
Несколько программ для распознавания текста – МАКСНЕТ
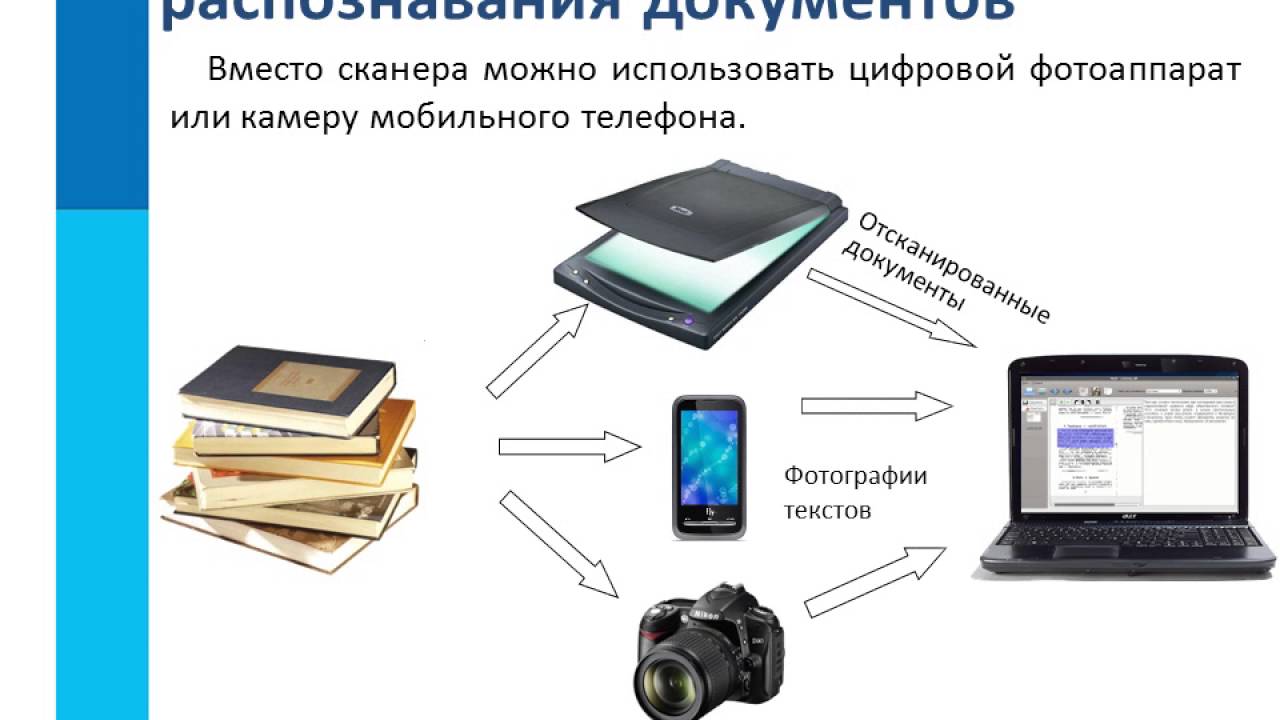
Даже если Вы уже не студент, наверняка Вы сталкивались с ситуациями, когда нужно внести корректировки в бумажные документы или их сканы. Вы же не делали все вручную? Наша статья для тех, кто хочет найти подходящую для своего девайса программу распознавания текста. Возможно, Вы подыщите достойную альтернативу привычному инструменту.
Работа описываемых программ основана на алгоритме оптического распознавания текста. Утилиты рассматривают буквы как набор точек, анализируют его и выдают результат в виде текста. Чем качественнее распознанный текст на выходе, тем выше вероятность того, что программа платная.
Софт
ABBYY FineReader
Это наиболее популярное решение задачи распознавания текста, как для дома, так и для работы. Имеются платная и пробная версии. Программа популярна не случайно: она способна качественно распознавать текст на 179 языках. Работает с бумажными документами, фотографиями и PDF.
Freemore OCR
Это бесплатная программа, которая может работать одновременно с несколькими принтерами. Преобразованный текст можно сохранить в формате txt или с одним из расширений, поддерживаемых MS Office. Библиотеку для распознавания русского языка необходимо устанавливать отдельно.
Simple OCR
Отличный вариант для распознавания рукописей. Программа точно расшифровывает текст и восстанавливает изображения, убирая из них шум. «Легкий» установочный файл, встроенный редактор текста и интуитивно понятный интерфейс порадуют пользователей, однако большой минус — программа не работает с русским языком.
Приложения
Office Lens
Приложение от Microsoft позволяет использовать смартфон как сканер для документов. Он распознает снимки с камеры и переводит их в текстовые документы DOCX, PPTX и PDF. Приложение доступно бесплатно как в Microsoft store, так и на Google play и App Store.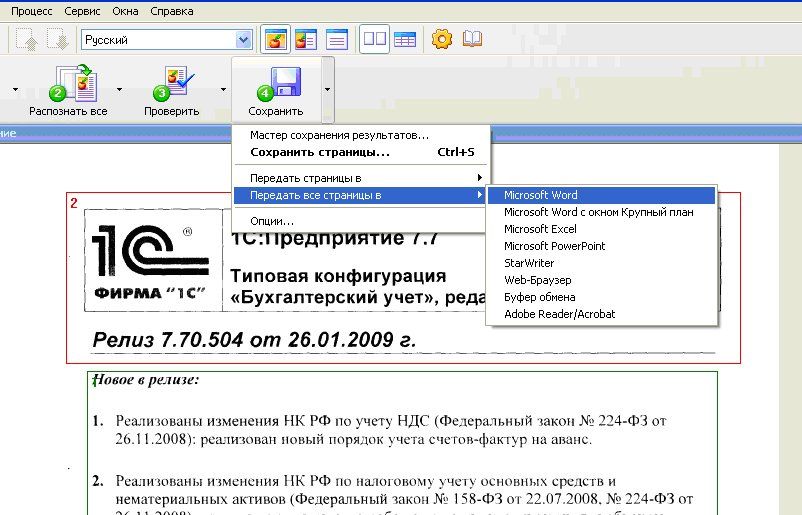
Adobe Scan
Аналогичный предыдущему приложению сервис от Adobe с более узким набором возможностей. Adobe Scan также может распознавать фотографии, но сохраняет результаты сканирования только в PDF.
Когда нужно быстро
Win Scan 2PDF
Это удобная, не требующая установки, утилита для быстрого преобразования файлов. Набор функций — минимальный для распознавания текста, единственный формат для сохранения — PDF.
Online OCR
Сайт для распознавания текста и таблиц на 46 языках. Сервис доступен бесплатно, для работы не нужна регистрация. Работает с изображениями распространенных форматов и PDF и переводит их в форматы DOCX, XLSX, TXT.
Мало кому нравится перенабирать текст документов руками, поэтому сервисов для этих целей создано множество. Как видите, кроме программ, существуют мобильные приложения и онлайн-сервисы.
Если Вам нужно пользоваться такими инструментами не слишком часто, бесплатных программ или пробных версий будет вполне достаточно.
Программа для распознавания текста с картинок, фото, сканеров, pdf, и д.р
В данной статье будет подробно рассмотрено каким образом может быть выполнено распознавание текста с картинки, фото, сканера, pdf файлов и др. на Вашем компьютере с помощью различного софта, разработанного специально для этих целей. Программы на русском языке, по этому трудностей вообще быть не должно в изучении.
Установка рограммы Abbyy FineReader.
- Скачать эту программу вы можете на нашем сайте, пройдя по ссылке http://all-freeload.net/redaktory/783-abbyy-finereader
- Запустив файл .exe Вы увидите окно, в котором выберите куда будет извлечён архив с временными файлами установки программы.
 По окончании установки файлы будут удалены. Выбрав нажмите установить(install).
По окончании установки файлы будут удалены. Выбрав нажмите установить(install).Далее перед Вами появится окно установки, нажимайте установка ABBYY FineReader Home Edition.
После чего выбираете язык и жмёте ок. В следующем окне так же жмите далее. Вам будет предложено принять условия соглашения, выбираете пункт я принимаю и далее.
Следующим этапом выбираете директорию, куда будет установлена программа и интеграцию с проводником и программами Windows.
И в следующем окне нажмите установить.
- Программа установлена, нажмите готово и запускайте её с ярлыка на рабочем столе.
 По окончании установки файлы будут удалены. Выбрав нажмите установить(install).
По окончании установки файлы будут удалены. Выбрав нажмите установить(install).Работа в программе Abbyy FineReader.
- Выбираете необходимое действие. На примере показано конвертирование изображения формата .jpg в текстовый документ.
- Выбираете изображение и нажимаете открыть.
- После нажатия кнопки продолжить программа откроет перед Вами документ Microsoft Word с изображением которое уже конвертировано и Вы можете работать с текстом.
Таким же путём программа Abbyy FineReader выполняет и другие действия по конвертированию различных форматов и считыванию текста со сканера.
Вторая программа для распознавания текста, называется CuneiForm.
Загрузить установочный файл которой, Вы так же можете у нас на сайте пройдя по ссылке http://all-freeload.net/redaktory/963-cuneiform
Преимущества CuneiForm перед аналогичным софтом заключается в том что разработчики сделали данную программу бесплатной, она поставляется в комплекте со сканерами определённых моделей и поддерживает распознавание более 20 языков. Работа в ней так же не будет сложной.
- Запустив установочный файл программы в появившемся окне нажмите далее, после чего отметьте что Вы согласны с условиями пользовательского соглашения и жмите далее. Выберите какие пользователи смогут работать с данной программой и нажмите далее.
В следующем окне выбираете директорию для установки программы и снова жмёте далее. После чего кнопку установить.
По завершении установки нажмите готово и запускайте программу с рабочего стола.
- После запуска программа будет давать Вам советы по работе в ней. Можете прочитать или закрыть.
На примере будет изображение формата .jpeg, которое мы конвертируем в .doc
Нажимаете кнопку файл
Затем строку открыть и выбираете изображение, которое Вам нужно.
- Затем, находите кнопку распознавание и жмёте на неё.
Так же для более подробной настройки воспользуйтесь мастером распознавания. Сверху жмёте на надпись и выбираете пункт мастера.
- После нескольких секунд программа покажет Вам текст с изображения, который Вы можете редактировать и сохранить. Для сохранения нажмите на кнопку распознавание и выберите пункт экспорт в MS Word.

Если возникли вопросы, задавайте в комментариях, мы обязательно поможем.
Смотрите также:
Программа для распознавания текста с изображений
В данной статье будет подробно рассмотрено каким образом может быть выполнено распознавание текста с. ..
..
Как удалить search yahoo из компьютера
Если вы являетесь активным и продвинутым пользователем интернета, то, конечно же, вы постоянно скачи…
Hangouts что это за программа?
Многие пользователи мобильных устройств на базе операционной системы Android часто не понимают для ч…
Добавить комментарий
Какие программы для распознавания текста использовать в офисе — Сводные таблицы Excel 2010
Меня часто спрашивают: «Отсканировали (сфотографировали) страничку, файл открывается, читается. Как теперь внести в этот документ исправления?» Ответ: просто так — никак! То, что вы отсканировали — изображение, картинка, набор разноцветных точек. Редактировать можно только документ, состоящий из знаков (символов).
Самое большее, что вы можете сделать с картинкой — в графическом редакторе (Paint, GIMP и т.
