
что это такое, и как это может быть выгодно вашей компании
Компания-разработчик мобильных приложений MOBGEN опубликовала на портале Medium.com статью, в которой рассказала о существующих решениях, принципах работы и перспективах развития технологий в области распознавания изображений. Как эта технология устроена, и как это может помочь вашему бизнесу, читайте далее.
Что такое технология распознавания изображений?
Распознавание изображений (некоторые также называют «компьютерным зрением») это технология, которая создана получать, обрабатывать, анализировать, и понимать изображения реального мира, с целью предоставить цифровую или символьную информацию.
Что вы сказали?
Не беспокойтесь. Мы понимаем, что это сложно. Позвольте перефразировать: когда вы загружаете свою фотографию, или фотографию ваших друзей на Facebook, все лица будут распознаны и пользователи будут автоматически отмечены: это и называется распознаванием изображений.

Хорошо, это звучит намного понятнее
Прекрасно! Потому что сейчас будет еще сложнее… Компьютерное зрение – очень широкая область компьютерных наук, так как сюда вовлечено множество аспектов, таких как машинное обучение, интеллектуальный анализ данных, расширение базы знаний, распознавание шаблонов, и другие. Исследования в данной области привели к технологиям, которые имитируют человеческое зрение. И для того, чтобы создать программное обеспечение, способное видеть, вам для начала понадобится пара линз.
Что вы имеете в виду?
Я имею в виду, что для того, чтобы обработать изображение, вам для начала нужно его снять с помощью камеры. Затем, программное обеспечение извлекает из него необходимую информацию, и после этого, совершает действия, основываясь на полученных данных. До недавних пор, цифровые камеры были неприлично дорогими, имели очень низкое разрешение, и распознавание изображений было невозможно совершать в режиме реального времени. Но с приходом мобильных телефонов и высокоскоростных камер, возможности стали безграничны.

Это невозможно…
Я так не думаю. Вот ссылка на это видео. Робот использует высокоскоростные камеры для распознавания движения руки человека. Анализируя шаблоны движения руки со скоростью 500 кадров в секунду, робот способен немедленно реагировать в ответ, и в результате выигрывать. Чтобы этого добиться, камера захватывает изображение очертаний руки, формирует объект и отравляет информацию программному обеспечению, которое распознает шаблон и генерирует реакцию робота в ответ. Объект руки человека формируется 60 мс, и затем робот выполняет все вышеперечисленное за 1 мс.
Хорошо, но я думал, что речь пойдет о мобильных …
Не беспокойтесь, мы дойдем и до этого. Одной из самых вызывающих и перспективных областей является обработка и распознавание изображений для имитации человеческого зрения: восприятия изображения, обработки и дальнейшей реакции.

Самое важное направление в алгоритмах распознавания шаблонов — вероятностная классификация. Когда изображение сравнивается с набором других сохраненных изображений, задается значение (вероятность) для каждого другого изображения, с которым оно совпадает. Комбинируя несколько алгоритмов вероятностных классификаций, которые применяются к тому же набору изображений, называемых «ансамблем», предоставляется итоговая оценка для каждого изображения, которая затем используется программой для предположения, на какие изображение это похоже.
Как вы могли представить, это довольно сложно для мобильного устройства. Вы можете подумать, что мощность процессора является проблемой. Так и есть! И самое тонкое место — база данных изображений, с которыми сравнивается оригинал. На примере робота, о котором уже говорилось, Вы можете иметь только ограниченное количество изображений (камень, ножницы, бумага), с которыми можно работать, но в примере с распознаванием изображений в Facebook, невозможно сохранять лица каждого человека, кто зарегистрирован в социальной сети на мобильном устройстве (это не совсем тот способ, по которому работает данная функция; Facebook сохраняет уникальный хэш для каждого человека, используя определенные характеристики лица как основу, но пример был предоставлен исключительно для того, чтоб объяснить идею).
Вы можете подумать, что мощность процессора является проблемой. Так и есть! И самое тонкое место — база данных изображений, с которыми сравнивается оригинал. На примере робота, о котором уже говорилось, Вы можете иметь только ограниченное количество изображений (камень, ножницы, бумага), с которыми можно работать, но в примере с распознаванием изображений в Facebook, невозможно сохранять лица каждого человека, кто зарегистрирован в социальной сети на мобильном устройстве (это не совсем тот способ, по которому работает данная функция; Facebook сохраняет уникальный хэш для каждого человека, используя определенные характеристики лица как основу, но пример был предоставлен исключительно для того, чтоб объяснить идею).
Чтоб решить эту и другие проблемы, распознавание изображений обычно выполняется на стороне сервера, где процессорная мощность, либо место для хранения данных не представляет проблем. Мобильные устройства могут просто отправлять изображение, и нейронная сеть или оборудование обработают запрос.
Одну минуту! Я видел, как это работает на мобильных устройствах без соединения с интернетом
Да, но тут только часть правды. Мобильному устройству все еще необходимо отправлять изображения на сервер, также как и серверу необходимо хранить их. Как только изображения окажутся там, сервер обработает изображение, сгенерирует намного меньший хэш, и вернет обратно в приложение. И затем, к примеру, вы можете зайти в режим полета и увидеть изображение на камере телефона, сравнение будет сделано в режиме оффлайн.
Спасибо за все эти объяснения. Теперь поговорим о деле
 Baidu разработали прототип DuLight: продукт для распознавания объектов, который поможет слепым «видеть» с помощью снимков всего, что их окружает и передавая обработанные данные через наушник. Однако, на продукцию в области искусственного интеллекта обычно налагаются этические и законодательные ограничения. Возьмем, к примеру, автомобильную индустрию и беспилотные автомобили от Google. Технология готова, но предстоит еще долгий процесс, прежде чем эти машины появятся на рынке.
Baidu разработали прототип DuLight: продукт для распознавания объектов, который поможет слепым «видеть» с помощью снимков всего, что их окружает и передавая обработанные данные через наушник. Однако, на продукцию в области искусственного интеллекта обычно налагаются этические и законодательные ограничения. Возьмем, к примеру, автомобильную индустрию и беспилотные автомобили от Google. Технология готова, но предстоит еще долгий процесс, прежде чем эти машины появятся на рынке. Хорошо, но я не планирую строить беспилотный автомобиль – что может технология распознавания изображений дать моему бизнесу?
Честно говоря, многое! Существует множество мелкомасштабных методов применения технологии распознавания изображений для получения преимуществ. Так как мы говорим о мобильных устройствах, давайте рассмотрим некоторые примеры использования технологии распознавания изображений в мобильной связи. Одним из крупнейших игроков в этой области является Blippar: платформа для визуального обнаружения, которая позволяет пользователям сканировать объекты и получать их описание, что делает физический мир интерактивным игровым полем.

Но существуют и такие маркетинговые компании, такие как Makeup Genius, TrackMyMaccas, и SnapFindShop, на которые стоит взглянуть. Эти брэнды применяют распознавание изображений для изучения социального обмена и привлечения пользователей.
Так вы говорите, что технология распознавания изображений может помочь мне привлечь клиентов?
Так как мы говорим о мобильных технологиях, слово «привлечение» так или иначе, всплыло бы в течение разговора. Мир приложений вращается вокруг привлечения пользователей: если вы не преуспели в этом, то есть шанс, что пользователь просто никогда не вернется к использованию вашего приложения. Распознавание изображений даст вашему приложению огромные возможности для расширения, поскольку технология позволит Вам выйти за пределы мобильного устройства в физический мир пользователя. Ваше приложение сможет предоставить что-то более материальное, что позволит создать сильную эмоциональную связь.

Чтобы распознавать картинки, не нужно распознавать картинки / Хабр
Посмотрите на это фото.Это совершенно обычная фотография, найденная в Гугле по запросу «железная дорога». И сама дорога тоже ничем особенным не отличается.
Что будет, если убрать это фото и попросить вас нарисовать железную дорогу по памяти?
Если вы ребенок лет семи, и никогда раньше не учились рисовать, то очень может быть, что у вас получится что-то такое:
Упс. Кажется, что-то пошло не так.
Давайте еще раз вернемся к рельсам на первой картинке и попробуем понять, что не так.
На самом деле, если долго разглядывать ее, становится понятно, что она не совсем точно отображает окружающий мир. Главная проблема, о которую мы немедленно споткнулись — там, например, пересекаются параллельные прямые. Ряд одинаковых (в реальности) фонарных столбов на самом деле изображен так, что каждый следующий столб имеет все меньшие и меньшие размеры.
Все это — эффекты перспективы, последствия того, что трехмерные объекты снаружи проецируются на двумерную сетчатку внутри глаза. Ничего отдельно магического в этом нет — разве что немного любопытно, почему эти искажения контуров и линий не вызывают у нас никаких проблем при ориентации в пространстве, но вдруг заставляют мозг напрячься при попытке взяться за карандаш.
Еще один замечательный пример — как маленькие дети рисуют небо.
Небо должно быть наверху — вот она, синяя полоска, пришпиленная к верхнему краю. Середина листа при этом остается белой, заполнена пустотой, в которой плавает солнце.
И так происходит всегда и везде. Мы знаем, что куб состоит из квадратных граней, но посмотрите на картинку, и вы не увидите там ни одного прямого угла — более того, эти углы постоянно меняются, стоит сменить угол обзора. Как будто где-то в голове у нас сохранена грубая схема правильного, трехмерного объекта, и именно к ней мы обращаемся в процессе рисования рельс, не сразу успевая сопоставить результат с тем, что видим своими глазами.
Как будто где-то в голове у нас сохранена грубая схема правильного, трехмерного объекта, и именно к ней мы обращаемся в процессе рисования рельс, не сразу успевая сопоставить результат с тем, что видим своими глазами.
На самом деле все еще хуже. Каким образом, например, на самой первой картинке с дорогой мы определяем, какая часть дороги расположена ближе к нам, а какая дальше? По мере удаления предметы становятся меньше, ок — но вы уверены, что кто-то не обманул вас, коварно разместив друг за другом последовательно уменьшающиеся шпалы? Далекие объекты обычно имеют бледно-голубоватый оттенок (эффект, который называется «атмосферная перспектива») — но предмет может быть просто окрашен в такой цвет, и в остальном казаться совершенно нормальным. Мост через железнодорожные пути, который едва видно отсюда, кажется нам находящимся позади, потому что его заслоняют фонари (эффект окклюзии) — но опять-таки, как вы можете быть уверены, что фонари просто не нарисованы на его поверхности? Весь этот набор правил, с помощью которых вы оцениваете трехмерность сцены, во многом зависит от вашего опыта, и возможно, генетического опыта ваших предков, обученных выживать в условиях нашей атмосферы, падающего сверху света и ровной линии горизонта.
Сама по себе, без помощи мощной аналитической программы в вашей голове, наполненной этим визуальным опытом, любая фотография говорит об окружающем мире ужасно мало. Изображения — это скорее такие триггеры, заставляющие вас мысленно представить себе сцену, большая часть знаний о которой уже есть у вас в памяти. Они не содержат реальных предметов — только ограниченные, сплющенные, трагически двумерные представления о них, которые, к тому же, постоянно меняются при движении. В чем-то мы с вами — такие же жители Флатландии, которые могут увидеть мир только с одной стороны и неизбежно искаженным.
 Попробуйте выглянуть в окно и подумать, что то, что вы видите — обман, искажение, безнадежная неполноценность.
Попробуйте выглянуть в окно и подумать, что то, что вы видите — обман, искажение, безнадежная неполноценность.Представьте, что вы — нейронная сеть.
Это не должно быть очень сложно — в конце концов, как-то так оно и есть на самом деле. Вы проводите свободное время за распознаванием лиц на документах в паспортном столе. Вы — очень хорошая нейронная сеть, и работа у вас не слишком сложная, потому что в процессе вы ориентируетесь на паттерн, строго характерный именно для человеческих лиц — взаимное расположение двух глаз, носа и рта. Глаза и носы сами по себе могут различаться, какой-то один из признаков иногда может оказаться на фотографии неразличимым, но вам всегда помогает наличие других. И вдруг вы натыкаетесь вот на такое:
Хм, думаете вы. Вы определенно видите что-то знакомое — по крайней мере, в центре, кажется, есть один глаз. Правда, странной формы — он похож на треугольник, а не на заостренный овал. Второго глаза не видно. Нос, который должен располагаться посередине и между глаз, уехал куда-то совсем в край контура, а рта вы вообще не нашли — опредленно, темный уголок снизу-слева совсем на него не похож. Не лицо — решаете вы, и выбрасываете картинку в мусорное ведро.
Не лицо — решаете вы, и выбрасываете картинку в мусорное ведро.
Так бы мы думали, если бы наша зрительная система занималась простым сопоставлением паттернов в изображениях. К счастью, думает она как-то по-другому. У нас не вызывает никакого беспокойства отсутствие второго глаза, от этого лицо не становится менее похожим на лицо. Мы мысленно прикидываем, что второй глаз должен находиться по ту сторону, и форма его обусловлена исключительно тем, что голова на фото повернута и смотрит в сторону. Кажется невозможно тривиальным, когда пытаешься это объяснить на словах, но кое-кто с вами бы на полном серьезе не согласился.
Самое обидное, что не видно, как можно решить этот вопрос механическим способом. Компьютерное зрение сталкивалось с соответствующими проблемами очень давно, с момента своего появления, и периодически находило эффективные частные решения — так, мы можем опознать сдвинутый в сторону предмет, последовательно передвигая свой проверочный паттерн по всему изображению (чем успешно пользуются сверточные сети), можем справляться с отмасштабированными или повернутыми картинками с помощью признаков SIFT, SURF и ORB, но эффекты перспективы и поворот предмета в пространстве сцены — похоже, вещи качественно другого уровня. Здесь нам нужно знать, как предмет выглядит со всех сторон, получить его истинную трехмерную форму, иначе нам не с чем работать. Поэтому чтобы распознавать картинки, не нужно распознавать картинки. Они лживы, обманчивы и заведомо неполноценны. Они — не наши друзья.
Здесь нам нужно знать, как предмет выглядит со всех сторон, получить его истинную трехмерную форму, иначе нам не с чем работать. Поэтому чтобы распознавать картинки, не нужно распознавать картинки. Они лживы, обманчивы и заведомо неполноценны. Они — не наши друзья.
Итак, важный вопрос — как бы нам получать трехмерную модель всего, что мы видим? Еще более важный вопрос — как при этом обойтись без необходимости покупать лазерный пространственный сканер (сначала я написал «чертовски дорогой лазерный сканер», а потом наткнулся на этот пост)? Даже не столько по той причине, что нам жалко, а потому, что животные в процессе эволюции зрительной системы явно каким-то образом обошлись без него, одними только глазами, и было бы любопытно выяснить, как они так.
Где-то в этом месте часть аудитории обычно встает и выходит из зала, ругаясь на топтание по матчасти — все знают, что для восприятия глубины и пространства мы пользуемся бинокулярным зрением, у нас для этого два специальных глаза! Если вы тоже так думаете, у меня для вас небольшой сюрприз — это неправда. Доказательство прекрасно в своей простоте — достаточно закрыть один глаз и пройтись по комнате, чтобы убедиться, что мир внезапно не утратил глубины и не стал походить на плоский аналог анимационного мультфильма. Еще один способ — вернуться и снова посмотреть на фотографию с железной дорогой, где замечательно видно глубину даже при том, что она расположена на полностью плоской поверхности монитора.
Доказательство прекрасно в своей простоте — достаточно закрыть один глаз и пройтись по комнате, чтобы убедиться, что мир внезапно не утратил глубины и не стал походить на плоский аналог анимационного мультфильма. Еще один способ — вернуться и снова посмотреть на фотографию с железной дорогой, где замечательно видно глубину даже при том, что она расположена на полностью плоской поверхности монитора.
Для некоторых действий они, похоже, и правда приносят пользу с точки зрения оценки пространственного положения. Возьмите два карандаша, закройте один глаз и попытайтесь сдвигать эти карандаши так, чтобы они соприкоснулись кончиками грифелей где-то вблизи вашего лица. Скорее всего, грифели разойдутся, причем ощутимо (если у вас получилось легко, поднесите их еще ближе к лицу), при этом со вторым открытым глазом такого не происходит. Пример взят из книги Марка Чангизи «Революция в зрении» — там есть целая глава о стереопсисе и бинокулярном зрении с любопытной теорией о том, что два смотрящих вперед глаза нужны нам для того, чтобы видеть сквозь мелкие помехи вроде свисающих листьев. Кстати, забавный факт — на первом месте в списке преимуществ бинокулярного зрения в Википедии стоит «It gives a creature a spare eye in case one is damaged».
Кстати, забавный факт — на первом месте в списке преимуществ бинокулярного зрения в Википедии стоит «It gives a creature a spare eye in case one is damaged».
Итак, бинокулярное зрение нам не подходит — и вместе с ним мы отвергаем стереокамеры, дальномеры и Kinect. Какой бы ни была способость нашей зрительной системы воссоздавать трехмерные образы увиденного, она явно не требует наличия двух глаз. Что остается в итоге?
Я ни в коем случае не готов дать точный ответ применительно к биологическом зрению, но пожалуй, для случая абстрактного робота с камерой вместо глаза остался один многообещающий способ. И этот способ — движение.
Вернемся к теме поездов, только на этот раз выглянем из окна:
То, что мы при этом видим, называется «параллакс движения», и вкратце он заключается в том, что когда мы двигаемся вбок, близкие предметы смещаются в поле зрения сильнее, чем далекие. Для движения вперед/назад и поворотов тоже можно сформулировать соответствующие правила, но давайте их пока проигнорируем. Итак, мы собираемся двигаться, оценивать смещения предметов в кадре и на основании этого определять их расстояние от наблюдателя — техника, которая официально называется «structure-from-motion». Давайте попробуем.
Итак, мы собираемся двигаться, оценивать смещения предметов в кадре и на основании этого определять их расстояние от наблюдателя — техника, которая официально называется «structure-from-motion». Давайте попробуем.
Прежде всего — а не сделали ли все, случайно, до нас? Страница «Structure from motion» в Википедии предлагает аж тринадцать инструментов (и это только опенсорсных) для воссоздания 3D-моделей из видео или набора фотографий, большинство из них пользуются подходом под названием bundle adjustment, а самым удобным мне показался Bundler (и демо-результаты у него крутые). К сожалению, тут возникает проблема, с которой мы еще столкнемся — Bundler для корректной работы хочет знать от нас модель камеры и ее внутренние параметры (в крайнем случае, если модель неизвестна, он требует указать фокусное расстояние).
Если для вашей задачи это не проблема — можете смело бросать чтение, потому что это самый простой и одновременно эффективный метод (а знаете, кстати, что примерно таким способом делались модели в игре «Исчезнование Итана Картера»?). Для меня, увы, необходимость быть привязанным к модели камеры — это условие, которого очень хотелось бы избежать. Во-первых, потому что у нас под боком полный ютуб визуального видео-опыта, которым хотелось бы в будущем пользоваться в качестве выборки. Во-вторых (и это, может быть, даже важнее), потому что наш с вами человеческий мозг, похоже, если и знает в цифрах внутренние параметры камеры наших глаз, то прекрасно умеет приспосабливаться к любым оптическим искажениями. Взгляд через объектив широкофокусной камеры, фишай, просмотр кино и ношение окулусрифта совершенно не разрушает ваших зрительных способностей. Значит, наверное, возможен и какой-то другой путь.
Для меня, увы, необходимость быть привязанным к модели камеры — это условие, которого очень хотелось бы избежать. Во-первых, потому что у нас под боком полный ютуб визуального видео-опыта, которым хотелось бы в будущем пользоваться в качестве выборки. Во-вторых (и это, может быть, даже важнее), потому что наш с вами человеческий мозг, похоже, если и знает в цифрах внутренние параметры камеры наших глаз, то прекрасно умеет приспосабливаться к любым оптическим искажениями. Взгляд через объектив широкофокусной камеры, фишай, просмотр кино и ношение окулусрифта совершенно не разрушает ваших зрительных способностей. Значит, наверное, возможен и какой-то другой путь.
Итак, мы печально закрыли страницу с Итаном Картером википедии и опускаемся на уровень ниже — в OpenCV, где нам предлагают следующее:
1. Взять два кадра, снятые с откалиброванной камеры.
2. Вместе с параметрами калибровки (матрицей камеры) положить их оба в функцию stereoRectify, которая выпрямит (ректифицирует) эти два кадра — это преобразование, которое искажает изображение так, чтобы точка и ее смещение оказывались на одной горизонтальной прямой.
3. Эти ректифицированые кадры мы кладем в функцию stereoBM и получаем карту смещений (disparity map) — такую картинку в оттенках серого, где чем пиксель ярче, тем большее смещение он выражает (по ссылке есть пример).
