Как использовать оптическое распознавание символов Microsoft в 2023 г.
У вас есть отсканированные документы или другие файлы, созданные когда-то давно и заархивированные, но вы возобновили эти документы и хотите знать, как можно изменить их содержимое? Этот вопрос больше не будет вас волновать, потому что функция оптического распознавания символов (OCR) сделала это возможным. Вы можете получить эту функцию во многих инструментах, используемых для создания документов, например, некоторые из инструментов оптического распознавания символов Microsoft. Функция оптического распознавания символов не широко извества среди инструментов Microsoft. С этой точки зрения, эта статья проинформирует вас об Office Lens, MS Word и Office 365, а так же об общих проблемах, связанных с инструментами оптического распознавания символов, и как их решить.
- Есть ли у Office Lens функция оптического распознавания символов? Есть ли у Word/Office 365 функция оптического распознавания символов?
- Лучшая альтернатива оптическому распознаванию символов Microsoft
- Сравнение функции оптического распознавания символов в PDFelement и Microsoft
Есть ли у Office Lens функция оптического распознавания символов?
Office lens – это один из инструментов Microsoft, который существует уже давно и вы можете использовать его для оцифровки документов в своем кабинете и менять их на устройствах с iOS, Mac или PC.
Оптическое распознавание символов в Office lens использует заднюю камеру на iPhone, iPad или iPod touch, чтоб запечатлеть изображение любого документа. Затем применяется сложный алгоритм масштабирования, чтобы выровнять заснятое содержимое, и далее получается делиться содержимым, экспортировать или редактировать его. Заметьте, что по умолчанию оно сохранит изображение документа, но если у вас также устновлен Word на вашем i-устройстве, оптическое распознавание символов Office экспортирует изображение как функционирующий Word-документ, и вы сможете менять содержимое этого документа прямо со своего устройства iOS.
Без хлопот, вот как пользоваться оптическим распознаванием символов Office lens:
Во-первых, скачайте Office OCR из App Store и установите его на своем i-устройстве. Дайте ему доступ к камере и следуйте пошаговой инструкции, как сканировать бумажный документ, а затем редактировать его в Word для iOS.
Шаг 1: В оптическом распознавании символов Microsoft lens перемещайтесь через селекторный диск над кнопкой затвора и выберите “Документ”. Затем наведите камеру вашего i-устройства на документ, чтобы текст выглядел наиболее четко, и наблюдайте за тем, как оптическое распознавание символов Office lens создает документ.
Затем наведите камеру вашего i-устройства на документ, чтобы текст выглядел наиболее четко, и наблюдайте за тем, как оптическое распознавание символов Office lens создает документ.
Шаг 2: Как только снимки выровняются с документом, нажмите кнопку “Снять”, чтобы запечатлеть изображение документа, и оптическое распознавание символов Office Lens автоматически определит масштаб документа и уберет нечеткие углы при выравнивании. Вы также можете настроить обрамление вручную, нажав кнопку “Обрезать” слева от кнопки “Готово”.
Шаг 3: После того, как вы завершили обрамление документа, вам будут предложены несколько вариантов экспорта документа. Выберите “Word” и оптическое распознавание символов Microsoft Lens запустит обработку отсканированного документа и преобразует его в DOCX-файл для word.
Шаг 4: После завершения обработки, Word запустит и скачает файл, а затем обработает его. Когда файл откроется, меняйте его соответственно.
