
Сравнение использования PyTesseract и PDF модулей и библиотек для распознавания сканов pdf — Разработка на vc.ru
Что делать если вы столкнулись с некачественным сканом?
3920 просмотров
PyTesseract — это пакет python для разработки OCR
OCR или же Оптическое распознавание символов (англ. Optical Character Recognition – OCR) – это технология, которая позволяет преобразовывать различные типы документов, такие как отсканированные документы, PDF-файлы или фото с цифровой камеры, в редактируемые форматы с возможностью поиска.
Так же, для задачи распознавания PDF-сканов подходят модули и библиотеки PDF для Python. Таких библиотек большое множество, для примера рассмотрим PyMuPDF.
PyTesseract
Первым делом, как и всегда, импортируем все необходимые библиотеки и так же указываем путь к cmd PyTesseract:
- Cv2(OpenCV) – тоже библиотека компьютерного зрения и машинного обучения, будем применять её для перевода в градации серого и в чёрно-белое изображение,
- pdf2image – библиотека для конвертации pdf в формат изображения.


import cv2 import pytesseract from pdf2image import convert_from_path
pages = convert_from_path(‘Zajavlenie_na_zagranpasport_obrazec.pdf’, 100) pages[0].save(‘out.jpg’, ‘JPEG’)
Следующим шагом конвертируем PDF в JPG. Обращаемся к нулевому элементу, т.к. в нашем документе несколько страниц, а нам не нужны все.
Далее с помощью библиотеки cv2 считываем получившееся изображение и переводим в другую цветовую градацию. С помощью PyTesseract в команде print преобразуем картинку в текст и выводим в консоль.
imgcv=cv2.imread(‘out.jpg’) imgcv=cv2.cvtColor(imgcv, cv2.COLOR_BGR2RGB) print(pytesseract.image_to_string(imgcv, lang=’rus’))
Для примера мы брали скан образца заполнения загран. паспорта.
PyMuPDF
Эта библиотека известна своей высокой производительностью и высоким качеством рендеринга. Отлично подходит для перевода больших PDF документов, как, например, в нашем случае — PDF учебника.
Так же импортируем библиотеки, но в этом примере нам потребуется только одна – PyMuPDF, импортируется как fitz.
import fitz
Теперь открываем сам PDF файл и в цикле по его страницам получаем и выводим текст.
file=fitz.open(‘Bakulin_A_Gravitaciya_I_Yefir.a6.pdf’) for pageNum, page in enumerate(file.pages(), start = 1): text= page.getText() print(text)
Текст распознан, сохранены абзацы, учебник размером в 400 страниц был преобразован в текст за 2 секунды.
Итог
PyTesseract мощный инструмент компьютерного зрения, может распознавать текст с изображений многих форматов (например, текст на дорожном знаке). Имеет возможность изменения параметров, что может повысить точность распознавания.
PyMuPDF отличная библиотека для преобразования

В заключении, можно сказать, что если в вашей задаче качественные экземпляры сканов, то не стоит сразу пытаться усложнять и использовать компьютерное зрение, а стоит попробовать модули и библиотеки предназначенные для распознавания PDF. Если же вы столкнулись с некачественным сканом, можно использовать компьютерное зрение и пробовать менять различные параметры.
Параметры преобразования документов PDF с возможностью поиска
Параметры преобразования документов PDF с возможностью поискаЭто диалоговое окно отображается в указанных ниже ситуациях.
- В диалоговом окне Профили PDF Create установите флажок С возможностью поиска и нажмите кнопку Параметры.
- Нажмите Преобразовать > Другие > PDF с возможностью поиска, затем выберите Параметры в диалоговом окне Преобразование страниц.
- Проверьте параметры распознавания текста в разделе Файл > Параметры > Документ > Документ PDF с возможностью поиска.

Эти параметры следует использовать для создания из файлов изображений или PDF-файлов, содержащих только изображения, поиск в которых невозможен. Список поддерживаемых типов файлов см. в разделе Create Assistant.
