
App Store: PDF Сканер: Скан Текста & OCR
Описание
С помощью приложения “Сканер” Вы можете превратить Ваш iPhone в портативный сканер. Это профессиональное приложение-сканер позволяет Вам сканировать документы, чтобы сохранять их, распечатывать их или делиться ими в считанные секунды. Лучший сканер – тот, который всегда с тобой!
• Легко делитесь сканами или отправляйте их по электронной почте
• Имейте сканер при себе в любом месте, дома, на работе или в поездках
• Сканируйте и храните копии важных файлов, не боясь их потерять
• Экономьте время и средства на расходы на сканирование
• Мгновенно сканируйте бизнес-квитанции, счета-фактуры и контракты
ВЫСОКОКАЧЕСТВЕННЫЕ СКАНЫ
Приложение “Сканер” предназначено для обеспечения высокого качества сканирования – до 300 dpi. Это отличное решение на одном уровне с лучшими современными настольными сканерами.
СКАНИРУЙТЕ ЛЮБОЙ ДОКУМЕНТ
Приложение “Сканер” отлично работает с любым типом документа.
МГНОВЕННЫЕ СКАНЫ
Приложение рассчитано на работу в считанные секунды. Нет необходимости ждать минуты для полного сканирования. Даже несколько страниц сканируются молниеносно!
ГИБКИЕ ФОРМАТЫ
Вы можете сохранить Ваши файлы в формате PDF или JPG. Опция распознавания текста (будет добавлена в ближайшее время) позволяет извлекать текст со страниц, а функция интеллектуального именования позволяет позже легко находить документы.
ПОЛНЫЕ НАСТРОЙКИ ХРАНЕНИЯ
Сохраните отсканированные файлы на iDevice или ПК. Приложение “Сканер” также позволяет хранить их непосредственно в предпочитаемом облачном сервисе (Dropbox, iCloud Drive, Box, Google Drive, Evernote)
ПОДПИСКА PRO
Приложение содержит следующие опции подписки:
– 1 год (29,99 долл. США)
Обратите внимание, что подписка автоматически продлевается, если автоматическое продление не отменить не менее чем за 24 часа до окончания текущего периода
Используя PDF Scanner, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями пользования:
Политика конфиденциальности http://getscannerapp. com/privacy.html
com/privacy.html
Условия пользования http://getscannerapp.com/terms.html
• Оплата будет оплачена на счет iTunes при подтверждении покупки
• Подписка автоматически возобновляется, если автоматическое продление не выключено по крайней мере за 24 часа до окончания текущего периода
• Счета будут взиматься за продление в течение 24 часов до окончания текущего периода и определить стоимость продления
• Подписки могут управляться пользователем, и автоматическое продление может быть отключено путем перехода к настройкам учетной записи пользователя после покупки
• Любая неиспользованная часть бесплатного пробного периода, если предлагается, будет конфискована, когда пользователь покупает подписку на эту публикацию, где это применимо
ИНТУИТИВНЫЙ И ПРОСТОЙ В ИСПОЛЬЗОВАНИИ
Приложение “Сканер” отличается приятным интерфейсом и простотой в использовании с момента его первого запуска. Начните сканировать все Ваши документы за считанные секунды!
И помимо всего этого, приложение “Сканер” может сканировать несколько страниц, поддерживает защищенные паролем PDF-файлы, настраивает контрастность и разрешение и многое другое!
Поэтому сделайте свою жизнь намного проще, скачав приложение “Сканер” и превратив свой iPhone в полноценный современный сканер!
Версия 2.7
Thank you for using PDF Scanner App! In this update:
+ Various improvements and performance enhancements
If you like Scanner App, please leave a review on the App Store.
Have any problems/ideas? Get in touch with us anytime at getscannerapp.com/support
Оценки и отзывы
Оценок: 229
Верните деньги!
Приложение купили без моего ведома третьи лица , через пароль! Пользоваться приложением не собираюсь! Пожалуйста, помогите решить эту проблему! Списали 2350!
Уважаемый Максим,
Пожалуйста, обратитесь в нашу службу поддержки нажав “Сообщить о проблеме” в Настройках.
Мы сделаем все возможное, чтобы помочь Вам решить эту проблему.
Верните оплату приложения!
Не распознает и 10% текста от общего объёма на листе,полный обман
Как отписаться от вашего приложения ???отпишите меня и не присылайте смс!
Как отписаться от вашего приложения ????
здравствуйте, пожалуйста, чтобы отписаться, перейдите по ссылке и следуйте инструкциям:
https://support.apple.com/en-us/HT202039
Разработчик ScannerApp не сообщил Apple о своей политике конфиденциальности и используемых им способах обработки данных. Подробные сведения доступны в политике конфиденциальности разработчика.
Нет сведений
Разработчик будет обязан предоставить сведения о конфиденциальности при отправке следующего обновления приложения.
Информация
- Провайдер
- Scanner App, LLC
- Размер
- 137,2 МБ
- Категория
- Бизнес
- Возраст
- 4+
- Copyright
- © PDF Scanner App 7bb9312f82
- Цена
- Бесплатно
- Сайт разработчика
- Поддержка приложения
- Политика конфиденциальности
Другие приложения этого разработчика
Вам может понравиться
Параметры преобразования документов PDF с возможностью поиска
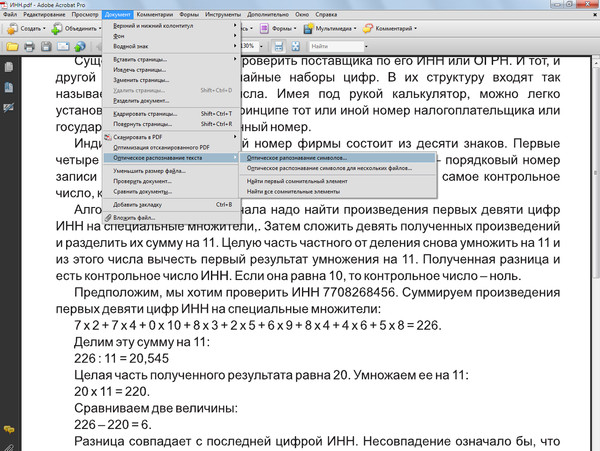
Параметры преобразования документов PDF с возможностью поискаЭто диалоговое окно отображается в указанных ниже ситуациях.
- В диалоговом окне Профили PDF Create установите флажок С возможностью поиска и нажмите кнопку Параметры.
- Нажмите Преобразовать > Другие > PDF с возможностью поиска, затем выберите Параметры в диалоговом окне Преобразование страниц.
- Проверьте параметры распознавания текста в разделе Файл > Параметры > Документ > Документ PDF с возможностью поиска.
Эти параметры следует использовать для создания из файлов изображений или PDF-файлов, содержащих только изображения, поиск в которых невозможен. Список поддерживаемых типов файлов см. в разделе Create Assistant.
