
Как проверить текст на ошибки в Ворде и онлайн
Проверить текст на ошибки можно непосредственно в текстовом редакторе Microsoft Word, в котором в большинстве случаев набираются тексты.
Чтобы ошибки набора проверить, найти и исправить, в программе имеется специальная функция.
Содержание:
- Проверка в Microsoft Word
- Как проверить в сервисе Орфограммка
Проверка правописания в Microsoft Word
Для её включения нажимаем Сервис – Правописание или чтобы получить тот же результат просто нажимаем клавишу F7.
В результате в тексте будет выделено слово, которое компьютер посчитал написанное с ошибкой. Грамматические ошибки редактор подчеркивает красным цветом.
Кроме того, открывается окно Правописание, в котором будут представлены правильные варианты написания.
Выберем верхний вариант с ошибкой и нажимаем Заменить.
Если есть уверенность на сто процентов, что это слово написано всё-таки правильно, нажимаем Пропустить или Добавить в словарь.
Если программа считает, что слово написано неправильно и оно подчёркнуто в тексте красным цветом, то можно поступить ещё проще.
Наводим курсор на проверяемое слово, затем нажимаем правой кнопкой мышки и в контекстном меню выбираем предлагаемое для замены.
Либо там же выбираем Пропустить или Добавить в словарь. Таким образом, при необходимости, можно проверить весь текст.
Как проверить текст на ошибки онлайн
Чтобы проверить текст в режиме онлайн, существует замечательный веб-сервис Орфограммка, находящийся по адресу orfogrammka.ru. Этот сервис считается лучшим при проверке правописания.
Большинство аналогичных сервисов могут проверить только орфографию. То есть способны проверить, правильно ли написаны отдельные слова в соответствии со своими словарями.
А сервис Орфограммка проводит проверку ещё и пунктуации, стилистики, типографики и неблагозвучие. В результате находится в текстах намного больше ошибок и тем самым упрощается жизнь копирайтера.
Несомненно, лучше изучить вовремя все правила русского языка и сразу писать без ошибок. Но в действительности получается так, что обращаясь именно к сервису Орфограммка, мы получаем возможность достаточно быстро найти и исправить ошибки в своих текстах.
Для проверки надо нажать на кнопку Начать работу. Дальше надо зарегистрироваться, войти в систему и произвести настройки пользователя.
Переходим в редактор, открывается окно Новый документ, вставляем в него проверяемый текст и нажимаем Проверить.
После окончания проверки ошибки подсвечиваются. Синим цветом – ошибки орфографии, зелёным – пунктуации, типографики – серым.
Сразу приводится статистика, сколько допущено тех или иных ошибок.
Чтобы перейти к исправлению, можно нажимать на сами слова с ошибками, либо справа есть лента ошибок, которую можно проскролить вниз.
Для каждой ошибки в ленте имеется краткое объяснение и приводится ссылка на правило, с которым можно тут же ознакомиться.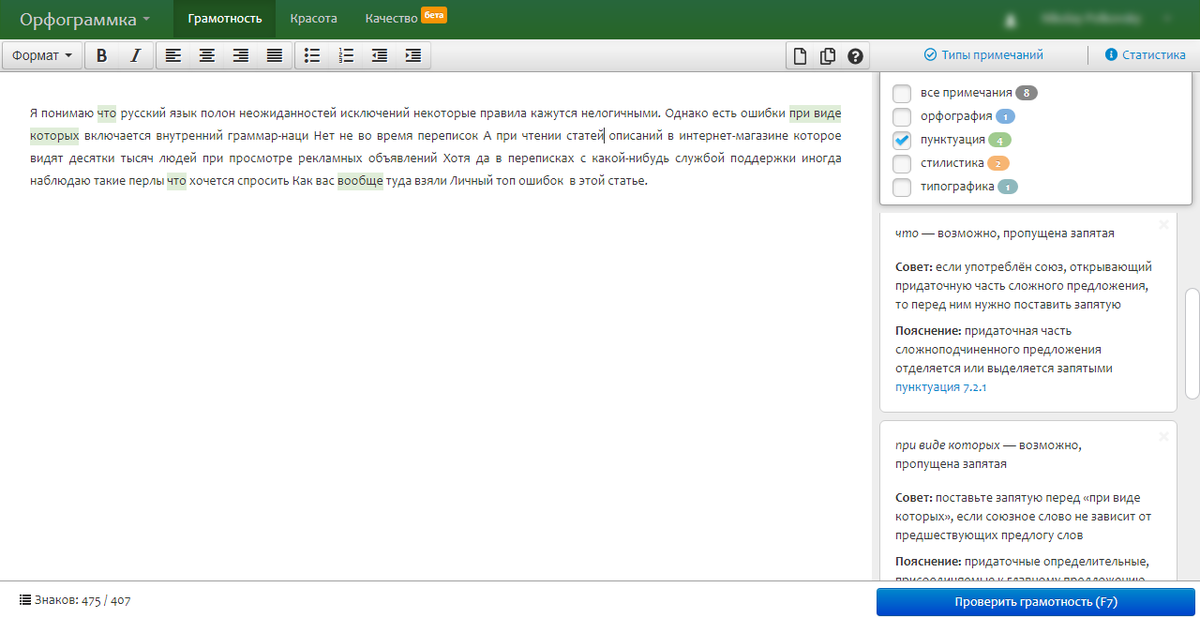
Надо иметь в виду, что некоторые слова сервис считает за ошибки, потому что их пока нет в русском языке. Это может быть название проекта или специфический сленг.
Таким образом, мы не только проверяем текст на ошибки, но и прокачиваем собственные познания русского языка. Это дает нам в будущем писать тексты уже без ошибок.
Для исправления ошибки достаточно нажать на слово в ленте, которое предлагается сервисом в качестве правильного написания, и в тексте происходит автоматическое исправление.
Текст можно набирать прямо в окне проверки, так как здесь присутствует типовой набор инструментов для этого.
При нажатии на вкладку Статистика, приводится очень подробная статистика текста, сколько в нём знаков, слов, предложений, параграфов. Приводятся часто встречающиеся слова и удобочитаемость текста.
Применение такой статистики даёт возможность выполнять самостоятельно анализ текста, отслеживать, как вы пишете. И, таким образом, постепенно улучшать свой стиль написания.
В сервисе, кроме того, что он предоставляет возможность проверить текст на ошибки, имеется богатая библиотека правил. Эти правила можно всегда прочитать, изучить и таким образом, прокачивать свои навыки по русскому языку.
Проверка орфографии | Документация PyCharm
PyCharm проверяет правописание всего вашего исходного кода, включая имена переменных, текст в строках, комментарии, литералы и сообщения фиксации. Для этой цели PyCharm предоставляет специальную проверку опечаток, которая включена по умолчанию.
Проверка опечаток обнаруживает и выделяет слова, не включенные ни в один словарь. Вы можете либо исправить написание, либо признать слово правильным (сохранив его в словаре). Отключите проверку опечаток, если хотите игнорировать все орфографические ошибки. Дополнительные сведения см. в разделе Отключение проверки орфографии.
Исправление слова с ошибкой
Поместите курсор на любое слово, выделенное при проверке опечаток.

Щелкните или нажмите Alt+Enter , чтобы отобразить доступные действия намерения.
Выберите одно из предложенных исправлений из списка.

В строковых литералах и комментариях изменяется только написание этого конкретного слова в точке вставки. Там, где доступен рефакторинг Rename, инспекция предлагает переименовать все вхождения символа .
Принять слово с ошибкой
Поместите курсор на слово, выделенное при проверке опечаток.
Щелкните или нажмите Alt+Enter , чтобы отобразить доступные действия намерения.
Выберите действие Сохранить в словарь, чтобы добавить слово в словарь пользователя и пропустить его в будущем.
Если вы добавили слово по ошибке, нажмите Ctrl+Z , чтобы удалить его из словаря.
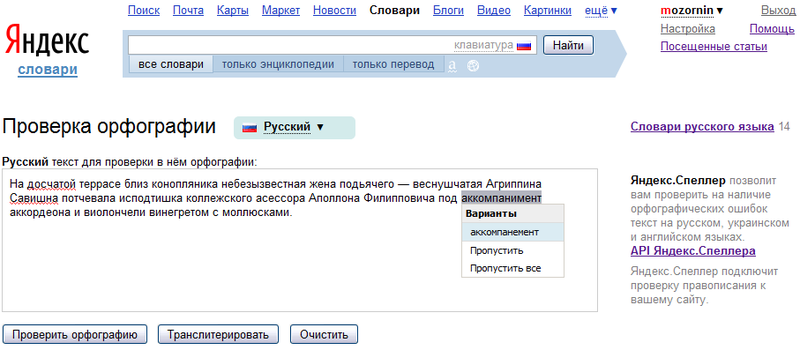
По умолчанию PyCharm сохраняет слова в глобальном словаре уровня приложения. Вы можете сохранить слова в словаре уровня проекта, если правописание верно только для этого конкретного проекта. Дополнительные сведения см. в разделе Выбор словаря по умолчанию для сохранения слов.
Нажмите F2 и Shift+F2 , чтобы просмотреть все проблемы в файле, включая опечатки.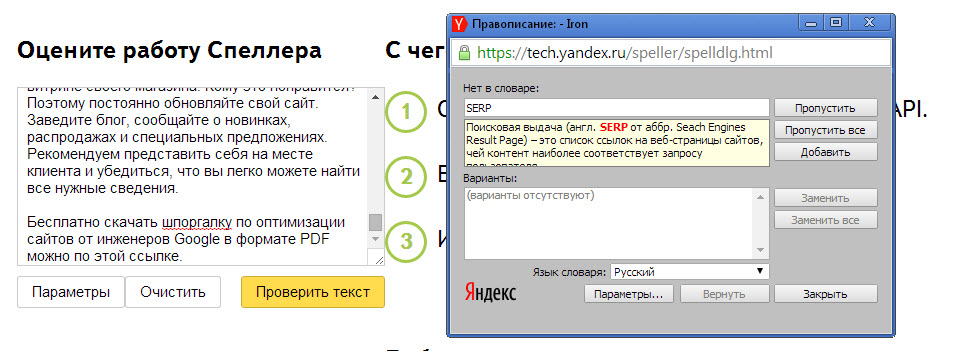
Настройка проверки опечаток
По умолчанию проверка опечаток проверяет весь текст, включая элементы кода, строковые литералы и комментарии во всех областях.
Нажмите Ctrl+Alt+S , чтобы открыть настройки IDE, и выберите Editor | Инспекции.
Разверните узел Вычитка и щелкните Опечатка на центральной панели.
В правой панели настройте проверку типовой опечатки:
Серьезность
Укажите уровень суровых и высокую зону, в котором до того, что на этот уровень.
Например, если вы хотите, чтобы опечатки выделялись больше, выберите «Ошибка» или «Предупреждение», чтобы выделить опечатки, похожие на синтаксические ошибки или предупреждения в вашем коде.
Опции
Укажите тип содержимого для проверки:
Код процесса: проверка различных элементов кода.
Обработка литералов: проверка текста внутри строковых литералов.
Обработка комментариев: проверка текста внутри комментариев.

Найти все орфографические ошибки
Проверка опечаток выделяет опечатки в текущем файле. Вы также можете запустить проверку всего проекта или набора файлов. Дополнительные сведения см. в разделе Запуск одной проверки.
В главном меню выберите Код | Анализ кода | Запустите проверку по имени… или нажмите Ctrl+Alt+Shift+I .
Во всплывающем окне «Введите название проверки» найдите и выберите проверку «Опечатка».
В диалоговом окне «Выполнить опечатку» выберите область, в которой вы хотите запустить проверку, и другие параметры, например фильтр по маске файла. Затем нажмите ОК.

PyCharm запустит проверку опечаток для всех файлов в выбранной области и покажет все найденные опечатки на отдельной вкладке окна инструмента «Проблемы».
Отключить проверку орфографии
Нажмите Ctrl+Alt+S , чтобы открыть настройки IDE, и выберите Редактор | Инспекции.
Снимите флажок рядом с пунктом Проверка опечаток.

PyCharm включает в себя объединенные словари для всех настроенных языков. Вы не можете изменить их напрямую, но вы можете расширить возможности проверки орфографии другими способами:
Сохранение слов во встроенный глобальный словарь или словарь проекта.
Добавьте текстовые файлы с расширением .dic, содержащие списки слов.
Если у вас установлен и включен подключаемый модуль Hunspell, вы можете добавить словари Hunspell, состоящие из двух файлов: файл DIC, содержащий список слов с применимыми правилами модификации, и файл AFF, в котором перечислены префиксы и суффиксы, регулируемые по определенному правилу модификации. Например, en_GB.dic и en_GB.aff.
Настройка словарей проверки орфографии
Нажмите Ctrl+Alt+S , чтобы открыть настройки IDE, и выберите Editor | Естественные языки | Написание.
Настройте список пользовательских словарей:
Чтобы добавить новый пользовательский словарь в список, щелкните или нажмите Alt+Insert и укажите расположение нужного файла.
Чтобы отредактировать содержимое пользовательского словаря в PyCharm, выберите его и щелкните или нажмите Enter . Соответствующий файл откроется в новой вкладке редактора.
Чтобы удалить пользовательский словарь из списка, выберите его и щелкните или нажмите Alt+Delete .


Выберите словарь по умолчанию для сохранения слов
По умолчанию PyCharm сохраняет слова в глобальный словарь уровня приложения. Вы можете сохранить слова в словаре уровня проекта, если правописание верно только для этого конкретного проекта.
Нажмите Ctrl+Alt+S , чтобы открыть настройки IDE, и выберите Editor | Естественные языки | Написание.
Выберите либо встроенный словарь уровня проекта, либо словарь уровня приложения, либо отключите параметр, чтобы запрашивать вас каждый раз, когда вы сохраняете слово.

Добавить разрешенные слова вручную
Нажмите Ctrl+Alt+S , чтобы открыть настройки IDE, и выберите Editor | Естественные языки | Написание.
Добавьте слова в список разрешенных слов. PyCharm добавляет принятые вручную слова в словарь уровня проекта.
Нельзя добавлять слова, которые уже присутствуют в одном из словарей, и слова со смешанным регистром, например
CamelCaseизмеиный_чехол.

Список допустимых слов также содержит слова, которые вы сохранили во встроенном глобальном словаре или словаре проекта. Хотя он не содержит слов, добавленных в словарь уровня проекта другими пользователями, и слов из других пользовательских словарей, проверка опечаток не выделяет их.
Совместное использование словарей
PyCharm хранит встроенный словарь уровня проекта вместе с другими файлами, связанными с проектом. Это означает, что любой, кто работает с проектом, имеет доступ к словам, хранящимся в этом словаре.
Чтобы поделиться своим словарем на уровне приложения, используйте встроенный подключаемый модуль IDE Settings Sync.
Последнее изменение: 07 ноября 2022 г.
Естественные языки Грамматика
php – Проблема с отображением русских букв в браузере, даже если установлена кодировка UTF-8
У вас настроен Apache для поддержки переопределения кодировки ? По умолчанию он использует ISO-8859-1 для по умолчанию и игнорирует любые переопределения, которые появляются на веб-страницах, которые он обслуживает.
Решение №1 из 3
Например, вы можете поместить это в файл .htaccess для вложенного каталога, и теперь ваши веб-страницы будут иметь свои переопределения:
AddDefaultCharset Off ДобавитьШарсет UTF-8 .html
В документации Apache указано:
Эта директива определяет значение по умолчанию для параметра charset типа мультимедиа (имя кодировки символов), которое должно быть добавлено к ответу тогда и только тогда, когда
тип содержимого— это либоtext/plain, либоtext/html. Это должно переопределить любой набор символов, указанный в теле ответа через элемент META, хотя точное поведение часто зависит от конфигурации клиента пользователя. ПараметрAddDefaultCharset Offотключает эту функцию.AddDefaultCharset Onвключает кодировку по умолчанию. Предполагается, что любое другое значение является используемой кодировкой, которая должна быть одной из зарегистрированных IANA значений кодировки для использования в типах носителей MIME.iso-8859-1 адддефаултчарсет utf-8
AddDefaultCharsetследует использовать только тогда, когда известно, что все текстовые ресурсы, к которым он применяется, находятся в этой кодировке символов, и слишком неудобно маркировать их наборы символов по отдельности. Одним из таких примеров является добавление параметра charset к ресурсам, содержащим сгенерированное содержимое, например устаревшие сценарии CGI, которые могут быть уязвимы для атак с использованием межсайтовых сценариев из-за того, что предоставленные пользователем данные включаются в выходные данные. Обратите внимание, однако, что лучшим решением будет просто исправить (или удалить) эти сценарии, поскольку установка кодировки по умолчанию не защищает пользователей, которые включили функцию «автоматического определения кодировки символов» в своем браузере.
 Например:
Например: Пока я не отключил AddDefaultCharset , я не мог заставить работать свои теги .
Решение № 2 из 3
Если у вас есть доступ для записи к файлам конфигурации Apache, вы можете изменить сам сервер. Однако вы должны убедиться, что больше ничего не зависит от старой непереопределяемой настройки. Это еще одна причина использовать .htaccess .
Если вы не можете ни изменить общую конфигурацию сервера, ни создать файл .htaccess , чьи собственные настройки будут соблюдаться для всего, что находится под ним, то ваш единственный вариант — использовать числовые объекты для всех кодовых точек, превышающих 127. Например, вместо
Целль-ам-Зее
вместо этого необходимо использовать
Целль-ам-Зее
или
Целль-ам-Зее
Преимущество этого в том, что больше не требуется переопределение и возня с сервером или с файлами .. Недостатком является то, что требуется дополнительный проход перевода, что мешает возможности напрямую редактировать файл с помощью редактора, который буквально понимает кодировку UTF-8. htaccess
htaccess
Объекты игнорируют кодировки
CYRILLIC CAPITAL LETTER TSE и т. д. Номера объектов всегда представляют собой номера кодовых точек Unicode; они никогда не являются числами из кодировки документа. В кодировке сервера или страницы учитываются только закодированные байты, а не незакодированные числа кодовых точек, которые всегда являются Unicode. Вот почему мы можем использовать что-то вроде é , а всегда означает СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ОСТРОЙ , потому что кодовая точка 233 всегда является этим символом, даже если сама веб-страница должна быть в какой-то другой кодировке (например, 142 в MacRoman или 221 в NextStep).