
Сканирование и распознавание. 300 лучших программ на все случаи жизни
Сканирование и распознавание
Ввести со сканера текст в компьютер – задача не слишком трудная. Однако работать с таким текстом невозможно: как и любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Отсюда возникают проблемы: во-первых, в графическом формате страница занимает слишком много места, и, скажем, отсканированная книга не на каждый жесткий диск поместится. И вторая, самая главная проблема: сканированный текст можно будет только читать, но не редактировать и не вставлять его фрагменты в создаваемый вами документ. Ведь сам сканер распознавать буквы именно как буквы не умеет: они для него – всего лишь пятна и точки черного цвета.
К счастью, на свете существуют программы, способные перевести сканированный текст из графического в текстовый формат – программы распознавания текста или OCR (Optical Character Recognition).
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами (именно так работали распознавалки первого поколения), но и самыми экзотическими, вплоть до рукописных.
Как видим, для того, чтобы получить электронную, готовую к редактированию копию любого печатного текста, программе OCR необходимо выполнить «цепочку» из множества отдельных операций:
Сканирование. За эту работу отвечает, собственно, не программа OCR, а встроенное в систему программное обеспечение вашего сканера.
Сегментация. Полученную со сканера «картинку» подхватывает OCR-программа. Но до распознавания еще далеко – сначала надо отделить текстовые элементы от графики, да и текст в ряде случаев разбить на отдельные куски (например, при многоколонной верстке).
Распознавание. На этом этапе текст переводится из графической формы в текстовую.
Проверка орфографии и правка. Встроенная система проверки орфографии «проходится» по тексту, проверяя и корректируя последствия работы системы распознавания.
Сохранение. Для дальнейшей обработки документ должен быть передан «на поруки» соответствующей программе – как правило, одному из продуктов семейства Microsoft Office. Или сохранен в формате, соответствующем его содержанию: текст – в DOC или RTF, таблица – в XLS.
Все эти операции в большинстве программ OCR могут выполняться как в автоматическом, с помощью программы-мастера, так и в ручном режиме, по отдельности.
С двумя первыми и последней операциями справится любая программа распознавания. А вот весь процесс целиком по зубам, увы, только нескольким продуктам, разработанным в нашей стране. Хотя в теории с русским текстом должны справляться еще несколько западных «распознавалок», качество их работы не может сравниться с CuneiForm от фирмы Cognitive и FineReader от ABBYY Software.
Обе программы вы можете приобрести отдельно или получить бесплатно вместе с купленным вами сканером. В частности, известная во всем мире компания HewlettPackard (на долю которой приходится значительная часть рынка сканеров в России) поставляет вместе со своей продукцией упрощенную версию CuneiForm.
FineReader
Сайт: http://www.abbyy.com
Размер: 35 140 Мб (Поставляется на CD)
Статус: Commercial
Цена: $130 (Professional), $260 (Corporate)
Именно эту программу чаще всего поминают, когда речь заходит о системах распознавания. И вполне заслуженно – компания ABBYY ( http://www.abbyy.com) смогла не просто создать удобный для пользователя и качественный продукт, но и, самое главное, удачно «раскрутить» его, обеспечив «Файнридеру» пламенную любовь всей компьютерной прессы. Одно это, согласитесь, многого стоит.
Другим удачным ходом разработчиков FineReader стало внедрение в продукт массы дополнительных функций, которые простому пользователю, возможно, и без надобности, но зато производят впечатление на определенные группы покупателей.
Как ни странно, большинство пользователей на деле интересуются совсем другим. Офисных работников интересует распознавание типовых форм документов, студентов – возможность быстро «передрать» для реферата многостраничный текст из учебника, сканируя и распознавая книжный разворот целиком, бухгалтеров – возможность автоматического распознавания таблиц и документов на бланках. Все это и многое другое FineReader умеет… или не все, а только частично, в зависимости от модификации продукта. Далеко не все возможности из нашего перечня включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером.
После завершения распознавания страницы FineReader предложит пользователю выбор: сканировать и распознавать дальше (для многостраничного документа) или сохранить полученный текст в одном из множества популярных форматов – от документов Microsoft Office до HTML или PDF. Можно, впрочем, сразу же перебросить документ в Word или Excel, и уже там исправить все огрехи распознавания (без них обойтись просто невозможно). При этом FineReader полностью сохраняет все особенности форматирования документов и его графическое оформление.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРесПрограммы сканирования для Android
2018. Smart Engines – система извлечения данных из документов
Российская компания Smart Engines разработала ряд приложений, которые (с помощью компьютерного зрения) умеют распознавать и считывать данные из различных стандартных документов (паспортов, ID-карт, водительских удостоверений, СНИЛС, банковских карт …). Такое приложение может здорово сэкономить время сотрудникам, заполняющим формы по клиентским документам (и, соответственно, сократить время ожидания клиентов). Кроме того, Smart Engines предлагает быструю разработку кастомных приложений для компаний. Например, они разработали мобильное приложение для IKEA, которое распознает этикетки IKEA и умеет извлекать из них артикул, ряд и место товара на складе.

2017. Adobe Scan – бесплатное приложение для сканирования в PDF
Хотя мобильных приложений для сканирования хватает, но не все они бесплатны и без ограничений, и не все умеют распознавать текст, как новенький Adobe Scan. Распознавание текста дает возможность производить поиск в документе, копировать текст и редактировать документ. Правда, для редактирования вам уже понадобится платная программа Adobe Acrobat DC. Все отсканированные документы попадают в ваш аккаунт в облачном хранилище Adobe Document Cloud, где ими можно управлять и расшаривать для других пользователей. Также, конечно, важно качество отсканированных документов и распознаваемого текста. И вот здесь разработчики приложения обещают вас удивить, потому что они построили приложение на базе искусственного интеллекта Adobe Sensei.
2015. Microsoft представила Office Lens – мобильное приложение для сканирования документов
Microsoft выпустила приложение Office Lens для iPhone и Android, которое позволяет сфотографировать бумажный документ, распознать текст и перевести его в электронный документ.
 Год назад аналогичное приложение появилось для Windows Phone. Office Lens автоматически обрезает, поворачивает и корректирует фотографию документа таким образом, чтобы она выглядела отсканированной. После этого приложение может распознать текст, который можно экспортировать в Word, OneNote, PowerPoint, PDF или отправить по почте. Таким образом можно сканировать не только бумажные документы, но и визитки, флипчарты после совещаний, листочки с заметками и т.д.
Год назад аналогичное приложение появилось для Windows Phone. Office Lens автоматически обрезает, поворачивает и корректирует фотографию документа таким образом, чтобы она выглядела отсканированной. После этого приложение может распознать текст, который можно экспортировать в Word, OneNote, PowerPoint, PDF или отправить по почте. Таким образом можно сканировать не только бумажные документы, но и визитки, флипчарты после совещаний, листочки с заметками и т.д.Программа для сканирования и распознавания текста, актуальный список
Главная страница » Софт / ПрограммыВашему вниманию предоставляют знаменитую и удобную в своем использовании хорошую программу под названием Optical Character Recognition, что в переводе означает Оптическое распознавание символов. Данные программы созданы для перевода некоторого изображения, рисунков и любых предоставленных документов в текст который после можно отредактировать в любых известных текстовых редакторах. Эти программы очень экономят время и предоставляют большой выигрыш в скорости набора, ко всему этому количество ошибок сводится к минимуму. Так что эти программы сохраняют все возможные иллюстрации, что тоже не мало важно.
Данные программы созданы для перевода некоторого изображения, рисунков и любых предоставленных документов в текст который после можно отредактировать в любых известных текстовых редакторах. Эти программы очень экономят время и предоставляют большой выигрыш в скорости набора, ко всему этому количество ошибок сводится к минимуму. Так что эти программы сохраняют все возможные иллюстрации, что тоже не мало важно.
Далее мы расскажем Вам о некоторых программах с помощью которых вы сможете совершить подобные процедуры, так называемые программы-помощники. Они распознают как русский текст, так и украинский, и английский. Зачастую программа автоматически определяет язык документа, но пожеланию эту настройку можно выполнить и в ручную.
Программы для сканирования и распознавания текста
И та, первой мы рассмотрим программу OCR CuneiForm. Эта программа является бесплатной. С лёгкостью сканирует и распознает текст, эта программа русского разработчика Cognitive Technologies.

Данная программа оптического распознавания символов зачастую идет в комплекте с некоторыми, выборочными моделями знаменитых фирм сканеров таких как: Canon, Oki, HP и другие. Самое интересное что, данные этой программы пользуются так же большим спросом у потребителей программы Corel Draw, это некая программа для обработки изображений.
Эта замечательная программа OCR CuneiForm очень быстро и надежно к тому же и качественно распознает любой выбранный текст, потому что в базе программы заложено около 20 разных языков, которые эта программа может распознать. Так же она с лёгкостью справится с распознанием смешанного языка в документе.
Следующей программой для рассмотрения будет ABBYY Finereader. Это очень популярная на рынке программа для распознавания всех текстов. Создатель – российская известная компания ABBYY.