Язык распознаваемого текста
извлекает текст из изображений, чтобы обеспечить возможность поиска в нем. Выберите язык, который используется в исходном документе.
Нераспознанные символы
Нераспознанные символы представляются в виде специального символа дефекта (по умолчанию это тильда: «~»). Например, если при оптическом распознавании не удалось распознать букву «з» в слове «распознать» и в качестве символа дефекта используется символ ~, в распознанном документе будет написано «распо~нать».
Например, если при оптическом распознавании не удалось распознать букву «з» в слове «распознать» и в качестве символа дефекта используется символ ~, в распознанном документе будет написано «распо~нать».
Символ дефекта можно задать в поле «Нераспознанные символы». По возможности используйте символ, не встречающийся в документах.
Сохранить исходные изображения
Если установить этот флажок, исходное изображение будет сохранено после преобразования.
Автоориентация страницы
Если установить этот флажок, ориентация страницы (альбомная или портретная) будет выбираться автоматически.
Обработать страницы
Укажите, какие страницы нужно обрабатывать при преобразовании PDF-документа в формат PDF с возможностью поиска.
- Страницы, содержащие только рисунки

- Все страницы Если выбран этот вариант, обрабатываются все страницы независимо от их содержимого.
-
- Использовать систему распознавания текста при обработке документов Этот флажок предписывает обрабатывать документы только с помощью системы распознавания текста. Внутри приложения все страницы будут преобразованы в растровые изображения, а затем обработаны системой распознавания текста. При этом отбрасываются все невизуальные и нестандартные элементы (например, скрытые объекты и знаки с нестандартными кодами). Это может помочь, если стандартная процедура преобразования в PDF с возможностью поиска не работает.
- Распознавать нестандартные кодировки текста Установите этот флажок для обработки страниц, содержащих текст с нестандартными шрифтами или кодировками.
Автоматически проверять результат после распознавания
(Доступно только в Power PDF.)
Установите этот флажок для интерактивной проверки орфографии в обработанном документе. Чтобы добавить или создать собственные словари, нажмите кнопку Пользовательские словари.
Чтобы добавить или создать собственные словари, нажмите кнопку Пользовательские словари.
Автоматически искать страницы только с изображениями (требуется перезапуск)
(Доступно только в Power PDF.)
Если установлен этот флажок, программа Power PDF проверяет каждый PDF-документ при его открытии, и если в документе есть страницы, содержащие только изображения, она предлагает преобразовать его в формат PDF с возможностью поиска. Проверка иногда занимает много времени, поэтому этот флажок по умолчанию снят.
Выводить сообщения на панели уведомлений
(Этот параметр доступен только в Power PDF и включается только при выборе вышеуказанного флажка.)
Выберите Выводить сообщения на панели уведомлений, чтобы программа Power PDF выводила информацию о страницах, содержащих только изображения, на панели уведомлений под лентой. Нажмите Сделать доступным для поиска, чтобы открыть диалоговое окно «Автоматическое определение» и выбрать настройки распознавания, которые будут применяться к таким страницам.
Снимите флажок Выводить сообщения на панели уведомлений, чтобы программа Power PDF без дополнительного уведомления сразу же открывала диалоговое окно «Автоматическое определение» при обнаружении страниц, содержащих только изображения.
Примечание
Если входной файл является текстовым или содержит доступный текстовый слой, обычный PDF-документ с возможностью поиска создается без оптического распознавания. В таких случаях параметры «Язык распознаваемого текста» и «Нераспознанные символы» не используются.
Как использовать альтернативу Adobe Acrobat OCR
Audrey Goodwin
2021-05-20 14:28:24 • Опубликовано : Сравнение Программного Обеспечения • Проверенные решения
Интересно, как использовать Adobe Acrobat OCR? На самом деле Adobe Reader OCR (оптическое распознавание символов) не существует, если вы хотите использовать OCR, то вам нужно использовать Adobe Acrobat OCR. Однако Acrobat OCR стоит гораздо дороже. Поэтому в этой статье мы представим альтернативу Adobe Acrobat OCR с более дешевой ценой – PDFelement , который включает в себя функцию распознавания текста, чтобы помочь вам легко работать с отсканированными документами.
Поэтому в этой статье мы представим альтернативу Adobe Acrobat OCR с более дешевой ценой – PDFelement , который включает в себя функцию распознавания текста, чтобы помочь вам легко работать с отсканированными документами.
БЕСПЛАТНО СКАЧАТЬ БЕСПЛАТНО СКАЧАТЬ КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
БЕСПЛАТНО СКАЧАТЬ
Как использовать альтернативу Adobe Acrobat OCR
PDFelement как лучшая альтернатива Adobe Acrobat, он не только имеет функцию OCR, но и поддерживает редактирование PDF, преобразование PDF, создание других форматов файлов в PDF, аннотирование PDF и шифрование PDF и другие.
Шаг 1: Откройте отсканированный PDF-файл
Если вы еще не отсканировали документ, вы можете использовать PDFelement для создания PDF-файла непосредственно из сканера. Если у вас уже есть отсканированный PDF-документ, вы можете нажать кнопку “Открыть файл”, чтобы открыть его с помощью PDFelement.
Шаг 2: Используйте OCR
После открытия отсканированного PDF-файла в нем вы получите уведомление с просьбой выполнить распознавание текста. Таким образом, вы можете нажать кнопку “Выполнить OCR” в уведомлении, вам нужно сначала загрузить и установить OCR, если вы еще не установили, то он будет выполнять OCR автоматически.
Таким образом, вы можете нажать кнопку “Выполнить OCR” в уведомлении, вам нужно сначала загрузить и установить OCR, если вы еще не установили, то он будет выполнять OCR автоматически.
БЕСПЛАТНО СКАЧАТЬ БЕСПЛАТНО СКАЧАТЬ КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
БЕСПЛАТНО СКАЧАТЬ
В новом всплывающем окне вы можете выбрать режим “Редактируемый текст” и нажать кнопку “Изменить язык”, чтобы выбрать правильный язык содержимого вашего документа.
Шаг 3: Редактирование PDF (необязательно)
После выполнения OCR вновь созданный PDF-файл будет автоматически открыт в PDFelement. Вы можете нажать кнопку “Редактировать”, чтобы отредактировать PDF-текст по мере необходимости. Затем нажмите кнопку “Файл” > “Сохранить как”, чтобы сохранить его на вашем компьютере.
БЕСПЛАТНО СКАЧАТЬ БЕСПЛАТНО СКАЧАТЬ КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
БЕСПЛАТНО СКАЧАТЬ
Видео о том, как OCR PDF с альтернативой Adobe Acrobat
PDFelement довольно прост в использовании для тех, кто хочет редактировать или конвертировать отсканированные файлы. Он также предлагает полнофункциональный пробный период без каких-либо затрат или ограничений по времени.
Он также предлагает полнофункциональный пробный период без каких-либо затрат или ограничений по времени.