Однако решение есть: оптическое распознавание символов (optical character recognition, OCR). Программа анализирует изображение, выделяет из него характерные очертания букв и цифр, а потом создает настоящий редактируемый документ. Примерно то же самое делаете вы, когда читаете написанное и набираете прочитанное на клавиатуре. Правда, в распознавании символов компьютеру еще очень далеко до человека. Люди безошибочно разбирают любые каракули, а программы OCR пока хорошо справляются только с четкими изображениями печатных букв. С технологией OCR тесно связан рукописный ввод, который используется в планшетах и смартфонах. Пользователь пальцем или стилусом рисует на сенсорном экране буквы и цифры, а смартфон распознает их. Вы могли заметить, что устройство верно воспринимает только аккуратно начерченные символы, а криво или косо нарисованные приводят его в замешательство.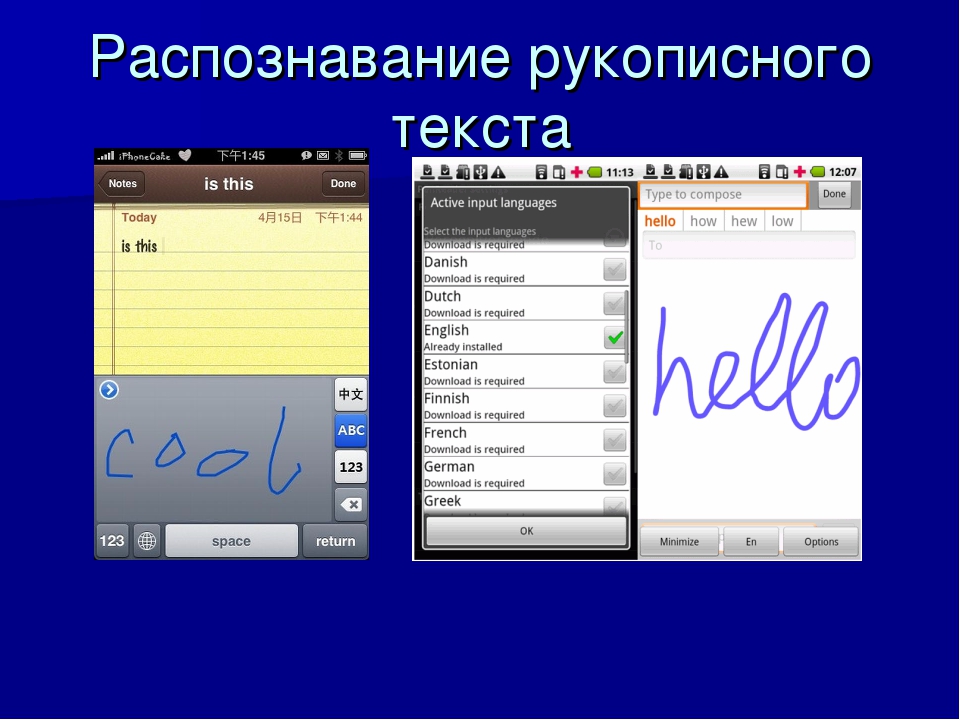
Весьма эффективное средство распознавания входит в состав пакета Microsoft Office. В предыдущих версиях пакета этим занималось отдельное приложение Microsoft Office Document Imaging (MODI). В Microsoft Office 2010 задача распознавания возложена на компонент OneNote. Примечательно, что теперь эта функция скромно именуется поиском и копированием текста в рисунках и вызывается «как бы между прочим». Как ею пользоваться?
Распознавание символов с помощью OneNote
- Изображение, текст с которого нужно распознать, любым образом вставьте в заметку OneNote. Например, перетащите мышью файл рисунка в окно OneNote или на ленте воспользуйтесь кнопками Вставка → Рисунок — как вам удобнее.
- В окне OneNote щелкните на рисунке правой кнопкой мыши и в контекстном меню выберите команду Копировать текст из рисунка (см. рис.). Весь текст, который программа сумеет распознать в изображении, будет скопирован в буфер обмена.
- Вставьте скопированный текст в любой документ. Пункт Поиск текста в рисунках в контекстном меню служит для выбора языка распознавания. Эта настройка позволяет точнее определить набор символов, ведь многие буквы разных алфавитов похожи по начертанию.
 Пункт Поиск текста в рисунках в контекстном меню служит для выбора языка распознавания. Эта настройка позволяет точнее определить набор символов, ведь многие буквы разных алфавитов похожи по начертанию.
Пункт Поиск текста в рисунках в контекстном меню служит для выбора языка распознавания. Эта настройка позволяет точнее определить набор символов, ведь многие буквы разных алфавитов похожи по начертанию.Одно из лучших приложений для распознавания документов и таблиц — ABBYY FineReader. Программа легко обрабатывает изображения документов со сложной структурой и очень точно воспроизводит ее в распознанном документе. Хотя в FineReader предусмотрено множество гибких настроек, с большинством типичных задач программа прекрасно справляется «на полном автомате». За простым и интуитивно понятным интерфейсом скрывается мощный интеллектуальный «движок». По умолчанию при запуске предлагается выбрать один из готовых сценариев.
Запуск программы ABBYY FineReader
Например, если вы выберете сценарий Сканировать в Microsoft Word, сначала откроется диалоговое окно сканирования. После сканирования первой страницы программа запрашивает, нужно ли сканировать следующую, либо можно переходить к следующему шагу. Когда получены изображения всех страниц, начинается их обработка и распознавание. Ход и результаты распознавания отображаются в главном окне программы. В левой части окна показаны эскизы страниц, а в рабочей области вы видите исходное изображение и рядом с ним — уже распознанный документ.
Когда получены изображения всех страниц, начинается их обработка и распознавание. Ход и результаты распознавания отображаются в главном окне программы. В левой части окна показаны эскизы страниц, а в рабочей области вы видите исходное изображение и рядом с ним — уже распознанный документ.
Главное окно ABBYY FineReader
Результат распознавания FineReader в соответствии со сценарием передает в другую программу или сохраняет. Например, в данном случае автоматически откроется окно Microsoft Word с новым документом. Как правило, в созданном документе заголовки, абзацы и другие составляющие оформления выглядят почти так же, как на исходном изображении. Подбирается даже наиболее похожий шрифт! Другие сценарии позволяют отправить результат распознавания в Microsoft Excel — это удобно, если на оригинале изображена таблица, сохранить его в виде документа Adobe Reader (PDF), вместо сканирования открыть сделанное раньше фото оригинала и т. д.
Кроме того, программу можно запустить в пошаговом режиме.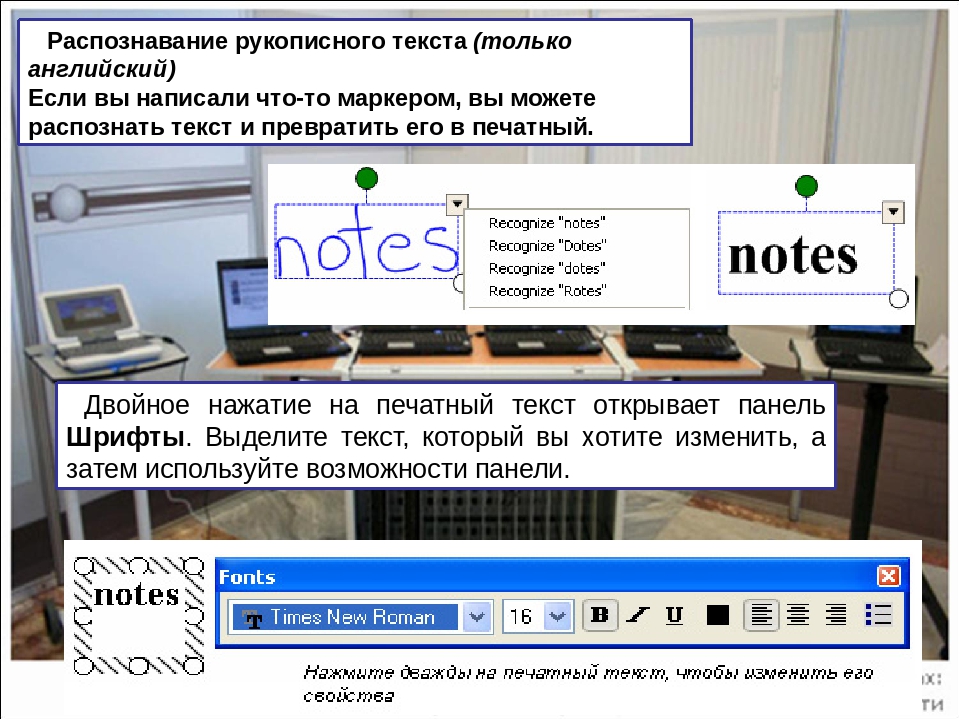 Для этого на панели инструментов нажмите кнопку Новое задание. Окно выбора сценариев закроется. Нажимая кнопки на панели инструментов, вы сможете последовательно и под полным контролем отсканировать документ или открыть готовое изображение, при необходимости исправить его дефекты и искажения, проанализировать и выделить то, что нужно распознавать, проверить и сохранить результат.
Для этого на панели инструментов нажмите кнопку Новое задание. Окно выбора сценариев закроется. Нажимая кнопки на панели инструментов, вы сможете последовательно и под полным контролем отсканировать документ или открыть готовое изображение, при необходимости исправить его дефекты и искажения, проанализировать и выделить то, что нужно распознавать, проверить и сохранить результат.
К сожалению, программа FineReader передает документы лишь в приложения Microsoft Office (если они установлены), а с пакетом OpenOffice.org она не знакома. В таком случае очевидный выход — сохранять результаты распознавания в универсальном формате RTF, который прекрасно «понимают» любые редакторы документов. Очень качественное, но коммерческое ПО ABBYY FineReader подходит тем, кто распознает текст с бумажных оригиналов часто и регулярно.
Существуют ли бесплатные альтернативы?
Давний конкурент ABBYY — компания Cognitive Technologies в 2007 г. выпустила бесплатную версию программы CuneiForm и открыла ее исходные тексты. С тех пор поддержкой проекта (www.cuneiform.ru) занялось сообщество программистов, а сама программа сегодня работает на платформах Windows, Linux, FreeBSD и Mac OS X. Другой полностью свободный проект — Tesseract. Бесплатная программа COCR2 примечательна тем, что распознает китайские иероглифы. В связке с электронным переводом, например Переводчиком Google, это приложение дает удивительную возможность прочитать и понять документацию на китайском прямо «с листа»! Коммерческими программами Readiris и CrystalOCR комплектуются многие МФУ. Для конечного пользователя OEM-лицензия является бесплатной — фактически она была оплачена при покупке аппарата.
С тех пор поддержкой проекта (www.cuneiform.ru) занялось сообщество программистов, а сама программа сегодня работает на платформах Windows, Linux, FreeBSD и Mac OS X. Другой полностью свободный проект — Tesseract. Бесплатная программа COCR2 примечательна тем, что распознает китайские иероглифы. В связке с электронным переводом, например Переводчиком Google, это приложение дает удивительную возможность прочитать и понять документацию на китайском прямо «с листа»! Коммерческими программами Readiris и CrystalOCR комплектуются многие МФУ. Для конечного пользователя OEM-лицензия является бесплатной — фактически она была оплачена при покупке аппарата.
Сервисы распознавания символов появились и в Интернете: FineReaderOnline.ru, Onlineocr.ru, Liveocr.com и некоторые другие. С помощью формы на веб-странице указывается путь к файлу изображения на вашем компьютере, а результат распознавания выдается опять же через Интернет. В принципе, сервисы работают на коммерческой основе: нужно зарегистрироваться на сайте и оплатить услугу. Однако ограниченное число страниц в течение суток они обрабатывают бесплатно.
Однако ограниченное число страниц в течение суток они обрабатывают бесплатно.
ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ OCR ДЛЯ БЕСШОВНОЙ ЦИФРОВОЙ ОБРАБОТКИ ТЕКСТА – ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
Возможно, вы заметили, что бумага не ушла, но цифровизация постепенно вступает во владение. Вот тут-то и появляется оптическое распознавание символов (OCR). Программное обеспечение OCR позволяет оцифровывать печатные или рукописные документы, делая их редактируемыми с помощью программ обработки текста.
Оптическое распознавание символов (OCR) – это программа, которая может конвертировать отсканированные, распечатанные или рукописные файлы изображений в машиночитаемый текстовый формат.
