
Пишем правильно: онлайн-сервисы для проверки орфографии
Иногда при составлении текстов мы просто не замечаем опечаток или ошибок, хотя они обязательно найдутся. Для исправления этого недоразумения существуют онлайн-сервисы проверки орфографии. Советуем пользоваться ими, особенно когда цена ошибки текста слишком велика: важный документ, большой тираж полиграфии и так далее.
Конечно, даже умный компьютер не идеален. Бывает сервис подчеркивают специфические термины, которые не знает и не указывает на смысловое содержание предложения. Но и это можно решить, если пользоваться сразу несколькими сайтами, так можно добиться максимального результата. Орфографические ошибки можно проверить Орфограммкой, Яндекс.Спеллером или Languagetool, подкорректировать оформление – Типографом, а об устранении стилистических ошибок позаботится Главред.
Главред (glvrd.ru)
Один из самых популярных сервисов.
На сайте можно провести онлайн работу над ошибками и узнать, насколько в лучшую (или худшую) сторону изменился текст. Пользуйтесь без фанатизма и без погони за максимальной оценкой. Опытные копирайтеры говорят, что после проверки и правок текст становится более информативным и понятным.
Орфограммка (orfogrammka.ru)
Платный сервис, который выявляет орфографические, грамматические, пунктуационные, стилистические, речевые и смысловые ошибки. Он поможет избавиться от тавтологии, варваризмов, найти и исправить опечатки, подобрать синонимы и даже расставить буквы «ё». За один раз можно проверить сразу текст объемом до 40 тысяч символов.
Он поможет избавиться от тавтологии, варваризмов, найти и исправить опечатки, подобрать синонимы и даже расставить буквы «ё». За один раз можно проверить сразу текст объемом до 40 тысяч символов.
Languagetool (languagetool.org)
Расширение устанавливается в браузер для проверки орфографии и грамматики. Умеет работать с документами в MS Word, LibreOffice, Google Docs, браузерами Firefox и Chrome.
Этот инструмент, предназначенный для выявления орфографических, грамматических, стилистических и других ошибок, удобен своей простотой, а также многоязычностью. Он поддерживает более 20 языков.
Яндекс.Спеллер (tech.yandex.ru/speller/)
Яндекс.Спеллер находит и выделяет орфографические ошибки в текстах на русском, украинском и английском языках. Система узнает слова с несколькими ошибками, а при анализе правильности написания слов учитывает контекст.
Орфограф (artlebedev.ru/orfograf/)
Созданный студией Артемия Лебедева «Орфограф» проверяет правильность текстов, написанных на русском и английском языках. Не включенные в словарь приложения слова выделяются цветом, который можно выбрать самостоятельно. Проверяются отдельные тексты или целые веб-страницы. Артемий плохого не посоветует.
Meta.ua (translate.meta.ua/ru/orthography/)
Сервис от meta.ua бесплатно проверяет русские, украинские и английские тексты на правописание и предлагает варианты замены неизвестных ему слов. Простая и удобная программка.
Типограф (typograf.ru)
Типограф помогает готовить тексты к размещению на сайтах: исправляет кавычки, неразрывные пробелы, спецсимволы, корректирует опечатки, проверяет правильность слов. Авторы заверяют, что программа способна автоматически исправлять около 95–99% неточностей. Бесплатным сервисом можно пользоваться до 1 июня, потом он станет платным.
Авторы заверяют, что программа способна автоматически исправлять около 95–99% неточностей. Бесплатным сервисом можно пользоваться до 1 июня, потом он станет платным.
И бонусом для проверки уникальности советуем Контент-Вотч, Текст.ру.
Правила русского языка, которые мы не можем запомнить: как решить эту проблему?
Найти лексические ошибки онлайн – Telegraph
Найти лексические ошибки онлайн
====================================
>> Перейти к скачиванию
====================================
Проверено, вирусов нет!
====================================
Проверка ошибок онлайн поможет найти ошибки и опечатки в тексте. Проверка текста на ошибки пригодится при анализе любого текста, если вы.
Бесплатный онлайн инструмент для проверки грамматики, лексики и исправления. грамматических и стилистических ошибок в английских текстах.
Программа для большинства найденных грамматических ошибок. На этой странице доступна форма для онлайн проверки орфографии и грамматики.
