
Приложения для распознавания текста с фото и сканера | ITMaster
Все сталкивались с пересылкой по электронной почте текстовых и прочих документов. При этом некоторые из них необходимо переводить в электронный вид. Иногда полученные файлы требуют редактирования. На помощь приходит функция распознавания текста со скана или картинки. Этим пользуются студенты, которые предпочитают справочники и литературу иметь в электронном виде.
Принцип работы
Сейчас в интернете можно найти научную, справочную, учебную, методическую и прочую литературу. Книги и статьи, выпущенные в прошлом, оцифрованы и представляют собой фотографии, сканы в различных форматах.
Для работы в текстовом редакторе понадобится программа, считывающая текст с картинки. Последние версии позволяют распознавать на изображении не только текст, но и таблицы.
Любой графический файл (растровый рисунок) состоит из точек. Оптическое распознавание букв основано на выделении точек, их анализе и преобразовании в текст. А процесс выглядит следующим образом:
Оптическое распознавание букв основано на выделении точек, их анализе и преобразовании в текст. А процесс выглядит следующим образом:
- Выделяются блоки, содержащие текст.
- Приложение блок выстраивает в линии.
- Линия делится на слова.
- Слова делятся на символы.
- Символ анализируется с шаблонами шрифтов.
- Программное обеспечение перебирает множество вариантов.
- В итоге распознавалка выдает текст, готовый к изменению в редакторе.
Все многообразие программного обеспечения делится на:
- бесплатные программы;
- платные программы;
- онлайн-сервисы.
Распознаватели предоставляют широкие возможности. После процедуры полученный файл можно сохранить в различных форматах: Word, Excel, PowerPoint, Jpeg, PDF.К тому же можно сделать перевод текста, сжатие файла, применить эффекты, отсканировать и даже проверить на антиплагиат.
Используемые программы
Среди платных и бесплатных программ встречаются как хорошо зарекомендовавшие себя продукты, так и не нашедшие широкого применения. По составленному рейтингу в сети большей популярностью пользуются следующие.
ПрограммаПоддерживаемые языкиФормат сохраненияДостоинстваAbbyy Fine Reader179DOC, DOCX, XLS, XLSX, PPT, PPTX, PDFСохраняет структуру, высокая скоростьCunei Form20RTF, TXT, HTMLПрисутствует редактор, обработка пакетами, сохраняется структура документаWin Scan 2PDF3PDFОтсутствие дополнительных инструментов, пакетная обработкаSimple OCR3DOC, TXT, TIFFТекстовый редакторVue Scan32PDF, JPG, TIFFСохранение шаблонов, всплывающие подсказкиRi Doc4DOC, DOCX, XLS, XLSX, PDF, JPG, TIFFРедактор, конвертерTop OCR11HTML, RTF, PDF, MP3Создание аудиофайловCapture TextНа кириллице и латиницеDOC, TXT, RTFИзвлечение текста и картинок и анимацииInformatik Scan3JPG, BMP, PNG, TIFF, PDFУдаление однотонных блоков, редактор текстаReadiris130DOC, XLS, RTF, TXT, PDF, JPG, TIFFОпределение рукописного текста
Abbyy Fine Reader
Программа для распознавания текста с картинки от разработчика ABBYY считается одной из лучших. В своем функционале имеет множество инструментов. В зависимости от версии она работает и с djvu-файлами.
В своем функционале имеет множество инструментов. В зависимости от версии она работает и с djvu-файлами.
Источник сканов
Сканирование. Перед началом работы с растровыми изображениями необходимо настроить сканер текста с фото. В настройках указывается максимальное количество точек на дюйм (DPI). Рекомендуемое значение не ниже DPI 300. Чем больше этот показатель, тем выше качество и меньше вероятность возникновения ошибок.
Цветность. От цветности зависит скорость сканирования. Среди основных ее настроек три варианта:
- Черно-белый — подходит для сплошного текста.
- Оттенками серого можно воспользоваться, если нужно сканировать документ, содержащий картинки, таблицы и текст.
- Цветным режимом пользуются, когда идет оцифровка журналов и периодики, для которых цветопередача важнее содержания.
Фотография. Программа для считывания текста с картинки работает не только со сканами, но и с фотографиями, снятыми на фотоаппарат или на смартфон в хорошем разрешении. Но как показывает практика, снимки со смартфона имеют искажения, которые влияют на распознавание.
Но как показывает практика, снимки со смартфона имеют искажения, которые влияют на распознавание.
Распознавание графических документов
Утилита работает почти со всеми популярными файлами с расширением jpeg, bmp, png, tiff. Рабочая область имеет два экрана. На левом находится исходник, на правом — результат. После загрузки фото в программу производится его распознавание, но не всегда процедура происходит корректно. Часто приходится прибегать к ручному режиму. Если есть выход в интернет, то полученный результат можно проверить на орфографические ошибки.
Текст. На панели инструментов есть иконка «Т», которая при выделении области исключает работу с таблицами и изображениями. При наличии на странице нескольких таблиц, выделять текст придется несколькими блоками. После чего нажимается иконка «Распознать».
Таблицы. Работа с таблицами сопряжена с некоторыми трудностями. Внутреннее содержание распознается и вставляется в Excel. Но если необходимо ту же таблицу разместить на странице Word, то ее придется создавать заново, а распознанные данные вставляются с ошибками.
Но если необходимо ту же таблицу разместить на странице Word, то ее придется создавать заново, а распознанные данные вставляются с ошибками.
Изображения. При необходимости копирования изображений со сканированного листа они просто выделяются, копируются и вставляются. Не нужно пользоваться графическим редактором для обрезки. Word обладает рядом инструментов для редактирования изображений.
Ненужные области. На отсканированных страницах встречаются области, мешающие работе, такие как реклама и колонтитулы. Перед работой с документами эти области следует удалить. В Fine Reader есть функция «ластик». С ее помощью ненужная область удаляется полностью до белого листа.
Работа с DJVU и PDF
Документы этих форматов не что иное, как графические изображения, преобразованные в формат меньшего объема. И хранить таких документов можно значительно больше на ограниченном объеме памяти.
Распознавание и чтение файлов djvu и pdf идет по всей странице, включая номера страниц и колонтитулы. Это затрудняет дальнейшее редактирование. Чтобы исключить лишнюю информацию в программе устанавливаются дополнительные настройки, ограничивающие рабочую область. Делается это следующим образом:
Это затрудняет дальнейшее редактирование. Чтобы исключить лишнюю информацию в программе устанавливаются дополнительные настройки, ограничивающие рабочую область. Делается это следующим образом:
- Редактирование → работа с изображениями.
- Активировать опцию «Обрезка».
- Установить границы обработки.
- Сохранить настройки кнопкой «Применить ко всем страницам».
Работа онлайн
Если на компьютере или ноутбуке мало места и нет желания возиться с установкой специального программного обеспечения, можно бесплатно воспользоваться онлайн-сервисами. Хороший и известный Img2txt. Сервис бесплатный, функционирует с 2014 года.
Войдя, через вкладку «Открыть» загружается необходимый файл. Далее, нажимается кнопка «Начать распознавание», запускается процедура сканирования текста с фотографии онлайн и его распознавание.
В качестве вывода специалистами отмечается, что широким функционалом обладают платные версии программ.Но если нужно просто распознавание текста для работы с текстовым редактором, то достаточно онлайн-сервисов.
Самостоятельная разметка данных для распознавания русского рукописного текста
В данной статье я опишу наш опыт создания датасета для обучения модели распознавания рукописного текста.
Предварительный анализ работ по этой теме показал, что в публичном доступе отсутствуют размеченные наборы данных на русском языке. Доступные данные либо описывают английский текст, либо не доступны для коммерческого использования. Нам не подходило такое условие, поэтому единственным вариантом стало создание собственных данных.
Общий принцип был заимствован у коллег из Казахстана – создание и заполнение табличных форм с двумя колонками на странице – печатной и рукописной, а затем разбивка скана либо фотографии страницы на мини-боксы с текстом.