Возможно, у вас есть книга или квитанция, которую вы напечатали или напечатали много лет назад, и вы хотите, чтобы она была в цифровом формате, но вы не хотите ее перепечатывать. OCR может быть очень полезным в таком случае.
Мы также можем использовать эту замечательную технологию для точного извлечения текста из изображений, преобразования печатной таблицы в электронную таблицу Excel или старой книги в PDF с текстами для поиска под изображениями страниц.
, мы представим вам лучшее бесплатное и платное программное обеспечение для распознавания текста на рынке.
Это основной вопрос, который у вас может возникнуть перед загрузкой OCR. Мы поможем вам выбрать, ответив на более конкретные вопросы:
Преобразуйте изображения в текст с помощью этих 8 программных решений OCR
Readiris 17 (рекомендуется)
Readiris 17 – последняя версия этого высокопроизводительного программного обеспечения для распознавания текста. Он поставляется с новым интерфейсом, новым механизмом распознавания и более быстрым управлением документами.
Вы можете легко конвертировать во многие различные форматы, включая аудиофайлы благодаря его устному распознаванию.
Readiris – это одно из самых мощных программ для распознавания текста, которое требует меньше усилий для начала работы. Хотя это платная программа, вы получаете то, за что платите. Readiris поддерживает большинство форматов файлов и поставляется с другими привлекательными функциями, которые упрощают процесс преобразования.
Например, изображения могут быть получены из подключенных устройств, таких как сканеры, и приложение также позволяет настраивать параметры обработки, такие как настройки DPI.
После завершения обработки Readiris определяет текстовые разделы или зоны и позволяет извлекать тексты либо из определенной зоны, либо из всего файла.
Readiris имеет редкую функцию сохранения в облаке, которая позволяет пользователям сохранять извлеченный текст в различные сервисы облачного хранения, такие как Google Drive, OneDrive, Dropbox и другие.
Он также имеет множество функций редактирования и обработки текста, что позволяет пользователям даже сканировать штрих-коды. Подписка начинается от 99 долларов, и предоставляется 10-дневная бесплатная пробная версия.
Лучший выбор качества Readiris- Точное восстановление текстов во всех видах файлов
- Много разных форматов выходных документов преобразования
- Легко создавать, изменять, подписывать и комментировать ваши PDF-файлы
ABBYY FineReader 14 (рекомендуется)
Microsoft OneNote также можно использовать в качестве OCR, несмотря на его функциональность в качестве хранителя заметок.
Существует опция «Копировать текст из рисунка», которая позволяет извлекать текст из изображений.
Его простота – вот что делает его уникальным; просто вставьте изображение в OneNote, затем щелкните правой кнопкой мыши изображение и выберите «Копировать текст из изображения», а OneNote сделает все остальное.
Он сохраняет текст в буфер обмена, а затем вы можете вставить текст в Microsoft Word или любую другую программу по вашему выбору.
Однако он не поддерживает таблицы и столбцы.
Обновление: последняя версия OneNote, которая поставляется с Windows 10, не имеет возможности распознавания текста. С другой стороны, OneNote, входящий в состав пакета Office, все еще можно использовать в качестве инструмента оптического распознавания текста.
- Получить Microsoft OneNote
Устраните любую проблему OneNote с помощью нашего подробного руководства!
Простое распознавание текста (бесплатно)
Простое распознавание текста – это удобный инструмент, который вы можете использовать для преобразования распечаток в печатном виде в редактируемые текстовые файлы.
Если у вас много рукописных документов и вы хотите преобразовать их в редактируемые текстовые файлы, тогда Simple OCR будет вашим лучшим вариантом.
Тем не менее, рукописное извлечение имеет ограничения и предлагается только в течение 14 дней бесплатной пробной версии. Машинная печать бесплатна и не имеет ограничений.
Существует встроенная проверка орфографии, которую вы можете использовать для проверки расхождений в преобразованном тексте. Вы также можете настроить программное обеспечение для чтения непосредственно со сканера.
Как и Microsoft OneNote, Simple OCR не поддерживает таблицы и столбцы.
- Проверьте Простое OCR
Бесплатный OCR
Free OCR использует Tesseract Engine, который был создан HP и теперь поддерживается Google.
Tesseract – очень мощный движок, и сегодня он считается одним из самых точных механизмов распознавания текста в мире.
Free OCR отлично справляется с форматами PDF и поддерживает устройства TWAIN, такие как цифровые камеры и сканеры изображений.
Кроме того, он поддерживает практически все известные файлы изображений и многостраничные файлы TIFF. Вы можете использовать программное обеспечение для извлечения текста из картинок, и оно делает это с высокой степенью точности.
И, как и другое программное обеспечение Free OCR, Free OCR не поддерживает вывод таблиц и столбцов.
- Получите бесплатное распознавание текста
Boxoft Free OCR (Бесплатно)
Boxoft Free OCR – еще один удобный инструмент, который вы можете использовать для извлечения текста из всех видов изображений.
Эта бесплатная программа проста в использовании и способна анализировать многостолбцовый текст с высокой степенью точности.
Он поддерживает несколько языков, включая английский, испанский, итальянский, голландский, немецкий, французский, португальский, баскский и многие другие.
Это программное обеспечение OCR позволяет вам сканировать ваши бумажные документы и конвертировать их в редактируемые тексты в течение очень короткого времени.
Хотя есть опасения, что это средство распознавания текста не очень хорошо извлекает текст из рукописных заметок, оно отлично работает с печатной копией.
- Проверьте Boxoft Бесплатный OCR
Хороший OCR лучше всего работает с одним из этих идеальных программ для сканирования, чтобы ускорить вашу работу!
Top OCR (Платный)
TopOCR отличается от типичного программного обеспечения OCR во многих аспектах, но выполняет работу точно. Лучше всего работает с цифровыми камерами и сканерами.
Его интерфейс также отличается, поскольку у него есть два окна – окно изображения (источника) и текстовое окно.
Как только изображение получено с камеры или сканера с левой стороны, извлеченный текст появляется с правой стороны, где находится текстовый редактор.
Программное обеспечение поддерживает форматы GIF, JPEG, BMP и TIFF. Вывод также может быть преобразован в несколько форматов, включая PDF, HTML, TXT и RTF.
Программное обеспечение также поставляется с настройками фильтра камеры, которые можно применять для улучшения изображения.
- Проверьте Top OCR
ABBYY FineReader Online (бесплатно)
Если вы хотите насладиться мощными функциями, которые ABBYY предлагает, но вы не хотите идти дорогим путем, то вы можете попробовать бесплатную онлайн-версию.
FineReader Online поддерживает множество входных файлов, таких как PDF, JPEG, JPG, PNG, DCX, PCX, TIFF, TIF и BMP. Поддерживаемые выходные файлы включают PDF, Word, Excel, e-Pub и Powerpoint.
Бесплатная версия позволяет вам конвертировать до 10 страниц в месяц, и она требует сначала сделать регистрацию, которая также бесплатна.
Однако, если вы интенсивный пользователь и хотите конвертировать больше страниц в месяц, вам нужно подписаться на платную версию.
Подписка начинается от 49 долларов за 2400 страниц в год и до 149 долларов за 12000 страниц в год. Вы также можете купить неограниченную версию (ABBYY FineReader Pro) за пожизненную плату в размере 169, 99 долларов США.
- Проверьте ABBYY FineReader Online
Заключение
Рынок наводнен программами OCR, которые могут извлекать текст из изображений и сэкономить вам много времени, которое вы могли бы потратить на перепечатывание документа.
Тем не менее, хорошее программное обеспечение OCR должно делать больше, чем извлекать текст из печатных документов. Он должен поддерживать макет, текстовые шрифты и текстовый формат в качестве исходного документа.
Мы надеемся, что эта статья поможет вам найти лучшее программное обеспечение для распознавания текста. Не стесняйтесь комментировать и делиться.
Программы оптического распознавания документов — урок. Информатика, 7 класс.
Очень часто появляется необходимость перевести в электронный вид текст каких-то документов, или даже книг. Можно затратить определённое время и просто набрать этот текст с помощью клавиатуры. Но, чем больше исходный текст, тем больше времени будет затрачено на его ввод в память компьютера.
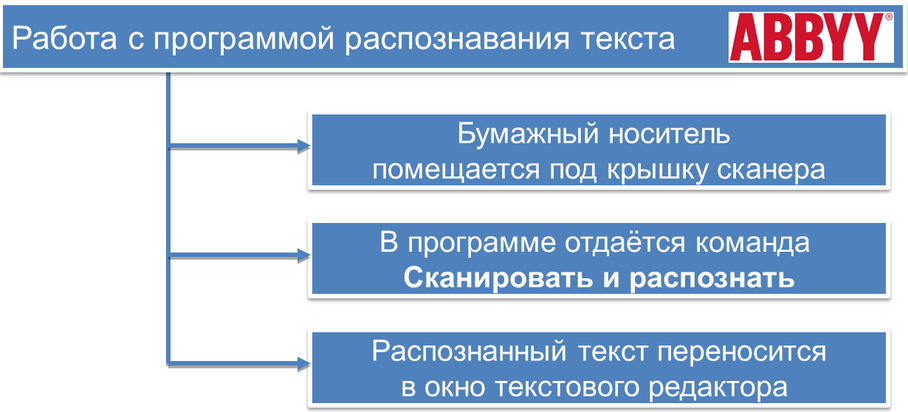
Поэтому для ввода текстов в память компьютера с бумажных носителей используют сканеры и программы распознавания символов.
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов.
Наиболее широко известна и распространена такая программа отечественных производителей — ABBYY FineReader.
Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках (на 179 языках), а также для распознавания смешанных двуязычных текстов.
Возможности программы ABBYY FineReader:
- Работает с разными моделями сканеров.
- Позволяет из бумажных документов, PDF-файлов и цифровых фото сделать редактируемый текст.
- Позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (многостраничными документами) и с бланками.
- Позволяет редактировать распознанный текст и проверять его орфографию.
- Сохраняет внешний вид документа, а также его структуру, то есть, расположение слов, абзацев, таблиц, изображений, заголовков и нумерация страниц останутся такими же, как и в оригинале.
- Экспортирует тексты в Word, Excel, PowerPoint или Outlook.

Преобразование бумажного документа в электронный вид происходит в пять этапов. Каждый из этих этапов программа FineReader может выполнять как автоматически, так и под контролем пользователя. Если все этапы проводятся автоматически, то преобразование документа происходит за один прием.
Пять этапов процесса обработки документа с помощью программы ABBYY FineReader:
- Сканирование документа (кнопка Сканировать).
- Сегментация документа (кнопка Сегментировать).
- Распознавание документа (кнопка Распознать).
- Редактирование и проверка результата (кнопка Проверить).
- Сохранение документа (кнопка Сохранить).

1) На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки. Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать.
2) Второй этап работы — сегментация, разбиение страницы на блоки текста. Если страница содержит колонки, иллюстрации, врезки, подрисуночные подписи или таблицы, то порядок распознавания требует коррекции. Содержимое страницы разбивается на блоки, внутри каждого из которых распознавание осуществляется в естественном порядке. Блоки нумеруются, исходя из порядка включения их в документ. При автоматической сегментации (кнопка Сегментировать) определение границ блоков осуществляется автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
При этом учитываются поля документа, просветы между колонками, рамки.
3) Процесс распознавания текста после сегментации начинается с щелчка на кнопке Распознать и полностью автоматизирован.
4) Когда распознавание данной страницы завершается, полученный текстовый документ отображается в окне Текст. Заключительные этапы работы позволяют отредактировать полученный текст с помощью средств, напоминающих текстовый редактор WordPad. Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить.
5) По щелчку на кнопке Сохранить запускается Мастер сохранения результатов. Он позволяет сохранить распознанный текст или передать его в другую программу (например, в Microsoft Word) для последующей обработки полученный текст можно сохранить в виде форматированного или неформатированного документа.
программы, системы и сервисы.