Проверка орфографии онлайн предназначена для быстрого нахождения ошибок и правильного написания слов как на компьютере, так и на телефоне.
проверка правописания онлайн. 8 360 179 179 слов проверено за все время работы сервиса. 78 883 031 грамматических и орфографических ошибок.
Онлайн проверка орфографии и исправление ошибок позволит бесплатно проверить правописание текста.
На нашем сайте вы можете выбрать профессионального корректора по проверке текстов на орфографию, который поможет найти ошибки в тексте.
Онлайн проверка часто нужна, когда нужно подготовить какой-нибудь текст, не допустив в нем ошибок. Сервис не только проверяет правильность.
Полезные ресурсы, на которых онлайн можно проверить пунктуацию и орфографию.
3.Мы уделяем большое значение образованию наших студентов. (Мы уделяем большое значение качеству образования наших.
GrammarBase – это онлайн сервис для проверки грамматики в текстах. GrammarBase проверяет тексты на орфографические ошибки.
Обзор сервисов онлайн проверки правописания. И время от времени будет совершать грамматические и пунктуационные ошибки.
Бесплатная проверка английского текста на ошибки. Проверка грамматики и орфографии происходит в режиме онлайн и позволяет сделать ваш текст.
Инструменты · Проверка орфографии · Проверка орфографии Семантический анализ текстаПроверка уникальностиОнлайн-проверка уникальности.
Нужно автоматически исправить ошибки в объемном тексте? Онлайн автокорректор текста. Проверка орфографии онлайн, исправление ошибок в.
Ginger s world class grammar checker, an online tool that will correct any mistake. Ginger исправляет грамматические и орфографические ошибки, а также.
Проверить текст на орфографические и синтаксические ошибки можно как в. Она, конечно же, уже смирилась с этим, но все же я стараюсь найти.
Лексические ошибки – нарушение правил лексики, прежде всего – употребление слов в. Онлайн-курс «Русский язык». А теперь вы можете потренироваться и найти речевые ошибки в данной статье или.
Рассмотрели лексические ошибки текстов на сайтах и указали несколько полезных ресурсов, которые помогут избавиться от ошибок. На этом ресурсе можно быстро найти любой словарь. Онлайн-проверка.
С помощью Яндекс.Спеллер можно найти и исправлять орфографические ошибки в русском, английском и украинском тексте.
Как протестировать точность механизма распознавания речи (ASR) и количество ошибок в словах
Прежде чем вкладывать кучу денег в внедрение службы ASR, важно убедиться, что вы выбрали лучший вариант для себя. Вы должны выбрать продукт, который обеспечивает максимальную точность для желаемого варианта использования, принимая во внимание другие соответствующие факторы, такие как цена, поддержка клиентов, простота использования и поддержка иностранных языков.
Проблема в том, что хотя каждый сервис объявляет свой собственный «ожидаемый» коэффициент ошибок, трудно определить, как именно они его рассчитали и насколько хорошо он будет обобщаться на ваши данные.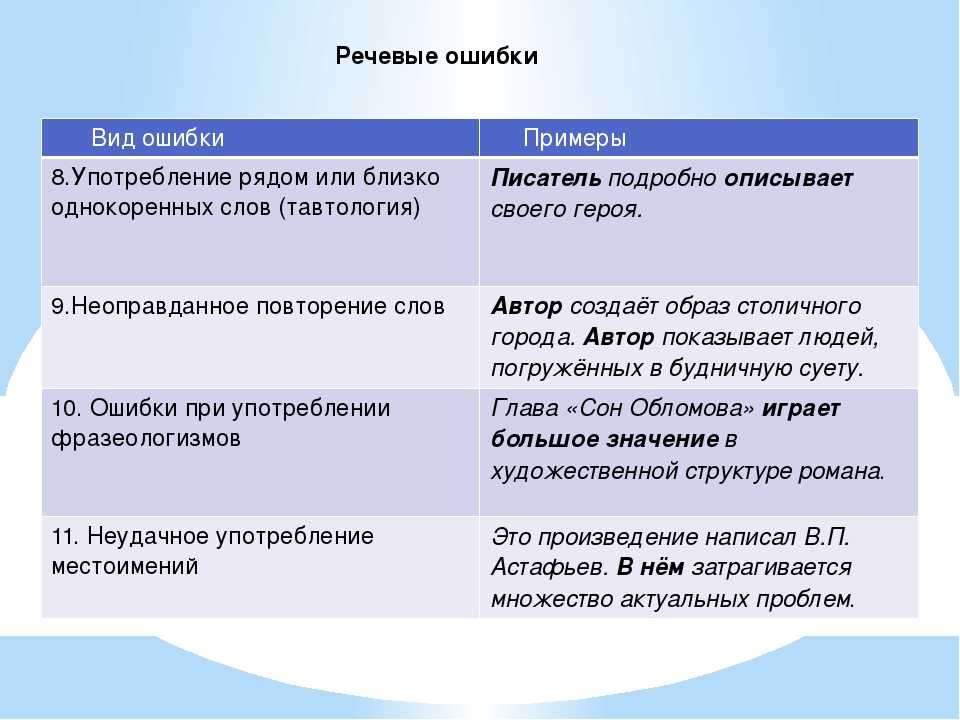 Хорошо известно, что частота ошибок в словах сильно различается в зависимости от типов текстовой транскрипции и стандартизации. К счастью, Rev предоставляет инструмент, который позволяет единообразно подсчитывать количество ошибок в словах для пакетов текстовой транскрипции. Таким образом, вы можете сравнить выходные данные каждой службы ASR на идентичных данных, чтобы точно оценить, какой из них лучше всего подходит для вашего варианта использования.
Хорошо известно, что частота ошибок в словах сильно различается в зависимости от типов текстовой транскрипции и стандартизации. К счастью, Rev предоставляет инструмент, который позволяет единообразно подсчитывать количество ошибок в словах для пакетов текстовой транскрипции. Таким образом, вы можете сравнить выходные данные каждой службы ASR на идентичных данных, чтобы точно оценить, какой из них лучше всего подходит для вашего варианта использования.
Некоторые первоначальные соображения
Прежде чем приступить к тестированию различных механизмов ASR, необходимо помнить о нескольких вещах.
- Используйте данные тестирования, соответствующие вашему варианту использования. Это означает, что если вы планируете использовать службу ASR для расшифровки подкастов, используйте аудио из одного из ваших шоу для теста! Не используйте случайный аудиоклип или видео, которые вы нашли в Интернете.
- Используйте образец файла достаточной длины. Вам нужно что-то, что длится как минимум несколько минут, а лучше меньше часа.

- Если вы предполагаете, что ваш исходный звук будет содержать техническую, иностранную или другую необычную терминологию, убедитесь, что ваш тестовый файл аналогичен. То же самое касается фонового шума и акустики окружающей среды.
После того, как вы определились с исходным файлом, вам нужно будет отправить его во все механизмы распознавания речи, которые вы хотите протестировать, и получить обратно созданные стенограммы. Получив их в любом формате (чаще всего это текстовый файл), вы можете перейти к следующему шагу.
Загрузка исходного кода FSTAlign и образа Docker
Rev создала инструмент под названием FSTAlign, который можно использовать для простого выравнивания и сравнения частоты ошибок в словах в расшифровках. Первое, что нужно сделать, это клонировать репозиторий git на локальный компьютер. Это даст вам доступ к исходному коду на случай, если вы захотите просмотреть или изменить реализацию инструмента. Однако это не обязательно для запуска инструмента (для этого мы будем использовать Docker).
Это даст вам доступ к исходному коду на случай, если вы захотите просмотреть или изменить реализацию инструмента. Однако это не обязательно для запуска инструмента (для этого мы будем использовать Docker).
Получить FSTAlign Word Error Rate Tester
Затем вам нужно перейти в этот каталог и выполнить следующую команду:
git submodule update --init --recursive
Это обновит все подмодули, загруженные в репозиторий.
Использование Docker
Мы будем использовать Docker для запуска инструмента FSTAlign. Docker хорош тем, что упаковывает все библиотеки, необходимые для инструмента, в виртуальный контейнер. Это здорово, потому что это означает, что вам не нужно ничего устанавливать (кроме Docker), вам просто нужно извлечь и запустить предоставленный образ Docker.
Чтобы загрузить образ, запустите
docker pull revdotcom/fstalign
По мере загрузки вы должны увидеть что-то вроде этого.
