
OCR | Документация Майкрософт – Power Automate
- Статья
- Чтение занимает 8 мин
Оцените свои впечатления
Да Нет
Хотите оставить дополнительный отзыв?
Отзывы будут отправляться в корпорацию Майкрософт. Нажав кнопку “Отправить”, вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт.
Отправить
Спасибо!
В этой статье
Инициация подсистем распознавания текста для выполнения соответствующих действий
Начать работу с действиями OCR
Power Automate позволяет пользователям читать, извлекать и управлять данными в ассортименте файлов с помощью оптического распознавания символов (OCR).
Чтобы создать механизм OCR и извлекать текст из изображений и документов с помощью OCR, используйте действие
Действие, в котором создается подсистема OCR, содержит параметры подсистемы. К ним относятся язык и множители ширины и высоты изображения. Переменная подсистемы OCR может использоваться в любом действии, содержащем возможности OCR.
К ним относятся язык и множители ширины и высоты изображения. Переменная подсистемы OCR может использоваться в любом действии, содержащем возможности OCR.
Warning
Множители изображений увеличивают размер изображения, чтобы сделать поиск и извлечение текста более эффективным. Учтите, что установка значений больше 3 может привести к ошибочным результатам.
Действия OCR
Если текст находится на экране (распознавание текста)
Помечает начало условного блока действий в зависимости от того, находится ли данный текст на экране или нет, используется распознавание текста
Входные параметры
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| If text | Н/Д | Существует, Не существует | Существует | Указывает, следует ли проверять наличие текста для анализа в указанном источнике. |
| OCR engine type | Нет | Переменная подсистемы распознавания текста, подсистема Tesseract | Переменная подсистемы распознавания текста | Тип используемой подсистемы распознавания текста. Выберите заранее настроенную подсистему распознавания текста или настройте новую. Выберите заранее настроенную подсистему распознавания текста или настройте новую. |
| OCR engine variable | Нет | OCREngineObject | Подсистема для распознавания текста. | |
| Text to find | Нет | Текстовое значение | Текст для поиска в указанном источнике | |
| Is regular expression | Н/Д | Логическое значение | Ложь | Указывает, нужно ли использовать регулярное выражение для поиска указанного текста |
| Search for text on | Н/Д | Весь экран, Окно переднего плана | Весь экран | Указывает, нужно ли искать заданный текста на всем видимом экране или только на окне переднего плана |
| Search mode | Н/Д | Источник целиком, Только определенная подобласть, Подобласть относительно изображения | Источник целиком | Указывает, следует ли сканировать весь экран (или окно) или только его определенную подобласть |
| Image(s) | Нет | Список изображения | Изображения, определяющие подобласть (относительно верхнего левого угла изображения) для поиска заданного текста | |
| X1 | Да | Числовое значение | Начальная координата X подобласти для поиска заданного текста | |
| Tolerance | Да | Числовое значение | 10 | Указывает, насколько искомое изображение может отличаться от изначально выбранного изображения. |
| Y1 | Да | Числовое значение | Начальная координата Y подобласти для поиска заданного текста | |
| X1 | Да | Числовое значение | Начальная координата X подобласти (относительно заданного изображения) для поиска заданного текста | |
| X2 | Да | Числовое значение | Конечная координата X подобласти для поиска заданного текста | |
| Y1 | Да | Числовое значение | Начальная координата Y подобласти (относительно заданного изображения) для поиска заданного текста | |
| Y2 | Да | Числовое значение | Конечная координата Y подобласти для поиска заданного текста | |
| X2 | Да | Числовое значение | Конечная координата X подобласти (относительно заданного изображения) для поиска заданного текста | |
| Y2 | Да | Числовое значение | Конечная координата Y подобласти (относительно заданного изображения) для поиска заданного текста |
Создаваемые переменные
| Аргумент | Тип | Описание |
|---|---|---|
| LocationOfTextFoundX | Числовое значение | Координата X точки, в которой текст появляется на экране. Если поиск выполняется в окне переднего плана, возвращаемая координата указывается относительно левого верхнего угла окна Если поиск выполняется в окне переднего плана, возвращаемая координата указывается относительно левого верхнего угла окна |
| LocationOfTextFoundY | Числовое значение | Координата X точки, в которой текст появляется на экране. Если поиск выполняется в окне переднего плана, возвращаемая координата указывается относительно левого верхнего угла окна |
Исключения
| Исключение | Описание |
|---|---|
| Невозможно проверить наличие текста в неинтерактивном режиме. | Указывает, что проверить наличие текста на экране в неинтерактивном режиме невозможно. |
| Недопустимые координаты подобласти | Указывает, что координаты заданной подобласти недопустимы. |
| Не удалось проанализировать текст с помощью распознавания текста. | Указывает, что произошла ошибка при попытке проанализировать текст с помощью распознавания текста |
| Подсистема распознавания текста недоступна | Указывает, что подсистема распознавания текста недоступна. |
Ожидание текста на экране (распознавание текста)
Ожидание, пока определенный текст не появится/исчезнет на экране, в окне переднего плана или относительно изображения на экране или в окне переднего плана, с использованием распознавания текста
Входные параметры
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| Wait for text to | Н/Д | Отобразить, Скрыть | Отобразить | Указывает, следует ли ждать появления или скрытия текста. |
| OCR engine type | Нет | Переменная подсистемы распознавания текста, подсистема Tesseract | Переменная подсистемы распознавания текста | Тип используемой подсистемы распознавания текста. Выберите заранее настроенную подсистему распознавания текста или настройте новую. |
| OCR engine variable | Нет | OCREngineObject | Подсистема для распознавания текста.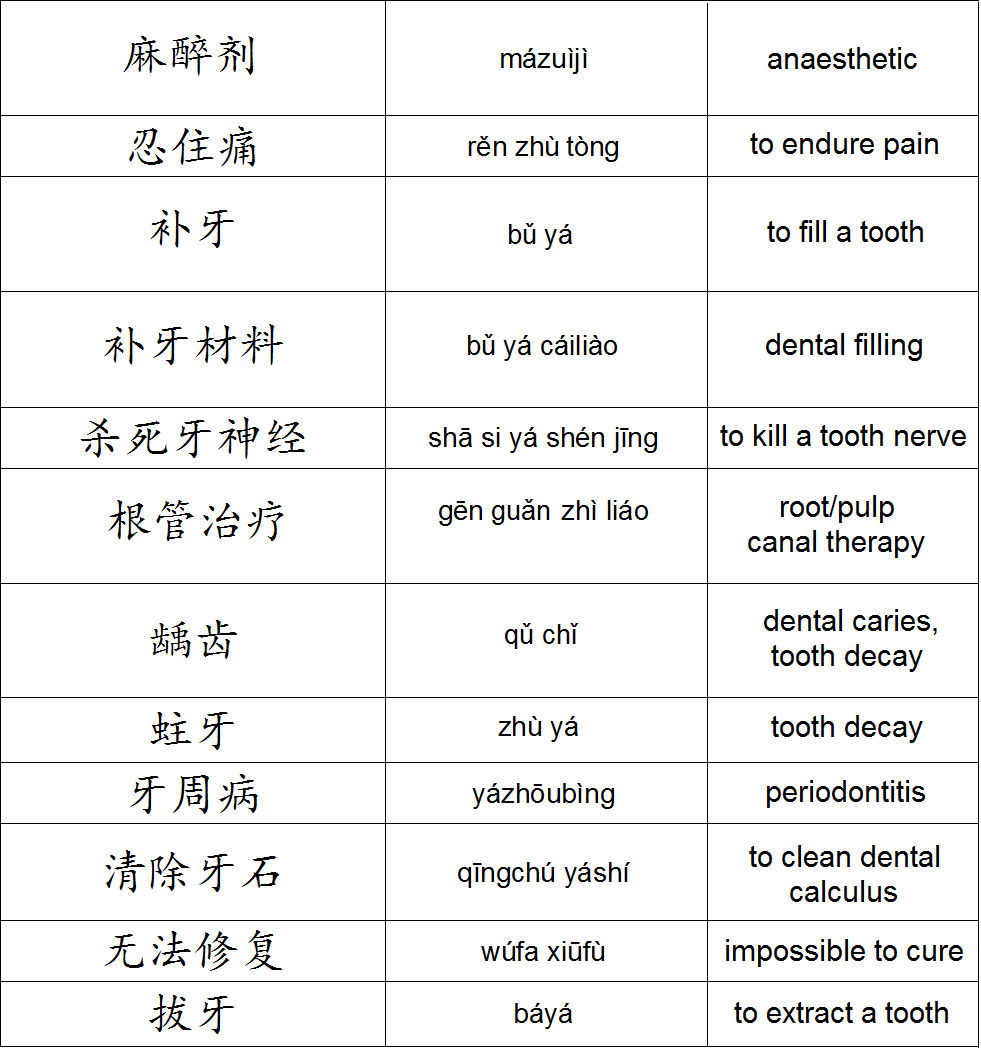 | |
| Text to find | Нет | Текстовое значение | Текст для поиска в указанном источнике | |
| Is regular expression | Н/Д | Логическое значение | Ложь | Указывает, нужно ли использовать регулярное выражение для поиска указанного текста |
| Search for text on | Н/Д | Весь экран, Окно переднего плана | Весь экран | Указывает, нужно ли искать заданный текста на всем видимом экране или только на окне переднего плана |
| Search mode | Н/Д | Источник целиком, Только определенная подобласть, Подобласть относительно изображения | Источник целиком | Указывает, следует ли сканировать весь экран (или окно) или только его определенную подобласть |
| Image(s) | Нет | Список изображения | Изображения, определяющие подобласть (относительно верхнего левого угла изображения) для поиска заданного текста | |
| X1 | Да | Числовое значение | Начальная координата X подобласти для поиска заданного текста | |
| Tolerance | Да | Числовое значение | 10 | Указывает, насколько искомое изображение может отличаться от изначально выбранного изображения. |
| Y1 | Да | Числовое значение | Начальная координата Y подобласти для поиска заданного текста | |
| X1 | Да | Числовое значение | Начальная координата X подобласти (относительно заданного изображения) для поиска заданного текста | |
| X2 | Да | Числовое значение | Конечная координата X подобласти для поиска заданного текста | |
| Y1 | Да | Числовое значение | Начальная координата Y подобласти (относительно заданного изображения) для поиска заданного текста | |
| Y2 | Да | Числовое значение | Конечная координата Y подобласти для поиска заданного текста | |
| X2 | Да | Числовое значение | Конечная координата X подобласти (относительно заданного изображения) для поиска заданного текста | |
| Y2 | Да | Числовое значение | Конечная координата Y подобласти (относительно заданного изображения) для поиска заданного текста |
Создаваемые переменные
| Аргумент | Тип | Описание |
|---|---|---|
| LocationOfTextFoundX | Числовое значение | Координата X точки, в которой текст появляется на экране. Если поиск выполняется в окне переднего плана, возвращаемая координата указывается относительно левого верхнего угла окна Если поиск выполняется в окне переднего плана, возвращаемая координата указывается относительно левого верхнего угла окна |
| LocationOfTextFoundY | Числовое значение | Координата X точки, в которой текст появляется на экране. Если поиск выполняется в окне переднего плана, возвращаемая координата указывается относительно левого верхнего угла окна |
Исключения
| Исключение | Описание |
|---|---|
| Невозможно проверить наличие текста в неинтерактивном режиме. | Указывает, что проверить наличие текста на экране в неинтерактивном режиме невозможно. |
| Недопустимые координаты подобласти | Указывает, что координаты заданной подобласти недопустимы. |
| Не удалось проанализировать текст с помощью распознавания текста. | Указывает, что произошла ошибка при попытке проанализировать текст с помощью распознавания текста |
| Подсистема распознавания текста недоступна | Указывает, что подсистема распознавания текста недоступна. |
Создать подсистему распознавания текста Tesseract
Создание подсистемы распознавания текста Tesseract
Note
Действия Подсистема MODI OCR и Создать подсистему распознавания текста Tesseract со временем поддерживаться не будут. Дополнительную информацию об устаревании можно найти в соответствующем сообщении в блоге.