Язык распознаваемого текста
извлекает текст из изображений, чтобы обеспечить возможность поиска в нем. Выберите язык, который используется в исходном документе.
Нераспознанные символы
Нераспознанные символы представляются в виде специального символа дефекта (по умолчанию это тильда: «~»). Например, если при оптическом распознавании не удалось распознать букву «з» в слове «распознать» и в качестве символа дефекта используется символ ~, в распознанном документе будет написано «распо~нать».
Символ дефекта можно задать в поле «Нераспознанные символы». По возможности используйте символ, не встречающийся в документах.
Сохранить исходные изображения
Если установить этот флажок, исходное изображение будет сохранено после преобразования.
Автоориентация страницы
Если установить этот флажок, ориентация страницы (альбомная или портретная) будет выбираться автоматически.
Обработать страницы
Укажите, какие страницы нужно обрабатывать при преобразовании PDF-документа в формат PDF с возможностью поиска.
- Страницы, содержащие только рисунки По умолчанию Power PDF обрабатывает только страницы с графическим (растровым) содержимым, не имеющие текстового слоя.
- Все страницы Если выбран этот вариант, обрабатываются все страницы независимо от их содержимого.
-
- Использовать систему распознавания текста при обработке документов Этот флажок предписывает обрабатывать документы только с помощью системы распознавания текста. Внутри приложения все страницы будут преобразованы в растровые изображения, а затем обработаны системой распознавания текста. При этом отбрасываются все невизуальные и нестандартные элементы (например, скрытые объекты и знаки с нестандартными кодами).

- Распознавать нестандартные кодировки текста Установите этот флажок для обработки страниц, содержащих текст с нестандартными шрифтами или кодировками.
- Использовать систему распознавания текста при обработке документов Этот флажок предписывает обрабатывать документы только с помощью системы распознавания текста. Внутри приложения все страницы будут преобразованы в растровые изображения, а затем обработаны системой распознавания текста. При этом отбрасываются все невизуальные и нестандартные элементы (например, скрытые объекты и знаки с нестандартными кодами).
Автоматически проверять результат после распознавания
(Доступно только в Power PDF.)
Установите этот флажок для интерактивной проверки орфографии в обработанном документе. Чтобы добавить или создать собственные словари, нажмите кнопку Пользовательские словари.
Автоматически искать страницы только с изображениями (требуется перезапуск)
(Доступно только в Power PDF.)
Если установлен этот флажок, программа Power PDF проверяет каждый PDF-документ при его открытии, и если в документе есть страницы, содержащие только изображения, она предлагает преобразовать его в формат PDF с возможностью поиска.
Выводить сообщения на панели уведомлений
(Этот параметр доступен только в Power PDF и включается только при выборе вышеуказанного флажка.)
Выберите Выводить сообщения на панели уведомлений, чтобы программа Power PDF выводила информацию о страницах, содержащих только изображения, на панели уведомлений под лентой. Нажмите Сделать доступным для поиска, чтобы открыть диалоговое окно «Автоматическое определение» и выбрать настройки распознавания, которые будут применяться к таким страницам.