 Что использовать для распознавания текста документов?
Что использовать для распознавания текста документов?Программы для распознавания текста знакомы всем, кто в процессе работы сталкивался с необходимостью перевода печатных символов в электронный формат. Современные решения от лидера отрасли ABBYY давно вышли за рамки массового сегмента: теперь они помогают бизнесу. Разработки в области распознавания текста востребованы в банковском деле, в образовании, энергетике и т. д. В этой статье мы расскажем о том, какие задачи бизнеса позволяют решать технологии ABBYY.
Система оптического распознавания текста ABBYY OCR: пара слов о технологии
В XXI веке программы распознавания текста востребованы не только у частных пользователей, но и в бизнесе. Главным образом они служат для автоматизации ввода и обработки данных из документов, за счет чего помогают экономить время и деньги. Десятки тысяч компаний во всем мире используют решения ABBYY для повышения конкурентоспособности. А начиналось все в 1993 году, когда была создана технология оптического распознавания символов (OCR — Optical Character Recognition) ABBYY. Поясним вкратце, в чем принцип ее работы.
Поясним вкратце, в чем принцип ее работы.
Текст отсканированного документа, его фотографию или PDF-файл можно просматривать с экрана компьютера, но их содержимое нельзя копировать и изменять. Технология оптического распознавания переводит изображение в формат, доступный для редактирования. Программа находит буквы, объединяет их в слова и предложения, воссоздавая текст. Каким образом она это делает?
Сначала система определяет структуру документа: выделяет текстовые блоки, таблицы, графики, сноски, ссылки, колонтитулы, номера страниц и другие элементы оформления. Этот процесс производится постранично. Затем программа делит текст на строки, слова и символы. После этого в работу включаются механизмы распознавания — классификаторы. Они анализируют каждый символ и предлагают ряд гипотез о том, на какую букву или знак он похож. Из списка предположений классификаторы выбирают то, которому присвоен наибольший вес, и программа выдает распознанный текст.
Отличительные особенности технологии оптического распознавания текста от ABBYY:
- Быстрота и точность распознавания.
- Полное сохранение исходной структуры и форматирования документа. Программа восстанавливает не только сам текст, но и все элементы оформления, включая иллюстрации, гиперссылки, сноски, колонтитулы и т. п.
- Поддержка более 190 языков. Система распознавания текста интегрирована со словарями, и при проверке гипотез учитываются данные о языке документа. Это ускоряет процесс распознавания и сводит к минимуму вероятность ошибок.
- Распознавание символов, набранных любым шрифтом.
- Возможность сохранения текста почти во всех редактируемых форматах (DOC, TXT, RTF, XLS, HTML, PDF), автоматической передачи документа в другие приложения.
- Автоматизация однотипных операций, что позволяет распознавать и обрабатывать документы еще быстрее.
ABBYY OCR: от теории к практике
Какова же прикладная польза от технологий оптического распознавания текста? Процесс оптимизации бизнеса с их помощью идет сразу в нескольких направлениях:
- Уменьшение времени на обработку документов. С программой оптического распознавания текста ручные операции сводятся к минимуму. За счет этого процессы ввода и обработки данных идут быстрее, а сотрудники освобождают рабочее время для более важных задач.
- Повышение качества ввода данных. Автоматизация практически исключает ошибки, неизбежные при выполнении операций вручную.
- Снижение материальных затрат на обработку документов.
- Повышение скорости и качества обслуживания клиентов, что ведет к росту лояльности.
 С программой оптического распознавания текста ручные операции сводятся к минимуму. За счет этого процессы ввода и обработки данных идут быстрее, а сотрудники освобождают рабочее время для более важных задач.
С программой оптического распознавания текста ручные операции сводятся к минимуму. За счет этого процессы ввода и обработки данных идут быстрее, а сотрудники освобождают рабочее время для более важных задач.Все это в комплексе влияет на конкурентоспособность компании и помогает бизнесу стать успешнее. Наглядно представить преимущества внедрения программы позволяет статистика:
Посмотрим, какие задачи решает программа распознавания текста в конкретных отраслях.
Банковская сфера
Сотрудники банков ежедневно работают с колоссальным объемом бумажной документации. Технологии распознавания текста позволяют экономить массу времени, труда и средств при осуществлении этих операций. Уже 80 российских банков, входящих в топ-100[1], оценили решения ABBYY. Вот примерный перечень задач, с которыми справляются решения ABBYY для распознавания текста:
Уже 80 российских банков, входящих в топ-100[1], оценили решения ABBYY. Вот примерный перечень задач, с которыми справляются решения ABBYY для распознавания текста:
Оптимизация сбора, хранения и обработки клиентских данных
Программа сканирует поступающие документы и автоматически проверяет, правильно ли они заполнены. После этого программа отправляет скан-образы сотруднику банка для верификации. При этом система умеет распознавать ключевые поля в зависимости от типа документа и сравнивать их содержимое с учетными данными. Верифицированные сотрудниками скан-образы автоматически сохраняются в архив. Любые данные из документов можно передавать в информационные системы банка.
Пример
Система потокового ввода клиентских данных от ABBYY успешно используется «Россельхозбанком». Решение позволило создать централизованное хранилище документов с онлайн-доступом, минимизировать потерю информации, ускорить взаимодействие между головным офисом и 78 филиалами. Благодаря автоматизированному вводу данных сотрудники банка теперь ежемесячно обрабатывают 4 млн страниц[2].
Благодаря автоматизированному вводу данных сотрудники банка теперь ежемесячно обрабатывают 4 млн страниц[2].
Быстрая обработка документов для выдачи кредита
Когда клиент предоставляет документы для получения кредита, система сканирует их и автоматически проверяет правильность оформления. Также программа определяет, все ли необходимые данные имеются. Автоматизация ввода и анализа документов позволяет как минимум в два раза сократить сроки обработки кредитных заявок[3].
Автоматический ввод данных при открытии счета юрлица
До внедрения технологий распознавания текста сотрудник банка вносил данные для открытия расчетного счета вручную. Для этого было необходимо проверить комплектность документов, удостовериться в корректности заполнения, отсканировать их, извлечь необходимые данные и передать на дальнейшую обработку в информационные системы банка. Программа выполняет все эти операции автоматически.
Автоматизация расчетно-кассовых операций
Чтобы провести платеж, сотрудник банка вводит в систему данные из платежных документов. В организациях, использующих решения ABBYY, этот процесс протекает в 5–10 раз быстрее[4]. Программа сканирует документы, распознает и извлекает необходимые данные, а потом выдает их оператору. При автоматическом вводе устраняется человеческий фактор, и ошибок практически не бывает.
В организациях, использующих решения ABBYY, этот процесс протекает в 5–10 раз быстрее[4]. Программа сканирует документы, распознает и извлекает необходимые данные, а потом выдает их оператору. При автоматическом вводе устраняется человеческий фактор, и ошибок практически не бывает.
Автоматизация валютного контроля
Финансовые операции с использованием иностранной валюты относятся к особо трудоемким и сложным банковским процессам, поскольку их осуществление требует строгого соблюдения норм валютного законодательства. Сотрудник банка должен проявлять особое внимание при вводе и проверке данных. Решения от ABBYY позволяют автоматизировать обработку документов валютного контроля, ускорить операции и практически полностью исключить ошибки.
Энергетика
Возможности технологий распознавания текстов востребованы и в энергетической отрасли. Прежде всего они используются для автоматизации обработки бумажных и электронных документов.
Автоматизированный ввод данных с приборов
Показания приборов используются и при коммерческом учете потребления электроэнергии, и при техническом обслуживании оборудования (результаты проведения испытаний). Данные чаще всего поступают на бумажных носителях. Показания приборов учета и измерительных устройств вводятся в информационную систему для обработки. Благодаря решениям ABBYY этот процесс происходит автоматически. Программа позволяет сократить сроки обработки документов, исключить ошибки ввода, уменьшить затраты труда персонала.
Данные чаще всего поступают на бумажных носителях. Показания приборов учета и измерительных устройств вводятся в информационную систему для обработки. Благодаря решениям ABBYY этот процесс происходит автоматически. Программа позволяет сократить сроки обработки документов, исключить ошибки ввода, уменьшить затраты труда персонала.
Автоматизация бухгалтерских операций
Через отделы бухгалтерии электросетевых компаний ежедневно проходит огромное количество финансовых документов. Каким бы внимательным ни был сотрудник, при таком объеме данных неизбежно возникают ошибки. Это приводит к потерям времени и средств, особенно при несвоевременном обнаружении. Не говоря уже о длительности самого процесса ручного ввода.
Внедрение решения по распознаванию текста на 50% сокращает затраты при обработке счетов-фактур[5], минимизирует ошибки ввода, предотвращает потерю данных. Программа сканирует, распознает и проверяет документы, автоматически извлекает из них нужную информацию и вводит ее в систему. Бухгалтеру остается только подтвердить, правильно ли распознаны данные.
Бухгалтеру остается только подтвердить, правильно ли распознаны данные.
Пример
Компания КЭС-Энергостройсервис, занимающаяся ремонтом объектов энергетики, столкнулась с проблемой чрезмерных затрат на документооборот. Чтобы получить нужные запчасти, приходилось ждать 3–7 дней: именно столько времени занимал процесс обработки и согласования документов. После внедрения платформы ABBYY FlexiCapture бухгалтеры стали выполнять эту работу за 1–3 часа[6].
Быстрая обработка заявок по технологическому присоединению физических и юридических лиц к электросетям
Прежде чем заключить с потребителем договор на технологическое присоединение к электросетям, сотрудники энергетической компании принимают и обрабатывают заявку. Несмотря на то что этот документ разрешается подавать в электронном виде, многие заявители по-прежнему предпочитают традиционные бумажные носители. Персоналу приходится вводить данные вручную, затрачивая лишнее время и труд.
С внедрением решения ABBYY все упрощается: бумажная заявка сканируется, затем программа помещает скан-копию в электронное хранилище, а распознанные данные передает в информационную систему, где они автоматически обрабатываются. Рутинная работа сотрудников сводится к минимуму, и они могут уделять время другим задачам.
Нефтегазовая отрасль
Нефтегазовые компании в своей работе тоже сталкиваются с большим объемом бумажной документации. Данные нужно оперативно и точно вносить в систему и обрабатывать. При этом необходимо, чтобы сотрудники имели к ним быстрый доступ. Понимая, что от этих процессов зависит эффективность бизнеса, руководители компаний стремятся автоматизировать обработку и хранение документов. Наиболее практичным решением представляется создание удобного электронного архива с широким спектром функциональных возможностей. ABBYY уже реализовала несколько таких проектов в нефтегазовой отрасли.
Например, в ОАО «Востокгазпром» удалось за короткое время оптимизировать ввод учетных и финансовых документов с помощью платформы ABBYY FlexiCapture. Перед разработчиками стояла задача обеспечить точность внесения данных, быстрый доступ к нужной информации. С этой целью было создано 25 шаблонов для обработки актов, накладных, кассовых ордеров и других стандартных типов документов предприятия.
Перед разработчиками стояла задача обеспечить точность внесения данных, быстрый доступ к нужной информации. С этой целью было создано 25 шаблонов для обработки актов, накладных, кассовых ордеров и других стандартных типов документов предприятия.
Система автоматически вписывает реквизиты документа в его архивную карточку, прикрепляет скан-копию и результат распознавания в доступном для полнотекстового поиска формате. Текстовые данные программа вносит в нужные поля, проверяет их в соответствии с заданными правилами, подсвечивает возможные ошибки. В результате работа сотрудника сводится к итоговому контролю и подтверждению экспорта документа.
Другие отрасли
Применение программ распознавания текста не исчерпывается перечисленными сферами. Решения от ABBYY востребованы и во многих других отраслях экономики, в частности в образовании, государственном секторе, производстве, логистике и транспорте, ритейле, телекоммуникациях и др.