4. Полученную карту смещений кладем в функцию с говорящим названием reprojectImageTo3D (понадобится еще и матрица Q, которую в числе прочих мы получим на шаге 2). Получаем наш трехмерный результат.
Черт, похоже, мы наступаем на те же грабли — уже в пункте 1 от нас требуют откалиброванную камеру (правда, OpenCV милостиво дает возможность сделать это самому). Но погодите, здесь есть план Б. В документации прячется функция с подозрительным названием stereoRectifyUncalibrated…
План Б:
1. Нам нужно оценить примерную часть смещений самим — хотя бы для ограниченного набора точек. StereoBM здесь не подойдет, поэтому нам нужен какой-то другой способ. Логичным вариантом будет использовать feature matching — найти какие-то особые точки в обоих кадрах и выбрать сопоставления. Про то, как это делается, можно почитать здесь.
Про то, как это делается, можно почитать здесь.
2. Когда у нас есть два набора соответствующих друг другу точек, мы можем закинуть их в findFundamentalMat, чтобы получить фундаментальную матрицу, которая понадобится нам для stereoRectifyUncalibrated.
3. Запускаем stereoRectifyUncalibrated, получаем две матрицы для ректификации обоих кадров.
4. И… а дальше непонятно. Выпрямленные кадры у нас есть, но нет матрицы Q, которая была нужна для завершающего шага. Погуглив, я наткнулся примерно на такой же недоумения пост, и понял, что либо я что-то упустил в теории, либо в OpenCV этот момент не продумали.
OpenCV: мы — 2:0.
4.1 Меняем план
Но погодите. Возможно, мы с самого начала пошли не совсем правильным путем. В предыдущих попытках мы, по сути, пытались определить реальное положение трехмерных точек — отсюда необходимость знать параметры камеры, матрицы, ректифицировать кадры и так далее. По сути, это обычная триангуляция: на первой камере я вижу эту точку здесь, а на второй здесь — тогда нарисуем два луча, проходящих через центры камер, и их пересечение покажет, как далеко точка от нас находится.

Это все прекрасно, но вообще говоря, нам не нужно. Реальные размеры предметов интересовали бы нас, если бы наша модель использовалась потом для промышленных целей, в каких-нибудь 3d-принтерах. Но мы собираемся (эта цель слегка уже расплылась, правда) запихивать полученные данные в нейросети и им подобные классификаторы. Для этого нам достаточно знать только относительные размеры предметов. Они, как мы все еще помним, обратно пропорциональны смещениям параллакса — чем дальше от нас предмет, тем меньше смещается при нашем движении. Нельзя ли как-то найти эти смещения еще проще, просто каким-то образом сопоставив обе картинки?
Само собой, можно. Привет, оптический поток.
Это замечательный алгоритм, который делает ровно то, что нам нужно. Кладем в него картинку и набор точек. Потом кладем вторую картинку. Получаем на выходе для заданных точек их новое положение на второй картинке (приблизительное, само собой). Никаких калибровок и вообще никаких упоминаний о камере — оптический поток, несмотря на название, можно рассчитывать на базе чего угодно. Хотя обычно он все-таки используется для слежения за объектами, обнаружения столкновений и даже дополненной реальности.
Хотя обычно он все-таки используется для слежения за объектами, обнаружения столкновений и даже дополненной реальности.
Для наших целей мы (пока) хотим воспользоваться «плотным» потоком Гуннара Фарнебака, потому что он умеет рассчитывать поток не для каих-то отдельных точек, а для всей картинки сразу. Метод доступен с помощью calcOpticalFlowFarneback, и первые же результаты начинают очень-очень радовать — смотрите, насколько оно выглядит круче, чем предыдущий результат stereoRectifyUncalibrated + stereoBM.
Большое спасибо замечательной игре Portal 2 за возможность строить собственные комнаты и играть в кубики. I’m doin’ Science!
# encoding: utf-8
import cv2
import numpy as np
from matplotlib import pyplot as plt
img1 = cv2.imread('0.jpg', 0)
img2 = cv2.imread('1.jpg', 0)
def stereo_depth_map(img1, img2):
# 1: feature matching
orb = cv2.ORB()
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb. detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
src_points = np.vstack([np.array(kp1[m.queryIdx].pt) for m in matches])
dst_points = np.vstack([np.array(kp2[m.trainIdx].pt) for m in matches])
# 2: findFundamentalMat
F, mask = cv2.findFundamentalMat(src_points, dst_points)
# 3: stereoRectifyUncalibrated
_, h2, h3 = cv2.stereoRectifyUncalibrated(src_points.reshape(src_points.shape[
0], 1, 2), dst_points.reshape(dst_points.shape[0], 1, 2), F, img1.shape)
rect1 = cv2.warpPerspective(img1, h2, (852, 480))
rect2 = cv2.warpPerspective(img2, h3, (852, 480))
# 3.5: stereoBM
stereo = cv2.StereoBM(cv2.STEREO_BM_BASIC_PRESET, ndisparities=16, SADWindowSize=15)
return stereo.compute(rect1, rect2)
def optical_flow_depth_map(img1, img2):
flow = cv2.calcOpticalFlowFarneback(img1, img2, 0. 5, 3, 20, 10, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
return mag
def plot(title, img, i):
plt.subplot(2, 2, i)
plt.title(title)
plt.imshow(img, 'gray')
plt.gca().get_xaxis().set_visible(False)
plt.gca().get_yaxis().set_visible(False)
plot(u'Первый кадр', img1, 1)
plot(u'Второй кадр (шаг вправо)', img2, 2)
plot(u'stereoRectifyUncalibrated', stereo_depth_map(img1, img2), 3)
plot(u'Первый кадр', optical_flow_depth_map(img1, img2), 4)
plt.show()
detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
src_points = np.vstack([np.array(kp1[m.queryIdx].pt) for m in matches])
dst_points = np.vstack([np.array(kp2[m.trainIdx].pt) for m in matches])
# 2: findFundamentalMat
F, mask = cv2.findFundamentalMat(src_points, dst_points)
# 3: stereoRectifyUncalibrated
_, h2, h3 = cv2.stereoRectifyUncalibrated(src_points.reshape(src_points.shape[
0], 1, 2), dst_points.reshape(dst_points.shape[0], 1, 2), F, img1.shape)
rect1 = cv2.warpPerspective(img1, h2, (852, 480))
rect2 = cv2.warpPerspective(img2, h3, (852, 480))
# 3.5: stereoBM
stereo = cv2.StereoBM(cv2.STEREO_BM_BASIC_PRESET, ndisparities=16, SADWindowSize=15)
return stereo.compute(rect1, rect2)
def optical_flow_depth_map(img1, img2):
flow = cv2.calcOpticalFlowFarneback(img1, img2, 0. 5, 3, 20, 10, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
return mag
def plot(title, img, i):
plt.subplot(2, 2, i)
plt.title(title)
plt.imshow(img, 'gray')
plt.gca().get_xaxis().set_visible(False)
plt.gca().get_yaxis().set_visible(False)
plot(u'Первый кадр', img1, 1)
plot(u'Второй кадр (шаг вправо)', img2, 2)
plot(u'stereoRectifyUncalibrated', stereo_depth_map(img1, img2), 3)
plot(u'Первый кадр', optical_flow_depth_map(img1, img2), 4)
plt.show()
 detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
src_points = np.vstack([np.array(kp1[m.queryIdx].pt) for m in matches])
dst_points = np.vstack([np.array(kp2[m.trainIdx].pt) for m in matches])
# 2: findFundamentalMat
F, mask = cv2.findFundamentalMat(src_points, dst_points)
# 3: stereoRectifyUncalibrated
_, h2, h3 = cv2.stereoRectifyUncalibrated(src_points.reshape(src_points.shape[
0], 1, 2), dst_points.reshape(dst_points.shape[0], 1, 2), F, img1.shape)
rect1 = cv2.warpPerspective(img1, h2, (852, 480))
rect2 = cv2.warpPerspective(img2, h3, (852, 480))
# 3.5: stereoBM
stereo = cv2.StereoBM(cv2.STEREO_BM_BASIC_PRESET, ndisparities=16, SADWindowSize=15)
return stereo.compute(rect1, rect2)
def optical_flow_depth_map(img1, img2):
flow = cv2.calcOpticalFlowFarneback(img1, img2, 0.
detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
src_points = np.vstack([np.array(kp1[m.queryIdx].pt) for m in matches])
dst_points = np.vstack([np.array(kp2[m.trainIdx].pt) for m in matches])
# 2: findFundamentalMat
F, mask = cv2.findFundamentalMat(src_points, dst_points)
# 3: stereoRectifyUncalibrated
_, h2, h3 = cv2.stereoRectifyUncalibrated(src_points.reshape(src_points.shape[
0], 1, 2), dst_points.reshape(dst_points.shape[0], 1, 2), F, img1.shape)
rect1 = cv2.warpPerspective(img1, h2, (852, 480))
rect2 = cv2.warpPerspective(img2, h3, (852, 480))
# 3.5: stereoBM
stereo = cv2.StereoBM(cv2.STEREO_BM_BASIC_PRESET, ndisparities=16, SADWindowSize=15)
return stereo.compute(rect1, rect2)
def optical_flow_depth_map(img1, img2):
flow = cv2.calcOpticalFlowFarneback(img1, img2, 0. 5, 3, 20, 10, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
return mag
def plot(title, img, i):
plt.subplot(2, 2, i)
plt.title(title)
plt.imshow(img, 'gray')
plt.gca().get_xaxis().set_visible(False)
plt.gca().get_yaxis().set_visible(False)
plot(u'Первый кадр', img1, 1)
plot(u'Второй кадр (шаг вправо)', img2, 2)
plot(u'stereoRectifyUncalibrated', stereo_depth_map(img1, img2), 3)
plot(u'Первый кадр', optical_flow_depth_map(img1, img2), 4)
plt.show()
5, 3, 20, 10, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
return mag
def plot(title, img, i):
plt.subplot(2, 2, i)
plt.title(title)
plt.imshow(img, 'gray')
plt.gca().get_xaxis().set_visible(False)
plt.gca().get_yaxis().set_visible(False)
plot(u'Первый кадр', img1, 1)
plot(u'Второй кадр (шаг вправо)', img2, 2)
plot(u'stereoRectifyUncalibrated', stereo_depth_map(img1, img2), 3)
plot(u'Первый кадр', optical_flow_depth_map(img1, img2), 4)
plt.show()
Итак, отлично. Смещения у нас есть, и на вид неплохие. Как теперь нам получить из них координаты трехмерных точек?
4.2 Часть, в которой мы получаем координаты трехмерных точек
Эта картинка уже мелькала на одной из ссылок выше.
Расстояние до объекта здесь рассчитывается методом школьной геометрии (подобные треугольники), и выглядит так: . А координаты, соответственно, вот так: . Здесь w и h — ширина и высота картинки, они нам известны, f — фокусное расстояние камеры (расстояние от центра камеры до поверхности ее экрана), и B — камеры же шаг. Кстати, обратите внимание, что мы тут слегка нарушаем общепринятые названия осей, когда Z направлена вверх — у нас Z смотрит «вглубь» экрана, а X и Y — соответственно, направлены по ширине и высоте картинки.
Кстати, обратите внимание, что мы тут слегка нарушаем общепринятые названия осей, когда Z направлена вверх — у нас Z смотрит «вглубь» экрана, а X и Y — соответственно, направлены по ширине и высоте картинки.
Ну, насчет f все просто — мы уже оговаривали, что реальные параметры камеры нас не интересуют, лишь бы пропорции всех предметов изменялись по одному закону. Если подставить Z в формулу для X выше, то можно увидеть, что X от фокусного расстояния вообще не зависит (f сокращается), поэтому разные его значения буду менять только глубину — «вытягивать» или «сплющивать» нашу сцену. Визуально — не очень приятно, но опять же, для алгоритма классификации — совершенно все равно. Так что зададим фокусное расстояние интеллектуальным образом — просто придумаем. Я, правда, оставляю за собой право слегка изменить мнение дальше по тексту.
Насчет B чуть посложнее — если у нас нет встроенного шагомера, мы не знаем, на какую дистанцию переместилась камера в реальном мире. Так что давайте пока немного считерим и решим, что движение камеры происходит примерно плавно, кадров у нас много (пара десятков на секунду), и расстояние между двумя соседними примерно одинаковое, т. е. . И опять же, дальше мы слегка уточним эту ситуацию, но пока пусть будет так.
е. . И опять же, дальше мы слегка уточним эту ситуацию, но пока пусть будет так.
import cv2
import numpy as np
f = 300 # раз мы занимаемся визуализацией, фокус я все-таки подобрал так, чтобы сцена выглядела условно реальной
B = 1
w = 852
h = 480
img1 = cv2.imread('0.jpg', 0)
img2 = cv2.imread('1.jpg', 0)
flow = cv2.calcOpticalFlowFarneback(img1, img2, 0.5, 3, 20, 10, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
edges = cv2.Canny(img1, 100, 200)
result = []
for y in xrange(img1.shape[0]):
for x in xrange(img1.shape[1]):
if edges[y, x] == 0:
continue
delta = mag[y, x]
if delta == 0:
continue
Z = (B * f) / delta
X = (Z * (x - w / 2.)) / f
Y = (Z * (y - h / 2.)) / f
point = np.array([X, Y, Z])
result.append(point)
result = np.vstack(result)
def dump2ply(points):
# сохраняем в формат .ply, чтобы потом открыть Блендером
with open('points. ply', 'w') as f:
f.write('ply\n')
f.write('format ascii 1.0\n')
f.write('element vertex {}\n'.format(len(points)))
f.write('property float x\n')
f.write('property float y\n')
f.write('property float z\n')
f.write('end_header\n')
for point in points:
f.write('{:.2f} {:.2f} {:.2f}\n'.format(point[0], point[2], point[1]))
dump2ply(result)
 ply', 'w') as f:
f.write('ply\n')
f.write('format ascii 1.0\n')
f.write('element vertex {}\n'.format(len(points)))
f.write('property float x\n')
f.write('property float y\n')
f.write('property float z\n')
f.write('end_header\n')
for point in points:
f.write('{:.2f} {:.2f} {:.2f}\n'.format(point[0], point[2], point[1]))
dump2ply(result)
ply', 'w') as f:
f.write('ply\n')
f.write('format ascii 1.0\n')
f.write('element vertex {}\n'.format(len(points)))
f.write('property float x\n')
f.write('property float y\n')
f.write('property float z\n')
f.write('end_header\n')
for point in points:
f.write('{:.2f} {:.2f} {:.2f}\n'.format(point[0], point[2], point[1]))
dump2ply(result)
Вот так выглядит результат. Надеюсь, эта гифка успела загрузиться, пока вы дочитали до этого места.
Для наглядности я взял не все точки подряд, а только границы, выделенные Canny-детектором
С первого взгляда (во всяком случае, мне) все показалось отличным — даже углы между гранями кубиков образовали симпатичные девяносто градусов. С предметами на заднем плане получилось похуже (обратите внимание, как исказились контуры стен и двери), но хэй, наверное, это просто небольшой шум, его можно будет вылечить использованием большего количества кадров или чем-нибудь еще.
Из всех возможных поспешных выводов, которые можно было здесь сделать, этот оказался дальше всех от истины.
В общем, основная проблема оказалась в том, что какая-то часть точек довольно сильно искажалась. И — тревожный знак, где уже пора было заподозрить неладное — искажалась не случайным образом, а примерно в одних и тех же местах, так что исправить проблему путем последовательного наложения новых точек (из других кадров) не получалось.Выглядело это примерно так:
Лестница сминается, местами превращаясь в аморфный кусок непонятно-чего.
Я очень долго пытался это починить, и за это время перепробовал следующее:
— сглаживать каринку с оптическим потоком: размытие по Гауссу, медианный фильтр и модный билатеральный фильтр, который оставляет четкими края. Бесполезно: предметы наоборот, еще сильнее расплывались.
— пытался находить на картинке прямые линии с помощью Hough transform и переносить их в неизменном прямом состоянии. Частично работало, но только на границах — поверхности по-прежнему оставались такими же искаженными; плюс никуда не получалось деть мысль в духе «а что если прямых линий на картинке вообще нет».
— я даже попытался сделать свою собственную версию оптического потока, пользуясь OpenCVшным templateMatching. Работало примерно так: для любой точки строим вокруг нее небольшой (примерно 10×10) квадрат, и начинаем двигать его вокруг и искать максимальное совпадение (если известно направление движения, то «вокруг» можно ограничить). Получилось местами неплохо (хотя работало оно явно медленнее оригинальной версии):
Слева уже знакомый поток Фарнебака, справа вышеописаный велосипед
С точки зрения шума, увы, оказалось ничуть не лучше.
В общем, все было плохо, но очень логично. Потому что так оно и должно было быть.
Иллюстрация к проблеме. Движение здесь — по-прежнему шаг вправо
Давайте выберем какую-нибудь зеленую точку из картинки выше. Предположим, мы знаем направление движения, и собираемся искать «смещенного близнеца» нашей зеленой точки, двигаясь в заданном направлении. Когда мы решаем, что нашли искомого близнеца? Когда наткнемся на какой-нибудь «ориентир», характерный участок, который похож на окружение нашей начальной точки. Например, на угол. Углы в этом отношении легко отслеживать, потому что они сами по себе встречаются довольно редко. Поэтому если наша зеленая точка представляет собой угол, и мы находим похожий угол в заданной окрестности, то задача решена.
Например, на угол. Углы в этом отношении легко отслеживать, потому что они сами по себе встречаются довольно редко. Поэтому если наша зеленая точка представляет собой угол, и мы находим похожий угол в заданной окрестности, то задача решена.
Чуть сложнее, но все еще легко обстоит ситуация с вертикальной линией (вторая левая зеленая точка). Учитывая, что мы двигаемся вправо, вертикальная линия встретится нам только один раз за весь период поиска. Представьте, что мы ползем своим поисковым окном по картинке и видим однотонный фон, фон, снова фон, вертикальный отрезок, опять фон, фон, и снова фон. Тоже несложно.
Проблема появляется, когда мы пытаемся отслеживать кусок линии, расположенной параллельно движению. У красной точки нет одного четко выраженного кандидата на роль смещенного близнеца. Их много, все они находятся рядом, и выбрать какого-то одного тем методом, что мы пользуемся, просто невозможно. Это функциональное ограничение оптического потока. Как нас любезно предупреждает википедия в соответствующей статье, «We cannot solve this one equation with two unknown variables», и тут уже ничего не сделаешь.
Вообще, если честно, то это, наверное, не совсем правда. Вы ведь можете найти на правой картинке соответствие красной точке? Это тоже не очень сложно, но для этого мы мысленно пользуемся каким-то другим методом — находим рядом ближайшую «зеленую точку» (нижний угол), оцениваем расстояние до нее и откладываем соответствующее расстояние на второй грани куба. Алгоритмам оптического потока есть куда расти — этот способ можно было бы и взять на вооружение (если этого еще не успели сделать).
На самом деле, как подсказывает к этому моменту запоздавший здравый смысл, мы все еще пытаемся сделать лишнюю работу, которая не важна для нашей конечной цели — распознавания, классификации и прочего интеллекта. Зачем мы пытаемся запихать в трехмерный мир все точки картинки? Даже когда мы работаем с двумерными изображениями, мы обычно не пытаемся использовать для классификации каждый пиксель — большая их часть не несет никакой полезной информации.
 Почему бы не делать то же самое и здесь?
Почему бы не делать то же самое и здесь?Собственно, все оказалось вот так просто. Мы будем рассчитывать тот же самый оптический поток, но только для «зеленых», устойчивых точек. И кстати, в OpenCV о нас уже позаботились. Нужная нам штука называется поток Лукаса-Канаде.
Приводить код и примеры для тех же самых случаев будет слегка скучно, потому что получится то же самое, но с гораздо меньшим числом точек. Давайте по дороге сделаем еще чего-нибудь: например, добавим нашему алгоритму возможность обрабатывать повороты камеры. До этого мы двигались исключительно вбок, что в реальном мире за пределами окон поездов встречается довольно редко.
С появлением поворотов координаты X и Z у нас смешиваются. Оставим старые формулы для расчета координат относительно камеры, и будем переводить их в абсолютные координаты следующим образом (здесь — координаты положения камеры, альфа — угол поворота):
(игрек — читер; это потому, что мы считаем, что камера не двигается вверх-вниз)
Где-то здесь же у нас появляются проблемы с фокусным расстоянием — помните, мы решили задать его произвольным? Так вот, теперь, когда у нас появилась возможность оценивать одну и ту же точку с разных углов, он начал иметь значение — именно за счет того, что координаты X и Z начали мешаться друг с другом. На самом деле, если мы запустим код, аналогичный предыдущему, с произвольным фокусом, мы увидим примерно вот что:
На самом деле, если мы запустим код, аналогичный предыдущему, с произвольным фокусом, мы увидим примерно вот что:
Неочевидно, но это попытка устроить обход камеры вокруг обычного кубика. Каждый кадр — оценка видимых точек после очередного поворота камеры. Вид сверху, как на миникарте.
