
Чтобы распознавать картинки, не нужно распознавать картинки / Хабр
Посмотрите на это фото.
Это совершенно обычная фотография, найденная в Гугле по запросу «железная дорога». И сама дорога тоже ничем особенным не отличается.
Что будет, если убрать это фото и попросить вас нарисовать железную дорогу по памяти?
Если вы ребенок лет семи, и никогда раньше не учились рисовать, то очень может быть, что у вас получится что-то такое:
Упс. Кажется, что-то пошло не так.
Давайте еще раз вернемся к рельсам на первой картинке и попробуем понять, что не так.
На самом деле, если долго разглядывать ее, становится понятно, что она не совсем точно отображает окружающий мир. Главная проблема, о которую мы немедленно споткнулись — там, например, пересекаются параллельные прямые. Ряд одинаковых (в реальности) фонарных столбов на самом деле изображен так, что каждый следующий столб имеет все меньшие и меньшие размеры. Деревья вокруг дороги, у которых поначалу различимы отдельные ветки и листья, сливаются в однотонный фон, который еще и вдобавок почему-то приобретает отчетливо-фиолетовый оттенок.
Все это — эффекты перспективы, последствия того, что трехмерные объекты снаружи проецируются на двумерную сетчатку внутри глаза. Ничего отдельно магического в этом нет — разве что немного любопытно, почему эти искажения контуров и линий не вызывают у нас никаких проблем при ориентации в пространстве, но вдруг заставляют мозг напрячься при попытке взяться за карандаш.
Еще один замечательный пример — как маленькие дети рисуют небо.
Небо должно быть наверху — вот она, синяя полоска, пришпиленная к верхнему краю. Середина листа при этом остается белой, заполнена пустотой, в которой плавает солнце.
И так происходит всегда и везде. Мы знаем, что куб состоит из квадратных граней, но посмотрите на картинку, и вы не увидите там ни одного прямого угла — более того, эти углы постоянно меняются, стоит сменить угол обзора. Как будто где-то в голове у нас сохранена грубая схема правильного, трехмерного объекта, и именно к ней мы обращаемся в процессе рисования рельс, не сразу успевая сопоставить результат с тем, что видим своими глазами.
На самом деле все еще хуже. Каким образом, например, на самой первой картинке с дорогой мы определяем, какая часть дороги расположена ближе к нам, а какая дальше? По мере удаления предметы становятся меньше, ок — но вы уверены, что кто-то не обманул вас, коварно разместив друг за другом последовательно уменьшающиеся шпалы? Далекие объекты обычно имеют бледно-голубоватый оттенок (эффект, который называется «атмосферная перспектива») — но предмет может быть просто окрашен в такой цвет, и в остальном казаться совершенно нормальным. Мост через железнодорожные пути, который едва видно отсюда, кажется нам находящимся позади, потому что его заслоняют фонари (эффект окклюзии) — но опять-таки, как вы можете быть уверены, что фонари просто не нарисованы на его поверхности? Весь этот набор правил, с помощью которых вы оцениваете трехмерность сцены, во многом зависит от вашего опыта, и возможно, генетического опыта ваших предков, обученных выживать в условиях нашей атмосферы, падающего сверху света и ровной линии горизонта.
Сама по себе, без помощи мощной аналитической программы в вашей голове, наполненной этим визуальным опытом, любая фотография говорит об окружающем мире ужасно мало. Изображения — это скорее такие триггеры, заставляющие вас мысленно представить себе сцену, большая часть знаний о которой уже есть у вас в памяти. Они не содержат реальных предметов — только ограниченные, сплющенные, трагически двумерные представления о них, которые, к тому же, постоянно меняются при движении. В чем-то мы с вами — такие же жители Флатландии, которые могут увидеть мир только с одной стороны и неизбежно искаженным.
Вообще мир вокруг прямо-таки полон свидетельств того, как перспектива все искажает. Люди, поддерживающие пизанскую башню, фотографии с солнцем в руках, не говоря уже про классические картины Эшера, или вот совершенно прекрасный пример —
Комната Эймса. Тут важно понять, что это не какие-то единичные подлянки, специально сделаные для того, чтобы обманывать.
показывает нам неполноценную картинку, просто как правило, мы способны ее «раскодировать». Попробуйте выглянуть в окно и подумать, что то, что вы видите — обман, искажение, безнадежная неполноценность.
Представьте, что вы — нейронная сеть.
Это не должно быть очень сложно — в конце концов, как-то так оно и есть на самом деле. Вы проводите свободное время за распознаванием лиц на документах в паспортном столе. Вы — очень хорошая нейронная сеть, и работа у вас не слишком сложная, потому что в процессе вы ориентируетесь на паттерн, строго характерный именно для человеческих лиц — взаимное расположение двух глаз, носа и рта. Глаза и носы сами по себе могут различаться, какой-то один из признаков иногда может оказаться на фотографии неразличимым, но вам всегда помогает наличие других. И вдруг вы натыкаетесь вот на такое:
Хм, думаете вы. Вы определенно видите что-то знакомое — по крайней мере, в центре, кажется, есть один глаз. Правда, странной формы — он похож на треугольник, а не на заостренный овал. Второго глаза не видно. Нос, который должен располагаться посередине и между глаз, уехал куда-то совсем в край контура, а рта вы вообще не нашли — опредленно, темный уголок снизу-слева совсем на него не похож. Не лицо — решаете вы, и выбрасываете картинку в мусорное ведро.
Второго глаза не видно. Нос, который должен располагаться посередине и между глаз, уехал куда-то совсем в край контура, а рта вы вообще не нашли — опредленно, темный уголок снизу-слева совсем на него не похож. Не лицо — решаете вы, и выбрасываете картинку в мусорное ведро.
Так бы мы думали, если бы наша зрительная система занималась простым сопоставлением паттернов в изображениях. К счастью, думает она как-то по-другому. У нас не вызывает никакого беспокойства отсутствие второго глаза, от этого лицо не становится менее похожим на лицо. Мы мысленно прикидываем, что второй глаз должен находиться по ту сторону, и форма его обусловлена исключительно тем, что голова на фото повернута и смотрит в сторону. Кажется невозможно тривиальным, когда пытаешься это объяснить на словах, но кое-кто с вами бы на полном серьезе не согласился.
Самое обидное, что не видно, как можно решить этот вопрос механическим способом. Компьютерное зрение сталкивалось с соответствующими проблемами очень давно, с момента своего появления, и периодически находило эффективные частные решения — так, мы можем опознать сдвинутый в сторону предмет, последовательно передвигая свой проверочный паттерн по всему изображению (чем успешно пользуются сверточные сети), можем справляться с отмасштабированными или повернутыми картинками с помощью признаков SIFT, SURF и ORB, но эффекты перспективы и поворот предмета в пространстве сцены — похоже, вещи качественно другого уровня.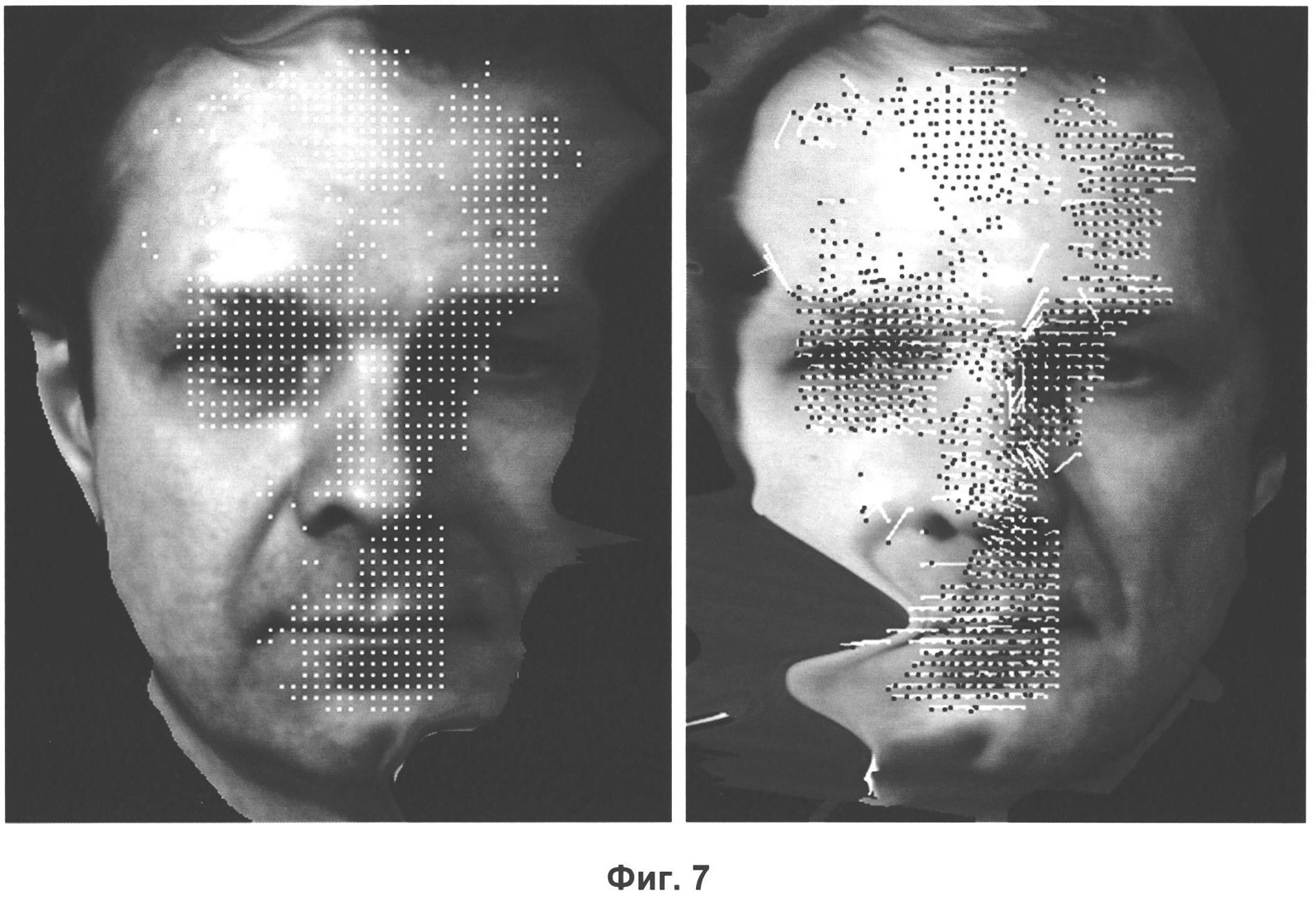
Итак, важный вопрос — как бы нам получать трехмерную модель всего, что мы видим? Еще более важный вопрос — как при этом обойтись без необходимости покупать лазерный пространственный сканер (сначала я написал «чертовски дорогой лазерный сканер», а потом наткнулся на
этот пост)? Даже не столько по той причине, что нам жалко, а потому, что животные в процессе эволюции зрительной системы явно каким-то образом обошлись без него, одними только глазами, и было бы любопытно выяснить, как они так.
Где-то в этом месте часть аудитории обычно встает и выходит из зала, ругаясь на топтание по матчасти — все знают, что для восприятия глубины и пространства мы пользуемся бинокулярным зрением, у нас для этого два специальных глаза! Если вы тоже так думаете, у меня для вас небольшой сюрприз — это неправда.
Для некоторых действий они, похоже, и правда приносят пользу с точки зрения оценки пространственного положения. Возьмите два карандаша, закройте один глаз и попытайтесь сдвигать эти карандаши так, чтобы они соприкоснулись кончиками грифелей где-то вблизи вашего лица. Скорее всего, грифели разойдутся, причем ощутимо (если у вас получилось легко, поднесите их еще ближе к лицу), при этом со вторым открытым глазом такого не происходит. Пример взят из книги Марка Чангизи «Революция в зрении» — там есть целая глава о стереопсисе и бинокулярном зрении с любопытной теорией о том, что два смотрящих вперед глаза нужны нам для того, чтобы видеть сквозь мелкие помехи вроде свисающих листьев.
Итак, бинокулярное зрение нам не подходит — и вместе с ним мы отвергаем стереокамеры, дальномеры и Kinect. Какой бы ни была способость нашей зрительной системы воссоздавать трехмерные образы увиденного, она явно не требует наличия двух глаз. Что остается в итоге?
Я ни в коем случае не готов дать точный ответ применительно к биологическом зрению, но пожалуй, для случая абстрактного робота с камерой вместо глаза остался один многообещающий способ. И этот способ — движение.
Вернемся к теме поездов, только на этот раз выглянем из окна:
То, что мы при этом видим, называется «параллакс движения», и вкратце он заключается в том, что когда мы двигаемся вбок, близкие предметы смещаются в поле зрения сильнее, чем далекие. Для движения вперед/назад и поворотов тоже можно сформулировать соответствующие правила, но давайте их пока проигнорируем. Итак, мы собираемся двигаться, оценивать смещения предметов в кадре и на основании этого определять их расстояние от наблюдателя — техника, которая официально называется «structure-from-motion». Давайте попробуем.
Итак, мы собираемся двигаться, оценивать смещения предметов в кадре и на основании этого определять их расстояние от наблюдателя — техника, которая официально называется «structure-from-motion». Давайте попробуем.
Прежде всего — а не сделали ли все, случайно, до нас? Страница «Structure from motion» в Википедии предлагает аж тринадцать инструментов (и это только опенсорсных) для воссоздания 3D-моделей из видео или набора фотографий, большинство из них пользуются подходом под названием bundle adjustment, а самым удобным мне показался
Bundler(и демо-результаты у него крутые). К сожалению, тут возникает проблема, с которой мы еще столкнемся — Bundler для корректной работы хочет знать от нас модель камеры и ее внутренние параметры (в крайнем случае, если модель неизвестна, он требует указать фокусное расстояние).
Если для вашей задачи это не проблема — можете смело бросать чтение, потому что это самый простой и одновременно эффективный метод (а знаете, кстати, что примерно таким способом делались модели в игре «Исчезнование Итана Картера»?). Для меня, увы, необходимость быть привязанным к модели камеры — это условие, которого очень хотелось бы избежать. Во-первых, потому что у нас под боком полный ютуб визуального видео-опыта, которым хотелось бы в будущем пользоваться в качестве выборки. Во-вторых (и это, может быть, даже важнее), потому что наш с вами человеческий мозг, похоже, если и знает в цифрах внутренние параметры камеры наших глаз, то прекрасно умеет приспосабливаться к любым оптическим искажениями. Взгляд через объектив широкофокусной камеры, фишай, просмотр кино и ношение окулусрифта совершенно не разрушает ваших зрительных способностей. Значит, наверное, возможен и какой-то другой путь.
Для меня, увы, необходимость быть привязанным к модели камеры — это условие, которого очень хотелось бы избежать. Во-первых, потому что у нас под боком полный ютуб визуального видео-опыта, которым хотелось бы в будущем пользоваться в качестве выборки. Во-вторых (и это, может быть, даже важнее), потому что наш с вами человеческий мозг, похоже, если и знает в цифрах внутренние параметры камеры наших глаз, то прекрасно умеет приспосабливаться к любым оптическим искажениями. Взгляд через объектив широкофокусной камеры, фишай, просмотр кино и ношение окулусрифта совершенно не разрушает ваших зрительных способностей. Значит, наверное, возможен и какой-то другой путь.
Итак, мы печально закрыли страницу с Итаном Картером википедии и опускаемся на уровень ниже — в OpenCV, где нам предлагают следующее:
1. Взять два кадра, снятые с откалиброванной камеры.
2. Вместе с параметрами калибровки (матрицей камеры) положить их оба в функцию stereoRectify, которая выпрямит (ректифицирует) эти два кадра — это преобразование, которое искажает изображение так, чтобы точка и ее смещение оказывались на одной горизонтальной прямой.
3. Эти ректифицированые кадры мы кладем в функцию stereoBM и получаем карту смещений (disparity map) — такую картинку в оттенках серого, где чем пиксель ярче, тем большее смещение он выражает (по ссылке есть пример).
4. Полученную карту смещений кладем в функцию с говорящим названием reprojectImageTo3D (понадобится еще и матрица Q, которую в числе прочих мы получим на шаге 2). Получаем наш трехмерный результат.
Черт, похоже, мы наступаем на те же грабли — уже в пункте 1 от нас требуют откалиброванную камеру (правда, OpenCV милостиво дает возможность сделать это самому). Но погодите, здесь есть план Б. В документации прячется функция с подозрительным названием stereoRectifyUncalibrated…
План Б:
1. Нам нужно оценить примерную часть смещений самим — хотя бы для ограниченного набора точек. StereoBM здесь не подойдет, поэтому нам нужен какой-то другой способ. Логичным вариантом будет использовать feature matching — найти какие-то особые точки в обоих кадрах и выбрать сопоставления. Про то, как это делается, можно почитать здесь.
Про то, как это делается, можно почитать здесь.
2. Когда у нас есть два набора соответствующих друг другу точек, мы можем закинуть их в findFundamentalMat, чтобы получить фундаментальную матрицу, которая понадобится нам для stereoRectifyUncalibrated.
3. Запускаем stereoRectifyUncalibrated, получаем две матрицы для ректификации обоих кадров.
4. И… а дальше непонятно. Выпрямленные кадры у нас есть, но нет матрицы Q, которая была нужна для завершающего шага. Погуглив, я наткнулся примерно на такой же недоумения пост, и понял, что либо я что-то упустил в теории, либо в OpenCV этот момент не продумали.
OpenCV: мы — 2:0.
4.1 Меняем план
Но погодите. Возможно, мы с самого начала пошли не совсем правильным путем. В предыдущих попытках мы, по сути, пытались определить
реальное положение трехмерных точек — отсюда необходимость знать параметры камеры, матрицы, ректифицировать кадры и так далее. По сути, это обычная триангуляция: на первой камере я вижу эту точку здесь, а на второй здесь — тогда нарисуем два луча, проходящих через центры камер, и их пересечение покажет, как далеко точка от нас находится.
Это все прекрасно, но вообще говоря, нам не нужно. Реальные размеры предметов интересовали бы нас, если бы наша модель использовалась потом для промышленных целей, в каких-нибудь 3d-принтерах. Но мы собираемся (эта цель слегка уже расплылась, правда) запихивать полученные данные в нейросети и им подобные классификаторы. Для этого нам достаточно знать только относительные размеры предметов. Они, как мы все еще помним, обратно пропорциональны смещениям параллакса — чем дальше от нас предмет, тем меньше смещается при нашем движении. Нельзя ли как-то найти эти смещения еще проще, просто каким-то образом сопоставив обе картинки?
Само собой, можно. Привет, оптический поток.
Это замечательный алгоритм, который делает ровно то, что нам нужно. Кладем в него картинку и набор точек. Потом кладем вторую картинку. Получаем на выходе для заданных точек их новое положение на второй картинке (приблизительное, само собой). Никаких калибровок и вообще никаких упоминаний о камере — оптический поток, несмотря на название, можно рассчитывать на базе чего угодно. Хотя обычно он все-таки используется для слежения за объектами, обнаружения столкновений и даже дополненной реальности.
Хотя обычно он все-таки используется для слежения за объектами, обнаружения столкновений и даже дополненной реальности.
Для наших целей мы (пока) хотим воспользоваться «плотным» потоком Гуннара Фарнебака, потому что он умеет рассчитывать поток не для каих-то отдельных точек, а для всей картинки сразу. Метод доступен с помощью calcOpticalFlowFarneback, и первые же результаты начинают очень-очень радовать — смотрите, насколько оно выглядит круче, чем предыдущий результат stereoRectifyUncalibrated + stereoBM.
Большое спасибо замечательной игре Portal 2 за возможность строить собственные комнаты и играть в кубики. I’m doin’ Science!
# encoding: utf-8
import cv2
import numpy as np
from matplotlib import pyplot as plt
img1 = cv2.imread('0.jpg', 0)
img2 = cv2.imread('1.jpg', 0)
def stereo_depth_map(img1, img2):
# 1: feature matching
orb = cv2.ORB()
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb. detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
src_points = np.vstack([np.array(kp1[m.queryIdx].pt) for m in matches])
dst_points = np.vstack([np.array(kp2[m.trainIdx].pt) for m in matches])
# 2: findFundamentalMat
F, mask = cv2.findFundamentalMat(src_points, dst_points)
# 3: stereoRectifyUncalibrated
_, h2, h3 = cv2.stereoRectifyUncalibrated(src_points.reshape(src_points.shape[
0], 1, 2), dst_points.reshape(dst_points.shape[0], 1, 2), F, img1.shape)
rect1 = cv2.warpPerspective(img1, h2, (852, 480))
rect2 = cv2.warpPerspective(img2, h3, (852, 480))
# 3.5: stereoBM
stereo = cv2.StereoBM(cv2.STEREO_BM_BASIC_PRESET, ndisparities=16, SADWindowSize=15)
return stereo.compute(rect1, rect2)
def optical_flow_depth_map(img1, img2):
flow = cv2.calcOpticalFlowFarneback(img1, img2, 0.
detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
src_points = np.vstack([np.array(kp1[m.queryIdx].pt) for m in matches])
dst_points = np.vstack([np.array(kp2[m.trainIdx].pt) for m in matches])
# 2: findFundamentalMat
F, mask = cv2.findFundamentalMat(src_points, dst_points)
# 3: stereoRectifyUncalibrated
_, h2, h3 = cv2.stereoRectifyUncalibrated(src_points.reshape(src_points.shape[
0], 1, 2), dst_points.reshape(dst_points.shape[0], 1, 2), F, img1.shape)
rect1 = cv2.warpPerspective(img1, h2, (852, 480))
rect2 = cv2.warpPerspective(img2, h3, (852, 480))
# 3.5: stereoBM
stereo = cv2.StereoBM(cv2.STEREO_BM_BASIC_PRESET, ndisparities=16, SADWindowSize=15)
return stereo.compute(rect1, rect2)
def optical_flow_depth_map(img1, img2):
flow = cv2.calcOpticalFlowFarneback(img1, img2, 0. 5, 3, 20, 10, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
return mag
def plot(title, img, i):
plt.subplot(2, 2, i)
plt.title(title)
plt.imshow(img, 'gray')
plt.gca().get_xaxis().set_visible(False)
plt.gca().get_yaxis().set_visible(False)
plot(u'Первый кадр', img1, 1)
plot(u'Второй кадр (шаг вправо)', img2, 2)
plot(u'stereoRectifyUncalibrated', stereo_depth_map(img1, img2), 3)
plot(u'Первый кадр', optical_flow_depth_map(img1, img2), 4)
plt.show()
5, 3, 20, 10, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
return mag
def plot(title, img, i):
plt.subplot(2, 2, i)
plt.title(title)
plt.imshow(img, 'gray')
plt.gca().get_xaxis().set_visible(False)
plt.gca().get_yaxis().set_visible(False)
plot(u'Первый кадр', img1, 1)
plot(u'Второй кадр (шаг вправо)', img2, 2)
plot(u'stereoRectifyUncalibrated', stereo_depth_map(img1, img2), 3)
plot(u'Первый кадр', optical_flow_depth_map(img1, img2), 4)
plt.show()
Итак, отлично. Смещения у нас есть, и на вид неплохие. Как теперь нам получить из них координаты трехмерных точек?
4.2 Часть, в которой мы получаем координаты трехмерных точек
Эта картинка уже мелькала на одной из ссылок выше.