Мы начали с выбора текстов. Чтобы модель показывала хорошие результаты на инференсе, она должна иметь высокую обобщающую способность.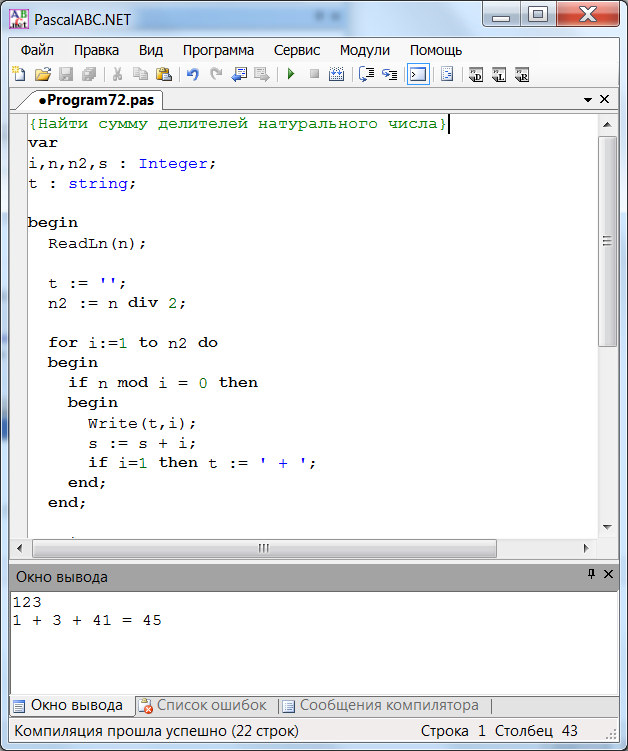 а-я ]+’, ‘ ‘, text) words = text.split()
words_total = len(words) – 3 while line_cnt > 0:
rand = np.random.randint(0, words_total)
if len(words[rand]) < 3 and len(words[rand + 1]) < 3:
continue
elif len(words[rand + 1]) < 3 and len(words[rand + 2]) < 3:
continue
elif len(words[rand]) < 3 and len(words[rand + 2]) < 3:
continue concat = ‘ ‘.join(words[rand: rand + words_per_line])
if len(concat) > 20:
continue line_cnt -= 1
yield concat
а-я ]+’, ‘ ‘, text) words = text.split()
words_total = len(words) – 3 while line_cnt > 0:
rand = np.random.randint(0, words_total)
if len(words[rand]) < 3 and len(words[rand + 1]) < 3:
continue
elif len(words[rand + 1]) < 3 and len(words[rand + 2]) < 3:
continue
elif len(words[rand]) < 3 and len(words[rand + 2]) < 3:
continue concat = ‘ ‘.join(words[rand: rand + words_per_line])
if len(concat) > 20:
continue line_cnt -= 1
yield concat
После этого csv-файлы импортируются в подготовленную Excel-форму, ключевым параметром в ней является верхний колонтитул, где прописан источник текста и номер страницы. Эта информация нужна для сопоставления с csv-файлами, сформированными на предыдущем шаге. Фрагмент формы выглядит следующим образом:
Следующий этап – заполнение форм. Распечатываем, раздаем коллегам, друзьям, знакомым, а также заполняем сами. У нас получилось более тысячи форм, что при 20 словосочетаниях на страницу позволило сформировать выбору из более чем двадцати тысяч примеров. Практика показала, что этого вполне достаточно для обучения модели.
У нас получилось более тысячи форм, что при 20 словосочетаниях на страницу позволило сформировать выбору из более чем двадцати тысяч примеров. Практика показала, что этого вполне достаточно для обучения модели.
После заполнения формы передаются на обработку. Для передачи в компьютер целесообразно использовать сканер, но мы просто фотографировали на телефон, этого оказалось достаточно. После этого изображение обрабатывается специальным ПО, которое формирует csv-файлы со строками формата – «текст – адрес картинки». Далее я кратко изложу принцип его работы.
В шапке каждой формы указан источник текста, из которого она сформирована – так программа понимает, из какого файла брать ground truth тексты – а также номер страницы – поскольку число примеров в форме фиксировано, мы можем легко вычислить offset – смещение относительно начала файла и выбрать нужный фрагмент текстов.
Описанные манипуляции реализованы в виде следующих двух функций:
def read_source(path, page): """ Вспомогательная функция для чтения сформированного csv-файла (labels будущей разметки) :param nrows: сколько строк считывать :param offset: смещение (пропуск N строк) :param path: путь к файлу :return: список из словосочетаний """ nrows = 20 offset = (page - 1) * nrows # на каждой странице у нас по 20 словосочетаний n = 0 with open(path, newline='') as file: answers = [] for _ in range(offset): # skip first 10 rows next(file) for row in csv.reader(file): answers.append(row[0]) # у нашего файла 1 столбец n += 1 if n >= nrows: break return answers def write_markup(labels_path, image_folder, labels_filename, page, gender): """ Принимает csv файл с labels и папку Формирование файла разметки для обучения модели :param gender: пол заполнившего лист :param labels_path: путь к файлу с текстами строк :param page: номер страницы (определяет смещение в csv-файле) :param labels_filename: называние файла с текстами строк :param image_folder: путь к папке с нарезанными изображениями :return: """ markup_file_path = './markup/markup_' + labels_filename + '.csv' labels = read_source(labels_path, page) image_list = os.listdir(image_folder) # половина ячеек таблицы - печатный текст (исходник) # такие ячейки пропускаем, берем только нечетные images = [image_folder + '/' + file for idx, file in enumerate(image_list) if idx % 2 == 1] assert labels, "Список текстов пустой" assert images, "Директория с нарезанными картинками пуста" assert len(labels) == len(images), "Несовпадение длин массивов картинок и текстов" # если файла не существует (пишем в него первый раз) - добавляем заголовок if not os. path.exists(markup_file_path): with open(markup_file_path, "w", newline='') as file: writer = csv.writer(file) writer.writerow(('label', 'image', 'gender')) # после этого добавляем в файл обработанные строки with open(markup_file_path, "a", newline='') as file: writer = csv.writer(file) for pair in zip(labels, images): row = (pair[0], pair[1], gender) writer.writerow(row)


Картинки нарезаются при помощи набора функций нашего Python-модуля table_slice. Работа с изображениями происходит при помощи библиотеки OpenCV – программа считывает контуры таблицы, фильтрует и затем сортирует их – нам не нужны слишком маленькие контуры, которые, вероятно, считаны ошибочно, а также слишком большие контуры, ограничивающие либо несколько ячеек таблицы, либо всю таблицу. Программный код этого модуля слишком большой для приведения в тексте статьи, с его основными идеями можно ознакомиться здесь.
Для ускорения обработки реализован интерфейс командной строки.
import os import argparse import cv2 import markup import table_slice as ts if __name__ == '__main__': # интерпретатор должен быть запущен в корневой папке проекта! parser = argparse.ArgumentParser() parser.add_argument("labels", choices=['blvrd', 'discipl', 'econ', 'journ', 'koms', 'mathstat'], help='Название файла с текстом. Не указывать расширение!') parser.add_argument("images", help='Файл с отсканированным изображением') parser.add_argument("page", type=int, help='Номер страницы') parser.add_argument("gender", type=int, choices=[0,1], help="Пол: 1 - М, 0 - Ж") parser.add_argument("--nocheck", action="store_true", help="Не запрашивать подтверждение записи") args = parser.parse_args() # аргументами должны быть только имена файлов, без путей # path дает кривые слеши, поэтому использую конкатенацию строк DST_IMG_FOLDER = './sliced/' + args.labels + '/' + args.images[:-4] # убираем расширение файла # папка с готовыми (нарезанными) изображениями SRC_IMG_FOLDER = './data/images' # папка с исходными (сканированными) изображениями SRC_LBL_FOLDER = './data/labels' # папка с нарезанными текстами (csv) LABELS_FILE_PATH = SRC_LBL_FOLDER + '/' + args.labels + '.csv' # путь к обрабатываемому файлу с ярлыками IMAGE_FILE_PATH = SRC_IMG_FOLDER + '/' + args.labels + '/' + args.images # путь к фотке, которую нарезаем img = cv2.imread(IMAGE_FILE_PATH, 0) # 0 для игнора цветовой палитры (читает ЧБ) if img is None: raise Exception("Не удалось прочитать исходный файл") # т.к. opencv не выдает ошибок чтения # обработка изображений состоит из бинаризации # получения границ таблицы и непосредственно нарезки img_bin = ts.binarize(img) img_vh, bitnot = ts.get_lines(img, img_bin) cropped_images = ts.get_images(img_vh, bitnot, img_bin, w_min=10, h_min=25, h_max=5, debug=False) if not os. path.exists(DST_IMG_FOLDER): # для каждой фотки - своя папка с нарезанными кусочками os.makedirs(DST_IMG_FOLDER) # папка называется именем файла исходной фотки for num, cropped_img in enumerate(cropped_images): enhanced_img = markup.increase_contrast(cropped_img) filename = DST_IMG_FOLDER + '/' + str(num).zfill(3) + '.jpg' # zfill делает названия 001, 002 и т.п. did_write = cv2.imwrite(filename, enhanced_img) # если не удалось записать файл, самостоятельно вызываем исключение if not did_write: raise Exception("Не удалось сохранить готовый файл") # получить из csv тексты с соответствующей страницы answers = markup.read_source(LABELS_FILE_PATH, args.page) # контроль ts.control(answers, cropped_images, args.nocheck) # формирование и запись csv разметки (формат "текст" - "путь к картинке") markup.write_markup(LABELS_FILE_PATH, DST_IMG_FOLDER, args.labels, args.page, args.gender) print("Файл разметки сформирован")


Для обработки изображение помещается в папку, соответствующую названию текста-источника, после чего в командной строке из корневой папки python-проекта выполняется команда вида:
python src/main. py blvrd IMG_1234.jpg 140 1 –nocheck
py blvrd IMG_1234.jpg 140 1 –nocheck
В данном случае обрабатывается изображение IMG_1234, текст для которого был взят из источника blvrd, номер страницы формы – 140, автор – мужчина, а дополнительная проверка корректности форм выключена (программа не будет запрашивать подтверждение пользователя перед записью в итоговый файл).
