
python – Распознать текст с обработанного изображения opencv
Вопрос задан
Изменён 9 месяцев назад
Просмотрен 175 раз
import cv2
def find_number(input_img, k):
haar_cascade = cv2.CascadeClassifier('cascade.xml')
dim = (int(input_img.shape[1]*k), int(input_img.shape[0] * k))
resized_img = cv2.resize(input_img, dim, interpolation=cv2.INTER_AREA)
gray_scale_img = cv2.cvtColor(resized_img, cv2.COLOR_BGR2GRAY)
pictures = haar_cascade.detectMultiScale(gray_scale_img, scaleFactor=1.40, minNeighbors=15, minSize=(20, 20))
recognized = []
for (x, y, w, h) in pictures:
cv2.rectangle(resized_img, (x, y), (x + w, y + h), (255, 0, 0), 2)
recognized.append(resized_img[y:y + h, x:x + w])
return recognized
img = cv2.
imread('test/26.jpg')
images = find_number(img, 0.9)
if len(images) > 0:
for i in range(len(images)):
cv2.imshow(str(i), images[i])
cv2.waitKey(0)
cv2.destroyAllWindows()

Код обрабатывает изображение, выводя автомобильный номер в качестве картинки. Нужно считать этот номер непосредственной с обработанной картинки. Каким образом это сделать? Уже и через pytesseract и easyocr пытался, ничего дельного не получалось.
- python
- opencv
1
Что бы не марочить мозги с библиотеками, вы можете воспользоваться api
import requests
def orc(url):
r = requests.post('https://api.ocr.space/parse/image', data={'url': url, 'isOverlayRequired': False, 'apikey': 'helloworld', "OCREngine": "2"})
return False if r.json()["IsErroredOnProcessing"] == True else r.json()["ParsedResults"][0]["ParsedText"].replace(" ", "")
test_url = orc('https://cdn.discordapp.
com/attachments/952990044539473980/953680748257370112/capha-1.png')
print(test_url)
2
Зарегистрируйтесь или войдите
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Применение OCR Tesseract совместно с Python
| Python
Как показывают исследования, Tesseract лучше всего справляется с работой, когда существует чёткое отделение текста переднего плана от фона. На практике это гарантировать чрезвычайно сложно. Следовательно, необходимо обучать классификаторы и детекторы, специфичные для данной задачи.
Тем не менее будет полезно воспользоваться OCR tesseract через язык программирования Python, когда нужно применить OCR к собственным проектам, при условии, что будут получены хорошие и чистые тексты.
Примеры таких проектов с OCR могут быть мобильный сканер документов, из которых нужно извлечь текстовую информацию или служба, которая сканирует бумажные медицинские карточки для размещения этой информации в базе данных…
В этой статье будет рассказано, как установить пакет Tesseract OCR для Python, а затем напишем простой Python скрипт для распознавания текста с картинок.
Установка пакета Tesseract для Python
Чтобы установить pytesseract воспользуемся менеджером пакетов Python pip.
$ python3 –m venv cv $ cd cv; source bin/activate
Затем установим Pillow (удобный клон PIL для Python) от которого зависит pytesseract.
$ pip install pillow $ pip install pytesseract
Примечание: pytesseract не обеспечивает настоящей привязки к Python. Скорее, он является простой обёрткой для двоичного файла tesseract. Если познакомиться с проектом по подробнее, то станет ясно, что библиотека сохраняет изображение во временный файл на диске, а затем вызывает двоичный файл tesseract и полученный результат записывает в файл.
Рассмотрим код, который отделяет текст переднего плана от фона, а затем применим установленный pytesseract.