Общие проблемы оптического распознавания символов Office Lens и решения, чтобы их исправить
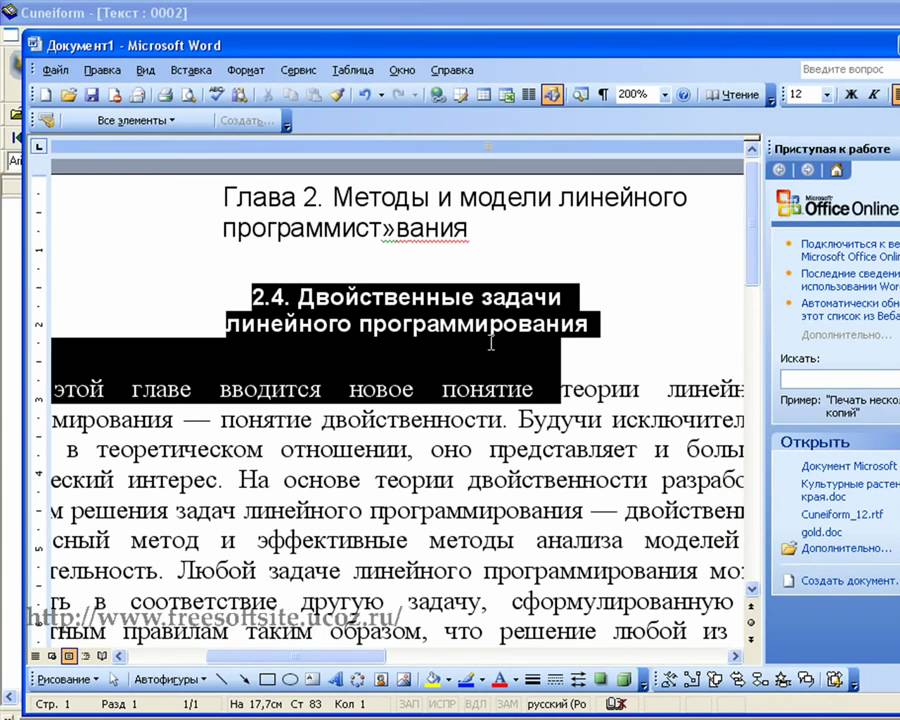
Оптическое распознавание символов Office Lens работает хорошо, но проблема возникает, когда вы отсканировали сразу большой объем данных. Когда вы пытаетесь обработать эти файлы в Word или загрузить их в PDF, может возникнут сообщение “Не удалось загрузить (нажмите, чтобы продолжить)”.
Когда вы пытаетесь обработать эти файлы в Word или загрузить их в PDF, может возникнут сообщение “Не удалось загрузить (нажмите, чтобы продолжить)”.
Решение этой проблемы – наличие быстрого интернет-соединения или попытка не работать с большим объемом данных за один раз.
Есть ли в Word функция оптического распознавания символов?
Microsoft Word – это широко используемый инструмент среди пользователей Windows для создания заметок напрямую в программе. Но есть ли в Word функция оптического распознавания символов? Поискав и прочитав ответы на форумах Microsoft, становится понятно, что у MS Word скорее всего не получается осуществить функцию оптического распознавания символов. Поэтому становится сложно создавать заметки из файлов с изображениями.
Еще в Windows 2003 и ранее, Microsoft Office Document Imaging (MODI), что является тем же самым, что и функция оптического распознавания символов, была функцией, установленной по умолчанию. Благодаря ей удавалось конвертировать текст в отсканированном изображении в Word-документ. Тем не менее, ее убрали в Office 2010 и пока еще не вернули обратно.
Тем не менее, ее убрали в Office 2010 и пока еще не вернули обратно.
Есть ли в Office 365 функция оптического распознавания символов?
Как и Word, функция оптического распознавания символов в Office 365 еще точно не определена. Но, как и в Word 2016 от Office 365 64-битной версии 1711 на Windows 10, вы можете скопировать и вставить изображение с текстом в новый Word-документ и сохранить его как PDF. Закройте документ и откройте заново PDF-файл в word. Вы получите сообщение, что документ можно конвертировать в текст с предупреждением, что вид документа может быть изменен. После чего вы можете скопировать и вставить содержимое как текст.
Тем не менее, эта функция в некоторых случаях не работала. Поэтому мы не можем с точностью утверждать, что в Office 365 есть функция оптического распознавания символов.