Программа автоматически контролирует корректность распознавания форм, правильность указания источника, соответствие количества нарезанных ячеек нормативному и другое. Обработка практически всегда происходит быстро и без ошибок. Практика показала, что основной причиной ошибок являются плохо пропечатанные контуры ячеек. Программа не даст записать не полностью считанную форму в файл. Результат работы представлен ниже.
Работа по разметке данных оказалась сложной и трудоемкой, однако это позволило нам сформировать уникальную выборку и в дальнейшем обучить ряд моделей, успешно распознающих написанный от руки русский текст.
КАК ПЕРЕВЕСТИ ПИСЬМЕННЫЙ ТЕКСТ В ПЕЧАТНЫЙ — 5 способов
Иногда приходится делать конспекты от руки, а потом перепечатывать. Но технологии придумали выход даже с такой ситуации. Достаточно лишь обладать почерком средней читаемости, смартфоном и одной из пяти программ для рукописного текста из нашего списка. Что делать дальше — научим.
Но технологии придумали выход даже с такой ситуации. Достаточно лишь обладать почерком средней читаемости, смартфоном и одной из пяти программ для рукописного текста из нашего списка. Что делать дальше — научим.
С помощью Windows 10 (рукописный ввод)
Обладателям аккуратного почерка необязательно скачивать сторонние приложения. Все что нужно — включить ввод от руки на своем Windows 10.
Следует только иметь девайс с сенсорным вводом на Win10 — это может быть ноут, монитор (как тот же ASUS VT229H) или планшет. Дальше стоит придерживаться инструкции.
1. Добавить иконку режима ввода пера — тогда можно писать в любом месте экрана
Для этого нужно кликнуть правой кнопкой мышки (ПКМ) на стрелочку в меню значков. Дальше выбрать пункт «Показать кнопку Windows Ink Workspace».
2. Найти программы для ввода текста
Открыть скачанные заранее Word или OneNote и коснуться стилусом поля для ввода. Теперь можно писать.
3. Конвертировать текст в печатный
Перейти в меню нужного приложения (находится сверху), нажать на «Набор инструментов» и выбрать «Текст».
Также есть альтернативное средство ввода рукописного текста — через режим планшета. Для его включения нужно нажать на иконку клавиатуры в меню значков. Дальше нужно сделать выбор между экранной клавиатурой и рукописным вводом. Выбрав «ручной режим», придется вводить текст в специальное окно, зато оно сразу будет переводить в печатный.
Всегда на связи: Программы для видеозвонков — топ 5 по функциональным возможностям
MetaMoJi Note
Программа для заметок для iOS и Android. Кроме перевода написанного текста в печатный, в MetaMoji можно создавать примечания. Кроме этого, в приложение также добавляются голосовые заметки: не нужно прописывать информацию вручную.
Для этого нужно сделать следующее:
- Включить встроенный диктофон, который будет записывать важную лекцию
- При необходимости, делать письменные заметки — они будут синхронизироваться по времени с аудиозаписью.
После этого, включая кнопку «Проиграть» аннотации будут подтягиваться к нужному моменту записи.
Режим ручного ввода доступен по умолчанию. Для этого нужно:
- Открыть документ.
- Тапнуть на виртуальный лист, тем самым спрятав клавиатуру.
- Можно писать, вводя текст вручную или копируя картинки.
- В ПК-версии MetaMoji Note Lite для запуска конвертации ручного ввода нужно нажать кнопку «Текст» и начать прописывать текст в появившемся окошке.
Можно обмениваться файлами через три облачных сервиса:
- Dropbox, который синхронизируется со Slack, Trello, Photoshop и линейкой Office.
- Evernote — приложением для заметок.
- Google Диск — облачным хранилищем для владельцев Гугл-почты.

При желании, можно синхронизировать все папки со встроенным облаком MetaMoJi. Правда, здесь бесплатны только первых 2 Гб. Дальше придется платить за онлайн-хранилище.
Важная информация: Что такое гибернация в ноутбуке или компьютере: 4 «за» и «против»
GoodNotes 5
Продвинутая версия оригинального приложения «Заметки» на iPad. Загрузить её можно в AppStore, заплатив $7,99 — это приложение только для Apple-экосистемы. Владельцам андроид-телефонов этой программой не воспользоваться.
Непрерывная вертикальная прокрутка позволяет быстро записывать любой объем информации. Программа мгновенно преобразовывает письменный текст в печатный и меняет шрифт — потом его можно скопировать куда угодно.
Также программа понравится тем, кому нужно регулярно чертить простые фигуры. Включив распознавание формы, прога «считывает» что хотел нарисовать человек и переводит рисунок в правильную геометрическую форму: от круга с квадратом до сердец и звезд.
Можно найти любую заметку через встроенный поиск, поэтому нужные мысли не потеряются, даже если строчить по 10 текстов в день. А благодаря коннекту с iCloud, данные синхронизируются с «яблочным» облаком, поэтому можно начать работать с планшета, а закончить с телефона, и наоборот.
Для живучести: Как не убить батарею ноутбука и продлить срок ее службы: 8 ценных советов
Pen to Print для Android и iOS
Подойдет тем, кто привык работать с бумагой, чтобы потом перевести письменный текст в печатный. Загрузить можно в Google Play и в App Store. Правда нужно быть готовым к ограниченному количеству функций в бесплатной версии — удастся только сканировать текст и копировать его построчно в другие программы.
Этот сканер текста умеет работать с книгами и рукописями. Достаточно навести фокус на лист с информацией и сфотографировать его внутри приложения.
Важно, чтобы при фотографировании в помещении было светло, а текст — разборчивый. Иначе придется самому исправлять ошибки, которые допустил искусственный интеллект.
В бесплатной версии получиться только сканировать и редактировать текст. Сохранять готовый результат прямо в приложении и отправлять его по почте можно лишь после оформления подписки.
Лучшие браузеры: Какой браузер выбрать: 5 лучших программ
Google Handwriting Input
Андроид-приложение, которое мастерски расшифровывает рукописный текст средней и плохой читаемости. Найти его можно только в Google Play — на iOS не установить. Дальше нужно запустить программу и тогда она появится в качестве отдельной клавиатуры, которую можно менять в настройках. Находят приложение по следующему пути: Настройки → «Язык и ввод» → «Настройки Рукописного ввода». Либо же можно зажать кнопку с глобусом и выбрать нужную клавиатуру.
Дальше можно начинать записывать свои мысли стилусом или пальцами. Приложение распознает знаки пунктуации, символы и некоторые эмодзи.
Назвать его отдельной программой сложно — скорее, это расширение к традиционной Android-клавиатуре. Поэтому подобная программа не подойдет владельцам телефонов Huawei, на них нельзя установить гугл-приложения.
При обычной портретной рекомендации получится писать только отдельные слова. Если же хочется записывать сразу предложения, придется включить альбомную ориентацию экрана и перевернуть устройство. Тогда панель ввода подстроится под экран и появится еще больше место для рукописей.
Чтобы понять, какая аппка лучшая в конкретном случае, следует сравнить их бок-о-бок в финальной таблице:
Учитывая то, что бумажки постоянно теряются, электронный документ остается на облаке пока его не удалят. Эти программы по переводу рукописного текста в печатный сэкономят время и нервы. Пользуйтесь и не благодарите!
