
Бесплатно проверьте орфографию онлайн и улучшите текст
Проверка текста…
Всего ошибок :
| Орфографические ошибки | |
| Другие ошибки |
Настройки
Скрыть
Правописание
Прочее
Посмотреть все ошибки
Копировать ссылку отчета Скопировано
Скачать отчёт в PDF Загружено
Отличная работа! Мы не нашли ошибок – в вашем тексте идеальная орфография.
Принцип работы инструмента проверки орфографии
Выберите страницу
Введите URL страницы, которую нужно проверить, или вставьте текст в редактор. Наш инструмент проверки орфографии выделит слова и предложения, требующие внимания, и предоставит вам полезные советы.
Внесите изменения
Скачайте отчёт о редактировании и предложениях, чтобы отследить необходимые изменения, или внесите изменения в онлайн-редакторе.
Удивите читателей идеальным текстом
Неважно, над чем вы работаете, – диссертацией, книгой или электронным письмом – всегда будет полезно убедиться в правильности написания текста и отсутствии ошибок. Также вы можете поставить напоминание, чтобы проверить любимые и самые популярные URL позже.
Популярные вопросы
Как работает проверка орфографии?
Проверка орфографии помогает найти ошибки в написании. Это происходит за счёт сравнения каждого слова в тексте или URL с тысячами правильно написанных слов. При отсутствии совпадений, инструмент предложит вам слова, похожие по звучанию и структуре, что поможет вам определить правильное написание.Как работает проверка грамматики?
Проверка грамматики проверяет текст и ищет грамматические ошибки, в том числе опечатки, неверную пунктуацию, согласование подлежащего и сказуемого, согласование сложных предложений и так далее. При обнаружении ошибки инструмент предоставит вам советы по исправлению. Проверка грамматики лучше всего работает на больших текстах, а именно на эссе, исследовательских работах и статьях.
Какие ошибки обнаруживает проверка орфографии?
Наш инструмент проверки орфографии обнаруживает не только орфографические ошибки. Конечно же он обнаружит возможные опечатки и предоставит варианты исправления. При этом он также выделяет пропущенные дефисы, грамматические ошибки и фразы и слова, которые могут быть излишними. Если вы хотите видеть только орфографические ошибки, вы можете отфильтровать результаты в левой части страницы.
2779850
2779850
Нравится этот инструмент? Оцените его!
4.8 (Проголосовало 60 пользователей)
Вы уже проголосовали! Отменить
Воспользуйтесь этим инструментом, чтобы оценить его
Это поле обязательно для заполнения Maximal length of comment is equal 80000 chars Минимальная длина комментария равна 10 символам Требуется адрес электронной почты Неверный адрес электронной почтыКак включить/выключить проверку орфографии в PowerPoint
Если вы обнаружили, что средства проверки правописания Microsoft Office мешают вам работать или по каким-то причинам не нужны, вы можете их отключить. Обнаружили, что проверка орфографии в PowerPoint не работает, и хотите включить или выключить ее? Конечно, вы можете это сделать. Ниже описано, как включить и выключить проверку орфографии в PowerPoint, в том числе как использовать высококачественный, простой в использовании, многофункциональный и интуитивно понятный PDF-редактор и инструмент управления PDF для проверки орфографии документов легко и быстро.
Обнаружили, что проверка орфографии в PowerPoint не работает, и хотите включить или выключить ее? Конечно, вы можете это сделать. Ниже описано, как включить и выключить проверку орфографии в PowerPoint, в том числе как использовать высококачественный, простой в использовании, многофункциональный и интуитивно понятный PDF-редактор и инструмент управления PDF для проверки орфографии документов легко и быстро.
Как включить и выключить проверку орфографии в PowerPoint?
Чтобы включить или выключить проверку орфографии в PPT, будь то проверка орфографии в PowerPoint 2007 или других программах, разница между ними невелика. В PowerPoint перейдите на вкладку “Рецензирование” и сразу на “Орфография и грамматика” или “Правописание”. В диалоговом окне будут выделены все неправильно написанные слова, и вы можете исправить слово, проигнорировать его или заменить по своему усмотрению, прежде чем программа перейдет к другому неправильно написанному термину. Однако вы можете отказаться от проверки грамматики и орфографии и включить или выключить ее.
Шаг 1. Откройте PowerPoint.
Перейдите к проверке правописания в PowerPoint, нажав на пункт “Файл” > “Параметры”.