Лучшая альтернатива оптическому распознаванию символов Microsoft
PDFelementэто мощный инструмент, который вы можете использовать для работы с PDF-файлами, создавая, форматируя и внося изменения.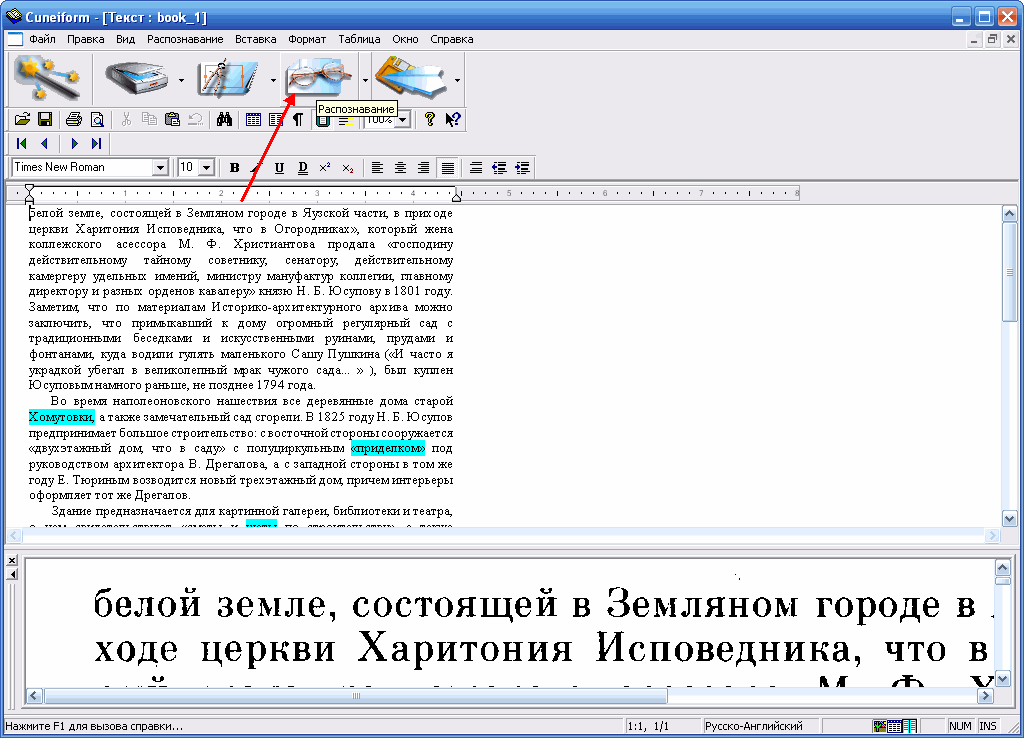 Важно, что вы можете использовать PDFelement как лучшую альтернативу оптическому распознаванию символов Microsoft и, не прикладывая усилий, менять содержимое файлов с изображениями.
Важно, что вы можете использовать PDFelement как лучшую альтернативу оптическому распознаванию символов Microsoft и, не прикладывая усилий, менять содержимое файлов с изображениями.
Скачать бесплатно
- Сделайте текст в изображении, редактируемом оптическим распознаванием символов.
- Утверждайте документы и добавляйте подписи электронно.
- Обрабатывайте документы обновременно, чтобы конвертировать, изымать данные, добавлять нумерацию и водные знаки.
- Защищайте PDF-файлы паролем.
- Конвертируйте PDF-файлы в Word, HTML и изображения.
Давайте пройдемся по инструкции, как провести оптическое распознавание символов в PDF, используя программу:
Шаг 1: Импорт документа
Вы можете импортировать уже созданный PDF-файл, нажав на “Открыть файл…” или “Создать PDF”, чтобы сделать ваши файлы PDF-файлами. Следуйте инструкциям на экране, чтобы завершить процесс загрузки.
Шаг 2: Проведите оптическое распознавание символов
Когда PDF-файл загружен, нажмите на вкладку “Конвертировать” в строке меню. И опять, нажмите “Оптическое распознавание символов”, чтобы перевести программу в режим оптического распознавания символов.
И опять, нажмите “Оптическое распознавание символов”, чтобы перевести программу в режим оптического распознавания символов.
Шаг 3: Настройки для оптического распознавания символов
Во всплывающем окошке, выберите “Редактируемый текст”. Определите язык для содержимого загруженого PDF-файла, нажав “Изменить язык”. По необходимости, настройте страницы загруженого содержимого, нажав “Настроить страницы”. Когда вы закончили настройку, нажмите кнопку “OK” чтобы начать оптическое распознавание символов в PDF-файле.
Шаг 4: Отредактируйте документ после оптического распознавания символов
Когда процесс оптического распознавания символов PDF-файла завершен, загруженый текст появится в новом окне. Нажмите на вкладку “Изменить” в строке меню и установите необходимые настройки. Зачем начните редактирование и форматирование загруженного текста по своему усмотрению.
Сравнение функции оптического распознавания символов в PDFelement и Microsoft
Функция оптического распознавания символов в Microsoft | Функция оптического распознавания символов в PDFelement Скачать бесплатно | |
|---|---|---|
| Оптическое распознавание символов | Кому-то нравится Office Lens | Да |
| Пакетное оптическое распознавание символов | Не всё | Да |
| Точность оптического распознавания символов | 70%-90% | 95%+ |
| Результат | Текст | Текст, PDF |
| Главные функции | Создание и организация заметок | Создать, редактировать, комментировать и конвертировать PDF-файлы |
| Скорость | Быстрая | Сверхбыстрая |
Сканирование текста и графики.