Для развлечений: Как сделать Gif анимацию за 5 минут: онлайн-сервисы, Фотошоп, приложения для телефонов
Самые смешные картины от нейросети Сбера ruDALL-E
Специалисты «Сбера» представили нейросеть ruDALL-E, способную «рисовать» изображения, исходя из запросов конкретных потребителей. По словам разработчиков, программа будет полезна в области создания дизайна интерьера, стоковых картинок, векторных изображений и каких-либо материалов для рекламы. 5-tv.ru рассказывает, как это работает.
Красиво и смешноСоздатели ruDALL-E утверждают, что работа с системой разделяется на три этапа. В начале пользователь должен составить письменный план того, что мечтает увидеть перед собой. Одна нейросеть считывает написанное и генерирует изображение. Затем подключается вторая нейросеть, которая определяет, какие из предложенных вариантов максимально красивы и подойдут заказчику. Третья нейросеть подключается немного позже и увеличивает удачную иллюстрацию в размере без потери качества, выдавая «клиенту» результат.
Известно, что уже существует две версии программы: ruDALL-E 12В и ruDALL-E XL. Различаются они возможностями: у первой — 12 миллиардов параметров, а у второй — 1,3 миллиарда. Как сообщили разработчики, на обучение нейросети ушло 23 тысячи часов. За это время «умный проект» проанализировал более 120 миллионов пар «текст-изображение».
В «Сбере» считают, что ruDALL-E — самый большой нейровычислительный проект, когда-либо существовавший на территории страны и СНГ. Вот такие красивые картинки по описанию природы, к примеру, он выдает.
press.sber.ru
Мемы пользователейА теперь взгляните на кадры, что предложены ниже — так развлекаются с ruDALL-E рядовые пользователи интернета. Людям понравилась необычная затея, и теперь почти каждый считает своим долгом создать уникальный шедевр при помощи нейросети.
«Лысая версия Моны Лизы!» — похвалился своей картиной Denis Shiryaev, замахнувшийся на легендарного Леонардо да Винчи.
✨ A bald version of the Mona Lisa generated with ruDall-E pic.twitter.com/J1FH9htmOb
— Denis Shiryaev (@Dostoevskiy) November 2, 2021
Не забыли юзеры протестировать систему на известных политиках. Под раздачу попала бывший канцлер Германии Ангела Меркель — ее «портрет» получился удивительно похожим на американского демократа, экс-госсекретаря Хиллари Клинтон. Немного «перекосило лицо» и у президента США Джо Байдена. На фото он словно помолодел на 40 лет!
Компания Сбер разработала нейросеть ruDALL-E, которая генерирует изображения из текстового описания на русском языке.
А вот так нейросеть сгенерировала по описанию Байдена и Меркель😊🤗
— Мозг_и_Барий (@debily_bl) November 2, 2021
🤪👍 pic.twitter.com/VQXfnHLA6R
Неожиданный шедевр появился при попытке изобразить Рэмбо с раменом.
По мнению ruDALL-E XL, так выглядит Рембо с раменом.
— Keyser Söma осенний (@keyser_soma) November 3, 2021pic.twitter.com/78cBfVInzC
Не обошли пользователи вниманием и популярные ругательные русские выражения. Так выглядит «екарный бабай».
Благодаря ruDALL-E XL теперь мы знаем как выглядит екарный бабай. #ruDalle pic.twitter.com/E4yssl4kRs
— Alexei ❌ KLENIN (@AlexeiKlenin) November 3, 2021
Ранее 5-tv.ru рассказал, как искусственный интеллект будет помогать московским гаишникам.
Кинотеатры, музеи и другие объекты культуры на территории Хабаровского края начали применять систему QR-кодов – Новости – События
Власти Хабаровского края в очередной раз разъяснили порядок применения новых антиковидных мер, предполагающих использование QR-кодов при посещении учреждений культуры. В Комсомольске-на-Амуре во время рабочей поездки заместитель председателя правительства по социальным вопросам Евгений Никонов провел брифинг, на котором ответил на вопросы журналистов. К нему присоединилась и главный санитарный врач региона Татьяна Зайцева, вместе они сообщили последние данные по статистике заболеваемости.
– Мы перешагнули цифру 400 по ежесуточному приросту заболевших. Это новый антирекорд, выздоравливает ежесуточно в два раза меньше человек. В госпиталях края сейчас проходят лечение около 100 тяжелых пациентов. При этом, по данным врачей, в реанимации нет ни одного привитого пациента – ни в хабаровских больницах, ни в комсомольских. Общий процент заболевших, которые до этого были вакцинированы, не превышает трех процентов. Вакцинация от коронавируса – единственная действенная мера на сегодня, поэтому и было принято решение на уровне правительства региона о временном введении QR-кодов, которые подтверждают вакцинацию их владельцев, – отметил Евгений Никонов.
В хабаровском кинотеатре «Гигант» сегодня принимали первых посетителей с QR-кодом. Процедура максимально простая и не требует дополнительных затрат от организации. Контролер считывает QR-код зрителя с помощью приложения в сотовом телефоне, на экране появляется информация о действительности кода. Как рассказал администратор кинотеатра «Гигант» Никита Вишняк, вся процедура занимает не больше 30 секунд.
– Просим на входе в зал показать паспорт и сам код, сканируем его камерой на мобильном телефоне так же, как сканируем электронный билет, все очень просто. Допускается также сертификат о прививке. У военнослужащих, например, это может быть только сертификат. Сначала был небольшой негатив от посетителей, но, когда объясняем, для чего все делается, начинают относиться с пониманием, – добавил Никита Вишняк.
Инцидентов, связанных с отсутствием у посетителя QR-кода или справки, в этом кинотеатре пока не зафиксировано.
Как отметили участники брифинга, ПЦР-тест может стать заменой QR-кода только для иностранного туриста, жителям края и гостям региона на руках необходимо иметь QR-код в электронном или распечатанном формате, либо сертификат о прививке, либо справку о перенесенном заболевании в течение последнего полугода. Будут приняты меры и против подделок. Организации уже проинформированы о возможности использования мобильного приложения «Госуслуги. СТОП Коронавирус» для проверки подлинности QR-кодов. По словам главного санитарного врача края Татьяны Зайцевой, количество рейдов на предприятия увеличат.
– Мы продолжаем отслеживать масочный режим и соблюдение дистанции, за минувшие выходные было выписано несколько протоколов в адрес торговых центров и объектов культуры в Хабаровске. Наряду с Роспотребнадзором полномочия на проведение рейдов имеют органы муниципальной власти, а также МВД. С введением ограничений эта работа усилится, – сообщила Татьяна Зайцева.
По словам специалистов, проанализировать действие новых ограничительных мер можно будет не ранее, чем через две недели, однако уже сейчас в мобильных пунктах вакцинации отмечается повышение активности населения. За минувшие выходные прививку сделали больше четырех тысяч человек, для сравнения, в сентябре еженедельная цифра не превышала 500 человек по краю.
Напомним, с 1 ноября, согласно постановлению правительства Хабаровского края, QR-код вакцинированного нужно предъявить при посещении кинотеатра, театра, филармонии, цирка, дома культуры, такие же правила начали действовать при посещении официальных физкультурных и профессиональных спортивных мероприятий, в том числе по футболу и хоккею. С 20 ноября система QR-кодов заработает на предприятиях общественного питания, в фитнес-центрах, спортивных клубах и бассейнах, а также при заселении в гостиницу и хостел.
Пресс-служба губернатора и правительства Хабаровского края
При использовании материалов ссылка на сайт www.khabkrai.ru обязательна
Как извлечь текст из изображения на iPhone, iPad и Mac
Существует ряд причин, по которым вы можете захотеть извлечь текст из изображения. Возможно, у вас есть визитная карточка, и вы хотите ввести данные в свои контакты, может быть, вам просто не нравится печатать абзацы текста, которые находятся на странице перед вами, в качестве альтернативы вам могли бы отправить форму для заполнения что вы предпочитаете делать на своем компьютере
Apple четко осознает, что это то, что люди хотят делать.Позже в этом году компания добавит новую функцию Live Text, которая сможет распознавать текст на изображениях и позволять вырезать и вставлять его или, в случае адреса электронной почты или номера телефона, щелкнуть по нему, чтобы позвонить или послать электронное письмо. Скорее всего, это будет удобная функция, но вам не нужно ждать выхода Monterey, iOS 15 и iPadOS 15 в конце этого года – вы можете сделать это сейчас, и на самом деле некоторые из приложений, предлагающих функции OCR, предлагают еще больше. функциональность, чем новая функция Apple.
В этой статье мы рассмотрим некоторые из имеющихся у вас опций OCR (оптического распознавания символов) и то, как функция Apple Live Text будет работать после ее запуска.
Лучшие приложения для распознавания текста
Во-первых, вот некоторые из лучших приложений для распознавания текста, которые вы можете использовать сейчас.
