функцию этого продукта мы и будем использовать для наших целей — преобразования фото в текст. Из статьи на нашем сайте вы можете более подробно узнать о возможностях Эбби Файн Ридер, а также о том, где скачать эту программу, если она еще не установлена на у вас на ПК.
Распознавание текста с помощью ABBYY FineReader
Скачав программу, установите ее на компьютер и запустите. Добавьте в окно изображение, текст на котором необходимо распознать. Сделать это можно простым перетаскиванием, а можно нажать кнопку «Открыть», расположенную на панели инструментов, а затем выбрать необходимый графический файл.
Теперь нажмите на кнопку «Распознать» и дождитесь, пока Эбби Файн Ридер просканирует изображение и извлечет из него весь текст.
Вставка текста в документ и экспорт
Когда FineReader распознает текст, его можно будет выделить и скопировать. Для выделения текста используйте мышку, для его копирования нажмите «CTRL+С».
Теперь откройте документ Microsoft Word и вставьте в него текст, который сейчас содержится в буфере обмена. Для этого нажмите клавиши «CTRL+V» на клавиатуре.
Урок: Использование горячих клавиш в Ворде
Помимо просто копирования/вставки текста из одной программы в другую, Эбби Файн Ридер позволяет экспортировать распознанный им текст в файл формата DOCX, который для MS Word является основным.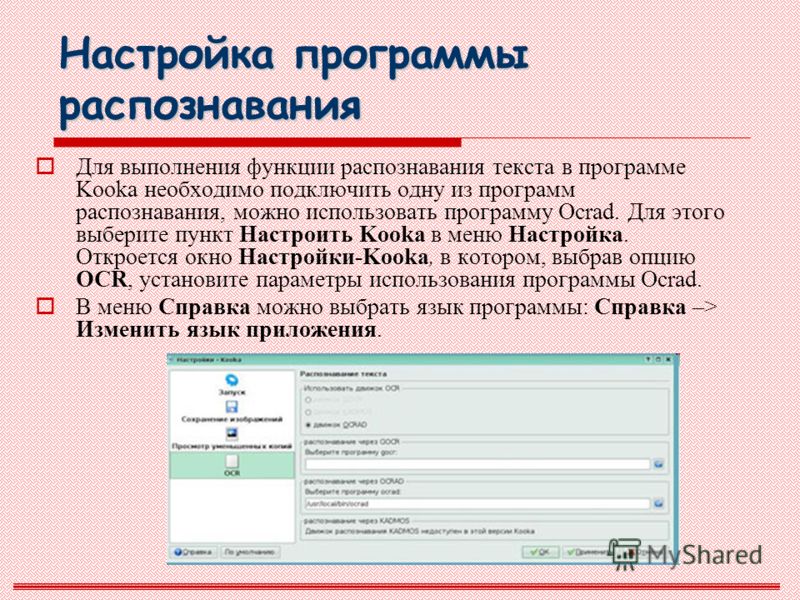 Что для этого требуется сделать? Все предельно просто:
Что для этого требуется сделать? Все предельно просто:
- выберите необходимый формат (программу) в меню кнопки «Сохранить», расположенной на панели быстрого доступа;
- кликните по этому пункту и укажите место для сохранения;
- задайте имя для экспортируемого документа.
После того, как текст будет вставлен или экспортирован в Ворд, вы сможете его отредактировать, изменить стиль, шрифт и форматирование. Наш материал на данную тему вам в этом поможет.
Примечание: В экспортированном документе будет содержаться весь распознанный программой текст, даже тот, который вам, возможно, и не нужен, или тот, который распознан не совсем корректно.
Урок: Форматирование текста в MS Word
Видео-урок по переводу текста с фотографии в Word файл
Преобразование текста на фото в документ Ворд онлайн
Если вы не хотите скачивать и устанавливать на свой компьютер какие-либо сторонние программы, преобразовать изображение с текстом в текстовый документ можно онлайн. Для этого существует множество веб-сервисов, но лучший из них, как нам кажется, это FineReader Online, который использует в своей работе возможности того же программного сканера ABBY.
Для этого существует множество веб-сервисов, но лучший из них, как нам кажется, это FineReader Online, который использует в своей работе возможности того же программного сканера ABBY.
ABBY FineReader Online
Перейдите по вышеуказанной ссылке и выполните следующие действия:
1. Авторизуйтесь на сайте, используя профиль Facebook, Google или Microsoft и подтвердите свои данные.
Примечание: Если ни один из вариантов вас не устраивает, придется пройти полную процедуру регистрации. В любом случае, сделать это не сложнее, чем на любом другом сайте.
2. Выберите пункт «Распознать» на главной странице и загрузите на сайт изображение с текстом, который нужно извлечь.
3. Выберите язык документа.
4. Выберите формат, в котором требуется сохранить распознанный текст. В нашем случае это DOCX, программы Microsoft Word.
5. Нажмите кнопку «Распознать» и дождитесь, пока сервис просканирует файл и преобразует его в текстовый документ.
6. Сохраните, точнее, скачайте файл с текстом на компьютер.
Примечание: Онлайн-сервис ABBY FineReader позволяет не только сохранить текстовый документ на компьютер, но и экспортировать его в облачные хранилища и другие сервисы. В числе таковые BOX, Dropbox, Microsoft OneDrive, Google Drive и Evernote.
После того, как файл будет сохранен на компьютер, вы сможете его открыть и изменить, отредактировать.
На этом все, из данной статьи вы узнали, как перевести текст в Ворд. Несмотря на то, что данная программа не способна самостоятельно справиться с такой, казалось бы, простой задачей, сделать это можно с помощью стороннего софта — программы Эбби Файн Ридер, или же специализированных онлайн-сервисов.
App Store: TextGrabber переводчик по фото
Наведите и распознайте любой текст в реальном времени! Результаты превращайте в действия: переводите, звоните, пишите, создавайте события, ищите на картах и в интернете.
ABBYY TextGrabber на лету оцифрует фрагменты печатного текста или QR-коды и превратит распознанный результат в действия: звоните, пишите, переводите на 100+ языков онлайн и 10 языков оффлайн, просматривайте в интернете или на картах, создавайте события в календаре, редактируйте, озвучивайте и делитесь любым удобным способом.
При наведении камеры на печатный текст приложение моментально захватывает информацию и распознает ее без подключения к интернету. Уникальный режим распознавания в реальном времени извлекает информацию на 60+ языках не только из документов, но и с любых поверхностей.
———————–
***** Победитель Mobile Star Awards в категориях “Mobile Productivity App” и “Mobile Image Capture App”
“The results get delivered relatively fast, which is great. A must have for students” – appadvice.com
“The Best Image-to-Text App for iPhone” – lifehacker.com
————————
КЛЮЧЕВЫЕ ПРЕИМУЩЕСТВА
• Перевод в режиме реального времени прямо на экране телефона на более чем 100 языков онлайн (полнотекстовый перевод) и 10 языков оффлайн (пословный перевод)
• Инновационный режим Real-Time Recognition на основе технологии ABBYY RTR SDK оцифрует печатный текст прямо в экране камеры без фотографирования.
• Распознавание текста на 60+ языках, в том числе русском, английском, немецком, испанском, греческом, турецком, китайском и корейском, без подключения к интернету.
• Все ссылки, номера телефонов, адреса электронной почты, почтовые адреса и даты после оцифровки становятся кликабельны: можно перейти по ссылке, позвонить по телефону, написать email, найти адрес на картах или добавить событие в календарь.
• Голосовые команды Siri. Распознавайте последнее фото из галереи с помощью команды Siri, которую можно настроить в основных настройках телефона.Siri shortcuts.
• Cчитыватель QR кодов.
• Озвучивание распознанного и переведенного текста с помощью системной функции VoiceOver.
• Удобный интерфейс для слабовидящих людей: можно увеличить размер шрифта и воспользоваться звуковыми подсказками к элементам интерфейса.
• Публикация текста в любое установленное на девайсе приложение через системное меню.
• Все оцифрованные данные сохраняются в истории, где их можно удалить, отредактировать или объединить.
————————
Бесплатная версия содержит рекламу и позволяет распознать и перевести 3 текста.
С ABBYY TextGrabber легко сканировать и переводить:
• Любые бумажные документы
• Tекст с экрана монитора, ТВ, смартфона
• Рецепты из кулинарных книг
• Статьи в журналах, газетах, книгах
• Этикетки и счетчики
• Инструкции и руководства по эксплуатации
• Текст состава продуктов на упаковке и многое другое…
————————
Совет по распознаванию:
Выбирайте соответствующий оригинальному тексту язык распознавания. Это особенно важно, если он отличается от установленного по умолчанию английского и русского.
————————
Автовозобновляемая Премиум-подписка позволяет получить доступ ко всем функциям приложения. Подписка продлевается автоматически в конце периода, если только вы не решите отменить подписку по крайней мере за 24 часа до окончания текущего периода. Оплата будет снята с вашего счета ITunes при подтверждении покупки. Вы можете управлять подпиской и отключить автоматическое обновление в настройках учетной записи после покупки. Все личные данные обрабатываются в соответствии с условиями стандартной политики конфиденциальности App Store.
Вы можете управлять подпиской и отключить автоматическое обновление в настройках учетной записи после покупки. Все личные данные обрабатываются в соответствии с условиями стандартной политики конфиденциальности App Store.
Privacy: https://www.abbyy.com/privacy/
Terms of Use: http://www.textgrabber.pro/en/eula/
————————
Твиттер: @ABBYY_Mobile
fb.com/Abbyy.Lingvo
vk.com/abbyylingvo
youtube.com/AbbyyMobile
————————
Пожалуйста, оставьте отзыв, если вам понравилось приложение ABBYY TextGrabber. Спасибо!
OCR online / Хабр
С технологией оптического распознавания текста я познакомился где-то в 1997 года, когда купил свой первый, тогде ещё ручной, чёрно-белый сканер Genius ScanMate 256 (кстати, всё ещё рабочий). К сканеру прилагалась программа Direct OCR на 3х дюймовой дискете (блин, откуда-то из подсознания все эти названия всплывают), которая всеми своими силами пыталась доказать, что можно быстро и почти без ошибок текст из книги ввести в компьютер. Ну, доказательства были не очень. FineReader, с которым я познакомился позже, делал это качественнее. Тема распознавания меня заинтересовала, я потратил довольно много времени на научно-популярные статьи о технологиях OCR.
Ну, доказательства были не очень. FineReader, с которым я познакомился позже, делал это качественнее. Тема распознавания меня заинтересовала, я потратил довольно много времени на научно-популярные статьи о технологиях OCR.
В 2001 году я готовил дипломную работу по web-технологиям. Долго думал о том, куда приложить знания. Поскольку меня интересовала технология OCR, я задумал совместить WEB и распознавание текстов. За само распознавание у меня должен был отвечать FineReader. С друзьями мы «разобрали» FineReader на отдельные DLL и выяснили, как вызывать отдельные функции этих библиотек, передавая двоичные данные изображений, и как получать обратно распознанный вариант текста. Над этим всем был построен простейший веб-интерфейс, чтобы загружать картинки, запускать распознавание и получать результат.
Первым ограничением на то время для нас оказалась смешная пропускная способность интернет. Страница A4, отсканированная в качестве 200 точек на дюйм и сохранённая в формате TIFF (который только и воспринимала программа FineReader) могла занимать несколько мегабайт в серых тонах, а если кто по ошибке или незнанию цветной вариант отсканирует, то объём увеличивался в три-четыре раза. Такой огромный по тем временам файл даже по локальной сети пересылался и обрабатывался с трудом, а через публичный Интернет — вообще трудно выполнимая задача.
Такой огромный по тем временам файл даже по локальной сети пересылался и обрабатывался с трудом, а через публичный Интернет — вообще трудно выполнимая задача.
Второй фактор — стоимость. При такой скорости пересылки файлов отсканированных страниц каждая страница стоила дорого. Мы также приняли во внимание, что обычно используются взломанные версии программ распознавания текстов, который достаются бесплатно или за копейки.