Расстояние до объекта здесь рассчитывается методом школьной геометрии (подобные треугольники), и выглядит так: . А координаты, соответственно, вот так: . Здесь w и h — ширина и высота картинки, они нам известны, f — фокусное расстояние камеры (расстояние от центра камеры до поверхности ее экрана), и B — камеры же шаг. Кстати, обратите внимание, что мы тут слегка нарушаем общепринятые названия осей, когда Z направлена вверх — у нас Z смотрит «вглубь» экрана, а X и Y — соответственно, направлены по ширине и высоте картинки.
Кстати, обратите внимание, что мы тут слегка нарушаем общепринятые названия осей, когда Z направлена вверх — у нас Z смотрит «вглубь» экрана, а X и Y — соответственно, направлены по ширине и высоте картинки.
Ну, насчет f все просто — мы уже оговаривали, что реальные параметры камеры нас не интересуют, лишь бы пропорции всех предметов изменялись по одному закону. Если подставить Z в формулу для X выше, то можно увидеть, что X от фокусного расстояния вообще не зависит (f сокращается), поэтому разные его значения буду менять только глубину — «вытягивать» или «сплющивать» нашу сцену. Визуально — не очень приятно, но опять же, для алгоритма классификации — совершенно все равно. Так что зададим фокусное расстояние интеллектуальным образом — просто придумаем. Я, правда, оставляю за собой право слегка изменить мнение дальше по тексту.
Насчет B чуть посложнее — если у нас нет встроенного шагомера, мы не знаем, на какую дистанцию переместилась камера в реальном мире. Так что давайте пока немного считерим и решим, что движение камеры происходит примерно плавно, кадров у нас много (пара десятков на секунду), и расстояние между двумя соседними примерно одинаковое, т. е. . И опять же, дальше мы слегка уточним эту ситуацию, но пока пусть будет так.
е. . И опять же, дальше мы слегка уточним эту ситуацию, но пока пусть будет так.
import cv2
import numpy as np
f = 300 # раз мы занимаемся визуализацией, фокус я все-таки подобрал так, чтобы сцена выглядела условно реальной
B = 1
w = 852
h = 480
img1 = cv2.imread('0.jpg', 0)
img2 = cv2.imread('1.jpg', 0)
flow = cv2.calcOpticalFlowFarneback(img1, img2, 0.5, 3, 20, 10, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
edges = cv2.Canny(img1, 100, 200)
result = []
for y in xrange(img1.shape[0]):
for x in xrange(img1.shape[1]):
if edges[y, x] == 0:
continue
delta = mag[y, x]
if delta == 0:
continue
Z = (B * f) / delta
X = (Z * (x - w / 2.)) / f
Y = (Z * (y - h / 2.)) / f
point = np.array([X, Y, Z])
result.append(point)
result = np.vstack(result)
def dump2ply(points):
# сохраняем в формат .ply, чтобы потом открыть Блендером
with open('points. ply', 'w') as f:
f.write('ply\n')
f.write('format ascii 1.0\n')
f.write('element vertex {}\n'.format(len(points)))
f.write('property float x\n')
f.write('property float y\n')
f.write('property float z\n')
f.write('end_header\n')
for point in points:
f.write('{:.2f} {:.2f} {:.2f}\n'.format(point[0], point[2], point[1]))
dump2ply(result)
ply', 'w') as f:
f.write('ply\n')
f.write('format ascii 1.0\n')
f.write('element vertex {}\n'.format(len(points)))
f.write('property float x\n')
f.write('property float y\n')
f.write('property float z\n')
f.write('end_header\n')
for point in points:
f.write('{:.2f} {:.2f} {:.2f}\n'.format(point[0], point[2], point[1]))
dump2ply(result)
Вот так выглядит результат. Надеюсь, эта гифка успела загрузиться, пока вы дочитали до этого места.
Для наглядности я взял не все точки подряд, а только границы, выделенные Canny-детектором
С первого взгляда (во всяком случае, мне) все показалось отличным — даже углы между гранями кубиков образовали симпатичные девяносто градусов. С предметами на заднем плане получилось похуже (обратите внимание, как исказились контуры стен и двери), но хэй, наверное, это просто небольшой шум, его можно будет вылечить использованием большего количества кадров или чем-нибудь еще.
Из всех возможных поспешных выводов, которые можно было здесь сделать, этот оказался дальше всех от истины.
В общем, основная проблема оказалась в том, что какая-то часть точек довольно сильно искажалась. И — тревожный знак, где уже пора было заподозрить неладное — искажалась не случайным образом, а примерно в одних и тех же местах, так что исправить проблему путем последовательного наложения новых точек (из других кадров) не получалось.
Выглядело это примерно так:Лестница сминается, местами превращаясь в аморфный кусок непонятно-чего.
Я очень долго пытался это починить, и за это время перепробовал следующее:
— сглаживать каринку с оптическим потоком: размытие по Гауссу, медианный фильтр и модный билатеральный фильтр, который оставляет четкими края. Бесполезно: предметы наоборот, еще сильнее расплывались.
— пытался находить на картинке прямые линии с помощью Hough transform и переносить их в неизменном прямом состоянии. Частично работало, но только на границах — поверхности по-прежнему оставались такими же искаженными; плюс никуда не получалось деть мысль в духе «а что если прямых линий на картинке вообще нет».
— я даже попытался сделать свою собственную версию оптического потока, пользуясь OpenCVшным templateMatching. Работало примерно так: для любой точки строим вокруг нее небольшой (примерно 10×10) квадрат, и начинаем двигать его вокруг и искать максимальное совпадение (если известно направление движения, то «вокруг» можно ограничить). Получилось местами неплохо (хотя работало оно явно медленнее оригинальной версии):
Слева уже знакомый поток Фарнебака, справа вышеописаный велосипед
С точки зрения шума, увы, оказалось ничуть не лучше.
В общем, все было плохо, но очень логично. Потому что так оно и должно было быть.
Иллюстрация к проблеме. Движение здесь — по-прежнему шаг вправо
Давайте выберем какую-нибудь зеленую точку из картинки выше. Предположим, мы знаем направление движения, и собираемся искать «смещенного близнеца» нашей зеленой точки, двигаясь в заданном направлении. Когда мы решаем, что нашли искомого близнеца? Когда наткнемся на какой-нибудь «ориентир», характерный участок, который похож на окружение нашей начальной точки. Например, на угол. Углы в этом отношении легко отслеживать, потому что они сами по себе встречаются довольно редко. Поэтому если наша зеленая точка представляет собой угол, и мы находим похожий угол в заданной окрестности, то задача решена.
Например, на угол. Углы в этом отношении легко отслеживать, потому что они сами по себе встречаются довольно редко. Поэтому если наша зеленая точка представляет собой угол, и мы находим похожий угол в заданной окрестности, то задача решена.
Чуть сложнее, но все еще легко обстоит ситуация с вертикальной линией (вторая левая зеленая точка). Учитывая, что мы двигаемся вправо, вертикальная линия встретится нам только один раз за весь период поиска. Представьте, что мы ползем своим поисковым окном по картинке и видим однотонный фон, фон, снова фон, вертикальный отрезок, опять фон, фон, и снова фон. Тоже несложно.
Проблема появляется, когда мы пытаемся отслеживать кусок линии, расположенной параллельно движению. У красной точки нет одного четко выраженного кандидата на роль смещенного близнеца. Их много, все они находятся рядом, и выбрать какого-то одного тем методом, что мы пользуемся, просто невозможно. Это функциональное ограничение оптического потока. Как нас любезно предупреждает википедия в соответствующей статье, «We cannot solve this one equation with two unknown variables», и тут уже ничего не сделаешь.
Вообще, если честно, то это, наверное, не совсем правда. Вы ведь можете найти на правой картинке соответствие красной точке? Это тоже не очень сложно, но для этого мы мысленно пользуемся каким-то другим методом — находим рядом ближайшую «зеленую точку» (нижний угол), оцениваем расстояние до нее и откладываем соответствующее расстояние на второй грани куба. Алгоритмам оптического потока есть куда расти — этот способ можно было бы и взять на вооружение (если этого еще не успели сделать).
На самом деле, как подсказывает к этому моменту запоздавший здравый смысл, мы все еще пытаемся сделать лишнюю работу, которая не важна для нашей конечной цели — распознавания, классификации и прочего интеллекта. Зачем мы пытаемся запихать в трехмерный мир
все точки картинки? Даже когда мы работаем с двумерными изображениями, мы обычно не пытаемся использовать для классификации каждый пиксель — большая их часть не несет никакой полезной информации. Почему бы не делать то же самое и здесь?
Почему бы не делать то же самое и здесь?
Собственно, все оказалось вот так просто. Мы будем рассчитывать тот же самый оптический поток, но только для «зеленых», устойчивых точек. И кстати, в OpenCV о нас уже позаботились. Нужная нам штука называется поток Лукаса-Канаде.
Приводить код и примеры для тех же самых случаев будет слегка скучно, потому что получится то же самое, но с гораздо меньшим числом точек. Давайте по дороге сделаем еще чего-нибудь: например, добавим нашему алгоритму возможность обрабатывать повороты камеры. До этого мы двигались исключительно вбок, что в реальном мире за пределами окон поездов встречается довольно редко.
С появлением поворотов координаты X и Z у нас смешиваются. Оставим старые формулы для расчета координат относительно камеры, и будем переводить их в абсолютные координаты следующим образом (здесь — координаты положения камеры, альфа — угол поворота):
(игрек — читер; это потому, что мы считаем, что камера не двигается вверх-вниз)
Где-то здесь же у нас появляются проблемы с фокусным расстоянием — помните, мы решили задать его произвольным? Так вот, теперь, когда у нас появилась возможность оценивать одну и ту же точку с разных углов, он начал иметь значение — именно за счет того, что координаты X и Z начали мешаться друг с другом. На самом деле, если мы запустим код, аналогичный предыдущему, с произвольным фокусом, мы увидим примерно вот что:
На самом деле, если мы запустим код, аналогичный предыдущему, с произвольным фокусом, мы увидим примерно вот что:
Неочевидно, но это попытка устроить обход камеры вокруг обычного кубика. Каждый кадр — оценка видимых точек после очередного поворота камеры. Вид сверху, как на миникарте.
К счастью, у нас все еще есть оптический поток. При повороте мы можем увидеть, какие точки переходят в какие, и рассчитать для них координаты с двух углов зрения. Отсюда несложно получить фокусное расстояние (просто возьмите две вышеприведенных формулы для разных значений альфа, приравняйте координаты и выразите f). Так гораздо лучше:
Не то что бы все точки легли идеально одна в другую, но можно хотя бы догадаться о том, что это кубик.
И, наконец, нам нужно как-то справляться с шумом, благодаря которому наши оценки положения точек не всегда совпадают (видите на гифке сверху аккуратные неровные колечки? вместо каждого из них, в идеале, должна быть одна точка). Тут уже простор для творчества, но наиболее адекватный способ мне показался таким:
Тут уже простор для творчества, но наиболее адекватный способ мне показался таким:
— когда у нас есть подряд несколько сдвигов в сторону, объединяем информацию с них вместе — так для одной точки у нас будет сразу несколько оценок глубины;
— когда камера поворачивается, мы пытаемся совместить два набора точек (до поворота и после) и подогнать один к другому. Эта подгонка по-правильному называется «регистрацией точек» (о чем вы бы никогда не догадались, услышав термин в отрыве от контекста), и для нее я воспользовался алгоритмом Iterative closest point, нагуглив версию для питона + OpenCV;
— потом точки, которые лежат в пределах порогового радиуса (определяем методом ближайшего соседа), сливаются вместе. Для каждой точки мы еще отслеживаем что-то типа «интенсивности» — счетчик того, как часто она объединялась с другими точками. Чем больше интенсивность — тем больше шанс на то, что это честная и правильная точка.
Результат может и не такой цельный, как в случае с кубиками из Портала, но по крайней мере, точный. Вот пара воссозданных моделей, которые я сначала загрузил в Блендер, покрутил вокруг них камеру и сохранил полученные кадры:
Вот пара воссозданных моделей, которые я сначала загрузил в Блендер, покрутил вокруг них камеру и сохранил полученные кадры:
Голова профессора Доуэля
Какая-то рандомная машина
Бинго! Дальше нужно их все запихать в распознающий алгоритм и посмотреть, что получится. Но это, пожалуй, оставим на следующую серию.
Слегка оглянемся назад и вспомним, зачем мы это все делали. Ход рассуждений был такой:
— нам нужно уметь распознавать вещи, изображенные на картинках
— но эти картинки каждый раз, когда мы меняем положение или смотрим на одну и ту же вещь с разных углов, меняются. Иногда до неузнаваемости
— это не баг, а фича: следствие того, что наши ограниченые сенсоры глаз видят только часть предмета, а не весь предмет целиком
— следовательно, нужно как-то объединить эти частичные данные от сенсоров и собрать из них представление о предмете в его полноценной форме.
Вообще говоря, это ведь наверняка проблема не только зрения. Это скорее правило, а не исключение — наши сенсоры не всемогущи, они постоянно воспринимают информацию об объекте частями — но любопытно, насколько все подобные случаи можно объединить в какой-то общий фреймворк? Скажем (возвращаясь к зрению), ваши глаза сейчас постоянно совершают мелкие и очень быстрые движения — саккады — перескакивая между предметами в поле зрения (а в промежутках между этими движениями ваше зрение вообще не работает — именно поэтому нельзя увидеть собственные саккады, даже уставившись в зеркало в упор). Мозг постоянно занимается упорной работой по «сшиванию» увиденных кусочков. Это — та же самая задача, которую мы только что пытались решить, или все-таки другая? Восприятие речи, когда мы можем соотнести десяток разных вариантов произношения слова с одним его «идеальным» написанием — это тоже похожая задача? А как насчет сведения синонимов к одному «образу» предмета?
Это скорее правило, а не исключение — наши сенсоры не всемогущи, они постоянно воспринимают информацию об объекте частями — но любопытно, насколько все подобные случаи можно объединить в какой-то общий фреймворк? Скажем (возвращаясь к зрению), ваши глаза сейчас постоянно совершают мелкие и очень быстрые движения — саккады — перескакивая между предметами в поле зрения (а в промежутках между этими движениями ваше зрение вообще не работает — именно поэтому нельзя увидеть собственные саккады, даже уставившись в зеркало в упор). Мозг постоянно занимается упорной работой по «сшиванию» увиденных кусочков. Это — та же самая задача, которую мы только что пытались решить, или все-таки другая? Восприятие речи, когда мы можем соотнести десяток разных вариантов произношения слова с одним его «идеальным» написанием — это тоже похожая задача? А как насчет сведения синонимов к одному «образу» предмета?
Если да — то возможно, проблема несколько больше, чем просто местечковый алгоритм зрительной системы, заменяющий нашим недоэволюционировавшим глазам лазерную указку сканера.
Очевидные соображения говорят, что когда мы пытаемся воссоздать какую-то штуку, увиденную в природе, нет смысла слепо копировать все ее составные части. Чтобы летать по воздуху, не нужны машущие крылья и перья, достаточно жесткого крыла и подъемной силы; чтобы быстро бегать, не нужны механические ноги — колесо справится гораздо лучше. Вместо того, чтобы копировать увиденное, мы хотим найти принцип и повторить его своими силами (может быть, сделав это проще/эффективней). В чем состоит принцип интеллекта, аналог законов аэродинамики для полета, мы пока не знаем. Deep learning и Ян Лекун, пророк его (и вслед за ним много других людей) считают, что нужно смотреть в сторону способности строить «глубокие» иерархии фич из получаемых данных. Может быть, мы сможем добавить к этому еще одно уточнение — способность объединять вместе релевантные куски данных, воспринимая их как части одного объекта и размещая в новом измерении?
App Store: Поиск по картинке – Картинки
*** Найдите похожие изображения или картинки с помощью системы обратного поиска изображений Google / Tineye / Yandex ***
Почему это приложение?
– Простота использования
– Быстро и надежно
– Поддержка камеры для захвата изображения
– Простой редактор изображений перед поиском
– Поддержка поисковых систем Google, Tineye и Яндекс.
Редактор изображений:
– Повернуть изображение
– Отразить изображение по горизонтали / вертикали
– Обрезать часть изображения
Типичные варианты использования:
– Найдите похожие изображения
– Узнайте, является ли изображение измененным или оригинальным
– Узнайте, является ли изображение поддельным или оригинальным
– Узнайте, новое ли изображение или просто старое, уже доступное в Интернете.
– Поиск по части изображения. Это полезно, если изображение состоит из нескольких изображений.
Обратный поиск изображений Premium
– Присоединяйтесь сейчас и наслаждайтесь всеми функциями!
– При покупке Reverse Image Search Premium вы будете использовать все платные функции и материалы.
– Премиум обратного поиска изображений оплачивается ежемесячно по ставке, соответствующей выбранному плану.
– Оплата будет снята с вашей учетной записи iTunes при подтверждении покупки.
– Согласно политике Apple Store, ваша подписка будет автоматически продлена после окончания бесплатного пробного периода.
– Подписки будут автоматически продлеваться, если автоматическое продление не будет отключено по крайней мере за 24 часа до окончания текущего периода.
– С вашего счета будет взиматься плата в соответствии с вашим планом за продление в течение 24 часов до окончания текущего периода. Вы можете управлять автоматическим продлением или отключить его в настройках своей учетной записи Apple ID в любое время после покупки.
– Политика конфиденциальности: http://aitube.doukantv.com/media/html/privacy_policy/imagesearch_policy.html
– Условия использования: http://aitube.doukantv.com/media/html/privacy_policy/imagesearch_term.html
Распознавание образов (кибернетика) – это… Что такое Распознавание образов (кибернетика)?
Автоматическое распознавание лиц специальной программой.
Теория распознава́ния о́бразов — раздел кибернетики, развивающий теоретические основы и методы классификации и идентификации предметов, явлений, процессов, сигналов, ситуаций и т. п. объектов, которые характеризуются конечным набором некоторых свойств и признаков. Такие задачи решаются довольно часто, например, при переходе или проезде улицы по сигналам светофора. Распознавание цвета загоревшейся лампы светофора и знание правил дорожного движения позволяет принять правильное решение о том, можно или нельзя переходить улицу в данный момент.
В процессе биологической эволюции многие животные с помощью зрительного и слухового аппарата решили задачи распознавания образов достаточно хорошо. Создание искусственных систем распознавания образов остаётся сложной теоретической и технической проблемой. Необходимость в таком распознавании возникает в самых разных областях — от военного дела и систем безопасности до оцифровки всевозможных аналоговых сигналов.
Традиционно задачи распознавания образов включают в круг задач искусственного интеллекта.
Направления в распознавании образов
Можно выделить два основных направления[1]:
- Изучение способностей к распознованию, которыми обладают живые существа, объяснение и моделирование их;
- Развитие теории и методов построения устройств, предназначенных для решения отдельных задач в прикладных задачах.

Формальная постановка задачи
Распознавание образов – это отнесение исходных данных к определенному классу с помощью выделения существенных признаков, характеризующих эти данные из общей массы несущественных данных.
При постановке задач распознования стараются пользоваться математическим языком, стараясь в отличии от теории искусственных нейронных сетей, где основой является получение результата путем эксперимента, заменить эксперимент логическими рассуждениями и математическими доказательствами [2].
Наиболее часто в задачах распознования образов рассматриваются монохромные изображения, что дает возможность рассматривать изображение как функцию на плоскости. Если рассмотреть точечное множество на плоскости T, где функция x(x,y) выражает в каждой точке изображения его характеристику – яркость, прозрачность, оптическую плотность, то такая функция есть формальная запись изображения.
Множество же всех возможных функций x(x,y) на плоскости T – есть модель множества всех изображений X. Вводя понятие сходства между образами можно поставить задачу распознавания. Конкретный вид такой постановки сильно зависит от последующих этапов при распозновании в соответствии с тем или иным подходом.
Методы распознавания образов
Для оптического распознавания образов можно применить метод перебора вида объекта под различными углами, масштабами, смещениями и т. д. Для букв нужно перебирать шрифт, свойства шрифта и т. д.
Второй подход — найти контур объекта и исследовать его свойства (связность, наличие углов и т. д.)
Еще один подход — использовать искусственные нейронные сети. Этот метод требует либо большого количества примеров задачи распознавания (с правильными ответами), либо специальной структуры нейронной сети, учитывающей специфику данной задачи.
Перцептрон как метод распознавания образов
Ф. Розенблатт вводя понятие о модели мозга, задача которой состоит в том, чтобы показать, как в некоторой физической системе, структура и функциональные свойства которой известны, могут возникать психологические явления – описал простейшие эксперименты по различению. Данные эксперименты целиком относятся к методам распознавания образов, но отличаются тем что алгоритм решения не детерминированный.
Данные эксперименты целиком относятся к методам распознавания образов, но отличаются тем что алгоритм решения не детерминированный.
Простейший эксперимент, на основе которого можно получить психологически значимую информацию о некоторой системе, сводится к тому, что модели предъявляются два различных стимула и требуется, чтобы она реагировала на них различным образом. Целью такого экперимента может быть исследование возможности их спонтанного различения системой при отсутствии вмешательства со стороны экспериментатора, или, наоборот, изучение принудительного различения, при котором экспериментатор стремится обучить систему проводить требуемую классификацию.
В опыте с обучением перцептрону обычно предъявляется некоторая последовательность образов, в которую входят представители каждого из классов, подлежащих различению. В соответствии с некоторым правилом модификации памяти правильный выбор реакции подкрепляется. Затем перцептрону предъявляется контрольный стимул и определяется вероятность получения правильной реакции для стимулов данного класса. В зависимости от того, совпадает или не совпадает выбранный контрольный стимул с одним из образов, которые использовались в обучающей последовательности, получают различные результаты:
В зависимости от того, совпадает или не совпадает выбранный контрольный стимул с одним из образов, которые использовались в обучающей последовательности, получают различные результаты:
- 1. Если контрольный стимул не совпадает ни с одним из обучающих стимулов, то эксперимент связан не только с чистым различением, но включает в себя и элементы обобщения.
- 2. Если контрольный стимул возбуждает некоторый набор сенсорных элементов, совершенно отличных от тех элементов, которые активизировались при воздействии ранее предъявленных стимулов того же класса, то эксперимент является исследованием чистого обобщения.
Перцептроны не обладают способностью к чистому обобщению, но они вполне удовлетворительно функционируют в экспериментах по различению, особенно если контрольный стимул достаточно близко совпадает с одним из образов, относительно которых перцептрон уже накопил определенный опыт.
Примеры задач распознавания образов
- Распознавание букв.

- Распознавание штрих-кодов.
- Распознавание автомобильных номеров.
- Распознавание лиц.
- Распознавание речи.
- Распознавание изображений.
- Распознавание локальных участков земной коры, в которых находятся месторождения полезных ископаемых.
Программы распознавания образов
- FineReader
- Readiris
- NI Vision (на основе программного комплекса
См. также
Примечания
- ↑ Ту Дж., Гонсалес Р. Принципы распознавания образов, М. 1978
- ↑ Файн В.С. Опознавание изображений, М. 1970
Ссылки
Литература
- Дэвид А. Форсайт, Джин Понс Компьютерное зрение. Современный подход = Computer Vision: A Modern Approach. — М.: «Вильямс», 2004. — С. 928. — ISBN 0-13-085198-1
- Джордж Стокман, Линда Шапиро Компьютерное зрение = Computer Vision. — М.: Бином. Лаборатория знаний, 2006. — С. 752. — ISBN 5947743841
- А.