 Вывод документа на печать
Вывод документа на печатьЦели урока:
- Образовательные: помочь учащимся получить представление об OCR – программах распознавания текста, познакомиться с возможностями данных программы, научить распознавать отсканированный текст, передавать и редактировать его в Word.
- Воспитательные: воспитание информационной культуры учащихся, внимательности, аккуратности, дисциплинированности, усидчивости.
- Развивающие: развитие познавательных интересов, навыков работы на компьютере, самоконтроля, умения конспектировать.
Задачи урока:
- Научить студентов работать со сканерами различных производителей.
- Научить студентов применять знания работы со сканером, и программой FineRiader в курсовом и дипломном проектировании;
- Продолжить отработку умений и навыков по работе в программе MS Word;
- Отработка понятийный аппарат, символику по данной теме;
- Вырабатывать умение творчески и логически мыслить;
- Расширить кругозор студентов.

Оборудование: Мультимедийный проектор, компьютер, компьютерная презентация.
План урока (90 минут):
- Орг. момент. (10 мин)
- Проверка домашнего задания. (20 мин)
- Теоретическая часть. (10 мин)
- Постановка задачи для практической работы. (5 мин)
- Выполнение практической работы. (30 мин)
- Закрепление знаний. (5 мин)
- Домашнее задание. (5 мин)
- Подведение итогов урока. (5 мин)
Ход урока
I. Организационный момент.
Приветствие, проверка присутствующих. Объяснение хода урока.
II. Проверка домашнего задания.
Проводится в виде защиты студентами доклада на тему сканирования.
Студенты на предыдущем занятии делятся на три группы. Каждая группа получила
домашнее задание подготовить реферат на определенную тему. Проводится защита
реферата одним из членов команды.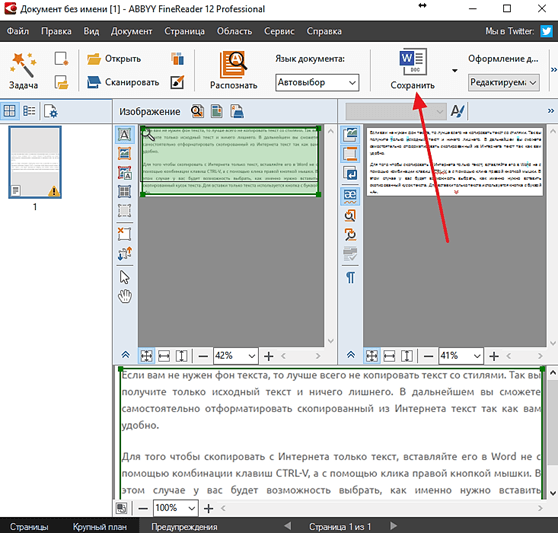
III. Теоретическая часть.
Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition – OCR).
Возможно, самая известная программа для распознавания текстов – это FineReader от компании ABBYY. Именно эту программу чаще всего вспоминают, когда речь заходит о системах распознавания.
FineReader – омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати, что достигается благодаря применению технологии “целостного целенаправленного адаптивного распознавания”.
FineReader имеет массы дополнительных функций, которые простому пользователю,
возможно, и без надобности, но зато производят впечатление на определенные
группы покупателей. Так, одним из козырей FineReader является поддержка
неимоверного количества языков распознавания – 176, в числе которых вы найдете
экзотические и древние языки, и даже популярные языки программирования.
Так, одним из козырей FineReader является поддержка
неимоверного количества языков распознавания – 176, в числе которых вы найдете
экзотические и древние языки, и даже популярные языки программирования.
Но далеко не все возможности включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером. Пакетное сканирование, грамотная обработка таблиц и изображений – для всего этого стоит приобрести профессиональную версию программы.
