
Распознавание текста онлайн с картинки или фото: Сервисы
Сегодня распознавание текста доступно не только с помощью специальных программ, которые нужно устанавливать на компьютер, эта услуга также может предоставляться в режиме онлайн.
Это означает, что пользователь заходит на определенный сайт, загружает исходную картинку, нажимает на одну или несколько кнопок и совершенно спокойно получает файл, который он может редактировать, в формате Microsoft Word.
Хотя, в некоторых случаях человек получает просто текст, который он уже самостоятельно может скопировать в Ворд и редактировать.
Мы разберем 5 лучших на сегодняшний день сервисов, которые прекрасно справляются со своей задачей и являются самыми удобными в использовании.
Содержание:
- img2txt
- Online-Ocr
- Free OCR
- New OCR или Free Online OCR
- ABBY Fine Reader online
Достаточно простой, возможно, самый простой в нашем списке, сервис, который не имеет каких-то особых «фишек». Зато с распознаванием текста с картинки он справляется просто прекрасно.
Зато с распознаванием текста с картинки он справляется просто прекрасно.
Список поддерживаемых форматов исходного изображения достаточно короткий – пользователь может загрузить только jpg, jpeg, png и bmp. Впрочем, этого вполне достаточно.
Кроме того, максимальный размер фото составляет 4 Мб. Опять же, на сегодняшний день это нормально, так как большинство картинок весят меньше.
С другой стороны, не каждому захочется перед использованием img2txt заходить еще на какие сервисы для конвертации и сжатия изображения. А если еще придется скачать какую-то программу, то тем более.
Преимущества img2txt такие:
- большое количество поддерживаемых языков;
- постоянная и реальная связь с разработчиками;
- все распознанные изображения можно просмотреть в разделе «Мои запросы»;
- максимальная простота.
Использование img2txt крайне простое.
Сначала необходимо нажать на кнопку «Выберете файл», загрузить исходник и нажать на кнопку «Загрузить».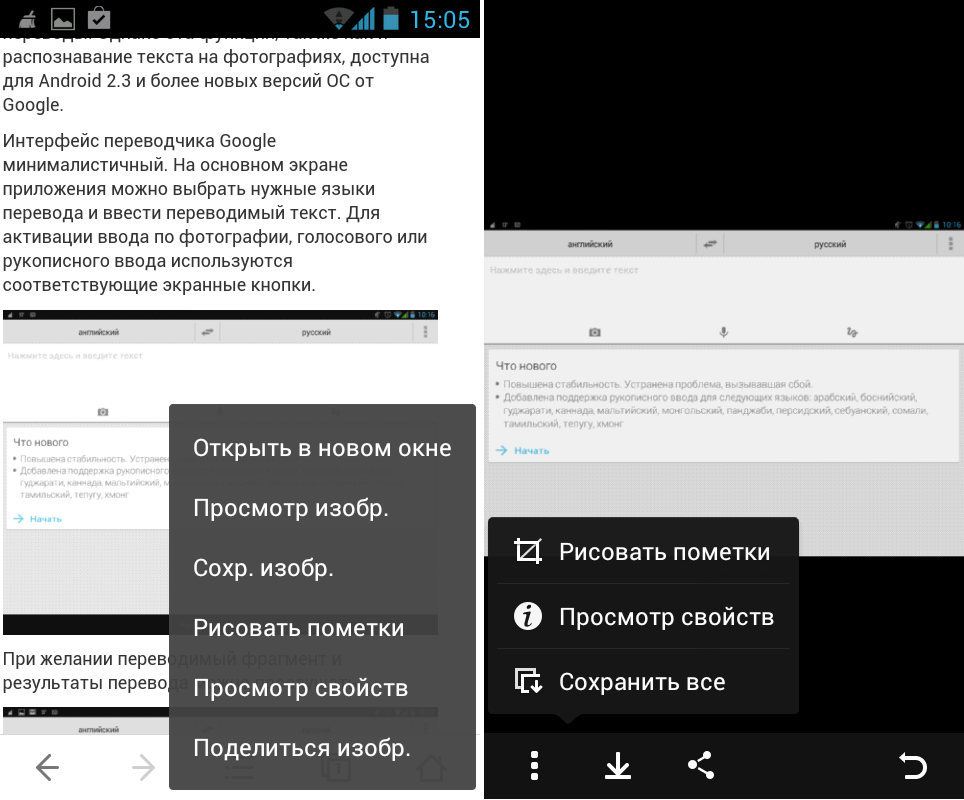
Затем нужно будет выбрать язык, на котором написан текст в нем, и нажать на кнопку «Начать распознавание». Результат будет представлен в отдельном окне в виде текста, который можно там же отредактировать или скопировать.