БЕСПЛАТНО СКАЧАТЬ БЕСПЛАТНО СКАЧАТЬ КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
БЕСПЛАТНО СКАЧАТЬ
- Он может извлекать данные из сотен идентичных форм PDF-файлов в один лист Excel в течение нескольких секунд.
- Он предлагает более 8000 шаблонов PDF-форм, которые помогут вам создать свою PDF-форму.
- OCR поддерживает более 20 языков, чтобы помочь конвертировать отсканированные документы, написанные на разных языках, в выбираемые, редактируемые и доступные для поиска PDF-файлы.
- Инструмент поддерживает преобразование PDF-файлов из более чем 300 форматов документов.
- Вы можете объединить или разделить документы из PDF-документа.
- Вы можете использовать пароль 256 Бейтса для защиты вашего PDF-файла от несанкционированных пользователей.
Как использовать Adobe Reader OCR
1.
 Редактирование документа с помощью Acrobat Pro OCR
Редактирование документа с помощью Acrobat Pro OCRЧтобы отредактировать отсканированный документ в Adobe Reader, необходимо сначала загрузить Adobe Acrobat DC Pro. Вы можете сделать это, перейдя на сайт Adobe Acrobat, выбрав свой план для платной версии (Standard за $12.99 или Pro за $14.99 в месяц), а затем загрузить приложение на свой компьютер. Adobe предоставляет вам БЕСПЛАТНЫЙ ПРОБНЫЙ период для версии Pro, который дает вам общее представление о приложении перед совершением сделки.
Как только вы загрузили приложение, мастер установки обычно проведет вас через остальную часть процесса установки, пока вы не установите приложение. Чтобы отредактировать отсканированный документ, следуйте этому руководству:
- Откройте отсканированный PDF-файл с помощью Adobe Reader. Есть много способов сделать это, но самый быстрый способ-это щелкнуть правой кнопкой мыши значок файла на вашем документе и выбрать “Открыть с помощью Adobe Reader” на вашем ПК с Windows.
- Как только файл откроется, перейдите в правую панель и нажмите кнопку “редактировать PDF.
 “Это должно запустить модуль OCR вместе с другими редакторскими функциями Adobe Reader, который должен преобразовать ваш отсканированный документ в редактируемую копию.
“Это должно запустить модуль OCR вместе с другими редакторскими функциями Adobe Reader, который должен преобразовать ваш отсканированный документ в редактируемую копию. - Затем вы можете щелкнуть в любом месте документа, чтобы вставить и отредактировать текст. Новый текст должен соответствовать существующему тексту с точки зрения размера шрифта и типа.
- После завершения редактирования сохраните файл.
2. Недостатки Acrobat Reader OCR
Adobe Reader является одним из наиболее распространенных инструментов PDF, используемых в настоящее время. Его популярность во многом объясняется тем, что он является инструментом PDF по умолчанию на многих ПК с Windows и Mac-устройствах. Бесплатная версия Adobe Reader позволяет вам довольно легко играть с текстом, печатать и добавлять комментарии и аннотации.
Однако Adobe Reader не включает в себя модуль OCR, что означает, что вы не можете просто загрузить отсканированный PDF-файл и активировать OCR. Вместо этого Adobe Reader предлагает автоматическое распознавание текста, которое обычно пытается обнаружить содержимое отсканированных документов – что иногда может быть неточным.
Кроме того, вам нужно будет взять на себя обязательство платить не менее $12,99 каждый месяц, чтобы использовать распознавание текста с Adobe Reader, и подписаться на годовую подписку.
Хотя имеет смысл инвестировать в большой бренд для редактирования PDF-документов,они не всегда соответствуют шумихе. Adobe Acrobat, например, требует от пользователей ежемесячных платежей, чтобы получить доступ к услугам, которые иногда доступны в интернете бесплатно. Так почему бы не попробовать более дешевую и лучшую альтернативу? Попробуйте скачать PDFelement бесплатно уже сегодня!
Скачать Бесплатно или Купить PDFelement прямо сейчас!
Скачать Бесплатно или Купить PDFelement прямо сейчас!
Купить PDFelement прямо сейчас!
Купить PDFelement прямо сейчас!
python – Как извлечь текст из файла PDF?
Я добавляю код для этого: У меня работает нормально:
# Это работает в python 3 # необходимые пакеты питона # табула-py==1.0.0 # PyPDF2==1.26.0 # Подушка==4.0.0 # pdfminer.six==20170720 импорт ОС импортный шутил предупреждения об импорте из io импортировать StringIO запросы на импорт таблица импорта из изображения импорта PIL из PyPDF2 импортировать PdfFileWriter, PdfFileReader из pdfminer.converter импортировать TextConverter из pdfminer.layout импортировать LAParams из pdfminer.pdfinterp импортировать PDFResourceManager, PDFPageInterpreter из pdfminer.pdfpage импортировать PDFPage предупреждения.filterwarnings("игнорировать") def download_file(url): local_filename = url.split('/')[-1] local_filename = local_filename.replace("%20", "_") r = запросы.get (url, поток = True) печать (р) с open(local_filename, 'wb') как f: Shutil.copyfileobj(r.raw, f) вернуть local_filename класс PDFExtractor(): def __init__(я, URL): self.url = URL-адрес # Загрузка файла в локальный def break_pdf(я, имя файла, start_page=-1, end_page=-1): pdf_reader = PdfFileReader (открыть (имя файла, «rb»)) # Чтение каждого pdf по одному total_pages = pdf_reader.
numPages если начальная_страница == -1: стартовая_страница = 0 elif start_page < 1 или start_page > total_pages: вернуть "Выбор стартовой страницы неверен" еще: стартовая_страница = стартовая_страница - 1 если end_page == -1: конечная_страница = всего_страниц elif end_page < 1 или end_page > total_pages - 1: вернуть «Неверный выбор конечной страницы» еще: конечная_страница = конечная_страница для i в диапазоне (start_page, end_page): вывод = PdfFileWriter() output.addPage (pdf_reader.getPage (я)) с open(str(i + 1) + "_" + имя файла, "wb") в качестве outputStream: output.write(outputStream) def extract_text_algo_1 (я, файл): pdf_reader = PdfFileReader (открыть (файл, 'rb')) # создание объекта страницы pageObj = pdf_reader.getPage(0) # извлечение extract_text со страницы текст = pageObj.
extractText() текст = текст.заменить("\n", "").заменить("\t", "") возвращаемый текст def extract_text_algo_2 (я, файл): pdfResourceManager = PDFResourceManager() retstr = StringIO() la_params = LAParams() устройство = TextConverter (pdfResourceManager, retstr, codec = 'utf-8', laparams = la_params) fp = открыть (файл, 'rb') интерпретатор = PDFPageInterpreter (pdfResourceManager, устройство) пароль = "" макс_страниц = 0 кэширование = Истина номер_страницы = установить () для страницы в PDFPage.get_pages(fp, page_num, maxpages=max_pages, password=password, caching=caching, check_extractable=Истина): интерпретатор.process_page(страница) текст = retstr.getvalue () текст = текст.заменить("\t", "").заменить("\n", "") fp.close() устройство.закрыть() retstr.close() возвращаемый текст def extract_text (я, файл): text1 = self.