Все версии FineReader, от самой простой до самой мощной, объединяет удобный
интерфейс. Для запуска процесса распознавания вам достаточно просто положить
документ в сканер и нажать единственную кнопку (мастер Scan & Read) на панели
инструментов программы. Все дальнейшие операции – сканирование, разбивку
изображения на “блоки” и, наконец, собственно распознавание программа выполнит
автоматически. Пользователю останется только установить нужные параметры
сканирования.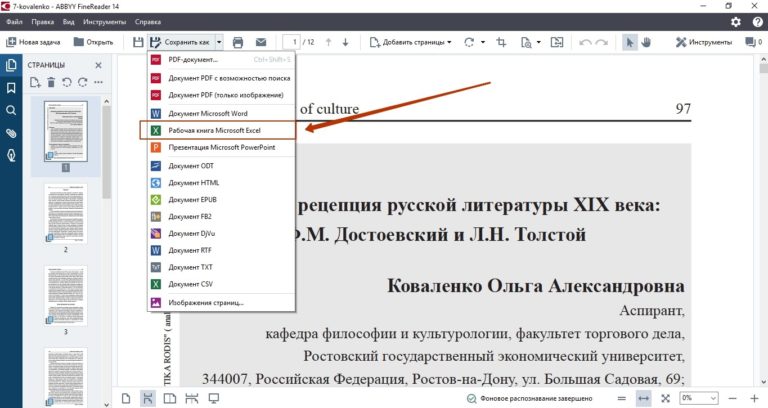
FineReader работает со сканерами через TWAIN-интерфейс. Это единый международный стандарт, введенный в 1992 году для унификации взаимодействия устройств для ввода изображений в компьютер (например, сканера) с внешними приложениями.
Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании. Качество изображения регулируется установкой основных параметров сканирования: типа изображения, разрешения и яркости.
Сканирование в сером является оптимальным режимом для системы распознавания. В случае сканирования в сером режиме осуществляется автоматический подбор яркости. Если Вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения.
Оптимальным разрешением для обычных текстов является – 300 dpi и 400–600 dpi
для текстов, набранных мелким шрифтом (9 и менее пунктов).
После завершения распознавания страницы FineReader предложит пользователю выбор: сканировать и распознавать дальше (для многостраничного документа) или сохранить полученный текст в одном из множества популярных форматов – от документов Microsoft Office до HTML или PDF. Можно, впрочем, сразу же перебросить документ в Word или Excel, и уже там исправить все огрехи распознавания (без ни обойтись просто невозможно). При этом FineReader полностью сохраняет все особенности форматирования документа и его графическое оформление.
IV. Постановка задачи для практической работы.
Теперь потренируемся работать с программой ABBYY FineReader.
Демонстрация презентации.
Прежде чем начать сканирование необходимо настроить программу (процесс настройки программы подробно изложен в презентации)
Блоки – это заключенные в рамку участки изображения. Блоки выделяют для того,
чтобы указать системе, какие участки, отсканированной страницы, надо
распознавать и в каком порядке.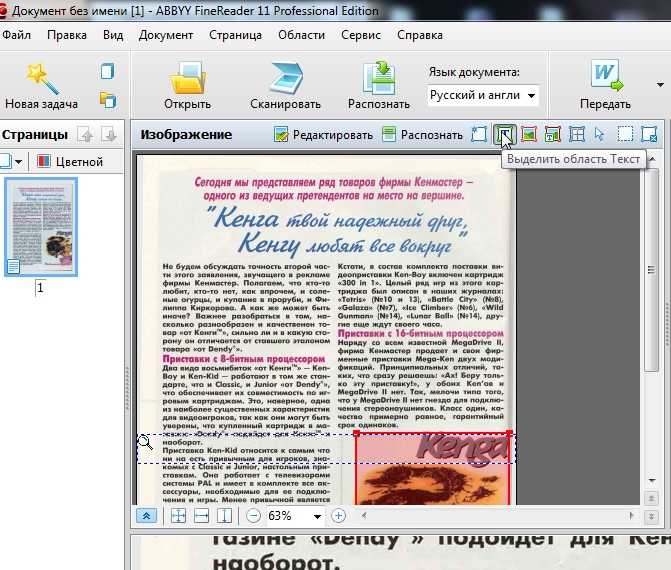 Также по ним воспроизводится исходное оформление
страницы. Блоки разных типов имеют различные цвета рамок.
Также по ним воспроизводится исходное оформление
страницы. Блоки разных типов имеют различные цвета рамок.
Рис. 1. Блоки (текст и картинка)
Текст – блок используется для обозначения текста. Он должен содержать только одноколоночный текст. Если внутри текста содержатся картинки, выделите их в отдельные блоки.
Таблица – этот блок используется для обозначения таблиц или текста, имеющего табличную структуру. При распознавании программа разбивает данный блок на строки и столбцы и формирует табличную структуру. В выходном тексте данный блок передается таблицей.