Входные параметры
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| Use other language | Н/Д | Логическое значение | Ложь | Указывает, следует ли использовать язык, не заданный в вариантах |
| Tesseract language | Н/Д | Английский, Немецкий, Испанский, Французский, Итальянский | Английский | Язык текста на изображении, распознаваемого подсистемой Tesseract |
| Language abbreviation | Нет | Текстовое значение | Сокращение используемого языка для Tesseract. | |
| Language data path: | Нет | Папка | Путь к папке, содержащей данные Tesseract для указанного языка | |
| Image width multiplier | Да | Числовое значение | 1 | Множитель ширины изображения |
| Image height multiplier | Да | Числовое значение | 1 | Множитель высоты изображения |
Создаваемые переменные
| Аргумент | Тип | Описание |
|---|---|---|
| OCREngine | OCREngineObject | Подсистема распознавания текста для использования с последующими действиями распознавания текста |
Исключения
| Исключение | Описание |
|---|---|
| Не удалось создать подсистему распознавания текста. | Указывает, что произошла ошибка при попытке создать подсистему распознавания текста. |
| Папка пути к данным не существует | Указывает, что папка, заданная для данных языка, не существует. |
Подготовьте потоки к предстоящему прекращению поддержки
Действие Создать подсистему распознавания текста Tesseract планируется удалить. Чтобы предотвратить сбой потоков после удаления, инициализируйте необходимые подсистемы Tesseract OCR непосредственно с помощью действий, которые их используют.
Этот метод инициализации подсистемы OCR обеспечивает те же параметры конфигурации, что и раньше, и устраняет необходимость в производимой переменной OCREngine.
Создать подсистему распознавания текста MODI
Создание подсистемы распознавания текста MODI
Note
Действия Подсистема MODI OCR и Создать подсистему распознавания текста Tesseract со временем поддерживаться не будут. Дополнительную информацию об устаревании можно найти в соответствующем сообщении в блоге.
Входные параметры
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| MODI language | Н/Д | Китайский (упрощенное письмо), Китайский (традиционное письмо), чешский, датский, нидерландский, английский, финский, французский, немецкий, греческий, венгерский, итальянский, японский, корейский, норвежский, польский, португальский, русский, испанский, шведский, турецкий | Английский | Язык текста изображения, распознаваемого подсистемой MODI |
| Image width multiplier | Да | Числовое значение | 1 | Множитель ширины изображения |
| Image height multiplier | Да | Числовое значение | 1 | Множитель высоты изображения |
Создаваемые переменные
| Аргумент | Тип | Описание |
|---|---|---|
| OCREngine | OCREngineObject | Подсистема распознавания текста для выполнения последующих действий распознавания текста |
Исключения
| Исключение | Описание |
|---|---|
Не удалось создать подсистему распознавания текста. | Указывает, что произошла ошибка при попытке создать подсистему распознавания текста. |
Подготовьте потоки к предстоящему прекращению поддержки
Подсистема MODI OCR будет удалена. Чтобы предотвратить сбой потоков после амортизации, замените инициализированные подсистемы MODI на подсистемы Tesseract.
Вы можете выполнить инициализацию напрямую через действия, требующие подсистемы, без использования действия Создать подсистему распознавания текста Tesseract.
Извлечь текст путем распознавания
Извлечение текста из заданного источника с помощью указанной подсистемы распознавания текста
Входные параметры
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| OCR engine | Нет | Переменная подсистемы распознавания текста, подсистема Tesseract | Переменная подсистемы распознавания текста | Тип используемой подсистемы распознавания текста. Выберите предварительно настроенную подсистему OCR или настройте новую. Выберите предварительно настроенную подсистему OCR или настройте новую. |
| OCR engine variable | Нет | OCREngineObject | Подсистема для распознавания текста. | |
| OCR source | Н/Д | Экран, Окно переднего плана, Изображение на диске | Экран | Источник изображения для распознавания текста |
| Image file path | Нет | Файл | Путь изображения для распознавания текста | |
| Search mode | Н/Д | Источник целиком, Только определенная подобласть, Подобласть относительно изображения | Источник целиком | Выбранный режим для распознавания текста |
| Image | Нет | Список изображения | Изображение, которое ограничивает сканирование подобластью относительно указанного изображения | |
| Tolerance | Да | Числовое значение | 10 | Указывает, насколько изображение может отличаться от изначально выбранного изображения.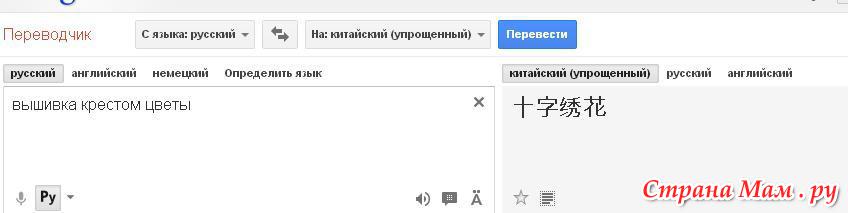 |
| X1 | Да | Числовое значение | Начальная координата X подобласти для ограничения сканирования | |
| X2 | Да | Числовое значение | Конечная координата X подобласти для ограничения сканирования | |
| Y1 | Да | Числовое значение | Начальная координата Y подобласти для ограничения сканирования | |
| Y2 | Да | Числовое значение | Конечная координата Y подобласти для ограничения сканирования | |
| Wait for image to appear | Н/Д | Логическое значение | Ложь | Следует ли ожидать появления изображения на экране или в окне переднего плана |
| Timeout | Да | Числовое значение | 0 | Указывает время ожидания выполнения операции, прежде чем действие будет признано неудачным. |
Создаваемые переменные
| Аргумент | Тип | Описание |
|---|---|---|
| OcrText | Текстовое значение | Результат после извлечения текста |
Исключения
| Исключение | Описание |
|---|---|
Не удалось извлечь текст с помощью распознавания текста. | Указывает, что произошла ошибка при попытке извлечь текст из заданного источника с помощью распознавания текста. |
| Файл изображения не найден. | Указывает, что файл по заданному пути не существует. |
| Изображение достопримечательности не найдено. | Указывает, что изображение достопримечательности не существует. |
| Подсистема распознавания текста недоступна | Указывает, что подсистема распознавания текста недоступна. |
| Невозможно получить текст на экране в неинтерактивном режиме. | Указывает, что получить текст на экране в неинтерактивном режиме невозможно. |
Система искусственного интеллекта распознает китайский текст лучше человека
Создана компьютерная система, которая распознает рукописный китайский текст эффективнее человека. Отдел науки «Газеты.Ru» рассказывает о других достижениях искусственного интеллекта, которые могут облегчить нашу жизнь.
Пишут так, что только компьютер разберет
На минувшей неделе была представлена система искусственного интеллекта, которая способна распознавать рукописный китайский текст. Само по себе это достижение неново: существует множество приложений, в том числе и со встроенными словарями, которые делают то же самое и существенно облегчают жизнь студентам, изучающим китайский язык. Подобные программы устанавливаются на смартфон с камерой, после чего владелец наводит объектив на текст, приложение «расшифровывает» его и автоматически вставляет иероглифы в словарь.Однако у подобных программ есть существенный минус: чаще всего они способны считывать только печатный текст. Написанные от руки китайские иероглифы отличаются от стандартизированного компьютерного шрифта так же сильно, как шрифт Times New Roman от рецепта, написанного непонятным почерком врача.
Само по себе это достижение неново: существует множество приложений, в том числе и со встроенными словарями, которые делают то же самое и существенно облегчают жизнь студентам, изучающим китайский язык. Подобные программы устанавливаются на смартфон с камерой, после чего владелец наводит объектив на текст, приложение «расшифровывает» его и автоматически вставляет иероглифы в словарь.Однако у подобных программ есть существенный минус: чаще всего они способны считывать только печатный текст. Написанные от руки китайские иероглифы отличаются от стандартизированного компьютерного шрифта так же сильно, как шрифт Times New Roman от рецепта, написанного непонятным почерком врача.
close
100%
Рецепт, выписанный китайским врачом
GaoxiaoОднако корпорации Fujitsu удалось решить эту проблему:
ее сотрудники разработали систему искусственного интеллекта, которая распознает рукописный китайский текст с эффективностью 96,7%.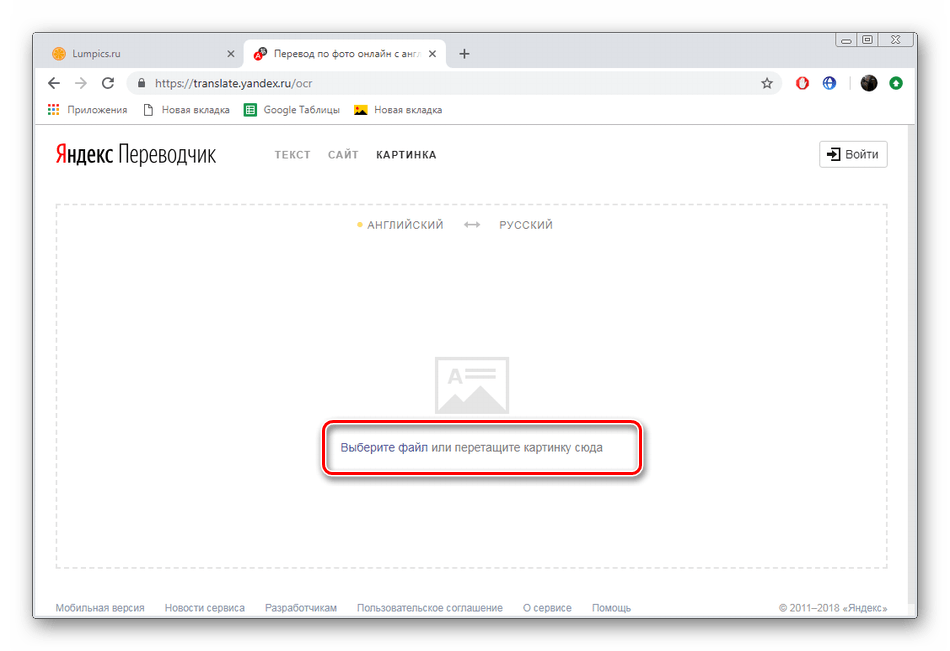 Человек делает это несколько хуже — для людей этот показатель равен 96,1%.
Человек делает это несколько хуже — для людей этот показатель равен 96,1%.
Подробнее ознакомиться с описанием системы можно на сайте ее создателей.
Работу над созданием технологии компания начала еще в 2010 году. В 2013 году первые результаты были представлены на самой престижной конференции по компьютерному распознаванию текстов и изображений International Conference on Document Analysis and Recognition. Тогда эффективность расшифровки рукописного китайского текста достигала 94,8%, что на тот момент стало рекордным показателем.
Функционирование системы искусственного интеллекта основано на следующем принципе: сначала она считывает общий вид иероглифа, распознавая его основные черты. После этого в дело вступает следующий «слой» электронных нейронов, которые «всматриваются» в детали символа. Особенность этого процесса заключается в том, что анализ иероглифа происходит как бы в трех измерениях: высота картинки, ее ширина и распознавание градации серых тонов.
close
100%
Принцип работы системы искусственного интеллекта
FujitsuДля того чтобы научить систему делать это, ученым пришлось увеличить число искусственных нейронных связей с 2,8 млн (показатель 2013 года) до 150 млн. Благодаря тому, что искусственный интеллект теперь может видеть вариации в цвете разных черт иероглифа, он способен создать трехмерную картинку иероглифа и оценить степень искажения черт, сравнив с наиболее похожим стандартным изображением.
Поделись улыбкою своей
Системы искусственного интеллекта способны считывать не только статичные тексты и изображения — исследователи из Малайзии смогли научить компьютер разбираться в значениях человеческой улыбки. Отчет о своем достижении они опубликовали в The International Journal of Artificial Intelligence and Soft Computing.