extract_text_algo_1(файл) text2 = self.extract_text_algo_2(файл) если len(text2) > len(str(text1)): вернуть текст2 еще: вернуть текст1 def extarct_table (я, файл): # Чтение pdf в DataFrame пытаться: df = tabula.read_pdf (файл, output_format = "csv") кроме: print("Ошибки чтения таблицы") возвращаться print("\nПечать содержимого таблицы: \n", df) print("\nВыполнена печать содержимого таблицы\n") def tiff_header_for_CCITT (я, ширина, высота, img_size, CCITT_group = 4): tiff_header_struct = '<' + '2s' + 'h' + 'l' + 'h' + 'hhll' * 8 + 'h' вернуть struct.pack (tiff_header_struct, b'II', # Индикация порядка байтов: Маленький индеец 42, # Номер версии (всегда 42) 8, # Смещение до первого IFD 8, # Количество тегов в IFD 256, 4, 1, ширина, # ImageWidth, LONG, 1, ширина 257, 4, 1, высота, # ImageLength, LONG, 1, длина 258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1 259, 3, 1, CCITT_group, # Compression, SHORT, 1, 4 = кодирование факса CCITT Group 4 262, 3, 1, 0, # Пороговое значение, SHORT, 1, 0 = WhiteIsZero 273, 4, 1, struct.
calcsize(tiff_header_struct), # StripOffsets, LONG, 1, длина заголовка 278, 4, 1, высота, # RowsPerStrip, LONG, 1, длина 279, 4, 1, img_size, # StripByteCounts, LONG, 1, размер extract_image 0 # последний ИФД ) def extract_image (я, имя файла): число = 1 pdf_reader = PdfFileReader (открыть (имя файла, 'rb')) для i в диапазоне (0, pdf_reader.numPages): страница = pdf_reader.getPage (я) пытаться: xObject = страница['/Ресурсы']['/XObject'].getObject() кроме: print("XObject не найден") возвращаться для объекта в xObject: пытаться: если xObject[obj]['/Subtype'] == '/Image': размер = (xObject[obj]['/Width'], xObject[obj]['/Height']) данные = xObject[obj]._data если xObject[obj]['/ColorSpace'] == '/DeviceRGB': режим = "RGB" еще: режим = "П" image_name = имя_файла.
split(".")[0] + str(число) печать (xObject [объект] ['/ фильтр']) если xObject[obj]['/Filter'] == '/FlateDecode': данные = xObject[obj].getData() img = Image.frombytes(режим, размер, данные) img.save(image_name + "_Flate.png") # save_to_s3(имя изображения + "_Flate.png") печать("Изображение_сохранено") число += 1 elif xObject[obj]['/Filter'] == '/DCTDecode': img = открыть (имя_изображения + "_DCT.jpg", "wb") img.write(данные) # save_to_s3(имя изображения + "_DCT.jpg") img.close() число += 1 elif xObject[obj]['/Filter'] == '/JPXDecode': img = открыть (имя_изображения + "_JPX.
jp2", "wb") img.write(данные) # save_to_s3 (имя изображения + "_JPX.jp2") img.close() число += 1 elif xObject[obj]['/Filter'] == '/CCITTFaxDecode': если xObject[obj]['/DecodeParms']['/K'] == -1: CCITT_группа = 4 еще: CCITT_группа = 3 ширина = xObject[obj]['/Width'] высота = xObject[obj]['/Height'] data = xObject[obj]._data # извините, getData() не работает для CCITTFaxDecode img_size = длина (данные) tiff_header = self.tiff_header_for_CCITT (ширина, высота, img_size, CCITT_group) img_name = image_name + '_CCITT.tiff' с открытым (img_name, 'wb') как img_file: img_file.
write(tiff_header + данные) # save_to_s3 (img_name) число += 1 кроме: Продолжать номер возврата def read_pages(self, start_page=-1, end_page=-1): # Загрузка файла локально загруженный_файл = загружаемый_файл(self.url) печать (скачанный_файл) # разбивка PDF на количество страниц в diff pdf файлах self.break_pdf(скачиваемый_файл, начальная_страница, конечная_страница) # создание объекта для чтения PDF pdf_reader = PdfFileReader (открыть (скачиваемый_файл, 'rb')) # Чтение каждого pdf по одному total_pages = pdf_reader.numPages если начальная_страница == -1: стартовая_страница = 0 elif start_page < 1 или start_page > total_pages: вернуть "Выбор стартовой страницы неверен" еще: стартовая_страница = стартовая_страница - 1 если end_page == -1: конечная_страница = всего_страниц elif end_page < 1 или end_page > total_pages - 1: вернуть «Неверный выбор конечной страницы» еще: конечная_страница = конечная_страница для i в диапазоне (start_page, end_page): # создание имени файла на основе страницы файл = ул(я + 1) + "_" + загруженный_файл print("\nНачало чтения страницы: ", i + 1, "\n -----------===-------------") file_text = self.
extract_text(файл) печать (текст_файла) self.extract_image(файл) self.extarct_table(файл) os.remove(файл) print("Страница остановлена: ", i + 1, "\n -----------===-------------") os.remove (скачанный_файл) # Я протестировал эти 3 pdf-файла # url = "http://s3.amazonaws.com/NLP_Project/Original_Documents/Healthcare-January-2017.pdf" url = "http://s3.amazonaws.com/NLP_Project/Original_Documents/Sample_Test.pdf" # url = "http://s3.amazonaws.com/NLP_Project/Original_Documents/Sazerac_FS_2017_06_30%20Annual.pdf" # создание экземпляра класса pdf_extractor = PDFExtractor(url) # Получение желаемых данных pdf_extractor.read_pages(15, 23)
4 бесплатных метода преобразования PDF в текст на Mac
В настоящее время все спрашивают, как конвертировать PDF в текст Mac ? Если у вас возникли проблемы с выделением текста в PDF-файле на Mac, не беспокойтесь — извлечь текст из PDF-файла на Mac очень просто. В этой статье я покажу вам, как это сделать, и это займет всего несколько секунд!
В этой статье я покажу вам, как это сделать, и это займет всего несколько секунд!
- Предварительный просмотр
- Автоматизатор
- Гугл документы
- PDNob Image TranslatorHOT
1. Конвертируйте PDF в текстовый файл с помощью предварительного просмотра
Существует ряд доступных инструментов, которые могут помочь вам извлечь текст из PDF на Mac. Самый простой и понятный вариант — использовать предварительный просмотр; Mac Preview очень легко конвертирует PDF в текст, который входит в состав macOS.
Чтобы извлечь текст с помощью Preview:
- ШАГ 1: Просто откройте файл PDF в режиме предварительного просмотра и выберите инструмент «Выбрать» на панели инструментов.