Картинка – этот блок используется для обозначения картинок. Он может содержать картинку или любую другую часть текста, которую Вы хотите передать в распознанный текст в качестве картинки.
Результаты распознавания можно сохранить в файл, передать во внешнее
приложение, не сохраняя на диск или скопировать в буфер обмена.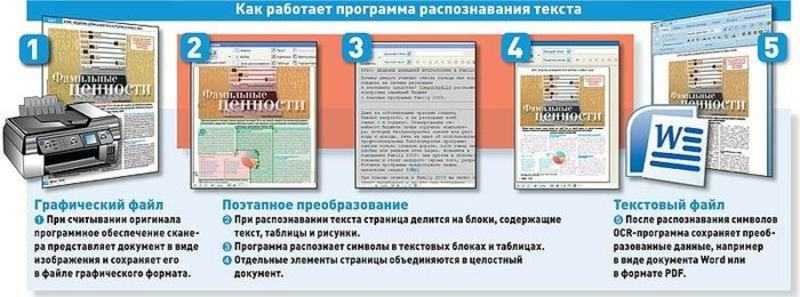
Прежде чем распознанный текст передавать в MS Word необходимо произвести проверку распознанного текста.
Рис. 2. Процесс проверки распознанного текста
Распознанный текст можно отправить в Microsoft Word. Для этого щелкните кнопку Передать в MS Word. Запуститься программа Microsoft Word и откроется распознанный текст, который вы можете редактировать и форматировать, сохранить в файл.
Рис. 3. Передача распознанного текста в MS Word
V. Выполнение практической работы
Учащиеся выполняют задание.
VI. Закрепление знаний
Компьютерное тестирование.
VII. Домашнее задание.
Подготовка материалов для сканирования. Реферат по другому предмету.
VII. Подведение итогов урока
Подведение итога урока. Выставление оценок.
На уроке мы познакомились с программами OCR, научились распознавать
отсканированное изображение с помощью программы ABBYY FineReader 5. 0.
0.
Литература.
- Е.В. Михеева. – Учебник “Информационные технологии в профессиональной деятельности” – М.: Издательский центр “Академия”, 2004.
- Е.В. Михеева. – Учебник “Практикум по информационным технологиям в профессиональной деятельности” – М.: Издательский центр “Академия”, 2004.
Приложение 1. Приложение содержит в себе “Карту занятия”.
Как использовать Microsoft OCR в 2023 году
Элиза Уильямс
06.01.2023, 19:15:57 • Подано по адресу: Сравнение программного обеспечения PDF • Проверенные решения
У вас есть отсканированные документы и другие файлы, созданные когда-то и заархивированные, но вы получили эти документы и вам интересно, как вам отредактировать их содержимое? Это больше не должно вас беспокоить, потому что функция оптического распознавания символов (OCR) сделала это возможным.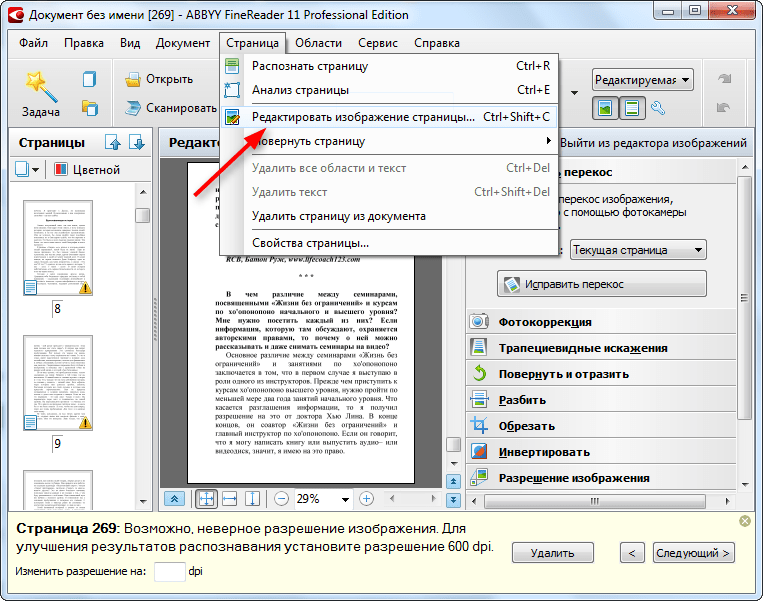 Вы можете получить доступ к этой функции в большинстве инструментов, используемых при создании документов, таких как некоторые из Инструменты Microsoft OCR . Функция OCR малоизвестна среди инструментов Microsoft. В связи с этим в этой статье рассказывается об Office Lens, MS Word и Office 365, а также о распространенных проблемах, связанных с этими инструментами OCR, и о том, как их исправить.