Шаг 2. Включите или выключите проверку орфографии.
Перейдите к опции “Проверка” и найдите категорию “При исправлении орфографии в PowerPoint” или выберите “Проверять орфографию по мере ввода”. То же самое сделайте с грамматикой, сняв или выбрав флажок “Проверять грамматику с правописанием”.
Лучшее программное обеспечение для работы с PDF.
Нелегко изменить свой PDF-файл так, как вы хотите, и многие люди, профессионалы, руководители, представители малого бизнеса, частные лица, просто оставляют его таким, какой он есть. Однако есть выход из положения с помощью Wondershare PDFelement – Редактор PDF-файлов, лучшего и очень рекомендуемого редактора PDF и инструмента управления PDF с большим количеством функций и инструментов, которые помогут вам сделать многое с вашими PDF и документами в других форматах, таких как Excel, PPT, EPUB, HTML и др.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Программа отличается высокой надежностью, простотой в использовании и понятным пользовательским интерфейсом, а также высокой интуитивностью. PDFelement был отмечен за эффективное редактирование документов, которые не только отличаются высоким качеством, но и не теряют своего первоначального форматирования, макетов и многого другого, особенно при конвертировании в PDF и из PDF.
PDFelement позволяет использовать множество инструментов, недоступных или дорогостоящих в других PDF-редакторах. Он позволяет выполнять определенные задачи, такие как конвертирование из PDF и в PDF в пакетном режиме, когда вам нужно обработать несколько документов, включая возможность использования первоклассного инструмента OCR (оптическое распознавание символов) для преобразования отсканированных и бумажных документов в PDF-документы, которые вы можете загружать, редактировать и просматривать по своему усмотрению.
Кроме того, PDFelement доступен для Mac и Windows, где вы можете использовать его для защиты ваших PDF файлов с помощью разрешений и паролей, добавления цифровых подписей, создания заполняемых PDF-форм, просмотра PDF-файлов с аннотациями и комментариями, конвертирования в десятки форматов, редактирования текста и изображений, а также создания PDF-документов с нуля. PDFelement остается лучшей альтернативой Adobe Acrobat, благодаря своей функциональности и простоте использования. PDFelement доступен как онлайн, так и офлайн, чтобы помочь вам быстро, удобно и легко выполнить все ваши задачи по редактированию PDF. Более того, вы можете получить доступ к нему на компьютерах Mac (поддерживается новая macOS 10.15 Catalina), Windows, iOS и Android.
PDFelement остается лучшей альтернативой Adobe Acrobat, благодаря своей функциональности и простоте использования. PDFelement доступен как онлайн, так и офлайн, чтобы помочь вам быстро, удобно и легко выполнить все ваши задачи по редактированию PDF. Более того, вы можете получить доступ к нему на компьютерах Mac (поддерживается новая macOS 10.15 Catalina), Windows, iOS и Android.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Как проверить орфографию в PDF-документах?
Шаг 1. Импортируйте PDF-документ в PDFelement.
Запустите PDFelement и импортируйте PDF-файл, который вы собираетесь проверить на орфографию, нажав “Добавить”.
Шаг 2. Выберите проверку орфографии.
После загрузки файла в PDFelement, вы можете нажать “Файл” и перейти в “Параметры”, где нужно выбрать “Общие” и “Включить проверку орфографии”.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Шаг 3. Запустите проверку орфографии.
Поскольку проверка орфографии теперь включена, перейдите к загруженному PDF-документу и начните проверять орфографию и улучшать грамматику по своему усмотрению. Перейдите на вкладку “Редактировать”, чтобы войти в режим редактирования. После включения этого режима перейдите к какому-либо тексту в PDF-документе, щелкните по нему, и все грамматические и орфографические ошибки будут отображены. Щелкнув правой кнопкой мыши на опечатках, вы можете исправить их, а также игнорировать исправления, заменить слова, либо добавить специальные термины, которые обычно используются.
Исправление грамматических ошибок | НЛП-прогресс
Исправление грамматических ошибок (GEC) — это задача исправления различных типов ошибок в тексте, таких как орфографические, пунктуационные, грамматические ошибки и ошибки выбора слов.
