App Store: Сканер текста – pdf converter
Сканер текста – это программа распознавания текста OCR, которая преобразует текст изображения в редактируемый цифровой текстовый контент, любой печатный текст, текст изображения, таблицы Excel, файлы PDF и т.д. могут быть отсканированы и распознаны, поддерживает пакетное сканирование, распознанный текст поддерживает перевод, редактирование, обмен и может быть экспортирован в TXT / PDF / Word / Excel и многие другие форматы. Это портативный текстовый экстрактор и инструмент управления, который может значительно повысить эффективность вашего офиса!
【 Изображение в текст 】
– Интеллектуальное распознавание OCR нескольких типов файлов: документов, изображений, рукописного текста, книг и т.д. для извлечения нужного текста
– Поддержка пакетной обработки
– Поддержка быстрого перевода результатов распознавания на другие языки
【 Распознавание таблиц Excel 】
– Поддерживает преобразование Excel в картинках в файлы Excel, интеллектуальный разбор текста таблицы, а также быстрое распознавание и генерацию таблиц Excel
【 Многоязыковое распознавание 】
– Поддержка распознавания нескольких языков: китайский, английский, японский, корейский, французский, немецкий и 20 других языков
【 Мультиформатный экспорт 】
– Экспорт в TXT / PDF / Word / Excel и другие форматы
【 Сканирование документов 】
– Сканирование удостоверений личности, банковских карт и т.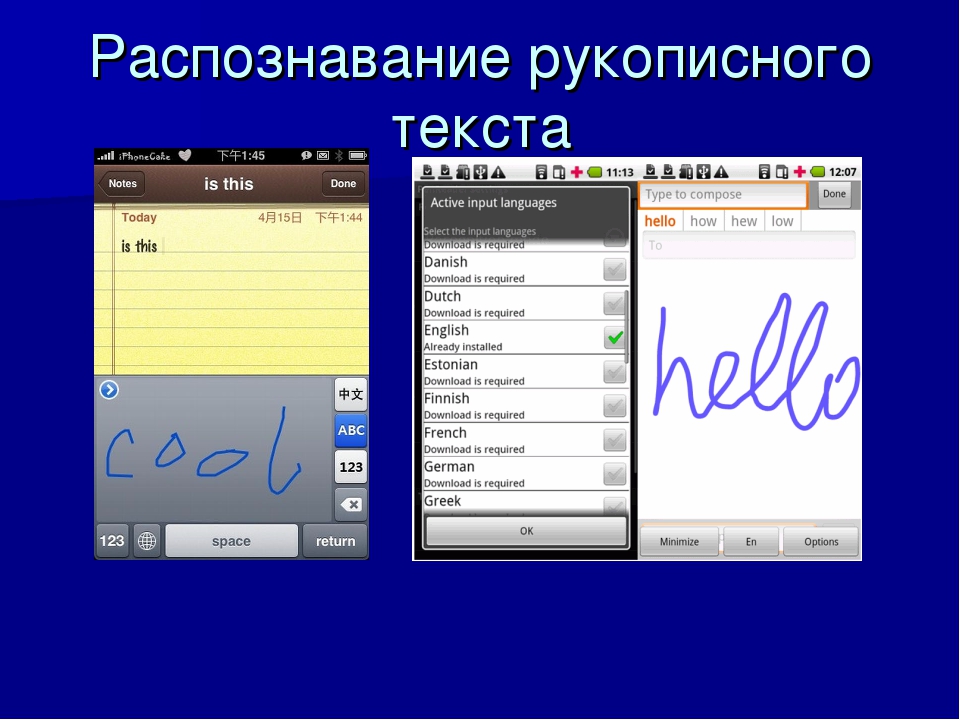 д. для создания электронных сканов высокой четкости
д. для создания электронных сканов высокой четкости
– Быстрое преобразование бумажных документов в сканы высокой четкости
— Совет по использованию —
Для обеспечения правильного результата распознавания сканов, при фотографировании, пожалуйста.
* Используйте как можно более четкое изображение
Политика конфиденциальности: http://apptermsuse.lofter.com/post/2017d158_12d72ee4f
Условия использования: http://apptermsuse.lofter.com/post/2017d158_12d72de9d
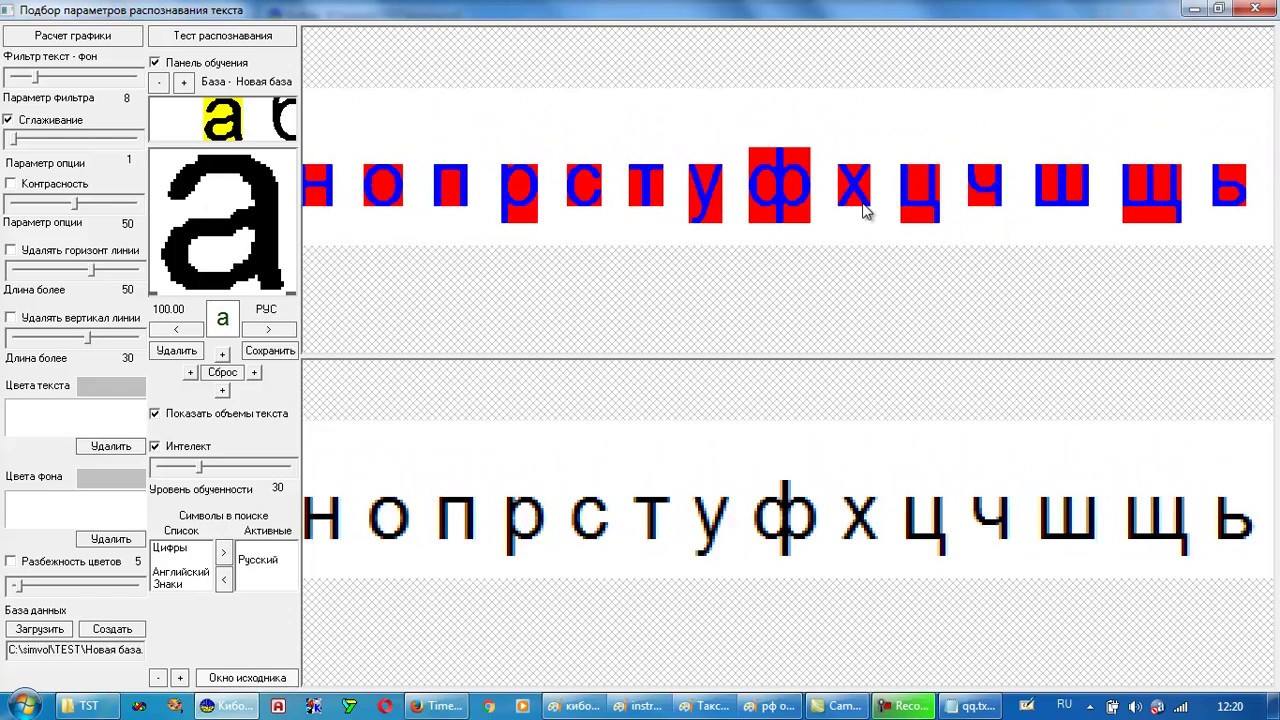
Ввод текста на iPad с помощью функции «От руки»
На поддерживаемых моделях iPad можно использовать Apple Pencil (продается отдельно) и функцию «От руки» для ввода текста. Не открывая и не используя экранную клавиатуру, можно быстро ответить на сообщение, записать напоминание и выполнить многие другие действия. Функция «От руки» преобразует рукописный текст в печатный непосредственно на iPad, поэтому конфиденциальность Ваших записей не нарушается.
Ввод текста в любом текстовое поле с помощью Apple Pencil
Пишите с помощью Apple Pencil в любом текстовом поле, а функция «От руки» может автоматически преобразовывать рукописный текст в печатный.
Функция «От руки» работает даже тогда, когда рукописный текст выходит за границы текстового поля.
Чтобы использовать быструю команду действия, коснитесь панели инструментов «От руки».
Доступные действия зависят от используемого приложения. В панели могут быть кнопки «Отменить» , «Показать клавиатуру» и другие.
Чтобы автоматически сворачивать панель инструментов во время ввода текста, коснитесь кнопки , затем включите параметр «Автоматически убирать в Dock». Чтобы отобразить всю панель инструментов, коснитесь ее свернутой версии.
Ввод текста с помощью Apple Pencil в приложении «Заметки»
Чтобы отобразить панель инструментов разметки в приложении «Заметки», коснитесь кнопки .

В панели инструментов «Разметка» коснитесь инструмента «Рукописный ввод» (слева от ручки).
Пишите с помощью Apple Pencil, и функция «От руки» автоматически преобразует рукописный текст в печатный.
Выделение и редактирование текста с помощью Apple Pencil
Во время ввода текста с помощью Apple Pencil и функции «От руки» можно выполнять следующие действия.
Удаление слова. Зачеркните его.
Вставка текста. Коснитесь области текста и удерживайте ее, затем пишите в открывшемся поле.
Соединение или разделение символов. Нарисуйте вертикальную линию между ними.
Выбор текста. Обведите текст или подчеркните его, чтобы выбрать текст и перейти к параметрам редактирования. Чтобы изменить область выделения, перетяните начало или конец выделенного текста.
Выбор слова. Дважды коснитесь слова.
Выбор абзаца.
 Трижды коснитесь слова в абзаце или перетяните Apple Pencil на абзац.
Трижды коснитесь слова в абзаце или перетяните Apple Pencil на абзац.
Прекращение преобразования рукописного текста в печатный
Откройте «Настройки» > «Apple Pencil», затем выключите функцию «От руки».
Топ-10 программ для распознавания текста в отсканированных файлах
OCR – это технология преобразования файлов, созданных на основе изображений, в редактируемый текст. К файлам, созданным на основе изображений, относятся документы, отсканированные из учебников, журналов или рукописный текст в печатный, обычно сохраняемые в формате PDF. Технология распознавания символов (OCR) позволяет извлечь текст из этих изображений и сделать его редактируемым. В этой статье мы представим 10 лучших бесплатных программ для распознавания текста, которые помогут вам с легкостью редактировать отсканированные PDF-файлы.
10 лучших бесплатных программ для распознавания текста
1. PDFelement
PDFelement обеспечивает удобную работу с отсканированными PDF-документами благодаря передовой технологии оптического распознавания символов. Эта функция позволяет распознавать текст отсканированных PDF-файлов, чтобы сделать текст и файл редактируемыми. Кроме того, с его помощью вы можете конвертировать ваши отсканированные PDF-файлы в другие редактируемые форматы, включая Excel, Word, PPT, Text и другие. Качество вашего оригинального документа будет полностью сохранено.
Эта функция позволяет распознавать текст отсканированных PDF-файлов, чтобы сделать текст и файл редактируемыми. Кроме того, с его помощью вы можете конвертировать ваши отсканированные PDF-файлы в другие редактируемые форматы, включая Excel, Word, PPT, Text и другие. Качество вашего оригинального документа будет полностью сохранено.
PDFelement оснащен мощными инструментами редактирования, которые позволяют вставлять, удалять или изменять текст, изображения и страницы. Вы также можете заполнять интерактивные и неинтерактивные формы и создавать новые формы с различными вариантами их заполнения.