К счастью, у нас все еще есть оптический поток. При повороте мы можем увидеть, какие точки переходят в какие, и рассчитать для них координаты с двух углов зрения. Отсюда несложно получить фокусное расстояние (просто возьмите две вышеприведенных формулы для разных значений альфа, приравняйте координаты и выразите f). Так гораздо лучше:
Не то что бы все точки легли идеально одна в другую, но можно хотя бы догадаться о том, что это кубик.
И, наконец, нам нужно как-то справляться с шумом, благодаря которому наши оценки положения точек не всегда совпадают (видите на гифке сверху аккуратные неровные колечки? вместо каждого из них, в идеале, должна быть одна точка). Тут уже простор для творчества, но наиболее адекватный способ мне показался таким:
Тут уже простор для творчества, но наиболее адекватный способ мне показался таким:
— когда у нас есть подряд несколько сдвигов в сторону, объединяем информацию с них вместе — так для одной точки у нас будет сразу несколько оценок глубины;
— когда камера поворачивается, мы пытаемся совместить два набора точек (до поворота и после) и подогнать один к другому. Эта подгонка по-правильному называется «регистрацией точек» (о чем вы бы никогда не догадались, услышав термин в отрыве от контекста), и для нее я воспользовался алгоритмом Iterative closest point, нагуглив версию для питона + OpenCV;
— потом точки, которые лежат в пределах порогового радиуса (определяем методом ближайшего соседа), сливаются вместе. Для каждой точки мы еще отслеживаем что-то типа «интенсивности» — счетчик того, как часто она объединялась с другими точками. Чем больше интенсивность — тем больше шанс на то, что это честная и правильная точка.
Результат может и не такой цельный, как в случае с кубиками из Портала, но по крайней мере, точный. Вот пара воссозданных моделей, которые я сначала загрузил в Блендер, покрутил вокруг них камеру и сохранил полученные кадры:
Вот пара воссозданных моделей, которые я сначала загрузил в Блендер, покрутил вокруг них камеру и сохранил полученные кадры:
Голова профессора Доуэля
Какая-то рандомная машина
Бинго! Дальше нужно их все запихать в распознающий алгоритм и посмотреть, что получится. Но это, пожалуй, оставим на следующую серию.
Слегка оглянемся назад и вспомним, зачем мы это все делали. Ход рассуждений был такой:
— нам нужно уметь распознавать вещи, изображенные на картинках
— но эти картинки каждый раз, когда мы меняем положение или смотрим на одну и ту же вещь с разных углов, меняются. Иногда до неузнаваемости
— это не баг, а фича: следствие того, что наши ограниченые сенсоры глаз видят только часть предмета, а не весь предмет целиком
— следовательно, нужно как-то объединить эти частичные данные от сенсоров и собрать из них представление о предмете в его полноценной форме.
Вообще говоря, это ведь наверняка проблема не только зрения. Это скорее правило, а не исключение — наши сенсоры не всемогущи, они постоянно воспринимают информацию об объекте частями — но любопытно, насколько все подобные случаи можно объединить в какой-то общий фреймворк? Скажем (возвращаясь к зрению), ваши глаза сейчас постоянно совершают мелкие и очень быстрые движения — саккады — перескакивая между предметами в поле зрения (а в промежутках между этими движениями ваше зрение вообще не работает — именно поэтому нельзя увидеть собственные саккады, даже уставившись в зеркало в упор). Мозг постоянно занимается упорной работой по «сшиванию» увиденных кусочков. Это — та же самая задача, которую мы только что пытались решить, или все-таки другая? Восприятие речи, когда мы можем соотнести десяток разных вариантов произношения слова с одним его «идеальным» написанием — это тоже похожая задача? А как насчет сведения синонимов к одному «образу» предмета?
Это скорее правило, а не исключение — наши сенсоры не всемогущи, они постоянно воспринимают информацию об объекте частями — но любопытно, насколько все подобные случаи можно объединить в какой-то общий фреймворк? Скажем (возвращаясь к зрению), ваши глаза сейчас постоянно совершают мелкие и очень быстрые движения — саккады — перескакивая между предметами в поле зрения (а в промежутках между этими движениями ваше зрение вообще не работает — именно поэтому нельзя увидеть собственные саккады, даже уставившись в зеркало в упор). Мозг постоянно занимается упорной работой по «сшиванию» увиденных кусочков. Это — та же самая задача, которую мы только что пытались решить, или все-таки другая? Восприятие речи, когда мы можем соотнести десяток разных вариантов произношения слова с одним его «идеальным» написанием — это тоже похожая задача? А как насчет сведения синонимов к одному «образу» предмета?
Если да — то возможно, проблема несколько больше, чем просто местечковый алгоритм зрительной системы, заменяющий нашим недоэволюционировавшим глазам лазерную указку сканера.
Очевидные соображения говорят, что когда мы пытаемся воссоздать какую-то штуку, увиденную в природе, нет смысла слепо копировать все ее составные части. Чтобы летать по воздуху, не нужны машущие крылья и перья, достаточно жесткого крыла и подъемной силы; чтобы быстро бегать, не нужны механические ноги — колесо справится гораздо лучше. Вместо того, чтобы копировать увиденное, мы хотим найти принцип и повторить его своими силами (может быть, сделав это проще/эффективней). В чем состоит принцип интеллекта, аналог законов аэродинамики для полета, мы пока не знаем. Deep learning и Ян Лекун, пророк его (и вслед за ним много других людей) считают, что нужно смотреть в сторону способности строить «глубокие» иерархии фич из получаемых данных. Может быть, мы сможем добавить к этому еще одно уточнение — способность объединять вместе релевантные куски данных, воспринимая их как части одного объекта и размещая в новом измерении?
Распознавание изображений для бизнеса
Распознавание изображений используется в бизнесе для:– анализа видео и снимков камер наблюдения (например, для распознавания клиентов, фиксации краж в магазине)
– классификации отсканированных документов и извлечения данных из них
– мониторинга социальных сетей (анализа эффективности маркетинговых акций, анализа конкурентов)
– распознавания одежды и аксессуаров на фотках (для электронной коммерции)
– автоматического контроля сотрудников по скриншотам экрана компьютера
Примеры использования распознавания изображений для бизнеса приведены ниже.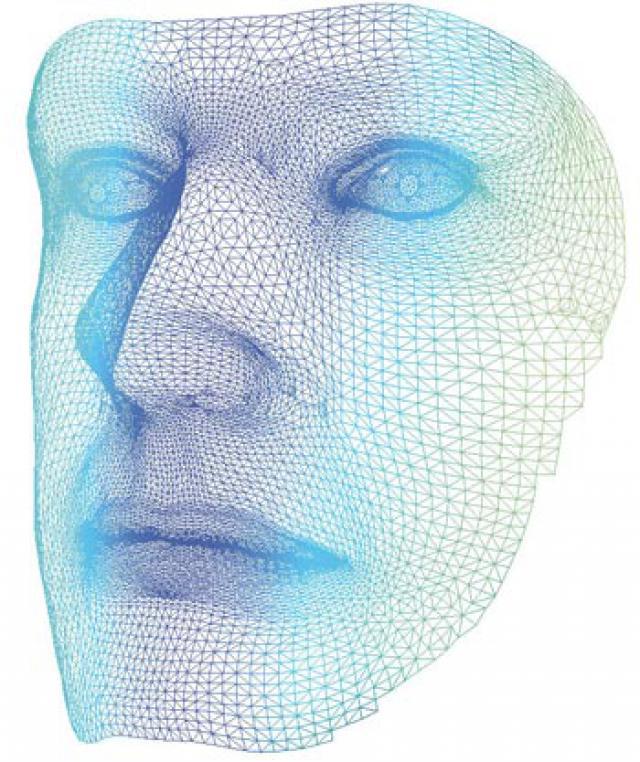
27.10.20. Microsoft Azure AI теперь описывает изображения так же хорошо, как и люди
Новая модель нейросети для генерации описаний к изображениям теперь доступна потребителям через Computer Vision в Azure Cognitive Services, которое является частью Azure AI, и позволяет разработчикам использовать эту возможность для улучшения доступности своих сервисов. Согласно результатам исследования, при оценке на тестах nocaps система ИИ создавала более содержательные и точные описания, чем это делали люди для тех же изображений. Новая модель уже используется в приложение Seeing AI и в конце этого года начнет работать в Microsoft Word и Outlook для Windows и Mac, а также в PowerPoint для Windows, Mac и в веб-версии. Автоматическое описание помогает пользователям получить доступ к важному содержимому любого изображения, будь то фотография, возвращенная в результатах поиска, или иллюстрация для презентации.
2020. Cisco купила разработчика ПО для автоматического распознавания картинки с камер видеонаблюдения
Cisco купила стартап Modcam, который разрабатывает ПО для автоматического распознавания картинки с камер видеонаблюдения. Предполагается, что активы купленного стартапа дополнят ассортимент смарт-камер Meraki, которым обладает Cisco. Технологии Modcam могут использоваться в системах видеонаблюдения для точного определения местоположения объектов и определения маршрута движения. Возможности интеллектуальных камер Cisco Meraki со своей стороны включают распознавание движений и объектов. Однако аналитика в рамках этого оборудования ограничивается лишь одной камерой.
Предполагается, что активы купленного стартапа дополнят ассортимент смарт-камер Meraki, которым обладает Cisco. Технологии Modcam могут использоваться в системах видеонаблюдения для точного определения местоположения объектов и определения маршрута движения. Возможности интеллектуальных камер Cisco Meraki со своей стороны включают распознавание движений и объектов. Однако аналитика в рамках этого оборудования ограничивается лишь одной камерой.
2020. Facebook представила ИИ-инструмент для распознавания товаров на фотографиях
Facebook запустила инструмент GrokNet, который может определять разные категории товаров на фотографии с помощью технологий искусственного интеллекта. Он распознаёт десятки тысяч разных атрибутов, например, бренды, цвета, размер. Этот инструмент уже интегрирован в торговую площадку Facebook Marketplace — с его помощью пользователи могут быстро создавать описание товара (сервис пока не доступен в России). Например, когда продавец загружает фотографию своего дивана, сайт предлагает указать характеристики «чёрный», «кожа», «секционный диван». ИИ-система «училась» распознавать изображения на базе, которая включает около 100 млн пользовательских фотографий в Marketplace.
2020. В СБИС появилось ИИ-распознавание первичных документов
В бухгалтерском модуле системы управления бизнесом СБИС появилась функция автоматического ввода/распознавания первичных документов. Она работает на технологии машинного обучения и позволяет распознавать товарные накладные (ТОРГ-12), УПД, счета-фактуры и авансовые отчеты. Достаточно отсканировать документ или сфотографировать с помощью смартфона и добавить картинку в систему. Она сама добавит документ в базу и извлечет из него данные (контагентов, номенклатуру товаров, затраты…). Разработчики обещают высокую точность распознавания даже на нечетких снимках. Многостраничные документы – тоже поддерживаются.
2019. Яндекс запустил сервис для распознавания лиц и изображений
В арсенале платформы Яндекс.Облако появился сервис Yandex Vision для анализа изображений при помощи машинного обучения. Например, при помощи сервиса компании могут распознавать тексты архивов и искать по ним данные, переводить тексты с изображений и модерировать контент пользователей. Бизнесу Yandex Vision может пригодиться для сканирования однотипных документов и занесения их в систему документооборота, например, по ключевым словам. Сервис также ищет лица людей на изображении и выделяет их прямоугольниками, но пока не распознает — с помощью этой функции нельзя находить похожие лица или идентифицировать личность. Яндекс уже определился с ценами на распознавания текста: 120 руб за 1000 картинок в месяц. Обнаружение лиц – пока бесплатно. Подобный сервис уже предоставляют Mail.ru и FindFace.
Например, при помощи сервиса компании могут распознавать тексты архивов и искать по ним данные, переводить тексты с изображений и модерировать контент пользователей. Бизнесу Yandex Vision может пригодиться для сканирования однотипных документов и занесения их в систему документооборота, например, по ключевым словам. Сервис также ищет лица людей на изображении и выделяет их прямоугольниками, но пока не распознает — с помощью этой функции нельзя находить похожие лица или идентифицировать личность. Яндекс уже определился с ценами на распознавания текста: 120 руб за 1000 картинок в месяц. Обнаружение лиц – пока бесплатно. Подобный сервис уже предоставляют Mail.ru и FindFace.
2017. Adobe представил свой искусственный интеллект – Sensei
Флагманские продукты компании Adobe – Photoshop и Premiere – предназначены для обработки изображений и видео. Это огромное поле работы для искусственного интеллекта. И такой интеллект появился – Adobe Sensei. Только представьте, что можно будет автоматически вырезать объект из фотографии или видео, или наложить фантастические эффекты. Кроме работы с графикой, Sensei будет использоваться для поиска и разметки изображений в Adobe Creative Cloud, для распознавания текста на фотографиях в Adobe Document Cloud и для предиктивной аналитики в системе управления маркетингом Adobe Marketing Cloud.
Кроме работы с графикой, Sensei будет использоваться для поиска и разметки изображений в Adobe Creative Cloud, для распознавания текста на фотографиях в Adobe Document Cloud и для предиктивной аналитики в системе управления маркетингом Adobe Marketing Cloud.
2015. Нейросеть Microsoft победила Google и Intel в конкурсе на распознавание изображений
Программа, разработанная командой Microsoft Research под руководством Цзянь Сана (на фото) показала лучший результат на шестом конкурсе по распознаванию изображений ImageNet. Ей удалось превзойти конкурентные системы от Google, Intel, Qualcomm и Tencent, а также ряда стартапов. Система компьютерного зрения Microsoft представляет собой очень глубокую нейросеть из 150 слоев, которую обучали с применением фреймворка глубокого остаточного обучения. Microsoft уже использует компьютерное зрение в своих продуктах: игровом сенсоре Kinect и системе распознавания лиц Windows Hello.
2015. Стартап Deepomatic получил $1. 4 млн на распознавание одежды на картинках
4 млн на распознавание одежды на картинках
Французский стартап Deepomatic получил $1.4 млн инвестиций от Alven Capital и нескольких бизнес-ангелов на развитие своей технологии компьютерного зрения, которая специализирована на распознавании элементов одежды. Идея в том, чтобы дополнять картинки с модной одеждой e-commerce ссылками. Например, вам понравились туфельки на девушке, изображенной на картинке – вы кликаете и попадаете на страничку интернет-магазина, где продаются эти туфли.
2015. Искусственный интеллект Baidu побил рекорд Google в распознавании изображений
Китайскаий интернет-гигант Baidu создал суперкомпьютер Minwa, который (по словам разработчиков) сумел превзойти рекорд компании Google по качеству распознавания изображений. Суперкомпьютер показал точность 95,42%, по сравнению с результатом 95,2%, показанным искусственным интеллектом Гугла. Minwa имеет 72 мощных центральных процессоров и 144 графических процессоров. В компьютере запрограммирована нейронная сеть, способная не только выполнить распознавание объектов на изображениях с высокой разрешающей способностью, но и самообучаться, что позволяет системе выявлять характерные особенности каждого из отдельных объектов. Таким образом, система может распознать изображение, представленное в любой форме, даже когда оно повернуто на некоторый угол и сфотографировано снова.
Таким образом, система может распознать изображение, представленное в любой форме, даже когда оно повернуто на некоторый угол и сфотографировано снова.
2014. Google создал алгоритм для создания подписей к изображениям на естественном языке
Разработчики из подразделения Google Research создали алгоритм обучения нейросети для автоматической генерации текстового описания объектов на изображениях на естественном (английском) языке. Он сочетает в себе алгоритмы компьютерного зрения и обработки естественного языка. К примеру, система способна создавать подписи наподобие «две собаки играют на траве» или «маленькая девочка в розовой шляпке надувает пузыри». Идея пришла благодаря последним достижениям в машинном переводе, где одна рекуррентная нейронная сеть (RNN) преобразует предложение на одном языке в векторную модель, а вторая – преобразует эту модель в предложение на другом языке. Вот инженеры и подумали, почему бы в качестве первой нейросети не использовать сверточную нейросеть для распознавания объектов на изображениях (CNN). Разработчики планируют использовать полученную систему, например, для помощи слепым людям и для усовершенствования поиска картинок на Google Images.
Разработчики планируют использовать полученную систему, например, для помощи слепым людям и для усовершенствования поиска картинок на Google Images.
2013. Cortica получил $1.5 млн от Mail.Ru на развитие технологии распознавания изображений
Израильский стартап Cortica получил $1.5 млн инвестиций от Mail.Ru для развития своей технологии распознавания изображений. Разработчики говорят, что их технология симулирует человеческий кортекс мозга (отсюда и название) и способна распознавать изображения с такой же высокой точностью, как человек. Для Mail.ru эта технология интересна прежде всего для таргетирования рекламы по картинкам, которые просматривают пользователи в социальных сетях (VK, Одноклассники).
2013. Google купил стартап DNNresearch – победителя конкурса распознавания изображений
Google купил канадский стартап DNNresearch, который в 2012 с большим перевесом выиграл конкурс ImageNet (в котором нейросети соревнуются в точности распознавания изображений). DNNresearch состоит всего из 3 человек – профессора Университета Торонто – Джорджа Хинтона (на фото) и его двух студентов. Ранее Гугл предоставлял Хинтону грант в размере $600K на его исследования в сфере компьютерного зрения. Для Гугла эта технология очень важна для улучшения поиска по картинкам в Google Images и по фоткам в Google Photos.
DNNresearch состоит всего из 3 человек – профессора Университета Торонто – Джорджа Хинтона (на фото) и его двух студентов. Ранее Гугл предоставлял Хинтону грант в размере $600K на его исследования в сфере компьютерного зрения. Для Гугла эта технология очень важна для улучшения поиска по картинкам в Google Images и по фоткам в Google Photos.
Академия 1С:Документооборот | Лушников и партнеры: Распознавание изображений на сервере 1С:Документооборот 8
Каким образом работает распознавание картинок в 1С:Документооборот?
В статье “Извлечение текстов в 1С:Документооборот” сказано, что 1С:Документооборот 8 умеет извлекать тексты из популярных офисных форматов файлов и использовать эту информацию для полнотекстового поиска по содержимому файлов. А вот если в СЭД помещен файл графического формата, то как получить распознанный текст из картинки? В данной статье пойдет речь о том, какие надо установить дополнительные программы на сервер 1С, чтобы работало автоматическое распознавание сканов файлов.
Настройка распознавания изображений в 1С:Документооборот в клиент-серверном варианте на живых примерах подробно рассмотрена в видео-курсе, заказать который можно по ссылке http://video.doc-lvv.ru/
Работа сканирования и распознавания в 1С:Документооборот 8 возможна только под Windows.
Чтобы настроить распознавание изображений на сервере нужно:
1. Установить программы CuneiForm, ImageMagic и Ghostscript.
2. Задать в настройках программы параметры распознавания и указать путь к программе ImageMagic.
Общая схема работы сканирования и распознавания указана на следующем рисунке.
Установку программы CuneiForm в файл-серверном варианте следует делать на компьютере пользователя под тем пользователем, который в дальнейшем будет с ней работать, а в клиент-серверном варианте на сервере 1С – под пользователем, под которым работает сервис 1С:Предприятия.
Установка CuneiForm
Программа CuneiForm нужна для распознавания графических файлов.
Находим в дистрибутиве cuneiform файл setup.exe. Запускаем его и устанавливаем.
Открываем 1С:Документооборот под Администратором. Переходим в настройки программы и устанавливаем флаг «Распознавание изображений с помощью CuneiForm».
Загрузим любую картинку с текстом.
Откроем ее на просмотр и убедимся, что там есть текст.
После отработки регламентного задания «Распознавание» увидим распознанный текст в текстовом образе.
Откроем теперь тестовый образ из карточки файла.
В текстовом образе карточки файла 1С:Документооборот будет находиться распознанный текст из картинки.
Установка Ghostscript
Программа Ghostscript нужна программе ImageMagic для преобразования графических файлов в формат pdf и обратно.
Находим в дистрибутиве Ghostscript файл gs901w32.exe. Запускаем его.
Нажимаем кнопку Setup.
Указываем путь установки и нажимаем кнопку Install.
Программа установлена.
Установка ImageMagic
Программа ImageMagic нужна для преобразования графических файлов в формат pdf и обратно.
