
Онлайн-проверка ошибок, бесплатный подготовительный тест
Советы, советы и образцы тестов для подготовки к тестам проверки ошибок
- Купить тесты
- Бесплатные тесты
Содержание страницы:
Перейти к:
- Что такое тесты проверки ошибок?
- Бесплатные примеры тестов для проверки ошибок
- Пример вопросов для проверки ошибок
- Как подготовиться к тесту на проверку ошибок
Обновлено:
Что такое тесты проверки ошибок?
Что такое проверка ошибок?
Тест на проверку ошибок — это тест на пригодность, который оценивает вашу способность обнаруживать ошибки в наборах данных или текста. Типичные вопросы, возникающие во время этих оценок, требуют эффективного сравнения правильной информации с адаптированной версией исходного текста.
Оригинальная и скопированная версии будут очень похожи. Однако в измененном тексте некоторые элементы были переставлены или заменены другими частями стенограммы . Цель состоит в том, чтобы определить утверждения, которые были написаны правильно, те, которые были изменены, и характер самого изменения. Предоставленные тексты, как правило, содержат алфавитные и цифровые символы, чтобы можно было оценить обе области, и имеют ограничение по времени для ответов на вопросы.
Однако в измененном тексте некоторые элементы были переставлены или заменены другими частями стенограммы . Цель состоит в том, чтобы определить утверждения, которые были написаны правильно, те, которые были изменены, и характер самого изменения. Предоставленные тексты, как правило, содержат алфавитные и цифровые символы, чтобы можно было оценить обе области, и имеют ограничение по времени для ответов на вопросы.
Для чего используются тесты проверки ошибок?
Тесты на проверку ошибок предоставляют полезную информацию как работодателям, так и кандидатам, сдающим тест. Отзывы, предоставленные кандидатам, прошедшим тест, показывают их текущий уровень способностей и то, сколько возможностей для улучшения есть, что может быть мотивационной информацией для кандидата, чтобы улучшить свои аналитические навыки и навыки проверки ошибок. Если обратная связь воспринимается положительно, и кандидат действует в соответствии с этим, чтобы внести улучшения, это может привести к некоторым реальным изменениям в производительности на работе, например, к меньшему количеству ошибок в электронных письмах, что создает у клиентов впечатление профессионализма, или, возможно, меньше числовых ошибок при оплате счетов и обработке счетов-фактур.
Убедившись в преимуществах тестов с проверкой ошибок, пришло время узнать, как справиться с ними, зная, чего ожидать. Основная хитрость заключается в том, чтобы иметь возможность сравнить исходный фрагмент текста с измененной версией рядом с ним. Некоторые изменения будут внесены в некоторые буквы, цифры и/или символы:
- предметов можно было поменять местами
- элементов могли быть удалены
- предметов можно было добавить
ПРОФЕССИОНАЛЬНЫЙ НАКОНЕЧНИК
Таким образом, на первый взгляд два фрагмента текста могут выглядеть одинаково, но при ближайшем и внимательном рассмотрении вы можете увидеть, что название компании, номер счета, номер телефона, суффикс адреса электронной почты и другие детали не совпадают.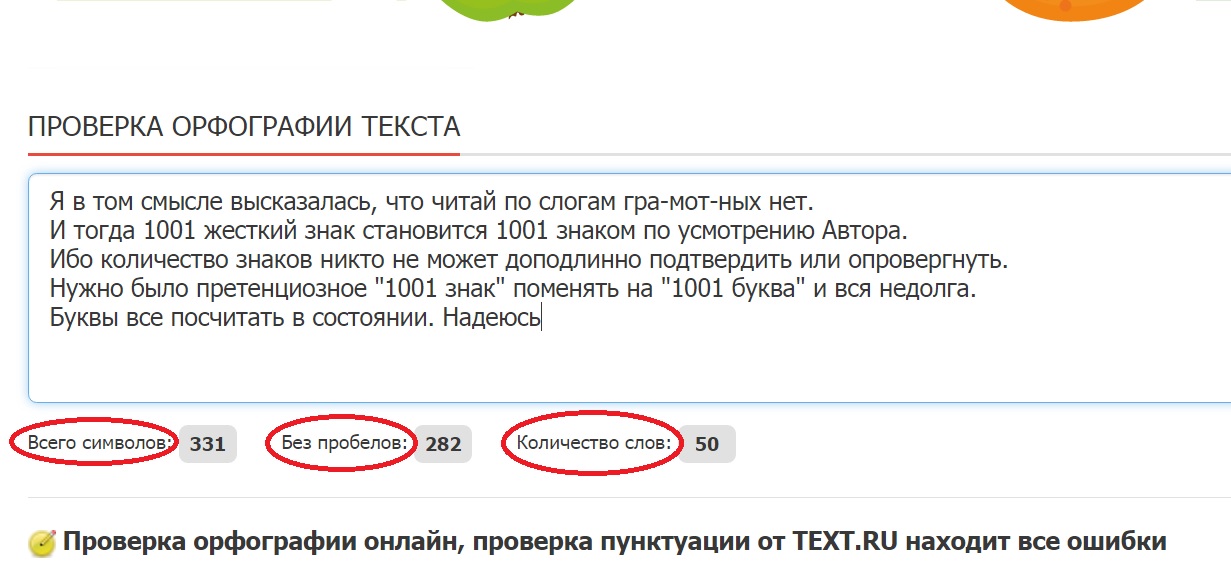
Бесплатный пример Тесты проверки ошибок