Данная программа очень популярна во многих регионах, она является одной из самых практичных и удобных программ, а также очень проста в своем использовании. Она имеет дополнительную функцию сохранения и оформления документов.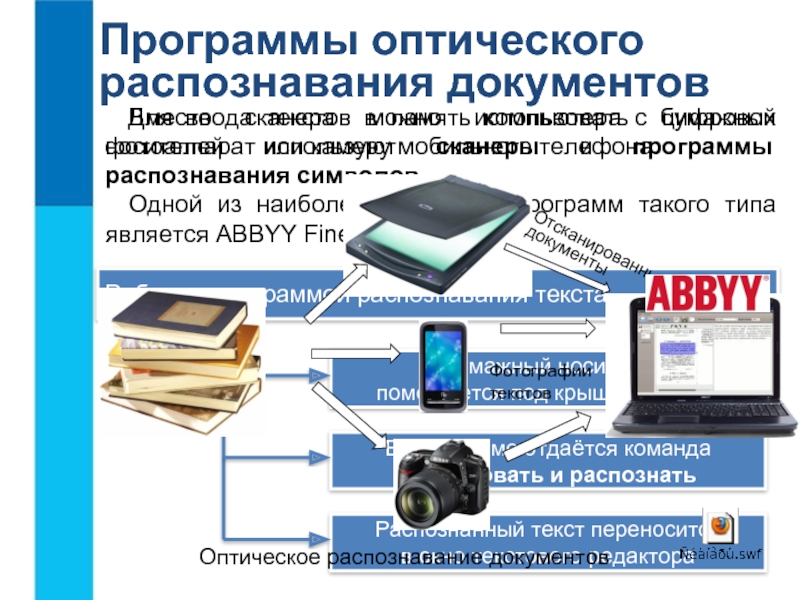 Она представлена тремя разными пакетами, которые имеют разницу в своем интерфейсе, а также отличаются некоторыми возможностями, стоимостью и типом лицензии. И так нашему вниманию предоставлены следующие пакеты распознавания:
Она представлена тремя разными пакетами, которые имеют разницу в своем интерфейсе, а также отличаются некоторыми возможностями, стоимостью и типом лицензии. И так нашему вниманию предоставлены следующие пакеты распознавания:
— Home Edition;
— Professional Edition;
— Corporate Edition.
Пакет Home Edition в основном предназначен исключительно для домашнего простого использования, он очень легкий в своем использовании. Очень удобное использования для тех, кто в основном хочет получить точную копию страницы с какой-либо книги, какого-либо журнала или других источников. Для дальнейшего редактирования в офисных программах. Интерфейс данной программы очень прост, все процедуры можно проделать с помощью нажатия всего лишь одной кнопочки, что очень удобно, легко и быстро.
Такой пакет распознавания разных символов как, Professional Edition и Corporate Edition, созданы для профессионального использования. В их дополнительных функциях присутствуют распознавание PDF файлов, а также в программы встроенный редактор текста и существуют программы которые проверяют орфографию. Версия Corporate более уникальна, её в основном используют в офисах, где налажена сетевая связь сканеров и других многофункциональных устройств. С помощью этой программы, редактировать и использовать полученные данные после сканирования могут сразу несколько пользователей.
Версия Corporate более уникальна, её в основном используют в офисах, где налажена сетевая связь сканеров и других многофункциональных устройств. С помощью этой программы, редактировать и использовать полученные данные после сканирования могут сразу несколько пользователей.
Возможности данных OCR намного шире, чем у предыдущей. В программе заложено около 180 языков, для распознавания, 38 из которых эта программа может проверить на орфографию. Уже версия Professional может распознать иврит, японский и китайский языки. Так же Finereader имеет возможность открывать все графические файлы различных форматов.
В предпоследней версии ABBYY Finereader 9.0 есть такая возможность распознавать разные изображения, которые были сделаны на цифровой фотоаппарат.
Программа ABBYY Finereader не является бесплатной, но она заслуживает своей цены.
Перейдем к рассмотрению следующей не менее интересной программы OmniPage – это программа для сканирования и распознания текстовых документов от компании Nuance Communications.
Главным плюсом этой программы является скорость. Она очень быстро и одновременно качественно распознает любые документы. В своей базе данных имеет около 120 языком с разными алфавитами, такими как: латинский, кириллица, и другие. Эта программа, также, как и ABBYY Finereader может распознавать изображения, полученные с цифровой фотокамеры.
Еще одним значительным плюсом этой программы, является возможность осуществлять работу с несколькими документами одновременно. Есть возможность, открывать, редактировать, распознавать и сохранять некоторое количество документов одновременно, что очень удобно.
Программа OmniPage имеет три версии, которые на данный момент выпускаются, это – Standard, Professional, Enterprise. Версия Professional очень удобна тем, что имеет возможность любой документ сохранить в PDF. Это очень удобно.
Ознакомится более подробно с данной программой вы можете на сайте www.nuance.com
Также нашему вниманию представлена еще одна программа Readiris производитель – компания I. R.I.S.
R.I.S.
Точно также как и выше предоставленные программы, данная программа создана для распознавания текста. Очень удобна в использовании, если требуется распознать таблицу либо иллюстрацию.
Существует две версии данного продукта – это Pro и Corporate . Данные программы распознают, как ближневосточные языки, так и восточные. В своей базе программа имеет 120 языков включая и русский. Версия Pro уступает Corporate в работе с PDF файлами.
Вконтакте
Одноклассники
Google+
NAPS2 для сканирования и распознавания текста
Сегодня хочу рассказать о такой замечательной программе как NAP2. Она предназначена для сканирования и распознавания текстов. Программа бесплатная скачать её можно на официальном сайте.
Раньше я пользовался для таких целей либо стандартными средствами Windows либо устанавливал FineReader. Стандартная программа Факсы и сканирование вполне устраивала, но она обладает минимальными возможностями. С её помощью можно просто сканировать и все. В принципе если вам больше ничего не нужно, то можно пользоваться. Зачем ставить лишний софт на компьютер.
С её помощью можно просто сканировать и все. В принципе если вам больше ничего не нужно, то можно пользоваться. Зачем ставить лишний софт на компьютер.
FineReader имеет более широкий функционал позволяет не только сканировать, но и распознавать тексты. А также сохранять в различные форматы. Так же можно сохранить несколько сканов в один документ. Но она платная и весить достаточно много, долго устанавливается, а также при использовании использует достаточно много ресурсов. Очень сложно найти ломаную версию.
И вот совсем недавно наткнулся на программу NAPS2. Во-первых, она бесплатная, во-вторых мало весит и быстро устанавливается. При работе практически не нагружает систему. Да и просто удобная программа для сканирования и распознавания текстов. Обладает широкими возможностями.
Сканирование и распознавание документов с помощью NAPS2
Как я уже говорил программа бесплатная. Заходим на официальный сайт скачиваем её и запускаем.
Скачать NAPS2 — https://naps2. ru/
ru/
После первого запуска необходимо настроить профиль для сканирования. Для этого кликаем на кнопку Профили в открывшемся окне выбираем Новый.
Открывается окно Настройка профиля. Для начала вводим имя профиля далее необходимо выбрать драйвер обычно это Драйвер TWAIN. Ниже кликаем выбрать сканер и выбираем установленный у вас. Далее нужно выбрать настройки сканера Предустановленные или Собственный интерфейс. Советую выбирать Собственный интерфейс. Так как если выбрать Предустановленный, то при сканировании у вас не будет появляться окно с настройками, и вы не сможете, например, выбрать цветное сканирование. На этом все кликаем везде ОК и зарываем все окна.
Теперь для того чтобы начать сканирование кликаем по кнопки Сканировать. Откроется окно настройки ( в том случае если вы выбрали Собственный интерфейс). Производим нужные настройки и нажимаем сканировать.
Для того чтобы распознать отсканированный документ кликаем Распознавание.
Программа NAPS2 может объединять несколько сканов в один. Для этого нужно кликнуть Импорт выбрать нужные сканы. После чего, например, выбрать Сохранить в PDF выбрать Все и программа сохранить все открытые сканы в один. Таким же образом можно сохранить все документы в одну картинку с форматами jpeg, gif, png.
Есть возможность отправки отсканированных документов по почте. Можно также сразу распечатать.
Можно отредактировать отсканированное изображение обрезать изменить яркость и контраст для этого кликаем на Изображение выбираем, например, обрезать.
Откроется окно, в котором необходимо отметить нужную область и кликнуть ОК.
В общем если вы ищите бесплатную программу для сканирования и распознавания текста, то NAPS2, то что вам нужно.
Академия 1С:Документооборот | Лушников и партнеры: Распознавание изображений на сервере 1С:Документооборот 8
Каким образом работает распознавание картинок в 1С:Документооборот?
В статье “Извлечение текстов в 1С:Документооборот” сказано, что 1С:Документооборот 8 умеет извлекать тексты из популярных офисных форматов файлов и использовать эту информацию для полнотекстового поиска по содержимому файлов. А вот если в СЭД помещен файл графического формата, то как получить распознанный текст из картинки? В данной статье пойдет речь о том, какие надо установить дополнительные программы на сервер 1С, чтобы работало автоматическое распознавание сканов файлов.
А вот если в СЭД помещен файл графического формата, то как получить распознанный текст из картинки? В данной статье пойдет речь о том, какие надо установить дополнительные программы на сервер 1С, чтобы работало автоматическое распознавание сканов файлов.
Настройка распознавания изображений в 1С:Документооборот в клиент-серверном варианте на живых примерах подробно рассмотрена в видео-курсе, заказать который можно по ссылке http://video.doc-lvv.ru/
Работа сканирования и распознавания в 1С:Документооборот 8 возможна только под Windows.
Чтобы настроить распознавание изображений на сервере нужно:
1. Установить программы CuneiForm, ImageMagic и Ghostscript.
2. Задать в настройках программы параметры распознавания и указать путь к программе ImageMagic.
Общая схема работы сканирования и распознавания указана на следующем рисунке.
Установку программы CuneiForm в файл-серверном варианте следует делать на компьютере пользователя под тем пользователем, который в дальнейшем будет с ней работать, а в клиент-серверном варианте на сервере 1С – под пользователем, под которым работает сервис 1С:Предприятия.
Установка CuneiForm
Программа CuneiForm нужна для распознавания графических файлов.
Находим в дистрибутиве cuneiform файл setup.exe. Запускаем его и устанавливаем.