Система искусственного интеллекта оказалась способной отличить друг от друга улыбки, выражающие счастье, грусть, злость, отвращение, страх, удивление, а также идентифицировать нейтральную улыбку.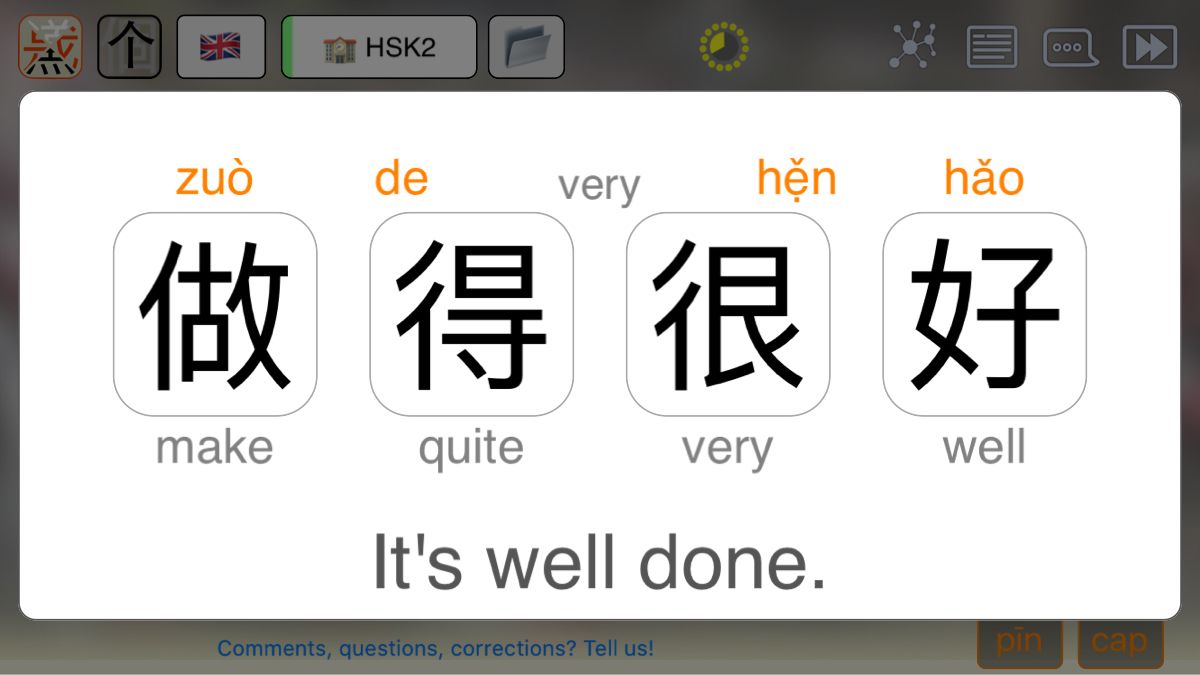 Компьютер при этом анализировал форму верхней и нижней губы по отдельности.
Компьютер при этом анализировал форму верхней и нижней губы по отдельности.
«В последние годы наблюдается все возрастающий интерес в улучшении всех аспектов взаимодействия между людьми и компьютерами, а особенно в улучшении способности компьютера определять эмоции человека, основываясь на выражении его лица», — комментирует ведущий автор исследования Картигаян Мутукаруппан. Ученые сосредоточились на изображениях губ человека, потому что именно наш рот является самым ярким выразителем эмоций.
Компьютер учится сам
Если предыдущему изобретению, судя по всему, еще предстоит ждать своего часа, до тех пор пока не будут изобретены общедоступные «умные» операционные системы (наподобие той, что фигурирует в фантастическом фильме «Она»), то ученые из Гетеборгского университета создали систему искусственного интеллекта, которая может принести пользу уже сейчас.
Исследователи разработали программу, которая способна имитировать процесс обучения маленьких детей.
Она осваивает базовую арифметику, грамматические правила и основы логики с нуля, руководствуясь теми же принципами, что и дети.
В качестве примера такого обучения создатели системы описывают следующую ситуацию. Допустим, ребенок осваивает умножение. Если он знает, что произведение двух и нуля — так же как трех и нуля — равно нулю, то может прийти к выводу, что умножение семнадцати на ноль также даст ноль. Но подобная логика иногда подводит: знание того, что произведение двух нулей равно нулю, а произведение двух единиц — единице, может привести к ошибочному заключению, что два, умноженное на два, также даст двойку. Ребенок — как только понимает, что пошел по ложному пути, — отказывается от такой логики и ищет новые способы решения задачи. Точно так же работает и система искусственного интеллекта. Подробнее с описанием ее функций можно ознакомиться на сайте Гетеборгского университета.
Авторы исследования полагают, что их изобретение может применяться для создания мультизадачных роботов, выполняющих разнообразные задачи по дому.
Переводчик с китайского на русский по фото онлайн
Если вы собрались путешествовать в Китай, то сетевой переводчик с китайского языка на русский по фотографии будет просто необходим. Чтобы перевести расписание самолётов в аэропорту в этой стране, вам нужно будет всего лишь запустить программу и навести камеру на малопонятный текст. Ознакомьтесь с лучшими приложениями в нашей статье.
Google Переводчик по фотографии с китайского языка на русский
Одной из лучших программ и приложений для перевода в интернете является Google Translate или Переводчик Гугл. Прежде всего из-за качества перевода, а также скорости работы. Сервис умеет работать со 103 языками мира и распознавать информацию по фото, голосовые сообщения, через камеру смартфона, текстовые сообщения. Ещё приложение сможет быстро перевести на ваш родной язык любой сайт в интернете. Для этого разработчик предлагает нам воспользоваться их браузером — Google Chrome.
Для этого разработчик предлагает нам воспользоваться их браузером — Google Chrome.
В 2017 году переводчик от компании Google значительно «поумнел». Так как его движок был полностью перенесён на нейросети. Также переводчик всегда готов рассмотреть другие варианты перевода того или иного слова. Вы можете указать правильный или даже неправильный вариант. Но со временем он будет изменён либо алгоритмом программы, либо другими пользователями обратно на правильный. Чтобы понять китайские иероглифы на изображении необходимо загрузить приложение для мобильных телефонов «Google Translate» для Android или iOS.
Дальнейший порядок действий:
- Откройте мобильный маркет на Андроид и iOS. Скачайте и установите его;
- Запустите приложение. В его окне можно увидеть пиктограмму фотоаппарата — нажмите её, чтобы загрузить изображение;
- Выберите пиктограмму телефона, чтобы начать переводить картинку.
Результат перевода появится в приложении.
Сфотографируйте результат, чтобы прочесть его позже в более комфортных условиях. Язык всегда можно сменить на верхней панели приложения. В том случае, если он автоматически установлен неправильно.
Читайте также: Яндекс Переводчик с эмодзи на русский язык онлайн.
Яндекс Переводчик – сервис для расшифровки китайских иероглифов онлайн
Две поисковые системы — Яндекс и Google уже давно соревнуются в интернете за звание лидера. И обе достойны быть лучшими. Переводчик, созданный российскими разработчиками всё же немного уступает сервису от Google по функциям. Он также способен переводить по фотографии и делает это хорошо. Потому что его движок также переведён на нейросеть. А тексты для преобразования основываются на миллионах уже переведённых в интернете статьях.
Особенности online переводчика:
| Функционал: | Пояснение: |
|---|---|
| Большая база языков | Переводчик позволяет трансформировать печатный текст на 95 языков мира. |
| Наличие подсказок | При вводе текста отображаются подсказки, которые помогают быстрее вводить слово, фразу или даже предложение. |
| Понятная транскрипция | Сервис Яндекс показывает транскрипцию китайского или любого другого языка. И помогает понять, как звучит то или иное слово при произношении. |
Алгоритм, при помощи которого распознаются тексты на картинках — собственная разработка компании Yandex.
Порядок работы с сервисом:
- Скачайте приложение Яндекс.Переводик из мобильного маркета и запустите на Айфоны и Андроид;
- Выберите китайский язык в верхней панели, если вы ещё этого не сделали;
- Наведите камеру мобильного на текст из китайских иероглифов;
- И прочитайте или сфотографируйте результат.
В момент использования переводчика на русский по фотоснимку, необходимо подключение к интернету. Так как приложение способно различать языки на изображении только online. Если вам не понятно обращение к вам китайца, вы можете попросить его говорить в микрофон смартфона, чтобы вы увидели текст на русском в приложении Яндекс. Для этого выберите соответствующий режим перевода.
Если вам не понятно обращение к вам китайца, вы можете попросить его говорить в микрофон смартфона, чтобы вы увидели текст на русском в приложении Яндекс. Для этого выберите соответствующий режим перевода.
Также, как и переводчик от Гугла способен переводить целые веб-сайты на разные доступные языки. Расшифровка по картинке доступна пока что только для 12 языков: французского, чешского, польского, английского, испанского, немецкого, португальского, украинского, русского, турецкого, китайского, итальянского. Ещё в мобильном приложении реализована поддержка Android Wear.
Это интересно: как скопировать текст с картинки онлайн.
Microsoft Переводчик – поможет преобразовать слово с китайского на русский по картинке
Вслед за популярными приложениями-переводчиками устремляется и разработка компании Майкрософт. Создатели самой популярной операционной системы для компьютеров также решили сказать своё слово в современном переводе. Этот переводчик умеет работать с китайским текстом и даже переводить его по изображению. Приложение доступно для мобильных платформ в Google Play и App Store. Как и его конкуренты, сервис умеет работать с фотографиями, скриншотами, распознавать голос, текстовые сообщения и работает с 60 языками.
Приложение доступно для мобильных платформ в Google Play и App Store. Как и его конкуренты, сервис умеет работать с фотографиями, скриншотами, распознавать голос, текстовые сообщения и работает с 60 языками.
Работает как онлайн, так и оффлайн. Способен переводить «на лету» беседу двух человек, разговаривающих на разных языках.
В приложении Майкрософт есть готовые разговорники для разных стран
Они были специально разработаны для путешествующих людей. А также для тех, кто хочет выучить определённый язык с целью путешествия. По умолчанию в приложении доступны несколько языков. Можно отдельно загрузить языковой пакет в самом приложении.
Разговорник доступен на веб-сайте Майкрософт — https://translator.microsoft.com/.
При этом вы можете общаться с человеком из Китая или любой другой страны. Чтобы воспользоваться разговорником и создать свою беседу, у вас должна быть учётная запись Microsoft.
А чтобы присоединиться к разговору:
- Перейдите на главную страницу переводчика;
- Укажите в форме своё имя и язык, на котором вы говорите;
Заполните форму для общения с иностранцем - Введите код беседы и нажмите кнопку «Войти».

Код, который требует система, вам должен предоставить собеседник. К такой беседе на сайте может присоединиться до 100 человек. На сайте можно проговаривать предложения, которые должен услышать ваш собеседник. Или печатать текстом сообщения. При этом текст будет автоматически переведён на стороне собеседника.
Это может быть полезным: как включить голосовой ввод в Гугл документе.
Словари ABBYY Lingvo — профессиональный онлайн-переводчик по фото
Компания ABBYY уже давно зарекомендовала себя в интернете как лучший разработчик электронных словарей для перевода. Сегодня в мобильных магазинах можно найти их приложение, которое также легко сможет преобразовать текст с китайского на русский язык.
Ссылки на загрузку приложения для двух популярных мобильных платформ для Андроид и для iOS.
Мобильное приложение, разработанное ABBYY два года подряд (2015, 2016) находилось в списке лучших. Поэтому с ним стоит познакомиться. Загрузите и запустите его на своём мобильном устройстве.
Порядок действий:
- Наведите камеру на текст, который хотите перевести онлайн;
- Отрегулируйте окно фокуса, в котором будет осуществляться перевод;
- Выберите любое слово, чтоб его перевести.
Нажмите на слово в тексте, чтобы увидеть перевод
Это, конечно же, не так удобно, как перевод в Яндекс или Google переводчике, которые моментально переводят весь текст. Но также удобно, когда текст небольшой. Каждое слово сопровождается дополнительной информацией. Которая открывается по нажатию на контекстное окно. На сайте также можно скачать ознакомительную версию словарей для мобильных устройств и не только.
На главной странице сайта ABBYY есть ссылки для загрузки словарей для MAC, Android, iOS, Windows.