Рис. №1. Использование сервиса img2txt
Этот сервис не особо сильно отличается по функционалу от предыдущего и выполняет те же функции. Только в данном случае основное направление работы заключается в конвертации файлов pdf в один из форматов Word.
Это означает, что в результате Вы получаете не просто текст, который можно скопировать и дальше работать с ним, Вы получаете полноценный файл в формате Ворд.
Разумеется, такой подход намного более прогрессивен и удобен для пользователя.
Конечно, распознавание с фото здесь тоже присутствует.
Кроме pdf, в качестве исходников можно брать файлы в форматах jpg, bmp, tiff gif.
Опять же, в некоторых случаях возникнет необходимость конвертации, но это небольшая жертва, так как Online-Ocr работает действительно хорошо и ради этого можно немного потрудиться. При этом максимальный размер исходника здесь больше – 5 Мб.
При этом максимальный размер исходника здесь больше – 5 Мб.
Преимущества сервиса состоят в следующем:
- также большое количество языков, с которыми работает Online-Ocr;
- возможность конвертации в doc, docx и txt;
- есть бонусная программа;
- у каждого есть свой аккаунт, хотя распознавать файлы можно и без регистрации, бесплатно.
Чтобы использовать Online-Ocr, необходимо выполнить три шага, которые, собственно, указаны на самой странице с распознаванием.
Сначала нужно выбрать исходный файл, делается это путем нажатия кнопки «Select file…». Затем выбирается язык исходника и формат выходного файла. После этого остается просто нажать на кнопку «Convert» и процесс распознавания начнется.
Рис. №2. Процесс использования Online-Ocr
Несмотря на то, что название этого сервиса созвучно с Online-Ocr, у этих сайтов нет практически ничего общего, кроме предназначения.
В данном случае интерфейс еще проще, все функции также сосредоточены на одной единственной странице и не разделяются на несколько – так действительно легче.
Кроме того, очень важно, что здесь исходный файл можно загружать не только с компьютера, но и с какого-то другого сайта. То есть пользователь может ввести URL, где хранится исходник. После этого сервис автоматически скачает его и распознает.
Доступных форматов здесь еще больше – jpg, png, bmp, pdf, jpeg, tiff, tif, gif и, конечно же, pdf. Больше и допустимый размер исходной картинки – 6 Мб.
Другие преимущества данного сервиса такие:
- возможность использовать ссылку на исходную картинку;
- большое количество поддерживаемых форматов;
- также много поддерживаемых языков;
- подробные инструкции (правда, только на английском).
А использовать Free OCR крайне просто.
Сначала необходимо загрузить файл или указать ссылку на него в полях сверху, поставить галочку напротив языка, на котором написан текст. А в конце останется просто нажать на кнопку «Start».
Результат также будет представлен в отдельном окне, а не в файле Word. Но его можно скачать в формате txt.
Но его можно скачать в формате txt.
Рис. №3. Использование Free OCR
Здесь все характеристики еще лучше, а преимущества более очевидные.
Так среди форматов исходных файлов присутствуют не только традиционные jpeg, png, gif, bmp, tiff, а еще и jfif, pbm, pgm, ppm, pcx, bzip2. Есть даже такая экзотика как bzip, gzip и djvu. Кроме того, можно даже взять docx и odt.
Конечно же, Вы можете использовать pdf в качестве исходника. Результат можно будет скачать в формате doc, txt и, опять же, pdf.
Доступных языков здесь аж 58 и ограничений на количество распознаваний нет. Мы об этом не говорили, но у всех предыдущих сервисов они есть, правда они очень большие и рядовой пользователь вряд ли до них дойдет.
Таким образом, можно выделить следующие преимущества New OCR:
- большое количество исходных форматов;
- большое количество языков;
- возможно переворачивать изображение.
Пользоваться сервисом еще проще.