Открываем 1С:Документооборот под Администратором. Переходим в настройки программы и устанавливаем флаг «Распознавание изображений с помощью CuneiForm».
Загрузим любую картинку с текстом.
Откроем ее на просмотр и убедимся, что там есть текст.
После отработки регламентного задания «Распознавание» увидим распознанный текст в текстовом образе.
Откроем теперь тестовый образ из карточки файла.
В текстовом образе карточки файла 1С:Документооборот будет находиться распознанный текст из картинки.
Установка Ghostscript
Программа Ghostscript нужна программе ImageMagic для преобразования графических файлов в формат pdf и обратно.
Находим в дистрибутиве Ghostscript файл gs901w32.exe. Запускаем его.
Нажимаем кнопку Setup.
Указываем путь установки и нажимаем кнопку Install.
Программа установлена.
Установка ImageMagic
Программа ImageMagic нужна для преобразования графических файлов в формат pdf и обратно.
Находим в дистрибутиве ImageMagic файл ImageMagick-6.9.1-6-Q8-x86-dll.exe. Запускаем его.
Нажимаем кнопку Next.
Соглашаемся с условиями лицензионного соглашения.
Читаем полезную информацию.
Указываем путь установки.
Указываем название папки стартового меню.
Указываем компоненты, которые надо установить.
Подтверждаем установку. Нажимаем кнопку Install.
Читаем полезную информацию.
Программа установлена. Нажимаем кнопку Finish.
Теперь, чтобы на сервере 1С происходило преобразование отсканированных pdf-файлов в графические файлы с последующим распознаванием нам надо указать общие настройки распознавания.
В программе 1С:Документооборот в настройках программы нажимаем на кнопку «Настройки распознавания», включаем использование ImageMagick и указываем путь к программе.
Далее загрузим в папку файлов многостраничный pdf.
После того, как отработает регламентное задание «Распознавание» мы в текстовом образе увидим распознанный текст.
OCR-сканеры: Android-приложения для сканирования документов
Чтобы отправить бумажный документ по электронной почте, вовсе необязательно использовать ПК в связке со сканером — достаточно воспользоваться камерой смартфона и сделать снимок. Если же необходимо внести коррективы — в таком случает не обойтись без программ, которые не только помогут оцифровать документ, но и обладают дополнительными возможностями. Такие мобильные сканеры на порядок проще и удобнее в использовании.
Мобильных сканеров в Play Store не так уж и мало. Но интерес вызывают те из них, которые имеют функцию оптического распознавания текста (OCR). Некоторые читатели могут возразить, что есть бесплатная возможность выполнить OCR в том же Google Drive. И будут правы… отчасти. Google и вправду предлагает замечательную функцию распознавания текста, преобразовывая PDF-файлы и изображения в текстовые документы, но здесь есть свои ограничения.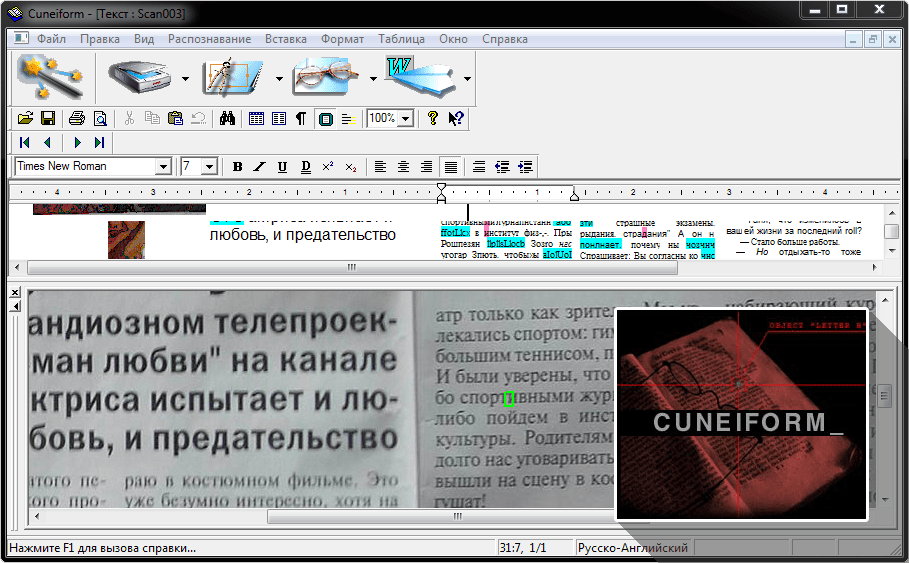 К тому же, результат не всегда желаемый, а манипуляций приходится делать гораздо больше. В этой статье мы рассмотрим несколько достойных кандидатов на роль мобильного сканера с OCR-функцией.
К тому же, результат не всегда желаемый, а манипуляций приходится делать гораздо больше. В этой статье мы рассмотрим несколько достойных кандидатов на роль мобильного сканера с OCR-функцией.
Первым и, пожалуй, наиболее известным инструментом для распознавания текста можно считать приложение от компании ABBYY. Для мобильных платформ программа получила название ABBYY TextGrabber + Translator и объединила функции OCR и переводчика.
Интерфейс приложения содержит всего лишь две основные кнопки на экране, отвечающие за добавление изображения из галереи и создание снимка с помощью стоковой камеры устройства с поддержкой только одиночного режима сканирования. В приложении доступно более 60 языков, в том числе и украинский. Весь процесс распознавания занимает не больше минуты. Что касается распознанного текста – здесь не все однозначно, конечный результат очень сильно зависит от качества полученного изображения. К сожалению, никаких инструментов, кроме кадрирования, в приложении нет. Ко всему прочему, TextGrabber не содержит встроенных средств для исправления перспективы, настройки яркости и контраста. Лучше дела обстоят со скриншотами, которые программа распознает значительно уверенней, но также не идеально. Распознанный текст не сохраняет никакого форматирования оригинального документа. Его можно отредактировать, скопировать в буфер, передать в другие приложения, в том числе и социальные сети, отправить по SMS или электронной почте. Не очень приятным моментом при этом является то, что программа автоматически добавляет к тексту подпись «Captured by ABBYY TextGrabber». Ранее распознанные тексты сохраняются в приложении, их можно просмотреть в «Истории».
Ко всему прочему, TextGrabber не содержит встроенных средств для исправления перспективы, настройки яркости и контраста. Лучше дела обстоят со скриншотами, которые программа распознает значительно уверенней, но также не идеально. Распознанный текст не сохраняет никакого форматирования оригинального документа. Его можно отредактировать, скопировать в буфер, передать в другие приложения, в том числе и социальные сети, отправить по SMS или электронной почте. Не очень приятным моментом при этом является то, что программа автоматически добавляет к тексту подпись «Captured by ABBYY TextGrabber». Ранее распознанные тексты сохраняются в приложении, их можно просмотреть в «Истории».
Бонусом в программе идет вторая часть функциональной нагрузки — Translator. Это перевод распознанного текста на более чем 40 языков мира благодаря интеграции с сервисом Google Translate. Такую возможность можно использовать, например, для перевода вывесок, надписей и небольших фрагментов текста. Для более объемной информации — польза весьма сомнительная. Работает переводчик при выполнении двух условий: хороший результат распознавания и подключение к интернету.
Работает переводчик при выполнении двух условий: хороший результат распознавания и подключение к интернету.
В результате ABBYY TextGrabber + Translator несколько разочаровал. Приложение имеет отличную скорость и стабильность работы, однако ему крайне не хватает дополнительных функций предобработки изображений, что, несомненно, улучшило бы конечный результат. ABBYY TextGrabber представлен только в платной версии. На текущий момент цена программы в Google Play неоправданно высокая и составляет 159 грн.
Самое популярное по количеству загрузок приложение-сканер. Это не просто утилита для сканирования изображений, а настоящий программный комплекс со множеством функций. CamScanner выгодно отличается наличием встроенной камеры, которая позволяет распознавать визитные карточки, текстовые документы и QR-коды в одиночном и пакетном режимах. Любопытной особенностью интерфейса камеры является опция, которая демонстрирует уровень наклона устройства.
Программа автоматически определяет границы документа, исправляет перспективу, но последнее слово за редактированием оставляет за пользователем, в распоряжении которого — полноценный редактор изображений с готовыми шаблонами и ручной регулировкой яркости, контрастности и детализации. Результат сканирования сохраняется в PDF-файл. Для каждого документа можно установить более детальные настройки. В приложении предусмотрена система тегов, с помощью которой можно легко сортировать отсканированные документы, если таковых накопилось немалое количество.
Результат сканирования сохраняется в PDF-файл. Для каждого документа можно установить более детальные настройки. В приложении предусмотрена система тегов, с помощью которой можно легко сортировать отсканированные документы, если таковых накопилось немалое количество.