Руководство:Как Скопировать Текст из Изображения
2. FreeOCR
Полностью бесплатный онлайн-инструмент для распознавания текста, который не требует регистрации или указания адреса электронной почты. Работает с различными файлами изображений, включая GIF, JPG, BMP, TIFF или PDF с многостолбцовым текстом. Распознает более 30 различных языков. Размер загрузки ограничен до 2 МБ или 5000 пикселей, можно загружать не более 10 изображений в час.
3. i2OCR
i2OCR работает со следующими типами файлов изображений: JPEG, TIF, BMP, PNG, PBM, GIF, PPM, PGM или изображения, доступные по ссылке (URL). Программа позволяет конвертировать изображения с вашего локального диска или онлайн. Без регистрации. Поддержка PDF-документов с многостолбцовым текстом и распознавание текстов на 33 языках. В отличие от FreeOCR, нет ограничений по количеству загруженных изображений.
4. Online OCR
Online OCR позволяет конвертировать фотографии и цифровые изображения в текст. Распознает тексты на 32 языках и конвертирует отсканированные PDF-файлы в Word, RTF и текстовые форматы. С помощью данной программы можно также извлекать текст из изображений в форматах JPG, JPEG, BMP, TIFF и GIF и преобразовывать его в редактируемые документы Word, TXT, PDF, Excel или HTML. Конвертирование до 15 изображений в час.
5. Free Online OCR
Free Online OCR позволяет конвертировать скриншоты, отсканированные документы, факсы и фотографии в форматы текст с возможностью поиска и редактирования, например, TXT, DOC, RTF и PDF. Программа поддерживает такие форматы, как BMP, PDF, PNG, TIFF, JPG(JPEG), и GIF.
Программа поддерживает такие форматы, как BMP, PDF, PNG, TIFF, JPG(JPEG), и GIF.
6. Cvisiontech
Cvisiontech также поддерживает одновременную загрузку нескольких файлов TIFF, PDF, BMP и JPG. Перед загрузкой необходимо убедиться, что размер любого из загруженных файлов менее 100 МБ. Программа позволяет сжимать файлы и оптимизировать их для веб-сайта.
7. SuperGeek Free Document OCR
SuperGeek Free Document OCR – удобная и мощная программа для конверирования изображений и распознавания текста (OCR), подходящая как для профессионального, так и для домашнего использования. Позволяет читать текст из JPG, JPEG, TIF, TIFF, PNG, BMP, PSD, GIF, EMF, WMF, J2K, DCX, PCX, JP2 и т.д. и конвертировать файлы данных типов в редактируемые документы MSWord и TXT всего за несколько кликов.
8. onOCR
Программа onOCR справляется с различными отсканированными PDF или файлами изображений независимо от их размера. Free OCR помогает преобразовывать нередактируемые документы в тексты с возможностью копирования и редактирования. Вы можете обрабатывать как крупные, так и мелкие изображения и преобразовывать их в редактируемый текст.
Вы можете обрабатывать как крупные, так и мелкие изображения и преобразовывать их в редактируемый текст.
9. Investintech
Able2Extract от Investintech – это инструмент для работы PDF с возможностью конвертирования отсканированных PDF в один из более чем 10 различных типов редактируемых файлов. С его помощью вы можете преобразовывать файлы практически любого типа в защищенные PDF, просматривать и редактировать PDF и преобразованные файлы, а также извлекать текст из отсканированных документов.
10. OCRgeek
OCRGeek.com позволяет вам выполнять распознавать тексты онлайн в пакетном режиме. Вы можете без проблем загружать по несколько файлов одновременно. Процесс распознавания происходит быстро и просто. Загруженные вами документы будут организованы и одновременно преобразованы в формат TXT. Форматы ввода, которые поддерживает OCRgeek: JPG, PNG, TIFF, PDF, DJVU, GIF и BMP.
Видео: 5 лучших программ для распознавания текста (OCR)
Ручная забота: роботы расшифруют документы, заполненные письменно | Статьи
Новая российская система распознавания текста способна оперативно оцифровывать документы, содержащие в себе как напечатанные, так и рукописные фрагменты. Основную работу выполняет искусственный интеллект, который в сложных случаях прибегает к помощи человека. В настоящее время новинку уже используют в одной из страховых компаний при оцифровке заполненных вручную заявлений. Заинтересовались ею также энергетики и банкиры — широкое внедрение системы позволит бизнесу сократить операционные затраты на обслуживание клиентов и исключить ошибки при работе с бумагами. В перспективе подобные алгоритмы могут найти применение и в медицинском обслуживании, что снимет значительную часть нагрузки со специалистов.
Кооперация интеллектов
Распознавание напечатанного текста сегодня не представляет проблем для современных офисных систем, однако множество документов клиенты всё еще продолжают заполнять от руки. Это вынуждает специалистов просматривать их глазами, а затем перепечатывать вручную. Избавить менеджеров от рутины должна помочь новая российская разработка, способная оцифровывать документы, заполненные по старинке.
Это вынуждает специалистов просматривать их глазами, а затем перепечатывать вручную. Избавить менеджеров от рутины должна помочь новая российская разработка, способная оцифровывать документы, заполненные по старинке.
Фото: ТАСС/Артем Геодакян
— При работе нашей системы используется сразу несколько нейронных сетей, каждая из которых выполняет свою собственную функцию на определенном этапе работы, — рассказал ведущий ИИ-разработчик компании Dbrain Владислав Заборовский. — Происходит это следующим образом:
Однако совсем без помощи человека применяемые алгоритмы пока не обходятся. Например, если искусственный интеллект хорошо справляется с текстом, который был написан от руки печатными буквами, то, для того чтобы совладать с обычным почерком, ему зачастую требуется содействие людей.
— В этом разработке помогают пользователи, зарегистрированные в сервисе «Яндекс.Толока» (проект, позволяющий людям зарабатывать, выполняя легкие задания. — «Известия»). Система в режиме реального времени высылает им задания по распознаванию отдельных фрагментов текста, о значении которых нейросетью ранее было выдано предположение, — пояснил Владислав Заборовский. — При этом система следит за этим процессом и использует полученные данные для обучения, которое позволяет ей в дальнейшем лучше выполнять работу.
По словам специалистов, к сложным кейсам по распознаванию можно отнести случаи, когда при заполнении документа происходит выход текста за края полей или если слова пишут в столбик, что может сбить машину с толку. При этом работа людей не нарушает неприкосновенность персональных данных и корпоративной информации.
Фото: ТАСС/Евгений Софронеев
— В рамках работы с Dbrain исполнители «Яндекс.Толока» распознают объекты из документов в обезличенном виде — как правило, это происходит, когда система не уверена в качестве машинного распознавания, — отметили в пресс-службе компании «Яндекс».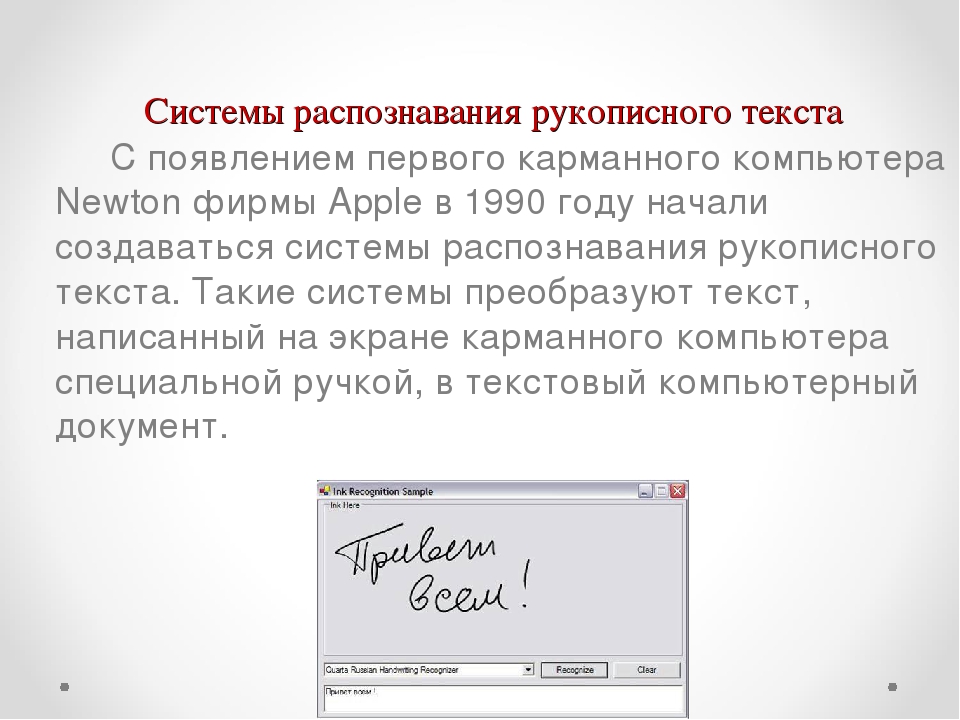 — При этом одни люди переводят изображение рукописного текста в цифровой формат, а другие проверяют их вердикты, что обеспечивает контроль качества на выходе.
— При этом одни люди переводят изображение рукописного текста в цифровой формат, а другие проверяют их вердикты, что обеспечивает контроль качества на выходе.
Сложная задача
Как показывает практика, за счет решения, соединившего работу нейросети и человека, при обработке документов удается избежать большинства опечаток и ошибок, которые могут делать работники компаний, пока еще не автоматизировавших свои бизнес-процессы.
— Заслуга разработчика в том, что в процессе обработки рукописей активно применяют нейросети, — отметил президент компании Docsvision и член Рабочей группы по развитию разработки программного обеспечения для обработки документов Минкомсвязи РФ Владимир Андреев. — При этом сочетание труда людей и работы нейросети я вижу впервые — думаю, такое решение действительно может улучшить технологии и быть полезным для бизнеса.
месте с тем, по мнению эксперта, задача распознавания рукописного текста исключительно с помощью систем искусственного интеллекта является наиболее сложной для IT-отрасли, поскольку даже нейронные сети в мозге человека далеко не всегда могут разобрать почерк другого человека, а иногда и свой собственный. Именно поэтому многие компании пока просто не берутся за разработку систем, способных выполнять такие задачи.
Именно поэтому многие компании пока просто не берутся за разработку систем, способных выполнять такие задачи.
Фото: Depositphotos
На сегодняшний день новинку уже используют в энергетике, страховании и банковской сфере. В частности, она внедрена в одной из страховых фирм для оцифровки заполненных вручную заявлений для выплаты компенсаций после автомобильных аварий. Как показала практика, среднее время, затраченное программой на обработку документов одного клиента, обычно не превышает нескольких минут. При этом от сотрудника требуется лишь отсканировать бумаги и загрузить файлы в систему. В перспективе подобные алгоритмы могут найти применение в медицинском обслуживании, что снимет значительную часть нагрузки со специалистов.
Недавно «Известия» писали о нейросети, которую научили определять COVID-19 по изображениям легких. Для этого программа анализируют оцифрованные рентген-снимки. Нейросеть составляет заключение, где указывает на наличие или отсутствие четырех характерных для коронавирусной пневмонии признаков и рассчитывает вероятность диагноза «COVID-19». Точность постановки диагноза по трем из четырех признаков доходит до 94%.