Находим в дистрибутиве ImageMagic файл ImageMagick-6.9.1-6-Q8-x86-dll.exe. Запускаем его.
Нажимаем кнопку Next.
Соглашаемся с условиями лицензионного соглашения.
Читаем полезную информацию.
Указываем путь установки.
Указываем название папки стартового меню.
Указываем компоненты, которые надо установить.
Подтверждаем установку. Нажимаем кнопку Install.
Читаем полезную информацию.
Программа установлена. Нажимаем кнопку Finish.
Теперь, чтобы на сервере 1С происходило преобразование отсканированных pdf-файлов в графические файлы с последующим распознаванием нам надо указать общие настройки распознавания.
В программе 1С:Документооборот в настройках программы нажимаем на кнопку «Настройки распознавания», включаем использование ImageMagick и указываем путь к программе.
Далее загрузим в папку файлов многостраничный pdf.
После того, как отработает регламентное задание «Распознавание» мы в текстовом образе увидим распознанный текст.
Интеллект в интернет-технологиях. Распознавание изображений,…
Привет, Вы узнаете про интеллект в интернет-технологиях распознавание изображений речи смысла, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое интеллект в интернет-технологиях распознавание изображений речи смысла , настоятельно рекомендую прочитать все из категории Распознавание образов
. Об этом говорит сайт https://intellect.icuИнтернет с каждым днем все больше напоминает самоорганизованный универсум, что эволюционирует с огромной скоростью. И хотя эта система еще не имеет полноценного искусственного интеллекта, зачатки его создания уже начинают появляться (например, виртуальный собеседник инф или Акинатор, который читает мысли, машинное зрение и голосовой интерфейс поисковых систем). В день, когда тест Тьюринга будет пройден и Интернет по функциональному инструмента превратится в незаменимого помощника, а для кого-то другая.
В день, когда тест Тьюринга будет пройден и Интернет по функциональному инструмента превратится в незаменимого помощника, а для кого-то другая.
Кто стоит за всем этим? Безусловно, это сообщества людей.Сообщества, объединенные общими идеями, целями и интересами, которые готовы тратить свое время и ресурсы на осуществление этих идей. Поэтому, с каждым днем в Интернете появляется все больше разумных программ, их функционал становится все шире, а посетители превращаются из потребителей в активных создателей контента.
Виртуальный собеседник (бот-консультант) – это специалист технической поддержки, который доступен круглосуточно и мгновенно отвечает на вопросы пользователей. Он общается на естественном языке. Он может не только помочь что-то найти на сайте, но и предложить полезную для пользователя информацию или товар.Бот сохраняет заданные ему вопросы.Благодаря этому владелец сайта может узнать, что ищут на сайте, чего не хватает, что можно улучшить, какая аудитория клиентов.
Бот является встроенным модулем. Для просмотра модуль бота нужно вставить короткий специальный код на необходимые страницы сайта.Консультант может иметь стандартное оформление. Но он также может быть оформлен как индивидуальный персонаж для конкретного сайта.
Бота нужно научить отвечать на вопросы посетителей. Начальное обучение производится на основании первоначального словаря. В дальнейшем, анализируя диалоги клиентов и бота, владелец сайта может продолжить обучение самостоятельно.
Все шаги по настройке бота, размещение его базы знаний , сбора диалогов и т.д., компания разработчик делает самостоятельно. В случае каких-либо вопросов или необходимых доработок – компания-разработчик поддерживает работу Бота-консультанта.
Продукты компании «Наносемантика»
http://www.nanosemantics.ru/
«Наносемантика» – лидер российского рынка технологий искусственного интеллекта, нацеленных на решение бизнес-задач. Компания с 2005 года занимается разработкой Инфив – виртуальных собеседников, управляемых искусственным интеллектом. «Наносемантика» развивает технологии и онлайн-сервисы, в основе которых лежит прямой диалог машины с пользователем.
«Наносемантика» развивает технологии и онлайн-сервисы, в основе которых лежит прямой диалог машины с пользователем.
- WebMoney
- Beeline Казахстан
- Эlixir банк
- Банк «Тинькофф Кредитные Системы»
- NETBYNET Холдинг
- «А-а-яй.ру»
ρБот-консультант для круглосуточной поддержки клиентов на сайте
http://chatbot.tw1.ru/business.htm
Консультант, который способен работать 24 часа в сутки 7 дней в неделю без отдыха и перерывов на обед – мечта для сервисных компаний с большим количеством клиентов, которые задают одинаковые вопросы.
Первопроходцем была небольшая канадская компания Tineye, второй – Google, а третьей – китайский поисковик Baidoo. Яндекс стал четвертым игроком и надеется, что за ними подтянется Microsoft. Впрочем, в Tineye очень небольшая база картинок (3500000000), а в Baidoo сильный перекос в китайский рынок. Для украинского пользователя уместным будет использование поиска в Яндексе и Google: их база изображений составляет десятки миллиардов изображений.
Картинку на сервис можно загрузить одним из трех способов:
- Ввести URL-адрес картинки и нажать на кнопку «Найти». Этот способ подойдет для поиска картинки, для которой известно ее адрес в Интернете.
- Скачать картинку со своего компьютера.
- Перетащить картинку с помощью мыши в указанное окно.
Зачем нужен сервис поиска похожей картинки?
- Для дизайнеров, художников иногда важно найти похожую картинку или фото, но в другом ракурсе.
- Сервис поможет найти сайт или Интернет-магазин, где можно найти или приобрести вещь, которая изображена на картинке.
- Для поиска информации о некотором человеке, животном или архитектурном сооружении.
Картинка, по которой ищут подобные изображения должна соответствовать следующим требованиям:
- Формат картинки – jpeg, gif, png,
- Размер картинки не более 8 Мб.
Сервис поиска изображений используют алгоритмы анализа и классификации данных, а для поиска изображений по визуальному содержанию применяются технологии компьютерного зрения и описания содержания изображений. Данная технология превращает загруженную картинку в набор «визуальных слов». После этого система среди миллиардов картинок, которые содержатся в ее базе данных выбирает изображение, имеющие сходные «визуальные слова» и выдает их пользователю. При этом поиск займет не более минуты.
Данная технология превращает загруженную картинку в набор «визуальных слов». После этого система среди миллиардов картинок, которые содержатся в ее базе данных выбирает изображение, имеющие сходные «визуальные слова» и выдает их пользователю. При этом поиск займет не более минуты.
Задачи, которые решает группа компьютерного зрения:
- Классификация изображений.
- Поиск дубликатов и похожих изображений.
- Распознавания текста.
- Понимание сцены и распознавания объектов на изображениях.
В таком сервиса есть несколько сценариев использования:
- Поиск такой же картинки, но другой: высшего качества, большого размера, без водяного знака или, наоборот, фотожабы с ней.
- Узнать, кто находится на картинке, то есть определить изображение человека с текстовыми описаниями на сайтах.
- Отражать не картинки, а сайты, где они размещены. Например, по фотографии дизайнерского стула, дизнаетися, где его можно купить.

Компьютерное зрение
Александр Крайнов, менеджер проектов компьютерного зрения
Разработчики Яндекса разработали собственный алгоритм, который сильно отличается от аналогов. Использована Яндексом технология компьютерного зрения называется Content Based Image Retrieval (CBIR) и внутри компании носит название «Сибирь».
Опираясь на обобщенные пределы объектов, контрастные области и другие ключевые элементы картинки, робот создает свою библиотеку изображений, подобно как обычный поисковик скачивает упрощенные текстовые версии веб-страниц при индексировании, и уже по ней ведет поиск. Способность к обобщению уже показывает поиск: иногда находится не просто такая же картинка, а другое изображение, содержащее такой же объект.
Этот алгоритм лучше всего работает с URL-адресом картинки, а не загруженной с компьютера. То есть, когда исходная картинка размещена в Интернете, а не на компьютере пользователя. Поскольку поисковая база очертания предметов формируется изображений, которые уже проиндексированы системой, поэтому, если изображение отсутствует в поисковой базе, хорошего результата не будет.
В отличие от сервиса Google, который различает цвета, новый алгоритм Яндекса не различает цвета, но способен анализировать очертания предметов. После проведенного анализа формируется поисковый запрос для стандартного (словесного) поиска по изображениям. Исключение составляют торговые марки и шрифты – популярные логотипы, как правило, программа распознает. То же самое относится и к памятникам и архитектурных изображений. Поэтому, поиск архитектурного памятника по загруженной картинкой (фотографией) будет успешнее, чем поиск по фотографии домашнего праздника.
Стоит отметить, что поиск по картинкам от Google тоже часто работает некорректно – в результатах часто демонстрируются различные изображения с похожей цветовой гаммой. Впрочем, понятно, что данное направление только начинает развиваться. Яндекс пошел своим путем, не отставая при этом от других конкурентов. Дальнейшие разработки Яндекс продвигаются в том же направлении, что и Google, внедрил технологию Goggles в мобильный поиск. Google Goggles позволяют искать в реальном времени по изображению, которая берется из камеры смартфона.
Google Goggles позволяют искать в реальном времени по изображению, которая берется из камеры смартфона.
Благодаря Голосовом интерфейса можно диктовать запросы в клиентской программе на устройстве, а не вводить их. Чтобы транскрибировать продиктованы слова в написанный текст, Google направляет выражения серверы, где используется технология распознавания шаблонов .
Для того, научить систему лучше распознавать правильные поисковые запросы, Google сохраняет высказывания, чтобы улучшать службы, в частности: данные о языке, страну, выражение и предположения системы о сказанном. Сохранены аудиоданные не содержат идентификатор учетной записи Google, если пользователь этого не указал.
Для каждого языка Голосовой интерфейс Google собирает голосовые фрагменты, которые позволяют создать модели языка, которые обеспечивают корректную работу сервисов. Google имеет базу аудио образов, произносятся носителями языка, отличаются акцентами, возрасту и индивидуальным особенностям, произносить часто употребляемые фразы в различных акустических условиях, например, в ресторане, на улице или в машине. Для каждого языка Google создает словарь, содержащий более миллиона распознанных слов.
Для каждого языка Google создает словарь, содержащий более миллиона распознанных слов.
Сервис работает на основе системы Speech Input API, благодаря которой и реализуется голосовое управление Интернет-браузером. Сервис сейчас воплощено в Google Поиск, Google Переводчик , Cmail, Google Docs.
Голосовой поиск Google
Voice Search – это расширение для Google Chrome, который позволяет осуществлять поиск или иные действия в Интернете с помощью своего голоса. На странице Google в строке поиска изображено иконку микрофона. Пользователь должен нажать на него и произнести громко и четко фразу или слово. Для получения озвученных ответов нужно использовать язык в соответствии с речевого интерфейса Google Chrome.
В случае запроса о заметных или общепризнанные объекты будет озвучена информация, которая берется из «Графа знаний» Google – базы, содержащей информацию о различных объектах, событиях и их связи между собой. Сведения из «графа знаний» обычно выводится справа от результатов поиска и предоставляет информацию по запросу, который ввел пользователь.
Это может быть, например, информация об актере, включая фильмы, в которых он снялся, и дату рождения. Озвучиванию будет подлежать, например, ответ на простые вопросы «Сколько долларов будет в 100 гривнах», «как называется столица Франции», «кто такой Мануэль Баррозу»
голосовой калькулятор
Поисковая система Google предлагает голосовой калькулятор Google , который позволяет с помощью устройств голосового ввода мгновенно получать ответ на любые, даже самые сложные расчеты.
Для запуска калькулятора нужно открыть Google Chrome и запустить google.com, лучше с открытым аккаунтом. Включаете устройство голосового ввода на компьютере и четко и ясно языком интерфейса Chrome произносите арифметическое действие. В поисковой строке появится калькулятор, на котором отображается действие и озвучено результат вычислений.
С калькулятором можно взаимодействовать вручную, мышкой или на цифровой клавиатуре набирая числа и переменные. В голосовом калькуляторе Google предусмотрено 15 алгебраических операций, со скобками, процентами, числом пи и е и другими переменными.
Голосовой переводчик Google
Google начал работы над универсальным переводчиком принципиально нового типа. Идея нового проекта заключается в создании сервиса, который позволит пользователям, общаются на разных языках, говорить друг с другом в режиме реального времени, причем именно «говорить», а не «переписываться». Иными словами переводчик должен распознать язык, перевести полученный в результате этого текст и воспроизвести его на другом языке.
Google Translate вполне успешно переводит тексты на 52 различных языка. Доработка уже существующих технологий до требуемого уровня займет еще несколько лет. Для перевода определенной фразы достаточно нажать на изображение микрофона в программе, сказать в микрофон нужные слова и программа автоматически отправит записанную речь на серверы Google, где состоится разбор звукового файла и перевод фразы. После текстового перевода можно прослушать произношение перевода и оригинального текста (синтезированный женский голос).
Google предупреждает, что пока функция носит экспериментальный характер, и не следует ожидать от нее 100% правильной работы.Правильном перевода могут помешать такие факторы как акцент, четкость произношения и посторонние шумы.
Для облачных сервисов Google применено несколько способов ввода текста. Сочетание редакторов IME или инструмента транслитерации ,виртуальных клавиатур и рукописного ввода позволяет поддерживать более 90 языков.
Как пользоваться различными способами ввода:
Распознавания рукописного текста в сервисах Google
Компания Google добавила к популярным сервисам функцию распознавания рукописного текста. Например, в Google Translate появилось специальное поле, поддерживает рукописный ввод данных.Например там можно нарисовать иероглиф и моментально узнать его точно обозначения. Новая возможность пригодится европейцам и американцам, изучающих азиатские языки (проект концентрируется именно на языках азиатских групп) и не знают их хитроумную письменность. На сегодня существует возможность распознавания текстов на украинском языке
На сегодня существует возможность распознавания текстов на украинском языке
Для ввода текста можно использовать мышку или тачпад, где есть нормальная поддержка рукописного ввода текста. Для начала работы с рукописным вводом следует включить соответствующую функцию в Gmail. В Google Docs достаточно будет использовать комбинацию Ctrl + Shift + K.
Новинка Google будут поэтапно включать для разных регионов, поэтому, такая функция может быть и отсутствует у пользователя. Для тех, кто печатает быстрее, чем пишет, подобная функция будет не нужна. Для пользователей, которые печатают языках, символов в которой больше, чем содержит стандартная клавиатура, нововведение может оказаться полезным.
https://support.google.com/plus/answer/2370300?hl=uk
Google вплотную занялась технологией распознавания лиц на фото. Для того, чтобы ускорить данный процесс, корпорация купила компанию PittPatt, которая занимается разработкой соответствующих технологий.PittPatt занимается не только распознаванием лиц на фотографиях, но и распознаванием фотографий вообще, с последующей разметкой (пометка) распознанных объектов.
Результаты разработок внедряются в различные программы и сервисы компании, как обычные, так и мобильные. Технология интегрируется в фото- и видеоприложения Picasa, Goggles, YouTube и Google+.
Я хотел бы услышать твое мнение про интеллект в интернет-технологиях распознавание изображений речи смысла Надеюсь, что теперь ты понял что такое интеллект в интернет-технологиях распознавание изображений речи смысла и для чего все это нужно, а если не понял, или есть замечания, то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Распознавание образов
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Распознавание изображений. Документооборот. 1С
Внимание! СЭД “Корпоративный документооборот” заменен на новый продукт СЭД “Наш документооборот” оптимизированный и переписанный “с нуля”.
Внимание! Описание на этой странице потеряло актуальность.
Система документооборота «Корпоративный документооборот» включает в себя механизм распознавания текста из графических файлов. Механизм распознавания текста может использоваться для решения следующих задач:
- Извлечение текста для организации полнотекстового поиска по файлам системы документооборота
- Создание новых текстовых (а также html) файлов на основе графических файлов
Для включения возможности распознавать текст в изображениях необходимо включить функциональную опцию «Использовать распознавание» в настройках параметров системы на закладке «Работа с файлами» (подсистема «Администрирование системы»). После включения этой опции станут доступными следующие пункты:
- Настройка системы распознавания изображений
- Установить компоненту CuneiForm
- Сформировать очередь на распознавание изображений
Вид формы настройки системы приведен на рисунке ниже:
нажмите для увеличения изображения
В форме настройки системы распознавания изображений можно указать, какой язык используется в большинстве файлов, а также требуется ли изменять автора файла после его распознавания.
Язык распознавания в дальнейшем можно будет установить для каждого конкретного пользователя системы, а также для каждого файла системы. Поддерживается распознавание следующих языков:
Английский, Немецкий, Французский, Русский, Шведский, Испанский, Итальянский, Русско-Английский, Украинский, Сербский, Хорватский, Польский, Датский, Португальский, Голландский, Чешский, Румынский, Венгерский, Болгарский, Словенский, Латышский, Литовский, Эстонский, Турецкий.
После настройки системы распознавания можно нажать на кнопку «Установить компоненту CuneiForm» для установки COM-компоненты CuneiForm версии 12 («CuneiForm.Puma»). Кроме установки компоненты распознавания необходимо установить и само приложение CuneiForm. Данное приложение является свободно-распространяемым и его можно скачать с официального сайта cuneiform.ru. Прямые ссылки на скачивание можно получить, нажав на ссылку «справка». После скачивания дистрибутива OCR CuneiForm V.12, запустите файл setup. exe и нажмите кнопку «Далее».
exe и нажмите кнопку «Далее».
После выполнения установки приложения и COM-компоненты система распознавания готова к работе. Если к моменту включения системы распознавания в СЭД «Корпоративный документооборот» уже существуют графические файлы, которые необходимо распознать, то можно поставить их в очередь на распознавание перейдя по ссылке «Сформировать очередь…». В дальнейшем все графические файлы, перемещаемые в СЭД, будут иметь признак необходимости распознавания. Изменить данный признак можно на закладке «Извлеченный текст» формы файла. Пользователь может установить значение «Нужно распознать» или «Не нужно распознавать» для выбранного файла.
Процесс распознавания в СЭД «Корпоративный документооборот» запускается через специальное регламентное задание «Файлы: Распознавание изображений». Регламентное задание доступно в подсистеме «Автоматическая обработка» как показано на рисунке ниже.
В случае работы базы данных СЭД «Корпоративный документооборот» в клиент-сервером режиме «1С», данное регламентное задание будет запускаться автоматически (по настроенному расписанию). В случае работы базы данных документооборота в обычном, файловом режиме «1С», потребуется запуск отдельного сеанса обработки регламентных заданий. Открыть такой сеанс можно нажав на кнопку «Открыть сеанс обработки» как показано на рисунке выше. Можно также выполнить однократный запуск регламентного задания распознавания изображений нажав на кнопку «Выполнить сейчас».
В случае работы базы данных документооборота в обычном, файловом режиме «1С», потребуется запуск отдельного сеанса обработки регламентных заданий. Открыть такой сеанс можно нажав на кнопку «Открыть сеанс обработки» как показано на рисунке выше. Можно также выполнить однократный запуск регламентного задания распознавания изображений нажав на кнопку «Выполнить сейчас».
Существует несколько вариантов (стратегий) выполняемых после распознавания графического файла действий системы СЭД «Корпоративный документооборот»:
- Поместить только в «Извлеченный текст». После распознавания текст будет помещен в специальное хранилище текста файла. Данное хранилище используется для полнотекстового поиска по текстам файлов системы Извлеченный текст можно посмотреть (и при необходимости изменить) на закладке «Извлеченный текст» формы файла.
- Создать новую html-версию файла. После извлечения текста из графического файла будет создана новая версия файла в формате HTML. Данная версия станет текущей версией, а исходный графический файл сохранится в предыдущей версии данного файла.
- Создать новую txt-версию файла. В данном варианте после извлечения текста из графического файла будет создана новая версия файла в формате TXT. Данная версия станет текущей версией, а исходный графический файл сохранится в предыдущей версии данного файла.
- Создать новый html-файл. При выборе данного варианта будет создан новый файл в формате html, при этом владельцем файла будет тот же владелец, что и у исходного файла (например, некий корпоративный документ).
- Создать новый txt-файл. При выборе данного варианта будет создан новый файл в формате txt, при этом владельцем файла будет тот же владелец, что и у исходного файла. Пример выполнения данного варианта для документа системы приведен на рисунке ниже.

В случае, если по какой-либо причине распознать документ не удалось, то файлу будет присвоен статус «Не удалось распознать». Пользователи могут устранить причину (например, установить дистрибутив CuneiForm) и повторно поставить данный файл в очередь на распознание, поменяв статус на «Нужно распознать».