 Л.Горелик, В.А.Скрипкин, Методы распознавания, М.: Высшая школа, 1989.
Л.Горелик, В.А.Скрипкин, Методы распознавания, М.: Высшая школа, 1989. - Ш.-К. Чэн, Принципы проектирования систем визуальной информации, М.: Мир, 1994.
Wikimedia Foundation. 2010.
Уильям Гибсон «Распознавание образов»
Почему решил прочитать: Гибсон, отзывы, номинации на различные фантпремии
В итоге: консюмеризм и потреблядство, прямо как у Паланика в БК. Тайлер Дарден пошёл на мир потребления войной, а у Кейс Поллард — просто аллергия на бренды, которую она умудряется монетизировать.
Ничего не имею против упоминания брендов в текстах романов, особенно, когда это оправданно стилистически, но в этой книге их до неприличия много.
Слог нейтральный, отстранённый, но тем больше радуют яркие и неожиданные метафоры Гибсона.
«Распознавание» — тот случай, когда из относительно недокрученных элементов собирается качественное целое, являющееся большим, чем просто сумма частей.
В романе не хватает напряжения и экшна для триллера, практически нет фантастики, чтобы отнести вещь к киберпанку, не самое глубокое проникновение в рекламный бизнес, чтобы можно было считать «Распознавание» производственным романом.
В итоге же — очень актуальное для начала двухтысячных высказывание о глобализации и о том, что искусство — это жизнь.
К тому же одна из первых серьёзных рефлексий на тему 11 сентября 2001 года. (Погуглил — вау! Я был прав! Это первый роман на тему 9/11!)
Линия пропавшего в катастрофе отца главной героини подозрительно перекликается с вышедшим существенно позже « Жутко громко и запредельно близко» Фоера.
Роман Фоера, конечно, оказался более резонансным, премированным и даже заслужил экранизацию. Но это потому, что там герой мальчик, а не 32-летняя тётя.
Кстати, об экранизациях Гибсона, на которые ему так не везёт. Думается, что и «Распознавание образов» неэкранизируемо. Экшна мало, линия с русскими мафиозными олигархами автоматически переводит картину в низшую лигу, как и пресловутый чемоданчик.
Причина культовости романа в русском ЖЖ для меня неясна. Людей гипнотизирует перечисление брендов? (Курточку «Баз Риксон» я бы себе тоже прикупил.) Ставят себя на место достаточно странной героини?
Распознавание образов | Понятия и категории
РАСПОЗНАВАНИЕ ОБРАЗОВ – раздел математической кибернетики, в рамках которого разрабатываются принципы и методы классификации и идентификации предметов, явлений, процессов, сигналов, ситуаций — всех тех объектов, которые могут быть описаны конечным набором некоторых признаков (см. Признак одномерный) или свойств, характеризующих объект. Как синонимы термина «образ» в некоторых методах используются термины класс, группа, таксон, кластер.
Описание объектов представляет собой n -мерный вектор, где n — кол-во одномерных признаков. В описании объекта допустимо отсутствие информации о значении того или иного признака. Если необходимо расклассифицировать предъявленные объекты по нескольким группам (образам) только на основе их описаний, то такая задача называется задачей кластерного анализа (таксономии, обучения без учителя, самообучения, автоматической классификации). Для задач собственно распознавание образов (обучения с учителем), кроме описания объектов, необходимы дополнительные сведения о принадлежности некоторых из них к тому или иному классу (обучающая выборка, обучающая последовательность, набор эталонов). Количество классов, конечно и задано. Классы могут пересекаться.
Основная задача распознавания образов заключается в том, чтобы исходя из обучающей последовательности определить класс, к которому принадлежит описание некоторого объекта, подвергаемого классификации или идентификации. К данной схеме приводится любая задача принятия решений, если процесс такого принятия базируется в основном на изучении ранее накопленного опыта.
К задачам распознавания образов относятся также задачи минимизации описания исходных объектов, выделения информативных признаков.
Задачи, решаемые методами распознавания образов, часто встречаются в социологических исследованиях. Для их решения накоплено большое число алгоритмов распознавания, ориентированных на специфику решения конкретных задач. Часто используются методы классификации. Наиболее актуальными для социологии являются методы распознавания образов, предназначенные для таких данных, хотя бы часть из которых была получена по шкалам низких типов. Таковыми являются, например, методы распознавания образов, лежащие в русле матрично-аппроксимационных подходов, методов поиска логических закономерностей, поиска взаимодействий.
Ю.Н. Толстова
Социологический словарь / отв. ред. Г.В. Осипов, Л.Н. Москвичев. М, 2014, с. 381-382.
Литература:
Распознавание образов в соц. иссл-ях. Новосибирск, 1967;
Загоруйко Н.Г. Методы распознавания и их применение. М., 1970;
Дюран Б., Оделл П. Кластерный анализ. М., 1977;
Стат. методы анализа социол. информации. М., 1979;
Классификация и кластер. М., 1980;
Типология и классификация в социол. иссл-ях. М., 1982;
Распознавание образов // Матем. энциклопедия. Т. 4. М., 1984.
Распознавание образов и анализ изображений в РУДН, профиль бакалавриата
Экзамены, минимальные баллы, бюджетные места, проходные баллы, стоимость обучения на программе Распознавание образов и анализ изображений, Российский университет дружбы народов
Сводная информация
202120202018
Проходной балл 2020: от 241 arrow_downward 10
Мест: 7
в тч квота: 1
Комбинация ЕГЭ 1
ЕГЭ – мин. баллы 2021
Математика (профиль) – 39
Русский язык – 40
Предмет по выбору абитуриента (или)
Физика – 39
Химия – 39
Информатика – 44
Иностранный – 30
Посмотрите варианты
Сводная информация
202120202018
Проходной балл 2020: от 155 arrow_upward 28
Мест: 4 arrow_upward 4
Стоимость: от 264800 Комбинация ЕГЭ 1
ЕГЭ – мин. баллы 2021
Математика (профиль) – 39
Русский язык – 40
Предмет по выбору абитуриента (или)
Физика – 39
Химия – 39
Информатика – 44
Иностранный – 30
Посмотрите варианты
Параметры программы
Квалификация: Бакалавриат;
Форма обучения: Очная;
Язык обучения: Русский;
На базе: 11 классов;
Срок обучения: 4 года;
Курс: Полный курс;
Военная кафедра: нет;
Общежитие: есть;
По учредителю: государственный;
Город: Москва;
Варианты программы
Статистика изменения проходного балла по годам
Проходные баллы на бюджет
2017: 221
2019: 251
2020: 241
Проходные баллы на платное
2017: 150
2019: 127
2020: 155
О программе
Программа направлена на обеспечение обучающимся условий для приобретения необходимого для осуществления профессиональной деятельности уровня знаний, умений, навыков, опыта деятельности; формирования общекультурных, общепрофессиональных, профессиональных и специальных компетенций в параллельных и высокопроизводительных вычислениях
Дисциплины, изучаемые в рамках профиля:
- Математический анализ;
- Линейная алгебра;
- Дискретная математика и комбинаторные алгоритмы;
- Математическая логика и теория алгоритмов;
- Логическое программирование;
- Дифференциальные уравнения;
- Теория вероятностей и математическая статистика;
- Теория конечных графов;
- Основы программирования;
- Технология программирования;
- Алгоритмы и анализ сложности;
- Теоретические основы информатики;
- Интеллектуальные системы;
- Интеллектуальный анализ данных;
- Архитектура вычислительных систем;
- Операционные системы;
- Основы администрирования операционных систем;
- Вычислительные системы, сети и телекоммуникации;
- Сетевые технологии;
- Основы проектирования сетей и систем телекоммуникаций;
- Основы разработки корпоративных инфокоммуникационных систем;
- Проектирование корпоративных систем;
- Администрирование сетевых подсистем;
- Администрирование локальных систем;
- Управление ИТ-сервисами и контентом;
- Информационная безопасность;
- Реляционные базы данных;
- Системы управления базами данных;
- Математическое моделирование;
- Имитационное моделирование;
- Теория автоматов и формальных языков;
- Неклассические логики;
- Java и ее приложения;
- Распознавание образов и анализ изображений
Дополнительные баллы к ЕГЭ от вуза
Золотой значок ГТО — 3
Аттестат с отличием — 10
Диплом СПО с отличием — 10
Волонтерство — до 3
Решение ИРЦЭ достигло 98% точности распознавания образов в мобильном устройстве
Интеграция Бизнес-приложения | ПоделитьсяРезидент кластера информационных технологий фонда «Сколково» — ООО «Институт развития цифровой экономики», выпустил новую версию цифровой платформы распознавания образов «СкайНет Энжн» (SkyNet Engine) с использованием технологий искусственного интеллекта. Специалисты компании существенно увеличили скорость и точность распознавания товаров на полках магазинов по фото непосредственно в мобильном устройстве. Теперь менее, чем за секунду можно достигнуть гарантированной точности распознавания в 98%, даже на обычных и недорогих смартфонах.
SkyNet Engine — инновационная платформа для моделей машинного обучения, созданная на основе собственных методик и ядра распознавания. По словам генерального директора ООО «ИРЦЭ» Хусейна Аз-зари, сегодня это единственная в России система распознавания образов, которая анализирует изображение в смартфоне или на планшете без подключения к Интернету.
«Российские и зарубежные аналоги — это программное обеспечение, которое устанавливается на мобильное устройство, отправляет фото/видео на серверы или облачные сервисы и получает результаты распознавания со значительной задержкой времени», — подчеркнул Хусейн Аз-зари.
Платформа SkyNet Engine может использоваться для разработки систем распознавания образов в разных отраслях. Решение уже применяется для розничной торговли, позволяя проверять наличие и качество размещения товаров, проанализировать долю полки для каждой категории товаров, своевременно актуализировать ценники на полках. Система также анализирует POS-материалы и специализированные стенды в торговых точках. Программная система распознавания образов «СкайНет Ритейл» (SkyNet Retail) на базе платформы SkyNet Engine значительно упрощает и ускоряет работу мерчендайзеров, аудиторов и торговых представителей.
В промышленности платформа распознавания может быть использована для разработки систем контроля качества на конвейере или мониторинга неисправностей в работе оборудования. В здравоохранении — для первичной диагностики некоторых заболеваний по фотографии и для анализа медицинских снимков. В сельском хозяйстве система поможет обнаружить вредителей, заметить болезни растений, контролировать созревание урожая.
«Область применения нашего «движка» обширна: его можно встраивать в мобильные приложения и системы видеонаблюдения для решения различных задач во многих отраслях экономики, — отметил Хусейн Аз-зари. — Например, на основе SkyNet Engine можно сделать приложение, идентифицирующее сотрудников для доступа в помещение. Зарубежные торговые сети также используют решение для мониторинга настроения пользователей. В этом направлении движутся и передовые отечественные ритейлеры: оценку эмоционального состояния покупателей проводят при дегустации продукции».
Платформа SkyNet Engine включена в Единый реестр российских программ для электронных вычислительных машин и баз данных Министерства связи и массовых коммуникаций Российской Федерации (№ 6078).
Новые типы атак можно выявлять даже без сигнатур и правил корреляции
БезопасностьВ 2019 году международная компания Mars начала внедрение системы автоматического распознавания товаров с помощью искусственного интеллекта на платформе SkyNet Engine во всех странах региона «Центральная Евразия, Беларусь и Турция».
За счет уникальных технологических преимуществ решение SkyNet Engine позволило компании Mars получать достоверные маркетинговые показатели в любой торговой точке за считанные секунды, несмотря на качество мобильной связи. В результате внедрения время работы мерчендайзеров в торговых точках сократилось примерно на 25%, что обеспечило значительный рост покрытия территории и существенно увеличило присутствие компании Mars на территории стран региона.
Более 70% данных, влияющих на оценку качества работы с торговыми точками и объемы продаж, заполняются автоматически на основе анализа фотографий в мобильном устройстве. С помощью платформы распознавания образов SkyNet Engine компания Mars получает в 5 раз больше маркетинговых данных, чем ранее. Теперь оценка представленности товаров ведется в разрезе каждой товарной позиции (SKU) как по собственным товарам, так и по товарам локальных и международных конкурентов, без увеличения затрат на получение такой информации. Использование SkyNet Engine позволило компании Mars остаться в лидерах в 2020 году и увеличить долю продаж несмотря на ограничения, связанные с пандемией.
В настоящее время более 800 мобильных сотрудников компании Mars работают с системой распознавания SkyNet Retail в 7 странах региона (Казахстан, Беларусь, Кыргызстан, Узбекистан, Армения, Грузия, Азербайджан). В ближайший год запланировано внедрение в остальных странах региона – в Молдавии, Монголии, Таджикистане, Туркменистане и Турции.
Владимир Бахур
Распознавание изображений у животных и людей
Исследователи когнитивных функций животных и человека часто используют фотографии или слайды вместо реальных объектов в своих исследованиях категоризации, распознавания лиц и т. Д., Но, как это ни парадоксально, мало экспериментов ни с животными, ни с людьми которые прямо рассмотрели вопрос об эквивалентности объекта и его изображения. Другими словами, не очевидно, что животные и люди действительно интерпретируют двумерные стимулы как трехмерные объекты, которые они представляют.Например, успех, достигнутый в обучении голубей [40], [63] или обезьян [13], [80], [112] классифицировать слайды фотографий, не доказывает, что животные понимают, что на самом деле представляют изображения, которые они классифицируют. Фактически, как мы увидим в этой статье, некоторые исследования продемонстрировали, что это не так, в то время как другие показали, что установление некоторой эквивалентности между реальным объектом и его графическим изображением зависит как от размеров стимула, так и от экспериментальных данных. и / или мотивационные условия.В настоящем обзоре делается попытка подвести итоги этого вопроса путем изучения доступной литературы для людей (в основном младенцев) и нечеловеческих субъектов.
В этом обзоре сначала будут рассмотрены эксперименты на людях, а затем будут рассмотрены исследования с нечеловеческими субъектами, причем последние будут разделены на три категории. К первой категории относятся случаи убедительных демонстраций, в которых животные могут относиться к картинкам как к стимулам, которые они представляют; мы можем предположить, что изображение распознается, когда животные реагируют на изображение так, как они реагировали бы, спонтанно или после некоторой тренировки, на реальный объект.Конечно, такие реакции могут варьироваться в зависимости от типа представленных изображений: социальное поведение с изображениями сородичей, страх с угрожающими стимулами, поведение хищников с изображениями добычи и т. Д .; спонтанные ответы и передача различных приобретенных ответов (наименование, категоризация, дискриминация, кросс-модальное сопоставление и т. д.) в других случаях. Вторая категория включает эксперименты, которые могут указывать на существование распознавания изображений, но на самом деле не являются демонстрациями, потому что экспериментальный план вызывает сомнения (например, когда задействован только один субъект) или результаты (предпочтения субъектов или просмотр времени, дискриминация людей или виды или различные спонтанные формы поведения) не обязательно вызываются предъявленными стимулами.Третья категория включает те эксперименты, которые показывают, что животные могут иметь трудности с распознаванием изображений.
Кроме того, среди исследований, в которых использовались изображения живых или неодушевленных предметов с животными, можно выделить два подкласса; Первый класс относится к исследованиям, изучающим выученные реакции на стимулы (как это часто бывает, когда испытуемыми являются приматы или птицы), в то время как второй класс исследований измеряет спонтанные или естественные реакции на стимулы (исследования этого типа часто встречаются в экспериментах с низшими позвоночными или беспозвоночными).В этом последнем случае для того, чтобы вызвать реакцию, может быть достаточно очень заметного признака высвобождающего стимула. Например, самец красногрудого животного реагирует на приманку (например, красный пучок красных перьев), как если бы это был настоящий сородич, даже если приманка не похожа на птицу [61]; цветная фотография сородича самца может вызвать аналогичную реакцию, но неясно, нужно ли в таких случаях обрабатывать и распознавать весь стимул. Однако, когда субъект обучается реагировать на реальные стимулы, а затем передает свою реакцию на изображения этих стимулов или может использовать видеоизображения для получения некоторой информации о природе реального объекта, это предполагает, что наиболее важные особенности изображенные стимулы рассматриваются и распознаются.Следовательно, поскольку обработка изображений может различаться в зависимости от типа реакции (спонтанной или усвоенной), эти два класса будут рассматриваться отдельно.
Третий классификационный ключ касается вопроса о предъявляемых стимулах, то есть о том, является ли изображение статичным (фотография, слайд, оцифрованное изображение) или движущимся изображением, что, конечно, подразумевает некоторое движение и часто звук и, таким образом, может значительно облегчить реакция испытуемых на раздражители. Например, движение хорошо известно как высвобождение хищного поведения [11] или может играть важную роль в ухаживании за многими видами (см., Например, ссылки.[35], [94]).
Amazon.com: School Zone – Алфавитные карточки
Уже почти 40 лет School Zone помогает сделать обучение интересным! Наш основанный на исследованиях контент, разработанный ведущими преподавателями, предоставляет отмеченные наградами современные продукты в цифровом и печатном виде для индивидуального стиля обучения и целей. Каждый продукт, помещенный в руки ребенка, полон красок, содержания и творчества. В каждой детали инновации сочетаются с воображением и вечными традициями. В том же духе School Zone олицетворяет успех и открывает возможности, смело вступая в новые медиа и платформы для общения с детьми там, где они есть.Родители ценят качество и внимание к деталям. Компания постоянно обновляет материалы, добавляя новые функции и контент, отражающие меняющиеся стандарты, развивающиеся методы обучения и общие передовые практики. Результат? Отличное обучение дома и в классе.
Джоан Хоффман, магистр медицины, является автором и соавтором сотен популярных сборников рассказов и учебных пособий для детей. Среди названий – Peter’s Dream , I Don’t Like Peas и The New Bike (последние два изданы под псевдонимом Мари Винье), Get Ready for Preschool , Kindergarten и Трио рабочих тетрадей для первого класса , а также целые серии рабочих тетрадей «Готовься», «Маленький мыслитель», «Я знаю!» И «Попробуй-шпион» и «Маленькая занятая книга».
Она также является соучредителем, вместе со своим покойным мужем Джеймсом Хоффманом, доктором философии, School Zone Publishing. Будучи дальновидной в бизнесе, она давно смотрела на мир глазами ребенка, наполняя свои истории и уроки радостью и интересом.
Как мать четверых детей в 70-х годах, как и мамы во всем мире на протяжении всей истории, она хотела лучшего для своих детей. И она знала, что у учителей нет времени давать ее детям все, что им нужно. Как учитель начальной школы, Хоффман много работала, чтобы дать своим ученикам то, что им нужно было изучить.И родители спрашивали ее, чем они могли бы помочь. Вот почему она основала School Zone – чтобы дать детям возможность раскрыть свой потенциал.
Она принесла с собой опыт работы в сфере розничной торговли, накопленный ранее при создании и управлении двумя региональными магазинами учебной литературы и товаров для учителей и родителей. Ее муж проявил свои таланты педагога и предпринимателя. Профессор педагогики, который также имел непосредственный опыт работы учителем начальной школы, он участвовал в программах подготовки учителей в нескольких колледжах и возглавлял компанию, которая публиковала учебные материалы.
Сочетая твердое редакционное суждение и творческие инстинкты с глубоким пониманием раннего образования, Джоан Хоффман была образцовым сторонником дизайн-мышления задолго до того, как оно стало концептуальным лейблом. Инновационный решатель проблем, она всегда стремилась обратиться к конечным пользователям и бросить вызов условностям. Отделение мимолетных тенденций от законных достижений имело важное значение для долговечности ее компании.
Результаты говорят сами за себя. Когда следующее поколение – сын Джонатан и дочь Дженнифер – взяли на себя творческие и стратегические руководящие роли в компании, основанной их родителями, School Zone полностью интегрировала платформы цифрового обучения.Компания получила эксклюзивную премию Apple в области дизайна интерфейса человека за разработку программного обеспечения, а ее приложения были частью первого поколения iPad, выпущенного в 2010 году. Флагманский продукт School Zone, Little Scholar Learning Tablet, получил признание и награды в масштабах всей отрасли. есть место для онлайн-обучения Anywhere Teacher. Вдохновленный мастерством мамы в рассказывании историй, сын Джонатан продолжил это наследие с Charlie & Company, оригинальной серией для детей от 3 до 7 лет, доступной на Oznnoz, Kidoodle.tv, ToonGoggles, BatteryPop, Ameba и Highbrow.
Джоан Хоффман говорит: «Приятно видеть, как дети и внуки некоторых из наших первоначальных клиентов наслаждаются нашими постоянно развивающимися книгами, приложениями, флэш-картами, играми, музыкой и другими продуктами – как печатными, так и цифровыми».
В 2019 году School Zone отмечает 40 годовщину годовщины, охватывая периоды пяти десятилетий и продав более 370 миллионов образовательных продуктов. Хоффман продолжает работать в компании, писать, придумывать и по-прежнему ставить детей, родителей и учителей на первое место.
Границы | Распознавание объектов в ментальных репрезентациях: инструкции по изучению диагностических функций с помощью визуальных ментальных образов
Введение
Традиционные исследования по распознаванию объектов часто фокусируются на восходящей обработке зрительных стимулов, начиная от определения свойств стимула клетками сетчатки до электрической трансдукции и окончательной нервной реакции. Это направление исследований было успешным в выявлении физиологических и нервных путей, участвующих в обнаружении и обработке свойств визуальных объектов, ведущих к когнитивному восприятию.Таким образом, визуальные ментальные образы представляют собой поток информации, противоположный потоку визуальных перцептивных явлений; тот, который требует отхода от традиционных взглядов снизу вверх, чтобы быть полностью понятым.
С появлением усовершенствованных технологий и улучшенных методов тестирования исследования визуальных ментальных образов превратились из простых предположений о в значительной степени недоступном теоретическом явлении в эффективную и достоверную область исследований с богатым эмпирическим опытом. Растущее число исследований продемонстрировало функциональную роль визуальных образов в различных задачах, таких как память (Slotnick et al., 2005; Albers et al., 2013), креативный дизайн (Dahl et al., 1999; D’Ercole et al., 2010) и эмоциональные расстройства (Holmes and Mathews, 2010). В недавнем обзоре Pearson et al. (2015) изложили очень практическое значение ментальных образов в исследовании и лечении психических заболеваний, что привело к призыву продвигать поиск ментальных образов в качестве основной цели психопатологических вмешательств. Подобные обсуждения не только иллюстрируют меняющееся отношение к значимости ментальных образов, но также подчеркивают потенциальные преимущества дальнейшего исследования этого сложного процесса.Однако, несмотря на значительный рост, достигнутый в этой области исследований, нынешнее понимание ментальных образов часто ограничивается общими операциями и характеристиками; И в разговорной, и в научной терминологии визуальные ментальные образы обычно служат широким и несколько абстрактным определением любой визуальной субстанции, существующей в «мысленном взоре». Но что именно человек «видит» во время воображаемых переживаний? Почему одни изображения или подкомпоненты изображений визуализируются более четко, чем другие, и что это говорит о процессе восприятия? На такие вопросы еще предстоит дать какой-либо окончательный или конкретный ответ, и цель этого обзора – оценить возможные пути работы над объяснением.Повышая точность, с которой мы идентифицируем визуальное содержание мысленных образов, может быть достигнуто более полное понимание его интерактивной связи с визуальным восприятием, что приведет к более совершенным выводам относительно создания когнитивных представлений.