GEC обычно формулируется как задание на исправление предложений. Система GEC принимает потенциально ошибочное предложение в качестве входных данных и, как ожидается, преобразует его в исправленную версию. См. приведенный ниже пример:
| Ввод (ошибочный) | Выход (исправлено) |
|---|---|
| Она видит, что прошлой ночью Тома поймал полицейский в парке. | Вчера вечером она видела, как полицейский поймал Тома в парке. |
Общая задача CoNLL-2014
Тестовый набор общих задач CoNLL-2014 является наиболее широко используемым набором данных для тестирования систем GEC. Тестовый набор содержит 1312 предложений на английском языке с аннотациями ошибок, сделанными двумя экспертами-аннотаторами. Модели оцениваются с помощью счетчика MaxMatch (Dahlmeier and Ng, 2012), который вычисляет F 9 на основе диапазона.0027 β

Параметр общей задачи запрещает системам использовать только общедоступные наборы данных для обучения, чтобы обеспечить справедливое сравнение между системами. Ниже приведены самые высокие опубликованные баллы по набору тестов CoNLL-2014. Проводится различие между статьями, в которых сообщается о результатах ограниченной совместной постановки задач CoNLL-2014 для обучения с использованием только общедоступных наборов обучающих данных ( Ограничено
Ограничено :
| Модель | Ф0.5 | Бумага / Источник | Код |
|---|---|---|---|
| ESC (Кориб и др., NAACL 2022) | 69,51 | Удивительно простая комбинация систем для исправления грамматических ошибок | официальный |
T5 (t5. 1.1.xxl), обученный cLang-8 (Rothe et al., ACL-IJCNLP 2021) 1.1.xxl), обученный cLang-8 (Rothe et al., ACL-IJCNLP 2021) | 68,87 | Простой рецепт исправления многоязычных грамматических ошибок | T5, cLang-8 |
| Помеченные искажения – ансамбль (Stahlberg and Kumar, 2021) | 68,3 | Генерация синтетических данных для исправления грамматических ошибок с использованием тегированных моделей искажения | Официальный |
| TMTC (Lai et al., ACL Findings 2022) | 67.02 | Управляемые типом многооборотные исправления для исправления грамматических ошибок | официальный |
| Тегирование последовательностей + преобразования на уровне токенов + двухэтапная тонкая настройка + (BERT, RoBERTa, XLNet), ансамбль (Omelianchuk et al., BEA 2020) | 66,5 | GECToR — исправление грамматических ошибок: тег, а не перезапись | Официальный |
Неглубокое агрессивное декодирование с BART (12+2), одиночная модель (луч = 1) (Sun et al. , ACL 2021) , ACL 2021) | 66,4 | Мгновенное исправление грамматических ошибок с поверхностным агрессивным декодированием | Официальный |
| DeBERTa(L) + RoBERTa(L) + XLNet (Тарнавский и др., ACL 2022) | 65,3 | Сборка и анализ знаний о больших последовательностях тегов для исправления грамматических ошибок | Официальный |
| Тегирование последовательностей + преобразования на уровне токенов + двухэтапная тонкая настройка + XLNet, одна модель (Омельянчук и др., BEA 2020) | 65,3 | GECToR — исправление грамматических ошибок: тег, а не перезапись | Официальный |
| Трансформатор + предварительная подготовка с псевдоданными + BERT (Канеко и др., ACL 2020) | 65,2 | Модели кодировщика-декодерамогут извлечь выгоду из предварительно обученных моделей маскированного языка при исправлении грамматических ошибок | Официальный |
Трансформатор + предварительная тренировка с псевдоданными (Kiyono et al. , EMNLP 2019) , EMNLP 2019) | 65,0 | Эмпирическое исследование включения псевдоданных в исправление грамматических ошибок | Официальный |
| Ансамбль Seq2Edits + полная переоценка последовательности (Stahlberg and Kumar, EMNLP 2020) | 62,7 | Seq2Edits: Преобразование последовательности с использованием операций редактирования на уровне интервала | Официальный |
| Маркировка последовательности с редактированием с использованием BERT, более быстрый вывод (ансамбль) (Awasthi et al., EMNLP 2019) | 61,2 | Модели параллельного итеративного редактирования для преобразования локальной последовательности | Официальный |
| Трансформатор с копией дополнений + предварительный поезд (Чжао и Ван, NAACL 2019) | 61,15 | Улучшение исправления грамматических ошибок посредством предварительного обучения архитектуры с дополненной копией с немаркированными данными | Официальный |
Маркировка последовательности с редактированием с использованием BERT, ускоренный вывод (одиночная модель) (Awasthi et al. , EMNLP 2019) , EMNLP 2019) | 59,7 | Модели параллельного итеративного редактирования для преобразования локальной последовательности | Официальный |
| CNN Seq2Seq + оценка качества (Chollampatt and Ng, EMNLP 2018) | 56,52 | Нейронная оценка качества исправления грамматических ошибок | Официальный |
| SMT + BiGRU (Grundkiewicz and Junczys-Dowmunt, 2018) | 56,25 | Производительность, близкая к человеческому уровню, при исправлении грамматических ошибок с помощью гибридного машинного перевода | нет данных |
| Трансформатор (Junczys-Dowmunt et al., 2018) | 55,8 | Подход к исправлению нейронных грамматических ошибок как задаче машинного перевода с низким уровнем ресурсов | Официальный |
| CNN Seq2Seq (Chollampatt and Ng, 2018) | 54,79 | Многослойная сверточная нейронная сеть кодировщика-декодера для исправления грамматических ошибок | Официальный |
Без ограничений :
| Модель | Ф0. 5 5 | Бумага / Источник | Код |
|---|---|---|---|
| CNN Seq2Seq + Fluency Boost (Ge et al., 2018) | 61,34 | Достижение производительности на уровне человека в автоматическом исправлении грамматических ошибок: эмпирическое исследование | нет данных |
Restricted : используются только общедоступные наборы данных. Без ограничений : использует закрытые наборы данных.
CoNLL-2014 10 Аннотации
Брайант и Нг, 2015 г. выпустили 8 дополнительных аннотаций (в дополнение к двум официальным аннотациям) для общего набора тестов CoNLL-2014 (ссылка).
Ограничено :
| Модель | Ф0.5 | Бумага / Источник | Код |
|---|---|---|---|
| SMT + BiGRU (Grundkiewicz and Junczys-Dowmunt, 2018) | 72. 04 04 | Производительность, близкая к человеческому уровню, при исправлении грамматических ошибок с помощью гибридного машинного перевода | нет данных |
| CNN Seq2Seq (Chollampatt and Ng, 2018) | 70,14 (измерено Ge et al., 2018) | Многослойная сверточная нейронная сеть кодировщика-декодера для исправления грамматических ошибок | Официальный |
Без ограничений :
| Модель | Ф0.5 | Бумага / Источник | Код |
|---|---|---|---|
| CNN Seq2Seq + Fluency Boost (Ge et al., 2018) | 76,88 | Достижение производительности на уровне человека в автоматическом исправлении грамматических ошибок: эмпирическое исследование | нет данных |
Restricted : используются только общедоступные наборы данных. Без ограничений : использует закрытые наборы данных.
Без ограничений : использует закрытые наборы данных.
JFLEG
Набор тестовJFLEG, выпущенный Napoles et al., 2017, состоит из 747 английских предложений с 4 ссылками на каждое предложение. Модели оцениваются с помощью показателя GLEU (Napoles et al., 2016).
Ограничено :
| Модель | ГЛЕУ | Бумага / Источник | Код |
|---|---|---|---|
| Коррупция с тегами (Stahlberg and Kumar, 2021) | 64,7 | Генерация синтетических данных для исправления грамматических ошибок с использованием тегированных моделей искажения | Официальный |
| Трансформатор + предварительная подготовка с псевдоданными + BERT (Kaneko et al., ACL 2020) | 62,0 | Модели кодировщика-декодера могут извлечь выгоду из предварительно обученных моделей маскированного языка при исправлении грамматических ошибок | Официальный |
| SMT + BiGRU (Grundkiewicz and Junczys-Dowmunt, 2018) | 61,50 | Производительность, близкая к человеческому уровню, при исправлении грамматических ошибок с помощью гибридного машинного перевода | нет данных |
Трансформатор (Junczys-Dowmunt et al. , 2018) , 2018) | 59,9 | Подход к исправлению нейронных грамматических ошибок как задаче машинного перевода с низким уровнем ресурсов | нет данных |
| CNN Seq2Seq (Chollampatt and Ng, 2018) | 57,47 | Многослойная сверточная нейронная сеть кодировщика-декодера для исправления грамматических ошибок | Официальный |
Без ограничений :
| Модель | ГЛЕУ | Бумага / Источник | Код |
|---|---|---|---|
| CNN Seq2Seq + Fluency Boost и вывод (Ge et al., 2018) | 62,42 | Достижение производительности на уровне человека в автоматическом исправлении грамматических ошибок: эмпирическое исследование | нет данных |
Restricted : используются только общедоступные наборы данных. Без ограничений : использует закрытые наборы данных.
Без ограничений : использует закрытые наборы данных.
Общая задача BEA — 2019
Общая задача BEA — набор данных 2019 года, выпущенный для общей задачи BEA по исправлению грамматических ошибок, предоставляет более новый и больший набор данных для оценки моделей GEC в 3 треках на основе наборов данных, используемых для обучения:
- Ограниченный путь
- Трек без ограничений
- Трек с низким ресурсом
Наборы для обучения и разработки публикуются публично, а производительность модели GEC оценивается по баллу F-0,5. Выходные данные модели в тестовом наборе должны быть загружены в Codalab (общедоступно), где отображаются метрики ошибок по категориям. Набор тестов состоит из 4477 предложений (больше и разнообразнее, чем набор данных CoNLL-14), а результаты оцениваются с помощью инструментария ERRANT. Опубликованные данные собираются из 2 источников:
- Write & Improve, онлайн-платформа, которая помогает учащимся, для которых английский язык не является родным, писать.
- LOCNESS, корпус, состоящий из эссе, написанных носителями английского языка.
Ниже приведено описание дорожек с сайта BEA:
Ограниченный трек: В треке с ограниченным доступом участники могут использовать только следующие наборы обучающих данных:
.- FCE (Yannakoudakis et al., 2011)
- Lang-8 Corpus of Learner English (Mizumoto et al., 2011; Tajiri et al., 2012)
- ЯДРО (Dahlmeier et al., 2013)
- W&I+LOCNESS (Bryant et al., 2019; Granger, 1998)
Обратите внимание, что мы ограничиваем участников предварительно обработанным Lang-8 Corpus of Learner English, а не необработанным, многоязычным Lang-8 Learner Corpus, поскольку в противном случае участникам пришлось бы фильтровать сам сырой корпус. Мы также не разрешаем использовать наборы общих тестов CoNLL 2013/2014 в этом треке.
Отслеживание без ограничений: В неограниченном треке участники могут использовать что угодно и что угодно для создания своих систем.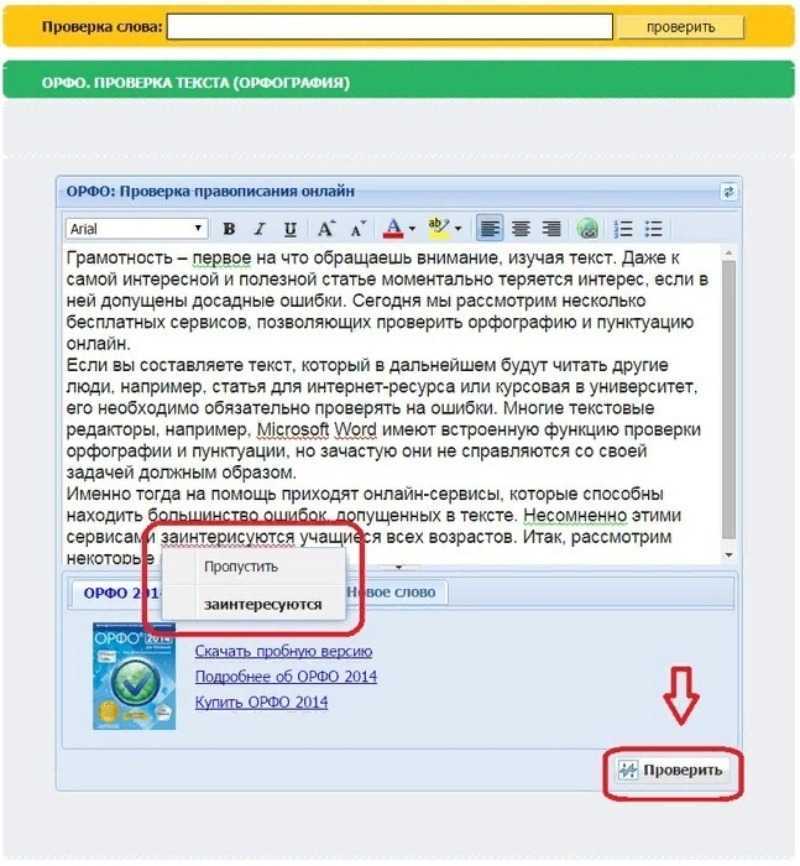 Сюда входят проприетарные наборы данных и программное обеспечение.