Вы можете получить доступ к этой функции в большинстве инструментов, используемых при создании документов, таких как некоторые из Инструменты Microsoft OCR . Функция OCR малоизвестна среди инструментов Microsoft. В связи с этим в этой статье рассказывается об Office Lens, MS Word и Office 365, а также о распространенных проблемах, связанных с этими инструментами OCR, и о том, как их исправить.
- Выполняет ли Office Lens распознавание символов? Есть ли в Word/Office 365 оптическое распознавание символов?
- Лучшая альтернатива Microsoft OCR
- Сравнение PDFelement и Microsoft OCR
Выполняет ли Office Lens распознавание текста?
Office Lens — это один из инструментов Microsoft, который существует уже некоторое время, и вы можете использовать его для оцифровки документов в вашем кабинете и изменения их прямо на устройстве iOS, Mac или ПК.
Office Lens OCR использует заднюю камеру iPhone, iPad или iPod touch для захвата изображения любого документа. Затем он использует сложный алгоритм масштабирования для выравнивания захваченного контента, а затем позволяет делиться, экспортировать или редактировать контент. Обратите внимание, что по умолчанию он сохраняет изображение документа, но если на вашем iDevice также установлен Word, вы даже можете экспортировать изображение в Office OCR как работающий документ Word, чтобы вы могли правильно редактировать содержимое этого документа. с вашего iOS-устройства.
Затем он использует сложный алгоритм масштабирования для выравнивания захваченного контента, а затем позволяет делиться, экспортировать или редактировать контент. Обратите внимание, что по умолчанию он сохраняет изображение документа, но если на вашем iDevice также установлен Word, вы даже можете экспортировать изображение в Office OCR как работающий документ Word, чтобы вы могли правильно редактировать содержимое этого документа. с вашего iOS-устройства.
Без лишних слов, вот как использовать OCR Office Lens:
Сначала загрузите Office OCR из App Store и установите его на свое устройство iDevice. Разрешите доступ к камере и следуйте следующему пошаговому руководству, чтобы отсканировать бумажный документ, а затем отредактировать его с помощью Word для iOS.
Шаг 1 : В Microsoft Lens OCR наведите селектор над кнопкой спуска затвора и выберите «Документ». Затем наведите камеру своего iDevice на документ, чтобы текст был как можно более четким, и внимательно наблюдайте, как OCR Office Lens кадрирует документ.
Шаг 2 : После точного выравнивания рамок с документом просто нажмите кнопку «Затвор», чтобы сделать снимок документа, и OCR Office Lens автоматически масштабирует документ и удаляет нечетные углы в выравнивании. Вы также можете точно настроить кадрирование вручную, нажав кнопку «Обрезка» слева от кнопки «Готово».
Шаг 3 : После того, как вы завершите создание документа, вам будет предложено несколько вариантов экспорта документа. Выберите «Word», и Microsoft Lens OCR начнет обрабатывать отсканированный документ и преобразовывать его в файл DOCX для слова.
Шаг 4 : После завершения обработки Word запустит и загрузит файл, а затем обработает его. Когда файл открыт, отредактируйте его соответствующим образом.
Распространенные проблемы OCR Office Lens и способы их устранения
OCR Office Lens работает нормально, но проблема возникает при сканировании большого объема данных одновременно. Когда вы пытаетесь обработать эти файлы в Word или загрузить в PDF, вы можете столкнуться с сообщением «Не удалось загрузить (нажмите, чтобы повторить попытку)».
Решением этой проблемы является наличие быстрого подключения к Интернету или попытка избежать работы с большими объемами данных на ходу.
Есть ли в Word OCR?
Microsoft Word — широко используемый инструмент пользователями Windows для создания заметок путем непосредственного связывания с программой. Но есть ли в Word OCR? После наведения и чтения ответов на форумах сообщества Microsoft, MS Word, скорее всего, не выполняет распознавание текста. Это затруднило создание заметок из файлов изображений.