Бесплатный пример Тесты проверки ошибок
Бесплатный тест проверки ошибок
БесплатноЭтот бесплатный тест на числовое мышление содержит всего 5 вопросов и считается простым.
Начать тест 1 вопросов PDF Решения PDF
Тест проверки ошибок 1
ПремиумОшибка проверки теста 2
ПремиумТест проверки ошибок 3
ПремиумТест проверки ошибок 4
ПремиумПримеры вопросов для проверки ошибок
Лучший способ ознакомиться с тестами проверки ошибок и типами вопросов, которые вам могут задавать, — это самостоятельно попробовать несколько примеров вопросов. В реальных тестах будет строгое ограничение по времени, обычно вам будет 14 минут , чтобы ответить на 28 вопросов .
Итак, давайте рассмотрим несколько примеров, сложность которых возрастает с каждым вопросом:
Q1: Определите, есть ли какие-либо ошибки в столбце чисел, и укажите, в чем они заключаются.
Q1 Решение: В этом примере правильный текст показан справа, и кандидату был предоставлен список, содержащий изменения, а также исходный номер. Задача состоит в том, чтобы констатировать, есть ли ошибки и определить, где и какие они. В этом примере измененные числа выделены красным цветом и являются типичными ошибками «транспонирования», когда элементы исходного текста меняются местами, а остальное остается в исходном формате.
Итак, первый пример был довольно простым, но мы только разминаемся… Теперь вы знаете, как работают эти вопросы, давайте попробуем что-нибудь посложнее.
Q2: Элементы слева переставлены правильно, если нет, то где ошибки?
Q2 Решение: Этот пример немного отличается, так как есть только одно изменение для каждого исходного элемента, и он содержит как алфавитные, так и числовые элементы, это также может сначала показаться более сложным, потому что два полных столбца делают его более пугающим . Ошибки снова выделены красным цветом и имеют стандартный формат.
Ошибки снова выделены красным цветом и имеют стандартный формат.
Теперь давайте попробуем еще один примерный вопрос… На этот раз вам нужно будет проверить гораздо больше информации…
Q3: Правильно ли переставлены элементы слева, если нет, то где ошибки?
Q3 Решение: Этот последний пример немного сложнее, поскольку он вводит идею множественных « типов », представленных здесь как Название компании , Номер счета и статус , этот тип вопроса требует особого внимания, поскольку в каждой строке может быть более одной ошибки. Задача требует точного сравнения двух таблиц, чтобы обнаружить ошибки и указать, где они находятся. Вопросы, предполагающие множественные возможности возникновения ошибок, могут быть наиболее полезными, поскольку процесс поиска ошибок очень похож на тот, который необходим в повседневных задачах.
Как подготовиться к тесту на проверку ошибок
При подготовке к тесту на проверку ошибок или любому другому тесту могут быть полезны следующие советы:
- Хорошо отдохните прошлая ночь.
 После достаточного сна ваш разум отдохнул и может лучше сосредоточиться на поставленной задаче.
После достаточного сна ваш разум отдохнул и может лучше сосредоточиться на поставленной задаче. - Сохраняйте спокойствие – Приходите пораньше, чтобы не беспокоиться о том, успеете ли вы вовремя на автобус или метро. Используйте дыхательные упражнения для расслабления.