Они находятся внизу страницы. Скачать напрямую с сайта нельзя. Вы должны оставить свою электронную почту в форме для загрузки. После чего ждать, пока система не пришлёт вам ссылку на скачивание. Загружать можно отдельно словари для двух языков. Перейдите в раздел загрузки, чтобы найти переводчик с китайского языка на русский по картинке или фото, работающий онлайн для мобильного телефона. Таким образом приложение будет «весить» значительно меньше.
Перейдите в раздел загрузки, чтобы найти переводчик с китайского языка на русский по картинке или фото, работающий онлайн для мобильного телефона. Таким образом приложение будет «весить» значительно меньше.
Пять советов, как вовремя распознать аппендицит — Российская газета
Подсчитано, что в нашей стране острый аппендицит настигает ежегодно около миллиона человек.
Смертность из-за него вроде бы невысока: всего 0,2-0,3%, но за столь незначительными цифрами кроется около 3000 человеческих жизней, которые врачам не удается спасти. И в летний период, когда многие люди находятся на дачах и далеко от врачей, особенно важно уметь отличать аппендицит от обычных болей в животе, чтобы вовремя обратиться к врачу.
Слепой, но опасный
Аппендикс – короткий и тонкий слепой червеобразный отросток длиной 7-10 см, расположенный на конце слепой кишки (начальный отдел толстой кишки). Как и любой отдел кишечника, аппендикс вырабатывает кишечный сок, но так мало, что особой роли в пищеварении он не играет. Поэтому его долгое время считали “ошибкой природы” и удаляли больным при первой возможности. Но недавно ученые обнаружили в слепом отростке лимфоидные клетки, такие же, как в миндалинах человека. А поскольку эти клетки обладают свойствами защищать организм от инфекций, то родилось предположение, что аппендикс – часть иммунной системы.
Поэтому его долгое время считали “ошибкой природы” и удаляли больным при первой возможности. Но недавно ученые обнаружили в слепом отростке лимфоидные клетки, такие же, как в миндалинах человека. А поскольку эти клетки обладают свойствами защищать организм от инфекций, то родилось предположение, что аппендикс – часть иммунной системы.
Однако количество защитных клеток в нем, как оказалось, весьма незначительно и сильного влияния на иммунитет оказать не может. Так что большинство специалистов по-прежнему уверены, что пользы от червеобразного отростка нет, а вот вред в случае его воспаления может быть существенный: вовремя не диагностированный острый аппендицит может стоить не только здоровья, но и жизни.
Виноваты зубы?
Специалисты не сходятся во мнении о точных причинах развития аппендицита. Однако группы риска определены.
Например, люди, страдающие такими болезнями, как хроническая ангина, воспаление легких, затяжные простуды, заболевания желудочно-кишечного тракта, кариес. В результате этих заболеваний инфекции по кровеносному руслу проникают в аппендикс и провоцируют там воспалительный процесс. Так что здоровые зубы – залог здоровья для аппендикса.
В результате этих заболеваний инфекции по кровеносному руслу проникают в аппендикс и провоцируют там воспалительный процесс. Так что здоровые зубы – залог здоровья для аппендикса.
Существует также стрессовая теория. Она основана на том, что в результате волнения у человека происходит резкое сужение кровеносных сосудов и это приводит к внезапному обескровлению червеобразного отростка и развитию его воспаления.
Но чаще всего возникновение аппендицита объясняют засорением соединения толстой кишки и червеобразного отростка, что часто случается при запорах и хронических колитах.
Как его опознать?
У большинства людей аппендикс находится примерно на середине расстояния между пупком и правой подвздошной костью. В этом месте при аппендиците и ощущается максимальная боль. Но если червеобразный отросток приподнят к правому подреберью, ближе к печени, боль будет проявляться в этой области. А если аппендикс опущен в нижнюю часть таза, то у женщин аппендицит легко спутать с воспалением придатков, у мужчин – мочевого пузыря.
При расположении отростка за слепой кишкой, когда он завернут к почке и мочеточнику, возникает боль в пояснице, отдает в пах, в ногу, в область таза. Если же отросток направлен внутрь живота, тогда появляются боли ближе к пупку, в среднем отделе живота и даже под ложечкой.
Боли возникают внезапно, без всякой явной причины. Поначалу они не слишком сильные – их можно еще терпеть. А иногда уже с первых минут приступа острого аппендицита они становятся невыносимыми и протекают по типу колики.
Боль будет мучить человека до тех пор, пока живы нервные окончания отростка. Когда же произойдет его омертвение, нервные клетки погибнут и боли ослабнут. Но это не повод для успокоения. Аппендицит не “рассосется”. Наоборот, отступление боли – повод для немедленной госпитализации. Острый аппендицит сопровождается и другими симптомами. В начале заболевания появляется общее недомогание, слабость, ухудшается аппетит. Вскоре может возникнуть тошнота, иногда и рвота, но однократная. Характерна температура в пределах 37,2-37,7 градуса, иногда сопровождаемая ознобом. На языке появляется белый или желтоватый налет.
Характерна температура в пределах 37,2-37,7 градуса, иногда сопровождаемая ознобом. На языке появляется белый или желтоватый налет.
Распознать аппендицит помогут простые приемы. Но, учтите, проводить самодиагностику надо очень осторожно.
1. Легко постучите подушечкой согнутого указательного пальца в области правой подвздошной кости – при аппендиците там всегда бывает больно.2. Для сравнения также постучите по левой подвздошной области, что в случае воспаления аппендикса не вызовет болезненных ощущений. Внимание: самим проводить пальпацию (ощупывание живота руками) нельзя, есть опасность разорвать аппендикс, что обычно приводит к перитониту.3. Попробуйте громко кашлянуть: усиление боли в правой подвздошной области подскажет, что у вас начинается аппендицит.4. Слегка надавите ладонью в том месте живота, где больше всего болит. Подержите здесь руку 5-10 секунд. Боль при этом немного ослабнет. А теперь уберите руку. Если в этот момент появится боль, это признак острого аппендицита.5. Примите позу эмбриона, то есть лягте на правый бок и подтяните ноги к туловищу. При аппендиците боль в животе ослабнет. Если же вы повернетесь на левый бок и выпрямите ноги, она усилится. Это тоже признак острого аппендицита.
А теперь уберите руку. Если в этот момент появится боль, это признак острого аппендицита.5. Примите позу эмбриона, то есть лягте на правый бок и подтяните ноги к туловищу. При аппендиците боль в животе ослабнет. Если же вы повернетесь на левый бок и выпрямите ноги, она усилится. Это тоже признак острого аппендицита.Но этим самодиагностика должна ограничиваться. Не медлите с обращением к врачу, поскольку и сам аппендицит, и все заболевания, под которые он может маскироваться (почечная колика, обострение панкреатита или холецистита, язвенные болезни желудка и 12-перстной кишки, острые воспаления мочевого пузыря, почек, женских органов), требуют госпитализации!
Как лечить
Если поставлен диагноз “острый аппендицит”, первоочередное лечение одно – экстренная операция. В настоящее время существует щадящий лапароскопический метод, при котором червеобразный отросток можно удалить без большого разреза. К сожалению, в нашей стране такой вид операций из-за плохой технической оснащенности больниц пока недостаточно распространен.
Главная задача послеоперационного периода – избежать осложнений, например, нагноений послеоперационной раны. В их возникновении чаще всего нет никакой вины хирурга. А быть этому осложнению или не быть, зависит от состояния червеобразного отростка в момент операции – чем больше степень воспаления, тем выше опасность нагноения.
Если операция прошла удачно, молодым пациентам уже на 6-7-е сутки снимают швы и выписывают из больницы. А вот людям пожилого возраста, а также с хроническими заболеваниями (сахарным диабетом, гипертонией, ишемией сердца и др.) швы снимают на 2-3 дня позже. После этого рану желательно скреплять лейкопластырем.
Около месяца не принимайте ванну и не ходите в баню: водные и температурные нагрузки на неокрепшую рубцовую ткань делают шов более грубым, широким и некрасивым. Не меньше трех месяцев, а пожилым полгода нельзя поднимать тяжести. Избегайте спортивных занятий, вызывающих напряжение мышц живота. Старайтесь не простужаться: вам опасно кашлять.
Тяжелый случай
Если пытаться “перетерпеть” аппендицит, может возникнуть перитонит – воспаление брюшной полости. Его симптомы:
Его симптомы:
нарастающая боль по всему животу, тошнота, рвота, в тяжелых случаях – сонливость, заторможенность, синюшный оттенок лица;
пульс до 120-140 ударов в минуту, температура до 39-40 С;
язык обложен белым налетом, потом становится сухим, как корка, губы высыхают и трескаются;
живот вздувается, болит во всех своих областях, но особенно справа.
Лечится перитонит только оперативным путем. Причем операция весьма сложная и длительная. К сожалению, спасти пациента удается не всегда. Вот почему при появлении любых болей в животе ни в коем случае нельзя затягивать с визитом к врачу. Как говорится, мы никого не хотим пугать, но помнить о том, как опасен аппендицит, следует каждому.
Китайская грамота
Слово «иероглиф» в русском языке стало нарицательным. Часто его используют для того, чтобы обозначить нечто непонятное и непостижимое. И правильно делают! Для людей, выросших в европейской культуре, иероглифы, действительно, часто становятся камнем преткновения.
Почему сложны иероглифы
Иероглиф – собирательное название для систем письменности, принятых в восточных языках: японском, китайском и, частично, корейском. Кстати, это слово известно еще со времен Древней Греции. Им в античности обозначали начертание «округлых» греческих букв, высеченных на камне.
Первые иероглифы появились в Китае еще в 16 веке до нашей эры. Из Поднебесной они были позаимствованы японцами и корейцами. Считается, что иероглифы помогают жителям Востока понимать письменность друг друга, даже не владея языком соседней страны. К примеру, в современном Китае насчитывается 3000 диалектов. И их носители прекрасно понимают друг друга. Кстати, можно попробовать почитать текст на болгарском языке, чтобы убедиться: понимать письменный язык ближайших соседей можно и в Европе.
Особенность иероглифов состоит в том, что они обозначают не отдельные буквы, а слоги или слова (слова из одного слога часто встречаются в восточных языках). Сама по себе такая система письма не оригинальна. Она, к примеру, принята и в иврите, где отсутствуют гласные буквы, аналогичные звукам А и Е. Но, если в иврите всего-то 22 буквы, то счет китайских иероглифов идет на тысячи.
Сама по себе такая система письма не оригинальна. Она, к примеру, принята и в иврите, где отсутствуют гласные буквы, аналогичные звукам А и Е. Но, если в иврите всего-то 22 буквы, то счет китайских иероглифов идет на тысячи.
«Минимальным» объемом грамотности в Китае считается знание полутора-двух тысяч иероглифов. Такого объема достаточно сельским жителям и мелким служащим. Чтобы читать газеты и журналы, нужно иметь «лексикон» из 3000 иероглифов. Словари обычно содержат от 6 до 10 тысяч, а в словаре «Море китайских иероглифов», изданном в 1994 году, их насчитывается более 84 тысяч.
Главное отличие иероглифа от привычных нам латиницы и кириллицы – обилие графических элементов. Наши буквы, как правило, являются единым знаком, элементы которого не имеют собственного значения. В иероглифическом письме важны каждая черточка, точка или крючок. Если напечатан или написан иероглиф неразборчиво, носитель языка поймет его значение по контексту, как мы понимаем значение слов, написанных с ошибками.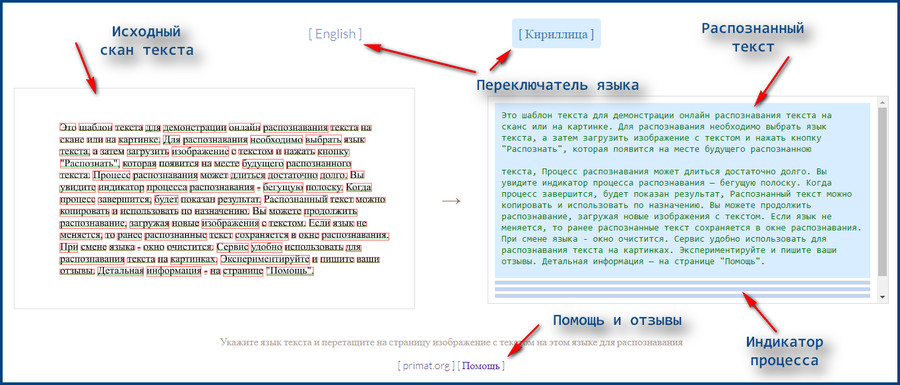 А вот европейцу придется туго: смысл фразы потеряется или изменится до неузнаваемости.