Примечание: Для решения задачи организации полнотекстового поиска по файлам офисных приложений предназначен механизм извлечения текстов из офисных файлов (MS Word, MS Excel, а также файлов OpenOffice). В отличие от распознавания изображений данный механизм извлекает тексты не из графических файлов, а из файлов офисных приложений. Механизм запускается регламентным заданием «Файлы: Извлечение текста (из офисных файлов)».
Смотрите также:
14 хитростей Google Docs, которые помогут работать быстрее
Google Docs — текстовый редактор, который незаметно обходит на повороте пакет MS Office. Даже эту статью мы писали в документе Google. Кажется, чем тут удивить? Но даже в знакомом инструменте есть фишки, о которых знают только контент-джедаи. Собрали те, которыми пользуемся сами и смело рекомендуем.
Комментарии и задачи соавторам
Бывает так, что в тексте нужно оперативно отметить соавтора. Идеальный способ сделать это — оставить комментарий. Комментарий присваивается отдельному слову, абзацу или всему разделу. Выдели часть текста, вызови контекстное меню ПКМ и кликни пункт «Оставить комментарий».
Комментарий присваивается отдельному слову, абзацу или всему разделу. Выдели часть текста, вызови контекстное меню ПКМ и кликни пункт «Оставить комментарий».
Альтернативный способ — нажать на иконку, появляющуюся справа при каждом выделении текстового фрагмента.
оставление комментариев в тексте
добавление примечаний в документЕсли хочешь оставить адресный комментарий, добавь соавтора через символ @. Но это еще не все. В поле комментария ты можешь назначить задачу исполнителю. Нажми на соответствующий чек-бокс, и пользователь получит электронное письмо с уведомлением о том, что его отметили. Идеальный и быстрый способ получить ответ или делегировать задачу.
окно с возможностью изменения и удаления комментария
возможные действия с заметками на полях документаКлючевые документы в «Избранном»
Наверное, ты обращал внимание на звездочку рядом с названием. Это сделано не для красоты. Щелкнув на значок, ты добавишь файл в «Избранные».
Избранное
Иконка избранное в документахВ чем профит? Документы под звездочкой автоматически сохраняются на диске Google в папке «Помеченные». Это удобный способ держать под рукой все важные файлы. Естественно, эти документы никуда не денутся и из общих папок.
список документов на Гугл Диске
список документовНовый документ в один клик
Открытие нового файла в Google Docs — не слишком сложная задача, но есть способ ее ускорить. Вместо того чтобы переходить на пустую страницу через кнопку «Файл», просто введи docs.new или doc.new в поисковую строку браузера. Откроется новый документ. Совет актуален, если ты уже авторизован в Google. В противном случае система попросит залогиниться.
Новый документ в поисковой строке
поисковая строкаАналогичным способом ты можешь открыть новый лист таблиц Google (для этого набери sheet.new) или новый слайд презентаций — напиши slide.new.
Найти ссылки и изображения, не выходя из документа
Google не был бы ведущей системой поиска, если бы не интегрировал поисковые возможности во все продукты своей экосистемы. Так что есть способ поискать текст и изображения прямо в текстовом редакторе. Нажимай «Инструменты» > «Расширенный поиск». Справа откроется поисковая строка.
Так что есть способ поискать текст и изображения прямо в текстовом редакторе. Нажимай «Инструменты» > «Расширенный поиск». Справа откроется поисковая строка.
поиск в документах
поисковая строка в Google DocsС помощью этого инструмента ты также найдешь изображения. Выбери вкладку «Картинки», найди изображение и наведи на него курсор. Ты увидишь значок плюса, который позволит щелчком добавить визуал прямо в документ. Легкий поиск не отменяет ограничений по авторским правам — следи за этим, чтобы избежать неприятностей.
поиск по картинкам в Google
инструмент документовДополнения
Google Docs — удобный инструмент сам по себе. Но многие пытаются сделать его еще лучше. Если тебе не хватает каких-то функций, загляни в меню «Дополнения». Там собраны все надстройки. Возможно, найдешь то, что ищешь.
набор дополнений к Google Docs
выбор дополненийДополнения помогут создавать диаграммы, менять стили, проверять текст, переводить и так далее. Установка занимает несколько секунд и не грузит систему. Не будем перечислять все возможные расширения (их несколько тысяч). Вот некоторые, которыми пользуются наши редакторы.
Translate+ — переводчик. Удобное дополнение для перевода в одном окне — помогает не прыгать между вкладками браузера.
Свежий Взгляд — проверка тавтологии. Этот инструмент ищет в тексте фонетически или морфологически сходные слова, которые расположены рядом, и подсвечивает их. Удобный помощник в редактуре текста.
LanguageTool — проверка правописания. Если ты привык полагаться на правки от Google Docs, эта надстройка придется по вкусу. Конечно, алгоритм не сравнится с профессиональным корректором. Но хоть что-то.
Image Extractor — экспорт изображений. В Google Docs есть неприятная особенность — картинки из текста нельзя сохранить напрямую. Расширение Image Extractor поможет выгрузить изображения в два клика.
DocSecrets — приложение для шифрования отдельных частей текста. Хочешь скрыть важную информацию от посторонних глаза? Установи пароль с помощью этой надстройки.
Отключение уведомлений
Если ты страдаешь легким тайм-менеджментом и привык разбирать почту по часам, запоминай лайфхак. В настройках Google есть возможность выбрать тип уведомлений. Зайди в окно комментариев и выбери один из трех вариантов:
- Все — получаешь уведомления о каждом комментарии.
- Только мои — получаешь уведомления, где ты отмечен (через символ @).
- Ничего — не получаешь уведомления.
настройка уведомлений
форма настройки уведомленийИзменить настройки ты можешь в любой момент.
Распознавание текста в картинках и PDF-файлах
У тебя есть файл PDF или картинка с текстом, который нужно перепечатать? Не набирай вручную, а используй инструмент Google Docs. Загрузи файл на Google Диск, щелкните файл правой кнопкой мыши и выбери «Открыть с помощью» > «Документы Google». Google Docs преобразует исходный файл в текст.
распознавание картинки
распознавание картинкиТочность инструмента пока не 100%-я — ты вряд ли сможешь распознать старую ксерокопию. Но для большинства современных документов этот способ работает.
пример распознавания текста
распознавание картинки в Google DocСчетчик слов на экране
Довольно часто у маркетолога возникает потребность посчитать символы в словах. Это нужно, чтобы заплатить копирайтеру или ограничить текст для рекламного объявления. В Google Docs можно включить подсчет набираемых символов, тогда ты будешь видеть статистику онлайн. Это делается на экране статистики (Ctrl + Shift + C или «Инструменты» > «Статистика») — жми флажок «Показывать статистику слов при вводе текста».
окно, показывающее статистику
отображение статистических данныхТаким же образом отслеживай количество страниц и символов. Если устал следить за словами, отключи инструмент тем же способом.
Личный словарь
Словарь digital-маркетинга пополняется быстрее академических мануалов и даже быстрее Google. Если ты устал от вечных красных подчеркиваний, добавь термины и другие слова в личный словарь. Он находится в разделе «Инструменты» > «Грамматика и орфография».
словарь Google Docs
добавление новых слов в словарьПосле легкой манипуляции Google будет на одной волне с тобой.
Редактирование изображений
В Google Docs есть собственный графический редактор. Он не сравнится с мощностью «Фотошопа» или «Фигмы», но может помочь в решении простых задач. Выбери раздел «Вставка» > «Рисунок» > «Новый». Увидишь область для рисования. Сюда ты можешь загрузить рисунок или скопировать скриншот экрана.
редактирование изображений
изменить изображений в Google DocsФункция рисования может пригодиться, если ты хочешь изменить изображение. Например, обвести определенное место на карте или подчеркнуть важный элемент рисунка. Доступные фичи находятся на панели инструментов графического редактора. Нажатие кнопки «Сохранить и закрыть» добавит изображение в тело документа.
Быстрые сочетания клавиш
Если работа с панелью инструментов кажется утомительным, ускоряй работу с помощью быстрых клавиш. Они экономят массу времени и позволяют не отвлекаться от содержания текста. Но кроме пресловутых Ctrl + C и Ctrl + V в документах Google предусмотрено еще 140 функциональных комбинаций. Вот топ самых полезных:
- Ctrl + / — вызывает список горячих клавиш;
- Ctrl + K — вставить/изменить ссылку;
- Ctrl + F — искать по документу;
- Ctrl + Alt + C — скопировать форматирование;
- Ctrl + Alt + V — вставить форматирование;
- Ctrl + A — выделить документ;
- Ctrl + Alt + цифры 1–6 — стиль заголовка;
- Ctrl + Shift + 7 — нумерованный список;
- Ctrl + Shift + 8 — маркированный список;
- Ctrl + Alt + M — добавить комментарий;
- Ctrl + Shift + F — скрыть меню.
Со всеми комбинациями быстрых клавиш ознакомься в справке по Google Docs.
Голосовой ввод
Этот инструмент очень полезен, если ты хочешь дать отдохнуть своему зрению. С его помощью нельзя надиктовать объемные тексты с множеством сложных терминов, но с небольшими он справится вполне эффективно. Встроенный ИИ достаточно неплохо распознает русскую речь и различные команды «запятая», «точка», «новая строка» и т. д. К сожалению, функция доступна только для браузера Chrome.
голосовой ввод в Google Docs
инструменты голосовго вводаДля запуска сервиса нажми на пункт «Голосовой ввод» во вкладке «Инструменты» или сочетание клавиш Ctrl + Shift + S. Если иконка микрофона красная — запись включена. Для приостановки ввода нажми на значок микрофона.
Автозамена символов
Открыть этот сервис можно, щелкнув на «Настройки…» в разделе «Инструменты». С его помощью можно настроить замену одних символов и слов на другие. Например, на стандартной клавиатуре ПК отсутствует тире (не путать с дефисом и подчеркиванием).
окно настройки автозамены
инструмент для замены слов или символов в автоматическом режимеГораздо проще задать автозамену сочетания символов (например, двух дефисов) на тире. В левых полях укажи исходные символы, а в правых — их конечные эквиваленты. Тут же можно разрешить или запретить замену прямых кавычек парными. Кстати, привычных «елочек» в Google Docs по какой-то причине нет, но это можно исправить автозаменой.
Закладки в документе
Иногда бывает, что необходимо дать ссылку не на весь Google Docs, который может быть довольно объемным, а на отдельный абзац. В этом случае на помощь придут закладки.
добавление закладок в документ
как добавить закладкуУстанови курсор в необходимое место в тексте, а затем выбери вкладку «Вставка» > «Закладка». Нажми на флажок — теперь ты сможешь поделиться ссылкой на отдельный фрагмент текста.
О чем-то забыли рассказать, или пользуешься другими хитростями? Поделись в комментариях.
12 лучших приложений для распознавания изображений, которые стоит попробовать в 2021 году
Давайте отправимся в путешествие, чтобы изучить 12 лучших приложений для распознавания изображений, которые вы должны попробовать в 2021 году. Приложения для распознавания изображений, упомянутые в этом списке, не расположены в каком-либо определенном порядке. Однако их выбирают на основе их характеристик, качества и рейтингов.
Распознавание изображений находится на подъеме, и мы наблюдаем экспоненциальный рост технологий распознавания изображений. С помощью таких технологий, как искусственный интеллект и машинное обучение, технология распознавания изображений была значительно улучшена.
Кроме того, благодаря включению функции распознавания изображений в смартфоны использование этой технологии в значительной степени нормализовалось. Технология распознавания изображений интегрирована в смартфоны через мобильные приложения.
Пользователи могут удобно загружать приложения для распознавания изображений из Google Play Store или App Store и использовать их для поиска, распознавания и идентификации определенных объектов.
Однако выбор лучших приложений для идентификации может быть трудным, поскольку существует множество приложений, использующих ту же технологию.Единственный способ провести различие между ними – проанализировать их качество, точность, технологию и методы работы.
Итак, без лишних слов, давайте углубимся в детали!
Что такое приложение для распознавания изображений?
Приложение для распознавания изображений использует технологию распознавания изображений для идентификации объектов, людей, письма, местоположения и многого другого.
Эти приложения для распознавания используют машинное обучение + зрение и искусственный интеллект для распознавания изображений.Более того, эта технология жизнеспособна в будущем исключительно благодаря своим преимуществам.
Благодаря технологии распознавания изображений такие задачи, как поиск визуального контента, управление автономными роботами и предотвращение несчастных случаев посредством идентификации объектов, становятся все более и более возможными, чем когда-либо.
Некоторые из самых известных имен в мире технологий, такие как Google, Facebook, IBM, Apple и Microsoft, инвестируют в программы распознавания изображений и связанные с ними программы.
Итак, вот некоторые из лучших приложений для распознавания объектов, которые вы должны попробовать прямо сейчас.
1. Google Lens
Источник изображения: Google Play Store
Google стремится быть новаторским и революционным. Они еще раз доказали это с помощью приложения для распознавания изображений Google Lens.
Благодаря передовым исследованиям и решениям, таким как искусственный интеллект и машинное обучение, совершенно очевидно, что они уже извлекли выгоду из технологии распознавания изображений, сделав ее более продвинутой в нескольких аспектах.
Приложение для распознавания объектов Google Lens использует камеру вашего смартфона и просматривает информацию в Интернете.Метод работы этого приложения аналогичен поиску картинок Google. Он отлично подходит для распознавания объектов и сопоставления их с контекстной информацией.
Более того, методология работы и производительность этого приложения для идентификации фотографий дополнительно усилены за счет искусственного интеллекта, работающего за сервисом с базой данных из миллионов изображений.
Рейтинги : 4.7
Скачать : Android.
2. Aipoly Vision
Aipoly Vision устанавливает планку еще выше, предлагая выдающиеся функции в качестве приложений для распознавания изображений . Это приложение доказывает, что вам не нужно быть высокотехнологичной ИТ-компанией, чтобы создавать что-то вдохновляющее и инновационное.
Приложение для распознавания изображений Aipoly Vision разработано, чтобы помочь людям с ослабленным зрением и дальтонизмом идентифицировать объекты, просто направив на них камеру своего смартфона.
Aipoly Vision – лучшее приложение для тех, у кого серьезные проблемы со зрением. Приложение способно определять растения, текст, еду, продукты и другие объекты.
Более того, опыт машинного обучения приложения также помогает ему учиться с течением времени, пока пользователи предоставляют данные.
Рейтинг : 3.0s
Скачать : iOS – Android
3. TapTapSee
TapTapSee – еще одно отличное приложение для распознавания объектов, разработанное для слепых и слабовидящих людей. Это отличное приложение использует камеру смартфона для распознавания всего, на что вы направляете камеру.
Уникальной особенностью этого приложения для идентификации фотографий является функция озвучивания, которая позволяет приложению произносить имя идентифицированного объекта вслух за вас.
Рейтинг : 3.9
Скачать : iOS – Android
4. Поиск кулачка
Источник изображения: DPreview
Cam Find – это приложение, которое определяет объекты по изображению для вас. Самая интуитивно понятная функция приложения – это система визуального поиска, с помощью которой пользователь может искать в физическом мире.
Простой интерфейс этого приложения для распознавания изображений позволяет делать снимки объектов. Система визуального поиска, стоящая за приложением, сообщит вам, что это за объект.
Приложение генерирует несколько результатов в виде изображений, видео и веб-содержимого, чтобы помочь вам найти то, что вы искали. Эти результаты также расширяют знания пользователя.
Кроме того, приложение также позволяет пользователям делиться находками со своими друзьями и семьей из приложения. Вы также можете сохранить свои выводы в своем профиле. Кроме того, приложение работает на основе Cloud-Sight Image Recognition API.
Рейтинг : 2.6
Скачать : iOS – Android
5.ScreenShop
Источник изображения: Dribble
ScreenShop создан для обслуживания модного сообщества, то есть знаменитостей, моделей и икон. Приложение для идентификации фотографий помогает пользователям найти покупаемый объект на изображении.
С помощью ScreenShop вы можете сделать снимок покупаемого товара, который вы видите на картинке. Проанализировав скриншот, ScreenShop подскажет, где вы можете найти одежду, аксессуары или товары, изображенные на картинке.
Каталог ScreenShop постоянно обновляется, что позволяет вам найти практически все, что вы ищете.Таким образом, приложение отлично подходит для молодого поколения и обеспечивает более быстрый и удобный процесс покупок.
Рейтинг: 3.9
Скачать : iOS – Android
6. Flow (на базе Amazon)
Источник изображения: TheVerge
Хотя это приложение для распознавания изображений создано A9 Innovation, Flow работает на Amazon.
С более чем 45 миллионами товаров на Amazon гигант электронной коммерции должен был найти способ сделать покупки более быстрыми и доступными.Итак, они разработали приложение для распознавания объектов Flow.
Это приложение использует камеру вашего телефона для распознавания объектов перед ним. После идентификации приложение отображает соответствующие результаты, найдя объект в магазине.
Однако недостатком использования этого приложения для распознавания объектов является то, что его охват ограничен продуктами магазина Amazon. Тем не менее, это отличное приложение для распознавания изображений, поэтому оно есть в этом списке.
Рейтинг : Не доступен.
Загрузить : Недоступно.
7. LeafSnap
Источник изображения: Life & soulmagazine
LeafSnap – это инновационное приложение для распознавания объектов, разработанное коллективными усилиями исследователей из Колумбийского университета, Университета Мэриленда и Смитсоновских институтов.
Это захватывающее приложение для визуального распознавания использует программное обеспечение для визуального распознавания, чтобы идентифицировать растения и деревья по фотографиям их листьев.
Кроме того, приложение замечательно для путешественников, потому что оно определяет деревья и растения и расширяет знания пользователя о природе.В приложении также есть несколько изображений деревьев, цветов и растений с высоким разрешением.
Поскольку способность идентифицировать растения и деревья – это не то, что большинство из нас делает ежедневно (если только наша работа не зависит от этого), LeafSnap позволяет пользователям удобно узнавать растение, фотографируя его на свои мобильные телефоны.
Рейтинг : 4.7
Загрузить: iOS – Android
8. Amazon Rekognition
Источник изображения: Amazon
Amazon Rekognition – это не просто приложение для идентификации объектов ; это также приложение для распознавания лиц и сопоставления фотографий . С технической точки зрения, это искусственный интеллект, лежащий в основе Rekognition, который постоянно развивается, используя возможности данных, которые он получает от Amazon и крупных технологических компаний.
Такое понимание и использование данных сделало Rekognition одним из лучших коммерческих приложений для идентификации изображений на рынке.
Более того, некоторые из основных преимуществ этих приложений включают анализ и потоковую передачу статических изображений и видеопоследовательностей, а также беспрепятственную идентификацию объектов, продуктов, людей, текста и изображений.
Загрузить: Amazon
Рейтинг: Нет данных
9. Google Images
Google снова попадает в этот список и не без особой причины. У них определенно есть интерес к технологии распознавания изображений. Технологический гигант Google использует самые инновационные технологии, чтобы заинтересовать своих пользователей и повлиять на них. Эта технология дала нам возможность обсудить еще одно новаторское приложение для распознавания vi sual.
На этот раз Google предлагает своей аудитории сервис «Google Images».Используя изображения Google, пользователь может пролистывать миллионы изображений, пока не найдет то, которое искал.
Вы также можете загружать графику в сервисы Google. Возможности машинного обучения в Google Images будут анализировать и искать похожие файлы в Интернете и показывать вам соответствующие результаты.
Кроме того, вы также можете использовать поиск изображений Google для выявления плагиата и фотомонтажа; однако этот конкретный процесс идентификации выполняется вручную, поэтому вы должны сделать это самостоятельно.Кроме того, вы также можете сохранять изображения с помощью функций коллекции в Google Images.
Картинок Google в режиме «Поиск картинок» чрезвычайно полезен для выявления плагиата и фотомонтажа. Все, что вам нужно сделать, это проверить это самостоятельно.
10. Вивино
Источник изображения: Vivino
Да! В цифровом мире также есть приложение для любителей вина. Vivino – это приложение для идентификации объектов, которое позволяет пользователю делать снимки любой винной этикетки или винной карты ресторана, чтобы быстро получить подробную информацию о напитке, его рейтингах и обзорах.
Vivino утверждает, что у нее самый большой винный рынок в мире. На этом огромном рынке пользователь может легко выбрать лучшее вино, определив его.
После выбора вина пользователь может оформить заказ. Команда доставки Vivino аккуратно доставит его прямо к вашему порогу.
Более того, попробовав вино, пользователи могут также добавлять комментарии и обзоры, оценивать вино вместе с другими пользователями Vivino и получать рекомендации о том, как попробовать другие вина.
Рейтинг : 4.9
Скачать : iOS – Android
11. Мама калорий
Вам понравилась еда, которую вы едите? Хотите узнать об этом или узнать больше? Вот отличное приложение для распознавания изображений, которое позволит вам получить подробную информацию о еде, которую вы потребляете, с точки зрения калорий.