Точность постановки диагноза по трем из четырех признаков доходит до 94%.
ЧИТАЙТЕ ТАКЖЕ
Какая лучшая бесплатная программа OCR или ICR для транскрипции рукописи?
Хавьер спрашивает:
Я писатель рассказов и сказок. Я ищу бесплатную программу оптического распознавания символов (OCR) или интеллектуального распознавания символов (ICR), чтобы сканировать мои старые рукописи из изображений или фотографий, чтобы я мог преобразовать их в файлы Microsoft Word.
Существуют ли бесплатные и точные программы, способные сделать это? К сожалению, у меня нет сканера, но у меня есть доступ к цифровой камере с разрешением 20 мегапикселей.
Ответ Каннона:
Как вы уже упоминали, существует несколько видов технологий распознавания символов, которые могут автоматически преобразовывать рукописные или печатные надписи в цифровые символы. Уровень точности этих видов программного обеспечения сильно различается в разных реализациях. Некоторые конвертируют по буквам, а другие могут конвертировать целые слова. Существует три основных категории этого программного обеспечения:
Существует три основных категории этого программного обеспечения:
- Оптическое распознавание символов (OCR)
- Интеллектуальное распознавание символов (ICR)
- Интеллектуальное распознавание слов (IWR)
Оптическое распознавание символов
По правде говоря, OCR — это общий термин, и часто все методы, описанные в этой статье, называются OCR — Википедия, однако, дает OCR свою собственную классификацию, но современные реализации, как правило, объединяют несколько методов. Так что же это делает? OCR преобразует отдельные печатные или рукописные буквы в цифровые символы. Таким образом, программа просматривает документ, а затем пытается преобразовать его в простой текст, угадывая, что представляет собой каждый символ.
Программное обеспечение не идеально. Программное обеспечение OCR может неправильно истолковывать отдельные символы с похожим внешним видом, что приводит к ошибочным словам и неточным выводам. В большинстве случаев пользователи могут копировать текст, сгенерированный программой OCR, в текстовый процессор и автоматически исправлять орфографические ошибки. Часто ошибки будут отображаться в виде похожих символов. Например, буква «d» может быть представлена как «cl».
Часто ошибки будут отображаться в виде похожих символов. Например, буква «d» может быть представлена как «cl».
Но когда дело доходит до рукописных текстов, распознавание текста не очень хорошо. По крайней мере, большинство бесплатных реализаций трагически плохи. Есть некоторые коммерческие продукты, которые действительно могут записать рукописную транскрипцию, но их цена делает их полностью недоступными для широкой публики. Например, есть программное обеспечение Lexmark для чтения оптических дисков ReadSoft. Это корпоративное программное обеспечение стоит тысячи долларов.
Интеллектуальное распознавание символов
ICR — это подмножество OCR, которое специализируется на преобразовании рукописного текста в отдельные цифровые символы. Учитывая, что ваши заметки и рукописи написаны от руки, наиболее полезной является программа ICR. Однако я не уверен, насколько точно они могут конвертировать тексты, написанные на иностранных языках, таких как испанский. Как и в случае с OCR, пользователи могут улучшить качество выводимых текстов, скопировав их в текстовый процессор с включенной корректировкой орфографии, а затем отредактировав вручную.
Интеллектуальное распознавание слов
Последней эволюцией OCR и ICR является программное обеспечение Intelligent Word Recognition. Вместо того, чтобы распознавать отдельные символы, он пытается перевести все рукописные слова. Как и OCR и ICR, интеллектуальное распознавание слов часто неправильно переводит слова и требует, чтобы пользователь вручную исправлял любые допущенные ошибки.
Что такое лучшее бесплатное программное обеспечение для распознавания текста?
Тессеракт
Есть много доступных вариантов. Тессеракт, вероятно, лучшее программное обеспечение для оптического распознавания текста с открытым исходным кодом. Насколько мне известно, он смотрит только на отдельных персонажей, а не на целые слова.
Потому что вы используете Microsoft Word (который имеет лучшую, наиболее настраиваемую проверку орфографии
в бизнесе), вы можете просто скопировать весь текст в Word, а затем запустить проверку орфографии, чтобы убрать орфографические ошибки.
Тессеракт на самом деле является механизмом OCR, который запускается из командной строки. Если вы не готовы справиться с трудностями владения инструментом командной строки, вы, вероятно, захотите установить что-то более удобное для пользователя. Существует загружаемый «интерфейс» (или графический пользовательский интерфейс), который позволяет использовать Tesseract в качестве инструмента перетаскивания: PDF OCR X. Сначала установите пакет программного обеспечения, а затем запустите его. Вы увидите окно:
Затем вы просто перетащите файл изображения в окно. Как только изображение загрузится, запустите программу транскрипции OCR. Это может занять минуту или около того.
К сожалению, он оказался совершенно неадекватным для обработки вашего текста. Вот как это выглядит после извлечения текста из документа:
Microsoft OneNote
Поскольку, похоже, вы уже используете Microsoft Office, возможно, лучшим вариантом также является Microsoft. Я предполагаю, что у вас есть копия Microsoft Office, в которую входит OneNote. Это оснащено довольно продвинутой технологией OCR.
Кроме того, как на iOS, так и на Android имеется также совершенно бесплатный объектив Microsoft Office, который может конвертировать JPEG (и другие форматы изображений) непосредственно в текст. Что делает мобильные версии такими замечательными, так это то, что вы можете снимать изображения, загружать их в систему облачных вычислений Microsoft, а затем запускать извлечение текста из OneNote на рабочем столе.
Процесс довольно прост. Сначала сфотографируй свой текст. Если вы решили использовать приложение OneNote, вам нужно всего лишь сохранить файл в своей учетной записи OneDrive. В противном случае перенесите изображение на свой компьютер и перетащите на OneNote.
Затем щелкните правой кнопкой мыши на изображение и выберите копия Текст с картинки из контекстного меню.
Затем щелкните правой кнопкой мыши пустую часть OneNote (или в приложении для чтения текста) и вставьте текст в. Вывод текста из вашего документа выглядит следующим образом:
К сожалению, результаты OneNote не дают ничего хорошего, создавая полную чушь. Это может быть вызвано сочетанием таких факторов, как искаженное изображение или запись, которые не выполняются по прямой линии, или просто потому, что программное обеспечение недостаточно хорошее.
Это может быть вызвано сочетанием таких факторов, как искаженное изображение или запись, которые не выполняются по прямой линии, или просто потому, что программное обеспечение недостаточно хорошее.
Google Keep
На данный момент лучшее решение для распознавания рукописных документов относится к машинному обучению: в частности, глубокому обучению. Глубокое обучение — это сложный метод обучения компьютера выполнению задач, в которых раньше только человек преуспел, таких как распознавание лиц (Picasa распознает лица
, хочешь верь, хочешь нет). Google недавно приобрел DeepMind, который разрабатывает технологию глубокого обучения
, Это приобретение ключа имело большой эффект: Microsoft проигрывает Google в OCR
, Сейчас Google предлагает один из самых продвинутых (и бесплатных) методов: Google Keep.
Google Keep (который мы впервые рассмотрели в 2013 году
) также предлагает мобильную версию своего приложения для Android. Как и в OneNote, вы можете снимать изображения и передавать их прямо в облако Google. Просто перетащите изображение в окно Google Keep. Затем нажмите на кнопку меню (три вертикальные точки) и выберите Захватить текст изображения из контекстного меню.
Просто перетащите изображение в окно Google Keep. Затем нажмите на кнопку меню (три вертикальные точки) и выберите Захватить текст изображения из контекстного меню.
Вот как это выглядит после извлечения текста:
Google Keep Wins
Как видите, Google Keep доминирует в конкурентной борьбе. Результаты могут быть еще более улучшены с помощью инструмента для редактирования изображений
увеличить контраст и выровнять изображение.
Надеюсь, эти варианты помогут. Если вам нужны дополнительные параметры распознавания текста, ознакомьтесь с 5 лучшими инструментами распознавания текста
, для дополнительной информации.
Распознавание рукописного текста упростит работу государства с гражданами
Цифровые технологии улучшают многие процессы как в государственном, так и в корпоративном секторах, однако остаются сферы, процессы в которых еще не автоматизированы. Например, распознавание рукописных текстов. О том, в каких сферах может применяться цифровой анализ текстовых данных, и какие технологии для этого уже существуют, говорили на круглом столе, организованном Аналитическим центром.
«Мы видим запросы на распознавание рукописных текстов и в регионах, и в федеральных органах исполнительной власти. Проводя этот круглый стол, мы хотим выделить те бизнес-цели и задачи, которые можно решить совместными усилиями заказчиков, в лице ФОИВов, и бизнеса», – пояснил руководитель Аналитического управления Департамента управления данными АЦ Андрей Чукарин.
Руководитель лаборатории данных Департамента управления данными АЦ Сюзана Тевдорадзе добавила, что иногда при обработке данных часть рукописной информации не попадает в анализ. «Перед нами стоит задача по работе с обращениями граждан, которые приходят в органы исполнительной власти. Это неструктурированные тексты, написанные разными почерками, с неизвестным количеством опечаток и ошибок. Это может быть и электронный документ, и бумажный. Нам надо понять, какие существуют технологии для анализа таких документов», – пояснила эксперт.
Рынок распознавания рукописных текстов начал развиваться около 30 лет назад, когда появилась потребность в расшифровке отсканированных документов, рассказал генеральный директор компании «Parascript» Александр Филатов. Затем, по его словам, стали востребованы технологии верификации подписей, распознавания рукописных адресов и банковских чеков. «Сейчас показатель распознавания рукописных адресов – 96%. Результат зависит от того, насколько компания в нем заинтересована, потому что им надо накопить базу референсных данных», – пояснил Филатов. Он добавил, что одним из самых сложных направлений работы является обработка естественного языка. «Когда вы обрабатываете структурированные документы, у вас есть определенные шаблоны, которые помогают понять смысл написанного, а когда текст написан в свободной форме, определить, о чем он, – более сложная настройка», – объяснил эксперт.
Затем, по его словам, стали востребованы технологии верификации подписей, распознавания рукописных адресов и банковских чеков. «Сейчас показатель распознавания рукописных адресов – 96%. Результат зависит от того, насколько компания в нем заинтересована, потому что им надо накопить базу референсных данных», – пояснил Филатов. Он добавил, что одним из самых сложных направлений работы является обработка естественного языка. «Когда вы обрабатываете структурированные документы, у вас есть определенные шаблоны, которые помогают понять смысл написанного, а когда текст написан в свободной форме, определить, о чем он, – более сложная настройка», – объяснил эксперт.
Распознавание рукописного текста, в том числе детского почерка, может быть востребовано в системе образования, добавил исполнительный директор по исследованию данных Sber AI Денис Димитров. «Это не только упростит жизнь учителям, но в перспективе сделает возможным автоматическую проверку домашних работ», – пояснил Димитров.