А вот европейцу придется туго: смысл фразы потеряется или изменится до неузнаваемости.
И это – проблемы не только тех, кому приходится изучать иероглифические языки. Чем большую роль играют восточные в мировой экономике, тем чаще нам приходится иметь дело с текстами на китайском, японском или корейском языках. А значит – и работать с ними.
Также
по теме
Как работают системы распознавания
С латинской или кириллической письменностью системы распознавания (OCR) работают уже с уверенной, высокой скоростью. Многие программы способны «разобрать» не только печатный, но и письменный вариант текста.
Проблемой перестает быть и низкое качество оригинала, такие тексты система часто умеет не только распознавать, но и «на лету» исправлять. Но там, где носитель восточного языка справляется с особенностями начертания или качеством отображения текста благодаря своему мышлению, машина откровенно «пасует». Научить компьютер думать, как китайцы и японцы, смог только искусственный интеллект.
Научить компьютер думать, как китайцы и японцы, смог только искусственный интеллект.
До недавних пор китайское и японское письмо распознавались OCR так же, как и европейские символы – на основе классификаторов. Выглядит алгоритм работы просто, строится от общего к частному. Система разделяет документ на страницы, каждая из них – на текстовые блоки, затем идут строки, слова, и, наконец, символы. Последнее – самое сложное. Для каждой буквы добавляются отдельные признаки начертания, символы и слова классифицируются, а система на основе классификации учится предлагать наиболее подходящие варианты «прочтения» текста.
Наверное, был бы очень занятным эксперимент, в котором один и тот же текст распознавался разными версиями одной и той же OCR. Сравнение результатов их работы стало бы отличной иллюстрацией того, как со временем совершенствовались такие решения. Повторимся: здесь важна не только точность распознавания, но и его скорость.
А теперь давайте усложним задачу и предложим OCR-системе в качестве виртуального задания распознать иероглифический текст. Если при работе с европейскими алфавитами приходится классифицировать самое большее – несколько десятков символов, то «китайская грамота» предполагает, что эту работу нужно сделать для тысяч иероглифов.
Необходимость распознать нечеткую копию или рукописный вариант делают такую задачу сверхсложной. А о скорости распознавания документа и ресурсах компьютера, которые необходимы для решения задачи, говорить не приходится. Поэтому вплоть до 2018 года работа OCR с иероглифическими документами была не слишком уверенной и совсем не быстрой.
Нейросети для иероглифов
Все изменилось в 2018 году. Специалисты компании ABBYY, которая развивает знаменитый FineReader уже два десятка лет, нашли решение для задач, связанных с распознаванием иероглифов. Было решено применить нейросети.
Первоначально в ABBYY решили использовать одну сверточную сеть для распознавания всех иероглифов. Такой шаг представлялся логичным: подобный тип нейронных сетей разрабатывался в том числе и для распознавания текста. Кроме того, у компании был успешный опыт ее применения для работы с рукописными латинскими символами.
Однако, оказалось, что одна нейронная сеть работает либо слишком плохо (совершает ошибки в распознавании), либо крайне медленно. Не помогало и использование сложных архитектур. Проблемой стало большое число классов, по которым приходилось обучаться нейронной сети.
И тогда в компании решили применить другой подход – использовать двухуровневую систему. В ней «алфавит» разбивается на группы похожих символов. Первая сеть анализирует изображение иероглифа и определяет, к какой группе он принадлежит. А дальше в работу включается вторая сеть, которая и проводит итоговую классификацию внутри группы.
Результат протестировали на коллекции японских и китайских текстов. Сравнение показало, что при использовании одной сети скорость работы системы составляет около 370 символов в секунду при качестве распознавания в 97%. В быстром режиме ей удавалось распознать 570 символов в секунду, но качество распознавания снижалось до 92%.
А вот двухуровневая сеть дала принципиально иные результаты. Обычный режим позволил обрабатывать 520 символов с более чем 97-процентным качеством, а быстрый – более 650 символов в секунду практически с таким же результатом работы.
Не только китайский и японский
Иероглифическое письмо – самый наглядный пример работы OCR со сложными задачами. Принципы и технологии распознавания, которые были реализованы для китайского и японского письма, могут применяться и для документов на других языках – хинди, тамильском или арабском.
К примеру, работа OCR с арабской вязью связана с необходимостью «разрезать» слово на символы. Но таких вариантов в этом языке оказалось слишком много. Специалисты ABBYY специально для него разработали end-to-end сеть и научили ее при помощи «набора» из сотен тысяч изображений текстов на арабском работать не с отдельными символами, а целыми словами. Кстати, такое решение отлично подошло и для распознавания европейских языков в том случае, если тексты набираются дизайнерскими шрифтами.Банки дадут клиентам возможность запретить выдачу онлайн-кредитов — РБК
Как опция будет работать
Возможность защититься от мошеннических кредитов самостоятельно появится у всех клиентов ВТБ. Эта технология может быть востребована теми клиентами, кто уже оформил кредит, или у кого нет такой необходимости, рассказал представитель ВТБ. Такое ограничение на ранней стадии оформления кредита позволит определить — подает ли заявку клиент по собственной воле или под влиянием мошеннической схемы. «Если клиент включит это ограничение, то мошенники не смогут оформить кредит, даже если получат от клиента всю необходимую информацию. При этом мошенник не поймет причину отказа в кредите», — сказал представитель ВТБ, добавив, что, когда клиенту понадобятся кредитные средства, ему нужно будет дополнительно подтвердить свое намерение банку.
Читайте на РБК Pro
Кроме функционала по ограничению кредитов онлайн, ВТБ разрабатывает целый комплекс мер, которые вместе должны сократить потенциальный объем хищений на 20%, говорит Печатников. Банк планирует запустить в середине 2022 года возможность ограничивать круг получателей переводов, скрывать в личном кабинете баланс, историю операций и персональные данные, дополнительно подтверждать операции с помощью бесконтактной технологий, голосовой биометрии, селфи, подтверждение операции через код на e-mail и т.д. ВТБ также разрабатывает сервис оценки уровня безопасности клиентов, который будет рекомендовать пользователям «ВТБ Онлайн» включать настройки для повышения уровня защищенности.
Промсвязьбанк уже предоставляет функционал по ограничению онлайн-операций, но для этого нужно обратиться в отделение банка. «Функция позволяет защитить клиента от возможных действий злоумышленников: при любой попытке оформить кредитный продукт через мобильное приложение или интернет-банк система банка фиксирует такую попытку, определяет, совершал ли действие сам клиент и в этом случае просит лично обратиться в банк для снятия ограничений», — рассказал представитель банка.
Другие крупные банки не ответили на запросы РБК.
Бизнес пожаловался на отказы банков в «антикризисных» кредитахПомогут ли ограничения
Скорее всего, на возможность блокировать выдачу кредитов онлайн обратят внимание только те клиенты, у которых и так высокий уровень финансовой грамотности. Те же клиенты, которые ведутся на звонки мошенников, не будут знать и о новых возможностях защиты, считает генеральный директор компании SafeTech Денис Калемберг. «Даже если банк планирует просвещать своих клиентов о появившихся ограничениях, вряд ли он будет делать это массово. Банкам нужно, чтобы их клиенты могли оформлять кредиты легко, быстро и без посещения офиса, поэтому продвижение этой истории — выстрел себе в ногу», — говорит эксперт.
Запрет на онлайн-кредитование — слишком жесткая и неудобная мера в первую очередь для самого клиента, считает руководитель управления кредитных рисков розничного сегмента Райффайзенбанка Алексей Крамарский. «Допустим, он поставил блок и спокойно забыл о нем, а спустя время решил взять кредит в приложении, ведь это удобно и быстро, но он не может этого сделать и сталкивается с негативным опытом — надо идти в отделение снимать запрет», — рассуждает Крамарский. По его мнению, более эффективным решением будет повышение уровня защищенности банковского приложения и повышение финансовой грамотности населения.
Злоумышленники используют много схем для отъема денег, но хотя бы в части оформления кредитов эта мера затруднит работу злоумышленников и защитит от потерь средств некоторых клиентов банков, считает главный эксперт «Лаборатории Касперского» Сергей Голованов. Руководитель отдела исследования цифровых рисков DRP Group-IB Яков Кравцов полагает, что ограничение онлайн-выдачи кредитов будет эффективным какое-то время, пока мошенники не найдут новый способ, как заставить жертву перевести деньги. «Радикально решить вопрос поможет лишь ликвидация мошеннических групп и их инфраструктуры», — подчеркивает он.
Чтобы обойти эти ограничения, мошенники могут с помощью методов социальной инженерии отправить клиентов оформлять кредиты сразу в отделение банка, считает директор по противодействию мошенничеству BI.ZONE Антон Окошкин. «Схема уже используется: по просьбам злоумышленников жертвы снимают деньги с собственных счетов в отделениях или банкоматах, берут кредиты в сторонних организациях, распоряжаются своим имуществом в интересах мошенников», — перечисляет он.
(PDF) Распознавание рукописных китайских иероглифов на основе концептуального обучения
Это произведение находится под лицензией Creative Commons Attribution 4.0 License. Для получения дополнительной информации см. Https://creativecommons.org/licenses/by/4.0/.
Эта статья принята к публикации в следующем номере этого журнала, но не отредактирована полностью. Контент может измениться до окончательной публикации. Информация для цитирования: DOI
10.1109 / ACCESS.2019.2930799, IEEE Access
Xu et al.: Распознавание рукописных китайских иероглифов на основе концептуального обучения
современных методов на наборе данных ICDAR-2013.
ПОДТВЕРЖДЕНИЕ
Авторы благодарят за финансовую поддержку Гуан-
донг Ключевая лаборатория экологически чистых химических продуктов
Technology и «Программа талантов Чжуцзян» High Tal-
Ent Project провинции Гуандун (2017GC010614).
Мы благодарим LetPub за лингвистическую помощь при подготовке этой рукописи
.Мы также благодарим CASIA
(http://www.nlpr.ia.ac.cn/databases/handwriting/Home.html)
за его базу данных CASIA-OLHWDB.
Авторы благодарны всем рецензентам за предложения и идеи, которые улучшили статью.
ССЫЛКИ
[1] Р. Пламондон и С. Н. Шрихари, «Распознавание рукописного ввода онлайн и офлайн
: всесторонний обзор», IEEE Trans. Pattern Anal. Мах. Интел.,
т. 22, нет. 1, стр.63–84, январь 2000 г., DOI: 10.1109 / 34.824821.
[2] К. Л. Лю, С. Джегер и М. Накагава, «Онлайн-распознавание китайских
символов: современное состояние», IEEE Trans. Pattern Anal. Мах. Интел.,
т. 26, вып. 2, стр. 198–213, июнь 2004 г., DOI: 10.1109 / tpami.2004.1262182.
[3] Т. Плётц и Г. А. Финк, «Марковские модели для распознавания плоского почерка
: обзор», Междунар. J. Doc. Анальный. Признание., Т. 12, вып. 4. С. 269–298,
Октябрь 2009 г., DOI: 10.1007 / s10032-009-0098-4.
[4] А. Грейвс, М. Ливицки, С. Фернандес, Р. Бертолами, Х. Бунке и Дж.
Шмидхубер, «Новая коннекционистская система распознавания произвольного почерка –
», IEEE Trans. Pattern Anal. Мах. Intell., Т. 31, вып. 5,
pp. 855–868, май 2009 г., DOI: 10.1109 / tpami.2008.137.
[5] Т. Ван, Д. Дж. Ву, А. Коутс и А. Й. Нг, «Сквозное распознавание текста
со сверточными нейронными сетями», в Proc. ICPR 2012, Цукуба, Япония,
2012, стр.3304–3308.