Сначала с помощью кнопки «Выберите файл» указываем исходник, а в поле ниже вписываем возможные языки, на которых он написан. Жмем «Upload». Откроется новая страница, на которой изображение можно еще и повернуть.
После этого нужно нажать на кнопку «OCR». Внизу, под картинкой будет результат. Если нажать на «Download», появится список форматов, в которых результат можно загрузить.
Рис. №4. Использование New OCR
Всемирно известная программа с таким же названием, которая предназначена для распознавания картинок со сканера, давно снискала огромное уважение среди пользовательской общественности.
Теперь то же самое делает и онлайн сервис с тем же предназначением. Здесь больше языков, чем во всех предыдущих сервисах. А размер исходника может быть аж 100 Мб.
Правда, доступных форматов исходных файлов здесь не так уж и много.
Преимущества ABBY Fine Reader online такие:
- большое количество форматов выходных файлов;
- множество языков;
- богатый функционал.

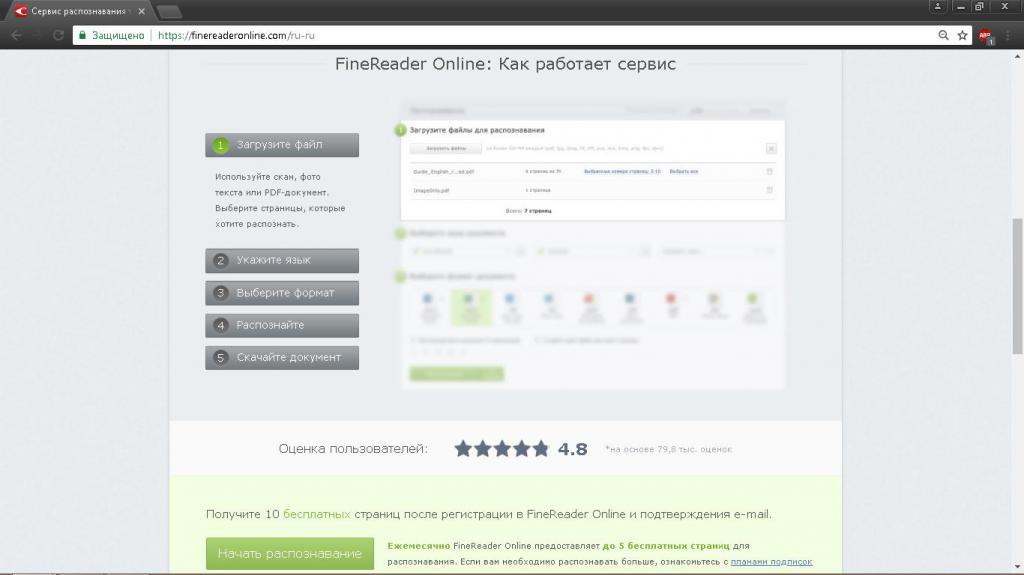
Чтобы использовать ABBY Fine Reader online, необходимо перейти на вкладку «Распознавание». Дальше с помощью кнопки «Загрузить файлы» необходимо выполнить соответствующую операцию.
На следующем шаге предстоит выбрать язык – всего их можно выбрать аж 3. Дальше останется выбрать формат выходного файла, а их здесь очень много.
Рис. №5. Использование ABBY Fine Reader online
Более подробно об использовании ABBY Fine Reader online можно узнать из видео ниже.
Интернет Сервисы
Отзывы
Машины, читающие архив: программное обеспечение для распознавания рукописного текста
Любой исследователь, который использовал онлайн-архивы газет, репозитории оцифрованных книг или даже такие ресурсы, как «Кабинетные документы» Национального архива в Интернете, признает революцию, созданную технологией оптического распознавания символов (OCR). Именно эта технология позволяет нам искать не только название или дату, но и слова, написанные внутри книги, газеты или архивного документа. OCR изменил способ проведения исследований многими учеными и открыл огромные области научных исследований, которые ранее были невообразимы. Для тех из нас, кто работает с архивными коллекциями, эта революция всегда сопровождалась одной оговоркой: OCR не работает с рукописными документами. Именно по этой причине мы так взволнованы новой платформой под названием Transkribus, разработанной проектом READ, финансируемым ЕС. Это впервые дает возможность использовать компьютеры для «чтения» рукописных документов.