Распознавание текста с помощью Tesseract и Python
Создадим файл с именем ocr.py:
from PIL import Image import pytesseract import cv2 import os image = '/tmp/tests.png' preprocess = "thresh" # загрузить образ и преобразовать его в оттенки серого image = cv2.imread(image) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # проверьте, следует ли применять пороговое значение для предварительной обработки изображения if preprocess == "thresh": gray = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] # если нужно медианное размытие, чтобы удалить шум elif preprocess == "blur": gray = cv2.medianBlur(gray, 3) # сохраним временную картинку в оттенках серого, чтобы можно было применить к ней OCR filename = "{}.png".format(os.getpid()) cv2.imwrite(filename, gray)
Теперь применим OCR к изображению, используя pytesseract:
# загрузка изображения в виде объекта image Pillow, применение OCR, а затем удаление временного файла
text = pytesseract.image_to_string(Image.open(filename))
os.remove(filename)
print(text)
# показать выходные изображения
cv2.imshow("Image", image)
cv2.imshow("Output", gray)
input(‘pause…’)
Вызов оператора pytesseract.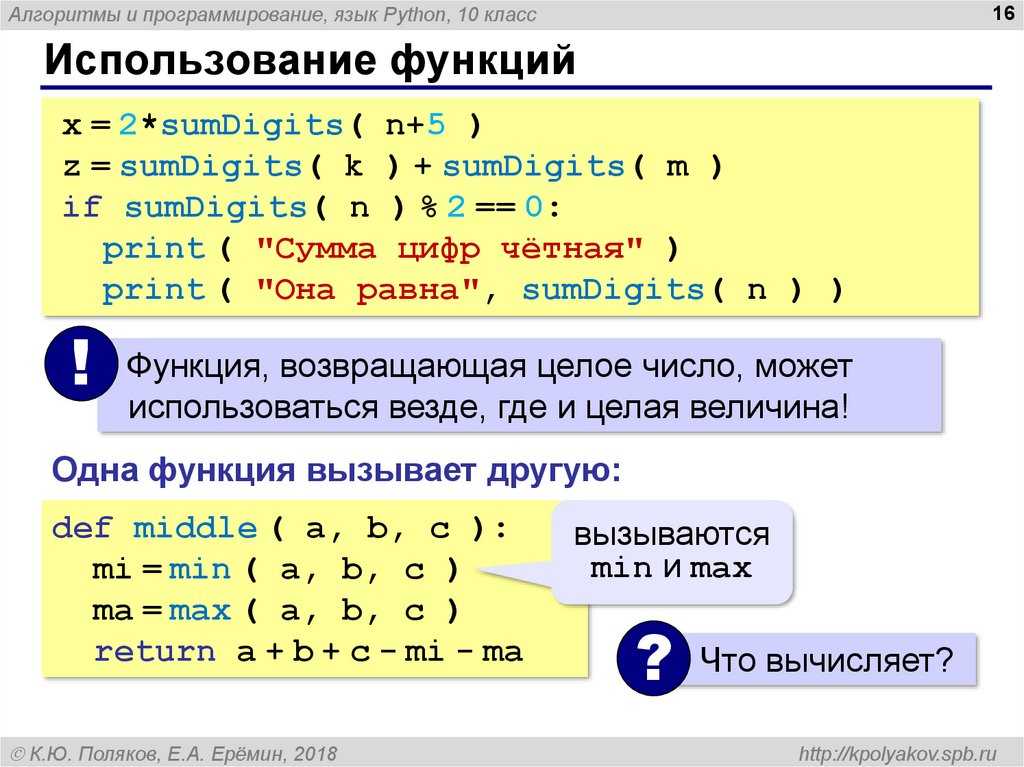 image_to_string преобразует изображение в строку текста. Обратите внимание, что была передана ссылка на временный файл картинки.
image_to_string преобразует изображение в строку текста. Обратите внимание, что была передана ссылка на временный файл картинки.
print(text) – распечатывает результата распознавания скрипта в терминал. В ваших собственных приложениях вы можете выполнить некоторые дополнительные действия, например, проверку орфографии или обработку естественного языка.