- Прочтите инструкции – Простых ошибок можно избежать, внимательно прочитав инструкции. Там могут быть конкретные инструкции, чтобы отметить определенные поля или различные способы отметить выбранный вами ответ.
- Дважды проверьте свой выбор – Быстро осмотрите глаза, прежде чем переходить к следующему вопросу, просто чтобы увидеть, соответствует ли выбранный вами ответ смыслу вопроса. Убедитесь, что вы выбрали именно тот ответ, который хотели.
- Правильно распоряжайтесь своим временем – Тщательно сбалансируйте повторное чтение вопросов и ответов, выявление ошибок и проверку ответов, чтобы не тратить слишком много времени на один вопрос и чтобы у вас было достаточно времени, чтобы ответить на все вопросы.
- Запросить отзыв – Если можно, запросить отзыв после теста. Это даст вам хорошее представление о ваших сильных и слабых сторонах.
 После достаточного сна ваш разум отдохнул и может лучше сосредоточиться на поставленной задаче.
После достаточного сна ваш разум отдохнул и может лучше сосредоточиться на поставленной задаче.
Наконец, мы желаем вам удачи!
[PDF] Исправление ошибок OCR для неограниченного вьетнамского рукописного текста
- DOI: 10.1145/3368926.3369686
- Идентификатор корпуса: 209450735
title={Исправление ошибок OCR для неограниченного вьетнамского рукописного текста},
автор={Куок-Дунг Нгуен и Дык-Ань Ле и Иван Зелинка},
booktitle={SoICT 2019},
год = {2019}
} - Quoc-Dung Nguyen, D. Le, I. Zelinka
- Информатика
Постобработка является важным шагом в обнаружении и исправлении ошибок в текстах, созданных с помощью OCR. В этой статье мы представляем модель автоматической постобработки OCR, которая включает этапы обнаружения и исправления ошибок для выходных текстов OCR с неограниченным вьетнамским почерком. Мы предлагаем гибридный подход к созданию и оценке кандидатов на исправление ошибок как в неслоговых, так и в реальных слогах, на основе лингвистических особенностей, а также характеристик ошибок выходных данных OCR…
Мы предлагаем гибридный подход к созданию и оценке кандидатов на исправление ошибок как в неслоговых, так и в реальных слогах, на основе лингвистических особенностей, а также характеристик ошибок выходных данных OCR…
Просмотр на ACM
vanlanguni.edu.vnИсправление ошибок оптического распознавания текста для вьетнамского рукописного текста с использованием нейронного машинного перевода
- Д. К. Нгуен, А. Д. Ле, М. Н. Фан, П. Кромер, И. Зелинка
Информатика
VAN LANG INTERNATIONAL CONFERENCE ON HERITAGE AND TECHNOLOGY CONFERENCE PROCEEDING, 2021: VanLang-HeriTech, 2021- 2021
частота ошибок в словах в выходных текстах OCR вышеуказанной модели AED.
VSEC: модель на основе трансформатора для вьетнамской коррекции орфографии
- Dinh-Truong Do, Nguyen Ha, Thang Bui, Dinh-Hieu Vo
Информационная наука
Pricai
- 2021
Эта бумага
9000 2021 9000 2. новый метод исправления вьетнамских орфографических ошибок с использованием модели глубокого обучения, основанной на архитектуре Transformer, которая решает проблемы опечаток и орфографических ошибок.
новый метод исправления вьетнамских орфографических ошибок с использованием модели глубокого обучения, основанной на архитектуре Transformer, которая решает проблемы опечаток и орфографических ошибок.Исправление ошибок OCR с использованием шаблонов исправления и алгоритма самоорганизующейся миграции
- Quoc-Dung Nguyen, D. Le, Nguyet-Minh Phan, I. Zelinka
Computer Science
Pattern Anal. заявл.
- 2021
В этой статье предлагается новый подход к исправлению ошибок постобработки OCR с использованием редактирования шаблона коррекции и эволюционного алгоритма, который в основном использовался для решения задач оптимизации.
На пути к оптимизированной для определенного периода нейронной сети для исправления ошибок распознавания исторических текстов на иврите
Разработан новый многоэтапный метод создания искусственных обучающих наборов данных с ошибками OCR и оптимизацией гиперпараметров для построения эффективной нейронной сети для посткоррекции OCR на иврите, который продемонстрировал, что он превосходит модели нейронного машинного перевода и ведущие в отрасли средства проверки орфографии.