Третий фактор — востребованность. Чтобы человек стал пользоваться онлайн-сервисом по распознаванию текста, надо как минимум три фактора: наличие сканера, наличие Интернет и отсутствие возможности самостоятельно распознать текст. Было трудно представить себе большое количество таких «криворуких» и «глупых» пользователей.
Проект был реализован, но оставлен «под сукном» как бесперспективный.
Два года назад я предлагал своим коллегам по работе обдумать вариант повторной реализации проекта. Ситуация изменилась: интернет стал быстрее (файлы mp3 уже давно больше по объёму, чем отсканированная страница в формате JPG), сканеры стоят чуть ли не повсеместно (а ещё текст можно просто сфотографировать), пользователи стараются не нагружать себе голову всякими программами и пользуются онлайн-сервисами. У FineReader есть API, а FLASH позволяет сделать достаточно удобный web-интерфейс для управления загрузкой и распознаванием. Но мы не пришли к общему мнению и, можно сказать, упустили возможность сделать полезный и востребованный сервис который можно выгодно продать ABBYY или гуглю.
У FineReader есть API, а FLASH позволяет сделать достаточно удобный web-интерфейс для управления загрузкой и распознаванием. Но мы не пришли к общему мнению и, можно сказать, упустили возможность сделать полезный и востребованный сервис который можно выгодно продать ABBYY или гуглю.
Сейчас компания ABBYY уже сама реализовала онлайн-версию Fine Reader для распознавания текстов (поддерживает 6 языков, включая русский; понимает документы, написанные сразу на нескольких языках, поддерживает ввод в форматах TIFF (включая многостраничные файлы), JPEG, BMP, PNG, PCX, GIF, DjVu; поддерживает вывод в форматах Microsoft® Word, Excel®, Rich Text Format, TXT, searchable PDF).
А на днях хорошо известный сервис Google Docs API продоставил возможность проверить то же самое у себя на демо-странице. Гугль позволяет загрузить изображение в высоком разрешении (до 10 Мегабайт) в формате JPG, PNG или GIF. Распознавание длится около двух минут. Поддерживается пока только латинский алфавит.
Ссылки по теме:
Покопавшись в поисковиках, я нашёл ещё несколько сервисов (некоторые созданы буквально в этом году) по распознаванию текстов в online. Вот некоторые из них:
Вот некоторые из них:
- OnlineOCR (28 языков, включая русский; поддерживает ввод в форматах TIFF (multi-page), JPEG/JPG, BMP, PCX, PNG, GIF, PDF (multi-page), файлы до 20 мб; вывод в PDF, MS Word, MS Excel, HTML, RTF, TXT)
- Free OCR (6 языков, русского нет; ввод в форматах PDF (только первая страница), JPG, GIF, TIFF or BMP, файл до 2х мегабайт; вывод в текстовом формате)
- OCR Terminal (6 языков, русского нет; ввод в форматах PNG, JPEG, GIF, BMP, multi-page TIFF and PDF; вывод в форматах DOC, TXT, RTF, PDF)
- Небольшой список бесплатных и коммерческих систем оптического распознавания в онлайн-режиме
P.S. Также хотел бы отметь удобство системы
EverNoteи тот факт, что эта система включает в себя распознавание надписей и текстов
P.S.S. Я бы хотел получить отзыв о работе таких сервисов от хабравцев. Есть ли среди вас те, кто пользовался распознаванием в online-finereader, google docs и других сервисах? Ваш отзыв (а лучше даже примеры распознавания и технические ограничения) я добавлю в пост.
Updated: перенесено в
Сервисы.
Распознавание текста онлайн с фото
Для того чтобы распознать текст на каких-либо сканированных документах, не всегда обязательно устанавливать специализированные в данной сфере программы. Можно воспользоваться онлайн-версиями распознавателей сканированного текста, которые позволяют работать в любом современном браузере. Выбрать именно такой вариант для распознавания какого-либо сканированного текста следует еще и в том случае, если данного текста не слишком много. Что касается онлайн-распознавателей текста, то их сегодня достаточно много, но давайте рассмотрим несколько наиболее популярных сервисов данного типа. Сразу хочется отметить, что будут рассмотрены те онлайн-сервисы, которые предоставляют возможность распознавания текста качественно и бесплатно.
Немалой популярностью пользуется такой сервис распознавания текста, как Google Документы. Данный сервис предоставляет немало возможностей для распознавания текстов в разных форматах. Но здесь есть одно но. Чтобы начать работать с данным сервисом вам нужно будет зарегистрироваться в системе Google. Сделать это будет несложно.
Но здесь есть одно но. Чтобы начать работать с данным сервисом вам нужно будет зарегистрироваться в системе Google. Сделать это будет несложно.
Стоит заметить, что в данном сервисе есть ограничение на размер текста, который необходимо будет распознать. Файлы формата PNG, JPG, и GIF и PDF не должны быть больше 2 Мб. Что касается сохранения распознанных документов, то после распознания их можно сохранять в следующих форматах, а именно в форматах DOC, TXT, PDF, PRT и ODT.
Для тех, кто не желает где-либо регистрироваться, а хочет просто осуществить распознавание текста, подойдет другой сервис. Называется он как OCR Convert. Данный сервис также бесплатен и поддерживает основные форматы файлов.
Распознанный текст здесь будет сохраняться в виде url ссылки, которая имеет расширение TXT. Данную ссылку в дальнейшем можно будет вставить в нужный именно вам файл. Что касается ограничения на размеры и количество документов, которые можно распознать за один раз, то за раз можно загрузить 5 документов, но их объем должен быть меньше 5 Мб.
Ну и еще одним хорошим онлайн-сервисом для распознавания текста является сервис NewOCR. Здесь также не нужно регистрироваться. И большой плюс данного сервиса, что здесь нет практически никаких ограничений. Данный сервис способен распознать одновременно несколько файлов разных форматов. Распознанный текст можно будет сохранить в 6 форматах, а именно TXT, DOC, ODT, RTF, PDF, HTML. Можно привести еще много различных онлайн-сервисов для распознавания текста. Но именно в этих трех онлайн-сервисах есть главные качества, которые помогут распознать различные типы файлов. Эти сервисы обладают хорошим качеством, являются бесплатными, и в них практически нет никаких ограничений.
Бесплатный OCR API
Получите бесплатный ключ API OCR
Зарегистрируйтесь здесь, чтобы получить бесплатный ключ API OCR. OCR API обеспечивает простой способ анализа изображений и многостраничных PDF-документов (PDF OCR)
и получение результатов извлеченного текста, возвращенного в формате JSON. OCR API имеет три уровня / уровня.
Бесплатный план OCR API имеет ограничение скорости 500 запросов в течение одного дня на IP-адрес , чтобы предотвратить случайную рассылку спама.
OCR API имеет три уровня / уровня.
Бесплатный план OCR API имеет ограничение скорости 500 запросов в течение одного дня на IP-адрес , чтобы предотвратить случайную рассылку спама.
Для еще более быстрого реагирования и гарантированного 100% времени безотказной работы доступны планы PRO.
PRO OCR API работает на физически иных серверах, чем наша бесплатная служба OCR API.
Вы получите URL-адреса глобальных конечных точек PRO и свой ключ API в приветственном письме сразу после
вы зарегистрировались для учетной записи PRO или PRO PDF.PRO OCR API также можно приобрести как локально устанавливаемое локальное программное обеспечение OCR.
| План API | Бесплатно | ПРО | PRO PDF | Предприятие |
|---|---|---|---|---|
| Стоимость | Бесплатно | 30 долларов в месяц | 60 $ / мес. | 299 $ + / месяц |
| Зарегистрироваться и получить ключ API | Зарегистрируйтесь для бесплатно API-ключ | Купить ключ PROAPI | Купить PRO PDFAPI Key | Связаться с отделом продаж |
| Запросов / месяц | 25 000 | 300 000 | 300 000 | Custom |
| Дополнительные преобразования * | нет данных | 10 долларов США / 100 000 | 20 долларов США / 100 000 | Включено |
| Ограничение размера файла | 1 МБ | 5 МБ | 100 МБ + | 100 МБ + |
| Ограничение страницы PDF | 3 | 3 | 999+ | 999+ |
| Создание PDF с возможностью поиска | Да (с водяным знаком) | Есть | Есть | Есть |
| Скорость | Быстро | Быстрее (больше серверов, меньше нагрузка) | Самый быстрый (собственный сервер) | |
| Ограничение скорости ** | 500 звонков / ДЕНЬ | 6000 звонков / 1 час | 6000 звонков / 1 час | Custom |
| Соглашение об уровне обслуживания (SLA) | нет данных | 100% время безотказной работы или возврат денег (выделенные резервные серверы в США / ЕС / Азии) | Пользовательское местоположение | |
* Дополнительные преобразования: мы автоматически взимаем , а не за дополнительные преобразования. Вместо этого, если вы достигнете предела, мы свяжемся с вами, и вы сможете решить, хотите ли вы оплатить дополнительные преобразования или остановиться на текущий расчетный период.
Вместо этого, если вы достигнете предела, мы свяжемся с вами, и вы сможете решить, хотите ли вы оплатить дополнительные преобразования или остановиться на текущий расчетный период.
** Для тарифных планов PRO мы можем изменить ограничение скорости по умолчанию, если это необходимо.
Вы можете проверить производительность и время безотказной работы API на странице статуса API.
Теперь пора начать: ниже вы найдете пример кода для вызова API из Postman, AutoHotKey (AHK), cURL,
C #, ASP.СЕТЬ, Дельфи,
iOS, Java (приложение для Android),
Node.JS NPM, Python, C ++ / QT,
Рубин,
и Javascript. (Если у вас есть примеры кода для других языков, сообщите нам, и мы добавим их в этот список).
Более быстрое распознавание текста с тарифами PRO
В наших планах OCR PRO мы используем избыточные высокопроизводительные конечные точки API в регионах США, ЕС и Азии.Мы гарантируем 100% безотказную работу или возврат денег. Наши размещенные планы PRO OCR:
Помимо подключения к нашим серверам PRO OCR, вы также можете напрямую купить наше программное обеспечение для оптического распознавания текста и разместить его у себя. Этот вариант описан в следующем абзаце ниже.
верхнийOCR.space Локальный автономный сервер OCR
| OCR.space Local – Enterprise Image и PDF OCR |
|---|
OCR. space – это мощное серверное программное обеспечение OCR для автоматического ввода документов и преобразования PDF.
С OCR.space Local вы можете установить и разместить наш популярный OCR API и программное обеспечение для создания PDF с возможностью поиска на вашем собственном ПК и / или в вашем центре обработки данных.Полностью поддерживается установка в виртуализированных и облачных средах, таких как Amazon AWS AMI или Microsoft Azure.
Технически локальный сервер OCR идентичен нашему популярному онлайн-сервису OCR API. Переход с облака на локальную среду или наоборот
не требует изменения кода. space – это мощное серверное программное обеспечение OCR для автоматического ввода документов и преобразования PDF.
С OCR.space Local вы можете установить и разместить наш популярный OCR API и программное обеспечение для создания PDF с возможностью поиска на вашем собственном ПК и / или в вашем центре обработки данных.Полностью поддерживается установка в виртуализированных и облачных средах, таких как Amazon AWS AMI или Microsoft Azure.
Технически локальный сервер OCR идентичен нашему популярному онлайн-сервису OCR API. Переход с облака на локальную среду или наоборот
не требует изменения кода. Локальная версия имеет те же функции, параметры API и такое же качество OCR, что и OCR.план космоса ПРО PDF,
но работает на 100% локально и в автономном режиме – он никогда не подключается к Интернету. |
| OCR.пространство доступно как размещенное решение (подписка) или как устанавливаемое программное обеспечение (единовременная оплата). |
| Для получения дополнительной информации и заказа локальных лицензий OCR.space обратитесь в отдел продаж. |
Конечная точка бесплатного OCR API (POST)
Free OCR APIhttps: // api. ocr.space/parse/image API поддерживает
ocr.space/parse/image API поддерживает https: // (SSL) и простые http: // соединения.