Снимите флажок Выводить сообщения на панели уведомлений
Примечание
Если входной файл является текстовым или содержит доступный текстовый слой, обычный PDF-документ с возможностью поиска создается без оптического распознавания.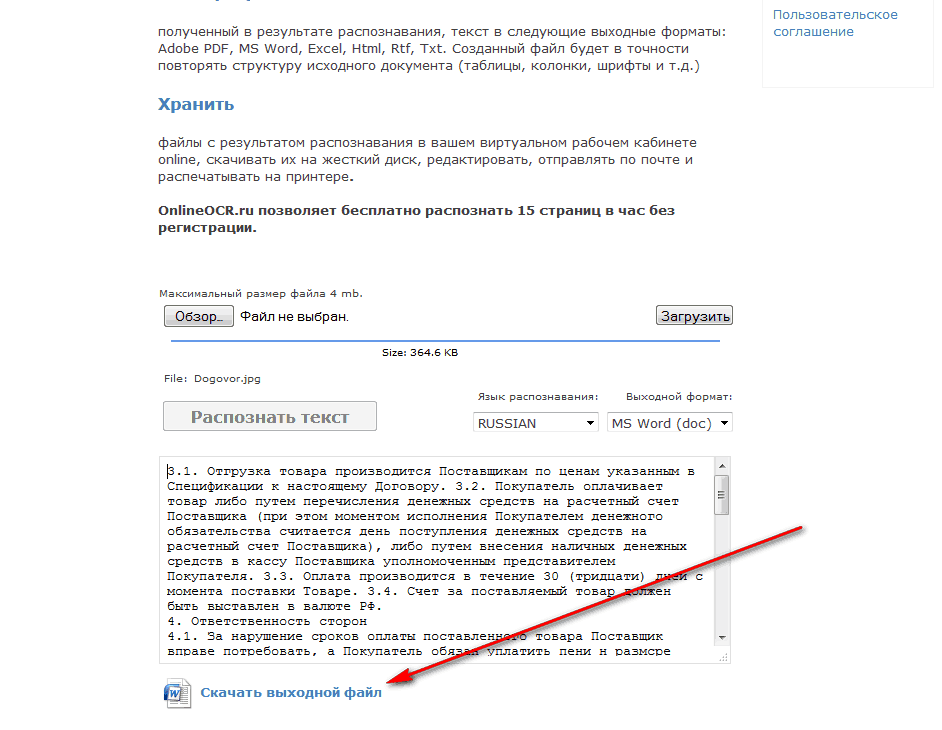 В таких случаях параметры «Язык распознаваемого текста» и «Нераспознанные символы» не используются.
В таких случаях параметры «Язык распознаваемого текста» и «Нераспознанные символы» не используются.
4 лучших способа: как распознавать текст в PDF
Возможность выбирать, копировать, вставлять и искать текст в PDF — это, в первую очередь, одна из самых полезных функций PDF-документов.
Поэтому наличие PDF-файла, в котором вы не можете распознать текст, может вызывать разочарование и отнимать много времени. Особенно, если единственная альтернатива — переписать весь текст.
Распознавание текста в PDF-файлах — это то, что позволяет нам редактировать, искать, выделять и взаимодействовать с текстом в PDF-документе.
В некоторых PDF-файлах уже есть распознаваемый текст, а в других нет.
Если в вашем PDF нет, то это руководство для вас!
Мы собрали самые надежные, самые популярные и самые бесплатные способы распознавания текста в PDF-файлах, чтобы вы могли сделать с ними больше.
Читайте дальше, чтобы продолжить, или воспользуйтесь нашим Оглавлением и перейдите прямо к нужному разделу!
Что нужно знать перед началом работы
- Некоторые PDF-файлы основаны на тексте (имеют редактируемый и доступный для поиска текст), а другие PDF-файлы основаны на изображениях (которые представляют собой просто изображения документа, а не фактический текст).

- Для распознавания текста в PDF-файлах вам понадобится технология оптического распознавания символов (OCR), которая превращает PDF-файлы на основе изображений в текст, который вы можете редактировать.
- Лучший способ распознать текст в PDF — использовать PDF-редактор с OCR, который мгновенно выполняет OCR и редактирует PDF-файлы всего за несколько кликов.
Что означает распознавание текста в PDF?
Проще говоря, существует два типа PDF-файлов:
1. Текстовые PDF-файлы
2. PDF-файлы на основе изображений
PDF-файлы на основе изображений — это PDF-файлы, созданные из изображений или изображений. Хотя они могут отображать текст в документе, по сути это изображение, и вы не сможете редактировать, искать или взаимодействовать с каким-либо текстом в PDF.
С другой стороны, текстовые PDF-файлы — это документы, которые изначально содержали текст, а затем были преобразованы в формат PDF. Примеры этого включают документы Word, которые экспортируются в PDF. Поскольку текстовые PDF-файлы содержат фактический текст, редактор PDF сможет взаимодействовать с текстом внутри документа.