- ШАГ 2: Затем выберите текст, который вы хотите извлечь, и скопируйте его в буфер обмена.
- ШАГ 3: Вы можете вставить текст в новый документ или использовать его по своему усмотрению!
Это сделано! Извлекать текст из PDF на Mac очень просто.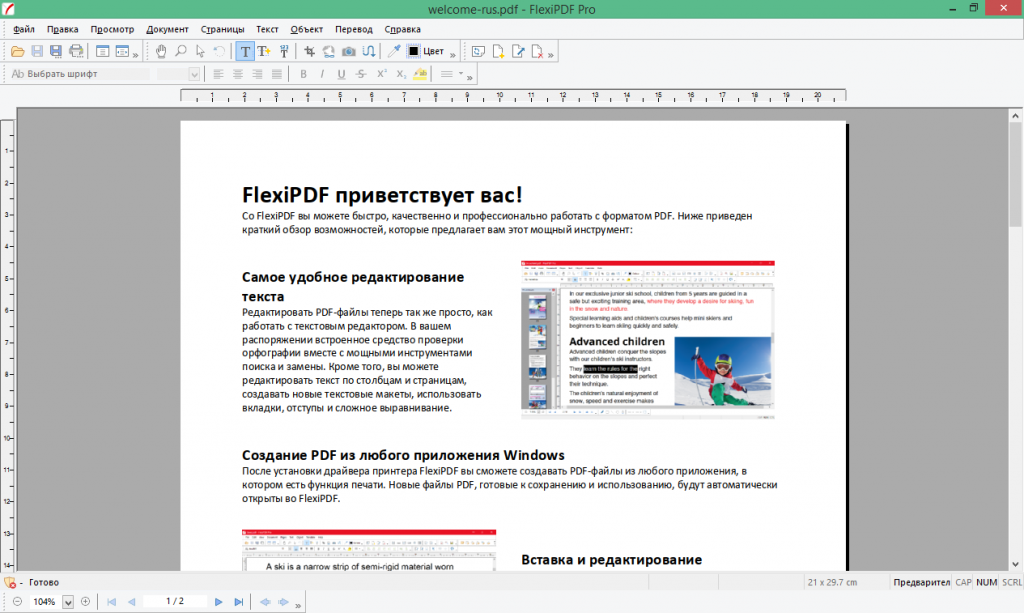
2. Конвертируйте PDF в текст бесплатно с помощью Automator
Этот метод является одним из самых простых и быстрых способов извлечения текста из PDF-изображения Mac без установки внешнего профессионального сканера OCR. Это широко используемая и заслуживающая доверия программа со встроенной функцией OCR.
Если вы хотите извлечь текст из PDF-файла с помощью Automator, вы также можете сделать это очень легко.
Вот как:
- ШАГ 1: Откройте Automator и выберите тип «Рабочий процесс».
- ШАГ 2: В строке поиска введите «извлечь текст из PDF» и выберите действие «Извлечь текст из PDF».
- ШАГ 3:Теперь перетащите действие «Открыть PDF» в рабочий процесс и выберите нужный файл PDF.
- ШАГ 4:Наконец, нажмите кнопку «Выполнить», чтобы извлечь текст из PDF!
3. Конвертировать pdf в текстовые гугл документы
Если вы хотите извлечь текст из PDF-изображения Mac, используя документы Google, это очень просто.
Вот как:
- ШАГ 1: Откройте Google Docs и нажмите кнопку «Создать».
- ШАГ 2: Выберите «Загрузить файл» и выберите нужный файл PDF.
- ШАГ 3. После загрузки файла щелкните правой кнопкой мыши миниатюру изображения файла и выберите «Открыть с помощью» > «Документы Google». Он будет автоматически преобразован в текст.
Валлах!! ваш текст был извлечен из PDF.
4. Конвертируйте pdf в word с помощью PDNob Image Translator
Все сталкиваются с проблемами при копировании и переводе PDF-файлов, вы не можете скачать некоторые PDF-файлы, вы не можете выбрать текст в PDF Mac, но теперь это решено. Существует ряд бесплатных онлайн-инструментов, которые помогут вам извлечь текст из PDF на Mac. Самый популярный — PDNob Image Translator.
Как использовать этот инструмент:
Шаг 1. Бесплатная загрузка
Шаг 2. Быстрый старт
Чтобы начать, нажмите Command+1 на Mac или выберите «Захват текста» в строке меню.
Шаг 3. Скриншот и OCR
Сделайте снимок запрошенного текста, и выбранный текст будет сразу распознан.
Шаг 4. Перевод
Завершите перевод целевого текста, щелкнув символ перевода.
Преимущества этого инструмента:
- Извлечение текста из изображения : Использование технологии снимков экрана и оптического распознавания символов для извлечения данных из отсканированных изображений.
- Извлечение текста из PDF : Использование снимков экрана и методов оптического распознавания символов для извлечения данных из отсканированных PDF-файлов.
- Языковая поддержка OCR : Поддерживает распознавание 8 языков.
- Переводчик изображений : перевод текста OCR на другой язык.
- Перевести более чем на 100 языков : Участвуйте в переводе бесплатно!
PDNob — это бесплатный онлайн-инструмент, который поможет вам извлечь текст из PDF на Mac. Он прост в использовании и поддерживает более 100 языков. Вы также можете перевести текст на другой язык, используя значок перевода. Теперь, когда вы не можете выделить текст в PDF mac, войдите в PDNob.
Вы также можете перевести текст на другой язык, используя значок перевода. Теперь, когда вы не можете выделить текст в PDF mac, войдите в PDNob.
Вывод
Существует несколько способов преобразования pdf в текст mac . Но если вы хотите извлечь текст из изображения, PDF-файла или любой части экрана вашего Mac, вы можете попробовать PDNob Image Translator. Извлекать текст из PDF на Mac теперь легко и удобно! Теперь у вас есть ответ на вопрос, как скопировать текст из pdf mac.
Часто задаваемые вопросы
В: Какие есть другие варианты извлечения текста из PDF на Mac?
О. Существует ряд других инструментов и методов для извлечения текста из PDF на Mac, включая Automator, Adobe Acrobat Pro, Google Docs и другие. У каждого метода есть свои плюсы и минусы, поэтому важно учитывать ваши конкретные потребности и предпочтения при выборе инструмента или метода. Некоторые инструменты могут лучше подходить для извлечения текста из отсканированных документов или файлов изображений, в то время как другие могут предлагать расширенные возможности редактирования и добавления аннотаций. В конечном счете, лучший вариант будет зависеть от вашей уникальной ситуации.
В конечном счете, лучший вариант будет зависеть от вашей уникальной ситуации.
В: Почему я не могу использовать предварительный просмотр для преобразования PDF в текст на Mac?
Если у вас возникли проблемы с выделением или копированием текста из PDF-файла в программе «Просмотр» на Mac, вы можете попробовать следующее.
- Проверьте, требует ли файл PDF пароль для редактирования.