Конечная точка API OCR “GET”
Использование OCR API никогда не было таким простым …
Помимо полнофункционального OCR API “POST” по адресу / parse / image , мы предоставляем дополнительную конечную точку OCR API.
на / parse / ImageUrl для запросов GET.Хотя он не так универсален, как POST API,
Это простой в использовании. Все, что вам нужно для вызова api, находится внутри URL-адреса.
Пример (просто щелкните ссылку, чтобы запустить OCR) :
https://api. ocr.space/parse/imageurl?apikey=helloworld&url=http://i.imgur.com/fwxooMv.png
ocr.space/parse/imageurl?apikey=helloworld&url=http://i.imgur.com/fwxooMv.png
Язык распознавания текста по умолчанию – английский. Чтобы использовать другой язык, добавьте к URL-адресу и язык .Вы также можете запросить координаты x / y слова с помощью isOverlayRequired :
https://api.ocr.space/parse/imageurl?apikey=helloworld&url=http://i.imgur.com/s1JZUnd.gif&language=chs&isOverlayRequired= правда
Важное ограничение конечной точки GET api заключается в том, что он позволяет отправлять только изображения и PDF-файлы с помощью метода URL , как только
Запросы HTTP POST могут предоставлять серверу дополнительные данные в теле сообщения.GET-запросы включают все
необходимые данные в URL. Таким образом, GET api не поддерживает загрузку файлов (параметр file ). или строки BASE64 (
или строки BASE64 ( base64image ).
GET API прост и быстр в использовании. Просто обратите внимание, что URL-адрес с ключом api может храниться в истории вашего браузера. Но это , а не проблема безопасности, потому что даже если кто-то получит доступ к вашему личному ключу API, он или она не может получить доступ к какой-либо информации о вас или документах, включенных в OCR, потому что мы вообще не храним такую информацию.В худшем случае кто-то использует все ваши бесплатные преобразования. Если это может быть проблемой для вашего приложения, просто продолжайте использовать POST-версию API с полным SSL-шифрованием или переключитесь на PRO OCR API, который предоставляет дополнительные возможности.
верхний В таблице ниже перечислены все возможные параметры API. В качестве дополнительной документации мы опубликовали образец коллекции вызовов API, которую вы можете загрузить в Postman. И последнее
но не в последнюю очередь: наша бесплатная онлайн-форма ocr на главной странице – это не что иное, как POST-вызов конечной точки бесплатного OCR API, и ее также можно использовать для тестирования.
| Ключ | Значение | Описание |
|---|---|---|
апики | Ключ API (отправляем в шапке) | Получите бесплатный ключ API |
url или файл или base64Image | url : URL-адрес удаленного файла изображения (убедитесь, что он имеет правильный тип содержимого) файл : файл многокомпонентного закодированного изображения с именем файла base64Image : изображение или PDF в виде строки в кодировке Base64 | Вы можете использовать три метода для загрузки входного изображения или PDF. Мы рекомендуем метод URL-адреса для файлов размером> 10 МБ для более быстрой загрузки. Мы рекомендуем метод URL-адреса для файлов размером> 10 МБ для более быстрой загрузки. |
язык | [Необязательно] Арабский = ара Болгарский = бул Китайский (упрощенный) = chs Китайский (традиционный) = cht Хорватский = грн Чешский = чешских крон Датский = дан Голландский = dut Английский = англ. Финский = фин Французский = fre Немецкий = ger Греческий = gre Венгерский = гунн Корейский = крон Итальянский = ita Японский = иен Польский = pol Португальский = или Русский = рус Словенский = slv Испанский = spa Шведский = swe Турецкий = тур | Язык, используемый для OCR. Если язык не указан, по умолчанию используется английский Если язык не указан, по умолчанию используется английский eng . ВАЖНО: Код языка всегда состоит из |
isOverlayRequired | [Необязательно] Логическое значение | По умолчанию = False Если true, возвращает координаты ограничивающих рамок для каждого слова.Если false, текст OCR возвращается только как текстовый блок (это уменьшает ответ JSON). Данные наложения можно использовать, например, для отображения текста поверх изображения.  |
тип файла | [Необязательно] Строковое значение: PDF, GIF, PNG, JPG, TIF, BMP | Заменяет автоматическое определение типа файла на основе типа содержимого.Поддерживаемые форматы файлов изображений: png, jpg (jpeg), gif, tif (tiff) и bmp. Для документа ocr api поддерживает формат Adobe PDF. Поддерживаются многостраничные файлы TIFF. |
обнаружение | [Необязательно] истина / ложь | Если установлено значение true, api правильно автоповорачивает изображение и устанавливает TextOrientation параметр
в ответе JSON. Если изображение повернуто на , а не на , тогда TextOrientation = 0, в противном случае это степень поворота, например. грамм. «270». Если изображение повернуто на , а не на , тогда TextOrientation = 0, в противном случае это степень поворота, например. грамм. «270». |
isCreateSearchablePdf | [Необязательно] Логическое значение | По умолчанию = Ложь Если верно, API создает PDF-файл с возможностью поиска. Этот параметр автоматически устанавливает isOverlayRequired = true. |
isSearchablePdfHideTextLayer | [Необязательно] Логическое значение | По умолчанию = Ложь . Если true, текстовый слой скрыт (не виден) |
масштаб | [Необязательно] истина / ложь | Если установлено значение true, api выполняет внутреннее масштабирование. Это может значительно улучшить результат распознавания текста, особенно для
сканирование PDF с низким разрешением. Обратите внимание, что в демонстрации на первой странице используется scale = true, но API по умолчанию использует scale = false. Также это
Сообщение на форуме OCR. Это может значительно улучшить результат распознавания текста, особенно для
сканирование PDF с низким разрешением. Обратите внимание, что в демонстрации на первой странице используется scale = true, но API по умолчанию использует scale = false. Также это
Сообщение на форуме OCR. |
isTable | [Необязательно] истина / ложь | Если установлено значение true, логика OCR гарантирует, что результат анализа текста всегда возвращается построчно.Этот переключатель рекомендуется для
таблица OCR, квитанция OCR, обработка счетов и все другие типы
входные документы, имеющие табличную структуру. |
OCRE Двигатель | [Необязательно] 1 или 2 | Двигатель 1 по умолчанию.См. Раздел «Механизмы распознавания текста». |
Совет: при передаче изображений из корзины Amazon AWS S3, облачного хранилища Google или аналогичных сервисов для использования с параметром «URL» убедитесь, что ссылка на файл имеет правильный тип содержимого.
Не должно
быть «Content-Type: application / x-www-form-urlencoded» (который, кажется, используется по умолчанию для AWS), но image / png или аналогичный для изображений.Для PDF-документов убедитесь, что тип содержимого не “image / pdf” , а application / pdf . Вы можете проверить тип содержимого ваших ссылок, например, с помощью
это средство проверки типов содержимого MIME (внешняя служба, а не наша). OCR API использует тип содержимого для автоматического определения нужного файла. Но если у вас неправильный тип содержимого и вы не можете его изменить (например,потому что вы не контролируете облачное хранилище), без проблем:
В этом случае вы можете перезаписать автоматическое определение типа файла, добавив
параметр
Вы можете проверить тип содержимого ваших ссылок, например, с помощью
это средство проверки типов содержимого MIME (внешняя служба, а не наша). OCR API использует тип содержимого для автоматического определения нужного файла. Но если у вас неправильный тип содержимого и вы не можете его изменить (например,потому что вы не контролируете облачное хранилище), без проблем:
В этом случае вы можете перезаписать автоматическое определение типа файла, добавив
параметр filetype = и напрямую сообщает API, какой тип документа вы отправляете (PNG, JPG, GIF, PDF).
Новое: если вам нужно определить состояние флажков, свяжитесь с нами по поводу функций оптического распознавания меток (OMR) (бета).
верхнийВыберите лучший механизм распознавания текста
OCR API предлагает два разных механизма OCR с разной логикой обработки. Мы рекомендуем вам попробовать и то, и другое.
затем используйте тот движок, который дает наилучший результат распознавания текста. Вы можете использовать обе системы распознавания текста с нашими
бесплатный онлайн-сервис OCR на главной странице
и с параметром OCREngine = 1/2 в вашем вызове API.
Мы рекомендуем вам попробовать и то, и другое.
затем используйте тот движок, который дает наилучший результат распознавания текста. Вы можете использовать обе системы распознавания текста с нашими
бесплатный онлайн-сервис OCR на главной странице
и с параметром OCREngine = 1/2 в вашем вызове API.
Особенности OCR Engine 1:
- – поддерживает больше языков (включая азиатские языки, такие как китайский, японский и корейский)
- – Быстрее
- – Поддерживает изображения большего размера
- – Поддержка многостраничного сканирования TIFF
- – Параметр: OCREngine = 1
Функции OCR Engine 2:
- – Только западные латинские языки символов (английский, немецкий, французский ,.
 ..)
..) - – Автоопределение языка. Неважно, какой язык оптического распознавания текста вы выберете, если он использует латинские символы
- – Обычно лучше при распознавании текста одним числом, распознавании символов одного символа и алфавитно-цифровом распознавании текста в целом (например, SUDOKO, Точечно-матричное распознавание текста, МСЗ OCR, Однозначное распознавание символов, Отсутствует первая буква после OCR, …)
- – Обычно лучше распознавать специальные символы, такие как @ + -…
- – Обычно лучше с повернутым текстом (Форум: обнаружение спама в изображениях)
- – Максимальный размер изображения: ширина 5000 пикселей и высота 5000 пикселей
- – Параметр: OCREngine = 2
Корпоративная поддержка: Оба механизма OCR доступны для автономного использования, а также для самостоятельного размещения в качестве локального OCR!
Возвращенный ответ JSON с результатом OCR идентичен для обоих движков! При необходимости вы можете переключаться между обоими двигателями. Функции, не упомянутые в этом сравнении движка OCR, одинаковы для обоих движков, например PDF OCR, определение ориентации
и поддержка сканирования чеков. Если у вас есть какие-либо вопросы об использовании Engine 1 или 2, задайте их на нашем форуме OCR API.
Функции, не упомянутые в этом сравнении движка OCR, одинаковы для обоих движков, например PDF OCR, определение ориентации
и поддержка сканирования чеков. Если у вас есть какие-либо вопросы об использовании Engine 1 или 2, задайте их на нашем форуме OCR API.
API возвращает результаты в формате JSON.Результат обычно содержит ExitCode, Подробная информация об ошибке (если произошла) и несколько проанализированных результатов для страниц изображений / PDF. Пожалуйста, проверьте ниже ответ, возвращаемый веб-API, и определение различных параметров. На приведенном ниже рисунке показаны успешные и ошибочные ответы.
{
"ParsedResults": [
{
"TextOverlay": {
«Строки»: [
{
«Слова»: [
{
"WordText": "Слово 1",
«Левый»: 106,
«Верх»: 91,
«Высота»: 9,
«Ширина»: 11
},
{
"WordText": "Слово 2",
«Левый»: 121,
«Верх»: 90,
«Высота»: 13,
«Ширина»: 51
}
. .
.
Больше слов
],
«MaxHeight»: 13,
«МинТоп»: 90
},
.
.
.
.
Больше строк
],
"HasOverlay": правда,
«Сообщение»: null
},
"FileParseExitCode": "1",
"ParsedText": "Это образец результата анализа",
"ErrorMessage": null,
«ErrorDetails»: нуль
},
{
"TextOverlay": нуль,
«FileParseExitCode»: -10,
"ParsedText": ноль,
"Сообщение об ошибке" : "... сообщение об ошибке (если есть) ",
"ErrorDetails": ".
.
.
Больше слов
],
«MaxHeight»: 13,
«МинТоп»: 90
},
.
.