В заключении, строки с cv2.imshow обрабатывают исходное и предварительно обработанное изображение на экране в отдельных окнах. input(‘pause…’) сообщает программе, что нужно ожидать пользовательского нажатия клавиши перед выходом из сценария.
Результаты OCR
Теперь, когда готов ocr.py протестируем его для выполнения OCR на некоторых примерах входных изображений.
В этом разделе проверим OCR двух образцов изображений.
- Сначала пропустим каждое изображение через двоичный файл Tesseract.
- Затем передадим каждое изображение скрипту ocr.py (который выполняет предварительную обработку перед отправкой их в tesseract).

- Сравним результаты обоих этих методов и выявим ошибки.
Пример картинки
Это изображение содержит на переднем плане текст черного цвета на фоне, который частично белый и частично рассеянный с искусственно создаваемыми круговыми пятнами.
$ tesseract /tmp/example_01.png stdout Noisy image to test Tesseract OCR
В этом случае Tesseract отлично справился с ошибками. Теперь подтвердим, что скрипт ocr.py также работает:
$ python ocr.py Noisy image to test Tesseract OCR
Скрипт правильно распознал текстовое содержимое из изображения выведя его в консоль.
Затем протестируем Tesseract и наш скрипт на изображении, предварительно обработанным фильтром с шумом «соль и перец».
Результаты работы двоичного файла tesseract:
$ tesseract /tmp/example_02.png stdout Detected 32 diacritics " Tesséra‘c't Will Fail With Noisy Backgrounds
К сожалению, tesseract не смог распознать текст без ошибок.
Однако, используя метод предварительной обработки blur в ocr.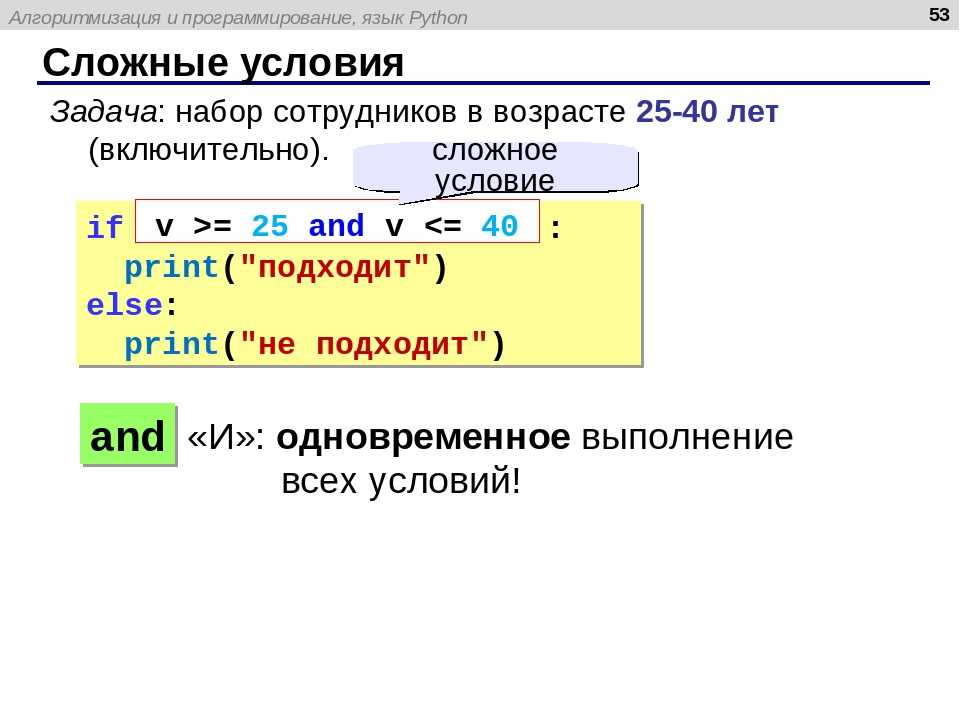 py, можем получить лучшие результаты, для этого установим переменную preprocess в blur.
py, можем получить лучшие результаты, для этого установим переменную preprocess в blur.