Психические образы предлагают уникальное преимущество перед визуальным восприятием в том, что объем потенциальной информации, доступной при последующем воспроизведении стимула, намного меньше количества, доступного во время перцептивного просмотра того же стимула.По определению, мысленные образы относятся к способности испытывать знакомые или новые визуальные стимулы в отсутствие соответствующей одновременной физической стимуляции (Pearson and Kosslyn, 2013). Поскольку ментальные образы основаны на восприятии воспоминаний в более позднее время и в более позднем месте, они неразрывно связаны с процессами памяти. Исследования показывают, что на нейронном уровне ментальные образы задействуют сети, перекрывающиеся с визуальной рабочей памятью (Albers et al., 2013), предполагая, что ментальные образы задействуют процесс, подобный восприятию, чтобы вспомнить сохраненную информацию и вернуть ее в текущее сознание для манипуляций. (Borst, Kosslyn, 2008; Borst et al., 2012). Тем не менее, процессы действительно кажутся, по крайней мере, частично различными, включая их зависимость от сенсорных визуальных сетей, которые коррелируют с силой базовых ментальных образов (Keogh and Pearson, 2011; см. Также Borst et al., 2012). Поэтому мысленные образы можно рассматривать как часть вывода памяти, особенно в тех случаях, когда воображается ранее просматриваемый стимул.
Естественные ограничения внимания и способности запоминания в процессе перехода с сенсорного уровня на перцепционный неизбежно приводят к потере и искажению некоторой визуальной информации.Другими словами, количество информации, доступной во время визуального воспоминания, как количественно, так и качественно уменьшается по сравнению с состоянием восприятия. Несмотря на это, многочисленные эмпирические исследования показали, что можно понять, назвать и описать свойства объекта только с помощью мысленных образов (например, Kosslyn et al., 1995; Walker et al., 2006; Palmiero et al., 2014). Следовательно, разумно сделать вывод, что уменьшенная информация, доступная в мысленном образе, должна быть по крайней мере достаточной, если не необходимой, для успешного распознавания объекта.Таким образом, процессы мысленных образов могут служить полезным и естественным фильтром, с помощью которого можно определить особенности изображения, которые имеют наибольшее когнитивное значение для зрителя. Изучая результат перцептивного просмотра в форме мысленных образов, количество альтернативных факторов, которые следует учитывать, значительно сокращается по сравнению с теми, которые присутствуют в сложной визуальной среде, основанной на ощущениях. Вместо того, чтобы пытаться измерить относительную классификационную ценность всех доступных характеристик в данном стимуле, исследователь может использовать содержание, сохраняемое в мысленном образе наблюдателя, для определения значимых визуальных сигналов.
Цель этого обзора – предположить, что визуальные мысленные образы, содержимое которых подверглось естественному процессу фильтрации с целью отсеивания информации об объекте, не имеющей отношения к распознаванию или категоризации в данном сценарии, обладают значительным потенциалом для идентификации характеристик объекта, которые критически важен для восприятия распознавания. Эти признаки, называемые отличительными или диагностическими признаками, представляют собой визуальные компоненты с классификационным значением, которые способствуют быстрому и эффективному распознаванию объектов (Baruch et al., 2014). В связи с отсутствием в настоящее время эмпирических исследований, которые непосредственно исследуют идентификацию диагностических признаков в ментальных образах, в этой статье вместо этого исследуется и обсуждается практическая целесообразность такого исследования:
(1) обзор известных поведенческих методов и методов нейровизуализации, которые использовались для успешного доступа к ментальным визуальным репрезентациям;
(2) оценка потенциала каждого метода для определения диагностических признаков на основе эффективности и специфичности, которых они, как было показано, достигают;
(3), предлагая возможные направления и последствия для изучения отличительных черт с помощью мысленных образов в будущих исследованиях.
Теоретические основы
Распознавание объектов в визуальном восприятии
Значение свойств объекта в визуальном восприятии признано давно. В одной из старейших и наиболее известных теорий, подчеркивающих важность отдельных визуальных частей, Бидерман (1987) предположил, что распознавание любого данного объекта зависит от взаимодействия между отдельными структурными компонентами и их общей конфигурацией в контексте целого. Хотя теория распознавания по компонентам (RBC) Бидермана основана на структурных геометрических формах, дальнейшие исследования показали, что общие визуальные характеристики не должны ограничиваться пространственно дискретными структурными частями.Характеристики могут быть интерпретированы как любая композиционная единица визуального стимула, включая контуры (Loffler, 2008), цвета или текстуры (Bramão et al., 2011a), или минимальные элементы контраста, такие как пятна Габора (Dong and Ren, 2015). . Настоящая статья учитывает это широкое разнообразие, принимая широкую концептуальную концепцию визуальных характеристик как любых «дискретных компонентов изображения, которые обнаруживаются независимо друг от друга» (Pelli et al., 2006). Однако из-за их доступности (в том смысле, что они легко понимаются и могут быть зафиксированы в когнитивных и нейронных измерениях), исследования и выводы, обобщенные в этом обзоре, наиболее подходят для выявления сложных форм, используемых для распознавания.Независимо от уровня специфичности, на котором они охарактеризованы, любые существенные особенности должны быть обнаружены и интегрированы в контексте окружающей информации (например, дополнительные характеристики объекта, семантический или ситуационный контекст, цели наблюдателя, набор объектов и т. Д .; Померанц и др. ., 1977; Мартелли и др., 2005).
Несмотря на обширную литературу, посвященную роли визуальных характеристик в восприятии объекта, точная степень, в которой различные индивидуальные особенности способствуют распознаванию, остается неубедительной.Некоторые теории предполагают, что отличительные особенности играют решающую роль в облегчении эффективной идентификации и категоризации объектов. Эти уникальные информативные визуальные компоненты ускоряют определение идентичности объекта в конкретном контексте, позволяя наблюдателю быстро и эффективно различать возможные альтернативы (Baruch et al., 2014). Подобно общим визуальным признакам, визуальное содержание отличительного или диагностического признака варьируется и может включать автономные компоненты, такие как структурная форма, или более распределенные элементы, такие как цвет (Bramão et al., 2011а, б). Важно отметить, что свойства отличительной черты в любой данной ситуации различаются в зависимости от контекста сценария просмотра (Baruch et al., 2014; Schlangen and Barenholtz, 2015), а также от внешних когнитивных факторов (например, избирательное внимание; Ballesteros и Mayas, 2015).
Существование отличительных черт в визуальном восприятии и их роль в распознавании объектов получили некоторую эмпирическую поддержку, хотя результаты ни в коем случае не являются окончательными. Первоначально считалось, что они играют неотъемлемую роль в распознавании новой точки зрения, диагностические особенности подтверждали контраргумент теории структурного описания, предложенной Бидерманом (1987).В то время как теория RBC предсказывала относительно стабильную производительность распознавания для новых точек зрения, пока соответствующие структурные особенности, или геоны, оставались видимыми, контраргумент варианта точки зрения утверждал, что эта закономерность возникает только тогда, когда различные диагностические функции были доступны наблюдателю (Tarr et al. , 1997). Считается, что эти информативные визуальные компоненты облегчают принятие решений как по классификации, так и по распознаванию, обеспечивая диагностическое различение возможных альтернатив.Обратите внимание на то, что значимость или степень, в которой особенность выделяется, является заметной или привлекающей внимание, не подразумевает диагностичности, которая указывает на полезность в процессах распознавания или классификации. Рассмотрим, например, разницу между тигром и зеброй; хотя полосы заметны и очень заметны, простого присутствия полос недостаточно, чтобы отличить одну от другой. В отличие от этого, когда задают задачу идентифицировать зебру в толпе крупного рогатого скота, полосы являются более исключающими; значимость и диагностичность частично совпадают.
Тенденция к повышенному вниманию к определенным характеристикам, а также их способность способствовать быстрому и эффективному распознаванию объектов в динамических сценариях, поддерживает правдоподобную перцептивную и когнитивную значимость отличительных черт. Эти результаты также предполагают, что основные отличительные черты, вероятно, останутся относительно нетронутыми в ментальных репрезентациях по нескольким причинам:
(1) их классификационная значимость снижает вероятность того, что они будут отфильтрованы как нерелевантная информация во время начального кодирования ментального представления;
(2) разумно предсказать, что отличительные признаки представляют значительную часть семантической информации об объекте в пространственно сжатой визуальной единице;
(3) их когнитивная релевантность, по-видимому, увеличивает их устойчивость к деградации информации и эффектам предвзятости, которые возникают между стадиями визуального восприятия и генерации мысленных образов.
Следовательно, отличительные особенности объекта являются главным кандидатом для эмпирического исследования, поскольку они представляют собой упрощенные, надежные единицы, которые представляют или закрепляют более крупное и сложное мысленное представление визуального стимула. Для иллюстрации рассмотрим пример молотка. Скорее всего, при чтении слова на ум приходит образ молотка. Есть ли части или особенности, которые кажутся более четкими, чем другие? Рассмотрим простой эксперимент по распознаванию, в котором участнику показывают изображение молотка с удаленной металлической головкой.Маловероятно, чтобы нечетко определенная деревянная ручка «активировала» (что отражается в любой конкретной мере интереса) представление о молотке так же эффективно, как и весь объект, с неповрежденной головкой молота. Однако, если бы манипуляции были обратными, с удаленной рукояткой и сохраненной головкой молотка, можно было бы ожидать гораздо большей «активации» абстрактной концепции «молотка», а также всех ассоциаций, которые эта концепция влечет за собой (см. Распространяющуюся теорию активации память; Андерсон, 1983).Способность подкомпонента более сильного стимула эффективно достигать когнитивной репрезентации в отсутствие некоторых из его типичных контекстов предполагает, что определенные характеристики являются более когнитивно диагностическими, чем другие. После того, как указанные диагностические признаки идентифицированы (например, головка молота в этом сценарии), процесс уменьшения – как это было сделано путем удаления сначала головки молота, а затем рукоятки – можно систематически продвигать, чтобы определить наименьший компонент или группу компонентов, способных эффективного представления познавательной концепции.Таким образом, могут быть идентифицированы визуальные особенности, необходимые для активации когнитивного представления любого данного объекта. При сравнении нескольких образцов и категорий стимулов можно идентифицировать любые сходства в отличительных признаках (например, структура формы, контраст, края и т. Д.). Эта уникальная способность дискретных диагностических элементов служить связующим звеном с более целостными или сложными когнитивными представлениями делает их ценным предметом изучения, способным осветить не только механизмы, лежащие в основе образов ментальных объектов, но и их связь с восприятием распознавания.Способность сокращать сложные объекты до их основных и самых основных компонентов может потенциально привести к усовершенствованным теориям и методам, способным приспособиться к широкому спектру взаимодействий между сценариями просмотра и характеристиками естественных визуальных стимулов – постоянной проблемой, с которой в настоящее время сталкиваются традиционные сенсорные восприятия. исследования в области распознавания объектов.
Здесь стоит отметить обширную работу, проделанную в области компьютерного зрения, связанную именно с вопросами, рассматриваемыми в этом обзоре.Недавнее исследование Ullman et al. (2016) краудсорсинговая диагностическая информация об отличительных особенностях, которые оказали значительное влияние на распознавание человеческих объектов. Ответы более 14000 человек-наблюдателей дали минимальные распознаваемые конфигурации (MIRC) на 10 изображениях в градациях серого, изображающих объекты разных классов. Множественные MIRC, каждый из которых содержал минимальную избыточную информацию об объекте относительно полного изображения объекта, были идентифицированы для каждого из изображений и позволили успешно классифицировать по ограниченным визуальным областям.Их исследование также показало, что текущие вычислительные модели не в состоянии точно воспроизводить процессы распознавания, основанные на особенностях человека (например, распознавание моделей для суб-MIRC по сравнению с MIRC не уменьшилось так резко, как у людей-наблюдателей, и модели не могут распознать другие подчиненные функции в MIRC). Репрезентативное исследование Ullman et al. (2016) показывает, что можно уменьшить сложные объекты до минимально распознаваемого уровня, согласованного большой группой наблюдателей, до такой степени, что вклад каждой особенности критически влияет на распознавание.Другие исследования, проведенные с помощью компьютерных игр, показывают многообещающие стимулы для стимулирования крупномасштабных «алгоритмов» данных и вычислений, выполняемых людьми под предлогом развлечения (von Ahn, 2006), и были собраны данные для меток объектов, а также местоположения объектов в пределах сцена. Эти методы и их потенциал для определения поведения распознавания, связанного с особенностями, у большого и разнообразного круга субъектов стоит помнить по мере продвижения обзора.
Хотя компьютерное зрение работает, детали которого выходят за рамки текущего обсуждения (см. Nixon and Aguado, 2012; Shokoufandeh et al., 2012 для недавних обзоров), актуален и информативен для понимания визуального познания, современные вычислительные модели не могут точно воспроизводить человеческие зрительные процессы и поэтому не будут подробно обсуждаться здесь. В следующем обзоре основное внимание уделяется методам, направленным на непосредственный доступ к процессам ментальных образов у людей прямым и поддающимся количественной оценке образом, с признанием того, что результаты обсуждаемых здесь методов могут быть надлежащим образом применены к сетевым вычислительным методам для повышения не только точности. компьютерных симуляторов, но понимание восприятия, связанного с особенностями, и более поздних ментальных образов.
Представления объектов в ментальных образах
Долгая и сложная история исследования ментальных образов привела как минимум к двум различным взглядам на их связь с визуальным восприятием. Согласно одной точке зрения, нейронные и феноменологические процессы, происходящие во время визуального восприятия и ментальных образов, схожи по функциям и структуре из-за общих основных нейронных механизмов. Эти общие черты распространяются и включают вовлечение в ранние, ретинотопно-картированные зрительные области, такие как первичная зрительная кора головного мозга (V1; Slotnick et al., 2005; Альберс и др., 2013; Пирсон и др., 2015). Эксперименты с использованием трансмагнитной черепной стимуляции дали подтверждающие доказательства нейронного перекрытия между восприятием и образами (Cattaneo et al., 2012). Общие механизмы также были предложены исследованиями сходного времени реакции в ответ на визуально воспринимаемые и мысленно генерируемые изображения, устойчивые к эффектам яркости, контраста, движения и ориентации (Broggin et al., 2012). Дальнейшие исследования даже продемонстрировали, что яркость воображаемого стимула способна вызвать непроизвольную реакцию сужения зрачка, согласующуюся с паттернами, наблюдаемыми во время перцептивного просмотра (Laeng and Sulutvedt, 2014).Однако даже те исследования, которые сообщают о значительном совпадении паттернов поведенческих реакций или нейронной активации между восприятием и образами, часто отмечают несоответствия в их полноте и единообразии. Например, манипуляции с пространственной частотой приводили к разным моделям времени реакции на реальные стимулы по сравнению с воображаемыми (Broggin et al., 2012). Было обнаружено, что в кортикальном плане общая активация, наблюдаемая во время образов и процессов восприятия, более последовательна в лобных и теменных областях коры, чем в ретинотопных визуальных областях, хотя и в этих областях были выявлены значительные уровни взаимной активации (Ganis et al., 2004). Однако сравнения с использованием более гибких аналитических методов, таких как многомерный анализ паттернов (MVPA), выявили более надежное перекрытие в ранних визуальных областях (Albers et al., 2013). Считается, что эти общие нейронные механизмы лежат в основе феноменологического сходства между визуальным восприятием и ментальными образами. Например, есть свидетельства того, что мысленные образы обладают несколькими пространственными качествами, присущими объектам, воспринимаемым в поле зрения (Kosslyn et al., 1983), на что указывают наблюдаемые эффекты мысленного пространственного вращения, мысленного сканирования и времени, необходимого для проверки размеров. задачи (D’Ercole et al., 2010). Структурные теории ментальных образов далее предполагают, что, подобно перцепционным стимулам, воображаемые образы поддерживают ограниченное разрешение и определенное ощущение пространственной протяженности (см. Обзор Finke, 1985), включая пространственно эквивалентные отдельные единицы (Kosslyn et al., 1983) и в целом. похожий визуальный контент (Нанай, 2014).
Природа и степень общих нейронных основ, лежащих в основе процессов восприятия и воображения, ставятся под сомнение в нескольких уникальных клинических случаях.Яркие мысленные образы были идентифицированы по крайней мере у одного пациента, демонстрирующего сильно локализованное корковое повреждение V1, что привело к серьезному дефициту выполнения перцептивных задач (Bridge et al., 2011). Нейронные записи, собранные с помощью функциональной магнитно-резонансной томографии (фМРТ), также показали, что модели активации пациента во время эпизодов мысленных образов были аналогичны таковым у здоровых зрячих субъектов; поведенческое тестирование подтвердило эти результаты. Дополнительные оценки показали значительно ослабленные способности к восприятию, предполагая, что визуальные ментальные образы остались нетронутыми в отсутствие здоровых ранних зрительных корковых сетей.Было обнаружено, что пациенты, испытывающие зрительную агнозию (Behrmann et al., 1994; Servos and Goodale, 1995), а также пациенты с врожденной глазной слепотой или пожизненным нарушением зрения, сохраняют способность к визуальным образам, хотя снижение работоспособности различается в зависимости от характера нарушения. в последнем (см. обзор Cattaneo et al., 2008). Недавно выявленное нейропсихологическое расстройство демонстрирует противоположную картину. Афантазия характеризуется неспособностью создавать визуальные ментальные образы, в то время как производительность распознавания перцептивных объектов остается неизменной (Bartolomeo, 2008; Zeman et al., 2015). Это интригующее состояние было зарегистрировано у нескольких здоровых людей, которые сообщили о внезапной потере способности создавать формы, формы и цвета в своем воображении (Bartolomeo, 2008; Moro et al., 2008; Zeman et al., 2010) . Хотя кортикальное поражение (Zeman et al., 2010), врожденное (Zeman et al., 2015) и психогенное (de Vito, Bartolomeo, 2015) происхождение обычно подозревается, в настоящее время это заболевание плохо изучено. Тем не менее, точная двойная диссоциация, предлагаемая этими уникальными клиническими случаями, предполагает, что нейронные корреляты перцептивного распознавания и ментальных образов, по крайней мере, частично различны.Однако выводы, сделанные из этих исследований, ограничены из-за непредсказуемой природы корковых повреждений и их влияния на когнитивные функции, а происхождение и последствия афантазии только начали получать тщательную эмпирическую оценку.
В совокупности существующая литература значительно разнится в отношении нейронной природы репрезентаций объектов в ментальных образах. Отсутствие убедительной поддержки какой-либо одной теории по сравнению с другой способствует агностической позиции в отношении точной природы ментальных репрезентаций и их нейронной основы.Этот обзор включает статьи независимо от того, в каком спектре теорий совпадают их выводы, и воздерживается от суждений о достоверности или точности выводов, основанных исключительно на теоретической перспективе.
Диагностические функции в ментальных образах
Хотя отличительные черты еще не идентифицированы напрямую в мысленных образах, соответствующие исследования подтверждают их существование в этой модальности. Несколько исследований фМРТ успешно предсказали категориальную классификацию воображаемого стимула с помощью вычислительного анализа, такого как классификаторы паттернов (Reddy et al., 2010) и модели воксельного кодирования для настройки на низкоуровневые визуальные функции во время задач просмотра (Naselaris et al., 2015). Принимая во внимание важную роль, которую отличительные черты, как полагают, играют в задачах перцепционной категоризации (Baruch et al., 2014), можно предположить, что высокодиагностические визуальные компоненты являются основными участниками этого типа нейронного декодирования. Однако наиболее информативные места, из которых могут быть приняты решения о декодировании, варьируются в разных исследованиях. Паттерны активации вентрально-височной коры оказались более надежными для декодирования категоризации изображений, чем паттерны в пределах ранних ретинотопных кортикальных областей (Reddy et al., 2010). Другое исследование сообщило о доказательствах того, что низкоуровневые визуальные особенности ментальных образов для запоминающихся сцен закодированы в ранних визуальных областях (Naselaris et al., 2015). Поведенческие данные, такие как время отклика и частота ошибок, показывают, что действительно возможно извлечь частичные особенности низкого уровня, такие как Т-образные соединения, из целостных ментальных представлений с таким же мастерством, как перцепционные оценки, хотя свойства высокого уровня, включая глобальную симметрию, легче оцениваются в обоих условиях (Rouw et al., 1997). В совокупности эти эмпирические результаты добавляют содержание давним теориям, предполагающим, что составляющие единицы доступны в рамках целостных ментальных образов (Kosslyn et al., 1983).
Несмотря на несогласованность нейронных регионов, о которых сообщалось в исследованиях декодирования, способность предсказывать информацию о категориях из записей нейронной активности вообще имеет важное значение для выявления диагностической информации о признаках в ментальных образах:
(1), поскольку диагностические функции облегчают эффективную классификацию категорий восприятия посредством уникального распознавания визуальных признаков, нейронная активность, которая поддерживает классификацию категорий, может быть связана с информацией диагностических признаков, что указывает на то, что визуальная информация на основе компонентов напрямую представлена через нейронные субстраты;
(2), поскольку точные местоположения в потоке нейронной визуальной обработки, в которых представлены отличительные признаки, остаются неясными, можно предположить, что содержимое диагностических признаков может существовать как в областях с высоким, так и с низким уровнем зрения.
Исследование и оценка методов
Поведенческие методы
Анкеты
Несмотря на то, что мысленные образы – это сложная и абстрактная концепция, для которой можно нацеливаться, несколько инструментов анкетирования самоотчетов продемонстрировали успешное и надежное измерение различных аспектов визуальных представлений. Особо следует отметить широко используемый Опросник яркости визуальных ментальных образов (VVIQ; Marks, 1973) и его более поздние версии, Опросник яркости визуальных ментальных образов-2 (VVIQ-2; Marks, 1995) и Яркость визуальных умственных образов. Пересмотренная версия вопросника к изображениям (VVIQ-RV; Marks, 1995; Campos, 2011).В каждом из этих опросов участникам предлагается визуализировать определенные сцены, такие как закат, и сообщать о четкости и детализации сгенерированных изображений с использованием ответов по шкале Лайкерта. Варианты VVIQ различаются тем, требуют ли они от участника визуализации с открытыми или закрытыми глазами. Критическое статистическое тестирование исходного VVIQ и обоих его вариантов указывает на высокую внутреннюю валидность для измерения конструкта мысленных образов (Campos, 2011). Кроме того, Plymouth Sensory Imagery Questionnaire (Psi-Q) – это уникальная оценка, способная обеспечить высоконадежные измерения индивидуальной склонности к восприятию ярких образов в различных модальностях (Andrade et al., 2014). Продемонстрированная внутренняя валидность элементов оценки, которые требуют от участников создания подробных сцен, указывает на то, что люди способны воспринимать множественные и конкретные визуальные компоненты в ментальных представлениях, и что эти компоненты могут быть надежно зафиксированы с помощью простых элементов опроса.