[6] К. Л. Лю, Ф. Инь, Д. Х. Ван и К. Ф. Ван, «Распознавание рукописных китайских символов онлайн и офлайн:
» 46, нет. 1. С. 155–162, январь 2013 г., DOI:
10.1016 / j.patcog.2012.06.021.
[7] М. Козельски, П. Дётч и Х. Ней, «Улучшения в системе RWTH
для автономного распознавания рукописного ввода», в Proc. ICDAR 2013, Вашингтон,
округ Колумбия, США, 2013 г., стр.935–939, DOI: 10.1109 / icdar.2013.190.
[8] П. Дётч, М. Козельски и Х. Ней, «Быстрое и надежное обучение рекуррентных нейронных сетей
для распознавания плоского почерка», в Proc. ICFHR
2014, Ираклион, Греция, 2014, стр. 279–284, DOI: 10.1109 / icfhr.2014.54.
[9] G. Bideault, L. Mioulet, C. Chatelain и T. Paquet, «Определение рукописного текста –
десять слов и REGEX с использованием двухэтапной архитектуры BLSTM-HMM», в
Proc. SPIE / IS&T Electron.Imaging, Сан-Франциско, Калифорния, США, 2015 г., стр.
94020G, DOI: 10.1117 / 12.2075796.
[10] А. Грейвс и Дж. Шмидхубер, «Распознавание плоского почерка с помощью многомерных рекуррентных нейронных сетей
», Proc. NIPS’08, Ванкувер,
Канада, 2008 г., стр. 545–552.
[11] Т. Блюш, Дж. Лорадур и Р. Мессина, «Сканируйте, посещайте и читайте: End-
до конца рукописного распознавания абзацев с вниманием MDLSTM», в
Proc. ICDAR 2017, Киото, Япония, 2017, стр.1050–1055, DOI: 10.1109 / ic-
dar.2017.174.
[12] А. Грейвс, С. Фернандес, Ф. Гомес и Дж. Шмидхубер, «Временная классификация Connectionist
», в Proc. ICML ’06, Питтсбург, Пенсильвания, США, 2006 г.,
стр. 369–376, DOI: 10.1145 / 1143844.1143891.
[13] М. Канг и Д. Палмер-Браун, «Нейронная сеть с адаптивной функцией модального обучения
, применяемая для распознавания рукописных цифр», Инф. Sci., Т. 178,
нет. 20. С. 3802–3812, октябрь 2008 г., DOI: 10.1016 / j.ins.2008.05.011.
[14] Ф. Замора-Мартинес, В. Фринкен, С. Эспанья-Бокера, М. Дж. Кастро-Бледа,
А. Фишер и Х. Бунке, «Языковые модели нейронных сетей для автономного распознавания рукописного текста
, ”Распознавание образов., Т. 47, нет. 4, pp. 1642–1652,
апрель 2014 г., DOI: 10.1016 / j.patcog.2013.10.020.
[15] С. Импедово, «Более двадцати лет достижений на Frontiers в области распознавания рукописного ввода
», Pattern Recognit., Vol. 47, нет.3, pp. 916–928,
март 2014 г., DOI: 10.1016 / j.patcog.2013.05.027.
[16] М. Ядерберг, К. Симонян, А. Ведальди и А. Зиссерман, Синтетические данные
и искусственные нейронные сети для распознавания текста естественной сцены, 2014.
[Онлайн]. Доступно: https://arxiv.org/abs/1406.2227v4, дата обращения: 6 июня,
2019.
[17] А. Познанский и Л. Вольф, «CNN-n-грамм для распознавания рукописных слов –
.ция »в сб. CVPR 2016, Лас-Вегас, Невада, США, 2016 г., стр.2305–2314,
DOI: 10.1109 / cvpr.2016.253.
[18] К. Л. Лю, Ф. Инь, К. Ф. Ван и Д. Х. Ван, «Конкурс распознавания рукописного текста ICDAR 2011 Chinese
», в Proc. ICDAR 2011, Пекин,
Китай, 2011, стр. 1464–1469, DOI: 10.1109 / icdar.2011.291.
[19] В. Ян, Л. Джин, Д. Тао, З. Се и З. Фэн, «DropSample: новый метод train-
ing для улучшения глубоких сверточных нейронных сетей для крупномасштабных
неограниченных рукописное распознавание китайских иероглифов »Pattern Recog-
нит., т. 58, стр. 190–203, октябрь 2016 г., DOI: 10.1016 / j.patcog.2016.04.007.
[20] В. Ян, Л. Цзинь, З. Се и З. Фэн, «Улучшенная глубокая сверточная нейронная сеть
для онлайн-распознавания рукописных китайских символов с использованием специфичных для предметной области знаний
», в Proc. ICDAR 2015, Тунис, Тунис, 2015,
стр. 551–555, DOI: 10.1109 / icdar.2015.7333822.
[21] А. Грейвс, С. Фернандес и Дж. Шмидхубер, «Многомерные рекурсивные нейронные сети
», Proc.ICANN 2007, Порту, Португалия, 2007, стр.
549–558, DOI: 10.1007 / 978-3-540-74690-4_56.
[22] Х. Рен, В. Ван, К. Лу, Дж. Чжоу и К. Юань, «Сквозной распознаватель
для воздушно-написанных рукописных китайских иероглифов на основе нового повторяющегося нейронного канала
.сетей »в сб. ICME 2017, Гонконг, Китай, 2017, стр. 841–846,
DOI: 10.1109 / icme.2017.8019443.
[23] З. Се, З. Сунь, Л. Джин, Х. Ни и Т. Лайонс, «Изучение пространственно-семантического контекста
с полностью сверточной рекуррентной сетью для онлайн-рукописного текста
Китайское распознавание текста», IEEE Пер.Pattern Anal. Мах. Intell., Т. 40,
нет. 8. С. 1903–1917, август 2018 г., DOI: 10.1109 / tpami.2017.2732978.
[24] X. Y. Zhang, F. Yin, Y. M. Zhang, C. L. Liu и Y. Bengio, «Рисование
и распознавание китайских иероглифов с помощью рекуррентной нейронной сети», IEEE
Trans. Pattern Anal. Мах. Intell., Т. 40, нет. 4, pp. 849–862, апр.2018 г.,
DOI: 10.1109 / tpami.2017.2695539.
[25] X. Qu, W. Wang, K. Lu, and J. Zhou, «Расширение данных и выделение направленных карт
функций для распознавания рукописных китайских иероглифов в воздухе
на основе сверточной нейронной сети. Распознавание образов.Lett., Vol.
111, стр. 9–15, август 2018 г., DOI: 10.1016 / j.patrec.2018.04.001.
[26] З. Гахрамани, «Вероятностное машинное обучение и искусственный интеллект
gence», Nature, vol. 521, нет. 7553, стр. 452–459, май 2015 г., DOI:
10.1038 / nature14541.
[27] Б. М. Лейк, Р. Салахутдинов, Дж. Б. Тененбаум, «Человеческий уровень контроля
, кроме обучения посредством индукции вероятностной программы», Наука, т. 9, с. 350,
нет. 6266, стр. 1332–1338, декабрь.2015 г., DOI: 10.1126 / science.aab3050.
[28] А. Ахмед и А. Бикмал, Одноразовое концептуальное обучение с помощью simu-
последующее развитие эволюционного инстинкта, 2017. [Онлайн]. Доступно:
https://arxiv.org/abs/1708.08141v1, дата обращения: 6 июня 2019 г.
[29] Л. Лам, С.В. Ли и С.Ю. Суен, «Методологии разбавления – сводка
. внимательный опрос », IEEE Trans. Pattern Anal. Мах. Intell., Т. 14, вып. 9,
pp. 869–885, сентябрь 1992 г., DOI: 10.1109 / 34.161346.
[30] К. Лю, Ю. С. Хуанг и К. Ю. Суен, «Идентификация точек развилки на
скелетах рукописных китайских иероглифов», IEEE Trans. Выкройка
Анал. Мах. Intell., Т. 21, нет. 10. С. 1095–1100, октябрь 1999 г., DOI:
10.1109 / 34.799914.
[31] К. В. Ляо и Дж. С. Хуанг, «Сегментация штрихов по кривой Бернштейна-Безье
подгонки», Pattern Recognit., Vol. 23, нет. 5, pp. 475–484, May 1990,
DOI: 10.1016 / 0031-3203 (90)
-v.
[32] Л. Ф. О. Чамон и А. Рибейро, «Жадная выборка графических сигналов»,
IEEE Trans. Сигнальный процесс., Т. 66, нет. 1. С. 34–47, сентябрь 2018 г., DOI:
10.1109 / tsp.2017.2755586.
[33] Ф. Инь, К. Ф. Ван, Х. Ю. Чжан и К. Л. Лю, «Конкурс распознавания рукописного текста ICDAR 2013 Chinese
», в Proc. ICDAR 2013, Вашингтон,
, округ Колумбия, США, 2013 г., стр. 1464–1470, DOI: 10.1109 / icdar.2013.218.
[34] X. Y. Zhang, Y. Bengio и C.Л. Лю, «Онлайн и офлайн –
распознавание письменных китайских иероглифов: всестороннее исследование и новый тест
», Pattern Recognit., Vol. 61, стр. 348–360, январь 2017 г., DOI:
10.1016 / j.patcog.2016.08.005.
[35] Х. Рен, В. Ван и К. Лю, «Распознавание онлайн рукописных китайских символов
с использованием RNN с новыми вычислительными архитектурами», Pattern Recog-
nit., Vol. 93, стр. 179–192, сентябрь 2019 г., DOI: 10.1016 / j.patcog.2019.04.015.
[36] X.Цюй, В. Ван, К. Лу и Дж. Чжоу, «Распознавание рукописных китайских иероглифов
в воздухе с разреженным представлением с учетом местности для оптимизированного классификатора прототипа
», Pattern Recognit., Vol. 78, стр. 267–276, июн 2018 г.,
DOI: 10.1016 / j.patcog.2018.01.021.
14 ТОМ 4, 2016
Копирование текста с изображений и распечаток файлов с помощью OCR в OneNote
OneNote поддерживает оптическое распознавание символов (OCR), инструмент, который позволяет копировать текст с изображения или распечатки файла и вставлять его в заметки чтобы вы могли вносить изменения в слова.Это отличный способ делать такие вещи, как копирование информации с отсканированной визитки в OneNote. После извлечения текста вы можете вставить его в другое место в OneNote или в другую программу, например Outlook или Word.
Извлечь текст из одного изображения
Щелкните изображение правой кнопкой мыши и выберите Копировать текст с изображения .
Примечание: В зависимости от сложности, разборчивости и количества текста, отображаемого на вставленном вами рисунке, эта команда может быть недоступна сразу в меню, которое появляется при щелчке правой кнопкой мыши на изображении.Если OneNote все еще читает и преобразует текст на изображении, подождите несколько секунд и повторите попытку.
Щелкните место, куда вы хотите вставить скопированный текст, а затем нажмите Ctrl + V.
Извлечение текста из изображений распечатанного многостраничного файла
Щелкните правой кнопкой мыши любое изображение и выполните одно из следующих действий:
Нажмите Копировать текст с этой страницы распечатки , чтобы скопировать текст только с текущего выбранного изображения (страницы).
Нажмите Копировать текст со всех страниц распечатки , чтобы скопировать текст со всех изображений (страниц).
Щелкните место, куда вы хотите вставить скопированный текст, а затем нажмите Ctrl + V.
Примечание: Эффективность оптического распознавания символов зависит от качества изображения, с которым вы работаете.После вставки текста с изображения или распечатки файла рекомендуется просмотреть его и убедиться, что текст распознан правильно.