Именно эта технология позволяет нам искать не только название или дату, но и слова, написанные внутри книги, газеты или архивного документа. OCR изменил способ проведения исследований многими учеными и открыл огромные области научных исследований, которые ранее были невообразимы. Для тех из нас, кто работает с архивными коллекциями, эта революция всегда сопровождалась одной оговоркой: OCR не работает с рукописными документами. Именно по этой причине мы так взволнованы новой платформой под названием Transkribus, разработанной проектом READ, финансируемым ЕС. Это впервые дает возможность использовать компьютеры для «чтения» рукописных документов.
PROB 11/2105/1 – Вы можете прочитать это завещание от 1849 года?
Технология, лежащая в основе Transkribus, все еще очень нова, и Национальный архив запустил пилотный проект для проверки возможности использования этого типа программного обеспечения для распознавания рукописного текста (HTR). Для этого проекта мы решили сосредоточиться на нашей коллекции завещаний PROB 11. Причины этого в значительной степени были обусловлены технологиями; эти тома содержат копии завещаний клерков, поэтому почерк очень однороден, и они являются юридическими документами и, следовательно, имеют структурированные языковые модели. Они также представляют собой необыкновенную коллекцию документов, содержащих сведения о людях, местах, материальных благах, социальных и экономических связях и других факторах во времени и пространстве. Однако, как скажет вам любой, кто пользовался этими документами, их не так-то просто читать — по этой причине они оказались отличным тестом для этой новой технологии.
Причины этого в значительной степени были обусловлены технологиями; эти тома содержат копии завещаний клерков, поэтому почерк очень однороден, и они являются юридическими документами и, следовательно, имеют структурированные языковые модели. Они также представляют собой необыкновенную коллекцию документов, содержащих сведения о людях, местах, материальных благах, социальных и экономических связях и других факторах во времени и пространстве. Однако, как скажет вам любой, кто пользовался этими документами, их не так-то просто читать — по этой причине они оказались отличным тестом для этой новой технологии.
Программное обеспечение Transkribus работает путем обучения модели точной транскрипции документов. Исследователи загружают изображения некоторых своих документов, а затем сопоставляют правильную транскрипцию с текстом на изображениях. Это позволяет модели изучить стиль движений рук и языка. Эти обучающие данные называются «наземной истиной». Затем обученную модель можно использовать для автоматической расшифровки похожих типов документов с точки зрения языка, почерка и т. д. Как и следовало ожидать, чем больше обучающих данных вы вводите, тем лучших результатов вы можете добиться от своей модели.
д. Как и следовало ожидать, чем больше обучающих данных вы вводите, тем лучших результатов вы можете добиться от своей модели.
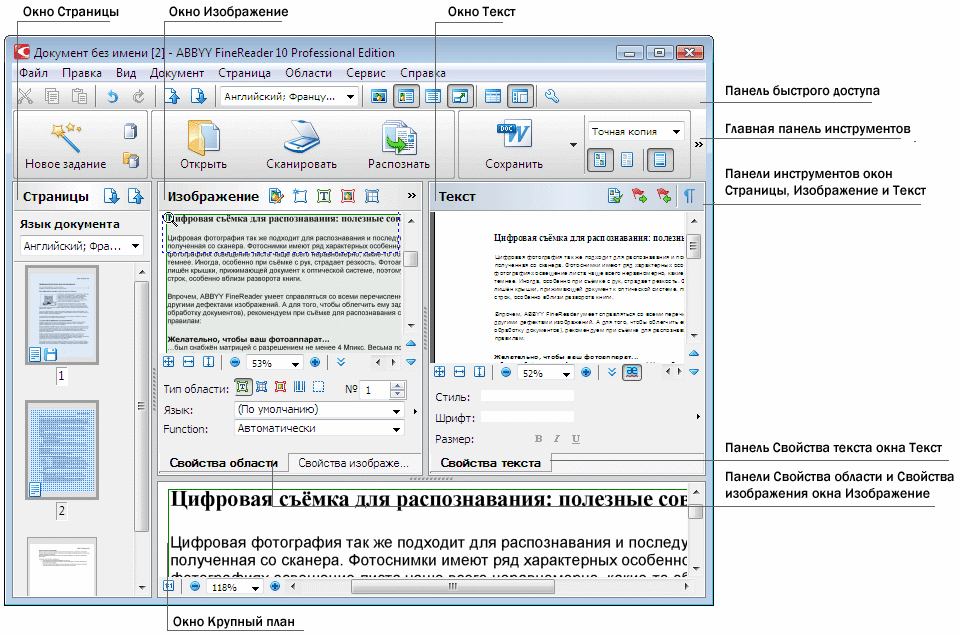
Сегментация — добавление текстовых областей и базовых линий
Первым этапом процесса HTR является загрузка изображений ваших документов на платформу, а затем выполнение задачи, называемой сегментацией. Это влечет за собой определение «текстовых областей» и строк текста. По сути, это говорит программе, где искать текст. Этот процесс в значительной степени автоматизирован, но иногда необходимо проверять и корректировать результаты. Как только это будет завершено, вы можете либо загрузить свои тренировочные данные, либо, когда у вас есть модель, запустить программное обеспечение HTR для автоматической транскрипции.