.
.
Больше строк
],
"HasOverlay": правда,
«Сообщение»: null
},
"FileParseExitCode": "1",
"ParsedText": "Это образец результата анализа",
"ErrorMessage": null,
«ErrorDetails»: нуль
},
{
"TextOverlay": нуль,
«FileParseExitCode»: -10,
"ParsedText": ноль,
"Сообщение об ошибке" : "... сообщение об ошибке (если есть) ",
"ErrorDetails": ". .. подробное сообщение об ошибке (если есть)"
}
.
.
.
],
"OCRExitCode": "2",
"IsErroredOnProcessing": ложь,
"ErrorMessage": null,
«ErrorDetails»: нуль
"SearchablePDFURL": "https: // ....." (если запрошено, иначе null)
"ProcessingTimeInMilliseconds": "3000"
}
.. подробное сообщение об ошибке (если есть)"
}
.
.
.
],
"OCRExitCode": "2",
"IsErroredOnProcessing": ложь,
"ErrorMessage": null,
«ErrorDetails»: нуль
"SearchablePDFURL": "https: // ....." (если запрошено, иначе null)
"ProcessingTimeInMilliseconds": "3000"
}
| Ключ | Значение | Описание |
|---|---|---|
Результаты анализа | OCR результаты | Результаты OCR для изображения или для каждой страницы PDF.Для PDF: каждая страница имеет собственный результат распознавания текста и сообщение об ошибке (если есть) |
OCRExitCode | Целое число | Код выхода показывает, было ли OCR выполнено успешно, частично или с ошибкой |
IsErroredOnProcessing | верно / неверно | Если ошибка возникает при разборе страниц изображения / PDF |
Сообщение об ошибке | Текст | Сообщение об ошибке возникла при разборе образа |
Сведения об ошибке | Текст | Подробное сообщение об ошибке |
Доступный для поискаPDFURL | Ссылка | См. PDF-файл с возможностью поиска PDF-файл с возможностью поиска |
| РЕЗУЛЬТАТ РАЗБОРА ИЗОБРАЖЕНИЯ / СТРАНИЦЫ | ||
FileParseExitCode | Код выхода для каждого проанализированного результата | Код выхода, возвращенный механизмом синтаксического анализа 0: Файл не найден 1: Успешно -10: Ошибка синтаксического анализа механизма OCR -20: Тайм-аут -30: Ошибка проверки - 99: Неизвестная ошибка |
ParsedText | Разобранный текст | Проанализированный текст изображения |
TextOverlay | Наложение данных для текста в изображении / pdf | Только если для isOverlayRequired установлено значение True |
линий | Массив строк в наложенном тексте | Содержит массив всех строк.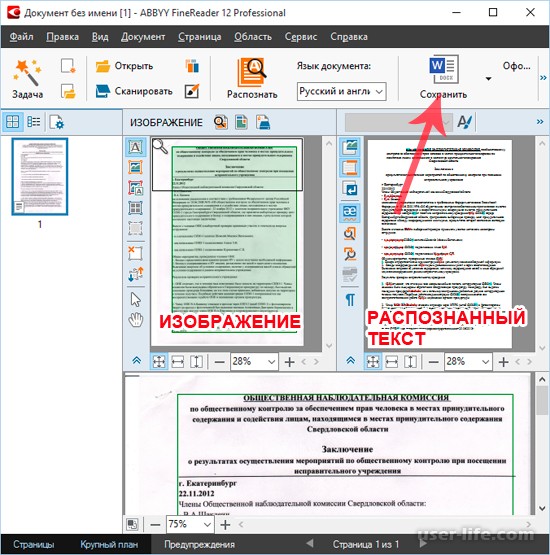 Каждая строка будет содержать массив слов Каждая строка будет содержать массив слов |
слов | Массив слов в строке | Содержит слова с конкретными деталями слова, такими как его текст и позиция. |
WordText | Текст слова | Содержит текст конкретного слова |
Левый | Расстояние слова слева (в пикселях (px)) | Содержит расстояние (в пикселях) слова от левого края изображения. |
Верх | Расстояние слова сверху (в пикселях) | Содержит расстояние (в пикселях) слова от верхнего края изображения. |
Высота | Высота слова | Содержит высоту (в пикселях) слова |
Ширина | Ширина слова | Содержит ширину (в пикселях) слова |
MaxHeight | Максимальная высота строки | Содержит высоту (в пикселях) линии |
MinTop | Минимальное расстояние линии от верхнего края изображения | Содержит расстояние (в пикселях) линии от верхнего края в исходном размере изображения |
HasOverlay | Оверлей присутствует или нет | Истина / Ложь в зависимости от того, присутствует ли оверлей для проанализированного результата или нет |
Сообщение об ошибке | Текст | Сообщение об ошибке, возвращаемое механизмом синтаксического анализа |
Сведения об ошибке | Текст | Подробное сообщение об ошибке, возвращаемое механизмом синтаксического анализа для целей отладки |
Вы можете создавать PDF-файлы с возможностью поиска (иногда также называемые Sandwich PDF-файлы) непосредственно через API. PDF-файл возвращается как ссылка для скачивания
в ответе API JSON форма
PDF-файл возвращается как ссылка для скачивания
в ответе API JSON форма "SearchablePDFURL": "..." .
Ссылка для скачивания действительна в течение одного часа, по истечении этого времени документ удаляется с наших серверов OCR.
Переключатель isCreateSearchablePdf = true запускает создание PDF-файла с возможностью поиска. По умолчанию,
добавленный текстовый слой виден – это идеальный вариант для тестирования результата, так как вы можете сравнить вывод OCR напрямую с отсканированным изображением.Добавляя isSearchablePdfHideTextLayer = true , вы делаете текстовый слой невидимым.
Создание PDF-файла с возможностью поиска на основе результатов распознавания текста требует дополнительного времени обработки, поэтому вам следует активировать только этот параметр.
функция, если вам нужен результат OCR в формате PDF.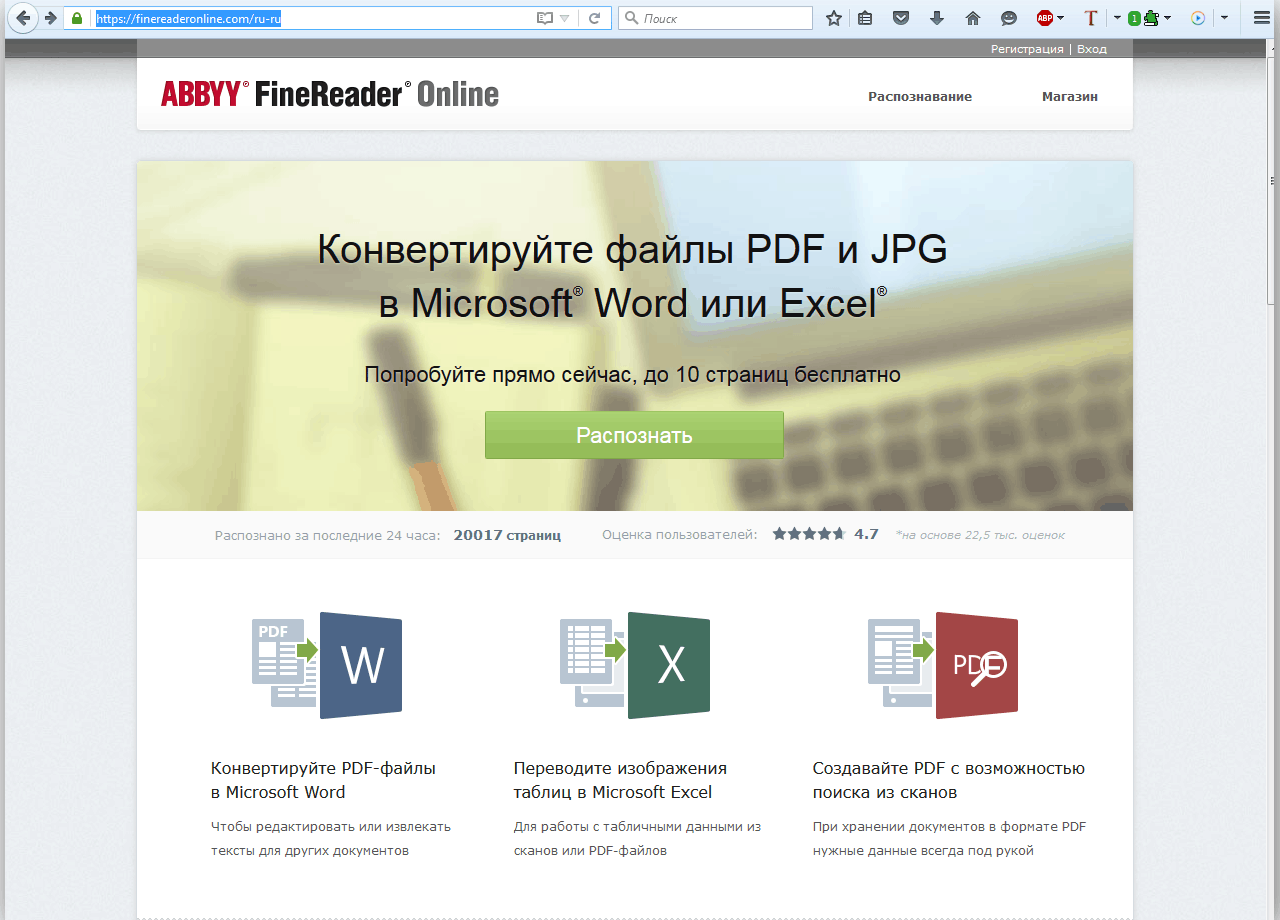
ПРИМЕЧАНИЕ. Вы должны использовать и параметров, isCreateSearchablePdf = true и isSearchablePdfHideTextLayer = false или true , в противном случае сгенерированный PDF-файл не содержит текстового слоя.
При использовании с уровнем бесплатного OCR API сгенерированный PDF-файл содержит водяной знак «Создано OCR.space» в правом нижнем углу. С PRO OCR API водяной знак не добавляется в PDF.
верхнийСамый быстрый способ протестировать OCR API – это выполнить вызов GET – просто скопируйте URL-адрес в свой веб-браузер.
Тестовый API с приложением Postman
Начало работы: используйте бесплатную
Приложение Postman для Windows, Mac и Linux
чтобы протестировать OCR API и поиграть с различными параметрами.
Совет: Если у вас установлен Postman, вы можете нажать кнопку «Запустить в Postman» выше, чтобы импортировать набор из шести тестовых вызовов API в Postman .В примерах используется ключ api helloworld, и они готовы к запуску без каких-либо дополнительных изменений.(a) Предоставить изображение / PDF-файл для распознавания текста через URL-адрес
На скриншотах ниже показаны настройки отправки изображения / PDF-файла по URL-адресу. Обратите внимание, что кодировка установлена на multipart / form-data .
Во всех случаях (загрузка файла через URL, файл или base64) ключ API (пароль) отправляется в заголовке:
(b) Загрузите изображение / PDF-файл для распознавания текста с вашего сервера / ПК
То же приложение Postman, но на этот раз мы используем настройку «Файл» для загрузки изображения или PDF.
(c) Отправить изображение как строку Base64
То же приложение Postman, но на этот раз мы используем параметр «Base64Image» для отправки изображения в виде строки.
Совет: убедитесь, что после вставки строки base64 в Postman нет лишней «новой строки».Если есть, API будет (по праву) вернуть «Недействительное изображение base64». ошибка.
Тестовая строка BASE64
Ссылки открывают текстовый файл в браузере: Image Base64 String, TIFF Base64 String,
PDF как строка Base64. Вы можете копировать и
вставьте содержимое этих текстовых файлов непосредственно в поле «base64image» Postman или в любой другой тестовый код.