# image =/tmp/example_02.png и preprocess=blur $ python ocr.py Tesseract Will Fail With Noisy Backgrounds
Этап предварительной обработки blur позволило Tesseract правильно распознать OCR и вывести желаемый текст.
Таким образом были получены приемлемые результаты с tesseract для OCR, но лучшая точность будет получена от обучения пользовательских классификаторов символов на определенных наборах шрифтов, которые используются на реальных изображениях.
Примечание. Если текст повернут, нужно также выполнить предварительную обработку.
Резюме
В этой статье было продемонстрировано применение OCR движка tesseract с языком программирования Python. Что позволило нам применять алгоритмы OCR из собственных сценариев Python.
Самый большой недостаток связан с ограничениями самого Tesseract – он работает когда на переднем плане есть чрезвычайно чистые фрагменты текста.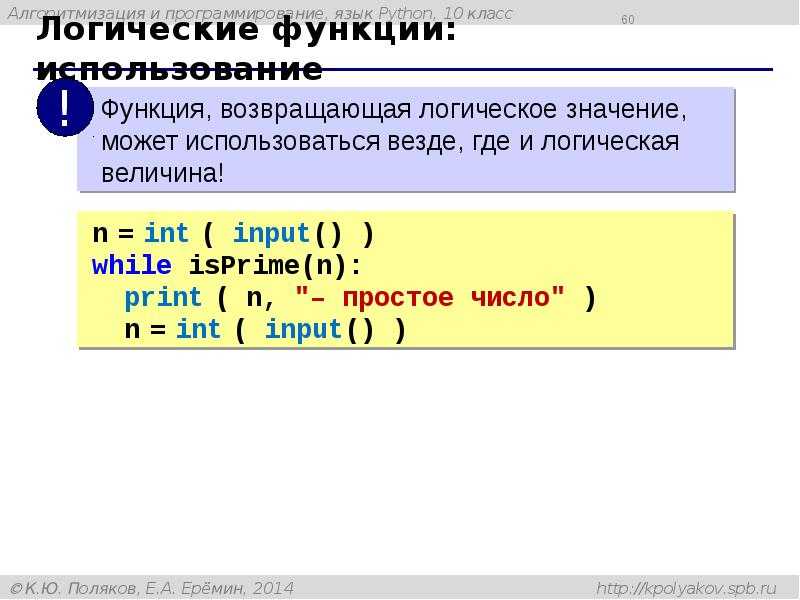 Кроме того, эти фрагменты должны быть как можно более высокого разрешения (DPI), а символы входного изображения не были подвергнуты «пикселированию» после сегментации.
Кроме того, эти фрагменты должны быть как можно более высокого разрешения (DPI), а символы входного изображения не были подвергнуты «пикселированию» после сегментации.
OCR не является новой технологией, но по-прежнему является областью исследований в компьютерной науке, особенно при применении OCR к реальным изображениям. Глубокое обучение и сверточные нейронные сети (CNN), безусловно, позволяют получать более высокую точность, но до почти идеальной системы распознавания ещё очень далеко. Кроме того, сейчас предлагается много OCR приложений на разных сайтах, в которых применены лучшие из алгоритмов распознавания, но они являются коммерческими и требуют лицензирования для использования в собственных проектах.