Calorie Mama мгновенно определяет пищу и калории, из которых она состоит, используя камеру вашего смартфона и технологию распознавания объектов, основанную на технологии машинного обучения .
Это приложение отлично подходит для тех, кто заботится о своем здоровье. Он предоставляет пользователям огромные возможности, помогая им отслеживать ежедневное потребление калорий, чтобы они могли жить счастливой и здоровой жизнью.
Рейтинг : 4.8
Загрузить: iOS – Android
12. LogoGrab
LogoGrab разработан Visua Technologies. Основная функция приложения – это идентификация логотипов, текста, объектов и коммерческих материалов.Однако самым выдающимся аспектом LogoGrab является функция обнаружения сцены.
Хотя это приложение для идентификации фотографий предлагает ограниченное удобство использования, оно может эффективно и точно идентифицировать конкретные компании, работающие на рынке. Вот почему LogoGrab считается лучшим инструментом для поиска даже самых скрытых логотипов, фотографий и коммерческого материала.
Более того, основная идея приложения – идентифицировать и предоставлять маркетологам информацию об активах бренда. Кроме того, заслуживает похвалы инновационное применение технологии идентификации изображений в LogoGrab.
Рейтинг: Нет данных
Загрузка: нет данных
Заключение
Вот наш полный список из 12 лучших приложений для распознавания изображений, которые вы можете использовать для удовлетворения своих потребностей в распознавании изображений. Выше мы упомянули несколько различных приложений, которые служат для различных целей, поэтому вы можете выбрать лучшее из них в соответствии с вашими требованиями.
Более того, технология распознавания изображений ориентирована на будущее. В ближайшие годы мы увидим несколько улучшений и нововведений в этой конкретной области.
На данный момент это самые интуитивно понятные, продвинутые и революционные приложения, доступные для Android и iOS.
Более того, если вы ищете компанию по разработке приложений для iOS или Android, чтобы получить вдохновляющее и инновационное приложение для распознавания изображений для вашего бизнеса, нажмите кнопку ниже, чтобы связаться с нами.
[Обновлено] 10 лучших средств распознавания изображений
Получите бесплатную демонстрацию распознавания изображений!
Для брендов это означает доступ к большему количеству данных, чем когда-либо прежде, особенно данных на основе изображений.Пользователи социальных сетей полностью восприняли идею обмена фотографиями вместо текста или сопроводительного текста.
Свидетельство того факта, что «фотография стоит тысячи слов» в реальной жизни, можно увидеть в растущей популярности платформ социальных сетей, основанных на фотографиях, таких как Snapchat. Во втором квартале 2020 года у Snapchat было 238 миллионов активных пользователей по всему миру в день. Рост по сравнению с 203 миллионами DAU во всем мире в том же квартале 2019 года.
Очень важна способность выявлять, анализировать и использовать эту растущую тенденцию.В будущем цифрового маркетинга, в котором будут доминировать визуальные данные, должна существовать технология распознавания изображений. Без него бренды упускают массу ценных данных.
В этом посте я собираюсь перечислить несколько потрясающих инструментов распознавания изображений . У них разные функции, возможности и цены. Я включил проприетарную технологию распознавания изображений Talkwalker – подробности позже – потому что ИМХО она лучшая. Уровни точности и простота использования гарантируют, что он выделится из толпы.
За 30 дней логотип DHL был обнаружен почти 10 000 раз.
На изображении выше показано огромное количество логотипов DHL, которые публикуются или просматриваются в Интернете. От маркетинговых кампаний DHL до рекламных баннеров на гоночных трассах.
В этом случае фильтр использовался только для поиска изображений, содержащих ссылку на F1 / Формулу 1 в тексте. Почти 18% – 1800 упоминаний – включали ссылку на F1 / Формулу 1. Из этих изображений только 8 ссылались на DHL.
Значение?
Логотип DHL тесно связан с F1. Эти впечатления – 1800 упоминаний – были бы упущены, если бы отслеживался только текст.
Какая трата!
Скачать сравнительную таблицу средств распознавания изображений!
Что такое распознавание изображений?
Хорошо, распознавание изображений . Компьютер, использующий свои «глаза», как вы бы использовали свои.
Ознакомьтесь с разделом «Что такое анализ изображений?», Если вам нужна более подробная информация.
Распознавание изображений – это создание нейронной сети, которая обрабатывает все пиксели, составляющие изображение. Эти сети представлены кучей изображений уже идентифицированных объектов, чтобы сеть могла изучать и распознавать похожие объекты.
Например, AI будут показаны тысячи изображений обуви. ИИ узнает, какие изображения обуви должны содержать. Покажите изображение слона, и искусственный интеллект сравнит все пиксели изображения слона со всеми изображениями обуви, которые он видел.Не найдя совпадений или не найдя их, ИИ распознает в объекте слона.
Вот примеры инструментов, о которых вы, возможно, слышали, но не осознавали, используемую технологию распознавания изображений …
- Сравнение цен – сделайте снимок продукта, который вы хотите купить, и используйте приложение, такое как Google Shopper, чтобы узнать, какие магазины поблизости взимают
- Беспилотные автомобили – использование компьютерного зрения и распознавания изображений для идентификации пешеходов, дорожных знаков и других транспортных средств
- Поиск изображений – укажите в Google изображение или URL-адрес, и поисковая система покажет вам, где изображение было использовано в Интернете, одновременно найдя похожие
- Какой сериал? – такое приложение, как израильское TVTak – Shazam of TV – идентифицирует шоу, которое вы смотрите, с помощью технологии распознавания видео или изображений в вашем iPhone
- Собака это или нет? – Не Hotdog, приложение для распознавания изображений, без которого вам не обойтись… если вам абсолютно необходимо идентифицировать … хот-дог
Почему я должен использовать распознавание изображений?
Данные, полученные с помощью инструментов распознавания изображений , можно использовать по-разному. От понимания ваших клиентов и их интересов до создания целевой рекламы для определенных групп. Представьте себе возможность размещать рекламу в Facebook на основе индивидуальных предпочтений и увлечений людей.
Просто, ВАУ!
Любители собак могут увидеть рекламу самых модных новых угощений для собак, а любители кошек могут получить рекомендации относительно лучших кормов для кошек.
Инструменты распознавания изображений помогут вам лучше понять свою клиентскую базу. Оцените, что поможет вам выйти на новый рынок, убедитесь, что никто не злоупотребляет вашим логотипом, и проанализируйте истинный охват вашего маркетинга. Он может дать вам представление о потребителях в цифровом формате, в котором вы так отчаянно нуждаетесь, и откроет вам глаза на новые возможности, которые вы так легко могли упустить. Технология распознавания изображений – это, по сути, компас, необходимый каждому бизнесу для навигации в сложной местности современного цифрового мира.
Этот пост даст вам некоторое представление о различных доступных инструментах распознавания изображений и поможет вам решить, какой из них лучше всего подходит для вашего бизнеса и вашего бренда.
Что умеют инструменты распознавания изображений?
Инструменты распознавания изображений могут распознавать, анализировать и интерпретировать изображения. Намного эффективнее, чем вы и ваша команда. Они сэкономят вам время и деньги. Инструменты распознавания изображений могут сортировать бесчисленное количество изображений и быстро возвращать данные, уникальные для вашего бизнеса.
Я составил список из 10 лучших инструментов для распознавания изображений и того, что их отличает. Взглянуть!
Talkwalker | Запатентованная технология распознавания изображений
Технология распознавания изображений Talkwalker позволяет выполнять поиск в базе данных, содержащей более 30 000 логотипов, а также сцен и объектов. Это означает, что у вас есть доступ практически к любой информации о компании, которая может вам понадобиться. Помимо огромного объема изображений, которые он может распознать, он также использует адаптируемую запатентованную технологию для одновременного анализа текста и изображений.
Получите мою бесплатную демонстрацию распознавания изображений!
Запатентованная технология распознавания изображений Talkwalker – от максимального увеличения охвата вашей рекламы до получения предупреждений каждый раз, когда кто-то публикует информацию о вашем бренде, – это инструмент, который расширит ваши существующие знания о вашем бренде и поможет вам использовать эти знания в процессе работы. продолжайте развивать свой бизнес.
Рооооони !!!
Распознавание изображений обнаружит логотипы Martini, Texaco, Michelin, несмотря на отсутствие упоминания.
Это означает, что рентабельность инвестиций от спонсорства может быть точно измерена.
Вы нашли идеальное изображение, но оно не того размера. Вам нужно изображение, похожее на то, что у вас есть.
Вам нужен поиск обратного изображения Google!
Как следует из названия, этот инструмент распознавания изображений позволяет загружать изображение и выполнять поиск по нему.
Вы выполняете поиск по изображению, а не по словам. Прохладный!
Самое замечательное в этом инструменте то, что он так же интуитивно понятен, как и типичный текстовый поиск Google, и сохраняет возможности Google.
Примеры того, как вы могли бы использовать этот инструмент, включают …
- Вам нужно найти источник изображения, чтобы вы могли правильно указать его
- Поиск случаев ненадлежащего использования принадлежащего вам изображения – нарушение прав на товарный знак
Если изображение существует в Интернете, поиск обратного изображения Google поможет вам найти то, что вы ищете.
Вставьте URL-адрес или загрузите изображение.
Загрузка приведенного выше снимка экрана из F1 приносит кучу данных распознавания изображений.
Google API Cloud Vision позволяет анализировать изображения разными способами. От распознавания откровенного содержания до обнаружения эмоциональных сигналов на лицах. Благодаря такому широкому набору функций это универсальный инструмент, который можно адаптировать к вашим конкретным потребностям.
Помимо своей гибкости, этот инструмент распознавания изображений несет в себе мощь Google и все, что следует из названия. Это означает, что это один из самых мощных инструментов, который вы найдете.
Инструмент распознавания изображений с возможностями Google!
Еще одно громкое имя в веб-мире, Amazon предлагает инструмент распознавания изображений с уникальными предложениями.
Amazon Rekognition не только анализирует неподвижные изображения, но и может анализировать видео.
Это высокотехнологичная программа, способная …
- Обнаружение объектов, сцен и действий – игра в футбол, на велосипеде, на пляже, в городе и т. Д.
- Распознавание лиц – идентификация человека на фото или видео
- Анализ лица – улыбка, глаза открыты, очки, борода, пол
- Путь – e.грамм. движение спортсменов во время игры для анализа после игры
- Обнаружение небезопасного содержимого – определение небезопасного или неприемлемого содержимого в изображениях и видео
- Распознавание знаменитостей – определите звезд из своих библиотек видео и изображений
- Текст в изображениях – обнаружение и распознавание текста, такого как названия улиц, подписи, названия продуктов, номера автомобилей
Amazon заверяет пользователей, что постоянно обучающийся инструмент распознавания изображений интуитивно понятен для интеграции и использования.
Преимущество Amazon Rekognition в том, что вы платите только за используемые данные. Это означает, что минимальных сборов нет. Это позволяет вам использовать программу так, как вы считаете нужным, и получать доступ ко всем преимуществам мощной системы, не нарушая при этом денег.
Обнаружение небезопасного контента и распознавание знаменитостей.
Объекты и сцены, распознавание и анализ лиц, отслеживание людей.
Clarifai | Поиск похожих изображений
Этот инструмент распознавания изображений позволяет искать изображения, используя другие изображения.Представьте себе потенциальное использование?
Например, вы можете захотеть найти изображения на основе сходства, а слова могут увести вас далеко.
Повторюсь – картинка стоит тысячи слов, если не больше.
Как бы вы ни пытались описать изображение для поисковой системы, вы, скорее всего, никогда не поймете, что именно в изображении вы хотите, чтобы эта машина нашла. Инструмент распознавания изображений Clarifai сделает всю работу за вас. Это поможет вам найти похожие изображения, просто выбрав фотографии и указав инструменту, что делать.
Инструмент анализирует фото и распознает млекопитающих, диких животных, улицу, траву, животных, стадо, слоновую кость … слона!
Визуальный поиск, рекомендации и обнаружение, аналитика клиентов.
LogoGrab | Распознавание логотипа и знака
Имя, которое одновременно броское и информативное, служит мостом для компаний, желающих перейти в новую эру маркетинга и взаимодействия с потребителями. LogoGrab знает свою нишу и хорошо ее заполняет, начиная с запатентованного механизма адаптивного обучения и кончая эталоном самого быстрого и точного инструмента на рынке.
Разработанный для технологических компаний, рекламных агентств и брендов, LogoGrab ориентирован на монетизацию и взаимодействие на мобильных платформах. Это делает его идеальным инструментом для тех, кто хочет получить максимальную отдачу от своего присутствия в социальных сетях.
LogoGrab может похвастаться тем, что их инструмент легко интегрируется в большинство существующих платформ. Это означает, что переход к LogoGrab и ценной информации, которую он может предоставить, будет плавным и безболезненным – еще одна особенность и без того потрясающего инструмента.
Встраивайте определение логотипа и SKU для изображений и видео в любой проект.
Получите бесплатную демонстрацию распознавания изображений!
IBM – гигант в мире технологий – находится в авангарде разработки передовых технологий, которые не только делают современный мир лучше, но и подталкивают его к новым возможностям.
Его инструменты распознавания изображений – одни из лучших. Одним из основных преимуществ IBM Image Detection является его обучаемость. Другими словами, IBM предоставляет платформу с широкими возможностями настройки, которую можно настроить для выполнения практически любой задачи, которая вам нужна.
Как это круто? !!
Анализируйте изображения сцен, объектов, лиц, цветов, продуктов и другого содержимого.
Инструмент распознавания изображений идентифицирует бренды на изображении.
Imagga | Catorgorize images
Инструмент распознавания изображений Imagga предоставляет несколько автоматических опций для сортировки, организации и отображения ваших изображений на основе категории, цвета, тега – которые также могут быть автоматизированы – или пользовательского ввода.Это означает, что у вас есть несколько встроенных опций, но вы также можете развиваться в соответствии с вашими конкретными потребностями. Двойственность Imagga позволяет ему соответствовать любым обстоятельствам и уровню квалификации.
Если вам нужен способ упорядочить вещи, не тратя драгоценное время компании, или вам нужно убедиться, что на вашей странице не отображается явный контент, у Imagga есть инструмент для вас, а если нет, вы можете его создать!
Универсальные решения для распознавания изображений для разработчиков и предприятий.
CloudSight | распознать, классифицировать, понять
В то время как некоторые инструменты ориентированы на узкоспециализированное выполнение и приложение, другие пытаются максимально повысить удобство, сохраняя при этом впечатляющую функциональность.CloudSight идеально подходит для тех, кто ищет простой в использовании и самоописываемый «легкий» инструмент.
Этот инструмент распознавания изображений упрощает процесс распознавания, категоризации и понимания. Это позволяет вам практически отказаться от использования визуальных элементов.
Это может означать …
- Разрешение программе писать естественно звучащую подпись
- Простая интеграция изображений в ваше торговое онлайн-пространство
- Раскрытие ключевого материала в вашем видеоконтенте
CloudSight интуитивно понятен до отказа, без ущерба для функциональности, которую вы ожидаете от первоклассного инструмента распознавания изображений.
Отлично!
Дважды круто!
EyeEm | Оцените эстетический рейтинг фото
Для тех из вас, кто любит фотографию, осознавая ее потенциал в растущем мире изображений, распознавание изображений EyeEm является идеальным инструментом. Специально для тех, кто пользуется платформами социальных сетей.
Благодаря автоматическим тегам и подписям это здорово, если вы хотите использовать теги, которые не только лучше всего подходят для ваших изображений, но и способствуют увеличению экспозиции.EyeEm выходит за рамки этого, используя распознавание изображений для оценки эстетического рейтинга фотографии.
Звучит круто, не так ли?
Это полезно для тех, кто основывает свой успех на фотографии и взаимодействии с публикациями. Оценка фотографий на основе их эстетической привлекательности может помочь вам выбрать наилучшее из возможных изображений для максимального вовлечения.
Инструмент можно научить распознавать ваш уникальный стиль, чтобы ваши сообщения сохраняли целостную эстетику, которую вы ищете при создании страницы на основе изображений.
Инструмент распознавания изображений, который оценивает фотографии на основе их эстетической привлекательности.
Ваш вывод из этого списка заключается в том, что независимо от того, чего вы хотите от инструмента распознавания изображений, есть идеальный инструмент для вас и вашего бренда.
Технология распознавания изображений принесет пользу любому бизнесу, независимо от его размера, продукта или рынка. От мегакорпораций, стремящихся к максимальной узнаваемости бренда, до независимых фотографов, желающих расширить свой рынок с помощью платформ социальных сетей.Распознавание изображений – ключ к навигации в нашем информационном мире.
Что выделит вас из массы данных? Что делает ваш бренд лучше, чем у конкурентов? Как лучше всего определить идеальный рынок для того, что вы предлагаете, а затем целенаправленно и эффективно выйти на него? Как вы можете гарантировать, что идентичность вашего бренда не используется и не злоупотребляется?
Ответ – распознавание изображений.
Предварительно разработанный инструмент, который сделает за вас охоту. позволяя вам тратить больше времени на развитие вашего бизнеса.Индивидуальная программа, дающая представление о потребителях вашего рынка в цифровом формате – у вас есть выбор. В мире бесконечной информации инструменты распознавания изображений сортируют все это и открывают дверь к безграничным возможностям. Нажмите ниже и найдите свой логотип в Интернете!
Франсуа является членом команды Talkwalker Marketing.
Франсуа – творческий человек, который любит делиться тем, что узнает. Его любимые темы – SEO, SEA и SMA. Он любит посмеяться и пошутить, и он не может начать день без чашки крепкого кофе.
Обратный поиск изображений – поиск похожих фотографий в Интернете
Вы можете сделать много замечательных вещей с помощью обратного просмотра фотографий, но вот некоторые из них:
Узнать больше об объекте изображения
Помните нашего милого щенка? С помощью обратного просмотра изображений мы наконец обнаружили, что щенок принадлежит к породе сиба-ину, которая является самой маленькой из шести оригинальных и самобытных пород шпицев, произрастающих в Японии.Мы также обнаружили, что эта симпатичная вещица довольно маневренна и прекрасно справляется даже с гористой местностью.
Найти визуально похожие изображения
Думаете, вам нужно почти одно и то же изображение, но в разных стилях? Google Обратный поиск изображений. Мета позволяет вам находить визуально похожие или похожие изображения на образец.
Найдите первоисточники изображений
Если вы хотите найти источник изображения, чтобы присвоить должное имя владельцу изображения, но у вас возникли трудности с выяснением того, кто является первоначальным создателем, тогда инструмент поиска источника изображения – лучшее решение для вашего запроса.
Найдите плагиатские фотографии
Похитители фотографий могут подумать, что они умены, но загрузка в поиске картинок в Google делает вас умнее! Если у вас есть много оригинальных фотографий и вы хотите знать, использует ли кто-то их без вашего разрешения или каких-либо кредитов, тогда инструмент обратного изображения Google – ваш новый приятель. Вы даже сможете увидеть, на скольких других страницах есть ваше изображение.
Создание возможностей для обратных ссылок
Не просто используйте инструмент поиска изображений, чтобы найти людей, которые используют ваши фотографии без указания авторства, попросите их упомянуть вас как автора и дать обратную ссылку на вашу страницу.Отлично подходит для SEO!
Определять людей, места и продукты
Есть фотографии людей, мест или продуктов, которых вы не знаете? Не волнуйтесь! Просто загрузите их, и обратный поиск фотографий поможет их найти, если в Интернете есть идентичные изображения или информация.
Откройте для себя больше версий определенного изображения
Возможно, ваша текущая версия образа не справляется со своей задачей. При обратном поиске изображения вы можете получить больше версий определенного изображения, означает ли это другой размер, формат или не такое размытое.
Обнаружение поддельных аккаунтов
Думаете, что вы слишком симпатичны и кто-то может использовать вашу фотографию в поддельной учетной записи в социальной сети? Позвольте обратному поиску изображений помочь сохранить вашу личную репутацию в чистоте, и если вы думаете, что стали жертвой кошачьей ловли, и кто-то другой использует поддельную личность в учетной записи в социальных сетях. Выполнение обратного поиска изображений мошенников с помощью инструмента обратного поиска фотографий может выявить реального человека.
10 лучших приложений для распознавания изображений для iOS и Android – Data Catchup
Приложения для распознавания изображений удобны для мобильных устройств и помогают в идентификации объектов.В результате развития искусственного интеллекта мы стали свидетелями улучшения компьютерного зрения, распознавания лиц и категоризации объектов на основе алгоритмов машинного обучения.