По крайней мере, один инструмент опроса попытался определить конкретную информацию о форме, представленную в визуальных ментальных образах. Шкала ментальных образов (MIS; D’Ercole et al., 2010) был разработан, чтобы использовать взаимосвязь между вербальными описаниями и ментальными образами, чтобы напрямую преобразовать структурные особенности, присутствующие в ментальных репрезентациях, в точные вербальные описания. Как отмечают создатели, такая шкала выгодна для визуальных и коммуникативных областей, таких как архитектура и дидактика искусства. Чтобы проверить MIS, участникам дали словесное описание произведения искусства и попросили ответить на вопросы, связанные с одним из шести факторов, описывающих аспекты ментальных образов и процесс формирования изображения: скорость формирования изображения, стабильность, размеры, уровень детализации. , Расстояние и перспектива (D’Ercole et al., 2010). Результаты исследования показали, что ответы участников подтверждают предложенную шестифакторную модель, предполагающую, что на мысленные образы влияют внутренние пространственные свойства. Что касается изучения диагностических признаков, этот инструмент демонстрирует, что надежная и подробная оценка визуальных ментальных образов достижима только с помощью словесных описаний. Если эту специфичность повысить до уровня независимых дискретных компонентов объекта, возможно, что MIS или аналогичные инструменты смогут нацеливать и идентифицировать дискретные классифицирующие визуальные признаки посредством самоотчета.
Опросник объектно-пространственных изображений (OSIQ; Blajenkova et al., 2006) приближается к уровню специфичности, необходимому для выявления отличительных черт путем оценки предпочтений объектных изображений на уровне индивида. Однако цель OSIQ состоит в том, чтобы выявить индивидуальные тенденции к представлению изображений целостным, подобным картинкам образом или пространственно, посредством компиляции отдельных частей; анкета не включает точную оценку формы. Тесты OSIQ демонстрируют разные уровни предпочтения целостного и частичного представления у разных людей.Эти результаты имеют важное значение для любого исследования, изучающего ментальные образы, потому что индивидуальное предпочтение целостных представлений может привести к увеличению количества ошибок типа II при попытке доступа к визуальной информации на основе частей. По сравнению с OSIQ, не было показано, что VVIQ характеризует эти пространственные предпочтения (Blajenkova et al., 2006), что может быть результатом сосредоточения VVIQ на контекстных визуальных образах сцены, а не на независимых объектах. Тем не менее, в будущих исследованиях было бы разумно учитывать возможность индивидуальных различий в стиле репрезентации при выборе меры анкеты, а также при анализе и интерпретации результатов исследования.
Есть несколько преимуществ и недостатков в использовании анкет для изучения ментальных образов. С одной стороны, опросы позволяют собирать большой объем подробных данных за относительно короткий промежуток времени, гораздо больше, чем физиологические или биологические измерения; Описанные выше анкеты содержат в среднем 32 пункта. Все элементы состоят из простой шкалы Лайкерта, варьирующейся от 5 до 7 ступеней. Кроме того, эти меры практически не требуют технических навыков или критериев приемлемости, что делает инструменты доступными для широкого и представительного населения.Надежность самоотчетных ответов этого типа также подтверждается поведенческими результатами, указывающими на то, что люди, как правило, имеют надежное и точное метапознание своего собственного воображаемого опыта (Pearson et al., 2011). Однако возникает ряд сложностей, когда человека просят устно описать или физически воссоздать визуальный контент. Например, искажения восприятия и отсутствие художественных способностей могут исказить рисунки участников, а словесные описания могут быть неверно истолкованы или неполными.Действительно, исследования рисунков нехудожников показали, что ошибки рисования положительно коррелируют с искажениями восприятия, закодированными во время первоначального наблюдения за изображением (Ostrofsky et al., 2015). Что наиболее важно, сама природа анкет затрудняет изучение конкретных отличительных черт без искусственной систематической ошибки. Более того, даже когда предвзятость сведена к минимуму, ответы, вероятно, будут захватывать только те пространственно дискретные формы, которые поддаются канонической лексической маркировке.
Несмотря на эти недостатки, высокий уровень владения письменными анкетами для доступа к конструкту ментальных образов требует их рассмотрения в качестве отражателей отличительных черт ментальных образов. Чтобы максимально использовать преимущества, предоставляемые их экономичным и портативным форматом, вопросники, оценивающие конкретную структуру формы визуализированных изображений, лучше всего применять к большой группе респондентов. Использование обширной популяции снижает влияние индивидуальных предубеждений и репрезентативных предпочтений на ответы.Любые существенные закономерности, наблюдаемые в ответах и между ответами, затем могут быть идентифицированы и нацелены на дальнейший более глубокий анализ. Между тем, индикаторы индивидуальных предпочтений, такие как Psi-Q и OSIQ, следует рассматривать для использования в качестве ковариат при измерении частичной информации об объекте в мысленных образах, независимо от используемой основной методологии. Даже искажения восприятия, выявленные с помощью рисунков, могут быть полезны для вывода визуальных аспектов, которым уделяется наибольшее внимание во время кодирования, тем самым предлагая особенности большей относительной когнитивной значимости.Если диагностические признаки очень информативны для идентификации данного объекта, шаблоны среди признаков или аспектов формы, о которых сообщает большая и разнообразная группа, обладают потенциалом для идентификации естественных признаков диагностического объекта. Хотя отличительные признаки, зафиксированные с помощью анкет, скорее всего, будут ограничены пространственно дискретными, именуемыми компонентами объекта, эти данные затем могут быть использованы для направления дальнейших эмпирических исследований для оценки качества, надежности и валидности этих компонентов в качестве перцепционных диагностических признаков.
Поведение двигателя
Жестовые двигательные движения также исследовались как индикатор содержания репрезентации ментального объекта. Следуя установленной связи между функциональными двигательными действиями и использованием инструментов, в одном из таких исследований было изучено, может ли человек приобретать функциональные репрезентации объектов, просто представляя использование новых объектов и визуализируя соответствующие соответствующие жесты рук (Paulus et al., 2012). Участникам были показаны изображения четырех искусственно созданных объектов с уникальными функциональными концами, которые требовали особых захватов для рук, чтобы их можно было поднести к уху или носу.Перед обучением участников проинструктировали о правильном действии, связанном с каждым объектом, и попросили представить заметный эффект, возникающий в результате этого действия (например, почувствовать запах или услышать звук). Каждый участник был обучен двум из четырех новых объектов в течение трех обучающих блоков, перемежающихся между тремя чередующимися тестовыми блоками. Обучающие блоки состояли из изображения стимула, отображаемого на экране, с последующим представлением фотографии, на которой актер изобразил объект в его правильном месте финального действия.Представления объектов оценивались в последующих тестовых испытаниях, во время которых участников просили указать нажатием кнопки, соответствует ли объект, показанный в демонстрации действия, изображению объекта, которое было отображено непосредственно перед этим. Результаты исследования выявили более медленное время реакции на изображения, на которых обучаемый объект был изображен в неправильном конечном месте, а не в правильном. Однако это время отклика не зависело от того, удерживался ли объект в демонстрации действия правильным или неправильным захватом (Paulus et al., 2012). Чувствительность к конечному местоположению, связанному с действием, предлагаемая шаблонами времени отклика, указывает на то, что участники успешно получили представления объектов, которые включали информацию о типичном местоположении конечной цели. Авторы исследования предполагают, что надлежащий захват не был так сильно закодирован в репрезентациях объекта, как двигательное действие, из-за того, что участникам было дано указание только визуализировать заметный эффект, возникающий в результате манипуляции захватом, и они никогда не получали физического, конкретного опыта в этом аспекте.Однако исследователи отмечают, что этот эффект также может быть связан с новизной объектов, включенных в их исследование, и предсказывают, что захват может быть более актуальным и раскрывать представления объектов, когда они связаны со стимулами, с которыми участники имели предыдущий опыт.
Результаты исследования, проведенного Paulus et al. (2012) служат, чтобы проиллюстрировать важность цели объекта как ключевой особенности функциональных представлений объекта. Поскольку двигательное планирование требует понимания объекта, с которым нужно взаимодействовать, которое в некоторых случаях полностью определяется уникальной функциональной целью, весьма вероятно, что двигательные образы связаны с типом визуальных мысленных образов, выполняемых во время распознавания объекта.Взаимодействие между зрительным познанием и эффективным двигательным планированием наблюдалось как у взрослых (Janczyk and Kunde, 2012), так и у младенцев (Barrett et al., 2008). Хотя моторное планирование считается аналитическим по сравнению с восприятием объекта, которое, как утверждается, обычно основывается на комбинированных характеристиках (Janczyk and Kunde, 2012), это может способствовать развитию моторного планирования как более доступного пути, с помощью которого можно идентифицировать индивидуальные особенности, важные для визуального восприятия. управляемое поведение. Paulus et al. (2012) исследование добавляет дополнительную поддержку относительной диагностике (в данном случае диагностике для классификации соответствующего захвата или движения) конкретных характеристик объекта по сравнению с другими, а также предлагает потенциальный путь для идентификации целостных компонентов объекта через связанные двигательные поведения.Предыдущие исследования показывают, что конечные цели объектов, скорее всего, несут категориальную информацию, относящуюся к их использованию и средствам или поведению действий, с помощью которых это использование эффективно достигается (например, Creem and Proffitt, 2001). Многочисленные исследования моторных образов, исследуемых с помощью технологии ближнего инфракрасного диапазона, дополнительно проливают свет на эти открытия; они обсуждаются в разделе «Нейронная активность».
Неявная связь между жестами и когнитивным пониманием объектов имеет интригующий потенциал для изучения отличительных черт, но также имеет значительные недостатки.Подобно анкетам, задачи на двигательное поведение представляют собой неинвазивный и недорогой метод оценки различных частей объекта, которые определяют естественное интерактивное поведение. Однако такое тестирование занимает значительно больше времени, чем проведение опроса, а полученные данные требуют сложной оценки и тщательной интерпретации. Чтобы избежать смешения новизны и неопытности, исследования моторного поведения в отношении отличительных черт лучше всего применять к экологически значимым объектам, с которыми участники ранее имели физические взаимодействия.Категориальная классификация, подразумеваемая определенными жестами, может позволить эффективное декодирование объекта, основанное только на наблюдении (Rosenbaum et al., 1992). Однако этот тип жестовых отношений строго ограничен объектами, которыми можно манипулировать, и, более того, объектами, которыми можно манипулировать, которые связаны с четко узнаваемым стереотипным жестом. Тем не менее, неявная оценка характеристик или категорий объекта посредством функциональных двигательных движений может пролить свет на пространственное расположение и качества характеристик, которые обычно используются в двигательных движениях.Исходя из установленной функциональной связи между двигательными действиями, такими как захват, и конечным местоположением объекта (Rosenbaum et al., 1992), двигательное поведение, следовательно, может указывать на важные структурные особенности инструментов и других объектов, которыми можно манипулировать. Этот метод можно комбинировать с данными, собранными с помощью других методов, используемых для оценки диагностических характеристик объекта, таких как анкеты или нейрофизиологические измерения, чтобы сформировать более полное понимание ментального представления объекта и его когнитивно информативных отличительных черт.
Отслеживание глаз
Движения глаз, связанные с воображаемыми визуальными задачами, аналогичны тем, которые наблюдаются во время перцептивных задач. Спонтанные движения глаз во время визуализации сцены отражают паттерны направленности, сравнимые с теми, которые связаны с перцепционным наблюдением (Laeng and Teodorescu, 2002). Участники сообщают, что испытывают повышенные трудности в создании визуальных мысленных образов, когда им приказывают ограничить движения глаз при этом. При визуализации в условиях этого ограничения описания воображаемой сцены участниками становятся менее подробными и ограничиваются элементарными элементами (Laeng and Teodorescu, 2002).Повышенная сложность, с которой создаются подробные визуальные ментальные образы при ограничении движений глаз, означает автоматическую, возможно, взаимозависимую связь между движениями глаз и обработкой визуальных воображаемых сцен.
Предсказание связи между содержанием мысленных образов и сопутствующими глазодвигательными движениями ни в коем случае не ново, и оно получило эмпирическую поддержку, датированную несколькими десятилетиями (Brandt and Stark, 1997; Spivey and Geng, 2001; Laeng and Teodorescu, 2002). ; Йоханссон и др., 2006; Хольм и Мянтюля, 2007; Райан и др., 2007; Ханнула и Ранганат, 2009; Уильямс и Вудман, 2010; Йоханссон и Йоханссон, 2014; Martarelli et al., 2016). При прямом сравнении между визуальным осмотром и мысленной визуализацией повторяющиеся последовательности фиксации на схематических стимулах в виде шахматной доски были записаны и проанализированы по отношению к путям сканирования, наблюдаемым во время мысленных образов одних и тех же стимулов (Brandt and Stark, 1997). Сначала участников ознакомили со стимулом в виде шахматной доски в течение 20 секунд, а затем предложили визуализировать узор на пустой сетке в течение 10 секунд, после чего последовал второй период просмотра в течение 10 секунд.Протокол был повторен трижды; стимулы поворачивались на 90 ° в каждом последующем испытании, а движения глаз регистрировались с помощью устройства для видеонаблюдения за глазами. Анализ редактирования строки наблюдаемых путей сканирования в двух условиях выявил высокую степень сходства саккадических паттернов, предполагая, что движения глаз могут играть роль в организации визуального содержания ментального представления в отсутствие физических стимулов. Хотя указание размера сетки и местоположения оставалось относительно постоянным, пути сканирования, наблюдаемые во время испытаний изображений, оказались примерно на 20% меньше, чем наблюдаемые во время пробных просмотров, что указывает на аналогичную, но не идентичную взаимосвязь между саккадами и представлениями, которые они отражают (Brandt and Stark, 1997), возможно, из-за несоответствия между изображениями и их физическими аналогами.Тем не менее, параллели, наблюдаемые в глазодвигательных паттернах в этом эксперименте, убедительно подтверждают использование поведения движения глаз в качестве показателя характеристик объекта.
Хотя точная природа взаимосвязи между саккадами и восприятием объекта все еще обсуждается, есть некоторые свидетельства того, что саккады индексируют внимание к определенным характеристикам объекта во время визуального поиска. Данные отслеживания взгляда предполагают, что на саккадические паттерны влияет информация о периферийных объектах, полученная во время визуального поиска, что отражает внимание к конкретным визуальным особенностям на основе доступной информации об объектах (Herwig and Schneider, 2014).Ранние фиксации также выполняются объектами, которые сохраняют неизменные низкоуровневые визуальные свойства, но изменяются, чтобы проявлять присущие объекту аномалии, такие как неестественное вращение или распределение цвета, что подразумевает влияние анализа периферийных объектов на саккадическое движение глаз (Becker et al., 2007). Эти данные подтверждают возможность того, что саккады индексируют релевантные объектно-специфические особенности, основанные на досаккадической обработке изображения наблюдателем.
Есть несколько ограничений, которые необходимо учитывать при применении отслеживания движения глаз для изучения обнаружения особенностей объекта как в задачах восприятия, так и в задачах воображения.Первым из них является потенциальное смешение скрытого внимания, во время которого наблюдатель распределяет увеличенные ресурсы когнитивного внимания на определенное место в поле зрения, не совершая саккадических движений глаз (Mccarley et al., 2002). Способность манипулировать вниманием при отсутствии изменений в физическом поведении дополнительно снижает надежность движений глаз как прямого и надежного индикатора активной когнитивной обработки. Исследования, демонстрирующие плохую работу памяти, несмотря на точные саккады для расположения ранее отображаемых стимулов, предполагают, что свойства объекта не обязательно кодируются в сочетании с пространственным расположением (Richardson and Spivey, 2000; Johansson and Johansson, 2014).Точно так же тесты, включающие манипуляции движениями глаз во время мысленных образов, показали более сильное неблагоприятное воздействие на пространственные аспекты умственных образов, чем на визуальные детали (de Vito et al., 2014). Этим проблемам способствуют отсутствие пространственной чувствительности и точности как в оборудовании для отслеживания движения глаз, так и в фовеа человека.
Тем не менее, взаимосвязь между глазодвигательными движениями и пространственным расположением может быть использована в интересах исследования особенностей объекта. Если бы отдельные особенности объекта были приравнены к независимым, отличным пространственным местоположениям, подобно дизайну, используемому Брандтом и Старком (1997), эта связь могла бы предоставить возможность индексировать внимание отдельных особенностей посредством отслеживания взгляда.Приравнивая дискретные зрительные компоненты к уникальным местоположениям за пределами фовеального поля зрения, участники с большей вероятностью будут выполнять глазодвигательные движения, чтобы зафиксировать отдельные зрительные особенности, тем самым увеличивая пространственное разрешение, с которым могут быть идентифицированы конкретные отличительные особенности. Порядок, частота или продолжительность фиксации на определенных единицах могут указывать на особенность, которая более заметна, чем другие, и затем могут быть проверены на эффективность при категоризации для определения диагностичности.Этот тип исследования можно применить к поиску визуальных объектов и впоследствии сравнить с аналогичным условием мысленных образов. Перед попыткой такого эксперимента со стимулами реальных объектов необходимо решить несколько проблем, включая решение о подходящем размере, при котором части объекта должны быть очерчены, таким образом управляя объемом общей информации об объекте, которую содержит каждая единица. Кроме того, изменение размера объекта может изменить восприятие объекта Sterzer and Rees (2006), а изменение пространственной конфигурации изображения может иметь пагубные последствия для его целостных свойств, тем самым влияя на способ его обработки (например, .г., Martelli et al., 2005). Поскольку цель исследования распознавания объектов – получить доступ к естественному восприятию стимулов и определить свойства, которые способствуют этому восприятию, важно минимизировать количество систематической ошибки, вносимой экспериментальными манипуляциями. Эти проблемы должны быть тщательно рассмотрены, чтобы сделать уверенные выводы из ассоциации между характеристиками объекта и пространственным расположением, но преимущества для понимания внимания к классификационным визуальным компонентам могут быть существенными.
Нейронная активность
Функциональная магнитно-резонансная томография
Большое количество исследований нейровизуализации предполагает, что информация об отличительных объектах представлена на нейронном уровне и, следовательно, может быть обнаружена записывающим оборудованием мозга. Данные, собранные с помощью фМРТ, использовались для успешного декодирования как идентичности объекта, так и классификации категорий не только визуально воспринимаемых стимулов, но и мысленно генерируемых изображений (Thirion et al., 2006; Reddy et al., 2010). С точки зрения восприятия низкоуровневые визуальные особенности, столь же точные, как ориентация краев, были декодированы на основе нейронной активности и использованы для надежной классификации того, какая из небольшого набора ориентаций стимула просматривалась участником (Kamitani and Tong, 2005). Исследование, включающее мысленные образы 60 штриховых рисунков объектов, каждый из которых относится к одной из 12 категорий, показало, что каждая категория была отмечена аналогичным распределением активированных вокселов, которое оставалось стабильным по категориям и субъектам, особенно в височной, затылочной и веретенообразной извилине кортикального слоя. регионах (Behroozi, Daliri, 2014).Последовательность активации вокселей, наблюдаемая у разных людей, предполагает, что записанные нейронные реакции были вызваны каким-то внутренним свойством или особенностями самого стимула, которые указывают на его принадлежность к определенной категории, тем самым снижая вероятность того, что индивидуальные различия или факторы смещения повлияли на паттерн нервной системы. отклик. В других исследованиях были обнаружены аналогичные отличные результаты в отсутствие визуальной стимуляции, такие как диссоциация воображаемого лица и стимулов места на основе соответствующих специфичных для стимулов корковых областей (O’Craven and Kanwisher, 2000), классификация категорий воображаемых объектов, отраженная в вентральная височная кора (Reddy et al., 2010), воссоздание простых стимулов в виде шахматной доски на основе активации, обнаруженной в ранних ретинотопных областях (Thirion et al., 2006), и даже декодирования категории и идентичности содержания сновидений (Horikawa et al., 2013). По крайней мере, некоторые исследования мысленных образов, включающих воображение простых стимулов, достигли ограниченного успеха в этой области благодаря использованию MVPA (Reddy et al., 2010; Albers et al., 2013; Behroozi and Daliri, 2014). Эти результаты предполагают, что информация, относящаяся к категории и идентичности воображаемых стимулов, отражается в нейронной активности аналогично тому, как это происходит во время просмотра, и которая доступна с помощью существующих технологий, хотя дифференцировать ее может быть сложнее, чем при перцептивной активности.
Впечатляющая точность и гибкость, с которой данные фМРТ, как было показано, фиксируют информацию о конкретных характеристиках, подтверждают возможность того, что различимые компоненты объекта отражаются в нейронной активности, связанной с ментальными образами, тем самым обеспечивая прямые средства доступа к диагностическим характеристикам через ментальные представления. Если отличительных черт действительно достаточно для классификации категорий, как предполагает теория, они могут вносить значительный вклад в нейронные паттерны, наблюдаемые в исследованиях, подобных тем, которые описаны выше.Чтобы проверить это, категориальные стимулы, которые, как обнаружено, вызывают аналогичные паттерны нейронной активации, могут быть систематически сегментированы на набор визуальных составляющих частей (аналогично Ullman et al., 2016). Затем эти части могут быть представлены индивидуально во время фМРТ, чтобы определить, какие из естественных единиц, если таковые имеются, способны вызывать нейронную реакцию, аналогичную той, которая связана с исходным, неповрежденным объектом. Хотя этот метод сегментации исключает случаи, в которых целостная информация служит диагностическим признаком, до тех пор, пока перцепционные сравнения ограничиваются групповым уровнем, а не индивидуальным уровнем, отличительные визуальные признаки, полезные для распознавания в этом типе задач, должны быть общими. через несколько экземпляров.Это связано с тем, что глобальная информация включает конкретную конфигурацию нескольких функций и поэтому менее полезна для эффективной категоризации нескольких объектов, некоторые из которых могут не разделять все характеристики, содержащиеся в целостном представлении.
Электроэнцефалография
В дополнение к фМРТ, электроэнцефалография (ЭЭГ) использовалась для изучения ментальных репрезентаций, выраженных через электрическую нейронную активность (например, Shourie et al., 2014). Исследования в области ментальных образов, связанных с объектами, с использованием ЭЭГ сравнительно немногочисленны, но проделанная работа успешно использовалась для декодирования образов движения с целью управления интерфейсом мозг-компьютер (например,г., Townsend et al., 2004; см. обзор Choi, 2013), предполагая, что ЭЭГ способна различать общие категории воображаемых действий. В заметном и значительном отклонении от общей тенденции сосредоточиться на целостной информации в мысленных образах, в одном исследовании была предпринята попытка изучить роль частичной информации об объекте через изменения, наблюдаемые в спектре ЭЭГ (Li et al., 2010). Участникам были показаны серые линейные рисунки 60 общих объектов, содержащих то, что исследователи определили как отдельные, именуемые, пространственно дискретные особенности.Во время экспериментальной задачи были собраны данные ЭЭГ, в то время как участникам предъявляли стимул рисования линий в течение 500 мс. После паузы в 4000 мс участников просили сгенерировать мысленное изображение ранее просмотренного рисунка линии в соответствии с отображаемой репликой слова целостного или частичного изображения. Эти лексические подсказки ссылаются либо на каноническое имя всего объекта, либо на имя одной из его семантически значимых частей (например, слово «лампа» указывает на состояние целостного образа, тогда как «абажур» указывает на образ только для определенной области объекта. стимул; Ли и др., 2010). Нажатие кнопки в поле ответа указывает начальную точку времени для каждого воображаемого эпизода. Результаты исследования показали, что наибольшие различия между перцептивными и воображаемыми задачами существуют в пределах спектров тета- и альфа-диапазона. Хотя оба состояния вызвали ответы, значительно превышающие пороговые значения, частичные изображения показали более раннее «время всплеска» и более низкую альфа-мощность, чем целостное состояние, а различия когерентности наблюдались в лобных и центрально-височных областях электродов (Li et al., 2010). Авторы предполагают, что раннее начало времени, связанное с состоянием частичного изображения, указывает на то, что частичная визуальная информация проявляется независимо от генерации целостного изображения, и что более сильная тета-сила в этом состоянии отражает более сложную обработку, необходимую для получения деталей объекта. Однако одновременное снижение энергии альфа-диапазона в задаче частичного изображения предлагается отражать «творческий или модифицирующий процесс», который не требуется для простого восстановления в памяти целостных изображений (Li et al., 2010). Эти результаты предполагают, что, несмотря на очевидную независимость от целостной информации, формирование частичных образов, по-видимому, включает сложные взаимодействия с соответствующим целостным контекстом. Это может иметь важные последствия для понимания взаимосвязи между отдельными диагностическими функциями и всем представлением, с которым они связаны. Подобно Ullman et al. (2016), эти результаты также предполагают, что отличительные особенности могут быть встроены в более крупную конфигурацию, или диагностическая функция может фактически включать набор отдельных функций.Это важное соображение при попытке идентифицировать минимально диагностические области, но исследование Li et al. (2010) предполагает, что ЭЭГ может быть чувствительной к этому процессу.