Именно в этом направлении сейчас работает компания «Dbrain», рассказал ее генеральный директор Алексей Хахунов. «В год в России генерируется около 1 млрд рукописных школьных работ. На их проверку уходит почти 40% рабочего времени учителя. Мы хотим сделать так, чтобы учителям вообще не пришлось проверять работы школьников. Мы сделали систему, которая умеет распознавать 91% текста. ИИ учился на тетрадях школьников 5-11 классов», – отметил Хахунов. Он добавил, что также сейчас развиваются технологии, позволяющие распознавать рукописную часть ЕГЭ, автоматизировать ввод данных из документов физических лиц и анализировать почерк исторических деятелей.
«В год в России генерируется около 1 млрд рукописных школьных работ. На их проверку уходит почти 40% рабочего времени учителя. Мы хотим сделать так, чтобы учителям вообще не пришлось проверять работы школьников. Мы сделали систему, которая умеет распознавать 91% текста. ИИ учился на тетрадях школьников 5-11 классов», – отметил Хахунов. Он добавил, что также сейчас развиваются технологии, позволяющие распознавать рукописную часть ЕГЭ, автоматизировать ввод данных из документов физических лиц и анализировать почерк исторических деятелей.
Участники круглого стола отметили, что распознавание рукописного текста также может быть востребовано для анализа юридических документов и судебных протоколов.
Parascript ICR and Handwriting Recognition PageVolume (лицензия Click, 1 time), Up to 120000
Программное обеспечение Parascript FormXtra Capture – комплексное решение для распознавания документов. Решение предназначено для обработки больших объемов сложных документов, имеет встроенный распознаватель банковских чеков и позволяет пользователю индивидуально настроить правила обработки результатов. FormXtra Capture имеет встроенную систему интерактивного тестирования распознавания с вычислением процента ошибок для отдельных полей и форм целиком. С помощью этого продукта компании из самых разнообразных областей деятельности (страховые, финансовые, торговые компании, банки) могут осуществить автоматизацию полного цикла обработки данных, получив возможность контролировать процессы распознавания и ввода данных.
Решение предназначено для обработки больших объемов сложных документов, имеет встроенный распознаватель банковских чеков и позволяет пользователю индивидуально настроить правила обработки результатов. FormXtra Capture имеет встроенную систему интерактивного тестирования распознавания с вычислением процента ошибок для отдельных полей и форм целиком. С помощью этого продукта компании из самых разнообразных областей деятельности (страховые, финансовые, торговые компании, банки) могут осуществить автоматизацию полного цикла обработки данных, получив возможность контролировать процессы распознавания и ввода данных.
FormXtra Capture способствует поддержанию уровня безопасности, предоставляя развитый инструмент для разграничения прав доступа. Масштабируемая модульная архитектура и обширная функциональность позволяют встроить FormXtra Capture в уже работающую систему обработки данных, приспособить продукт к нуждам конкретного вида бизнеса, не тратя существенных дополнительных средств.
Расширенная функциональность в обработке документов любого типа
FormXtra Capture идентифицирует тип документа, используя при классификации усовершенствованные, гибкие критерии, а не только жестко фиксированные шаблоны, предопределяющие размеры и вид того или иного элемента документа (таблицы, «шапки» или другие специфические части документа).
Распознавание любых типов данных
Благодаря использованию технологий оптического посимвольного распознавания (OCR) и интеллектуального распознавания (ICR), FormXtra Capture читает практически все типы данных: печатный текст, рукопечатный текст (как заключенный, так и не заключенный в рамки), слитный рукописный текст (написанный в свободной, естественной манере), 1D/2D штрихкоды, метки
(OMR).
Смешанный сбор данных со структурированных и полуструктурированных документов
Программа может находить и обрабатывать как фиксированные поля (местоположение которых на форме фиксировано), так и динамические поля (местоположение которых заранее не известно; известно лишь, что поле должно присутствовать на одной из страниц документа определенного типа). Такая возможность увеличивает гибкость обработки больших объемов документации и сокращает количество классов документов, которые необходимо описать и обрабатывать отдельно.
Такая возможность увеличивает гибкость обработки больших объемов документации и сокращает количество классов документов, которые необходимо описать и обрабатывать отдельно.
Обнаружение и обработка полей любых типов в любом месте документа
Обрабатывает структурированные и полуструктурированные документы, а также формы, которые не соответствуют предварительно заданному шаблону, например, уменьшенные в размере факсы и таблицы. FormXtra Capture позволяет описывать сложные схемы взаимного расположения разных полей в документе, поля сложной внутренней структуры.
Механизмы для обеспечения высокой защищенности обработки конфиденциальной информации
FormXtra Capture предоставляет развитый инструмент для описания сложных схем валидации и кроссвалидации данных – от задания простейших правил (проверка попадания значения поля в заданный диапазон), до сложных сценариев, предписывающих двойную слепую обработку поля с аудитом расхождений и исправлением ошибок. При этом, в целях соблюдения конфиденциальности (например, при обработке персональных данных) есть возможность показывать аудитору не всю страницу (или документ), а только лишь участок документа, соответствующий одному полю.
При этом, в целях соблюдения конфиденциальности (например, при обработке персональных данных) есть возможность показывать аудитору не всю страницу (или документ), а только лишь участок документа, соответствующий одному полю.
Обработка входящей почты
FormXtra Capture позволяет обрабатывать входящую почту и ее содержимое, что позволяет находить адреса на конверте, либо в теле документа, чтобы использовать эти данные для переадресации.
Обработка записей о платежах и денежных переводах
Решение позволяет воспользоваться высококачественными механизмами распознавания чеков,
созданными компанией Parascript для специфических банковский приложений, и использовать их для повышения точности обработки форм.
Модуль Parascript Signature Verification позволяет автоматически проверить подлинность подписи как в цифровом формате, так и на бумажном документе. Parascript Signature Verification обеспечивает быстрое заверение подлинности подписи или выявление подделки через сопоставление с оригиналом. Модуль удаляет все нежелательные элементы, окружающие подпись, чтобы выявить чистое изображение, при этом можно сопоставлять подписи на любом типе документа в любом месте документа, используя структурированные зоны, ключевые слова и т. д.
Модуль удаляет все нежелательные элементы, окружающие подпись, чтобы выявить чистое изображение, при этом можно сопоставлять подписи на любом типе документа в любом месте документа, используя структурированные зоны, ключевые слова и т. д.
Модуль ICR and Handwriting Recognition позволяет распознавать различные виды ручного письма в любом документе или в его части, написанные как печатными буквами, так и курсивом.
✅ Купите Parascript ICR and Handwriting Recognition PageVolume (лицензия Click, 1 time), Up to 120000 на официальном сайте
✅ Лицензия Parascript ICR and Handwriting Recognition PageVolume (лицензия Click, 1 time), Up to 120000 по выгодной цене
✅ Parascript ICR and Handwriting Recognition PageVolume (лицензия Click, 1 time), Up to 120000, лицензионное программное обеспечение купите в Москве и других городах России
Предлагаем также:Распознавание рукописного текста | Полностью доступные для поиска рукописные рукописи
Распознавание рукописного текста | Полностью доступные для поиска рукописные рукописи Искусственный интеллект меняет возможность обнаружения рукописных рукописей.
Распознавание рукописного текста изменит науку и типы вопросов, которые могут задавать исследователи. У технологии огромный потенциал.
Д-р Патрик Сперо , директор библиотеки Американского философского общества
Adam Matthew Digital – первое издательство, использующее искусственный интеллект для распознавания рукописного текста (HTR) для своих коллекций рукописных рукописей.
Приложение HTR использует последние достижения в области нейронных сетей и использует сложные алгоритмы для определения вероятных комбинаций символов для поиска искомого термина.
Это позволяет идентифицировать соответствующий рукописный текст на уровне документа с автоматическим поиском, развернутым с помощью метаданных, что позволяет пользователям легко перемещаться между выделенными результатами поиска.
Распознавание рукописного текста (HTR) теперь улучшено, чтобы обеспечить редактируемые, полностью доступные для поиска транскрипции рукописных ресурсов, созданные на платформе одним щелчком мыши.
HTR отображаются рядом с исходным активом и предоставляют вашим пользователям дополнительный источник данных для поиска, расширяя возможности обнаружения ваших коллекций и позволяя пользователям исследовать их гораздо глубже, добавляя глубину и масштаб своим исследованиям.
Узнайте больше о HTR Transcriptions на quartexcollections.com
Теперь доступно в:
Узнайте больше о распознавании рукописного текста:
Влияние распознавания рукописного текста (HTR)
Заставьте распознавание рукописного текста работать на вас
Для того, чтобы предоставить вам лучший онлайн-опыт, этот веб-сайт использует файлы cookie.Удалить куки
Этот сайт использует файлы cookie для хранения информации на вашем компьютере.
Некоторые из этих файлов cookie необходимы для работы нашего сайта, а другие помогают нам совершенствоваться, давая нам некоторое представление о том, как используется сайт. Дальнейшая информация
Дальнейшая информация
Я согласен – скрыть это сообщение
Этот сайт использует файлы cookie для хранения информации на вашем компьютере.
Некоторые из этих файлов cookie необходимы для работы нашего сайта, а другие помогают нам совершенствоваться, давая нам некоторое представление о том, как используется сайт.
Эти файлы cookie устанавливаются, когда вы отправляете форму, входите в систему или взаимодействуете с сайтом, делая что-то, что выходит за рамки нажатия на несколько простых ссылок.
Мы также используем некоторые необязательные файлы cookie для анонимного отслеживания посетителей или улучшения вашего опыта на этом сайте. Если вас это не устраивает, мы не будем устанавливать эти файлы cookie, но некоторые полезные функции на сайте могут быть недоступны.
Чтобы контролировать сторонние файлы cookie, вы также можете изменить настройки своего браузера.
Используя наш сайт, вы принимаете условия нашей Политики конфиденциальности.
Почему распознавание рукописного ввода до сих пор было таким сложным
В чем отличие решения для распознавания рукописного ввода на основе искусственного интеллекта от Automation Hero.
09 марта 2020 г., автор Jess McCuan
Представьте, что у вас довольно (кхм) пушистая работа: вы обработчик претензий в компании по страхованию домашних животных, которая занимается страхованием собак, кошек, экзотических птиц и других существ. Ваш отдел может просматривать от 400 до 500 документов с претензиями в день, в которых подробно описываются такие процедуры, как рентген собак, прививки и всевозможные обследования и рецепты.
В то время как пациенты могут быть приятными, некоторые аспекты работы становятся более чем неприятными. Если вы считаете, что почерк обычного врача неряшлив, попробуйте интерпретировать заметки ветеринаров, которые охватывают многие виды и могут быть либо полностью написаны от руки, либо наполовину распечатаны на компьютере, а наполовину написаны по широкому спектру клинических форм. Иногда ветеринары подписывают свои имена, в то время как другие сотрудники ставят свои подписи, используя старомодную бумагу и чернила. Даже наметанный глаз может спутать такую фразу, как «очевидные поражения на лапах», с «аберрантными поражениями на лапах», которые имеют совершенно разные медицинские значения.Страховщики домашних животных поручают десяткам сотрудников, включая специализированных ветеринарных медсестер, интерпретировать такие записи. В конце концов, эти сотрудники тратят сотни часов на утомительную работу.