Важно: строка base64 должна начинаться с типа содержимого документа. Например, используйте data: image / jpeg; base64, здесь строка данных , данные: изображение / png; base64, строка данных здесь или для документов PDF данные: приложение / pdf; base64, строка данных здесь . Большинство онлайн-сервисов преобразования изображений в base64 не
добавьте этот заголовок, они просто предоставляют строку необработанных данных.Таким образом, вы должны добавить его вручную, когда используете такие строки для тестирования.
Командная строка cURL
(a) Предоставить изображение / PDF-файл для распознавания текста через URL-адрес
curl https://api.ocr.space/Parse/Image -H "apikey: helloworld" --data "isOverlayRequired = true & url = http: //dl.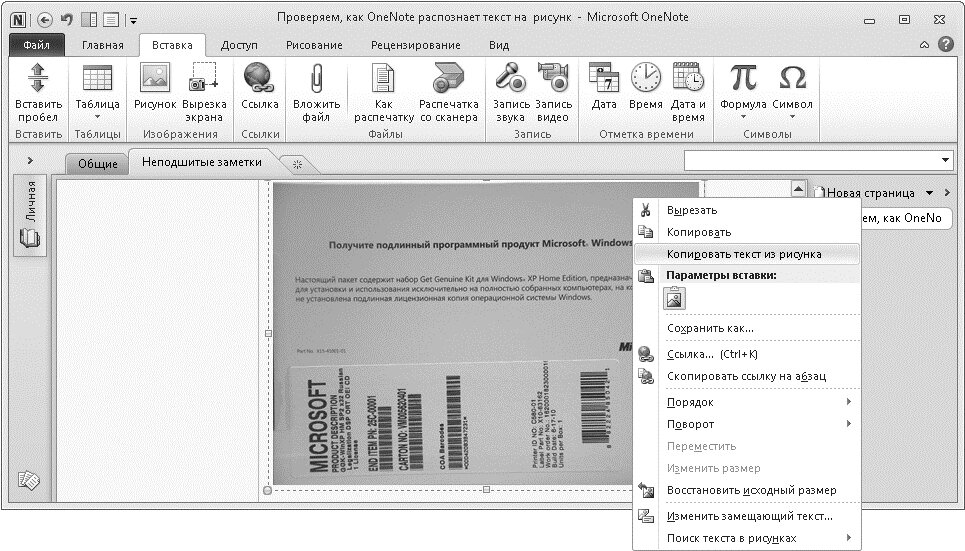 a9t9.com/blog/ocr-online/screenshot.jpg&language = eng "
a9t9.com/blog/ocr-online/screenshot.jpg&language = eng "
curl – это инструмент командной строки и библиотека с открытым исходным кодом для передачи данных с синтаксисом URL.Библиотека libcurl переносима. Он строится и работает одинаково практически на любой платформе (Windows, Mac, Linux, …).
(b) Загрузите изображение / PDF-файл для распознавания текста с вашего сервера / ПК
curl -H "apikey: helloworld" --form "[email protected]" --form "language = eng" --form "isOverlayRequired = true" https://api.ocr.space/Parse/Image
Примечание: @ снимок экрана.jpg предполагает, что изображение с именем «screenshot.jpg» находится в том же каталоге, что и cURL.exe. Обратите внимание, что isOverlay требует (по умолчанию: no), а параметры language (по умолчанию: eng) являются необязательными.
(c) Отправить изображение в виде строки в формате Base64
curl -H "apikey: helloworld" --form "base64Image = data: image / jpeg; base64, / 9j / AAQSk [здесь длинная строка]" --form "language = eng" --form "isOverlayRequired = false" https: // api.ocr.space/parse/image
Строка base64 в этом примере усечена. Вы можете скачать полную командную строку как командный файл Windows с GitHub.
У нас есть несколько тестовых строк base64, доступных для загрузки.
верхнийC # (проект Visual Studio)
Существует готовый пример проекта Visual Studio C # для
с помощью OCR API из C # на GitHub.
Тестовое приложение позволяет быстро загружать и тестировать любое изображение с помощью OCR API.
В качестве реального примера рассмотрим популярный инструмент повышения производительности «ShareX»:
ShareX использует OCR.space PRO API, и доступен полный исходный код C #.
верхнийiOS: Objective-C и Swift
Предоставленные пользователем фрагменты кода для Цель-C и Swift – хорошая отправная точка для приложений iPhone с функциями распознавания текста.
верхнийAndroid: Java
Используете Android? Взгляните на этот образец приложения для Android
который использует бесплатный OCR API. В
Джава
app показывает, как вызвать API с помощью
В
Джава
app показывает, как вызвать API с помощью HttpsURLConnection от пользователя «bsuhas». И тут
это другое, отличное от пользователя “Globalizer” репо на Java.Спасибо обоим за предоставленный фрагмент кода.
Веб-приложение PHP OCR API Demo
Для PHP у нас есть полное, готовое к запуску демонстрационное веб-приложение, которое позволяет пользователю выбрать документ, а затем загрузить его. изображение или PDF-документ в OCR API.
Вы найдете
полный исходный код на Github
.
Питон
Вот пример того, как получить доступ к API из Python с помощью команды requests.post .
Полный исходный код можно найти на GitHub. (спасибо пользователю Zaargh за предоставленный фрагмент кода).Еще одна оболочка Python для нашего OCR SDK доступна от пользователя GitHub a4fr (спасибо всем за создание фрагментов кода).
верхнийAutoHotKey (AHK)
AHK – популярный рекордер макросов для Windows. Для проектов автоматизации Windows, требующих
распознавать текст на изображениях, вы можете подключиться к OCR API с CreateFormData (PostData, ContentType, oForm) . Это сообщение на форуме AHK содержит подробности.
Это сообщение на форуме AHK содержит подробности.
C ++ / QT
Используете C ++? Jhiroka из UCLA поделился с нами этим примером: пример приложения C ++ / QT OCR API.
Если вы используете библиотеку C ++ Casablanca для вызова HTTP POST, обратите внимание, что вам нужно URL-адрес кодировать данные изображения поверх кодировки Base64.Библиотека C ++ Casablanca, похоже, не делает это автоматически (в отличие от Postman), поэтому используйте функцию web :: uri :: encode_data_string для кодирования данных файла после кодирования запроса Base64.
Перейти
Пользователь Маттео создал репозиторий Github с модулем Go для OCR API.
Рубин
Используете Ruby? Suyesh поделился с нами этим Ruby gem (библиотекой): OCR API Ruby gem.
Perl
Используете Perl? Затем взгляните на этого пользователя OCR API, отправленного на Perl OCR.космический модуль.
Powershell
У нас есть фрагмент кода OCR Powershell. Это включает скачивание сгенерированный сэндвич PDF.
верхнийJavascript
Расширение Chrome
Расширение Copyfish для Chrome, Edge и Firefox с открытым исходным кодом использует наш OCR API. Вы можете найти его исходный код Javascript здесь. Сюда входит код, показывающий, как обрабатывать возвращенные данные наложения текста.
Обратите внимание, что расширение Copyfish использует версию PRO OCR API.
Вы можете найти его исходный код Javascript здесь. Сюда входит код, показывающий, как обрабатывать возвращенные данные наложения текста.
Обратите внимание, что расширение Copyfish использует версию PRO OCR API.
Проверьте это: вы можете установить расширение Copyfish OCR в Хром, Край, а также Fire Fox.
верхнийNPM / Node.js
Последняя версия оболочки OCR API Node.JS принадлежит пользователю DavideViolante .
Он позволяет указать конечные точки OCR Space API (бесплатно и PRO). Старые оболочки Node.JS: Пользователь Dennis.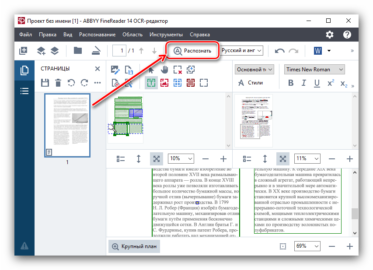 K опубликовал пакет NPM для OCR API и Anthony Luzquiños выпустил обновленный пакет NPM для OCR API.
K опубликовал пакет NPM для OCR API и Anthony Luzquiños выпустил обновленный пакет NPM для OCR API.
JQuery
Это пример JQuery, показывающий, как сделать запрос к api с помощью AJAX и получить результаты изображения для обработки.
верхний
- // Подготавливаем данные формы
- var formData = new FormData ();
- formData.append ("файл", fileToUpload);
- formData.append ("url", "URL-of-Image-or-PDF-file");
- formData.append («язык», «англ.»);
- formData.append ("apikey", "Ваш-API-ключ-здесь");
- formData.
append ("isOverlayRequired", True);
- // Асинхронно отправить запрос на анализ OCR
- jQuery.ajax ({
- url: https://api.ocr.space/parse/image,
- data: formData,
- dataType: 'json',
- cache: false,
- contentType: false,
- processData: false,
- type: 'POST',
- success: function (ocrParsedResult) {
- // Получить проанализированные результаты, код выхода и сообщение об ошибке и подробности
- var parsedResults = ocrParsedResult ["ParsedResults"];
- var ocrExitCode = ocrParsedResult ["OCRExitCode"];
- var isErroredOnProcessing = "ocrParsedResult49";
- var errorDetails = ocrParsedResult ["ErrorDetails"];
- var processingTimeInMilliseconds = ocrParsedResult ["ProcessingTimeInMilliseconds"];
- // Если мы получили проанализированные результаты, то переберите результаты, чтобы что-то сделать
- if (parsedResults! = Null) {
- // Цикл через проанализированные результаты
- $.
each (parsedResults, function (index, value) {
- var exitCode = value ["FileParseExitCode"];
- var parsedText = value ["ParsedText"];
- var errorMessage = value ["ParsedTextFileName4
- "];
- var errorDetails = значение ["ErrorDetails"];
- var textOverlay = значение ["TextOverlay"];
- var pageText = '';
- переключатель (+ exitCode) {
- case 1:
- pageText = parsedText;
перерыв- ;
- case 0:
- case -10:
- case -20:
- case -30:
- case -99:
- default:
- pageText + = "Error:" + errorMessage;
- перерыв;
- }
- $.каждый (textOverlay ["Lines"], функция (индекс, значение) {
- ..........................
- .. ........................
- ........................ ..
- ПЕРЕХОДИТЕ ПО СТРОКАМ И ПОЛУЧИТЕ СЛОВА ДЛЯ ОТОБРАЖЕНИЯ НАВЕРХ ИЗОБРАЖЕНИЯ В КАЧЕСТВЕ НАЛОЖЕНИЯ
- .
.........................
- ..........................
- ...................... ....
- });
- ..........................
- ..........................
- ..........................
- ВАШ КОД ЗДЕСЬ
- ........ ..................
- ..........................
- .. ........................
- });
- }
- }
- });
Распознавание таблиц, API OCR таблиц: как извлечь данные таблицы из PDF или изображения
Одним из многих вариантов использования OCR является извлечение данных из изображений таблиц – подобных тому, которое вы найдете в отсканированном PDF-файле.Другой
Типы документов, такие как квитанции, счета-фактуры, контракты и т. д., также имеют тот же макет и пользуются нашей функцией распознавания текста в таблицах. Для всех этих документов мы рекомендуем
что вы включаете, отметьте опцию Сканирование чеков и / или распознавание стола на первой странице. Если вы используете OCR API, вы получите тот же результат
включив режим OCR стола.
В результате текст с оптическим распознаванием текста сортируется построчно – точно так же, как вы находите его в таблице.Это делает OCR API идеальным SDK для захвата чеков.
Пример анализа таблицы
На снимке экрана ниже показан результат OCR изображения сканирования таблицы, в данном случае из китайского учебника. При активном режиме OCR таблицы, структура вывода текста такая же, как в таблице.
Мы выделили несколько строк желтым, чтобы визуально помочь вам сравнить левое входное изображение и извлеченное OCR. данные таблицы справа.
В OCR API переключатель isTable = true запускает логику сканирования таблицы.
Более подробная информация доступна в разделе флагов OCR в таблице.