Если ни Tesseract, ни сторонние сервисы не предоставят достаточной точности, то нужно переосмыслить свой набор данных и задуматься о обучении своего классификатора символов. Это особенно предпочтительно, если набор данных зашумлён и/или содержит очень специфические шрифты.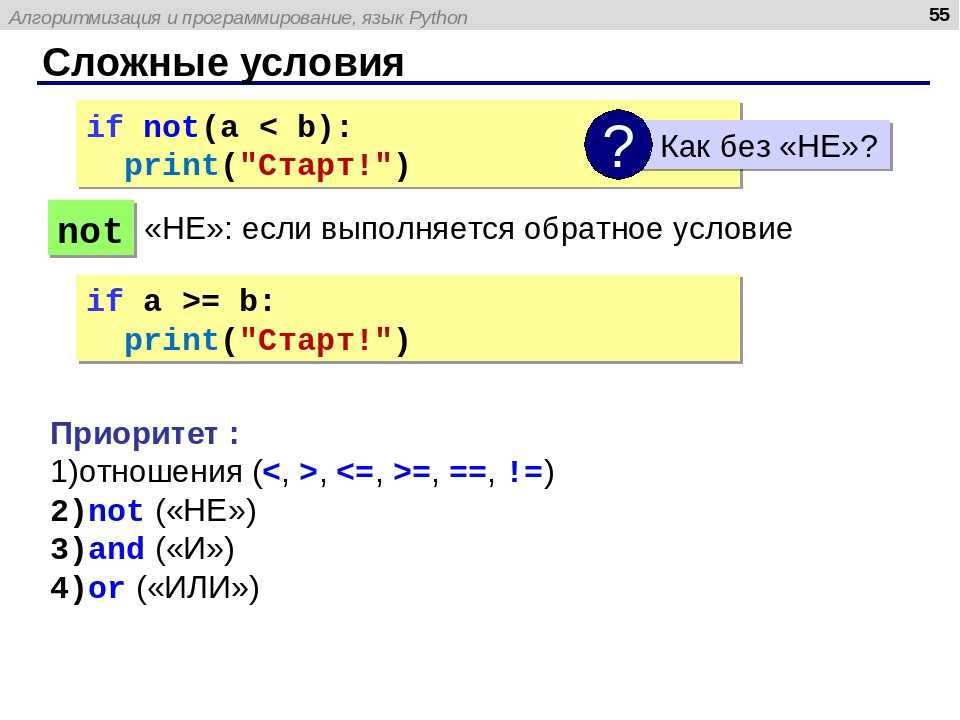 Примеры конкретных шрифтов включают в себя цифры на кредитной карте, номера счета и номера маршрута, найденные в проездных билетах или стилизованный текст, используемый в графическом дизайне.
Примеры конкретных шрифтов включают в себя цифры на кредитной карте, номера счета и номера маршрута, найденные в проездных билетах или стилизованный текст, используемый в графическом дизайне.
Учебники по программированию на Python
Как выполнить базовое распознавание изображений с помощью Python
Существует множество приложений для распознавания изображений. Одним из самых крупных, с которыми люди больше всего знакомы, является распознавание лиц, то есть искусство сопоставления лиц на фотографиях с личностями. Однако распознавание изображений идет гораздо дальше. Это может позволить компьютерам переводить письменный текст на бумаге в цифровой текст, это может помочь в области машинного зрения, где роботы и другие устройства могут распознавать людей и объекты.
Здесь наша цель — начать использовать машинное обучение в форме распознавания образов, чтобы научить нашу программу тому, как выглядит текст. В этом случае мы будем использовать числа, но это может быть преобразовано ко всем буквам алфавита, словам, лицам, вообще к чему угодно. Чем сложнее изображение, тем сложнее должен быть код. Однако когда дело доходит до букв и символов, все относительно просто.
В этом случае мы будем использовать числа, но это может быть преобразовано ко всем буквам алфавита, словам, лицам, вообще к чему угодно. Чем сложнее изображение, тем сложнее должен быть код. Однако когда дело доходит до букв и символов, все относительно просто.
Как это делается? Как и любую проблему, особенно в программировании, нам нужно просто разбить ее на шаги, и проблема станет легко решаемой. Давайте сломаем это!
Во-первых, вам понадобятся образцы документов, чтобы помочь с этой серией, вы можете получить образцов изображений здесь .