Иногда ветеринары подписывают свои имена, в то время как другие сотрудники ставят свои подписи, используя старомодную бумагу и чернила. Даже наметанный глаз может спутать такую фразу, как «очевидные поражения на лапах», с «аберрантными поражениями на лапах», которые имеют совершенно разные медицинские значения.Страховщики домашних животных поручают десяткам сотрудников, включая специализированных ветеринарных медсестер, интерпретировать такие записи. В конце концов, эти сотрудники тратят сотни часов на утомительную работу.
Возможность распознавания рукописного текста
Чтобы помочь в борьбе с этой проблемой, появилось множество компаний, занимающихся распознаванием рукописного ввода, оптическим распознаванием символов, которое преобразует изображения рукописного текста в машинно-кодированный текст для интерпретации и ввода данных. идти более плавно.Более старые фирмы, такие как ABBYY и IRIS, начали заниматься распознаванием текста в 80-х, и теперь все, от IBM до Adobe, вместе с более мелкими стартапами, набрасываются на рынок, который к 2025 году достигнет 13 миллиардов долларов.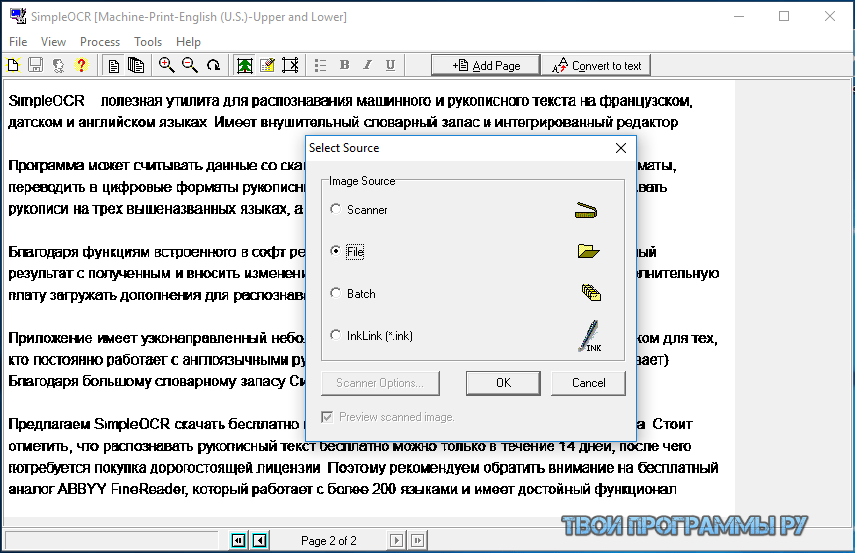
Проблема в том, что даже после десятилетия исследований, большинству готовых программ для распознавания рукописного ввода не хватает сложности, что может привести к низким показателям точности. Особенно когда дело доходит до интерпретации сложных коллажей информации, таких как любимые формы выше, где структурированные данные располагаются бок о бок с полуструктурированными и неструктурированными данными, а необычные красочные слова втиснуты в печатные формы со слишком маленькими рамками.
OCR, старомодный способ
Это потому, что, хотя программное обеспечение OCR улучшилось, в основном оно работало на одних и тех же принципах на протяжении десятилетий. Программное обеспечение сканирует документ, удаляя артефакты и шумы, такие как пыль или случайные следы. Он увеличивает буквы, цифры и другие символы, которые необходимо перевести. Затем большинство программ буквально «выпрямляет» символы и подготавливает их к интерпретации. Он оценивает каждый — это «p» или «q»? — сравнение его с другими p и q в сохраненном каталоге. Затем он анализирует целые слова. Это «цветок» или «цветочек»? Программа выбирает «цветок», так как это слово существует в сохраненном словаре.
Затем он анализирует целые слова. Это «цветок» или «цветочек»? Программа выбирает «цветок», так как это слово существует в сохраненном словаре.
Решение OCR от Automation Hero работает совершенно по-другому. Самая большая разница заключается в следующем: вместо использования системы, похожей на гигантский словарь, которая ищет и сравнивает слова со всеми известными словами в мире, OCR Automation Hero использует только ваш набор слов.
Вместо использования системы, похожей на гигантский словарь, которая ищет и сравнивает слова со всеми известными словами в мире, OCR использует только ваш набор слов.
Для предметной области, во главе с ИИ
Наше OCR на основе ИИ начинается с использования набора данных для обучения, который специфичен для предметной области, т. е. уникален для одной конкретной отрасли или компании. Мы также можем использовать практический набор данных прошлых документов вашей компании. Это означает, что набор практических данных является узкоспециализированным, что приводит к гораздо более точной интерпретации отраслевых слов и их контекста. Поскольку наше решение OCR экономит свои вычислительные мощности для этой более узкой области, оно гораздо лучше оснащено для точной интерпретации проблемных случаев и необычно грязного почерка.
Поскольку наше решение OCR экономит свои вычислительные мощности для этой более узкой области, оно гораздо лучше оснащено для точной интерпретации проблемных случаев и необычно грязного почерка.
Вот как это работает. Допустим, вы страховая компания. Вы регулярно обрабатываете документы, связанные с понятием «квадратные метры». Но архитекторы и инспекторы по строительству торопливо пишут эти слова, и ваше традиционное программное обеспечение оптического распознавания символов с трудом их распознает, а это означает, что ввод данных о площади в квадратных футах по-прежнему является утомительным ручным процессом.
Наше решение для распознавания рукописного ввода использует практический набор данных, специфичный для предметной области, то есть речь идет только о недвижимости и имуществе.Таким образом, по сравнению с традиционным программным обеспечением для распознавания рукописного ввода наше OCR лучше справляется с распознаванием вариаций «квадратных метров» и способов, которыми архитекторы и строительные инспекторы могут это отметить. Он будет знать, что «квадратные метры», «квадратные футы» и «квадратные футы» означают, например, «квадратные метры». Или ИИ может со временем узнать, что некоторые буквы часто транспонируются или сжимаются аналогичным образом при написании от руки.
Он будет знать, что «квадратные метры», «квадратные футы» и «квадратные футы» означают, например, «квадратные метры». Или ИИ может со временем узнать, что некоторые буквы часто транспонируются или сжимаются аналогичным образом при написании от руки.
По сравнению с традиционным оптическим распознаванием текста наша платформа лучше распознает варианты «квадратных метров» и то, как архитекторы и строительные инспекторы могут это отметить.Например, он будет знать, что «квадратные метры», «квадратные футы» и «квадратные футы» означают «квадратные метры». Это означает, что одно поле, поле или физическая часть страницы может быть самой сложной. Затем мы применяем наш собственный подход OCR к этому конкретному полю, снова уменьшая вероятность ложных срабатываний. В долгосрочной перспективе это означает, что больше информации правильно вводится в базу данных вашей компании без ручной проверки.
Меньше теряется при переводе
Этот подход применим и к материалам на иностранных языках.
Допустим, ваша компания регулярно получает контракты на английском языке с небольшим количеством голландского языка. Вместо использования программного обеспечения, которое сравнивает все языки мира, наш инструмент OCR обучается на наборе данных, который включает только английский и голландский языки. Это было бы сразу лучше, чем традиционное программное обеспечение для распознавания рукописного ввода, в выявлении проблемных случаев, странных обозначений или идиом на двух языках.
Если вы уже используете традиционное программное обеспечение для распознавания текста и хотите сохранить его, не проблема. Платформа Automation Hero может интегрировать существующее программное обеспечение OCR, либо используя переведенную информацию в качестве источника данных, либо увеличивая масштаб в сложных случаях. Поскольку наши алгоритмы быстро учатся обрабатывать необычные слова и пограничные случаи, они могут быстро обрабатывать документы, которые ранее вызывали ошибки.
Рукописный текст: все еще висит на
В мире, который стал цифровым, все еще есть много рукописного материала.
В Соединенных Штатах, стране с зияющим цифровым разрывом, почерк по-прежнему правит в некоторых регионах. Использование мобильных технологий в сельской местности растет, а использование ноутбуков и настольных компьютеров — нет. Это означает, что компании, требующие от клиентов заполнения более длинных форм, такие как страховые компании и банки, должны вводить огромные стопки рукописных документов. Некоторые отрасли, независимо от того, где они расположены, также просто медленно оцифровывались. Возьмем, к примеру, строительство, которое наводнено рукописными отчетами по оборудованию.Или ветеринарные кабинеты, которые могут быть заполнены грязными рукописными рецептами для щенков на долгие годы.
Машины чтения архива: программа распознавания рукописного текста
Любой исследователь, который использовал онлайн-архивы газет, репозитории оцифрованных книг или даже такие ресурсы, как «Документы кабинета министров онлайн» Национального архива, признает революцию, созданную технологией оптического распознавания символов (OCR).
Именно эта технология позволяет нам искать не только название или дату, но и слова, написанные внутри книги, газеты или архивного документа.OCR изменил способ проведения исследований многими учеными и открыл огромные области научных исследований, которые ранее были невообразимы. Для тех из нас, кто работает с архивными коллекциями, эта революция всегда сопровождалась одной оговоркой: OCR не работает с рукописными документами. Именно по этой причине мы так взволнованы новой платформой под названием Transkribus, разработанной проектом READ, финансируемым ЕС. Это впервые дает возможность использовать компьютеры для «чтения» рукописных документов.
PROB 11/2105/1 – Вы можете прочитать это завещание от 1849 года?
Технология, лежащая в основе Transkribus, все еще очень новая, и Национальный архив запустил пилотный проект, чтобы проверить возможность использования этого типа программного обеспечения для распознавания рукописного текста (HTR). Для этого проекта мы решили сосредоточиться на нашей коллекции завещаний PROB 11.
Причины этого в значительной степени были обусловлены технологиями; эти тома содержат копии завещаний клерков, поэтому почерк очень однороден, и они являются юридическими документами и, следовательно, имеют структурированные языковые модели.Они также представляют собой необыкновенную коллекцию документов, содержащих сведения о людях, местах, материальных благах, социальных и экономических связях и других факторах во времени и пространстве. Однако, как скажет вам любой, кто пользовался этими документами, их не так-то просто читать — по этой причине они оказались отличным тестом для этой новой технологии.
Программное обеспечение Transkribus работает путем обучения модели точной транскрипции документов. Исследователи загружают изображения некоторых своих документов, а затем сопоставляют правильную транскрипцию с текстом на изображениях.Это позволяет модели изучить стиль движений рук и языка. Эти обучающие данные называются «наземной истиной». Затем обученную модель можно использовать для автоматической расшифровки похожих типов документов с точки зрения языка, почерка и т.
д. Как и следовало ожидать, чем больше обучающих данных вы вводите, тем лучших результатов вы можете добиться от своей модели.
Сегментация — добавление текстовых областей и базовых линий
Первым этапом процесса HTR является загрузка изображений ваших документов на платформу, а затем выполнение задачи, называемой сегментацией.Это влечет за собой определение «текстовых областей» и строк текста. По сути, это говорит программе, где искать текст. Этот процесс в значительной степени автоматизирован, но иногда необходимо проверять и корректировать результаты. Как только это будет завершено, вы можете либо загрузить свои тренировочные данные, либо, когда у вас есть модель, запустить программное обеспечение HTR для автоматической транскрипции.