документации OCR API
Испытательный стол OCR
Вы можете протестировать парсинг таблиц и извлечение данных прямо на нашей главной странице. Вот оригинал скана таблицы учебника.В этом случае выбран китайский язык OCR:
Ссылка на изображение таблицы – https://ocr.space/Content/Images/table-ocr-original.jpg – просто вставьте его в поле URL на главной странице.
OCR API FAQ
FAQ – Часто задаваемые вопросы
1.Вы храните документы на своих серверах?
Мы делаем , а не , храним какие-либо документы / изображения на наших серверах, как описано в нашей политике конфиденциальности.
2. Доступна ли эта услуга круглосуточно и без выходных?
Да!
3. Можно ли использовать бесплатный сервис в коммерческом проекте?
Да, вы можете использовать бесплатный API в коммерческом проекте, но он не дает никаких гарантий (безотказной работы).
4. В чем разница между бесплатным OCR API и коммерческой версией?
5. Что произойдет, если вы пропустите 100% гарантию безотказной работы?
Наш SLA (соглашение об уровне обслуживания) прост: 100% гарантия бесперебойной работы – если обе точки доступа когда-либо выходят из строя одновременно, мы возвращаем 100% вашего ежемесячного счета.
6. Что произойдет, если я недоволен учетной записью PRO по другой причине, кроме времени безотказной работы?
Пожалуйста свяжитесь с нами. Если мы не сможем решить проблему, мы вернем вам деньги за текущий месяц в полном объеме.
7. Храните ли вы мою кредитную карту на своих серверах?
№ . Мы не храним платежную информацию на наших серверах. Все платежи по подписке управляются Fastspring. Вы можете редактировать, обновлять и отменять подписку PRO / PROPDF в любое время на их клиентском портале.
8. Каковы URL-адреса коммерческих точек доступа OCR API?
Вы получите URL-адреса трех глобальных точек доступа и свой ключ API в приветственном письме сразу после того, как зарегистрируетесь в учетной записи PRO или PRO PDF.
9. Где расположены точки доступа?
Бесплатная точка доступа OCR API находится в ЕС, а коммерческая версия также имеет точки доступа в США и Азии. Если вам нужно конкретное место, просто дайте нам знать.
10. Я инди-разработчик. Я ищу бесплатное / недорогое решение для распознавания текста.
Вы нашли правильное место 🙂
11.Вы могли бы предупредить меня о предстоящем запланированном простое?
да. Есть два способа получать оповещения: подписывайтесь на нас в Твиттере или зарегистрируйтесь на уровне Free OCR API. Мы отправляем электронное письмо всем зарегистрированным пользователям, если приближается запланированный простой.
12. Я получаю сообщение о том, что ключ API недействителен. Пройдет ли какое-то время, прежде чем он станет активным?
Все ключи API (бесплатные и PRO) сразу становятся активными.Если у вас возникли проблемы с API, выполните следующие действия:
13. Если здесь нет ответа на ваш вопрос, …
…пожалуйста свяжитесь с нами.
Топ-10 лучших программ для оптического распознавания текста в 2021 году
Зачем вам нужно программное обеспечение для оптического распознавания текста?
Компании все больше переходят на цифровые технологии, чтобы ускорить рост, и программное обеспечение оптического распознавания текста стало ключевым решением в этом контексте. Сканирование и обработка документов, таких как счета-фактуры, квитанции и изображения, для поиска ценных данных традиционно выполнялись вручную, что чревато ошибками и задержками. Программные решения OCR помогают предприятиям экономить время и ресурсы, которые в противном случае были бы потрачены на ввод данных и ручную проверку.Программное обеспечение OCR автоматизирует сбор данных из отсканированных документов / изображений и оцифровывает данные в удобных и редактируемых форматах, которые вписываются в рабочие процессы организации.
Современное программное обеспечение для оптического распознавания текста является быстрым, точным и может справляться с общими ограничениями обработки документов, такими как плохо отформатированные отсканированные изображения, рукописные документы, изображения / отсканированные изображения низкого качества и дефекты, которые традиционно требовали длительного ручного вмешательства. Все больше и больше организаций автоматизируют рабочие процессы обработки документов, чтобы перейти на безбумажный режим и использовать облачные цифровые решения, улучшающие чистую прибыль.
Что такое OCR и для чего нужна программа OCR?
OCR или оптическое распознавание символов – это технология, которая идентифицирует и распознает текст в отсканированных документах, фотографиях или изображениях. Программное обеспечение OCR использует эту технологию для извлечения данных из PDF-файлов или отсканированных документов путем преобразования их в машиночитаемые текстовые данные, которые можно редактировать и сохранять для более удобной обработки для дальнейшей обработки. Подробное описание оптического распознавания текста и его вариантов использования см. В этом руководстве.
OCR также используется в различных других случаях использования, таких как извлечение таблиц из PDF-файлов, извлечение текста из изображений или извлечение текста из PDF-файлов или других нередактируемых форматов.
Сегодня программное обеспечение OCR используется для автоматического ввода данных, распознавания образов, услуг преобразования текста в речь, индексации документов для поисковых систем, когнитивных вычислений, интеллектуального анализа текста, ключевых данных и машинного перевода среди различных других приложений. Эти инструменты могут преобразовывать любые отсканированные документы, PDF-файлы или типы изображений в файлы xml, xlsx или csv.
Лучшее программное обеспечение для оптического распознавания текста для вашего бизнеса
Давайте посмотрим на некоторые из лучших программ оптического распознавания текста, доступных на рынке.
Nanonets
Nanonets – это программное обеспечение для распознавания текста на основе искусственного интеллекта, которое автоматизирует сбор данных для интеллектуальной обработки счетов-фактур, квитанций, идентификационных карт и т. Д.Nanonets использует расширенное распознавание текста, машинное обучение обработки изображений и глубокое обучение для извлечения релевантной информации из неструктурированных данных. Он быстрый, точный, простой в использовании, позволяет пользователям создавать собственные модели оптического распознавания текста с нуля и имеет некоторые аккуратные интеграции с Zapier. Оцифровывайте документы, извлекайте поля данных и интегрируйтесь со своими повседневными приложениями через API в простом, интуитивно понятном интерфейсе.
Nanonets IntroВ чем отличие Nanonets от программного обеспечения для распознавания текста?
Плюсы:
- Современный пользовательский интерфейс
- Обрабатывает большие объемы документов
- Разумная цена
- Простота использования
- Когнитивный сбор данных – минимальное вмешательство
- Не требует собственной команды разработчиков
- Алгоритм / models можно обучить / переобучить
- Отличная документация и поддержка
- Множество вариантов настройки
- Широкий выбор вариантов интеграции
- Работает с неанглийскими языками или несколькими языками
- Практически не требуется постобработка
- Бесшовная двусторонняя интеграция с несколькими бухгалтерскими программами
- Отличный API для разработчиков
Минусы:
- Не могу справиться с очень высокими скачками объема
- Пользовательский интерфейс захвата таблиц может быть лучше
Nanonets online OCR & OCR У API есть много интересных вариантов использования. , которые можно оптимизировать эффективность вашего бизнеса, сокращение затрат и ускорение роста. Узнайте, как варианты использования Nanonets могут применяться к вашему продукту.
Запланировать демонстрацию
ABBYY Flexicapture
FlexiCapture – это стабильная, масштабируемая программа для создания образов и извлечения данных документов, которая автоматически преобразует документы любой структуры, языка или содержания в пригодные для использования и доступные бизнес-данные.
ABBYY FlexiCapture для счетов – демонстрационное видеоПлюсы:
- Отлично распознает изображения
- Легко сохранить бумажный результат в системе
- Хорошо интегрируется с ERP-системами
- Автоматизирует извлечение данных из документов (в определенной степени). )
Минусы:
- Первоначальная настройка может быть сложной и сложной
- Автоматическая обработка счетов не настроена
- Нет готовых шаблонов
- Трудно настроить
- Нет ресурсов
- Может быть лучше интеграция с решениями RPA
- Низкая точность с изображениями / документами с низким разрешением
- Пакетные проверки задерживаются, даже если есть ошибка только в определенном разделе
- Сообщения об ошибках строки появляются даже для элементов, которые следует пропустить
- RESTful API недоступен в локальной версии 90 503
- Клавиатурный редактор OCR для ручных исправлений
- Исключительно понятный интерфейс
- Экспорт в несколько форматов
- Уникальная функция сравнения документов
- Отсутствует полнотекстовая индексация для быстрого поиска
- Требуется обучение
- Цены могут быть непомерно высокими
- Невозможность просмотра истории изменений документа
- Невозможно объединить несколько файлов в один
- Может потребоваться постобработка
- Сначала пользовательский интерфейс может быть ошеломляющим
- Медленно обрабатывать большие файлы
- Имеет надежный набор инструментов для улучшения изображений
- Высокая точность
- Пользовательский интерфейс не интуитивно понятный
- Конфигурация для AP Automation интеграция не может быть простой улучшено
- Настраивает сложные приложения для сбора данных
- Механизм сканирования
- Простота использования
- Очень небольшая онлайн-поддержка
- Пользовательский интерфейс может быть более интуитивно понятным 9049 громоздкий
- Медленный
- Создание настраиваемого потока непросто
- Пакетная фиксация требует времени
- Простота настройки
- Очень хорошо интегрируется с другими сервисами Google
- Хранение информации
- Скорость
- ИИ-модулям не хватает соответствующей документации
- модули и библиотеки сложны
- Не подходят для Python или других языков кодирования
- Устаревшая документация по API
- Дорого
- Не подходит для развертываний гибридного облака
- Не подходит для сценариев использования, требующих пользовательских алгоритмов AI
- Модель выставления счетов с оплатой по факту
- Простота использования
- Невозможно обучить
- Различная точность
- Не предназначено для рукописных документов
Хотите очистить данные из документов PDF, преобразовать таблицу PDF в Excel или автоматизировать извлечение таблиц? Воспользуйтесь парсером PDF Nanonets или парсером PDF, чтобы очищать данные PDF или анализировать файлы PDF в любом масштабе!
Docparser
Docparser – это облачное программное обеспечение для обработки документов и распознавания текста, которое может автоматизировать малозначимые задачи и рабочие процессы для предприятий.
Плюсы:
- Простая установка
- Интеграция Zapier
Минусы:
- Веб-перехватчики иногда выходят из строя
- Требуется некоторое обучение, чтобы подобрать правила синтаксического анализа
- Подход OCR – невозможно обрабатывать неизвестные шаблоны
- Пользовательский интерфейс может быть лучше
- Медленная загрузка страниц
- Документация может быть лучше
Adobe Acrobat DC
Adobe предоставляет комплексный редактор PDF со встроенным OCR функциональность.
Плюсы:
- Стабильность / совместимость.
- Простота использования
Минусы:
- Дорогое
- Не эксклюзивное программное обеспечение OCR
- Тяжелое в системе
- Занимает много места на жестком диске
- Сложно до 9 интегрироваться с такими сервисами, как Sharepoint или Dropbox
- Требуется лицензия Adobe Creative Cloud.
Klippa
Klippa предоставляет решения для автоматизированного управления документами, обработки, классификации и извлечения данных для оцифровки бумажных документов в вашей организации.
Плюсы:
- Быстрая установка
- Отличная поддержка
- Отличный API для разработчиков
- Ясная и краткая документация по API
- Хорошо сочетается с бухгалтерскими программами
- Конкурентоспособная цена
- Интеграция
- Распознавание OCR может быть лучше
- Ограниченные настройки шаблона
- Ограниченные настройки white-label
- Массовые корректировки не поддерживаются
- НДС часто отображается неправильно
- Приложение часто дает сбой
- Не удается обучить модель OCR
- Процесс выбора непрост, так как существует множество вариантов.
- Обучение и работа с пользовательскими данными – Большинство программ OCR довольно жестко относятся к типу данных, с которыми они могут работать. На Нанонец такие ограничения не распространяются. Nanonets использует ваши собственные данные для обучения моделей, которые лучше всего подходят для удовлетворения конкретных потребностей вашего бизнеса.