Отделение китайских иероглифов от зашумленного фона с помощью GAN
Отделение напечатанных или рукописных символов от зашумленного фона полезно для многих приложений, включая автоматическое выставление оценок на тестовой бумаге. Сложная структура китайских иероглифов затрудняет достижение цели из-за легкой потери мелких деталей и общей структуры восстановленных иероглифов.В этой статье предлагается метод разделения китайских иероглифов на основе генеративной состязательной сети (GAN). Мы использовали ESRGAN в качестве базовой сетевой структуры и применили расширенную свертку и новую функцию потерь, которые улучшают качество реконструированных символов. Были протестированы четыре популярных китайских шрифта (Hei, Song, Kai и Imitation Song) при сборе реальных данных, а предложенный дизайн сравнивался с другими подходами семантической сегментации. Результаты экспериментов показали, что предложенный метод эффективно отделяет китайские иероглифы от шумного фона.В частности, наши методы достигают лучших результатов с точки зрения точности пересечения по объединению (IoU) и оптического распознавания символов (OCR).
1. Введение
Преобразование бумажных документов в электронные, а затем их распознавание с помощью технологии оптического распознавания символов (OCR) широко используется в повседневной жизни. В последние годы с развитием технологии машинного обучения точность распознавания OCR значительно повысилась [1–3]. Теперь мы можем обрабатывать документ как с машинно-напечатанным, так и с рукописным текстом, а затем распознавать их по отдельности [4, 5].Подобные приложения можно найти в архивировании и обработке исторических документов [6, 7]. В сфере образования появились соответствующие технологии автоматической оценки экзаменационных работ, которые значительно снижают нагрузку на учителей и студентов. Взяв в качестве примера рисунок 1, экзаменационная работа с ответами учащихся может быть сначала обработана с помощью OCR, а затем распознанные ответы могут быть автоматически оценены и выставлены машиной. При определенных обстоятельствах, поскольку получить шаблон тестовой бумаги нелегко, также необходимо напрямую идентифицировать напечатанный шаблон тестовой бумаги.
Чтобы добиться автоматической оценки экзаменационных работ, одной из технических проблем, которые необходимо решить, является обработка перекрывающихся символов. Это может произойти, если ученик начальной школы не научился хорошо писать или не поставил аннотацию на контрольную работу. Текущая технология OCR не может обрабатывать смешанную ситуацию напечатанного текста и рукописного текста на одном и том же изображении. Как правило, с помощью технологии распознавания текста распознается только один тип текста [8]. Наши ранние эксперименты показали, что при распознавании печатного текста точность OCR значительно снижалась, если вокруг печатного текста были рукописные штрихи или рукописные символы.Еще хуже было то, что машина не могла найти текстовую область, которую необходимо было распознать. Поэтому желательно отделить рукописные символы от напечатанных на экзаменационной бумаге и затем соответствующим образом обработать различные типы текста. Кроме того, для китайских иероглифов разделение рукописного ввода и печати становится более трудным, поскольку структура шрифта намного сложнее, чем у западных шрифтов [9, 10]. Небольшая потеря или увеличение количества штрихов может полностью изменить значение символов, что затрудняет эффективное разделение, когда рукописные шрифты и печатные шрифты сильно перекрываются.
Отделение китайских иероглифов от шумного фона (особенно с перекрытиями) можно рассматривать как проблему семантической сегментации изображения. Предыдущие методы глубокого обучения [11–13] показали успех в других приложениях. Однако эти методы имеют низкую производительность из-за сложной структуры китайских иероглифов. Чтобы отличить китайские иероглифы от похожих шрифтов, мы использовали подход на основе GAN [14–19]. Сеть под названием DESRGAN была разработана для шумоподавления фона и восстановления структуры штрихов и мелких деталей целевых китайских иероглифов.Наш метод использовал ESRGAN [19] в качестве базовой сетевой структуры и применял расширенную свертку к остаточным в-остаточным плотным блокам. Была введена новая функция потерь, которая может измерять целостность каркаса шрифта. Затем генератор обученной модели GAN использовался для разделения целевых персонажей.
Наш основной вклад включает следующее: (a) мы предложили новую сетевую структуру и функцию потерь, которая достигает цели отделения китайских иероглифов от шумного фона, особенно когда символы сильно перекрываются; (b) предложенный метод показал наилучшие результаты как по точности IoU, так и по распознаванию текста; и (c) предоставляется наш набор данных (по запросу) для дальнейшего исследования.
2. Сопутствующие работы
Многие приложения для обработки документов нуждаются в решении проблемы разделения рукописного и напечатанного текста. В рамках проекта Maurdor был создан реалистичный корпус аннотированных документов на французском, английском и арабском языках для поддержки эффективной разработки и оценки метода извлечения [20]. DeepErase [21] использует нейронные сети для стирания артефактов рукописного ввода на отсканированных документах и извлекает только текст, написанный пользователем. Артефакты рукописного ввода, на которые нацелена DeepErase, в основном включают табличную структуру, поля для заполнения пустых полей и подчеркивания.Гуо и Ма [22] использовали алгоритм распознавания аннотаций, напечатанный машиной и написанный вручную, основанный на скрытой марковской модели. Ориентируясь исключительно на английский и другие латинские языки, их алгоритм может определять положение рукописной части в документе в виде ограничивающей рамки. Загорис и др. [23] предложили метод распознавания и отделения рукописного содержимого от изображений документа, смешанных с рукописными и напечатанными символами, с помощью пакета визуальной модели слова. Их метод сначала вычисляет дескриптор для каждого интересующего блока, а затем классифицирует дескриптор на рукописный текст, машинно-напечатанный текст или шум.Однако мало исследований было сосредоточено на сильно перекрывающихся текстах, особенно на китайских иероглифах, которые структурно более сложны, чем английский или другие латинские языки.
Последние методы глубокого обучения предоставляют новые способы решения проблемы разделения рукописного ввода и печати. Ли и др. [5] обрабатывает разделение печатного / рукописного текста в единой структуре с помощью условных случайных полей. Их алгоритм выполняет извлечение только на уровне связных компонентов (CC). Каждая копия подразделяется на печатную и рукописную, независимо от того, перекрываются они или нет.U-Net [11], который хорошо справляется со многими задачами сегментации, основан только на сверточных слоях и идее распространения контекстной информации на слои с более высоким разрешением во время повышающей дискретизации. Pix2Pix [17] переводит входное изображение в соответствующее выходное изображение. С парным набором данных для обучения он может выводить четкие и реалистичные изображения. Такие особенности делают его привлекательным для решения нашей проблемы сегрегации персонажей. Однако парный набор обучающих данных может быть нелегко найти в реальных приложениях.CycleGAN [16] – это подход к обучению переводить изображение из исходного домена в целевой без парных примеров. Схема кодирования CycleGAN заключается в том, чтобы скрыть часть информации о входном изображении в низкоамплитудном высокочастотном сигнале, добавленном к выходному изображению [14]. Другой способ решить проблему разделения напечатанного – рассматривать изображение, наложенное от руки и напечатанное, как изображение с низким разрешением, и нейронная сеть определяет, какая часть должна быть улучшена в процессе сверхразрешения одного изображения.SRGAN [18] использует функцию потери восприятия, которая состоит из состязательной потери и потери контента. Основываясь на SRGAN, ESRGAN [19] улучшает структуру сети, вводя остаточный в-остаточном плотном блоке, и вычисляет потери восприятия, используя функции до активации, а не после активации. Эти методы значительно улучшают общее визуальное качество реконструкции. Благодаря своей универсальности методы сверхвысокого разрешения на основе GAN потенциально могут улучшить низкое качество изображений документов, которое связано с низким качеством сканирования и разрешением.Лат и Джавахар [24] сверхразрешают изображения документов с низким разрешением перед их передачей в механизм распознавания текста и значительно повышают точность распознавания тестовых изображений. Однако мы обнаружили, что существующие подходы не могут обеспечить удовлетворительных результатов сегрегации.
Кроме того, ведутся исследования по синтезу почерка. Грейвс [25] использует рекуррентные нейронные сети с долговременной кратковременной памятью для создания очень реалистичного скорописного почерка в самых разных стилях. Его алгоритм использует расширение, которое позволяет сети генерировать последовательности данных, обусловленные некоторой высокоуровневой последовательностью аннотаций (например,g., символьная строка). Lian et al. [10] предлагают систему для автоматического синтеза личного почерка для всех (например, китайских) символов в библиотеке шрифтов. Их работа показала возможность изучения стиля на небольшом количестве (всего 1%) тщательно отобранных образцов, написанных от руки обычным человеком. Хотя рукописные шрифты, создаваемые их моделями, обладают лучшими визуальными эффектами, их поток автономной обработки требует подготовки траектории написания каждого штриха для всех символов, что требует больших усилий вручную.Zhang et al. [9] используют рекуррентную нейронную сеть в качестве генеративной модели для рисования китайских иероглифов. В их рамках используется условная генеративная модель с встраиванием символов для указания RNN идентичности персонажа, который должен быть сгенерирован. Встраивание символов, которое обучается совместно с генеративной моделью, по существу ограничивает модель поиском символов с похожей траекторией письма (или подобной формой) во встроенном пространстве. Chang et al. [26] формулируют создание китайских рукописных символов как проблему изучения стиля.Технически они используют CycleGAN для изучения соответствия существующего печатного шрифта персонализированному рукописному стилю. В нашей работе эти методы использовались для создания набора данных для обучения и оценки предлагаемого DESRGAN.
3. Дизайн
Наш метод, основанный на архитектуре GAN, показан на рисунке 2. Учитывая китайский иероглиф с шумным фоном (например, перекрытие), генерирующая сеть отделяет целевой символ, который может быть напечатан или написан от руки, от входное изображение.Поскольку каждый штрих в китайском иероглифе практически незаменим, особое внимание следует уделять сохранению целостности структуры китайского иероглифа. Мы использовали сетевую структуру, аналогичную ESRGAN [19], в качестве нашей магистральной сети с некоторыми существенными изменениями. Плотная структура соединений сети генераторов ESRGAN напрямую передает штрихи китайских иероглифов и скелетную информацию, извлеченную из промежуточного уровня, на следующий уровень. Предложенная сеть генераторов DESRGAN удалила исходный уровень повышающей дискретизации ESRGAN и дополнительно заменила исходные ядра свертки ядрами расширенной свертки.VGG19 использовался для реализации дискриминатора, который проверяет, является ли изображение, созданное генеративной сетью, настоящим или фальшивым.
В ESRGAN функция потерь представляет собой взвешенную сумму трех компонентов: потери восприятия, которая измеряет расстояние между разделенным изображением и характеристиками наземного истинного изображения до активации в предварительно обученном VGG19, состязательная потеря, основанная на вероятностях релятивистский дискриминатор и потеря контента, который оценивает расстояние в 1 норму между отдельным напечатанным или рукописным изображением символа и основной истиной.
Потеря восприятия определяется как где представляет функции до активации в предварительно обученном VGG19, обозначает чистое напечатанное или рукописное изображение символа и обозначает смешанное изображение рукописных и напечатанных символов.
Состязательный проигрыш для генератора определяется как где, – сигмоидальная функция, – нетрансформированный выходной сигнал дискриминатора и представляет собой операцию взятия среднего значения для всех поддельных данных в мини-пакете.
Потеря восприятия играет важную роль в задачах компьютерного зрения, таких как сверхвысокое разрешение, когда критически важна насыщенность деталей восстановленного изображения.Он разработан для улучшения высокочастотных деталей и предотвращения размытых и неприятных визуальных эффектов. Однако цель, которую мы здесь хотим достичь, – как можно больше отделить печатную часть от перекрывающегося почерка и косвенно улучшить точность распознавания при последующем оптическом распознавании текста. В связи с этим мы считаем, что общая структура символа и целостность штрихов более важны, чем высокочастотные детали для инструментов OCR. Возьмем, к примеру, случай на Рисунке 3: из-за отсутствия штриха в центре восстановленного изображения инструменты OCR выводят символ «九», отличный от правильного «丸».
Таким образом, был исследован новый член потерь на основе градиента, который может измерять целостность каркаса шрифта. Градиенты изображения – это мощные элементы формы, широко используемые в задачах компьютерного зрения. Для данного перекрывающегося изображения, восстановленного изображения и его истинности были вычислены градиенты и, обозначенные как и, соответственно. Вместо того, чтобы полагаться на потери на уровне всего изображения, мы опираемся на идеи гриддинга и max-pooling. Как видно на рисунке 3, вся область изображения разделена на квадратную полосу (или) ячеек, а потеря целостности была определена как наибольшая среднеквадратичная ошибка между каждой ячейкой и, где и – ширина и высота ячейки.С помощью этой стратегии оценивается целостность каждой клетки скелета. При потере целостности будет обнаружена ячейка с серьезным несоответствием между восстановленными штрихами и наземными штрихами.