Добавление транскрипций «основной правды»
Мы начали экспериментировать с программным обеспечением некоторое время назад и получили хорошие результаты от модели, обученной на относительно небольшом наборе обучающих данных (примерно 15 000 слов).
Точность транскрипции OCR и HTR измеряется с точки зрения частоты ошибок в словах (WER) и частоты ошибок в символах (CER). Наша первая модель достигла WER 39% и CER 21%. Воодушевленные этими цифрами, мы подготовили еще несколько обучающих данных и разработали новую модель, основанную примерно на 37 000 слов. К счастью, это показало значительный шаг вперед в точности, с WER 28% и CER 14%.
Сравнение правильного текста с автоматически созданной транскрипцией
Это был хороший результат, но ясно, что более четверти всех слов были неправильными, а значит, еще многое предстоит сделать.Проблема заключалась в том, что расшифровка большого количества этих завещаний — сложная и трудоемкая операция. Поэтому мы обратились к нашему сообществу онлайн-добровольцев, чтобы помочь разработать больший набор обучающих данных. Благодаря потрясающей работе ряда преданных делу людей мы быстро накопили дополнительные 60 000 слов транскрипции, которые в настоящее время используются для обучения новой и улучшенной модели.
Мы возлагаем большие надежды на то, чего сможет достичь эта новая модель, но я думаю, будет справедливо сказать, что пройдет некоторое время, прежде чем мы сможем полагаться исключительно на компьютеры, чтобы читать все эти хитрые рукописные документы для нас.Между тем, этот тип технологии предлагает другие потенциальные возможности, прежде всего с точки зрения поиска по ключевым словам, что может оказать более глубокое влияние на архивные коллекции в краткосрочной перспективе. Проще говоря, вы можете использовать этот тип технологии для поиска рукописных документов, даже если уровень точности недостаточно хорош для создания транскрипции. Это связано с тем, что транскрипция может показать только одну возможность для слова на странице, тогда как само программное обеспечение предлагает несколько вариантов для каждого слова.Используя умные инструменты, вы можете искать эти несколько вариантов с гораздо большей вероятностью найти правильное слово.
Этот тип технологии может революционизировать способы работы исследователей с архивными коллекциями, и мы очень рады экспериментировать с этим.
Однако эта работа возможна только благодаря приверженности и самоотверженности наших добровольцев, которые проделали большую часть основной работы с точки зрения транскрипции. Это еще раз подчеркивает взаимосвязь между захватывающими новыми цифровыми технологиями и более традиционной архивной практикой.
Мы продолжаем эту работу, используя HTR, и скоро сообщим о прогрессе с нашей новой моделью.
Извлечение рукописного текста из отсканированных PDF-файлов и изображений
Механизмы оптического распознавания символов (OCR) в первую очередь ориентированы на машинный печатный текст и могут давать низкую точность для рукописного текста. Интеллектуальное распознавание символов (ICR) — это усовершенствованная система распознавания, которая используется для распознавания рукописного текста.Это позволяет автоматически преобразовывать текст изображения в буквенные коды, которые можно использовать в компьютерах и приложениях для обработки текста.
Хотя многие процессы связаны с компьютерными операциями и реализованы в цифровой среде, бумага по-прежнему широко используется в большинстве основных бизнес-процессов, таких как выдача ипотечных кредитов, выполнение заказов, контракты и другие документы, которые обычно требуют рукописного ввода и подписи.
В настоящее время оцифровка бумажных документов играет важную роль, и выбор правильного программного обеспечения для сбора данных имеет решающее значение, поскольку распознавание рукописного ввода, в отличие от распознавания печатного текста, является более сложной задачей, которая обычно включает продвинутые алгоритмы глубокого обучения.
AlgoDocs: распознаватель рукописного ввода с глубоким обучением
AlgoDocs способен с высокой точностью преобразовывать рукописный текст в машинный печатный текст.
С ICR от AlgoDocs вы можете автоматизировать рабочий процесс обработки документов и избавиться от ручного ввода данных. Отсканируйте бумажные документы с рукописным текстом и позвольте AlgoDocs автоматически извлекать данные и преобразовывать их в Excel или JSON.
Рассмотрим следующую часть отсканированного документа, которая содержит таблицу из двух столбцов, заполненных рукописными цифрами.
Если вы загрузите это изображение в свою учетную запись на AlgoDocs, вы увидите следующий вывод со 100% точностью.AlgoDocs использует передовые механизмы ICR, обученные алгоритмам искусственного интеллекта и глубокому обучению.
Приведенный выше пример включает в себя в основном цифры.
Другой пример с символами приведен ниже.
Ниже приведен текст, извлеченный AlgoDocs из изображения выше.
Как мы видим, AlgoDocs хорошо справляется с извлечением рукописного текста из отсканированных документов.
Не стесняйтесь начать бесплатную подписку прямо сейчас и протестировать свои рукописные отсканированные документы.Вы можете использовать AlgoDocs бесплатно навсегда с 50 страницами в месяц. Если вам нужно обработать большее количество страниц, ознакомьтесь с нашими доступными тарифными планами.
Если у вас есть особые требования и вам нужно индивидуальное решение, свяжитесь с нами по телефону
support algodocs.com .
Оптическое распознавание символов — самая важная функция
Одна из проблем, с которой часто сталкиваются люди, читая почерк друга.Во времена написания почтовых писем было сложнее, но с компьютеризацией инструмент распознавания стал намного проще и эффективнее.
Важно, чтобы люди и компьютеры находились в равных условиях для предоставления необходимой информации. Компьютеры используют такие устройства, как клавиатуры и мыши или другие инструменты ввода, чтобы мы могли общаться с ними.
Набирать письмо на компьютере гораздо проще для людей и машин, чем писать его от руки, поэтому оптическое распознавание символов (OCR) не может читать рукописные буквы на нескольких языках.
Что такое оптическое распознавание символов (OCR)?
Технология оптического распознавания символов OCR (OCR) представляет собой процесс, который преобразует тексты, конвертирует pdf, конвертирует изображения, цифровое изображение, написанное от руки или конвертирует печатное, в машиночитаемый.
Хотя это может быть не так эффективно, компьютеры также могут иметь некоторые базовые возможности OCR. Их понимание далеко не так хорошо, как у человека, но они все же способны распознавать формы, чего более чем достаточно для перевода введенного текста в письмо, электронную почту, твит или любую другую форму общения.
Компьютеры должны работать усерднее людей для любой задачи. Если вы хотите, чтобы компьютер читал старую книгу или читал текст, сначала поднесите к сканеру сгенерированное на нем изображение этой страницы.
Страницы, созданные с помощью сканера, обычно имеют формат JPEG. Будь то изображение страницы или Эйфелевой башни, они ничего не значат для вашего компьютера, если вы сначала их не отсканируете.
Для того, чтобы преобразовать все бумажные документы в читаемый компьютером формат, такой как ввод данных, вам сначала понадобится какое-то сканирующее устройство.
Преимущества OCR
Когда дело доходит до компьютеров, могут легко возникнуть такие ошибки, как стирание цифрового файла.
Программное обеспечение для преобразованияНо хорошая новость заключается в том, что файлы легко заменить с помощью программного обеспечения для оптического распознавания символов — все, что вам нужно, — это печатная копия оригинального или последнего черновика.
преобразует отсканированные документы в загружаемые файлы текстового редактора и позволяет сохранять каждый документ с индивидуальным именем. Пример: после сохранения документа его можно легко найти, выполнив поиск по его файлу или учетной записи, без необходимости проходить процесс категоризации и хранения.
После того, как вы отсканировали документ, важно отредактировать распознавание текста в вашем текстовом процессоре. Альтернативой является обработка этого извлечения данных как отдельного документа и сохранение его в формате документа pdf.
- Печатные семейные рецепты
- Договоры аренды
- Резюме
- Контракты
Когда вы получаете цифровые документы, вы можете легко освободить место в своих шкафах.
Система с открытым исходным кодомПросто превратите бумажную версию в редактируемые цифровые файлы и сэкономьте место для хранения!
— полезный инструмент для облегчения доступа к документам.С помощью компьютерной программы с голосовым управлением слепые люди могут легко сканировать учебники, журналы, визитные карточки и входящие факсы в программы обработки текстов.
Как работает OCR?
OCR применим как к людям, так и к машинам. Люди полагаются на это, чтобы понимать текстовую информацию, передаваемую от машины; самым современным примером этого может быть Википедия. Чтобы OCR работало правильно, ваши документы должны быть сначала напечатаны одним и тем же шрифтом.Но даже в этом случае одна буква могла выглядеть иначе, чем другая.
Есть 2 способа решить эту проблему.
Распознавание образов
Предположим, если бы все писали букву «А» в одинаковом формате, было бы легче найти компьютер, который может ее распознать. Вам нужно будет только сравнить файлы изображений отсканированных документов с сохраненной версией «А», если они совпадают, то это документ.
Это как Золушка и ее фея-крёстная «если туфли вам подходят».
Чтобы буквы были одинакового размера и высоты, в 1960-х годах был разработан специальный шрифт под названием tesseract ocr systems-A. Его можно было использовать для таких вещей, как банковские чеки и печатные рекламные материалы, требующие надежного, разборчивого текста.
Штрихи этого шрифта были тщательно разработаны. Мир до сих пор не приспособился к записи в формате OCR-A, из-за которого компьютеры с трудом распознают текст, написанный людьми. Технология сделала следующий шаг и научила OCR-программы распознавать письменный извлеченный текст, буквы некоторых распространенных шрифтов.
Это означает, что они не могли прочитать обычный печатный текст, но они могут распознать любой шрифт, который вы им отправляете.
Обнаружение признаков
Обнаружение признаков известно как интеллектуальное распознавание символов. Этот более обширный метод сканирования может обнаруживать одни и те же буквы, но разными способами.
Например, если у вас есть заглавная буква А с горизонтальными линиями внутри, следуя этим шаблонам, компьютеры могут читать слова с помощью распознавания образов.Но большая часть печатных материалов в мире не в формате OCR, а рукописный текст еще менее вероятен. Однако эту проблему можно решить — когда в нейронных сетях обнаруживаются паттерны, они проходят через распознавание символов, чтобы определить, что это такое. Затем компьютеры имеют программы искусственного интеллекта, которые автоматически извлекают эти шаблоны.
Как оптическое распознавание символов улучшает управление документами и организацию прибыли?
У вас на столе куча бумаг, и, поскольку вы застряли в поисках определенных фрагментов вручную, это занимает много времени.Вы рассматриваете возможность сканирования всего в компьютер с использованием обычных средств.
Вам, как человеку, не будет легче с обычными средствами. Используйте бесплатное онлайн-программное обеспечение OCR, и вы сможете работать с документами, как если бы вы использовали форматы файлов Microsoft Word, Adobe Acrobat или PDF.
Технологии, к счастью, дали нам возможность искать анналы документов любого размера за несколько мгновений.