Добавление «наземных» транскрипций
Мы начали экспериментировать с программным обеспечением некоторое время назад и получили хорошие результаты от модели, обученной на относительно небольшом наборе обучающих данных (примерно 15 000 слов). Точность транскрипции OCR и HTR измеряется с точки зрения частоты ошибок в словах (WER) и частоты ошибок в символах (CER). Наша первая модель достигла WER 39% и CER 21%. Воодушевленные этими цифрами, мы подготовили еще несколько обучающих данных и разработали новую модель, основанную примерно на 37 000 слов. К счастью, это показало значительный шаг вперед в точности, с WER 28% и CER 14%.
Точность транскрипции OCR и HTR измеряется с точки зрения частоты ошибок в словах (WER) и частоты ошибок в символах (CER). Наша первая модель достигла WER 39% и CER 21%. Воодушевленные этими цифрами, мы подготовили еще несколько обучающих данных и разработали новую модель, основанную примерно на 37 000 слов. К счастью, это показало значительный шаг вперед в точности, с WER 28% и CER 14%.
Сравнение правильного текста с автоматически созданной транскрипцией
Это был хороший результат, но ясно, что более четверти всех слов были неправильными, а значит, еще многое предстоит сделать. Проблема заключалась в том, что расшифровка большого количества этих завещаний — сложная и трудоемкая операция. Поэтому мы обратились к нашему сообществу онлайн-добровольцев, чтобы помочь разработать больший набор обучающих данных. Благодаря потрясающей работе ряда преданных делу людей мы быстро накопили дополнительные 60 000 слов транскрипции, которые в настоящее время используются для обучения новой и улучшенной модели.
Мы возлагаем большие надежды на то, чего сможет достичь эта новая модель, но я думаю, будет справедливо сказать, что пройдет некоторое время, прежде чем мы сможем полагаться исключительно на компьютеры, чтобы читать все эти хитрые рукописные документы для нас. . Между тем, этот тип технологии предлагает другие потенциальные возможности, прежде всего с точки зрения поиска по ключевым словам, что может оказать более глубокое влияние на архивные коллекции в краткосрочной перспективе. Проще говоря, вы можете использовать этот тип технологии для поиска рукописных документов, даже если уровень точности недостаточно хорош для создания транскрипции. Это связано с тем, что транскрипция может показать только одну возможность для слова на странице, тогда как само программное обеспечение предлагает несколько вариантов для каждого слова. Используя умные инструменты, вы можете искать эти несколько вариантов с гораздо большей вероятностью найти правильное слово.
Технологии этого типа могут революционизировать методы работы исследователей с архивными коллекциями, и мы очень рады экспериментировать с ними. Однако эта работа возможна только благодаря приверженности и самоотверженности наших добровольцев, которые проделали большую часть основной работы с точки зрения транскрипции. Это еще раз подчеркивает взаимосвязь между захватывающими новыми цифровыми технологиями и более традиционной архивной практикой.
Однако эта работа возможна только благодаря приверженности и самоотверженности наших добровольцев, которые проделали большую часть основной работы с точки зрения транскрипции. Это еще раз подчеркивает взаимосвязь между захватывающими новыми цифровыми технологиями и более традиционной архивной практикой.
Мы продолжаем эту работу с использованием HTR и скоро сообщим о ходе работы с нашей новой моделью.