Adobe Scan – превращает снимки экрана, сохраненные изображения, фотографии, визитки и даже заметки на белой доске в цифровой файл и разблокирует текст с помощью оптического распознавания текста. Приложение предназначено для iPad и iPhone. Вы можете бесплатно скачать его здесь.
LiveScan – это приложение также может извлекать текст из изображений. Он доступен для Mac, iPhone и iPad. Есть бесплатная версия, которая ограничена 50 символами на одно обнаружение, но вы можете использовать ее столько, сколько захотите.В противном случае это 99 пенсов в месяц или единовременный платеж в размере 8,99 фунтов стерлингов. Он даже имеет параметры определения языка, поэтому вы можете использовать английский, французский, немецкий или китайский языки. Поскольку бесплатная версия ограничена 50 символами, вы, вероятно, сочтете ее лучшим вариантом для копирования адресов электронной почты и номеров телефонов. Вы можете скачать его в App Store здесь.
TextSniper – это приложение для Mac может извлекать текст из изображений, отсканированных бумажных документов, PDF-файлов и даже видео. Это стоит 8,99 фунтов стерлингов / 9,99 долларов США в Mac App Store здесь.
SnipCopy – это приложение для iPad и iPhone извлекает текст из изображений, PDF-файлов и всего на экране.Приложение разработано для iPad, но также будет работать на компьютерах Mac M1. Получите его в App Store здесь.
Scanner Pro, Readdle – это еще одно приложение-сканер, разработанное для iPad и iPhone, оно также работает в iMessage. Он отсканирует бумажный документ и позволит вам сохранить цифровую версию. Существует бесплатная семидневная пробная версия, за которой следует подписка за 3,49 фунтов стерлингов в месяц, но, к сожалению, вам необходимо подписаться на подписку, прежде чем вы сможете использовать какие-либо функции. Конечно, вы можете отменить подписку в любое время.Получите его в App Store здесь.
Как извлечь текст из изображения с помощью Adobe Scan
Мы попробовали Adobe Scan. Здесь вы можете сканировать доску, форму, документ или визитную карточку. Или же вы можете выбрать фотографию из приложения «Фото».
Если вы решите «сканировать» документ перед собой, у вас будет возможность выбрать текст, а затем скопировать текст. Затем текст будет скопирован в буфер обмена. Если текст включает номер телефона, вы увидите возможность позвонить, а при наличии адреса электронной почты вы увидите возможность позвонить по нему.
Что такое Live Text?
На WWDC 2021 Apple представила ряд новых функций, которые появятся в iOS 15, iPadOS 15 и macOS Monterey. Одним из самых впечатляющих был Live Text, который записывает изображения и преобразует их в текст, который затем можно вставлять в документы, электронные письма или что угодно. Это также позволяет вам увидеть номер телефона на фотографии, а затем набрать его напрямую, не набирая ничего.
Вот как использовать Live Text на iPhone, iPad и Mac.
Как использовать Live Text на iPhone и iPadЧтобы использовать функцию Live Text, ваш iPhone должен работать под управлением iOS 15 или iPadOS 15. Это означает, что вы можете либо подождать, пока он не выйдет в конце этого года (примерно в сентябре, когда ожидается прибытие iPhone 13), либо подписаться на Программа Apple Beta Software. Последний является самым быстрым, поскольку вы можете использовать его сегодня, но имейте в виду, что бета-версия программного обеспечения может содержать ошибки и вызывать проблемы. Так что, если вы действительно не можете продержаться до осени, мы рекомендуем дождаться выхода полной версии iOS 15 или iPadOS 15.В противном случае прочтите наше руководство о том, как установить бета-версию iOS 15 на iPhone.
Живой текст в приложении камерыПосле того, как у вас установлена и запущена iOS 15 или iPadOS 15, получить доступ к функции Live Text будет просто, поскольку она встроена непосредственно в приложение камеры. Итак, вот что делать:
- Откройте приложение камеры
- Получите изображение, которое вы хотите запечатлеть в кадре
- Нажмите кнопку «Живой текст», которая появляется в правом нижнем углу изображения.
- Коснитесь текста на изображении и выберите его, как в любом документе.
- Выберите Копировать в появившемся меню.
- Откройте целевой документ, затем нажмите «Вставить», чтобы увидеть преобразованный текст.
Также возможно преобразовать текст в существующих фотографиях. Вот как:
- Откройте приложение «Фото».
- Откройте фотографию, которую хотите использовать.
- Проведите пальцем по текстовой области изображения.
- Выберите Копировать.
- Наконец, вставьте его в целевой документ.
Если на изображении, о котором идет речь, есть номер телефона, например, на стороне здания, вы можете использовать его прямо с изображения с помощью Live Text.
- Открыть изображение
- Увеличьте число
- Нажмите кнопку «Живой текст» в правом нижнем углу рамки.
- Номер теперь должен стать ссылкой, поэтому коснитесь его, чтобы открыть контекстное меню
- Выберите, какую опцию вы хотите использовать – «Позвонить», «Отправить сообщение», «Копировать» и т. Д.
После того, как вы обновите свой Mac до macOS Monterey (или подписались на программу бета-тестирования, упомянутую выше), вы сможете воспользоваться преимуществами новой функции Live Text. Первоначально казалось, что Live Text будет доступен только для Mac M1, но с тех пор Apple открыла эту функцию и для Intel Mac, хотя она, вероятно, будет ограничена более поздними моделями. Читайте: Apple, в конце концов, принесет OCR-подобный Live Text на Intel Mac.
Вы не можете использовать камеру Mac так же, как на iPhone или iPad, но вы все равно можете взаимодействовать с текстом на изображениях, которые вы найдете в приложении «Фото».
Это довольно просто: вы просто открываете изображение, нажимаете на текст или число, а затем взаимодействуете с ним через появившееся меню.
В macOS Monterey появится множество других замечательных функций, в том числе масштабные обновления Safari, введение быстрых заметок и ярлыков, а также многие другие.Чтобы узнать, что вас ждет, ознакомьтесь с нашим руководством по macOS Monterey.
Напишите хороший замещающий текст для описания изображений
Некоторым людям с трудностями чтения или нарушениями зрения необходимо настроить отображение текста, чтобы его было легче читать. Когда текст представлен как изображение текста, это ограничивает их способность изменять внешний вид этого текста. Поэтому везде, где это возможно, используйте текст вместе с CSS для применения стиля (например, цвета, шрифта или размера).
Если вы используете онлайн-редактор контента для написания контента, стили будут выполнены автоматически.Если вы чувствуете, что вам нужен текст, который отличается от стиля, параметры форматирования, предоставляемые онлайн-редакторами контента, должны позволить вам обновить стиль для этого текста.
Только в крайних случаях, например, при использовании логотипа, вы можете использовать изображение текста, а не текста. Если вы это сделаете, вам нужно будет предоставить тот же текст, что и альтернативный текст изображения, чтобы пользователи программ чтения с экрана могли получить доступ к тексту.
Примеры
✗ Плохой пример
В редакторе WYSIWYG можно загрузить изображение некоторого текста (скажем, «вкусные блины») и вставить его на страницу с альтернативным текстом, который точно соответствует тексту:

Одним из недостатков здесь является то, что программы чтения с экрана в некоторых контекстах будут читать альтернативный текст с добавлением «графики», и вы можете не захотеть, чтобы пользователь знал, что текст на самом деле является изображением. Кроме того, текст внутри изображения нельзя перевести на другие языки, выбрать для копирования / вставки или изменить размер без ухудшения его качества.
✓ Используйте CSS и веб-шрифты
Напишите текст как текст в редакторе и позвольте издательской системе применить стиль.
За кулисами текст будет стилизован с использованием веб-шрифтов и свойств CSS, таких как background , text-shadow и color .
.pancakes-text {
семейство шрифтов: PancakeFont, FallbackFont, sans-serif;
цвет: песочно-коричневый;
text-shadow: 0,02em 0,02em 0 Коричневый,
0 0 0,5 мкм фиолетовый;
}
Редактор кода
Вы можете поэкспериментировать со стилями текста CSS в этом редакторе кода, используя приведенные выше правила в качестве отправной точки.
JAWS® – Freedom Scientific
Самая популярная программа для чтения с экрана для Windows Что такое программа для чтения с экрана? Программа чтения с экрана – это программа, которая позволяет слепому или слабовидящему пользователю читать текст, отображаемый на экране компьютера с помощью синтезатора речи или дисплея Брайля. JAWS, J ob A ccess W с S peech, это самая популярная в мире программа чтения с экрана, разработанная для пользователей компьютеров, у которых потеря зрения не позволяет им видеть содержимое экрана или перемещаться с помощью мыши.JAWS обеспечивает вывод речи и шрифта Брайля для наиболее популярных компьютерных приложений на вашем ПК.