Основные функции программы доступны в бесплатной версии CamScanner. Ограничения коснулись загрузки в Evernote и OneDrive и возможности экспортировать распознанный текст, в сохраненных PDF-файлах присутствует водяной знак. Лицензионный ключ, стоимостью ~24 грн. (с учетом скидки), позволяет оценить возможности OCR. Как оказалось, среди языков распознавания отсутствует украинский и русский. Соответственно, на текущий момент практической пользы от OCR-функции для большинства украиноязычных и русскоязычных пользователей в приложении нет. На примере документа с английским текстом можно отметить, что процесс распознавания CamScanner – наиболее быстрый из всех рассматриваемых в данной статье программ с очень хорошим результатом и сохранением абзацев.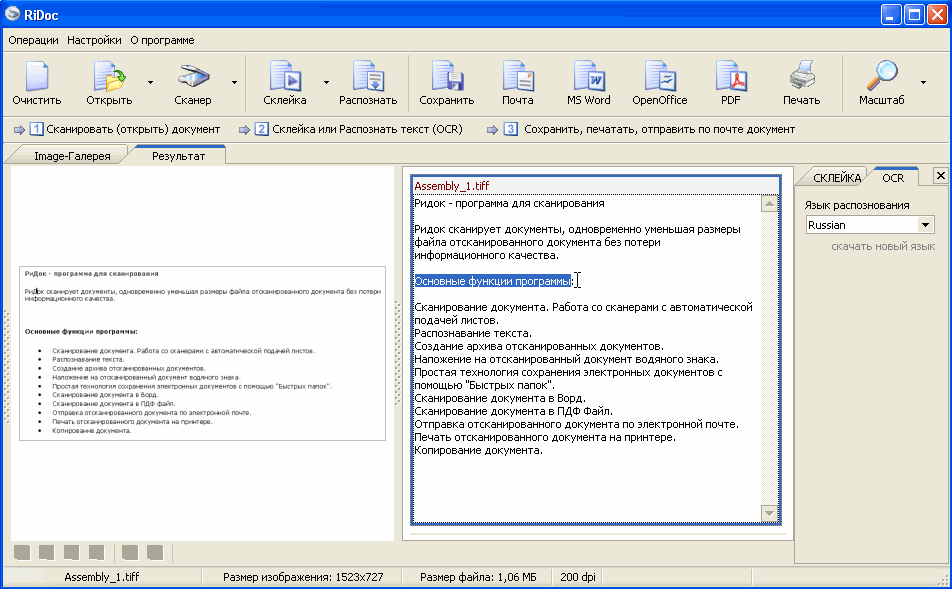
Стоить заметить, что некоторые функции приложения становятся доступны только после регистрации в сервисе. К таковым относится синхронизация с облачными хранилищами, включая собственное «облако» от CamScanner, и социальные функции, которые позволяют оставлять комментарии, открывать доступ к документам другим пользователям сервиса или делиться с ними ссылками. Среди дополнительных функций в программе есть резервное копирование и восстановление данных на SD-карте, установка пароля на просмотр защищенных документов, экспорт с возможностью загрузки в облако или печати с помощью виртуального принтера Google. В результате CamScanner — отличный инструмент для сканирования различных документов. К сожалению, удачно реализованная функция OCR не содержит ни украинского, ни русского языка, что может стать ключевым моментом при выборе OCR-сканера.
Mobile Document Scanner (MDScan) — программа, пришедшая из Nokia Ovi Store, которая по праву может считаться ветераном среди мобильных инструментов для оцифровки изображений.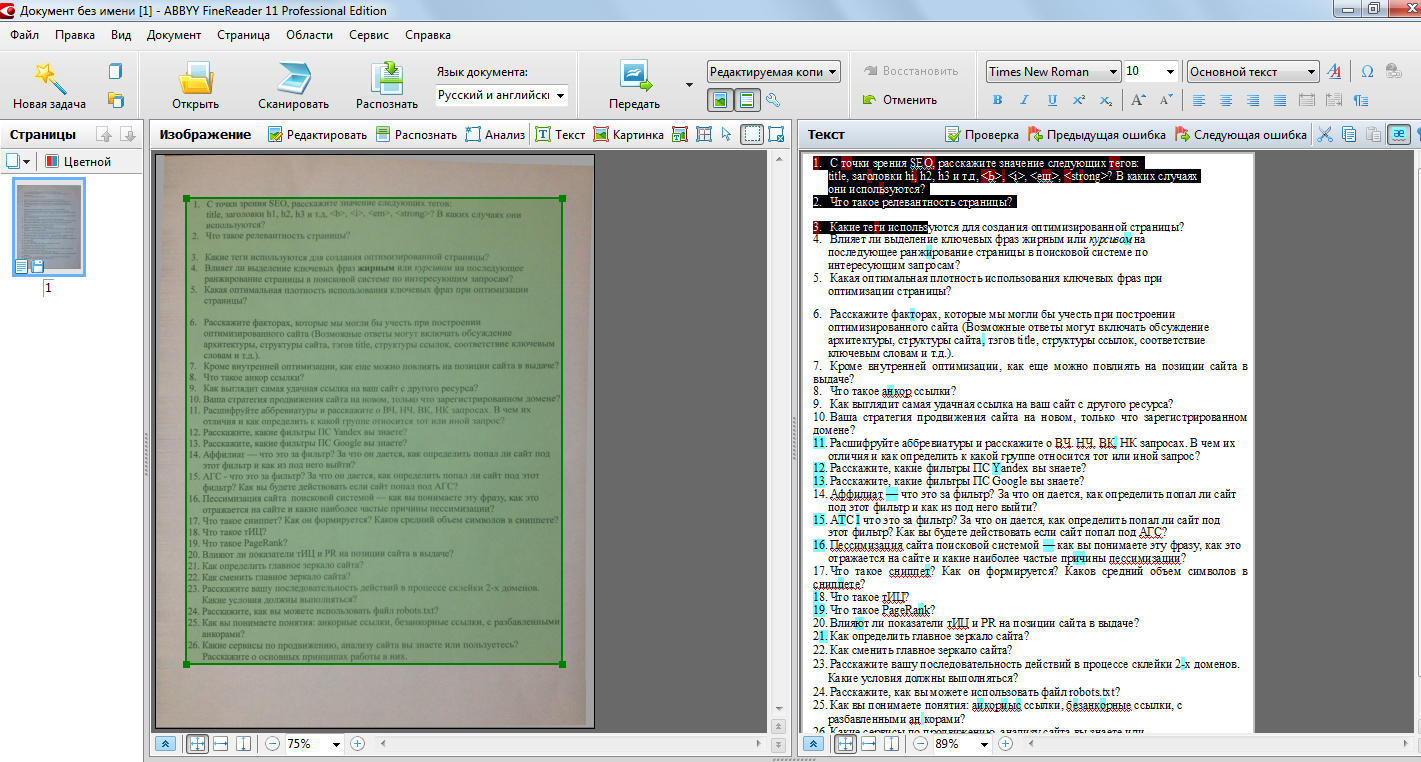 Приложение имеет собственный интерфейс камеры, поддерживает как одиночный, так и многостраничный режимы сканирования. Главной особенностью программы являются шаблоны предобработки и постобработки изображений. MDScan автоматически очищает документ, удаляя лишние элементы и фон. Возможность ручной коррекции яркости/контрастности здесь отсутствует, но и с готовыми шаблонами можно добиться вполне приличного результата. В автоматическом режиме программа не умеет корректно определять границы текста, а вручную это реализовано не очень удобно. Из инструментов постобработки в MDScan есть кисть для рисования и добавление подписи.
Приложение имеет собственный интерфейс камеры, поддерживает как одиночный, так и многостраничный режимы сканирования. Главной особенностью программы являются шаблоны предобработки и постобработки изображений. MDScan автоматически очищает документ, удаляя лишние элементы и фон. Возможность ручной коррекции яркости/контрастности здесь отсутствует, но и с готовыми шаблонами можно добиться вполне приличного результата. В автоматическом режиме программа не умеет корректно определять границы текста, а вручную это реализовано не очень удобно. Из инструментов постобработки в MDScan есть кисть для рисования и добавление подписи.
Оцифрованные страницы можно объединять, разъединять, передавать в другое приложение или отправлять на печать, а сам документ можно сохранить в ZIP и PDF-файл. Все вышеперечисленное доступно пользователю в бесплатной версии приложения. Правда, придется смириться с рекламой, водяным знаком на документах и ограничением на сканирование не более 4 страниц в пакетном режиме.
Что касается OCR-функции, то такая возможность появилась в последней версии MDScan и активируется после покупки программы (~16 грн.). Надо признать, на текущий момент распознавание текста выглядит очень сырым. Во-первых, найти эту функцию и воспользоваться ею оказалось не так просто. А во-вторых, сам процесс длится настолько долго, что не каждый пользователь дождется результата. Хотя сам результат, при условии хорошей читаемости текста, может оказаться вполне годным. Единственное, что хотелось бы отметить – это умение программы корректно выделять абзацы.
Основной задачей этого приложения является преобразование изображения в текст с последующим его редактированием. По своим возможностям программа очень похожа на ABBYY Text Grabber + Translator. Здесь также отсутствует пакетный режим сканирования, нет инструмента для исправления перспективы, но есть интеграция с сервисом Google Translate для перевода распознанного текста на другой язык. Однако, в отличие от приложения ABBYY, OCR Instantly все же предоставляет возможность вручную корректировать снимки с помощью функции Enhance. В данном случае это всего пара ползунков, отвечающих за настройку экспозиции и уменьшение шума.
В данном случае это всего пара ползунков, отвечающих за настройку экспозиции и уменьшение шума.
OCR работает быстро и выдает неплохие результаты. Языковые пакеты, в том числе украинский и русский, загружаются в настройках. Программа хорошо распознает текст как со снимка, сделанного камерой устройства, так и со скриншота. Распознанный текст размещается под изображением с сохранением всех абзацев. Его можно скопировать в буфер обмена или передать в другое установленное на устройстве приложение через системное меню «Поделиться».
OCR Instantly имеет и платную версию (~75 грн.), которая отличается отсутствием рекламы, расширенным OCR, возможностью выбора нескольких языков распознавания и полноэкранным редактированием текста. Кроме того, в Pro-версии приложения можно найти несколько интересных дополнений. Например, черный и белый списки символов (на случай если есть проблема с распознаванием определенного символа) или инструмент Dewarp — для выравнивания строк текста. И, разумеется, платный OCR Instantly позволяет сохранять результаты распознавания в TXT, JPG и PDF файл.