Еще в Windows 2003 и более ранних версиях функция Microsoft Office Document Imaging (MODI), аналогичная OCR, была установлена по умолчанию. Он смог преобразовать текст в отсканированном изображении в документ Word. Однако в Office 2010 он был удален, и его еще предстоит вернуть.
Есть ли в Office 365 OCR?
Как и Word, OCR Office 365 точно не определен. Но, как и в случае с Word 2016 из 64-разрядной версии Office 365 версии 1711 в Windows 10, вы можете скопировать и вставить изображение с текстом в новый документ Word и сохранить его в формате PDF. Закройте документ и снова откройте PDF в Word. Вы получите уведомление о том, что оно может быть преобразовано в текст, и предупреждение о том, что оно может изменить способ просмотра. После чего вы можете скопировать и вставить содержимое как текст.
Закройте документ и снова откройте PDF в Word. Вы получите уведомление о том, что оно может быть преобразовано в текст, и предупреждение о том, что оно может изменить способ просмотра. После чего вы можете скопировать и вставить содержимое как текст.
Однако несколько раз это не срабатывало. При этом мы не можем сказать наверняка, что в Office 365 есть OCR.
Лучшая альтернатива Microsoft OCR
Wondershare PDFelement — PDF Editor — это надежный инструмент, который можно использовать для работы с PDF-файлами при создании, форматировании и редактировании. Важно отметить, что вы можете использовать PDFelement как лучшую альтернативу Microsoft OCR и легко изменять содержимое файлов изображений.
Попробуйте бесплатно Попробуйте бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
- Сделать текст на изображениях редактируемым с помощью OCR.
- Утверждайте и добавляйте подписи к документам в цифровом виде.
- Пакетная обработка документов для преобразования, извлечения данных, добавления номера Бейтса и водяного знака.
- Безопасные PDF-файлы с защитой паролем.
- Преобразование документов PDF в файлы Word, HTML и изображения.
- Сравните два файла PDF, чтобы быстро найти различия.
- Быстрое объединение нескольких PDF-файлов в один.

Давайте рассмотрим руководство по распознаванию PDF с помощью программы:
Шаг 1: Импорт документа
Вы можете импортировать уже созданные PDF-файлы, нажав «Открыть PDF» или «Создать PDF», чтобы создать PDF-файлы из Ваши документы в первую очередь. Следуйте инструкциям на экране, чтобы завершить процесс загрузки.
Шаг 2. Выполните распознавание символов
После загрузки PDF-файла щелкните вкладку «Инструменты» в строке меню. Снова нажмите «OCR», чтобы перевести программу в режим OCR.
Шаг 3. Настройки оптического распознавания символов
Во всплывающем окне выберите «Сканировать в редактируемый текст». Определите язык для извлеченного содержимого PDF, коснувшись «Изменить языки». При необходимости настройте страницы извлеченного содержимого в области «Диапазон страниц». Когда вы закончите настройку, нажмите кнопку «ОК», чтобы запустить OCR PDF.
Определите язык для извлеченного содержимого PDF, коснувшись «Изменить языки». При необходимости настройте страницы извлеченного содержимого в области «Диапазон страниц». Когда вы закончите настройку, нажмите кнопку «ОК», чтобы запустить OCR PDF.
Попробуйте бесплатно Попробуйте бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Шаг 4. Редактирование документа после OCR
По завершении процесса OCR PDF извлеченный текст отображается в новом окне. Нажмите на вкладку «Редактировать» в верхней правой строке меню и настройте соответствующие параметры. Затем начните редактировать и форматировать извлеченный текст по своему усмотрению.
Сравнение PDFelement и Microsoft OCR
Microsoft OCR | PDFelement OCR Скачать Скачать | |
|---|---|---|
| ОКР | Некоторым нравится Office Lens | Да |
| Пакетное оптическое распознавание символов | Не все | Да |
| Точность оптического распознавания символов | 70%-90% | 95%+ |
| Выход | Текст | Текст, PDF |
| Основные характеристики | Создание и систематизация заметок | Создание, редактирование, комментирование и преобразование PDF-файлов |
| Рабочая скорость | Быстро | Сверхбыстрый |
Бесплатная загрузка или Купить PDFelement прямо сейчас!
Бесплатная загрузка или Купить PDFelement прямо сейчас!
Купить PDFelement прямо сейчас!
Купить PDFelement прямо сейчас!
Список вики
Используйте приведенный ниже список для доступа к определенной вики.