Таким образом, общие потери генератора равны где, и α – коэффициенты для уравновешивания различных членов потерь.
4. Настройки эксперимента
4.1. Набор данных
В этой работе мы сосредоточимся на методах разделения на уровне персонажей. Для обработки документа некоторые существующие связанные технологии, такие как анализ макета [27–29] и анализ связанных компонентов [30], могут помочь определить расположение символов.Поэтому мы предполагаем, что есть некоторые внешние модули, которые могут помочь нам примерно разделить напечатанные символы из полного документа. Для эксперимента был создан набор данных, содержащий только перекрывающиеся печатные и рукописные символы, как описано ниже.
Рукописные изображения символов, используемые для синтеза, взяты из набора данных CASIA HWDB (CASIA Handwritten Database) 1.1 [31], который содержит изображения 3755 широко используемых изображений китайских иероглифов, написанных 300 разными авторами.В частности, мы случайным образом выбрали рукописные изображения от четырех разных авторов (идентификаторы писателя 1003, 1062, 1187 и 1235) для синтеза.
Печатные изображения символов, используемые в синтезе, включают изображения тех же 3755 широко используемых китайских иероглифов, которые перечислены в CASIA HWDB 1.1. Кроме того, в набор данных печатного изображения, который содержит в общей сложности 3769 символов, были добавлены базовые символы (знак плюс, минус, знак равенства и поле ответа) и арабские цифры от 0 до 9. Эти 3769 символов были напечатаны на бумаге формата A4 четырьмя шрифтами (Song, Hei, Kai и Imitation Song).Распечатанная бумага была отсканирована и преобразована в изображение. Затем сканированное изображение было обрезано на уровне символа, чтобы получить отпечатанные изображения для синтеза.
Существующие исследования по разделению на уровне пикселей рукописных и печатных символов немногочисленны. В настоящее время нет общедоступного набора данных перекрывающихся рукописных и печатных символов с аннотациями на уровне пикселей. Поэтому в этой работе используются рукописные изображения персонажей и напечатанные изображения символов для синтеза образцов рукописных символов, наложенных на печатные символы.Как показано на рисунке 4, метод синтеза изображения состоит в том, чтобы вычислить минимальное значение серого цвета пикселей двух изображений в одной и той же позиции и использовать это минимальное значение как значение серого соответствующего пикселя составного изображения.
Выбранные образцы рукописного ввода сопоставляются с напечатанными образцами путем случайного сопоставления. Окончательные результаты сопряжения таковы: напечатанный Hei случайным образом сопрягается с рукописным идентификатором 1003 писателя CASIA HWDB; напечатанная песня случайным образом сочетается с рукописным кодом автора CASIA HWDB ID 1062; напечатанный Кай случайным образом соединен с рукописным кодом писателя CASIA HWDB ID 1187; и напечатанная имитационная песня, случайно соединенная с рукописным кодом автора CASIA HWDB ID 1235.
Исходя из этого, мы имеем в виду набор 708 китайских иероглифов, который содержит различные базовые компоненты китайских иероглифов, предложенный Lian et al. [10] при изучении синтеза рукописных китайских иероглифов [10] (коллекция китайских иероглифов в их работе содержит в общей сложности 775 символов, из которых 67 необычных символов отсутствуют в наборе данных CASIA HWDB). Изображения, содержащие эти 708 китайских иероглифов, также составляют обучающий набор данных на этапе обучения. Мы предполагаем, что модели нужно только изучить особенности этих 708 китайских иероглифов для достижения цели разделения, а не изучать особенности всех 3769 символов.Уменьшение количества символов в обучающем наборе положительно сказывается как на усилиях по сбору данных, так и на стоимости вычислений. Поэтому, как показано на рисунке 5, 708 соответствующих образцов из образцов рукописного ввода и печатных образцов были выбраны для синтеза случайных пар в качестве обучающего набора. Остальные образцы также берутся в качестве тестовой выборки методом случайного парного синтеза. Результирующий обучающий набор содержит 2832 образца (708 образцов для каждого типа шрифта), а тестовый набор содержит 12244 образца. Этот набор данных используется как набор данных, обычно используемый во всех последующих экспериментах.
4.2. Показатели оценки
В качестве показателей оценки использовались как пересечение по Union (IoU), так и точность распознавания текста. Разделение рукописных знаков и печатных знаков можно по существу рассматривать как семантическую сегментацию смешанного изображения рукописных и печатных знаков. Наиболее часто используемая метрика количественной оценки при семантической сегментации изображений – IoU. Таким образом, IoU использовался в качестве одного из показателей количественной оценки для оценки качества разделения рукописного текста и печатных символов.
Поскольку это исследование представляет собой сегментацию на уровне пикселей смешанных рукописных печатных изображений, IoU рассчитывается по количеству пикселей в соответствующей категории (т. Е. Фоновой и напечатанной). Перед вычислением IoU изображение сначала преобразуется в двоичную форму, и черная область после преобразования в двоичную форму считается областью печати, а белая область рассматривается как область фона. В процессе бинаризации алгоритм Оцу сначала используется для вычисления среднего порога бинаризации всех напечатанных образцов в тестовом наборе, и это единое пороговое значение используется для бинаризации всех образцов.В нашем синтезированном наборе данных средний порог бинаризации, рассчитанный алгоритмом Оцу для тестового набора, равен 184. Наконец, мы делим пересечение отделенной печатной части (или фона) и напечатанной части (или фона) в наземной истине на их объединение. .
Одно из приложений, на которое нацелено это исследование, – это автоматическая оценка экзаменационных работ для учащихся начальной и средней школы. Таким образом, основная цель отделения рукописных знаков от печатных в данном исследовании – повысить точность распознавания печатного и рукописного текста и предотвратить ухудшение распознавания печатного текста из-за интерференции рукописных штрихов или символов на изображении. экзаменационная бумага.Таким образом, точность OCR для печатных символов используется в качестве еще одного показателя количественной оценки для разделения рукописных и печатных символов.
Инструмент OCR, используемый для расчета точности OCR, – это Chinese_OCR [32], исходный код которого открыт на Github. Эта модель распознает китайские иероглифы с высокой скоростью и точностью. Это очень удобно для оценки точности распознавания отдельных печатных образцов. При вычислении точности OCR, поскольку Chinese_OCR не может обнаружить текст изображения с одним символом, нам пришлось сначала горизонтально объединить каждые 25 образцов в длинное изображение для OCR.Затем было подсчитано правильное количество символов и идентифицировано в соответствии с порядком символов на длинном изображении.
4.3. Model Training
Эксперимент проводился на ПК с процессором Intel Xeon E5-2603 v3 @ 1,600 ГГц, графическим процессором NVIDIA Tesla P40 24 ГБ и 64 ГБ памяти. На ПК установлена операционная система CentOS 7, а используемая среда глубокого обучения – PyTorch 1.2.0.
Чтобы проверить эффективность модели DESRGAN, для сравнения были выбраны U-Net, Pix2pix и CycleGAN, которые обычно используются в семантической сегментации изображений.Обе модели Pix2pix и CycleGAN были обучены в течение 200 эпох с размером пакета, установленным равным 1. Скорость обучения первых 100 эпох оставалась на уровне 0,0002, а скорость обучения последних 100 эпох линейно снижалась до 0. U-Net был обучен для 200 эпох с размером пакета, установленным на 100. Скорость обучения изначально составляла 0,01, а затем снижалась до десятой части своего значения через каждые 50 эпох.
Заодно мы сравнили с ESRGAN, чтобы убедиться в эффективности предложенной модификации ESRGAN.И ESRGAN, и DESRGAN сначала использовали потерю L1 для обучения своих генераторов в течение 2500 эпох отдельно с размером пакета, установленным на 16. Начальная скорость обучения составляла 0,0002, а затем уменьшалась вдвое после каждых 200000 итераций. Затем, в сочетании с сетью дискриминатора, метод обучения GAN используется для обучения 2500 эпох с размером пакета, установленным равным 16. Начальная скорость обучения составляла 0,00001 и уменьшалась вдвое после 50 000, 100 000, 200 000 и 300 000-го. итераций. На протяжении всей нашей работы коэффициент состязательного проигрыша и коэффициент потери контента устанавливаются равными 0.005 и 0,01 соответственно.
5. Результаты и обсуждение
5.1. Визуальные эффекты результатов разделения
Мы проверили несколько методов глубокого обучения, включая предложенный DESRGAN, и визуально сравнили результаты разделения китайских иероглифов в тестовой выборке. Чтобы понять эффективность отделения напечатанных китайских иероглифов от шумного фона, мы синтезировали рукописные / напечатанные образцы данных с наложением и протестировали пять методов (например, CycleGAN, Pix2pix, U-Net, ESRGAN и DESRGAN).На рисунках 6–9 показаны результаты этих пяти методов вместе с основной истиной разделения. Чтобы лучше понять влияние небольшой потери или увеличения штрихов на результат разделения, результаты распознавания инструмента OCR были дополнительно помещены рядом с результатами разделения.
Были протестированы четыре популярных типа печатных китайских шрифтов: Hei, Kai, Song и Imitation Song. Для всех протестированных типов шрифтов ESRGAN и DESRGAN дали наиболее визуально приятные результаты.Как показано на рисунках 6–9, другие методы не могут полностью исключить рукописные штрихи в результате разделения. Однако не все шрифты одинаковы, и некоторые из них (например, шрифт Song и шрифт Imitation Song) содержат гораздо более тонкие штрихи. В результате ESRGAN не смог восстановить некоторые кажущиеся тривиальными штрихи или удалить артефакты, которые труднее отличить от наложенного почерка. Чем сложнее структура китайских иероглифов или чем выше вероятность появления подобных структур, тем легче инструментам распознавания текста предсказать кажущиеся верными, но по существу неверные результаты.Только DESRGAN дал результаты разделения, которые дали наиболее успешные предсказания OCR (см. Рисунки S1-S4 в дополнительном материале для получения дополнительных результатов разделения печатных символов).
Поскольку DESRGAN может эффективно отделить напечатанную часть от перекрывающегося изображения, следующий вопрос заключается в том, способна ли она разделять рукописную часть. По сути, эта задача сложнее, потому что почерк у разных людей разный. В этом тесте сравнивались только ESRGAN и DESRGAN, потому что остальные три метода дают плохие результаты.Мы не сообщали о результатах распознавания, потому что не было найдено подходящего инструмента OCR для распознавания рукописного ввода. На рисунках 10–13 показан визуальный эффект отделения рукописных частей от наложенных напечатанных символов четырьмя разными типами шрифтов. Наилучший эффект разделения был получен при использовании шрифта Imitation Song (Рисунок 10) и шрифта Song (Рисунок 11), тогда как шрифт Hei дал худший эффект (Рисунок 13). Мы предположили, что это связано с тем, что штрихи напечатанных символов в шрифте Hei более толстые, а цвета более темные, что больше мешает рукописным символам.Тем не менее, DESRGAN произвел меньше артефактов и реконструировал лучшую структуру символов, чем ESRGAN (см. Рисунки S5-S8 в Дополнительных материалах для большего количества результатов разделения рукописного ввода).
5.2. Количественный анализ
Как показано в таблице 1, IoU результатов разделения напечатанных символов подтвердили предыдущее сравнение визуальных эффектов. И ESRGAN, и DESRGAN достигли лучших результатов, чем другие методы глубокого обучения, и DESRGAN имеет небольшое преимущество перед ESRGAN.Следует отметить, что с помощью визуального анализа DESRGAN лучше восстанавливает важные детали, которые составляют лишь небольшую часть от общего числа пикселей.
Чтобы изучить влияние предложенной функции потерь, мы провели эксперименты при трех различных настройках (т.е.,, и). Таблица 2 показывает, что предложенная функция потерь практически не повлияла на IoU.Это соответствует нашим ожиданиям, потому что основная цель новой функции потерь – улучшить общую структуру персонажей.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||