Scanbot можно назвать по-настоящему мобильным сканером. Приложение выполнено в концепции Material Design, выглядит современно и не перегружено лишними функциями. Основное предназначение программы — сканирование различных видов документов с последующим сохранением в PDF или JPG файл. Главным преимуществом Scanbot перед конкурентами является собственный интеллектуальный интерфейс камеры. Достаточно навести камеру на объект, как программа тут же обнаруживает текстовый документ, QR или штрих-код, определяет его границы, корректирует перспективу и оптимизирует качество изображения. Все это происходит в автоматическом режиме. Если результат не устраивает, можно внести изменения вручную. Кроме того, независимо от источника добавления изображения — камеры или галереи, Scanbot поддерживает как одиночный, так и пакетный режимы сканирования. Еще одно достоинство приложения — работа с облачными хранилищами с поддержкой автоматической загрузки отсканированных документов в выбранное «облако».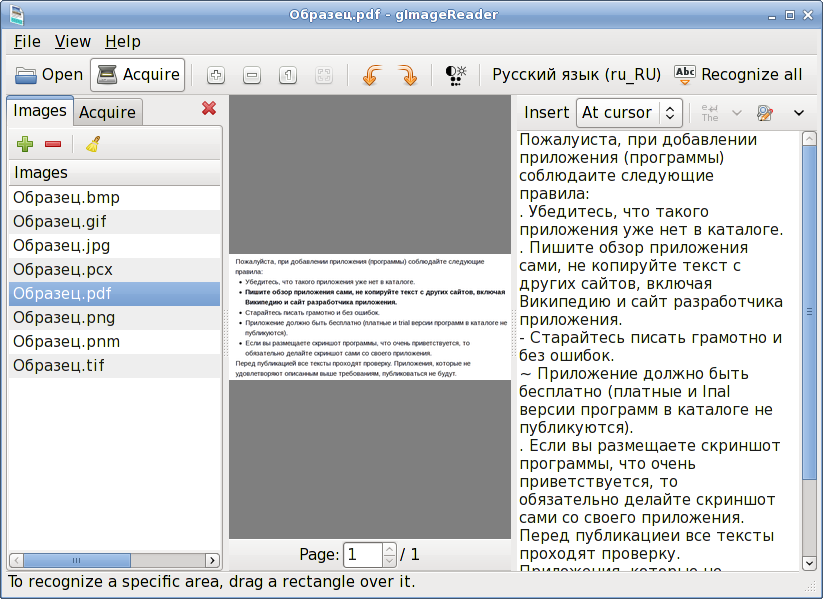 Результат сканирования также сохраняется на SD-карте.
Результат сканирования также сохраняется на SD-карте.
OCR-функция присутствует в платной версии Scanbot Pro (~87 грн.) и доступна после установки языкового модуля, в котором содержатся украинский и русский языки. Процесс распознавания происходит очень долго, причем в автоматическом режиме. Соответственно, возможности выбрать язык вручную приложение не дает. Из-за этого текст документа может быть определен неправильно, и тогда на выходе получим бессмысленный набор символов. Хотя, в целом, результаты разнятся и могут быть как непригодными для восприятия, так и вполне хорошими. В Pro-версии также содержатся инструменты для редактирования отсканированного документа: создание подписи, заметки и маркер для выделения текста. Приятным бонусом идут темы оформления программы. К недостаткам Scanbot можно отнести длительный процесс создания многостраничного PDF-файла, отсутствие возможности добавлять или удалять отдельные страницы в документе, а также неудобная реализация сохранения отсканированного документа в файл.
Итоги
Подводя итоги, хочется обратить внимание на то, что все рассмотренные приложения в полной мере раскрывают свои функциональные возможности (в частности, OCR) в платных версиях. Это говорит о том, что весь этот софт является узкоспециализированным и нацелен в большинстве своем на тех пользователей, которые будут использовать его в своей профессиональной или учебной деятельности. Исключение — OCR Instantly, в котором OCR-функция представлена в бесплатной версии.
Что касается качества распознавания, то многое, разумеется, зависит от камеры мобильного устройства, условий, при которых делается снимок, и наличия в приложении инструментов для обработки этих снимков. Все программы показывают приблизительно одинаковый результат. Чуть хуже проявил себя ABBYY TextGrabber + Translator – в данном случае основной проблемой приложения является недостаточная функциональность и отсутствие каких-либо инструментов обработки изображения. В компании ABBYY нам сообщили, что позиционируют TextGrabber + Translator как базовое решение, но в этом году собираются выпустить для Android приложение FineScanner, в котором будет больше функций..png) CamScanner и вовсе не имеет украинского и русского языков распознавания, однако в целом оставил положительное впечатление. Scanbot и Mobile Document Scanner отметились долгоиграющим процессом распознавания. Не последнюю роль в выборе OCR-сканера играет их стоимость, которая сильно варьируется от символической до необоснованно высокой.
CamScanner и вовсе не имеет украинского и русского языков распознавания, однако в целом оставил положительное впечатление. Scanbot и Mobile Document Scanner отметились долгоиграющим процессом распознавания. Не последнюю роль в выборе OCR-сканера играет их стоимость, которая сильно варьируется от символической до необоснованно высокой.
Free OCR Software – Программное обеспечение для оптического распознавания символов и сканирования для Windows
О FreeOCR
FreeOCR – это бесплатное программное обеспечение для оптического распознавания символов для Windows, которое поддерживает сканирование с большинства сканеров Twain, а также может открывать большинство отсканированных PDF-файлов и многостраничных изображений Tiff, а также популярных форматов файлов изображений. FreeOCR выводит простой текст и может экспортировать напрямую в формат Microsoft Word.
Free OCR использует последнюю версию Tesseract (v3. 01) Двигатель OCR. Он включает в себя установщик Windows, очень прост в использовании и поддерживает открытие многостраничных документов в формате TIFF, документов Adobe PDF и факсов, а также большинства типов изображений, включая сжатые файлы Tiff, которые сам по себе механизм Tesseract не может прочитать. Теперь он может сканировать с использованием Драйверы сканирования Twain и WIA.
01) Двигатель OCR. Он включает в себя установщик Windows, очень прост в использовании и поддерживает открытие многостраничных документов в формате TIFF, документов Adobe PDF и факсов, а также большинства типов изображений, включая сжатые файлы Tiff, которые сам по себе механизм Tesseract не может прочитать. Теперь он может сканировать с использованием Драйверы сканирования Twain и WIA.
FreeOCR V4 включает Tesseract V3, который повышает точность и имеет анализ макета страницы, поэтому более точные результаты могут быть достигнуты без использования инструмента выбора зоны.
Программное обеспечение для сканирования
Помимо OCR FreeOCR может сканировать и сохранять изображения в формате JPG, и в настоящее время мы работаем над возможностью «Сканировать в PDF» с возможностью сохранения в формате PDF с возможностью поиска.
Двигатель OCR
Включенный механизм Tesseract OCR PDF является продуктом с открытым исходным кодом, выпущенным Google.![]() Он был разработан в Hewlett Packard Laboratories в период с 1985 по 1995 год.В 1995 году он был одним из трех лучших исполнителей на конкурсе на точность распознавания текста, организованном Университетом Невады в Лас-Вегасе. Исходный код движка Tesseract теперь поддерживается Google, и проект можно найти здесь: http://code.google.com/p/tesseract-ocr/
Он был разработан в Hewlett Packard Laboratories в период с 1985 по 1995 год.В 1995 году он был одним из трех лучших исполнителей на конкурсе на точность распознавания текста, организованном Университетом Невады в Лас-Вегасе. Исходный код движка Tesseract теперь поддерживается Google, и проект можно найти здесь: http://code.google.com/p/tesseract-ocr/
Лицензия
FreeOCR – это бесплатная программа для оптического распознавания текста и сканирования, с которой вы можете делать все, что захотите, в том числе в коммерческих целях. Включенный движок Tesseract OCR распространяется под Apache V2.0 лицензия.
Smart ID Engine: программное обеспечение для сканирования идентификаторов
Smart ID Engine
– точный, быстрый и безопасный SDK для сканирования удостоверений личности, паспортов и водительских прав. Smart ID Engine – комплексный инструмент для автоматического сканирования идентификаторов с аутентификацией документов, проверкой согласованности данных и сопоставлением лиц более 1810 типов документов, удостоверяющих личность, из 210 выпусков по всему миру. SDK поддерживает сканирование удостоверений личности, паспортов, водительских прав, виз и видов на жительство в странах: Европейского Союза, СНГ (Содружества Независимых Государств), Южной, Центральной и Северной Америки, Австралии, Океании и Новой Зеландии, стран Среднего и Дальнего Востока, стран Азии и Африки.Smart ID Engine автоматически определяет тип отсканированного документа, удостоверяющего личность, выполняет OCR его текстовых полей на более чем 100 языках (поддерживаются арабский, китайский, корейский, японский и многие другие), распознает штрих-коды, извлекает фотографии, подписи и графические зоны. Автоматическая проверка целостности данных, проверка действительности документа и автономная проверка лица в мобильных приложениях для Android или iOS; настольные приложения для Windows, Linux и macOS; веб-приложения или серверные решения.
SDK поддерживает сканирование удостоверений личности, паспортов, водительских прав, виз и видов на жительство в странах: Европейского Союза, СНГ (Содружества Независимых Государств), Южной, Центральной и Северной Америки, Австралии, Океании и Новой Зеландии, стран Среднего и Дальнего Востока, стран Азии и Африки.Smart ID Engine автоматически определяет тип отсканированного документа, удостоверяющего личность, выполняет OCR его текстовых полей на более чем 100 языках (поддерживаются арабский, китайский, корейский, японский и многие другие), распознает штрих-коды, извлекает фотографии, подписи и графические зоны. Автоматическая проверка целостности данных, проверка действительности документа и автономная проверка лица в мобильных приложениях для Android или iOS; настольные приложения для Windows, Linux и macOS; веб-приложения или серверные решения.