- Читать документы. электронные письма, веб-сайты и приложения
- Простая навигация с помощью мыши
- Отсканируйте и прочтите все ваши документы, включая PDF
- Легкое заполнение веб-форм
- Простота использования с базовым обучением в формате Daisy
- Экономьте время с беглым чтением и анализатором текста
- Посещайте Интернет с помощью нажатия клавиш для просмотра веб-страниц
Характеристики
- Два многоязычных синтезатора: Eloquence и Vocalizer Expressive
- Говорящая установка
- Удобная функция оптического распознавания текста для файлов изображений или недоступных документов PDF
- Поддерживает камеру PEARL для прямого доступа к печати документов или книг
- Встроенный бесплатный DAISY Player и полный набор базовых учебных пособий в формате DAISY
- Работает с Microsoft Office, Google Docs, Chrome, Internet Explorer, Firefox, Edge и многими другими.
- Поддерживает Windows® 11, Windows 10, Windows Server® 2019 и Windows Server 2016, включая сенсорные экраны и жесты
- Поддержка содержимого MathML, представленного в Internet Explorer, отображаемого с помощью MathJax
- Экономьте время с беглым чтением и анализатором текста
- Быстрый поиск информации с помощью Research It
- Полностью совместим с ZoomText, Fusion, MAGic и программой сканирования и чтения OpenBook
Расширенные функции
- JAWS Tandem Center доступен бесплатно, чтобы помочь с поддержкой и обучением
- Дополнительная поддержка Tandem Direct, Citrix, служб терминалов и удаленного рабочего стола
- Мощный язык сценариев для настройки взаимодействия с пользователем в любом приложении
- Включает драйверы для всех популярных дисплеев Брайля.
- Включает голоса для более чем 30 различных языков
- Доступна поддержка через киоск
Чтобы использовать JAWS для Windows, вам потребуется персональный компьютер под управлением Microsoft® Windows® со следующим:
| Описание | Спецификация |
|---|---|
| JAWS Home Edition и JAWS Professional | Windows® 11, Windows 10, Windows 7, Windows Server® 2019 и Windows Server 2016. |
| Скорость процессора | Процессор минимум 1,5 ГГц |
| Память (RAM) | Рекомендуется 4 ГБ (64-разрядная версия) Рекомендуется 2 ГБ (32-разрядная версия) |
| Требуемое пространство на жестком диске | Для установки голосов Vocalizer Expressive, Vocalizer Direct или RealSpeak Solo Direct требуется от 20 МБ до 690 МБ на голос (размеры файлов зависят от установленного голоса) |
| Видео | Адаптер дисплея с разрешением экрана не менее 800 x 600 с 16-битным цветом (рекомендуется разрешение экрана 1024 x 768 с 32-битным цветом) |
| Звук | Звуковая карта, совместимая с Windows (для речи) |
Примечание: На предыдущей веб-странице загрузок JAWS есть более старые версии JAWS для компьютеров, все еще работающих под управлением Windows 7 (JAWS 2021 и более ранние), Windows Vista (JAWS 17 и более ранние) или Windows XP (JAWS 15 и более ранние) .
Документация JAWS
Ресурсы для сценариев JAWS
Предыдущая документация JAWS
Если вы хотите просмотреть документацию по более ранним версиям JAWS, посетите страницу «Предыдущие загрузки JAWS для Windows» и загрузите соответствующую версию JAWS. Установите эту программу, а затем загляните в папку «Справка», чтобы найти документацию по продукту.
Добавить альтернативный текст к изображению в Microsoft Word
Обзор
Люди, которые не могут видеть изображения в документах Microsoft Word, рассчитывают, что автор предоставит альтернативный текст для описания содержания изображения.Используемый альтернативный текст должен описывать важные аспекты изображения, но быть достаточно кратким, чтобы не перегружать пользователя. Когда программа чтения с экрана встречает изображение в документе Word, пользователю зачитывается альтернативный текст, помогая ему понять, что происходит на изображении.
Примечание:
Если вы используете изображения в декоративном контексте и они не содержат информативного содержимого (например, цветное изображение разделительной полосы между абзацами содержимого), альтернативный текст не требуется.
Добавить альтернативный текст к изображению
Чтобы добавить замещающий текст к изображению в Word:
- Вставьте изображение, которое хотите использовать, в документ.
- Щелкните изображение правой кнопкой мыши, а затем в появившемся меню щелкните.
- На панели «Формат изображения» щелкните.
- Щелкните стрелку рядом с, чтобы развернуть параметры альтернативного текста.
В поле «Описание» введите описание изображения.
Если у вас есть подробное изображение, которое требует подробного описания, вы можете ввести краткое описание описания в поле «Заголовок».Это позволяет пользователям решить, нужно ли им полное описание изображения или нет. В противном случае вы можете оставить поле «Заголовок» пустым.
- По завершении закройте панель «Формат изображения».
Примечание:
В версии Word для Microsoft 365 вы также можете добавить альтернативный текст для изображений, щелкнув изображение правой кнопкой мыши и выбрав. Имейте в виду, что эта опция не предоставляет поле заголовка; для подробных изображений, которым может потребоваться заголовок, выполните указанные выше действия, чтобы добавить альтернативный текст и заголовок.
Подробнее о создании альтернативного текста для изображений см. Общие рекомендации по созданию документов со специальным доступом.
Как извлечь текст из снимка экрана в Windows 10
Оптическое распознавание символов существует уже много лет, и оно улучшено, так что фотографии напечатанного текста, например, из книги, можно читать точно. Большинство приложений OCR нацелены на отсканированные документы или PDF-файлы, которые не позволяют пользователям копировать текст. Тем не менее, если вам когда-нибудь понадобится извлечь текст из снимка экрана, инструмент OCR – это то, что вам нужно.
Инструмент распознавания текста OneNote
Если у вас есть OneNote 2016 на ПК с Windows 10, все, что вам нужно сделать для извлечения текста из снимка экрана, – это вставить снимок экрана в заметку / страницу, щелкнуть его правой кнопкой мыши и выбрать «Копировать текст из изображения» в контекстном меню. . В более новых версиях OneNote по-прежнему есть эта функция, но она основана на облаке. Это означает, что вам нужно будет вставить изображение, подождать несколько минут, а затем появится опция «Копировать текст из изображения».
После копирования вы можете вставить его где угодно, в том числе на ту же страницу OneNote.
PhotoScan OCR
OneNote отлично работает, но заставляет немного подождать, прежде чем можно будет извлечь текст, и сначала вам нужно вставить снимок экрана на страницу. Процесс в основном намного дольше, чем нужно. Если вам нужно более быстрое решение, попробуйте PhotoScan . Это бесплатное приложение, но в нем есть расширенные функции, которые вам необходимо купить. Для OCR достаточно бесплатной версии.
Установите PhotoScan из Microsoft Store.
Откройте приложение и просмотрите его краткое руководство. Нажмите «Обзор фото» и добавьте снимок экрана, из которого вы хотите извлечь текст.
Приложение автоматически покажет вам весь текст, найденный на изображении, и вы можете скопировать его в буфер обмена и вставить куда угодно.
Текст будет читаться слева направо, но приложение не будет заботиться о каких-либо «границах» или «разделителях», разделяющих текст.Это означает, что текст в окне приложения не будет отличаться от текста на панели задач. На предыдущем снимке экрана приложение нашло и отобразило текст из окна командной строки, а также отобразило текст из панели задач, то есть кнопку выбора языка, а также время и дату. Время и дата не отображаются вместе. Вместо этого между ними вставляется текст кнопки выбора языка.
Если это проблема для вас, и вам нужно, чтобы приложение сохраняло текст отдельно, вы можете обрезать изображение на более мелкие части, чтобы каждая часть содержала только определенный текст, который приложение будет читать.Это займет немного времени, но это проще, чем печатать текст самостоятельно.
Как скопировать текст с изображения на Android
Вы когда-нибудь хотели скопировать текстовое содержимое изображения? Или, может быть, вы хотите отправить содержание учебника другу, не печатая его полностью? Благодаря некоторым приложениям в магазине Google Play вы можете извлекать текст из печатных материалов (газет, книг, журналов, продуктов и т. Д.), Фотографируя материал.Впоследствии вы можете поделиться извлеченным текстом в других приложениях, преобразовать в PDF и перевести в PDF.