Оттуда извлеките папку zip и переместите каталог «images» туда, где вы пишете этот скрипт. В нем у вас должен быть каталог «images». В нем у вас есть несколько простых изображений, которые мы будем использовать, а затем у вас есть куча примеров чисел в каталоге чисел.
Как только вы это сделаете, вам понадобится Язык программирования Python . Эта конкретная серия была создана с использованием Python 2. 7. Вы можете пройти это с Python 3, хотя могут быть некоторые незначительные отличия.
7. Вы можете пройти это с Python 3, хотя могут быть некоторые незначительные отличия.
Вам также понадобятся Matplotlib, NumPy и PIL или Pillow. Вы можете следить за видео для установки, или вы также можете использовать pip install. Во время моего видео установка pip не была тем методом, который я бы рекомендовал. С любой более новой версией Python 2 или 3 вы получите pip, а поддержка pip есть почти во всех пакетах.
Не знаете, что такое pip и как устанавливать модули?
Pip , вероятно, самый простой способ установки пакетов. После установки Python вы сможете открыть командную строку, например cmd.exe в Windows или bash в Linux, и ввести:
pip install numpy
pip install matplotlib
Возникли проблемы? Нет проблем, для этого есть учебник: pip install Python modules tutorial .
Если у вас все еще есть проблемы, не стесняйтесь обращаться к нам, используя контакты в нижнем колонтитуле этого веб-сайта.
Когда у вас есть все зависимости, вы готовы перейти к следующей части!
Следующий учебник:
Python для распознавания изображений — OpenCV
OpenCV — это библиотека распознавания изображений с открытым исходным кодом.
Используется для машинного обучения, компьютерного зрения и обработки изображений. Вы можете извлечь максимальную пользу из OpenCV при интеграции с мощными библиотеками, такими как Numpy и Pandas.
УСТАНОВКА PYTHON 3.X
Откройте Терминал/Командную строку и введите:
~ pip install opencv-python
НАЧАЛО РАБОТЫ (КАК ЧИТАТЬ ИЗОБРАЖЕНИЯ)
1.Откройте PyCharm.
2.Импорт cv2.
3. Вставьте тестовое изображение в каталог.
4.Создайте переменную для хранения изображения с помощью функции imread() .
5. Отобразите изображение с помощью функции imshow().
6. Добавьте задержку с помощью функции waitkey() .
1
2
3
4
5
6
импорт cv2
# ЗАГРУЗИТЬ ИЗОБРАЖЕНИЕ, ИСПОЛЬЗУЯ «IMREAD»
img = cv2.imread("Ресурсы/lena.png")
# ОТОБРАЖАТЬ
cv2.imshow("Лена Содерберг", изображение)
cv2.waitKey(0)
ВОСПРОИЗВЕДЕНИЕ ВИДЕО С ИСПОЛЬЗОВАНИЕМ ФУНКЦИИ VideoCapture()
Откройте PyCharm.
Импорт cv2.
Вставьте тестовое видео в каталог.
Создайте переменную для хранения видео с помощью функции VideoCapture().
Создайте бесконечный цикл while для непрерывного отображения каждого кадра видео.
Показать видео с помощью функции imshow().
Добавьте задержку с помощью функции waitkey().
1
2
3
4
5
6
7
8
9
импорт cv2
ширина кадра = 640
высота кадра = 480
cap = cv2.VideoCapture("Ресурсы/тест_видео.mp4")
пока верно:
успех, img = cap.read()
img = cv2. resize (img, (frameWidth, frameHeight))
cv2.imshow ("Результат", изображение)
сломать
resize (img, (frameWidth, frameHeight))
cv2.imshow ("Результат", изображение)
сломать
ДОСТУП К ТРАНСЛЯЦИИ С ВЕБ-КАМЕРЫ
Откройте PyCharm.
Импорт cv2.
Создайте переменную для хранения видео с помощью функции VideoCapture().
Передайте параметр 0 в VideoCapture(0) для доступа к веб-камере.