Источник: Datacatchup.comGoogle Lens
Google Объектив – прекрасный исследовательский инструмент с камерой смартфона для распознавания памятников, мест, продуктов, декора, текстового поиска, животных, переводит языки, просто наведя камеру на текстовое слово и удерживая кнопку в течение нескольких секунд, чтобы включить камеру и перейти к выбору язык.
Вы можете сфотографировать карточка контакта, чтобы сохранить адрес, номер телефона, имя контакта и URL-ссылку Веб-сайт. Вам не нужно вводить вручную на мобильном устройстве.
AIPoly Vision
Приложение для людей с ослабленным зрением и дальтонизмом, которое помогает им распознавать объекты или цвета по наведению камеры смартфона.
Магазин экранов
Это приложение полюбилось покупателям модной одежды, которые случайно натолкнулись на любимый предмет и захотят его приобрести.Приложение Screen Shop идентифицирует товары после того, как любитель моды делает снимок, видео или снимок экрана, и приложение отображает соответствующие товары, доступные в интернет-магазинах.
Источник: DatacatchupTapTap See
Прекрасное распознавание объектов приложение для людей с ослабленным зрением и полной слепотой, чтобы помочь им идентифицировать объекты с помощью объектива камеры смартфона, озвучивая объект идентифицированы.
Чтобы включить это приложение на iOS, вам необходимо включить «закадровый голос», а на смартфонах Android вы должны включить «ответ».
Youtube: Datacatchup
Cam Find
Cam Find предлагает мобильный визуальный поиск путем фотографирования объекта, который, в свою очередь, распознается приложением и сообщает вам, что это такое, отображая такие результаты, как изображения, видео и местные предложения по покупкам. Cam find можно пометить как приложение поисковой системы распознавания изображений.
Источник: DatacatchupFlow на базе Amazon
Это приложение для распознавания изображений позволяет сканировать визитные карточки для добавления новых телефонных контактов.Flow powered by amazon также идентифицирует такие продукты, как DVD, компакт-диски, видеоигры, обложки для книг и упакованные товары для дома.
Google Обратное изображение
Это приложение очень удобно, так как помогает пользователю искать похожие изображения, загруженные пользователем. Эти пользовательские поисковые запросы могут отличаться из-за необходимости в размере изображения, более высоком качестве изображения и т. Д.
Привязка к листу
Приложение для визуального распознавания природных видов, разработанное исследователями Колумбийского университета, Смитсоновского института и Университета Мэриленда, чтобы помочь идентифицировать виды деревьев по фотографиям их листьев с помощью изображений с высоким разрешением.
Источник: DatacatchupCalorie Mama
Приложениедля подсчета калорий использует технологию распознавания фотографий, чтобы помочь пользователям отслеживать питание с помощью изображений их еды, сканируя контент и вычисляя общее количество калорий по одной фотографии.
Вивино
Vivino – это распознавание изображений приложение для винных этикеток, чтобы получить подробную информацию о любом вине, взяв изображение винной этикетки. Это приложение также предоставляет мгновенную подробную информацию о любом вине, включая рейтинги и обзоры сообщества.
Следите за нами и ставьте лайки:
Введение в распознавание изображений – AI для чайников (1/4)
Прочтите наше введение в распознавание изображений и компьютерное зрение и откройте для себя наиболее многообещающую область глубокого обучения.
Когда дело доходит до изображений, искусственный интеллект существует под разными названиями с 60-х годов: компьютерное зрение и распознавание изображений . Но что такое компьютерное зрение?
Компьютерное зрение – это искусство и наука, позволяющая компьютерам понимать изображения.
Вы можете этого не осознавать, но ваш мозг действительно прекрасная машина. Из одного изображения он может получить больше информации, чем мы знаем, что делать. Взгляните на картинку ниже.
Барри – классный пес. Ему нравится заниматься серфингом на Гавайях.Если спросить, что это на изображении, вы, вероятно, ответите мне, что на пляже есть собака с каким-то бодибордом, в красных солнцезащитных очках и гавайском ожерелье из искусственных цветов…
Спойлер! День, когда компьютер сможет одновременно достичь такого уровня точности и универсальности, еще не наступил.К счастью для нас – иначе мы бы вышли из бизнеса – уже есть несколько практических примеров использования, в которых компьютерное зрение оказывается очень ценным.
Скажи мне, что видишь
Итак, чему же мы учим компьютеры? Просто: распознавайте, идентифицируйте и находите объекты с разной степенью точности. Барри и его друг Даки покажут вам, что я имею в виду. Для простоты я проиллюстрирую четыре основные задачи, используемые сегодня в реальных приложениях:
- Классификация.
- Маркировка.
- Обнаружение.
- Сегментация.
Классификация и маркировка
Классификация (слева): мы почти уверены, что есть только собака, а не кошка. Маркировка (справа): есть и собака, и утка.Первая и самая простая задача, которую мы можем выполнить, – это определить, что находится на изображении и насколько мы уверены в этом, то есть процент вероятности на двух картинках выше. Следует учитывать два основных момента:
- Какой список объектов вы хотите обнаруживать?
Это называется онтология .На первом изображении это кошки и собаки. Чтобы он был (очень) простым, вам необходимо заранее сообщить алгоритму, какие классы объектов он должен идентифицировать. И, как и все простые вещи … на самом деле все гораздо сложнее. Не всегда нужно перечислять все объекты. Однако это открытая область исследований, называемая обучением без учителя, поэтому мы пока воздержимся от нее. - Есть ли на одном снимке несколько объектов?
Если есть только один элемент одновременно, мы называем его классификацией (слева).В противном случае, когда несколько объектов находятся на одном изображении, это называется с тегом (справа).
Обнаружение и сегментация
Обнаружение (слева): мы знаем, в каком квадрате на изображении находятся Даки и Барри. Сегментация (справа): у нас есть информация на уровне пикселей.Теперь, когда мы ответили на вопрос “Что”, возникает вопрос: Где объекты, которые мы ищем? Это можно сделать двумя способами:
- Обнаружение выводит прямоугольник или ограничивающую рамку на изображении, где находятся объекты.Он может быть подвержен небольшим ошибкам и неточностям в позиции, но это очень надежная технология.
- Сегментация идет еще дальше. Для каждого пикселя, наиболее атомарного элемента информации в изображении, мы определяем, каким объектам он принадлежит, если таковые имеются. В результате получается очень точная карта, хотя для этого требуется много тщательно аннотированных данных. Это утомительная задача, когда нужно проделывать ее для каждого пикселя, но она может дать впечатляющие результаты. Это одна из причин, почему варианты использования в здравоохранении, особенно для обнаружения рака , становятся все более и более распространенными.
Это были четыре основных строительных блока компьютерного зрения. Однако у вас также есть идентификация экземпляра, обнаружение ключевых точек лица, распознавание действий, отслеживание, оптическое распознавание символов, генерация изображения, передача стиля, шумоподавление, оценка глубины, 3D-реконструкция, оценка движения, оптический поток и т. Д. Идея у вас есть ; еще много чего нужно сделать!
Традиционное компьютерное зрение и глубокое обучение
Артур Кларк, написавший 2001: Космическая одиссея , сказал это лучше, чем кто-либо другой: «Любая достаточно продвинутая технология неотличима от магии.«Я считаю, что до тех пор, пока вы точно не объясните, как что-то работает, вы никогда не поймете и не примете это. Это особенно верно, когда дело касается искусственного интеллекта. Как только вы начнете чистить лук, вы поймете, что это еще одна технология со своими сильными и слабыми сторонами. Его не следует бояться больше, чем бояться электричества.
Настоящий поворотный момент и самое фундаментальное различие между традиционным компьютерным зрением и тем, что сейчас называется глубоким обучением, заключается в том, как вы создаете алгоритмы.
- Новые способы.
При глубоком обучении все опирается на примеров . Вам понадобится коллекция из нескольких изображений кошек и собак; затем алгоритм будет строить на своих знаниях данные изображения, чтобы делать прогнозы на изображениях, которые он никогда раньше не видел. Это так называемое обобщение . Предупреждение ⚠️️ 🚨. Вы всегда должны очень подозрительно относиться к людям, которые говорят об алгоритмах, как если бы они были разумными существами и имели мотивы , что я только что сделал.То, что они, кажется, учатся так же, как и мы, не означает, что они действительно способны думать. - Старые способы.
С другой стороны, традиционное компьютерное зрение в основном основано на правилах. Это означает, что вы будете смотреть на изображения того, что вы хотите обнаружить, а затем использовать свое воображение и логическое мышление. Цель? Разработайте набор из правил и инструкций , которые приведут к желаемому результату.
Правила и инструкции
Давайте посмотрим на примеры правил и инструкций.
Разве не было бы мило, если бы вам не пришлось останавливаться на платной автомагистрали, чтобы оплатить проезд? Как насчет того, чтобы ваш сумасшедший сосед перестал мчаться по дороге, когда ваши дети играют? А если бы ваша гаражная дверь могла автоматически распознавать вас и открываться сама? Вам нужно сначала обнаружить номерные знаки, а затем уметь их читать.
А пока давайте сосредоточимся на части обнаружения. Есть шесть основных шагов, которые я собираюсь проиллюстрировать на примере нашего служебного автомобиля Deepomobile:
.- Шаг 1. Здесь особо нечего сказать, кроме того, что очень удобно перейти из точки А в точку Б и заставить всех повернуться.
- Шаг 2. Сначала мы преобразуем изображение в черно-белое путем объединения красно-зеленого и синего каналов. Затем мы размываем , чтобы удалить мелкие артефакты и обнаружить более общие формы.
- Шаг 3. Вычисляется величина градиента . Проще говоря, градиент – это разница между двумя соседними пикселями.Чем он выше, тем больше различаются пиксели, поэтому он используется для определения краев.
- Шаг 4. Непревзойденное подавление гарантирует, что даже если один край охватывает несколько пикселей, мы будем рассматривать только наиболее вероятную линию.
- Шаг 5. Порог гистерезиса усиливает это и обеспечивает чистые края.
- Шаг 6. Края преобразуются в геометрических линий , которые затем, в свою очередь, используются для определения прямоугольной формы номерного знака.
Каждый шаг имеет собственный набор параметров и требует особой настройки. Как следствие, традиционные методы компьютерного зрения не всегда надежны при изменении условий. Например, если мы разработали наш детектор номерных знаков для работы в гараже, то его использование на улице, в тени, ночью или при широком освещении может дать неоптимальные результаты, что сделает его бесполезным.
Заключение
Короче говоря, мы разрабатывали конкретные и индивидуальные рецепты для каждой задачи компьютерного зрения.Теперь, благодаря глубокому обучению, мы создаем алгоритмы, которые учатся создавать свои собственные правила.
На следующей неделе мы рассмотрим, как мы работаем сейчас и что на самом деле означает термин «глубокое обучение». Следите за обновлениями!
Распознавание изображений с помощью глубокого обучения и нейронных сетей
Время чтения: 10 минутПриятно осознавать, что мы, люди, смогли задействовать машины с нашими собственными естественными навыками: обучением на примере и восприятием внешнего мира.Единственная проблема заключается в том, что требуется значительно больше времени и усилий, чтобы научить компьютеры «видеть», как мы. Но если мы подумаем о практической цели, которую эта возможность уже приносит организациям и предприятиям, усилия окупаются.
Из этой статьи вы узнаете, что такое распознавание изображений и как оно связано с компьютерным зрением. Вы также узнаете, что такое нейронные сети и как они учатся распознавать то, что изображено на изображениях. Наконец, мы обсудим некоторые варианты использования этой технологии в различных отраслях.
Что такое распознавание изображений и компьютерное зрение?
Распознавание изображений (или классификация изображений) – это задача идентификации изображений и их категоризации по одному из нескольких заранее определенных отдельных классов. Таким образом, программное обеспечение и приложения для распознавания изображений могут определять, что изображено на картинке, и отличать один объект от другого.
Область исследования, направленная на обеспечение машин с этой способностью, называется компьютерное зрение . Классификация изображений, являясь одной из задач компьютерного зрения (CV), служит основой для решения различных задач CV, в том числе:
Классификация изображений с локализацией – размещение изображения в заданном классе и рисование ограничивающей рамки вокруг объекта, чтобы показать, где оно находится на изображении.
Сравнение классификации изображений и классификации изображений с локализацией. Источник: KDnuggets
Обнаружение объектов – категоризация нескольких различных объектов на изображении и отображение местоположения каждого из них с помощью ограничивающих рамок. Итак, это разновидность классификации изображений с задачами локализации множества объектов.
Объектная (семантическая) сегментация – определение конкретных пикселей, принадлежащих каждому объекту в изображении, вместо рисования ограничивающих рамок вокруг каждого объекта, как при обнаружении объекта.
Сегментация экземпляра – различение нескольких объектов (экземпляров), принадлежащих к одному классу (каждого человека в группе).
Разница между обнаружением объектов, семантической сегментацией и сегментацией экземпляра. Источник: Условные случайные поля соответствуют глубоким нейронным сетям для семантической сегментации
Исследователи могут использовать модели глубокого обучения для решения задач компьютерного зрения. Глубокое обучение – это метод машинного обучения, который фокусируется на обучении машин обучению на собственном примере.Поскольку в большинстве методов глубокого обучения используются архитектуры нейронных сетей, модели глубокого обучения часто называют глубокими нейронными сетями.
Глубокие нейронные сети: «как» в основе распознавания изображений и других методов компьютерного зрения
Распознавание изображений – одна из задач, в которой глубокие нейронные сети (DNN) превосходны. Нейронные сети – это вычислительные системы, предназначенные для распознавания образов. Их архитектура вдохновлена структурой человеческого мозга, отсюда и название. Они состоят из трех типов слоев: входных, скрытых и выходных.Входной слой получает сигнал, скрытый слой обрабатывает его, а выходной слой принимает решение или прогноз относительно входных данных. Каждый сетевой уровень состоит из взаимосвязанных узлов (искусственных нейронов ), которые выполняют вычисления.
Что делает нейронную сеть глубокой? Количество скрытых слоев: в то время как традиционные нейронные сети имеют до трех скрытых слоев, глубокие сети могут содержать их сотни.
Архитектура нейронной сети, каждый уровень состоит из узлов.Количество скрытых слоев необязательно. Источник: MathWorksКак нейронные сети учатся распознавать шаблоны
Как понять, является ли человек, проходящий по улице, знакомым или незнакомцем (такие осложнения, как близорукость, не включены)? Мы смотрим на них, подсознательно анализируем их внешность, и если некоторые присущие им черты – форма лица, цвет глаз, прическа, телосложение, походка или даже выбор моды – совпадают с конкретным человеком, которого мы знаем, мы узнаем этого человека.Эта умственная работа занимает мгновение.
Итак, чтобы распознавать лица, система должна сначала изучить их особенности. Его необходимо обучить предсказывать, является ли объект X или Z. Модели глубокого обучения изучают эти характеристики иначе, чем модели машинного обучения (ML). Вот почему подходы к обучению моделей также различаются.
Обучение моделей глубокого обучения (например, нейронных сетей)
Чтобы построить модель машинного обучения, которая может, например, прогнозировать отток клиентов, специалисты по данным должны указать, какие входные характеристики (свойства проблемы) модель будет учитывать при прогнозировании результата.Это может быть образование клиента, доход, этап жизненного цикла, характеристики продукта или используемые модули, количество взаимодействий со службой поддержки и их результаты. Процесс конструирования признаков с использованием знаний предметной области называется проектированием признаков .
Если бы мы обучили модель глубокого обучения, чтобы увидеть разницу между собакой и кошкой, используя конструкцию признаков… Что ж, представьте себе сбор характеристик миллиардов кошек и собак, которые живут на этой планете. Мы не можем создать точные характеристики, которые будут работать для каждого возможного изображения, учитывая такие сложности, как изменчивость объекта в зависимости от точки обзора, беспорядок на фоне, условия освещения или деформация изображения.Должен быть другой подход, и он существует благодаря природе нейронных сетей.
Нейронные сети изучают функции непосредственно на основе данных, с помощью которых они обучаются, поэтому специалистам не нужно извлекать функции вручную.
«Сила нейронных сетей заключается в их способности изучать представление в ваших обучающих данных и как наилучшим образом связать его с выходной переменной, которую вы хотите предсказать. В этом смысле нейронные сети изучают картографирование. С математической точки зрения они способны обучаться любой функции отображения, и было доказано, что они являются универсальными алгоритмами аппроксимации », – отмечает Джейсон Браунли в ускоренном курсе по многослойным перцептронным нейронным сетям .
Обучающие данные в данном случае представляют собой большой набор данных, содержащий множество примеров каждого класса изображений. Когда мы говорим о большом наборе данных, мы действительно имеем в виду именно это. Например, набор данных ImageNet содержит более 14 миллионов аннотированных людьми изображений, представляющих 21 841 концепцию (наборы синонимов или синсеты в соответствии с иерархией WordNet), в среднем по 1000 изображений на концепцию.
Каждое изображение помечено (помечено) категорией, к которой оно принадлежит – кошка или собака. Алгоритм исследует эти примеры, изучает визуальные характеристики каждой категории и, в конечном итоге, узнает, как распознавать каждый класс изображений.Этот типовой стиль обучения называется контролируемое обучение .
Иллюстрация того, как нейронная сеть распознает собаку на изображении. Источник: TowardsDataScience
Каждый уровень узлов тренируется на выходе (наборе функций), созданном предыдущим слоем. Таким образом, узлы в каждом последующем слое могут распознавать более сложные и подробные особенности – визуальные представления того, что изображено на изображении. Такая «иерархия возрастающей сложности и абстракции» известна как иерархия признаков .
Пример иерархии признаков, изученный с помощью модели глубокого обучения на лицах от Lee et al. (2009). Источник: ResearchGate.net
Итак, чем больше уровней в сети, тем выше ее прогностическая способность.
Ведущей архитектурой, используемой для задач распознавания и обнаружения изображений, являются сверточные нейронные сети (CNN). Сверточные нейронные сети состоят из нескольких слоев с небольшими коллекциями нейронов, каждый из которых воспринимает небольшие части изображения.Результаты всех коллекций в слое частично перекрываются, создавая полное представление изображения. Слой ниже затем повторяет этот процесс для нового представления изображения, позволяя системе узнать о композиции изображения.
История глубоких CNN восходит к началу 1980-х годов. Но только в 2010-х исследователям удалось добиться высокой точности решения задач распознавания изображений с помощью глубоких сверточных нейронных сетей. Как? Они начали обучать и развертывать CNN с использованием графических процессоров (GPU), которые значительно ускоряют сложные системы на основе нейронных сетей.Объем обучающих данных – фото или видео – также увеличился, потому что камеры для мобильных телефонов и цифровые камеры начали быстро развиваться и стали доступными.
Примеры использования распознавания изображений
Теперь вы знаете о распознавании изображений и других задачах компьютерного зрения, а также о том, как нейронные сети учатся присваивать метки изображению или нескольким объектам на изображении. Давайте обсудим несколько реальных приложений этой технологии.
Обнаружение логотипа в аналитике социальных сетей
Бренды отслеживают текстовые сообщения в социальных сетях с упоминанием своего бренда, чтобы узнать, как потребители воспринимают, оценивают, взаимодействуют с их брендом, а также что они говорят о нем и почему.Это называется социальным слушанием. Тип социального слушания, который фокусируется на отслеживании разговоров на основе визуальных данных, называется (барабанная дробь, пожалуйста)… визуальным слушанием.
Тот факт, что более 80 процентов изображений в социальных сетях с логотипом бренда не имеют названия компании в подписи, усложняет визуальное восприятие. Как разобраться в этом деле? С распознаванием логотипа.
СтартапMeerkat провел эксперимент, чтобы показать, как распознавание логотипа может помочь визуальному восприятию. В течение шести месяцев стартаперы собирали твиты со словами, обычно используемыми в контексте пива, например, пиво , сервеза, барбекю, бар и другие.Они обучили систему распознавания логотипов популярных пивных брендов: Heineken, Budweiser, Corona, Bud Light, Guinness и Stella Artois. И они использовали его для анализа изображений из твитов, содержащих логотипы брендов.
Логотип Heineken в разных контекстах. Источник: Meerkat’s Medium
Специалистыпроиндексировали метаданные твитов, чтобы получить представление о рыночной доле каждого бренда и его потребителях.
Сначала они сравнили количество постов с логотипами каждого бренда с их долей на рынке и обнаружили, что эти два параметра не взаимосвязаны.Затем специалисты извлекли географические координаты почти 73% изображений в твиттере, чтобы оценить присутствие бренда в регионах. Затем они построили процентное содержание каждого пива для пяти ведущих стран в наборе данных. Например, Bud Light является самым популярным в США, в то время как у Heineken есть поклонники в разных странах с наибольшими долями в США и Великобритании. Команда также проанализировала изображения с лицами, чтобы определить пол пьющих пиво. Разница была незначительной: фотографии разместили на 1,34% больше мужчин.