- Проверить, является ли текст изображением. Если это так, вы не можете полагаться на предварительный просмотр для извлечения текста. Вместо этого вы можете попробовать PDNob Image Translator для извлечения текста из изображения.
- Проверьте, выбран ли инструмент «Выделение текста».
Как распознать текст в PDF
Откройте файл PDF, содержащий отсканированное изображение, в Acrobat для Mac или ПК. Нажмите на инструмент «Редактировать PDF» на правой панели. Acrobat автоматически применяет к документу оптическое распознавание символов (OCR) и преобразует его в полностью редактируемую копию PDF-файла. Щелкните текстовый элемент, который вы хотите отредактировать, и начните печатать.
Щелкните текстовый элемент, который вы хотите отредактировать, и начните печатать.
Почему мой PDF не распознает текст?
Если вы не можете выделить текст на странице, то документ недоступен для поиска . Чтобы применить операцию «Распознать текст» к PDF-файлу, исходное разрешение сканера должно быть установлено на 72 dpi или выше. Обратите внимание, что сканирование с разрешением 300 dpi дает лучший текст для преобразования. При разрешении 150 dpi точность распознавания немного ниже.
Как включить распознавание текста в Adobe?
OCR включен по умолчанию.
…
Отключить или отключить автоматическое распознавание для отсканированных документов
- Выберите «Инструменты» > «Редактировать PDF».
- Чтобы отключить автоматическое распознавание текста, выполните следующие действия: На правой панели снимите флажок Распознавать текст. …
- Чтобы включить автоматическое распознавание текста, выполните следующие действия: На правой панели установите флажок Распознать текст.
19 сентября 2022 г.
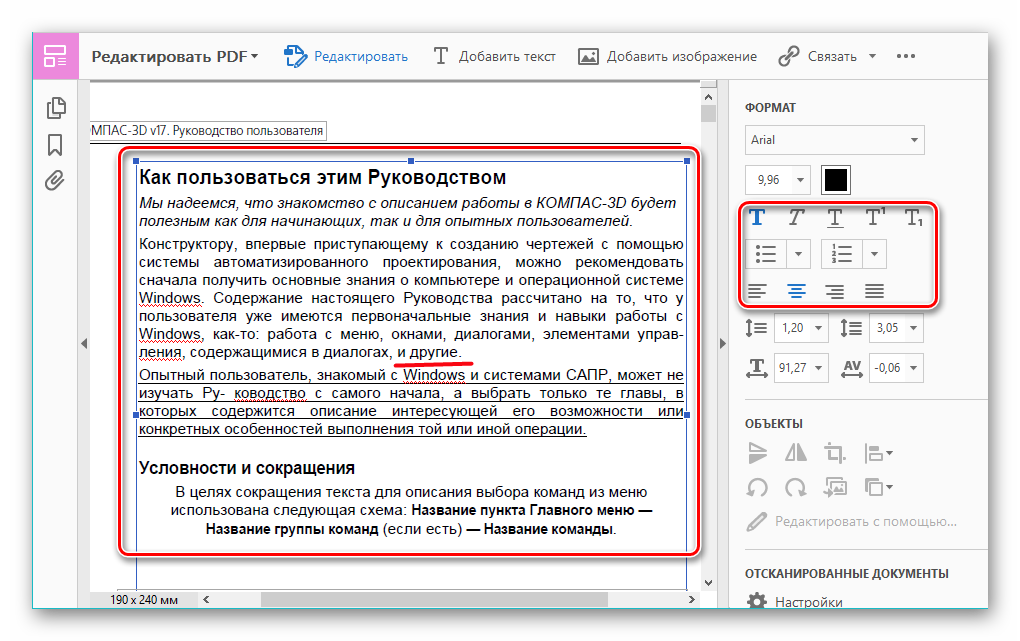
Как идентифицировать и редактировать текст в PDF?
Выберите Инструменты > Редактировать PDF > Редактировать . Пунктирные контуры обозначают текст и изображения, которые вы можете редактировать. Выберите текст, который хотите изменить. На правой панели «Формат» выберите шрифт, размер шрифта или другие параметры форматирования.
Как идентифицировать данные в PDF?
: Вы используете инструменты редактирования для удаления контента.
…
Откройте PDF-файл в Acrobat и выполните одно из следующих действий:
- Выберите «Инструменты» > «Редактировать».
- В меню «Правка» выберите «Редактировать текст и изображения».
- Выберите текст или изображение в PDF, щелкните правой кнопкой мыши и выберите Редактировать.
- Выберите текст или изображение в PDF-файле, выберите «Редактировать» в всплывающем контекстном меню.
19 сентября 2022 г.
Как сделать текст PDF доступным для поиска?
Следующие инструкции относятся к тому, чтобы сделать PDF-файл доступным для поиска по тексту в Adobe Acrobat Professional или Standard: Нажмите «Инструменты» > «Распознавание текста» > «В этом файле». Откроется всплывающее окно «Распознать текст». Выберите Все страницы, затем нажмите OK .
Что означает OCR в PDF?
Что такое OCR? OCR расшифровывается как « Optical Character Recognition ». Это технология, которая распознает текст в цифровом изображении. Он обычно используется для распознавания текста в отсканированных документах и изображениях. Программное обеспечение OCR можно использовать для преобразования физического бумажного документа или изображения в доступную электронную версию с текстом.
Adobe распознает текст?
Acrobat может распознавать текст в любом файле PDF или файле изображения на десятках языков. Все, что вам нужно сделать, это открыть отсканированный документ или изображение, которое вы хотите распознать, а затем нажать синюю кнопку «Инструменты» в правом верхнем углу панели инструментов. На этой боковой панели выберите вкладку «Распознать текст», затем нажмите кнопку «В этом файле».
На этой боковой панели выберите вкладку «Распознать текст», затем нажмите кнопку «В этом файле».
Где распознать текст в Acrobat DC?
Оптическое распознавание символов (OCR) в Adobe Acrobat Pro DC
- Откройте PDF-файл в Adobe Acrobat Pro DC.
- Нажмите Сканировать и распознавать на правой панели:
- Нажмите «Распознать текст» на появившейся верхней панели инструментов.
- Щелкните В этом файле в раскрывающемся меню.
- Нажмите Настройки на появившейся панели инструментов.
Другие элементы…•21 окт. 2021 г.
Есть ли в Adobe Acrobat OCR?
Adobe Acrobat Export PDF поддерживает оптическое распознавание символов или OCR при преобразовании PDF-файла в Word (.
Как распознать PDF в Интернете?
Онлайн-OCR для PDF-файлов, файлов Microsoft Office и изображений
- Откройте онлайн-инструмент OCR.
 🛠
🛠 - Перетащите файл в область перетаскивания. 🗂
- Выберите выходной формат. 👉
- Выберите вариант «конвертировать с OCR». 👉
- Выберите язык документа. 🗣
- Подождите, пока программа обработает ваш файл. ⏳
- Загрузите редактируемый документ. 💻
20 августа 2020 г.