Эти приложения часто называют сканерами текста или оптическими считывателями символов , и они могут извлекать текст из изображений с помощью метода, известного как оптическое распознавание символов.
Реклама – Продолжить чтение ниже
Оптическое распознавание символов или оптическое распознавание символов, часто сокращенно OCR, представляет собой механическое или электронное преобразование изображений печатного, рукописного или напечатанного текста в машинно-кодированный текст, будь то из отсканированного документа, фотографии документа, сцены. -фотография (например, текст на вывесках и рекламных щитах на альбомной фотографии) или из текста субтитров, наложенного на изображение (например, из телетрансляции).
Википедия
В Google PlayStore есть ряд приложений для сканирования текста (Text Scanner, Google Keep, Office Lens, TurboScan, Docufy Scanner и т. Д.), Которые можно использовать для извлечения текста из изображений на смартфоне Android. Однако в этом руководстве мы покажем вам, как копировать текст с изображения с помощью приложения Text Fairy OCR Text Scanning.
1. Установите приложение Text Fairy на свое устройство из Google PlayStore
.2.Запустите приложение и щелкните значок « Camera », чтобы извлечь текст из нового изображения. Это откроет камеру вашего телефона.
3. Кроме того, вы можете нажать значок « Image », чтобы извлечь текст из существующего изображения. Откроется Галерея вашего телефона.
4. Сделайте снимок или выберите изображение страницы, документа, файла, которое вы хотите преобразовать в текст.
ПРИМЕЧАНИЕ : Во время захвата изображения убедитесь, что вы держите камеру в устойчивом положении и чтобы изображение не было темным.Наконец, приложение Text Fairy OCR не может читать почерк.
5. Обрежьте изображение, чтобы выбрать раздел страницы, из которого вы хотите извлечь текст.
6. Приложение начинает считывать текст на обрезанном участке захваченного / выбранного изображения.
7. По завершении (т.е. 100%) приложение отображает на экране сообщение « Прошло хорошо, ». Затем вы можете перейти к выбору совместного использования извлеченного текста, его копирования или преобразования в PDF.
8. Нажмите « Копировать », чтобы скопировать часть (или весь) извлеченный текст.На странице копирования вы все равно можете перевести извлеченный текст на другой язык, нажав кнопку перевода.
По умолчанию Text Fairy может читать тексты на английском, русском и немецком языках. Однако вы можете загрузить больше языков. Нажмите кнопку меню >> Добавить язык >> Нажмите « Загрузить », чтобы добавить предпочтительный язык.
Text Fairy не совсем идеален при извлечении текста, так как я заметил, что у приложения были проблемы с правильным извлечением слов с знаками препинания, таких как апострофы, кавычки и двойные кавычки.Я, однако, рекомендую Text Fairy по сравнению с другими сканерами и считывателями текста с оптическим распознаванием текста, потому что он полностью бесплатен, не требует регистрации, не требует рекламы и распознает печатный текст более чем на 50 языках.
СвязанныеЧто это такое, как это написать и почему это важно для SEO
Если вы тратите время на оптимизацию содержимого, заголовков, подзаголовков и метаописаний своего блога или веб-сайта для поисковых систем, следующее изображение должно вас насторожить:
Снимок экрана выше является первой страницей результатов поисковой системы (SERP), которую Google создает для поискового запроса “Примеры таблиц Excel”.«Обратите внимание на то, как, помимо вкладки« Изображения »вверху, Google помещает значительный пакет интерактивных изображений в начало основной страницы результатов – до того, как результаты обычного текста станут даже видимыми.
Сегодня почти 38% результатов выдачи Google показывают изображения – и этот показатель, вероятно, будет расти. Это означает, что, несмотря на все ваши усилия по поисковой оптимизации, вы все равно можете упустить другой источник органического трафика: изображения вашего сайта. Как вы попадаете в этот источник трафика? Альтернативный текст изображения.
Что такое замещающий текст?
Альтернативный текст, также называемый альтернативными тегами и альтернативными описаниями, представляет собой письменную копию, которая появляется вместо изображения на веб-странице, если изображение не загружается на экран пользователя.Этот текст помогает инструментам чтения с экрана описывать изображения для читателей с ослабленным зрением и позволяет поисковым системам лучше сканировать и оценивать ваш сайт.
Независимо от того, проводите ли вы SEO для своего бизнеса или нет, оптимизация альтернативного текста изображения вашего веб-сайта – это ваш билет к созданию лучшего пользовательского опыта для ваших посетителей, независимо от того, как они впервые нашли вас.
Как добавить замещающий текст к изображениям
В большинстве систем управления контентом (CMS) щелчок по изображению в теле сообщения блога приводит к созданию модуля оптимизации изображений или расширенного текста, в котором вы можете создавать и изменять замещающий текст изображения.
Давайте рассмотрим, что делать дальше для CMS Hub и WordPress ниже.
Как добавить замещающий текст в HubSpot CMS
В HubSpot, как только вы щелкнете изображение и щелкните значок редактирования (который выглядит как карандаш), появится всплывающее окно оптимизации изображения.
Вот как выглядит это окно оптимизации изображения в CMS на вашем портале HubSpot:
Ваш замещающий текст затем автоматически записывается в исходный HTML-код веб-страницы, где вы можете дальше редактировать замещающий текст изображения, если ваша CMS не имеет легко редактируемого окна замещающего текста.Вот как этот тег alt может выглядеть в исходном коде статьи:
Как добавить замещающий текст в WordPress CMS
В WordPress при нажатии на изображение автоматически откроется вкладка Block на боковой панели. В разделе «Настройки изображения» добавьте замещающий текст в пустое поле.
Когда вы будете готовы, щелкните Обновить на панели инструментов в верхней части экрана.
Самое главное правило альтернативного текста? Будьте описательными и конкретными. Имейте в виду, однако, что это правило замещающего текста может потерять свое значение, если ваш замещающий текст также не учитывает контекст изображения. Замещающий текст может не попасть в цель тремя разными способами. Рассмотрим примеры ниже.
3 примера замещающего текста изображений (хорошее и плохое)
1. Ключевое слово в сравнении с деталями
Неверный замещающий текст
alt = "Стена офиса HubSpot Сингапур Фрески на рабочем месте входящий маркетинг оранжевые стены отправить его" Что не так со строкой замещающего текста выше? Слишком много ссылок на HubSpot.Использование замещающего текста для вставки ключевых слов во фрагментированные предложения добавляет к изображению слишком много путаницы и недостаточного контекста. Эти ключевые слова могут быть важны для издателя, но не для поисковых роботов.
Фактически, замещающий текст выше затрудняет для Google понимание того, как изображение соотносится с остальной частью веб-страницы или статьи, на которой оно публикуется, что препятствует ранжированию изображения по соответствующим ключевым словам longtail , которые имеют более высокий уровень интереса. их.
Что еще хуже, если вы наберете слишком много ключевых слов, вы можете понести штраф Google.
Хороший альтернативный текст
Принимая во внимание неправильный альтернативный текст (см. Выше), лучший альтернативный текст для этого изображения может быть:
alt = "Оранжевая фреска с надписью" отправить "на стене в сингапурском офисе HubSpot" 2. Детали против специфики
Изображение через Уинслоу Таунсон
Неверный замещающий текст
alt = "Бейсболист отбивает мяч на бейсбольном поле" Строка замещающего текста выше технически следует первому правилу замещающего текста – быть описательной – но она не является описательной в правильном смысле.Да, на изображении выше показано бейсбольное поле и игрок, отбивающий бейсбольный мяч. Но это также фотография Фенуэй-Парка – и Дэвида Ортиса из Red Sox № 34, показывающего один на правом поле. Это важные особенности, которые Google потребуется для правильной индексации изображения, если оно, скажем, в блоге о спорте в Бостоне.
Хороший альтернативный текст
Принимая во внимание неправильный альтернативный текст (см. Выше), лучший альтернативный текст для этого изображения может быть:
alt = "Дэвид Ортис из команды Boston Red Sox отбивает мяч с домашней площадки в Fenway Park" 3.Специфика и контекст
Изображение через UCLA
Оба изображения выше имеют четкий контекст, который может помочь нам написать хороший альтернативный текст – один взят из офиса HubSpot, а другой – Fenway Park. Но что, если у вашего изображения нет официального контекста (например, названия места), которым можно было бы его описать?