Загрузка тестовых данных
Мы также будем использовать некоторые тестовые данные, предоставленные Rev, хотя, конечно, в какой-то момент вам придется использовать свои собственные данные. Данные Rev размещены в этом репо. Весь репозиторий довольно большой, поэтому вместо этого мы сделаем то, что называется разреженной проверкой , что позволит нам загружать только интересующие нас подкаталоги. Сначала запустите следующее в своем терминале.
Данные Rev размещены в этом репо. Весь репозиторий довольно большой, поэтому вместо этого мы сделаем то, что называется разреженной проверкой , что позволит нам загружать только интересующие нас подкаталоги. Сначала запустите следующее в своем терминале.
mkdir наборы речевых данных cd наборы речевых данных git инициировать git remote add -f origin https://github.com/revdotcom/speech-datasets.git
На этом этапе наш локальный репозиторий все еще будет пуст, но Git получит соответствующие объекты. Все, что осталось, это проверить те, которые мы хотим. Для этого нам нужно кратко обновить наш git config с помощью следующей команды:
git config core.sparseCheckout true
Теперь нам просто нужно указать, какие папки мы хотим получить локально, указав их в .git/ файл info/sparse-checkout. Идите вперед и запустите следующее:
эхо-заработок21/выход/* >> .git/info/sparse-checkout эхо-заработок21/transcripts/nlp_references/* >> .git/info/sparse-checkout
Это говорит Git вытащить все подкаталоги выходного каталога в нашу локальную файловую систему, а также папку «transcripts/nlp_references», которая содержит справочные тексты. Наконец, чтобы выполнить извлечение, запустите
Наконец, чтобы выполнить извлечение, запустите
git pull origin main
Теперь у вас должен быть доступ к выходной папке и всем подпапкам. Они содержат стенограммы разговоров о доходах компании, созданные шестью различными поставщиками распознавания речи: Amazon, Google, Microsoft, Rev, Speechmatics и Kaldi. Выходные данные были преобразованы в файлы «.nlp» для использования с инструментом FSTAlign.
Получить FSTAlign Word Error Rate Tester
Использование FSTAlign
Использовать инструмент FSTAlign очень просто. Ознакомьтесь с выводом команды справки FSTAlign.
Вер. FST Выравнивание Использование: ./fstalign [ОПЦИИ] [ПОДКОМАНДА] Параметры: -h,--help Распечатать это справочное сообщение и выйти --help-all Развернуть всю справку --version Показать версию fstalign. Подкоманды: wer Получите WER между эталоном и гипотезой. align Производит выравнивание между файлом NLP и вводом, подобным CTM.
Мы видим, что есть две основные команды: «wer» и «align».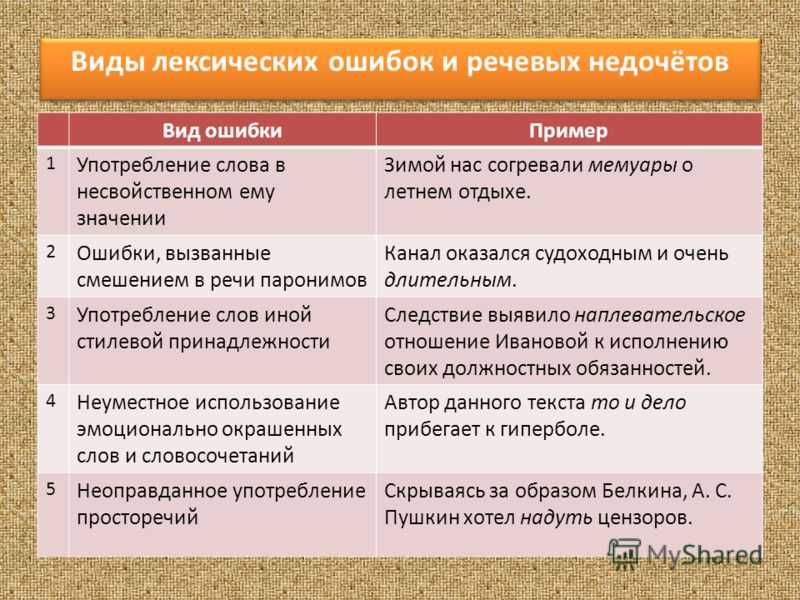 Тот, который мы будем использовать, — это «wer», который берет расшифровку стенограммы и ссылку и вычисляет частоту ошибок в словах стенограммы, относящейся к ссылке. Команда «выравнивание» производит выравнивание двух, что полезно, если вы хотите углубиться. Однако это выходит за рамки данного руководства.
Тот, который мы будем использовать, — это «wer», который берет расшифровку стенограммы и ссылку и вычисляет частоту ошибок в словах стенограммы, относящейся к ссылке. Команда «выравнивание» производит выравнивание двух, что полезно, если вы хотите углубиться. Однако это выходит за рамки данного руководства.
Запуск FSTAlign
Теперь давайте запустим инструмент. Это легко сделать с помощью Docker, в частности с помощью команды «docker run». Единственный трюк заключается в монтировании наших локальных каталогов в контейнер, чтобы у Docker был доступ к нашим файлам расшифровки. Во-первых, убедитесь, что вы находитесь в корневом каталоге «speech-datasets». Затем выполните следующую команду из вашего терминала
docker run -v $(pwd)/earnings21/output/:/fstalign/outputs -v $(pwd)/earnings21/transcripts/nlp_references/:/fstalign/references -it revdotcom/fstalign
Это глупо, так что мы сломаем его. «Docker run» просто говорит докеру запустить указанный контейнер. «-i» говорит ему работать в интерактивном режиме, что позволяет нам перейти в оболочку докера и запустить fstalign вручную. Флаг «-t» указывает тег образа, который мы хотим запустить. Для нас это «revdotcom/fstalign», то есть изображение, которое мы вытащили ранее. Наконец, два флага «-v» позволяют нам монтировать наши локальные файлы в интерактивный контейнер. Мы загружаем как выходные данные, так и ссылки. Флаг «-v» требует абсолютных путей, поэтому мы добавляем к относительному пути «$(pwd)».
«-i» говорит ему работать в интерактивном режиме, что позволяет нам перейти в оболочку докера и запустить fstalign вручную. Флаг «-t» указывает тег образа, который мы хотим запустить. Для нас это «revdotcom/fstalign», то есть изображение, которое мы вытащили ранее. Наконец, два флага «-v» позволяют нам монтировать наши локальные файлы в интерактивный контейнер. Мы загружаем как выходные данные, так и ссылки. Флаг «-v» требует абсолютных путей, поэтому мы добавляем к относительному пути «$(pwd)».
Узнайте о наборе данных Rev’s Earnings-21
После запуска этой команды вы должны оказаться внутри контейнера с установленным fstalign. Потрясающий! Введите «ls», чтобы увидеть, как все выглядит. Вы должны получить вывод, который выглядит примерно так:
CMakeLists.txt bin build outputs references sample_data src test третья сторона
Инструмент fstalign установлен в папке build. Чтобы запустить его, выполните следующую команду.
./build/fstalign wer --ref references/4320211.nlp --hyp outputs/google/4320211.nlp
Флаг «–ref» указывает путь к справочному файлу, т. е. к «правильному» выводу, созданному транскриптором-человеком. Флаг «–hyp» указывает путь к «предложенному» выводу, созданному службой распознавания речи. В этом случае мы проверим вывод системы Google ASR на первой из расшифровок телефонных разговоров о доходах. Когда вы запустите команду, вы должны получить вывод, который выглядит примерно так. (нажмите на изображение, чтобы увидеть код)
На третьем снимке экрана вы можете увидеть процент ошибочных слов, напечатанный для всех 10 говорящих во время разговора. Вуаля, вот оно! Это все, что вам нужно знать, чтобы использовать инструмент. Теперь вы можете выполнять сравнения WER для всех ваших тестовых аудиофайлов и для всех рассматриваемых систем ASR.
ASR Accuracy Rates
Этот инструмент помогает разработчикам проводить собственные тесты точности и коэффициента ошибок для всех систем автоматического распознавания речи, доступных сегодня на рынке. Rev часто тестирует самые большие и популярные ASR на рынке и неизменно считает, что Rev AI является наиболее точным.
Rev часто тестирует самые большие и популярные ASR на рынке и неизменно считает, что Rev AI является наиболее точным.
Попробуйте Rev AI API преобразования речи в текст бесплатно
Преобразование речи в текст для учащихся с ограниченными возможностями, приложения, инструменты и программное обеспечение
Инструменты преобразования речи в текст доступны на вашем компьютере через ваше устройство, браузер или расширения. Впервые эта технология была представлена в 1936 году с первым устройством преобразования текста в речь, и со временем она продолжала развиваться с использованием более передовых и улучшенных технологий. Речевые технологии, установленные на компьютерах или устройствах с различными приложениями и программным обеспечением, помогают всем, кто страдает дислексией или другими нарушениями обучаемости.
Содержание
История технологии преобразования речи в текст
1936 – Первые инструменты для преобразования текста в речь
Хотите верьте, хотите нет, но первым преобразованием речи в текст был первый в мире электронный синтезатор голоса, созданный в 1936 году Гомером Дадли в телефонной лаборатории Bell в Мюррей-Хилл, штат Нью-Джерси. Преобразователь речи в текст, первое электронное устройство, которое могло генерировать непрерывную человеческую речь в электронном виде, стало первым устройством преобразования текста в речь.
Преобразователь речи в текст, первое электронное устройство, которое могло генерировать непрерывную человеческую речь в электронном виде, стало первым устройством преобразования текста в речь.
Хотя, не так эффективно, как наш современный текст в речь, Voder был слышен. Согласно сайту Smithsonian.com, Водер «мог издавать около 20 различных звуков и чириканий, которыми оператор мог манипулировать с помощью 10 клавиш, пластины для запястья и педали».
С 1950-х по 1960-е годы
В истории технологии программного обеспечения для распознавания речи это была эпоха «детского лепета»; можно было понять только числа и цифры. В 1952 году компания Bell Laboratories изобрела «Одри», которая могла понимать только числа. Но в 1962 году технология «обувной коробки» смогла понять 16 слов на английском языке. Позже распознавание голоса было расширено до 9 согласных и 4 гласных.
Министерство обороны США внесло большой вклад в разработку систем распознавания речи и с 19С 71 по 1976 год он финансировал программу DARPA SUR (исследование понимания речи). В результате Карнеги-Меллон разработал «Гарпию», способную понимать 1011 слов. В нем использовалась более эффективная система поиска логических предложений. Были также параллельные достижения в области технологий, такие как разработка устройства Bell Laboratories, которое могло понимать голос более чем одного человека.
В результате Карнеги-Меллон разработал «Гарпию», способную понимать 1011 слов. В нем использовалась более эффективная система поиска логических предложений. Были также параллельные достижения в области технологий, такие как разработка устройства Bell Laboratories, которое могло понимать голос более чем одного человека.
Технология преобразования речи в текст развивалась с 1970-х по 1990-е годы
Было несколько прорывов в технологии преобразования речи в текст. Вклад Министерства обороны США поддерживал технологию распознавания речи с 1971 по 1976 год в рамках разработки программы DARPA SUR (исследование понимания речи). Согласно веб-сайту Total Voice Technologies, «Гарпия», разработанная Карнеги-Меллон, могла понимать 1011 слов.
Поиск логических предложений также был способностью Гарпии. Технологии Bell не остались в стороне, компания разработала устройство, способное понимать голос более чем одного человека.
Согласно хронологии веб-сайта Total Voice Technologies, 1980-е годы оказались многообещающим временем для технологии преобразования речи в текст. Используя статистику для определения вероятности того, что слово образовано от неизвестного звука, скрытая марковская модель не полагалась на фиксированные шаблоны или речевые паттерны. Эта технология в основном использовалась в промышленности и бизнес-приложениях.
Используя статистику для определения вероятности того, что слово образовано от неизвестного звука, скрытая марковская модель не полагалась на фиксированные шаблоны или речевые паттерны. Эта технология в основном использовалась в промышленности и бизнес-приложениях.
В 80-х годах распознавание речи не было безупречным, для того чтобы система распознавания речи была успешной, между каждым произнесенным словом должен быть перерыв.
В 90-х более быстрые компьютеры и процессоры способствовали развитию технологии преобразования речи в текст. В 1994 году была основана компания Nuance. Nuance развернула свое первое крупномасштабное коммерческое речевое приложение в 1996 году. Это приложение представляло собой автоматизированный центр обработки вызовов.
Маркетинг Автоматизация колл-центра сократит штат сотрудников колл-центра.
Современная технология преобразования речи в текст
Сегодня технологии речи используются повсеместно и могут распознавать произносимые слова и преобразовывать их в текст. Мы взаимодействуем со средствами распознавания речи, когда звоним в компании с автоматизированным обслуживанием клиентов. Голосовые помощники могут точно отвечать на ответы звонящего.
Мы взаимодействуем со средствами распознавания речи, когда звоним в компании с автоматизированным обслуживанием клиентов. Голосовые помощники могут точно отвечать на ответы звонящего.
В настоящее время все крупные технологические компании вложили значительные средства в развитие распознавания речи. Amazon Alexa, Apple Siri и Google Home используются в домах и распознавании речи, которые могут управлять устройствами в умных домах. Распознавание речи также используется в автомобилях с навигацией, при совершении звонков по мобильному телефону и получении информации о ресторанах, кинотеатрах и магазинах.
Преобразование речи в текст при дислексии и дисграфии
Это очень полезно для молодых учащихся с дисграфией или дислексией, которым очень трудно писать простые предложения, когда они хотят написать большую историю. Преобразование речи в текст может быть очень полезно для учащихся при поиске предметов в Интернете. Однако могут случиться странные ошибки, которые вызовут разочарование.
Программное обеспечение для преобразования речи в текст постоянно совершенствуется, но еще не идеально. Иногда преобразование речи в текст с трудом «понимает» намерения пользователя или разные акценты. Однако это можно решить с помощью функции воспроизведения, чтобы ваши слова могли быть прочитаны пользователями. Этот инструмент помогает убедиться, что текст говорит то, что вы хотели.
В средних и старших классах, а также в колледжах использование речи в текст для успешного написания чего-то столь сложного, как бумага, требует некоторой подготовки. Трудно планировать последовательность ваших идей и говорить полными, беглыми предложениями. Студенту придется много переделывать и корректировать, но если схема и идеи хорошо продуманы, корректировок может быть меньше.
Популярные инструменты для преобразования речи в текст
В настоящее время на рынке доступно несколько популярных инструментов для преобразования речи. Преобразование речи в текст Программное обеспечение для преобразования речи в текст, используемое в школах, помогает учащимся писать и работать в соответствии со своими способностями.
Программное обеспечение берет то, что они говорят, и записывает их для ученика. Они могут отредактировать его для большей точности и ясности, и процесс ускорится, а также даст учащимся уверенность и возможность продуктивно излагать свои идеи. Согласно веб-сайту Dragon Speech Recognition Resolution, студенты и бизнес-профессионалы используют программное обеспечение для повышения производительности своей работы, «работая быстрее и умнее».
Расширения браузера для преобразования текста в речь
На вашем компьютере и устройствах есть инструменты и расширения для преобразования текста в речь, которые также дадут вам возможность говорить и печатать ваши слова. Если вы хотите прочитать свои слова, включите TTS или преобразование текста в речь. Установка соответствующего расширения позволит вам выделить текст, который вы хотите прочитать, и выбрать произнесение в своем расширении, таком как браузеры Chrome или Google Chrome.
Бизнес-блог Elegant Themes перечисляет « 10 лучших инструментов преобразования речи в текст для ускорения процесса написания». Этот список включает голосовое преобразование документов Google, Window и диктовку Apple, а также многое другое.
Этот список включает голосовое преобразование документов Google, Window и диктовку Apple, а также многое другое.
Современные речевые технологии создают благоприятную среду для обучения и письма для учащихся и взрослых с дислексией и дисграфией. Технологии, которые в основном были созданы и разработаны частным сектором и правительством США, приносят пользу учащимся и взрослым с дислексией и другими трудностями в обучении. В то время как технология совершенствуется, среда обучения для этих студентов и взрослых также будет улучшаться и приводить их к успеху.
Ниже приведены дополнительные инструменты и ресурсы преобразования речи в текст
- 10 лучших инструментов преобразования речи в текст для ускорения процесса письма
- 8 программ для преобразования голоса в текст, которые помогут вам работать быстрее
- Лучшее приложение преобразования речи в текст 2019 года
Фото Alphacolor на Unsplash
Захавит Паз — соучредитель фонда LD Resources.