С помощью цифровых копий вы можете наслаждаться контролем и возможностью аудита их и слабовидящих.Вместо того, чтобы отправлять бумажные документы сотрудникам для проверки вручную, сохранение и хранение документов можно полностью автоматизировать или удалять старые записи при необходимости.
Цифровые документы более точны, доступны для поиска и предоставляют лучшие возможности управления.
Программное обеспечение для управления документамиснижает вероятность неправильного обращения или неправильной идентификации конфиденциальных документов. Цифровые формы документов позволяют пользователям полностью контролировать свои документы.
Как работает распознавание рукописного ввода?
Некоторые символы заменяют аккуратный компьютерный текст, напечатанный лазером.Печатные компьютерные тексты гораздо легче сканировать, чем набросанные от руки заметки.
Когда дело доходит до человеческого почерка, мозги побеждают компьютеры. Мы получаем приблизительное представление о том, что написано на любой заметке, какой бы грязной она ни была.
Облегчение распознавания
Чтение рукописных заметок затруднено для компьютеров, поскольку они должны полагаться на устройства почтовой сортировки для определения почтовых индексов на конвертах. Эти машины для сортировки почты лучше считывают небольшие объемы разборчивого текста и цифры, написанные прописными буквами и разделенные промежутками для облегчения идентификации.
Вы, должно быть, видели формы с механизмом распознавания, разработанным таким образом, что ячейки для каждой буквы или цифры разделены красными линиями. У некоторых даже есть розовый цвет исключения, чтобы помочь людям отделить текст, написанный людьми, от написанного компьютером.
Что такое оптический считыватель символов на практике?
Мы часто не используем бесплатное программное обеспечение OCR в нашей отрасли.
Эти отрасли ежедневно сканируют не сотни, а миллионы документов — это сумасшедшее количество! И тем не менее, эти отрасли еще не используют OCR.Нам нужно отсканировать печатную страницу книги, чтобы мы могли отредактировать ее и использовать в любой статье на нашем веб-сайте.
Так выглядит повседневное распознавание текста.
- Распечатка . Распечатки должны быть максимально четкими, чтобы обеспечить точность документа. Убедитесь, что вы не ставите под угрозу четкость, чередуя цвета чернил или печатая светлый текст на темной бумаге.
- Сканирование – Используйте оптический сканер для распечаток. Вам понадобится сканер с полистовой подачей, если вы используете OCR, и он определяет расположение страниц на вашей странице.Современные программы OCR будут сканировать каждую страницу автоматически или использовать планшетные сканеры для сканирования одной страницы за раз, в зависимости от того, какую программу вы решите использовать.
- Двухцветный- OCR (оптическое распознавание символов) использует черно-белую версию отсканированной страницы PDF. Факсы используют тот же процесс, что и сканирующие машины.
- OCR — программы OCR обрабатывают каждое изображение посимвольно, слово за словом, строка за строкой. Но в 90-х вы, должно быть, заметили, что программы OCR были достаточно медленными, чтобы смотреть, как они читают.Теперь, с современным программным обеспечением и массивными жесткими дисками, это происходит мгновенно.
- Первичное исправление ошибок — Некоторые программы позволяют просматривать документы на наличие исправлений и ошибок. Программа OCR выделит орфографические ошибки и распознает опечатки, чтобы вы могли немедленно их исправить. Лучшие версии этих программ используют анализ ближнего соседа, чтобы найти любые другие ошибки, которые могут быть пропущены, например, если два слова пишутся одинаково, но означают разные вещи.
- Анализ макета — Хорошая программа OCR позволяет искать слово или предложение в тексте и обнаруживает многостраничные тексты, несколько столбцов текста, таблицы, изображения и т. д.
- Вычитка – Лучшие программы OCR не всегда так точны, как человеческий глаз, но последний этап – вычитка человеком. Делается это по старинке: все внимательно прочитывается на наличие ошибок.
Заключение
Установите OCR на свой компьютер или мобильные устройства, и у вас больше не будет стопок бумажных документов в офисе. Вы можете преобразовать все свои старые данные в цифровой формат.
Программное обеспечение для распознавания рукописного ввода для безопасного вождения
Бизнес-вызов
Команда Intellias завершила научно-исследовательский проект приложения автомобильной клавиатуры Android с несколькими премиальными функциями, включая распознавание рукописного ввода.Это был ответ нашей компании на рыночный спрос на решение, которое решит некоторые из наиболее распространенных проблем и потребностей в инклюзивности, с которыми ежедневно сталкиваются водители:
- Сложные и отвлекающие интерфейсы ставят под угрозу безопасность
- Шумная обстановка в автомобиле заглушает голосовых помощников
- Ограничения скорости устанавливают ограничения на использование ввода текста с клавиатуры
- Вибрация автомобиля затрудняет нажатие клавиш и искажает качество рукописного текста
- Удобство ввода для левшей и слабослышащих водителей часто упускается из виду
Помня обо всех этих проблемах водителей, мы составили контрольный список жестких требований к нашему продукту.
Intellias успешно провела научно-исследовательский проект, который демонстрирует наши сильные технологические возможности и опыт в области нейронных сетей, машинного обучения и искусственного интеллекта. После серии совещаний и семинаров мы подтвердили, что наше решение предлагает эффективный метод ввода.
Решение доставлено
Наша команда разработчиков Android и машинного обучения, специалистов по безопасности и обслуживанию, дизайнеров и инженеров по обеспечению качества приступила к работе над нашим продуктом R&D.
Специальное приложение для клавиатуры Android поддерживает несколько режимов пользовательского ввода: стандартный, смахивание и распознавание рукописного ввода. Он может понимать текст, написанный от руки, и позволяет водителям эффективно общаться с информационно-развлекательной системой автомобиля, не отрывая глаз от дороги. Это решение чрезвычайно интуитивно понятно, оно распознает любой естественный почерк: прописные, строчные, курсив, блочный и даже наложенный текст.
Благодаря интеграции системы с пользовательской информацией водители могут вводить пункт назначения, просматривать достопримечательности на карте, изменять настройки климат-контроля, включать свою любимую музыку и звонить или отправлять сообщения своим контактам — и все это одним движением пальца.Возможность приложения захватывать рукописный текст из отсканированных изображений и даже предлагать и предсказывать слова на основе привычек и стиля письма пользователя обеспечивает удобство для водителей и повышает безопасность.
Распознавание рукописного ввода
Наше программное обеспечение для распознавания рукописного ввода, реализованное с помощью платформы TensorFlow, преобразует изображения слов в цифровой текст. Мы построили сверточную нейронную сеть (CNN) и обучили ее на автономном наборе данных IAM изображений слов.Входное изображение, представленное векторами и временными дельтами, подается в модель CNN, которая извлекает соответствующие функции. Затем выходные данные карты объектов обрабатываются, алгоритм выявляет корреляции со словами и генерируется цифровой текст. Эта модель распознает рукописный текст на изображениях со значительной точностью.
Многосимвольное распознавание (MCR)
Для реализации модели многосимвольного распознавания мы использовали MXNet и ResNet в качестве опорных нейронных сетей, а также специальные функции предварительной и постобработки для обработки движений пальцев во время вождения.Наш подход MCR состоит из трех шагов:
- Обнаружение текстовых областей путем выделения признаков с помощью сверточной нейронной сети
- Распознавание символов с помощью сверточной нейронной сети
- Применение языковой модели для исправления ошибок
Исправление и подсказка слов
Мы разработали модели исправления слов и подсказки/прогноза слов, используя классические подходы машинного обучения.Вычисляя расстояние Левенштейна, модель исправления слов исправляет неправильно идентифицированные слова и повышает точность обнаружения слов.
Кроме того, мы внедрили подход к обучению с подкреплением, основанный на образцах почерка водителей в тестовых автомобилях, чтобы улучшить модели с помощью отзывов о взаимодействии с пользователем. Текстовые исправления при вводе пользователем будут собраны, и модель будет соответствующим образом обновлена.
Модель предложения слов предсказывает следующее слово или фразу, чтобы свести к минимуму требуемый объем ввода. Эта модель основана на извлечении биграмм и n-грамм, а также на статистике из исторических пользовательских данных.Он учитывает контекст написания, словари языка и местонахождения и даже поведенческие и орфографические предпочтения пользователя.
Решение также включает механизм подсказок на основе местоположения, чтобы подсказывать пользователю при поиске определенного адреса или места.
В зависимости от местоположения пользователя система извлекает запрошенную информацию из базы данных карты NDS и предлагает местоположение или название улицы. Имея многолетний опыт создания решений для определения местоположения и картографирования, наши инженеры обладают всеми необходимыми знаниями для создания и обновления баз данных о местоположении и их интеграции с приложениями автомобильной клавиатуры.
Помимо разработки технического решения, включающего в себя саму клавиатуру и серверную часть, позволяющую достичь высокой точности распознавания, мы также решили другие проблемы, связанные с машинным обучением:
Наше решение включает в себя службу обновления по беспроводной сети (OTA), которая позволяет легко распространять только что обученные модели машинного обучения для распознавания рукописного ввода на транспортные средства. Таким образом, точность распознавания автомобилей на дороге может со временем повышаться.
- Получение достаточных обучающих данных
Мы использовали самые современные технологии для увеличения данных, чтобы расширить набор обучающих данных, дополняя данные распознавания нескольких символов смесью реальных и искусственных данных.
Для этого мы придерживались подходов Autoencoder и GAN и использовали только данные реального почерка для создания расширенных образцов данных. Кроме того, мы использовали классические подходы к дополнению, включая вращение данных, масштабирование, сдвиг и искажения для учета движения транспортного средства.
Бизнес-результат
Поскольку автомобильные гиганты во всем мире продолжают поднимать планку безопасности, комфорта и эффективности вождения, автомобильным компаниям важно оставаться на шаг впереди перед лицом жесткой конкуренции.Разработанное нами приложение для клавиатуры позволит автопроизводителям поддерживать уровень удовлетворенности клиентов выше среднего по отрасли и даже повышать его со временем. Наше быстродействующее решение предлагает интуитивно понятное взаимодействие и практически не требующий усилий ввод данных. Он инклюзивен по своей природе и может похвастаться впечатляющей точностью распознавания слов. Это приложение является фундаментальным шагом к изменению опыта вождения для пользователей.
Инженеры Intellias привнесли в этот проект большой отраслевой опыт и важные навыки, в том числе компетентность в области автомобилестроения, опыт работы с системами определения местоположения и навигации, навыки разработки программного обеспечения для Android и знания в области машинного обучения.
Теперь, когда мы достигли приемлемого и достаточного уровня точности для распознавания рукописного текста, следующим шагом будет улучшение нашей нейронной сети путем тестирования ее на моделях автомобилей. Мы также планируем провести дополнительные исследования классических подходов к компьютерному зрению — извлечения и классификации краев — для дальнейшего повышения производительности и оптимизации этого продукта для встроенного использования. После того, как мы приблизим цель качества к ожидаемому уровню, нашей следующей целью будет обучение модели распознаванию более 30 языков и превращение нашего решения в многоязычный продукт.
Распознавание рукописного ввода — Quantian Technologies
Распознавание рукописного ввода (HWR) — это способность компьютеров распознавать рукописный текст на любом носителе, таком как бумага, фотографии, документы и т.