- Простота в использовании и гибкость – Адаптация Nanonet к конкретным бизнес-потребностям проста и понятна. Nanonets может справиться со всем, от создания пользовательских моделей OCR и их переобучения до добавления новых полей и обработки интеграции.
- Постоянно учится и переобучается – Компании часто сталкиваются с динамично меняющимися требованиями и потребностями. Чтобы преодолеть потенциальные препятствия, программное обеспечение Nanonets OCR позволяет легко повторно обучать ваши модели с использованием новых данных.Это позволяет вашей модели OCR адаптироваться к непредвиденным изменениям.
- Настройка, настройка, настройка – Наносети могут захватывать любое количество полей текста / данных и представлять их в любом желаемом виде. Собранные данные могут быть представлены в виде таблиц или строк или в любом другом формате по вашему выбору с настраиваемыми правилами проверки. Всегда помните, что Nanonets не привязаны к шаблону вашего документа!
- Практически не требует постобработки – В то время как большинство программ оптического распознавания текста просто захватывают и выгружают данные, Nanonets извлекает только релевантные данные и автоматически сортирует их в интеллектуально структурированные поля, упрощая просмотр и понимание.Это избавляет от большого количества времени, затрачиваемого на доработку и проверку.
- С легкостью справляется с общими ограничениями данных – Nanonets использует методы глубокого обучения и обнаружения объектов для преодоления общих ограничений данных, которые значительно влияют на распознавание и извлечение текста среди других программ OCR. Nanonets AI может распознавать и обрабатывать рукописный текст, изображения с низким разрешением, изображения с новыми или курсивными шрифтами и разных размеров, изображения с темным текстом, наклонный текст, случайный неструктурированный текст, шум изображения, размытые изображения и многое другое.Традиционное программное обеспечение OCR просто не приспособлено для работы в таких условиях; им требуются данные с очень высоким уровнем достоверности, что не является нормой в сценариях реальной жизни.
- Работает с неанглийскими или несколькими языками – Поскольку Nanonets фокусируется на обучении с пользовательскими данными, он уникально расположен для создания единой модели, которая может извлекать текст из документов на любом языке или на нескольких языках одновременно.
- Не требует внутренней команды разработчиков – Не нужно беспокоиться о найме разработчиков и привлечении талантов для персонализации Nanonets API в соответствии с требованиями вашего бизнеса.Наносети были созданы для беспроблемной интеграции. Вы можете легко интегрировать Nanonets с большинством CRM, ERP, контент-сервисов или программного обеспечения RPA.
- OnlineOCR.net
- FreeOCR.
- SimpleOCR
- GOCR
- Office Lens
- English OCR
- Easy Screen OCR
- A9t9
- Сканирование фотографий
- Capture2Text
- Adobe Scan
- OCR 9494 с помощью Microsoft OneNote Обновление от мая 2021 года: этот пост был первоначально опубликован в январе 2021 года и с тех пор обновлен.
- Prepostseo
- imagetotext.info
- Myfreeocr
- Pdfsimpli
- Text-image.com
- Расширенные функции распознавания текста позволяют легко конвертировать и редактировать отсканированные PDF-файлы.
- Редактировать PDF-текст, изображения и ссылки так же просто, как вносить изменения в Word.
- С легкостью добавляйте подписи, пароли, водяные знаки, знаки и произвольные фигуры в PDF-файлы.
- Простые инструменты разметки и аннотации
- Вы можете легко создавать PDF-файлы из широкого спектра форматов документов.
- Вы также можете конвертировать файлы PDF в другие форматы, такие как Excel, MS Word и другие.
- не установлен по умолчанию, но легко добавить и использовать
- возможности: базовые
- для рукописных / машинописных / отсканированных изображений низкого качества: бесполезно
- установлен по умолчанию с Acrobat Standard или Professional (не с Acrobat Reader)
- определение макета
- исправление подозрительных символов вручную
- функция чтения вслух будет выполнять оптическое распознавание текста на страницах только с изображениями
- обрабатывать несколько файлов одновременно
- OCR в текстовые файлы (только с помощью пакетной обработки)
- для рукописных / машинописных / отсканированных изображений низкого качества: бесполезно.
- поддерживает распознавание символов из разных источников
- позволяет исправлять после обработки
- поддерживает различные европейские языки
- экспорт в различные форматы
- Распознавание не всегда точное
- распознанный текст не может быть встроен в PDF
- имеет как минимум одну опечатку («отдельный»)
- копирует текст только из цветных изображений
- не может копировать все виды текста с изображений
- отсутствует мобильная версия
- не может читать все иностранные языки
- простота использования
- может создавать многостраничные PDF-файлы
- позволяет вводить свойства документа
- не может получать изображения непосредственно со сканера
- не может распознать текст в отсканированных изображениях
- полученный текст содержал много ошибок
Против
У онлайн-API OCR и OCR наносетей есть много интересных вариантов использования, которые могут оптимизировать производительность вашего бизнеса, сократить расходы и ускорить рост. Узнайте, как варианты использования Nanonets могут применяться к вашему продукту.
Другие примечательные упоминания: Veryfi , Readiris , Infrrd , Rossum и Hypatos .
Вот краткое сравнение всего перечисленного выше программного обеспечения оптического распознавания текста по некоторым важным функциям и параметрам программного обеспечения оптического распознавания текста:
Чем отличается Nanonets от программного обеспечения оптического распознавания текста?Программное обеспечение Nanonets OCR простое и гибкое в настройке , требующее всего около 1 дня.Автоматизация обрабатывает неструктурированных данных без особого труда, а ИИ также легко обрабатывает общих ограничений данных . Информация из документов с дефектами и изъянами извлекается довольно легко. Он обрабатывает многостраничных счетов-фактур и легко идентифицирует многострочных счетов ; то, что не удается большинству устаревших и современных инструментов распознавания текста. Nanonets настраивает заголовки столбцов , что позволяет более эффективно обрабатывать сложные счета-фактуры.AI Nanonets также обеспечивает высокую точность при обработке документов, требующих минимальной доработки или доработки.
Преимущества использования наносетей не ограничиваются большей точностью, удобством и масштабируемостью. Вот 8 причин, которые подчеркивают уникальное преимущество Nanonets:
Есть ли бесплатное программное обеспечение для распознавания текста?
Помимо упомянутых выше профессиональных передовых решений OCR, существует бесплатное программное обеспечение OCR, которое в определенной степени выполняет эту работу. Эти бесплатные решения, работающие на механизмах оптического распознавания текста с открытым исходным кодом (например, Tesseract), помогают преобразовывать фотографии, файлы PDF, TIFF или отсканированные документы в редактируемые форматы цифрового текста. Хотя они могут быть не в состоянии обрабатывать сложные бизнес-документы в большом масштабе, они подходят для извлечения текста из простых документов с прямым форматированием.
Эти бесплатные решения OCR поставляются либо в виде веб-приложений, автономного программного обеспечения, которое необходимо установить на различных платформах, либо в качестве дополнительной функции в полноценной службе редактирования документов. Обратите внимание, что бесплатное программное обеспечение OCR регулярно не обрабатывает рукописные документы, таблицы с несколькими столбцами, длинные позиции или изображения / отсканированные изображения низкого качества.
Вот несколько бесплатных опций для вашего рассмотрения:
Вот слайд, на котором резюмируются выводы, сделанные в этой статье. Вот альтернативная версия этого поста.
5 БЕСПЛАТНЫХ ОНЛАЙН-ИЗОБРАЖЕНИЙ ДЛЯ ТЕКСТА ИНСТРУМЕНТЫ ДЛЯ ИЗВЛЕЧЕНИЯ ТЕКСТА ИЗ БИЗНЕС-ДОКУМЕНТОВ
В наш век цифровых технологий нет ничего необычного в том, что приходится извлекать текст из изображения, чтобы сделать его доступным для редактирования. Это особенно верно с учетом того, что мы полагаемся на бумажные документы, которые можно преобразовать в форматы, редактируемые в цифровом виде, только с помощью программного обеспечения OCR.
Оптическое распознавание символов (OCR) – это метод распознавания образов на основе искусственного интеллекта, используемый для распознавания текста в изображении и преобразования его в редактируемый цифровой документ.
В этой статье будет представлен список многих программ оптического распознавания символов (OCR), которые могут помочь вам в извлечении текста из изображений на различных устройствах. В зависимости от ваших требований один из этих инструментов должен соответствовать потребностям вашего бизнеса.
Что такое оптическое распознавание символов (OCR)?Когда изображения преобразуются в письменный текст с помощью оптического распознавания символов (OCR), этот процесс называется оптическим распознаванием символов.Доступны различные виды программного обеспечения для оптического распознавания текста, которое может помочь вам извлекать текст из изображений и превращать их в файлы с возможностью поиска. Эти программы принимают широкий спектр форматов изображений и преобразуют их в широко используемые форматы файлов, такие как word, excel и простой текст. Эти решения могут принести пользу как частным лицам, так и компаниям, что делает управление документами и облачное хранилище быстрым и простым.
Какую роль он играет в деловом мире?Копирование текста с изображений требует времени, но с онлайн-конвертером изображений в текст работа часов может быть завершена за минуты.Этот инструмент повышает продуктивность вашей компании, поскольку позволяет сэкономить значительное количество времени другими способами. Этот метод также может помочь вам снизить дополнительные расходы, которые вы можете понести, заплатив сотрудникам за то, чтобы они вручную интерпретировали текст с изображений и записывали его на компьютере.
Топ-5 лучших инструментов преобразования изображения в текст для бизнесаКонвертер фотографий в изображения Prepostseo – это совершенно бесплатное приложение.В дополнение к этому инструменту Prepostseo предоставляет различные другие инструменты, помогающие в решении связанных технических проблем. Технологии Prepostseo помогают преобразовывать изображения в текст без дополнительных регистрационных сборов. Это позволяет вам загружать несколько файлов одновременно, если вы этого хотите. Принимаются соответствующие меры для защиты конфиденциальности информации клиента.
Эффективно понимает и доставляет текст с использованием оптического распознавания символов изображения, который может быть написан любым стилем и шрифтом и на любом языке.Он также способен распознавать математические уравнения, что является фантастикой. Кроме того, он способен определять более 100 различных языков. Помимо английского, он поддерживает несколько других западных языков.
Это простая бесплатная программа оптического распознавания текста, которая предоставляет все основные функции, которые могут вам понадобиться от этого типа программного обеспечения. Это программа распознавания текста только для Windows, которая, как утверждается, обеспечивает максимально возможный уровень точности.Он работает со всеми основными форматами изображений, а также с документами Photoshop.
С обычным текстом он отлично справляется с задачей, сохраняя преобразованный текст в формате DOC или TXT после завершения преобразования. Вместо использования шаблонной структуры программа сканирует бумагу в поисках важной информации с помощью искусственного интеллекта.
В качестве бонуса это одно из самых быстрых и удобных приложений для распознавания текста. Как и все лучшие приложения, оно объединяет множество надежных функций в простом и удобном для навигации дизайне.
Это надежная и масштабируемая программа для визуализации документов и извлечения данных, которая автоматически преобразует документы любого формата, языка или содержания в ценные и доступные бизнес-данные. Он разработан для использования в различных средах. Кроме того, программное обеспечение OCR позволяет отправлять преобразованные файлы PDF в предварительно запрограммированные процессы без необходимости делать что-либо вручную.
Кроме того, встроенная программа проверки орфографии поможет вам исправить любые ошибки, которые могли произойти в процессе преобразования.В нем это необычная функция. Он позволяет пользователям хранить извлеченный текст у различных поставщиков облачных хранилищ, что делает его ценным инструментом.
Pdfsimpli – это самое современное программное обеспечение для оптического распознавания символов (OCR), доступное сегодня на рынке, и это идеальное решение для всех, кому требуется быстрое и точное распознавание текста. Это OCR хорошо работает при работе с большими объемами материала и включает в себя сложные возможности коррекции для более сложных работ.