Примеры этого включают документы Word, которые экспортируются в PDF. Поскольку текстовые PDF-файлы содержат фактический текст, редактор PDF сможет взаимодействовать с текстом внутри документа.
Если вы пытаетесь редактировать или искать текст в PDF-документе, PDF-файл должен быть текстовым или преобразованным в него.
Как определить, является ли мой PDF-файл текстовым или графическим?
Самый простой способ это определить — попытаться выбрать или выделить текст с помощью мыши. Если вы не можете выделить какой-либо текст, это означает, что ваш PDF-файл основан на изображениях.
Как распознавать текст в PDF с помощью редактора PDF (рекомендуется)
Самый надежный способ распознавания текста в PDF — использование редактора PDF с функцией OCR. OCR мгновенно преобразует текст из изображений и PDF-файлов на основе изображений в реальный текст, который вы можете редактировать, искать и взаимодействовать с ним.
Мы рекомендуем PDF-редактор PDF Pro + OCR: наш универсальный PDF-редактор, создатель, конвертер, слияние и инструмент OCR. Нам это нравится, потому что оно простое в использовании, доступное, но мощное. Но эти шаги будут аналогичны выбранному вами редактору PDF.
Нам это нравится, потому что оно простое в использовании, доступное, но мощное. Но эти шаги будут аналогичны выбранному вами редактору PDF.
У вас нет редактора PDF? Скачайте PDF Pro бесплатно уже сегодня!
1. Откройте PDF в PDF Pro.
2. Щелкните вкладку OCR > Текущий файл .
3. Выберите Редактируемый текст или Доступный для поиска текст (в зависимости от ваших потребностей), затем нажмите Выполнить .
Вот оно! Это так же просто, как 1, 2, 3!
Ваш PDF-файл теперь содержит текст, с которым вы можете взаимодействовать, редактировать, искать и выполнять другие действия.
Как распознавать текст в PDF с помощью Adobe Acrobat
Обратите внимание, что этот метод работает только с Adobe Acrobat (программное обеспечение для редактирования PDF от Adobe). Это не будет работать с Adobe Reader, который является просто программой Adobe для открытия и просмотра PDF-файлов.
Для использования Adobe Acrobat требуется подписка, и он часто немного убивает из-за слишком большого количества кнопок, всплывающих окон и некоторой кривой обучения.
- Откройте PDF-файл в Adobe Acrobat.
- Инструменты.
- Распознать текст.
- В этом файле.
- ОК.
Как распознать текст в формате PDF в Microsoft Word
Если у вас есть доступ к Microsoft Word, вы можете использовать его для распознавания текста в документе PDF. Обратите внимание, что этот метод не идеален, так как OCR не является основной работой Word. Этот метод подвержен проблемам с пробелами и форматированием, поэтому он лучше работает с PDF-файлами, в которых мало изображений. Но этот метод может быть полезен в крайнем случае.
Вместо того, чтобы преобразовывать ваш PDF-файл в один с распознаванием текста, этот метод приведет к созданию совершенно нового PDF-файла с распознаваемым текстом внутри него.
1. Запустите Microsoft Word.
2. Нажмите Открыть > Просмотреть .
3. Найти и Открыть PDF-файл.
4. Нажмите Ок .
5. Нажмите Файл > Экспорт > Создать файл PDF/XPS .
6. Назовите и опубликуйте новый PDF-документ.
Теперь у вас есть новый PDF-документ с распознаваемым текстом!
Как распознать текст в PDF в Документах Google (бесплатно)
Документы Google, как и Word, можно использовать в крайнем случае для распознавания текста в документах PDF. Этот метод Google Docs имеет многие из тех же недостатков, что и метод Word, например, он подвержен проблемам с форматированием и пробелами и лучше работает с PDF-файлами без большого количества (или каких-либо) изображений.
Как и метод Word, этот метод приведет к созданию нового PDF-файла с распознаваемым текстом.
- Загрузите PDF-файл на Google Диск.