Здесь вам нужно будет использовать тему статьи или веб-страницы, на которой вы публикуете изображение. Вот несколько плохих и хороших примеров альтернативного текста в зависимости от причины, по которой вы его публикуете:
Для статьи о посещении бизнес-школы
Неверный замещающий текст
alt = "Женщина, указывающая на экран компьютера человека" Строка замещающего текста выше обычно проходит как приличный замещающий текст, но, учитывая, что наша цель – опубликовать это изображение со статьей о поступлении в бизнес-школу, мы упускаем некоторые варианты ключевых слов, которые могли бы помочь Google связать изображение с отдельными разделами статьи.
Хороший альтернативный текст
Принимая во внимание неправильный альтернативный текст (см. Выше), лучший альтернативный текст для этого изображения может быть:
alt = "Профессор бизнес-школы указывает на экран компьютера студента" Для веб-страницы образовательного программного обеспечения для учителей бизнес-школ
Неверный замещающий текст
alt = "Учитель указывает на экран компьютера ученика" Строка замещающего текста выше почти так же описательна и конкретна, как и хороший замещающий текст из предыдущего примера, так почему же ее недостаточно для веб-страницы, посвященной программному обеспечению для образования? Этот пример еще глубже погружается в тему бизнес-школы и указывает, что идеальной аудиторией для этой веб-страницы являются учителя.Следовательно, замещающий текст изображения должен это отражать.
Хороший альтернативный текст
Принимая во внимание неправильный альтернативный текст (см. Выше), лучший альтернативный текст для этого изображения может быть:
alt = "Профессор, использующий образовательное программное обеспечение для обучения учащегося бизнес-школы" Оптимальные методы работы с замещающим текстом изображения
В конечном итоге замещающий текст изображения должен быть конкретным, но также репрезентативным для темы поддерживаемой им веб-страницы. Уловили идею? Вот несколько важных ключей к написанию эффективного замещающего текста изображения:
- Опишите изображение и будьте конкретны. Используйте как предмет изображения, так и контекст, чтобы направлять вас.
- Добавьте контекст, относящийся к теме страницы. Если на изображении нет узнаваемого места или человека, добавьте контекст на основе содержимого страницы. Например, альтернативным текстом для стандартного изображения человека, печатающего на компьютере, может быть «Женщина, оптимизирующая веб-сайт WordPress для SEO» или «Женщина, изучающая бесплатные платформы для ведения блогов», в зависимости от темы веб-страницы.
- Держите замещающий текст короче 125 символов .Инструменты чтения с экрана обычно перестают читать замещающий текст на этом этапе, отсекая длинный альтернативный текст в неудобные моменты при вербализации этого описания для слабовидящих.
- Не начинайте замещающий текст с «изображение …» или «изображение …» Перейти прямо к описанию изображения. Инструменты чтения с экрана (и Google, если на то пошло) идентифицируют его как изображение из исходного HTML-кода статьи.
- Используйте ключевые слова, но экономно. Включайте целевое ключевое слово вашей статьи только в том случае, если его легко включить в альтернативный текст.Если нет, рассмотрите семантических ключевых слов или просто самые важные термины в длиннохвостом ключевом слове. Например, если ключевое слово заголовка вашей статьи – «как привлечь потенциальных клиентов», вы можете использовать «создание потенциальных клиентов» в своем замещающем тексте, поскольку «как» может быть трудно естественным образом включить в замещающий текст изображения.
- Не впихивайте ключевое слово в замещающий текст каждого изображения. Если ваше сообщение в блоге содержит серию изображений тела, включите ключевое слово хотя бы в одно из этих изображений. Определите изображение, которое, по вашему мнению, наиболее репрезентативно для вашей темы, и назначьте ему ключевое слово.Придерживайтесь более эстетичных описаний в окружающих СМИ.
- Проверьте орфографические ошибки. Слова с ошибками в замещающем тексте изображения могут нанести вред пользователю или запутать поисковые системы при сканировании вашего сайта. Вы должны просмотреть замещающий текст, как и любой другой контент на странице.
- Не добавляйте замещающий текст к каждому изображению. Вы должны добавить замещающий текст к большинству изображений на веб-странице в целях SEO, UX и доступности, однако есть исключения. Например, изображения, которые носят исключительно декоративный характер или описаны в тексте рядом, должны иметь пустой атрибут alt.Для получения более подробной информации о том, когда добавлять замещающий текст, а когда нет, ознакомьтесь с этим деревом решений.
Как альтернативный текст влияет на SEO
Согласно Google, альтернативный текст используется – в сочетании с алгоритмами компьютерного зрения и содержимым страницы – для понимания тематики изображений.
Таким образом, замещающий текстпомогает Google лучше понять не только содержание изображений, но и веб-страницу в целом. Это может помочь увеличить вероятность того, что ваши изображения появятся в результатах поиска изображений.
При создании контента по теме подумайте, как ваша аудитория может предпочесть находить ответы на свои вопросы по этой теме. Во многих случаях поисковикам Google не нужен классический синий результат поиска с гиперссылкой – им нужно само изображение, встроенное в вашу веб-страницу.
Например, посетитель, ищущий, как удалить дубликаты в Excel, может предпочесть снимок экрана, чтобы сразу понять, как выполнить задачу.
Источник изображения
Поскольку это изображение имеет оптимизированный замещающий текст, оно появляется в результатах поиска изображений по ключевому слову longtail «как удалить дубликаты в Excel.”Поскольку сообщение также появляется в результатах веб-поиска по тому же ключевому слову, посетители могут попадать на сообщение в блоге через эти два разных канала.
Почему важен замещающий текст изображения?
Мы уже упоминали несколько причин, по которым замещающий текст изображения важен, а именно: доступность, удобство для пользователя и трафик изображений. Понимание этих причин поможет вам написать лучший альтернативный текст для ваших изображений. Ниже мы более подробно рассмотрим основные причины, по которым замещающий текст изображения важен.
Доступность
Еще в 1999 году W3C опубликовал свои рекомендации 1.0 по обеспечению доступности веб-контента, чтобы объяснить, как сделать контент более доступным для пользователей с ограниченными возможностями. Одно из этих правил заключалось в том, чтобы «предоставить эквивалентные альтернативы звуковому и визуальному контенту». Это означало, что любые веб-страницы, включая изображения (или фильмы, звуки, апплеты и т. Д.), Должны включать информацию, эквивалентную своему визуальному или слуховому содержанию.
Например, скажем, веб-страница содержит изображение направленной вверх стрелки, которая ведет к оглавлению.Текстовым эквивалентом может быть «Перейти к содержанию». Это позволит пользователю с программой чтения с экрана или другой вспомогательной технологией понять назначение изображения, не видя его.
Другими словами, замещающий текст помогает обеспечить доступность вашего визуального контента для всех пользователей, включая людей с нарушениями зрения.
Взаимодействие с пользователем
Альтернативный текст не только обеспечивает лучший пользовательский интерфейс для пользователей с ограниченными возможностями – он обеспечивает лучший пользовательский интерфейс для всех пользователей. Скажем, у посетителя соединение с низкой пропускной способностью, поэтому изображения на вашей веб-странице не загружаются.Вместо того, чтобы просто видеть значок неработающей ссылки, они также увидят замещающий текст. Это позволит им понять, что изображение должно было передать.
Например, пользователь может видеть изображение слева. Если они не могут – из-за инвалидности, проблемы с пропускной способностью или по другой причине – они услышат или увидят замещающий текст справа. Это поможет улучшить взаимодействие с пользователем, чем если бы не было альтернативного текста.
Источник изображения
Трафик изображений
Одна из самых важных вещей, которую может сделать для вас замещающий текст изображения, – это превратить ваши изображения в результаты поиска с гиперссылками, которые появляются либо в Картинках Google, либо в виде пакетов изображений.Пакеты изображений – это особые результаты, отображаемые в виде горизонтального ряда ссылок на изображения, которые могут появляться в любой органической позиции (включая первое место в поисковой выдаче, как показано в примере во вступлении).
изображений, которые появляются либо в изображениях Google, либо в пакетах изображений, предоставляют еще один способ привлечь обычных посетителей. Это может привести к увеличению количества посетителей на тысячи – по крайней мере, в случае с HubSpot.
Начиная с 2018 года команда HubSpot Blog внедрила новую стратегию SEO, которая отчасти была более сосредоточена на оптимизации замещающего текста изображений.Это помогло увеличить трафик изображений в блоге на 779% менее чем за год, в результате чего количество обычных просмотров увеличилось на 160 000. Вы можете узнать больше об успехах команды в этом сообщении в блоге.
Добавление замещающего текста изображения на ваш сайт
Итак, с чего начать разработку альтернативного текста для сообщений в блогах и веб-страниц? Рассмотрите возможность проведения базового аудита вашего существующего контента, чтобы увидеть, где вы можете включить замещающий текст в ранее немаркированные изображения.