Подход с использованием словесных подсказок, используемый для манипулирования экспериментальным условием мысленных образов в Li et al. (2010) еще предстоит пройти валидацию как надежный метод для создания целостных и частичных изображений, и он является основной проблемой при интерпретации результатов исследования. Использование словесных подсказок, основанных на именованных частях объекта, вызывает искусственное разделение изображения на пространственно дискретные особенности, определяемые узнаваемыми, но произвольными структурными особенностями, интерактивные отношения между ними и общим целостным представлением неясны.Однако есть свидетельства того, что вербальные реплики способны вызывать мысленные образы с некоторой степенью точности, как демонстрируют инструменты письменного опроса, такие как MIS (D’Ercole et al., 2010), и что категория мысленного образа может быть различимым в данных ЭЭГ (Симанова и др., 2010). Кроме того, вычислительная модель, используемая для декодирования активности человеческого мозга для прогнозирования активации фМРТ, связанной со значением существительных (Mitchell et al., 2008), показывает, что словесные сигналы могут изменять нервную и, соответственно, когнитивную активность.Следовательно, хотя манипуляции с частью объекта, примененные в Li et al. (2010) требует тщательного изучения, открытие исследования, согласно которому паттерны в спектре активности ЭЭГ были способны различать некоторый уровень вариации ментальных представлений, по-прежнему заслуживает рассмотрения при исследовании частичных особенностей ментальных образов.
Функциональная спектроскопия в ближнем инфракрасном диапазоне
Функциональная ближняя инфракрасная спектроскопия (fNIRS) – относительно новая технология, которая быстро набирает популярность благодаря своей портативности и гибкости экспериментального применения.Эта система сочетает в себе пространственную чувствительность фМРТ с удобством и временным разрешением ЭЭГ за счет неинвазивного измерения скорости диффузии ближнего инфракрасного света, когда он проецируется через череп. На записи, полученные с помощью fNIRS, влияет относительная концентрация оксигенированного и деоксигенированного гемоглобина в корковом кровотоке, и поэтому они концептуализируются как косвенное измерение нервной активности (Kamran and Hong, 2013). Эту сравнительно недавнюю методологию еще предстоит напрямую применить к задачам, связанным с генерацией визуальных мысленных образов.Тем не менее, исследования восприятия младенцев, а также значительная база литературы по декодированию моторных образов демонстрируют неоднозначные доказательства гемодинамических реакций, записанных с помощью fNIRS, как показателя личных психических и зрительных процессов.
В исследовании обработки изображений у младенцев использовалась fNIRS для исследования нейронных коррелятов, лежащих в основе индивидуализации объекта (Wilcox et al., 2005). Используя вариант задания с узким экраном (Wilcox and Baillargeon, 1998), младенцев знакомили с двумя совершенно разными объектами, мячом и коробкой, которые последовательно появлялись с противоположных сторон узкого или широкого экрана.Время поведенческой реакции показало, что младенцы дольше смотрели в условиях узкого экрана, предполагая, что младенцы были способны различать стимулы как два отдельных объекта, которые не могли логически поместиться за экраном одновременно по одной и той же оси. Вариации гемодинамического ответа, измеренные с помощью NIRS во время узких скрининговых испытаний, были локализованы в первичной зрительной и нижней височной коре, что указывает на то, что индивидуализация объекта связана с уникальными, обнаруживаемыми паттернами нейронной активности в этих областях (Wilcox et al., 2005). Хотя исследователи признают, что еще предстоит проделать большую работу, прежде чем связь между вариациями оксигенированного и деоксигенированного гемоглобина и когнитивных функций будет хорошо изучена (но см. Chen et al., 2015), их исследование действительно поддерживает fNIRS как жизнеспособное средство индексации частных визуальные явления, связанные с процессами распознавания объектов. Кроме того, способность fNIRS различать нейронную активность, на которую влияют вариации в различных локальных особенностях, дает надежду на обнаружение отличительных признаков при распознавании объектов.
Некоторые проблемы остаются при рассмотрении fNIRS как меры ментальных образов. С одной стороны, относительно устоявшаяся работа по исследованию образов движения может содержать ключи для руководства будущим применением этой технологии к репрезентациям объектов. Большая часть этой литературы посвящена декодированию образов движения для применения в технологии интерфейса мозг-компьютер (см. Обзор Naseer and Hong, 2015). Соответственно, измерения NIRS часто регистрируются из областей моторной коры, которые, как правило, легко проникают в ближнюю инфракрасную область.Хотя эксперименты, которые применяют fNIRS к декодированию образов движения, не пытаются напрямую получить доступ к визуальным мысленным образам, их результаты демонстрируют потенциал данных fNIRS для облегчения надежного декодирования частных внутренних событий. Это может указывать на то, что те же методы могут быть применены к ментальным образам зрительного объекта, пока могут быть достигнуты соответствующие корковые поверхности (будет обсуждаться позже в этом разделе). Если к нейронным субстратам ментальных образов действительно можно получить доступ, высокое временное и пространственное разрешение, обеспечиваемое технологией fNIRS, может стать полезным средством для поиска диагностических функций, представленных в ментальных образах.К сожалению, скептицизм в отношении точности и полезности записей fNIRS, даже в отношении изображений движения, остается (например, Waldert et al., 2012), что не позволяет с уверенностью рекомендовать применение технологии fNIRS в ее текущем состоянии для декодирования изображений объектов.
Сводка показателей нейронной активности
Исследование ментальных образов посредством мозговой активности явно выгодно, поскольку эти методы не требуют, чтобы люди открыто сообщали о своих личных ментальных переживаниях.Несмотря на продемонстрированный успех нейрофизиологических методов записи в доступе к мысленным образам, все же существует ряд ограничений, которые необходимо учитывать при изучении их значения для идентификации отличительных черт в репрезентациях объектов. Например, подобно набору стимулов, используемому Бехрузи и Далири (2014), успешное декодирование информации о категории или идентичности в фМРТ часто зависит от набора изображений, из которых можно декодировать ответы, за некоторыми исключениями (например,г., Тирион и др., 2006). Это требование ограничивает гибкость, с которой методы нейронной визуализации могут индексировать создание естественных образов в реальных сценариях, которые содержат несколько переменных и огромный набор возможностей для визуальных стимулов. Однако следует отметить, что некоторым исследованиям удалось раздвинуть границы этого набора до впечатляющих пределов и по-прежнему сообщать об успехе в декодировании компонентов ментальных образов (например, Miyawaki et al., 2008; Horikawa et al., 2013). В дополнение к фМРТ, динамика ЭЭГ, вероятно, способна улавливать эффекты, вызванные обработкой пространственно определенных компонентов объекта (Li et al., 2010). Однако, как упоминалось выше, манипулирование пространственным разрешением определенных признаков с помощью словесных сигналов создает несколько проблем, и пока что ЭЭГ продемонстрировала успех в основном на уровне общей или вышестоящей классификации. Проблема избежания искусственных предубеждений, вызванных произвольным выделением структурных особенностей, распространяется на любую перцептивную оценку ментальных образов. Требуются тщательные и творческие экспериментальные разработки, чтобы разработать метод, позволяющий получить доступ к дискретным диагностическим визуальным признакам в том виде, в каком они возникают естественным образом и на уровне, доступном для ЭЭГ.
Хотя результаты исследований fNIRS показывают ограниченную способность классифицировать двигательные образы и процессы зрительного восприятия, есть несколько проблем, которые влияют на эту область исследований применительно к обнаружению признаков в ментальных образах объектов. Во-первых, характер проникновения инфракрасного света, используемого fNIRS, ограничивает запись областями коры, лежащими близко под черепом, примерно на 2–3 см ниже кортикальной поверхности (Wilcox et al., 2005). К счастью, есть свидетельства того, что корковые области обработки изображений доступны через ближний инфракрасный диапазон.В дополнение к записям, полученным от первичной и вентральной зрительной коры у младенцев (Meek et al., 1998; Wilcox et al., 2005), было показано, что fNIRS успешно индексирует гемодинамические изменения в зрительной коре взрослого человека во время задач восприятия (Takahashi et al. ., 2000). Кроме того, записи fNIRS, собранные в первичной зрительной коре головного мозга взрослых, и дополнительные нейрофизиологические измерения показывают, что fNIRS способна выявлять закономерности селективности стимула, а также специфичности области (Chen et al., 2015). Эти исследования показывают потенциал для применения методологий fNIRS и гибридных fNIRS для визуального представления функций в ментальных образах взрослых. Однако, учитывая многочисленные находки, которые указывают на то, что области за пределами ранней зрительной коры головного мозга вносят значительный вклад в визуальные ментальные образы (см. Vetter et al., 2014), остаются сомнения относительно того, можно ли использовать fNIRS для надежного и тщательного исследования нейронные корреляты дискретных черт в ментальных представлениях.
Дополнительным преимуществом методов нейровизуализации является то, что их данные поддаются широкому спектру статистического анализа, который позволяет интерпретировать сложные паттерны активации для выявления корреляций между визуальной и семантической информацией. Многие из этих методов, включая MVPA и поддержку векторного машинного обучения, позволяют учитывать несколько факторов при сопоставлении активности мозга с информацией о категориях (см. De Martino et al., 2008; Kriegeskorte, 2011; Chen et al., 2014; Haxby et al. ., 2014 для обзоров). Другие статистические методы, такие как наивное байесовское моделирование, дали надежные прогнозы классификации семантических категорий для изображений и слов (Behroozi and Daliri, 2014). Разнообразие статистических методов, которые могут быть применены к данным нейровизуализации, увеличивает их потенциал для вывода выводов между нейронной активностью и процессами распознавания семантических объектов, что в конечном итоге может позволить делать конкретные прогнозы в отношении информации о характеристиках объекта в ментальных образах.
В целом, фМРТ нейронные записи перцепционной и ментальной визуальной обработки обладают большим потенциалом для индексации отличительных черт в репрезентациях объектов, тогда как ЭЭГ и fNIRS кажутся более слабыми методами. Чувствительность к содержанию объекта, продемонстрированная данными фМРТ, ясно указывает на их полезность для доступа к дискретным визуальным элементам, необходимым для различения различных категорий объектов. Результаты ЭЭГ отражают эффекты частичных образов в динамике мозговых волн, но текущая работа ограничивается общими и разрозненными эффектами в целостном и полномасштабном исследованиях.неголистические эффекты. Кроме того, есть основания полагать, что технология fNIRS может быть способна записывать мысленные образы, выраженные в первичных зрительных корковых областях взрослых. Однако еще предстоит проделать большую работу, прежде чем fNIRS можно будет уверенно применять к воображаемым представлениям в области моторных или объектных изображений. Учитывая, что fNIRS и EEG очень совместимы и повышают точность при совместном использовании для исследования процессов восприятия (например, Putze et al., 2014), сочетание пространственной чувствительности и широкого диапазона fMRI с временным разрешением EEG или fNIRS может улучшить слабые стороны каждого из них улучшают их успех в доступе к диагностическим функциям, преобладающим во время визуальных образов.
Выводы и выводы
Цель этого обзора двоякая: предположить, что ментальные образы являются выгодным и действенным методом оценки характеристик диагностических объектов, и продемонстрировать, что, несмотря на отсутствие в настоящее время прямых исследований диагностических признаков в ментальных образах, свидетельства их отношения и инструменты, наиболее подходящие для их изучения, предлагаются существующей литературой. Каждый метод измерения имеет свои уникальные преимущества и недостатки для изучения роли диагностических визуальных компонентов в обработке объектов (см. Таблицу 1).Раннее, недостаточно развитое состояние этой области способствует систематическому методологическому подходу, способному фиксировать широкий спектр информации. Для достижения этого подходы к измерению должны сочетаться с целью извлечения выгоды из методологических сильных сторон и компенсации недостатков с упором на сбор больших и разнообразных объемов данных. Здесь обобщены общие значения и полезность каждого метода для изучения отличительных черт в визуальных образах, а также сделаны предложения для будущих направлений.
ТАБЛИЦА 1. Методологические плюсы и минусы для доступа к содержанию ментальных образов объектов.
Инструменты письменного опроса, такие как опросник яркости визуальных ментальных образов, MIS (Marks, 1973, 1995) и опросник объектно-пространственных образов (Blajenkova et al., 2006), полезны для сбора большого количества подробных и умеренно надежных самоанализа. данные отчета. Фундаментальные методологические проблемы, связанные с просьбой воссоздать или выразить словами свой внутренний опыт, ограничивают возможности применения этого инструмента в качестве прямой индивидуальной оценки диагностических признаков.Объединение ответов в большой группе дает лучшую возможность выявить значимые тенденции, касающиеся природы классификационных характеристик объекта. Кроме того, простота использования и быстрое администрирование инструментов самооценки облегчает их сочетание с другими формами измерения. Рассмотрение ответов на анкету вместе с нейрофизиологическими данными, собранными с помощью таких методов, как отслеживание глаз, ЭЭГ и фМРТ, дает несколько преимуществ:
(1) способствует быстрому росту относительно неразвитой области семантически обозначенных визуальных признаков;
(2) позволяет идентифицировать важные индивидуальные различия в стиле создания изображений и учитывать их при интерпретации дополнительных косвенных измерений;
(3) он дает представление о когнитивных процессах, обнаруживаемых самоотчетом, что может обеспечивать информативные, конкретные связи между семантической классификацией и биологической активностью, тем самым дополняя интерпретации, полученные из физиологических или неврологических записей.
Исследования двигательного поведения подразумевают значительную взаимосвязь между целенаправленными действиями и ментальными представлениями, которая опосредована функциональной стороной манипулируемых объектов. Однако при освоении без физической практики эти отношения, по-видимому, ограничиваются крупномасштабным целенаправленным поведением, которое, как ожидается, приведет к соответствующим последствиям. Поскольку точное двигательное поведение, такое как захват, не было показано, чтобы иметь прямую корреляцию с полученными образами мысленными представлениями, этот подход может подходить только для предметов, которые связаны с очевидными и уникальными целенаправленными движениями, таких как инструменты.Тем не менее наблюдаемая корреляция между пространственно дискретными структурными компонентами объекта и двигательным поведением поддерживает вероятность того, что в ментальных репрезентациях существуют различные черты, и что когнитивно значимые черты могут косвенно выражаться через физические действия.
Результаты отслеживания взгляда показывают, что саккады похожи между состояниями восприятия и мысленных образов и, таким образом, отражают значимые когнитивные процессы. Хотя саккадические движения глаз в любом состоянии могут вовлекать внимание к пространственному расположению в большей степени, чем к индивидуальным особенностям, эта взаимосвязь может быть использована для исследования диагностических признаков.Если бы характеристики объекта были надежно отождествлены с отдельными пространственными местоположениями таким образом, чтобы искусственно не изменять целостное представление объекта, саккадические движения глаз могли бы позволить более прямой указатель внимания на характерные особенности объекта, а не на пространственное положение, которое затем может быть протестированным на классификационную полезность. Кроме того, такой метод может предотвратить возможные затруднения скрытого внимания, требуя явных движений глаз, чтобы зафиксировать отдельные особенности. Этот подход может быть применен к задачам распознавания перцептивных объектов, результаты которых могут служить ориентиром и сравниваться с аналогичными исследованиями ментальных образов.Прямая оценка диагностических характеристик в условиях восприятия и образов, таких как это, может привести к более глубокому пониманию более широких взаимодействий между характеристиками объекта, обработкой восприятия и ментальными образами.
Записи нейронной активности, полученные с помощью фМРТ, составляют наиболее широко используемую область исследований внутренних зрительных образов. Этот метод обеспечивает прямой указатель содержания мысленных образов, избегая при этом сложностей, связанных с вербальным или визуальным переводом личных мысленных переживаний.Классификация категорий, достигнутая с помощью зависимых от уровня кислорода в крови колебаний, измеренных с помощью фМРТ, в значительной степени подразумевает наличие диагностической информации о признаках в мысленных образах, а также их выражение посредством нейронной активности. Были идентифицированы отчетливые паттерны активности, связанные с определенными категориями воображаемых объектов, и было обнаружено, что они остаются стабильными у разных людей. В целом, методы фМРТ демонстрируют заметные перспективы в улучшении понимания роли диагностических характеристик объекта в репрезентации объектов через лежащие в основе нейронные механизмы ментальных образов.Предварительные результаты исследований ЭЭГ также предполагают, что целостные и неголистические изображения частичных компонентов объекта могут отражаться в динамике мозговых волн, но информация о конкретных характеристиках еще не идентифицирована, что позволяет предположить, что ее лучше всего сочетать с такими методами, как фМРТ. Детальный уровень специфичности, достигаемый с помощью фМРТ, ограничен отсутствием временного разрешения, тогда как ЭЭГ ограничивается пространственным разрешением.
Работа с восприятием, проведенная с помощью fNIRS, дает неубедительные доказательства того, что гемодинамические реакции являются надежным индикатором активности, связанной с изображениями.Хотя исследования восприятия с использованием fNIRS все еще находятся на начальной стадии, исследования индивидуализации объектов и двигательных образов предполагают потенциал для будущего применения fNIRS к событиям мысленных образов. К сожалению, ближняя инфракрасная область в настоящее время ограничена мелкими областями коры головного мозга, участвующими в визуальной обработке, и надежность гемодинамического ответа для нейронного декодирования еще предстоит подтвердить. Чтобы учесть широко распространенные и разнообразные нейронные корреляты формирования мысленных образов, fNIRS следует комбинировать с более широкими измерительными инструментами, такими как ЭЭГ или фМРТ, чтобы способствовать эффективному индексированию визуализируемых характеристик объекта.
Методы и результаты, рассмотренные в этой статье, призваны подтвердить осуществимость и ценность исследования перцептивных диагностических функций с помощью визуальных ментальных репрезентаций. Внутренний визуальный опыт, возникающий в отсутствие перцептивного ввода, потенциально может быть уникально информативным для понимания того, каким образом визуальная информация преобразуется и транслируется для создания семантически значимых представлений объектов. Воспользовавшись естественными процессами фильтрации информации, налагаемыми физическими и когнитивными ограничениями визуальных и нейронных систем человека, можно получить доступ к большому количеству семантической информации через сжатый, концентрированный источник в виде отличительных признаков.Ментальные образы предлагают значительные преимущества по сравнению с прямыми перцептивными оценками, поскольку во время естественного восприятия потенциальный объем идентифицирующей информации об объекте намного больше, чем когда объект вызывается только с помощью образов, отчасти потому, что нерелевантная информация была отброшена – или, по крайней мере, , не подчеркнутые – в мысленных представлениях. Изучая распознавание объекта исключительно в том виде, в каком оно происходит во время процессов восприятия, исследователь вынужден учитывать чрезмерное количество возможностей при определении свойств стимула, наиболее важных для его идентификации.Однако эта процедура плохо отражает естественные зрительные процессы. Подходя к визуальному восприятию с уровня его конечной цели – ментального представления – и оценивая взаимосвязь между исходным входом и его конечным выходом, исследователь может достичь более полного и точного понимания взаимодействия между зрением и познанием.
Вклад автора
SR разработал концепцию, провел исследование и написал текст этой рукописи.
Заявление о конфликте интересов
Автор заявляет, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Рецензент DL и ведущий редактор заявили о своей общей принадлежности, а ведущий редактор заявляет, что процесс, тем не менее, соответствовал стандартам справедливой и объективной проверки.
Благодарности
Автор благодарит Dr.Энтони Кейт за его руководство во время планирования и подготовки этой работы, а также докторов. Дайане, Беллу и ЛаКонту за их помощь в разработке концепций и поиске соответствующих исследований. Автор выражает благодарность Вирджинскому технологическому институту OASF за публикацию этой статьи.