OCR Online: PDF в Word
Загрузите PDF-файл или изображение.
Скачать как редактируемый текст.
OCR Online
Если у вас есть много физических документов, которые необходимо оцифровать, или если вы часто работаете с отсканированными PDF-файлами, программное обеспечение OCR может сэкономить вам много времени и усилий. Технология оптического распознавания символов не идеальна и может привести к ошибкам при преобразовании текста, но в целом она очень точна и может быть полезным инструментом для всех, кому необходимо работать с отсканированными документами или изображениями. Итак, если вы еще не пробовали онлайн-инструмент OCR SuperTool, стоит попробовать его сегодня!
Итак, если вы еще не пробовали онлайн-инструмент OCR SuperTool, стоит попробовать его сегодня!
PDF в MS Word
Этот SuperTool преобразует PDF в документ .docx или Word, а также упрощает копирование и вставку текста предварительно просматриваемой страницы. Документ Word отформатирован с разрывами строк, как показано в PDF.
OCR JPEG и PNG
Этот онлайн-инструмент OCR SuperTool работает с несколькими форматами изображений, такими как JPEG и PNG. Загрузите свое изображение сегодня, чтобы прочитать этот текст! Сделайте фото на свой телефон, а затем конвертируйте его здесь!
Почему OCR?
OCR (оптическое распознавание символов) — это технология, позволяющая сканировать документ или изображение и преобразовывать текст в цифровой формат, который можно редактировать, искать и копировать. Некоторые общие вещи, которые люди ищут в сочетании с OCR, включают:
- Программное обеспечение сканера. Многие люди используют сканеры для оцифровки физических документов, и они могут искать программное обеспечение OCR, которое можно использовать вместе со сканером для преобразования отсканированных документов в текстовые файлы.
- Средства редактирования PDF: OCR часто используется для редактирования отсканированных PDF-файлов, поэтому люди могут искать инструменты редактирования PDF, включающие функции OCR.
- Языковая поддержка: программное обеспечение OCR часто может распознавать текст на нескольких языках, поэтому люди могут искать программное обеспечение OCR, поддерживающее определенный язык. OCR SuperTool работает с десятками языков со всего мира.
- Точность: технология OCR не идеальна и может привести к ошибкам при преобразовании текста. Люди могут искать программное обеспечение OCR, которое, как известно, имеет высокие показатели точности. Что ж, OCR SuperTool — один из лучших!
- Интеграция с другим программным обеспечением: Некоторые люди могут искать программное обеспечение OCR, которое можно легко интегрировать с другими инструментами или программным обеспечением, которое они используют, например, с текстовыми процессорами или системами управления документами. Мы можем разработать рабочие процессы всех типов, основанные на OCR.
 Свяжитесь с нами для получения подробной информации.
Свяжитесь с нами для получения подробной информации.
Преобразование отсканированного PDF в Word
Распознавание этого PDF и превращение его в документ Word! Существует множество различных типов документов, для которых люди используют OCR, в том числе:
- Физические документы: программное обеспечение OCR часто используется для оцифровки физических документов, таких как контракты, счета-фактуры и формы. Сканируя эти документы и используя OCR для преобразования текста в цифровой формат, вы можете хранить и упорядочивать свои документы в электронном виде, упрощая доступ к ним и обмен ими.
- Отсканированные PDF-файлы: OCR часто используется для редактирования отсканированных PDF-файлов. Если у вас есть отсканированный PDF-файл, который необходимо отредактировать, вы можете использовать онлайн-программу распознавания текста SuperTool для преобразования отсканированного PDF-файла в текстовый документ, который вы можете редактировать и даже сохранять как новый PDF-файл (сначала загрузите как документ Word, затем изменить, Печать как новый PDF).

- Изображения с текстом: программное обеспечение OCR также можно использовать для извлечения текста из изображений, таких как фотографии или снимки экрана. Это может быть полезно, если вам нужно извлечь текст из изображения для использования в документе или для других целей.
- Рукописные документы: наше программное обеспечение OCR способно распознавать рукописный текст, что может быть полезно для оцифровки рукописных заметок или документов.
- Исторические документы: программное обеспечение OCR можно использовать для оцифровки и сохранения исторических документов, таких как старые газеты или рукописи.