- Б. Ли, Хайме Мирс, Дэниел С. Велд
Информатика
ArXiv
- 2020
Модель распознавания визуального контента, обученная на аннотациях ограничивающих прямоугольников к фотографиям, иллюстрациям, картам, комиксам и редакционным карикатурам, собранным в рамках инициативы Библиотеки Конгресса по краудсорсингу Beyond Words и дополнен дополнительными аннотациями, в том числе заголовками и рекламными объявлениями.
Future Data and Security Engineering: 7-я международная конференция, FDSE 2020, Quy Nhon, Вьетнам, 25–27 ноября 2020 г., материалы
- T. K. Dang, J. Kung, M. Takizawa, Tai-Myung Chung
Информатика
FDSE
- 2020
Цель состоит в том, чтобы понять технологические и социально-экономические барьеры, присущие блокчейну. в самом стеке технологии блокчейна и разрабатывать полезные блокчейн-решения независимо от фундаментальной институциональной реорганизации.
в самом стеке технологии блокчейна и разрабатывать полезные блокчейн-решения независимо от фундаментальной институциональной реорганизации.
Статистическое изучение подслов во вьетнамском языке
- Д. К. Нгуен, Т. Ле
Linguistics
THE 1ST INTERNATIONAL CONFERENCE ON INNOVATIONS FOR COMPUTING, ENGINEERING AND MATERIALS, 2021: ICEM, 2021
- 2021
Candidate word generation for OCR errors using optimization algorithm
- D. T. Pham, D. Q. Nguyen, A. D. Ле, М. Н. Фан, П. Кромер
1-Я МЕЖДУНАРОДНАЯ КОНФЕРЕНЦИЯ ВАН ЛАНГА ПО НАСЛЕДИИ И ТЕХНОЛОГИЯМ, 2021: VanLang-HeriTech, 2021
- 2021
An In-depth Analysis of OCR Errors for Unconstrained Vietnamese Handwriting
- Quoc-Dung Nguyen, D. Le, Nguyet-Minh Phan, I. Zelinka
Computer Science
FDSE
- 2020
ПОКАЗАНО 1-10 ИЗ 24 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантность Наиболее влиятельные документыНедавность
Сквозная система распознавания вьетнамского почерка без ограничений
- A. D. Le, Hung Tuan Nguyen, M. Nakagawa
Информатика
SN Вычисл. науч.
- 2020
 D. Le, Hung Tuan Nguyen, M. Nakagawa
D. Le, Hung Tuan Nguyen, M. NakagawaПредставлена модель кодировщика-декодера на основе внимания (AED) для распознавания рукописного вьетнамского текста, которая полностью обучена предсказывать текст на основе заданного входного изображения, поскольку все части являются дифференциальными компонентами.
Неконтролируемый и управляемый данными подход к проверке орфографии во вьетнамских текстах, отсканированных с помощью оптического распознавания символов
- Cong Duy Vu Hoang, A. Aw
Информатика
- 2012
В этой статье предлагается полностью автоматический подход, сочетающий этапы обнаружения и исправления ошибок в рамках уникальной схемы, разработанной без присмотра и управляемой данными, подходящей для языков с ограниченными ресурсами.
Распознавание произвольного вьетнамского почерка с помощью модели кодировщика-декодера, основанного на внимании Конкурс на распознавание рукописного текста.
База данных неограниченных вьетнамских онлайн-экспериментов по распознаванию почерка и распознаванию рекуррентными нейронными сетями
- Хунг Туан Нгуен, К. Нгуен, П. Бао, М. Накагава
Информатика
Распознавание образов.
- 2018
Эффективный метод онлайн-распознавания вьетнамских рукописных символов
- Де Као Тран
Информатика
SoICT ’12
6
0006
Экспериментальные исследования показывают, что распознавание рукописных символов, основанное на 45 выбранных функциях, может конкурировать по скорости распознавания и времени отклика с другими хорошо известными тестами на стандартных базах данных, таких как UNIPEN и IRONOFF.
ICFHR 2018 — Конкурс по распознаванию рукописного текста на вьетнамском языке в Интернете с использованием HANDS-VNOnDB (VOHTR2018)
краткое описание соответствующих методов.