Список литературы
Альберс, А. М., Кок, П., Тони, И., Дейкерман, Х. К., и де Ланге, Ф. П. (2013). Общие представления рабочей памяти и мысленных образов в ранней зрительной коре. Curr.Биол. 23, 1427–1431. DOI: 10.1016 / j.cub.2013.05.065
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Андерсон, Дж. Р. (1983). Распространяющаяся теория активации памяти. J. Словесное обучение. Вербальное поведение. 22, 261–295. DOI: 10.1016 / S0022-5371 (83)
-3CrossRef Полный текст | Google Scholar
Андраде, Дж., Мэй, Дж., Дипроуз, К., Боуг, С.-Дж., и Ганис, Г. (2014). Оценка яркости ментальных образов: опросник сенсорных образов Плимута. Br. J. Psychol. 105, 547–563. DOI: 10.1111 / bjop.12050
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Баллестерос, С., и Майас, Дж. (2015). Избирательное внимание влияет на концептуальное восприятие объекта и распознавание: исследование с участием молодых и пожилых людей. Фронт. Psychol. 5: 1567. DOI: 10.3389 / fpsyg.2014.01567
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Барретт Т.М., Траупман Э. и Нидхэм А. (2008).Визуальное ожидание младенцами структуры объекта при планировании схватывания. Infant Behav. Dev. 31, 1–9. DOI: 10.1016 / j.infbeh.2007.05.004
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Барух, О., Кимчи, Р., Голдсмит, М. (2014). Внимание к отличительным особенностям при распознавании объектов. Vis. Cogn. 22, 1184–1215. DOI: 10.1080 / 13506285.2014.987860
CrossRef Полный текст | Google Scholar
Берманн, М., Москович, М.и Винокур Г. (1994). Сохранность зрительных образов и нарушение зрительного восприятия у пациента с зрительной агнозией. J. Exp. Psychol. Гм. Восприятие. Выполнять. 20, 1068–1087. DOI: 10.1037 / 0096-1523.20.5.1068
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Бидерман И. (1987). Распознавание по компонентам: теория понимания человеческого образа. Psychol. Ред. 94, 115–117. DOI: 10.1037 / 0033-295X.94.2.115
CrossRef Полный текст | Google Scholar
Блаженкова, О., Кожевников М., Мотс М.А. (2006). Объектно-пространственные образы: новая анкета с самоотчетом по изображениям. Заявл. Cogn. Psychol. 20, 239–263. DOI: 10.1002 / acp.1182
CrossRef Полный текст | Google Scholar
Борст, Г., Ганис, Г., Томпсон, В. Л., и Косслин, С. М. (2012). Представления в мысленных образах и рабочей памяти: свидетельства от различных типов визуальных масок. Mem. Cogn. 40, 204–217. DOI: 10.3758 / s13421-011-0143-7
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Борст, Г., и Кослин, С. М. (2008). Визуальные ментальные образы и визуальное восприятие: структурная эквивалентность, выявленная процессами сканирования. Mem. Cogn. 36, 849–862. DOI: 10.3758 / MC.36.4.849
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Bramão, I., Inacio, F., Faisca, L., Reis, A., and Petersson, K. M. (2011a). Влияние цветовой информации на распознавание объектов цветовой и нецветной диагностики. J. Gen. Psychol. 138, 49–65.DOI: 10.1080 / 00221309.2010.533718
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Bramão, I., Reis, A., Petersson, K. M., and Faísca, L. (2011b). Роль цветовой информации в распознавании объектов: обзор и метаанализ. Acta Psychol. 138, 244–253. DOI: 10.1016 / j.actpsy.2011.06.010
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Брандт, С.А., и Старк, Л.В. (1997). Спонтанные движения глаз во время визуальных образов отражают содержание визуальной сцены. J. Cogn. Neurosci. 9, 27–38. DOI: 10.1162 / jocn.1997.9.1.27
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Бридж, Х., Харролд, С., Холмс, Э. А., Стокс, М., и Кеннард, К. (2011). Яркие визуальные ментальные образы при отсутствии первичной зрительной коры. J. Neurol. 259, 1062–1070. DOI: 10.1007 / s00415-011-6299-z
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Broggin, E., Savazzi, S., and Marzi, C.А. (2012). Подобные эффекты визуального восприятия и образов на время простой реакции. Q. J. Exp. Psychol. 65, 151–164. DOI: 10.1080 / 17470218.2011.594896
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кампос, А. (2011). Внутренняя непротиворечивость и конструктивная достоверность двух версий пересмотренной анкеты яркости визуальных образов. Восприятие. Mot. Навыки 113, 454–460. DOI: 10.2466 / 04.22.PMS.113.5.454-460
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Каттанео, З., Бона, С., Сильванто, Дж. (2012). Кросс-адаптация в сочетании с TMS выявляет функциональное перекрытие между зрением и образами в ранней зрительной коре. Нейроизображение 59, 3015–3020. DOI: 10.1016 / j.neuroimage.2011.10.022
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Cattaneo, Z., Vecchi, T., Cornoldi, C., Mammarella, I., Bonino, D., Ricciardi, E., et al. (2008). Образные и пространственные процессы при слепоте и нарушении зрения. Neurosci. Biobehav.Ред. 32, 1346–1360. DOI: 10.1016 / j.neubiorev.2008.05.002
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Чен, Л.-К., Сандманн, П., Торн, Дж. Д., Херрманн, К. С., Дебенер, С. (2015). Ассоциация одновременных сигнатур fNIRS и ЭЭГ в ответ на слуховые и зрительные стимулы. Brain Topogr. 28, 710–725. DOI: 10.1007 / s10548-015-0424-8
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Чен, М., Хан, Дж., Ху, X., Цзян, X., Го, Л., и Лю, Т. (2014). Обзор кодирования и декодирования визуальных стимулов с помощью FMRI: перспектива анализа изображений. Brain Imaging Behav. 8, 7–23. DOI: 10.1007 / s11682-013-9238-z
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Крим, С. Х., и Проффитт, Д. Р. (2001). Захват предметов за ручки: необходимое взаимодействие между познанием и действием. J. Exp. Psychol. Гм. Восприятие. Выполнять. 27, 218–228. DOI: 10.1037 / 0096-1523.27.1.218
CrossRef Полный текст | Google Scholar
Даль Д. В., Чаттопадхай А. и Горн Г. Дж. (1999). Использование визуальных мысленных образов в дизайне новых продуктов. Дж. Марк. Res. 36, 18–28. DOI: 10.2307 / 3151912
CrossRef Полный текст | Google Scholar
Де Мартино, Ф., Валенте, Г., Стаерен, Н., Эшбернер, Дж., Гебель, Р., и Формизано, Э. (2008). Объединение многовариантного выбора вокселей и вспомогательных векторных машин для отображения и классификации пространственных паттернов фМРТ. Нейроизображение 43, 44–58. DOI: 10.1016 / j.neuroimage.2008.06.037
PubMed Аннотация | CrossRef Полный текст | Google Scholar
де Вито, С., и Бартоломео, П. (2015). Отказываясь представить? О возможности психогенной афантазии. Комментарий к Zeman et al. (2015). Cortex 74, 334–335. DOI: 10.1016 / j.cortex.2015.06.013
PubMed Аннотация | CrossRef Полный текст
де Вито, С., Буонокоре, А., Боннефон, Ж.-Ф., и Сала, С. Д. (2014).Движение глаз нарушает пространственные, но не визуальные ментальные образы. Cogn. Процесс. 15, 543–549. DOI: 10.1007 / s10339-014-0617-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Д’Эрколе М., Кастелли П., Джаннини А. М. и Сбрилли А. (2010). Шкала ментальных образов: новый инструмент измерения для оценки структурных особенностей ментальных представлений. Измер. Sci. Technol. 21: 54019. DOI: 10.1088 / 0957-0233 / 21/5/054019
CrossRef Полный текст | Google Scholar
Донг, Б., и Рен, Г. (2015). Новый метод классификации сцен, основанный на локальных особенностях габора. Math. Пробл. Англ. 2015: 109718. DOI: 10.1155 / 2015/109718
CrossRef Полный текст | Google Scholar
Ганис, Г., Томпсон, В. Л. и Косслин, С. М. (2004). Области мозга, лежащие в основе визуальных мысленных образов и визуального восприятия: исследование фМРТ. Cogn. Brain Res. 20, 226–241. DOI: 10.1016 / j.cogbrainres.2004.02.012
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ханнула, Д.Э. и Ранганат К. (2009). Это есть в глазах: активность гиппокампа предсказывает выражение памяти в движениях глаз. Нейрон 63, 592–599. DOI: 10.1016 / j.neuron.2009.08.025
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хэксби, Дж. В., Коннолли, А. К., и Гунтупалли, Дж. С. (2014). Расшифровка нейронных репрезентативных пространств с использованием многомерного анализа паттернов. Annu. Rev. Neurosci. 37, 435–456. DOI: 10.1146 / annurev-neuro-062012-170325
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хервиг, А., и Шнайдер, В. X. (2014). Прогнозирование характеристик объекта через саккады: свидетельства распознавания объектов и визуального поиска. J. Exp. Psychol. Gen. 143, 1903–1922. DOI: 10.1037 / a0036781
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Янчик, М., Кунде, В. (2012). Визуальная обработка действий препятствует сходству релевантных и нерелевантных характеристик объекта. Психон. Бык. Ред. 19, 412–417. DOI: 10.3758 / s13423-012-0238-6
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Йоханссон, Р., Холсанова, Дж., И Холмквист, К. (2006). Изображения и устные описания вызывают сходные движения глаз во время мысленных образов. И при свете, и в полной темноте. Cogn. Sci. 30, 1053–1079. DOI: 10.1207 / s15516709cog0000_86
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Камран М.А., Хонг К.-С. (2013). «Косвенное измерение активации мозга с помощью fNIRS», в материалах материалов 13-й Международной конференции по контролю, автоматизации и системам (ICCAS) 2013 г. , Кванджу, 1633–1636.DOI: 10.1109 / ICCAS.2013.6704193
CrossRef Полный текст | Google Scholar
Кослин, С. М., Райзер, Б. Дж., Фара, М. Дж., И Флигель, С. Л. (1983). Создание визуальных образов: единицы и отношения. J. Exp. Psychol. Gen. 112, 278–303. DOI: 10.1037 / 0096-3445.112.2.278
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кослин, С. М., Томпсон, В. Л., Ким, И. Дж., И Альперт, Н. М. (1995). Топографические представления ментальных образов в первичной зрительной коре. Природа 378, 496–498.
PubMed Аннотация | Google Scholar
Лаенг, Б., Теодореску, Д.-С. (2002). Пути сканирования глаз во время визуальных образов воспроизводят пути восприятия той же визуальной сцены. Cogn. Sci. 26, 207–231. DOI: 10.1016 / S0364-0213 (01) 00065-9
CrossRef Полный текст | Google Scholar
Ли, Дж., Тан, Ю., Чжоу, Л., Ю, К., Ли, С., и Дан-ни, С. (2010). Динамика ЭЭГ отражает частичные и целостные эффекты в генерации мысленных образов. J. Zhejiang Univ. Sci. B 11, 944–951. DOI: 10.1631 / jzus.B1000005
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Маркс, Д. Ф. (1973). Различия в визуальных образах при запоминании картинок. Br. J. Psychol. 64, 17–24. DOI: 10.1111 / j.2044-8295.1973.tb01322.x
CrossRef Полный текст | Google Scholar
Маркс, Д. Ф. (1995). Новые направления исследования ментальных образов. J. Ment. Снимок 19, 153–167.
Google Scholar
Мартарелли, К.С., Чике, С., Лаенг, Б., и Маст, Ф. В. (2016). Использование пространства для представления категорий: понимание с позиции взгляда. Psychol. Res. doi: 10.1007 / s00426-016-0781-2 [Epub перед печатью].
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Маккарли Дж. С., Крамер А. Ф. и Петерсон М. С. (2002). Открытое и скрытое объектно-ориентированное внимание. Психон. Бык. Ред. 9, 751–758. DOI: 10.3758 / BF03196331
CrossRef Полный текст | Google Scholar
Мик, Дж.Х., Фирбанк, М., Элвелл, К. Э., Аткинсон, Дж., Брэддик, О., и Вятт, Дж. С. (1998). Региональные гемодинамические реакции на визуальную стимуляцию у бодрствующих младенцев. Pediatr. Res. 43, 840–843. DOI: 10.1203 / 00006450-199806000-00019
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Митчелл, Т.М., Шинкарева, С.В., Карлсон, А., Чанг, К.-М., Малав, В.Л., Мейсон, Р.А., и др. (2008). Прогнозирование активности человеческого мозга, связанной со значениями существительных. Наука 320, 1191–1195.DOI: 10.1126 / science.1152876
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Мияваки Ю., Утида, Х., Ямасита, О., Сато, М., Морито, Ю., Танабе, Х. С. и др. (2008). Реконструкция визуального изображения на основе активности человеческого мозга с использованием комбинации многомасштабных локальных декодеров изображений. Нейрон 60, 915–929. DOI: 10.1016 / j.neuron.2008.11.004
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Моро В., Берлучки Г., Лерх Дж., Томайуоло, Ф., и Аглиоти, С. М. (2008). Избирательный дефицит ментальных зрительных образов при сохранности первичной зрительной коры и зрительного восприятия. Cortex 44, 109–118. DOI: 10.1016 / j.cortex.2006.06.004
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Нанай Б. (2014). Перцептивное содержание и содержание мысленных образов. Philos. Stud. 172, 1723–1736. DOI: 10.1007 / s11098-014-0392-y
CrossRef Полный текст | Google Scholar
Населарис, Т., Олман, К. А., Стэнсбери, Д. Э., Угурбил, К., и Галлант, Дж. Л. (2015). Воксельная модель кодирования для ранних визуальных областей декодирует мысленные образы запомненных сцен. Нейроизображение 105, 215–228. DOI: 10.1016 / j.neuroimage.2014.10.018
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Никсон М., Агуадо А. С. (2012). Извлечение функций и обработка изображений для компьютерного зрения (3). Сент-Луис, Миссури: Academic Press.
Google Scholar
О’Крэвен, К.М. и Канвишер Н. (2000). Мысленные образы лиц и мест активируют соответствующие области мозга, специфичные для стимулов. J. Cogn. Neurosci. 12, 1013–1023. DOI: 10.1162 / 089892137549
CrossRef Полный текст | Google Scholar
Острофский Дж., Козбельт А., Коэн Д. Дж. (2015). Предубеждения при рисовании при наблюдении предсказываются предубеждениями в восприятии: эмпирическим подтверждением гипотезы неправильного восприятия точности рисования в отношении двух угловых иллюзий. В.J. Exp. Psychol. 68, 1007–1025. DOI: 10.1080 / 17470218.2014.973889
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Пальмиеро, М., Маттео, Р. Д., Белардинелли, М. О. (2014). Представление концептуальных знаний: визуальные, слуховые и обонятельные образы по сравнению с семантической обработкой. Cogn. Процесс. 15, 143–157. DOI: 10.1007 / s10339-013-0586-9
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Пирсон, Дж., Населарис, Т., Холмс, Э.А., Кослин, С.М. (2015). Ментальные образы: функциональные механизмы и клиническое применение. Trends Cogn. Sci. 19, 590–602. DOI: 10.1016 / j.tics.2015.08.003
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Померанц, Дж. Р., Сагер, Л. К., и Стоувер, Р. Дж. (1977). Восприятие целого и их составных частей: некоторые эффекты конфигурационного превосходства. J. Exp. Psychol. Гм. Восприятие. Выполнять. 3, 422–435. DOI: 10.1037 / 0096-1523.3.3.422
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Putze, F., Hesslinger, S., Tse, C.-Y., Huang, Y., Herff, C., Guan, C., et al. (2014). Гибридная классификация процессов слухового и зрительного восприятия на основе фНИРС-ЭЭГ. Фронт. Neurosci. 8: 373. DOI: 10.3389 / fnins.2014.00373
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Редди, Л., Цучия, Н., Серр, Т. (2010). Чтение мысленным взором: расшифровка информации о категории во время мысленных образов. Нейроизображение 50, 818–825. DOI: 10.1016 / j.neuroimage.2009.11.084
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ричардсон Д. К. и Спайви М. Дж. (2000). Репрезентация, пространство и Голливудские площади: взгляд на вещи, которых больше нет. Познание 76, 269–295.
Google Scholar
Розенбаум, Д. А., Воган, Дж., Барнс, Х. Дж., И Йоргенсен, М. Дж. (1992). График движения планирования: выбор рукояток для манипулирования предметом. J. Exp. Psychol. Учиться. Mem. Cogn. 18, 1058–1073. DOI: 10.1037 / 0278-7393.18.5.1058
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Rouw, R., Kosslyn, S.M, and Hamel, R. (1997). Обнаружение высокоуровневых и низкоуровневых свойств в визуальных образах и визуальном восприятии. Познание 63, 209–226. DOI: 10.1016 / S0010-0277 (97) 00006-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Сервос П. и Гудейл М. А.(1995). Сохранились зрительные образы в зрительной форме агнозии. Neuropsychologia 33, 1383–1394. DOI: 10.1016 / 0028-3932 (95) 00071-A
CrossRef Полный текст | Google Scholar
Шокуфанде, А., Кесельман, Ю., Демирчи, М. Ф., Макрини, Д., и Дикинсон, С. (2012). Сопоставление функций многие-ко-многим в распознавании объектов: обзор трех подходов. IET Comput. Vis. 6, 500–513.
Google Scholar
Шури, Н., Фироозабади, М., и Бади, К.(2014). Анализ сигналов ЭЭГ художников и нехудожников во время визуального восприятия, мысленных образов и отдыха с использованием приблизительной энтропии. Biomed Res. Int. 201: 764382. DOI: 10.1155 / 2014/764382
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Симанова И., ван Гервен М., Остенвельд Р. и Хагоорт П. (2010). Определение категорий объектов из событийной ЭЭГ: к расшифровке концептуальных представлений. PLoS ONE 5: e14465. DOI: 10.1371 / journal.pone.0014465
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Слотник, С. Д., Томпсон, В. Л., и Косслин, С. М. (2005). Визуальные ментальные образы вызывают ретинотопически организованную активацию ранних зрительных областей. Cereb. Cortex 15, 1570–1583. DOI: 10.1093 / cercor / bhi035
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Спайви, М. Дж., И Гэн, Дж. Дж. (2001). Глазодвигательные механизмы активируются образами и памятью: движения глаз к отсутствующим объектам. Psychol. Res. 65, 235–241. DOI: 10.1007 / s004260100059
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Такахаши К., Огата С., Ацуми Ю., Ямамото Р., Шиоцука С., Маки А. и др. (2000). Активация зрительной коры, отображаемая с помощью 24-канальной ближней инфракрасной спектроскопии. J. Biomed. Опт. 5, 93–96. DOI: 10.1117 / 1.429973
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Tarr, M.J., Bülthoff, H.H., Забинский М. и Бланц В. (1997). В какой степени уникальные детали влияют на узнаваемость при изменении точки зрения? Psychol. Sci. 8, 282–289.
Google Scholar
Тирион Б., Дюшене Э., Хаббард Э., Дюбуа Дж., Полайн Ж.-Б., Лебихан Д. и др. (2006). Обратная ретинотопия: вывод визуального содержания изображений из паттернов активации мозга. Нейроизображение 33, 1104–1116. DOI: 10.1016 / j.neuroimage.2006.06.062
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Таунсенд, Г., Graimann, B., and Pfurtscheller, G. (2004). Непрерывная классификация ЭЭГ при моделировании воображения движения асинхронного ИМК. IEEE Trans. Neural Syst. Rehabil. Англ. 12, 258–265. DOI: 10.1109 / TNSRE.2004.827220
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ульман, С., Ассиф, Л., Фетая, Э., и Харари, Д. (2016). Атомы распознавания в человеческом и компьютерном зрении. Proc. Natl. Акад. Sci. США 113, 2744–2749. DOI: 10.1073 / pnas.1513198113
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Вальдерт, С., Тюшаус, Л., Каллер, К. П., Аэрцен, А., и Меринг, К. (2012). fNIRS демонстрирует слабую настройку на направление движения руки. PLoS ONE 7: e49266. DOI: 10.1371 / journal.pone.0049266
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Уокер П., Гэвин Бремнер Дж., Меррик К., Коутс С., Купер Э., Лоули Р. и др. (2006). Визуальные мысленные представления, поддерживающие рисование объекта: как наименование нового объекта новым счетным существительным влияет на рисование объекта маленькими детьми. Vis. Cogn. 13, 733–788. DOI: 10.1080 / 13506280544000318
CrossRef Полный текст | Google Scholar
Wilcox, T., and Baillargeon, R. (1998). Индивидуализация объекта в младенчестве: использование особой информации в рассуждениях о событиях окклюзии. Cogn. Psychol. 37, 97–155. DOI: 10.1006 / cogp.1998.0690
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Уилкокс, Т., Бортфельд, Х., Вудс, Р., Рук, Э., и Боас, Д. А. (2005).Использование ближней инфракрасной спектроскопии для оценки нейронной активации во время обработки объектов у младенцев. J. Biomed. Опт. 10, 11010. DOI: 10.1117 / 1.1852551
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Уильямс, М., и Вудман, Г. (2010). Использование движений глаз для измерения внимания к объектам и функциям в зрительной рабочей памяти. J. Vis. 10, 764–764. DOI: 10.1167 / 10.7.764
CrossRef Полный текст | Google Scholar
Земан, А.З. Дж., Делла Сала, С., Торренс, Л. А., Гунтуна, В.-Э., МакГонигл, Д. Дж., И Логи, Р. Х. (2010). Феноменология потери образов при неизменном выполнении зрительно-пространственного задания: случай «слепого воображения». Neuropsychologia 48, 145–155. DOI: 10.1016 / j.neuropsychologia.2009.08.024
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Как фотографии ваших детей используются в технологиях видеонаблюдения
Однажды в 2005 году мать из Эванстона, штат Иллинойс., присоединился к Flickr. Она загрузила несколько фотографий своих детей, Хлои и Джаспера. Потом она более или менее забыла о существовании своего аккаунта.
Спустя годы их лица занесены в базу данных, которая используется для тестирования и обучения некоторых из самых сложных систем искусственного интеллекта в мире.
Подборка изображений из базы данных MegaFace.
миллионов изображений Flickr были помещены в базу данных под названием MegaFace.Теперь некоторые из этих лиц могут подать в суд.
Автор: Кашмир Хилл и Аарон Кролик
Детские рисунки Хлои и Джаспера Папы – это типично тупой образ: улыбающиеся вместе со своими родителями; высунув языки наружу; костюм на Хэллоуин. Их мать, Доминик Аллман Папа, загрузила их на Flickr после того, как присоединилась к сайту обмена фотографиями в 2005 году.
Никто из них не мог предвидеть, что 14 лет спустя эти изображения будут находиться в беспрецедентно огромной базе данных распознавания лиц под названием MegaFace.Содержащий изображения почти 700 000 человек, он был загружен десятками компаний для обучения нового поколения алгоритмов идентификации лиц, используемых для отслеживания протестующих, слежки за террористами, выявления проблемных игроков и слежки за общественностью в целом.
«Это отвратительно и неудобно», – сказал Мкс. Папа, которому сейчас 19 лет, учится в колледже в Орегоне. «Я хотел бы, чтобы они сначала спросили меня, хочу ли я принять в этом участие. Я считаю, что искусственный интеллект – это круто, и я хочу, чтобы он был умнее, но обычно вы просите людей участвовать в исследованиях.Я узнал это в биологии в старшей школе ».
Хлоя Папа Аманда Люсье для The New York Times
По закону, у большинства американцев, внесенных в базу данных, не нужно спрашивать разрешения, но папы должны были это сделать.
Как жители Иллинойса, они находятся под защитой одного из самых строгих законов штата о конфиденциальности: Закона о конфиденциальности биометрической информации – меры 2008 года, предусматривающей финансовые штрафы за использование отпечатков пальцев или сканирования лица жителя Иллинойса без согласия.
Те, кто использовал базу данных – компании, включая Google, Amazon, Mitsubishi Electric, Tencent и SenseTime – по-видимому, не знали о законе и, как следствие, могли нести огромную финансовую ответственность, по мнению нескольких юристов и профессоров права, знакомых с законодательством.
Как родился MegaFace
Как папы и сотни тысяч других людей оказались в базе данных? Это окольный рассказ.
На заре технологии распознавания лиц исследователи разрабатывали свои алгоритмы с явного согласия испытуемых: в 1990-х годах в университеты приходили добровольцы в студии, чтобы сфотографироваться с разных ракурсов.Позже исследователи обратились к более агрессивным и скрытым методам сбора лиц в более крупном масштабе, подключению к камерам наблюдения в кафе, кампусах колледжей и общественных местах и сканированию фотографий, размещенных в Интернете.
По словам Адама Харви, художника, отслеживающего наборы данных, существует, вероятно, более 200, содержащих десятки миллионов фотографий примерно одного миллиона человек. (Некоторые наборы являются производными от других, поэтому на рисунках есть дубликаты.) Но у этих тайников были недочеты. Например, изображения с камер видеонаблюдения часто бывают низкого качества, а сбор снимков в Интернете обычно приводит к появлению слишком большого количества знаменитостей.
В июне 2014 года, стремясь продвинуть дело компьютерного зрения, Yahoo представила то, что она назвала «крупнейшей когда-либо выпущенной общедоступной мультимедийной коллекцией», включающей 100 миллионов фотографий и видео. Yahoo получила изображения – все из которых имели лицензии Creative Commons или коммерческое использование – от Flickr, дочерней компании.
Создатели базы данных заявили, что их мотивация заключалась в том, чтобы выровнять игровое поле в машинном обучении.Исследователям нужны огромные объемы данных для обучения своих алгоритмов, а сотрудники всего нескольких компаний, богатых информацией, таких как Facebook и Google, имели большое преимущество перед всеми остальными.
«Мы хотели расширить возможности исследовательского сообщества, предоставив им надежную базу данных», – сказал Дэвид Айман Шамма, который до 2016 года был директором по исследованиям в Yahoo и участвовал в создании проекта Flickr. Пользователи не были уведомлены о том, что их фото и видео были включены, но г-н Шамма и его команда создали то, что, по их мнению, было защитой.