Можно ли отсканировать документ и отредактировать текст?
Вы можете отсканировать документ и преобразовать текст в данные, которые можно редактировать с помощью программы обработки текстов . Этот процесс называется OCR (оптическое распознавание символов). Чтобы сканировать и использовать OCR, вам нужно использовать программу OCR, такую как программа ABBYY FineReader.
Как сделать недоступный для поиска файл PDF доступным для поиска?
Как преобразовать отсканированный PDF в PDF с возможностью поиска с помощью Adobe?
- Запустите Adobe Acrobat.
- Откройте отсканированный файл PDF с помощью Adobe.
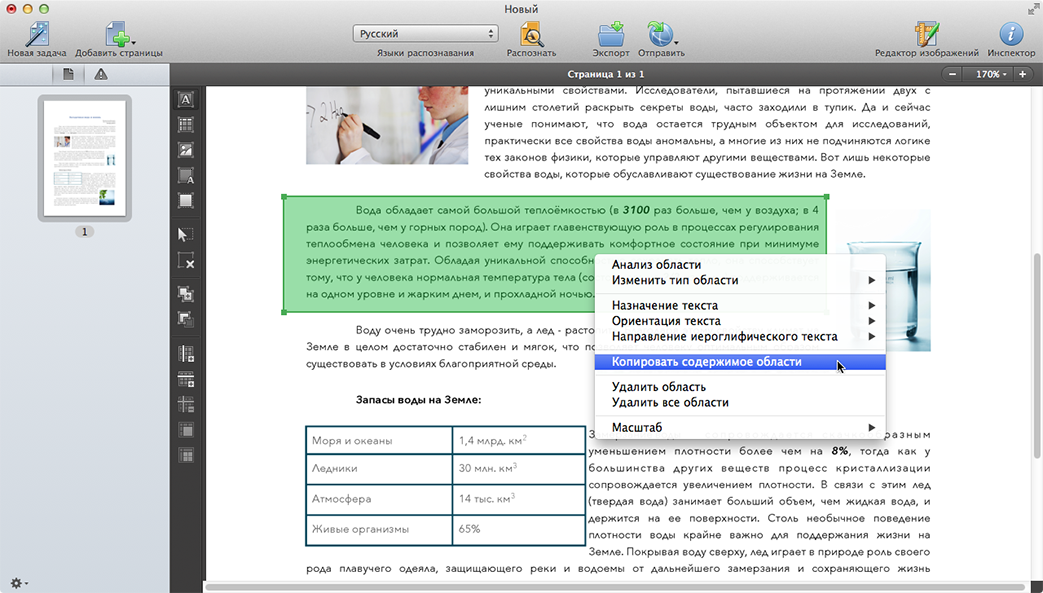
- Выберите «Инструменты»> «Улучшение сканирования»> «Распознать текст»> «В этом файле» начните обработку OCR в отсканированном PDF-файле.
- Когда все будет готово, сохраните файл PDF с возможностью поиска.
Как затемнить текст в PDF-файле, не редактируя его?
Как затемнить текст в файлах PDF
- Откройте наш онлайн-редактор PDF.
- Нажмите и перетащите PDF-файл на панель инструментов.
- Нажмите на квадратный символ и выберите «Прямоугольник».
- Убедитесь, что установлен черный цвет, и измените его размер, чтобы он закрывал текст.
- Нажмите «Готово» и сохраните документ.
17 сентября 2021 г.
Есть ли у Adobe инструмент редактирования?
С помощью инструмента «Редактировать» в Acrobat вы можете безвозвратно удалить текст и графику из документа PDF. Сделайте копию своего PDF-файла, чтобы случайно не потерять то, что хотите сохранить, и выполните следующие действия, чтобы выбрать текст или изображения и отредактировать их. 1. Выберите Инструменты › Редактировать.
1. Выберите Инструменты › Редактировать.
Почему я не могу найти Redact в Adobe?
Чтобы найти инструмент редактирования, вам нужно будет прокрутить страницу почти до конца. Redact находится в разделе «Защита и стандартизация» инструментов . Найдя инструмент, нажмите «Добавить». Добавьте инструмент «Редактировать» в меню «Действия» для быстрого доступа к нему в будущем.
Доступен ли для поиска документ PDF?
Как правило, PDF-файлы, созданные из Microsoft Office Word и других документов, по своей природе доступны для поиска , так как исходный документ содержит текст, который воспроизводится в PDF, но при создании PDF из отсканированного документа необходимо применить процесс OCR для распознавания символов в изображении.
Можно ли сделать отсканированный файл PDF доступным для поиска?
После того, как вы воспользуетесь инструментом «Распознать текст» для преобразования отсканированного изображения в пригодный для использования файл PDF, вы сможете выбирать и выполнять поиск по тексту в этом файле , что упрощает поиск, изменение и повторное использование информации из вашей старой бумаги. документы. Выберите инструмент «Найти текст» и введите текст для поиска в поле «Найти».
документы. Выберите инструмент «Найти текст» и введите текст для поиска в поле «Найти».
Что такое текстовый поиск?
Электронные документы должны быть доступны для поиска по тексту. Этот позволяет читателям искать слово или фразу в вашем документе, чтобы легче переходить к определенным разделам . Если вы сохраняете документ Word в формате PDF, ваш документ должен быть автоматически доступен для поиска по тексту.
Как распознать PDF в Windows 10?
Откройте меню «Файл», выберите «Сохранить как» и добавьте «-ocr. pdf» на имя файла. Выдвиньте меню «Документ», выберите «Распознавание текста OCR», а затем выберите «Распознать текст с помощью OCR…» и «Пуск». Запустится процесс распознавания текста.
Как бесплатно извлечь текст из PDF?
С помощью оптического распознавания символов (OCR) вы можете извлечь любой текст из документа PDF в простой текстовый файл. И это просто: просто загрузите свой PDF-файл, а мы сделаем все остальное. После того, как вы предоставили свой файл, PDF2Go будет использовать OCR, чтобы получить текст из вашего PDF и сохранить его как файл TXT.
После того, как вы предоставили свой файл, PDF2Go будет использовать OCR, чтобы получить текст из вашего PDF и сохранить его как файл TXT.
Какое лучшее бесплатное распознавание символов?
12+ лучших бесплатных программ для распознавания текста для Windows [Обновленный список 2022]
- Сравнение лучших инструментов оптического распознавания символов.
- #1) Нанонеты.
- #2) OCRSpace.
- #3) FreeOCR.
- #4) OnlineOCR.
- #5) Простое распознавание текста.
- #6) Adobe Acrobat Pro DC.
- #7) PDFelement.
Другие элементы…
Как отличить текст от изображения?
Оптическое распознавание символов (OCR) — это технология распознавания образов на основе искусственного интеллекта, позволяющая идентифицировать текст внутри изображения и превращать его в редактируемый цифровой документ . Если вам когда-либо понадобится редактировать цифровые данные, такие как квитанции, счета-фактуры или банковские выписки, обычно в формате изображения, программное обеспечение OCR может вам помочь.
Какая версия Adobe Acrobat поддерживает распознавание текста?
Acrobat Standard поддерживает режимы оптического распознавания символов «Изображение с возможностью поиска» и «Изображение и текст с возможностью поиска». Он не поддерживает режим OCR «Редактируемый текст и изображения» на отсканированных документах. Acrobat Pro поддерживает три режима оптического распознавания символов для отсканированных документов: Изображение с возможностью поиска.
Как Ctrl F работает в PDF?
Просто откройте PDF-файл в Adobe Acrobat и щелкните инструмент «Редактировать PDF» в правом меню . В зависимости от размера файла полное преобразование может занять несколько минут. Как только это будет сделано, вы можете нажать Ctrl + F для поиска по тексту.
Как преобразовать документ PDF в документ Word?
Как преобразовать файлы PDF в документы Word:
- Откройте файл PDF в Acrobat.
- Щелкните инструмент «Экспорт PDF» на правой панели.

- Выберите Microsoft Word в качестве формата экспорта, а затем выберите «Документ Word».
- Нажмите «Экспорт». Если ваш PDF-файл содержит отсканированный текст, конвертер Acrobat Word автоматически запустит распознавание текста.
Другие элементы…
Существует ли бесплатное программное обеспечение для распознавания текста?
7 лучших бесплатных приложений OCR для преобразования изображений в текст
- OCR с использованием Microsoft OneNote. Microsoft OneNote имеет расширенные функции распознавания текста, которые работают как с изображениями, так и с рукописными заметками. …
- Простое распознавание символов. …
- Сканирование фотографий. …
- (a9t9) Бесплатное приложение для распознавания текста для Windows. …
- Захват2Текст. …
- OCR сканирования изображения. …
- OCR с документами Google.
Что делает сканирование и распознавание текста в Adobe?
OCR — это сокращение от оптического распознавания символов, технологии, которая преобразует печатные документы в файлы цифровых изображений. Это цифровой копировальный аппарат, который использует автоматизацию для преобразования отсканированного документа в машиночитаемые PDF-файлы, которые вы можете редактировать и делиться ими.
Это цифровой копировальный аппарат, который использует автоматизацию для преобразования отсканированного документа в машиночитаемые PDF-файлы, которые вы можете редактировать и делиться ими.
Является ли Google OCR бесплатным?
Google Диск предоставляет быстрый и простой способ конвертировать изображения и PDF-файлы в редактируемый текст бесплатно с помощью встроенной функции OCR.
Как преобразовать PDF в Word без OCR?
Как конвертировать PDF в Word без OCR
- Перейдите к нашему конвертеру PDF в Word.
- Выберите файл, который хотите преобразовать. …
- Нажмите кнопку Преобразовать в Word.
- Загрузите преобразованный файл на свой компьютер или сохраните его в DropBox или Google Drive.
Что такое PDF с возможностью поиска?
PDF-файлы с возможностью поиска
Текстовый слой добавляется к слою изображения, обычно расположенному под . Такие PDF-файлы почти неотличимы от исходных документов и полностью доступны для поиска. Текст в доступных для поиска документах PDF можно выбирать, копировать и размечать.
Такие PDF-файлы почти неотличимы от исходных документов и полностью доступны для поиска. Текст в доступных для поиска документах PDF можно выбирать, копировать и размечать.
Как удалить текст из отсканированного файла PDF?
2. Удалить текст из отсканированного PDF-файла
- Открытие PDF-файла: нажмите кнопку «Открыть PDF-файл», чтобы открыть PDF-документ.
- Выберите страницу с конфиденциальным содержимым: наведите указатель мыши на список страниц и щелкните страницу с нежелательным содержимым.
- Выберите инструмент «Ластик» и «Стереть»: …
- Сохранить стертый PDF:
Могу ли я что-то отсканировать, а затем отредактировать?
Оптическое распознавание символов или OCR — это широко распространенная технология, позволяющая сканировать документы и превращать их в редактируемые электронные копии, которые затем можно легко редактировать . Многие производители программного обеспечения предлагают OCR, например Adobe OCR. Microsoft является одним из таких производителей программного обеспечения.
Microsoft является одним из таких производителей программного обеспечения.
Можете ли вы что-нибудь отсканировать и превратить в документ Word?
Лучший способ отсканировать документ в Microsoft Word — использовать наше бесплатное приложение Office Lens на смартфоне или планшете . Он использует камеру вашего устройства для захвата документа и может сохранять непосредственно в формате Word в виде редактируемого документа. Оно доступно бесплатно на iPad, iPhone, Windows Phone и Android.
Как сделать PDF доступным для поиска без Acrobat?
Как сделать файл PDF доступным для поиска в Интернете с помощью OCR
- Доступ к онлайн-конвертеру PDF в Word.
- Перетащите файл PDF в синюю панель инструментов.
- Выберите параметр «Преобразовать в Word с OCR».
- Загрузите файл Word с доступным для поиска содержимым.
- Щелкните «Word to PDF» в нижнем колонтитуле, чтобы сохранить его как PDF-файл с возможностью поиска.

25 октября 2019 г.
Как искать текст на изображении в PDF?
После того, как вы воспользуетесь инструментом «Распознать текст» для преобразования отсканированного изображения в пригодный для использования файл PDF, вы сможете выбирать и выполнять поиск по тексту в этом файле, что упрощает поиск, изменение и повторное использование информации из ваших старых бумажных документов. Выберите инструмент «Найти текст» и введите текст для поиска в поле «Найти». .
Как преобразовать JPEG в PDF с возможностью поиска?
Как конвертировать файлы JPG и отсканированные документы в PDF:
- Откройте файл в Acrobat.
- Щелкните инструмент «Улучшить сканирование» на правой панели.
- Выберите файл, который хотите преобразовать. Чтобы начать, выберите «Выбрать файл» и нажмите «Пуск». …
- Отредактируйте свой PDF-файл: щелкните значок «Исправить подозреваемые» (увеличительное стекло).
 …
… - Сохранить как новый файл PDF:
Как редактировать PDF без Adobe?
Нажмите «Создать» на странице Документов Google и загрузите файл на диск. После загрузки файла в главном окне щелкните файл правой кнопкой мыши и выберите «Открыть с помощью», а затем «Документы Google». В вашем браузере откроется новая вкладка с редактируемым содержимым.
Где находится инструмент редактирования в Adobe?
Войдите в меню Инструменты и выберите Редактировать. Выберите «Выбрать файл» и найдите свой PDF-файл. Выберите нужный тип редактирования в раскрывающемся меню «Пометить для редактирования». Функция «Текст и изображения» работает со словами и графикой, «Страница» затемняет целые страницы, а «Найти текст» позволяет находить определенные фразы.
Как редактировать PDF?
Как редактировать файлы PDF:
- Откройте файл в Acrobat.
- Щелкните инструмент «Редактировать PDF» на правой панели.