Программное обеспечение НЕ передает данные клиента сторонним службам и / или третьим лицам для ручной обработки, НЕ сохраняет и не хранит их – процесс распознавания выполняется в локальной оперативной памяти устройства и НЕ требует доступа в Интернет. доступ.
доступ.
Smart ID Engine – это инструмент автоматического сбора данных для процесса удаленного подключения и программы идентификации клиентов (CIP) для банков, страховых компаний, операторов связи, микрофинансовых организаций, брокеров, туристических агентств, риэлторов, игрового бизнеса, торговых площадок, онлайн-торговых платформ, и другие организации электронной торговли.SDK помогает обеспечить удобное, быстрое и безопасное обслуживание клиентов в офисах и удаленно с помощью нашего современного SDK для сканирования идентификаторов. Это позволяет оптимизировать предоставление финансовых, страховых, транспортных услуг, продажу билетов и SIM-карт через торговые киоски и терминалы самообслуживания с использованием мощного и экологически чистого OCR. Smart ID Engine (ранее известный как Smart IDReader) автоматически сканирует данные с видео, фотографий или сканированных изображений паспортов, удостоверений личности, водительских прав, виз, видов на жительство, различных сертификатов и т. Д.Программное обеспечение автономно работает на устройствах конечных пользователей: мобильных телефонах, планшетах, интеллектуальных камерах, терминалах, а также настольных компьютерах и серверах.
Д.Программное обеспечение автономно работает на устройствах конечных пользователей: мобильных телефонах, планшетах, интеллектуальных камерах, терминалах, а также настольных компьютерах и серверах.
Запатентованная экологически чистая технология оптического распознавания GreenOCR®, разработанная нашим ученым, обеспечивает точное распознавание текста на более чем 100 языках. GreenOCR® поддерживает распознавание символов в таких системах письма, как арабский, персидский, урду, японский (кандзи, катакана и хирагана), китайский (упрощенный и традиционный), корейский (хангыль), кириллица, латынь и другие.Как часть подхода Green AI, Smart ID Engine тщательно оптимизирован для минимизации воздействия на окружающую среду на всех этапах обработки документов.
Smart ID Engine автоматически определяет тип документа и точно извлекает данные под разными углами и условиями освещения. Процесс сканирования водительских прав США в видеопотоке на мобильном телефоне занимает ~ 250 мс на кадр, а сканирование немецких удостоверений личности занимает ~ 150 мс. Если человеческое моргание длится 150–300 мс, наш SDK предоставляет мобильным приложениям возможность мгновенного сканирования идентификаторов.Высокопроизводительные решения Smart ID Engine в конфигурации сервера могут обрабатывать сотни фотографий и документировать видеопотоки в минуту.
Если человеческое моргание длится 150–300 мс, наш SDK предоставляет мобильным приложениям возможность мгновенного сканирования идентификаторов.Высокопроизводительные решения Smart ID Engine в конфигурации сервера могут обрабатывать сотни фотографий и документировать видеопотоки в минуту.
Важными преимуществами Smart ID Engine являются соблюдение индивидуальных прав и свобод, высокие стандарты безопасности обработки персональных данных – GDPR, CCPA, HIPAA, соответствие нормативным требованиям KYC в CIP и AML, создание расширенных возможностей управления пользовательским интерфейсом и минимизация воздействия на окружающую среду (Green AI).
Программное обеспечение сканирования Smart ID Engine распространяется как отдельный SDK (комплект разработчика программного обеспечения), содержащий API сканирования идентификаторов (интерфейс прикладного программирования) и все необходимое описание, документацию и примеры использования для различных языков программирования. Разработчикам предоставляется API сканирования, который помогает интегрировать сканирование идентификационных документов в программное обеспечение на языках C, C ++, C #, Java, Python, PHP, Swift и Objective C. Также возможно сканирование паспортов, удостоверений личности, водительских прав. с приложениями, разработанными с помощью React Native и Flutter framework.
Разработчикам предоставляется API сканирования, который помогает интегрировать сканирование идентификационных документов в программное обеспечение на языках C, C ++, C #, Java, Python, PHP, Swift и Objective C. Также возможно сканирование паспортов, удостоверений личности, водительских прав. с приложениями, разработанными с помощью React Native и Flutter framework.
Библиотека сканирования чрезвычайно компактна – средний размер расширения мобильного приложения со встроенным ПО Smart ID Engine для сканирования одного типа документов, удостоверяющих личность, не превышает 10 мегабайт. Это позволяет добавить сканер идентификаторов в мобильное приложение без значительных затрат времени на загрузку и затрат.
СпецификацияSmart ID Engine SDK (pdf)
Узнайте больше о сканировании удостоверений личности, сканировании водительских прав и сканировании паспортов.
Отправить запрос
ПО для сканера паспортов и удостоверений личности
Поддерживаемые типы документов Электронные паспорта, iDL и eDL, визы, вид на жительство, адресные карты, 1D и 2D штрих-коды
Функции обработки изображений Автоматическая обрезка изображения документа и фотографии на предъявителя, автоповорот документов, визуализация OVD, удаление отражений (антибликовое покрытие)
Возможность чтения OCR Соответствующие ИКАО документы в соответствии со спецификацией ИКАО 9303, часть 1, часть 1v2, часть 2, часть 3 и часть 3v2 для оптического распознавания символов MRZ типа ID-1, ID-2 и ID-3, водительские права в одну строку в соответствии со спецификацией ISO18013, часть 2
Возможность считывания штрих-кода 1D штрих-коды (2 из 5 с чередованием, 2 из 5 промышленных, Code 128, Code 39, EAN-8 и EAN-13), 2D штрих-коды, используемые в BCBP и других документах (форматы PDF 417, QR Code®, DataMatrix ™ и Aztec) из бумажных документов и многих мобильных устройств, совместимых с AAMVA PDF417 и IATA BCBP
Аутентификация документа Проверка согласованности данных: МСЗ vs. Сравнение VIZ, штрих-кодов и RFID, проверка Jura IPI (невидимая личная информация), фотография на предъявителя паспорта и RFID DG2, проверка чернил B900, проверка срока годности, проверка контрольной суммы MRZ, автоматическая проверка шаблона защиты документа (необязательно)
Сравнение VIZ, штрих-кодов и RFID, проверка Jura IPI (невидимая личная информация), фотография на предъявителя паспорта и RFID DG2, проверка чернил B900, проверка срока годности, проверка контрольной суммы MRZ, автоматическая проверка шаблона защиты документа (необязательно)
Особенности модуля RFID Все стандартизированные скорости до 848 Кбит / с, Чтение и запись бесконтактных ИС в соответствии с: ISO 14443 Тип A и B, BSI TR-03105, слот SAM доступен как дополнительный аксессуар
Комплект для разработки программного обеспечения (SDK) C / C ++, C #, Delphi, Java, VB. NET, Visual Basic 6.0
NET, Visual Basic 6.0
Включено в SDK Журналы изменений, Демонстрационные приложения, Руководство по демонстрации FPR, Руководство по установке, Справочное руководство для программистов, Примеры программ в исходном коде
IRISmart Security – программа для распознавания удостоверений личности и паспортов
Технические ссылки
Языки интерфейса: английский, испанский, французский, русский, упрощенный китайский, традиционный китайский, корейский, японский, итальянский, польский, голландский, немецкий, арабский, датский, финский, венгерский, норвежский, португальский (PT), португальский BR, румынский, шведский, Украинский, болгарский, каталонский, чешский, греческий, иврит, турецкий.
языков распознавания: афан-оромо, африкаанс, албанский, арабский, астурийский, аймара, азербайджанский (латиница), балийский, баскский, бемба, биколь, бислама, боснийский (кириллица), боснийский (латиница), бразильский, бретонский, болгарский, болгарский. Английский, белорусский, белорусско-английский, каталонский, кебуанский, чаморро, китайский (упрощенный), китайский (традиционный), корсиканский, хорватский, чешский, датский, голландский, английский (Великобритания), английский (США), эсперанто, эстонский, фарерский, Фарси, фиджийский, финский, французский, фризский, фриульский, галисийский, ганда, немецкий, немецкий (Швейцария), греческий, греко-английский, гренландский, гаитянский креольский, хани, иврит, хилигайнон, венгерский, исландский, идо, илокано, индонезийский, Интерлингва, ирландский (гэльский), итальянский, японский, яванский, капампанганский, казахский, киконго, киньяруанда, корейский, курдский, латынь, латышский, литовский, люба, люксембургский, македонский, македонско-английский, мадурский, малагасийский, малайский, мэнский (гэльский) ), Маори, майя, мексиканский, минангкабау, молдавский, монгольский (кириллица), науатль, норвежский, числовой , Ньянджа, нюнорск, окситанский, папиаменто, пиджин английский (Нигерия), польский, португальский, кечуа, ретороманский, румынский, руди, русский, русско-английский, самоанский, сардинский, шотландский (гэльский), сербский, сербский (латинский) , Сербско-английский, шона, словацкий, словенский, сомалийский, сото, испанский, суданский, суахили, шведский, тагальский, таитянский, татарский (латиница), тетум, ток писин, тонга, тсвана, турецкий, туркменский (латинский), украинский, Украинско-английский, узбекский, варайский, валлийский, волоф, коса, сапотек, зулусский.
Минимальная необходимая конфигурация системы
Для Windows®:
- Процессор 1 ГГц или лучше
- Microsoft® Windows® 10, 8.1, 8, 7 (64-разрядная версия)
- 1 ГБ ОЗУ (рекомендуется 2 ГБ)
- 400 МБ свободного места на жестком диске
- Интернет-соединение для загрузки и активации программного обеспечения
Дополнительные настройки сканирования – вкладка «Дополнительные настройки»
Вы можете выбрать эти дополнительные настройки сканирования на Epson Вкладка «Расширенные настройки сканирования 2».Не все настройки регулировки могут быть доступны, в зависимости от других выбранных вами настроек или ваших особенности сканера.
- Удалить фон
- Удаляет фон с ваших оригиналов.
- Улучшение текста
- Повышает резкость отображения букв в текстовых документах.
- Автоматическая сегментация областей
- Делает черно-белые изображения более четкими, а распознавание текста – более точным. точный, отделяя текст от графики.
- Отсев
- При сканировании выбранный цвет не распознается. Этот параметр доступно, только если вы выбрали оттенки серого или черно-белый. Белый в качестве параметра «Тип изображения».
- Улучшение цвета
- Усиливает оттенки цвета, выбранного на отсканированном изображении. изображение. Этот параметр доступен, только если вы выбрали оттенки серого или черно-белый. Белый в качестве параметра «Тип изображения».
- Яркость
- Регулирует общую яркость и темноту сканируемого изображения. изображение.
- Контраст
- Регулирует разницу между светлыми и темными участками общее отсканированное изображение.
- Гамма
- Регулирует плотность средних тонов отсканированного изображения.
- Порог
- Регулирует уровень, на котором отображаются черные области в тексте и штриховых рисунках.
 очерчены, улучшая распознавание текста в OCR (оптический символ
Признание) программы.
очерчены, улучшая распознавание текста в OCR (оптический символ
Признание) программы. - Маска нерезкости
- Делает края определенных областей изображения более четкими.Выключи это возможность оставить более мягкие края.
- Удаление сетки
- Удаляет рябь, которая могла появиться в слегка затененных местах. области изображения, например оттенки кожи. Эта опция улучшает результаты, когда сканирование журналов или газет. (Результаты дескрининга не отображаются на изображении для предварительного просмотра, только в отсканированном изображении.)
- Заливка кромок
- Исправляет затенение по краям изображения, заполняя тени с черным или белым.
- Удаление перфорационных отверстий
- Удаляет тени от отверстий по краям оригинал.
- Двойной вывод изображения
- Дважды сканирует исходное изображение с разными настройками вывода. (Только для Windows).
Программное обеспечение для оптического распознавания символов – обзор
Рекомендации по цифровому захвату текста и фотографических изображений
Процессы оцифровки текстовых и фотоматериалов в определенной степени схожи.Для обоих типов источников вывод выполняется в виде цифровых изображений, а мастера сохраняются в формате TIFF. Однако рекомендации по разрешению и битовой глубине различаются из-за принципиально разного содержимого, а количество деталей, которые необходимо захватить, больше для фотоматериалов. Сложность фотографических процессов и форматов также требует более широкого диапазона спецификаций и более универсального оборудования для оцифровки. В то время как оцифрованные фотографии остаются в основном изображениями, оцифрованные текстовые документы необходимо дополнительно обрабатывать и преобразовывать, чтобы текстовое содержимое стало доступным для поиска.
Оцифровка текста фокусируется в первую очередь на вопросах разборчивости. Отсканированные страницы книг, газет, журналов и других текстовых документов могут быть представлены как изображения и / или как текст с возможностью поиска. Оцифрованный текст не только должен быть разборчивым для человеческого глаза, но также должен распознаваться и обрабатываться программным обеспечением, если необходимо создать текст с возможностью поиска. Размер текста в исходном текстовом материале является важным фактором при определении технических характеристик. Для документов с мелким шрифтом рекомендуется более высокое разрешение и битовая глубина.Особенности исходных документов, такие как рукописный или напечатанный текст, их редкость или наличие иллюстраций, также играют роль в корректировке спецификаций.
Таблица 3.2 основана на последних рекомендациях, подготовленных Ассоциацией библиотечных коллекций и технических служб, подразделением Американской библиотечной ассоциации (ALCTS, 2013). Важно помнить, что перечисленные характеристики представляют собой минимум рекомендаций. Повышение разрешения настоятельно рекомендуется для раритетных книг с богато украшенным и неправильным шрифтом, а также для рукописей, разборчивость которых может быть проблемой.
Таблица 3.2. Рекомендации по минимальной оцифровке текстовых материалов
| Исходный материал | Разрешение сканирования | Битовая глубина | Режим захвата | Примечания |
|---|---|---|---|---|
| Книги и другой текст без изображений (нередкие) 300 ppi | 902 902 битОттенки серого | Разрешение можно регулировать в соответствии с деталями, которые должны быть представлены. | ||
| Книги и другой текст с изображениями (нередкие) | 400 ppi | 8-битный или 24-битный | Оттенки серого или цветной | Разрешение можно регулировать в соответствии с отображаемыми деталями.Рекомендуется захват в цвете (24-битный RGB). |
| Редкие книги | 400 ppi | 24 бита | Цвет | Для менее стандартизованных шрифтов может потребоваться увеличение разрешения. |
| Рукописи | 400 ppi | 24 бита | Цвет | Для трудно читаемых рукописных документов может потребоваться повышение разрешения. |
Изображения страниц, созданные как прямой вывод цифрового преобразования, недоступны для поиска.Оцифрованные документы можно преобразовать в текст с полной возможностью поиска либо с помощью ручного ввода, либо с помощью автоматической обработки с помощью программного обеспечения OCR. Гибридный подход может сочетать обработку OCR с проверкой точности и ручным исправлением. Современная технология OCR может обрабатывать печатный или печатный текст с различной степенью точности, но не способна преобразовывать рукописный текст. Рукописи и другие рукописные документы должны быть напечатаны, чтобы их можно было найти для поиска. Из-за большого количества оцифрованных исторических документов и рукописей существует большой исследовательский интерес к разработке решений для машинного распознавания рукописного текста (Romero et al., 2011; Sánchez et al., 2014). Однако эти усилия остаются на экспериментальной стадии.
На практике наиболее доступный для поиска текст оцифрованных печатных или печатных документов создается с помощью программного обеспечения OCR (Lesk, 2004; Yongli, 2010). OCR – это процесс, который преобразует текст оцифрованной печатной страницы в текстовый файл с возможностью поиска. Это достигается за счет того, что программное обеспечение OCR анализирует отсканированные изображения страниц, распознает группы символов (слов), сравнивает их со своим словарем и, наконец, переводит символы в машиночитаемый цифровой текстовый формат.Учреждения, занимающиеся культурным наследием, использовали широкий спектр проприетарного программного обеспечения для оптического распознавания текста, включая ABBYY FineReader, Adobe Acrobat, OmniPage или Readiris Pro. Также растет интерес к использованию инструментов OCR с открытым исходным кодом, таких как Tesseract, которые обеспечивают большую настройку и, в частности, поддерживают обработку OCR оцифрованных исторических документов (Blanke et al., 2012). Технология OCR в основном используется для создания текста с возможностью поиска в оцифрованных книгах, журналах и газетах. Все чаще он также рассматривается как важный компонент крупномасштабной оцифровки современных архивных коллекций (Miller, 2013).
Точность текста, созданного с помощью программного обеспечения OCR, варьируется. Высокий показатель в 99% может быть достигнут при распознавании печатных или печатных юридических или деловых документов на английском языке (Rice et al., 1996). Однако точность исторических документов, таких как газеты, снижается, где процент неисправленных OCR может составлять всего 68% (Klijn, 2008). Производительность программного обеспечения OCR играет важную роль, но точность обработанного текста также зависит от ряда других факторов, в том числе:
- •
Качество отсканированных изображений
- •
Читаемость оригинала текст
- •
шрифтов
- •
контраст между напечатанным текстом и фоном страницы
- •
макет
- •
- Качество языка и шрифта Текст OCR связан с состоянием исходных материалов (Klijn, 2008).Уровень точности снижается для исторических документов, напечатанных с использованием редких и трудно распознаваемых шрифтов, и для документов со сложной компоновкой, таких как газеты (Holley, 2009; Tanner et al., 2009). Еще одна проблема связана с написанием нелатинских языков, таких как арабский. Проекты оцифровки с участием исторических периодических изданий на арабском языке демонстрируют относительно низкую точность распознавания текста (Matusiak and Abu Harb, 2011). Кроме того, артефакты, присутствующие в исторических документах, такие как слезы, крапинки, плохая печать или кровотечение, снижают качество вывода OCR.
- •
Количество изображений для захвата
- •
Размер исходных фотографий
- •
Формат и средний – светоотражающие (фотографические отпечатки ) по сравнению с прозрачными (пленочные негативы, стеклянные пластины или слайды)
- •
Состояние и уникальные характеристики оригиналов
- •
Требования к работе с хрупкими оригиналами
- locr.c: Исходный код программы на языке C.
- foo.ps: образец документа, используемый для сканирование и генерация данных.
- foo.txt: Текстовая версия образца текст (кодировка ISO-8859-1).
- foo.pnm: отсканированная версия образца текста.
- foo.dat: Данные созданы из образца текста.
- gpl.txt: Стандартная общественная лицензия GNU.
- locr-0.1.0.tgz: Все это в отдельный файл.
- Режим создания данных: используется для создания базы данных
информация, которая будет использоваться позже в режиме распознавания. Пример: у нас есть
документ “foo.ps”, и мы хотим использовать его для компиляции данных. Сделайте
следующий:
- Распечатайте.
- Отсканируйте. Убедитесь, что на выходе получается pnm-файл P1 или P4 “foo.pnm”.
Рекомендуемое разрешение – 300 точек на дюйм.
В качестве альтернативы два предыдущих шага можно заменить следующими команда:
gs -sDEVICE = pnmraw -r300x300 -sOutputFile = foo.pnm -dNOPAUSE foo.ps quit.ps
- Напишите текстовую версию документа “foo.txt”.
- Создайте файл данных «foo.dat» с помощью следующей команды:
./locr -g -t foo.txt foo.pnm foo.dat
Исходный документ должен быть очень простым (одна колонка, нет картинки …), содержат широкий спектр персонажей (мы хотим собрать как можно больше информации) и быть практически идеальным (в противном случае программа будет делать ошибки, и собранная информация будет бесполезный).Протестируйте это с помощью программы для распознавания “foo.pnm” с помощью “foo.dat” как файл данных. Вывод должен быть идентичен “foo.txt”, за исключением, возможно, интервала между символами.
- Режим распознавания: использует информацию, ранее собранную в
файл данных для распознавания отсканированного текста. Например, после сканирования
document мы получаем файл PNM “document.pnm” и хотим его распознать.
используя “foo.dat” в качестве файла данных. Сделайте это с помощью следующей команды (
вывод идет в “document.out”):
./ locr -d foo.dat document.pnm document.out - Исходный документ (версия PDF)
- Документ в формате PNM
- Выход локатора (кодировка ISO-8859-1)
- Загрузить изображение как массив из нулей и единиц.
- Удалите пыль и снег.
- Составьте таблицу из блоков. (Блок – это набор смежных пикселей. Некоторые символы состоят из более чем одного блока, например, “i” имеет два блока: тело и точка.)
- Удалить нетипичные блоки (нереальных размеров). В этом случае картинки удалены.
- Найдите столбцы текста. Составьте таблицу из столбцов. Сортировать блоки по столбцы.
- В каждом столбце найдите строки текста. Составьте таблицу строк. Сортировать блоки по строкам и по положению в каждой строке.
- На каждой строке соедините блоки с перекрытием по горизонтали. Это трансформирует составные части каждого символа (например, тело и точка в “i”) в один объект.
- Вычислить атрибуты каждого символа (например: количество частей, количество отверстий, вертикальное положение на линии и т. д.)
- Для каждого символа сравните его атрибуты с атрибутами, хранящимися в файл данных. Выберите возможных «кандидатов». Сравните данный символ отобранным кандидатам и решите, какой из них наиболее близок. В окончательное сравнение производится путем вычисления расстояния Хэмминга (количество пикселей, где они различаются) между масштабированными версиями 16×16 символы. Если не найдено ни одного кандидата, достаточно похожего на текущий характер, ослабьте критерии и попробуйте еще раз.
Фотографические изображения представляют собой материалы, которые сложнее всего преобразовать в категорию статических 2D-материалов, и тем не менее они часто являются первыми кандидатами на проекты оцифровки, осуществляемые учреждениями культурного наследия. Авторы Рекомендации о минимальном оцифровывании подчеркивают, что «точное переформатирование исторических фотографий является одним из самых сложных типов статических носителей» (ALCTS, 2013, стр. 23). Эта трудность проистекает из разнообразия аналоговых материалов, которые использовались для записи фотографических изображений, от стеклянных пластин до различных типов негативов.Оригинальные негативы и отпечатки бывают разных размеров от 35 мм до 8 × 10 дюймов. Кроме того, негативы на пленке на нитратной и ацетатной основе, используемые в течение нескольких десятилетий 20-го века, являются химически нестабильными и представляют опасность для хранения. Однако, как обсуждалось ранее, оцифровка предоставляет огромную возможность фиксировать визуальную информацию об ухудшающихся пленочных материалах. Перед сканированием негативов могут потребоваться некоторые усилия по консервации, такие как очистка или выпрямление.Более того, представление визуального содержания фотографий в цифровом формате представляет собой уникальный набор проблем, связанных с воспроизведением тона и цвета.
Наличие оригинальных негативов вместе с отпечатками во многих коллекциях архивных фотографий вызывает дилемму при выборе источника для оцифровки. В общем, рекомендуется оцифровывать из наиболее оригинального источника (т. Е. С негатива). Общий принцип оцифровки «оцифровка оригинала или первого поколения исходного материала» особенно применим к коллекциям фотографий.Фрей (2000b) указывает, что «поскольку каждое поколение фотографических копий связано с некоторой потерей качества, использование промежуточных материалов немедленно подразумевает некоторое снижение качества» (стр. 114). Однако есть некоторые исключения из этого правила, особенно в тех случаях, когда есть существенные различия между негативом и отпечатком. В некоторых случаях фотографические оттиски были сделаны на заказ, и сканирование с этих производных будет превосходить простое сканирование с оригинального негатива. Негативы также могут быть в плохом состоянии из-за порчи.В таких ситуациях сканирование с промежуточного уровня – лучшее решение. В случае художественной фотографии имеет смысл сканировать и негатив, и отпечатки, если они доступны.
Необходимо оценить физические характеристики фотографий, чтобы выбрать наиболее подходящее оборудование и определить технические характеристики. Средство, формат и размер являются основными факторами, влияющими на выбор оборудования. Коллекции оригинальных источников необходимо оценить на предмет:
Размер оригинальных фотографий составляет особенно важно, потому что рекомендации по оцифровке фотографических изображений обычно основаны на пространственных размерах изображения.Поскольку пленочные негативы и отпечатки бывают разных размеров, обычной практикой является использование количества пикселей в длинном измерении в качестве меры и соответствующей корректировки разрешения. В ранних проектах оцифровки в качестве минимального размера рекомендовалось 4000 пикселей по длинной стороне. С улучшением возможностей оборудования для обработки изображений и более низкой стоимостью цифрового хранения в настоящее время рекомендуется 6000–8000 пикселей по длинной стороне, особенно для больших прозрачных пленок.
Таблица 3.3 представлен список рекомендуемых технических характеристик для ряда световозвращающих и прозрачных фотоматериалов. Таблица не охватывает все типы и размеры фотографий. Цель этой выборки – продемонстрировать наличие значительного разброса в разрешении, которое необходимо отрегулировать в соответствии с размером и типом исходного элемента. Это резюме основано на минимальных рекомендациях, подготовленных Ассоциацией библиотечных коллекций и технических служб (ALCTS, 2013). Рекомендации ALCTS включают минимальные спецификации для других типов статических материалов, таких как карты, чертежи, аэрофотосъемка и т. Д.Как подчеркивается в документе ALCTS, эти рекомендации служат отправной точкой, и для многих неподвижных изображений может потребоваться более высокое разрешение и большая битовая глубина (16 бит для оттенков серого и 48 бит для цвета).
Таблица 3.3. Рекомендации по минимальной оцифровке для фотографических изображений
| Размеры оригинала | Разрешение сканирования | Битовая глубина | Режим захвата | Пространственные размеры | ||||
|---|---|---|---|---|---|---|---|---|
| Светоотражающие материалы: Фотографии 902 902.печать | 400 пикселей на дюйм | 8 бит или 24 бит | Оттенки серого или цвет | 3200 × 4000 пикселей | ||||
| Печать 5 × 7 дюймов | 625 пикселей на дюйм | 8 бит или 24 бит | Оттенки серого 25 или цветной | 3125 × 4375 пикселей | ||||
| Печать 4 × 5 дюймов | 800 ppi | 8 бит или 24 бит | Оттенки серого или цвет | 3200 × 4000 пикселей | ||||
| Печать 4 × 2,5 дюйма | 1200 ppi | 8 или 24 бит | Цвет | 4800 × 3000 пикселей | ||||
| Прозрачные материалы: пленочные негативы и слайды | ||||||||
| 8 × 10 дюймов.негативная пленка | 800 пикселей на дюйм | 8 бит или 24 бита | Оттенки серого или цветные | 6400 × 8000 пикселей | ||||
| Негатив на пленке 4 × 5 дюймов | 1200 пикселей на дюйм | 8 бит или 24 бит | Оттенки серого или цвет | 4800 × 6000 пикселей | ||||
| 35-миллиметровая пленка или слайд | 4000 ppi | 8 бит или 24 бит | Оттенки серого или цвет | 5480 пикселей по длинному краю | ||||
Рекомендации для цифровых захват текста и фотографий претерпел незначительные изменения в связи с изменением технологий, но основные характеристики оставались относительно стабильными в последние два десятилетия.Несмотря на отсутствие официальных стандартов, существующие правила и методы оцифровки статических 2D-материалов уже давно устоялись. В отличие от форматов сохранения для временных носителей, которые все еще развиваются, TIFF как основной архивный формат для текста и изображений является стабильным и широко распространенным. Оцифровка текстовых документов и фотографий – это скорее вопрос эффективной практики, чем экспериментов, хотя преобразование универсальных фотоматериалов сопряжено с уникальными проблемами.В 2002 году Линч так прокомментировал прогресс в оцифровке материалов культурного наследия: «Мы очень хорошо умеем оцифровывать материалы в больших масштабах. У нас богатый опыт и большое количество успешных проектов »(Линч, 2002, стр. 3). В последнее десятилетие учреждения культурного наследия опирались на предыдущий опыт и увеличили усилия по оцифровке уникальных архивных и специальных коллекций, хотя и не в массовом масштабе.
Программа оптического распознавания символов для Linux
LOCR – Программа оптического распознавания символов для Linux Мигель А.ЛермаЯ работал над этим проектом Летом 2000 года . Потом я занялся другими проектами и так и не смог приехать вернемся к этому. В текущем состоянии алгоритм распознавания нуждается в улучшении (например, чтобы избежать путаницы с похожими символами, такими как 0 и O, 1 и l, распознавая курсив и т. д.), но я сделал это общедоступным чтобы другие могли воспользоваться его идеями.
Исходники (версия 0.1.0)
Как пользоваться
Сначала скомпилируйте его:
gcc -O2 locr.c -o locr
Далее используйте его.Работает в двух режимах: