
Автоматические конвейеры исправления орфографии — Документация DeepPavlov 1.1.0
Автоматические конвейеры исправления орфографии — Документация DeepPavlov 1.1.0Мы предоставляем два типа конвейеров для исправления орфографии: левенштейн_корректор использует простое расстояние Дамерау-Левенштейна для поиска кандидатов на исправление и бриллмур использует для этого модель ошибок, основанную на статистике. В обоих случаях коррекция кандидаты выбираются в зависимости от контекста с помощью языковой модели kenlm. Вы можете найти сравнение этих и других приближается к концу этого файла readme.
Примечание
Около 4,4 ГБ на диске требуется для русскоязычной модели и около 7 ГБ для англоязычной.
Быстрый старт
Сначала вам необходимо установить дополнительные требования:
python -m deeppavlov install
где — это путь к одному из предоставленных файлов конфигурации
или его название без расширения, например levenshtein_corrector_ru.
Вы можете запустить следующую команду, чтобы попробовать предоставленные конвейеры:
python -m deeppavlov взаимодействовать[-d]
, где — один из предоставленных файлов конфигурации.
С необязательным параметром -d все данные, необходимые для запуска
выбранный конвейер будет загружен, включая
соответствующую языковую модель.
После загрузки необходимых файлов вы можете использовать эти конфиги в своем код питона. Например, этот код будет считывать строки со стандартного ввода и печатать исправленные строки на стандартный вывод:
система импорта
из диппавлова импортировать build_model, конфиги
CONFIG_PATH=configs.spelling_correction.levenshtein_corrector_ru
модель = build_model (CONFIG_PATH, загрузка = True)
для строки в sys.stdin:
печать (модель ([строка]) [0], флеш = Истина)
levenshtein_corrector
Этот компонент находит все
кандидатов в статическом словаре на заданном расстоянии Дамерау-Левенштейна.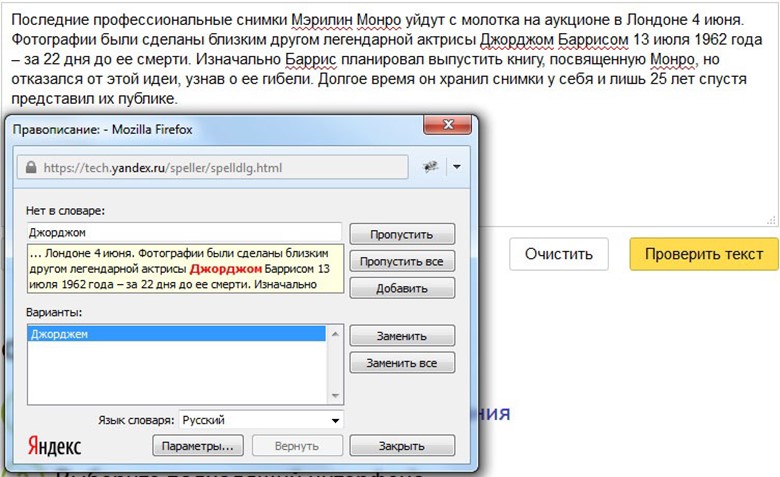 Он может разделить один токен на два, но по-другому не получится.
вокруг.
Он может разделить один токен на два, но по-другому не получится.
вокруг.
Параметры конфигурации компонента:
в— список из одного элемента: имя входа этого компонента в общая память цепейout— список из одного элемента: имя вывода этого компонента в общая память цепейclass_nameвсегда равно"spelling_levenshtein"илиdeeppavlov.models.spelling_correction.levenshtein.searcher_component:LevenshteinSearcherComponent.слов— список всех правильных слов (должна быть ссылка)max_distance— максимально допустимое расстояние Дамерау-Левенштейна между исходными словами и кандидатамиerror_probability— назначенная вероятность для каждого редактирования
brillmoore
Этот компонент основан на
Улучшенная модель ошибок для исправления орфографии зашумленного канала
Эрика Брилла и Роберта С.
Параметры конфигурации компонента:
в— список с одним элементом: имя входа этого компонента в общая память цепейout— список из одного элемента: имя вывода этого компонента в общая память цепейclass_nameвсегда равно"spelling_error_model"илиdeeppavlov.models.spelling_correction.brillmoore.error_model:ErrorModel.load_path— путь к предварительно обученной моделиwindow— размер окна для модели ошибок от0до4, по умолчанию1Кандидаты_счет— максимально допустимое количество кандидатов для каждого токен источникасловарь— описание статической модели словаря, экземпляр (или унаследовано от)deeppavlov.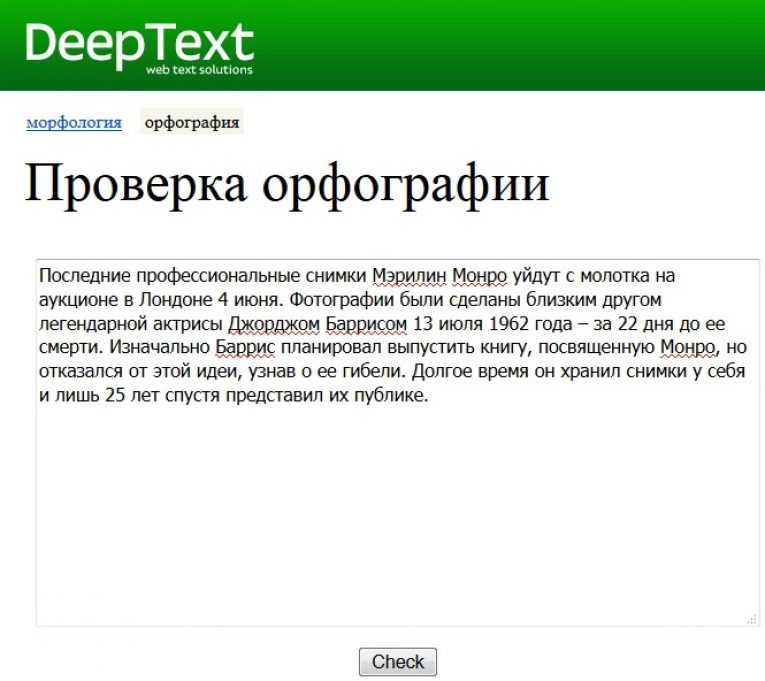 vocabs.static_dictionary.StaticDictionary
vocabs.static_dictionary.StaticDictionary class_name—"static_dictionary"для пользовательского словаря или одного из двух предоставленных:"russian_words_vocab"для автоматической загрузки и использования список русских слов из https://github.com/danakt/russian-words/"wikitionary_100K_vocab"для автоматической загрузки списка самых распространенных слов из Project Gutenberg из Викисловарь
имя_словаря— имя каталога, в котором будет находиться словарь. быть построен и загружен из, по умолчанию"словарь"для статический_словарьraw_dictionary_path
Конфигурация обучения
Для конфигурационного файла этапа обучения необходимо также включить эти параметры:
dataset_iterator— всегда должно быть установлено как"dataset_iterator": {"class_name": "typos_iterator"}class_nameвсегда равноtypos_iteratortest_ratio— отношение тестовых данных к обучению, от0,до1., по умолчанию
0.
dataset_readerclass_name—typos_custom_readerдля пользовательского набора данных или одного из два предоставленных:typos_kartaslov_readerдля автоматической загрузки и обрабатывать набор данных опечаток для русского языка из https://github.com/dkulagin/kartaslov/tree/master/dataset/orfo_and_typostypos_wikipedia_readerдля автоматической загрузки и обработать список распространенных орфографических ошибок в английском языке Википедия — https://en.wikipedia.org/wiki/Википедия:Lists_of_common_misspellings/For_machines
data_path— требуется для typos_custom_reader как путь к файл набора данных, где каждая строка содержит опечатку и правильное написание слова, разделенного символом табуляции
Конфигурация компонента для правописания_error_model тоже должен
have as fit_on параметр — список из двух элементов:
имена входных и выходных данных компонента в разделяемом цепочке
Память.
Языковая модель
Предоставляемые конвейеры используют KenLM для языковые модели процессов, поэтому, если вы хотите создавать свои собственные, мы предлагаем вам посетить его веб-сайт. Мы также предоставляем собственные языковые модели для английский (5,5 ГБ) и русский (3,1 ГБ) языков.
Сравнение
Мы сравнили наши трубопроводы с Яндекс.Спеллер, JamПравописание и PyHunЗаклинание на тестовом наборе для SpellRuEval соревнование об автоматической коррекции орфографии для русского языка:
Метод коррекции | Точность | Отзыв | Размер F | Скорость (предложений/с) |
|---|---|---|---|---|
Яндекс.Спеллер | 83.09 | 59,86 | 69,59 | |
Дамерау Левенштейн 1 + п. | 59,38 | 53,44 | 56,25 | 39,3 |
Hunspell + лм | 41.03 | 48,89 | 44,61 | 2.1 |
JamSpell | 44,57 | 35,69 | 39,64 | 136,2 |
Ханспелл | 30.30 | 34.02 | 32.06 | 20,3 |
 м.
м.Читать документы В: мастер
- Версии
- мастер
- последний
- 1.0.2
- 1.0.1
- 1.0.0
- 1.0.0rc1
- 1.0.0rc0
- 0,17,6
- 0,17,5
- 0.
 17.4
17.4 - 0.17.2
- 0.17.1
- 0.17.0
- 0.16.0
- 0.15.0
- 0.14.1
- 0.14.0
- 0.13.0
- 0.12.1
- 0.12.0
- 0.11.0
- 0.10.0
- 0.9.1
- 0.9.0
- 0.8.0
- 0.7.1
- 0.7.0
- 0.6.0
- 0.5.1
- 0.5.0
- 0.4.0
- 0.3.1
- 0.3.0
- 0.2.0
- 0.1.6
- 0.
 1.5.1
1.5.1 - 0.1.5
- 0.1.1
- 0.1.0
- 0.0.9
- 0.0.8
- 0.0.7
- 0.0.6.5
- Загрузки
- При прочтении документов
- Дом проекта
- Строит
Проверка орфографии для Python Ru Python спросил
Изменено 6 месяцев назад
Просмотрено 197 тысяч раз
Я новичок в Python и NLTK. Я занят приложением, которое может выполнять проверку орфографии (заменяет неправильно написанное слово на правильное). В настоящее время я использую библиотеку Enchant на Python 2.7, PyEnchant и библиотеку NLTK. Приведенный ниже код представляет собой класс, который обрабатывает исправление/замену.
В настоящее время я использую библиотеку Enchant на Python 2.7, PyEnchant и библиотеку NLTK. Приведенный ниже код представляет собой класс, который обрабатывает исправление/замену.
из импорта nltk.metrics edit_distance
класс SpellingReplacer:
def __init__(self, dict_name='en_GB', max_dist=2):
self.spell_dict = enchant.Dict(dict_name)
self.max_dist = 2
def заменить (я, слово):
если self.spell_dict.check(слово):
возвратное слово
предложения = self.spell_dict.suggest(слово)
если предложения и edit_distance(слово, предложения[0]) <= self.max_dist:
вернуть предложения[0]
еще:
возвратное слово
Я написал функцию, которая принимает список слов и выполняет replace() для каждого слова, а затем возвращает список этих слов, но с правильным написанием.
определение орфографической_проверки (список_слов):
проверенный_список = []
для элемента в word_list:
replacer = Заменитель орфографии()
r = replacer. replace(предмет)
checked_list.append(r)
вернуть проверенный_список
>>> word_list = ['машина', 'цвет']
>>> Проверка орфографии (слова)
['автомобиль', 'цвет']
replace(предмет)
checked_list.append(r)
вернуть проверенный_список
>>> word_list = ['машина', 'цвет']
>>> Проверка орфографии (слова)
['автомобиль', 'цвет']
Мне это не очень нравится, потому что это не очень точно, и я ищу способ добиться проверки орфографии и замены слов. Мне также нужно что-то, что может исправить орфографические ошибки, такие как «caaaar»? Существуют ли более эффективные способы проверки орфографии? Если так, то кто они? Как Google это делает? Потому что их подсказка по правописанию очень хороша.
Есть предложения?
- python
- python-2.7
- nltk
- проверка орфографии
- pyenchant
Пример использования:
из автозамены импорта Speller
заклинание = правописание (язык = 'en')
печать (заклинание ('caaaar'))
печать (заклинание ('mussage'))
печать (заклинание ('survice'))
печать (заклинание ('hte'))
Результат:
Цезарь сообщение услуга в
5
Я рекомендую начать с внимательного прочтения этого поста Питера Норвига. (У меня было что-то похожее, и я нашел это чрезвычайно полезным.)
(У меня было что-то похожее, и я нашел это чрезвычайно полезным.)
В частности, следующая функция имеет идеи, которые вам теперь нужны, чтобы сделать вашу проверку орфографии более сложной: разделение, удаление, перемещение и вставка неправильных слов в ' исправить их.
по умолчанию edits1 (слово): разбивает = [(слово[:i], слово[i:]) для i в диапазоне(len(word) + 1)] удаляет = [a + b[1:] для a, b в разбиениях, если b] транспонирует = [a + b[1] + b[0] + b[2:] для a, b в разбиениях, если len(b)>1] заменяет = [a + c + b[1:] для a, b в разделении для c в алфавите, если b] вставки = [a + c + b для a, b в разбиениях для c в алфавите] возвращаемый набор (удаляет + транспонирует + заменяет + вставляет)
Примечание. Выше приведен фрагмент из корректора орфографии Norvig
Хорошая новость заключается в том, что вы можете постепенно добавлять и улучшать свою программу проверки орфографии.
Надеюсь, это поможет.
1
Лучший способ проверки орфографии в Python: SymSpell, Bk-Tree или метод Питера Новига.
Самый быстрый — SymSpell.
Это Method1 : Ссылочная ссылка pyspellchecker
Эта библиотека основана на реализации Питера Норвига.
pip install pyspellchecker
из импорта проверки орфографии SpellChecker
заклинание = Проверка орфографии ()
# найти те слова, которые могут быть написаны с ошибками
с опечаткой = заклинание.неизвестно (['что-то', 'есть', 'происходит', 'здесь'])
для слова с ошибкой:
# Получить один «наиболее вероятный» ответ
печать (орфография. исправление (слово))
# Получить список «вероятных» вариантов
печать (заклинание.кандидаты (слово))
Method2: SymSpell Python
pip install -U symspellpy
2
Может быть, уже слишком поздно, но я отвечаю за будущие поиски.
ЧТОБЫ выполнить исправление орфографических ошибок, вам сначала нужно убедиться, что слово не является абсурдным или сленговым, например, caaaar, amazzzing и т. д. с повторяющимися алфавитами. Итак, сначала нам нужно избавиться от этих алфавитов. Как мы знаем, в английском языке слова обычно имеют максимум 2 повторяющихся алфавита, например, привет., поэтому мы сначала удаляем лишние повторы из слов, а затем проверяем их на правописание.
Для удаления лишних алфавитов вы можете использовать модуль регулярных выражений в Python.
д. с повторяющимися алфавитами. Итак, сначала нам нужно избавиться от этих алфавитов. Как мы знаем, в английском языке слова обычно имеют максимум 2 повторяющихся алфавита, например, привет., поэтому мы сначала удаляем лишние повторы из слов, а затем проверяем их на правописание.
Для удаления лишних алфавитов вы можете использовать модуль регулярных выражений в Python.
После этого используйте библиотеку Pyspellchecker из Python для исправления орфографии.
Для реализации перейдите по этой ссылке: https://rustyonrampage.github.io/text-mining/2017/11/28/spelling-correction-with-python-and-nltk.html
2
Попробуйте jamspell — он отлично работает для автоматического исправления орфографии:
import jamspell
корректор = jamspell.TSpellCorrector()
корректор.LoadLangModel('en.bin')
corrector.FixFragment('Некоторые отправлены с ошибкой')
# u'Какое-то предложение с ошибкой'
corrector.GetCandidates(['Некоторые', 'sentnec', 'с', 'ошибка'], 1)
# ('приговор', 'сенат', 'пахучий', 'страж')
2
В ТЕРМИНАЛЕ
pip install gingerit
ДЛЯ КОДА
от gingerit.gingerit import GingerIt text = input("Введите текст для исправления") результат = GingerIt().parse(текст) исправления = результат['исправления'] правильный текст = результат['результат'] print("Правильный текст:",correctText) Распечатать() печать("ИСПРАВЛЕНИЯ") для d в исправлениях: Распечатать("________________") print("Предыдущий:",d['текст']) print("Исправление:",d['правильно']) print("`Определение`:",d['определение'])
1
Вы также можете попробовать:
pip install textblob
из textblob import TextBlob
txt="машинное обучение"
б = TextBlob (txt)
print("после исправления орфографии: "+str(b.correct()))
после исправления орфографии: машинное обучение
2
вам нужно импортировать корпус на свой рабочий стол, если вы храните в другом месте, измените путь в коде. Я также добавил несколько изображений, используя tkinter, и это только для устранения ошибок, не связанных со словами!
определение min_edit_dist (слово1, слово2):
len_1 = len (слово1)
len_2 = len (слово2)
x = [[0]*(len_2+1) for _ in range(len_1+1)]#матрица, последний элемент которой -> расстояние редактирования
для я в диапазоне (0, len_1 + 1):
#инициализация базовых значений
х [я] [0] = я
для j в диапазоне (0, len_2+1):
х [0] [j] = j
для i в диапазоне (1,len_1+1):
для j в диапазоне (1, len_2+1):
если слово1[i-1]==слово2[j-1]:
х [я] [j] = х [я-1] [j-1]
еще :
х[i][j]= мин(х[i][j-1],x[i-1][j],x[i-1][j-1])+1
вернуть х [я] [j]
из импорта Tkinter *
деф получить_текст():
глобальное слово1
слово1=(app_entry. get())
path="C:\Documents and Settings\Owner\Desktop\Dictionary.txt"
ffile=open(путь,'r')
строки=ffile.readlines()
Distance_list=[]
print "Предложения поступают прямо до счета до 10"
для i в диапазоне (0,58109):
dist=min_edit_dist(word1,lines[i])
Distance_list.append(расстояние)
для j в диапазоне (0,58109):
если Distance_list[j]<=2:
печатать строки[j]
Распечатать" "
файл.close()
если __name__ == "__main__":
app_win = Тк()
app_win.title ("заклинание")
app_label = Label(app_win, text="Введите неправильное слово")
app_label.pack()
app_entry = запись (app_win)
app_entry.pack()
app_button = Кнопка (app_win, text="Получить предложения", command=retrive_text)
app_button.pack()
# Инициализировать цикл графического интерфейса
app_win.mainloop()
get())
path="C:\Documents and Settings\Owner\Desktop\Dictionary.txt"
ffile=open(путь,'r')
строки=ffile.readlines()
Distance_list=[]
print "Предложения поступают прямо до счета до 10"
для i в диапазоне (0,58109):
dist=min_edit_dist(word1,lines[i])
Distance_list.append(расстояние)
для j в диапазоне (0,58109):
если Distance_list[j]<=2:
печатать строки[j]
Распечатать" "
файл.close()
если __name__ == "__main__":
app_win = Тк()
app_win.title ("заклинание")
app_label = Label(app_win, text="Введите неправильное слово")
app_label.pack()
app_entry = запись (app_win)
app_entry.pack()
app_button = Кнопка (app_win, text="Получить предложения", command=retrive_text)
app_button.pack()
# Инициализировать цикл графического интерфейса
app_win.mainloop()
pyspellchecker — одно из лучших решений этой проблемы. Библиотека pyspellchecker основана на сообщении в блоге Питера Норвига. Он использует алгоритм расстояния Левенштейна для поиска перестановок в пределах расстояния редактирования 2 от исходного слова.
Есть два способа установить эту библиотеку. Официальный документ настоятельно рекомендует использовать пакет pipev.
Он использует алгоритм расстояния Левенштейна для поиска перестановок в пределах расстояния редактирования 2 от исходного слова.
Есть два способа установить эту библиотеку. Официальный документ настоятельно рекомендует использовать пакет pipev.
- установка с использованием
пунктов
pip установить pyspellchecker
- установка из исходников
git-клон https://github.com/barrust/pyspellchecker.git cd pyspellchecker установка python setup.py
следующий код является примером из документации
из импорта проверки орфографии SpellChecker
заклинание = Проверка орфографии ()
# найти те слова, которые могут быть написаны с ошибками
с опечаткой = заклинание.неизвестно (['что-то', 'есть', 'происходит', 'здесь'])
для слова с ошибкой:
# Получить один «наиболее вероятный» ответ
печать (орфография. исправление (слово))
# Получить список «вероятных» вариантов
печать (заклинание.кандидаты (слово))
из автозамены импортного заклинания для этого вам нужно установить, предпочитайте анаконду, и она работает только со словами, а не с предложениями, так что это ограничение, с которым вы столкнетесь.