Создайте бесконечный цикл while для непрерывного отображения каждого кадра видео с веб-камеры.
Отображение прямой трансляции с помощью функции imshow().
Добавьте бесконечную задержку с помощью waitKey(0).
1
2
3
4
5
6
7
8
910
11
импорт cv2
Ширина = 640
Высота = 480
крышка = cv2.VideoCapture (0)
cap.set(3, ширина кадра)
cap.set(4,высота кадра)
кап.набор(10, 150)
пока верно:
успех, img = cap.read()
cv2.imshow ("Результат", изображение)
сломать
ФУНКЦИИ OPENCV
Преобразование изображения в оттенки серого
Откройте PyCharm.

Импорт cv2.
Создайте переменную для хранения изображения, используя
функцию imread().Для преобразования в оттенки серого используйте
cv2.cvtColor()functionПередайте параметр местоположения изображения и
COLOR_BGR2GRAYдля преобразования.
1
2
3
4
5
импорт cv2
img = cv2.imread("Ресурсы/lena.png")
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow ("Серое изображение", imgGray)
cv2.waitKey(0)
Обнаружение границ
Открыть PyCharm.
Импорт cv2.
Создайте переменную для хранения изображения, используя
функция imread().Для обнаружения края используйте функцию
cv2.Canny()Передайте параметр местоположения изображения и порог для преобразования.
1
2
3
4
5
6
импорт cv2
img = cv2. imread("Ресурсы/lena.png")
imgCanny = cv2.Canny(img, 150, 200)
cv2.imshow ("Умное изображение", imgCanny)
cv2.waitKey(0)
imread("Ресурсы/lena.png")
imgCanny = cv2.Canny(img, 150, 200)
cv2.imshow ("Умное изображение", imgCanny)
cv2.waitKey(0)
ОБРЕЗКА ИЗОБРАЖЕНИЯ
Импорт numpy и cv2.
Создайте две переменные для хранения высоты и ширины изображения.
Создайте два пустых массива для хранения координат.
Первый массив – хранит координаты кадрируемого изображения.
Второй массив – хранит координаты полного изображения.
Обрежьте изображение с помощью функций getPerspective() и wrapPerspective().
1
2
3
4
5
6
7
8
9
10
11
изображение = cv2.imread("Активы/cards.jpg")
ширина, высота = 250, 350
point1 = np.float32([[111, 219], [287, 188], [154, 482], [352, 440]])
point2 = np.float32([[0, 0], [ширина, 0], [0, высота], [ширина, высота]])
матрица = cv2.getPerspectiveTransform (точка1, точка2)
Выход = cv2.warpPerspective (изображение, матрица, (ширина, высота))
cv2. imshow («Изображение», изображение)
cv2.imshow («Вывод», Вывод)
cv2.waitKey(0)
imshow («Изображение», изображение)
cv2.imshow («Вывод», Вывод)
cv2.waitKey(0)
РАСПОЗНАВАНИЕ ЛИЦ
Откройте PyCharm.
Импорт cv2.
3. Создайте переменную для хранения каскадного классификатора (чтобы узнать больше о каскадном классификаторе, нажмите здесь.Преобразование изображения в оттенки серого с помощью функции
cv2.cvtColor().Обнаружение лица с помощью
функции detectMultiscale().Нарисуйте прямоугольник вокруг обнаруженного лица.
1
2
3
4
5
6
7
8
9
10
11
12
13
14 импорт cv2
face_Cascade = cv2.CascadeClassifier("Ресурсы/haarcascade_frontalface_default.xml")
изображение = cv2.imread('Ресурсы/lena.png')
imgGray = cv2.cvtColor (изображение, cv2.COLOR_BGR2GRAY)
лица = face_Cascade.detectMultiScale (imgGray, 1.1, 4)
для (x, y, w, h) в гранях:
cv2.rectangle (изображение, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.