д. Это также часто называют распознаванием рукописного ввода (HTR). Оптическое распознавание символов (OCR) — это электронное преобразование рукописного или машинописного текста, будь то отсканированные документы или фотографии. HWR — это новая область исследований OCR, которую пытаются решить многие исследователи и технологические гиганты.Согласно отчетам, опубликованным marketandmarkets в 2021 году [1], объем мирового рынка распознавания рукописного ввода в 2016 году оценивается в 1039,3 млн долларов США. Ожидаемый среднегодовой темп роста в 15,7% с 2017 по 2025 год. Ожидается, что рынок HWR будет расти вместе с с ним, а также показать огромные улучшения на текущих уровнях точности.
Распознавание рукописного ввода имеет большое количество промышленных применений, от здравоохранения и фармацевтики до банковского дела и страхования. Технологии HWR можно использовать по разным причинам, например, для снижения трудозатрат, экономии времени, затрачиваемого на ручную оцифровку рукописных записей, повышения качества обслуживания клиентов и т.
д.HWR также может привести к автоматизации различных трудоемких процессов.
Разнообразный почерк, освещение изображения, разделение текста курсивом делают распознавание почерка сложной задачей для достижения хорошей точности. Тем не менее, продолжающиеся исследования, в которых используются современные архитектуры глубокого обучения, добились значительных успехов в повышении точности. Они оказались намного лучше, чем ранее использовавшиеся алгоритмы машинного обучения, в которых функции для обучения модели машинного обучения определялись человеком.
Текущее состояние и прогнозы на будущее
[1] Согласно новому отчету об исследовании рынка, опубликованному Credence Research «Рынок распознавания рукописного ввода (HWR) (по типу — онлайн и офлайн; по применению: автомобильная промышленность; образование и литература; предприятия и полевые услуги; здравоохранение и другие) — рост, Будущие перспективы, конкурентный анализ и прогноз на 2017–2025 годы», мировой рынок распознавания рукописного ввода (HWR) был оценен в 1039 долларов США.3 млн тонн в 2016 году, и ожидается, что среднегодовой темп роста составит 15,7% в период с 2017 по 2025 год. Технологии
HWR можно разделить на два типа: онлайновые и автономные методы. Онлайн-методы соответствуют извлечению машиночитаемых текстов из штрихов на сенсорных экранах. Автономные методы относятся к извлечению машиночитаемого текста из бумаги, журналов и т. д.
Рис. Доход мирового рынка распознавания рукописного ввода по типу
Основные игроки этого рынка сталкиваются с высокой конкуренцией. Ключом к выживанию на этом рынке являются более активные усилия по улучшению обслуживания, чтобы соответствовать меняющимся правилам и экономическим условиям на мировом рынке.Наряду с этим необходимо также повышение точности программного обеспечения HWR. Ключевыми игроками на рынке систем распознавания рукописного ввода (HWR) являются MyScript, Nuance Communications, Inc., SELVAS AI, Inc., Hanwang Technology Co., Ltd., Paragon Software Group, PhatWare Corporation, SinoVoice (Beijing Jietong Huasheng Technology Co.
Ltd.). .) и Sciometrics, LLC.
Множество приложений для мобильных устройств, планшетов и веб-платформ также доступны для онлайн-методов. В таблице ниже приведены некоторые из самых популярных приложений для распознавания рукописного ввода.
Таблица 1. Программное обеспечение для распознавания рукописного текста
Основные облачные сервисы, такие как AWS (Amazon Textract), Google Cloud (Google Vision) и Azure (Microsoft Azure Vision), также предоставляют API для распознавания рукописного ввода.
Варианты использования распознавания рукописного ввода
Здравоохранение
Все мы слышали анекдоты про неузнаваемый почерк врачей, а также сталкивались с этой проблемой на собственном опыте.Помимо шуток, согласно отчету Института медицины Национальной академии наук (IOM) за июль 2006 года, неузнаваемый почерк врачей ежегодно убивает более 7000 человек.
Использование технологии HWR может легко сэкономить время, деньги и жизни людей. Многие медицинские учреждения и больницы внедряют стратегии обработки данных для борьбы со смертями из-за неразборчивого письма. К ним относятся электронные медицинские карты (EHR), которые были приняты 71% врачей, как утверждается в опросе 2013 года.
Эти технологии также помогают смягчить такие проблемы, как зависимость от бумаги, нарушения нормативных требований, проблемы соответствия, подделки и мошенничество. Технологии HWR можно дополнительно использовать для оцифровки регистрационных форм пациентов и рукописных записей. Оцифровка также даст доступ к огромному количеству данных, которые можно использовать для анализа данных, чтобы получить значимую информацию.
Образование
Продолжается работа по ознакомлению детей и педагогов с вычислительными устройствами на раннем этапе.
Google для преподавателей — одна из таких кампаний, направленная на то, чтобы школы использовали технологии. С ростом использования планшетов в школах и колледжах технология HWR будет развиваться в сфере образования. Это мощный инструмент, который может улучшить опыт обучения студентов. Например, учащийся может делать рукописные заметки на своем iPad, что помогает лучшему пониманию. Эти заметки также могут быть преобразованы в текст, читаемый компьютером, с использованием методов распознавания рукописного ввода. Эти технологии были расширены в различных приложениях для создания заметок, приложениях для работы со сложными математическими суммами, а также в музыкальных приложениях.Например, математические приложения могут преобразовывать написанные от руки вопросы и уравнения в четкие машиночитаемые цифры и текст, которые можно использовать для получения желаемых ответов. Другие области применения включают преобразование нарисованных диаграмм в цифровые документы, сочинение музыки и даже оптимизацию процесса добавления ссылок на исследовательские работы за счет включения возможностей выделения и поиска.
Таким образом, технологии распознавания рукописного ввода могут принести пользу преподавателю и учащимся всех уровней, будь то первоклассник или студент старшего курса колледжа.
Банковское дело
Рис. Применение распознавания рукописного ввода в банковских приложениях
В настоящее время чеки, депонированные в банках, анализируются вручную, а затем вводятся в компьютер. Сотрудники банка также должны вручную проверять подпись и дату чеков. Это требует времени и ручных усилий, а также задерживает отражение баланса на банковском счете, на который распространяется льгота.Технологии распознавания рукописного ввода можно использовать для чтения этих чеков и других банковских документов, таких как формы, тратты и т. д., в гораздо более быстром темпе.
Интернет-библиотеки
Большое количество исторических книг и журналов было оцифровано, чтобы сделать их доступными для всего мира.
Однако большая часть этих усилий ограничивается фотографиями или сканами книг. Эти усилия могут стать еще более полезными, если текст этих исторических книг можно будет анализировать, запрашивать и индексировать поисковыми роботами.Распознавание почерка играет ключевую роль в оживлении документов средневековья и 20-го века, открыток, исследований и т. д.
Потребитель
Растет спрос на OCR и связанные с ним технологии со стороны потребителей. Это способствовало внедрению таких технологий в планшеты и смартфоны. Спрос резко вырос из-за увеличения количества устройств, на которых можно заработать.Технологии OCR, включая распознавание рукописного ввода, существуют уже десять лет. Однако широкое распространение мобильных устройств с сенсорным экраном увеличило внедрение таких технологий в повседневную жизнь. Технологии HWR могут стать реальной альтернативой использованию цифровых клавиатур в ближайшем будущем.
Будь то в мобильных приложениях, в смарт-часах, в качестве альтернативы клавиатуре смартфона или в приборной панели автомобиля, технология HWR набирает обороты.
Используемые методы
Распознавание рукописного текста можно разделить на две категории: автономный метод и онлайн-метод.
1. Онлайн-метод – Онлайн-метод включает устройства с сенсорным экраном, световое перо, стилус и т. д. Этот метод имеет доступ к такой информации, как ход и направление. Они также не сталкиваются с проблемой шумного фона.Их можно распознать с довольно высокой точностью по сравнению с автономными методами.
2. Автономный метод – Этот метод относится к тексту, записанному на нецифровом носителе, например на бумаге.

При этом информация, такая как ход, направление, недоступна, как в случае онлайн-методов. Помимо этого метода также могут быть проблемы с шумным фоном.
Текущие усилия в большей степени сосредоточены на распознавании рукописного ввода в автономном режиме, которому еще предстоит пройти долгий путь, прежде чем он достигнет приемлемой точности.Также автономный метод не требует дополнительных устройств, таких как световые ручки и стилусы.
Ранние попытки распознавания рукописного ввода использовали алгоритмы машинного обучения, такие как скрытые модели Маркова (HMM), машины опорных векторов (SVM) и т. д. Эти методы включали ввод предварительно обработанного текста, взаимодействие функций для определения ключевых элементов, таких как циклы, соотношение сторон и точки перегиба. Эти сгенерированные функции затем передаются в алгоритмы машинного обучения, такие как HMM и SVM.
Глубокое обучениеТакие методы имели ограниченную точность из-за необходимости идентификации признаков людьми. Кроме того, этот метод нельзя масштабировать, поскольку он не может охватывать разные языки.
решает эту проблему с использованием современных технологий, таких как сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN) и коннекционистская временная классификация [3].
Сверточные нейронные сетииспользуются для извлечения признаков из входных изображений.Слои свертки содержат три основные операции — использование свертки (ядро фильтра) для входного изображения, нелинейная функция ReLU и, наконец, слой объединения для уменьшения размера вывода CNN. Рекуррентная нейронная сеть (RNN) — это класс искусственных нейронных сетей, в которых связи между узлами образуют ориентированный граф вдоль временной последовательности. Используется LSTM-реализация RNN, поскольку она способствует долгосрочному распространению информации, тем самым улучшая обученную модель.
Наконец, для классификации изображений используется слой Connectionist Temporal Classification (CTC).CTC получает выходную матрицу RNN и исходный текст в качестве входных данных, с помощью которых он вычисляет значение потерь. CTC выдает окончательный текст на выходе.
Рис. Обзор архитектуры нейронной сети для распознавания рукописного ввода
Ограничения
Одной из главных проблем технологий HWR является точность. Многие технологии HWR не могут предсказать почерк многих людей, что делает их ненадежными для использования в реальных сценариях.Им также требуются огромные наборы данных и огромные вычислительные мощности для обучения моделей. В результате этого внедрение HWR на отраслевом уровне может быть довольно дорогим. Кроме того, способность модели к распознаванию во многом зависит от данных, используемых для обучения модели.
Заключение
Будущее HWR обнадеживает благодаря недавним успехам в уровне точности, массовому внедрению мобильных устройств и стремлению к безбумажным операциям.
Существует множество программ для распознавания рукописного ввода с различной точностью и ценой.
Некоторые популярные программы распознавания рукописного ввода:
- Amazon Textract
- Microsoft Azure Зрение
- Google Cloud Зрение API
- Infrrd.ai
- MicroBlink
- MyScript
При использовании программного обеспечения для распознавания рукописного ввода для бизнеса вы должны учитывать такие факторы, как точность распознавания символов, точность распознавания слов, скорость вычислений в случае, если результаты должны быть предоставлены в режиме реального времени, возможности непрерывного обучения, удобство интерфейса, если интерфейс будет использоваться людьми, и разумная цена.