Сюда входят проприетарные наборы данных и программное обеспечение.
Низкоресурсная дорожка (ранее неконтролируемая дорожка): В треке с низким уровнем ресурсов участники могут использовать только следующий набор обучающих данных: набор разработки W&I+LOCNESS.
Поскольку для достижения наилучшей производительности современные современные системы полагаются на максимально возможное количество аннотированных данных об учащемся, целью направления с низкими ресурсами является поощрение исследований систем, которые не полагаются на большие объемы данных об учащемся. Это направление должно представлять особый интерес для исследователей, работающих над GEC для языков, для которых не существует больших обучающих корпусов.
Результаты тестового набора WI-LOCNESS:
Ограниченный трек :
| Модель | Ф0.5 | Бумага / Источник | Код |
|---|---|---|---|
ESC (Кориб и др.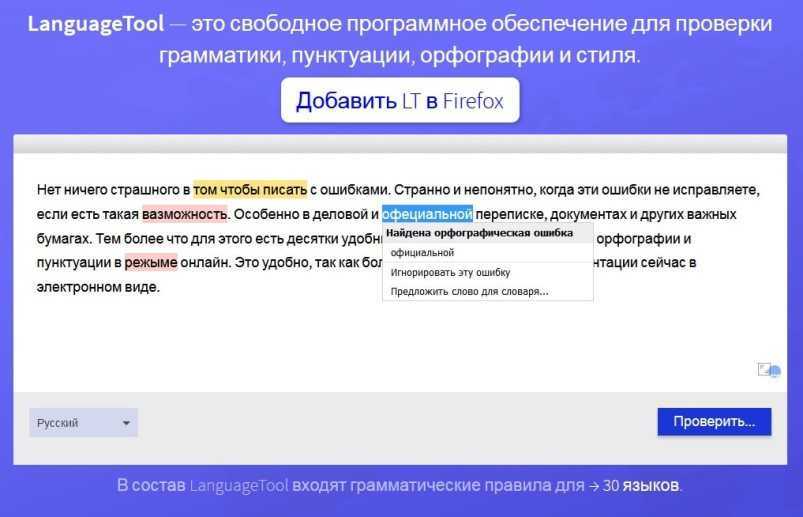 , NAACL 2022) , NAACL 2022) | 79,90 | Удивительно простая комбинация систем для исправления грамматических ошибок | официальный |
| TMTC (Lai et al., ACL Findings 2022) | 77,93 | Управляемые типом многооборотные исправления для исправления грамматических ошибок | официальный |
| DeBERTa(L) + RoBERTa(L) + XLNet (Тарнавский и др., ACL 2022) | 76.05 | Сборка и анализ знаний о больших последовательностях тегов для исправления грамматических ошибок | Официальный |
| GECToR большой без синтетической предварительной подготовки – ансамбль (Тарнавский и Омельянчук, 2021) | 76.05 | Улучшение маркировки последовательностей для исправления грамматических ошибок | Официальный |
| T5 (t5.1.1.xxl), обученный cLang-8 (Rothe et al., ACL-IJCNLP 2021) | 75,88 | Простой рецепт исправления многоязычных грамматических ошибок | T5, cLang-8 |
| Помеченные искажения – ансамбль (Stahlberg and Kumar, 2021) | 74,9 | Генерация синтетических данных для исправления грамматических ошибок с использованием тегированных моделей искажения | Официальный |
Тегирование последовательностей + преобразования на уровне токенов + двухэтапная тонкая настройка + (BERT, RoBERTa, XLNet), ансамбль (Omelianchuk et al.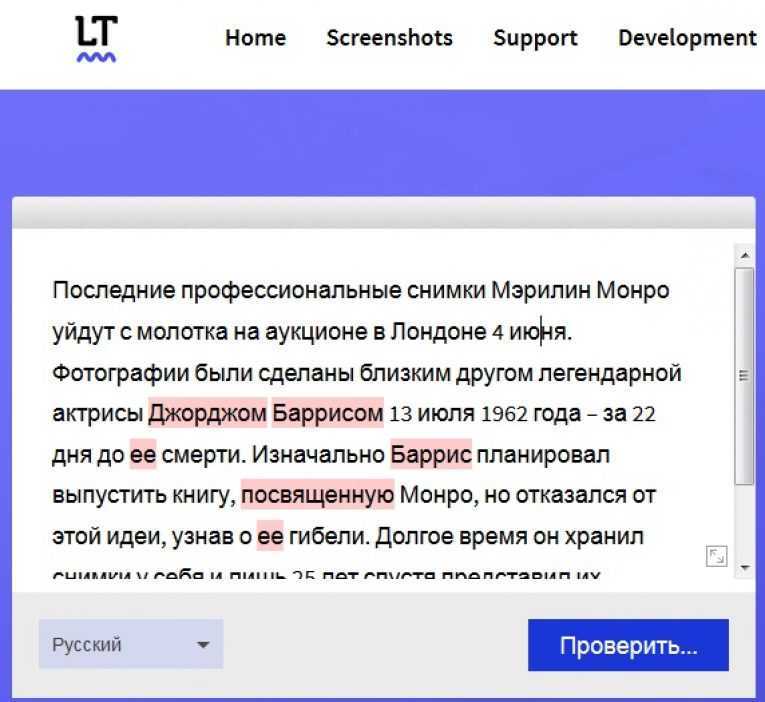 , BEA 2020) , BEA 2020) | 73,6 | GECToR — исправление грамматических ошибок: тег, а не перезапись | Официальный |
| Комбинация BEA | 73,18 | Учимся комбинировать исправления грамматических ошибок | официальный |
| Неглубокое агрессивное декодирование с BART (12+2), одиночная модель (луч=1) (Sun et al., ACL 2021) | 72,9 | Мгновенное исправление грамматических ошибок с поверхностным агрессивным декодированием | Официальный |
| Тегирование последовательностей + преобразования на уровне токенов + двухэтапная тонкая настройка + XLNet, одна модель (Омельянчук и др., BEA 2020) | 72,4 | GECToR — исправление грамматических ошибок: тег, а не перезапись | Официальный |
Трансформатор + предварительная тренировка с псевдоданными (Kiyono et al.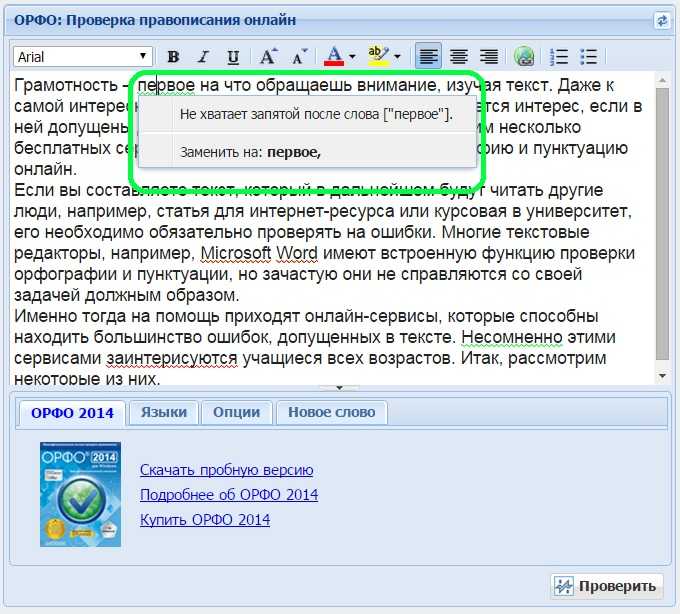 , EMNLP 2019) , EMNLP 2019) | 70,2 | Эмпирическое исследование включения псевдоданных в исправление грамматических ошибок | нет данных |
| Трансформатор + предварительная подготовка с псевдоданными + BERT (Канеко и др., ACL 2020) | 69,8 | Модели кодировщика-декодера могут извлечь выгоду из предварительно обученных моделей маскированного языка при исправлении грамматических ошибок | Официальный |
| Трансформатор | 69,47 | Нейронные системы коррекции грамматических ошибок с неконтролируемым предварительным обучением на синтетических данных | Официально: Код скоро будет обновлен |
| Трансформатор | 69,00 | Нейронная система исправления грамматических ошибок, построенная на лучшем предварительном обучении и последовательном переносе обучения | Официальный |
| Сборка моделей | 66,78 | Системы LAIX в общей задаче BEA-2019 GEC | нет данных |
Трек с низким ресурсом :
| Модель | Ф0. 5 5 | Бумага / Источник | Код |
|---|---|---|---|
| Трансформатор | 64,24 | Нейронные системы исправления грамматических ошибок с неконтролируемым предварительным обучением на синтетических данных | Официально: Код скоро будет обновлен |
| Трансформатор | 58,80 | Система исправления нейронных грамматических ошибок, построенная на лучшем предварительном обучении и обучении с последовательным переносом | Официальный |
| Сборка моделей | 51,81 | Системы LAIX в общей задаче BEA-2019 GEC | нет данных |
№ по каталогу :
- Хелен Яннакудакис, Екатерина Кочмар, Клаудия Ликок, Нитин Маднани, Ильдико Пилан, Торстен Зеш, в материалах четырнадцатого семинара по инновационному использованию НЛП для создания образовательных приложений
- Кристофер Брайант, Мариано Феличе и Тед Бриско.
 2017. Автоматическая аннотация и оценка типов ошибок для исправления грамматических ошибок. В материалах 55-го ежегодного собрания Ассоциации компьютерной лингвистики (Том 1: Длинные статьи). Ванкувер, Канада.
2017. Автоматическая аннотация и оценка типов ошибок для исправления грамматических ошибок. В материалах 55-го ежегодного собрания Ассоциации компьютерной лингвистики (Том 1: Длинные статьи). Ванкувер, Канада.
Проверка орфографии и грамматики в PowerPoint для Интернета
PowerPoint для Интернета Дополнительно… Меньше
По мере ввода PowerPoint в Интернете сообщает об обнаружении возможных орфографических, грамматических или стилистических ошибок, подчеркивая слова.
Тип:
Правописание
Пример:
Работает для файлов, хранящихся в:
OneDrive,
OneDrive для работы или учебы,
SharePoint в Microsoft 365
Тип:
Грамматика
Пример:
Работает с файлами, хранящимися в:
OneDrive для работы или учебы,
SharePoint в Microsoft 365
Тип:
Предлагаемое уточнение записи
Пример:
Работает для файлов, хранящихся в:
OneDrive для работы или учебы,
SharePoint в Microsoft 365
Исправить ошибку
Чтобы исправить ошибку (или Игнорировать предложение), щелкните правой кнопкой мыши подчеркнутый термин :
Совет: Возможно, введенное вами слово написано правильно, но веб-словарь PowerPoint не распознает его. Это может быть торговая марка, аббревиатура или что-то подобное.
Это может быть торговая марка, аббревиатура или что-то подобное.
Проверка слайда на правильность написания, грамматики и стиля
Если ваш файл хранится в OneDrive для работы или учебы или в SharePoint в Microsoft 365, вы можете указать PowerPoint для Интернета проверять слайд на предмет орфографии, грамматики и стиля.
На вкладке Review выберите Check Slide > Check Slide .
Панель Editor открывается в правой части окна браузера. Любые орфографические или грамматические ошибки, а также предлагаемые улучшения написания перечислены на панели редактора , чтобы вы могли просмотреть и принять решение.
Отключение маркеров проверки во всем файле
Если ваш файл хранится в OneDrive для работы или учебы или в SharePoint в Microsoft 365, вы можете скрыть все маркеры, которые показывают ошибки проверки.
На вкладке Обзор ленты выберите стрелку на кнопке Настройки редактора .
В появившемся меню выберите Скрыть ошибки проверки правописания .
Эта команда включает и выключает маркеры. Используйте его снова позже, если вы хотите показать маркеры проверки правописания в этой презентации.
Отключение средства проверки правописания для отдельных слов или блока текста
Если ваш файл хранится в OneDrive для работы или учебы или в SharePoint в Microsoft 365, вы можете отключить проверку правописания для определенного термина или для всего поля, содержащего текст.
Перейдите к шагу 2, если вы хотите изменить язык проверки для всего текстового поля или в текстовом поле, выберите слово или слова, которые вы не хотите проверять.
Щелкните правой кнопкой мыши выбранные слова или само текстовое поле и выберите Установить язык проверки правописания .
Выберите Не проверять орфографию или грамматику .
Изменение языка проверки правописания
Изменение языка проверки для всего файла не поддерживается. Вы можете изменить язык проверки только для выбранных слов или блока текста.
Вы можете изменить язык проверки только для выбранных слов или блока текста.
Перейдите к шагу 2, если вы хотите изменить язык проверки для всего поля текста или выберите слово или слова, для которых вы хотите изменить язык проверки.
Щелкните правой кнопкой мыши поле или выбранные слова и выберите Установить язык проверки правописания .
В поле Пометить выделенный текст как выберите язык, который вы хотите изменить, и нажмите OK .
Чтобы изменить язык кнопок и меню в приложениях Office Online, см.