Возможности программы по распознаванию текста позволяют оптимизировать бизнес-процессы и за счет этого повысить конкурентоспособность компании. Автоматизированная обработка документов экономит время сотрудников и снижает затраты на обработку данных. Удобство и функциональность решений ABBYY уже оценили многие предприятия из разных сфер бизнеса.
Автоматизированная обработка документов экономит время сотрудников и снижает затраты на обработку данных. Удобство и функциональность решений ABBYY уже оценили многие предприятия из разных сфер бизнеса.
P.S. ABBYY — мировой лидер в области технологий интеллектуальной обработки информации. С продуктами и отраслевыми решениями компании можно ознакомиться на сайте www.abbyy.com.
Программы распознавания и перевода текста для Android-смартфона
Как быстро внести в телефон новый контакт с бумажной визитной карточки или реквизиты платежа с квитанции без QR-кода? Поможет приложение распознавания текста с камеры, которое можно запустить на любом телефоне под управлением Android.
Что может программа для распознавания текста
- Распознать текст объявления, чтобы вытащить из него номер телефона.
- Быстро перевести объявление на иностранном языке или переслать его в виде текста другому человеку.
- Заплатить по реквизитам, не вбивая БИК и других кодов с квитанции.
- Сделать из страницы учебника шпаргалку.

TextGrabber от Abbyy
Компания ABBYY известна своим программным обеспечением для распознавания и перевода текстов с листа. Скачать приложение для мобильно телефона можно по ссылке из официального магазина Google.
При старте отображается окно для сканирования с камеры.
Чтобы усложнить задачу приложению, мы предложили ему распознать текст с экрана компьютера. На следующем этапе предлагается выделить фрагмент. Это позволит убрать картинки и поднять тем самым качество распознавания.
Вот полученный фрагмент на русском языке (оригинальный). Желтым шрифтом — слова, распознанные неуверенно. При сканировании с бумаги качество будет лучше.
После нажатия кнопки Перевести получаем английский вариант.
Для профессионального перевода программа TextGrabber вряд ли подойдет, но с меню в европейском ресторане справится. Бесплатная версия поддерживает до трех языков. Платная может переводить оффлайн с 10 языков. Онлайн можно использовать более 100!
Онлайн можно использовать более 100!
Text Fairy
Приложение Text Fairy можно установить из официального магазина Google Play по этой ссылке. Распознаются фотографии текста. Выделяем фрагмент.
Помогаем программе определиться, сколько в тексте колонок, и указываем язык, чтобы улучшить распознавание.
Как видим по качеству распознавания, с русским языком у Text Fairy дела обстоят хуже, чем у TextGrabber. Процесс перевода картинки в буквы занял раз в 10 дольше.
Точно распознался только заголовок. Его мы и попробовали перевести.
Здесь использован переводчик от Google, своего не предусмотрено. Это натолкнуло нас на идею сравнить результат с тем, что позволяют получить мобильные переводчики. Без долгого процесса распознавания вот такую картинку показал Google Translate.
Вот так перевел текст Яндекс.
Перевод текст грабберам лучше не доверять, а воспользоваться для этого специальными приложениями-переводчиками.

Топ-5 приложений и программного обеспечения для оптического распознавания символов (OCR) – Codpast
При написании письменных работ теперь есть больше способов, чем когда-либо, сократить количество, которое нам действительно нужно печатать. Это означает, что мы можем тратить больше времени на то, чтобы записать наши замечательные мысли, вместо того, чтобы тратить его на поиски клавиши Shift. Есть отличное новое программное обеспечение «Speech Text» и несколько довольно хороших служб онлайн-перевода. Однако одна вещь, которую многие упускают из виду, – это оптическое распознавание символов (OCR.) OCR отлично подходит для передачи текста из физических источников непосредственно в цифровой документ. Существуют различные типы программ и приложений OCR для настольных и мобильных устройств. Они различаются по цене, но у каждого приложения или сервиса есть свои ключевые особенности. Если вас ежедневно окружают документы, скорее всего, мы нашли приложение OCR, которое вам подходит.
Вас также может заинтересовать эта статья: Обзор конвертера изображений в Excel: OCR с классным трюком в рукаве
1.Сканер PDF: сканирование документов + OCR (для пользователей Android / бесплатно)
Одним из самых популярных приложений OCR, которое продолжает получать восторженные отзывы за простоту использования, является «PDF Scanner: Document Scan + OCR». Доступное для пользователей Android, приложение импортирует изображения, а также файлы PDF и позволяет добавлять в документы свою персональную подпись. Его размер составляет всего 5 МБ, и его также можно загрузить бесплатно. Несмотря на то, что это бесплатное приложение, нет ограничений на количество документов, которые вы можете сканировать, и нет водяных знаков, поэтому ваши документы готовы к работе.https://play.google.com/
2. ONLINE OCR (Desktop / Free)
ONLINE OCR (Desktop / Free)
Это OCR можно найти в Интернете, оно очень простое и легкое в использовании. Что хорошо в «бесплатном онлайн-распознавании текста», так это то, что оно поддерживает 46 языков, включая итальянский, португальский, испанский, японский и китайский. Он работает путем выбора и загрузки файла (размером до 5 МБ) и преобразования его в файл Microsoft Word, Excel или обычный текстовый файл. После регистрации у вас есть возможность покупать больше страниц в час, от 3 фунтов стерлингов.43 за 50 страниц до 276,39 фунтов стерлингов за 50000 страниц. При регистрации и регистрации у вас также есть возможность конвертировать многостраничные документы PDF, RTF, Excel и файлы размером до 100 МБ. http://www.onlineocr.net/
3. OmniPage Standard 18 (настольный ПК / стоимость 54,99 фунтов стерлингов)
Для тех, кто хочет использовать OCR на профессиональном уровне и не против потратить немного денег, OmniPage Standard 18 обойдется вам в 54,99 фунтов стерлингов. Совсем недавно он был удостоен награды «Золотой призер» и занял 1-е место в рейтинге лучших отзывов.com список обзоров и сравнений программного обеспечения OCR. Несмотря на то, что это наш самый дорогой вариант, это не самое дорогое распознавание текста. По цене набор функций впечатляет; возможность воссоздавать бумажные или PDF-документы в электронные файлы, текстовые файлы с возможностью поиска по словам, обрабатывать большое количество документов, но, что наиболее важно, вы можете ожидать, что каждый новый файл будет точно соответствовать цвету, макету и шрифту исходного документа.
Совсем недавно он был удостоен награды «Золотой призер» и занял 1-е место в рейтинге лучших отзывов.com список обзоров и сравнений программного обеспечения OCR. Несмотря на то, что это наш самый дорогой вариант, это не самое дорогое распознавание текста. По цене набор функций впечатляет; возможность воссоздавать бумажные или PDF-документы в электронные файлы, текстовые файлы с возможностью поиска по словам, обрабатывать большое количество документов, но, что наиболее важно, вы можете ожидать, что каждый новый файл будет точно соответствовать цвету, макету и шрифту исходного документа.
https://www.business.com/reviews/omnipage-standard/
4.Office Lens (мобильный / бесплатно)
Разработанный Microsoft, Office Lens – еще одно средство распознавания текста для мобильных устройств. Его основное предназначение – оцифровка заметок на досках или классных досках. Он также может делать цифровые копии ваших печатных документов, визитных карточек или плакатов и обрезать их, его популярность связана с его способностью улучшать и оптимизировать захваченные изображения, автоматически масштабируя изображения по размеру.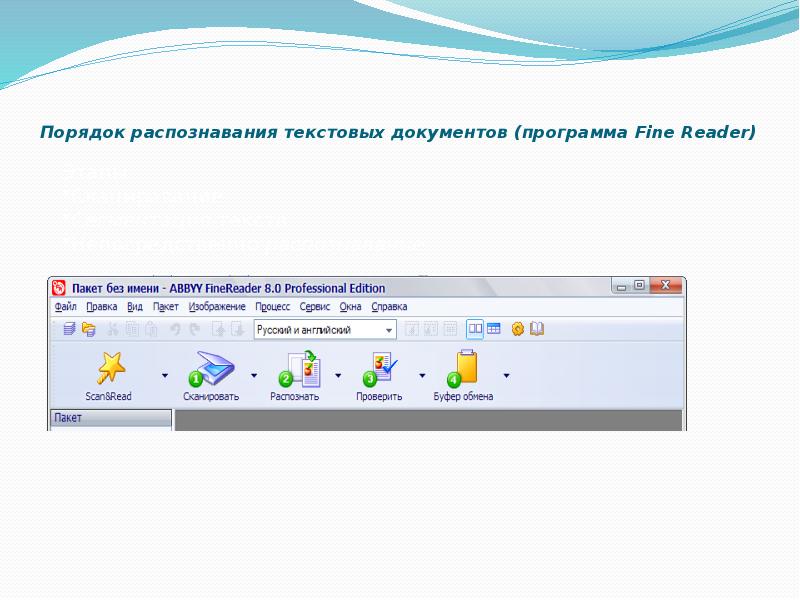 Office Lens можно загрузить в App Store и Google Play.
Office Lens можно загрузить в App Store и Google Play.
После сканирования изображение можно сохранить в OneNote, OneDrive или локально на устройстве по вашему выбору.Вы также можете конвертировать изображения в файлы Word (.docx), PowerPoint (.pptx) или PDF (.pdf). https://play.google.com/store/
5. Google Документы
Для тех, кто уже знаком с Документами Google, вы можете использовать оптическое распознавание текста, встроенное в Google Диск. Для достижения наилучших результатов шрифт документов должен быть установлен на Arial или Times New Roman. Вы можете еще больше улучшить результат, убедившись, что отсканированное изображение имеет равномерное освещение и четкий контраст между цветами.Изображения можно обрабатывать индивидуально (файлы jpg, png и gif) или в многостраничных документах PDF. Он также поддерживает ряд языков, от филиппинского, финского до идиш и зулусский. Разрешение вашего документа также должно быть не менее 10 пикселей в высоту, чтобы у Документов Google были хорошие шансы распознать ваш текст. https://support.google.com
Разрешение вашего документа также должно быть не менее 10 пикселей в высоту, чтобы у Документов Google были хорошие шансы распознать ваш текст. https://support.google.com
Слова Джеймса Чайлдса
Если вам нравится этот пост, подпишитесь на этот блог, подпишитесь на нашу рассылку новостей или подпишитесь на нас в Facebook или Twitter, чтобы быть в курсе нового контента.Вам также могут понравиться наши подкасты.
Codpast – это мультимедийная продукция с сайта www.extraordinaire.tv
Топ 4 лучших бесплатных программ для распознавания текста
Извлекайте текст из изображений или отсканированных документов. Преобразуйте изображения в текст с помощью приложений для распознавания текста. Программа OCR будет сравнивать содержимое изображений с буквами или словами, которые есть в их базе данных; он распознает текст из изображений или других типов файлов и преобразует их в редактируемый текстовый файл (Word, TXT. .).
.).
Это либо отсканированные документы, которые вам нужны в текстовом формате, либо файлы PDF, полученные по электронной почте, программа OCR (оптического распознавания символов) сделает это. Сфера использования может расширяться до счетов-фактур, карточек, огромных списков, изображений или текста, сделанных с помощью смартфонов.
Эти программы обычно конвертируют текст из изображений в редактируемые документы Word, Text, Excel, PDF, Html.
Вот список из 4 лучших бесплатных программ ocr .Когнитивный OpenOCR (клинопись)
Это приложение отлично работает и распознает множество языков ввода, включает мастер, который проведет пользователя по всем предлагаемым параметрам и функциям, прост в использовании и дает отличные результаты.Является одним из лучших продуктов в этой нише, автоматически корректирует входной файл для обеспечения наилучшего разрешения и генерирует качественные результаты с правильными словами.