В целом, OCR — полезный инструмент для всех, кому необходимо работать с отсканированными документами или изображениями в личных или профессиональных целях. Используя OCR, вы можете сэкономить время и усилия, преобразовывая отсканированные документы в цифровой формат и извлекая текст из изображений.
Количество страниц
Примечание.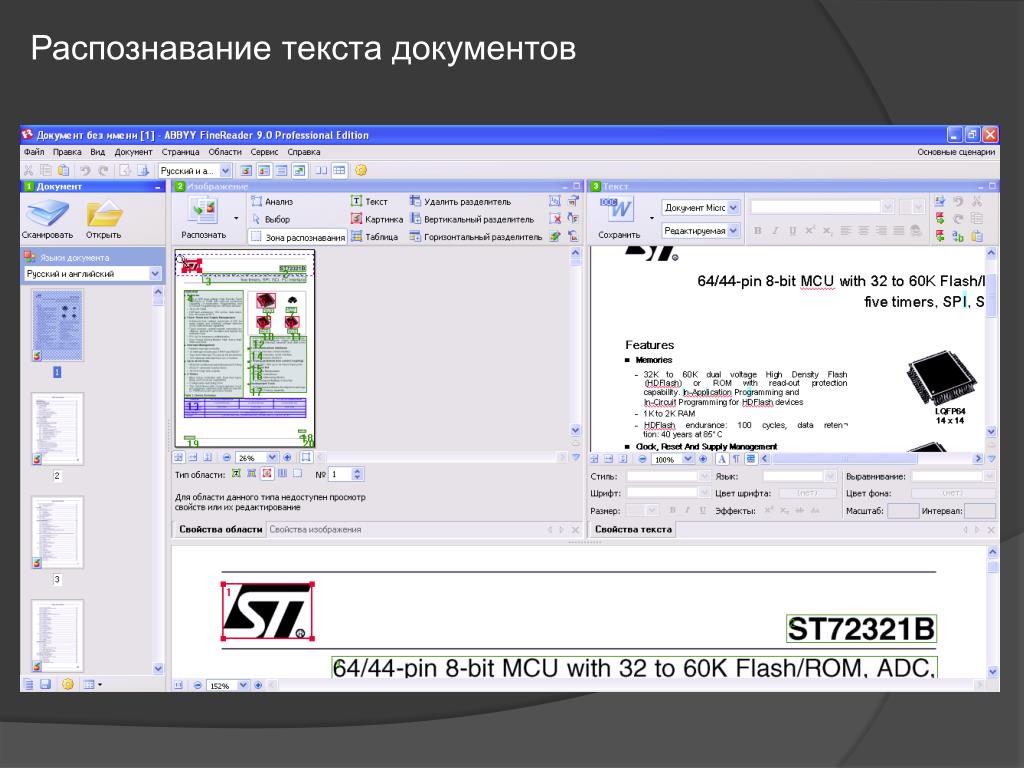 Каждая страница с OCR считается одной загрузкой. Например, загруженный 10-страничный файл PDF считается как 10 страниц или 10 загрузок. Кроме того, каждая просмотренная страница вычитается из вашего пособия. Нажмите «Зарегистрироваться» в приложении выше, чтобы узнать цены и узнать больше о планах. Обращайтесь к нам с вопросами о ценах: мы стремимся быть честными и предлагаем одни из самых низких цен на оптическое распознавание символов (и, возможно, самые низкие за высокое качество, которое мы предлагаем!)
Каждая страница с OCR считается одной загрузкой. Например, загруженный 10-страничный файл PDF считается как 10 страниц или 10 загрузок. Кроме того, каждая просмотренная страница вычитается из вашего пособия. Нажмите «Зарегистрироваться» в приложении выше, чтобы узнать цены и узнать больше о планах. Обращайтесь к нам с вопросами о ценах: мы стремимся быть честными и предлагаем одни из самых низких цен на оптическое распознавание символов (и, возможно, самые низкие за высокое качество, которое мы предлагаем!)
24-часовой план: 300 страниц
Ежемесячный план: 2 000 страниц
Годовой план: 50 000 страниц
Сделать PDF доступным для поиска
Распознавание PDF-файла, чтобы вы могли искать в нем слова или фразы по вашему выбору! Поиск в отсканированных или растровых файлах PDF невозможен. Однако, как только вы распознаете текст и преобразуете его в документ Word, вы сможете легко выполнять поиск. Попробуйте и посмотрите/поищите сами!