- Откройте PDF-файл в Документах Google. (Дважды щелкните PDF > Открыть с помощью Google Docs).
- Нажмите Файл > Загрузить > Как PDF (.pdf) .
Теперь у вас есть PDF-документ с распознаваемым текстом!
OCR Распознавание текста в любом PDF!
Если вам срочно нужен бесплатный способ распознавания текста в PDF, мы показали вам, как это сделать в Google Docs или Microsoft Word!
Эти методы не идеальны и часто возникают при проблемах с пробелами и форматированием. Особенно с файлами PDF, которые содержат много изображений.
Если для вас важна надежность, вы захотите инвестировать в редактор PDF со встроенной технологией OCR. Таким образом, вы можете мгновенно распознавать и взаимодействовать с любым PDF-файлом всего за несколько кликов!
Когда дело доходит до редакторов PDF, мы рекомендуем PDF Pro: наш универсальный редактор PDF, создатель, конвертер, слияние и инструмент OCR.
PDF Pro — это наша доступная и серьезная альтернатива Adobe.
Что значит “без шуток”?
Это означает, что PDF Pro был создан простым и удобным в использовании, но без ущерба для мощности или качества. Никаких бесконечных всплывающих окон, запутанных кнопок и крутых кривых обучения! Просто откройте PDF-файл и приступайте к работе.
PDF Pro поможет вам:
- Редактирование отсканированного документа
- Удаление подписи из PDF
- Изменение размера изображения PDF
- Преобразование PDF в PDF/A
- Отправка фотографии в формате PDF
- Защита PDF паролем в Windows 10
У вас нет редактора PDF? Загрузите PDF Pro бесплатно сегодня или купите сейчас!
Распознать текст в PDF на планшете онлайн
Распознать текст в PDF на планшете онлайн | докхабформы заполнены
формы подписаны
формы отправлены
01. Загрузите документ со своего компьютера или из облачного хранилища.
Загрузите документ со своего компьютера или из облачного хранилища.
02. Добавляйте текст, изображения, рисунки, фигуры и многое другое.
03. Подпишите документ онлайн в несколько кликов.
04. Отправка, экспорт, факс, загрузка или распечатка документа.
Пошаговое руководство по распознаванию текста в PDF на планшете
Эффективный документооборот давно перешел с аналогового на цифровой. Для перехода на следующий уровень эффективности требуется только легкий доступ к функциям изменения, которые не зависят от того, какое устройство или интернет-браузер вы используете. Если вам нужно распознать текст в PDF на планшете, вы можете сделать это так же быстро, как и на любом другом устройстве, которое есть у вас или членов вашей команды. Легко изменять и создавать документы, пока вы подключаете свое устройство к Интернету. Простой набор инструментов и интуитивно понятный интерфейс — все это неотъемлемая часть работы с DocHub.
DocHub — это мощное решение для создания, изменения и обмена PDF-файлами или любыми другими документами, а также для улучшения процессов работы с документами. Вы можете использовать его для распознавания текста в PDF на планшете, так как вам нужно только подключение к Интернету. Мы адаптировали его для работы с любыми системами, которые люди используют для работы, поэтому проблемы совместимости исчезают, когда дело доходит до редактирования PDF. Просто придерживайтесь этих простых шагов, чтобы сразу распознать текст в PDF на планшете.
- Откройте веб-браузер на своем устройстве.
- Откройте сайт DocHub и выберите Войти, если у вас уже есть профиль. Если вы этого не сделаете, перейдите к регистрации профиля, которая займет всего несколько минут, а затем введите свой адрес электронной почты, придумайте пароль или используйте свою учетную запись электронной почты для регистрации.
- Как только вы увидите панель инструментов, загрузите файл для редактирования.
 Вы можете выбрать его на своем устройстве или использовать ссылку на его местоположение в облачном хранилище.
Вы можете выбрать его на своем устройстве или использовать ссылку на его местоположение в облачном хранилище. - В режиме редактирования внесите все изменения и распознайте текст в PDF на планшете.
- Сохраните изменения в документе и загрузите его на свое устройство или сохраните в своей учетной записи DocHub для будущих изменений.
Совместимость нашего качественного программного обеспечения для редактирования PDF не зависит от того, какое устройство вы используете. Попробуйте наш универсальный редактор DocHub; вам никогда не придется беспокоиться о том, будет ли он работать на вашем устройстве. Ускорьте процесс редактирования, просто зарегистрировав учетную запись.
Упрощенное редактирование PDF с помощью DocHub
Удобное редактирование PDF
Редактировать PDF так же просто, как работать в документе Word. Вы можете добавлять текст, рисунки, выделения, а также редактировать или комментировать документ, не влияя на его качество. Нет растеризованного текста или удаленных полей. Используйте онлайн-редактор PDF, чтобы получить идеальный документ за считанные минуты.
Нет растеризованного текста или удаленных полей. Используйте онлайн-редактор PDF, чтобы получить идеальный документ за считанные минуты.
Слаженная работа в команде
Совместная работа над документами с вашей командой с помощью настольного компьютера или мобильного устройства. Позвольте другим просматривать, редактировать, комментировать и подписывать ваши документы в Интернете. Вы также можете сделать свою форму общедоступной и поделиться ее URL-адресом где угодно.
Автоматическое сохранение
Каждое изменение, которое вы вносите в документ, автоматически сохраняется в облаке и синхронизируется на всех устройствах в режиме реального времени. Не нужно отправлять новые версии документа или беспокоиться о потере информации.
Интеграция с Google
DocHub интегрируется с Google Workspace, поэтому вы можете импортировать, редактировать и подписывать документы прямо из Gmail, Google Диска и Dropbox. По завершении экспортируйте документы на Google Диск или импортируйте адресную книгу Google и поделитесь документом со своими контактами.
Мощные инструменты для работы с PDF на вашем мобильном устройстве
Продолжайте работать, даже если вы находитесь вдали от компьютера. DocHub работает на мобильных устройствах так же легко, как и на компьютере. Редактируйте, комментируйте и подписывайте документы, удобно используя свой смартфон или планшет. Нет необходимости устанавливать приложение.
Безопасный обмен документами и их хранение
Мгновенно обменивайтесь документами, отправляйте их по электронной почте и факсу безопасным и совместимым способом. Установите пароль, поместите свои документы в зашифрованные папки и включите аутентификацию получателя, чтобы контролировать доступ к вашим документам. После завершения сохраните свои документы в безопасности в облаке.
Отзывы DocHub
44 отзыва
Отзывы DocHub
23 оценки
15 005
10 000 000+
303
100 000+ пользователей
Повышение эффективности с надстройкой DocHub для Google Workspace
Получайте доступ к документам, редактируйте, подписывайте их и делитесь ими прямо из ваших любимых приложений Google Apps.
Установить сейчас
Как распознать текст в PDF на планшете
5 из 5
36 голосов
[Музыка] [Музыка] [Аплодисменты] [Музыка] [Музыка] [Музыка] [Музыка] вы
Связанные функции
Есть вопросы?
Ниже приведены некоторые распространенные вопросы наших клиентов, которые могут дать вам ответ, который вы ищете. Если вы не можете найти ответ на свой вопрос, пожалуйста, не стесняйтесь обращаться к нам.
Свяжитесь с нами
Как искать слово в PDF на Android?
Как искать в PDF на Android. Перейдите к программе чтения PDF-файлов на своем телефоне и запустите приложение. Выберите конкретный PDF-файл, который вы хотите найти. Посмотрите в правый верхний угол экрана и найдите увеличительное стекло. Коснитесь увеличительного стекла и введите текст, который хотите найти.
Почему docHub не распознает текст?
Если программа OCR не распознает отсканированный текст, дважды проверьте, чтобы изображение было четким, светлым и прямым. Внесите необходимые коррективы и повторно отсканируйте документы. В большинстве случаев это решит проблему.
Почему OCR не распознает текст?
Если программа OCR не распознает отсканированный текст, дважды проверьте, чтобы изображение было четким, светлым и прямым. Внесите необходимые коррективы и повторно отсканируйте документы. В большинстве случаев это решит проблему.
Как включить распознавание текста в PDF?
Запустите приложение docHub Acrobat и с помощью меню «Открыть файл» откройте отсканированный PDF-документ. Выберите Инструменты на главной панели инструментов. Дважды щелкните инструмент «Улучшить сканирование». Разверните раскрывающееся меню «Распознать текст».
Выберите Инструменты на главной панели инструментов. Дважды щелкните инструмент «Улучшить сканирование». Разверните раскрывающееся меню «Распознать текст».
Как заставить docHub PDF распознавать текст?
Щелкните инструмент «Редактировать PDF» на правой панели. Acrobat автоматически применяет к документу оптическое распознавание символов (OCR) и преобразует его в полностью редактируемую копию PDF-файла. Щелкните текстовый элемент, который вы хотите отредактировать, и начните печатать. Новый текст соответствует внешнему виду исходных шрифтов на отсканированном изображении.
Как включить распознавание текста в PDF?
Затем, чтобы запустить OCR: откройте файл PDF, для которого вы хотите запустить OCR. Выдвиньте меню «Файл», выберите «Сохранить как» и добавьте -ocr. pdf к имени файла. Выдвиньте меню «Документ», выберите «Распознавание текста OCR», а затем выберите «Распознавание текста с помощью OCR» и запустите
pdf к имени файла. Выдвиньте меню «Документ», выберите «Распознавание текста OCR», а затем выберите «Распознавание текста с помощью OCR» и запустите
. Почему мой PDF не распознает текст?
Решение 1. Получите версию документа, не содержащую отображаемый (редактируемый) текст. Это сообщение появляется, если документ PDF уже содержит редактируемый текст. Получите копию документа, не содержащую редактируемый текст. Решение 2. Преобразуйте PDF в TIFF и обратно, а затем повторно запустите OCR.
Почему мой PDF-файл не доступен для поиска по тексту?
Найдите и выберите документ, который вы хотите сделать доступным для поиска, затем нажмите «Открыть». Перейдите в «Инструменты» и выберите «Распознать текст». Нажмите Стиль вывода PDF Изображение с возможностью поиска. Затем выберите ОК.
Затем выберите ОК.
Как включить редактирование текста в PDF?
Как редактировать файлы PDF: Откройте файл в Acrobat. Нажмите на инструмент «Редактировать PDF» на правой панели. Используйте инструменты редактирования Acrobat: добавляйте новый текст, редактируйте текст или обновляйте шрифты, используя выбор из списка «Формат». Сохраните отредактированный PDF-файл: назовите файл и нажмите кнопку «Сохранить».
Как заставить docHub автоматически распознавать текст?
Отключение или отключение автоматического распознавания текста для отсканированных документов Выберите Инструменты Редактировать PDF. Чтобы отключить автоматическое распознавание текста, выполните следующие действия: На правой панели снимите флажок Распознавать текст. Чтобы включить автоматическое распознавание текста, сделайте следующее: На правой панели установите флажок Распознать текст.
Чтобы включить автоматическое распознавание текста, сделайте следующее: На правой панели установите флажок Распознать текст.
Узнайте, почему наши клиенты выбирают DocHub
Отличное решение для документов в формате PDF, требующее минимум предварительных знаний.
“Простота, знакомство с меню и удобство для пользователя. Легко перемещаться, вносить изменения и редактировать все, что вам может понадобиться. Поскольку он используется вместе с Google, документ всегда сохраняется, поэтому вам не нужно беспокоиться об этом. .”
Пэм Дрисколл Ф.
Преподаватель
Подписчик ценных документов для малого бизнеса.
“Мне нравится, что DocHub невероятно доступен по цене и настраивается. Он действительно делает все, что мне нужно, без большого ценника, как у некоторых из его более известных конкурентов. Я могу отправлять защищенные документы напрямую своим клиентам по электронной почте и через в режиме реального времени, когда они просматривают и вносят изменения в документ».