БесплатноOCR
FreeOCR от Paperfile прост и удобен в использовании, дает очень хорошие результаты, вам не нужно вносить много исправлений.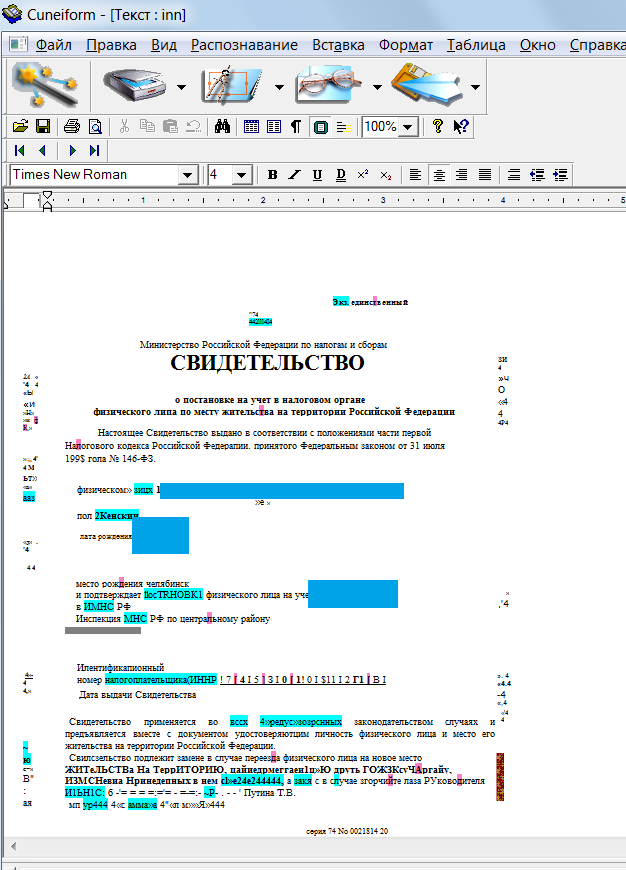 Одна интересная особенность заключается в том, что она позволяет изменять порядок текста, что полезно для некоторых языков, где люди читают справа налево. Примечание: программа предлагает установить дополнительное программное обеспечение, внимательно прочтите, что вы принимаете при установке.
Одна интересная особенность заключается в том, что она позволяет изменять порядок текста, что полезно для некоторых языков, где люди читают справа налево. Примечание: программа предлагает установить дополнительное программное обеспечение, внимательно прочтите, что вы принимаете при установке.
Бесплатное распознавание текста в Word
Отличается современным интерфейсом, который позволяет легко получить доступ ко всем задачам, включает функции поворота, если изображение не подогнано под размер экрана, результаты требуют некоторых исправлений.
SimpleOCR
У этой программы старый интерфейс, и результаты требуют многих исправлений. Некоторые плюсы могут заключаться в том, что пакетная обработка нескольких файлов один раз и включает проверку орфографии, которая предлагает новые слова для исправления сломанных.
Лучшее программное обеспечение OCR – Распознавание текста и рукописного ввода OCR
Оптическое распознавание символов (OCR)
OCR – это процесс извлечения слов (и, возможно, информации о макете и форматировании) из файлов изображений, таких как факсы и PDF-файлы, прикрепленных к электронным письмам, и преобразования их в текст. После того, как изображение было отсканировано на компьютер, программа OCR переводит текстовые изображения в реальный текст, который компьютер может прочитать. OCR лучше всего работает с печатным текстом либо в случаях, когда исходная распечатка отсутствует, либо при сканировании распечатанных или машинописных листов.
После того, как изображение было отсканировано на компьютер, программа OCR переводит текстовые изображения в реальный текст, который компьютер может прочитать. OCR лучше всего работает с печатным текстом либо в случаях, когда исходная распечатка отсутствует, либо при сканировании распечатанных или машинописных листов.
Оптическое распознавание меток (OMR)
В процессе OMR оптический считыватель меток обнаруживает метки на отсканированном бланке. Программное обеспечение OMR – это компьютерное приложение, которое использует сканер изображений для обработки опросов, ведомостей посещаемости, тестов, контрольных списков и других печатных форм. Программное обеспечение OMR – это высоконадежный и специализированный метод точного чтения и сканирования данных.
Распознавание штрих-кода
Штрих-код представляет символы в виде наборов параллельных полос различной толщины и разделения, которые считываются оптически при поперечном сканировании. Программное обеспечение для распознавания штрих-кодов автоматически обнаруживает и декодирует популярные типы штрих-кодов в любом направлении на отсканированных документах. Программное обеспечение собирает данные о продуктах и клиентах, сохраняя их на вашем компьютере.
Программное обеспечение для распознавания штрих-кодов автоматически обнаруживает и декодирует популярные типы штрих-кодов в любом направлении на отсканированных документах. Программное обеспечение собирает данные о продуктах и клиентах, сохраняя их на вашем компьютере.
Интеллектуальное распознавание символов (ICR)
Вам нужно преобразовать рукописный ввод в текст? ICR – это компьютерный перевод рукописных и рукописных символов. Программное обеспечение ICR иногда используется вместе с программным обеспечением OCR во время обработки форм. Однако в то время как программное обеспечение OCR может считывать неструктурированный машинно-напечатанный текст хорошего качества, программное обеспечение ICR предъявляет строгие требования к дизайну.Программное обеспечение ICR выполняет анализ изображения, чтобы точно выровнять изображение, сопоставить зоны ICR с предсказуемыми полями данных и начать категоризацию данных как набранные символы, отпечатки от руки или другие типы данных.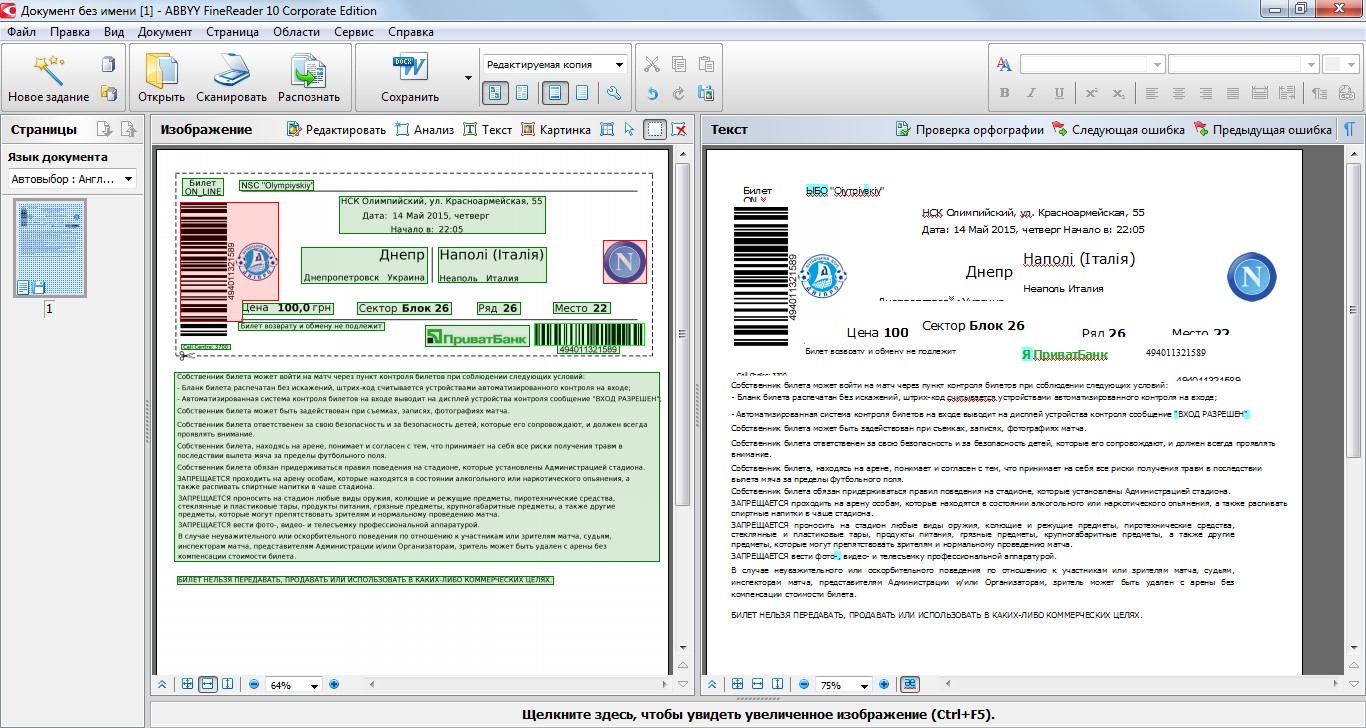 Программное обеспечение ICR позволяет добиться автоматического документооборота, что значительно повышает вашу эффективность.
Программное обеспечение ICR позволяет добиться автоматического документооборота, что значительно повышает вашу эффективность.
Двойное голосование
Технология двойного голосования позволяет параллельно использовать механизм OCR и систему голосования. В качестве альтернативы, любой из механизмов OCR может применяться индивидуально на уровне поля для повышения точности распознавания.
Многопоточность для многопроцессорной архитектуры
Эта технология предусматривает несколько потоков на операцию для оптимальной пропускной способности многоядерных процессоров для приложений, работающих с большим количеством изображений.
обзоров программного обеспечения – 5 лучших бесплатных программ для распознавания текста – Бесплатное распознавание текста в Word
Допустим, вы хотите редактировать и анализировать информацию в книге с помощью компьютера. Как бы ты это сделал? Кажется очевидным, просто отсканировать книгу. Но отсканированный документ – это просто изображение, и мало что можно сделать для редактирования текста на изображении. Поэтому большинство людей вручную набирают текст заново. Эти люди не знают, что существует технология, называемая оптическим распознаванием символов ( OCR ). Эта технология анализирует напечатанный текст на изображениях и преобразует его в данные, редактируемые на компьютере. Вот почему мы предоставляем информацию и источники загрузки Best Free OCR Software в этом посте.
Поэтому большинство людей вручную набирают текст заново. Эти люди не знают, что существует технология, называемая оптическим распознаванием символов ( OCR ). Эта технология анализирует напечатанный текст на изображениях и преобразует его в данные, редактируемые на компьютере. Вот почему мы предоставляем информацию и источники загрузки Best Free OCR Software в этом посте.
Когда вам предлагают страницу с письменным текстом, подобную этой, она имеет для вас ценность только в том случае, если вы можете распознать язык и прочитать его.Мозг распознает шаблоны символов (которые представляют собой буквы, числа и знаки препинания) и преобразует символы в слова, а слова в предложения.
Компьютеры тоже могут распознавать символы и преобразовывать их в текст. Сначала вы должны представить компьютеру изображение текста, отсканированный файл или изображение с цифровой камеры. Изображение – это не что иное, как набор пикселей. Другими словами, изображение текста ничем не отличается от изображения Эйфелевой башни. Итак, программное обеспечение OCR помогает компьютеру преобразовывать изображение текста в текст.Это программное обеспечение конвертирует изображения текста в файл DOC или файл TXT. Затем эти форматы можно редактировать и изменять с помощью таких программ, как Microsoft Word.
Другими словами, изображение текста ничем не отличается от изображения Эйфелевой башни. Итак, программное обеспечение OCR помогает компьютеру преобразовывать изображение текста в текст.Это программное обеспечение конвертирует изображения текста в файл DOC или файл TXT. Затем эти форматы можно редактировать и изменять с помощью таких программ, как Microsoft Word.
Процесс OCR
OCR включает в себя процесс. Каждый шаг процесса важен для определения точности окончательного текста.
Улучшение печати. Процесс OCR начинается с того, что распечатанный документ необходимо преобразовать. Если на нем есть отметины, пятна от кофе и плохой контраст, программа склонна делать ошибки при распознавании символов.Вы можете сделать фотокопию отпечатка, чтобы улучшить его качество.
Отсканируйте распечатанный документ. Программа OCR работает с файлами изображений. Отсканируйте документ, чтобы преобразовать его в изображение. Хорошая цифровая камера – хороший вариант, так как она дает четкие изображения документов.
Черно-белый (двухцветный). Вам необходимо преобразовать отсканированные файлы в черно-белые. Процесс OCR является двоичным (есть символ или нет). Черный цвет на изображении является частью узора, который нужно распознать, а белый – фоном.
Распознавание символов. Следующий этап – оптическое распознавание символов. Скорость этого процесса зависит от используемой программы распознавания текста. Большинство из этих программ анализируют каждый символ на изображении один за другим. Целью программ OCR является распознавание символов, но хорошие программы распознают изображения, таблицы и другие элементы макета в отсканированных документах.
Исправление ошибок. Процесс не идеален, так как существует множество факторов, которые могут повлиять на точность.Программы оптического распознавания текста имеют встроенные средства проверки правописания и выделяют любое слово с потенциально орфографической ошибкой. Некоторые из этих программ настолько сложны, что выявляют несоответствие слов и грамматические ошибки.

Как правило, так работает процесс распознавания текста. Всегда проверяйте окончательную работу, особенно если исходный документ был низкого качества.
Программное обеспечение
OCR имеет много преимуществ для предприятий, студентов, юристов, медицинских работников и многих других людей.Вот 5 основных причин, по которым вам нужно программное обеспечение для оптического распознавания текста.
Избегать повторного набора
Альтернативой технологии OCR является набор текста вручную. Перепечатка уже существующей работы утомительна и пустая трата драгоценного времени. С OCR вам больше не нужно повторно вводить что-либо, что уже существует.
Редактировать печатный текст
После того, как программа OCR отсканировала и преобразовала файлы изображений в текст, вы можете легко редактировать текст.Вы можете добавлять новую информацию и даже добавлять изображения к исходному тексту.
Быстрый цифровой поиск
Отсканированные документы теперь можно сохранять как текстовые документы. В этом формате вы можете легко выполнить быстрый поиск по ключевой фразе. Секретарям больше не нужно просматривать горы файлов, чтобы найти счет.
Освободить место
Оформление документов, особенно в деловой среде, действительно может занимать физическое пространство.Как только вы отсканируете все документы и сохраните их в doc. или в формате PDF, вам больше не нужны файлы и картотеки. Таким образом, вы сэкономите много места в офисе.
Быстрый доступ к информации
Сохранение документов в цифровом виде не только экономит место в офисе, но и обеспечивает быстрый доступ к документам. Кроме того, к этим файлам можно получить доступ удаленно.

Мы не просто случайно выбрали лучшее бесплатное программное обеспечение для распознавания текста. Мы протестировали и пересмотрели каждое программное обеспечение, принимая во внимание следующие факторы:
Мы протестировали и пересмотрели каждое программное обеспечение, принимая во внимание следующие факторы:
Точность
Точность – это то, что отличает хорошую программу распознавания текста от плохой.Тем не менее, нереально ожидать 100% точности от любого программного обеспечения для распознавания текста. Такие факторы, как качество исходных отсканированных документов и качество самого сканера, сильно влияют на конечный результат. Хорошие программы OCR всегда достигают 98% при использовании с хорошим сканером и с оригинальными документами в отличном состоянии. Пока вы не протестируете программу, всегда относитесь к заявлениям производителя о точности с недоверием.
Многоязычная поддержка
Некоторые программы OCR распознают более одного языка.Такие программы должны быть вашим выбором, если вы будете сканировать документы на другом языке. Программа OCR сканирует отдельный символ, чтобы определить, что это за буква. Программное обеспечение, запрограммированное для распознавания только английских символов, не будет точно интерпретировать специальные символы, такие как β, или буквы с диакритическими знаками, такие как é. Такое программное обеспечение будет представлять эти символы с ближайшим эквивалентом на английском языке.
Такое программное обеспечение будет представлять эти символы с ближайшим эквивалентом на английском языке.
При использовании программного обеспечения, поддерживающего несколько языков, вы должны указать язык документа, чтобы он мог точно распознавать текст.
Поддержка рукописного ввода
Печатный текст (напечатанный на принтере) легко распознается любой программой OCR. Однако рукописный текст – это совсем другое испытание. У людей очень разные почерки. Некоторые пишут аккуратно, в то время как большинство почерков недостаточно разборчиво для человека, не говоря уже о компьютерах. Однако достойные программы OCR могут распознавать аккуратно написанный от руки текст. Итак, если вы собираетесь архивировать рукописные документы, поищите программы OCR, которые распознают рукописный текст.
Уровень автоматизации
Программное обеспечение OCR может работать как автоматически, так и в интерактивном режиме. Если вам нужно сканировать много документов одновременно, вам следует подумать о программах распознавания текста, которые запускаются автоматически.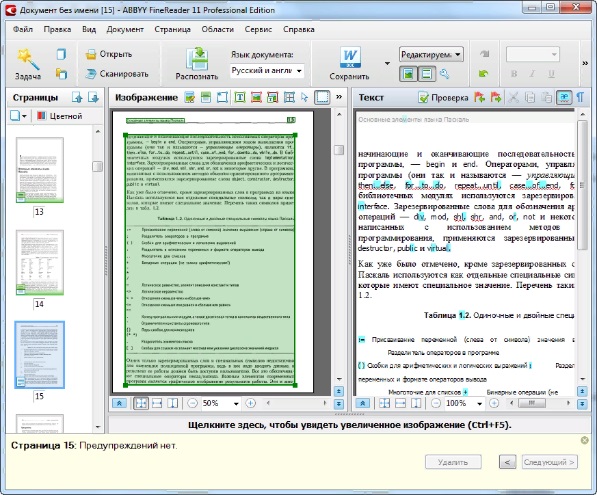 С помощью такой программы за несколько щелчков мышью вы начинаете сканирование документов, переходите к другим задачам и возвращаетесь, чтобы найти редактируемый файл PDF, TXT или DOC. Большинство бесплатных программ OCR имеют ограниченную автоматизацию. Однако вы обнаружите, что интерактивный ввод дает наиболее точные результаты.
С помощью такой программы за несколько щелчков мышью вы начинаете сканирование документов, переходите к другим задачам и возвращаетесь, чтобы найти редактируемый файл PDF, TXT или DOC. Большинство бесплатных программ OCR имеют ограниченную автоматизацию. Однако вы обнаружите, что интерактивный ввод дает наиболее точные результаты.
Сохранение макета
Основное назначение этих программ – преобразование текста изображения в текст.Некоторые не сохранят макет исходного документа. Следовательно, вам придется много редактировать в окончательной копии. Хорошая программа должна сохранять исходный макет, поэтому в окончательной копии потребуются незначительные работы по редактированию. Некоторые из рассмотренных ниже программ сохранят столбцы, таблицы и графические изображения в исходном документе.
После опробования и тестирования различных программ, основанных на факторах, описанных выше, вот обзоры лучшего бесплатного программного обеспечения для распознавания текста.
1.Бесплатное распознавание текста в Word
Free OCR to Word – лучшее бесплатное программное обеспечение для распознавания текста, которое открывает широкий спектр форматов файлов изображений и преобразует текст в изображениях в редактируемый текст. Он имеет интуитивно понятный пользовательский интерфейс, обеспечивающий быстрый доступ ко всем функциям. Функция «Открыть» позволяет открывать изображения, уже сохраненные на вашем компьютере. Функция «сканирование» позволяет программному обеспечению напрямую сканировать файлы в подключенном сканере. Программа хорошо работает со сканерами всех основных производителей. Отсканированный файл или изображение отображается в левом окне.
Функция «OCR» быстро отобразит любой распознанный текст в правом окне. Затем вы можете сохранить распознанный текст как файл TXT или файл .doc. Если вас не устраивают результаты, вы можете использовать ярлык «Очистить текст в правом окне» и снова сгенерировать текст.
Точность окончательного текста зависит от состояния исходного документа. Вам нужно будет вычитать окончательный текст и исправить любые слова с орфографическими ошибками.
Вам нужно будет вычитать окончательный текст и исправить любые слова с орфографическими ошибками.
Плюсы
Минусы
Может быть неточно
Плохое сохранение макета
Скачать бесплатно OCR в Word
2.Клинопись OpenOCR
Cuneiform OpenOCR изначально был коммерческим продуктом, но теперь доступен бесплатно. У него отличный движок OCR, хотя может показаться, что это не так из-за устаревшего пользовательского интерфейса. Вы можете открывать файлы изображений, сохраненные на компьютере, или сканировать изображения напрямую со сканера. Перед процессом оптического распознавания текста исходное изображение можно повернуть, увеличить или уменьшить, или определенную область изображения можно выбрать для распознавания.
Поскольку он распознает 20 языков, используйте мастер распознавания, чтобы указать язык ввода. После процесса OCR вы можете использовать функцию проверки правописания, чтобы исправить орфографические ошибки из доступных предложений. Это программное обеспечение распознает таблицы и изображения и сохраняет их в отдельном файле. Кроме того, он сохраняет исходный макет, текст и стили форматирования, такие как полужирный шрифт и курсив. Вы можете редактировать сгенерированный текст или сохранить его для редактирования позже, или экспортировать его в другую программу, такую как Microsoft Word.
После процесса OCR вы можете использовать функцию проверки правописания, чтобы исправить орфографические ошибки из доступных предложений. Это программное обеспечение распознает таблицы и изображения и сохраняет их в отдельном файле. Кроме того, он сохраняет исходный макет, текст и стили форматирования, такие как полужирный шрифт и курсив. Вы можете редактировать сгенерированный текст или сохранить его для редактирования позже, или экспортировать его в другую программу, такую как Microsoft Word.
Плюсы
Минусы
https: // когнитивный-openocr-cuneiform.forumer.it/
3. FreeOCR
FreeOCR – это легкая программа, работающая на Tesseract Engine, мощном механизме распознавания текста, впервые разработанном HP Labs, но в настоящее время поддерживаемом Google. Это программное обеспечение сканирует изображения по одному, но может выполнять пакетное сканирование файлов PDF. На выходе получается обычный текст. Он не сохраняет форматирование или макет исходного документа. Он может сканировать прямо со сканера и позволяет выполнять простые функции предварительного просмотра изображения, такие как поворот и масштабирование.
Он не сохраняет форматирование или макет исходного документа. Он может сканировать прямо со сканера и позволяет выполнять простые функции предварительного просмотра изображения, такие как поворот и масштабирование.
Обладает интуитивно понятным пользовательским интерфейсом. Функции сканирования, открытия и распознавания текста легко найти. Точность результатов впечатляет. Чтобы избежать проблем с разметкой, выберите блок текста, который программа должна распознавать, и выберите «обрезать изображение в выбранную область». Одним из главных плюсов этого программного обеспечения является то, что оно поддерживает 11 языков.
Плюсы
Минусы
https://www.free-ocr.com/
4. ABBYY FineReader Online
ABBYY FineReader – это программа для распознавания текста премиум-класса со всеми функциями и функциями, которые необходимы вам для распознавания текста.Он быстрый и точный, может справиться с большими объемами работы. Он имеет расширенную проверку орфографии и другие инструменты исправления. Но это дорого, что делает ABBYY FineReader online хорошей альтернативой.
Он имеет расширенную проверку орфографии и другие инструменты исправления. Но это дорого, что делает ABBYY FineReader online хорошей альтернативой.
Онлайн-версия ограничена тем, что позволяет сканировать только 10 страниц в месяц. Но он имеет все остальные функции премиум-версии. Тем не менее, вы должны зарегистрироваться, чтобы получить доступ к бесплатной онлайн-версии. Он поддерживает очень много форматов входных файлов, и вы можете выбирать форматы вывода, такие как PDF, Word, Excel, PowerPoint и e-Pub.
Плюсы
Поддерживает 193 языка
Сохранение исходящих файлов в облачных сервисах хранения, таких как Google Drive, Box и OneDrive
Множество вариантов вывода
Онлайн-сервис; не требует установки
Распознает столбцы, таблицы и изображения
Минусы
http://finereaderonline. com/en-us
com/en-us
5.Документы Google
Google Docs более популярен как текстовый процессор, чем программа оптического распознавания текста. Google включил механизм распознавания текста, который он использует для сканирования онлайн-книг и PDF-файлов в Документах. Возможности Docs OCR ограничены, поскольку вы можете сканировать только загруженные файлы, а не файлы непосредственно со сканера. Используйте кнопку «Загрузить», чтобы импортировать файлы для распознавания текста. В диалоговом окне установите флажок «Преобразовать текст из файлов PDF и изображений в документы Google». После завершения загрузки файла он появляется в виде текстового документа, который вы можете редактировать.Все изменения автоматически сохраняются на Google Диске.
Плюсы
Минусы
Нет распознавания макета
Без автоматизированных функций
Использование лучшего бесплатного программного обеспечения для распознавания текста – самый простой способ преобразовать книги, журналы и другие печатные и рукописные материалы в цифровой контент. Существует множество программ оптического распознавания текста, некоторые из них платные, некоторые бесплатные.Рассмотренные здесь – лучшее бесплатное программное обеспечение для распознавания текста. Все они удовлетворяют основным функциям, необходимым для программного обеспечения OCR. При выборе вы должны спросить себя: «Для чего мне нужно программное обеспечение OCR?»
Существует множество программ оптического распознавания текста, некоторые из них платные, некоторые бесплатные.Рассмотренные здесь – лучшее бесплатное программное обеспечение для распознавания текста. Все они удовлетворяют основным функциям, необходимым для программного обеспечения OCR. При выборе вы должны спросить себя: «Для чего мне нужно программное обеспечение OCR?»
Следите за нами и ставьте лайки:
OCR – Обзор оптического распознавания символов, сравнение, лучшие продукты, реализации, поставщики.
Оптическое распознавание символов (оптическое распознавание символов, OCR) – это механическое или электронное преобразование изображений печатного, рукописного или напечатанного текста в машинно-кодированный текст, будь то отсканированный документ, фотография документа, фотография сцены (для например, текст на вывесках и рекламных щитах на альбомной фотографии) или из текста субтитров, наложенного на изображение (например, из телетрансляции). Базовый процесс OCR включает в себя изучение текста документа и перевод символов в код, который можно использовать для обработки данных. OCR иногда также называют распознаванием текста.
Базовый процесс OCR включает в себя изучение текста документа и перевод символов в код, который можно использовать для обработки данных. OCR иногда также называют распознаванием текста.
Он широко используется в качестве формы ввода данных из распечатанных бумажных записей данных, будь то паспортные документы, счета-фактуры, банковские выписки, компьютеризированные квитанции, визитные карточки, почта, распечатки статических данных или любая подходящая документация. Программа OCR лучше всего работает с текстом, который уже был напечатан, либо в тех случаях, когда исходная распечатка была утеряна, либо при сканировании листов, набранных на пишущей машинке.Однако хорошее программное обеспечение OCR также может переводить рукописный текст, хотя частота ошибок при таком преобразовании, как правило, намного выше.
Фактический термин «программное обеспечение оптического распознавания текста» может ввести в заблуждение, поскольку в большинстве современных версий фактически не используется оптическое распознавание символов, а используется цифровое распознавание символов. Это связано с тем, что несколько лет назад эти области фактически объединились, и в обеих областях был принят более привлекательный термин оптическое распознавание символов. Программное обеспечение для распознавания символов значительно продвинулось в последние годы, и современные программы значительно лучше своих предшественников распознают текст.
Это связано с тем, что несколько лет назад эти области фактически объединились, и в обеих областях был принят более привлекательный термин оптическое распознавание символов. Программное обеспечение для распознавания символов значительно продвинулось в последние годы, и современные программы значительно лучше своих предшественников распознают текст.
состоят из комбинации аппаратного и программного обеспечения, которое используется для преобразования физических документов в машиночитаемый текст. Оборудование, такое как оптический сканер или специализированная печатная плата, используется для копирования или чтения текста, в то время как программное обеспечение оптического распознавания обычно выполняет расширенную обработку. Программное обеспечение технологии OCR также может использовать преимущества искусственного интеллекта (AI) для реализации более продвинутых методов интеллектуального распознавания символов (ICR), таких как определение языков или стилей почерка.
Процесс OCR чаще всего используется для преобразования бумажных юридических или исторических документов в PDF-файлы. После помещения в эту электронную копию пользователи могут редактировать, форматировать и выполнять поиск в документе, как если бы он был создан с помощью текстового процессора.
Первым шагом OCR является использование сканера для обработки физической формы документа. После копирования всех страниц программа оптического распознавания символов преобразует документ в двухцветную или черно-белую версию. Отсканированное изображение или растровое изображение анализируется на наличие светлых и темных областей, где темные области идентифицируются как символы, которые необходимо распознать, а светлые области идентифицируются как фон.
Затем темные области обрабатываются для поиска буквенных или цифровых цифр. Продукты OCR могут различаться по своим методам, но, как правило, подразумевают нацеливание на один символ, слово или блок текста за раз. Затем персонажи идентифицируются с использованием одного из двух алгоритмов:
Распознавание образов – в программы распознавания текста загружаются примеры текста в различных шрифтах и форматах, которые затем используются для сравнения и распознавания символов в отсканированном документе.
Обнаружение функций – программы оптического распознавания текста применяют правила, касающиеся особенностей конкретной буквы или цифры, для распознавания символов в отсканированном документе.Функции могут включать в себя количество наклонных линий, пересеченных линий или кривых в символе для сравнения. Например, заглавная буква «А» может быть сохранена в виде двух диагональных линий, которые пересекаются с горизонтальной линией посередине.
Когда символ идентифицируется, он преобразуется в код ASCII, который может использоваться компьютерными системами для обработки дальнейших манипуляций. Пользователи должны исправить основные ошибки, вычитать и убедиться, что сложные макеты были правильно обработаны, прежде чем сохранять документ для будущего использования.
Высокоточное оптическое распознавание символов (OCR)
Самое мощное в отрасли решение для оптического распознавания текста для предприятий.
Признает
С точностью более 97% документы на разных языках (115+) и форматах (300+), включая изображения, Office, CAD, электронную почту и устаревшие документы.
Расширяет
Помимо программного обеспечения для оптического распознавания текста, включающего высококачественные услуги преобразования, публикации и улучшения документов в PDF на единой платформе.
Доставляет
Больше, чем доступные для поиска PDF и PDF / A, поскольку предлагает несколько выходных форматов (XML, текст и т. Д.), Которые позволяют обрабатывать большие данные, файловые документы и аналитику договоров.
Автоматизирует
Преобразование для устранения ручных усилий, повышения согласованности и ускорения бизнес-процессов.
Адаптирует
Для удовлетворения растущих потребностей бизнеса с помощью настраиваемой среды управления рабочим процессом.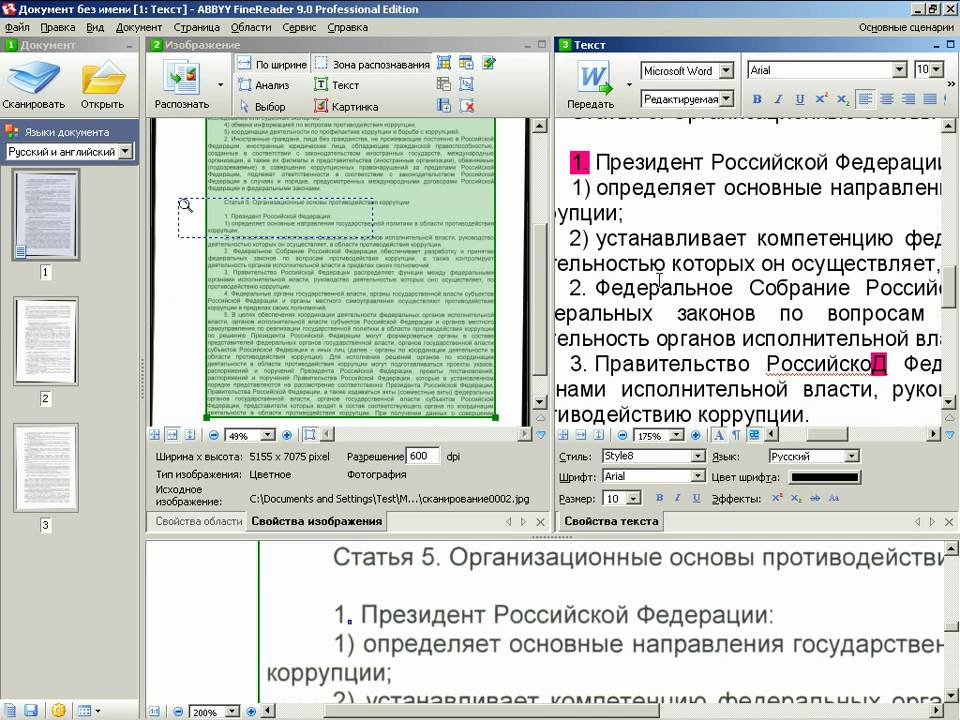
объединяет
В любой бизнес-системе, среде или географическом регионе, что обеспечивает гибкие варианты развертывания.
Весы
Легко для поддержки нескольких направлений бизнеса и потребностей обработки пиковых объемов.
Как сделать OCR в Ubuntu | Small Business
При сканировании документов на компьютер вы можете обнаружить, что некоторые из основных функций программ чтения PDF, такие как поиск или выделение, не работают с отсканированными документами.Это означает, что вам нужна программа оптического распознавания символов (OCR), которая может передавать фактический текст – в отличие от изображения текста – в компьютер. Операционная система Ubuntu предлагает несколько программ для облегчения операций распознавания текста, все они доступны в репозиториях Ubuntu.
Оптическое распознавание символов
Оптическое распознавание символов – это программа, с помощью которой текст распознается на изображениях и помещается в документ. Когда вы сканируете такие предметы, как книги, на компьютер, сканер сохраняет отсканированное содержимое как изображение.Программное обеспечение OCR сканирует книгу и распознает разницу между символами и изображениями, а также между самими символами, так что документы, отсканированные из книг, состоят из текста, а не из изображения текста. Это позволяет программному обеспечению PDF выполнять поиск и комментировать отсканированный текст.
Ubuntu OCR Packages
В дистрибутиве Linux Ubuntu есть много доступных OCR-пакетов. Вы можете установить такие пакеты, как Tessaract и Cuneiform, через репозиторий Ubuntu или другие программные пакеты OCR.Обратите внимание, что программы OCR, такие как Tessaract и CuneiForm, не имеют графических пользовательских интерфейсов (GUI). OCRFeeder, однако, поставляется с графическим интерфейсом пользователя, но ему не хватает точности программ OCR Tessaract и CuneiForm.
Tessaract и Cuneiform
Tessaract был разработан лабораториями HP в 1985 году и выпущен как открытый исходный код в 2005 году. Tessaract может распознавать макет и дизайн, такие как многоколоночные документы, и символы примерно на 40 языках. CuneiForm был разработан Cognitive Technologies и имеет версии для Windows и Linux.CuneiForm не имеет компонента графического интерфейса, но может работать внутри других графических интерфейсов пользователя, таких как OCRFeeder. Tessaract принимает несжатые файлы TIFF в качестве входных данных и запускается из командной строки, как в следующем примере:
$> tessaract testpdf.tif output.txt
OCRFeeder
OCRFeeder на самом деле не выполняет задачи OCR, а скорее для этого использует так называемые механизмы распознавания текста. Это означает, что вы можете включить OCRFeeder для использования Tessaract, CuneiForm или других программ OCR.Таким образом, вы можете установить программу OCR через репозиторий Ubuntu, а затем таким же образом установить OCRFeeder и использовать его для поиска этой программы OCR и выполнения ее команд через графический интерфейс OCRFeeder.