Они не распространяли фотографии пользователей напрямую, а скорее давали ссылки на фотографии; таким образом, если пользователь удалил изображения или сделал их личными, они больше не были бы доступны через базу данных.
Но эта гарантия была ошибочной. The New York Times обнаружила уязвимость в системе безопасности, которая позволяет получить доступ к фотографиям пользователя Flickr даже после того, как они стали личными. (Скотт Кинзи, представитель компании SmugMug, которая приобрела Flickr у Yahoo в 2018 году, сказал, что этот недостаток «потенциально затрагивает очень небольшое количество наших участников сегодня, и мы активно работаем над тем, чтобы как можно быстрее развернуть обновление.Бен МакАскилл, главный операционный директор компании, добавил, что коллекция Yahoo была создана «за много лет до нашего сотрудничества с Flickr».
Кроме того, некоторые исследователи, получившие доступ к базе данных, просто загрузили версии изображений, а затем распространили их, включая команду из Вашингтонского университета. В 2015 году два школьных профессора информатики – Ира Кемельмахер-Шлизерман и Стив Зейтц – и их аспиранты использовали данные Flickr для создания MegaFace.
Содержащий более четырех миллионов фотографий примерно 672 000 человек, он многообещал для тестирования и совершенствования алгоритмов распознавания лиц.
Наблюдение за уйгурами и выездными порноактерами
Что важно для исследователей Вашингтонского университета, в MegaFace были такие дети, как Хлоя и Джаспер Папа. Системы распознавания лиц, как правило, плохо работают с молодыми людьми, но Flickr дал шанс улучшить это с помощью множества детских лиц по той простой причине, что люди любят публиковать фотографии своих детей в Интернете.
В 2015 и 2016 годах Вашингтонский университет провел «MegaFace Challenge», пригласив группы, работающие над технологией распознавания лиц, использовать набор данных для проверки того, насколько хорошо работают их алгоритмы.
Школа попросила людей, загружающих данные, согласиться использовать их только в «некоммерческих исследовательских и образовательных целях». В нем приняли участие более 100 организаций, включая Google, Tencent, SenseTime и NtechLab. В целом, согласно выпуску новостей университета за 2016 год, с базой данных работали «более 300 исследовательских групп».Он был публично процитирован исследователями из Amazon и, по словам г-на Харви, Mitsubishi Electric и Philips.
Некоторые из этих компаний подвергались критике за то, как клиенты используют свои алгоритмы: технология SenseTime использовалась для мониторинга уйгурского населения в Китае, а технология NtechLab использовалась для выявления актеров порнографии и выявления незнакомцев в метро в России.
Директор по маркетингу SenseTime Джун Джин сказал, что исследователи компании использовали базу данных MegaFace только в академических целях.«Исследователи должны использовать один и тот же набор данных, чтобы их результаты были сопоставимы на равных», – написала г-жа Цзинь в электронном письме. «Поскольку MegaFace является наиболее широко известной базой данных в своем роде, она фактически превратилась в набор для обучения распознаванию лиц и тестов для глобального академического и исследовательского сообщества».
Представитель NtechLab Николай Грунин сказал, что компания удалила MegaFace после участия в испытании, и добавил, что «основная сборка нашего алгоритма никогда не обучалась на этих изображениях.В Google от комментариев отказались.
Пресс-секретарь Вашингтонского университета отказалась предоставить ведущим исследователям MegaFace возможность взять интервью у них, заявив, что они «перешли к другим проектам и у них нет времени, чтобы это комментировать». Попытки связаться с ними индивидуально не увенчались успехом.
Создание MegaFace частично финансировалось Samsung, премией Google за исследования для факультетов и Национальным научным фондом / Intel.
В последние годы г-жа Кемельмахер-Шлизерман продала Facebook компанию по замене лица и передовую технологию глубокого подделки, преобразовав аудиоклипы Барака Обамы в реалистичное синтетическое видео, на котором он произносит речь.Сейчас она работает над «лунным проектом» в Google.
‘Что за черт? Это помешательство
MegaFace остается общедоступным для загрузки. Когда New York Times недавно запросила доступ, он был предоставлен в течение минуты.
MegaFace не содержит имен людей, но его данные не анонимны. Представитель Вашингтонского университета сказал, что исследователи хотели соблюдать лицензии Creative Commons для изображений. В результате каждая фотография включает числовой идентификатор, который ведет к исходной учетной записи фотографа Flickr.Таким образом, The Times смогла отследить многие фотографии в базе данных до людей, которые их сделали.
“Что за черт? Это безумие », – сказал Ник Альт, предприниматель из Лос-Анджелеса, когда сказал, что его фотографии были в базе данных, включая фотографии детей, которые он сделал на публичном мероприятии в Плайя-Виста, Калифорния, десять лет назад.
фотографий г-на Альт, включая подборку изображений с сайта MegaFace.
«Причина, по которой я изначально обратилась на Flickr, заключалась в том, что вы могли установить лицензию как некоммерческую.Совершенно верно, я бы не позволил использовать свои фотографии в проектах по машинному обучению. Я чувствую себя таким тупицей из-за того, что опубликовал эту фотографию. Но я сделал это 13 лет назад, еще до того, как конфиденциальность стала нормой ».
Другой субъект, попросивший называть его Дж., Сейчас 15-летний второкурсник средней школы в Лас-Вегасе. Фотографии, на которых он был маленьким, есть в базе данных MegaFace, благодаря тому, что его дядя разместил их в альбоме Flickr после воссоединения семьи десять лет назад. J. не верил в то, что внесение его в базу данных без его разрешения не было незаконным, и его беспокоят последствия.
Начиная со средней школы, он был участником программы Ассоциации ВВС под названием CyberPatriot, которая пытается направить молодых людей с навыками программирования на карьеру в области кибербезопасности. «Из-за этого я очень защищаю свой цифровой след», – сказал он. «Я стараюсь не публиковать свои фотографии в Интернете. Что, если я решу работать на АНБ? »
Дж., Мистеру Альт и большинству других американцев на фотографиях мало что осталось. Закон о конфиденциальности в Соединенных Штатах, как правило, настолько либерален, что компании могут свободно использовать лица миллионов людей без их ведома, чтобы способствовать распространению технологии распознавания лиц.Но есть исключение.
В 2008 году Иллинойс принял дальновидный закон, защищающий «биометрические идентификаторы и биометрическую информацию» его жителей. Два других штата, Техас и Вашингтон, приняли собственные законы о биометрической конфиденциальности, но они не так надежны, как закон в Иллинойсе, который строго запрещает частным лицам собирать, фиксировать, покупать или иным образом получать биометрические данные человека, в том числе сканирование их «геометрии лица» – без согласия этого человека.
«Сами фотографии не подпадают под действие Закона о конфиденциальности биометрической информации, но сканирование фотографий должно быть.Простое использование биометрических данных является нарушением закона », – заявила Фэй Джонс, профессор права в Университете Иллинойса. «Использование этого в алгоритмическом конкурсе, когда вы не уведомили людей, является нарушением закона».
Жители Иллинойса, такие как Папы, чьи отпечатки лица используются без их разрешения, имеют право подать иск, сказала г-жа Джонс, и имеют право на получение 1000 долларов за использование или 5000 долларов, если использование было «неосторожным». The Times попыталась измерить, сколько людей из Иллинойса находится в базе данных MegaFace; один подход, использующий информацию о местоположении, сообщаемую самими участниками, предлагал 6000 человек, а другой, использующий метаданные геотегирования, указывал целых 13000 человек.
Их биометрия, вероятно, обрабатывалась десятками компаний. По мнению нескольких экспертов по правовым вопросам в Иллинойсе, совокупная ответственность может составить более миллиарда долларов и может стать основанием для коллективного иска.
«У нас в штате Иллинойс много амбициозных юристов по коллективным искам», – сказал Джеффри Видман, управляющий партнер Fox Rothschild в Чикаго. «В Иллинойсе этот закон прописан с 2008 года, но в течение десяти лет его практически игнорировали. Я гарантирую вам, что в 2014 или 2015 годах об этой потенциальной ответственности никто не обращал внимания.Но теперь технология догнала закон ».
Дело против Facebook на 35 миллиардов долларов
Примечательно, что закон штата Иллинойс вообще существует. По словам Мэтью Куглера, профессора права Северо-Западного университета, который исследовал закон штата Иллинойс, он был вдохновлен банкротством в 2007 году компании Pay by Touch, в досье которой хранились отпечатки пальцев многих американцев, в том числе иллинойцев; были опасения, что он может продать их при ликвидации.
Согласно законодательным и лоббистским записям, никто из представителей технологической индустрии не принял во внимание законопроект.
«Когда был принят закон, никто из тех, кто сейчас этим озабочен, не думал об этом», – сказал г-н Куглер. Кремниевая долина теперь знает о законе. Bloomberg News сообщал в апреле 2018 года, что лоббисты Google и Facebook пытались ослабить его положения.
С 2015 года в Иллинойсе было подано более 200 коллективных исков о неправомерном использовании биометрических данных жителей, в том числе дело против Facebook на 35 миллиардов долларов за использование распознавания лиц для отметки людей на фотографиях.Этот иск набрал обороты в августе, когда Апелляционный суд девятого округа Соединенных Штатов отклонил аргументы компании о том, что люди не понесли «конкретного вреда».
В последние годы технологические компании стали действовать более осторожно в штатах с биометрическим законодательством. Когда в 2018 году Google выпустил функцию сопоставления селфи с известными произведениями искусства, жители Иллинойса и Техаса не смогли ею воспользоваться. А камеры видеонаблюдения Google Nest не предлагают стандартной функции распознавания знакомых лиц в Иллинойсе.
«Это жутко, что ты нашел меня. Я всегда жил с философией, что то, что я выкладываю, должно быть публичным, но я не мог себе этого представить », – сказала Венди Пирсолл, издатель и член городского совета в Вудстоке, штат Иллинойс, чьи фотографии вместе с фотографиями ее троих дети, находились в базе данных MegaFace.
«Мы не можем использовать приложение« Веселое искусство »; почему вы используете лица наших детей для тестирования своего программного обеспечения? » она добавила. «Мои фотографии там привязаны к Иллинойсу. Несложно выяснить, где были сделаны эти снимки.Я не очень-то счастлив, но я бы подбодрил кого-нибудь еще, чтобы тот согласился после этого.
Конфиденциальный нигилизм
Доминик и Джордж Папа с сыном Джаспером в их доме в Эванстоне, штат Иллинойс, в начале этого месяца. Тейлор Гласкок для The New York Times
Некоторые судебные процессы в штате Иллинойс были урегулированы или отклонены, но большинство из них в силе, и г-н Куглер, профессор права Северо-Запада, отметил, что основные юридические вопросы остались без ответа.Неясно, какова будет юридическая ответственность компании, которая делает фотографии, загруженные в Иллинойсе, но обрабатывает данные о лицах в другом штате или даже в другой стране.
«Обвиняемые будут творчески подходить к поиску аргументов, потому что никто не хочет застревать в руках с этим дорогим горячим картофелем», – сказал он.
Представитель Amazon Web Services заявил, что использование набора данных «соответствует требованиям B.I.P.A.», но отказался объяснить, как это сделать. Марио Фанте, представитель Philips, написал в электронном письме, что компании «никогда не было известно о каких-либо жителях Иллинойса, включенных в вышеупомянутый набор данных.”
Виктор Балта, представитель Вашингтонского университета, сказал: «Любое использование фотографий в базе данных исследователей является законным. U.W. является государственным исследовательским университетом, а не частной организацией, и закон штата Иллинойс нацелен на частные организации ».
Некоторые из иллинойцев, которых мы нашли в MegaFace и с которыми связались, были безразличны к использованию своих лиц.
«Я знаю, что когда вы загружаете информацию в Интернет, ее можно использовать неожиданным образом, поэтому я не удивлен, – сказал Крис Шойфеле, веб-разработчик из Спрингфилда.«Когда вы загружаете информацию в Интернет и делаете ее общедоступной, вы должны ожидать, что она будет очищена».
А как насчет сюжетов его фотографий? Мистер Шойфеле рассмеялся. «Я не говорил об этом своей жене», – сказал он.
«Нигилизм конфиденциальности» – это все более привычный термин для обозначения отказа от попыток контролировать данные о себе в цифровую эпоху. То, что случилось с Хлоей Папа, может, в зависимости от вашей точки зрения, служить аргументом в пользу крайней бдительности или полной смирения: кто мог предположить, что снимок малыша в 2005 году будет способствовать, через полтора десятилетия, развитию передовых технологий. технология наблюдения?
«Мы привыкли торговать удобством ради конфиденциальности, так что это притупило наши чувства по поводу того, что происходит со всеми собранными о нас данными», – сказала г-жа Ф.Джонс, профессор права. «Но люди начинают просыпаться».
Распознавание изображений – Pimics Docs
Приложение с поддержкой искусственного интеллекта ускоряет управление изображениями, их присвоение товарам, классификацию и заполнение метаданных. Распознавание изображений – это первая часть управления изображениями с использованием искусственного интеллекта.
Настройки параметров
Прежде чем вы начнете использовать это расширение и импортировать картинки в Pimics, вам необходимо настроить параметры.Подробнее о параметрах вы найдете в разделе Что нужно сделать в первую очередь. Для распознавания картинки важны три обязательных поля:
- Ключ подписки и конечная точка для доступа к API Azure. Без этих двух полей ваш искусственный интеллект и все расширение не будут работать.
- Номера ключевых слов , чтобы определить, какие числовые ряды должны использоваться для ключевых слов, созданных AI. Вы можете использовать разные числовые серии для ключевых слов, созданных с помощью распознавания изображений, и для ваших общих ключевых слов, которые вы будете использовать для экспорта в электронную коммерцию или печатный каталог.
Импорт изображений
Импорт изображений или других типов документов является стандартной функцией Pimics (см. Дополнительные Расширения и модули). Pimics предлагает вам больше способов импорта изображений. Если вы хотите импортировать больше изображений, самый простой вариант – Загрузить лист документов (Рабочие листы / Загрузить документ или Цифровые активы / Загрузить документы). Вы можете узнать больше об импорте документов в разделе Импорт.
После того, как ваши документы уже импортированы, вам необходимо вручную назначить их элементам или группам в вашей структуре с помощью действия Назначить или непосредственно в карточке товара или карточке группы.Искусственный интеллект помогает вам в этом процессе, создавая ключевые слова для всех загруженных изображений, а затем распределяя их по элементам или группам на основе существующих изображений в структуре и ключевых слов, созданных для них.
Ключевые слова распознавание
Весь процесс обработки изображений с использованием искусственного интеллекта разбит на небольшие части. Во время импорта выполняется процесс распознавания ключевых слов. Результат всего процесса доступен в AI Picture List (Pimics AI / AI Picture List).Эта страница представляет собой список импортированных изображений, который дополнен важной информацией и функциями, например:
- Используемые ключевые слова флаг, указывающий, доступны ли ключевые слова или нет.
- Распознать изображение – это функция, с помощью которой вы можете вызвать процесс распознавания изображений для изображений, которые вы уже импортировали до того, как начали использовать Pimics AI Extension. Этот процесс обычно выполняется во время импорта, и на этом этапе генерируются ключевые слова.
- Ключевые слова изображения AI используется для отображения ключевых слов, созданных в процессе импорта.
AI Picture Keywords предлагает для каждого изображения более одного ключевого слова, и вы можете определить, является ли это ключевое слово релевантным для вас или нет, используя действие Отметить / Снять отметку релевантного ключевого слова . Назначая ключевое слово как релевантное, вы определяете, что ключевое слово должно использоваться для следующего шага, присвоения изображения.
Распознавание объектов | Библиотека Vuforia
Эта страница относится к Vuforia Engine API версии 9.8 и ранее. Он устарел и больше не будет активно обновляться. Мы рекомендуем перейти на API Vuforia Engine 10 до того, как эта страница будет удалена в феврале 2022 года. Эквивалент этой страницы или темы можно найти здесь: Объектные цели.
Object Recognition позволяет обнаруживать и отслеживать сложные трехмерные объекты, в частности игрушки (например, фигурки и транспортные средства) и другие небольшие потребительские товары. Используйте сканер объектов и прилагаемое к нему изображение сканирования объекта-мишени, чтобы легко сканировать детализированные игрушки, модели и обучающие инструменты.
Использование распознавания объектов
Object Recognition можно использовать для создания разнообразных интерактивных возможностей работы с 3D-объектами. Этим опытом можно было бы дополнить игрушку трехмерным контентом, чтобы оживить ее, наложить руководство пользователя поверх устройства бытовой электроники или провести нового сотрудника через интерактивный процесс обучения для рабочего устройства. Еще одно простое применение распознавания объектов – разблокировать новый контент в приложении при распознавании продукта.
Предварительные требования
Поддерживаемые объекты
Для правильной работы распознавания объектов физический объект должен быть:
- Непрозрачный, жесткий и не содержит движущихся частей или содержит очень мало движущихся частей.
- Податливые или деформируемые объекты не поддерживаются, а объекты с шарнирными элементами не поддерживаются как целые объекты, но вы можете использовать несочлененные области объекта в качестве цели объекта. См. Раздел Руководства по сканеру объектов Vuforia для целевого изображения сканирования объекта, чтобы узнать больше об исключении части объекта с помощью отбраковки.
- Поверхность объекта должна иметь большое количество контрастных элементов и богатую текстуру.
- В дополнение к спецификациям объектов, Vuforia Target Manager поддерживает только файлы .OD (объектные данные), созданные приложением сканера для создания объектной цели.
Хорошими примерами объектных целей являются игрушки, такие как фигурки и транспортные средства. Дополнительные сведения см. В разделе «Продукты, поддерживаемые объектными целями». См. Также Сравнение методов отслеживания объектов, чтобы узнать о других возможностях отслеживания объектов, наделенных Vuforia.
Поддерживаемые среды
Объект Цели следует рассматривать в помещении при умеренно ярком и рассеянном освещении. Насколько это возможно, поверхности объекта должны быть равномерно освещены и не содержать теней от других предметов или людей. Это также следует учитывать при сканировании объекта.
Создание объектов-мишеней
Сканер объектов
Чтобы включить распознавание объектов в вашем приложении, вам необходимо создать объектную цель.Объект-цель создается путем сканирования физического трехмерного объекта с помощью сканера объектов Vuforia. Объект должен быть размещен на прилагаемом к нему отпечатанном целевом изображении сканирования объекта, которое доступно в загруженном пакете сканера объектов Vuforia.
Для получения полного руководства по сканеру объектов Vuforia обратитесь к руководству по сканеру объектов Vuforia.
ПРИМЕЧАНИЕ: Сканер объектов доступен только для устройств под управлением Android. Пожалуйста, обратитесь к странице Поддерживаемые версии для получения дополнительной информации.
Подготовка и сканирование
Вы можете создать объектную цель для своего приложения, используя следующий рабочий процесс:
- Подготовьте среду и отсканируйте физический объект с помощью сканера объектов Vuforia, который доступен здесь, и следуя приведенному выше руководству, чтобы создать файл .OD.
- Затем вы загружаете файл в Vuforia Target Manager, где выбираете создание объекта Object Target , который упаковывает его в базу данных устройства. В одну базу данных устройства можно включить до 20 целевых объектов.
- Загрузите базу данных и добавьте ее в проект распознавания объектов Vuforia, разработанный в Android Studio, Visual Studio, Xcode или Unity:
- См. Как использовать распознавание объектов в Unity и как создавать и загружать цели в Unity
- См. Как использовать распознавание объектов в приложении Android для интеграции объекта Target в ваше собственное приложение.
Образцы
В качестве альтернативы, проект Vuforia Object Recognition Unity Sample предоставляет предварительно настроенную сцену распознавания объектов и объектную цель, которые вы можете использовать в качестве справочной и отправной точки для ваших собственных приложений распознавания объектов.
Расширенные темы
Использование слежения за устройством с объектами-целями
Устройство отслеживания устройств повышает надежность отслеживания за счет использования особенностей среды, окружающей цель. Это позволяет использовать меньшие цели и позволяет отслеживать цели дальше от камеры. Кроме того, он включает расширенное слежение, при котором ваша цель может быть отслежена, даже если объектная цель больше не находится в поле зрения камеры.
ПРИМЕЧАНИЕ: Цели объекта лучше всего работают с отслеживанием устройств, когда объект неподвижен во время взаимодействия с пользователем.
Для получения дополнительной информации см .: Отслеживание устройств
Использование нескольких целей одновременно
Для ваших конкретных сценариев и лучших вариантов использования Vuforia предлагает одновременное отслеживание целей и различных типов целей. Вы также можете управлять количеством отслеживаемых целей, чтобы снизить нагрузку на устройства. Позвольте одновременно отслеживать до двух объектов-целей в вашем сценарии и пойти еще дальше, комбинируя и отслеживая другие типы целей Vuforia вместе с ними, чтобы получить привлекательный опыт.
Посетите, обнаруживайте и отслеживайте несколько целей одновременно для получения дополнительной информации.
Обзор API объектной цели
ObjectTarget отслеживается ObjectTracker. Соответствующий TrackableResult (в данном случае ObjectTargetResult) возвращает данные отслеживания объекта Target.
Дополнительную информацию см. В обзоре ObjectTracker API.
Модель окклюзии
Погрузите своих пользователей, закрыв ваш цифровой контент позади и под объектом Object Target.Используйте либо ограничивающую рамку, либо подробную цифровую модель вашего объекта, чтобы создать эффект маскировки на вашем целевом объекте.
Следуйте инструкциям по использованию модели окклюзии в Unity.
Новый инструментDoNotPay делает ваши фотографии недоступными для распознавания лиц.
Приложение для роботов-юристов DoNotPay внедряет новую функцию, которая слегка изменяет фотографии, чтобы приложения искусственного интеллекта не могли идентифицировать вас. Эта функция, получившая название Photo Ninja, предназначена для предотвращения использования ваших фотографий, загруженных в сеть, в злонамеренных целях.
DoNotPay взимает 3 доллара в месяц и взамен будет делать все, от конкурсных парковочных билетов до отмены бесплатных пробных версий до даты их продления – в основном все, что можно легко автоматизировать, DoNotPay хочет позаботиться об этом за вас.
Adversarial AI – С новой функцией Photo Ninja пользователи загружают свои фотографии в DoNotPay, а его алгоритмы вставляют скрытые изменения, которые сбивают с толку инструменты распознавания лиц. Этот тип замаскированного изображения можно назвать «примером состязательности», в котором используется способ работы алгоритмов искусственного интеллекта для нарушения их поведения.Это растущая область исследований, поскольку роль ИИ продолжает расти, а технология используется в потенциально опасных или, по крайней мере, в целях нарушения конфиденциальности.
DoNotPay
« Photo Ninja использует новую серию стеганографии, обнаружения возмущений, видимого наложения и несколько других процессов улучшения на основе искусственного интеллекта, чтобы защитить ваши изображения от обратного поиска изображений без ущерба для внешнего вида вашей фотографии», говорит компания.
Системы искусственного интеллекта обучены анализировать изображения, глядя на данные на уровне пикселей, и состязательные примеры могут обмануть их, изменив цвета пикселей достаточно тонким способом, чтобы человеческий глаз не заметил ничего другого, но компьютер не смог классифицировать изображение, как обычно, или интерпретирует его как совершенно другое изображение.