Это не только измерение узнаваемости бренда. Компании используют обнаружение логотипов для расчета рентабельности инвестиций от спонсирования спортивных мероприятий или для определения того, использовался ли их логотип не по назначению.
Анализ медицинских изображений
Программное обеспечениена основе моделей глубокого обучения помогает рентгенологам справляться с огромной нагрузкой по интерпретации различных медицинских изображений: компьютерной томографии (КТ) и ультразвукового сканирования, магнитно-резонансной томографии (МРТ) или рентгеновских лучей. IBM подчеркивает, что радиолог отделения неотложной помощи должен ежедневно обследовать до 200 пациентов.Кроме того, некоторые медицинские исследования содержат до 3000 изображений. Неудивительно, что на медицинские изображения приходится почти 90 процентов всех медицинских данных.
Радиологические инструменты на основе искусственного интеллекта не заменяют врачей, а помогают им принимать решения. Они выявляют острые аномалии, выявляют пациентов из группы высокого риска или тех, кто нуждается в срочном лечении, чтобы радиологи могли расставить приоритеты в своих рабочих списках.
Исследовательское подразделение IBM в Хайфе, Израиль, работает над Cognitive Radiology Assistant для анализа медицинских изображений.Система анализирует медицинские изображения, а затем объединяет это понимание с информацией из медицинских карт пациента и представляет результаты, которые рентгенологи могут принять во внимание при планировании лечения.
Демонстрационная версия инструмента IBM Eyes of Watson для обнаружения рака груди, использующего компьютерное зрение и машинное обучение. Источник: IBM Research
.Ученые из этого отдела также разработали специализированную глубокую нейронную сеть для выявления аномальных и потенциально злокачественных тканей груди.
Aidoc предоставляет еще одно решение, использующее глубокое обучение для сканирования медицинских изображений (в частности, компьютерной томографии) и определения приоритетности списков пациентов. Решение получило разрешения Управления по контролю за продуктами и лекарствами США (FDA), Терапевтические товары Австралии (TGA) и маркировку CE Европейского Союза для обозначения трех опасных для жизни состояний: тромбоэмболии легочной артерии, перелома шейного отдела позвоночника и внутричерепного кровоизлияния.
Среди клиентов компании – Мемориальный медицинский центр UMass в Вустере, штат Массачусетс, больница Монтефиоре Найак в округе Рокленд, штат Нью-Йорк, и центр визуализации Global Diagnostics Australia.
Приложения для распознавания произведений искусства
Magnus – это приложение на основе распознавания изображений, которое проведет любителей и коллекционеров искусства «через джунгли искусства». Когда пользователь делает фотографию произведения искусства, приложение предоставляет такие данные, как автор, название, год создания, размеры, материал и, что наиболее важно, текущая и историческая цена. В приложении также есть карта с галереями, музеями и аукционами, а также выставленными на данный момент произведениями искусства.
Магнус получает информацию из базы данных, содержащей более 10 миллионов изображений произведений искусства; информация о товарах и ценах собрана в краудсорсинге.Интересный факт: Леонардо Ди Каприо инвестировал в приложение, сообщает Магнус на своей странице в Apple Store.
Посетители музея могут утолить свою жажду знаний с помощью таких приложений, как Smartify. Smartify – это музейный гид, который вы можете использовать в десятках всемирно известных художественных мест, таких как Музей Метрополитен в Нью-Йорке, Смитсоновская национальная портретная галерея в Вашингтоне, округ Колумбия, Лувр в Париже, Рейксмузеум Амстердама, Королевская академия искусств в Лондон, Государственный Эрмитаж в Санкт-Петербурге и другие.
Как работает Smartify. Источник: Smartify
Чтобы получить подробную информацию о произведении искусства, приложение сопоставляет отсканированные произведения искусства с цифровыми изображениями в базе данных, которая содержала почти 50 000 произведений искусства по состоянию на 2017 год. Соучредитель Smartify Анна Лоу объясняет, как приложение работает следующим образом: «Мы сканируем произведения искусства, используя фотографии или цифровые изображения, а затем создают цифровые отпечатки произведений искусства, что означает, что они сокращаются до набора цифровых точек и линий.”
Распознавание лиц для повышения качества обслуживания в аэропорту
Распознавание лиц становится все более популярным среди авиакомпаний, которые используют его для улучшения посадки и регистрации. Эти обновления имеют два основных направления: следовать тенденциям самообслуживания и этой биометрической технологии и сделать работу в аэропорту более безопасной и быстрой. Чем меньше шагов должны сделать пассажиры и персонал для выполнения предполетных процедур, тем лучше.
Посадочное оборудование сканирует лица путешественников и сопоставляет их с фотографиями, хранящимися в базах данных органов пограничного контроля (т.e., Служба таможенного и пограничного контроля США), чтобы подтвердить свою личность и данные о рейсе. Это могут быть фотографии с удостоверений личности, виз или других документов.
Например, компанияAmerican Airlines начала использовать распознавание лиц на выходах на посадку в Терминале D международного аэропорта Даллас / Форт-Уэрт, штат Техас. Вместо использования посадочных талонов путешественники сканируют свое лицо. Единственное, что не изменилось, так это то, что для прохождения проверки безопасности при себе должны быть паспорт и билет. Биометрическая посадка работает на основе согласия.
Биометрическая посадка для пассажиров American Airlines. Источник: The Dallas Morning News
В 2018 году компания American тестировала биометрию в течение 90 дней в Терминале 4 международного аэропорта Лос-Анджелеса с целью расширения использования технологий, если испытание пройдет успешно.
Многие авиакомпании также используют распознавание лиц в качестве дополнительной опции для посадки: JetBlue, British Airways, AirAsia, Lufthansa или Delta. Последний установил сумку самообслуживания на Миннеаполис-Стрит.Международный аэропорт имени Пола в 2017 году.
Визуальный поиск продукта
Границы между покупками онлайн и офлайн исчезли с тех пор, как в игру вошел визуальный поиск. Например, в приложении Urban Outfitters есть функция Scan + Shop, благодаря которой потребители могут отсканировать товар, который они найдут в обычном магазине или напечатанный в журнале, получить его подробное описание и сразу же заказать его. Визуальный поиск также расширяет возможности покупок в Интернете.
Приложения с этой возможностью работают от нейронных сетей.Сетевые сети обрабатывают изображения, загруженные пользователями, и генерируют описания изображений (теги), например, тип одежды, ткань, стиль, цвет. Описания изображений сопоставляются с товарами на складе вместе с соответствующими тегами. Результаты поиска представлены на основе оценки сходства.
В статье о том, как ритейлеры используют ИИ, мы посвятили раздел о визуальном поиске. Там вы также можете прочитать о том, как технологии распознавания изображений и лиц превратили безналичные магазины, такие как Amazon Go, в реальность, а также о том, как они обеспечивают питание систем наблюдения или позволяют персонализировать магазины.
Работа продолжается по
Во второй половине 20-го века исследователи подсчитали, что, помимо прочего, на решение проблемы компьютерного зрения потребуется относительно короткое время. В 1966 году математик и бывший содиректор лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института Сеймур Пейперт координировал проект Summer Vision. У исследователей был амбициозный план: за одно лето построить значительную часть системы с возможностями компьютерного зрения, какими мы их знаем сегодня. «Основная цель проекта – создать систему программ, которые будут разделять видиосектор на области, такие как вероятные объекты, вероятные области фона и хаос», – говорится в описании проекта .
Ну прошло гораздо больше времени. Современное программное обеспечение может распознавать большое количество повседневных предметов, человеческие лица, печатный и рукописный текст на изображениях и других объектах (ознакомьтесь с нашей статьей об API распознавания изображений). Но работа продолжается, и мы продолжим наблюдать, как все больше и больше все больше предприятий и организаций внедряют распознавание изображений и другие задачи компьютерного зрения, чтобы выделиться среди конкурентов и оптимизировать операции.
Как создать приложение для распознавания изображений, такое как Vivino
Этикетки формируют наше восприятие мира. Обычно мы предпочитаем знать названия объектов, людей и мест, с которыми мы взаимодействуем, или даже больше – какой бренд относится к тому или иному продукту, который мы собираемся приобрести, и какие отзывы о его качестве дают другие. Устройства, оснащенные функцией распознавания изображений, могут автоматически обнаруживать эти этикетки. Программное обеспечение для распознавания изображений для смартфонов – это именно тот инструмент для захвата и определения имени на цифровых фотографиях и видео.
Благодаря разработке высокоточных, контролируемых и гибких алгоритмов распознавания изображений теперь можно идентифицировать изображения, текст, видео и объекты. Давайте узнаем, что это такое, как это работает, как создать приложение для распознавания изображений и какие технологии использовать при этом.
Что такое распознавание изображений в искусственном интеллекте?
В настоящее время распознавание изображений использует как искусственный интеллект, так и классические подходы глубокого обучения, чтобы можно было сравнивать разные изображения друг с другом или со своим собственным репозиторием для определенных атрибутов, таких как цвет и масштаб.Системы на основе искусственного интеллекта также начали превосходить компьютеры, которые обучены менее подробным знаниям предмета.
AI-распознавание изображений часто считается одним термином, обсуждаемым в контексте компьютерного зрения, машинного обучения как части искусственного интеллекта и обработки сигналов. Короче говоря, распознавание изображений является частным из трех. Таким образом, в принципе, программное обеспечение для распознавания изображений не должно использоваться как синоним обработки сигналов, но его определенно можно рассматривать как часть большой области искусственного интеллекта и компьютерного зрения.Давайте подробнее рассмотрим, что означает каждое из четырех понятий.
Распознавание изображений. Поскольку изображение является ключевым элементом ввода и вывода, распознавание изображений предназначено для понимания визуального представления определенного изображения. Другими словами, это программное обеспечение обучено извлекать много полезной информации и играет важную роль в предоставлении ответа на такой вопрос, как изображение. Так обычно понимают термин «распознавание изображений».
Обработка сигналов. На входе может быть не только изображение, но и различные сигналы, такие как звуки и биологические измерения. Эти сигналы полезны, когда дело доходит до распознавания голоса, а также для различных приложений, таких как распознавание лиц. SP – это более широкая область, чем технология идентификации изображений, и в сочетании с глубоким обучением она способна обнаруживать закономерности и взаимосвязи, которые до сих пор не наблюдались.
Компьютерное зрение. Это целая научная дисциплина, которая занимается созданием искусственных систем, получающих информацию из таких входных источников, как изображения, видео или другие многомерные гиперспектральные данные. Процесс компьютерного зрения включает такие методы, как обнаружение лиц, сегментация, отслеживание, оценка позы, локализация и отображение, а также распознавание объектов. Эти данные обрабатываются интерфейсами прикладного программирования (API), о которых мы поговорим позже в этой статье.
Машинное обучение. Это общий термин для всех вышеперечисленных понятий. ML охватывает распознавание изображений, обработку сигналов и компьютерное зрение. Кроме того, это довольно общая структура с точки зрения ввода и вывода – он принимает любой знак для ввода, возвращающего любую количественную или качественную информацию, сигнал, изображение или видео в качестве вывода. Такое разнообразие запросов и ответов обеспечивается за счет использования большого и сложного набора обобщенных алгоритмов машинного обучения.
Как работает программа распознавания изображений
Обнаружение изображений выполняется двумя разными методами.Эти методы называются методами нейронных сетей. Первый метод называется классификацией или обучением с учителем , а второй метод называется обучением без учителя .
При обучении с учителем используется процесс, чтобы определить, относится ли конкретное изображение к определенной категории, а затем оно сравнивается с уже обнаруженными изображениями в этой категории. При обучении без учителя используется процесс, чтобы определить, входит ли изображение в категорию само по себе.Нейронные сети – это сложные вычислительные методы, предназначенные для классификации и отслеживания изображений.
Вам следует знать, что приложение для распознавания изображений, скорее всего, будет использовать комбинацию контролируемых и неконтролируемых алгоритмов.
Метод классификации (также называемый контролируемым обучением) использует алгоритм машинного обучения для оценки особенности изображения, называемой важной характеристикой. Затем он использует эту функцию, чтобы сделать предположение о том, может ли изображение быть интересным для данного пользователя.Алгоритм машинного обучения сможет определить, содержит ли изображение важные для пользователя функции.
Метаданные классифицируют изображения и извлекают такую информацию, как размер, цвет, формат и формат границ. Изображения разделены на разные теги, называемые информационными классами, и каждый тег связан с изображением. Эти информационные классы используются механизмом распознавания для понимания «значения» изображения.
Данные, используемые для идентификации изображений, например: «милый ребенок» или «изображение собаки», должны быть помечены, чтобы быть полезными.Это требует анализа данных с помощью таких методов извлечения информации, как классификация или перевод.
Итак, распознавание образов при обработке изображений – это многоэтапный процесс, который включает:
- Обнаружение исходного изображения
- Анализ и классификация данных
- Обучение с подкреплением
- Процесс обучения ИИ
- Мониторинг и воспроизведение тренировочного процесса
Как выбрать API распознавания изображений?
Еще один важный компонент, о котором следует помнить при создании приложения для распознавания изображений, – это API.С начала революции искусственного интеллекта и машинного обучения были разработаны различные API-интерфейсы компьютерного зрения. Лучшие API распознавания изображений используют преимущества последних технологических достижений и дают вашему приложению распознавания фотографий возможность предлагать лучшее сопоставление изображений и более надежные функции. Таким образом, размещенные службы API доступны для интеграции с существующим приложением или использования для создания определенной функции или всего бизнеса.
Не у каждой компании достаточно ресурсов для инвестирования в создание всей команды инженеров компьютерного зрения.Итак, ниже приведен список API-интерфейсов распознавания изображений, на которые нужно обратить внимание, если вы хотите, чтобы некоторые готовые решения с открытым исходным кодом упростили вашу жизнь:
API Google Cloud Vision. API Google Cloud Vision позволяет загружать изображения или создавать собственные наборы данных для распознавания изображений. Это помогает вам искать известные человеческие модели и создавать на их основе изображения. Он доступен в Google Cloud Platform (GCP). Вы можете интегрировать это с некоторыми проектами обработки изображений, а также в свои собственные приложения.
Amazon Rekognition. Один из лучших способов распознавания изображений – использовать эту систему Amazon. Amazon Rekognition предлагает множество API-интерфейсов, которые позволяют обучать ваш собственный механизм визуального распознавания и выполнять сегментацию изображений и видео, обнаруживая и анализируя объекты, лица или некоторый откровенный контент, распознавая знакомые лица или лица знаменитостей и многое другое.
IBM Watson Visual Recognition. Служба Watson Visual Recognition в IBM Cloud подходит для многих приложений, поскольку позволяет пользователям гибко использовать API.Предварительно обученные модели, предоставляемые службой Visual Recognition, можно использовать для создания приложений, которые могут работать во многих условиях. Затем эта модель обучается обнаруживать определенные классы объектов.
API компьютерного зрения Microsoft. Это программное обеспечение для распознавания изображений является неотъемлемой частью Azure Cognitive Services. Это позволяет идентифицировать и анализировать контент в изображениях. Кроме того, с его помощью вы можете попробовать научить свое компьютерное зрение распознавать лица и эмоции людей.Внедрить службу компьютерного зрения в ваше приложение несложно – просто добавьте вызов API.
Clarifai API. Это один из лучших сервисов поиска изображений. Он предлагает на выбор планы Community (с бесплатным ключом API), Essential и Enterprise. Можно как использовать готовые модели распознавания изображений, так и создавать собственные модели, обученные индивидуально. Готовые модели могут распознавать лица, цвета, одежду, распознавать еду и многое другое. Он значительно быстрее, чем другие поисковые системы, поскольку использует вывод вместо прямого поиска.
Как предприятия могут использовать распознавание изображений?
Преимущества распознавания изображений находят применение во всем мире. Итак, вопрос не только в том, как создать приложение для распознавания изображений, но и в том, как создать приложение для распознавания изображений, которое может улучшить ваш бизнес. Используя огромные объемы данных для обучения компьютеров распознаванию изображений, техника машинного обучения может привести к трем большим положительным изменениям, которые мы обсудим ниже.
1. Улучшена возможность обнаружения продукта с помощью визуального поиска. Хорошо обученная модель распознавания изображений позволяет точно маркировать товары. У таких приложений обычно есть каталог, в котором продукты упорядочены по определенным критериям. Такая точная организация ряда маркированных продуктов позволяет эффективно и быстро находить то, что нужно пользователю. Благодаря сверхмощному ИИ эффективность внедрения тегов может постоянно расти, в то время как автоматическая маркировка продуктов сама по себе позволяет свести к минимуму человеческие усилия и снизить количество ошибок.
2. Повышение вовлеченности аудитории в социальных сетях. Распознавание изображений и лиц в социальных сетях уже стало реальностью. Социальные сети, такие как Facebook и Instagram, побуждают пользователей делиться изображениями и отмечать на них своих друзей. А их обученные модели искусственного интеллекта мгновенно распознают сцены, людей и эмоции. Некоторые сети пошли еще дальше, автоматически создав хэштеги для обновленных фотографий. Все это может улучшить взаимодействие с пользователем и помочь людям осмысленно организовать свои фотогалереи.
3. Оптимизированная реклама и интерактивный маркетинг. Еще одним преимуществом использования технологии идентификации изображений в приложении является оптимизация мобильной рекламы. Интерактивные маркетинговые кампании во многом зависят от знания клиента. Фактически, максимизировать эффективность рекламы в некоторых мобильных приложениях можно, изменив их дизайн и добавив в них технологию идентификации изображений. В конце концов, технология идентификации изображений – это всего лишь еще один инструмент в наборе инструментов для маркетинга приложений.
Примеры лучших приложений для распознавания изображений
Провидцы продолжают придумывать все больше интересных идей для проектов по распознаванию изображений. Однако некоторые вертикали более благоприятны для распознавания изображений, чем другие. Чтобы проиллюстрировать вышеуказанные преимущества для бизнеса, давайте рассмотрим несколько примеров того, как распознавание изображений успешно работает в приложениях из совершенно разных отраслей.
1. Vivino – сканирование винных этикеток.
Vivino – это самое загружаемое мобильное винное приложение в мире, которое, среди прочего, использует распознавание изображений, обученное на огромной базе данных винных бутылок и фотографий этикеток, чтобы создать идеальное изображение для ваших любимых вин.С Vivino вы также можете заказывать свои любимые вина по запросу через приложение и получать всевозможную статистику о них, такую как бренд, цена, рейтинг и многое другое. Vivino очень интуитивно понятен и имеет простую навигацию, гарантируя, что вы сможете получить всю необходимую информацию, сделав снимок бутылки вина, которое вы хотите купить, еще находясь в винном магазине.
2. PictureThis – распознавание разновидностей деревьев, растений или цветов.
Picture Это одно из самых популярных приложений для идентификации растений, которое имеет базу данных, содержащую более 10 000 видов растений.Приложение позволяет определять сорта растений по фотографиям. После того, как фотография растения сделана или загружена из телефонной галереи, PictureThis анализирует изображение, сравнивая его с изображениями в своей базе данных, и получает результат. Затем это поможет вам определить, соответствует ли это совпадению. Кроме того, в приложении вы найдете советы по уходу за растениями, напоминания о поливе и красивые обои.
3. Zebra Medical Vision – медицинская диагностическая визуализация на основе искусственного интеллекта.
Zebra Medical Vision – компания, занимающаяся глубоким обучением в области медицинской визуализации, чья платформа для анализа изображений позволяет выявлять риски и предлагать пути лечения онкологических пациентов.Это возможно благодаря мощной технологии распознавания изображений на основе искусственного интеллекта. Механизм Zebra анализирует полученные изображения (рентгеновские снимки и компьютерную томографию), используя свою базу данных сканирований и инструменты глубокого обучения, тем самым помогая рентгенологам справляться с растущими рабочими нагрузками. Помимо внедрения программного обеспечения искусственного интеллекта для выявления потенциальных рисков, Zebra Medical Vision разработала множество приложений, которые упрощают визуальную оценку и руководство пациентами с онкологическими заболеваниями.
Заключение
Машинное обучение, компьютерное зрение и распознавание изображений, очевидно, становятся обычным явлением и больше не являются чем-то экстраординарным.Сложно создать приложение для распознавания изображений и преуспеть в этом. Однако с правильной командой инженеров ваша работа, проделанная в области компьютерного зрения, окупится. Изучите рынок, определите план развития своего проекта, выберите API-интерфейсы и решите, как именно вы собираетесь включить распознавание изображений и связанные с ним технологии в свое будущее приложение.