Вам доступна встроенная проверка орфографии для выявления любых несоответствий в преобразованном тексте. Хотя некоторые люди обеспокоены тем, что это OCR не работает должным образом, при извлечении текста из рукописных заметок, в действительности оно работает исключительно хорошо при использовании печатной версии.
Другой лучший инструмент распознавания текста для деловых документов – text-image.com. Это веб-программа для обработки текста, включая инструменты редактирования и стили, которые помогут вам форматировать текст и абзацы.Кроме того, в нем есть функция распознавания текста, которая позволяет бесплатно преобразовывать файлы PDF в редактируемый текст.
Макет и важные компоненты документа также определяются программой автоматически. Он также позволяет извлекать информацию из различных документов и отображать ее в табличном формате. Кроме того, вы можете поделиться своими документами с кем угодно, и они будут просматривать эти документы в режиме реального времени.
Этот инструмент позволяет модифицировать инструмент распознавания текста в соответствии с вашими требованиями.Автоматическое сканирование, а также ручное сканирование позволяют полностью контролировать передачу текста. Кроме того, у вас есть возможность заархивировать свой документ и добавить ограничения, чтобы ограничить возможность изменять и дублировать его.
ЗаключениеКомпании все больше полагаются на технологии для ускорения роста, и программное обеспечение оптического распознавания символов (OCR) стало решающим решением в этом контексте. Как вы можете понять из приведенного выше списка, на рынке доступно большое количество бесплатных онлайн-инструментов, в которых используется Optical Character.Программные пакеты распознавания для преобразования изображений в текст на ваш выбор. В результате я надеюсь, что этот пост помог вам определить инструмент, который наилучшим образом соответствует вашим желаниям и сэкономит ваше драгоценное время.
Следите за нами и ставьте лайки:
Top 4 Программа для распознавания текста для рукописного ввода Бесплатная загрузка
OCR – оптическое распознавание символов – эта новейшая технология OCR преобразует рукописный текст в редактируемый и доступный для поиска текст на вашем компьютере.Вы можете OCR отсканированных PDF-файлов или PDF-файлов на основе изображений в цифровые файлы и преобразовать отсканированный почерк в текст. Технология была разработана в 1933 году и с каждым годом совершенствуется. Теперь инструменты OCR могут преобразовывать газеты, письма, книги, рукописные или печатные материалы в редактируемый текст для компьютера. Технология рукописного ввода OCR чрезвычайно точна при переводе шрифтов и типов текста в точный цифровой текст. В этой статье мы порекомендуем 5 лучших программ для распознавания рукописного ввода, включая PDFelement Pro.
Часть 1. Рекомендуемое программное обеспечение для распознавания рукописного ввода OCR
№1. PDFelement Pro
PDFelement ProPDFelement Pro – идеальный инструмент распознавания текста для файлов PDF. Он может автоматически распознавать отсканированные PDF-файлы и делать их редактируемыми с помощью встроенных инструментов редактирования. Этот инструмент предлагает на выбор несколько языков OCR и позволяет редактировать текстовые изображения и другие элементы PDF.
Основные характеристики этого инструмента распознавания текста для PDF-файлов:
Скачать сейчас >>
№2. OmniPage Ultimate
В сочетании с искусственным интеллектом и нейронными сетями программное обеспечение OmniPage Ultimate обеспечивает выдающиеся результаты. Это распознавание рукописного текста OCR включает распознавание более чем 120 языков, что гарантирует, что преобразованный текст будет максимально точным. Он также включает новейшую технологию OCR, которая очень хорошо распознает рукописный текст.Он может сделать ваш PDF-документ легко редактируемым, доступным для совместного использования и поиска. Более того, вы можете получить бесплатную пробную версию на их официальном сайте.
Скачать сейчас >>
№3. SimpleOCR
SimpleOCR – одно из самых популярных бесплатных программ для распознавания рукописного ввода, доступных в Интернете. Это довольно просто, но оно также включает OCR для преобразования отсканированных рукописных PDF-файлов, включая все ваши потребности для OCR рукописного ввода. Однако, если вам нужны расширенные функции, вам понадобится платная версия.
Скачать сейчас >>
№4. ABBYY FineReader
ABBYY – компания, которая много лет специализируется на OCR-индустрии. ABBYY FineReader предлагает пользователям лучшие результаты распознавания текста для цифровых фотоаппаратов. В последней версии ABBYY FineReader реализована технология распознавания текста на основе искусственного интеллекта, которая упрощает оцифровку, извлечение, редактирование, совместное использование и защиту всех типов документов COR.
Скачать сейчас >>
Часть 2.Советы по распознаванию рукописного ввода OCR
Использование технологии OCR: технология OCR может быть чрезвычайно полезна для многих профессионалов. Вы можете быстро и легко оцифровать любой рукописный документ и превратить его в редактируемый текст, который можно изменить на своем компьютере.
Советы. Для получения наилучших результатов распознавания текста убедитесь, что ваши документы четкие, и используйте мощный сканер. Самое главное, выберите профессиональную программу распознавания текста, такую как PDFelement ProPDFelement Pro, которая гарантирует точные результаты.Вы также можете попробовать использовать онлайн-инструменты, но имейте в виду, что они довольно ограничены.
Оптическое распознавание символов (OCR) | Портал службы спасения данных C3S
Поиск подходящих и подходящих инструментов оптического распознавания символов (OCR) для автоматического распознавания скриптов из отсканированных записей, часто встречается инструмент Microsoft Office Document Imaging (MODI), Adobe Acrobat и платное программное обеспечение Omnipage или Abbyy FineReader.Помимо этого, есть также пара онлайн-инструментов и бесплатное программное обеспечение. Ниже приведены некоторые ссылки, основные описания и рекомендации.
Реализованы инструменты в стандартных программах: Microsoft Office Document Imaging (MODI)https://support.microsoft.com/en-us/help/982760/install-modi-for-use-with-microsoft-office-2010
https: // acrobat.adobe.com/us/en/acrobat/how-to/ocr-software-convert-pdf-to-text.html
Эти реализованные инструменты имеют невысокую стоимость, но также низкую точность. В то время как инструмент Microsoft Document Imaging ограничен 4 языками (английский, французский, немецкий и итальянский), инструмент Adobe Acrobat поддерживает 42 языка. У них есть проблемы с распознаванием рукописных и машинописных отчетов, и поэтому они не подходят для оцифровки большинства исторических климатических данных.
Инструменты OCR с открытым доступом: OCR.Spacehttps: // ocr.космос /
Служба OCR.Space Online OCR преобразует отсканированные изображения или (смартфон) изображения текстовых документов в редактируемые файлы с помощью технологий OCR. Он использует самое современное программное обеспечение для оптического распознавания текста. Сервисом Online OCR можно пользоваться бесплатно, регистрация не требуется. Программное обеспечение OCR принимает форматы JPG, PNG или PDF (PDF OCR с полной поддержкой многостраничных документов и многоколоночного текста). Он поддерживает 24 языка, размер изображений / PDF не должен превышать 6144 КБ, и он может обрабатывать только печатные документы.Также доступны Pro-версии. На следующем рисунке показан пример OCR с OCR.Space.
ОНЛАЙН OCRhttps://onlineocr.net/
Извлечение текста из (многостраничного) PDF-файла и изображений (JPG, BMP, TIFF, GIF) до 15 МБ с поддержкой 46 языков и преобразование в редактируемые форматы вывода Word, Excel и Text. Возможно использование без установки и регистрации. Также доступны Pro-версии.
СКАЧАТЬ: CuneiFormhttps: // www.softpedia.com/get/Office-tools/Other-Office-Tools/CuneiForm.shtml
CuneiForm – это быстрый и удобный инструмент, функция которого состоит в том, чтобы действовать как программное обеспечение для распознавания текста, позволяя превращать отсканированные документы в редактируемый текст всего за несколько щелчков мышью. Приложение довольно простое для понимания и работы, позволяющее загружать изображения как из локальных папок, так и со сканирующего устройства. Он поддерживает ввод различных форматов, включая JPG, BMP или PNG.
Бесплатная OCR 5.41https: // freeocr.informer.com/
FreeOCR предназначен для распознавания текста на изображениях. Инструмент имеет удобный интерфейс; кроме того, вы можете получить помощь из онлайн-документации. К счастью, он поддерживает импорт изображений из различных источников. Таким образом, помимо использования сканера, вы также можете делать снимки с веб-камеры, а также открывать изображения и документы PDF.
Плюсы
Минусы
https: // gt-text.en.softonic.com/
GT Text считывает шрифт с изображений и копирует их в буфер обмена. Область изображения для этого может быть выбрана произвольно. Инструмент поддерживает форматы файлов BMP, JPG, GIF, TIF и PNG.
Плюсы
Минусы
https: // wiki.gnome.org/Apps/OCRFeeder
OCRFeeder – это система анализа макета документа и оптического распознавания символов. Учитывая изображения, он автоматически обрисовывает в общих чертах свое содержимое, распознает графику и текст и выполняет распознавание текста поверх последнего. Он генерирует несколько форматов, являющихся его основным ODT. Он имеет полный графический пользовательский интерфейс GTK, который позволяет пользователям исправлять любые нераспознанные символы, определять или исправлять ограничивающие рамки, устанавливать стили абзацев, очищать входные изображения, импортировать PDF-файлы, сохранять и загружать проект, экспортировать все в несколько форматов и т. Д.
PDF OCRhttps://pdf-ocr.informer.com/
PDF OCR может помочь вам распознать текст в отсканированных документах PDF. Более того, он может создавать новые PDF-файлы из серии изображений. Приложение имеет удобный интерфейс. При запуске программы вам будет предложено выбрать один из двух режимов: сканированное изображение в PDF или сканированное PDF в текст. К сожалению, как только вы войдете в один из этих режимов, вы не сможете переключиться на другой, если не перезапустите программу.
Плюсы
Минусы
Все бесплатное программное обеспечение и онлайн-инструменты имеют то преимущество, что они бесплатны.
ABBYY Finereader
ABBYY FineReader PDF – это программа для распознавания текста с поддержкой редактирования файлов PDF.Программа позволяет конвертировать графические документы в редактируемые электронные форматы.
Обработка документов с помощью ABBYY FineReader Server – демонстрационное видеоПлюсы:
Требуется программное обеспечение PDF OCR для извлечения изображений в текст или PDF данные? Хотите преобразовать PDF в таблицу или PDF в текст? Оцените возможности онлайн-распознавания текста Nanonets в действии!
Kofax Omnipage
Omnipage – это мощное программное обеспечение для распознавания текста в PDF-файлах, которое может автоматизировать выполнение крупных корпоративных задач распознавания текста.Этот инструмент специализируется на извлечении таблиц, сопоставлении позиций и интеллектуальном извлечении.
Плюсы:
Минусы:
IBM Datacap
Datacap упрощает ввод, распознавание и классификацию бизнес-документов для извлечения из них важной информации.Datacap имеет мощный механизм распознавания текста, множество функций, а также настраиваемые правила. Он работает по нескольким каналам, включая сканеры, мобильные устройства, многофункциональные периферийные устройства и факс.
Плюсы:
Минусы:
Начните использовать Наносети для автоматизации .Попробуйте различные модели OCR или запросите демонстрацию сегодня. Узнайте, как варианты использования Nanonets могут применяться к вашему продукту.
Google Document AI
Одно из решений в пакете Google Cloud AI, Document AI (DocAI) – это консоль обработки документов, которая использует машинное обучение для автоматической классификации, извлечения, обогащения данных и получения информации в документах.
Плюсы:
Минусы:
AWS Textract автоматически извлекает текст и другие данные из отсканированных документов с помощью машинного обучения и распознавания текста.Он также используется для идентификации, понимания и извлечения данных из форм и таблиц. Для получения дополнительной информации ознакомьтесь с этим подробным описанием AWS Textract.
Плюсы:
Минусы: