
FreeOCR для Windows cкачать [бесплатно]
FreeOCR – бесплатная программа для распознавания отсканированного текста.
Она работает не только с файлами изображений на винчестере, но и с pdf файлами и непосредственно со сканером. Для сканирования необходим только подключенный сканер.
Для установки данной утилиты необходим доступ к интернету, т.к. запускаемый установочник весит около 150 Кб, и из интернета он будет качать необходимые для корректной работы базы и словари. В общей сложности программа займет на жестком диске не более 11 Мб.
Возможности FreeOCR
Интерфейс программы хоть и на английском, но прост и понятен. Стандартное для многих программ ленточное меню отсутствует. Вместо него – большие иконки с выбором требуемой работы. Окно разбито на две половины:
- Слева отображается распознаваемый текст;
- Справа результат работы программы.
Необходимо помнить, что как и родной английский интерфейс, она лучше всего справляется с распознанием именно английских текстов.
Для дальнейшей автоматизации программы необходимо вручную вводить распознаваемый язык каждый раз (для этого надо дополнительно скачивать словари с языками и в настройках указывать путь к ним – в правом верхнем углу). Программа слабо справляется с текстами в которых изобилуют различные математические и другие символы. Такие тексты придется проверять потом вручную.
Преимущества FreeOCR
Безусловным плюсом FreeOCR является абсолютное отсутствие настроек (все процессы автоматизированы), что позволяет не тратить на это время. Импортируется полученная информация по умолчанию в word-документ. На панели расположены только самые необходимые кнопки.
В итоге, можно сказать, что данная программа отлично зарекомендовала себя как распознаватель именно английского текста.
Программы для распознавания текста
Утомительное перепечатывание текста для приведения его в электронный вид давно уже отошло в прошлое, ведь сейчас существуют довольно продвинутые системы распознавания, работа с которыми требует минимального вмешательства пользователя. Программы для оцифровки текста востребованы как в офисе, так и дома. В настоящее время существует довольно большое разнообразие различных приложений для распознавания текста, но какие из них действительно лучшие? Попробуем разобраться в этом вопросе.
Программы для оцифровки текста востребованы как в офисе, так и дома. В настоящее время существует довольно большое разнообразие различных приложений для распознавания текста, но какие из них действительно лучшие? Попробуем разобраться в этом вопросе.
ABBYY FineReader
Эбби Файн Ридер – самая популярная программа для сканирования и распознавания текста в России, а, возможно, и в мире. Данное приложение имеет в своем арсенале все необходимые инструменты, что и позволило ему достичь такого успеха. Кроме сканирования и распознавания, ABBYY FineReader позволяет производить расширенное редактирование полученного текста, а также выполнять ряд других действий. Программа отличается очень качественным распознаванием текста и быстротой работы. Мировую популярность она заслужила также благодаря возможности оцифровки текстов на многих языках мира, а также мультиязычному интерфейсу. Среди немногих недостатков FineReader можно, разве что, выделить большой вес приложения и необходимость платить за пользование полноценной версией.
Скачать ABBYY FineReader
Урок: Как распознать текст в ABBYY FineReader
Readiris
Главным конкурентом Эбби Файн Ридер в сегменте оцифровки текста является приложение Readiris. Это функциональный инструмент для распознавания текста как со сканера, так и с сохраненных файлов различных форматов (PDF, PNG, JPG и др.). Хотя по функционалу данная программа несколько уступает ABBYY FineReader, она значительно превосходит большинство других конкурентов. Главной же фишкой Readiris является возможность интеграции с целым рядом облачных сервисов для хранения файлов. Недостатки у Readiris практически те же, что и у ABBYY FineReader: большой вес и необходимость платить немалые деньги за полноценную версию.
Скачать Readiris
VueScan
Разработчики VueScan главное внимание сконцентрировали все-таки не на процессе распознавания текста, а на механизме сканирования документов с бумажных носителей. Причем программа хороша именно тем, что работает с очень большим перечнем сканеров.
Скачать VueScan
CuneiForm
Приложение CuneiForm – отличное решение для распознавания текста с фото, изображений, сканера. Популярность оно приобрело благодаря применению особой технологии оцифровки, совмещающей шрифтонезависимое и шрифтовое распознавание. Это позволяет максимально точно распознавать текст, учитывая даже элементы форматирования, но при этом сохранять высокую скорость работы. В отличии от большинства программ для распознавания текста, эта абсолютно бесплатна.
Скачать CuneiForm
WinScan2PDF
В отличии от CuneiForm, единственной функцией WinScan2PDF является оцифровка полученного со сканера текста в формат PDF. Главное преимущество этой программы – простота использования. Она подойдет тем людям, которые очень часто сканируют бумажные документы и распознают текст в формате PDF. Главный недостаток ВинСкан2ПДФ связан с очень ограниченным функционалом. Собственно, больше ничего данный продукт не умеет делать, кроме указанной выше процедуры. Он не может сохранять результаты распознавания в другой формат, кроме PDF, а также не предоставляет возможности оцифровки файлов изображений, которые уже хранятся на компьютере.
Скачать WinScan2PDF
RiDoc
РиДок является универсальным офисным приложением для сканирования документов и распознавания текста. Его функционал все-таки немного уступает ABBYY FineReader или Readiris, но и стоимость заметно меньше. Поэтому по соотношению «цена – качество» RiDoc выглядит даже предпочтительнее. В то же время, существенных ограничений по функционалу программа не имеет, и одинаково хорошо выполняет как задачу сканирования, так и распознавания. Фишкой РиДок является возможность уменьшения изображений без потери качества. Единственный существенный недостаток – не совсем корректная работа по распознаванию мелкого текста.
Его функционал все-таки немного уступает ABBYY FineReader или Readiris, но и стоимость заметно меньше. Поэтому по соотношению «цена – качество» RiDoc выглядит даже предпочтительнее. В то же время, существенных ограничений по функционалу программа не имеет, и одинаково хорошо выполняет как задачу сканирования, так и распознавания. Фишкой РиДок является возможность уменьшения изображений без потери качества. Единственный существенный недостаток – не совсем корректная работа по распознаванию мелкого текста.
Скачать RiDoc
Безусловно, среди перечисленных программ любой пользователь сможет отыскать ту, которая ему придется по душе. Выбор будет зависеть как от конкретных задач, которые приходится чаще всего решать, так и от финансового состояния.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТ
|
|
ABBYY FineReader: как работать
|
|
Как установить ABBYY FineReader 11
|
|
|
|
Как запустить ABBYY FineReader
|
Как настроить ABBYY FineReader 12 Professional
|
|
|
|
ABBYY FineReader – как переводить
|
<
ABBYY FineReader: как распознать текст
|
|
|
|
|

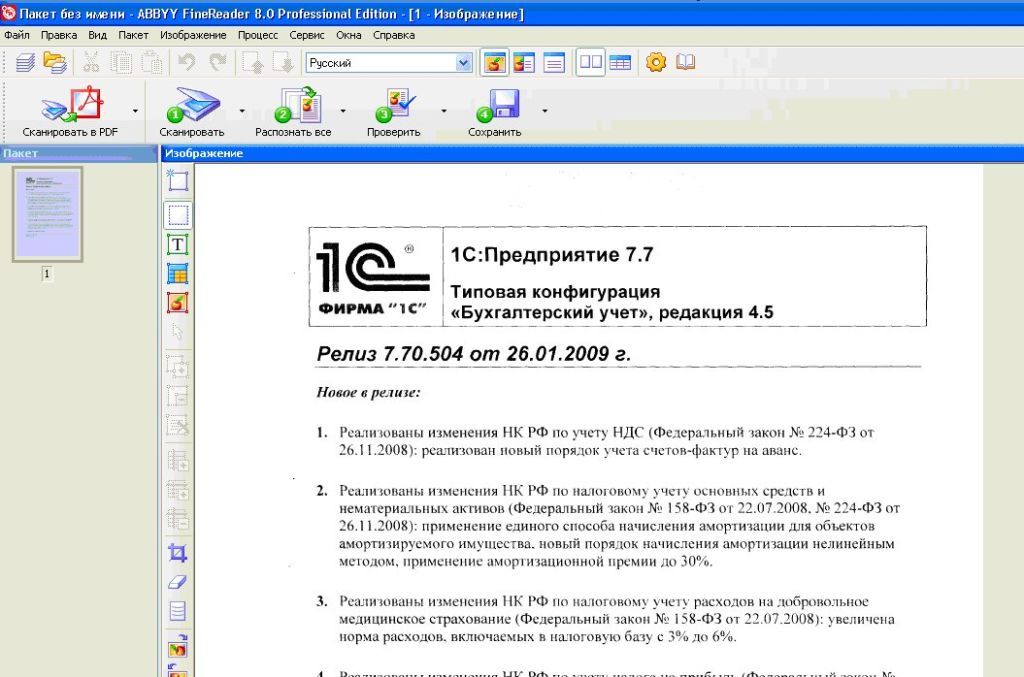 Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.
Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.
 exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке.
exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке.
 Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.
Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.
 Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания.
Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания.
 Тщательный режим будет удобен для работы с некачественными текстовыми файлами, текстами на цветном фоне или сложными таблицами. Быстрое распознавание рекомендовано для больших объемов файлов или когда ограничены временные рамки.
Тщательный режим будет удобен для работы с некачественными текстовыми файлами, текстами на цветном фоне или сложными таблицами. Быстрое распознавание рекомендовано для больших объемов файлов или когда ограничены временные рамки.

Программы оптического распознавания документов — урок. Информатика, 7 класс.
Очень часто появляется необходимость перевести в электронный вид текст каких-то документов, или даже книг. Можно затратить определённое время и просто набрать этот текст с помощью клавиатуры. Но, чем больше исходный текст, тем больше времени будет затрачено на его ввод в память компьютера.
Поэтому для ввода текстов в память компьютера с бумажных носителей используют сканеры и программы распознавания символов.
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов.
Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов.
Наиболее широко известна и распространена такая программа отечественных производителей — ABBYY FineReader.
Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках (на 179 языках), а также для распознавания смешанных двуязычных текстов.
Возможности программы ABBYY FineReader:
- Работает с разными моделями сканеров.
- Позволяет из бумажных документов, PDF-файлов и цифровых фото сделать редактируемый текст.
- Позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (многостраничными документами) и с бланками.
- Позволяет редактировать распознанный текст и проверять его орфографию.
- Сохраняет внешний вид документа, а также его структуру, то есть, расположение слов, абзацев, таблиц, изображений, заголовков и нумерация страниц останутся такими же, как и в оригинале.

- Экспортирует тексты в Word, Excel, PowerPoint или Outlook.

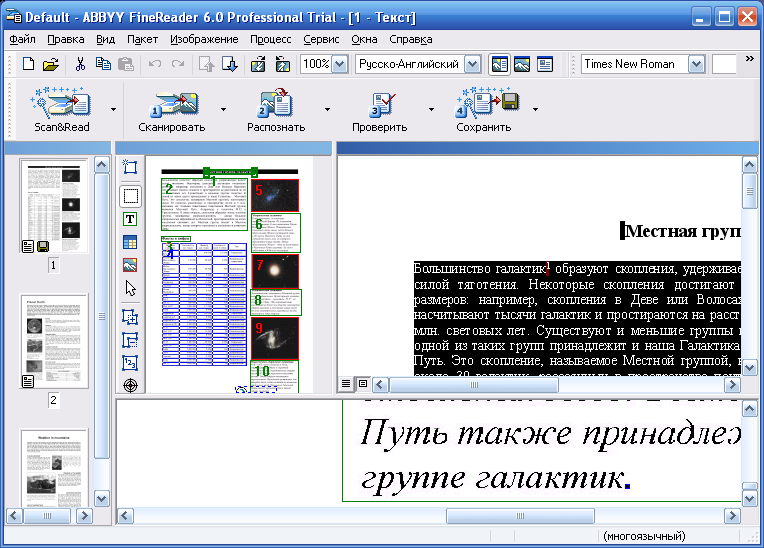
Преобразование бумажного документа в электронный вид происходит в пять этапов. Каждый из этих этапов программа FineReader может выполнять как автоматически, так и под контролем пользователя. Если все этапы проводятся автоматически, то преобразование документа происходит за один прием.
Пять этапов процесса обработки документа с помощью программы ABBYY FineReader:
- Сканирование документа (кнопка Сканировать).
- Сегментация документа (кнопка Сегментировать).
- Распознавание документа (кнопка Распознать).
- Редактирование и проверка результата (кнопка Проверить).
- Сохранение документа (кнопка Сохранить).
1) На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки. Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать.
Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать.
2) Второй этап работы — сегментация, разбиение страницы на блоки текста. Если страница содержит колонки, иллюстрации, врезки, подрисуночные подписи или таблицы, то порядок распознавания требует коррекции. Содержимое страницы разбивается на блоки, внутри каждого из которых распознавание осуществляется в естественном порядке. Блоки нумеруются, исходя из порядка включения их в документ. При автоматической сегментации (кнопка Сегментировать) определение границ блоков осуществляется автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
3) Процесс распознавания текста после сегментации начинается с щелчка на кнопке Распознать и полностью автоматизирован.
4) Когда распознавание данной страницы завершается, полученный текстовый документ отображается в окне Текст. Заключительные этапы работы позволяют отредактировать полученный текст с помощью средств, напоминающих текстовый редактор WordPad. Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить.
Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить.
5) По щелчку на кнопке Сохранить запускается Мастер сохранения результатов. Он позволяет сохранить распознанный текст или передать его в другую программу (например, в Microsoft Word) для последующей обработки полученный текст можно сохранить в виде форматированного или неформатированного документа.
Преобразование сканированных документов в текст (технология OCR)
Вы можете сканировать документы и преобразовывать их в текст с помощью программы обработки текста. Технология, позволяющая компьютерам «читать» текст с физических объектов, назывется OCR. Для сканирования и последующего распознавания текста необходимо установить соответствующую программу, например, ABBYY FineReader, которая включена в комплект поставки устройства.
Примечание|
В некоторых странах приложение ABBYY FineReader Sprint Plus может быть не включено в комплект поставки. |
Перечисленные далее типы документов не могут быть распознаны или затрудняют распознавание:
рукописные тексты;
копии с других копий;
факсы;
текст с плотно расположенными символами или строками;
текст в таблицах или подчеркнутый текст;
текст с наклоном или с размером символов меньше 8 пунктов.
Обратитесь к одному из следующих разделов, чтобы выполнить сканирование и распознать текст с помощью программы ABBYY FineReader.
Автоматический режим: Преобразование сканированных документов в текст в автоматическом режиме Офисный режим: Преобразование сканированных документов в текст в офисном режиме Простой режим: Преобразование сканированных документов в текст в простом режиме Профессиональный режим: Преобразование сканированных документов в текст в профессиональном режимеПреобразование сканированных документов в текст в автоматическом режиме
|
Запустите ABBYY FineReader одним из следующих способов. |

В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6.0 Sprint > ABBYY FineReader 6.0 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
Откроется окно ABBYY FineReader.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. |
 Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan.
Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan.|
Щелкните Scan (Сканировать). Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader. |
|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Преобразование сканированных документов в текст в офисном режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6 Sprint > ABBYY FineReader 6 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Для параметра Image Type (Тип изображения) выберите значение Color (Цвет), Grayscale (Оттенки серого) или Black&White (Черно-белый). |

|
Выберите значение Document Table (Планшет для документов) для параметра Document Source (Источник документа). |
|
Выберите значение параметра Size (Размер), соответствующее размеру загруженных документов. |
|
Выберите 300 для параметра Resolution (Разрешение). |
|
Щелкните Scan (Сканировать). Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader. |

|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Преобразование сканированных документов в текст в простом режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6 Sprint > ABBYY FineReader 6 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Для параметра Document Type (Тип документа) выберите Magazine (Журнал), Newspaper (Газета) или Text/Line Art (Текст/штриховой рисунок). |
|
Для параметра Image Type (Тип изображения) выберите значение Color (Цвет) или Black&White (Черно-белый). |
|
Для параметра Destination (Назначение) выберите значение Printer (Принтер) или Other (Другое). |
|
Если вы выбрали Other (Другое), для параметра Resolution (Разрешение) выберите значение 300. |
|
Щелкните Scan (Сканировать). |
 Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader.
Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader.|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Преобразование сканированных документов в текст в профессиональном режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6 Sprint > ABBYY FineReader 6 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Выберите Reflective (Непрозрачный) для параметра Document Type (Тип документа). |
|
Выберите значение Document Table (Планшет для документов) для параметра Document Source (Источник документа). |
|
Выберите значение Document (Документ) для параметра Auto Exposure Type (Тип автоэкспозиции). |
|
Выберите Black & White (Черно-белый), 24-bit Color (Цветной 24 бита) или 48-bit Color (Цветной 48 бит) для параметра Image Type (Тип изображения). |
|
Выберите 300 для параметра Resolution (Разрешение). |
|
Щелкните Scan (Сканировать). Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader. |
|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
FineReader – распознавание текста. Microsoft Office
FineReader – распознавание текста
Ввести со сканера текст в компьютер – задача не слишком трудная. Однако работать с таким текстом невозможно: как и любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Отсюда возникают проблемы: во-первых, в графическом формате страница занимает слишком много места, и, скажем, отсканированная книга не на каждый жесткий диск поместится. И вторая, самая главная проблема: сканированный текст можно будет только читать, но не редактировать и не вставлять его фрагменты в создаваемый вами документ. Ведь сам сканер распознавать буквы именно как буквы не умеет: они для него – всего лишь пятна и точки черного цвета.
К счастью, на свете существуют программы, способные перевести сканированный текст из графического в текстовый формат – программы распознавания текста или OCR.
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами (именно так работали распознавалки первого поколения), но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы. И самое главное – корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст – это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата – скажем, формата Microsoft Word или Excel.
Как видим, для того чтобы получить электронную, готовую к редактированию копию любого печатного текста, программе OCR необходимо выполнить «цепочку» из множества отдельных операций:
Сканирование. За эту работу отвечает, собственно, не программа OCR, а встроенное в систему программное обеспечение вашего сканера. Именно с его помощью вы можете задать нужные вам параметры сканирования – например, разрешение (рекомендуется 300 dpi), цветовой режим (для простых текстов достаточно черно-белого или LineArt) – и выделить ту область документа, которую вам необходимо «скопировать» в компьютер.
Сегментация. Полученную со сканера «картинку» подхватывает OCR-программа. Но до распознавания еще далеко – сначала надо отделить текстовые элементы от графики, да и текст в ряде случаев разбить на отдельные куски (например, при многоколоночной верстке).
Распознавание. На этом этапе текст переводится из графической формы в обычную текстовую.
Проверка орфографии и правка. Встроенная система проверки орфографии «проходится» по тексту, проверяя и корректируя последствия работы системы распознавания. Спорные слова и символы выделяются особым предупреждающим цветом. Потом наступает очередь пользователя, который также может внести свою лепту в этот ответственный процесс.
Сохранение. Для дальнейшей обработки документ должен быть передан «на поруки» соответствующей программе – как правило, одному из продуктов семейства Microsoft Office. Или сохранен в формате, соответствующем его содержанию: текст – в DOC или RTF, таблица – в XLS… Да и встроенную графику желательно в документе оставить…
Все эти операции в большинстве программ OCR могут выполняться как в автоматическом, с помощью программы-мастера, так и в ручном режиме, по отдельности. С двумя первыми и последней операциями с легкостью справится любая программа распознавания. А вот весь процесс целиком по зубам, увы, только нескольким продуктам, разработанным в нашей стране. Тут надо сделать небольшую поправку: на самом деле корректно работать с русским языком умеют практически все современные «распознавалки», вне зависимости от того, где они были разработаны. Более того, в состав Microsoft Office-2003 уже включена абсолютно бесплатная программа распознавания Microsoft Office Document Scanning! Однако для российских пользователей само понятие «программа распознавания текста» чаще всего неразрывно связано с программой FineReader. Ибо компания ABBYY смогла не просто создать удобный для пользователя и качественный продукт, но и, самое главное, удачно «раскрутить» его.
Одним из козырей FineReader является поддержка неимоверного количества языков распознавания – 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования (Basic, С/C++, COBOL, Fortran, Java, Pascal)! Так что FineReader сможет без запинки справиться с древнегреческим свитком или с бледными распечатками исходных текстов программ, сделанных вашими предками лет 30 назад. Как ни странно, большинство пользователей на деле интересуется совсем другим. Офисных работников интересует распознавание типовых форм документов, студентов – возможность быстро «передрать» для реферата многостраничный текст из учебника, сканируя и распознавая книжный разворот целиком, бухгалтеров – возможность автоматического распознавания таблиц и документов на бланках… Все это и многое другое FineReader умеет… или не все, а только частично, в зависимости от модификации продукта. Далеко не все возможности из нашего перечня включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером. Пакетное сканирование, грамотная обработка таблиц и изображений – для всего этого стоит приобрести профессиональную версию программы – FineReader Pro. Заодно она умеет безукоризненно читать штрихкоды, позволяет добавлять в базу данных новые языки. А самая мощная (и дорогостоящая) версия – FineReader Office – без труда справится и с распознаванием любых бланков и форм! Все версии FineReader, от самой простой до самой мощной, объединяет, на мой взгляд, главное достоинство программы – интерфейс. Для запуска процесса распознавания вам достаточно просто положить документ в сканер и нажать единственную кнопку (мастер Scan & Read) на панели инструментов программы. Все дальнейшие операции – сканирование, разбивку изображения на «блоки» и, наконец, собственно распознавание программа выполнит автоматически. Пользователю останется только установить нужные параметры сканирования – рекомендуется разрешение в 300 dpi и режим черно-белого изображения или LineArt. Впрочем, текст можно отсканировать и в цветном режиме: в этом случае FineReader сможет грамотно распознать цветовое выделение шрифтов и сохранить его в готовом документе.
После завершения распознавания страницы FineReader предложит пользователю выбор: сканировать и распознавать дальше (для многостраничного документа) или сохранить полученный текст в одном из множества популярных форматов – от документов Microsoft Office до HTML или PDF. Можно, впрочем, сразу же перебросить документ в Word или Excel и уже там исправить все огрехи распознавания (без них обойтись просто невозможно). При этом FineReader полностью сохраняет все особенности форматирования документов и графическое оформление.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРесКак распознать текст? Программа для распознавания текста
Функция распознавания текста может понадобиться в тех случаях, когда нужно перевести текст из книжного формата, в физическом варианте, в электронный. Ну, представим такую ситуацию: у нас есть книга на руках, которую нужно перенести на компьютер в файл Ворд, как будто мы её перепечатали сами с клавиатуры.
Здесь есть два варианта, либо сделать все как нужно, перепечатав текст из книги руками самому, и потратив на это уйму времени, либо второй вариант – это воспользоваться специальной программой для распознавания текста. Одна из таких называется ABBYY FineReader. О ней то мы сегодня и будем говорить.
Программа ABBYY FineReader была разработана специально для осуществления возможности распознавания текста, который отсканирован из книги, журнала, газеты и прочих печатных изданий.
Давайте я на реальном примере покажу Вам, как распознать текст после сканирования или после скачивания уже отсканированной книги, в программе ABBYY FineReader.
Подготовьте программу: найдите её, скачайте, установите, запустите. Подготовьте текст, который вам нужно распознать. Отсканируйте его, если нужно.
А теперь давайте запустим программу ABBYY FineReader. Процесс распознавания текста я буду показывать на примере последней, 11-ой, на данный момент версии.
Распознавание текста в программе ABBYY FineReader
Например, нам нужно книгу в PDF формате конвертировать в обычный текст в страницы Word. Для этого в открывшемся окне программы выбираем задачу «Файл (PDF/изображение) в Microsoft Word».
Нам сразу же предлагают указать на компьютере PDF файл для распознавания текста, который в нём имеется.
В течение нескольких минут выбранный файл будет открываться. Мы можем наблюдать за процессом.
Затем произойдет распознавание текста и по окончанию весь текст программа FineReader переместит в Word файл и откроет его.
Нам остается только исправить некоторые ошибки, если они будут, и сохранить файл в любое место на своем компьютере.
Кроме этого мы можем сами в программе распознанный текст передать или даже сразу сохранить в Ворд файл.
Также в программе ABBYY FineReader можно распознать текст сразу со сканера, то есть кладем печатный вариант в сканер и в программе выбираем чтобы она сразу распознавала текст.
Есть и другие варианты.
Надеюсь эти примеры по распознаванию текста в программе ABBYY FineReader вам понятны и с другими способами вы уже разберетесь сами.
Ранее я уже писал урок про то, как распознать текст, но там мы использовали не программу FineReader, а онлайн сервис. Впрочем, если вам эта тема интересна, то рекомендую почитать этот урок: Как распознать текст онлайн.
Удачи!
Интересные статьи по теме:
12 Лучшее бесплатное программное обеспечение OCR для Windows и Mac
OCR относится к процессу, в котором электронное оборудование проверяет символы, напечатанные на бумаге, определяет форму, обнаруживая темные и светлые узоры, а затем преобразует форму в компьютерный текст с помощью распознавания символов. Это означает распознать текст на изображении и затем извлечь его в редактируемый документ.
Двумя основными целями OCR являются хранение документов и повторное использование документов и их содержимого. В то же время OCR может также искать документы, чтобы упростить рабочий процесс и упростить обработку, поэтому большинство компаний будут использовать программное обеспечение OCR.Как выбрать хорошее программное обеспечение для распознавания текста? В этой статье будут представлены 12 бесплатных программ распознавания текста, которые помогут вам легко обрабатывать файлы.
FreeOCR – это бесплатное программное обеспечение для оптического распознавания символов для Windows, которое поддерживает сканирование с большинства сканеров, а также может открывать большинство отсканированных файлов PDF и многостраничных изображений, а также популярных форматов файлов изображений.
Механизм Tesseract OCR PDF этого программного обеспечения является продуктом с открытым исходным кодом, выпущенным Google. Он был разработан в Hewlett Packard Laboratories в период с 1985 по 1995 год.В 1995 году он был одним из трех лучших исполнителей на конкурсе на точность распознавания текста, организованном Университетом Невады в Лас-Вегасе.
2. Readiris
Readiris позволяет объединять и разделять, редактировать и комментировать, защищать и подписывать файлы PDF. Это также глобальное решение для преобразования, редактирования и преобразования всех ваших бумажных документов в различные цифровые форматы интуитивно с помощью нескольких щелчков мышью. Механизм оптического распознавания символов позволяет восстанавливать тексты во всех типах файлов с идеальной точностью, сохраняя исходный формат для различных исходных или целевых форматов файлов.
Плюсы:
- Простое создание, изменение, подписание и аннотирование файлов PDF
- Множественные выходные форматы преобразования
- Редактируйте текст, встроенный в ваши изображения, с помощью OCR
Минусы:
- Без сканирования визиток
Поддерживаемые языки:
Readiris распознает более 130 языков. Он использует собственные словари, что делает его невероятно точным.Если вы хотите изменить язык конвертации, посмотрите это видео.
3. Adobe Acrobat Pro DC
Adobe Acrobat Pro DC может подключаться к вашим файлам PDF из любого места и делиться ими с кем угодно. С помощью этого программного обеспечения вы можете просматривать отчет на своем телефоне, редактировать предложение на планшете и добавлять комментарии к презентации в браузере. Вы можете сделать больше, не пропуская ни одной доли.
С помощью инструмента распознавания текста в Adobe Acrobat Pro DC можно мгновенно извлекать текст и преобразовывать отсканированные документы в редактируемые PDF-файлы.
Плюсы:
- Мгновенное преобразование
- Точно соответствует шрифтам
- Работает с Office
- Идеально подходит для архивирования
Минусы:
- В бесплатной версии отсутствуют некоторые функции
- Богатый набор функций может быть ошеломляющим для новых пользователей
Поддерживаемые языки:
По умолчанию OCR использует язык, выбранный в диалоговом окне «Моя информация».Механизм OCR использует выбранный язык для интерпретации отсканированного текста. Выбор правильного языка повышает точность преобразования, поскольку механизм распознавания текста использует для преобразования словари для конкретного языка. Для нелатинских языков, таких как японский, механизм OCR не сможет интерпретировать и преобразовать текст, если вы не выбрали соответствующий язык.
4. Microsoft OneNote
Microsoft OneNote – это ваша цифровая записная книжка, в которой можно редактировать заметки с помощью шрифтов, выделения или рукописных примечаний.С OneNote на всех ваших устройствах вы никогда не пропустите ни одной вспышки вдохновения.
OneNote также поддерживает OCR, инструмент, который позволяет копировать текст с изображения или распечатки файла и вставлять его в заметки, чтобы вы могли вносить изменения в слова. Это отличный способ делать такие вещи, как копирование информации с отсканированной визитки в OneNote. После извлечения текста вы можете вставить его в другое место в OneNote или другой программе, например Outlook или Word.
Плюсы:
- Делитесь записными книжками с коллегами, друзьями и семьей
- Позволяет легко делать заметки на нескольких платформах и устройствах
Минусы:
- Новичкам посложнее
Поддерживаемые языки:
Microsoft OneNote в настоящее время распознает печатный текст на 21 языке: упрощенный китайский, традиционный китайский, чешский, датский, голландский, английский, финский, французский, немецкий, греческий, венгерский, итальянский, японский, корейский, норвежский, польский, португальский, русский, Испанский, шведский и турецкий.
Wondershare PDFelement Pro – еще одно настольное программное обеспечение с функцией распознавания текста. С помощью этого программного обеспечения вы можете легко конвертировать PDF в Word, Excel, PPT, JPG, PNG, RTF и т. Д. Конвертер очень прост в использовании и отлично работает с отличным качеством вывода.
Благодаря функции оптического распознавания текста в Wondershare PDFelement Pro вы можете не только распознавать и редактировать текст в любых отсканированных PDF-файлах и файлах с изображениями, но также выполнять поиск и копировать текст из любых отсканированных PDF-файлов и файлов с изображениями.
Плюсы:
- Поддержка нескольких языков
- Распознавать и редактировать текст в любых отсканированных и графических PDF-файлах
- Поиск и копирование текста из любых отсканированных документов и файлов PDF с изображениями
Минусы:
- Не поддерживается встраивание видеофайлов при создании PDF-файлов
Поддерживаемые языки:
OCR поддерживает десятки языков, таких как: английский, португальский, японский, испанский, немецкий, итальянский, французский, болгарский, китайский упрощенный, китайский традиционный, хорватский, каталонский, греческий, чешский, корейский, польский, цыганский, русский, Словацкий, тайский, турецкий, украинский и голландский.
6. SimpleOCR
SimpleOCR – лучшее программное обеспечение для распознавания текста, если вы имеете дело с многоколоночным содержимым, нестандартными цветными изображениями шрифтов, которые могут быть не самого лучшего качества, поскольку этот инструмент в конечном итоге даст вам высококачественный результат.
Если у вас есть сканер и вы не хотите перепечатывать документы, SimpleOCR – это быстрый и бесплатный инструмент для этого. Бесплатное ПО SimpleOCR на 100% бесплатное и никоим образом не ограничено. Кто угодно может использовать SimpleOCR для бесплатных домашних пользователей, учебных заведений и даже корпоративных пользователей.
Плюсы:
- Простота использования
- Имеет встроенную проверку орфографии для проверки неточностей в преобразованном тексте.
Минусы:
- Рукописное извлечение имеет ограничения и предлагается только в течение 14 дней бесплатной пробной версии
- Не поддерживает таблицы и столбцы
Поддерживаемые языки:
7. Boxoft Free OCR
Boxoft Free OCR – это полностью бесплатная программа, которая поможет вам извлекать текст из всех видов изображений.Бесплатная программа может анализировать текст из нескольких столбцов и поддерживает несколько языков. Вы даже можете сканировать свои бумажные документы, а затем сразу же преобразовывать содержимое OCR из отсканированных файлов в редактируемый текст.
Плюсы:
- Простота использования
- Поддержка нескольких языков
- Принимает несколько форматов файлов
Минусы
Поддерживаемые языки:
Он может поддерживать английский, французский, немецкий, итальянский, голландский, испанский, португальский, баскский и т. Д.
8. VueScan
VueScan – это компьютерная программа для сканирования изображений, особенно фотографий, в том числе негативов. Он поддерживает оптическое распознавание символов текстовых документов. Программное обеспечение можно загрузить и использовать бесплатно, но при сканировании добавляется водяной знак, пока не будет приобретена лицензия.
Плюсы:
- Простота использования
- Работает на 6000+ сканерах
- Работает в Windows, macOS X и Linux
Минусы:
- Новичкам посложнее
Поддерживаемые языки:
VueScan имеет оптическое распознавание текста для английского языка.Он поддерживает болгарский, каталонский, китайский (упрощенный), китайский (традиционный), чешский, датский , и так далее. Есть 32 дополнительных языка, которые вы можете использовать, загрузив один из файлов ocr_xx.bin. Чтобы добавить язык OCR, вы можете прочитать инструкции и следовать инструкциям по добавлению языка.
9. ABBYY FineReader
ABBYY FineReader – это программа, которая может конвертировать, редактировать, публиковать и совместно работать над PDF-файлами и отсканированными изображениями на цифровом рабочем месте. Это универсальное приложение для оптического распознавания текста и PDF для повышения производительности при работе с документами.Он может преобразовывать отсканированное изображение в текст с максимальной точностью среди других удобных функций, когда дело доходит до документов.
Плюсы:
- Оцифровка бумажных документов и сканированных изображений с помощью OCR
- Автоматизировать процедуры оцифровки и преобразования
- Оцифровка документооборота
Минусы
- Функция без управления версиями позволяет пользователям просматривать историю изменений документа
Поддерживаемые языки:
ABBYY FineReader теперь распознает в общей сложности 184 языка и обеспечивает широчайшую языковую поддержку, объединяя в одном пакете европейские, азиатские, африканские и ближневосточные языки.
10. Easy Screen OCR
Easy Screen OCR – это легкое и простое приложение для распознавания и перевода снимков экрана ПК. Он также поддерживает распознавание скриншотов. Вам не нужно повторно набирать текст с изображений. Просто попробуйте это бесплатное приложение OCR, чтобы скопировать текст. Кроме того, он может извлекать текст из скриншотов, изображений, а затем переводить их на другие языки. Поддержка перевода на 20 языков.
Плюсы:
- Простота использования
- Два режима оптического распознавания символов
- Поддержка более 100 языков
Минусы:
- Поддержка только OCR захваченного снимка экрана
- Невозможно преобразовать извлеченный текст в другие форматы
Поддерживаемые языки:
Easy Screen OCR поддерживает распознавание более 100 языков по всему миру.Он поддерживает упрощенный китайский, английский, кантонский, японский, корейский, французский, испанский, Таиланд, арабский, русский и т. Д.
11. Бесплатное распознавание текста в Word
Free OCR to Word также является настольной программой OCR. Бесплатное распознавание текста в Word позволяет идентифицировать текст в файлах изображений и преобразовывать его в электронный документ. Он может выполнять OCR для всех ключевых и многих редких форматов изображений, включая JPG / JPEG, TIF / TIFF, BMP, GIF, PNG, EMF, WMF, JPE, ICO, JFIF, PCX, PSD, PCD, TGA и так далее.
Плюсы:
- Высокая точность распознавания текста до 98%
- Может извлекать текст из JPG, BMP, PNG, GIF, TIF и др.
Минусы:
- Возможно неточно
- Плохое удержание макета
Поддерживаемые языки:
Эта услуга поддерживает 46 языков, включая китайский, японский, корейский и другие.
12. PDFMate PDF Converter
PDFMate PDF Converter – это простое и бесплатное приложение для преобразования PDF в другие форматы.Вам больше не нужно будет беспокоиться о проблемах при копировании или редактировании файлов PDF с его помощью. Бесплатный инструмент PDF также позволяет конвертировать JPG в формат PDF.
Обладая встроенной технологией оптического распознавания текста, это бесплатное программное обеспечение позволяет пользователям преобразовывать отсканированные PDF-файлы в редактируемый текст или файлы Microsoft Word. Когда вы добавили в программу файл PDF с изображением, перейдите к расширенным настройкам, чтобы включить оптическое распознавание текста, а затем выберите текст в качестве формата вывода. Нажмите кнопку конвертировать, и через несколько секунд в строке состояния отобразится успех.Тогда вы увидите, что все символы правильно распознаны.
Плюсы:
- Легко и быстро с пакетным преобразованием
- Высокое качество
- Поддержка нескольких языков
Минусы:
Поддерживаемые языки:
PDFMate PDF Converter поддерживает преобразование файлов PDF на всех языках: английском, японском, традиционном китайском, упрощенном китайском, корейском, латинском, турецком, греческом, немецком, французском, итальянском, португальском, испанском, русском, польском, чешском, словацком , Украинский, болгарский, хорватский, румынский и др.
Выводы
Мы составили список 12 лучших бесплатных программ оптического распознавания текста для ПК. У всех есть свои достоинства и недостатки. Вы можете выбрать подходящий. Мы надеемся, что эта статья поможет вам найти лучшее программное обеспечение для распознавания текста. Если у вас есть хорошая идея, свяжитесь с нами.
Ошибка 404 | Страница не найдена
КОМПАНИЯ
О EasePDF
Контакт
Конфиденциальность
Условия использования
Политика в отношении файлов cookie
РЕСУРСОВ
FAQ
Темы
Карта сайта
ОСОБЕННОСТИ
PDF в Word
PDF в Excel
PDF в PPT
Word в PDF
JPG в PDF
Сжать PDF
Разделить PDF
Разблокировать PDF
Добавить водяной знак
Интернет-платформа FlipBook
ГОРЯЧИЕ ТЕМЫ
Как загрузить электронные книги в формате PDF из библиотеки Genesis (LibGen)
12 веб-сайтов, таких как Library Genesis, для загрузки бесплатных электронных книг в формате PDF
5 лучших способов удалить водяной знак из PDF
Как бесплатно конвертировать изображения JPG в PDF
11 лучших альтернатив и конкурентов iLovePDF 2020
Как бесплатно разблокировать PDF-файл, защищенный паролем
Как конвертировать XLS / XLSX в PDF (5 вариантов)
6 лучших сайтов для бесплатного чтения онлайн-книг
Как преобразовать PDF в изображение
БЮЛЛЕТЕНЬ
Подпишитесь на нас!
Сообщество EasePDF
Ошибка 404 | Страница не найдена
КОМПАНИЯ
О EasePDF
Контакт
Конфиденциальность
Условия использования
Политика в отношении файлов cookie
РЕСУРСОВ
FAQ
Темы
Карта сайта
ОСОБЕННОСТИ
PDF в Word
PDF в Excel
PDF в PPT
Word в PDF
JPG в PDF
Сжать PDF
Разделить PDF
Разблокировать PDF
Добавить водяной знак
Интернет-платформа FlipBook
ГОРЯЧИЕ ТЕМЫ
Как загрузить электронные книги в формате PDF из библиотеки Genesis (LibGen)
12 веб-сайтов, таких как Library Genesis, для загрузки бесплатных электронных книг в формате PDF
5 лучших способов удалить водяной знак из PDF
Как бесплатно конвертировать изображения JPG в PDF
11 лучших альтернатив и конкурентов iLovePDF 2020
Как бесплатно разблокировать PDF-файл, защищенный паролем
Как конвертировать XLS / XLSX в PDF (5 вариантов)
6 лучших сайтов для бесплатного чтения онлайн-книг
Как преобразовать PDF в изображение
БЮЛЛЕТЕНЬ
Подпишитесь на нас!
Сообщество EasePDF
7 лучших бесплатных программ для оптического распознавания текста для преобразования изображений в текст
Хотите бесплатное программное обеспечение для распознавания текста? В этой статье собраны семь лучших программ, которые ничего не стоят.
Что такое OCR?
Программа оптического распознавания символов (OCR) преобразует изображения или даже рукописный текст в текст.Программное обеспечение OCR анализирует документ и сравнивает его со шрифтами, хранящимися в их базе данных, и / или отмечая особенности, характерные для символов. Некоторые программы OCR также используют программу проверки орфографии, чтобы «угадать» нераспознанные слова. Трудно достичь 100% точности, но большая часть программного обеспечения стремится к точному приближению.
Программное обеспечение OCR может помочь студентам, исследователям и офисным работникам повысить производительность труда.Итак, давайте поиграем с еще несколькими и найдем лучшее программное обеспечение для оптического распознавания текста, соответствующее вашим потребностям.
1.OCR с использованием Microsoft OneNote
Microsoft OneNote имеет расширенные функции распознавания текста, которые работают как с изображениями, так и с рукописными заметками.
- Перетащите отсканированное изображение или сохраненное изображение в OneNote.Вы также можете использовать OneNote, чтобы закрепить часть экрана или изображение в OneNote.
- Щелкните правой кнопкой мыши вставленное изображение и выберите Копировать текст с изображения . Скопированный оптически распознанный текст попадает в буфер обмена, и теперь вы можете вставить его обратно в OneNote или в любую программу, например Word или Блокнот.
OneNote также может извлекать текст из многостраничной распечатки одним щелчком мыши.Вставьте распечатку нескольких страниц в OneNote, а затем щелкните правой кнопкой мыши текущую выбранную страницу.
- Щелкните Копировать текст с этой страницы распечатки , чтобы получить текст только с этой выбранной страницы.
- Щелкните Копировать текст со всех страниц распечатки , чтобы скопировать текст со всех страниц одним снимком, как вы можете видеть ниже.
Обратите внимание, что точность OCR также зависит от качества фотографии.Вот почему оптическое распознавание почерка все еще немного нечеткое для OneNote и другого программного обеспечения для распознавания текста на рынке. Тем не менее, это одна из ключевых функций OneNote, которую вы должны использовать при каждой возможности.
Хотите узнать, как OneNote сравнивается с платным программным обеспечением для распознавания текста? Прочтите наше сравнение OneNote и OmniPage.
2.SimpleOCR
Трудность, с которой я столкнулся с распознаванием рукописного ввода с помощью инструментов MS, могла найти решение в SimpleOCR.Но программа предлагает распознавание рукописного ввода только в виде 14-дневной бесплатной пробной версии. Распознавание машинной печати, хотя не имеет ограничений .
Программное обеспечение выглядит устаревшим, поскольку не обновлялось с версии 3.1, но вы все равно можете попробовать его из-за простоты.
- Настройте его для чтения прямо со сканера или путем добавления страницы (форматы JPG, TIFF, BMP).
- SimpleOCR предлагает некоторый контроль над преобразованием с помощью функций выделения текста, выбора изображения и игнорирования текста.
- Преобразование в текст переводит процесс на этап проверки; пользователь может исправить неточности в преобразованном тексте с помощью встроенной проверки орфографии.
- Конвертированный файл можно сохранить в формате DOC или TXT.
SimpleOCR отлично справлялся с обычным текстом, но его обработка многоколоночных макетов разочаровывала. На мой взгляд, точность преобразования инструментов Microsoft была значительно лучше, чем SimpleOCR.
Загрузить: SimpleOCR для Windows (бесплатно, платно)
3.Сканирование фотографий
Photo Scan – это бесплатное приложение для распознавания текста для Windows 10, которое можно загрузить из Microsoft Store.Приложение, созданное Define Studios, поддерживается рекламой, но это не мешает работе. Приложение представляет собой сканер OCR и считыватель QR-кода в одном флаконе.
Наведите приложение на изображение или распечатку файла.Вы также можете использовать веб-камеру вашего ПК, чтобы дать ему изображение. Распознанный текст отображается в соседнем окне.
Функция преобразования текста в речь выделена. Щелкните значок динамика, и приложение прочитает вслух то, что только что отсканировало.
С рукописным текстом не очень хорошо, но распознания печатного текста было достаточно.Когда все будет сделано, вы можете сохранить текст OCR в нескольких форматах, таких как текст, HTML, Rich Text, XML, формат журнала и т. Д.
Загрузить: Photo Scan (Бесплатная покупка в приложении)
4.(a9t9) Бесплатное приложение OCR для Windows
(a9t9) Бесплатное программное обеспечение OCR – это приложение для универсальной платформы Windows.Таким образом, вы можете использовать его с любым устройством Windows, которое у вас есть. Существует также онлайн-эквивалент OCR, работающий на том же API.
(a9t9) поддерживает 21 язык для преобразования изображений и PDF в текст.Приложение также можно использовать бесплатно, а поддержку рекламы можно удалить с помощью покупки в приложении. Как и большинство бесплатных программ OCR, это идея для печатных документов, а не для рукописного текста.
Загрузить: a9t9 Free OCR (бесплатно, покупка в приложении)
5.Capture2Text
Capture2Text – это бесплатное программное обеспечение для распознавания текста для Windows 10, которое дает вам сочетания клавиш для быстрого распознавания текста на экране.Также не требует установки.
Используйте сочетание клавиш по умолчанию WinKey + Q , чтобы активировать процесс распознавания текста.Затем вы можете использовать мышь, чтобы выбрать часть, которую хотите захватить. Нажмите Enter, и выделение будет оптически распознано. Захваченный и преобразованный текст появится во всплывающем окне и также будет скопирован в буфер обмена.
Capture2Text использует движок Google OCR и поддерживает более 100 языков.Он использует Google Translate для преобразования захваченного текста на другие языки. Загляните внутрь Настройки , чтобы настроить различные параметры, предоставляемые программным обеспечением.
Загрузить: Capture2Text (бесплатно)
6.Easy Screen OCR
Easy Screen OCR не является бесплатным.Но я упоминаю об этом здесь, потому что это быстро и удобно. Вы также можете бесплатно использовать его от до 20 раз по без какой-либо подписки. Программа работает из панели задач или панели задач. Щелкните правой кнопкой мыши значок Easy Screen OCR и выберите в меню Capture . Сделайте снимок экрана любого изображения, веб-сайта, видео, документа или чего-либо еще на экране, перетащив курсор мыши.
Затем Easy Screen OCR отображает диалоговое окно с тремя вкладками.Вкладка снимков экрана дает вам предварительный просмотр захваченного текста. Нажмите кнопку OCR, чтобы прочитать текст с изображения. Оптически преобразованный текст теперь можно скопировать из вкладки «Текст» диалогового окна.
Вы можете установить языки распознавания для OCR в настройках программного обеспечения.Поддерживается более 100 языков, так как в программе используется механизм распознавания текста Google.
Загрузить: Easy Screen OCR (9 долларов в месяц)
Также: OCR с Google Docs
Если вы находитесь далеко от своего компьютера, попробуйте функции распознавания текста на Google Диске.В Google Docs есть встроенная программа OCR, которая может распознавать текст в файлах JPEG, PNG, GIF и PDF. Но все файлы должны быть не более 2 МБ, а текст – 10 пикселей или больше. Google Диск также может автоматически определять язык в отсканированных файлах, хотя точность с нелатинскими символами может быть невысокой.
- Войдите в свою учетную запись Google Drive.
- Нажмите New> File Upload . Кроме того, вы также можете нажать Мой диск> Загрузить файлы .
- Найдите на своем компьютере файл, который вы хотите преобразовать из PDF-файла или изображения в текст. Нажмите кнопку Открыть , чтобы загрузить файл.
- Документ теперь находится на вашем Google Диске.Щелкните документ правой кнопкой мыши и выберите Открыть с помощью> Документы Google .
- Google конвертирует ваш PDF-файл или файл изображения в текст с помощью OCR и открывает его в новом документе Google.Текст доступен для редактирования, и вы можете исправить те части, в которых OCR не смог его правильно прочитать.
- Вы можете загружать оптимизированные документы в различных форматах, поддерживаемых Google Диском. Выберите из меню «Файл »> «Загрузить как ».
Бесплатное программное обеспечение для оптического распознавания текста
, которое вы можете выбратьХотя бесплатные инструменты подходили для печатного текста, они не справлялись с обычным курсивом рукописного текста.Я лично предпочитаю использовать оптическое распознавание текста в Microsoft OneNote, потому что вы можете сделать его частью рабочего процесса создания заметок. Photo Scan – универсальное приложение для Магазина Windows, которое поддерживает разрывы строк в различных форматах документов, в которые вы можете сохранять.
Но не позволяйте вашему поиску бесплатных конвертеров OCR на этом заканчиваться.Есть много других альтернативных способов распознавания текста и изображений. И раньше мы протестировали несколько онлайн-инструментов OCR. Держите их тоже рядом.
Кредит изображения: nikolay100 / Depositphotos
12 ненужных программ и приложений Windows, которые следует удалитьХотите знать, какие приложения для Windows 10 удалить? Вот несколько ненужных приложений, программ и вредоносного ПО для Windows 10, которые вам следует удалить.
Читать далее
Об авторе Сайкат Басу (Опубликовано 1544 статей)Сайкат Басу – заместитель редактора по Интернету, Windows и производительности.После того, как он избавился от грязи MBA и десятилетней маркетинговой карьеры, он теперь увлечен тем, что помогает другим улучшить их навыки рассказывания историй. Он следит за пропавшей оксфордской запятой и ненавидит плохие скриншоты. Но идеи фотографии, фотошопа и производительности успокаивают его душу.
Более От Сайката БасуПодпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Пожалуйста, подтвердите свой адрес электронной почты в письме, которое мы вам только что отправили.
|
|
Программа оптического распознавания символов для преобразования отсканированных документов и изображений
Вы хотите сделать цифровой формат из бумажной копии любого документа? Если вы это сделаете, технология OCR (аббревиатура от «Optical Character Recognition») – это то, что вам нужно.
Оптическое распознавание символов широко используется для цифровой репликации. В частности, технология OCR делает больше, чем просто считывает шрифты из отсканированных документов или изображений, полученных в цифровом виде – она может распознавать разрывы строк в документе, разделять столбцы, превращать изображения в графику, позволяет выполнять поиск текста по ключевым словам, разрешать редактирование документа. и т. д. Процесс довольно прост, легок в управлении и может занять всего несколько секунд.
Безбумажная концепция до OCR
Сканеры и устройства захвата изображений были введены с одной целью: превратить бумажные документы в электронные форматы файлов, которые можно хранить в электронном виде.
Основные 5 преимуществ превращения физической документации в электронные библиотеки:
- Более простой поиск данных : Информация легко доступна через компьютерные сети и / или Интернет любому человеку, имеющему надлежащие учетные данные. Больше не нужно посещать архивную комнату и тратить время на поиск конкретного бумажного документа.
- Больше места: Большой объем бумаги может занять много места, в то время как такое же количество цифровых документов может уместиться на одном жестком диске и оставить место для большего количества!
- Лучшее управление : Создание электронных папок и организация цифровых файлов намного эффективнее, чем работа с бумагой.
- Повышенная безопасность: Цифровые документы можно легко создавать резервные копии на нескольких дисках. Это делает их намного более защищенными от стихийных бедствий. Кроме того, администраторы могут зашифровать данные и запретить доступ к файлам всего несколькими щелчками мыши.
- Упрощенный просмотр и совместное использование : Электронные документы можно просматривать и передавать неограниченное количество раз, даже не покидая рабочего стола.
С появлением сканирующих устройств и концепции безбумажного офиса компании смогли сэкономить время и значительно сократить эксплуатационные расходы.
Тем не менее, вскоре возникла потребность в технологии, которая могла бы превратить эти отсканированные документы с изображениями в файлы с возможностью поиска и многократного использования в попытке сделать офисную работу еще более эффективной. Именно тогда OCR вышло на сцену и навсегда изменило способ работы с документами.
От рабочего стола к рабочему столу: как работает распознавание текста?
Для людей не имеет значения, является ли документ отсканированным файлом, файлом на основе изображения или любым другим цифровым форматом файла. Если мы видим буквы, цифры, символы и изображения, мы их понимаем.Но с компьютерами все не так просто.
По сути, технология OCR помогает компьютерам разбивать структуру документа на элементы, которые можно расшифровать. В программе OCR то, что начинается как блок текста, отделенный от других функций форматирования, становится строкой текста, затем словами и, наконец, отдельными символами. После завершения сканирования алгоритм OCR реплицирует каждый символ один за другим, а затем повторно собирает весь документ с одним важным отличием – текст теперь извлекается из изображения и его можно редактировать.
Несмотря на то, что технология OCR значительно улучшилась с момента своего появления, ошибки все еще возникают. Если исходный документ написан от руки, разорван, размазан, старый, заляпанный кофе или имеет какие-либо отметки, препятствующие легкому распознаванию содержимого, аппарату будет сложно «прочитать» и перевести его в точную электронную версию файла.
Однако расширенные программы OCR сводят к минимуму количество ошибок преобразования при каждом обновлении версии, и теперь они очень надежны и экономичны.Когда дело доходит до отсканированного текста и документации по изображениям, программное обеспечение для оптического распознавания текста обеспечивает скорость, гибкость и контроль, необходимые в любой профессиональной рабочей среде.
Преимущества технологии OCR
Если вы хотите преобразовать документ в редактируемый цифровой формат, лучше всего использовать программу оптического распознавания текста. Это быстрая и надежная альтернатива ручному вводу. Процесс оптического распознавания символов может сэкономить время и усилия при разработке цифровой копии документа.
Программное обеспечениесо встроенной технологией OCR может преобразовывать документ во множество различных электронных форматов, таких как Microsoft Word, Text (и Rich Text), Excel, и, конечно же, оно также может преобразовывать отсканированные файлы PDF.
Все документы, созданные с помощью программы OCR, можно редактировать, и вы можете изменять их содержимое по своему усмотрению. Если вы сравните стоимость OCR со стоимостью ручного ввода данных, OCR будет намного дешевле. Он уже является неотъемлемой частью офисного оборудования большинства крупных компаний и ценен в отраслях, которые интенсивно сканируют документацию, таких как юридические отделы и юридические бюро, финансовые и страховые компании, государственные учреждения, учреждения здравоохранения, отделы кадров, юриспруденция и реальная сфера деятельности. фирмы по недвижимости и т. д.
OCR улучшил все аспекты безбумажной концепции, сделав документы доступными для поиска, редактирования, доступа, перевода… Документооборот стал менее затратным по времени и ресурсам, что привело к повышению производительности офиса и снижению операционных расходов для компаний.
Преобразование OCR с помощью Able2Extract Professional
Как уже упоминалось, программы оптического распознавания текста с высокой точностью могут считывать и преобразовывать объемы отсканированных данных за очень короткий промежуток времени, создавая редактируемые документы, которые часто не содержат ошибок.Примером такого программного обеспечения является Able2Extract Professional.
Able2Extract Professional прост в использовании и может конвертировать отсканированные PDF-файлы и изображения, содержащие текст, в самые популярные электронные форматы: MS Word, Excel, PowerPoint, HTML, OpenOffice и т. Д. Он оснащен самой передовой технологией оптического распознавания символов, которая очень удобна. рекомендуется пользователям, имеющим большой объем бумажной документации, которую необходимо преобразовать в редактируемый цифровой формат.
Как распознать PDF-файл в Able2Extract
С Able2Extract преобразование отсканированных файлов на основе изображений так же просто, как преобразование исходных PDF-файлов.
Шаг 1: Откройте отсканированный PDF-файл или файл изображения, содержащий текст, нажав кнопку Открыть на главной панели инструментов.
Шаг 2: Выберите , что вы хотите преобразовать, с помощью параметров на правой панели или путем перетаскивания соответствующего содержимого (по умолчанию выбирается весь документ).
Шаг 3: Выберите один из доступных вариантов преобразования на вкладке Преобразовать на главной панели инструментов и следуйте инструкциям, чтобы завершить преобразование OCR.
Able2Extract Professional автоматически распознает ваш PDF-файл как отсканированный и по умолчанию запустит преобразование OCR, поэтому вам не нужно беспокоиться о каких-либо ненужных действиях. Ваш контент будет извлечен точно с минимальными затратами времени или потраченными впустую.
Возьмите Able2Extract Professional OCR для бесплатного тест-драйва.
OCR PDF-файлов, отсканированных изображений и т. Д. И сохранение распознанного текста как PDF или текста с возможностью поиска с помощью программы DocuFreezer OCR Converter
Почему у меня такое плохое распознавание текста? 7 шагов для повышения точности распознавания текста
Текст может быть неправильным или поврежденным после преобразования с помощью OCR.Краткий совет – убедитесь, что входные файлы имеют высокое качество – большой формат и высокое разрешение. Понимание ограничений процесса OCR может помочь вам помочь механизму OCR в получении более точных результатов. Результаты распознавания считаются хорошими, если распознанный текст имеет точность 98-99% (неверно 1-2% распознавания).
Ниже приведены несколько советов, которые помогут вам добиться лучших результатов распознавания текста.
# 1 Улучшение качества исходных изображений
Одним из наиболее важных факторов является DPI (количество точек на дюйм).Сканируйте документы с разрешением 300 и выше. Желательно сканировать с разрешением 600 точек на дюйм, чтобы получить как можно больше информации об изображении. При высоком разрешении изображения механизм OCR должен уметь распознавать высокие контрасты, границы символов, пиксельный шум и выровненные символы.
# 2 Выберите выходной формат без потерь при сканировании
Чтобы программа OCR могла более точно извлекать текст, выберите формат файла без потерь, например TIFF. Если вы сканируете в TIFF без сжатия, никакая информация об изображении (грубо говоря, пиксели) не будет потеряна.Поэтому при сканировании исходного файла выберите формат файла без потерь, например TIFF или высококачественный PDF.
# 3 Повышение контрастности изображений
Контраст и плотность – важные факторы, которые необходимо учитывать перед распознаванием текста. При использовании сканера (или редактора изображений, если нет возможности отсканировать документ еще раз), вы можете настроить гамму и контраст, чтобы получить более четкие результаты. Отрегулируйте высокий контраст так, чтобы символы были различимы.
# 4 Увеличить размер текста исходных изображений
Рекомендуемый размер текста в отсканированных документах – 10 пунктов или больше.Для достижения наилучших результатов старайтесь, чтобы высота текста была не менее 20 пикселей.
Для разумной точности существует минимальный размер текста. Учитывайте разрешение, а также размер точки – точность оптического распознавания текста падает ниже 10 пунктов, быстро ниже 8 пунктов (с разрешением 300 точек на дюйм). При 10pt и 300 DPI высота по оси x обычно составляет около 20 пикселей. Если высота x меньше 10 пикселей, у вас очень мало шансов на получение точных результатов, а буквы ниже 8 пикселей будут «удалены».
Быстрая проверка – это подсчет пикселей по x-высоте ваших символов (x-height – высота нижнего регистра).Вы можете сделать это с помощью инструмента для сохранения снимков экрана (например, Lightshot) или редактора изображений, такого как Photoshop.
# 5 Выбирайте только те языки, которые указаны в ваших документах
Если в используемом вами программном обеспечении оптического распознавания текста есть возможность выбирать между языками (например, DocuFreezer), выбирайте только те, которые есть в исходных документах. Чем меньше языков выбрано – тем лучше. Это поможет избежать неправильного толкования персонажей.
# 6 Избегайте поворота или перекоса текста и делайте строки текста горизонтальными
Когда страница отсканирована не прямо, текст может быть повернут.Если текст страницы слишком перекошен или повернут, это серьезно влияет на качество распознавания текста. Чтобы решить эту проблему, попробуйте снова отсканировать документ, чтобы линии слов были горизонтальными. Как вариант, слегка поверните цифровое изображение с помощью редактора изображений.
# 7 Убрать темные границы и другие объекты рядом с персонажами
Отсканированные страницы могут иметь темные края по краям. Их можно обрабатывать как дополнительные символы, особенно если они различаются по форме и градации.