Можно ли использовать Adobe Acrobat для распознавания текста?
Adobe Acrobat — это мощный инструмент для редактирования PDF-файлов, предлагающий широкий спектр функций, в том числе возможность добавлять и удалять текст и изображения, комментировать и выделять PDF-файлы, заполнять и сохранять PDF-формы и многое другое. Однако одна функция, недоступная в Adobe Acrobat, — это возможность редактировать текст в отсканированном PDF-файле. Если у вас есть отсканированный PDF-файл, который необходимо отредактировать, вам потребуется программное обеспечение OCR (оптическое распознавание символов), чтобы преобразовать отсканированный PDF-файл в текстовый документ, который вы можете редактировать.
Однако одна функция, недоступная в Adobe Acrobat, — это возможность редактировать текст в отсканированном PDF-файле. Если у вас есть отсканированный PDF-файл, который необходимо отредактировать, вам потребуется программное обеспечение OCR (оптическое распознавание символов), чтобы преобразовать отсканированный PDF-файл в текстовый документ, который вы можете редактировать.
Существует ряд доступных программ оптического распознавания символов, как бесплатных, так и платных. Эти инструменты позволяют сканировать PDF-файл или изображение и преобразовывать текст в цифровой формат, который можно редактировать, искать и копировать. Преобразование SuperTool Online OCR основано на сложном искусственном интеллекте и компьютерном зрении, которых нет в бесплатных службах OCR. Хорошей новостью является то, что OCR SuperTool обеспечивает более точный вывод.
Пять способов подумать о том, что делает OCR!
- Распознавание текста: OCR или оптическое распознавание символов — это технология, используемая для распознавания и извлечения текста из отсканированных документов или изображений.
 Его часто называют распознаванием текста из-за этой способности распознавать и извлекать текст.
Его часто называют распознаванием текста из-за этой способности распознавать и извлекать текст. - Сканирование документов: OCR часто используется для оцифровки физических документов путем их сканирования и преобразования текста в цифровой формат. В результате ее часто называют технологией сканирования документов.
- Редактирование PDF: OCR часто используется для редактирования отсканированных PDF-файлов путем преобразования их в текстовые документы, которые можно редактировать и сохранять как новые PDF-файлы. Из-за этого OCR иногда называют инструментом редактирования PDF.
- Преобразование изображения в текст: OCR также можно использовать для извлечения текста из изображений, таких как фотографии или снимки экрана. Эта способность преобразовывать изображения в текст — еще одна причина, по которой OCR часто называют инструментом преобразования изображения в текст.
- Распознавание рукописного ввода: некоторые программы OCR способны распознавать рукописный текст, что может быть полезно для оцифровки рукописных заметок или документов.
 В результате OCR иногда называют программным обеспечением для распознавания рукописного ввода.
В результате OCR иногда называют программным обеспечением для распознавания рукописного ввода.
Supported Languages
| Afrikaans |
| Albanian |
| Arabic (العربية) |
| Armenian |
| Belarusian |
| Bengali |
| Bulgarian |
| Catalan |
| Chinese |
| Croatian |
| Czech |
| Danish |
| Dutch |
| English |
| Estonian |
| Filipino |
| Финский |
| Французский |
| Немецкий |
| Греческий |
| Gujarati (ગુજરાતી) |
| Hebrew (עברית) |
| Hindi (हिन्दी) |
| Hungarian |
| Icelandic |
| Indonesian |
| Italian |
| Japanese |
| Кхмерский |
| Корейский |
| Лаосский |
| Латышский |
| Macedonian |
| Malay |
| Malayalam |
| Marathi |
| Nepali |
| Norwegian |
| Persian |
| Polish |
| Portuguese |
| Punjabi |
| Румынский |
| Русский |
| Русский |
| Сербский |
| Serbian |
| Slovak |
| Slovenian |
| Spanish |
| Swedish |
| Tamil |
| Telugu |
| Thai |
| Turkish |
| Ukrainian |
| Вьетнамский |
| Идиш |
Отправьте сообщение, чтобы сообщить нам, как этот онлайн-инструмент OCR работает для вас.